describing generic expertise models as object-oriented analysis patterns: the heuristic...
TRANSCRIPT

ArticleDescribing genericexpertise models as object-oriented analysis patterns:the heuristic multi-attribute decision pattern
Angeles Manjarres1 andSimon Pickin2
(1) Departamento de Inteligencia Artificial,Universidad Nacional de Educacion a Distancia(UNED), Senda del Rey s/n 28040 Madrid, SpainE-mail: amanja�dia.uned.es(2) IRISA/INRIA Rennes, Campus Universitaire deBeaulieu, Avenue de General Leclerc, 35042Rennes Cedex, FranceE-mail: simon.pickin�irisa.fr
Abstract: We report on work concerning the use ofobject-oriented analysis and design (OAD) methods inthe development of artificial intelligence (AI) softwareapplications, in which we compare such techniques tosoftware development methods more commonly used inAI, in particular CommonKADS. As a contribution toclarifying the role of OAD methods in AI, in this paperwe compare the analysis models of the object-orientedmethods and the CommonKADS high-level expertisemodel. In particular, we study the correspondencesbetween generic tasks, methods and ontologies inmethodologies such as CommonKADS and analysispatterns in object-oriented analysis. Our aim in carryingout this study is to explore to what extent, in areas of AIwhere the object-oriented paradigm may be the mostadequate way of conceiving applications, an analysislevel ‘pattern language’ could play the role of thelibraries of generic knowledge models in the morecommonly used AI software development methods. As acase study we use the decision task — its importancearising from its status as the basic task of the intelligentagent — and the associated heuristic multi-attributedecision method, for which we derive a corresponding
142 Expert Systems, July 2002, Vol. 19, No. 3
decision pattern described in the unified modellinglanguage, a de facto standard in OAD.
Keywords: AI development methodologies, expertisemodels, CommonKADS, knowledge model libraries,OO analysis patterns, decision task
1. Introduction
Considerable effort has been invested in the definition ofsoftware development methodologies in the artificial intelli-gence (AI) field. Though the initial emphasis was on thehigh-level analysis, more recently the need to support thewhole development cycle has also been addressed. Theusual requirements capture and modelling phase is inter-preted in AI as the reproduction of the knowledge models,in the sense of Newell (1982), which human experts sup-posedly use to carry out the intelligent tasks that are tobe implemented.
The most common methodological perspective is that ofthe well-known KADS and CommonKADS expertisemodel (Schreiber et al., 1994a), this also being the basisof many other methodologies. This model is based on theseparation of knowledge into three layers:
� the inference layer, containing the functional specifi-cation of the inferences used, their input and outputbeing specified abstractly as domain roles;
� the domain layer, containing the knowledge about theentities that are to play the domain roles;
� the task layer, containing knowledge about the taskitself and about the control flow in which the infer-ences are to be embedded.
The notion of problem-solving method describes how a taskis solved — in the sense of decomposing it into subtasks —a complete solution being obtained by decomposing a taskrecursively until a level of directly implementable primi-tives is obtained. In the CommonKADS expertise model,therefore, the concept of problem-solving method straddlesthe inference and the task layer. In the CommonKADSframework, there are held to be three types of separatelyreusable entities: tasks, methods and domains. Dependencesbetween these entities are treated in the so-calledassumptions (Akkermans et al., 1993; Benjamins & Pierret-Golbreich, 1996; Fensel & Benjamins, 1998); the way inwhich these assumptions are dealt with in order to effectthe reuse of the three different entities has more recentlybeen encapsulated in the notion of adapters (Fensel, 1997).

A good deal of work in this area has therefore con-centrated on looking for recurrent abstractions with whichto construct libraries of generic tasks, problem-solvingmethods, and method and domain ontologies (Breuker &Van de Velde, 1994; Benjamins, 1995), to be used as build-ing blocks in the construction of the knowledge modelsused to solve a wide range of AI problems. Libraries havebeen compiled dealing with different levels of the develop-ment process and using differing degrees of formality.More recently, attention has turned to making theselibraries more manageable and formalizing the process ofreusing these different components (see Benjamins et al.,1998; Fensel et al., 1999; Fensel & Motta, 2001, forexample).
1. 1. A software engineering perspective
From the software engineering perspective, several objec-tions could be made to this approach. First, in spite of thefact that notations have been defined to support the processof defining, refining, verifying and validating models in thecontext of these methodologies (e.g. (ML)2: see vanHarmelen & Balder, 1992), the most widely used are tooinformal (the case of the conceptual modelling language(CML): Schreiber et al., 1994b) and the resulting modelsare consequently rather ambiguous and imprecise, as wasobserved some time ago (Fensel & Harmelen, 1994). Thelack of support for the development process in the initialapproaches to using the expertise model has also been crit-icized by AI researchers. In the last few years work hasbeen done to try to address these issues; several differentformal notations have been introduced (see Landes, 1994;Pierret-Golbreich & Talon, 1996; Brazier et al., 1997) anddevelopment environments incorporating verification andvalidation (Fensel et al., 1999), as well as a more formalapproach to reuse, have been proposed. However, theseefforts have in general led to rather unwieldy and complexmethods and tools and it is not clear how these could beadapted in order to achieve widespread acceptance outsidea research environment.
Second, though these methodologies defend the completeautonomy of analysis with respect to later stages of thedevelopment cycle, claiming total independence of pro-gramming language and other implementation require-ments, the separation of the system functionality from thedomain data characteristic of a functional perspective onmodelling expert knowledge, coupled with the use of a sep-arate control structure, means that this type of approachis, on the whole, oriented towards traditional proceduralprogramming. Finally, in many cases, the expediency of thetask/method/domain trichotomy could be called intoquestion. An approach using different types of autonomoussupposedly separately reusable components, whose interde-pendences then have to be addressed by introducing othercomplex entities (e.g. adapters) into the architecture, and
Expert Systems, July 2002, Vol. 19, No. 3 143
which obliges independent consideration of the func-tionality of a problem-solving method (its so-calledcompetence) and that of the tasks that it solves, could becriticized for being impractical and overly complex.
Object-oriented (OO) analysis and design (OAD) langu-ages are viewed by many as a suitable compromise betweenformality and flexibility, and the OO perspective is normallymore adequate for specifying systems with complexdynamic behaviour, particularly those containing a stronglyinteractive component, as well as reactive systems such asrobots or other event-driven systems. In software engineer-ing in general, OAD is widely recognized to promote abetter understanding of the requirements, clearer and betterstructured designs and more easily maintainable systems,as well as facilitating component reuse. This recognition isbased on experience in developing systems of greatly vary-ing sizes and complexity and has led to the current situationin software engineering where a large and growing part ofsoftware development is undertaken using OAD methods.Reuse considerations form an integral part of the OOapproach, e.g. class libraries have been extensively used forsome time. Concerning modern approaches to reuse, it isworth emphasizing the appearance in the last decade of theconcept of an OO pattern, roughly defined as a recurrentpractical solution to a commonly occurring problem, andthe development of pattern libraries at the design, imple-mentation and even analysis levels.
