analisa sentimen terhadap aplikasi - repository bsi
TRANSCRIPT

i
ANALISA SENTIMEN TERHADAP APLIKASI
PEMBELAJARAN DARING MENGGUNAKAN ALGORITMA
KLASIFIKASI DATA MINING
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Ilmu Komputer (M.Kom)
RECHA ABRIANA ANGGRAINI
14002216
PROGRAM PASCASARJANA MAGISTER ILMU KOMPUTER
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER
NUSA MANDIRI
2020

ii
ANALISA SENTIMEN TERHADAP APLIKASI
PEMBELAJARAN DARING MENGGUNAKAN ALGORITMA
KLASIFIKASI DATA MINING
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Ilmu Komputer (M.Kom)
RECHA ABRIANA ANGGRAINI
14002216
PROGRAM PASCASARJANA MAGISTER ILMU KOMPUTER
SEKOLAH TINGGI MANAJEMEN INFORMATIKA DAN KOMPUTER
NUSA MANDIRI
2020

iii
SURAT PERNYATAAN ORISINALITAS DAN BEBAS PLAGIARISM
Yang bertandatangan dibawah ini:
Nama : Recha Abriana Anggraini
NIM : 14002216
Program Studi : Ilmu Komputer
Jenjang : Strata Dua (S2)
Konsentrasi : Data Mining
Dengan ini menyatakan bahwa tesis yang telah saya buat dengan judul:
“Analisa Sentimen Terhadap Aplikasi Pembelajaran Daring Menggunakan
Algoritma Klasifikasi Data Mining” adalah hasil karya sendiri, dan semua sumber
baik yang kutip maupun yang dirujuk telah saya nyatakan dengan benar dan tesis
belum pernah diterbitkan atau dipublikasikan dimanapun dan dalam bentuk
apapun.
Demikianlah surat pernyataan ini saya buat dengan sebenar-benarnya Apabila
dikemudian hari ternyata saya memberikan keterangan palsu dan atau ada pihak
lain yang mengklaim bahwa tesis yang telah saya buat adalah hasil karya milik
seseorang atau badan tertentu, saya bersedia diproses baik secara pidana maupun
perdata dan kelulusan saya dari Program Studi Ilmu Komputer (S2) Sekolah
Tinggi Manajemen Informatika dan Komputer Nusa Mandiri dicabut/dibatalkan.
Jakarta, 05 Agustus 2020
Yang menyatakan,
Recha Abriana Anggraini

iv
v

vi
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Allah SWT, yang telah
melimpahkan rahmat dan karunia-Nya, sehingga pada akhirnya penulis dapat
menyelesaikan tesis ini tepat pada waktunya. Tesis ini penulis sajikan dalam
bentuk buku yang sederhana. Adapun judul tesis yang penulis ambil yaitu
“Analisa Sentuimen Terhadap Aplikasi Pembelajaran Daring Menggunakan
Algoritma Klasifikasi Data Mining”.
Tujuan penulisan tesis ini adalah sebagai salah satu syarat untuk
mendapatkan gelar Magister Ilmu Komputer (M.Kom) pada Program Studi Ilmu
Komputer (S2) STMIK Nusa Mandiri. Dalam penyusunan tesis ini penulis
melakukan riset dan analisis data dari komentar yang diberikan pengguna aplikasi
pembelajaran daring yang ada di google playstore untuk mengetahui
kecenderungan komentar yang diberikan, apakah cenderung positif atau negatif.
Penulis juga mencari dan menganalisa berbagai macam sumber referensi, baik
dalam bentuk jurnal ilmiah, buku-buku literatur, internet, dll yang terkait dengan
pembahasan pada tesis ini.
Penulis menyadari bahwa tanpa bimbingan dan dukungan dari semua pihak
dalam pembuatan tesis ini, maka penulis tidak dapat menyelesaikan tesis ini tepat
pada waktunya. Untuk itu, pada kesempatan ini penulis ingin mengucapkan
terima kasih yang sebesar-besarnya kepada :
1. Kepala STMIK Nusa Mandiri Jakarta
2. Ketua Program Studi Ilmu Komputer STMIK Nusa Mandiri Jakarta
3. Bapak Dr. Windu Gata, M.Kom selaku pembimbing tesis yang telah
berkenan menyediakan waktu dan tenaga serta membagikan ilmu dalam
membimbing penulis untuk menyelesaikan tesis ini.
4. Orang tua dan partner tercinta yang selalu memberikan motivasi, doa dan
dukungan baik moril maupun materiil yang tidak dapat terbalaskan dengan
apapun juga.
5. Teman-teman seperjuangan, khususnya kelas 14.2B yang sangat luar biasa.

vii
6. Dan untuk seluruh teman-teman diluar sana yang ikut membantu penulis
yang tidak dapat disebutkan satu persatu.
Akhir kata, penulis berharap laporan tesis ini memiliki nilai positif
tersendiri bagi setiap orang yang membacanya. Penulis menyadari, dalam
penyajian tesis ini masih banyak kekurangannya. Besar harapan penulis agar
para pembaca memberikan masukan berupa kritik dan saran yang membangun
demi kesempurnaan laporan tesis ini.
Jakarta, 05 Agustus 2020
Penulis,
Recha Abriana Anggraini

viii
SURAT PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH
UNTUK KEPENTINGAN AKADEMIS
Yang bertandatangan dibawah ini, saya:
Nama : Recha Abriana Anggraini
NIM : 14002216
Program Studi : Ilmu Komputer
Jenjang : Strata Dua (S2)
Konsentrasi : Data Mining
Jenis Karya : Tesis
Demi pengembangan ilmu pengetahuan, dengan ini menyetujui untuk
memberikan ijin kepada pihak Program Studi Ilmu Komputer (S2) Sekolah Tinggi
Manajemen Informatika dan Komputer Nusa Mandiri (STMIK Nusa Mandiri)
Hak Bebas Royalti Non-Eksklusif (Non-exclusive Royalti-Free Right) atas
karya ilmiah kami yang berjudul : “Analisa Sentimen Terhadap Aplikasi
Pembelajaran Daring Menggunakan Algoritma Klasifikasi Data Mining” beserta
perangkat yang diperlukan (apabila ada).
Dengan Hak Bebas Royalti Non-Eksklusif ini pihak STMIK Nusa Mandiri
berhak menyimpan, mengalih-media atau bentuk-kan, mengelolaannya dalam
pangkalan data (database), mendistribusikannya dan menampilkan atau
mempublikasikannya di internet atau media lain untuk kepentingan akademis
tanpa perlu meminta ijin dari kami selama tetap mencantumkan nama kami
sebagai penulis/pencipta karya ilmiah tersebut.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak
STMIK Nusa Mandiri, segala bentuk tuntutan hukum yang timbul atas
pelanggaran Hak Cipta dalam karya ilmiah saya ini.
Demikian pernyataan ini saya buat dengan sebenarnya.
Jakarta, 05 Agustus 2020
Yang menyatakan,
Recha Abriana Anggraini

xi
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
DAFTAR ISI
Halaman sampul .......................................................................................... i
Halaman judul ............................................................................................ ii
Surat Pernyataan Orisinalitas dan Bebas Plagiarisme ................................ iii
Lembar Persetujuan dan Pengesahan Tesis ................................................ iv
Lembar Konsultasi Pembimbing ................................................................ v
Kata Pengantar ........................................................................................... vi
Surat Pernyataan dan Persetujuan Publikasi .............................................. viii
Abstrak ....................................................................................................... ix
Daftar Isi ..................................................................................................... xi
Daftar Tabel ............................................................................................... xii
Daftar Gambar ............................................................................................ xiii
Daftar Lampiran ......................................................................................... xiv
BAB I. Pendahuluan .................................................................................. 1
1.1. Latar Belakang Penulisan .......................................................... 1
1.2. Identifikasi Masalah .................................................................. 2
1.3. Tujuan Penelitian ....................................................................... 3
1.4. Ruang Lingkup Penelitian ......................................................... 3
1.5. Sistematika Penulisan ................................................................ 3
BAB II. Landasan Teori ............................................................................. 5
2.1. Tinjauan Pustaka ....................................................................... 5
2.1.1. Sentimen analysis .......................................................... 5
2.1.2. Data mining ................................................................... 5
2.1.3. Text mining .................................................................... 6
2.1.4. Aplikasi mobile .............................................................. 10
2.1.5. Ruang guru ..................................................................... 10
2.1.6. Zenius ............................................................................ 11
2.1.7. Naïve Bayes ................................................................... 11
2.1.8. K-Nearest Neighbour ..................................................... 12
2.1.9. Decision Tree ................................................................. 13
2.1.10. KNIME .......................................................................... 13
2.1.11. Webharvy ....................................................................... 13
2.1.12. Gataframework .............................................................. 14
2.2. Tinjauan Studi ........................................................................... 14
2.3. Tinjauan Objek Penelitian ......................................................... 24
BAB III. Metodologi Penelitian ................................................................. 25
BAB IV. Hasil Penelitian Dan Pembahasan .............................................. 29
BAB V. Penutup ........................................................................................ 63
5.1. Kesimpulan ............................................................................... 63
5.2. Saran ......................................................................................... 63
Daftar Pustaka ............................................................................................ 64
Daftar Riwayat Hidup ................................................................................ 67

xii
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
DAFTAR TABEL
Tabel 2.1. Perbedaan peranan data mining ................................................ 6
Tabel 2.2. Rangkuman penelitian terkait ................................................... 14
Tabel 4.1. Hasil pelabelan terhadap dataset review pengguna aplikasi
ruangguru .................................................................................................... 35
Tabel 4.2. Hasil pelabelan terhadap dataset review pengguna aplikasi
zenius .......................................................................................................... 35
Tabel 4.3. Perbandingan komentar sebelum dan sesusah case folding ...... 37
Tabel 4.4. Perbandingan komentar sebelum dan sesudah regex filter ....... 37
Tabel 4.5. Hasil stemming .......................................................................... 38
Tabel 4.6. Perbandingan komentar sebelum dan sesudah di stopeord ....... 39
Tabel 4.7. Term yang dibentuk dari proses pembentukan BoW ................ 40
Tabel 4.8. Pembobotan TF-IDF ................................................................. 42
Tabel 4.9. Confussion matrix dari dataset ruangguru yang diolah dengan
metode decision tree dan cross validation .................................................. 46
Tabel 4.10. Confussion matrix dari dataset ruangguru yang diolah dengan
metode decision tree dan partitioning ....................................................... 46
Tabel 4.11. Confussion matrix dari dataset ruangguru yang diolah dengan
metode naïve bayes dan cross validation ................................................... 49
Tabel 4.12. Confussion matrix dari dataset ruangguru yang diolah dengan
metode naïve bayes dan partitioning ......................................................... 49
Tabel 4.13 Confussion matrix dari dataset ruangguru yang diolah dengan
metode KNN dan cross validation ............................................................. 51
Tabel 4.14. Confussion matrix dari dataset ruangguru yang diolah dengan
metode KNN dan partitioning ................................................................... 51
Tabel 4.15. Confussion matrix dari dataset zenius yang diolah dengan
metode decision tree dan cross validation ................................................. 53
Tabel 4.16. Confussion matrix dari dataset zenius yang diolah dengan
metode decision tree dan partitioning ....................................................... 53
Tabel 4.17. Confussion matrix dari dataset zenius yang diolah dengan
metode naïve bayes dan cross validation ................................................... 56
Tabel 4.18. Confussion matrix dari dataset zenius yang diolah dengan
metode naïve bayes dan partitioning ......................................................... 56
Tabel 4.19. Confussion matrix dari dataset zenius yang diolah dengan
metode KNN dan cross validation ............................................................. 58
Tabel 4.20. Confussion matrix dari dataset zenius yang diolah dengan
metode KNN dan partitioning ................................................................... 58
Tabel 4.21. Perbandingan nilai akurasi dari masing-masing hasil
Pengujian .................................................................................................... 59

xiii
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
DAFTAR GAMBAR
Gambar 3.1. Model penelitian usulan ........................................................ 26
Gambar 4.1. Contoh review positif dari pengguna aplikasi ruangguru ...... 31
Gambar 4.2. Contoh review negative dari pengguna aplikasi ruangguru .. 32
Gambar 4.3. Contoh review positif dari pengguna aplikasi zenius ............ 33
Gambar 4.4. Contoh review negative dari pengguna aplikasi zenius ........ 34
Gambar 4.5. Proses preprocessing data dengan gataframework.com ....... 36
Gambar 4.6. Proses preprocessing data dengan KNIME .......................... 36
Gambar 4.7. Model penelitian pengolahan dataset review pengguna
aplikasi ruangguru ...................................................................................... 43
Gambar 4.8. Model penelitian pengolahan dataset review pengguna
aplikasi zenius ............................................................................................ 45
Gambar 4.9. ROC curve dari algoritma decision tree untuk dataset
ruangguru dengan partitioning ................................................................... 47
Gambar 4.10. Tree view dari dataset aplikasi ruangguru ........................... 48
Gambar 4.11. ROC curve dari algoritma naïve bayes untuk dataset
ruangguru dengan partitioning ................................................................... 50
Gambar 4.12. ROC curve dari algoritma KNN untuk dataset
ruangguru dengan partitioning ................................................................... 52
Gambar 4.13. ROC curve dari algoritma decision tree untuk dataset
zenius dengan partitioning ......................................................................... 54
Gambar 4.14. Tree view dari dataset aplikasi zenius ................................. 55
Gambar 4.15. ROC curve dari algoritma naïve bayes untuk dataset
zenius dengan partitioning ......................................................................... 57
Gambar 4.16. ROC curve dari algoritma KNN untuk dataset
zenius dengan partitioning ......................................................................... 59
Gambar 4.17. Flowchart aplikasi analisa sentimen aplikasi pembelajaran
daring .......................................................................................................... 61
Gambar 4.18. Tampilan Halaman home aplikasi analisa sentimen
pembelajaran daring ................................................................................... 61
Gambar 4.19. Tampilan halaman testing data ............................................ 62
Gambar 4.20. Tampilan halaman hasil pengkategorian ............................. 62
Gambar 4.21. Tampilan halaman detail preprocessing ............................. 63

xiv
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
DAFTAR LAMPIRAN
Lampiran 1. Contoh data komentar pengguna aplikasi ruangguru ............ 68
Lampiran 2. Contoh data komentar pengguna aplikasi zenius .................. 69
Lampiran 3. Contoh preprocessing dataset ............................................... 70

ix
ix
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
ABSTRAK
Nama Lengkap : Recha Abriana Anggraini
NIM : 14002216
Program Studi : Ilmu Komputer
Jenjang : Strata Dua (S2)
Konsentrasi : Data Mining
Judul Tesis : “Analisa Sentimen Terhadap Aplikasi Pembelajaran
Daring Menggunakan Algoritma Klasifikasi Data Mining”
Belajar merupakan kegiatan yang harus dilakukan makhluk hidup tanpa mengenal
batasan umur. Kegiatan belajar kini didukung oleh perkembangan teknologi yang
semakin massif sehingga mempermudah manusia. Berkat perkembangan
teknologi, muncullah berbagai alternatif metode pembelajaran seperti
pembelajaran daring. Pembelajaran daring biasanya didukung oleh berbagai
aplikasi yang disediakan diberbagai store yang dapat didownload melalui
smartphone secara gratis maupun berbayar. Salah satu store penyedia aplikasi
tersebut adalah google playstore. Banyaknya pengguna suatu aplikasi akan
memunculkan banyak penilaian yang diberikan terhadap aplikasi tersebut, baik
penilaian positif maupun negatif. Dalam penelitian ini, penulis melakukan
klasifikasi sentiment terhadap dua palikasi pembelajaran daring yang popular di
Indonesia yaitu ruangguru dan zenius dengan algoritma klasifikasi data mining.
Tahapan pengolahan data dimulai dengan preprocessing data, modelling sampai
dengan evaluasi. Dari hasil pengolahan data yang dilakukan, dapat diketahui
bahwa algoritma KNN dengan cross validation berhasil mengklasifikasikan
sentiment pengguna aplikasi tersebut dengan akurasi tertinggi.
Kata kunci: text mining, sentiment, data mining, klasifikasi, ruangguru, zenius,
pembelajaran daring.

x
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
ABSTRACT
Name : Recha Abriana Anggraini
NIM : 14002216
Study of Program : Ilmu Komputer
Levels : Strata Dua (S2)
Concentrations : Data Mining
Title : “Analisa Sentimen Terhadap Aplikasi Pembelajaran
Daring Menggunakan Algoritma Klasifikasi Data Mining”
Learning is an activity that must be carried out by living things without knowing
age restrictions. Learning activities now supported by increasingly massive
technological developments that make it easier. Because technological
developments, various alternative learning methods have emerged, such as online
learning. Online learning is usually supported by various applications provided in
stores that can be downloaded via smartphones for free or paid. One of the store
application providers is Google Play Store. Increasing users of an application will
bring up many ratings given to the application, both positive or negative ratings.
In this study, we conducted a sentiment classification of two popular online
learning applications in Indonesia, namely Ruangguru and Zenius with data
mining classification algorithms. Stages of data processing begins with data
preprocessing, modeling until evaluation. From the results of data processing, we
know that the KNN algorithm with cross validation has succeeded in classifying
the user application sentiments with the highest accuracy.
Keywords: text mining, sentiment, data mining, classification, ruangguru, zenius,
online learning.

1
1
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
BAB I
PENDAHULUAN
1.1. Latar Belakang
Pembelajaran merupakan suatu kegiatan atau system yang membantu
individu dalam berinteraksi untuk belajar terhadap lingkungan belajarnya. teori
merupakan suatu asas yang tersusun dalam kejadian-kejadian tertentu dalam dunia
nyata [9]. Saat ini kegiatan pembelajaran semakin dimudahkan berkat
perkembangan teknologi yang semakin pesat. Salah satu yang ditawarkan dalam
kemudahan tersebut adalah tersedianya berbagai aplikasi yang mendukung
aktifitas belajar yang dapat dengan udah di download melalui playstore dan di
akses melalui smartphone mulai dari yang gratis sampai dengan berbayar.
Banyaknya aplikasi-aplikasi yang ada tentu saja membuat orang semakin mudah
dalam menentukan pilihan untuk menggunakan aplikasi sesuai zona nyaman dan
juga kebutuhannya, dengan demikian maka akan bermunculan opini-opini serta
penilaian baik dan buruknya aplikasi tersebut. Proses penilaian aplikasi yang
digunakan dapat melalui berbagai cara antara lain melalui media sosial atau
playstore yang menyediakan aplikasi tersebut. Salah satu store yang menyediakan
fitur untuk menilai aplikasi tersebut adalah google playstore.
Penilaian dari konsumen sangat dibutuhkan oleh perusahaan pengembang
aplikasi untuk evaluasi serta peningkatan fitur dari aplikasi yang dibuat. Untuk
mengetahui apakah penilaian dari sebuah aplikasi cenderung positif atau negatif
maka diperlukan analisis terhadap penilaian tersebut. Salah satu analisis yang
sering dilakukan adalah analisa sentimen (sentiment analysis). Analisis Sentimen
saat ini memiliki peran penting dalam analisis media sosial dan, lebih umum,
dalam menganalisis pendapat pengguna tentang umum topik atau ulasan
pengguna tentang produk / layanan sejumlah besar aplikasi [5].
Sentimen analisis merupakan salah satu bidang dari Natural Language
Processing (NLP) yang berperan untuk membangun sistem untuk mengenali dan
mengeskstraksi opini atau pendapat atau penilaian seseorang terhadap suatu
aplikasi atau sesuatu yang terjadi di media sosial dalam bentuk teks. Penilaian
yang didapatkan oleh sebuah aplikasi melalui google playstore adalah berupa teks

2
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
atau opini yang ditulis oleh pengguna, opini tersebut dapat berupa review baik
ataupun buruk ataupun berupa kritik dan saran yang dapat digunakan untuk
mengembangkan aplikasi ke arah yang lebih baik sesuai dengan yang disarankan
oleh pengguna. Pengolahan data review yang didapatkan oleh aplikasi melalui
platform google playstore yang kemudian di analisa dengan analisa sentimen akan
menghasilkan kecenderungan penilaian terhadap aplikasi tersebut apakah
cenderung positif atau negatif. Hasil dari pengolahan data ini dapat dijadikan
sebagai bahan dasar evaluasi bagi pengembang aplikasi. Dalam penelitiannya
yang berjudul “Sentiment-aware Analysis of Mobile Apps User Reviews
Regarding Particular Updates” [28] menyebutkan bahwa aplikasi seluler online
kontemporer (aplikasi) pasar memungkinkan pengguna untuk meninjau aplikasi
yang mereka gunakan. Ulasan ini adalah aset penting yang mencerminkan
kebutuhan dan keluhan pengguna mengenai aplikasi tertentu, yang mencakup
berbagai aspek kualitas aplikasi seluler. Dengan menyelidiki konten ulasan
tersebut, pengembang aplikasi dapat memperoleh informasi bermanfaat yang
memandu pekerjaan pemeliharaan dan evolusi di masa depan. Selanjutnya
bersama dengan pembaruan aplikasi, ulasan yang diberikan pengguna khususnya
keluhan dan pujian tentang pembaruan tertentu.
Penelitian ini bertujuan untuk melakukan analisa terhadap opini atau
penilaian pengguna dan mengklasifikasikan opini tersebut menjadi 2 kelas yaitu
positif dan negatif menggunakan algoritma klasifikasi data mining, data yang
akan diolah adalah yang didapatkan dari google play store untuk aplikasi
pembelajaran. Aplikasi pembelajaran yang akan diteliti adalah aplikasi ruang guru
dan zenius.
1.2. Identifikasi Masalah
Opini atau pendapat pengguna aplikasi pembelajaran daring berupa negatif
maupun positif yang mereka berikan melalui platform google playstore akan
diklasifikasikan menjadi 2 kelas yaitu kelas positif dan negatif dengan
menggunakan beberapa algoritma klasifikasi data mining. Dari pengolahan data
yang dilakukan akan diketahui model klasifikasi menggunakan algoritma apa
yang menghasilkan klasifikasi sentimen dengan nilai akurasi terbaik dalam
pengklasifikasian opini yang diberikan pengguna terhadap aplikasi pembelajaran

3
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
serta bagaimana hasil akurasi dari tiap-tiap algoritma klasifikasi data mining
dalam mengklasifikasikan sentimen dari aplikasi pembelajaran.
1.3. Tujuan Penelitian
Tujuan dari penelitian ini adalah mengimplementasikan algoritma
klasifikasi data mining untuk mengklasifikasikan sentimen dari penilaian
pengguna aplikasi pembelajaran daring yang diperoleh dari google playstore ke
dalam 2 kelas yaitu kelas positif dan negatif menggunakan algoritma klasifikasi
data mining seperti naive bayes, K-NN, dan decision tree.
1.4. Ruang Lingkup Penelitian
Agar pokok bahasan penelitian ini tidak keluar dari fokus utama yang
dikerjakan oleh peneliti, maka peneliti memberikan batasan ruang lingkup
penelitian sebagai berikut:
1. Algoritma yang digunakan adalah algoritma klasifikasi data mining seperti
Naive Bayes, K- Nearest Neighbour (K-NN), dan Decision Tree
2. Dataset yang digunakan adalah review pengguna aplikasi ruang guru dan
zenius yang ada di google playstore
3. Atribut dari sentimen yang diklasifikasikan terdiri dari 2 atribut yaitu positif
dan negatif.
1.5. Sistematika Penulisan
Sistematika penulisan dalam tesis ini terdiri dari beberapa bab yang disusun
sebagai berikut:
BAB I PENDAHULUAN
Pada bab pendahuluan ini diuraikan fakta yang berkaitan dengan
permasalahan yang akan diteliti, mendeskripsikan mengenai latar belakang
masalah, identifikasi masalah, tujuan penelitian, ruang lingkup penelitian,
hipotesis dan sistematika penulisan.
BAB II LANDASAN/KERANGKA PEMIKIRAN
Bab ini membahas tentang landasan teoritis yang digunakan oleh peneliti
untuk menunjang penelitian yang mencakup tinjauan pustaka, tinjauan
studi dan tinjauan objek penelitian.

4
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
BAB III METODOLOGI PENELITIAN
Bab ini membahas tentang metode pengumpulan data yang digunakan
dalam penelitian serta membahas tentang rencana penelitian serta konsep
dari penelitian yang nantinya akan digunakan sebagai solusi penyelesaian
masalah yang diangkat dalam penelitian ini.
BAB IV HASIL PENELITIAN DAN PEMBAHASAN
Bab ini berisi tentang analisa dan pembahasan yang dilakukan dimulai dari
pengambilan data, pengolahan data dengan algoritma Naive Bayes, K-NN,
dan Decision Tree untuk mendapatkan akurasi dari masing-masing
algoritma yang digunakan serta menjelaskan hasil penelitian dan
penerapan hasil penelitian.
BAB V PENUTUP
Bab ini berisi tentang kesimpulan dari pembahasan pada bab-bab
sebelumnya dan saran untuk penelitian selanjutnya.

