sands: a service-oriented architecture for clinical decision support in a national health...
TRANSCRIPT

SANDS: A Service-Oriented Architecture for Clinical DecisionSupport in a National Health Information Network
Adam Wright, Ph.D.1,2 and Dean F. Sittig, Ph.D.3,4
1Clinical Informatics Research and Development, Partners HealthCare, Boston, MA
2Division of General Medicine, Brigham & Women’s Hospital, Harvard Medical School, Boston, MA
3Department of Medical Informatics, Northwest Permanente, PC, Portland, OR
4Department of Medical Informatics and Clinical Epidemiology, Oregon Health and Science University,Portland, OR
AbstractIn this paper we describe and evaluate a new distributed architecture for clinical decision supportcalled SANDS (Service-oriented Architecture for NHIN Decision Support), which leverages currenthealth information exchange efforts and is based on the principles of a service-oriented architecture.The architecture allows disparate clinical information systems and clinical decision support systemsto be seamlessly integrated over a network according to a set of interfaces and protocols describedin this paper. The architecture described is fully defined and developed, and six use cases have beendeveloped and tested using a prototype electronic health record which links to one of the existingprototype National Health Information Networks (NHIN): drug interaction checking, syndromicsurveillance, diagnostic decision support, inappropriate prescribing in older adults, information atthe point of care and a simple personal health record. Some of these use cases utilize existing decisionsupport systems, which are either commercially or freely available at present, and developed outsideof the SANDS project, while other use cases are based on decision support systems developedspecifically for the project. Open source code for many of these components is available, and an opensource reference parser is also available for comparison and testing of other clinical informationsystems and clinical decision support systems that wish to implement the SANDS architecture.
The SANDS architecture for decision support has several significant advantages over otherarchitectures for clinical decision support. The most salient of these are:
1. Greater modularity than other architectures, allowing for work to be distributed.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customerswe are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resultingproof before it is published in its final citable form. Please note that during the production process errors may be discovered which couldaffect the content, and all legal disclaimers that apply to the journal pertain.Conflicts of InterestIt is our hope that the SANDS architecture will be an enabling step towards wider adoption of clinical decision support. We are awarethat there have been intellectual-property-related concerns surrounding the adoption of service-oriented architectures for decision support(71). In recognition of these concerns, we are making the full specifications of the architecture freely available, and are simultaneouslyreleasing a collection of open source tools, libraries and reference implementations to guide those who wish to implement SANDS. Whilewe foresee a wide variety of business models developing around SANDS, we believe that no single person or entity should try to own,control or restrict access to such a network, just as no entity owns or controls the Internet. To that end, we pledge not to seek anyexclusionary intellectual property rights to SANDS, such as patents, which would allow us or others to exert such control. Instead, wewill work through open standards processes to ensure that anyone who wishes to access SANDS, either as a provider or consumer ofdecision support services, can do so freely.
NIH Public AccessAuthor ManuscriptJ Biomed Inform. Author manuscript; available in PMC 2009 December 1.
Published in final edited form as:J Biomed Inform. 2008 December ; 41(6): 962–981. doi:10.1016/j.jbi.2008.03.001.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

2. The potential for creating and sustaining a commercial market for clinical decisionsupport.
3. Reduced cost and risk of trying new decision support systems because of its abilityto easily integrate a variety of decision support services, and to easily remove them,if desired, as well.
4. Significant freedom for developers of clinical decision support systems to choose theway they represent knowledge and internally implement their system, in comparisonto other approaches which constrain such developers to a particular knowledgerepresentation formalism.
5. Unification of the direction and agenda of decision support research and developmentwith promising near-term efforts to improve interoperability of clinical systems.
IntroductionMyriad studies have shown that clinical decision support can reduce medical errors andimprove healthcare quality in both inpatient and ambulatory settings (1,2). However, only asmall number of sites (generally academic medical centers and large integrated deliverynetworks) make significant use of the most advanced and effective decision supportinterventions (3). This lack of wide-spread use stems from a variety of causes, ranging fromtechnical to political to economic; however, perhaps the main cause is resources: academicmedical centers and integrated delivery networks are more likely to have the time, money, andexperience required to design, develop, and implement such systems.
A partial solution to closing this gap seems to be content sharing – having the successful sitesshare their content with the rest of the hospitals and providers. In fact, medical informatics hasworked on a variety of approaches for sharing content, starting with Arden Syntax in 1989(4,5). However, to this day, none of these content sharing systems have seen significantadoption and many have never made it out of the lab.
In this paper, we introduce a new approach to sharing decision support content which leveragesexisting work towards developing a National Health Information Network (NHIN). We callthis approach SANDS: a Service-oriented Architecture for NHIN Decision Support. SANDSdiffers significantly from prior approaches to sharing clinical content. These prior approachesgenerally involved developing a lingua franca for encoding clinical knowledge. However,because clinical knowledge is diverse and complex, and not always easy to represent in a singlestandardized format (e.g., if-then rules or Bayesian logic), such approaches necessarilyconstrain the scope and type of clinical knowledge which can be represented. SANDS, bycontrast, defines a set of interfaces that a decision support service should make available, butleaves the choice of knowledge representation up to the implementer.
This paper follows a paper we presented at the American Medical Informatics Association(AMIA) Annual Symposium in 2007. There, we presented an overview of the SANDSarchitecture as well as some early timing data. This paper significantly expands the descriptionof the SANDS architecture, includes substantially more timing data and adds three additionalmodes of evaluation. (6)
HypothesisSANDS is designed to surmount the limitations of existing architectures described in theprevious section. It is hypothesized that SANDS can provide significant advantages overexisting decision support architectures in the areas of transferability, scalability andintegrability, defined as:
Wright and Sittig Page 2
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Transferability
The ability to take a known-successful intervention in operation at one site and transfer itto another site.
Scalability
The ability to provide a wide variety of kinds of decision support (such as patient level alertsand reminders, information interventions, panel or population-wide interventions, patient-oriented decision support, etc.) within a given architecture.
Integrability
The ability to readily integrate a decision support system into a clinical system. This coversissues such as proper terminology and data-field mapping as well as issues likesupportability and maintainability of knowledge content.
The purpose of this paper is to describe the SANDS architecture, as well as a working prototypeof the architecture we have developed.
Overview of the ArchitectureSANDS is a service-oriented architecture for clinical decision support involving clinicalsystems (which are the clients of SANDS), services that provide patient data (such as an NHIN)and services which make clinical decision support inferences. SANDS differs from previousefforts because it places layers of abstraction in front of both the clinical decision supportservices (CDS) and the clinical information system (CIS). Moreover, this architecture explicitlycontemplates the case where a patient’s record is spread across multiple clinical systems andthe parallel case where several disparate clinical decision support systems are needed to fullyinform a decision. The case where a patient’s record is spread across several systems and needsto be reassembled to provide a complete clinical picture is the exact case that efforts to createa National Health Information Network (NHIN) are targeting and, as such, the patient data halfof the architecture will draw heavily on existing developments in the NHIN space.
On the decision support network side, one could imagine a case where a physician would liketo query several different decision support service providers for different kinds of decisionsupport for a given patient. For example, if the physician were prescribing a new drug to adiabetic patient, he or she might want to query a guideline service provided by the AmericanDiabetes Association for the latest guidelines in diabetes management (7), and might also wantto send the proposed prescription to a drug-interaction checking service such as the oneprovided by Thomson Micromedex (Thomson Corporation, Denver, CO). This architecturealso explicitly allows for the case where one decision support system queries another – forexample, the American Diabetes Association might develop a decision support module forevidence-based diabetic care, and that module may in turn depend on another module, providedby the American Heart Association, that defines hypertension.
An Example Use CaseTo fully understand this architecture, it is perhaps best to operationalize it. Consider a casewith two care providers: Dr. Anderson, a primary care provider, who uses Epic’s EHR (EpicSystems Corporation, Madison, WI); and Dr. Baxter, a gastroenterologist who uses theLogician EHR (now called the Centricity Physician Office EHR [GE Healthcare, Waukesha,WI]). They share a common patient in Frank Jones. Mr. Jones sees Dr. Baxter for managementof severe Gastroesophageal Reflux Disease (GERD), but today presents to his primary careprovider, Dr. Anderson, complaining of a sore throat, which Dr. Anderson diagnoses as
Wright and Sittig Page 3
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

streptococcal pharyngitis. Dr. Anderson plans to prescribe erythromycin to treat the infection,but first asks Mr. Jones what medications he’s on. Mr. Jones reports that he is taking Lipitorand Aspirin, as prescribed by Dr. Anderson, as well as Prevacid for his GERD, as prescribedby Dr. Baxter. Seeing no danger, Dr. Anderson initiates a prescription for erythromycin in herclinical system, but before the prescription is accepted, the decision support network is queried.A message, containing the intended prescription, as well as a pointer to Mr. Jones’ record inthe NHIN is sent to a drug checking service that Dr. Anderson subscribes to. This service sendsa medication list query to the NHIN interface which uses its record locator service to find thatMr. Jones has records in two disparate clinical systems: those of Drs. Anderson and Baxter.The NHIN interface requests the medication lists in these systems, aggregates them and returnsthem to the drug checking service. This service notices, however, that Dr. Baxter’s medicationlist indicates that Mr. Jones is actually on Propulsid for his GERD, not Prevacid, as Mr. Joneshad indicated to Dr. Anderson. There is a very severe and potentially fatal interaction betweenPropulsid and Erythromycin, and the system provides this information to Dr. Anderson’sclinical system which raises an alert and blocks the prescription. Although this may seem likea simple case, it’s important to note that, even though the FDA engaged in a significant outreachand public relations campaign to make doctors aware of this interaction it was responsible fora significant number of fatalities (8,9). In the end, the FDA had to withdraw Propulsid fromthe market because it was unable to reliably prevent the two drugs from being co-prescribed.A decision support architecture such as the one described herein (or another safety mechanism,such as pharmacist verification) may be necessary to reduce the risk of certain drugs to a levelthat would justify keeping them on the market.
Architectural Key PointsThis example highlights several key points about the SANDS architecture. First, thearchitecture is defined entirely by interfaces. There are no restrictions on the internal knowledgerepresentation approach taken by the decision support components, and there are no restrictionson the way that the clinical systems store clinical data internally. As long as the systems exportthe appropriate interfaces, they are compliant with the requirements of this architecture. Thisinterface-driven approach is sometimes generically called a Service Oriented Architecture(SOA). SOAs are currently making significant inroads in the healthcare IT space. KaiserPermanente (10), MD Anderson Cancer Center (11), the Mayo Clinic (10) and the PartnersHealthcare System (12) have all announced plans to migrate their clinical systems to an SOA.None, however, has yet announced plans to fully migrate their decision support to an SOA,largely because there is no clear architecture over which to do so. This paper aims to fill thatgap.
The Role of StandardsBuilding an SOA for decision support requires a significant number of standards. Thesestandards fall roughly into two groups: healthcare informatics standards, such as Health Level7 (HL7) (13–16), the Systematized Nomenclature of Medicine SNOMED (17), NationalCouncil for Prescription Drug Programs (NCPDP) SCRIPT (16), RxNorm (18,19) andNational Drug Codes (NDC) (20,21) which might be used to describe drugs, or transfer patientdata; and SOA-related standards, such as the Simple Object Access Protocol (SOAP) andExtensible Markup Language (XML), which are used to transport data between services, andthe Universal Description, Discovery, and Integration language (UDDI) and the Web ServiceDefinition Language (WSDL), which are used for discovery of services, and interfacedefinition. Depending on the application domain, other standards may also be required.Standards are not a major focus of this paper, in large part because robust standardsharmonization activities coordinated by the ANSI Healthcare Information TechnologyStandards Panel (HITSP) under contract from the Office of the National Coordinator for HealthInformation Technology, are currently underway (22,23). The expected result of these
Wright and Sittig Page 4
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

activities is a set of harmonized standards ready for adoption. Because the HITSP process isongoing, this paper will preferentially use standards approved by HITSP, augmented by otherstandards as needed.
Developing the SANDS ArchitectureIntroduction to the Prototype
Some architectures and standards have been developed in a vacuum (that is, without a real,working prototype). Experience suggests that development of any architecture is most likelyto be successful when it proceeds in parallel with development of a prototype (24). There arebound to be challenges, edge cases or special requirements which simply cannot be anticipatedwhen an architecture is developed by simply writing it down.
To that end, as we proceeded through research on the SANDS architecture, we simultaneouslydeveloped a working prototype of the architecture, as well as a prototype EMR. Together, theseprototypes provided useful tools to test assumptions about the architecture and they also helpedto further specify the architecture. While the full technical specification of the architecture isavailable, no written specification can be fully specified without ambiguities. These prototypes,which are also available publicly under an open source license, help increase the specificity ofthe architecture’s description.1.
Overview of the NHINAs described in the previous section, the SANDS architecture has two interface facets: thepatient data interface (here, the NHIN) and the decision support interface. Because there iscurrently no actual NHIN, we chose to use a prototype NHIN. The Office of the NationalCoordinator for Health Information Technology (ONC) funded four consortia (led byAccenture, IBM, Northrop Grumman and CSC) to develop prototype NHINs. Each prototypewas required to connect local exchange efforts in three distinct geographic markets. For theSANDS prototype we interfaced with the prototype developed by CSC and the MarkleFoundation which unites exchanges in Indianapolis, Massachusetts and Mendocino, CA. Thisprototype was selected because it was the most mature at the time, had the greatest diversityof local exchange architectures and because it was freely available.
Most decision support interventions will require two types of data to make their inferences.First, inferences generally require data which describe the context in which inferences are beingmade. Second, inferences also frequently require more general background data about thepatient, beyond the current context. For example, a drug interaction checker needs to know thedrugs that are about to be ordered (the contextual data), as well as the drugs a patient is currentlytaking (the background data). Without both types of information no inference can be made.
In the SANDS architecture contextual data come from the current invocation but backgrounddata come from the NHIN. The key advantages of using the NHIN for background data are theability to consolidate patient data from multiple sources and the standardized view of patientdata that an NHIN affords.
Querying the NHINThe NHIN prototype used in this paper is queried over the Internet. The query is a standardSOAP message – an XML standard for making remote function calls over the Internet. Thepayload of the message is an HL7 XML request formatted in accordance with the technical
1Both the specifications and a reference parser are available under an open source license fromhttp://medir.ohsu.edu/~wrightad/sands/.
Wright and Sittig Page 5
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