It is relevant to note at this point that the roots of theOO paradigm are to be found in AI as well as in conven-tional software engineering. Many key OO ideas have longbeen used (albeit informally) in the development of knowl-edge-based systems (KBSs) as stated in Kaindl (1994).Minsky’s idea of ‘frames’ (Minsky, 1975) already includedthe integration of ‘adjoint procedures’ with logic-styledeclarations. Different frame languages for knowledge rep-resentation evolved from this basic idea (see Bobrow &Winograd, 1977; Roberts & Goldstein, 1977; Fikes &Kehler, 1985). We assert that OO methodologies constitutea more appropriate means of analysing and designingcertain types of AI software than the usual AI method-ologies, in which a predominantly functional perspectiveis generally taken. We therefore make the correspondencebetween the expertise model of the usual AI methodologiesand the OO analysis model, whereupon the genericexpertise models (‘task templates’, in CommonKADSterminology) can be viewed as corresponding to OO analy-sis patterns. Our approach, then, is to describe AI genericmodels as analysis patterns in a suitable OO analysis anddesign language, and to accomplish this task we havechosen to use the unified modelling language (UML)(Object Management Group, 2000), a language which hasrapidly acquired the status of a de facto standard in OAD.
As a case study, we use the KADS-style decision expert-ise model presented in Manjarres et al. (1999; 2000). Ourmain reason for choosing this particular model is that it can

be viewed as the basis of the intelligent agent model andis therefore of some importance in modern AI, constitutinga good starting point for an AI analysis pattern library. InPickin and Manjarres (2000) we presented the correspond-ing analysis pattern. In the present paper we compare andcontrast these two models with a view to identifying thecorrespondences between the two approaches.
1. 2. Structure of this paper
In the following section, we discuss the possibility ofanalysing and designing AI problems from a completelyOO perspective. In Section 3, we briefly discuss the basisand the applicability of a decision task. In Section 4, wepresent the basic inference scheme of the correspondingKADS-style expertise model. In Section 5, we describe thecorresponding UML decision pattern. Finally, in Section 6,we draw conclusions about formulating OO analysispatterns in AI, in particular with the UML.
2. An OO perspective on the analysis of AI tasks
We first briefly indicate the reasoning behind the expertisemodel and the task/method/domain trichotomy and putforward a point of view on how a fully OO approach couldconstitute an alternative. Next, we argue for the suitabilityof the OO approach, compared to the functional approach,for knowledge modelling, and we recapitulate the mainrecognized benefits of the OO approach in software engin-eering indicating, where it is of interest, the relevance toknowledge engineering. Finally, we present the concept ofOO analysis pattern and argue for the utility in the AI fieldof a library of analysis patterns.
2. 1. An alternative to the task/method/domain trichotomy
Many definitions of KBSs place emphasis on the fact thatin order to carry out their objectives they need a largeamount of knowledge about their environment. This beingthe case, the implementation of such systems can easilybecome too dependent on the exact specification of theenvironment, with many of the assumptions made aboutthis environment being hidden. It is easy to see that suchsystems will then be difficult to maintain and evolve andthat a simple-minded approach to KBS development is atodds with reuse objectives. These considerations are at theorigin of the development of knowledge models, such asthe KADS expertise model, in which a functional definitionof the task is defined independently of the domain knowl-edge, with a view to reusing it across a wide range ofdomains, and in which the assumptions which the taskmakes about the domain are made explicit.
A common characterization of software development hasit that the analysis/specification phase is primarily con-cerned with what is required of the system under develop-
144 Expert Systems, July 2002, Vol. 19, No. 3
ment, while the design and implementation phases are con-cerned with how the system is to carry out this specifiedfunctionality. It is claimed that the main distinguishingfeature of KBSs is that a large amount of knowledge con-cerning the ‘how’ is essential even in the high-level analy-sis phase in order to meet the requirements. It is this featureof KBSs that leads to the separation of the notions of taskand method, the argument being that the task defined bythe problem specification is often of too high a degree ofcomplexity, or even intractable, so that heuristics (to beobtained from an expert) are needed in order to produce aworkable software system from it. In fact, it is sometimesstated that procedural knowledge of how to perform thetask may be the only form in which knowledge of the func-tionality of the KBS to be developed is available. This pro-cedural knowledge is captured in the problem-solvingmethod, which describes how the domain knowledge canbe used to achieve the goals of the task, and its reuse indifferent tasks thus corresponds to the reuse of problem-solving methods independently of tasks. Broadly speaking,a method solves a given task either by introducing assump-tions about it, in order to reduce its complexity, or byimposing restrictions on the domain knowledge. Thisprocedural knowledge was often not made very explicit inearlier KBSs, being hidden, for example, in the orderingof rules.
Concerning the first characteristic of a KBS, it can beargued that the laudable objective of facilitating reuse doesnot justify the creation of a task/domain dichotomy, withthe consequent danger of losing data encapsulation, and thatthese issues can be addressed, as in other areas of computerscience, simply by method (in the OO sense) and dataabstraction and by specialization. Moreover, it can beargued that, while the introduction of knowledge modelsmay be an important advance in KBS development, a func-tional paradigm is not necessarily the most adequate forknowledge modelling (see Section 2.2).
Concerning the second characteristic of a KBS, it shouldfirst be borne in mind that the rising complexity of softwaresystems has often led to more of the ‘how’ being introducedinto the analysis phase of applications which are not easilyclassified as KBSs. The current emphasis in the analysisphase of business software development, for example, on‘business rules’ and ‘business logic’, describing the keyaspects of the ‘business processes’, reflects this trend.It is therefore of interest to see how these issues have beenaddressed in widely used OO software developmentmethods.
It can also be argued that the attempt to accomplish inde-pendent reuse of tasks, methods and domains is somewhatartificial and that the task/method/domain trichotomy doesnot provide sufficient added value to justify the additionalcomplexity it introduces. A given method is not suitablefor solving any given task in any given domain, only afamily of related tasks in a family of domains, the size of

this family depending on the abstraction level of the methodspecification. Thus, according to this argument, task,method and domain are too interrelated for the objective ofseparate reuse to be realistic. Part of the perceived need formethods as separate entities (specifically the ‘operationalspecification’) simply reflects the need for a dynamic view,which is catered for in OAD methods. It is therefore ofinterest to see if the ideas behind the task, method anddomain concepts can be reflected in the different descrip-tion techniques of widely used OO software developmentmethods — using abstraction levels and specialization —without treating them as separate entities. In particular, thecompetence of a method can simply be viewed as a taskwhich is related to the task to be solved by some type ofconformance relation, and the assumptions of the methodabout the domain can be captured in the structuring of theknowledge and in the pre- and post-conditions1 of themethod application.
In an OO development method treating task, method anddomain in a unified manner, the allowed movementsthrough the three-dimensional space of tasks, methods anddomains of Fensel and Motta (2001) would correspond todifferent possible specializations of a single, very abstractmodel. If such a method can be shown to be adequate tomodel AI software for which the expertise model approachis currently proposed, even if it is only suitable for parti-cular types of such software, the simplicity of reuse in sucha setting is then a powerful argument in its favour. Inaddition, with an OO approach, augmented with recentideas on components and patterns, reuse techniques canbuild on a solid body of existing work.
Current approaches based on the KADS expertise modelare likely to prove too cumbersome and complex to everbe widely used, and a more unified approach based onwell-known methods and tools may have more chance ofsuccess. It is also acknowledged (see Van Eck et al., 2001)that current expertise model approaches are generallyoriented towards centralized, monolithic reasoning so thatit may prove difficult to adapt them to the parallel and dis-tributed context, whereas the OO approach has alreadymade great progress in this direction. However, implicit inthe expertise model approach is the application of high-level reuse. Therefore, for a purely OO approach to be suc-cessful, it must also address the issue of high-level reuse.For this, we turn to the notion of analysis pattern.