5
5
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
BAB II
LANDASAN TEORI
2.1. Tinjauan Pustaka
Dalam penyusunan laporan ini, penulis melakukan beberapa tinjauan
pustaka dan literatur-literatur lain yang berhubungan dengan konsep penelitian
untuk mengklasifikasikan sentimen. Tinjauan pustaka ini meliputi beberapa hal
seperti:
2.1.1. Sentiment analysis
Sentiment analysis adalah proses analisis dari berbagai data berupa
pandangan atau opini sehingga dihasilkan kesimpulan dari berbagai opini yang
ada, hasil dari sentiment analysis dapat berupa persentase sentimen positif,
negatif, atau netral. Beberapa pengguna juga menginginkan keluaran yang
dihasilkan berupa representasi visual dari data teks atau nama lainnya word plot
[10].
Sentiment analysis (SA) atau Opinion mining (OM) adalah studi
komputasi atas pendapat, sikap, dan emosi orang terhadap suatu entitas. Entitas
dapat mewakili individu, acara, atau topik. Opinion mining bertugas untuk
mengekstraksi dan menganalisis pendapat orang tentang suatu entitas, sementara
Sentiment Analysis adalah untuk mengidentifikasi sentimen yang diungkapkan
dalam suatu teks lalu menganalisisnya. Oleh karena itu, tujuan utama dari
Sentiment Analysis adalah untuk menemukan pendapat, mengidentifikasi
sentimen yang diungkapkan, dan kemudian mengklasifikasikan polaritasnya
(positif, negatif, ataupun netral) [16].
2.1.2. Data mining
Writen, Ian H. Frank (2011) menyatakan bahwa data mining adalah proses
ekstraksi suatu data (sebelumnya tidak diketahui, bersifat implisit, dan dianggap
tidak berguna) menjadi informasi atau pengetahuan atau pola dari data yang
jumlahnya besar [7].
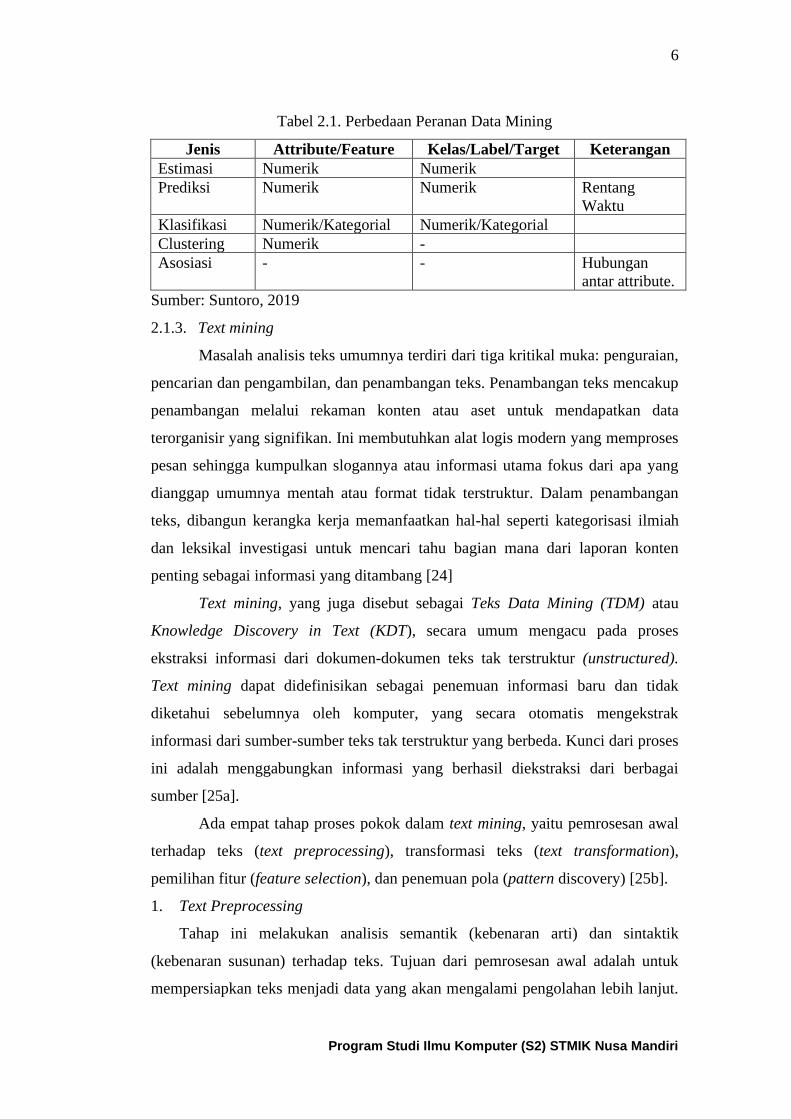
Secara umum terdapat 5 (lima) peranan dalam data mining, yaitu estimasi,
prediksi, klasifikasi, clustering dan asosiasi. Tabel 2.1 menunjukkan perbedaan
masing-masing peranan data mining.
6
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Tabel 2.1. Perbedaan Peranan Data Mining
Jenis Attribute/Feature Kelas/Label/Target Keterangan
Estimasi Numerik Numerik
Prediksi Numerik Numerik Rentang
Waktu
Klasifikasi Numerik/Kategorial Numerik/Kategorial
Clustering Numerik -
Asosiasi - - Hubungan
antar attribute.
Sumber: Suntoro, 2019
2.1.3. Text mining
Masalah analisis teks umumnya terdiri dari tiga kritikal muka: penguraian,
pencarian dan pengambilan, dan penambangan teks. Penambangan teks mencakup
penambangan melalui rekaman konten atau aset untuk mendapatkan data
terorganisir yang signifikan. Ini membutuhkan alat logis modern yang memproses
pesan sehingga kumpulkan slogannya atau informasi utama fokus dari apa yang
dianggap umumnya mentah atau format tidak terstruktur. Dalam penambangan
teks, dibangun kerangka kerja memanfaatkan hal-hal seperti kategorisasi ilmiah
dan leksikal investigasi untuk mencari tahu bagian mana dari laporan konten
penting sebagai informasi yang ditambang [24]
Text mining, yang juga disebut sebagai Teks Data Mining (TDM) atau
Knowledge Discovery in Text (KDT), secara umum mengacu pada proses
ekstraksi informasi dari dokumen-dokumen teks tak terstruktur (unstructured).
Text mining dapat didefinisikan sebagai penemuan informasi baru dan tidak
diketahui sebelumnya oleh komputer, yang secara otomatis mengekstrak
informasi dari sumber-sumber teks tak terstruktur yang berbeda. Kunci dari proses
ini adalah menggabungkan informasi yang berhasil diekstraksi dari berbagai
sumber [25a].
Ada empat tahap proses pokok dalam text mining, yaitu pemrosesan awal
terhadap teks (text preprocessing), transformasi teks (text transformation),
pemilihan fitur (feature selection), dan penemuan pola (pattern discovery) [25b].
1. Text Preprocessing
Tahap ini melakukan analisis semantik (kebenaran arti) dan sintaktik
(kebenaran susunan) terhadap teks. Tujuan dari pemrosesan awal adalah untuk
mempersiapkan teks menjadi data yang akan mengalami pengolahan lebih lanjut.

7
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Operasi yang dapat dilakukan pada tahap ini meliputi part-of-speech (PoS)
tagging, menghasilkan parse tree untuk tiap-tiap kalimat, dan pembersihan teks.
Teknik yang biasa dilakukan dalam penelitian di Indonesia pada tahap
preprocessing antara lain [25c]:
a. Annotation removal bertujuan untuk menghapus dan menghilangkan
karakter yang dianggap tidak perlu dan tidak penting.
b. Regex filter digunakan untuk mencocokan string teks, seperti karakter
tertentu, kata-kata, atau pola karakter dan mengelompokkannya.
c. Remove emoticon digunakan untuk mengkonversi bahkan menghilangkan
simbol emoticon.
d. Indonesian Stemming digunakan untuk mencari kata dasar dari kata-kata
berbahaa Indonesia.
e. Transformation Not prosesnya tidak menghapus kata melainkan
mengambil untuk menilai bahwa kalimat yang diproses mengandung
kalimat negatif. Selanjutnya akan ditambahkan ke sebuah variabel yang
sudah ditentukan untuk dihitung. Misalnya kasus sentimen analisis yang
membutuhkan penilaian pada kalimat positif dan negatif.
f. Stopword removal biasanya digunakan untuk menghilangkan kalimat
tidak penting seperti kata penghubung.
g. Punctuation bertujuan menghapus semua karakter non alphabet misalnya
simbol, spasi dan lain-lain.
h. N-chars filter berfungsi untuk menetapkan batasan minimal karakter yang
dimiliki oleh sebuah kata.
2. Text Transformation
Transformasi teks atau pembentukan atribut mengacu pada proses untuk
mendapatkan representasi dokumen yang diharapkan. Pendekatan representasi
dokumen yang lazim digunakan oleh model “bag of words” dan model ruang
vector (vector space model). Transformasi teks sekaligus juga melakukan
pengubahan kata-kata ke bentuk dasarnya dan pengurangan dimensi kata di dalam
dokumen. Tindakan ini diwujudkan dengan menerapkan stemming dan
menghapus stop words.

8
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
3. Feature Selection
Pemilihan fitur (kata) merupakan tahap lanjut dari pengurangan dimensi pada
proses transformasi teks. Walaupun tahap sebelumnya sudah melakukan
penghapusan kata-kata yang tidak deskriptif (stopwords), namun tidak semua
kata-kata di dalam dokumen memiliki arti penting. Oleh karena itu, untuk
mengurangi dimensi, pemilihan hanya dilakukan terhadap kata-kata yang relevan
yang benar-benar merepresentasikan isi dari suatu dokumen. Ide dasar dari
pemilihan fitur adalah menghapus kata-kata yang kemunculannya di suatu
dokumen terlalu sedikit atau terlalu banyak. Algoritma yang digunakan pada text
mining, biasanya tidak hanya melakukan perhitungan pada dokumen saja, tetapi
juga pada feature . Empat macam feature yang sering digunakan:
a. Character, merupakan komponan individual, bisa huruf, angka, karakter
spesial dan spasi, merupakan block pembangun pada level paling tinggi
pembentuk semantik feature, seperti kata, term dan concept. Pada
umumnya, representasi character-based ini jarang digunakan pada
beberapa teknik pemrosesan teks.
b. Words.
c. Terms merupakan single word dan multiword phrase yang terpilih secara
langsung dari corpus. Representasi term-based dari dokumen tersusun dari
subset term dalam dokumen.
d. Concept, merupakan feature yang di-generate dari sebuah dokumen secara
manual, rule-based, atau metodologi lain.
e. Pattern Discovery
Pattern discovery merupakan tahap penting untuk menemukan pola atau
pengetahuan (knowledge) dari keseluruhan teks. Tindakan yang lazim
dilakukan pada tahap ini adalah operasi text mining, dan biasanya
menggunakan teknik-teknik data mining. Dalam penemuan pola ini, proses
text mining dikombinasikan dengan proses-proses data mining. Masukan
awal dari proses text mining adalah suatu data teks dan menghasilkan
keluaran berupa pola sebagai hasil interpretasi atau evaluasi. Apabila hasil
keluaran dari penemuan pola belum sesuai untuk aplikasi, dilanjutkan
evaluasi dengan melakukan iterasi ke satu atau beberapa tahap

9
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
sebelumnya. Sebaliknya, hasil interpretasi merupakan tahap akhir dari
proses text mining dan akan disajikan ke pengguna dalam bentuk visual.
4. Ekstraksi Dokumen
Teks yang akan dilakukan proses text mining, pada umumnya memiliki
beberapa karakteristik diantaranya adalah memiliki dimensi yang tinggi, terdapat
noise pada data, dan terdapat struktur teks yang tidak baik. Cara yang digunakan
dalam mempelajari suatu data teks, adalah dengan terlebih dahulu menentukan
fitur-fitur yang mewakili setiap kata untuk setiap fitur yang ada pada dokumen.
Sebelum menentukan fitur-fitur yang mewakili, diperlukan tahap preprocessing
yang dilakukan secara umum dalam teks mining pada dokumen, yaitu case
folding, tokenizing, filtering, stemming, tagging dan analyzing.
a. Case folding dan Tokenizing
Case folding adalah mengubah semua huruf dalam dokumen menjadi
huruf kecil. Hanya huruf “a” sampai dengan “z” yang diterima. Karakter selain
huruf dihilangkan dan dianggap delimiter. Tahap tokenizing / parsing adalah
tahap pemotongan string input berdasarkan tiap kata yang menyusunnya.
b. Filtering
Filtering adalah tahap mengambil kata-kata penting dari hasil token. Bisa
menggunakan algoritma stoplist (membuang kata yang kurang penting) atau
wordlist (menyimpan kata penting). Stoplist/stopword adalah kata-kata yang
tidak deskriptif yang dapat dibuang dalam pendekatan bag-of-words. Contoh
stopwords adalah “yang”, “dan”, “di”, “dari”, dan seterusnya.
c. Stemming
Tahap stemming adalah tahap mencari root kata dari tiap kata hasil
filtering. Pada tahap ini dilakukan proses pengembalian berbagai bentukan kata
ke dalam suatu representasi yang sama. Tahap ini kebanyakan dipakai untuk
teks berbahasa Inggris dan lebih sulit diterapkan pada teks berbahasa
Indonesia. Hal ini dikarenakan bahasa Indonesia tidak memiliki rumus bentuk
baku yang permanen. Stemming merupakan suatu proses yang terdapat dalam
sistem IR yang mentransformasi kata-kata yang terdapat dalam suatu dokumen
ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu.
Sebagai contoh, kata bersama, kebersamaan, menyamai, akan distem ke root
wordnya yaitu “sama”. Proses stemming pada teks berbahasa Indonesia

10
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa
Inggris, proses yang diperlukan hanya proses menghilangkan sufiks.
Sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks
juga dihilangkan.
2.1.4. Aplikasi Mobile
Aplikasi Mobile adalah perangkat lunak yang berjalan pada perangkat
mobile seperti smartphone atau tablet PC. Aplikasi Mobile juga dikenal sebagai
aplikasi yang dapat diunduh dan memiliki fungsi tertentu sehingga menambah
fungsionalitas dari perangkat mobile itu sendiri. Untuk mendapatkan mobile
application yang diinginkan, user dapat mengunduhnya melalui situs tertentu
sesuai dengan sistem operasi yang dimiliki. Google Play dan iTunes merupakan
beberapa contoh dari situs yang menyediakan beragam aplikasi bagi pengguna
Android dan iOS untuk mengunduh aplikasi yang diinginkan [14].
2.1.5. Ruang Guru
PT Ruang Raya Indonesia (Ruangguru) adalah perseroan terbatas yang
bergerak di bidang pendidikan nonformal yang didirikan menurut dan berdasarkan
hukum yang berlaku di Indonesia serta telah memperoleh Izin Pendirian Satuan
Pendidikan Nonformal dan Izin Operasional Lembaga Kursus Pelatihan dengan
Nomor 3/A.5a/31.74.01/-1.851.332/2018. Ruangguru merupakan perusahaan
teknologi terbesar di Indonesia yang berfokus pada layanan berbasis pendidikan.
Kami telah memiliki lebih dari 15 juta pengguna serta mengelola 300.000 guru
yang menawarkan jasa di lebih dari 100 bidang pelajaran. Ruangguru
mengembangkan berbagai layanan belajar berbasis teknologi, termasuk layanan
kelas virtual, platform ujian online, video belajar berlangganan, marketplace les
privat, serta konten-konten pendidikan lainnya yang bisa diakses melalui web dan
aplikasi Ruangguru. Ruangguru juga telah dipercaya untuk bermitra dengan 32
(dari 34) Pemerintah Provinsi dan 326 Pemerintah Kota dan Kabupaten di
Indonesia. Ruangguru juga telah memenangkan sejumlah penghargaan di dalam
dan luar negeri, termasuk Solver of MIT, Atlassian Prize, UNICEF Innovation to
Watch,Google Launchpad Accelerator, dan ITU Global Industry Award.
Perusahaan ini didirikan sejak tahun 2014 oleh Belva Devara dan Iman Usman,
yang keduanya berhasil masuk dalam jajaran pengusaha sukses di bawah 30 tahun

11
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
melalui Forbes 30 under 30 untuk sektor teknologi konsumen di Asia. Di tahun
2019, mereka mendapat penghargaan sebagai Emerging Entrepreneur dari Ernst
& Young [18].
2.1.6. Zenius
Zenius adalah pelopor startup teknologi pendidikan di Indonesia. Zenius
memproduksi konten pendidikan untuk semua level pendidikan dari SD, SMP,
dan SMA beserta persiapan ujian nasional dan tes masuk perguruan tinggi. Sejak
tahun 2004, Zenius mempunyai visi untuk membentuk Indonesia yang cerdas dan
cerah. Kami memulai perjalanan kami pada tahun 2008 dengan produk CD/DVD,
sebelum beralih ke website zenius.net pada tahun 2010. Hingga sekarang kami
berhasil meluncurkan mobile apps yang bisa diungguh melalui iOS dan Android.
Sekarang, Zenius telah memiliki lebih dari 74,000 video pembelajaran dan
puluhan ribu latihan soal [30].
2.1.7. Naïve Bayes
Naive Bayes (NB) adalah sebuah metode klasifikasi sederhana yang
mengaplikasikan teorema Bayes. Dalam perhitungan probabilitas, NB
mengasumsikan bahwa nilai atribut suatu kelas tidak memiliki keterkaitan dengan
keberadaan atribut dikelas lain. Meski dalam kenyataanya setiap atribut hampir
dipastikan memiliki ketergantungan dengan atribut lain, namun dengan asumsi
naif seperti ini membuat Naive Bayes mudah dalam perhitungan [1]. Pada
algoritma NB, sejumlah petunjuk yang disebut atribut diperlukan untuk membantu
membentuk kelas yang sesuai untuk sampel dianalisis, di mana kehadiran fitur-
fitur tertentu dalam kelas tidak terkait dengan fitur lainnya [19]
Metode pengklasifikasian dengan menggunakan metode probabilitas dan
statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu
memprediksi peluang di masa depan berdasarkan pengalaman di masa
sebelumnya sehingga dikenal sebagai teori Bayes [2]. Formula umum teorema
Bayes:
P(C|E) =P(E|C)P(C)
P(E)…………………… . . (2.5)

12
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Keterangan:
a. P(C|E) : Probabilitas akhir bersyarat (conditional probability) suatu
hipotesis C terjadi jika diberikan bukti (evidence) E terjadi.
b. P(E|C) : Probabilitas sebuah bukti E terjadi akan memengaruhi hipotesis
C.
c. P(C) : Probabilitas awal (priori) hipotesis C terjadi tanpa memandang
bukti apapun.
d. P(E) : Probabilitas awal (priori) bukti E terjadi tanpa memandang
hipotesis/bukti yang lain.
2.1.8. K-Nearest Neighbour (K-NN)
Algoritma K-Nearest Neighbour (KNN) adalah algoritma
pengklasifikasian data sederhana dimana penghitungan jarak terpendek dijadikan
ukuran untuk mengklasifikasikan suatu kasus baru berdasarkan ukuran kemiripan.
Algoritma KNN tergolong dalam algoritma supervised yaitu proses pembentukan
algoritma diperoleh melalui proses pembelajaran (learning) pada record-record
lama yang sudah terklasifikasi dan hasil pembelajaran tersebut dipakai untuk
mengklasifikasikan record baru dengan output yang belum diketahui [17]. Metode
pembelajaran berbasis instance ditentukan oleh tiga sifat sebagai berikut:
1. Menyimpan semua data pelatihan selama proses pembelajaran.
2. Generalisasi diluar data pelatihan ditunda sampai nilai diprediksi untuk kasus
baru, karena setiap pertanyaan baru dijawab dengan membandingkan kasus
baru dengan data pelatihan.
3. Dari data pelatihan KNN mencari kasus yang mirip dengan kasus baru. Dalam
K-Nearest Neighbours setiap instance didefinisikan oleh sejumlah atribut dan
semua instance di dalam data diwakili oleh jumlah atribut yang sama,
meskipun mungkin ada beberapa nilai atribut yang hilang. Salah satu atribut
ini disebut atribut kelas yang berisi nilai kelas (label) dari data, yang nilainya
diperkirakan untuk instance baru yang tidak terlihat.
Aturan 1-NN mengasumsikan nilai tetangga terdekat menjadi kelas dari
instance baru. K dapat berupa sejumlah tetangganya, K = 1, 2, 3, 4,…, n, dimana
n adalah jumlah kasus. Kedekatan tetangga didefinisikan berdasarkan atribut yang
mendefinisikan instance baru dan instance pelatihan. Instance pelatihan yang nilai

13
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
atributnya mirip dengan instance baru dianggap sebagai yang terdekat, tetapi
sering kali instance serupa persis tidak ditemukan, jadi instance terdekat adalah
yang paling tidak memiliki perbedaan [13].
2.1.9. Decision Tree
Metode pohon keputusan mengubah fakta yang sangat besar menjadi
pohon keputusan yang merepresentasikan rules [29]. Kelebihan dari metode
pohon keputusan adalah:
1. Daerah pengambilan keputusan yang sebelumnya kompleks dan sangat
global, dapat diubah menjadi lebih simpel dan spesifik
2. Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena ketika
menggunakan metode pohon keputusan maka sampel diuji hanya berdasarkan
kriteria atau kelas tertentu
3. Fleksibel untuk memilih fitur dari node internalyang berbeda, fitur yang
terpilih akan membedakan suatu kriteria dibandingkan kriteria yang lain
dalam node yang sama. Kefleksibelan metode pohon keputusan ini
meningkatkan kualitas keputusan yang dihasilkan jika dibandingkan ketika
menggunakan metode penghitungan satu tahap yang lebih konvensional
2.1.10. Knime
Platform KNIME Analytics adalah perangkat lunak sumber terbuka untuk
membuat aplikasi dan layanan ilmu data. Intuitif, terbuka, dan terus menerus
mengintegrasikan pengembangan baru, KNIME membuat pemahaman data dan
merancang alur kerja ilmu data dan komponen yang dapat digunakan kembali
dapat diakses oleh semua orang. Dengan Platform Analisis KNIME, Anda dapat
membuat alur kerja visual dengan antarmuka grafis gaya intuitif, seret dan lepas,
tanpa perlu pengkodean [8].
2.1.11. Webharvy
WebHarvy dapat dengan mudah mengekstraksi Teks, HTML, Gambar,
URL & Email dari situs web, dan menyimpan konten yang diekstraksi dalam
berbagai format. Webharvy sangat mudah digunakan, mulai mengumpulkan data
dalam hitungan menit, mendukung semua jenis situs web. Menangani login,
pengiriman formulir, dll. Ekstrak data dari banyak halaman, kategori & kata
14
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
kunci. Penjadwal built-in, dukungan Proxy / VPN, Smart Help dan banyak lagi
[27].
2.1.12. Gataframework
Pada tahun 2018, seseorang bernama Windu Gata mengembangkan
aplikasi berbasis web untuk pra-pemrosesan text mining seperti Indonesian
stopwords, Indonesian stemming, Indonesian Acronym, Indonesian Slank dan
lainnya dimaksudkan untuk membantu peneliti dalam melakukan penelitian di
bidang penambangan teks bahasa Indonesia. Aplikasi ini dibangun menggunakan
kerangka kerja yang disebut kerangka kerja GATA
(http://www.gataframework.com). Aplikasi ini merupakan alternatif dalam teks
pra-pemrosesan Indonesia, aplikasi juga menyediakan fitur antarmuka program
aplikasi (API) untuk mengirim data dari aplikasi eksternal [21].
2.2. Tinjauan studi (Penelitian terkait)
Penelitian mengenai analisa sentimen telah lama dilakukan dan hasil dari
penelitian tersebut juga telah banyak yang dipublikasikan. Tinjauan studi terhadap
penelitian sebelumnya dilakukan untuk dapat mengetahui metode, data, dan juga
model penelitian yang sudah pernah dilakukan. Tinjauan studi yang mendukung
penelitian ini sebagai berikut:
Tabel 2.2. Rangkuman penelitian terkait
Peneliti Dataset Masalah Metode Hasil
Muhammad
Romy
Firdaus, Fikri
Muhammad
Rizki, Favian
Muhammad
Gaus, Indra
Kusumajati
Susanto
(2020)
Data
komentar
pengguna
ruang guru
yang diambil
dari
youtube.com
Kepuasan
pelanggan adalah
evaluasi pasca
pemakaian produk.
Kepuasan
pelanggan
mewakili suatu
fokus strategi
terpusat untuk
perusahaan yang
berorientasi
pelanggan
diberbagai industri.
Sentimen dari
komentar yang
diberikan
pelanggan terhadap
suatu produk dapat
mencerminkan
Sentiment
analysis
Hasil dari
penerapan
metode
tersebut
menunjukka
n respon di
komentar
YouTube
terhadap
fitur
ruangbelajar
dari
Ruangguru
kebanyakan
pengguna
memberikan
respon
dengan
sentimen
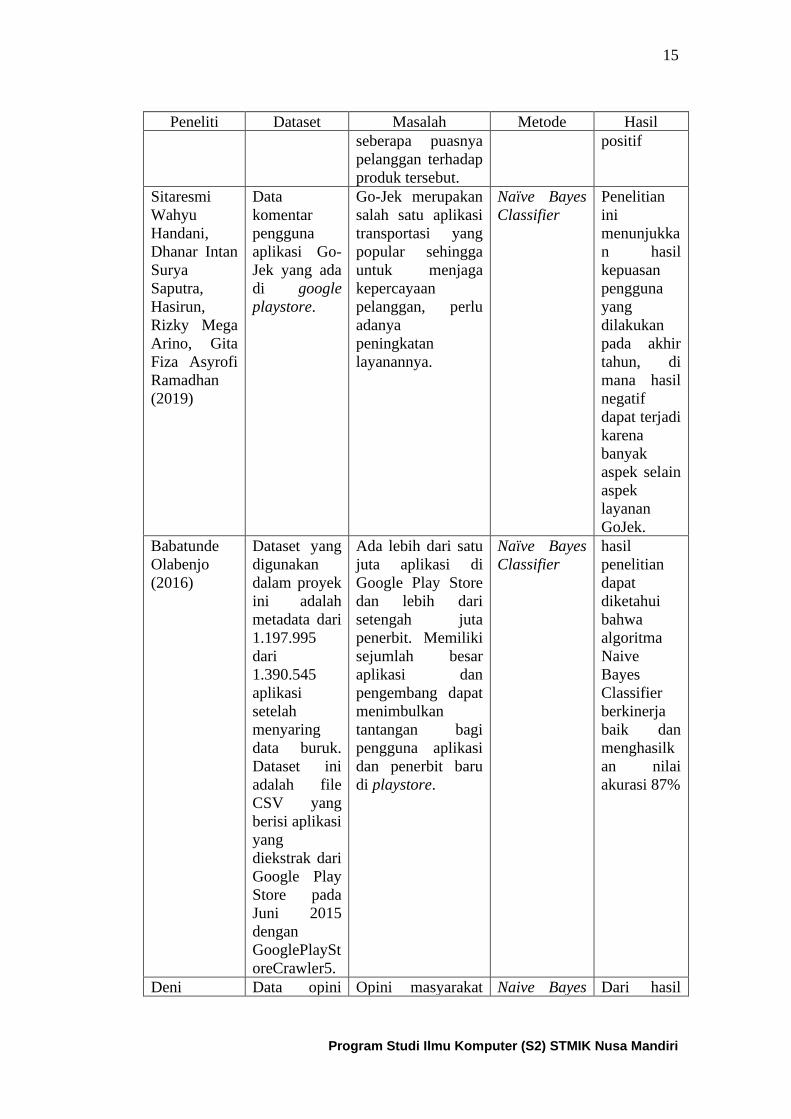
15
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Peneliti Dataset Masalah Metode Hasil
seberapa puasnya
pelanggan terhadap
produk tersebut.
positif
Sitaresmi
Wahyu
Handani,
Dhanar Intan
Surya
Saputra,
Hasirun,
Rizky Mega
Arino, Gita
Fiza Asyrofi
Ramadhan
(2019)
Data
komentar
pengguna
aplikasi Go-
Jek yang ada
di google
playstore.
Go-Jek merupakan
salah satu aplikasi
transportasi yang
popular sehingga
untuk menjaga
kepercayaan
pelanggan, perlu
adanya
peningkatan
layanannya.
Naïve Bayes
Classifier
Penelitian
ini
menunjukka
n hasil
kepuasan
pengguna
yang
dilakukan
pada akhir
tahun, di
mana hasil
negatif
dapat terjadi
karena
banyak
aspek selain
aspek
layanan
GoJek.
Babatunde
Olabenjo
(2016)
Dataset yang
digunakan
dalam proyek
ini adalah
metadata dari
1.197.995
dari
1.390.545
aplikasi
setelah
menyaring
data buruk.
Dataset ini
adalah file
CSV yang
berisi aplikasi
yang
diekstrak dari
Google Play
Store pada
Juni 2015
dengan
GooglePlaySt
oreCrawler5.
Ada lebih dari satu
juta aplikasi di
Google Play Store
dan lebih dari
setengah juta
penerbit. Memiliki
sejumlah besar
aplikasi dan
pengembang dapat
menimbulkan
tantangan bagi
pengguna aplikasi
dan penerbit baru
di playstore.
Naïve Bayes
Classifier
hasil
penelitian
dapat
diketahui
bahwa
algoritma
Naive
Bayes
Classifier
berkinerja
baik dan
menghasilk
an nilai
akurasi 87%
Deni Data opini Opini masyarakat Naive Bayes Dari hasil
16
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Peneliti Dataset Masalah Metode Hasil
Rusdiaman
dan Didi
Rosiyadi
(2019)
publik
mengenai
tokoh
masyarakat
yang
dilontarkan
melalui
media sosial
terhadap tokoh
publik sangat
mudah tersebar
melalui media
sosial, opini
tersebut dapat
berupa opini
negatif ataupun
positif, semakin
hari opini tersebut
semakin banyak
dan tentunya
menjadi sebuah
data yang jika
diolah dapat
menghasilkan
informasi yang
berguna dimasa
depan.
Classifier
Support
Vector
Machine
pengolahan
data dengan
metode
tersebut
dapat
diperoleh
nilai akurasi
sebesar
73.96%
untuk
metode
Support
Vector
Machine
dan 71.94%
untuk
metode
Naive Bayes
Classifier.
Elly
Indrayuni
dan
Mochamad
Wahyudi
(2015)
Data review
hotel diambil
dari situs
www.tripadvi
sor.com
Pada saat liburan.
hotel merupakan
salah satu produk
pariwisata yang
sangat penting
untuk
dipertimbangkan
baik dari segi
fasilitas, pelayanan
ataupun jarak
tempuh perjalanan
wisata, Sebelum
memutuskan untuk
menentukan hotel
untuk menginap
sebaiknya
wisatawan
mengetahui dengan
detail informasi
mengenai hotel
tersebut, hal ini
dapat diperoleh
dengan membaca
opini atau hasil
review dari
pengalaman
wisatawan lain
yang tentunya
Naive Bayes
Classifier
Hasil
penelitian
menunjukka
n
peningkatan
akurasi 2%
untuk
algoritma
Naive
Bayes dari
82,67%
menjadi
84,67%
setelah
penerapan
fitur
character n-
gram.
17
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Peneliti Dataset Masalah Metode Hasil
membutuhkan
waktu yang cukup
lama.
Suwanda
Aditya
Saputra, Didi
Rosiyadi,
Windu Gata,
Syepri
Maulana
Husain
(2019)
Data diambil
dari google
play dari
ulasan
pengguna e-
wallet
Layanan e-wallet
saat ini umum
digunakan banyak
orang terutama
mereka yang
berada dalam usia
produktif. Alasan
utama mereka
menggunakan e-
wallet adalah
karena praktis.
Mereka tidak perlu
menyiapkan uang
tunai saat
bertransaksi.
Sedangkan bagi
penjual, mereka
tidak perlu repot
menyediakan
kembalian karena
pembayaran pasti
dilakukan dengan
nominal yang
sesuai dan
beberapa layanan
e-wallet di
Indonesia yang
muncul dalam
bentuk mobile
wallet atau aplikasi
sehingga
bermunculan
berbagai macam
penilaian terhadap
aplikasi e-wallet
tersebut.
Naive Bayes
Classifier
Hasil dari
cross
validation
NB tanpa
FS adalah
82.30 %
untuk
accuracy
dan 0.780
untuk AUC.
Sedangkan
untuk NB
dengan FS
adalah
83.60 %
untuk
accuracy
dan 0.801
untuk AUC.
Peningkatan
sangat
signifikan
dengan
penggunaan
Feature
Selection
Lutfi Budi
Ilmawan dan
Edi Winarko
(2015)
Ulasan
tekstual
aplikasi pada
Google Play
yang
dilakukan
untuk menilai
perangkat
Google dalam
application store-
nya, Google Play,
saat ini telah
menyediakan
sekitar
1.200.000 aplikasi
mobile. Dengan
Naive Bayes
Classifier
dan Support
Vector
Machine
Hasil dari
klasifikasi
menggunak
an
algoritma
Naive Bayes
menunjukka
n nilai
18
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Peneliti Dataset Masalah Metode Hasil
mobile sejumlah aplikasi
tersebut membuat
pengguna memiliki
banyak pilihan.
Selain itu,
pengembang
aplikasi mengalami
kesulitan dalam
mencari tahu
bagaimana
meningkatkan
kinerja aplikasinya.
akurasi
sebesar
83.87%
sedangkan
nilai akurasi
yang
ditunjukkan
oleh
algoritma
Support
Vector
Machine
sebesar
89.49%.
Vibhor
Singh,
Priyansh
Saxena,
Siddharth
Singh and S.
Rajendran
(2017)
Data review
film yang
diambil dari
tiga sumber
yang berbeda
yaitu situs
web pribadi
peneliti,
flixster, dan
Ulasan pelanggan
penting untuk
berbagai bidang
(mis. Film, Produk,
Layanan). Tinjauan
film
memainkan peran
vital dalam
menggambarkan
keberhasilan dan
kegagalannya.
Orang-orang
sekarang menjadi
sangat spesifik
tentang film apa
yang akan ditonton
dan yang tidak
boleh ditonton.
Karenanya orang
tidak ingin
membuang waktu
untuk film yang
ulasannya buruk.
Saat ini ulasan
online penting
untuk rekomendasi
pribadi.
Naive Bayes,
Decision
tree, K-NN
Hasil dari
pengolahan
data yang
telah
dilakukan
menunjukka
n nilai
akurasi dari
algoritma
Naive Bayes
sebesar
54.10%, K-
NN sebesar
50.28%,
dan
Decision
Tree
sebesar
40.26%.
Sucitra
Sahara dan
Rizqi Agung
Permana
(2019)
Dataset yang
digunakan
adalah data
komentar
masyarakat
Aplikasi game
berbasis android
ataupun ios kini
sudah merambah ke
semua pengguna
K-Nearest
Neighbour
Hasil
pengklasifik
asian
menggunak
an metode
19
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Peneliti Dataset Masalah Metode Hasil
yang telah
menggunaka
n aplikasi
games anak
yang ada
pada kolom
komentar
website
penyedia
aplikasi.
smartphone mulai
dari dewasa remaja
sampai anak-anak,
maka dari itu para
vendor aplikasi
maupun pihak
pebisnis berlomba
menciptakan
aplikasi guna
meraup
keuntungan, mulai
kualitas dan
performa tinggi
sampai kualitas
yang masih sering
diragukan
khususnya pada
pengguna aplikasi
game anak dibawah
umur yang
membuat orang tua
khawatir dengan
yang di konsumsi
anaknya
K-NN
menunjukka
n nilai
akurasi
sebesar
78.50%.
Lopamudra
Dey, Sanjay
Chakraborty,
Anuraag
Biswas,
Beepa Bose,
dan Sweta
Tiwari
(2016)
Data review
film dari situs
www.imdb.c
om dan data
review hotel
yang diunduh
dari
OpinRank
Review
Dataset
(http://archiv
e.ics.uci.edu/
ml/datasets/O
pinRan
k+Review+D
ataset)
The
Kemunculan Web
2.0 telah
menyebabkan
peningkatan jumlah
konten sentimental
yang tersedia di
Web. Konten
semacam itu sering
ditemukan di situs
web media sosial
dalam bentuk
ulasan film atau
produk, komentar
pengguna,
testimoni, pesan di
forum diskusi, dll.
Penemuan tepat
waktu atas konten
web yang
sentimental atau
berargumentasi
memiliki sejumlah
keunggulan, yang
K-Nearest
Neighbour
dan Naive
Bayes
Nilai
akurasi dari
review film
menggunak
an
algoritma
Naive Bayes
sebesar
82.43% dan
K-NN
sebesar
69.81%.
Sedangkan
nilai akurasi
dari review
hotel
dengan
metode
Naive Bayes
menghasilk
an nilai
akurasi
sebesar

