prueba de fisher
TRANSCRIPT

UNIVERSIDAD AUTONOMA DEL ESTADO DE MEXICO
MAESTRIA EN ESTUDIOS SUSTENTABLES REGIONALES Y METROPOLITANOS
Lenin Valdés Tarango
Prueba Exacta de Fisher
Objetivo de la Técnica
Es una técnica para tablas 2x2, sirve para analizar datosconcretos (tanto nominales como ordinales) cuando dosmuestras independientes son pequeñas.
Introducción

Al estudiar las diferencias entre dos grupos, es necesariodeterminar si ambos grupos están relacionados o si sonindependientes. ”La prueba exacta de Fisher para tablas 2x2, se usa cuandodos puntuaciones, de dos muestras independientes al azar caen dentro de una dedos clases mutuamente concluyentes” (Siegel, 1995:129).
Conceptualización
La prueba exacta de Fisher “es una alternativa estadística a la prueba dePearson χ2 ya que permite analizar si dos variables dicotómicas están asociadascuando la muestra a estudiar es demasiado pequeña y no se cumplen lascondiciones necesarias para que la aplicación del test χ2 sea adecuada” (Diaz-Fernandez, 2004; 11: 304-308).
Contexto de aplicación
En los temas investigados se obtuvo información de áreasbiomédicas, es probable adaptar algún ejercicio al estudiourbano a través del conocimiento de grupos de personas quehagan uso del transporte público.
Notas: No cuento con la experiencia ni los conocimientos suficientes
en estadística no paramétrica para aplicar la técnica enalgún apartado de mi estudio.
No se logró identificar un ejemplo de caso concreto aplicableal contexto de mi tema de estudio.
Requisitos/supuestos
Se requiere la formación de dos grupos a partir de muestras
Se supondrá que no existen diferencias entre ambos grupos en la variable dicotómica medida, la cual es codificada, por conveniencia como +y-.
Ventajas

La prueba ayuda a determinar si los grupos difieren enproporciones en donde caen dentro de cualquiera de lasclasificaciones.
Notación de la Hipótesis
Supongamos que queremos contrastar la hipótesis de independencia poblacional para una tabla 2 × 2 se puede expresar como:
H0:p1=p2.
Alternativas
H1:p1≠p2H1:p1>p2H1:p1<p2
Variables
Las variables dependen del planteamiento del problema y reflejarán la dicotomía planteada. En el caso planteado es + -
Descripción de la técnica
La probabilidad exacta de observar un conjunto particular defrecuencias en una tabla de 2x2, cuando los totalesmarginales se consideran fijos, está dada por distribuciónhipergeométrica.
Tabla de descripción
GrupoVariable I II Combinación
+ A B A+B- C D C+D

Total A+C B+D N
Donde
p=[ (A+C )!A!C! ][ (B+D )!
B!D! ]N![ (A+B)! (C+D )! ]
Y así
p=(A+B )! (C+D )! (A+C)! (B+D )!
N!A!B!C!D!
Uso de la ecuación
Supóngase que
A=5B=4C=0D=10
GrupoVariable I II Combinación
+ 5 4 9- 0 10 10
Total 5 14 19
N= Número total de observaciones independientes que para estecaso es 19.
La probabilidad exacta de que esos 19 casos cayeran en lascuatro celdas tal como si hubieran sido asignados al azar,

puede determinarse mediante la ecuación con los valoressustituidos.
p=9!10!5!14!
19!5!4!0!10!=0.0108
Conociendo la hipótesis
H0:p1=p2.
Se puede reconocer que el resultado es verdadero ya que ladiferencia no es mayor ni significativa.
El ejemplo anterior fue comparativamente simple de calcular debido a que una delas celdas tuvo una frecuencia de cero. Pero, si ninguna de las celdas es cero,debemos identificar las desviaciones más extremas de la distribución supuesta porHo que podría ocurrir con los mismos totales marginales, y debemos tener encuenta esas posibles desviaciones extremas, para el establecimiento de la hipótesisnula: ¿Cuál es la probabilidad, cuando Ho es verdadera, de la ocurrencia delresultado obtenido o uno más extremo? Siegel, 1995:131).”
Así, si debemos aplicar una prueba estadística a la hipótesisnula para los datos correspondientes a la tabla 5.3 a,debemos sumar la probabilidad de su ocurrencia con laprobabilidad del resultado más extremo mostrado en la tabla5.3b. Calculamos cada p utilizando la ecuación.
Suponiendo los datos:
Tabla 1Grupo
I II4 1 51 6 75 7 12
Tabla 2