In summary, we look for ways of transferring the valu-able work done on defining the KADS expertise model, andthe subsequent work which builds on this model, to a purelyOO setting, with the aim of gaining from the relative sim-plicity and wide acceptance of the latter approach, as wellas the large amount of experience in its use. As part of thiswork, we study whether analysis patterns could provide the
1 Another question is what sort of constraint language would beadequate to express the required constraints.
Expert Systems, July 2002, Vol. 19, No. 3 145
counterpart to generic tasks, methods and ontologies in theOO setting.
2. 2. Suitability of the OO paradigm for modellinggeneric tasks in AI
The proposal to use OAD in the AI field is supported bothby its suitability for knowledge modelling and by its practi-cality from the engineering point of view, as we argue inthe following sections.
The inadequacy of the functional paradigm for much ofthe modelling of expert human knowledge can be arguedon the following principles.
1. It identifies human reasoning with a process of datatransformation and information flow between pro-cesses (functional paradigm: Chandrasekaran, 1987),ignoring well-established models which are closer tothe principles of cerebral dynamics underlying neuralnet approaches. Minsky’s metaphor of the mind as asociety of cooperative agents constitutes the essenceof these models (Minsky, 1986), in which thereasoning emerges from the interaction between com-municating processes/knowledge sources. Many para-digms of recognized interest, such as intelligentagents, blackboard architectures and other distributedAI models, basically share this perspective. The inte-gration, which these models assume, of functionalityand data in autonomous entities fits well with OAD.
2. The functional perspective is inadequate for systemswith complex dynamic behaviour, particularly thosecontaining a strongly interactive component (e.g.decision support systems and intelligent tutoringsystems) and, generally speaking, for strongly reactivesystems (robots or other event-driven systems). Inboth these cases, the dynamic behaviour is theessence of the task to be implemented and must there-fore be treated in the analysis phase. It cannot easilybe decoupled from the expertise model, as is done inapproaches which use complementary models such asthe KADS ‘cooperation model’ (Waern & Gala,1993). The latter model was conceived for specifyingthe functionality of the so-called ‘transfer tasks’which manage the transfer of information between asystem and possible external agents (moreover, thismodel does not seem to have had much success).
3. The OO perspective has provided the backdrop forrecent developments in the areas of reflection andmetaprogramming (see Zimmerman (1996) for asummary, Smith (1982) for seminal work in thisarea), which can in turn provide a basis for the model-ling of learning tasks, the most characteristic of AI.This approach to learning is particularly apt for show-ing its self-organizing and structural character andwas already present to a certain extent in the workon frame languages in the 1970s.

From the software engineering point of view the advantagesof using OO analysis in more detail, these advantages notbeing specific to the development of AI software, can besummarized as follows.
Emphasis on the modelling of the domain independentlyof the implementation details The functional approach toanalysis is geared towards the procedure-oriented program-ming paradigm induced by the predominant von Neumannarchitecture. It is perhaps surprising then that this type ofapproach is adopted in a discipline such as AI, the mainarea for the declarative versus procedural programmingdebate. In defending the importance of problem-solvingmethods, it has been alleged that the objective of declara-tive programming is unobtainable (Studer et al., 1998).While originally KBSs used simple and generic inferencemechanisms (unification, chaining and inheritance) and theencoded knowledge was purely declarative (in terms ofa set of Horn clauses, production rules and frames),knowledge engineers have progressively introduced expertknowledge about the dynamics, implicitly coding a controlknowledge by ordering the production rules and their prem-ises. However, recognizing the importance of specifyingthis procedural knowledge does not necessarily entail shift-ing emphasis from data to procedures, nor giving up theindisputable benefits of data encapsulation. In the firstphases of an OO development, special emphasis is placedon the abstraction of the problem domain. In the process ofrefinement of the analysis model, concrete implementationdetails are progressively added so that the frontier betweenanalysis and design is somewhat diffuse.
Preservation of the conceptual structure from analysis toimplementation As already mentioned, the functionalperspective on analysis is inevitably oriented towards pro-cedural programming. OO analysis, on the other hand, ismore adaptable to distinct implementation paradigms, pro-moting well-structured modular designs (see for exampleBooch (1994) for more details). Of course, it is particularlywell adapted to producing implementations in OO langu-ages, which are of growing popularity. The preservation ofthe conceptual structure of the domain in the application,from analysis to synthesis, without the need for contrivedtransformations between models, is clearly a desirablecharacteristic of any software development methodologyand one which the OO paradigm supports particularly well.Structure preservation has also received a good deal ofattention from AI researchers such as Schreiber et al.(1993) and van Harmelen and Aben (1996) though the finalsteps in which the implementation is derived are gener-ally neglected.
Greater reuse possibilities It has to be recognized that thefunctional perspective is less well adapted to reuse than theOO perspective. KADS/CommonKADS style libraries of
146 Expert Systems, July 2002, Vol. 19, No. 3
components assume the definition of reusable elements atthree separate levels (task, method and domain). Reuse thenimplies a complex process of selection and adaptation ofelements of different libraries whose coupling is subject tostrong restrictions, particularly when the reuse takes placesat the implementation level (see Fensel & Benjamins,1998). More recently the notion of adapters has been pro-posed to formalize the process of selecting and adaptingthe different components, and while this may be a neces-sary step in this context, it does little to reduce the com-plexity of reuse. AI could also benefit from the progressiveintroduction of databases and libraries of classes, compo-nents and patterns (covering reuse at the levels of analysis,design and implementation) which is taking place in the restof the software community, including the adapter pattern ofGamma et al. (1995) which seems to have provided muchof the inspiration for the above-mentioned adapter notion.
Suitable compromise between formality and informalityFormal methods promote the definition of structured con-cise and precise models at different levels of abstractionand the reasoning about these models, and can be usedthroughout the software life-cycle. Many benefits can beobtained from the appropriate use of formal notations(Bowen & Hinchey, 1995), especially when they areaccompanied by an operational semantics and the possi-bility of incremental refinement. They provide the meansto detect ambiguities in the initial requirements, they openup new possibilities for verification and validation through-out the development process, they facilitate maintenanceand product evolution, they enable automatic or semi-automatic generation of parts of the code (even if this codeis not of production quality, this possibility greatly facili-tates rapid prototyping) and they also serve to documentthe final code, among the uses of such documentation beingthat of facilitating reuse of library components. Theincrease in development costs in the earlier developmentphases associated with their use should be offset by adecrease in costs in the later phases of development, parti-cularly the testing, as well as in subsequent maintenanceand evolution. In AI, there has been a certain amount ofactivity in developing formal methods oriented towardsexpert systems for some time (Ginsberg, 1988; Miller,1990; Preece et al., 1992). In recent years, numerous stud-ies have been carried out concerning the introduction offormal methods in AI development methodologies, parti-cular attention being paid to specifying dynamic aspects(Van Eck et al., 2001). These have then been used to driveverification and validation, rapid prototyping, formalizingof the reuse process and even derivation of assumptions by‘inverse verification’ (Angele et al., 1998; Benjaminset al., 1998; Fensel et al., 1999; Fensel & Motta, 2001).However, while recognizing the important contribution thatformal methods can make, it is important to be aware thattheir successful uptake is influenced by many factors.

Experience has shown that introducing formal methods intothe software development process often runs into difficult-ies not concerned with the power of the method: they canbe over-restrictive, obliging over-specification of certainaspects and constricting the development process, and theirintroduction can be problematic from a practical point ofview, due to their real or perceived difficulty. In many cir-cumstances, a compromise between formality and flexi-bility is required. OAD languages are viewed by many as asuitable such compromise, particularly if they include somedeclarative high-level way of specifying operations such asthe object constraint language (OCL) (Warmer & Kleppe,1999).