20
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Peneliti Dataset Masalah Metode Hasil
terpenting dari pada
mencari sebuah
keuntungan dan
omset semata
55.09% dan
K-NN
sebesar
52.14%.
2.2.1. Penelitian Muhammad Romy Firdaus, Fikri Muhammad Rizki, Favian
Muhammad Gaus, Indra Kusumajati Susanto (2020)
Penelitian ini bertujuan untuk mengetahui dan menganalisis tanggapan
mengenai kepuasan pelanggan aplikasi ruangguru terhadap fitur ruangbelajar
dalam aplikasi ruangguru pada setiap jenjang pendidikan. Hal ini berguna untuk
mengetahui kekuatan dan kelemahan dari aplikasi ruangguru berdasarkan respon
sentimen dari pengguna ruangguru. Dataset yang digunakan dalam penelitian ini
adalah data komentar para pengguna aplikasi ruang guru yang ada di
youtube.com.
Untuk melihat bagaimana tingkat kepuasan dari pelanggan, digunakan
metode analisis sentimen dan juga topic modelling dalam pengolahan datanya
agar dapat dilihat respon seperti apa yang diberikan oleh pelanggan sehingga
dapat menjadi evaluasi bagi aplikasi ruangguru.
Hasil dari penerapan metode tersebut menunjukkan respon di komentar
YouTube terhadap fitur ruangbelajar dari Ruangguru kebanyakan pengguna
memberikan respon dengan sentimen positif, ini berarti para penggunanya merasa
puas dengan fitur ruangbelajar yang diberikan oleh ruangguru, dimana pengguna
yang memberikan respon dengan sentimen positif [15]
2.2.2. Penelitian Sitaresmi Wahyu Handani, Dhanar Intan Surya Saputra,
Hasirun, Rizky Mega Arino, Gita Fiza Asyrofi Ramadhan (2019)
Penelitian ini bertujuan untuk mengukur tingkat sentimen hasil analisis
yang diberikan oleh pelanggan kepada Go-Jek melalui kolom komentar di Play
Store. Pendapat pelanggan diambil untuk mendapatkan komentar positif, negatif
atau netral.
Proses analisis sentiment terdiri dari pengidentifikasian data, dilakukan
tahap praprocessing, mengklasifikasikan semua data menggunakan metode Naïve
Bayes kemudian hasil klasifikasi diurutkan sesuai dengan jenis yang telah
ditentukan. Hasil penelitian yang dilakukan pada akhir 2017 (November dan

21
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Desember), dan memperoleh hasil berupa sentimen negatif setelah dilakukan
perhitungan Vmap terhadap data. Penelitian ini menunjukkan hasil kepuasan
pengguna yang dilakukan pada akhir tahun, di mana hasil negatif dapat terjadi
karena banyak aspek selain aspek layanan GoJek [23].
2.2.3. Penelitian Babatunde Olabenjo (2016)
Penelitian ini bertujuan untuk mengklasifikasikan kategori yang pada
aplikasi yang ada di google playstore. Dikarenakan aplikasi di google playstore
sangat banyak dan kategori aplikasinya hampir lebih dari 41 kategori, hal ini
menjadi tantangan tersendiri bagi pengembang aplikasi untuk menentukan
kategori yang tepat bagi aplikasi terbaru mereka, karena jika salah dalam memilih
kategori dapat berakibat mengurangi penghasilan.
Dalam penelitian ini, peneliti membangun 2 variasi Naive Bayes Classifier
menggunakan metadata open source dari google playstore untuk
mengklasifikasikan kategori aplikasi terbaru. Klasifikasi ini kemudian dievaluasi
menggunakan berbagai evaluasi metode dan hasilnya dibandingkan satu sama
lain. Dari hasil perbandingan tersebut dapat diketahui bahwa algoritma Naive
Bayes Classifier berkinerja baik danmenghasilkan nilai akurasi 87% untuk
masalah klasifikasi ini dan berpotensi mengotomatiskan kategorisasi aplikasi
untuk penerbit aplikasi android di google playstore [3].
2.2.4. Penelitian Deni Rusdiaman dan Didi Rosiyadi (2016)
Penelitian ini melakukan analisa sentimen terhadap tokoh publik yang
diungkapkan masyarakat melalui jejaring sosial twitter. Tahapan yang dilakukan
dalam penelitian ini diantaranya adalah pengumpulan data menggunakan API
Twitter, memberikan label kepada setiap twit secara manual, Pre Processing Data
dan POS Tagging. Untuk medapatkan nilai akurasi dari proses analisa yang
dilakukan, penelitian ini menggunakan metode Naive Bayes Classifier dan
Support Vector Machine. Dari hasil pengolahan data dengan metode tersebut
dapat diperoleh nilai akurasi sebesar 73.96% untuk metode Support Vector
Machine dan 71.94% untuk metode Naive Bayes Classifier [4].
2.2.5. Penelitian Elly Indrayuni dan Mochamad Wahyudi (2015)
Penelitian ini bertujuan untuk membuktikan pengaruh penerapan character
n-gram pada tahap preprocessing berdasarkan tingkat akurasi yang dihasilkan

22
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
dalam mengklasifikasikan analisa sentimen review hotel menggunakan algoritma
Naive Bayes. Penerapan fitur n-gram karakter pada penelitian ini diharapkan dapat
meningkatkan nilai akurasi metode. N-gram dianggap mengurangi perbedaan
antara klasifikasi kelas positif dan negatif sehingga dapat meningkatkan akurasi
rata-rata akhir suatu algoritma.
Hasil klasifikasi sentimen dalam penelitian ini terdiri dari dua kelas label,
yaitu positif dan negatif. Keakuratan nilai yang dihasilkan akan menjadi patokan
untuk menemukan model uji terbaik untuk kasus klasifikasi sentimen. Evaluasi
dilakukan dengan menggunakan K-fold cross validation dengan jumlah fold 10.
Akurasi pengukuran diukur dengan matriks kebingungan dan kurva ROC. Hasil
penelitian menunjukkan peningkatan akurasi 2% untuk algoritma Naive Bayes
dari 82,67% menjadi 84,67% setelah penerapan fitur character n-gram [6].
2.2.6. Penelitian Suwanda Aditya Saputra, Didi Rosiyadi, Windu Gata, Syepri
Maulana Husain (2019)
Penelitian ini bertujuan untuk mengklasifikasikan penilaian pengguna
terhadap aplikasi e-wallet kedalam kelas positif dan negatif. Aplikasi e-wallet
yang digunakan dalam penelitian ini adalah OVO dimana penilaian penggunanya
yang akan diteliti diambil dari review aplikasi dalam google playstore. Metode
yang digunakan dalam penelitian ini adalah Naive Bayes Classifier (NB), dengan
optimasi penggunaan Feature Selection (FS) Particle Swarm Optimization. Hasil
dari cross validation NB tanpa FS adalah 82.30 % untuk accuracy dan 0.780 untuk
AUC. Sedangkan untuk NB dengan FS adalah 83.60 % untuk accuracy dan 0.801
untuk AUC. Peningkatan sangat signifikan dengan penggunaan Feature Selection
(FS) Particle Swarm Optimization [20].
2.2.7. Penelitian Lutfi Budi Ilmawan dan Edi Winarko (2015)
Penelitian ini bertujuan untuk membangun sistem yang dapat
mengklasifikasikan ulasan pengguna google play yang diberikan melalui aplikasi
mobile dengan menggunakan algoritma klasifikasi data mining berupa Naive
Bayes Classifier dan Support Vector Machine. Hasil dari klasifikasi menggunakan
algoritma Naive Bayes menunjukkan nilai akurasi sebesar 83.87% sedangkan nilai
akurasi yang ditunjukkan oleh algoritma Support Vector Machine sebesar
89.49%[11].

23
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
2.2.8. Penelitian Vibhor Singh, Priyansh Saxena, Siddharth Singh and S.
Rajendran (2017)
Penelitian ini bertujuan untuk mengklasifikasikan ulasan tentang film
menjadi dua kelas yaitu positif dan negatif untuk mengukur keberhasilan atau
kegagalan film tersebut dan juga untuk memberikan informasi kepada calon
penonton yang pemilih apakah film tersebut boleh ditonton atau tidak. Ada
berbagai pekerjaan yang dilakukan pada pengambilan pendapat dan pengambilan
teks. Penelitian ini berfokus pada menganalisis sentimen dari orientasi semantik
kata-kata yang terjadi dalam teks dengan mendefinisikan kamus secara manual
untuk kata-kata positif, negatif dan intensif yang disimpan dalam file teks yang
berbeda. Dalam penelitian ini peneliti mengekstrak data dari tiga sumber berbeda.
Pendapat yang harus dianalisis adalah preprocessed dan disimpan dalam file teks.
Data kemudian dibandingkan dengan bag of words peneliti untuk menemukan
jumlah sentimen positif dan negatif dalam ulasan film tersebut. Untuk
memprediksi peringkat film.
Algoritma yang digunakan dalam penelitian ini adalah Naive Bayes, K-NN,
dan Decision Tree. Hasil dari pengolahan data yang telah dilakukan menunjukkan
nilai akurasi dari algoritma Naive Bayes sebesar 54.10%, K-NN sebesar 50.28%,
dan Decision Tree sebesar 40.26% [26].
2.2.9. Penelitian Sucitra Sahara dan Rizqi Agung Permana (2019)
Penelitian yang dilakukan adalah menganalisa sentimen terhadap aplikasi
games yang ditujukan untuk anak-anak dengan menggunakan metode K-Nearest
Neighbour. Tujuan dari penelitian ini adalah untuk mengklasifikasikan sentimen
atau ulasan pengguna ke dalam kelas positif atau negatif untuk mengetahui
kualitas games tersebut apakah sesuai atau tidak untuk dikonsumsi anak-anak.
Hasil pengklasifikasian menggunakan metode K-NN menunjukkan nilai akurasi
sebesar 78.50% [22].
2.2.10. Penelitian Lopamudra Dey, Sanjay Chakraborty, Anuraag Biswas, Beepa
Bose, dan Sweta Tiwari (2016)
Memahami sentimen masyarakat terhadap berbagai entitas dan produk
memungkinkan layanan yang lebih baik untuk iklan kontekstual, sistem
rekomendasi, dan analisis tren pasar. Fokus penelitian ini adalah kerangka kerja

24
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
web crawling yang berfokus pada sentimen untuk memfasilitasi penemuan cepat
pada konten sentimental ulasan film dan ulasan hotel menggunakam analisis yang
sama. Penelitian ini menggunakan metode statistik untuk menangkap elemen gaya
subyektif dan polaritas kalimat. Sentimen yang diperoleh dari hasil crawling
tersebut kemudian akan diklasifikasikan menjadi sentimen positif atau negatif
dengan menggunakan metode data mining yaitu metode Naive Bayes Classifier
dan K-NN dan membandingkan keseluruhan akurasi, precision serta nilai recall.
Dari jumlah keseluruhan data masing-masing review sebesar 5000 data, diperoleh
hasil dari pengolahan data yang paling baik yaitu ketika melakukan fold ke 10
dengan jumlah data 4500 data training, hasil tersebut menunjukkan nilai akurasi
dari review film menggunakan algoritma Naive Bayes sebesar 82.43% dan K-NN
sebesar 69.81%. Sedangkan untuk hasil pengolahan data terhadap review hotel
dengan jumlah fold dan data yang sama menggunakan metode Naive Bayes
menghasilkan nilai akurasi sebesar 55.09% dan K-NN sebesar 52.14% [12].
2.3. Tinjauan Objek penelitian
Objek penelitian ini adalah beberapa aplikasi pembelajaran daring yang
populer di Indonesia dan terdapat pada situs google playstore seperti ruangguru
dan zenius. Dataset yang digunakan dalam penelitian ini adalah data ulasan atau
review pengguna aplikasi pembelajaran daring seperti ruang guru dan zenius yang
diambil dari google playstore. Dataset berupa teks berbahasa Indonesia yang
diperoleh dengan cara melakukan crawling terhadap situs google playstore yang
menampilkan review pelanggan. Dataset hasil crawling ini berupa dokumen teks
yang tidak menyertakan atribut lainnya. Data hasil crawling kemudian dibagi
menjadi dua bagian yaitu data training dan data testing.

25
25
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
BAB III
METODE PENELITIAN
Gambar 3.1. Model Penelitian Usulan

26
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Gambar 3.1 menunjukan model yang diusulkan dalam penelitian dengan
menggunakan metode yang diusulkan yaitu metode CRISP-DM. Penelitian ini
bertujuan untuk mengetahui hasil komparasi dan evaluasi algoritma klasifikasi
data mining pada review aplikasi embelajaran daring yang populer di Indonesia
seperti Ruangguru dan Zenius kedalam kategori positif dan negatif menggunakan
algoritma Naive Bayes Classifier, K-NN, dan Decision Tree. Dalam mendesain
metode penelitian eksperimen ini peneliti menggunakan metode penelitian standar
yang digunakan pada data mining yaitu CRISP-DM.
3.1. Bussines Understanding
Pemahaman terhadap bisnis atau apa yang akan di bahas pada tulisan ini
sebagai memahami objek penelitian, objek penelian yang akan diteliti pada
penelitian ini adalah dua aplikasi pembelajaran daring yang paling populer di
Indonesia yaitu Ruang guru dan Zenius. Adapun tahap ini bertujuan untuk
memahami bidang masalah, menghasilkan solusi yang tepat, dan mengungkapkan
faktor penting yang berpengaruh pada hasil penelitian. Pada penelitian yang akan
dilakukan ini terdapat kebutuhan pengkategorian dari review terhadap aplikasi
tersebut yang diperoleh dari penilaian pengguna aplikasi yang diambil dari google
playstore verifikasi terhadap penilaian tersebut penting dilakukan dan karena
jumlah penilaian pengguna yang sangat banyak sehingga dibutuhkan data mining
untuk melakukan pengkategorian.
3.2. Data Understanding
Pada tahap ini peneliti mengumpulkan, mengidentifikasi, dan memahami
data yang dimiliki. Data tersebut juga harus dapat diverifikasi kebenarannya. Data
yang akan digunakan dalam penelitian ini adalah data review pelanggan aplikasi
pembelajaran daring yang populer di Indonesia yaitu Ruangguru dan Zenius yang
diambil dari google playstore.
3.3. Data Preparation
Pada tahap ini data awal yang diperoleh dari pengumpulan data melalui
proses crawling pada google playstore dari masing-masing aplikasi pembelajaran
daring yang diambil. Review pengguna masing-masing aplikasi yang diambil
sebagai sampel adalah review atau komentar yang diberikan oleh pengguna
aplikasi dari tanggal 1 Januari 2020 sampai dengan 26 April 2020. Dari semua

27
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
data yang sudah terkumpul, tidak semua data dapat digunakan. Oleh karena itu
perlu dilakukan tahap preprocessing terhadap data tersebut, proses preprocessing
yang digunakan diantaranya adalah dengan melakukan case folding, normalize,
anotation removal, stemming, dan tokenizing, lalu melihat hasilnya.
3.4. Modelling
Dalam tahap Modelling ini akan dilakukan teknik pengklasifikasian data
yang paling akurat. Untuk membandingkan atau mengkomparasi, pada penelitian
ini akan digunakan algoritma Naive Bayes Classifier, K-NN, dan Decision Tree
dengan menggunakan tools Knime.
3.5. Evaluation
Model yang terbentuk dari proses modelling akan diuji menggunakan
confusion matrix sehingga dapat diketahui tingkat akurasi. Confusion Matrix akan
menggambarkan hasil akurasi mulai dari prediksi positif yang benar, prediksi
positif yang salah, prediksi negatif yang benar dan prediksi negatif yang salah.
Akurasi akan dihitung dari seluruh hasil prediksi yang benar (baik prediksi positif
dan negatif) dibandingkan dengan seluruh data testing. Semakin tinggi nilai
akurasi, semakin baik pula model yang dihasilkan. Pengujian juga diukur dengan
menggunakan ROC Curve. ROC Curve akan menggambarkan kelas positif dalam
bentuk kurva. Pengujian dilakukan dengan menghitung nilai Area Under Curve
(AUC), semakin tinggi nilai AUC dan ROC Curve, maka semakin baik pula
model klasifikasi yang terbentuk.
3.6. Deployment
Tahap ini adalah tahap terakhir dari CRISP-DM, yaitu hasil dari seluruh
tahapan yang sebelumnya digunakan secara nyata. Maknanya adalah melakukan
sesuatu berdasarkan pengetahuan yang didapatkan dari kegiatan mining terhadap
data. Penerapan dalam penelitian ini akan dikembangkan dengan NodeJs dan
ReactJs dengan konsep dasar web service.
Adapun rincian waktu kegiatan penelitian (Timeline) yang dilakukan dibuat
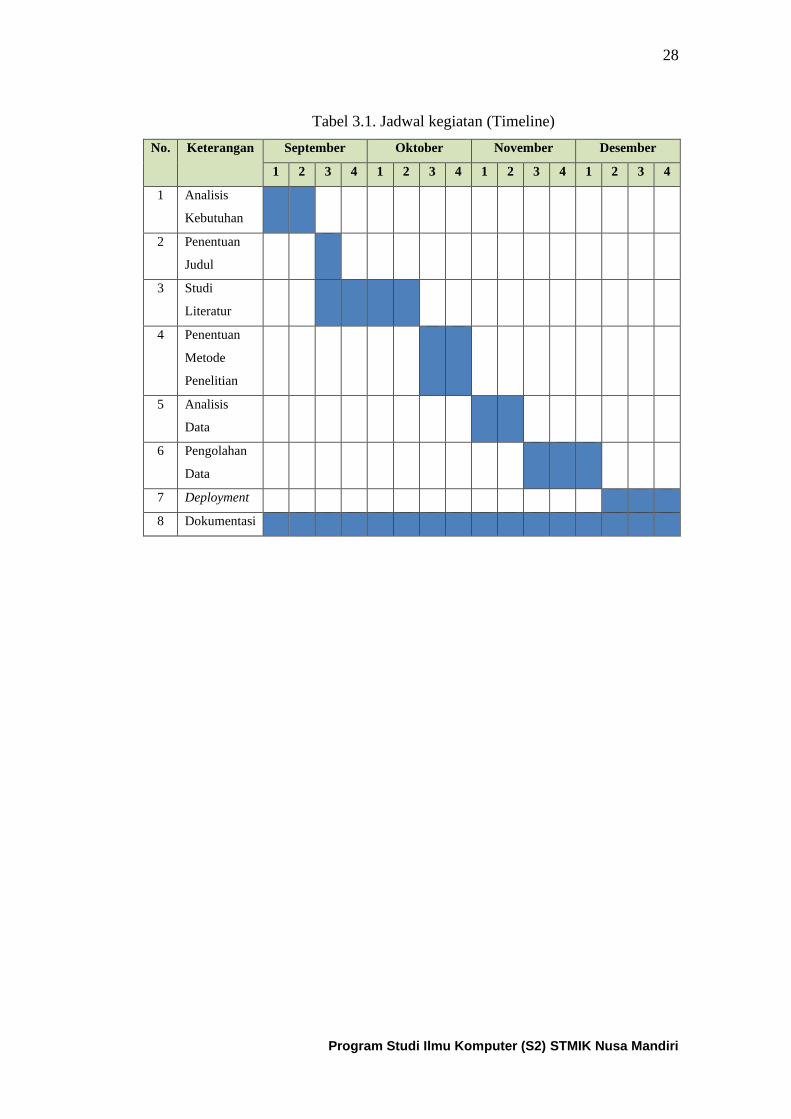
dalam bentuk tabel seperti yang ditampilkan pada tabel 3.1 di bawah ini:
28
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Tabel 3.1. Jadwal kegiatan (Timeline)
No. Keterangan September Oktober November Desember
1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4
1 Analisis
Kebutuhan
2 Penentuan
Judul
3 Studi
Literatur
4 Penentuan
Metode
Penelitian
5 Analisis
Data
6 Pengolahan
Data
7 Deployment
8 Dokumentasi