guidelines of the Markle Foundation’s Common Framework(http://www.connectingforhealth.org/commonframework/). This query includes demographicinformation about the patient, which is used by the NHIN’s record locator service (RLS) tofind him or her. Eligible fields include first and last name, date of birth, street address, city,state, ZIP code and institution-specific medical record numbers. The RLS uses a matchingalgorithm to locate relevant patient records, and passes this list to a disburser-aggregator (D/A) service which sends queries to clinical sites which maintain information about the matchedpatient. The Common Framework does not require that an RLS have any overarching masterpatient index or that an RLS assign an NHIN-wide patient identifier, so all queries to andthrough the RLS or D/A service are made with a full set of demographic query information,rather than passing an NHIN-level identifier. These systems retrieve the relevant records andreturn them to the D/A service which in turn aggregates them and returns them to the requestor.All of these transactions are carried out in accordance with a detailed set of privacy, securityand access control requirements, also described by the Common Framework.
The NHIN ResponseThe NHIN’s response is a series of XML-formatted HL7 data elements. The data elementsused vary depending on the type of clinical information represented. For example, Z01 Ordersare used for medication records and Z01 Observations are used for lab results. Figure 1 andFigure 2 show two example results. Figure 1 shows the XML format used to represent a simplelab result, and is labeled to show the following critical data elements:
1. A Logical Observation Identifiers Names and Codes (LOINC) code. LOINC is astandardized terminology for expressing observations, including lab results. ThisLOINC code represents absolute lymphocyte count.
2. A human-readable name describing the result.
3. The result value.
4. The units (in this case, thousands of cells per microliter.
5. A time stamp.
The complete interpretation of the data in Figure 1 is that the patient had an absolute lymphocytecount of 1.4 thousand cells per microliter on April 17, 2001. This is a simple example –however, more complex examples, such as microbiology cultures with antibiotic susceptibilitycan also be represented using HL7 standard extensions of this message format.
Figure 2 shows a medication dispensing record. The most critical fields of this record, whichare labeled in the diagram, include:
1. The timestamp for the medication record.
2. An NDC code for the record, as well as a human-readable description.
3. The route.
In this case, the complete interpretation is that 325 mg ferrous sulfate tablets were dispensedto the patient on April 14, 2006.
The Patient Data Class LibraryWhile, fundamentally, the patient data interface is the NHIN, as we developed prototypes itquickly became clear that parsing raw data from the NHIN was time consuming. Thus, wedeveloped a patient data class library, described in this section, which takes data from the NHINand processes it into a form more usable for common decision support tasks. This class libraryis in the spirit of a virtual medical record or VMR (25). While the class library, itself, is read-
Wright and Sittig Page 6
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

only, since it represents a view of data in the NHIN, new contents can be added simply bypublishing data to the NHIN, in accordance with the mechanisms that the NHIN itself provides.
The foundation of this class library comes from the data elements section of a functionaltaxonomy of clinical decision support which we previously published (26). This taxonomy wasbased on a thorough analysis of clinical decision support rules in use at Partners HealthCaresystem, and laid out an exhaustive list of the triggers, data elements, response actions andchoices offered by these rules. The Patient Data Class Library makes each of these elementsavailable to developers of decision support systems. In addition to greater ease-of-use thePatient Data Class Library also allows for more expansive prototyping of decision supportinterventions. Because current NHIN prototypes are in early stages they do not always supportthe complete complement of data types described in the taxonomy. However, the Patient DataClass Library provides a way around this limitation. In addition to its built-in support forpopulating data elements from the NHIN, it can also be populated with coded test data for usein experiments. This makes it possible to prototype decision support systems that require datanot yet available in early stage NHIN prototypes. This feature also allows us to create customtest patients for certain decision support interventions. For example, the NHIN prototype didnot contain any pediatric patients, but one test case we developed was for diagnostic decisionsupport with a special focus on pediatric patients. We were able to use the test-data feature ofthe Patient Data Class Library to test such interventions on simulated pediatric patients.
Elements of the Patient Data Class LibraryThe specific elements of the Patient Data Class Library are:
Demographics and Vital signs:• First Name• Last name• Gender• Race• Date of birth• Weight• Height• Care setting
Clinical information:• Observations• Drugs• Problems• Family history• Procedure history• Allergies• Other orders
For each of these elements one or more standard representation forms were chosen. Wherepossible these representation forms were based on standards approved by the HealthInformation Technology Standards Panel (HITSP) or the Consolidated Health Informatics
Wright and Sittig Page 7
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

working group (CHI) of the Federal Health Architecture (FHA) project, a coalition of federalagencies which work together to choose standards for sharing among federal agencies (27).The efforts of CHI have recently been mostly supplanted by HITSP, but there are cases whereCHI standards are available, but corresponding HITSP standards have not yet been chosen. Asummary of the chosen standards and representation formats is given in Table 1, with moredetail provided in this and subsequent sections.
Storing the patient’s first name and last name is easy because these are simply free-text stringelements. Gender and race are both stored according to enumerated types defined by HL7, the“HL7 Gender Vocabulary Domain” and the “HL7 Race Vocabulary Domain”. Thesevocabulary domains are intentionally extremely inclusive and are designed to be able torepresent any patient’s race or gender, regardless of whatever special conditions may apply.
Date of birth is stored as an HL7 formatted date (such as: YYYYMMDD or 20070405), whileweight and height are made available in both metric and standard units. Weight and height arespecial data elements as patients often have serial weight and height measurements stored. Insuch cases the most recent weight and height are available as discrete elements, but all historicweight and height measurements are made available in the observations section of the classlibrary. The observation section also allows metadata to be encoded; for example, whether theheight and weight are patient-reported or whether they were measured in the doctor’s office.Clinical decision support interventions that make significant use of these data elements shouldprocess the observations section directly to determine the best weight and height to use in theirinferences or calculations.
The final element of the demographics and vital signs section of the Patient Data Class Libraryis care setting (for example, whether the patient is in the doctor’s office for an ambulatory visit,is in a skilled nursing facility, or is currently admitted to the intensive care unit). In the casewhere more than one care setting applies to a patient at a given time, the highest acuity caresetting is used. These care settings are encoded according to the HL7 “Dedicated ClinicalLocation Role Type.”
Storing ObservationsObservations, which include such data elements as lab results, vital signs, nursingdocumentation and structured data entered by a physician are all made available through thePatient Data Class Library. For the current implementation of the library these elements areavailable in a form derived from the EHR-Lab Interoperability and Connectivity Specification(ELINCS) (28). Each observation made available through the Patient Data Class Librarycontains a timestamp, a Logical Observation Identifiers Names and Code (LOINC), a valueand, where applicable, the units that value was measured in, a normal range and a result flagindicated whether or not the value is abnormal. The LOINC vocabulary standard is key to theinterpretation and utility of observations in the Patient Data Class Library, and ensures thatobservations provide not only syntactic but semantic interpretability.
Storing Drug informationDrug information in the Patient Data Class Library is stored according to national drug code(NDC), name of drug, dosage instructions, start date, end date and the date that the prescriptionwas last filled. Selecting an appropriate drug vocabulary system was especially difficult andis discussed more fully in the discussion section. However, for most clinical decision supportinterventions, the current mode of storing drug data is sufficient; and, where more precise dataare required, a decision support invention can bypass the Patient Data Class Library and querythe NHIN directly.
Wright and Sittig Page 8
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

It is important to note that the drug information we had access to through the NHIN prototypeis based on claims data, which means that certain medication orders may be missing(particularly in the case where samples are dispensed, or drugs are received through a charitypharmacy or a prescription assistance program and no claim is filed). It would be useful iffuture generations of the NHIN provided medication orders directly from provider EHRs, andeven perhaps progress notes. A drug terminology other than NDC would be used in thiscircumstance, as NDC codes are generally used for fulfillment of prescription drugs, and aremuch too granular for physician orders. The VA’s National Drug File Reference Terminology(NDF-RT) is one example of a drug terminology designed for medication ordering rather thanfulfillment, and would be a more appropriate choice.
Storing ProblemsPatient problem list data includes a code describing the problem, a start date, end date, status,verified date, and comments. Problems can be encoded either according to the ICD-9 orSNOMED vocabularies with SNOMED strongly preferred. ICD-9 is available as a choice onlybecause many clinical information systems provide problem data in ICD-9 format. It isimportant that any clinical decision support intervention be able to interpret problem list entriesin both ICD-9 and SNOMED, or that such an intervention takes advantage of a translation layerto convert between the two problem vocabularies. Several such translation systems areavailable, including a commercial mapping developed by the American Health InformationManagement Association (AHIMA) and the Unified Medical Language SystemMetathesaurus, produced by the National Library of Medicine (29).
Family HistoryFamily history items are actually special cases of the problem element type. Each family historyelement is composed of a problem (in this case, a problem that a family member rather thanthe patient had), the relationship of the person suffering from the problem to the patient, thevital status of the problem sufferer (alive, dead or unknown), his or her current age, and age atdiagnosis. Relationships are encoded according to the HL7 “Personal Relationship Role Type.”
Procedure HistoryProcedure history elements are composed of a code (either a Current Procedural Terminology(CPT) code, or a SNOMED code), indication, service date and comment. The indication isstored as a problem type as described above.
AllergiesPerhaps the most difficult data elements to represent in this Patient Data Class Library are theallergies. Current standards for exchanging data on patient allergies are immature. The mostdetailed recommendation about allergy representation comes from a recommendation madeby CHI to the Secretary of Health and Human Services. This recommendation has beenreviewed by the National Committee on Vital and Health Statistics, although adoption of thestandard is extremely limited. The recommendation portion of the document actuallyrecommends 23 separate vocabulary standards for encoding the three key elements of an allergydescription: the allergen, reaction and severity. The Patient Data Class Library uses a simplifiedsystem for encoding allergies, employing SNOMED to describe the allergen, reaction andseverity. There are currently efforts underway, through HITSP, to harmonize allergy standardsand release a single, definitive implementation guide for allergy encoding. As these standardsmature, the Patient Data Class Library will be extended to match developments in the allergydomain.
Wright and Sittig Page 9
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Other OrdersThe final area of the Patient Data Class Library is other orders. This includes all non-drugorders, including laboratory orders, nursing orders and procedure orders. Laboratory ordersare encoded according to ELINCS, nursing orders according to HL7 version 3 Acts, andprocedure orders according to CPT. The choice of Acts for nursing orders was difficult, asthere is no widely used vocabulary standard for nursing orders. However, there is currently apromising effort underway to integrate a nursing order terminology system developed byMatney et al. at Intermountain Healthcare (30) into the HL7 version 3 RIM Act hierarchy.
CachingEarly tests of the patient data class library revealed unacceptable performance, primarily dueto very slow fetch time of data from the NHIN prototype (fetching all data for a patient took6–10 seconds). Analysis revealed that the delays were not primarily due to network latency,data transfer time or XML parsing overhead, but, instead, were a function of the current NHINprototype’s relatively slow performance in retrieving data from the original data sources. Thisperformance could likely be improved through a combination of strategies such as indexingand using more efficient data structures and algorithms. However, the internal design of theNHIN was outside of our control, so, to work around this problem, we employed a cachingstrategy. The first time data are requested from the Patient Data Class Library, the systemfetches that data from the NHIN and caches it. The library actually caches two different dataelements: first, the entire raw response from the NHIN, and second, a materialized instance ofthe Patient Data Class Library. This allows client applications to avoid re-querying the NHIN,regardless of whether they access patient data through the class library or by directly parsingthe NHIN response.
Because the SANDS architecture is distributed, it would be inefficient if every node had tokeep a cached copy of the patient’s data. Instead, a wide-area distributed hash table is employed.The hashing function is implemented by the patient data class library using the NHIN queryparameters, and the table is implemented by the memcached system (31). The memcachedsystem is widely used for data-driven web and web-service applications, such as Wikipedia.One important question with any caching strategy is currency, and two approaches are used inthe prototype to help ensure that data retrieved from the cache is current. First, all data enteredinto the cache is given a short expiration time (a few hours), and second, when new data arestored for a patient, the cached data objects for that patient are explicitly expired from thecache. In the present implementation, the clinical system is responsible for forcing expiration,but in the final form this would likely be a function of the record locator service. When theRLS received notice of new patient data from a clinical system, it would automatically expirethat patient’s cached data objects (or possibly even force an update of them).
The caching strategy reduced the overhead of retrieving data from several seconds to between0.1 and 0.3 seconds, ultimately allowing for acceptable performance, as described in theevaluation section.
Decision Support Service InterfaceIn addition to the Patient Data Class Library the architecture defines a decision support serviceinterface. This interface is fully described and specified in the schema and description availableonline or from the authors, but some of the critical design decisions are described in this section.The decision support service interface consists of two components: one for invoking decisionsupport services, and the other for returning structured interventions. Both components derivedirectly from the functional taxonomy described previously (26) in order to maximize theirapplicability to real clinical decision support scenarios.
Wright and Sittig Page 10
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Decision Support Service Invocation InterfaceThe decision support and service invocation interface is derived from the trigger axis of thedecision support taxonomy. This interface defines the way in which decision support servicesare invoked according to triggering clinical events. The general format for invocation is:
Consider, for example, a decision support service designed to alert a clinician when anextremely high or low lab value (sometimes called a panic value) is stored. This service willbe called whenever a new lab result is stored by a clinical system, a lab result stored triggerwould be used:
The two arguments passed to the Lab Result Stored invocation are an identifier for the patient(keyed to the NHIN Master Patient Index by ID 123456), and a LOINC code describing theresult is also passed to the service. In this case, the code is 2697-1, which is the code for aserum potassium value. It is important to note that the actual result is not passed along withthe invocation. It is the responsibility of the decision support service to fetch whatever patientdata are needed through the standard NHIN interface, thus freeing the calling clinical systemfrom having to predict what data elements the clinical decision support service needs to makean inference.
The invocation interface is built on top of standard Web service protocols, particularly SOAP,WSDL and UDDI. SOAP is a format for making remote object-oriented function calls. Theinvocation calls shown above look like local function calls, but they actually rely on SOAP totransport the function call to a remote service, and also to transport the result of that remotefunction call back to the caller. SOAP toolkits are available for most modern languages,including C, C++, C#, Java, PERL, Python, Visual Basic, PHP and Ruby. These toolkits makethe details of calling remote functions transparent to the users. SOAP is, in turn, dependent onthe WSDL standard, a way of describing remote functions. So, for example, the fact that aremote method called LabResultStored is provided by a decision support service, and that thatmethod requires two arguments is encoded in the WSDL format, which SOAP uses to encodeand decode function calls. The UDDI protocol provides discovery and description services, sothat new web services can be found by potential clients. All three of these standards are, inturn, built on top of HTTP, an application layer protocol which itself is built on the well-knownTCP and IP protocols.
While the service definition specifies a variety of common invocation methods, it is importantto note that, ultimately, the form of invocation and arguments required is determined by theprovider of a decision support service. This provides significant flexibility as new kinds ofdecision support workflows can be developed within the framework of the SANDSarchitecture. That said, where possible, it is certainly preferable to use the standard invocationpatterns as these are most likely to be supported by hooks in clinical systems.
Structured Intervention InterfaceThe expected result of a call to any decision support service is either instructions to take noaction or a set of one or more interventions describing actions to be taken automatically by theclinical system or proposed to the user. The interventions and the choices offered axes of the
Wright and Sittig Page 11
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