Rapprochement between different areas of softwareengineering As stated by Booch et al. (1998), themajority of languages, operating systems and software toolsare now OO to a greater or lesser extent, the suitability ofthis approach for the construction of systems of any sizeand complexity in all types of domain having now beenvalidated through significant experience. In recent years,factors such as the rise of the Internet and the rapidlyincreasing range of telecommunications services have ledto the development of complex intelligent systems and dis-tributed multiagent systems in areas not traditionally treatedby AI. This has in turn led to the development of sophisti-cated analysis, design and programming techniques in areasoutside conventional knowledge engineering. Thus, as thefrontiers separating knowledge engineering from the rest ofsoftware engineering become steadily more diffuse, itwould seem to be an appropriate time to seek a rapproche-ment from which both areas could derive significant benefit.Our particular interests lie in investigating how to applydevelopments in the rest of software engineering in AIanalysis. The use of an OO approach to knowledge model-ling has been put forward by some authors and some OOstyle patterns have been defined in AI, e.g. the blackboardarchitecture patterns of Buschman et al. (1996). At theimplementation language level, the OO perspective hasalready seen significant use in AI, in particular as anenhancement to concurrent logic languages (surveyed inDavison, 1992) or to rule-based languages such as Kappa,adding modularity and data encapsulation. The type ofmodularity imposed by a functional decomposition is diffi-cult to translate in a natural way to a program writtenaccording to classic AI paradigms such as logic program-ming or rule-based systems, as noted by Ignizo (1991).
Existence of powerful metaprogramming techniquesFrame-based languages and OO languages have commonroots. The main difference between them is the lack of dis-tinction between classes and instances in frame-based lang-uages, as well as their lack of modularity and data encapsul-ation (Heckerman & Horvitz, 1988). The former feature offrame-based languages provides a great deal of flexibility
Expert Systems, July 2002, Vol. 19, No. 3 147
in that it allows the internal structure of the instances to bemodified, this being of interest from an efficiency point ofview, particularly for the implementation of learning tasks.However, this can also be accomplished in OO languagesby incorporating metaprogramming concepts, for whichreason we propose that the analysis of AI problems froman OO perspective be carried out in the context of reflex-ive theories.
2. 3. Using OO analysis patterns specified in UML formodelling AI tasks
In many areas of computer science concepts resembling thegeneric knowledge models of methodologies such as Com-monKADS arise in the attempt to describe recurrent sol-utions. Among these, in the OAD area we find the notionof ‘software pattern’, generally considered to be one of themain advances in OO design in the 1990s. The extent towhich these ideas derive from those of Alexander concern-ing design in the fields of architecture and urban develop-ment (Alexander et al., 1977) is disputed, though fewwould deny the usefulness of the architecture analogy.Patterns are usually defined as recurrent practical solutionsto common problems, design elements which capturedomain expertise and in so doing provide a form ofreuse — of commonalities of different designs — at thedesign level. It is claimed that making the patterns whichconstitute a system explicit not only can reduce its develop-ment time but also can make it more flexible and easierto maintain.
Alexander’s definition of a pattern is ‘a recurring solutionto a common problem in a given context and system offorces’. Any presentation of such a recurring solution usu-ally includes a description of the problem addressed, theelements of which the solution is composed and therelations between them, the trade-offs made in its defi-nition, the circumstances in which it is applicable and theconstraints on its use. Again following Alexander, a patternlanguage is defined to be a collection of patterns togetherwith a set of rules or guidelines for combining them inorder to solve larger problems.
The analogy with architecture is more natural in thedesign phase of software development, and it is also in thisphase that the identification of recurrent solutions is morereadily accomplished. For these reasons, most of the workon patterns has concentrated to date on design phase pat-terns, the most widely known catalogue of such patternsbeing that of Gamma et al. (1995), who define design pat-terns as ‘descriptions of communicating objects and classesthat are customised to solve a general design problem in aparticular context. A design pattern names, abstracts, andidentifies the key aspects of a common design structure thatmake it useful for creating a reusable object-orienteddesign.’
Some authors such as Buschman et al. (1996) or Booch

et al. (1998) make a classification of different patternsbased on scale, large-scale patterns being referred to as‘architectural patterns’ or ‘frameworks’ (Fayad & Schmidt,1997). However, definitions often do not agree between dif-ferent authors and some even dispute that the latter entitiesshould be called patterns at all. These are concepts whichare difficult to pin down and some of the definitions areinevitably rather nebulous.
On the other hand, the notion of ‘idioms’ or ‘coding/programming patterns’ of, for example, Buschmann et al.(1996) relates more to a classification based on abstractionlevel. Riehle and Zullighoven (1996) extend such a classi-fication, identifying three types of patterns: ‘conceptualpatterns’, ‘design patterns’ and ‘programming patterns’.According to these authors, ‘conceptual patterns’ aredescribed in terms of concepts from an application domain,‘design patterns’ in terms of software design constructs and‘programming patterns’ in terms of programming languageconstructs. These conceptual patterns roughly correspondto the analysis patterns of Fowler (1997), a notable excep-tion to the relative lack of literature on analysis patterns.Our interest is focused on this, less well-accepted type ofpatterns, which we will understand to be high-level abstrac-tions commonly occurring across a large or small range ofdomains. The more well-known design patterns should bediscernable on extension and specialization of analysis pat-terns in the particular application domain.
As stated in Section 1, in this paper we discussemploying the UML to describe analysis patterns for usein the development of applications in the AI domain. TheUML (Booch et al., 1998) is the successor to the OMT(Rumbaugh et al., 1991), Booch (Booch, 1994) andOOSE/Objectory (Jacobson et al., 1992) notations and con-stitutes a de facto standard in the area of OO analysis, aposition which has been consolidated by OMG standardiz-ation. It has a more well-defined semantics than its prede-cessors, opening up the possibility of using automated orsemi-automated verification and validation technology: thecompleteness and semantic coherence of models written inUML can be partially checked with the help of softwaretools designed for this purpose. Significant development isexpected in the coming years both in the area of automaticvalidation and simulation of UML models (see for exampleJeron et al., 1998), and in the area of automatic code-gener-ation from UML models (not just from the class structure).On a more pragmatic note, reverse engineering possibilitiesare already offered by the more widely known toolsets. TheUML promotes iterative analysis processes at differentlevels of abstraction, making it particularly useful fordefining generic models which are to be specialized in dif-ferent concrete domains.
Thus, though the semantics of UML are not completelyformal, its syntax is based on a relatively formally definedmetamodel and the precision of the descriptions can beincreased by using it jointly with its associated OCL, a
148 Expert Systems, July 2002, Vol. 19, No. 3
logic-based language for specifying class invariants andpre- and post-conditions of operations. It is thus a semi-formal language which, at the same time as permitting acertain amount of rigour, is relatively flexible and easy tounderstand and manipulate, in contrast to most strictlyformal methods. As well as being relatively intuitive, itsgraphical notations are also similar to other well-known andwell-used notations facilitating its uptake by developers. Itsrole as documentation for the final code is enhanced by itsexpressiveness, since it permits the specification of aspectswhich will not be translated to code but which are of valuefor interpreting that code in its context.