29
29
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
BAB IV
HASIL PENELITIAN DAN PEMBAHASAN
Berdasarkan metodologi penelitian yang telah dipaparkan sebelumnya, pada
bab ini akan dijelaskan implementasi dari metodologi penelitian yang dilakukan
sebagai berikut:
4.1. Business Understanding
Pada tahapan business understanding, dilakukan pemahaman terhadap objek
penelitian. Pemahaman mengenai objek penelitian dilakukan dengan menggali
informasi melalui hasil review pengguna aplikasi pembelajaran daring yang
diberikan melalui google playstore. Pada tahap ini data review pengguna yang
masuk akan dikelompokkan berdasarkan isi dari masing-masing kategori.
Pada tahap ini juga dilakukan pemahaman untuk mencari metode dengan
pendekatan model pengkategorian terbaik agar dapat membantu pada saat proses
pengolahan data yang akan dilakukan dengan cara membandingkan hasil dari
pengolahan data dengan algoritma data mining. Adapun algoritma data mining
yang digunakan adalah algoritma Naive Bayes, Decision Tree, dan KNN untuk
mengetahui akurasi dari metode pengkategorian yang digunakan.
4.2. Data Understanding
Proses yang dilakukan dalam tahap ini adalah memahami data yang akan
digunakan sebagai objek penelitian untuk dapat dilanjtkan ke tahap preprocessing.
Pada tahap ini dilakukan proses pengambilan data mentah sesuai dengan atribut
yang dibutuhkan dari review pelanggan aplikasi pembelajaran daring ruangguru
dan zenius dari tanggal 1 Januari smpai dengan 26 April 2020 dengan
memperhatikan rating atau bintang.
Berikut adalah beberapa contoh review positif dan negatif yang diberikan
oleh pengguna terhadap aplikasi ruangguru dan zenius:
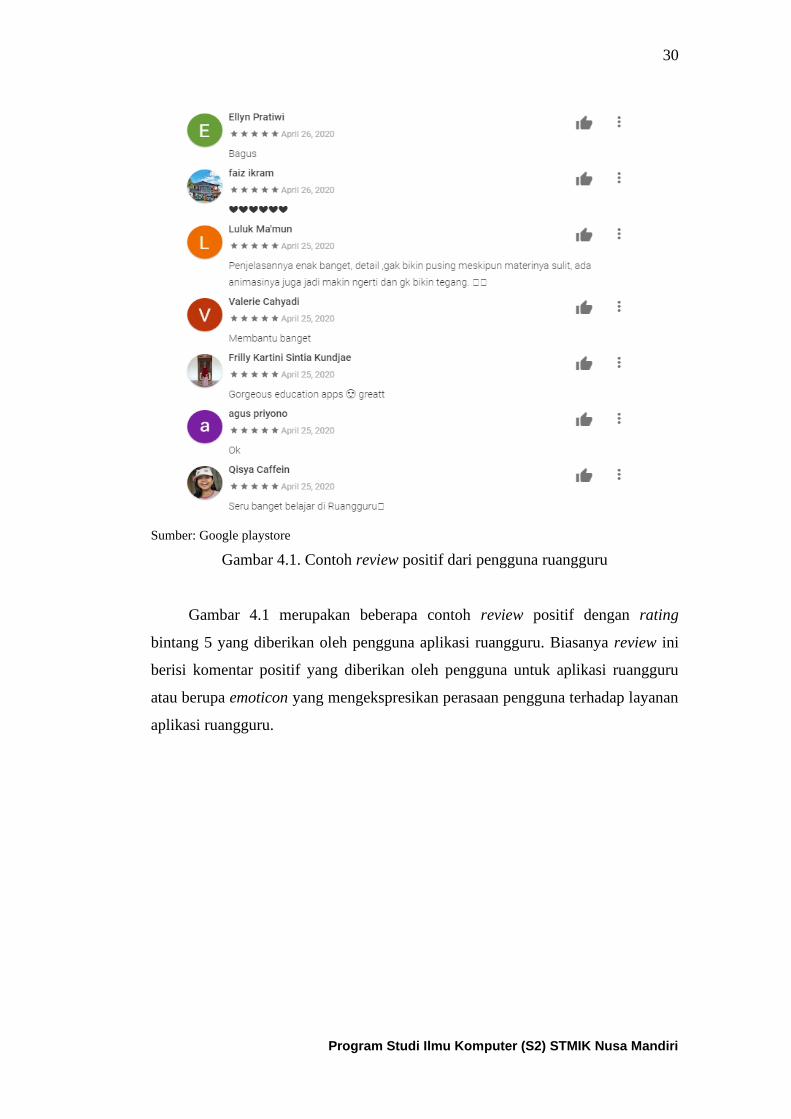
30
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: Google playstore
Gambar 4.1. Contoh review positif dari pengguna ruangguru
Gambar 4.1 merupakan beberapa contoh review positif dengan rating
bintang 5 yang diberikan oleh pengguna aplikasi ruangguru. Biasanya review ini
berisi komentar positif yang diberikan oleh pengguna untuk aplikasi ruangguru
atau berupa emoticon yang mengekspresikan perasaan pengguna terhadap layanan
aplikasi ruangguru.
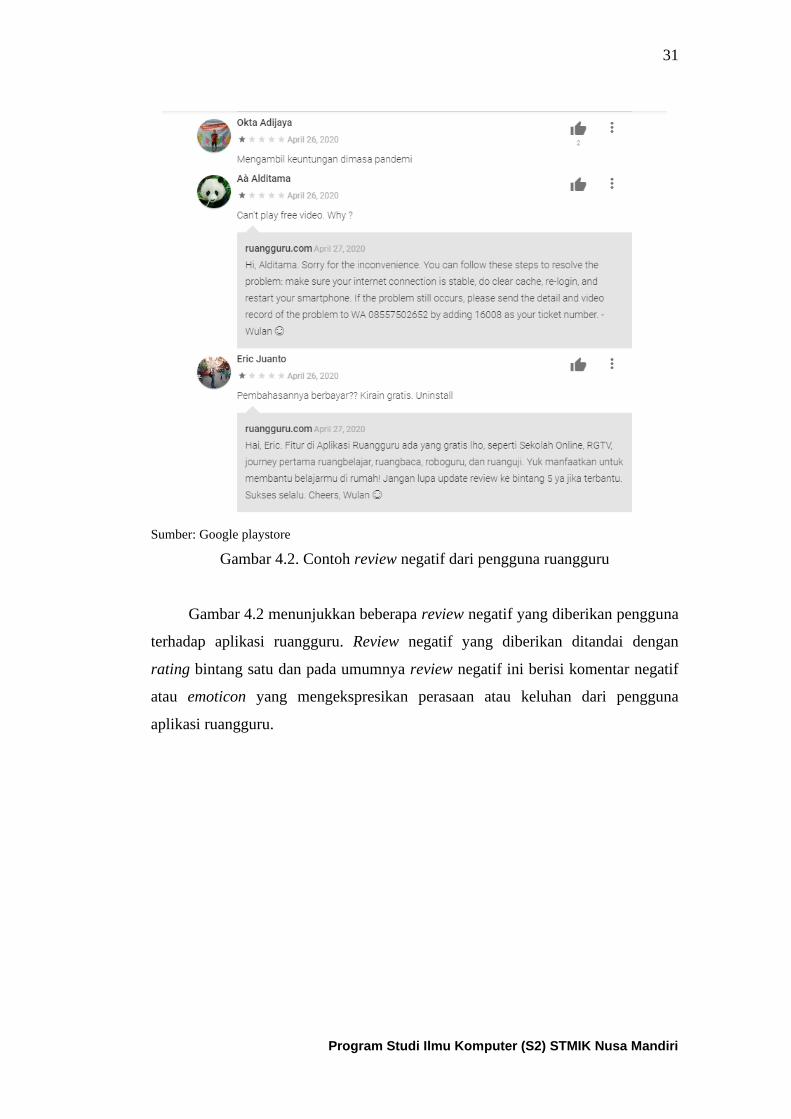
31
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: Google playstore
Gambar 4.2. Contoh review negatif dari pengguna ruangguru
Gambar 4.2 menunjukkan beberapa review negatif yang diberikan pengguna
terhadap aplikasi ruangguru. Review negatif yang diberikan ditandai dengan
rating bintang satu dan pada umumnya review negatif ini berisi komentar negatif
atau emoticon yang mengekspresikan perasaan atau keluhan dari pengguna
aplikasi ruangguru.
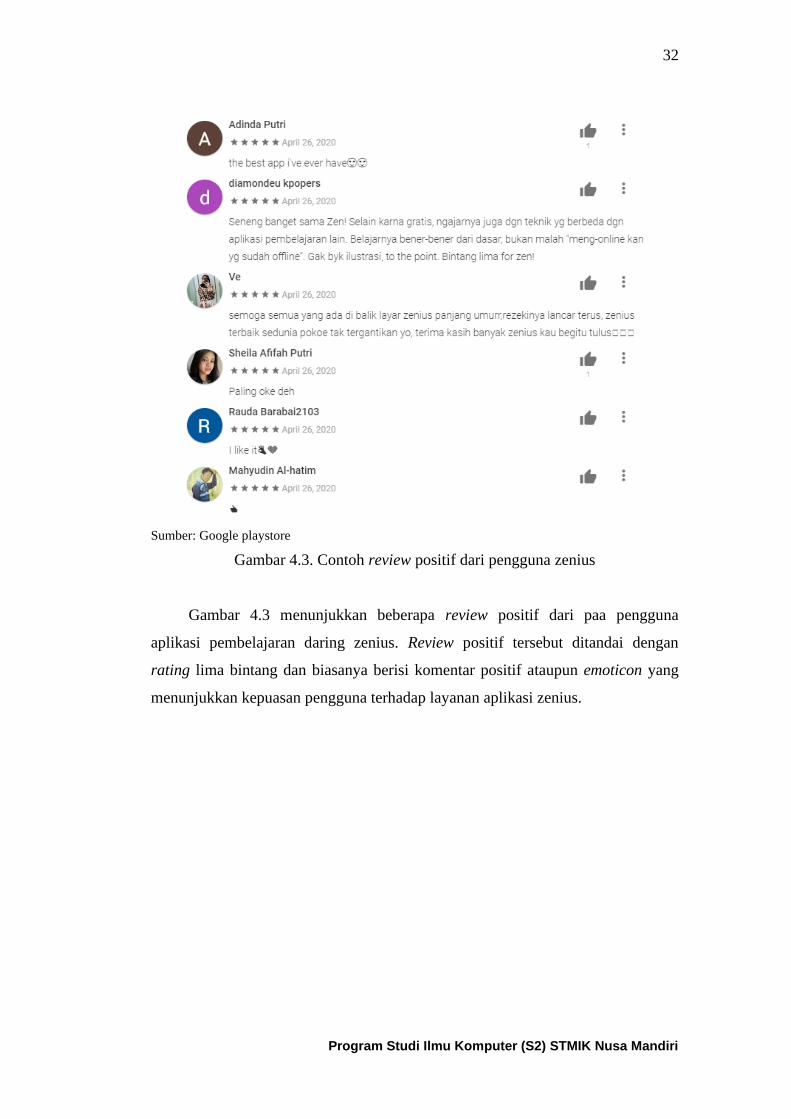
32
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: Google playstore
Gambar 4.3. Contoh review positif dari pengguna zenius
Gambar 4.3 menunjukkan beberapa review positif dari paa pengguna
aplikasi pembelajaran daring zenius. Review positif tersebut ditandai dengan
rating lima bintang dan biasanya berisi komentar positif ataupun emoticon yang
menunjukkan kepuasan pengguna terhadap layanan aplikasi zenius.
33
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: Google playstore
Gambar 4.4. Contoh review negatif dari pengguna zenius
Gambar 4.4 menunjukkan beberapa review negatif yang diberikan oleh para
pengguna aplikasi pembelajaran daring zenius. Review negtif ditandai dengan
rating bintang satu dan review negatif biasanya berisi komentar-komentar negatif
ataupun emoticon yang mengekspresikan perasaan pengguna atau keluhan
pengguna terhadap layanan yang diberikan oleh aplikasi zenius.
Data yang diperoleh dari proses crawling dari google playstore pada
aplikasi ruangguru sebelumnya berjumlah 3.997 data. Sedangkan untuk hasil
crawling pada aplikasi zenius data awal berjumlah 2.027.
4.3. Data Preparation
Tahap ini merupakan tahap proses penyiapan data yang bertujuan untuk
mendapatkan data yang bersih dan siap untuk digunakan dalam penelitian. Dari
data awal yang diperoleh kemudian dilakukan proses cleansing untuk
menghilangkan duplicate kata dan menghilangkan data yang tidak relevan dan
tidak berhubungan dengan masing-masing aplikasi tersebut. Setelah proses

34
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
cleansing dilakukan, diperoleh data sebanyak 1.785 data review aplikasi
ruangguru dan 1.003 data review aplikasi zenius. Dari data yang diperoleh
kemudian dibuat menjadi dataset dengan atribut dataset berupa text dan label. Text
berisi komentar-komentar pengguna aplikasi yang diberikan melalui google play
store dan label berisi kategori dari komentar tersebut berupa positif dan negatif.
Data review dari masing-masing aplikasi kemudian dikelompokkan menjadi satu
dan disimpan dalam microsoft excel dengan format .xlxs sehingga membentuk
dua dataset yaitu dataset ruangguru dan zenius.
Proses pelabelan dan pengkategorian dilakukan oleh tim verifikator, hal ini
sangat efisien karena dapat menekan biaya dibandingkan dengan menggunakan
jasa para ahli/pakar bahasa Indonesia untuk melakukan hal tersebut. Hasil dari
labelling dan pengkategorian yang dilakukan oleh tim verifikator bertujuan agar
status data menjadi normal dalam penelitian text mining. Adapun hasil dari tahap
ini adalah sebagai berikut:
Tabel 4.1. Hasil pelabelan terhadap dataset review aplikasi ruangguru
Label Jumlah
Positif 892
Negatif 893 Sumber: hasil penelitian
Tabel 4.1 menunjukkan jumlah data dari masing-masing kategori pada
data review pengguna aplikasi ruangguru yang akan digunakan dalam penelitian
ini.
Tabel 4.2. Hasil pelabelan terhadap dataset review aplikasi zenius
Label Jumlah
Positif 567
Negatif 436 Sumber: hasil penelitian
Tabel 4.2 menunjukkan jumlah data dari masing-masing kategori pada
data review pengguna aplikasi zenius yang akan digunakan dalam penelitian ini.
Tahapan awal yang akan dilakukan dalam penelitian ini adalah tahap text
preprocessing, peneliti menggunakan tools gataframework.com dan Knime untuk
melakukan tahap text preprocessing. Berikut merupakan tahapan yang dilakukan
dalam text preprocessing:

35
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: hasil penelitian
Gambar 4.5. Proses preprocessing dengan gataframework
Gambar 4.5 adalah proses preprocessing document menggunakan tools
gataframework.com. Dari hasil preprocessing menggunakan gataframework, data
belum sepenuhnya bersih sehingga dalam proses pengolahannya menggunakan
aplikasi Knime masih perlu ditambahkan beberapa proses preprocessing lagi.
Sumber: Hasil penelitian
Gambar 4.6. Proses preprocessing dengan Knime

36
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Gambar 4.6 adalah tahap preprocessing yang dilakukan dalam penelitian
ini, permodelan dibuat menggunakan tools Knime versi 4.1.3
4.3.1. Case Folding
Proses case folding bertujuan untuk mengkonversi komentar-komentar yang
diberikan oleh pengguna menjadi huruf kecil keseluruhan. Berikut adalah
perbandingan text sebelum dan sesudah melalui proses case folding:
Tabel 4.3. Perbandingan komentar sebelum dan sesudah dilakukan case folding
Data Sebelum Data Sesudah
Ruang Guru bagus banget buat belajar
apalagi saat dirumah
"ruang guru bagus banget buat belajar
apalagi saat dirumah"
Saya suka belajar dengan ZENIUS.
Penjelasan mudah dimengerti. karena
setiap materi diajarkan mulai dari
dasarnya sampai komplek. pembahasan
soal soal mudah dipahami. zennnnius
rekomended bangat buat dipakai belajar
setiap harinya. thanks zeniussssssss.
"saya suka belajar dengan zenius.
penjelasan mudah dimengerti. karena
setiap materi diajarkan mulai dari
dasarnya sampai komplek. pembahasan
soal soal mudah dipahami. zennnnius
rekomended bangat buat dipakai belajar
setiap harinya. thanks zeniussssssss." Sumber: Hasil penelitian
Tabel 4.3 menunjukkan hasil dari proses case converter yang dilakukan
pada tahap preprocessing. Pada tahap ini dapat dilihat bahwa semua huruf yang
ada diseragamkan menjadi huruf kecil semua.
4.3.2. Penggunaan @Annotation removal, Regex Filter dan emoticon
normalization
Tahap ini bertujuan untuk menghilangkan item yang tidak diperlukan seperti
@, #, emoticon dan juga penulisan huruf yang berlebihan sehingga merusak
makna kata. Berikut adalah perbandingan hasil text komentar asli dan yang telah
melalui tahap regex filter:
Tabel 4.4. Perbandingan komentar sebelum dan sesudah dilakukan regex filter
Data Sebelum Data Sesudah
salam 5,6 triliun. hahaha salam triliun hahaha
pembahasannya berbayar?? kirain
gratis. Uninstall
pembahasannya berbayar kirain gratis
uninstall
matematika soshumnya kok ga ada kak
di apk?
matematika soshumnya kok ga ada kak
di apk
thank you, zenius meski update, zenius thank you zenius meski update zenius

37
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Data Sebelum Data Sesudah
jgn prnah hapus yg ada ya. sukses
bareng zenius!
jgn prnah hapus yg ada ya sukses
bareng zenius Sumber: Hasil penelitian
Tabel 4.4 menunjukkan hasil perbandingan dari komentar yang diberikan
pengguna terhadap aplikasi yang menjadi objek penelitian.
4.3.3. Penggunaan N Chars Filter
Tahap ini bertujuan untuk memilah dokumen dengan menghilangkan
komentar pengguna yang jumlah karakternya kurang dari N. Nilai N yang
ditentukan dalam penelitian ini adalah 3 jadi jika ada komentar pengguna yang
jumlah karakternya kurang dari 3 otomatis akan dihilangkan.
4.3.4. Stemming
Stemming merupakan proses pembentukan kata menjadi kata dasar, dlam
penelitian ini proses stemming yang dilakukan menggunakan Indonesian
stemming dan bertujuan untuk membentuk kata dasar dari opini yang diberikan
oleh para pengguna aplikasi ruangguru dan zenius.
Tabel 4.5. Hasil stemming
Data sebelum Data sesudah
salah soal no seharusnya saya dapat
seratus
salah soal no harus saya dapat ratus
layanan tanya jawab via surel ditangani
bot cs saya sempat dihubungi orang yg
ngaku rg di wa tanya data niatnya mau
lapor untuk konfirmasi rupamya dikasih
bot maaf saja terima kasih telah
menjawab silakan telusuri laporan user
lain siapa tahu sempat mengalami
semoga tidak ada yg jadi korb full
review
layan tanya jawab via surel ditangani
bot cs saya sempat hubung orang yg
ngaku rg di wa tanya data niat mau
lapor untuk konfirmasi rupamya kasih
bot maaf saja terima kasih telah jawab
sila telusur lapor user lain siapa tahu
sempat alami moga tidak ada yg jadi
korb full review
ikut dalam progran kartu pra kerja
tanpa melalui tender yang jelas
ikut dalam progran kartu pra kerja
tanpa lalu tender yang jelas
saya suka belajar dengan zenius
penjelasan mudah dimengerti karena
setiap materi diajarkan mulai dari
dasarnya sampai komplek pembahasan
soal soal mudah dipahami zennnnius
rekomended bangat buat dipakai belajar
saya suka ajar dengan zenius jelas
mudah erti karena tiap materi ajar mulai
dari dasar sampai komplek bahas soal
soal mudah paham zennnnius
rekomended bangat buat pakai ajar tiap
hari thanks zeniussssssss
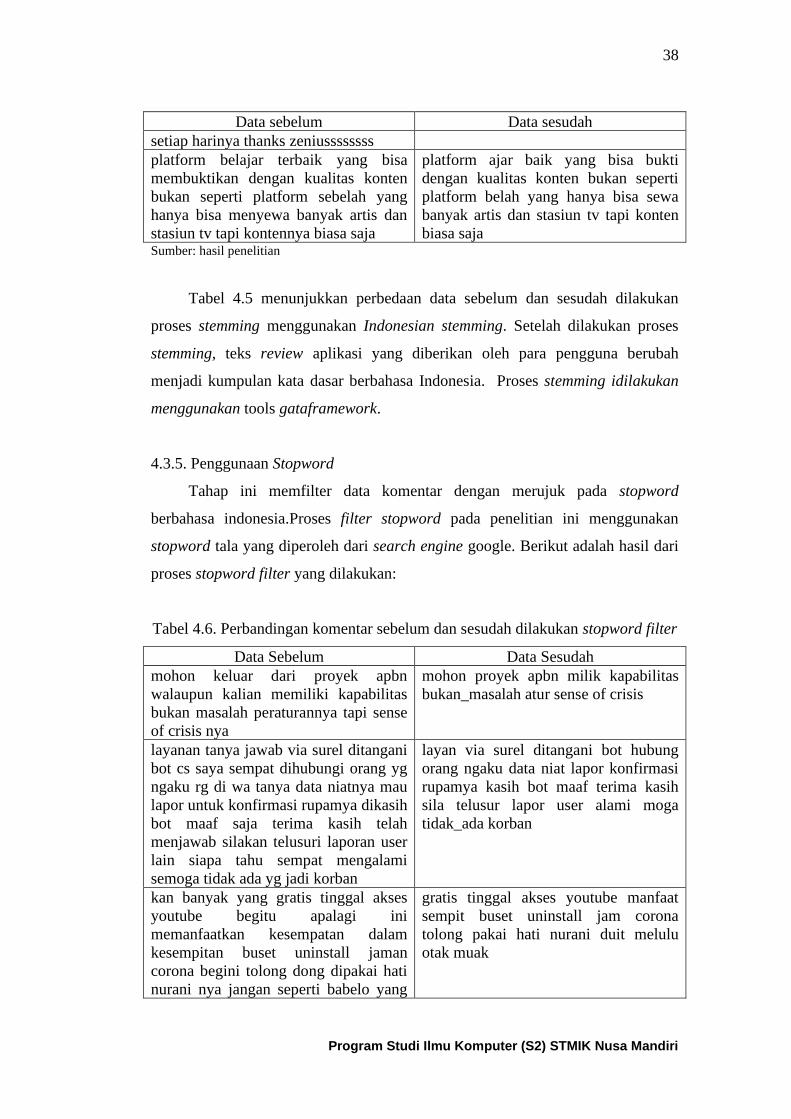
38
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Data sebelum Data sesudah
setiap harinya thanks zeniussssssss
platform belajar terbaik yang bisa
membuktikan dengan kualitas konten
bukan seperti platform sebelah yang
hanya bisa menyewa banyak artis dan
stasiun tv tapi kontennya biasa saja
platform ajar baik yang bisa bukti
dengan kualitas konten bukan seperti
platform belah yang hanya bisa sewa
banyak artis dan stasiun tv tapi konten
biasa saja Sumber: hasil penelitian
Tabel 4.5 menunjukkan perbedaan data sebelum dan sesudah dilakukan
proses stemming menggunakan Indonesian stemming. Setelah dilakukan proses
stemming, teks review aplikasi yang diberikan oleh para pengguna berubah
menjadi kumpulan kata dasar berbahasa Indonesia. Proses stemming idilakukan
menggunakan tools gataframework.
4.3.5. Penggunaan Stopword
Tahap ini memfilter data komentar dengan merujuk pada stopword
berbahasa indonesia.Proses filter stopword pada penelitian ini menggunakan
stopword tala yang diperoleh dari search engine google. Berikut adalah hasil dari
proses stopword filter yang dilakukan:
Tabel 4.6. Perbandingan komentar sebelum dan sesudah dilakukan stopword filter
Data Sebelum Data Sesudah
mohon keluar dari proyek apbn
walaupun kalian memiliki kapabilitas
bukan masalah peraturannya tapi sense
of crisis nya
mohon proyek apbn milik kapabilitas
bukan_masalah atur sense of crisis
layanan tanya jawab via surel ditangani
bot cs saya sempat dihubungi orang yg
ngaku rg di wa tanya data niatnya mau
lapor untuk konfirmasi rupamya dikasih
bot maaf saja terima kasih telah
menjawab silakan telusuri laporan user
lain siapa tahu sempat mengalami
semoga tidak ada yg jadi korban
layan via surel ditangani bot hubung
orang ngaku data niat lapor konfirmasi
rupamya kasih bot maaf terima kasih
sila telusur lapor user alami moga
tidak_ada korban
kan banyak yang gratis tinggal akses
youtube begitu apalagi ini
memanfaatkan kesempatan dalam
kesempitan buset uninstall jaman
corona begini tolong dong dipakai hati
nurani nya jangan seperti babelo yang
gratis tinggal akses youtube manfaat
sempit buset uninstall jam corona
tolong pakai hati nurani duit melulu
otak muak

39
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Data Sebelum Data Sesudah
duit duit duit melulu di otaknya jadi
muak saya nya
waaah jadi keren bangett abis diupdate
kak kalo boleh tolong tambahin soal
stan sama soal utbk biologi kakkkkk
hehehehehe makasih kakk
keren bangett abis diupdate kalo tolong
tambahin stan utbk biologi makasih
aplikasi sangat membantu untuk belajar
dirumah saat kondisi seperti ini
aplikasi bantu ajar rumah kondisi
terimakasih telah memberikan akses
pendidikan yang sama kepada seluruh
anak anak indonesia
terimakasih berik akses didik anak anak
indonesia
belajar harusnya gratis karena berbagi
ilmu ga bikin miskin ilmu semoga
kedepannya pemerintah bekerja sama
dengan perusahaan unicorn untuk
mengembangkan proses belajar yg
efisien dan gratis melalui aplikai yg
lebih mendukung kemajuan bangsa
ajar gratis ilmu bikin miskin ilmu moga
perintah usaha unicorn kembang proses
ajar efisien gratis aplikai dukung maju
bangsa
bagus banget kan ada virus corona aku
belajar nya disini terus juga guru nya
ramah mengajari kita sampai betul bisa
hayo buruan download aplikasi ruang
guru
bagus banget virus corona ajar guru
ramah ajar hayo buru download aplikasi
ruang guru
semua aplikasi mudah di gunakan dan
gampang di pahami
aplikasi mudah gampang paham
Sumber: Hasil penelitian
Tabel 4.6 menunjukkan hasil pengolahan data sebelum dan sesudah
dilakukan stopword filter terhadap data komentar yang diberikan oleh pengguna
terhadap aplikasi yang menjadi objek penelitian.
4.3.6. Bag Of Words
Tahap ini bertujuan untuk menemukan dan membentuk term dari data
komentar yang diberikan oleh pengguna aplikasi. Berikut adalah beberapa term
yang berhasil dibentuk:
Tabel 4.7. Term yang dibentuk dari proses pembentukan BoW
Teks Term
jangan jd maling uang rakyat jangan[]
maling[]
uang[]
rakyat[]
mohon proyek apbn milik kapabilitas
bukan_masalah atur sense of crisis
mohon[]
proyek[]