GrupoI II5 0 50 7 75 7 12
p= 5!7!5!7!12!4!1!1!6!
¿0,04419
p=5!7!5!7!
12!5!0!0!7!¿0.00126
Entonces la probabilidad de ocurrencia es
p=0.04419+0.00126p=0.04545
Para facilitar el cálculo de la probabilidad asociada son tablas de contingencia 2x2, puede utilizarse la tabla I del apéndice (pag374-375), la cual es aplicable a las tablas de contingencia 2x2 cuando N≤15. Dado su tamaño y arreglo.
Pasos para aplicar la tabla I:
Determine los totales por reglón y columna. Esto dará los resultados para S1 y S2.
X es la frecuencia observada en la celda donde se cruzanlos valores, más pequeño y el segundo más pequeño de renglón y columna.
Localice el renglón (N, S1, S2, X) en la tabla1. Haytres entradas “Obs.”, es la probabilidad unidireccionalde observar una diferencia igual o más extrema que laque se observó. La segunda entrada es la probabilidad deobservar una diferencia grande o mayor en la dirección

opuesta. Finalmente, la tercera entrada, “Total”, es laprobabilidad bidireccional de observar una diferenciagrande o mayor que la observada en cualquier dirección.
Oriente y rotule la tabla para asegurar que las entradasson consistentes con la hipótesis.
x - S1 (frecuencia más pequeña).
- -S2 (frecuencia más pequeña).
Aunque los cálculos de probabilidades asociadasunidireccionales y bidireccionales con la prueba exacta deFisher se facilitan considerablemente con la tabla I, esimportante que el usuario entienda la base o el fundamento dela prueba, a fin de que utilice la tabla efectivamente.Usaremos la tabla 5.5 para ilustrar su aplicación.
Supongamos que un investigador ha formado dos grupos a partirde muestras y la hipótesis nula plantea que no existendiferencias entre ambos grupos en la variable dicotómicamedida, la cual es codificada, por conveniencia, como + y - .La hipótesis alterna plantea que el grupo 1 excede al grupo 2en la proporción de respuestas +. Si planteamos que pi sea laprobabilidad de que un sujeto seleccionado al azar del grupo1 responda 4- y que p^ sea la probabilidad de que un sujetoelegido al azar del grupo 2 responda +, entonces la hipótesisnula y la alterna serían las siguientes:
Ho:p1=p2H1:p1>p2
Supongamos que N = 15 sujetos muestreados, sietepertenecientes al grupo 1 y ocho al grupo 2, y 5 sujetos delgrupo 1 respondieron 4- mientras un sujeto del grupo 2respondió + . Los datos pueden ser representados como en elarreglo II de la tabla. Así, en la muestra pi = 5/7 = 0.714 y

p2= 1/8 = 0.125. Para evaluar la hipótesis Hp, se debedeterminar la probabilidad de observar una tabla decontingencia de 2 X 2 tan extrema o más. En la tabla 5.5 semuestran todos los posibles resultados que tienen los mismostotales marginales. Para cada uno de estos siete posiblesresultados se proporcionan p1 y p2 junto con la probabilidadde muestrear esos arreglos resultantes cuando Ho es verdadera(utilizando la ecuación).Nótese que la probabilidad demuestrear el resultado observado es P[II] = 0.0336. Larevisión de la tabla 5.5 muestra sólo un arreglo con unresultado más extremo (por ejemplo, P^ — P^ > 0.714 — 0.125== 0.589), esto es, el resultado I que tiene probabilidad0.0014. Así, la probabilidad de observar un resultado o unomás extremo es la siguiente:
p = p[II] + p[I]= 0.0336 4- 0.0014= 0.035
Tabla P1 P2 P1-P2
P(tabla)
Obs Otras
Total
I + 6 0 6 0.857 0 0.857 0.0014 0.001 0.000 0.001- 1 8 9
7 8 15
II + 5 1 6 0.714 0.125 .589 0.0336 0.035 0.006 0.014- 2 7 9
7 8 15
III
+ 4 2 6 .0571 0.250 0.321 0.1958 0.231 0.084 0.315
- 3 6 97 8 15
IV + 3 3 6 .429 0.375 0.054 0.3916 0.622 0.378 1.000- 4 5 9
7 8 15
V + 2 4 6 .286 0.500 -0.214
0.2937 0.378 0.231 0.608
- 5 4 97 8 15
VI + 1 5 6 0.143 0.625 - 0.0783 0.084 0.035 0.119