decision support taxonomy form the basis of a structured message format for describingdecision support interventions. Figure 3 shows an example SANDS decision supportintervention. This example describes a menu of interventions that might be taken for a diabeticpatient with hyperlipidemia who is not currently on a hydroxymethylglutaryl-CoA reductaseinhibitor (a class of drugs used to lower cholesterol). This response consists of the followingparts:
1. A preamble, which describes the decision support rule that triggered the response.
2. A “notify” action, which prompts the receiving clinical system to notify the user ofthe information and options contained in the body of the message. This notificationhas severity 3 (the lowest severity).
3. The text of the notification: in this case “Patient has diabetes and most recent LDL(144) above target (100) and not on an HMG CoA-reductase inhibitor. RecommendHMG CoA-reductase inhibitor if not allergic.”
4. A GUID, or globally unique identifier. A GUID is a guaranteed-unique serial number.Decision support services have the option of passing a GUID along with their responseto a query. If they do, the calling clinical system is responsible for returning the choicetaken by the user along with the GUID to the decision support service that providedthe intervention. This information can either be used for further decision support orfor statistical purposes, such as evaluating the usefulness of the decision supportintervention. For example, if the designer of the intervention described herediscovered that clinicians were often refusing the intervention because of cost reasonsto patients, the CDS designer might revise the intervention to use a less expensivedrug.
5. A choice, to be offered by the clinical system to the user to order simvastatin, a genericHMG CoA-reductase inhibitor.
6. A choice to add an allergy to the HMG CoA-reductase inhibitor drug class.
7. A choice to add non-alcoholic cirrhosis to the patient’s problem list – this is acontraindication to HMG CoA-reductase inhibitor therapy.
8. A series of un-coded options to decline the suggested therapy for other reasons.
9. An option to remove diabetes from the patient’s problem list (this rule applies onlyto diabetic patients).
10. Options to defer the suggestion for five days, one month or three months (“P5D”,“P1M” and “P3M” respectively – these time durations are formatted according to ISO8601).
While the structured intervention message format describes the overall behavior that a clinicalsystem should carry out, it is important to note that it does not describe the precise way thatthe clinical system carries that behavior out. For example, consider an alert triggered by apatient’s rising potassium value. The decision support service would send a Notify event, butthe clinical system would have to determine what to do with it. If the responsible clinician iscurrently logged in to the computer the clinical system might provide a pop-up or othercontextual alert that a notification is available and allow the clinician to choose a response fromthe provided menu. However, if the responsible clinician is not logged in, the clinical systemmight instead page him or her with the information.
One significant challenge is how to reconcile actions across clinical systems. For example,consider the case where, in response to a drug-drug interaction alert, a provider chooses todiscontinue a medication ordered by another provider in another clinical system. There are a
Wright and Sittig Page 12
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

number of important clinical issues that arise in this case – should the provider who orderedthe now discontinued medication be alerted? How should this discontinuation be updated inhis or her clinical system? Is it acceptable for one provider’s medication list to be updated bythe actions of another provider, and if so, under what circumstances? As medical record systemsand medical information become increasingly distributed, consensus will have to be reachedaround these complicated technical and ethical questions.
A Reference ParserThe formal service definition is sufficient to fully describe the representation format used bythat standard, both with regards to triggers and to structured intervention responses. However,experience suggests that interpretation of such a standard will be most faithful when a workingimplementation of the standard is also provided to interested developers. As such, we havemade a reference parser available under an open-source license. Anyone interested indeveloping a service to participate in this architecture should ensure that the results that theirservice provides can be successfully interpreted by this reference parser. Anyone interested indeveloping a clinical system that parses results of decision support services should use thereference parser as the foundation or at least ensure that the parser that they develop has thesame behavior as the reference parser.
Building a PrototypePrototype Electronic Health Record
To showcase this decision support architecture and service interface, we developed a prototypeelectronic health record, called the SANDS Prototype Client. The SANDS Prototype Clienthas most of the functionality of a regular electronic health record, along with two specialfeatures. First, the SANDS prototype is unique amongst electronic health records becauseinstead of having its own internal data store it accesses the NHIN prototype to retrieve patientinformation. It features a problem list viewer and entry system (which updates the NHIN), aresults viewer, a medication list viewer and entry system and a progress note viewer and editor.All of these data are read from the Patient Data Class Library, which, in turn, reads data fromthe NHIN prototype. The other unique feature of the SANDS Prototype Client is, of course,its support of the SANDS architecture.
The next six sections of the paper describe sample use cases developed according to the decisionsupport service definition described earlier in this paper and more formally in the servicedescription and schema available online. These use cases were developed to provide real-worldvalidation of the architecture contemplated and the interfaces developed for it.
Drug Interaction CheckingThe first use case is drug-drug interaction checking. Many medications, when given incombination, interact, leading to a variety of possible adverse results including direct toxicity,or overactivity or underactivity of one or both of the interacting medications. These interactionsare frequent, and can be dangerous (32–35). However, automated alerting systems can beeffective at reducing both the rate of interacting medication orders, and harmful adversesequelae (36–40).
However, integrating the databases containing the drug-drug interaction knowledge intoclinical systems can be difficult, and in many cases, vendors of clinical systems haverelationships with a single drug information database provider limiting users of these clinicalsystems to only that drug information provider. In this use case, we developed a service fordrug interaction checking based on a commercial drug information database developed byLexi-Comp, Inc (Hudson, OH). The Lexi-Comp database was chosen because Lexi-Comp
Wright and Sittig Page 13
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

offers a pre-existing web service interface, which could be readily adapted to the standardizedinterface developed here.
The SANDS prototype client supports calling the drug interaction service in two modes: first,it can be called when the user clicks the “Check Drug Interactions” button. This button checksthe patient’s current consolidated medication list for drug interactions. Second, the service canbe called automatically when a new medication is ordered, to check for interactions betweenthat medication and the rest of the patient’s medication list.
Consider a sample case where a patient is taking both meperidine and his or her physicianattempts to order the monoamine oxidase inhibitor phenelzine. This combination canprecipitate a hypertensive crisis and ultimately cause death. When the user enteres the secondorder in the EHR, the EHR contacts the drug-drug interaction to request a check of the newrequest. This request is shown in Figure 4. The drug interaction service compares the newmedication order to the patient’s current medication list and generates a SANDS-formattedresponse, shown in Figure 5, which generates an alert shown to the user directly inside of theEHR.
Integrating the existing Lexi-Comp drug-drug interaction service with the prototype EHR usingthe SANDS architecture was achieved quite easily. The only major issue encountered in theintegration process related to the threshold for alerts. It is widely thought that commercial druginformation databases have too low a threshold for alerts (i.e. that they alert too often, and thatmany alerts they provide are not clinically relevant) (41–44), and that appeared to be the casehere. The Lexi-Comp drug interaction service has a severity grading system, but alerts gradedat the highest levels – those alerts that Lexi-Comp classifies as needing human intervention –are extremely common. For example, one sample patient’s consolidated medication list yielded750 alerts, 685 of which were graded as requiring human attention. While some of theinteractions were clinically significant (such as the example presented above), it would beimpractical for a clinician to review 685 separate alerts. Before a drug-drug interaction servicecould be deployed for real-world use, it would be important to thoughtfully pare down theinteraction database, a process already underway at some advanced sites (45,46).
Syndromic SurveillanceThe next use case we developed was for syndromic surveillance and reporting of reportablediseases to public health authorities. Unlike the previously presented use cases, there was nopre-existing service for this function. Instead we developed the decision support system denovo based on published documents from the Oregon Health Department. As in most states,epidemiologists at the Oregon Health Department track the spread of a variety of infectiousdisease. One key element of this tracking program is mandatory reporting of diseases. Someof this reporting is carried out by medical laboratories which are obligated to report positivetests for diseases in reportable groups. However, certain diseases, such as pertussis, are oftendiagnosed solely on clinical factors, so the responsibility for reporting the disease falls on theprovider that made the diagnosis. Although data about how often reportable diseases areactually reported are sparse, it is widely believed that there is significant underreporting ofdiseases, largely due to providers who either are not aware of the rules or who do not have thetime to comply with them. To support both providers and public health authorities wedeveloped a reporting system which takes all new diagnoses, at the time they are entered byproviders, and runs them through a filter to determine whether or not they represent reportablediseases. This use case makes interesting use of the SNOMED terminology. Problems reportedto the decision support system are reported according to SNOMED concept ID’s, whichprovides a good level of specificity. In many cases, determining whether a disease is reportableor not is a simple matter of comparing the concept ID being reported to a list of the conceptID’s for reportable diseases. However, in certain cases, the analysis is more complex. Consider,
Wright and Sittig Page 14
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