3. The decision task
In this section, we briefly describe the generic decision taskand its solution in accordance with the classical heuristicmulti-attribute problem-solving method presented in Keeneyand Raiffa (1976). This task is not found in the usual KADSlibraries of analysis, modification and synthesis tasks com-piled for example in Breuker and Van de Velde (1994), noris the heuristic multi-attribute method found in the librariesof problem-solving methods compiled in Breuker and Vande Velde (1994) and Benjamins (1995), although both havebeen treated in the literature (Fox & Ochoa, 1997;Manjarres et al., 1999; 2000). Basically, the resolution ofa decision task in accordance with the heuristic multi-attribute method consists of the assessment of a set of alter-natives in terms of the degree of satisfaction of a set ofobjectives.
The decision task is of well-known applicability in fieldssuch as economics or medicine. However, our main interestin defining a decision pattern arises from the fact that itconstitutes the basic task of an ‘intelligent agent’, the refer-ence for many computational paradigms and currently thefocus of much attention in AI research (Stuart & Norvig,1995).
Agent theories were inspired by Newell’s study of the‘interaction of intentional agents on the knowledge level’,in which the concept of ‘intelligent agent’ is identified withthe description of intelligent behaviour linked to the prin-ciple of rationality (Newell, 1982). This concept arises fromthe synthesis of diverse theories of intelligent behaviour,basically utilitarianism, behaviouralism and cognitive psy-chology. The objective of defining an associated compu-tational model lies at the origins of computer science and ofAI (see Putnam, 1960; Dennett, 1969; McCarthy & Hayes,1969). The main mathematical background for the theoryof intelligent agents is to be found in decision theory. Thistheory — combining probability and utility theories —establishes the connection between the probabilistic reason-ing and the action taken, providing the theoretical basis forthe design of rational agents operating in uncertain worlds.The existence of this well-defined basis constitutes another

reason for choosing this particular task as the one for whichwe define the corresponding OO pattern using the UML.
In the model described here, the agent’s knowledge of itsenvironment translates into knowledge about the availableresources (and restrictions on their use) and a decisionmodel. The available resources determine the decisionalternatives (the courses of action which can be chosen)and the decision model enables the consequences associatedwith these alternatives to be predicted. In the heuristicmulti-attribute decision method, the decision model refersto a set of objectives and makes it possible to predict theirdegree of satisfaction on choosing any of the alternativesas the decision. A rational decision depends on both therelative importance of the different objectives and theprobability or the degree to which they can be achievedthrough the available alternative actions. The performancemeasure of an agent is an assessment carried out on thebasis of the value of its state variables (an agent which hasacted effectively will be in an acceptable state, while anagent which has acted deficiently will be in a problemstate). A rational agent will choose an alternative which, inprinciple, leads it to an acceptable state. The performancestandard of the agent is identified with the expected degreeof satisfaction of an ultimate objective (goal), whichencompasses the entire set of objectives of the agent.Finally, the agent can receive feedback from its environ-ment enabling it to assess its performance and, through itsreflective capabilities, modify its own decision model(learn).
In a multiagent system, the agents also reason about theobjectives of other agents and communicate with each otherin order to coordinate their actions in the pursuit of com-mon objectives. A sophisticated local control integrates thereasoning about other agents with the local reasoning aboutthe problem resolution, so that the coordination decisionsare part of the local decisions. There has been a recentupsurge of interest in multiagent systems with the advent ofmore advanced Internet and telecom services, due to theirpossible uses in large-scale distributed systems. This pro-vides additional motivation for the development of thedecision pattern, which could constitute an essential part ofa multiagent system pattern.
4. KADS-style expertise model of the decision task
The description of the decision expertise model given hereis a summary of that given in Manjarres et al. (1999). Thepurpose of a decision task is to select a means of reachinga target state from a problem state. The selection is madefrom a set of alternatives which either are already availableor are to be identified as viable, as a function of some avail-able resources, subject to certain usage restrictions, in apossibly non-deterministic environment. The concept ofviable alternative can be instantiated as a course of action,a physical object, a message, a property etc. The case where
Expert Systems, July 2002, Vol. 19, No. 3 149
the set of alternatives is known beforehand can be viewedas a specific case of the CommonKADS ‘select’ inference.Similarly, the sequencing of a set of decision tasks consti-tutes a planning task.
Given a problem identified as a decision task, the heuris-tic decision method comprises the design and subsequentsystematic assessment of a set of alternatives, in a possiblynon-deterministic environment. This assessment is carriedout by weighing up any preferences among the possibleconsequences of the choice of alternatives against judge-ments about the uncertainty of these consequences, with theaim of selecting an ideal alternative (decision result). Aconsequence is defined as a prediction about the set ofimplications of adopting a certain decision and is quantifiedthough the value of a set of ‘attributes’ chosen to assess(or predict) the degree of satisfaction of a set of previouslyprioritized objectives. The assessment of the decisionsadopted (or simulated) enables the continual revision of thedecision model used.
A consequence is ‘certain’ when its connection to analternative is deterministic and is ‘uncertain’ when it is partof a set of consequences, each with a certain occurrenceprobability, associated with a particular alternative. Aconsequence is unidimensional or multidimensional (multi-attribute) according to whether the decision is a functionof a unique objective or multiple objectives, whosesatisfaction measure, or measures, then characterize thisconsequence.
In spite of the fact that we are ignoring the analysis ofuncertainty (determinism) the multi-attribute case reportedon in the work presented here is still complex. It proceedsby establishing an order in the set of consequences.
The solution method we describe is adapted to thosedecision problems where the decision is made by a singleindividual and where the consequences of an action can bedescribed in terms of cost and benefit measures, such asdecisions involving analysis of cost–benefit for the individ-ual in question (in the choice of a job, a house, a car, amedical treatment etc.), decisions which affect the costs andbenefits of other individuals or of organizations (publichealth, urban planning etc.), and decisions involvingeconomic or market analyses of the cost-effectiveness andcost–benefit etc.