40
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Teks Term
apbn[]
milik[]
kapabilitas[]
bukan_masalah[]
atur[]
sense[]
crisis[]
gratis tinggal akses youtube manfaat
sempit buset uninstall jam corona
tolong pakai hati nurani babelo duit duit
duit melulu otak muak
gratis[]
tinggal[]
akses[]
youtube[]
manfaat[]
sempit[]
buset[]
uninstall[]
jam[]
corona[]
tolong[]
pakai[]
hati[]
nurani[]
duit[]
melulu[]
otak[]
muak[]
aplikasi bagus coba nyata jurus anak
smk tidak_ada bantu siswa siswi sulit
ajar jurus smk
aplikasi[]
bagus[]
coba[]
nyata[]
jurus[]
anak[]
smk[]
tidak_ada[]
bantu[]
siswa[]
siswi[]
sulit[]
ajar[] Sumber: Hasil penelitian
Tabel 4.7 menunjukkan hasil term yang terbentuk dari beberapa data komentar
yang diberikan oleh pengguna aplikasi yang menjadi objek penelitian.
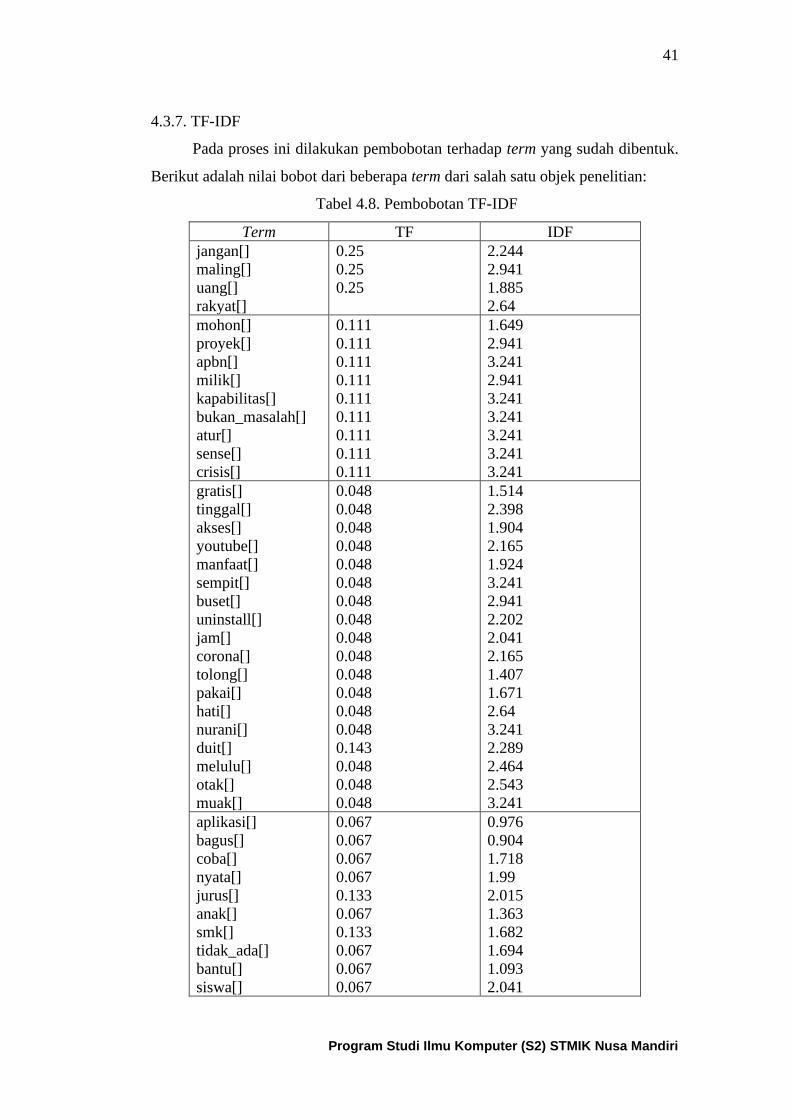
41
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
4.3.7. TF-IDF
Pada proses ini dilakukan pembobotan terhadap term yang sudah dibentuk.
Berikut adalah nilai bobot dari beberapa term dari salah satu objek penelitian:
Tabel 4.8. Pembobotan TF-IDF
Term TF IDF
jangan[]
maling[]
uang[]
rakyat[]
0.25
0.25
0.25
2.244
2.941
1.885
2.64
mohon[]
proyek[]
apbn[]
milik[]
kapabilitas[]
bukan_masalah[]
atur[]
sense[]
crisis[]
0.111
0.111
0.111
0.111
0.111
0.111
0.111
0.111
0.111
1.649
2.941
3.241
2.941
3.241
3.241
3.241
3.241
3.241
gratis[]
tinggal[]
akses[]
youtube[]
manfaat[]
sempit[]
buset[]
uninstall[]
jam[]
corona[]
tolong[]
pakai[]
hati[]
nurani[]
duit[]
melulu[]
otak[]
muak[]
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.048
0.143
0.048
0.048
0.048
1.514
2.398
1.904
2.165
1.924
3.241
2.941
2.202
2.041
2.165
1.407
1.671
2.64
3.241
2.289
2.464
2.543
3.241
aplikasi[]
bagus[]
coba[]
nyata[]
jurus[]
anak[]
smk[]
tidak_ada[]
bantu[]
siswa[]
0.067
0.067
0.067
0.067
0.133
0.067
0.133
0.067
0.067
0.067
0.976
0.904
1.718
1.99
2.015
1.363
1.682
1.694
1.093
2.041

42
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Term TF IDF
siswi[]
sulit[]
ajar[]
0.067
0.067
0.067
2.941
2.13
0.808 Sumber: Hasil penelitian
Tabel 4.8 menunjukkan hasil pembobotan TF-IDF terhadap term yang
dibentuk oleh data komentar dari aplikasi yang menjadi objek penelitian.
4.4. Modelling
Merupakan fase pemilihan teknik mining dengan menentukan algoritma
yang akan digunakan. Tools yang digunakan adalah Knime versi 4.1.3. Hasil
pengujian model yang dilakukan dengan mengklasifikasikan data review
pengguna aplikasi pembelajaran daring yang diperoleh dari google playstore
menggunakan algoritma Decision tree, Naive Bayes dan KNN. Aplikasi
pembelajaran daring yang menjadi objek penelitian ini adalah aplikasi ruangguru
dan aplikasi zenius.
4.4.1. Proses modelling data review dari pengguna aplikasi pembelajaran
ruangguru.
Sumber: Hasil penelitian
Gambar 4.7. Model penelitian pengolahan data review dari pengguna aplikasi
ruangguru

43
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Gambar 4.7 merupakan model yang dibuat untuk pengolahan data review
yang diberikan oleh pengguna aplikasi ruangguru menggunakan algoritma
decision tree, naive bayes dan KNN.
Desain model penelitian ini menggunakan excel reader, column filter, string
to document, pre-processing, document vector, category to class, color
handle,cross validation, partitioning, decision tree learner, naive bayes learner,
decision tree predictor, naive bayes predictor, K-Nearest Neighbor, scoring dan
ROC curve. Permodelan ini menggunakan excel reader sebagai media untuk
membaca file dataset. Column filter digunakan untuk filterisasi kolom dari atribut
dataset yang akan diolah. String to document digunakan untuk mengubah tipe
data pada kolom yang telah di filter menjadi dokumen. Pre-processing digunakan
untuk membersihkan dan menyelaraskan data. Category to class untuk
menentukan kelas yang digunakan sebagai label atau kategori adalah postif dan
negatif, kelas ini nantinya akan menunjukkan hasil klasifikasi dari tiap-tiap
algoritma yang digunakan dalam penelitian ini. Metode evaluation yang
digunakan adalah partitioning dan cross validation dimana metode partitioning
ini membagi dataset secara otomatis menjadi data training dan data testing
sedangkan metode cross validation melakukan evaluasi terhadap dataset dengan
sistem mengulang pengujian data sesuai dengan jumlah fold yang ditentukan.
Pada penelitian ini jumlah fold ditentukan sebanyak 10, dengan demikian berarti
model evaluasi dengan cross validation akan melakukan pengujian data dengan
melakukan pengulangan evaluasi sebanyak 10 kali. Decision tree learner dan
naive bayes learner berfungsi sebagai penghubung untuk menggunakan algoritma
predictor yaitu decision tree predictor dan naive bayes predictor sebagai penentu
klasifikasi. K-Nearest Neighbour merupakan salah satu algoritma yang
digunakakan untuk mengklasifikasikan data. Scoring digunakan untuk
menunjukkan hasil akurasi yang diperoleh. Sedangkan ROC curve adalah media
untuk menampilkan kurva ROC yang juga menunjukkan nilai AUC.

44
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
4.4.2. Proses modelling data review dari pengguna aplikasi pembelajaran zenius
Sumber: hasil penelitian
Gambar 4.8. Model penelitian pengolahan data review dari pengguna aplikasi
zenius
Gambar 4.8 menunjukkan desain model penelitian menggunakan tools
Knime untuk pengolahan dataset komentar pengguna aplikasi zenius. Alur dan
komponen yang digunakan dalam mengolah dataset komentar pengguna aplikasi
zenius sama dengan pengolahan dataset komentar pengguna aplikasi ruangguru.
4.5. Evaluation
Tahapan evaluasi bertujuan untuk menentukan nilai kegunaan dari model
yang telah berhasil dibuat pada langkah sebelumnya. Untuk evaluasi digunakan
partitioning. Berikut ini adalah hasil dari proses pengujian masing-masing dataset
aplikasi pembelajaran daring dengan metode decision tree, naive bayes, dan KNN.
4.5.1. Evaluation permodelan untuk dataset komentar pengguna aplikasi
ruangguru
Dataset hasil review aplikasi ruangguru setelah melalui tahap
preprocessing berjumlah 1.785 data. Data tersebut kemudian diolah dengan
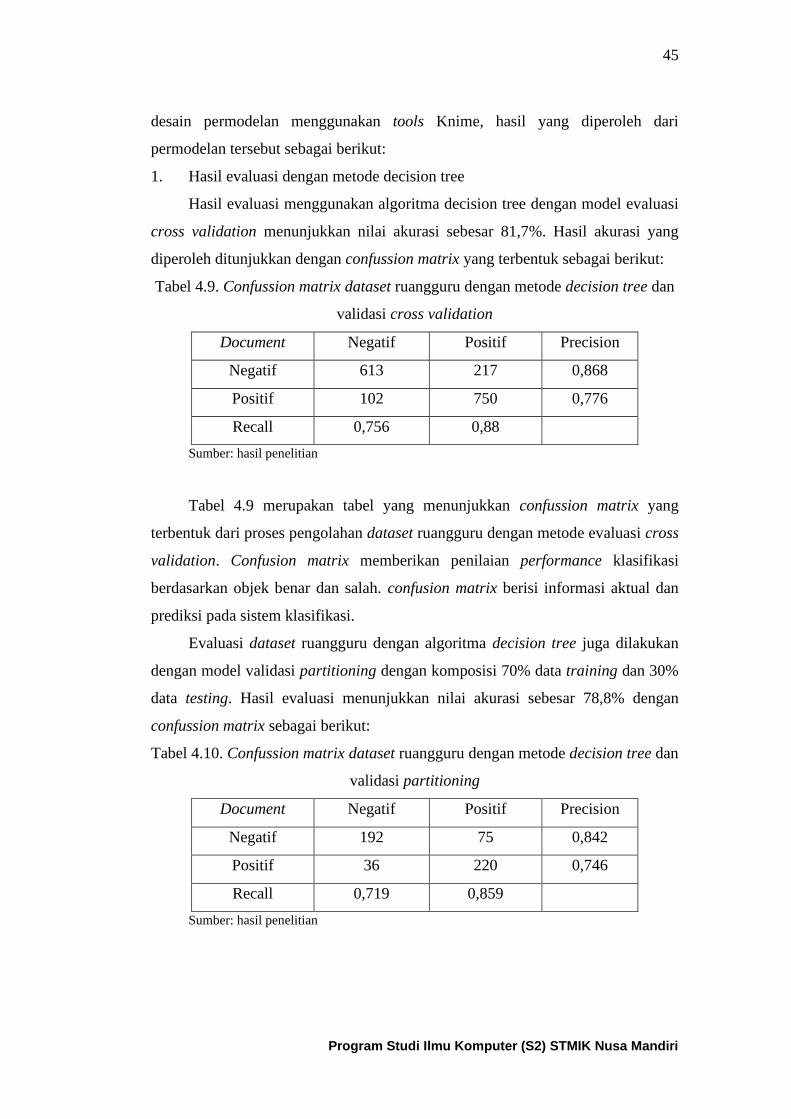
45
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
desain permodelan menggunakan tools Knime, hasil yang diperoleh dari
permodelan tersebut sebagai berikut:
1. Hasil evaluasi dengan metode decision tree
Hasil evaluasi menggunakan algoritma decision tree dengan model evaluasi
cross validation menunjukkan nilai akurasi sebesar 81,7%. Hasil akurasi yang
diperoleh ditunjukkan dengan confussion matrix yang terbentuk sebagai berikut:
Tabel 4.9. Confussion matrix dataset ruangguru dengan metode decision tree dan
validasi cross validation
Document Negatif Positif Precision
Negatif 613 217 0,868
Positif 102 750 0,776
Recall 0,756 0,88
Sumber: hasil penelitian
Tabel 4.9 merupakan tabel yang menunjukkan confussion matrix yang
terbentuk dari proses pengolahan dataset ruangguru dengan metode evaluasi cross
validation. Confusion matrix memberikan penilaian performance klasifikasi
berdasarkan objek benar dan salah. confusion matrix berisi informasi aktual dan
prediksi pada sistem klasifikasi.
Evaluasi dataset ruangguru dengan algoritma decision tree juga dilakukan
dengan model validasi partitioning dengan komposisi 70% data training dan 30%
data testing. Hasil evaluasi menunjukkan nilai akurasi sebesar 78,8% dengan
confussion matrix sebagai berikut:
Tabel 4.10. Confussion matrix dataset ruangguru dengan metode decision tree dan
validasi partitioning
Document Negatif Positif Precision
Negatif 192 75 0,842
Positif 36 220 0,746
Recall 0,719 0,859
Sumber: hasil penelitian
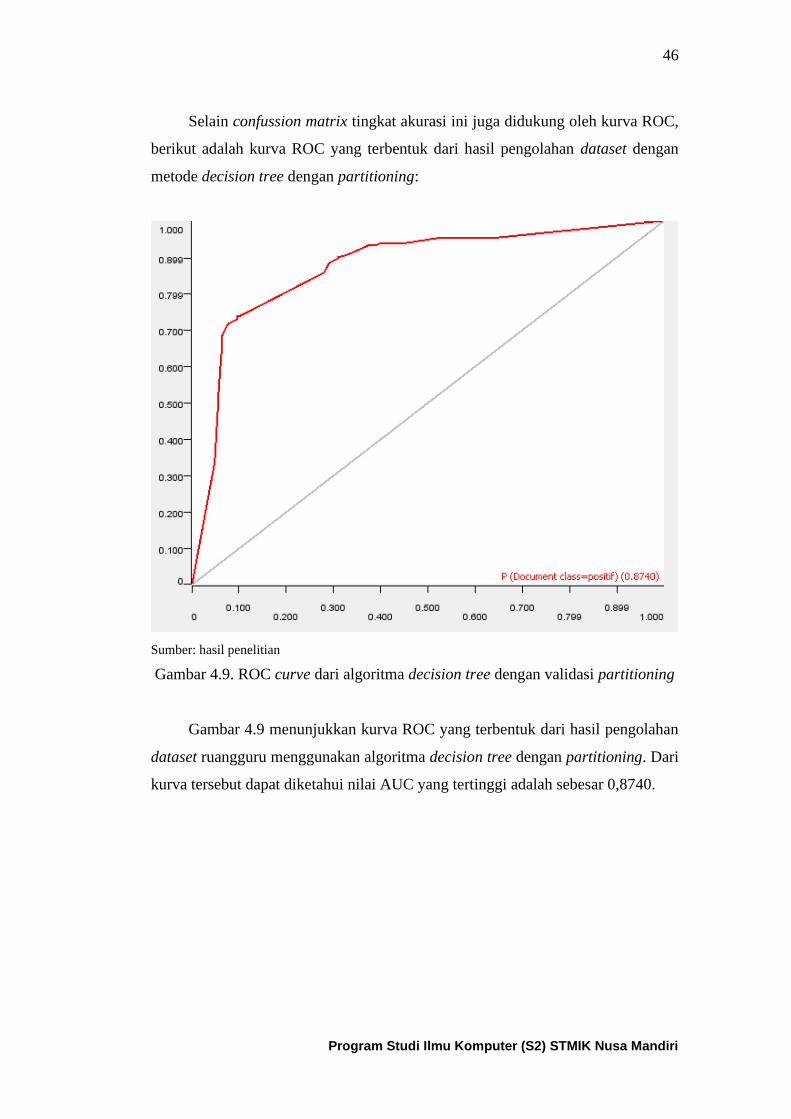
46
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Selain confussion matrix tingkat akurasi ini juga didukung oleh kurva ROC,
berikut adalah kurva ROC yang terbentuk dari hasil pengolahan dataset dengan
metode decision tree dengan partitioning:
Sumber: hasil penelitian
Gambar 4.9. ROC curve dari algoritma decision tree dengan validasi partitioning
Gambar 4.9 menunjukkan kurva ROC yang terbentuk dari hasil pengolahan
dataset ruangguru menggunakan algoritma decision tree dengan partitioning. Dari
kurva tersebut dapat diketahui nilai AUC yang tertinggi adalah sebesar 0,8740.
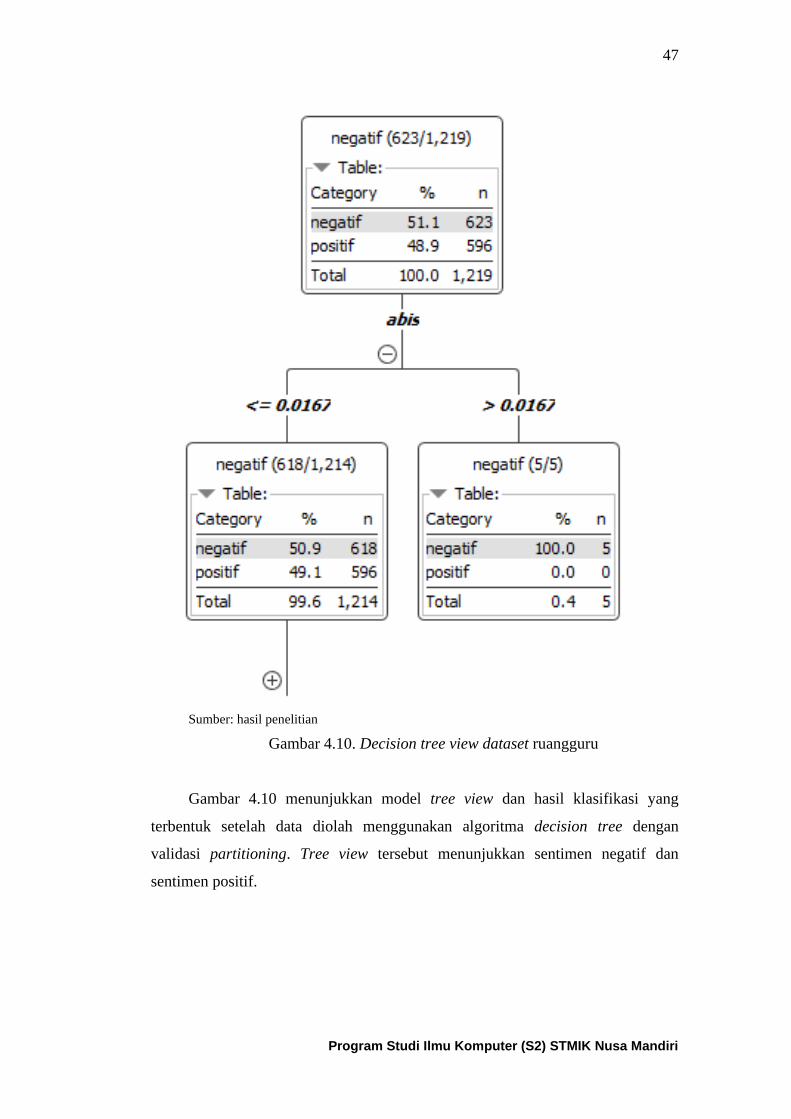
47
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: hasil penelitian
Gambar 4.10. Decision tree view dataset ruangguru
Gambar 4.10 menunjukkan model tree view dan hasil klasifikasi yang
terbentuk setelah data diolah menggunakan algoritma decision tree dengan
validasi partitioning. Tree view tersebut menunjukkan sentimen negatif dan
sentimen positif.