for example infection by the organism Nesseria gonorrhoeae, which is reportable underOregon law. While a SNOMED concept ID (15628003) exists for such an infection, there areactually 90 clinical concepts which descend from this term, all of which would be consideredreportable in Oregon. However because SNOMED has a robust semantic structure it isunnecessary to identify, a priori, all of these concepts. Instead, the rule is defined to includeSNOMED concept 15628003, and all of its descendents. If, in the future, new problems areadded under concept 15628003, any decision support system which uses the semanticstructures of SNOMED will automatically have the benefit of these updates, without needingto be modified.
In the current embodiment of this prototype, whenever a new problem is entered into theprototype electronic health record which is reportable under Oregon law a pop-up alert is givento the user based on a database which describes the reporting requirements for each disease.The alert informs the provider whether or not they need to contact the state epidemiologistdirectly or whether the automatic notification already sent is sufficient. If it is necessary tocontact the epidemiologist, the system provides detailed information to the clinician about thephone number to call and how long he or she has to report the disease. This is important becausesome diseases require immediate consultation with the epidemiologist while others can bereported days later.
Figure 6 shows an example of this feature. In this case, a diagnosis of pertussis was enteredfor a patient who lives in Multnomah County, Oregon. An alert is triggered. Because the patientlives in Multnomah County, the reporting number for the appropriate health department is alsoprovided. This service stands out amongst the others in that it not only provides an interfaceto an electronic health record, but also provides a separate interface to public healthmanagement systems. In this case, an epidemiologist with proper authorization can query thesystem for a list of all cases that match certain query parameters. For example, anepidemiologist might query the database to see where cases of pertussis were reported withinthe Portland metropolitan area over the past seven days. The current prototype system thenlinks to Google Earth, a 3-D map visualization program to provide a geospatial representationof the cases in the database. Figure 7 shows this visualization. This requires that the diseasereporting service, in turn, consults a geocoder service. Geocoding is the process of taking anaddress as might be stored in a patient’s electronic health record and converting that addressto a spatial location, usually the latitude and longitude at that point.
In the typical interaction between the electronic health record and the reporting service, theEHR would send a problem-added invocation to the reporting service. If necessary the reportingservice would respond to the EHR with a notify intervention, explaining that the problem mostrecently added represents a reportable disease.
This use case demonstrates three special aspects of this architecture. First, it shows the abilityof a single service to provide decision support to two different kinds of clinical systems. Thereare many use cases where this could be helpful: for example, a drug allergy warning servicewhich interfaces with both an electronic health record and a personal health record.
Second, this use case demonstrates service composition: the reporting service contacts anotherservice, the geocoder, to complete its work. Many cases of decision support will use servicecomposition. For example, a therapeutic reminder system might first query an allergy systemto determine whether or not the therapy that it is about to suggest is contraindicated due to apatient allergy.
Third, this use case demonstrates the ability to modularly replace services. In this project andanother related project, performed for the Oregon State Health Department, six differentgeocoding services were reviewed. Each of the services has advantages and disadvantages,
Wright and Sittig Page 15
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

with their primary differentiation being the quality of their mapping and their cost. A numberof free services are available, provided by Google(http://www.google.com/apis/maps/documentation/), Yahoo(http://developer.yahoo.com/maps/rest/V1/geocode.html) and others. These services generallyuse free but lower quality maps (such as the Census Tiger Line File). Paid services generallyuse higher quality maps, such as those from Tele Atlas (Tele Atlas NV, Ghent, Belgium) andNavteq (Navteq North America, Chicago, Illinois). Because one of the goals of this project isto showcase free software and free services, and because accuracy down to be house level isnot especially important for the public health use case, we chose to use the Google geocoderservice. The ability to freely choose from a variety of decision support services makesdevelopment, testing and maintenance of software much easier, and it is hoped that one daythe robust and competitive free market system we saw for geocoding services might bereplicated for decision support services.
Diagnostic Decision SupportThe next use case is a diagnostic decision support system. In our prototype architecture, webuilt an interface between the Isabel diagnostic decision support system (Isabel Healthcare,Reston, Virginia) and our prototype electronic health record. The Isabel system usesrudimentary natural language processing techniques to provide clinical decision supportdirectly from the medical literature and medical textbooks instead of using a comprehensivecoded knowledge base of medicine as previous systems have. It compares the structure andsemantic content of these books with a narrative report entered by the user. In this case theSANDS interface with Isabel sends the subjective and objective components of a progress note,as entered in our prototype electronic health record system, to Isabel for processing.
Isabel already provided a simple web service interface to enable their product to be integratedwith EMR systems. This interface was proprietary, however, so we developed a wrapper tomap the proprietary interface to the SANDS architecture standard interface. In many respectsthis interface was the easiest that we created because Isabel uses free text and has its ownnatural language processing engine and its own thesaurus. As such, it was not necessary toprovide any coded data to Isabel so there were no vocabulary standards issues to resolve.
Consider a simple case of a seven-year-old child with left ear pain. The provider has enteredthe subjective and objective components of his note:
Now, before proceeding to the assessment and plan, the provider activates the Isabel decisionsupport system over the prototype architecture by clicking a button in his electronic medicalrecord. This triggers the electronic medical record system to send a standard message to theIsabel decision support system containing the text of the note entered so far by the practitioner,as well as a pointer to the patient’s electronic medical record and the national health information
Wright and Sittig Page 16
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

network. The diagnostic decision support system uses this note as well as other backgroundinformation such as demographics retrieved from the NHIN. Figure 8 shows Isabel’s response.
Based on its knowledge base, Isabel provides a differential diagnosis list containing ninediagnoses across five physiologic systems. In this case, the first diagnosis proposed by Isabelis the correct one. Although this case may appear trivial to a human, it is still impressive giventhe past challenges that diagnostic decision support systems have faced. Published evidencesuggests that Isabel provides good accuracy, even in very complex cases (47–50).
One difficulty encountered in integrating Isabel into the decision support workflow was thefact that, in current versions, Isabel provides its differential diagnosis results in an unstructuredformat. This precluded developing a feature allowing the user to click a diagnosis in Isabel andhave it automatically added to the progress note or problem list. In future work, we hope tomap Isabel’s diagnoses to SNOMED so they can be more readily integrated into clinicalsystems. Were such codes already available, we would use the addProblem response type sothat a compliant electronic health record system could automatically add the chosen diagnosisto the problem list.
Inappropriate Prescribing in Older AdultsThe next use case is a drug-therapy decision support system designed to assist clinicians inprescribing medications for older adults. To this end, an expert consensus panel developedguidelines which specify drugs which are either unsafe in older adults, or which require doseadjustment (51). Although these guidelines are available, it is well-known that such drugs arestill frequently used in older adults, even when better alternatives are available (52).
Because no existing Beers criteria decision support service was available, we developed one,based on the guidance published in Archives of Internal Medicine (51). Figure 9 shows a samplealert raised by the service, in response to an order for metaxalone (Skelaxin®, a skeletal musclerelaxant) in an 83 year old female.
The inference pattern of this service is simple rule-based reasoning. The service maintains amemory-resident associative array (or dictionary), which binds medications to alert text. Whenthe service is invoked for a new medication order, it fetches the patient’s age. If the patient is65 or younger, no alert can be returned, and the logic terminates. If the patient is over 65, thearray is queried for the medication being ordered (an O(1) operation). If the medication is notfound, no alert is returned, and the logic terminates. However, if an alert is found, a notifyresponse containing the appropriate alert text is generated and returned to the requesting clinicalsystem.
One interesting facet of this use case is the method by which its content was developed. Whilethe Beers criteria were developed by an expert consensus panel, it has been formatted for usein a clinical information system through a wiki (the Clinfowiki: http://www.clinfowiki.org)using what Benkler has called “commons-based peer production” (53). In this model,collaborators (including the authors of this paper) have worked to refine the criteria, add alerttext and put the data into machine-readable format using wiki software (54). This method seemsto work fairly well, and the alerts are now available online(http://www.clinfowiki.org/wiki/index.php?title=Tab-separated_file_of_Beers_criteria_alerts), under the GNU Free Documentation License.
Information at the Point of CareDuring the course of caring for patients, clinicians have a variety of information needs (55).More recent studies have found similar results, and while use of computers for point of careinformation needs is increasing, print sources still dominate (56–58). It is known that, given
Wright and Sittig Page 17
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

the right tools, clinicians are willing to use electronic reference sources (58,59), and that good,usable electronic references sources exist (60).
However, it has been difficult to connect clinicians to these electronic resources for tworeasons: first, clinicians who are using an EHR and who wish to consult such a source mustgenerally open a web browser outside of the EHR, access the reference source and log-in, andthen must consult the source, while possibly switching back and forth between the EHR andthe reference source. These context switches impose a high cognitive burden. Second,clinicians frequently have contextual questions – for example, they are ordering a drug, andwant information on appropriate dosing. In many cases, they have already created this contextin their EHR by, for example, starting an order, and then they are forced to re-create the samecontext in the separate information tool. Various attempts, such as the Infobutton standard,have been made to more closely integrate information resources with clinical informationsystems, and early results are encouraging (61,62).
In this use case, we developed a decision support system for providing context-specificinformation to clinicians at the point of care. We used two information sources for our service:UpToDate and Google Co-op. UpToDate (Waltham, MA) is a commercial source of evidencesummaries for a variety of conditions that might be encountered in primary care. It is widelyused, and popular with clinicians (60). It is also expensive. Google Co-op, on the other hand,is free. It is a health search engine based on the main Google index, but supplemented withtags added by 26 trusted contributors, such as the Health on the Net Foundation, the MayoClinic, Kaiser Permanente, the National Library of Medicine and Harvard Medical School.These contributors add tags to articles, describing the type of information they contain, thushelping to improve the quality of search results for medical conditions and drugs. Both of thesesources use free-text search, and neither of their indexes are linked to any structured vocabulary,so direct, free-text search terms are passed to them through the decision support interface.
This decision support service is accessed by context menus in the SANDS prototype client.These menus allows the user to choose whether they want to query UpToDate or Google. Ifthe user wants to query Google, there are options to narrow the search to treatment, symptoms,tests / diagnosis, causes / risk factors, practice guidelines, patient handouts and clinical trials.These correspond to disease information tags in the Google Co-op knowledge base.
The same service is called regardless of what category is selected, with the information categoryselected by the user passed in to the decision support service as a parameter. In a typical usecase, a clinical system analyst at a hospital would use the user interface design toolkit providedby their clinical system vendor to develop a custom menu, where each item was a hook intoan information service. The clinical system designer would customize the menu items availablebased on the information sources that the hospital subscribes to and the information needs ofclinicians at that hospital. In future work, we intend to replace our self-developed system withthe HL7 Infobutton Manager standard (61), which provides similar functionality with severalimportant enhancements, including built in support for managing content licensing issues,which was an issue we faced several times with UpToDate, a commercial source with licenserestrictions.
A Simple Personal Health RecordThe final use case we developed was a simple personal health record, shown in Figure 10. Itis a web-based application that a patient would access. It provides a read-only view into thepatient’s medication list, as stored in the NHIN, allowing the patient to see what medicationsare active across a number of providers. The personal health record also provides drug-interaction checking and links to information resources targeted at patients. These services areactually identical to the previously discussed services provided through the EHR This is one
Wright and Sittig Page 18
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

of the key advantages of the SANDS architecture – because decision support content is exposedas services, the content can be reused across different end-user applications, such as the EHRand PHR described here.
EvaluationWe evaluated the SANDS architecture according to the framework described in the reviewpaper (63) which includes four elements:
1. Feature determination
2. Existence and Use
3. Utility
4. Coverage
In addition, we evaluated the performance of SANDS, in order to ensure that it was sufficientlyfast to enable use in real world clinical information systems.
Feature DeterminationSANDS was developed with the evaluation framework’s set of desirable features in mind, andit evaluates favorably against them. Specifically, SANDS:
• Avoids vocabulary issues, by using the NHIN, which already establishes vocabularyformats, to query patient data.
• Is shareable, because many clinical systems and users can query a single service.• Maintains content separate from code explicitly by means of a service contract
where the decision support content is embodied in a service called from theinformation system code.
• Enables automatic central updates because the content is stored centrally within theservice, so when the content is changed, no corresponding changes need to be madeto the calling clinical system.
• Allows content to be integrated into workflows by enabling decision supportservices to be called from within other clinical information systems.
• Supports event driven CDS through calls from clinical information systems duringthese events.
• Supports non-event driven CDS through calls from non-event-driven systems, suchas dashboards, registries and quality reporting applications.
• Support decision support across multiple patients in two ways: either by callingservices repeatedly and passing in single patient identifiers or, where supported, byallowing clients to pass in multiple patient identifiers as part of a single query.
• Enables separation of responsibilities by placing responsibility for maintainingcontent with the service developer and away from the clinical information systemimplementer.
• Enables composition of rules because decision support services can invoke otherservices.
• Allows black-box services where a service makes inferences and responds to querieswithout necessarily exposing its underlying logic to the client application.
Wright and Sittig Page 19
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