As an aid to understanding the above description of thedecision task, we very briefly summarize the goal of atherapy decision task (presented in Manjarres et al., 2000),viewed as a specialization of the generic decision task: toidentify the ideal therapy, from among a set of applicabletherapies, which enables the evolution from a pathologicalstate towards a healthy state. The therapy decision heuristicmulti-attribute method is then defined as the design andsubsequent assessment of a set of therapies, weighing upthe preferences for the health and quality-of-life prospects,and health system resource costs involved, with the aim of
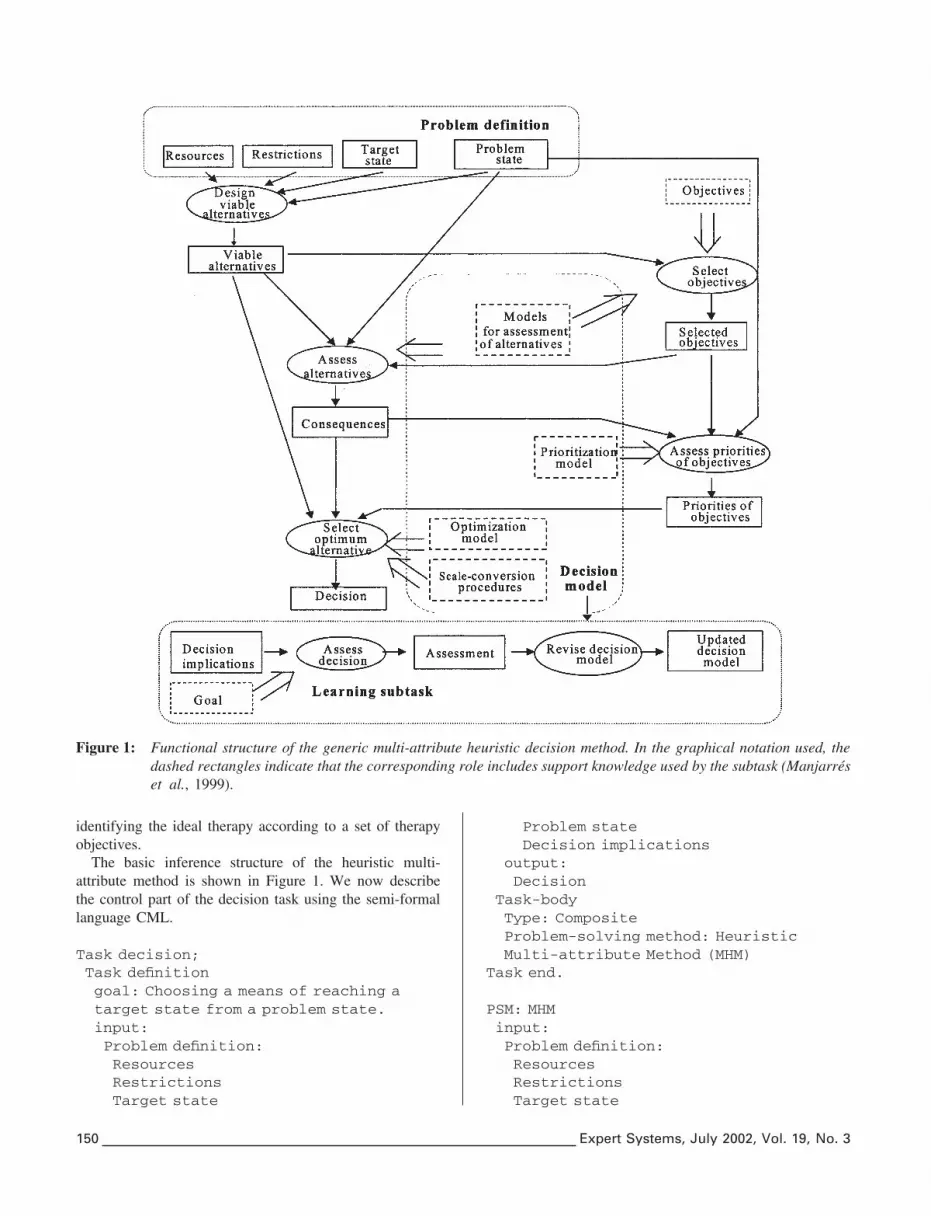
Figure 1: Functional structure of the generic multi-attribute heuristic decision method. In the graphical notation used, thedashed rectangles indicate that the corresponding role includes support knowledge used by the subtask (Manjarreset al., 1999).
identifying the ideal therapy according to a set of therapyobjectives.
The basic inference structure of the heuristic multi-attribute method is shown in Figure 1. We now describethe control part of the decision task using the semi-formallanguage CML.
Task decision;Task definitiongoal: Choosing a means of reaching atarget state from a problem state.input:Problem definition:ResourcesRestrictionsTarget state
150 Expert Systems, July 2002, Vol. 19, No. 3
Problem stateDecision implications
output:Decision
Task-bodyType: CompositeProblem-solving method: HeuristicMulti-attribute Method (MHM)
Task end.
PSM: MHMinput:Problem definition:ResourcesRestrictionsTarget state

Problem stateDecision implications
output:Decision
support-roles:GoalObjectivesDecision model:Models for assessment of alternativesScale-conversion proceduresOptimization modelPrioritization model
sub-tasks:Design viable alternativesSelect objectivesAssess priorities of objectivesAssess alternativesSelect optimum alternativeAssess decisionRevise decision model
additional-roles:Viable alternativesSelected objectivesPriorities of objectivesAssessmentConsequencesAssessmentUpdated decision model
control-structure-template:REPEATDesign viable alternatives (Problemdefinition → Viable alternatives)Select objectives (Objectives, Viablealternatives, Models for assessment ofalternatives → Selected objectives)Assess alternatives (Selectedobjectives, Viable alternatives, Modelsfor assessment of alternatives →Consequences)Assess priorities of objectives (Problemstate, Selected objectives,Consequences, Priorization model →Priorities of objectives)Select optimum alternative(Consequences, Viable alternatives,Priorities of objectives, Scale-conversion procedures, Optimizationmodel → Decision)
UNTIL Decision is madeAssess decision (Decision implications,Goal → Assesssment)IF Assessment is negativeRevise decision model (Assessment,Decision model → Updated decision model)
Expert Systems, July 2002, Vol. 19, No. 3 151
Decision model := Updated decision model
It should be pointed out that the CML has been slightlymodified to include a type of domain role which we call asupport-role (dashed rectangles in Figure 1). The knowl-edge which plays such a role parameterizes the decisiontask and is identified with what is usually denoted supportknowledge in KADS terminology (normally describedusing the CML clause static-roles), with the difference thatwe consider it to be modifiable, rather than absolutely staticas in KADS. The decision to make the support knowledgeexplicit is imposed by our view of the tasks which incorpor-ate learning as reflective tasks whose inferences inspect andmodify models of themselves, a perspective which is sharedby other researchers in the context of the analysis of AIknowledge models (Ram et al., 1992; Plaza & Arcos, 1993;Christodoulou & Keravnou, 1998). In the decision task, asubset of the support roles is modified by the subtask Revisedecision model, which we describe as being a learning task.This subset is encompassed by a single role, denotedDecision model, containing the description of the structureddata used by the set of procedures which make the decisionprocess operational.
Next, we briefly describe the subtasks identified and wesuggest some solution methods from those identified in theclassical CommonKADS libraries. The descriptions areinevitably highly generic, given the wide applicability ofthe proposed method.
Design viable alternatives In this subtask the viablealternatives are specified, in terms of their compo-nents and their structure (temporal, spatial or functional).The viable alternatives constitute a means ofgoing from a problem state to a target state,taking into account the available resources and therestrictions on their use. The task is carried out inthe most general case using a design method as given inBernaras and Van de Velde (1994) and Motta (1998) (sincethere is no existing set of alternatives, their design in termsof components has to be provided), and in the simple caseusing a select under criteria (Breuker et al., 1987)from a pre-specified set, where the criteria evaluate thefeasibility and expediency of adopting a given option.Another applicable method is the identification of alterna-tives by case-based reasoning: the options chosenare those which from past experience, stored in a case data-base, have provided satisfactory solutions to equivalentproblems. In this case, the subtask can in turn be decom-posed into a classification task (Clancey, 1985) —abstracting from the presentation of the problem and equat-ing with a case category — followed by a select of thedecisions adopted in those cases of the database whichbelong to the identified class.
As a generic design task, this inference should referto two input roles: design specification and

available resources. Since we are analysing adecision task, we separate each of these into two: thespecifications into that of the problem state and thatof the target state (initial and final state in a means–ends analysis) and the resources into the resourcesthemselves and the restrictions on their use.
Select objectives This is a select inference for whichthe criteria are the measurability of the satisfaction of theobjectives for each of the viable alternatives,this measurability being dependent on the availability ofthe knowledge required by the assessment models andthe level of decomposition considered in the aggregationstructure of the objectives (i.e. the accuracy in theassessment of the decision alternatives, thisaccuracy usually being incremented in the successive iter-ations of the control structure loop; see the CML descrip-tion above).
Assess alternatives Using the specification of theproblem state, this subtask associates a set of utilityvalues (attributes) to each viable alternative,denominated the consequence of that alternative. Eachattribute is a measure of the degree to which acriterion (specified by an objective) is fulfilled. Thissubtask is thus a CommonKADS assessment task(Valente & Lockenhoff, 1993), which in some casesinvolves a prediction subtask (Bredeweg, 1994).