0.482- 6 3 9
7 8 15
VII
+ 0 6 6 0 0.725 -0.750
0.0056 0.006 0.001 0.007
- 7 2 97 8 15
Nótese que ésta es la entrada Obs. en la tabla 5.5 y la tablaI del Apéndice (Pag.374-375) para el resultado II.
Supongamos que la hipótesis alterna fue enunciada bidireccionalmente, esto es,
H1:p1≠p2
Entonces, los arreglos resultantes que muestran diferenciasen posibles p mayores que el resultado observado II, son losresultados I y VII. El resultado VII es un valor más extremoque el resultado observado, pero en "otra" dirección. Laprobabilidad del resultado es P[VII] = 0.0056. Éste es elvalor (redondeado) que aparece en la tabla 5.5 en la entradaOtros y en la tabla I del Apéndice asociado con el resultadoII. Así, la probabilidad de observar un resultado tan extremocomo el resultado II en cualquier dirección es
P [II]+P[I ]+P[VII]=0.0336+0.0014+0.0056¿0.041
Esto es la entrada Total en la tabla 5.5 y en la tabla I delApéndice. Si aplicamos una prueba de dos colas en los datosobservados al nivel de significación a = 0.05, rechazaríamosH0 ya que la probabilidad observada es 0.041.
Supongamos que se ha observado el resultado III. Entonces,las proporciones observadas serían P1 = 4/7 = 0.571 y P2 =2/8 = 0.250. La diferencia es P1 — P2 = 0.321. Los resultadosmás extremos (en la misma dirección) son el I y el II. Por

tanto, la probabilidad asociada con la prueba unidireccionales
P[III ]4−P [I ]+P [II]=0.19584−0.00144−0.0336¿0.231
Para la prueba bidireccional, los resultados VI y VII son losmás extremos, pero en la dirección contraria. En este caso,la probabilidad de un resultado tan o más extremo encualquier dirección es
P [III]4−P [I]+P[II]+P [VI]+P[VII]¿0.19584−0.00144−0.03364−0.0783+0.0056
¿0.315El lector debería verificar su comprensión cabal paracalcular las entradas en las últimas tres columnas de latabla indicada.
Usos de la técnica
Se usa cuando las muestras son pequeñas y los datospueden ser comparados en función de las mismasvariables.
En la mayoría de los casos consultados se usa parapruebas experimentales en la medicina (uso detratamientos), la biología (pruebas de incidencia deplagas sobre productos específicos).
Advertencias
Presente las frecuencias observadas en una tabla 2x2 Determine los totales marginales. En algunos casos no será aplicable esta prueba para lo
que se deberá emplear la prueba ji.
Ejemplo1

En un estudio acerca de las situaciones en las cuales laspersonas amenazan con suicidarse saltando desde un edificio,un puente o una torre, se advirtió que el abucheo o elhostigamiento por parte de una multitud como espectadoraocurrían sólo en algunos casos. Varias teorías proponen queun estado psicológico de disminución de la identidad y laautoconciencia, conocido como deindividuación, puedecontribuir al fenómeno de hostigamiento. Se conocen algunosfactores que inducen reacciones en las multitudes, incluidosla temperatura, el ruido y la fatiga. En un esfuerzo porevaluar varias hipótesis concernientes al hostigamiento porparte de las multitudes, (L. Mann, 1981:703-709) revisó 21artículos publicados acerca de suicidio y examinó la relaciónentre el hostigamiento por parte de la multitud y el mes delaño; esto último se refería más bien al índice detemperatura. La hipótesis es que habría un incremento en elhostigamiento por parte de los espectadores cuando hicieracalor.
Datos
MultitudMes Hostigamiento No hostigamiento Combinado
Junio-septiembre 8 4 12Octubre-mayo 2 7 9
Total 10 11 21
Procedimiento de solución
Hipótesis nula. H0: el hostigamiento por parte de las multitudes novaría como una función de la temperatura. H1: existe un incrementoen el hostigamiento por parte de las multitudes durante los mesescalurosos.
Prueba estadística. Este estudio requiere una prueba paradeterminar la significación de las diferencias entre dos muestrasindependientes: multitudes que hostigaron y multitudes que nohostigaron. La variable dependiente, tiempo (estación) del año, esdicotómica. Puesto que N es pequeña, la prueba exacta de Fisherresulta apropiada.
Nivel de significación, a = 0.10 y N = 21.