• Free choice of programming language since services can be written in any language,so long as they expose the standard SANDS interfaces.
One important gap in SANDS’ features is the ability for the user to view and monitor the clinicaldecision support content. This is relatively easy with knowledge representation formalismssuch as Arden Syntax and GuideLine Interchange Format (GLIF), as the user can simply lookat the rules to see what they do. However, the nature of SANDS makes this difficult. Since therules are executed in a service away from the clinical information system, the user must dependon the service to provide accurate inferences. Although the user can (and should) ask to viewthe source rules for any decision support service being invoked, there is no way to be certainthat the rules have not been changed or modified. This is, in fact, perhaps SANDS’ mostsignificant limitation, and is an inherent limiting property of any service-oriented architecture.The solutions include developing some sort of trust relationship (likely enforced by a contract),or running local mirrors (i.e., versions of the service that are completely under the control ofthe local organization’s HIT department) of decision support services – a mode we are nowbeginning to prototype.
Existence and UseIn the review paper (63) we proposed an existence and use spectrum having four steps rangingfrom theoretical discussions (level 1) through widespread adoption (level 4). With SANDS,we achieved level 3 – advanced prototypes that demonstrate sharing of decision support contentacross sites. The development of external use cases, such as the Isabel diagnostic decisionsupport system and the Lexi-Comp drug-drug interaction system show that SANDS canincorporate decision support beyond just use cases developed specifically for SANDS. Overtime, we hope to take SANDS through a standards process, and eventually see itsimplementation in commercially available clinical systems, at which point it would progressto level 4 of the existence and use spectrum. In the meantime, we have made much of the codeand services we have developed available as free open-source software.
UtilityUtility, as defined in the evaluation model, has two facets: clinical utility and functional utility.Clinical utility is the ability to use a decision support architecture to do clinically useful things.Many of the SANDS use cases have simple face validity as possibly clinically useful, but morethan that, many of the decision support functions prototyped have actually been studiedclinically and found to have positive impacts on quality of care and patient safety – where theseare known, references are given in the prior section describing the use cases. Because SANDSis a conduit for delivering clinical decision support, it inherits clinical utility from the clinicalutility of the utility of the use cases implemented in it.
The other facet of utility is functional utility – the ability of an architecture to support a varietyof different kinds of clinical decision support. One advantage of SANDS is that it is extremelyflexible. Table 2 shows the use cases we developed for SANDS characterized across severaldimensions of functional utility. As the table suggests, these use cases exhibited a variety offunctional properties. Some, for example, were simple rule-based systems, while others madecomplex inferences using NLP. We also successfully created prototypes of freely availabledecision support rules as well as commercially available rules.
CoverageBecause the SANDS protocols and message formats were derived from the same taxonomyand rule-base as the coverage evaluation described in our review paper, SANDS achieved 100%coverage in the metric described in the model paper. It is important to note that this is not meantas a comparison against other architectures – if additional rule bases were added to the coverage
Wright and Sittig Page 20
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

evaluation, it is possible that SANDS would incompletely cover them, resulting in a lowercoverage metric. Conversely, other architectures could be extended to include the fullcomplement of triggers, data elements, interventions and response types needed to support theevaluation rule base, thus likewise achieving full coverage.
PerformanceAs mentioned in the introduction, early performance data about SANDS was previouslypresented at the 2007 American Medical Informatics Association Annual Symposium (6).Since this presentation, further performance data has been collected and additional analyseshave been performed.
A common goal of clinical system developers is sub-second response time (64) and one criticalquestion we faced was whether this ideal could be achieved using the SANDS architecture.The SANDS architecture is subject to five kinds of delay which are generally additive:
• Network latency: The time it takes for a packet to propagate between two hosts ona network. This is a startup cost of transmission – after the first packet, throughput isgoverned by transmission delay.
• Transmission delay: The time needed to transmit a message over the network oncelatency is overcome. With SANDS’ small message sizes, throughput is usually not amajor source of delay.
• Patient data fetch: SANDS fetches a patient’s clinical data from the NHIN. The costof this fetch can be fairly high so SANDS employs a caching strategy to reduce thisdelay.
• Parsing overhead: SANDS is based on Extensible Markup Language (XML)protocols and there is overhead in parsing the XML. Given the size of the messagesused in SANDS, the overhead is fairly small.
• Inference time: This is the actual time that the inference takes to run. This is noadditional overhead added by SANDS. Even tightly integrated decision supportsystems face this delay.
The latency delay of a typical transmission varies significantly depending on the physicaldistance between the client and server. Within a subnet, it is generally less than one millisecond.Within the continental United States, we observed times ranging from 3 ms to 170 ms, withtypical transmissions experiencing approximately 75 ms latency delay. Because the amount ofdata SANDS transmits is small, transmission delay tends to be very small, on the order of 1–3 ms. The patient data fetch time is a function of the NHIN architecture and tended to beunacceptably slow (on the order of 6–10 seconds). As a result, caching was employed, whichreduced the fetch delay to zero (when stored locally in the service), or on the order of 100–200ms, when stored in the cross-service distributed cache described previously. The parsingoverhead for SANDS messages was approximately 10 ms using Microsoft’s native XMLparser. The first four delays are all overhead added by SANDS. The final source of delay,inference time, is a property of the decision support service, and was the most variable. Simpleservices could complete their inferences very quickly (from 50–100 ms), while other servicestook nearly a second.
To assess the robustness of the SANDS architecture and the delays associated with it weconducted a timing and reliability study. We set up the system to automatically poll each servicein the SANDS implementation every 5 minutes (24 hours/day, 7 days/week) over a continuousfour week period (a total of 13,440 requests) and gathered data on the average response timesobserved. They varied significantly depending on the use cases, ranging from a total end-to-
Wright and Sittig Page 21
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

end time (including all five delays) of 73 ms for the services we developed to 138 ms forGoogle’s geocoder through 1382 ms for the drug-drug interaction service. Figure 11 shows therange and average times for each of the sources of delays across all the services with patientdata caching turned on. If patient data caching is turned off, the NHIN fetch adds delayesranging from 6 to 10 seconds, overwhelming the contributions of all other sources of delay.
As for reliability, seven of the nine (78%) SANDS decision support modules had sub-secondresponse times > 97% of the time. Overall, these results indicate that it is not only possible,but highly reliable and quick, to perform a variety of useful clinical decision supportinterventions using the SANDS architecture with sub-second response time as the standard.The syndromic surveillance and prescribing in the elderly services, which were self developed,had outstanding performance because they were optimized for efficiency and located locallyso a request to them did not have to traverse the Internet. The drug-drug interaction servicenever completed within 1 second, but almost always (99.83%) completed within 5 seconds.This is likely due to the data structures used by the developer of the service.
The last three services, called Geocoders, merit further comment. The syndromic surveillanceuse case has a mapping capability where cases of reportable diseases are displayed geospatially.To do this, a service called a Geocoder is used. A Geocoder takes an address and finds thecorresponding latitude and longitude. Three different free Geocoding services were tested andthe variation in performance was striking – Google’s Geocoder almost never failed, andreturned within 1 second 99.9% of the time. Yahoo’s Geocoder, doing the same task, failedtwice as often and took, on average, nearly twice as long, as seen in Table 3. Clearly, systemreliability and performance will be an important consideration for any user of the SANDSarchitecture. While the architecture itself imposes only minimal latency and overhead, theperformance of the same task, implemented by different developers, may vary greatly so it willbe important to carefully evaluate performance before choosing services.
DiscussionChallenges in Integrating Data
One key challenge encountered in development of the Patient Data Class library was dataintegration. The class library combines data from multiple sources, and sometimes these dataare duplicative or contradictory. For some data elements, such as demographics, discrepancieswere uncommon and usually of little significance (for example, discrepant spellings of thepatient’s first name). When present, they were resolved by using the most recent observationas the correct one. Vital signs were resolved in a similar fashion: all vital signs were stored andmade available with timestamps as observations. For height, weight and care setting the mostrecent value was also made available as a discrete value in the demographics component ofthe Patient Data Class Library
Integrating clinical information was more difficult. For some data elements, such asobservations and procedure history, the correct integrated set is simply the union of all non-duplicate elements stored in clinical systems on the national health information network.
However, for drugs in particular, the problem was much more difficult. We often encounteredpatients who had medication lists spread across a variety of clinical systems, often containingthe same drug with different doses or two drugs in a therapeutic class where co-administrationis very uncommon. We were not able to accurately reconcile such medication lists in a fullyautomated fashion. This problem is well understood and described in the literature (65,66) andis the focus of a number of active research projects, such as the RxSafe project in Lincoln City,OR (67). It is likely that any comprehensive solution will require human intervention, whetherit’s a clinician to reconcile the medication lists, a pharmacist or the patient himself. Luckily
Wright and Sittig Page 22
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

this problem cuts across all uses and users of integrated medication data, so it is likely to seesignificant attention in the future.
Challenges in data integration are not solely limited to medication information. For example,various data sources may contain differing (or conflicting) information and some mechanismis needed to decide which piece of information should be used. The current approach is to relyon the most recent instance of that data element, but this has significant limitations. Forexample, if the most recent data element is patient entered, but there is also a reasonably currentprovider entered instance of the same data element, perhaps it would be desirable to use thisinstance. The current NHIN prototype does not always provide sufficient metadata to makethese determinations, and would benefit from a clearer mechanism of indicating the relativeconfidence and reliability of data instances. The other option, of course, would be to promptthe user to ask the patient which instance of the data element to rely on. This option would beespecially appropriate in cases where the conflicting data instances result in clinicallysignificant differences in the result of the decision support inference. This mechanism couldalso be extended to prompting the user to enter missing data required to make an inference,such as height and weight for inferences which depend on calculated body surface area orcreatinine clearance.
Drug Terminology ChallengesMany systems, including the national health information network prototype that we used inthis paper use national drug codes or NDCs. These codes are popular because they are the basisof most pharmaceutical claims. Since nearly all pharmaceutical claims are processedelectronically they tend to be much more widely available than prescription data becauseelectronic prescribing is still rare. The most significant difficulty with NDCs is their specificity.Each individual dose form and quantity of a medication is assigned a unique national drugcode. That means that a common generic drug, like aspirin, may have dozens or hundreds ofapplicable NDCs. This creates a challenge for decision support, because any rule that referencesa given drug by its NDC must be aware of the fact that there could actually be many NDCs forthat drug, and that more may appear in the future. A further challenge is that NDCs can beunreliable. The code space for NDCs is managed in a decentralized fashion with the FDAassigning parent codes to all manufacturers of pharmaceuticals. These manufacturers thenassign NDCs from their code space whenever they produce a new drug. Unfortunately, thereare cases where manufacturers recycle drug codes, or simply assign the same drug code tomultiple drugs. And while manufacturers are required to report their assignments back to theFDA, there are cases where they fail to do so. As such, even in our limited prototype weencountered a number of situations where NDCs found on a patient’s drug list could not bematched by decision support systems. For example, the NDC code 00093086301 representsone form of ciprofloxacin. When this code was passed to the Lexi-Comp drug interactionservice the query failed. Although the service, of course, contains data on ciprofloxacin thisparticular NDC for Ciprofloxacin was not in its database. The same issue was encountered forNDC 68249020010 (for the drug Humibid, a brand name version of guaifenesin with potassiumguaiacolsulfonate) and for NDC 00591049950 (a generic 100 MG doxycycline hyclate tabletproduced by Watson Laboratories).
It is our strong recommendation that terminologies besides NDCs be used to describe drugs.The National Drug File Reference Terminology (NDF-RT) would be one good choice, butthere are actually many. This cause is helped by the RxNorm project of the National Libraryof Medicine (19). RXNorm is designed to be a comprehensive map amongst various drugterminologies. While it includes NDCs, it faces the same limitations that other terminologysystems based on NDCs have encountered: namely, that certain NDCs which have beenassigned to drugs do not appear in RxNorm. Another ray of hope comes from the NCPDP
Wright and Sittig Page 23
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

SCRIPT electronic prescribing standard (16). Electronic prescriptions using NCPDP SCRIPTuse robust drug vocabularies, and as more electronic prescriptions are written, the need to useclaims data (where NDCs are most commonly found) is lessened.
Problem List Terminology ChallengesWhile the largest terminological issue we encountered in the development of this prototypewas related to drugs, problem list terminology also provided some interesting challenges.Perhaps the most widely used system for encoding problems is ICD-9. While this works tosimplify billing, it is frequently the case that the level of detail required for describing a patient’sproblem for clinical purposes differs from the level of detail required for describing the sameproblem for billing purposes.
An initial version of the prototype system used ICD-9 codes because of their wide use andavailability and because the NHIN prototype used generally provides problem information inICD-9 format. However, ongoing use of the prototype quickly showed that ICD-9 codes wereinadequate for describing many common clinical problems, an issue which has been previouslydescribed in the literature (68). As such, we converted the problem list format for our prototypeto SNOMED. Because SNOMED is a very large terminology designed for a variety of clinicalpurposes, we employed a subset of the SNOMED terminology designed for problem lists anddeveloped by Kaiser Permanente and the Department of Veterans Affairs. This subset isfrequently used for problem lists and is available either directly from the Veterans Affairsadministration or via the UMLS. In addition to more clinically relevant problems, usingSNOMED provides several significant advantages for decision support developers. SNOMEDprovides a rich semantic structure and hierarchy of concepts so that it is possible to developrules that correctly handle generality. For example, SNOMED defines a heart disease conceptso it is possible to develop a rule that says “patients with a history of heart disease shouldreceive an influenza vaccination.” Then, even if the patient’s problem list does not contain theconcept “heart disease”, but contains a sub-concept such as “dilated cardiomyopathy” a ruleengine that exploits SNOMED’s concept network can correctly reason that the influenzavaccination rule still applies. While ICD-9 has its own concept hierarchy, it is much less richthan SNOMED’s and is designed for billing rather than clinical purposes.
Economics and Business ModelsAt present, a number of restraints hinder the development of a full and robust market for clinicaldecision support. For most purchasers of clinical systems, such as electronic health records orcomputerized physician order entry systems, the easiest option for purchasing decision supportcontent is to purchase it directly from their clinical system vendor. These vendors often havepartnerships with preferred content providers. This creates a significant degree of vendor lock-in because if that vendor’s customer wishes to employ a non-preferred clinical decision supportsystem, they may be forced to develop costly interfaces. With open standards-based systems,such as SANDS, purchasers of clinical information systems can instead adopt a building blockmodel – purchasing the clinical information system of their choice and then choosing,application by application, the decision support systems that best meet their needs.
We anticipate that with an architecture such as this we would see a variety of business modelsfor providing clinical decision support content. In some ways, one can conceptualize thisarchitecture as being a sort of Internet for clinical decision support. Just as the Internet has arich market of content suppliers ranging from paid providers of content to open source content,and even community edited content such as Wikipedia, so too could all of these models besupported in this decision support architecture. In many cases, we might expect that users wouldprefer to purchase decision support content from established vendors. However, it is also easyto imagine cases where individuals or organizations with an established interest in a topic might
Wright and Sittig Page 24
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