48
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
2. Hasil evaluasi dengan metode naive bayes
Hasil evaluasi menggunakan algoritma naive bayes dengan model validasi
cross validation menunjukkan nilai akurasi sebesar 48,9%. Hasil akurasi yang
diperoleh ditunjukkan dengan confussion matrix yang terbentuk sebagai berikut:
Tabel 4.11. Confussion matrix dataset ruangguru dengan metode naive bayes dan
validasi cross validation
Document Positif Negatif Precision
Positif 852 890 1
Negatif 0 0 0
Recall 0,489 0
Sumber: hasil penelitian
Tabel 4.11 merupakan tabel yang menunjukkan confussion matrix yang
terbentuk dari proses pengolahan dataset ruangguru menggunakan metode naive
bayes dan model validasi cross validation.
Evaluasi dataset ruangguru menggunakan algoritma naive bayes juga
dilakukan dengan menggunakan model validasi partitioning. Dari hasil
permodelan evaluasi dengan model validasi partitioning diperoleh nilai akurasi
sebesar 48,9%. Berikut merupakan confussion matrix yang terbentuk dari hasil
permodelan evaluasi dataset ruangguru dengan validasi partitioning:
Tabel 4.12. Confussion matrix dataset ruangguru dengan metode naive bayes dan
validasi partitioning
Document Positif Negatif Precision
Positif 256 0 0,489
Negatif 267 0 0
Recall 1 0
Sumber: hasil penelitian
Tabel 4.12 menunjukkan confussion matrix yang terbentuk dari hasil
pengolahan dataset ruangguru dengan algoritma naive bayes dan validasi
partitioning.
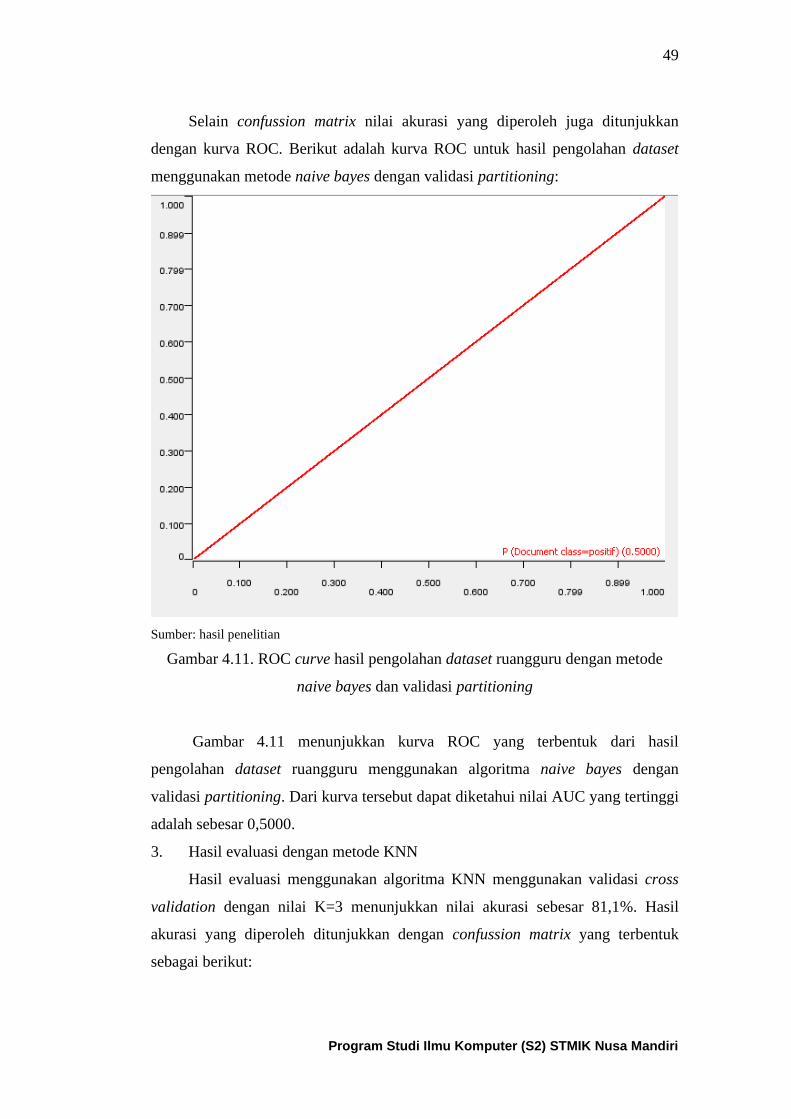
49
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Selain confussion matrix nilai akurasi yang diperoleh juga ditunjukkan
dengan kurva ROC. Berikut adalah kurva ROC untuk hasil pengolahan dataset
menggunakan metode naive bayes dengan validasi partitioning:
Sumber: hasil penelitian
Gambar 4.11. ROC curve hasil pengolahan dataset ruangguru dengan metode
naive bayes dan validasi partitioning
Gambar 4.11 menunjukkan kurva ROC yang terbentuk dari hasil
pengolahan dataset ruangguru menggunakan algoritma naive bayes dengan
validasi partitioning. Dari kurva tersebut dapat diketahui nilai AUC yang tertinggi
adalah sebesar 0,5000.
3. Hasil evaluasi dengan metode KNN
Hasil evaluasi menggunakan algoritma KNN menggunakan validasi cross
validation dengan nilai K=3 menunjukkan nilai akurasi sebesar 81,1%. Hasil
akurasi yang diperoleh ditunjukkan dengan confussion matrix yang terbentuk
sebagai berikut:
50
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Tabel 4.13. Confussion matrix dataset ruangguru dengan metode KNN dan
validasi cross validation
Document Negatif Positif Precision
Negatif 798 92 0,771
Positif 237 615 0,87
Recall 0,897 0,722
Sumber: hasil penelitian
Tabel 4.13 merupakan tabel yang menunjukkan confussion matrix yang
terbentuk dari proses pengolahan dataset ruangguru menggunakan algoritma KNN
dengan model validasi cross validation.
Selain menggunakan model validasi cross validation, pengolahan dataset
ruangguru dengan algoritma KNN juga dievaluasi menggunakan model vaidasi
partitioning. Hasil evaluasi algoritma KNN menggunakan validasi partitioning
menunjukkan nilai akurasi sebesar 79%. Confussion matrix yang terbentuk dari
hasil evaluasi tersebut sebagai berikut:
Tabel 4.14. Confussion matrix dataset ruangguru dengan metode KNN dan
validasi partitioning
Document Negatif Positif Precision
Negatif 239 28 0,745
Positif 82 174 0,861
Recall 0,895 0,68
Sumber: hasil penelitian
Tabel 4.14 menunjukkan nilai confussion matrix serta nilai recall dan
precision yang didapatkan dari pengolahan dataset ruangguru mengunakan
algoritma KNN dengan nilai K=3 dan model validasi partitioning idimana model
validasi ini membagi dataset imenjadi data training dan data testing.
Confusion matrix memberikan penilaian performance klasifikasi
berdasarkan objek benar dan salah. Dari confussion matrix tersebut juga terbentuk
kurva ROC yang mendukung hasil klasifikasi. Kurva ROC yang terbentuk dari
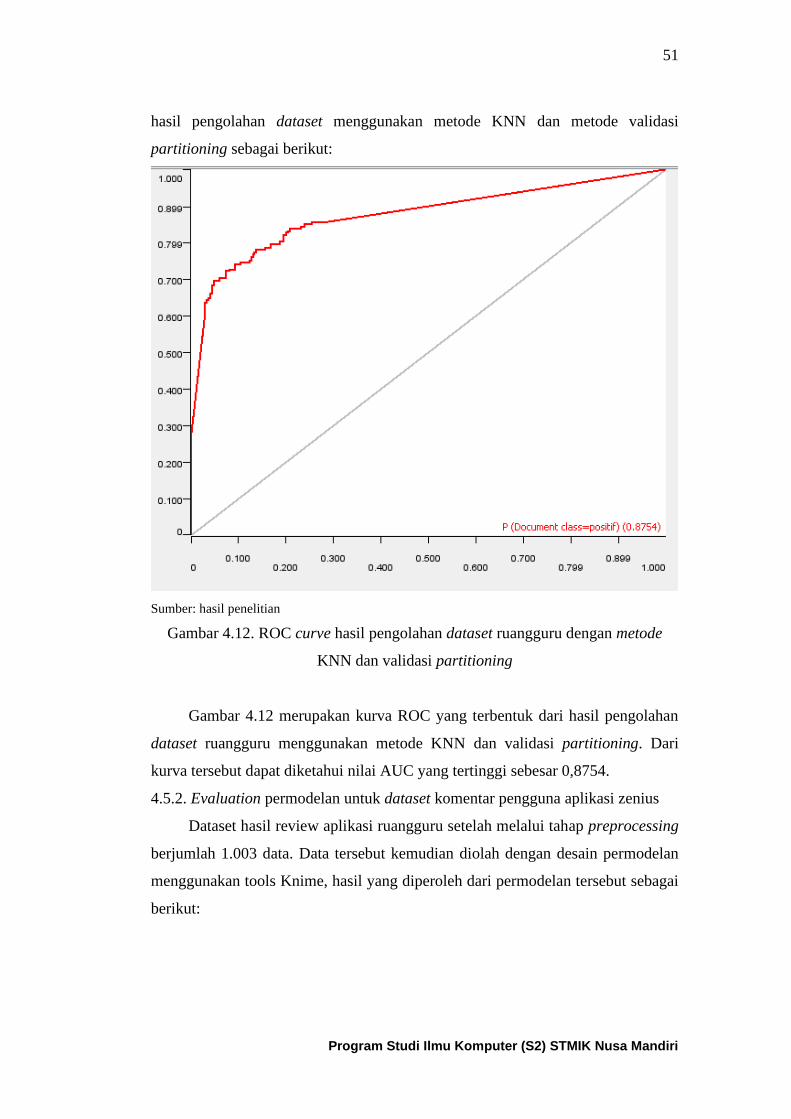
51
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
hasil pengolahan dataset menggunakan metode KNN dan metode validasi
partitioning sebagai berikut:
Sumber: hasil penelitian
Gambar 4.12. ROC curve hasil pengolahan dataset ruangguru dengan metode
KNN dan validasi partitioning
Gambar 4.12 merupakan kurva ROC yang terbentuk dari hasil pengolahan
dataset ruangguru menggunakan metode KNN dan validasi partitioning. Dari
kurva tersebut dapat diketahui nilai AUC yang tertinggi sebesar 0,8754.
4.5.2. Evaluation permodelan untuk dataset komentar pengguna aplikasi zenius
Dataset hasil review aplikasi ruangguru setelah melalui tahap preprocessing
berjumlah 1.003 data. Data tersebut kemudian diolah dengan desain permodelan
menggunakan tools Knime, hasil yang diperoleh dari permodelan tersebut sebagai
berikut:
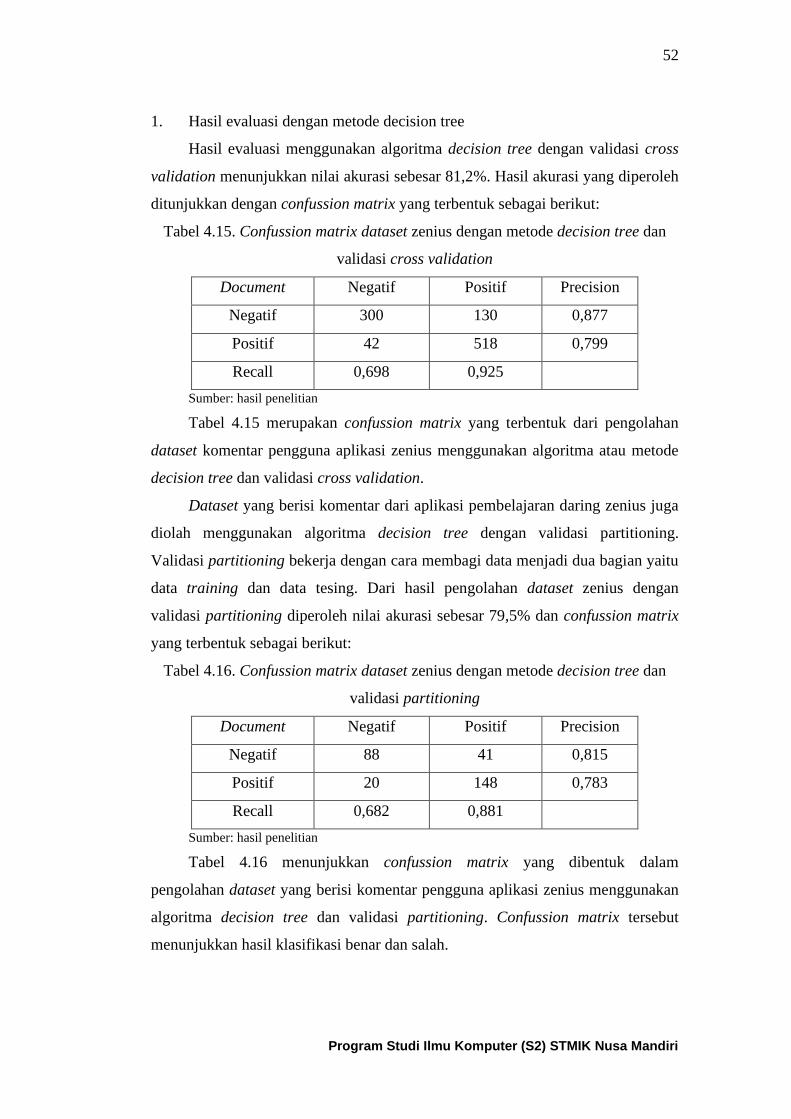
52
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
1. Hasil evaluasi dengan metode decision tree
Hasil evaluasi menggunakan algoritma decision tree dengan validasi cross
validation menunjukkan nilai akurasi sebesar 81,2%. Hasil akurasi yang diperoleh
ditunjukkan dengan confussion matrix yang terbentuk sebagai berikut:
Tabel 4.15. Confussion matrix dataset zenius dengan metode decision tree dan
validasi cross validation
Document Negatif Positif Precision
Negatif 300 130 0,877
Positif 42 518 0,799
Recall 0,698 0,925
Sumber: hasil penelitian
Tabel 4.15 merupakan confussion matrix yang terbentuk dari pengolahan
dataset komentar pengguna aplikasi zenius menggunakan algoritma atau metode
decision tree dan validasi cross validation.
Dataset yang berisi komentar dari aplikasi pembelajaran daring zenius juga
diolah menggunakan algoritma decision tree dengan validasi partitioning.
Validasi partitioning bekerja dengan cara membagi data menjadi dua bagian yaitu
data training dan data tesing. Dari hasil pengolahan dataset zenius dengan
validasi partitioning diperoleh nilai akurasi sebesar 79,5% dan confussion matrix
yang terbentuk sebagai berikut:
Tabel 4.16. Confussion matrix dataset zenius dengan metode decision tree dan
validasi partitioning
Document Negatif Positif Precision
Negatif 88 41 0,815
Positif 20 148 0,783
Recall 0,682 0,881
Sumber: hasil penelitian
Tabel 4.16 menunjukkan confussion matrix yang dibentuk dalam
pengolahan dataset yang berisi komentar pengguna aplikasi zenius menggunakan
algoritma decision tree dan validasi partitioning. Confussion matrix tersebut
menunjukkan hasil klasifikasi benar dan salah.
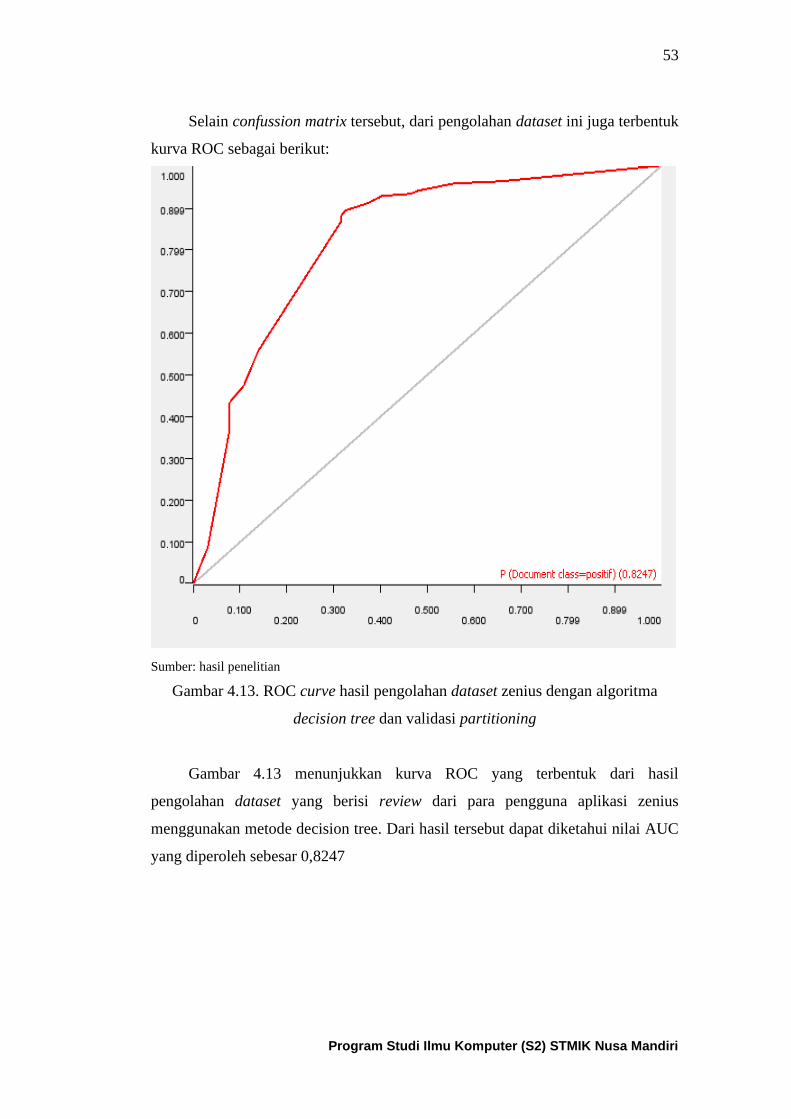
53
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Selain confussion matrix tersebut, dari pengolahan dataset ini juga terbentuk
kurva ROC sebagai berikut:
Sumber: hasil penelitian
Gambar 4.13. ROC curve hasil pengolahan dataset zenius dengan algoritma
decision tree dan validasi partitioning
Gambar 4.13 menunjukkan kurva ROC yang terbentuk dari hasil
pengolahan dataset yang berisi review dari para pengguna aplikasi zenius
menggunakan metode decision tree. Dari hasil tersebut dapat diketahui nilai AUC
yang diperoleh sebesar 0,8247

54
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: hasil penelitian
Gambar 4.14. Decision tree view dataset zenius
Gambar 4.14 menunjukkan model tree view dan hasil klasifikasi yang
terbentuk setelah data diolah menggunakan algoritma decision tree dengan
partitioning. Tree view tersebut menunjukkan sentimen negatif dan sentimen
positif yang terbentuk dari model.
2. Hasil evaluasi dengan metode naive bayes
Hasil evaluasi terhadap dataset yang berisi komentar pengguna aplikasi
zenius yang diolah menggunaka algoritma naive bayes dan validasi cross
validation menunjukkan nilai akurasi sebesar 59,5%. Confussion matrix yang
55
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
terbentuk dari hasil klasifikasi menggunakan algoritma naive bayes dan validasi
cross validation sebagai berikut:
Tabel 4.17. Confussion matrix dataset zenius dengan metode naive bayes dan
validasi cross validation
Document Negatif Positif Precision
Negatif 201 23 0,359
Positif 359 407 0,947
Recall 0,897 0,531
Sumber: hasil penelitian
Tabel 4.17 menunjukkan confussion matrix yang dibentuk dalam
pengolahan dataset yang berisi komentar pengguna aplikasi zenius menggunakan
algoritma naive bayes dan validasi cross validation. Confussion matrix tersebut
menunjukkan hasil klasifikasi benar dan salah.
Selain menggunakan validasi cross validation dalam penelitian ini juga
diterapkan pengolahan dataset komentar pengguna aplikasi pembelajaran daring
zenius menggunakan algoritma naive bayes dan validasi partitioning. Cara kerja
metode validasi ini dengan membagi dataset menjadi data training dan data
testing. Dari hasil evaluasi menggunakan validasi partitioning diperoleh nilai
akurasi sebesar 56,6% dengan confussion matrix sebagai berikut:
Tabel 4.18. Confussion matrix dataset zenius dengan metode naive bayes dan
validasi partitioning
Document Positif Negatif Precision
Positif 168 0 0,566
Negatif 129 0 0
Recall 1 0
Sumber: hasil penelitian
Tabel 4.18 menunjukkan confussion matrix yang terbentuk dari hasil
pengolahan dataset komentar pengguna aplikasi pembelajaran daring zenius
menggunakan algoritma naive bayes dan validasi partitioning. Confussion matrix
menunjukkan hasil klasifikasi data benar dan salah.
Berdasarkan hasil klasifikasi yang telah diperoleh, maka terbentuk kurva
ROC sebagai berikut:
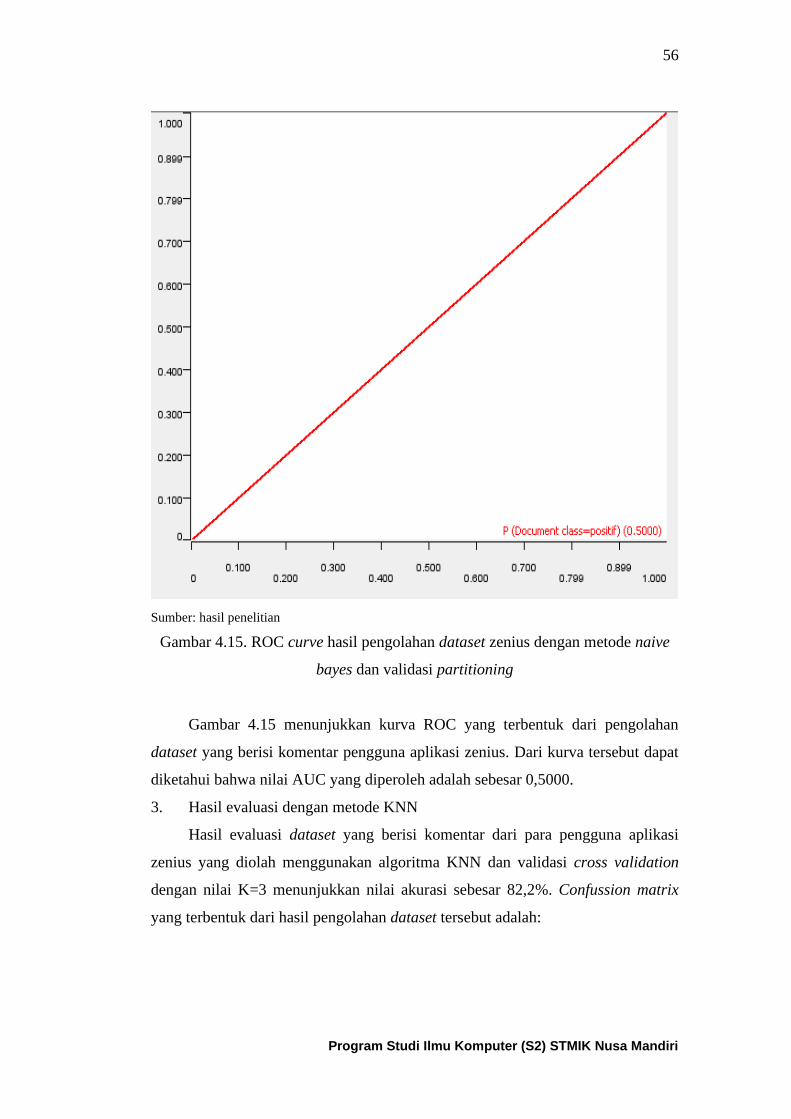
56
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: hasil penelitian
Gambar 4.15. ROC curve hasil pengolahan dataset zenius dengan metode naive
bayes dan validasi partitioning
Gambar 4.15 menunjukkan kurva ROC yang terbentuk dari pengolahan
dataset yang berisi komentar pengguna aplikasi zenius. Dari kurva tersebut dapat
diketahui bahwa nilai AUC yang diperoleh adalah sebesar 0,5000.
3. Hasil evaluasi dengan metode KNN
Hasil evaluasi dataset yang berisi komentar dari para pengguna aplikasi
zenius yang diolah menggunakan algoritma KNN dan validasi cross validation
dengan nilai K=3 menunjukkan nilai akurasi sebesar 82,2%. Confussion matrix
yang terbentuk dari hasil pengolahan dataset tersebut adalah:
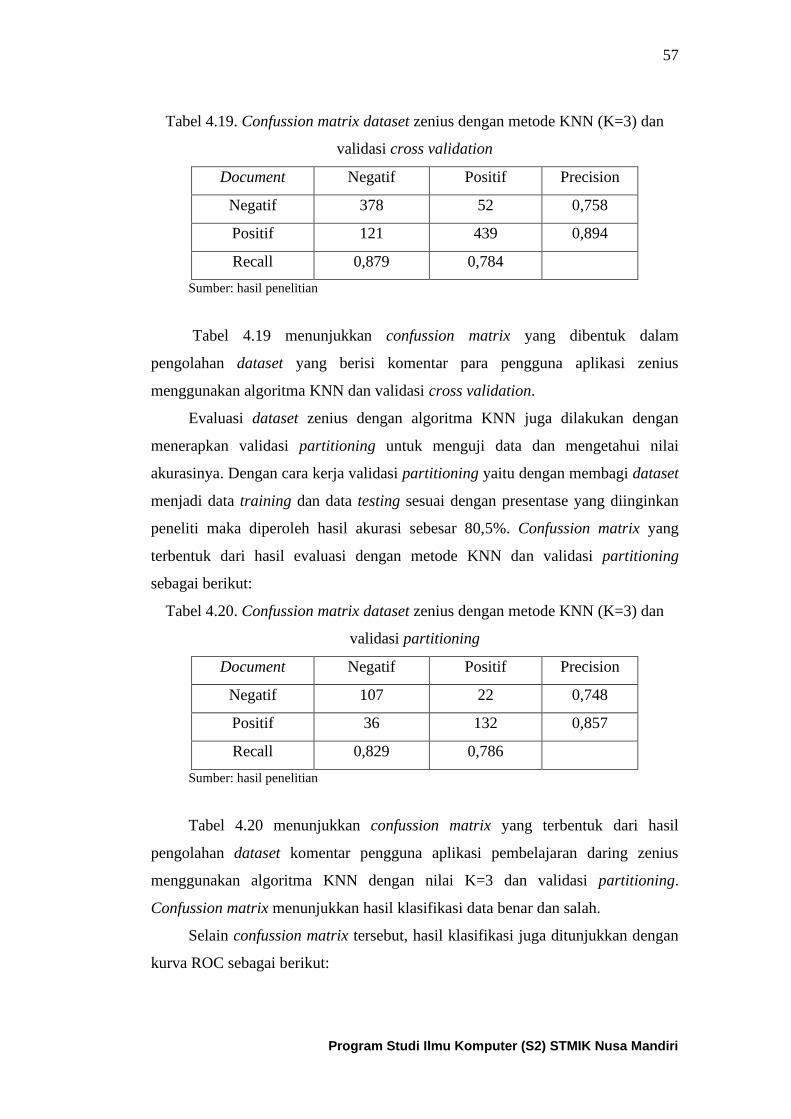
57
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Tabel 4.19. Confussion matrix dataset zenius dengan metode KNN (K=3) dan
validasi cross validation
Document Negatif Positif Precision
Negatif 378 52 0,758
Positif 121 439 0,894
Recall 0,879 0,784
Sumber: hasil penelitian
Tabel 4.19 menunjukkan confussion matrix yang dibentuk dalam
pengolahan dataset yang berisi komentar para pengguna aplikasi zenius
menggunakan algoritma KNN dan validasi cross validation.
Evaluasi dataset zenius dengan algoritma KNN juga dilakukan dengan
menerapkan validasi partitioning untuk menguji data dan mengetahui nilai
akurasinya. Dengan cara kerja validasi partitioning yaitu dengan membagi dataset
menjadi data training dan data testing sesuai dengan presentase yang diinginkan
peneliti maka diperoleh hasil akurasi sebesar 80,5%. Confussion matrix yang
terbentuk dari hasil evaluasi dengan metode KNN dan validasi partitioning
sebagai berikut:
Tabel 4.20. Confussion matrix dataset zenius dengan metode KNN (K=3) dan
validasi partitioning
Document Negatif Positif Precision
Negatif 107 22 0,748
Positif 36 132 0,857
Recall 0,829 0,786
Sumber: hasil penelitian
Tabel 4.20 menunjukkan confussion matrix yang terbentuk dari hasil
pengolahan dataset komentar pengguna aplikasi pembelajaran daring zenius
menggunakan algoritma KNN dengan nilai K=3 dan validasi partitioning.
Confussion matrix menunjukkan hasil klasifikasi data benar dan salah.
Selain confussion matrix tersebut, hasil klasifikasi juga ditunjukkan dengan
kurva ROC sebagai berikut:
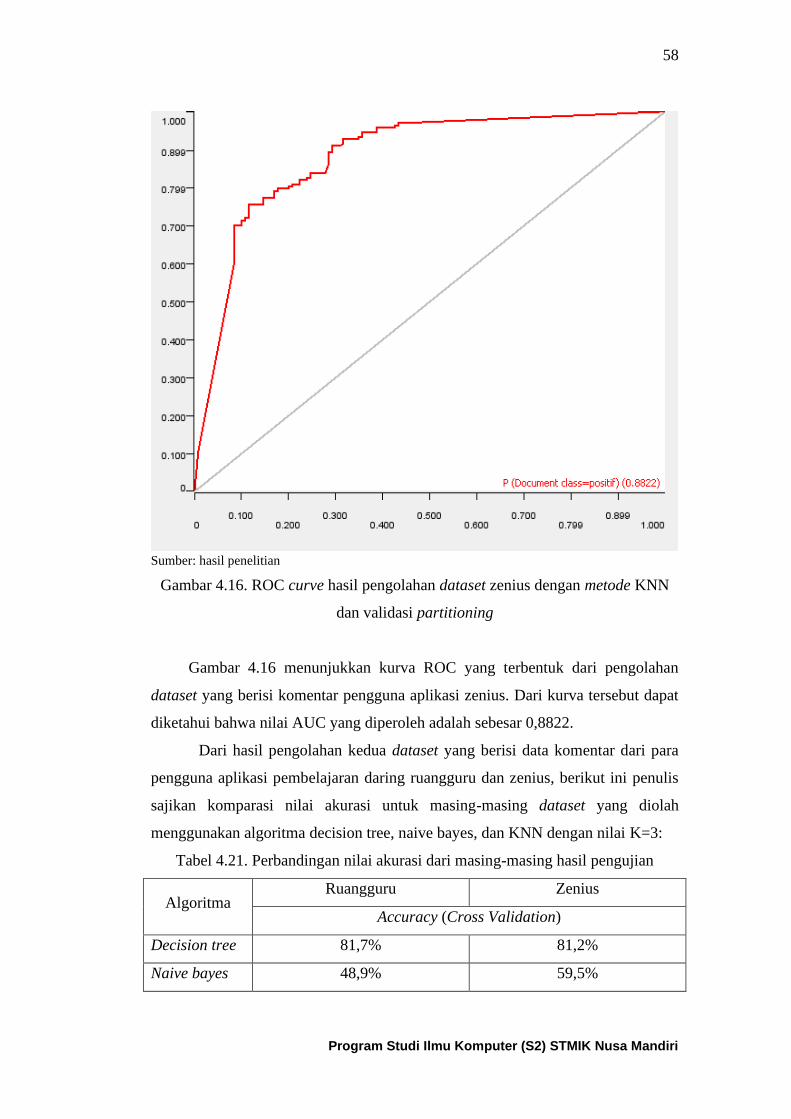
58
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Sumber: hasil penelitian
Gambar 4.16. ROC curve hasil pengolahan dataset zenius dengan metode KNN
dan validasi partitioning
Gambar 4.16 menunjukkan kurva ROC yang terbentuk dari pengolahan
dataset yang berisi komentar pengguna aplikasi zenius. Dari kurva tersebut dapat
diketahui bahwa nilai AUC yang diperoleh adalah sebesar 0,8822.
Dari hasil pengolahan kedua dataset yang berisi data komentar dari para
pengguna aplikasi pembelajaran daring ruangguru dan zenius, berikut ini penulis
sajikan komparasi nilai akurasi untuk masing-masing dataset yang diolah
menggunakan algoritma decision tree, naive bayes, dan KNN dengan nilai K=3:
Tabel 4.21. Perbandingan nilai akurasi dari masing-masing hasil pengujian
Algoritma Ruangguru Zenius
Accuracy (Cross Validation)
Decision tree 81,7% 81,2%
Naive bayes 48,9% 59,5%
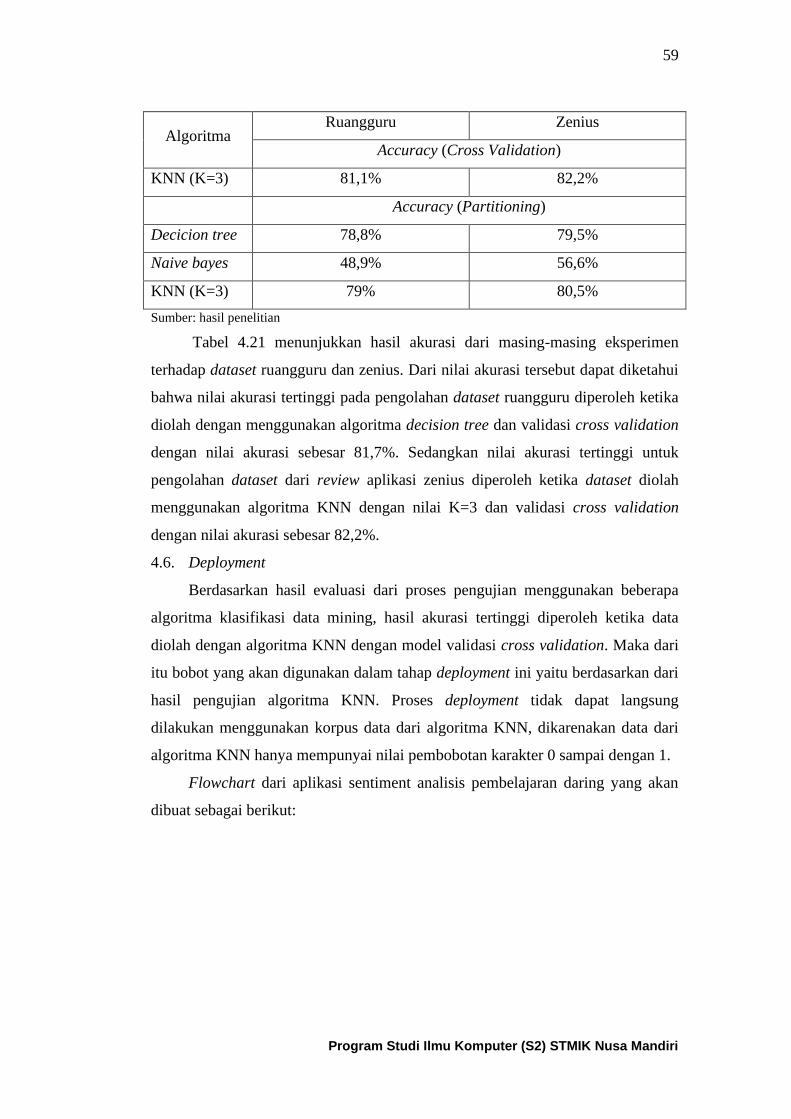
59
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Algoritma Ruangguru Zenius
Accuracy (Cross Validation)
KNN (K=3) 81,1% 82,2%
Accuracy (Partitioning)
Decicion tree 78,8% 79,5%
Naive bayes 48,9% 56,6%
KNN (K=3) 79% 80,5%
Sumber: hasil penelitian
Tabel 4.21 menunjukkan hasil akurasi dari masing-masing eksperimen
terhadap dataset ruangguru dan zenius. Dari nilai akurasi tersebut dapat diketahui
bahwa nilai akurasi tertinggi pada pengolahan dataset ruangguru diperoleh ketika
diolah dengan menggunakan algoritma decision tree dan validasi cross validation
dengan nilai akurasi sebesar 81,7%. Sedangkan nilai akurasi tertinggi untuk
pengolahan dataset dari review aplikasi zenius diperoleh ketika dataset diolah
menggunakan algoritma KNN dengan nilai K=3 dan validasi cross validation
dengan nilai akurasi sebesar 82,2%.
4.6. Deployment
Berdasarkan hasil evaluasi dari proses pengujian menggunakan beberapa
algoritma klasifikasi data mining, hasil akurasi tertinggi diperoleh ketika data
diolah dengan algoritma KNN dengan model validasi cross validation. Maka dari
itu bobot yang akan digunakan dalam tahap deployment ini yaitu berdasarkan dari
hasil pengujian algoritma KNN. Proses deployment tidak dapat langsung
dilakukan menggunakan korpus data dari algoritma KNN, dikarenakan data dari
algoritma KNN hanya mempunyai nilai pembobotan karakter 0 sampai dengan 1.
Flowchart dari aplikasi sentiment analisis pembelajaran daring yang akan
dibuat sebagai berikut:
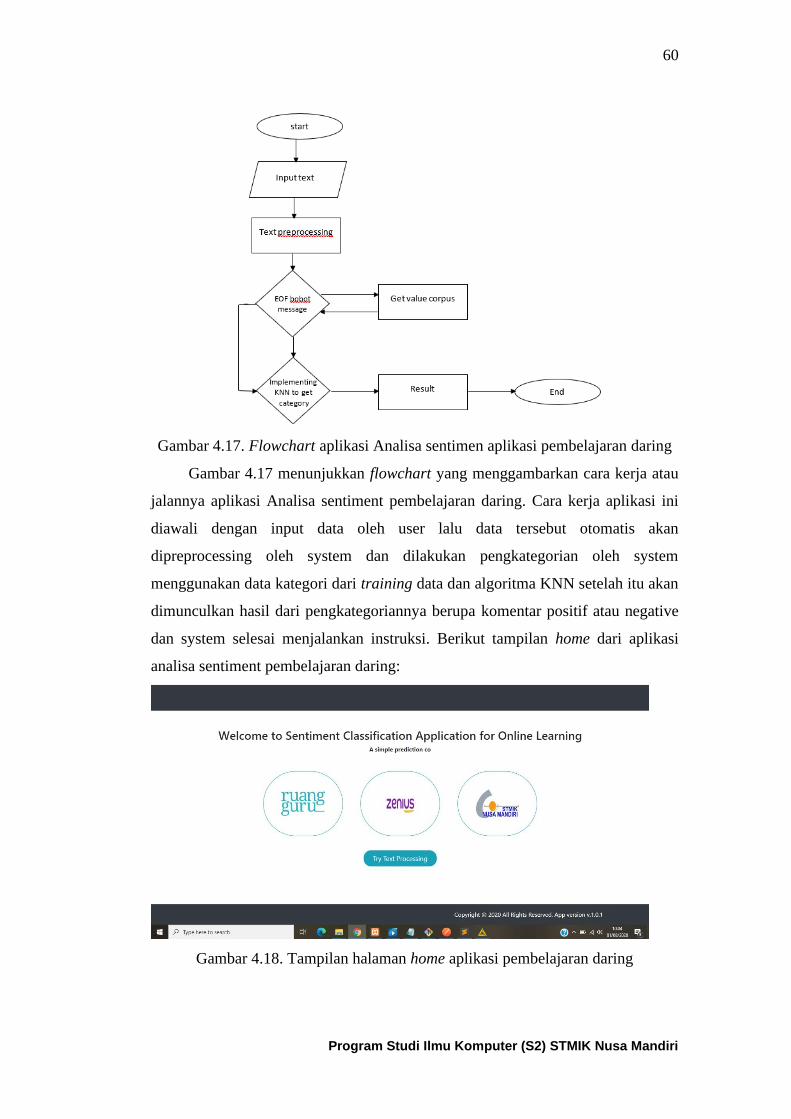
60
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Gambar 4.17. Flowchart aplikasi Analisa sentimen aplikasi pembelajaran daring
Gambar 4.17 menunjukkan flowchart yang menggambarkan cara kerja atau
jalannya aplikasi Analisa sentiment pembelajaran daring. Cara kerja aplikasi ini
diawali dengan input data oleh user lalu data tersebut otomatis akan
dipreprocessing oleh system dan dilakukan pengkategorian oleh system
menggunakan data kategori dari training data dan algoritma KNN setelah itu akan
dimunculkan hasil dari pengkategoriannya berupa komentar positif atau negative
dan system selesai menjalankan instruksi. Berikut tampilan home dari aplikasi
analisa sentiment pembelajaran daring:
Gambar 4.18. Tampilan halaman home aplikasi pembelajaran daring
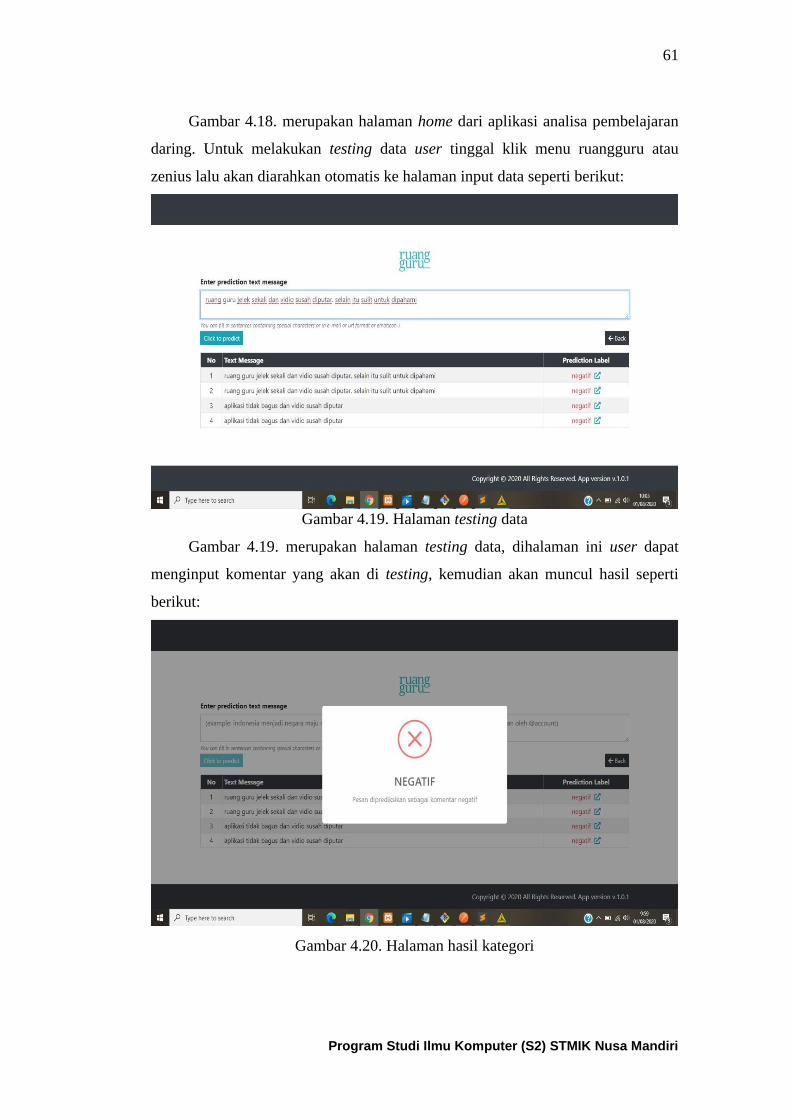
61
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Gambar 4.18. merupakan halaman home dari aplikasi analisa pembelajaran
daring. Untuk melakukan testing data user tinggal klik menu ruangguru atau
zenius lalu akan diarahkan otomatis ke halaman input data seperti berikut:
Gambar 4.19. Halaman testing data
Gambar 4.19. merupakan halaman testing data, dihalaman ini user dapat
menginput komentar yang akan di testing, kemudian akan muncul hasil seperti
berikut:
Gambar 4.20. Halaman hasil kategori
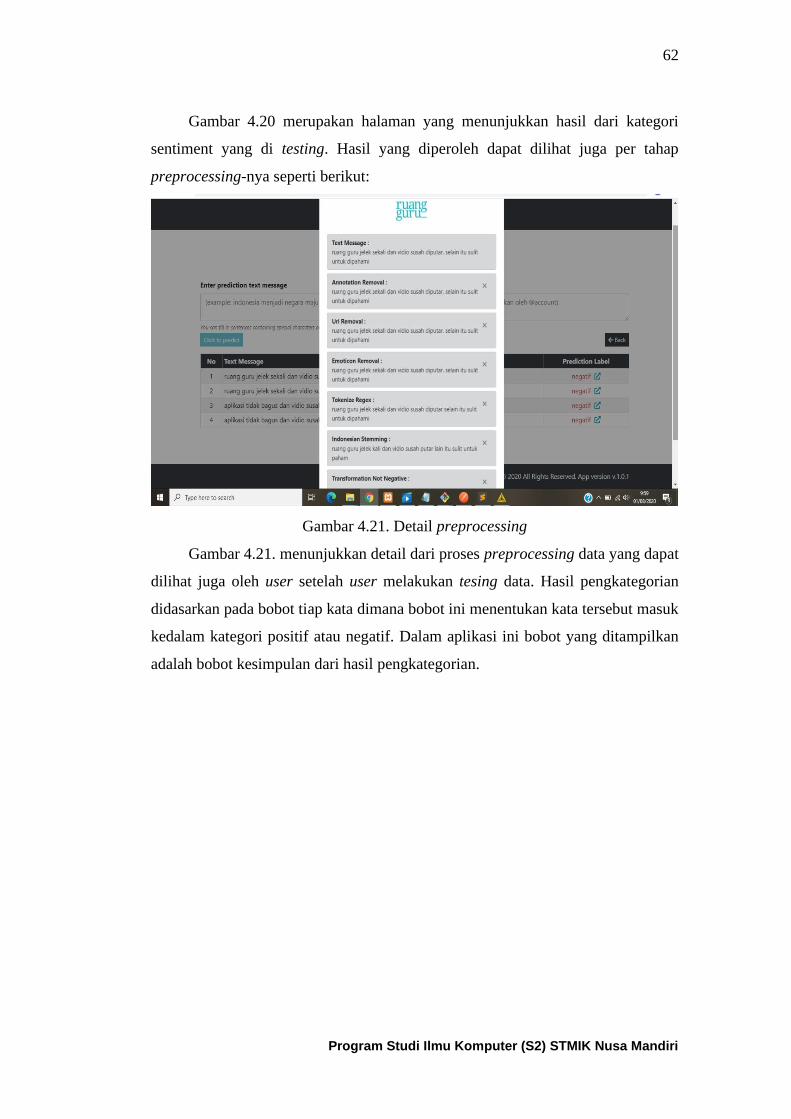
62
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Gambar 4.20 merupakan halaman yang menunjukkan hasil dari kategori
sentiment yang di testing. Hasil yang diperoleh dapat dilihat juga per tahap
preprocessing-nya seperti berikut:
Gambar 4.21. Detail preprocessing
Gambar 4.21. menunjukkan detail dari proses preprocessing data yang dapat
dilihat juga oleh user setelah user melakukan tesing data. Hasil pengkategorian
didasarkan pada bobot tiap kata dimana bobot ini menentukan kata tersebut masuk
kedalam kategori positif atau negatif. Dalam aplikasi ini bobot yang ditampilkan
adalah bobot kesimpulan dari hasil pengkategorian.