Distribución muestral. La probabilidad de ocurrencia cuando H0 esverdadera, de un conjunto de valores observados en una tabla de 2 X2, puede encontrarse utilizando la ecuación. Puesto que N> 15, nopuede utilizarse la tabla I.
Región de rechazo. Puesto que H1 predice la dirección de ladiferencia entre los grupos, la región de rechazo esunidireccional. H0 será rechazada si los valores de celdillaobservados difieren en la dirección predicha y si son de talmagnitud que la probabilidad asociada con su ocurrencia (o laocurrencia de tablas más extremas) cuando H0 es verdadera, es igualo menor que a = 0.10.
Decisión. La información de los artículos periodísticos estáresumida en la tabla anterior. En este estudio hubo 10 multitudesque hostigaron a los suicidas y 11 multitudes que no lo hicieron.La revisión de la tabla muestra que existen dos tablas adicionalesque producirían un resultado más extremo (unidireccional). Así, laprobabilidad de observar un conjunto de frecuencias de celdilla tanextremas o más extremas que la actualmente observada, se determinaal utilizar la ecuación:
p=(A+B)!(C+D)! ¿¿paracadatablaposible.Así
p= 12!9!10!11!21!8!4!2!7!
+ 12!9!10!11!21!9!3!1!8!
+ 12!9!10!11!21!10!2!0!9!
¿0.0505+0.0056+0.0002¿0.0563
Puesto que la probabilidad obtenida 0.0563 es menor que elnivel de significación escogido α = 0.10, debemos rechazar H0en favor de H1. Concluimos que el hostigamiento por parte delas multitudes que atestiguan una amenaza de suicidio esafectado por la temperatura (medida según el mes del año).
Potencia
La prueba exacta de Fisher es una de las más poderosaspruebas unidireccionales para datos, los cuales sonapropiados a las características de la prueba: variablesdicotómicas y en escala nominal.
Comandos SPSS
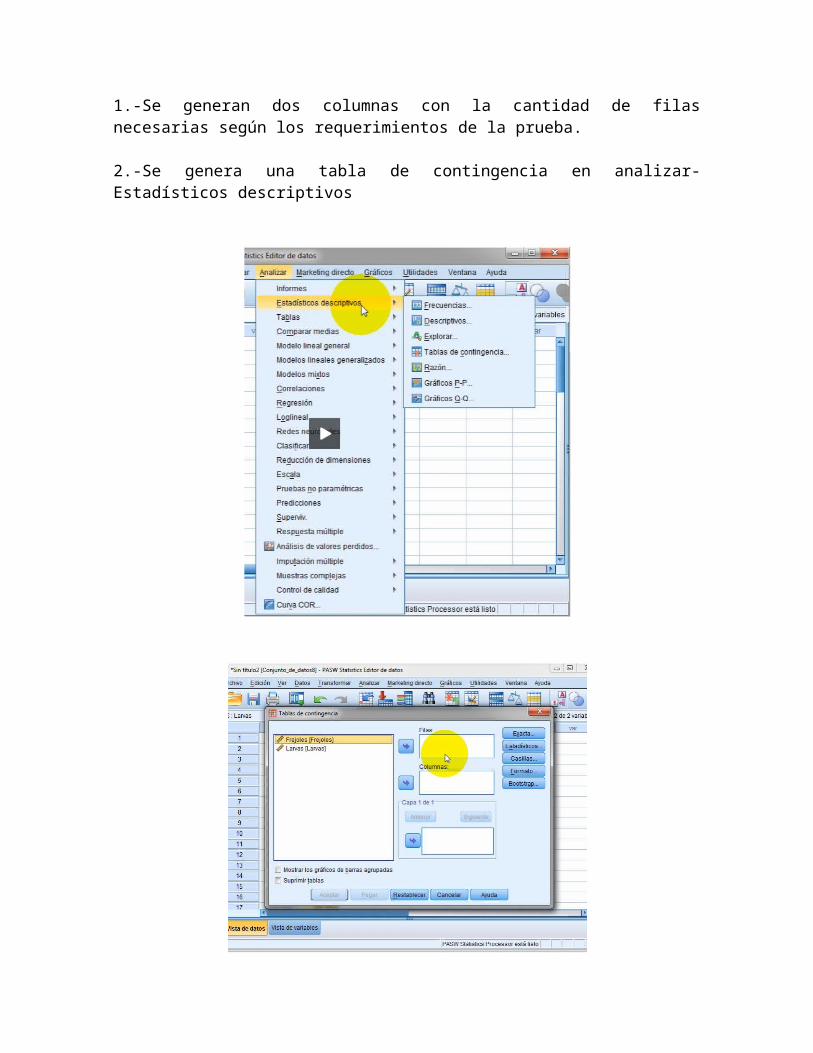
1.-Se generan dos columnas con la cantidad de filasnecesarias según los requerimientos de la prueba.
2.-Se genera una tabla de contingencia en analizar-Estadísticos descriptivos
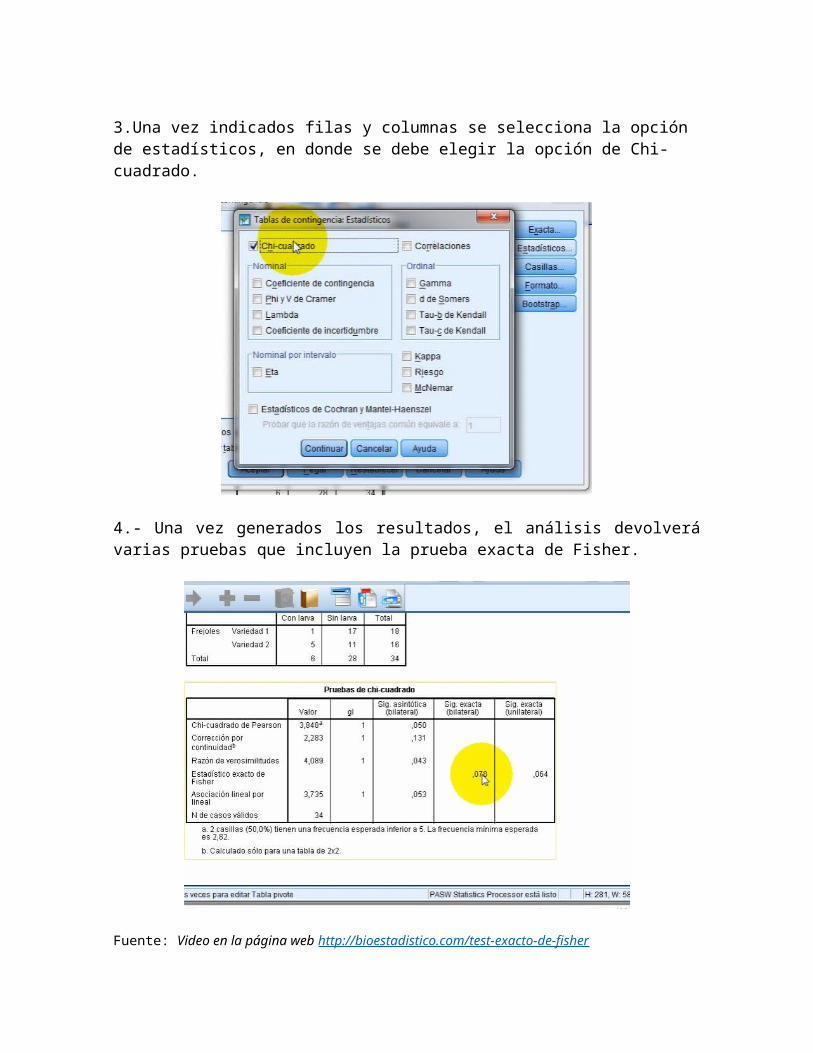
3.Una vez indicados filas y columnas se selecciona la opción de estadísticos, en donde se debe elegir la opción de Chi-cuadrado.
4.- Una vez generados los resultados, el análisis devolverávarias pruebas que incluyen la prueba exacta de Fisher.
Fuente: Video en la página web http://bioestadistico.com/test-exacto-de-fisher