provide free decision support content. For example, many medical specialty societies haveexpressed interest in providing electronic forms of the paper guidelines they currently publish.An architecture such as this one would provide an open and high-leverage way for specialtysocieties to increase the adoption and use of such guidelines. One might further imagine otherstakeholders that would be interested in providing clinical decision support systems. Considerfor example the syndromic surveillance and disease reporting system described earlier in thispaper. At present, public health departments spend large amounts of money developing diseasetracking systems and publicizing them to encourage providers to report diagnoses of reportablediseases. Some of these resources could instead be dedicated to providing electronic decisionsupport systems such as the one developed here which would automate portions of this process.Then, users of clinical systems who wish to automatically report reportable diseases couldsimply add this decision support service to their clinical system. Both the provider of a decisionsupport system (in this case, the public health department) and the consumer of the service (inthis case, a care provider) have strong incentives to cooperate around such a free decisionsupport service.
Because of the exciting potential for a variety of business models to flourish we were carefulto avoid being prescriptive about the business model or economic relationship between serviceproviders and service consumers. Instead, any provider or consumer who can communicateaccording to the decision support standard defined in this paper would be welcome toparticipate. The business relationship, if any, between the provider and the consumer wouldbe determined by the two parties.
One concern that arises when there is a business relationship between a provider of clinicalinformation and a provider of clinical care is the issue of liability. In the 1980’s, there wasmuch debate in the field of informatics about whether clinical systems and clinical decisionsupport systems should be regulated as medical devices, and whether there should be liabilityon the part of system providers for errors or omissions in their content or systems (69). Whilethis question is still not settled law, the strong direction is that decision support content shouldbe regulated and held liable using the same principles that apply to medical textbooks (whichare, after all, a paper form of clinical decision support). In this paradigm, so long as there is ahuman intermediary between the device or system and the patient, that intermediary is theresponsible provider, and there is no consequential liability for the system provider. That said,content providers and purchasers could certainly contract for additional indemnification – forexample, a drug information provider might guarantee that their system will not miss anydocumented high severity drug interactions. In the reverse, a free content provider mightrequire that hospitals which employ its service indemnify the content provider against liabilityfor content errors. This is a form of insurance, and it is possible that it, too, might become abasis of competition in a marketplace for clinical decision support. All things being equal, adecision support service which offered indemnity would be more attractive than one that didn’t.If, on the other hand, there was an additional cost for this indemnity, providers and purchaserswould have to conduct internal cost benefit analyses to determine the cost and value of suchindemnity protection. The issue of liability and indemnification is challenging, and it is unlikelyto be resolved until a body of case law is established in the courts, or until the legal situationis clarified through regulation or legislation. It is worth noting that this issue affects all decisionsupport involving a third-party content provider, regardless of the technical architectureemployed.
Organizational Issues and ImplicationsIn addition to the economic implications, there are also organizational implications to considerwith any clinical decision support or clinical system, and this architecture is no different. Thebest evidence suggests that a phased approach to the implementation of any new clinical system
Wright and Sittig Page 25
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

or clinical decision support intervention is most likely to be successful (70). However, phasedimplementations are often very difficult to execute when using a monolithic system becausethe parts of the system often fail to function unless integrated into a whole. The SANDSarchitecture is inherently designed for extreme modularity. It would be conceivable that onemight initially deploy a clinical system with no decision support turned on. After the issuessurrounding the deployment settle out, the implementer could then slowly turn on clinicaldecision support modules as user experience and organizational priorities dictate.
Moreover, an architecture such as SANDS allows an organization to be more responsive touser feedback. For example, if users report that they are extremely satisfied with the userinterface of a new clinical system, but very dissatisfied with the accuracy of the drug interactionalerts that the system produces, it would be easy to keep the same clinical system, but substitutea different drug interaction service. It would even be possible to conduct trials of variousdecision support services to determine which service provides the greatest accuracy and usersatisfaction. Modularity would be much more difficult to achieve with other decision supportarchitectures.
ConclusionSANDS has several significant advantages over other architectures for clinical decisionsupport, the most salient advantages include:
• Modularity: An SOA provides more modularity than other architectures, allowingfor work to be distributed. With a fully realized architecture medical specialtysocieties might, for example, each produce guidelines in their area of expertise, butmake them available for consumption by anyone.
• A Market for Decision Support: Commercial services can play a role in an SOA,by providing services and content for which they charge a fee.
• Trialability / switchability: An SOA reduces the cost and risk of trying new decisionsupport systems: a hospital or healthcare provider could always connect to a newdecision support service and try it out, but could freely disconnect if it did not performas desired.
• Maximal Expressiveness: An SOA specifies the interfaces a service must provide,but imposes no restrictions on its implementation.
• Alignment with Interoperability: Finally, the key advantage of this architecture isits potential to “unstick" progress on decision support, by uniting the direction ofclinical decision support with promising near-term efforts to improve interoperability.
References1. Chaudhry B, Wang J, Wu S, et al. Systematic review: impact of health information technology on
quality, efficiency, and costs of medical care. Annals of internal medicine 2006 May 16;144(10):742–752. [PubMed: 16702590]
2. Kawamoto K, Houlihan CA, Balas EA, Lobach DF. Improving clinical practice using clinical decisionsupport systems: a systematic review of trials to identify features critical to success. BMJ (Clinicalresearch ed.) 2005 Apr 2;330(7494):765. [PubMed: 15767266]
3. Chaudhry B, Wang J, Wu S, et al. Systematic Review: Impact of Health Information Technology onQuality, Efficiency, and Costs of Medical Care. Ann Intern Med 2006;144(10)
4. Hripcsak G. Arden Syntax for Medical Logic Modules. MD Comput 1991 Mar–Apr;8(2):76–78.[PubMed: 2038238]
5. Health Level 7. Arden Syntax for Medical Logic Systems Standard Version 2.6. Ann Arbor, MI: HealthLevel 7; 2007.
Wright and Sittig Page 26
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

6. Wright A, Sittig DF. SANDS: An Architecture for Clinical Decision Support in a National HealthInformation Network. AMIA Annu Symp Proc. 2007
7. American Diabetes Association. Standards of medical care in diabetes -- 2007. Diabetes Care 2007Jan;(30 Suppl 1):S4–S41. [PubMed: 17192377]
8. Jones JK, Fife D, Curkendall S, Goehring E Jr, Guo JJ, Shannon M. Coprescribing and codispensingof cisapride and contraindicated drugs. Jama 2001 Oct 3;286(13):1607–1609. [PubMed: 11585484]
9. Wysowski DK, Bacsanyi J. Cisapride and fatal arrhythmia. N Engl J Med 1996 Jul 25;335(4):290–291. [PubMed: 8657260]
10. HL7 Services Specification Project Workgroup, OMG Healthcare Domain Task Force. HealthcareServices Specification Project: The Business Case and Importance of Services (presentation). 2007[cited 2007 2007 Feb 09]. Available from:http://hssp.wikispaces.com/space/showimage/2007-01_07_HSSP_Public_Slide_Deck_Version_1.2.ppt
11. Lamont J. Decision support systems prove vital to healthcare. KM World. 2007 Feb 01;12. Glaser J, Flammini S. The Service-Oriented Solution for Health IT. HHN Most Wired. 2007 Feb 1;13. Bakken S, Campbell KE, Cimino JJ, Huff SM, Hammond WE. Toward vocabulary domain
specifications for health level 7-coded data elements. J Am Med Inform Assoc 2000 Jul–Aug;7(4):333–342. [PubMed: 10887162]
14. Dolin RH, Alschuler L, Beebe C, et al. The HL7 Clinical Document Architecture. J Am Med InformAssoc 2001 Nov–Dec;8(6):552–569. [PubMed: 11687563]
15. Dolin RH, Alschuler L, Boyer S, et al. HL7 Clinical Document Architecture, Release 2. J Am MedInform Assoc 2006 Jan–Feb;13(1):30–39. [PubMed: 16221939]
16. Huff SM. Clinical data exchange standards and vocabularies for messages. Proc AMIA Symp1998:62–67. [PubMed: 9929183]
17. Spackman K. SNOMED RT and SNOMEDCT. Promise of an international clinical terminology. MDComput 2000 Nov–Dec;17(6):29. [PubMed: 11189756]
18. Coonan KM. Medical informatics standards applicable to emergency department informationsystems: making sense of the jumble. Acad Emerg Med 2004 Nov;11(11):1198–1205. [PubMed:15528585]
19. Parrish F, Do N, Bouhaddou O, Warnekar P. Implementation of RxNorm as a Terminology MediationStandard for Exchanging Pharmacy Medication between Federal Agencies. AMIA Annu Symp Proc2006:1057. [PubMed: 17238676]
20. Gibson JT, Barker KN. Quality and comprehensiveness of the National Drug Code Directory onmagnetic tape. Am J Hosp Pharm 1988 Feb;45(2):337–340. [PubMed: 3364432]
21. Cobb WM. The National Drug Code system: its purpose and potential. Hosp Formul 1976 Nov;11(11):593–595. [PubMed: 1028790]
22. US Department of Health and Human Services. Health Information Technology Initiative. MajorAccomplishments: 2004–2006. 2007.
23. Halamka JD. Harmonizing healthcare data standards. J Healthc Inf Manag 2006 Fall;20(4):11–13.[PubMed: 17091782]
24. Vegoda P. Introducing the IHE (Integrating the Healthcare Enterprise) concept. J Healthc Inf Manag2002 Winter;16(1):22–24. [PubMed: 11813518]
25. Johnson, PD.; Tu, SW.; Musen, MA.; Purves, I. A virtual medical record for guideline-based decisionsupport; Proc AMIA Symp; 2001. p. 294-298.
26. Wright A, Goldberg H, Hongsermeier T, Middleton B. A Description and Functional Taxonomy ofRule-Based Decision Support Content at a Large Integrated Delivery Network. J Am Med InformAssoc. 2007 Apr 25;
27. Office of the National Coordinator for Health Information Technology. Presidential Initiatives:Consolidated Health Informatics. 2006 [cited 2007 Feb 15]. Available from:http://www.hhs.gov/healthit/chiinitiative.html
28. Calinforna Healthcare Foundation. ELINCS: Developing a National Lab Data Standard for EHRs.Oakland, CA: California Healthcare Foundation; 2005.
Wright and Sittig Page 27
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

29. Brouch K. AHIMA project offers insights into SNOMED, ICD-9-CM mapping process. J Ahima2003 Jul–Aug;74(7):52–55. [PubMed: 12891795]
30. Matney S, Dent C, Rocha RA. Development of a compositional terminology model for nursing orders.Int J Med Inform 2004 Aug;73(7–8):625–630. [PubMed: 15246043]
31. Fitzpatrick B. Distributed caching with memcached. Linux Journal 2004;2004(124)32. Bates DW, Boyle DL, Vander Vliet MB, Schneider J, Leape L. Relationship between medication
errors and adverse drug events. J Gen Intern Med 1995 Apr;10(4):199–205. [PubMed: 7790981]33. Leape LL, Bates DW, Cullen DJ, et al. ADE Prevention Study Group. Systems analysis of adverse
drug events. Jama 1995 Jul 5;274(1):35–43. [PubMed: 7791256]34. Leape LL, Brennan TA, Laird N, et al. The nature of adverse events in hospitalized patients. Results
of the Harvard Medical Practice Study II. N Engl J Med 1991 Feb 7;324(6):377–384. [PubMed:1824793]
35. Stanaszek WF, Franklin CE. Survey of potential drug interaction incidence in an outpatient clinicpopulation. Hosp Pharm 1978 May;13(5):255–257. [PubMed: 10236769]61, 63.
36. Batesc DW, Leape LL, Cullen DJ, et al. Effect of computerized physician order entry and a teamintervention on prevention of serious medication errors. Jama 1998 Oct 21;280(15):1311–1316.[PubMed: 9794308]
37. Bates DW, O'Neil AC, Boyle D, et al. Potential identifiability and preventability of adverse eventsusing information systems. J Am Med Inform Assoc 1994 Sep–Oct;1(5):404–411. [PubMed:7850564]
38. Bates DW, Teich JM, Lee J, et al. The impact of computerized physician order entry on medicationerror prevention. J Am Med Inform Assoc 1999 Jul–Aug;6(4):313–321. [PubMed: 10428004]
39. Teich JM, Merchia PR, Schmiz JL, Kuperman GJ, Spurr CD, Bates DW. Effects of computerizedphysician order entry on prescribing practices. Arch Intern Med 2000 Oct 9;160(18):2741–2747.[PubMed: 11025783]
40. Feldstein AC, Smith DH, Perrin N, et al. Reducing warfarin medication interactions: an interruptedtime series evaluation. Arch Intern Med 2006 May 8;166(9):1009–1015. [PubMed: 16682575]
41. Spina JR, Glassman PA, Belperio P, Cader R, Asch S. Clinical relevance of automated drug alertsfrom the perspective of medical providers. Am J Med Qual 2005 Jan–Feb;20(1):7–14. [PubMed:15782750]
42. van der Sijs H, Aarts J, Vulto A, Berg M. Overriding of drug safety alerts in computerized physicianorder entry. J Am Med Inform Assoc 2006 Mar–Apr;13(2):138–147. [PubMed: 16357358]
43. Weingart SN, Toth M, Sands DZ, Aronson MD, Davis RB, Phillips RS. Physicians' decisions tooverride computerized drug alerts in primary care. Arch Intern Med 2003 Nov 24;163(21):2625–2631. [PubMed: 14638563]
44. Kuperman GJ, Bobb A, Payne TH, et al. Medication-related clinical decision support in computerizedprovider order entry systems: a review. J Am Med Inform Assoc 2007 Jan–Feb;14(1):29–40.[PubMed: 17068355]
45. Greim JA, Shek C, Jones L, et al. Enterprise-wide drug-drug interaction alerting system. AMIA AnnuSymp Proc 2003:856. [PubMed: 14728361]
46. Shah NR, Seger AC, Seger DL, et al. Improving acceptance of computerized prescribing alerts inambulatory care. J Am Med Inform Assoc 2006 Jan–Feb;13(1):5–11. [PubMed: 16221941]
47. Bavdekar SB, Pawar M. Evaluation of an Internet delivered pediatric diagnosis support system(ISABEL) in a tertiary care center in India. Indian Pediatr 2005 Nov;42(11):1086–1091. [PubMed:16340049]
48. Ramnarayan P, Tomlinson A, Rao A, Coren M, Winrow A, Britto J. ISABEL: a web-based differentialdiagnostic aid for paediatrics: results from an initial performance evaluation. Arch Dis Child 2003May;88(5):408–413. [PubMed: 12716712]
49. Ramnarayan P, Winrow A, Coren M, et al. Diagnostic omission errors in acute paediatric practice:impact of a reminder system on decision-making. BMC Med Inform Decis Mak 2006;6:37. [PubMed:17087835]
50. Ramnarayan P, Roberts GC, Coren M, et al. Assessment of the potential impact of a reminder systemon the reduction of diagnostic errors: a quasi-experimental study. BMC Med Inform Decis Mak2006;6:22. [PubMed: 16646956]
Wright and Sittig Page 28
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