61
63
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
BAB V
PENUTUP
5.1. Kesimpulan
Berdasarkan hasil eksperimen yang dilakukan terhadap dataset aplikasi
pembelajaran daring yang berisi komentar pengguna mengenai aplikasi ruangguru
dan zenius dapat ditarik kesimpulan bahwa algoritma data mining berupa decision
tree, naive bayes, dan KNN dapat digunakan untuk mengklasifikasikan sentimen
pengguna aplikasi pembelajaran daring dengan kelas positif dan negatif. Dari
hasil akurasi dan nilai AUC yang diperoleh dapat diketahui bahwa sentimen yang
dihasilkan dari pengguna aplikasi ruangguru dan zenius adalah negatif. Dari hasil
akurasi yang diperoleh, algoritma yang memiliki nilai akurasi tertinggi dalam
pengklasifikasian sentimen dari aplikasi pembelajaran daring ini adalah algoritma
decision tree dan KNN dengan jenis validasi cross validation.
5.2. Saran
Untuk penelitian selanjutnya diharapkan dapat menggunakan algoritma lain
seperti SVM, random fores dan lain-lain agar dapat diketahui nilai akurasinya
serta dapat dilakukan model pengklasifikasian yang berbeda dari penelitian ini.
Selain itu dapat juga ditambahkan fitur optimasi agar hasil akurasi yang diperoleh
dapat lebih maksimal. Agar penelitian lebih akurat, dapat juga menambahkan
jumlah dataset.

64
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
DAFTAR PUSTAKA
[1] A. E. Sari, S. Widowati, and K. M. Lhaksmana, “Klasifikasi Ulasan
Pengguna Aplikasi Mandiri Online di Google Play Store dengan
Menggunakan Metode Information Gain dan Naive Bayes Classifier,” vol.
6, no. 2, pp. 9143–9157, 2019.
[2] A. F. Kamal and B. Widjajanto, “Text Mining Untuk Analisa Sentiment
Ekspedisi Jasa Pengiriman Barang Menggunakan Metode Naive Bayes
Pada Aplikasi J&T Express,” Ijccs, no. x, pp. 1–5, 2017.
[3] B. Olabenjo, “Applying Naive Bayes Classification to Google Play Apps
Categorization,” 2016, [Online]. Available:
http://arxiv.org/abs/1608.08574.
[4] D. Rusdiaman and D. Rosiyadi, “ANALISA SENTIMEN TERHADAP
TOKOH PUBLIK MENGGUNAKAN METODE NAÏVE BAYES
CLASSIFIER DAN SUPPORT VECTOR MACHINE,” vol. 4, no. 2, pp.
230–235, 2019.
[5] E. Di Rosa and A. Durante, “App2Check: A machine learning-based
system for sentiment analysis of app reviews in Italian language,” CEUR
Workshop Proc., vol. 1696, pp. 8–13, 2016.
[6] E. Indrayuni and M. Wahyudi, “PENERAPAN CHARACTER N-GRAM
UNTUK SENTIMENT ANALYSIS REVIEW HOTEL
MENGGUNAKAN ALGORITMA NAIVE BAYES,” pp. 83–88, 2015.
[7] J. Suntoro, Data Mining: Algoritma dan Implementasi dengan
Pemrograman PHP. Jakarta: PT Elex Media Komputindo, 2019.
[8] Knime, “KNIME Quickstart Guide,” 2019. [Online]. Available:
https://docs.knime.com/2019-
12/analytics_platform_quickstart_guide/index.html#introduction.
[Accessed: 26-Apr-2020].
[9] Kompasiana.com, “Macam-macam Teori Pembelajaran dalam Dunia
Pendidikan,” 2020. .
[10] Kompasiana.com, “‘Sentiment Analysis’, Menganalisis Opini

65
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
Menggunakan Program Komputer,” 2018. [Online]. Available:
https://www.kompasiana.com/mdanimlywn/5bd9235fab12ae20454e1fc2/se
ntiment-analysis-menganalisis-opini-menggunakan-program-komputer.
[Accessed: 26-Apr-2020].
[11] L. B. Ilmawan and E. Winarko, “Aplikasi Mobile untuk Analisis Sentimen
pada Google Play,” vol. 9, no. 1, pp. 53–64, 2015.
[12] L. Dey, S. Chakraborty, A. Biswas, B. Bose, and S. Tiwari, “Sentiment
Analysis of Review Datasets Using Naïve Bayes‘ and K-NN Classifier,”
Int. J. Inf. Eng. Electron. Bus., vol. 8, no. 4, pp. 54–62, 2016, doi:
10.5815/ijieeb.2016.04.07.
[13] M. E. Syed, “Attribute weighting in K-nearest neighbor classification,”
University of Tampere, 2015.
[14] M. Irsan, “Rancang Bangun Aplikasi Mobile Notifikasi Berbasis Android
Untuk Mendukung Kinerja Di Instansi Pemerintahan,” J. Penelit. Tek.
Inform., vol. 1, no. 1, pp. 115–120, 2015.
[15] M. R. Firdaus, F. M. Rizki, and F. M. Gaus, “Analisis Sentimen Dan Topic
Modelling Dalam Aplikasi Ruangguru,” vol. 4, pp. 66–76, 2020.
[16] M. Z. Nafan and A. E. Amalia, “Kecenderungan Tanggapan Masyarakat
terhadap Ekonomi Indonesia berbasis Lexicon Based Sentiment Analysis,”
J. Media Inform. Budidarma, vol. 3, no. 4, p. 268, 2019, doi:
10.30865/mib.v3i4.1283.
[17] R. D. Probo, B. Irawan, R. Rumani, M. 3, P. S1, and S. Komputer,
“ANALISIS DAN IMPLEMENTASI PERBANDINGAN ALGORITMA
KNN (K- NEAREST NEIGHBOR) DENGAN SVM (SUPPORT
VECTOR MACHINE) UNTUK PREDIKSI PENAWARAN PRODUK
Comparative Analysis and Implementation of KNN (K-Nearest Neighbor)
with SVM (Support Vector Machine) Algorithm ,” vol. 3, no. 3, pp. 4988–
4995, 2016.
[18] Ruangguru, “About Us,” Ruangguru.com, 2020. [Online]. Available:
https://www.ruangguru.com/about/. [Accessed: 26-Apr-2020].
[19] R. Watrianthos, S. Suryadi, D. Irmayani, M. Nasution, and E. F. S.
Simanjorang, “Sentiment analysis of traveloka app using naïve bayes

66
Program Studi Ilmu Komputer (S2) STMIK Nusa Mandiri
classifier method,” Int. J. Sci. Technol. Res., vol. 8, no. 7, pp. 786–788,
2019, doi: 10.31227/osf.io/2dbe4.
[20] S. A. Saputra, D. Rosiyadi, W. Gata, and S. M. Husain, “Analisis Sentimen
E-Wallet Pada Google Play Menggunakan Algoritma,” vol. 1, no. 10, pp.
3–8, 2019.
[21] S. Kurniawan, W. Gata, D. A. Puspitawati, I. K. S. Parthama, H. Setiawan,
and S. Hartini, “Text Mining Pre-Processing Using Gata Framework and
RapidMiner for Indonesian Sentiment Analysis,” IOP Conf. Ser. Mater.
Sci. Eng., vol. 835, no. 1, 2020, doi: 10.1088/1757-899X/835/1/012057.
[22] S. Sahara and R. A. Permana, “METHODE K-NN FOR ANALYS
SENTIMENT REVIEW KIDS APPS,” vol. 8, no. 2, pp. 127–137, 2019.
[23] S. Wahyu Handani, D. Intan Surya Saputra, Hasirun, R. Mega Arino, and
G. Fiza Asyrofi Ramadhan, “Sentiment analysis for go-jek on google play
store,” J. Phys. Conf. Ser., vol. 1196, no. 1, 2019, doi: 10.1088/1742-
6596/1196/1/012032.
[24] S. Yadav and S. Yadav, “Text Mining of VOOT Application Reviews on
Google Play Store,” Int. Res. J. Eng. Technol. e-ISSN, pp. 1204–1208,
2018.
[25] Sulhaerati, L. Kurnia, A. Kurniansyah, and A. A. Yuhana, “ANALISIS
TANGGAPAN PASAR TERHADAP PERUSAHAAN RITEL RAKSASA
INDOMART DAN ALFAMART,” 2017.
[26] V. Singh, P. Saxena, S. Singh, and S. Rajendran, “Opinion Mining and
Analysis of Movie Reviews,” Indian J. Sci. Technol., vol. 10, no. 19, pp. 1–
6, 2017, doi: 10.17485/ijst/2017/v10i19/112756.
[27] Webharvy, “WebHarvy,” webharvy, 2020. [Online]. Available:
https://www.webharvy.com/.
[28] X. Li, Z. Zhang, and K. Stefanidis, Sentiment-aware Analysis of Mobile
Apps User Reviews Regarding Particular Updates, no. November. 2018.
[29] Y. P. Tanjung, S. R. Sentinuwo, and A. Jacobus, “Penentuan Daya Listrik
Rumah Tangga Menggunakan Metode Decision Tree,” J. Tek. Inform., vol.
9, no. 1, 2016, doi: 10.35793/jti.9.1.2016.14141.
[30] Zenius.net, “About Zenius,” Zenius.net, 2020.

67
DAFTAR RIWAYAT HIDUP
A. Biodata Mahasiswa
N I M : 14002216
Nama Lengkap : Recha Abriana Anggraini
Tempat dan Tanggal Lahir: Cilacap, 05 Oktober 1996
Jenis Kelamin : Perempuan
Alamat : Tinggarjati RT02/01, Gentasari, Kroya, Cilacap
No Telp : 0895375241852
Email : [email protected]
B. Riwayat Pendidikan Formal dan Non-Formal
1. SDN 5 Gentasari, Tahun 2002-2008
2. SMPN 4 Kroya, Tahun 2008-2011
3. SMK YPE Sampang, Tahun 2011-2014
4. D3 Manajemen Informatika AMIK BSI Purwokerto, Tahun 2014-2017
5. S1 Sistem Informasi Universitas BSI Bandung, Tahun 2017-2018
C. Riwayat Pengalaman Organisasi / Pekerjaan
1. Instruktur UBSI Tasikmalaya 2019-Sekarang
Jakarta, 05 Agustus 2020
(Recha Abriana Anggraini)

68
LAMPIRAN
Lampiran 1. Contoh data komentar pengguna aplikasi ruangguru
No Text
1 Ruangguru sangat membantu saya saat sedang belajar, apalagi disaat
sedang ada pandemi covid-19 ini yang menjadikan siswa-i tidak bisa pergi
ke bimbel maupun ke sekolah. Sukses selalu untuk ruangguru! Doakan
saya agar dapat merain ptn yang saya inginkan
2 SERUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU BANGET
BELAJARNYA
3 Sangat bagus dan membantu dalam pembelajaran. Seru belajarnya karena
seperti game. Tapi juga ada videonya jadinya kayak belajar di sekolah ama
guru.
4 Kan sekarang ada covid 19, apa nggak lebih bagus kalau ruangguru
membantu belajar semua siswa indonesia, dengan menggratiskan semua
layanan selama indonesia masih lockdown
5 Bagus bgt dan sangat membantu proses belajar!!! Sukaa!! Tapi masih ada
beberapa kesalahan, terutama di soal2 bacaan tps sbmptn. Masih suka ada
kesalahan pengetikan dan terkadang soal dan jawaban tidak nyambung.
Mohon diperbaikiii
6 Rugi kalo nggak di instal cepet 2 masalahnya kalau nggak punya pulsa
dapet paket 30GB juga koh tapi kelemahannya aku masih belum tahu cara
dapetin koin yang caranya nggak bayar loh jadi aku kasih bintang 4 aslinya
tapi mbok dapet bonus jadi aku kasih bintang 5 makasih ruang guru
7 Sorry neng... Maap udah shitcommenting... Developernya sabar banget ya
nanggepin comment-comment sampah kayak gini... Salutt
8 Ruangguru telah memudahkan kami dalam memahami materi pelajaran yg
ada. Selain itu, admin2 dan timnya sangat baik dan ramah, mereka selalu
berusaha untuk memberikan pelayanan yg terbaik kepada para
penggunanya. Terima kasih, Ruangguru . Terus semangat berinovasi
untuk memajukan pendidikan di Indonesia