Ejemplo 2
Nota: En la Fuente del ejemplo no está planteado con losdatos enunciados, ni el nivel de significación.
Se desea averiguar si existen diferencias en la prevalenciade obesidad entre hombres y mujeres o si, por el contrario,el porcentaje de obesos no varía entre sexos. Tras serobservada una muestra de 14 sujetos se obtuvieron losresultados que se muestran.
Tabla de contingencia para estudiar lasdiferencias en la prevalencia de obesidad entresexos. Estudio de prevalencia sobre 14 sujetos.
Obesidad
Sexo Sí No Total
Mujeres 1 (a) 4 (b) 5 (a+b)
Hombres 7 (c) 2 (d) 9 (c+d)
Total 8 (a+c) 6 (b+d) 14 (n)
En esta tabla a=1, b=4, c=7 y d=2. Los totales marginales sonasí a+b=5, c+d= 9, a+c=8 y b+d=6. La frecuencia esperada entres de las cuatro celdas es menor de 5, por lo que noresulta adecuado aplicar el prueba , aunque sí el pruebaexacta de Fisher. Si las variables, sexo y obesidad, fuesenindependientes, la probabilidad asociada a los datos que hansido observados vendría dada por:
Tabla 3. Posibles combinaciones de frecuencias con los mismos