51. Fick DM, Cooper JW, Wade WE, Waller JL, Maclean JR, Beers MH. Updating the Beers criteria forpotentially inappropriate medication use in older adults: results of a US consensus panel of experts.Arch Intern Med 2003 Dec 8–22;163(22):2716–2724. [PubMed: 14662625]
52. van der Hooft CS, Jong GW, Dieleman JP, et al. Inappropriate drug prescribing in older adults: theupdated 2002 Beers criteria--a population-based cohort study. Br J Clin Pharmacol 2005 Aug;60(2):137–144. [PubMed: 16042666]
53. Benkler Y. Coase's Penguin, or, Linux and the Nature of the Firm. Yale Law Journal 2002;112(3):367–445.
54. Leuf, B.; Cunningham, W. The Wiki way: quick collaboration on the Web. Boston, MA, USA:Addison-Wesley Longman Publishing Co., Inc.; 2001.
55. Gorman PN, Helfand M. Information seeking in primary care: how physicians choose which clinicalquestions to pursue and which to leave unanswered. Med Decis Making 1995 Apr–Jun;15(2):113–119. [PubMed: 7783571]
56. Covell DG, Uman GC, Manning PR. Information needs in office practice: are they being met? AnnIntern Med 1985 Oct;103(4):596–599. [PubMed: 4037559]
57. Ely JW, Burch RJ, Vinson DC. The information needs of family physicians: case-specific clinicalquestions. J Fam Pract 1992 Sep;35(3):265–269. [PubMed: 1517722]
58. Westbrook JI, Gosling AS, Coiera E. Do clinicians use online evidence to support patient care? Astudy of 55,000 clinicians. J Am Med Inform Assoc 2004 Mar–Apr;11(2):113–120. [PubMed:14662801]
59. Schilling LM, Steiner JF, Lundahl K, Anderson RJ. Residents' patient-specific clinical questions:opportunities for evidence-based learning. Acad Med 2005 Jan;80(1):51–56. [PubMed: 15618093]
60. Campbell R, Ash J. Comparing bedside information tools: a user-centered, task-oriented approach.AMIA Annu Symp Proc 2005:101–105. [PubMed: 16779010]
61. Cimino JJ, Li J, Graham M, et al. Use of online resources while using a clinical information system.AMIA Annu Symp Proc 2003:175–179. [PubMed: 14728157]
62. Maviglia SM, Yoon CS, Bates DW, Kuperman G. KnowledgeLink: impact of context-sensitiveinformation retrieval on clinicians' information needs. J Am Med Inform Assoc 2006 Jan–Feb;13(1):67–73. [PubMed: 16221942]
63. Wright A, Sittig DF. A Framework and Model for Evaluating Clinical Decision Support Architectures.Submitted to Journal of Biomedical Informatics. 2008
64. Doherty WJ, Thadhani AJ. The economic value of rapid response time. IBM Report.65. Hamann C, Poon E, Smith S, et al. Designing an electronic medication reconciliation system. AMIA
Annu Symp Proc 2005:976. [PubMed: 16779263]66. Poon EG, Blumenfeld B, Hamann C, et al. Design and implementation of an application and associated
services to support interdisciplinary medication reconciliation efforts at an integrated healthcaredelivery network. J Am Med Inform Assoc 2006 Nov–Dec;13(6):581–592. [PubMed: 17114640]
67. Gorman, P. RxSafe: Using IT to Improve Medication Safety for Rural Elders. 2006 [cited 2007 Feb09]. Available from: http://medir.ohsu.edu/~gormanp/slides/051003_RxSafe2_HO.pdf
68. Campbell JR, Payne TH. A comparison of four schemes for codification of problem lists. Proc AnnuSymp Comput Appl Med Care 1994:201–205. [PubMed: 7949920]
69. Miller RA, Schaffner KF, Meisel A. Ethical and legal issues related to the use of computer programsin clinical medicine. Ann Intern Med 1985 Apr;102(4):529–537. [PubMed: 3883869]
70. Gross PA, Bates DW. A pragmatic approach to implementing best practices for clinical decisionsupport systems in computerized provider order entry systems. J Am Med Inform Assoc 2007 Jan–Feb;14(1):25–28. [PubMed: 17068354]
71. Nadkarni P, Miller R. Service-oriented Architecture in Medical Software: Promises and Perils. J AmMed Inform Assoc 2007 Mar–Apr;14(2)
Wright and Sittig Page 29
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Figure 1.A sample lab result record from the NHIN. The record is formatted as an HL7 observationsegment and indicates that an absolute lymphocyte count of 1.4 thousand cells per microliteron April 17, 2001.
Wright and Sittig Page 30
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Figure 2.Sample medication record from the NHIN. This record indicates that 325 mg ferrous sulfatetablets were dispensed to the patient on April 14, 2006.
Wright and Sittig Page 31
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Figure 3.Sample response from a SANDS decision support service. This response indicates that thepatient’s low density lipoprotein level is elevated and offers the user a variety of possibleresponses, including starting the patient on simvastatin, an antihyperlipidemic agent.
Wright and Sittig Page 32
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Figure 4.A SOAP request showing an invocation of the DDI web service. Mark 1 shows the medicationbeing ordered (the contextual data) for the drug phenelzine, a monoamine oxidase inhibitor.Mark 2 shows the data used to locate the patient in the NHIN. Although a site specific MRNis included, the RLS uses this information to find records for the patient at any participatingsite.
Wright and Sittig Page 33
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Figure 5.A SANDS-formatted response from the DDI service. The response indicates that there is apotentially fatal interaction between the ordered drug, phenelzine and the drug meperidinewhich the patient is currently taking. Because the reaction is so severe, the only choice offeredis canceling the order – the user cannot proceed.
Wright and Sittig Page 34
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Figure 6.An alert reminding the clinician that pertussis is a reportable illness in Oregon and providinginstructions on how to report it. This alert was raised because the user added pertussis as aproblem in the background EHR window.
Wright and Sittig Page 35
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
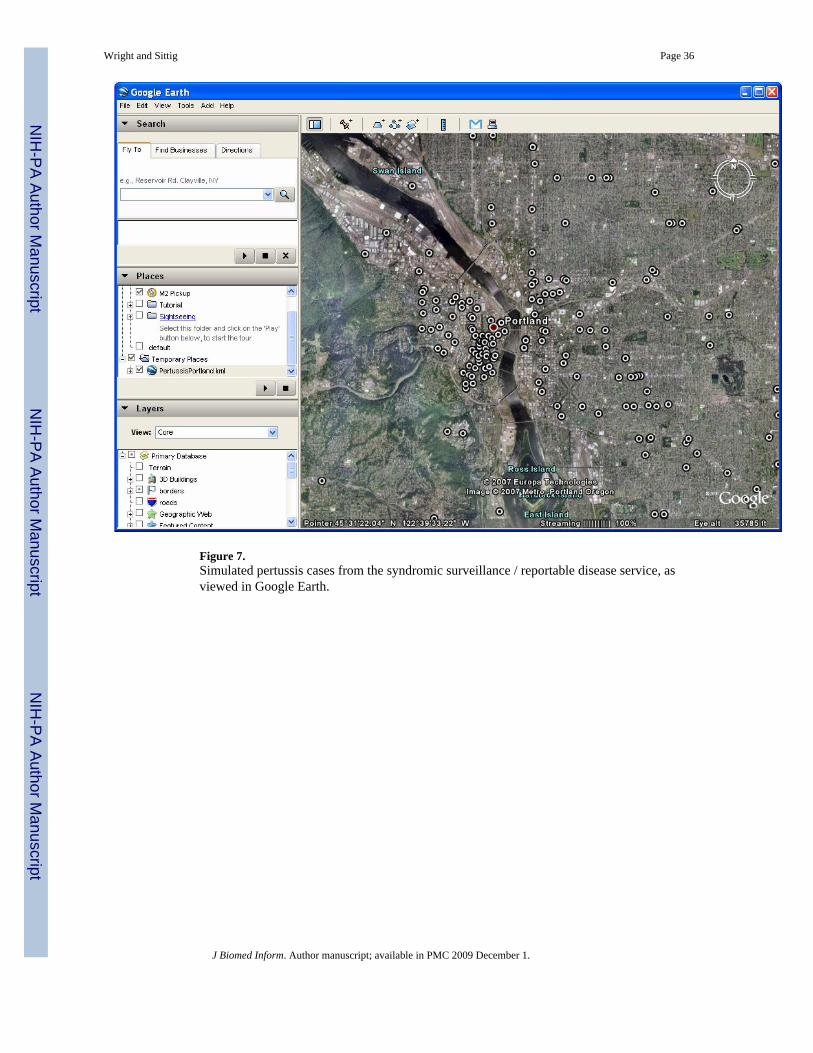
Figure 7.Simulated pertussis cases from the syndromic surveillance / reportable disease service, asviewed in Google Earth.
Wright and Sittig Page 36
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
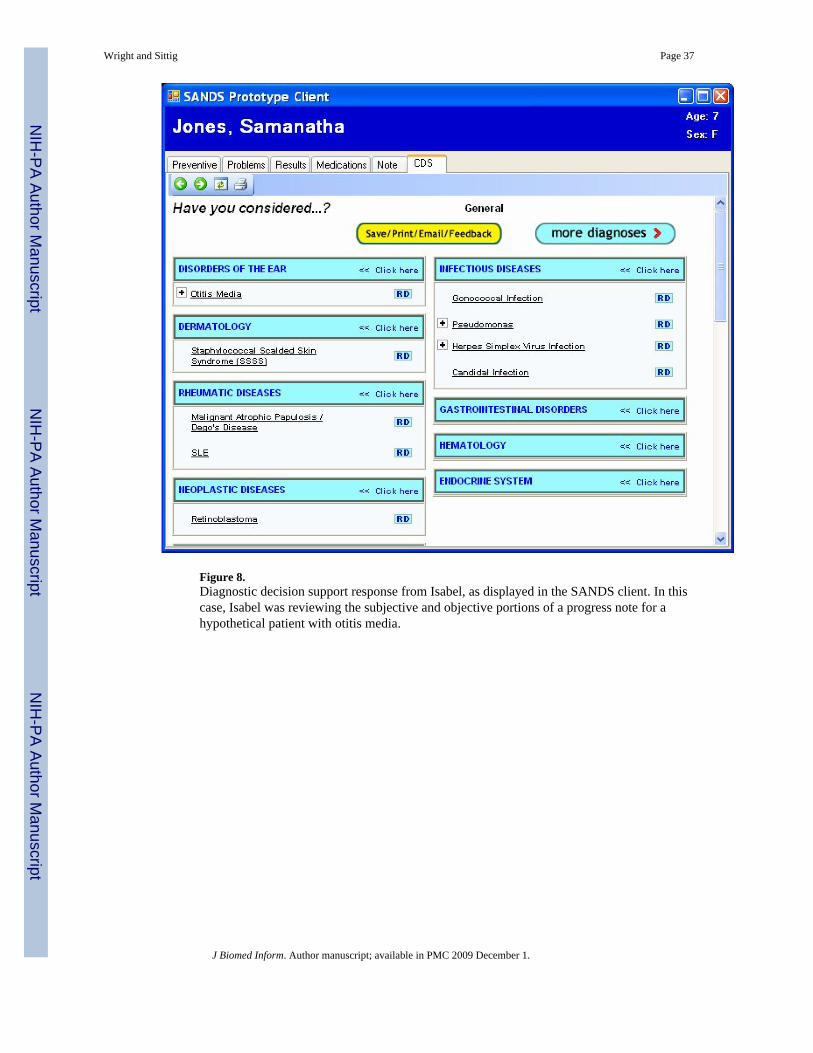
Figure 8.Diagnostic decision support response from Isabel, as displayed in the SANDS client. In thiscase, Isabel was reviewing the subjective and objective portions of a progress note for ahypothetical patient with otitis media.
Wright and Sittig Page 37
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
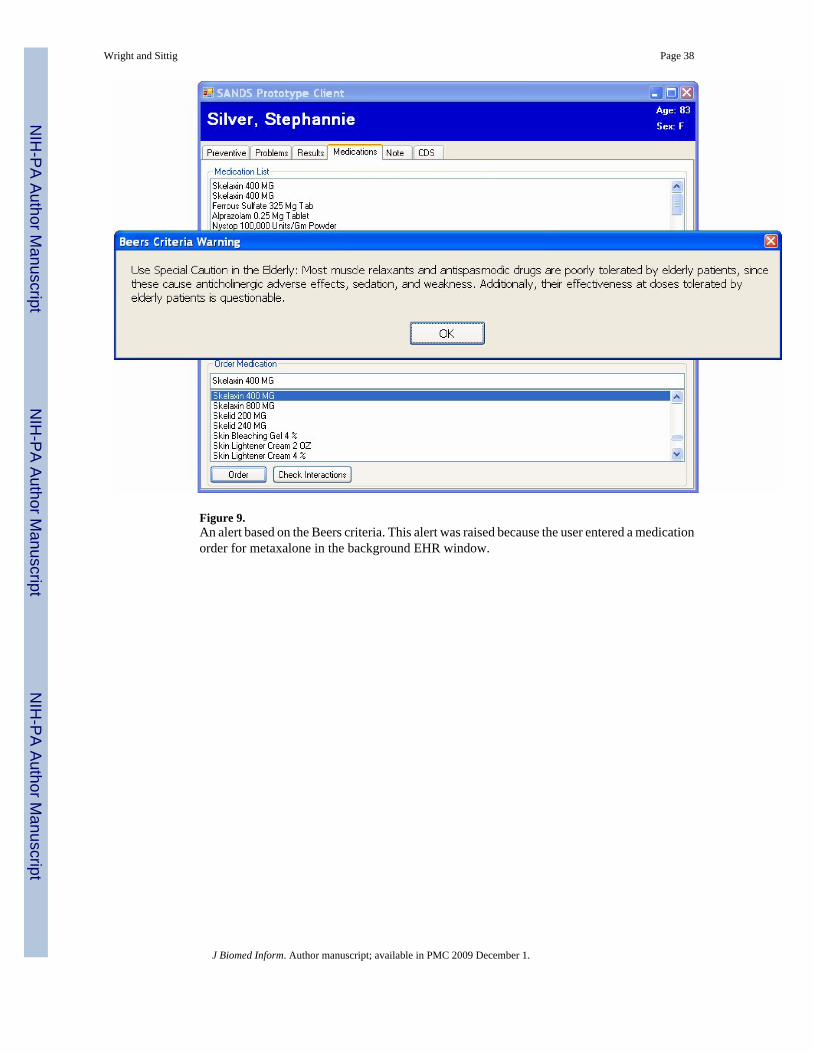
Figure 9.An alert based on the Beers criteria. This alert was raised because the user entered a medicationorder for metaxalone in the background EHR window.
Wright and Sittig Page 38
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