Assess priorities of objectives This subtask associates, toeach of the selected objectives, values whichreflect the relative preference (priority) betweenthem. We are in fact dealing with a ‘comparativeassessment’ task, not described in the literature, inwhich the assessment of an objective is conditionedby the characteristics of the overall set of objectives. Thecriteria used for the assignment of priorities may bethe relevance of the objectives, the reliability of themeasurement of their satisfaction, or more complex criteriawhich are functions of the concrete values of the attri-butes defining the consequences of the alterna-tives.
Assess decision This is again an assessment task,in which an in-depth estimate of the implications ofthe decision adopted is made — either afterexperiencing them or by using a predictive model which ismore exhaustive and exact than the one incorporated intothe decision model (the executor of this task couldtherefore be external system software or a humanoperator) — and then compared to the goal: the expecteddegree of satisfaction in the target state of theultimate objective of the hierarchy of objectives. Theresult of this assessment indicates whether or not thedecision fulfils expectations. If the assessment is
152 Expert Systems, July 2002, Vol. 19, No. 3
negative, it is refined, whereupon the deficiencies in theresult and the possible associated causes of thesedeficiencies (faults in the decision model, in-completeness in the set of objectives considered orinadequate weighting of these objectives) are indicated.
Revise decision model The objective of this task is toredefine the decision model, as a function of the con-clusions obtained in its assessment, when thedecision adopted does not fulfil expectations. Once thedecision task has been implemented, the executor of thissubtask could again be either the user or maintainer of theproduct, or external system software. In the latter case, thissubtask would be a modification task and together withthe assess decision task would constitute alearning subtask, in which the implications ofthe decision perform the feedback function.
In order to be complete, the specification of the decisionexpertise model should include the domain model and theassumptions. We will not treat these aspects here, sinceour intention is only to present a brief summary of the taskwhich will enable us to confront the two different analysisperspectives: the functional perspective of KADS/CommonKADS and the OO perspective. Different types ofassumptions and a model of a generic decision domain havebeen extensively described in Manjarres et al. (1999) andtheir specialization in the therapy decision domain is givenin Manjarres et al. (2000).
5. The heuristic multi-attribute decision pattern
The UML metamodel comprises elements which describestructural and static aspects (the conceptual or logical ones,i.e. classes, collaborations, use cases and active classes, beingof interest mostly for analysis purposes), elements whichdescribe behavioural or dynamic aspects (interactions, activitydiagrams and state machines) and relations and connectionsbetween these different elements (dependence, association,generalization and realization). Different sets of elementscan be represented in structural diagrams (class and objectdiagrams) and behavioural diagrams (use case, interaction,state and activity diagrams). Figure 2 shows the part playedby the different entities used in KADS/CommonKADSexpertise models (upper part) and their equivalents in UMLmodels (lower part).
In this section we present the OO analysis pattern corre-sponding to the KADS-style decision expertise modelpresented in the previous section, showing at the same timesome general correspondence rules between elements of therespective metamodels KADS/CommonKADS and UML.This correspondence can be seen to be non-trivial in somecases due to the fact that these metamodels characterizeessentially different approaches to analysis, thus alsodemonstrating the inherent cost involved in translating a
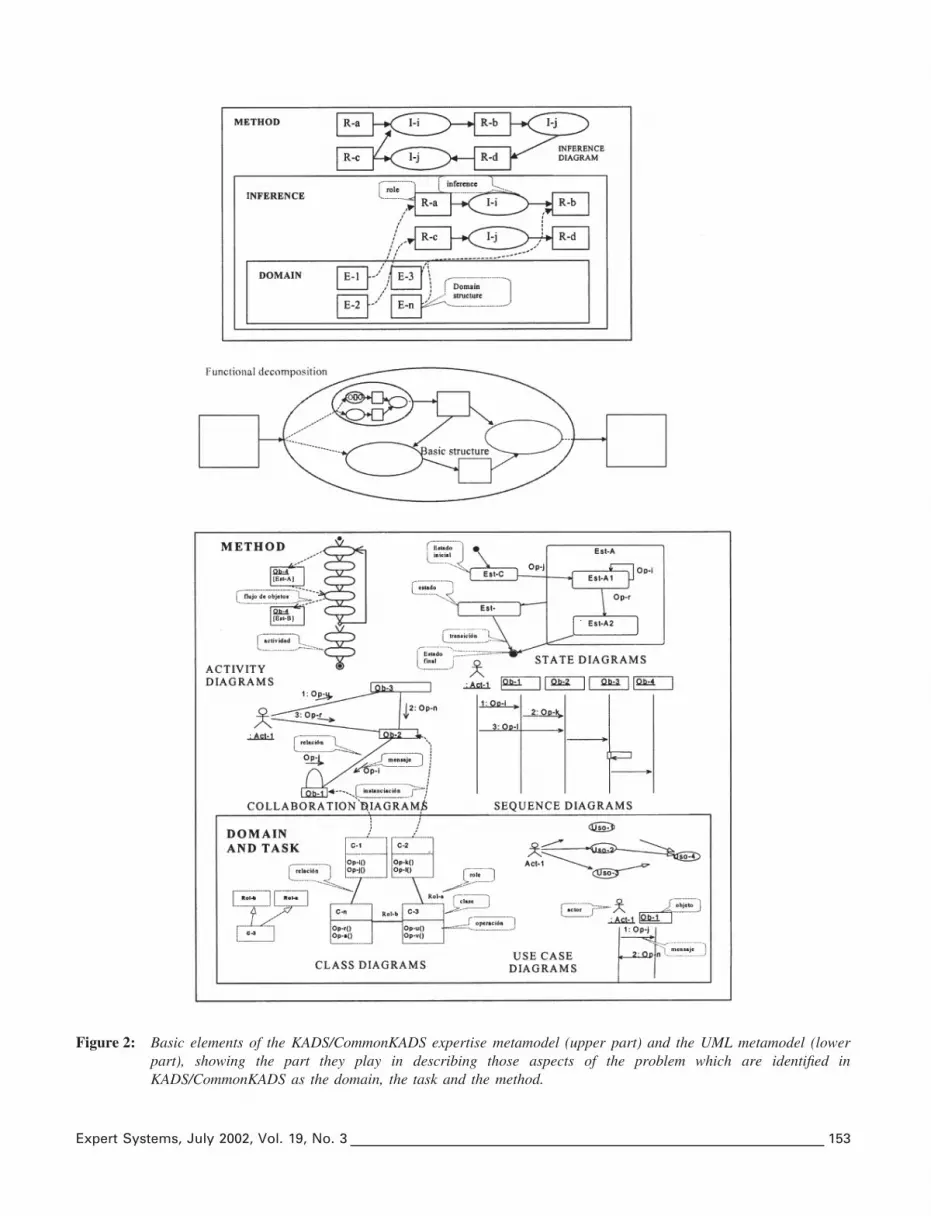
Figure 2: Basic elements of the KADS/CommonKADS expertise metamodel (upper part) and the UML metamodel (lowerpart), showing the part they play in describing those aspects of the problem which are identified inKADS/CommonKADS as the domain, the task and the method.
Expert Systems, July 2002, Vol. 19, No. 3 153

functional-perspective analysis model to a non-functional-perspective design model. Note that the expressive powerof the UML means that it can also partially cover the func-tional modelling perspective.
Comparing the decision expertise model and the corre-sponding UML decision pattern it can be observed thatseveral different perspectives on a system are integrated ina UML model whereas KADS/CommonKADS only treatsthe functional perspective and the three parts of this vision(task, method and domain) are only weakly linked. Notealso that the modelling unit of a UML model, the object,breaks the task/method/domain trichotomy of a KADS/CommonKADS model.