totales marginales de filas y columnas que en la Tabla 2.
Obesidad ObesidadSi No Si No
(i
)Mujeres 0 5 5
(i
v)Mujeres 3 2 5
Hombres 8 1 9 Hombres 5 4 9
8 6 14 8 6 14
(i
i)Mujeres 1 4 5
(v
)Mujeres 4 1 5
Hombres 7 2 9 Hombres 4 5 9
8 6 14 8 6 14
(i
ii
)
Mujeres 2 3 5(v
i)Mujeres 5 0 5
Hombres 6 3 9 Hombres 3 6 9
8 6 14 8 6 14
La Tabla 3 muestra todas las posibles combinaciones defrecuencias que se podrían obtener con los mismos totalesmarginales que en la Tabla 2. Para cada una de estas tablas,se ha calculado la probabilidad exacta de ocurrencia bajo lahipótesis nula, según la ecuación. Los resultados obtenidosse muestran en la Tabla 4. El valor de la p asociado a laprueba exacta de Fisher puede entonces calcularse sumando lasprobabilidades de las tablas que resultan ser menores oiguales a la probabilidad de la tabla que ha sido observada:
Tabla 4. Probabilidad exacta asociada con cadauna de las disposiciones de frecuencias de laTabla 3.
a b c d p
(i) 0 5 8 1 0,0030(ii) 1 4 7 2 0,0599(iii) 2 3 6 3 0,2797