Figure 10.A sample personal health record, showing how SANDS services originally designed for usein an electronic health record can be reused in other systems, such as personal health records.This example shows a patient’s medication list and allows him or her to seek information onthe medications using one of the reference information services.
Wright and Sittig Page 39
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
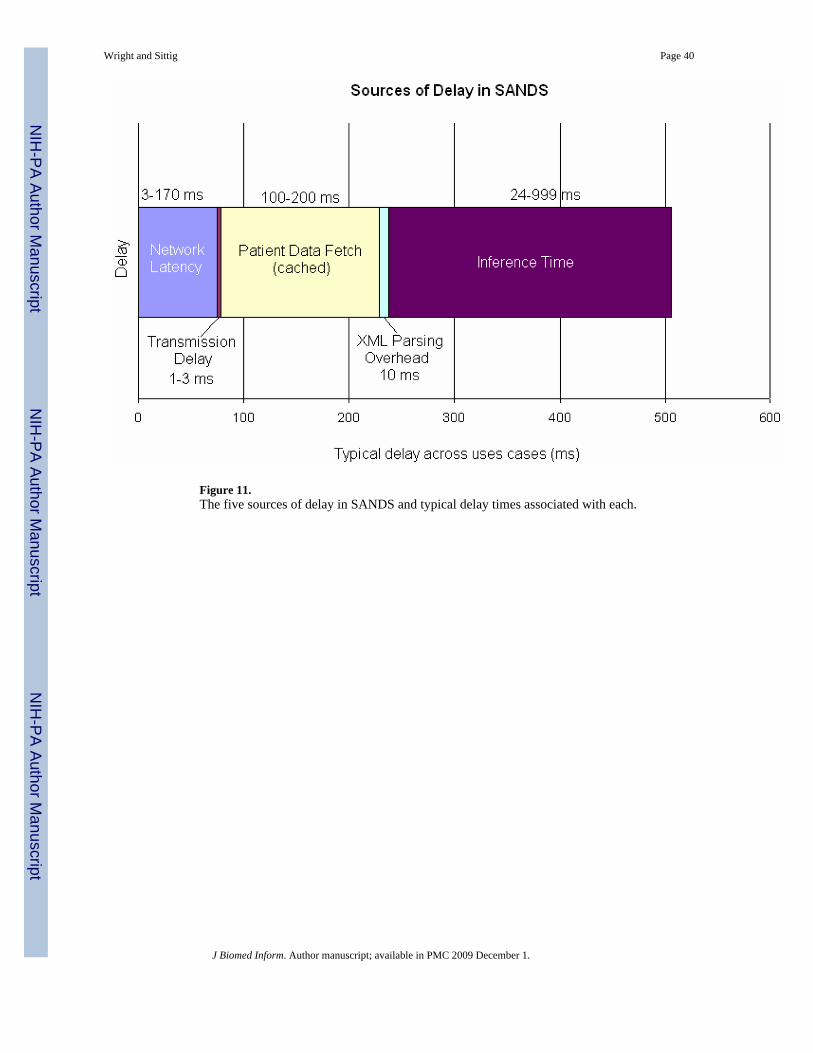
Figure 11.The five sources of delay in SANDS and typical delay times associated with each.
Wright and Sittig Page 40
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript

NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
Wright and Sittig Page 41
Table 1Data elements available through the Patient Data Class Library and the formats in which they are represented.
Data Elements Storage Format
First Name Free-text string
Last name Free-text string
Gender HL7 Gender Vocabulary Domain
Race HL7 Race Vocabulary Domain
Date of birth HL7 formatted date
Weight Numeric value in kilograms
Height Numeric value in centimeters
Care setting Dedicated Clinical Location Role Type
Observations ELINCS with LOINC
Drugs National drug codes.
Problems SNOMED and ICD-9
Family history HL7 Personal Relationship Role Type and SNOMED or ICD-9
Procedure history CPT or SNOMED
Allergies SNOMED
Other orders ELINCS, HL7 version 3 acts and CPT
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.
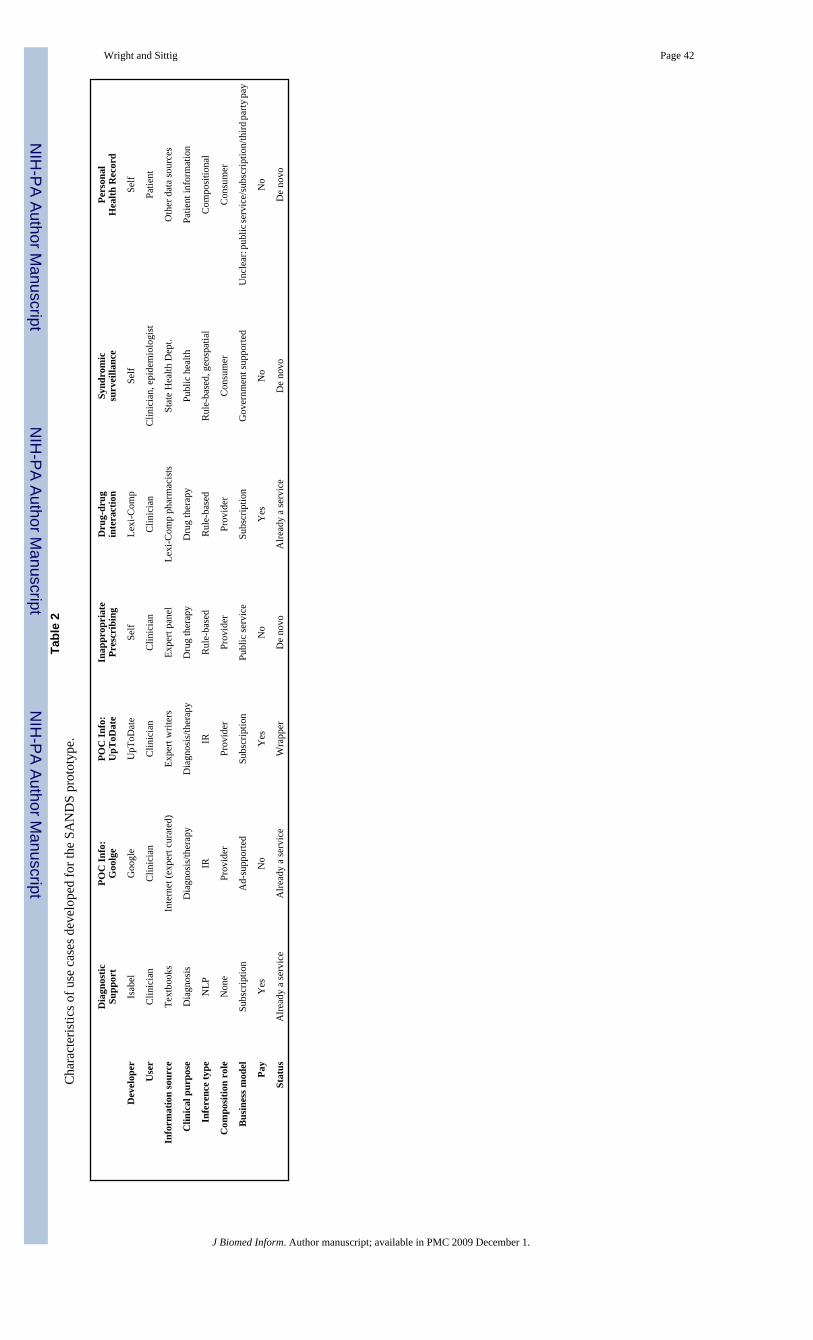
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
NIH
-PA Author Manuscript
Wright and Sittig Page 42Ta
ble
2C
hara
cter
istic
s of u
se c
ases
dev
elop
ed fo
r the
SA
ND
S pr
otot
ype.
Dia
gnos
ticSu
ppor
tPO
C In
fo:
Goo
lge
POC
Info
:U
pToD
ate
Inap
prop
riat
ePr
escr
ibin
gD
rug-
drug
inte
ract
ion
Synd
rom
icsu
rvei
llanc
ePe
rson
alH
ealth
Rec
ord
Dev
elop
erIs
abel
Goo
gle
UpT
oDat
eSe
lfLe
xi-C
omp
Self
Self
Use
rC
linic
ian
Clin
icia
nC
linic
ian
Clin
icia
nC
linic
ian
Clin
icia
n, e
pide
mio
logi
stPa
tient
Info
rmat
ion
sour
ceTe
xtbo
oks
Inte
rnet
(exp
ert c
urat
ed)
Expe
rt w
riter
sEx
pert
pane
lLe
xi-C
omp
phar
mac
ists
Stat
e H
ealth
Dep
t.O
ther
dat
a so
urce
s
Clin
ical
pur
pose
Dia
gnos
isD
iagn
osis
/ther
apy
Dia
gnos
is/th
erap
yD
rug
ther
apy
Dru
g th
erap
yPu
blic
hea
lthPa
tient
info
rmat
ion
Infe
renc
e ty
peN
LPIR
IRR
ule-
base
dR
ule-
base
dR
ule-
base
d, g
eosp
atia
lC
ompo
sitio
nal
Com
posi
tion
role
Non
ePr
ovid
erPr
ovid
erPr
ovid
erPr
ovid
erC
onsu
mer
Con
sum
er
Bus
ines
s mod
elSu
bscr
iptio
nA
d-su
ppor
ted
Subs
crip
tion
Publ
ic se
rvic
eSu
bscr
iptio
nG
over
nmen
t sup
porte
dU
ncle
ar: p
ublic
serv
ice/
subs
crip
tion/
third
party
pay
Pay
Yes
No
Yes
No
Yes
No
No
Stat
usA
lread
y a
serv
ice
Alre
ady
a se
rvic
eW
rapp
erD
e no
voA
lread
y a
serv
ice
De
novo
De
novo
J Biomed Inform. Author manuscript; available in PMC 2009 December 1.