69
Lampiran 2. Contoh data komentar pengguna aplikasi zenius
No Text
1 apps ny zenius dh tmbh keren, apps sudah membantu gw, gw ank smp tp
blajar materi sma di zen, alhasil gw sering msk semifinal bbrp lomba fisika
makasih bgt,yg blm download gk bakal rugi lh soalny keren banget
2 saya suka belajar dengan zenius. penjelasan mudah dimengerti. karena
setiap materi diajarkan mulai dari dasarnya sampai komplek. pembahasan
soal soal mudah dipahami. zennnnius rekomended bangat buat dipakai
belajar setiap harinya. thanks zeniussssssss.
3 aku mau play video materi kok gabisa kenapa yaaa??? padahal sinyal
oke
4 tombol fullscreen perlu ditap beberapa kali baru aktif , ketika jump video
maju/mundur , gambarnya jadi rusak
5 Setelah pemakaian selama 8 bulan, saya rasa cara penyampaian materi
kurang baik untuk dipahami, beberapa kata ada yang terus menerus diulang
- ulang (sebenarnya tidak dperlukan) ditambah tulisan di dalam animasinya
sebagian besar kurang jelas alias sulit untuk dibaca. Mungkin hal ini
terdengar sepele
6 Kenapa saya tidak bisa register ataupun log in ya?,tulisannya selalu log in
failed atau register failed
7 Aplikasi nya memang didengar bagus tetapi saya tidak tahu server nya
down apa internet saya yg error karna saya ngestuck di loading profile.
Pertama² waktu saya mau daftar malah dibilangnya email saya sudah
dipake sama orang lain dan waktu saya coba email yg lain baru bisa
8 Ketika saya mencoba login di aplikasi menggunakan akun gmail saya kok
tidak bisa login ya? Muncul tulisan kata sandi tidak valid, padahal email
dan passwordnya sudah sesuai. Tapi kalau saya login di web malah bisa.
Jadinya saya pakai akun twitter saya untuk login di aplikasi dan akun gmail
di web.
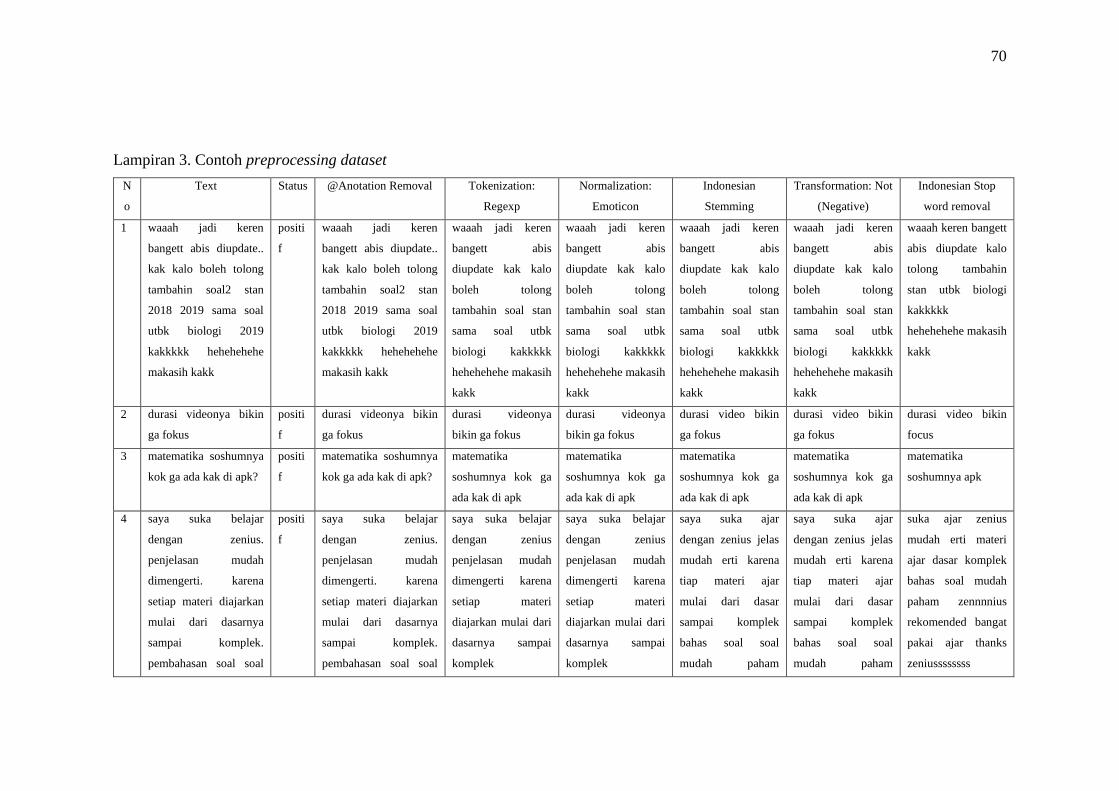
70
Lampiran 3. Contoh preprocessing dataset
N
o
Text Status @Anotation Removal Tokenization:
Regexp
Normalization:
Emoticon
Indonesian
Stemming
Transformation: Not
(Negative)
Indonesian Stop
word removal
1 waaah jadi keren
bangett abis diupdate..
kak kalo boleh tolong
tambahin soal2 stan
2018 2019 sama soal
utbk biologi 2019
kakkkkk hehehehehe
makasih kakk
positi
f
waaah jadi keren
bangett abis diupdate..
kak kalo boleh tolong
tambahin soal2 stan
2018 2019 sama soal
utbk biologi 2019
kakkkkk hehehehehe
makasih kakk
waaah jadi keren
bangett abis
diupdate kak kalo
boleh tolong
tambahin soal stan
sama soal utbk
biologi kakkkkk
hehehehehe makasih
kakk
waaah jadi keren
bangett abis
diupdate kak kalo
boleh tolong
tambahin soal stan
sama soal utbk
biologi kakkkkk
hehehehehe makasih
kakk
waaah jadi keren
bangett abis
diupdate kak kalo
boleh tolong
tambahin soal stan
sama soal utbk
biologi kakkkkk
hehehehehe makasih
kakk
waaah jadi keren
bangett abis
diupdate kak kalo
boleh tolong
tambahin soal stan
sama soal utbk
biologi kakkkkk
hehehehehe makasih
kakk
waaah keren bangett
abis diupdate kalo
tolong tambahin
stan utbk biologi
kakkkkk
hehehehehe makasih
kakk
2 durasi videonya bikin
ga fokus
positi
f
durasi videonya bikin
ga fokus
durasi videonya
bikin ga fokus
durasi videonya
bikin ga fokus
durasi video bikin
ga fokus
durasi video bikin
ga fokus
durasi video bikin
focus
3 matematika soshumnya
kok ga ada kak di apk?
positi
f
matematika soshumnya
kok ga ada kak di apk?
matematika
soshumnya kok ga
ada kak di apk
matematika
soshumnya kok ga
ada kak di apk
matematika
soshumnya kok ga
ada kak di apk
matematika
soshumnya kok ga
ada kak di apk
matematika
soshumnya apk
4 saya suka belajar
dengan zenius.
penjelasan mudah
dimengerti. karena
setiap materi diajarkan
mulai dari dasarnya
sampai komplek.
pembahasan soal soal
positi
f
saya suka belajar
dengan zenius.
penjelasan mudah
dimengerti. karena
setiap materi diajarkan
mulai dari dasarnya
sampai komplek.
pembahasan soal soal
saya suka belajar
dengan zenius
penjelasan mudah
dimengerti karena
setiap materi
diajarkan mulai dari
dasarnya sampai
komplek
saya suka belajar
dengan zenius
penjelasan mudah
dimengerti karena
setiap materi
diajarkan mulai dari
dasarnya sampai
komplek
saya suka ajar
dengan zenius jelas
mudah erti karena
tiap materi ajar
mulai dari dasar
sampai komplek
bahas soal soal
mudah paham
saya suka ajar
dengan zenius jelas
mudah erti karena
tiap materi ajar
mulai dari dasar
sampai komplek
bahas soal soal
mudah paham
suka ajar zenius
mudah erti materi
ajar dasar komplek
bahas soal mudah
paham zennnnius
rekomended bangat
pakai ajar thanks
zeniussssssss
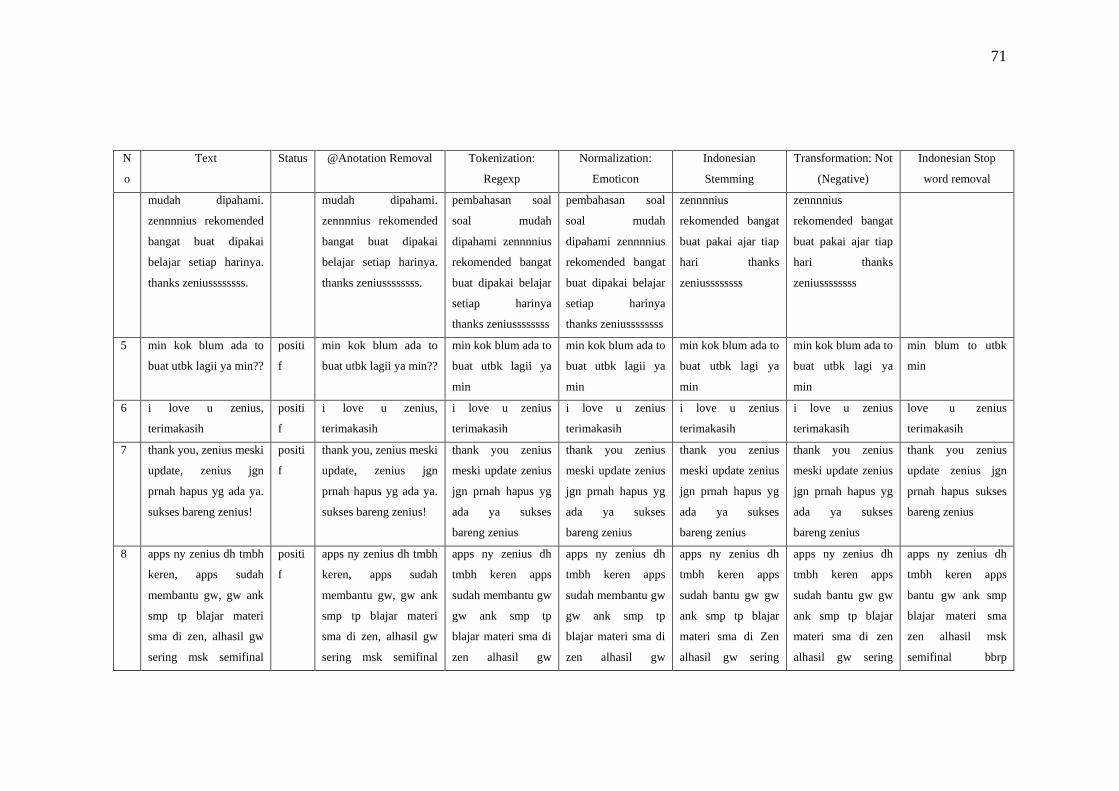
71
N
o
Text Status @Anotation Removal Tokenization:
Regexp
Normalization:
Emoticon
Indonesian
Stemming
Transformation: Not
(Negative)
Indonesian Stop
word removal
mudah dipahami.
zennnnius rekomended
bangat buat dipakai
belajar setiap harinya.
thanks zeniussssssss.
mudah dipahami.
zennnnius rekomended
bangat buat dipakai
belajar setiap harinya.
thanks zeniussssssss.
pembahasan soal
soal mudah
dipahami zennnnius
rekomended bangat
buat dipakai belajar
setiap harinya
thanks zeniussssssss
pembahasan soal
soal mudah
dipahami zennnnius
rekomended bangat
buat dipakai belajar
setiap harinya
thanks zeniussssssss
zennnnius
rekomended bangat
buat pakai ajar tiap
hari thanks
zeniussssssss
zennnnius
rekomended bangat
buat pakai ajar tiap
hari thanks
zeniussssssss
5 min kok blum ada to
buat utbk lagii ya min??
positi
f
min kok blum ada to
buat utbk lagii ya min??
min kok blum ada to
buat utbk lagii ya
min
min kok blum ada to
buat utbk lagii ya
min
min kok blum ada to
buat utbk lagi ya
min
min kok blum ada to
buat utbk lagi ya
min
min blum to utbk
min
6 i love u zenius,
terimakasih
positi
f
i love u zenius,
terimakasih
i love u zenius
terimakasih
i love u zenius
terimakasih
i love u zenius
terimakasih
i love u zenius
terimakasih
love u zenius
terimakasih
7 thank you, zenius meski
update, zenius jgn
prnah hapus yg ada ya.
sukses bareng zenius!
positi
f
thank you, zenius meski
update, zenius jgn
prnah hapus yg ada ya.
sukses bareng zenius!
thank you zenius
meski update zenius
jgn prnah hapus yg
ada ya sukses
bareng zenius
thank you zenius
meski update zenius
jgn prnah hapus yg
ada ya sukses
bareng zenius
thank you zenius
meski update zenius
jgn prnah hapus yg
ada ya sukses
bareng zenius
thank you zenius
meski update zenius
jgn prnah hapus yg
ada ya sukses
bareng zenius
thank you zenius
update zenius jgn
prnah hapus sukses
bareng zenius
8 apps ny zenius dh tmbh
keren, apps sudah
membantu gw, gw ank
smp tp blajar materi
sma di zen, alhasil gw
sering msk semifinal
positi
f
apps ny zenius dh tmbh
keren, apps sudah
membantu gw, gw ank
smp tp blajar materi
sma di zen, alhasil gw
sering msk semifinal
apps ny zenius dh
tmbh keren apps
sudah membantu gw
gw ank smp tp
blajar materi sma di
zen alhasil gw
apps ny zenius dh
tmbh keren apps
sudah membantu gw
gw ank smp tp
blajar materi sma di
zen alhasil gw
apps ny zenius dh
tmbh keren apps
sudah bantu gw gw
ank smp tp blajar
materi sma di Zen
alhasil gw sering
apps ny zenius dh
tmbh keren apps
sudah bantu gw gw
ank smp tp blajar
materi sma di zen
alhasil gw sering
apps ny zenius dh
tmbh keren apps
bantu gw ank smp
blajar materi sma
zen alhasil msk
semifinal bbrp
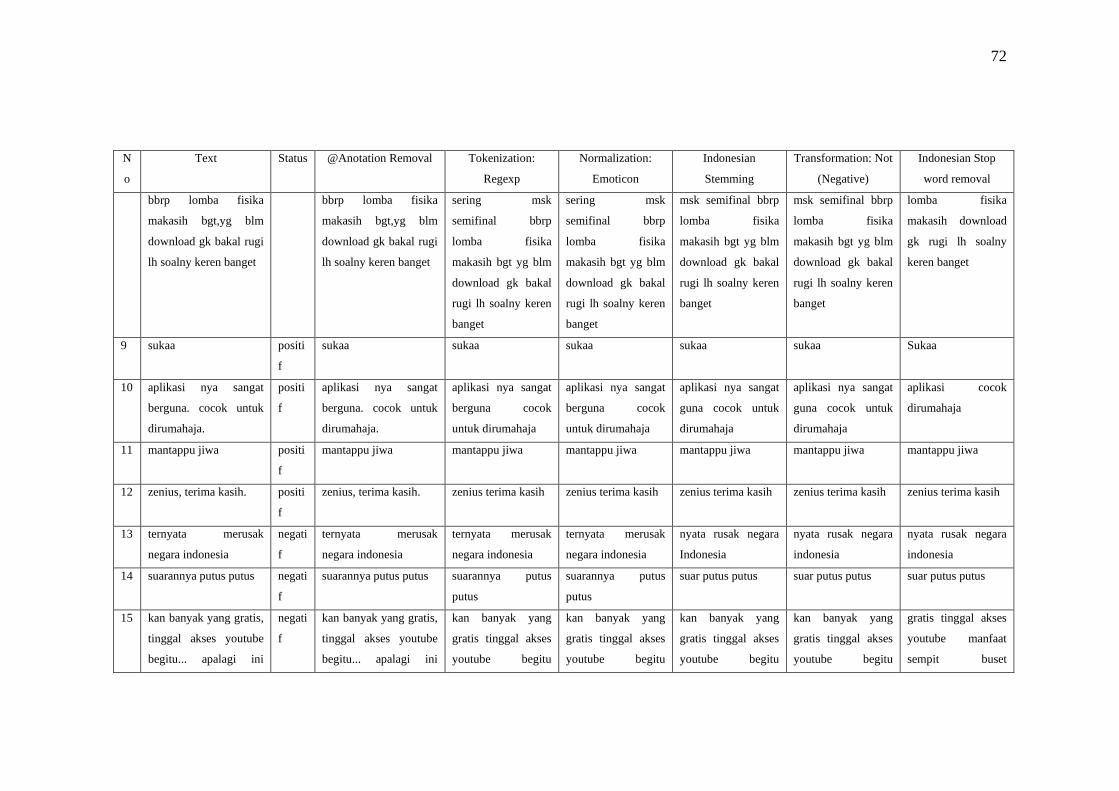
72
N
o
Text Status @Anotation Removal Tokenization:
Regexp
Normalization:
Emoticon
Indonesian
Stemming
Transformation: Not
(Negative)
Indonesian Stop
word removal
bbrp lomba fisika
makasih bgt,yg blm
download gk bakal rugi
lh soalny keren banget
bbrp lomba fisika
makasih bgt,yg blm
download gk bakal rugi
lh soalny keren banget
sering msk
semifinal bbrp
lomba fisika
makasih bgt yg blm
download gk bakal
rugi lh soalny keren
banget
sering msk
semifinal bbrp
lomba fisika
makasih bgt yg blm
download gk bakal
rugi lh soalny keren
banget
msk semifinal bbrp
lomba fisika
makasih bgt yg blm
download gk bakal
rugi lh soalny keren
banget
msk semifinal bbrp
lomba fisika
makasih bgt yg blm
download gk bakal
rugi lh soalny keren
banget
lomba fisika
makasih download
gk rugi lh soalny
keren banget
9 sukaa positi
f
sukaa sukaa sukaa sukaa sukaa Sukaa
10 aplikasi nya sangat
berguna. cocok untuk
dirumahaja.
positi
f
aplikasi nya sangat
berguna. cocok untuk
dirumahaja.
aplikasi nya sangat
berguna cocok
untuk dirumahaja
aplikasi nya sangat
berguna cocok
untuk dirumahaja
aplikasi nya sangat
guna cocok untuk
dirumahaja
aplikasi nya sangat
guna cocok untuk
dirumahaja
aplikasi cocok
dirumahaja
11 mantappu jiwa positi
f
mantappu jiwa mantappu jiwa mantappu jiwa mantappu jiwa mantappu jiwa mantappu jiwa
12 zenius, terima kasih. positi
f
zenius, terima kasih. zenius terima kasih zenius terima kasih zenius terima kasih zenius terima kasih zenius terima kasih
13 ternyata merusak
negara indonesia
negati
f
ternyata merusak
negara indonesia
ternyata merusak
negara indonesia
ternyata merusak
negara indonesia
nyata rusak negara
Indonesia
nyata rusak negara
indonesia
nyata rusak negara
indonesia
14 suarannya putus putus negati
f
suarannya putus putus suarannya putus
putus
suarannya putus
putus
suar putus putus suar putus putus suar putus putus
15 kan banyak yang gratis,
tinggal akses youtube
begitu... apalagi ini
negati
f
kan banyak yang gratis,
tinggal akses youtube
begitu... apalagi ini
kan banyak yang
gratis tinggal akses
youtube begitu
kan banyak yang
gratis tinggal akses
youtube begitu
kan banyak yang
gratis tinggal akses
youtube begitu
kan banyak yang
gratis tinggal akses
youtube begitu
gratis tinggal akses
youtube manfaat
sempit buset
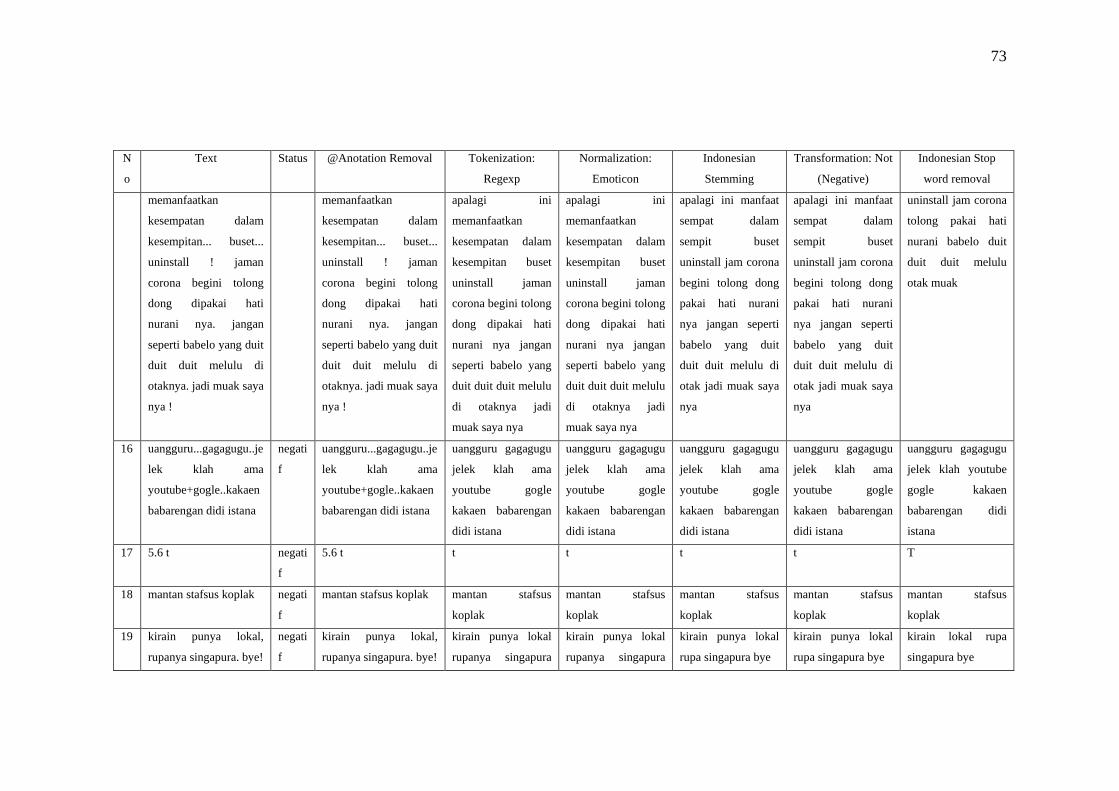
73
N
o
Text Status @Anotation Removal Tokenization:
Regexp
Normalization:
Emoticon
Indonesian
Stemming
Transformation: Not
(Negative)
Indonesian Stop
word removal
memanfaatkan
kesempatan dalam
kesempitan... buset...
uninstall ! jaman
corona begini tolong
dong dipakai hati
nurani nya. jangan
seperti babelo yang duit
duit duit melulu di
otaknya. jadi muak saya
nya !
memanfaatkan
kesempatan dalam
kesempitan... buset...
uninstall ! jaman
corona begini tolong
dong dipakai hati
nurani nya. jangan
seperti babelo yang duit
duit duit melulu di
otaknya. jadi muak saya
nya !
apalagi ini
memanfaatkan
kesempatan dalam
kesempitan buset
uninstall jaman
corona begini tolong
dong dipakai hati
nurani nya jangan
seperti babelo yang
duit duit duit melulu
di otaknya jadi
muak saya nya
apalagi ini
memanfaatkan
kesempatan dalam
kesempitan buset
uninstall jaman
corona begini tolong
dong dipakai hati
nurani nya jangan
seperti babelo yang
duit duit duit melulu
di otaknya jadi
muak saya nya
apalagi ini manfaat
sempat dalam
sempit buset
uninstall jam corona
begini tolong dong
pakai hati nurani
nya jangan seperti
babelo yang duit
duit duit melulu di
otak jadi muak saya
nya
apalagi ini manfaat
sempat dalam
sempit buset
uninstall jam corona
begini tolong dong
pakai hati nurani
nya jangan seperti
babelo yang duit
duit duit melulu di
otak jadi muak saya
nya
uninstall jam corona
tolong pakai hati
nurani babelo duit
duit duit melulu
otak muak
16 uangguru...gagagugu..je
lek klah ama
youtube+gogle..kakaen
babarengan didi istana
negati
f
uangguru...gagagugu..je
lek klah ama
youtube+gogle..kakaen
babarengan didi istana
uangguru gagagugu
jelek klah ama
youtube gogle
kakaen babarengan
didi istana
uangguru gagagugu
jelek klah ama
youtube gogle
kakaen babarengan
didi istana
uangguru gagagugu
jelek klah ama
youtube gogle
kakaen babarengan
didi istana
uangguru gagagugu
jelek klah ama
youtube gogle
kakaen babarengan
didi istana
uangguru gagagugu
jelek klah youtube
gogle kakaen
babarengan didi
istana
17 5.6 t negati
f
5.6 t t t t t T
18 mantan stafsus koplak negati
f
mantan stafsus koplak mantan stafsus
koplak
mantan stafsus
koplak
mantan stafsus
koplak
mantan stafsus
koplak
mantan stafsus
koplak
19 kirain punya lokal,
rupanya singapura. bye!
negati
f
kirain punya lokal,
rupanya singapura. bye!
kirain punya lokal
rupanya singapura
kirain punya lokal
rupanya singapura
kirain punya lokal
rupa singapura bye
kirain punya lokal
rupa singapura bye
kirain lokal rupa
singapura bye
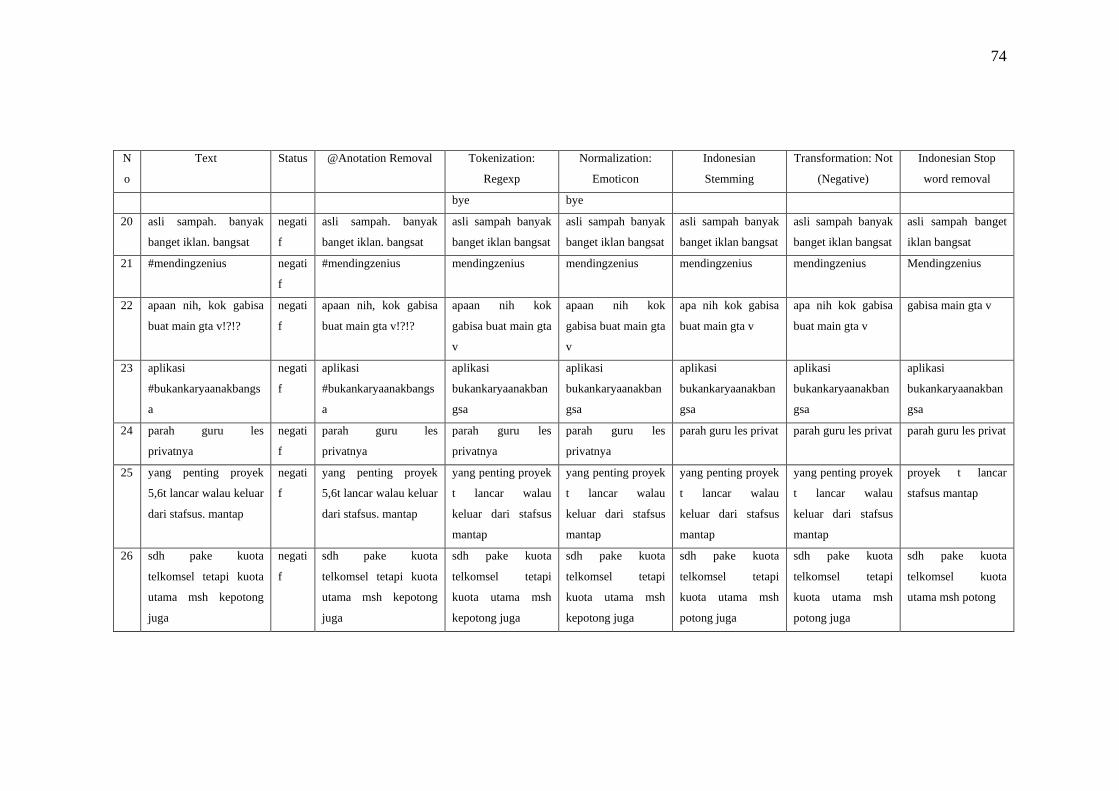
74
N
o
Text Status @Anotation Removal Tokenization:
Regexp
Normalization:
Emoticon
Indonesian
Stemming
Transformation: Not
(Negative)
Indonesian Stop
word removal
bye bye
20 asli sampah. banyak
banget iklan. bangsat
negati
f
asli sampah. banyak
banget iklan. bangsat
asli sampah banyak
banget iklan bangsat
asli sampah banyak
banget iklan bangsat
asli sampah banyak
banget iklan bangsat
asli sampah banyak
banget iklan bangsat
asli sampah banget
iklan bangsat
21 #mendingzenius negati
f
#mendingzenius mendingzenius mendingzenius mendingzenius mendingzenius Mendingzenius
22 apaan nih, kok gabisa
buat main gta v!?!?
negati
f
apaan nih, kok gabisa
buat main gta v!?!?
apaan nih kok
gabisa buat main gta
v
apaan nih kok
gabisa buat main gta
v
apa nih kok gabisa
buat main gta v
apa nih kok gabisa
buat main gta v
gabisa main gta v
23 aplikasi
#bukankaryaanakbangs
a
negati
f
aplikasi
#bukankaryaanakbangs
a
aplikasi
bukankaryaanakban
gsa
aplikasi
bukankaryaanakban
gsa
aplikasi
bukankaryaanakban
gsa
aplikasi
bukankaryaanakban
gsa
aplikasi
bukankaryaanakban
gsa
24 parah guru les
privatnya
negati
f
parah guru les
privatnya
parah guru les
privatnya
parah guru les
privatnya
parah guru les privat parah guru les privat parah guru les privat
25 yang penting proyek
5,6t lancar walau keluar
dari stafsus. mantap
negati
f
yang penting proyek
5,6t lancar walau keluar
dari stafsus. mantap
yang penting proyek
t lancar walau
keluar dari stafsus
mantap
yang penting proyek
t lancar walau
keluar dari stafsus
mantap
yang penting proyek
t lancar walau
keluar dari stafsus
mantap
yang penting proyek
t lancar walau
keluar dari stafsus
mantap
proyek t lancar
stafsus mantap
26 sdh pake kuota
telkomsel tetapi kuota
utama msh kepotong
juga
negati
f
sdh pake kuota
telkomsel tetapi kuota
utama msh kepotong
juga
sdh pake kuota
telkomsel tetapi
kuota utama msh
kepotong juga
sdh pake kuota
telkomsel tetapi
kuota utama msh
kepotong juga
sdh pake kuota
telkomsel tetapi
kuota utama msh
potong juga
sdh pake kuota
telkomsel tetapi
kuota utama msh
potong juga
sdh pake kuota
telkomsel kuota
utama msh potong