(iv) 3 2 5 4 0,4196(v) 4 1 4 5 0,2098(vi) 5 0 3 6 0,0280
Otro modo de calcular el valor de p correspondienteconsistiría en sumar las probabilidades asociadas a aquellastablas que fuesen más favorables a la hipótesis alternativaque los datos observados. Es decir, aquellas situaciones enlas que la diferencia en la prevalencia de obesidad entrehombres y mujeres fueran mayor que la observada en larealidad. En el ejemplo, sólo existe una tabla más extremaque la correspondiente a los datos observados (aquella en laque no se observa ninguna mujer obesa), de forma que:
(2)
Este sería el valor de la p correspondiente a unplanteamiento unilateral. En este caso la hipótesis acontrastar sería que la prevalencia de obesidad es igual enhombres y mujeres, frente a la alternativa de que fuese mayoren los varones. Cuando el planteamiento se hace con unaperspectiva bilateral, la hipótesis alternativa consiste enasumir que existen diferencias en la prevalencia de obesidadentre sexos, pero sin especificar de antemano en qué sentidose producen dichas diferencias. Para obtener el valor de la pcorrespondiente a la alternativa bilateral deberíamosmultiplicar el valor obtenido en (2) por dos:
Como se puede observar, las dos formas de cálculo propuestasno tienen porqué proporcionar necesariamente los mismosresultados. El primer método siempre resultará en un valor dep menor o igual al del segundo método. Si recurrimos a unprograma estadístico como el SPSS para el cómputo del test,éste utilizará la primera vía para obtener el p-valorcorrespondiente a la alternativa bilateral y el segundométodo de cálculo para el valor de p asociado a unplanteamiento unilateral. En cualquier caso, y a la vista delos resultados, no existe evidencia estadística de asociación

entre el sexo y el hecho de ser obeso en la población deestudio.
Ejemplo 3
Consideremos el siguiente ejemplo: 13 individuos fueronoperados de la rodilla.Los pacientes fueron clasificados según la dolencia enrodilla girada o rodilla directa y según el resultado de laoperación en muy bueno o aceptable. La siguiente tablamuestra los resultados obtenidos.
Para estos datos, tenemos que el valor observado del odds ratio es
0=3x12x7
=0.213
Si conociéramos los valores marginales, es claro que el valorde la primera casilla (podría ser cualquiera de ellas) determina los valores de los otros 3 casilleros:

Si en realidad 0 = 1, tendríamos que la probabilidad de observar un valor n11 en la casilla (1, 1) estará dada por la distribución multinomial:
En nuestro caso particular, si _ = 1 tendríamos que la probabilidad de observar n11 = 3 sería
Si quisiéramos realizar un test para las hipótesis:
Ho:0=1vs.H1:0<1
Deberíamos computar las probabilidades de todas las tablas que tiene 0 menor que el observado. Recordemos que por la propiedad vista en clase 0 es función creciente de n11, por ello las otras tablas favorables a H1 serían aquellas con n11 menor al observado (Valderrama, 1995;35). En nuestro ejemplo hay solo una posible:
con probabilidad

por lo tanto el p–valor sería
0.27972+0.03497=0.31469
Si quisiéramos realizar un test para las hipótesis:Ho:0=1vs.H1:0>1
Deberíamos computar las probabilidades de todas las tablas que tiene 0 mayor al observado. Con el mismo criterio que antes consideraremos las tablas con n11 mayor al observado, que en nuestro caso son
con probabilidad
0 = 1.33
por lo tanto el p–valor sería

0.27972+0.489510+0.19580=0.96503
Finalmente, si nos interesase testearHo:0=1vs.H1:0≠1
un criterio posible para calcular el p–valor es el de sumar la probabilidad de todas las tablas cuya probabilidad es menor o igual a la observada.
Las Tablas 3 y 5 son las tablas que tienen la propiedad de tener probabilidad menor o igual a la tabla observada con unaprobabilidad asociada igual a 0.03497 y 0.19580, respectivamente.
Por lo tanto el p–valor para el test bilateral sería:
0.27972+0.03497+0.19580=0.51047
Bibliografía
Ocaña, F., M. Valderrama, A. Aguilera y R. Gutiérrez Jáimez (1995). Repercusión económica en granada de los estudiantes universitarios foráneos. Ars harmaceutica, 36, 59–71.
Ruiz-Maya, L., F. J. Martín-Pliego, J. M. Montero y P. Uriz Tomé (1995). Análisis Estadístico de Encuestas: Datos Cualitativos. AC, Madrid.35
Mesografía
Diaz-Fernandez, “Asociación de variables cualitativas: El prueba exacta de Fisher y el test deMcNemar” Cadernos de Atención Primaria, VOL.11 2004. Publicaciónelectrónica:http://www.agamfec.com/pdf/CADERNOS/VOL11/VOL11_5/14_Invest_N11_5.pdfFecha de Consulta 10 de mayo de 2013.
http://bioestadistico.com/test-exacto-de-fisher
http://www.fisterra.com/mbe/investiga/fisher/fisher.asp