Just as the KADS/CommonKADS analysis given in theprevious section provides a functional vision of the reason-ing processes involved in a decision task, so the OO analy-sis given below corresponds to an interpretation of thedecision as being the result of interaction between differentagents, in accordance with Minsky’s metaphor.
The presentation of the pattern of this paper does notconform to any of the commonly used pattern forms.According to Riehle and Zullighoven (1996), the best wayto describe a pattern depends on the intended usage, and inthis respect analysis patterns and design patterns are quitedistinct; it is not clear which, if any, of the more well-known forms is the most suitable in the analysis patterncase. Nevertheless, the introduction of the decisionexpertise model of the previous section can be viewed asthe presentation of the ‘context’ and the ‘problem’ and thedescription given in the following sections as that of the‘solution’. As regards the trade-offs in its definition con-cerning, for example, the restriction to determinism or theKADS-style assumptions, these are treated in both this andthe previous section.
The analysis pattern presented describes a structure ofclasses and abstract parameterizable and extendiblecollaborations for the modelling of decision problems indiverse domains. The classes of the pattern being abstract,none of them can have real instances, and in any applicationdomain concrete subclasses must be defined. The instanceswhich figure in the interaction diagrams show the corre-sponding roles played by these classes, thus representingprototypical instances. Neither has any implementationmethod been indicated for the operations, as these are con-sidered to be specific to the different decision domains;child classes are needed to provide implementations. Inparticular, once the decision pattern has been instantiatedin a specific domain, distinct child classes of a particularclass, with different solution methods defined for their oper-ations, can coexist (polymorphism).
The operations of the classes DesignModel andDecisionModel (classes which represent the principalcollaborations intervening in solving the decision task —see Figures 3 and 4) coincide with the upper level of thebasic inference diagram of the decision task described in
154 Expert Systems, July 2002, Vol. 19, No. 3
the previous section (and presented in more detail in Man-jarres et al., 1999). The operations of the rest of the classes(subcontracted by the DesignModel and DecisionModeloperations) can be identified with subtasks resulting fromadditional decompositions of these tasks. A progressiverefinement of these classes in the context of a concretedecision problem concludes with the appearance of im-plementation classes, which in some cases will be generic(defined in the usual class libraries) and in other cases veryspecific to the domain considered. The operations of theseclasses will in both cases be identified with primitive infer-ences of the expert models in methodologies such asKADS/CommonKADS.
Among the notations offered by the UML we considerthe class, activity and interaction diagrams to be the mostuseful for describing the decision pattern. We have notincluded any state diagrams in the pattern since the detailsof the dynamic behaviour of the objects specified is notsignificant at this abstraction level (note that the dynamiccreation of associations has been specified by OCLconstraints). With respect to the data types, note that wehave assumed the existence of the primitive types of OCL,including the collection types, as types in the UMLdiagrams.
We have found the need to establish guidelines concern-ing certain subtle modelling points due to the relativenovelty of the UML and the corresponding lack of a largebank of accumulated experience in its use as well as theambiguities in some of the concrete syntax definitions. Inaddition, the notation is overloaded in certain cases so thatthere exist alternative forms of representing certain aspectsof the models. For this reason, below we briefly commenton some of the modelling decisions adopted. At the sametime we comment on the main differences between theKADS/CommonKADS analysis presented previously andthe analysis presented here. We illustrate the argumentswith fragments of our proposed decision pattern.
5. 1. Integration of the domain and task/method parts ofthe functional description in class diagrams
In OO approaches to analysis, the domain entities are notunconnected to the operations in which they are involved.This type of analysis starts by structuring the domain andidentifying classes of objects and relations between them,before adding attributes and distributing responsibilities(operations) between the classes identified, thus definingtheir interfaces. Figures 3–6 show the principal class dia-grams of the heuristic multi-attribute decision pattern.
The class and object model precedes the other modelssince the static structures are usually more clearly defined,being less dependent on the application details and morestable as the development progresses. It reflects the expert’sknowledge of the application domain and the generalknowledge about the real world, independently of the use

Figure 3: Class diagram representing the relations of the Design Model class.
made of this knowledge in any given functionality. Thedevelopment process usually continues with the design ofthe use cases and activity diagrams followed by theassociated interaction diagrams and, for complex classes,state diagrams. However, it should not be forgotten that theanalysis process is iterative in nature so that, after havinganalysed the dynamic aspects, the model may be restruc-tured and new operations and classes identified. Given that
Expert Systems, July 2002, Vol. 19, No. 3 155
operations modify objects, evidently they cannot be com-pletely specified, particularly the more complex ones, untilthe dynamic and functional aspects have been defined.
OO analysis adds a semantic nuance to the concept ofrelation, associating it to the problem of distributingresponsibilities. A responsibility is a contract or obligationon a class, and defining a well-balanced structure ofrelations is equivalent to defining a balanced distribution

Figure 4: Class diagram representing the relations of the Decision Model class.
of responsibilities. Playing a role in a relation implies carry-ing out certain functions, so that the roles that an objectplays are related to the semantics of the interfaces that itoffers. In showing the different types of relations, the classdiagrams describe the potential collaborations betweenobjects. Thus, the domain ontologies modelled via classstructures acquire behavioural and functional dimensions,such modelling clearly breaking the task/method/domaintrichotomy of the functional perspective.
This type of analysis of the static knowledge of aproblem unifies the concepts of ontology, method and taskreuse. The most generic and abstract classes describe con-cepts and operations common to families of problems,while the most specific classes will be exclusive to parti-cular application domains. The classes identified includeoperations which correspond to subtasks (inferences, in thecase of the simplest classes; higher-level tasks, in the caseof the more complex classes) in the KADS/CommonKADSexpertise model, whose concrete decomposition methodsare not specified in the abstract definition of the classes.Thus, the structuring of knowledge into classes is inevitablyassociated with a concrete decomposition of the tasks. Theclose connection between the task resolution methods andthe structuring of the domain is also recognized in theKADS/CommonKADS methodology, it being admitted thatthe application of a particular method imposes strongassumptions on the domain model.
While the KADS/CommonKADS description of the
156 Expert Systems, July 2002, Vol. 19, No. 3
heuristic multi-attribute method referred to in Manjarreset al. (1999) emphasizes the distinction between the task,method and domain parts, in the UML model presentedin this paper emphasis is placed on the ontologies of adecision domain and on their structural relations, fromwhere the distribution of responsibilities (attributes andoperations), and the potential collaborations which implementthe functionality, derive. The subtasks and inferences ident-ified (designViableAlternatives, assessmentProcedure, %) are distributed among the abstract enti-ties of a decision domain (DesignModel, Attribute,%) according to ‘responsibility distribution’ criteria. Therelations between objects determine contracts or obligationscontracted and, in general, can be viewed as representingconnections through which service requests are transmitted(thus the create signal, respectively optimize message, issent through the Instantiate, respectively Compo-sition, relation). The domain roles of the KADSexpertise model (see Figure 1) can correspond to differentelements of the decision pattern. They can appear asclass definitions (e.g. the classes Alternative andObjective correspond to the roles of the same name),class attributes (e.g. the attribute priority — of theclass Relevance — corresponds to the role of the samename) or relations between classes (e.g. the relationsIsCompatibleWith and CanBeCombinedWithcorrespond to the role Restrictions).
Usually, one of the fundamental criteria for the assign-
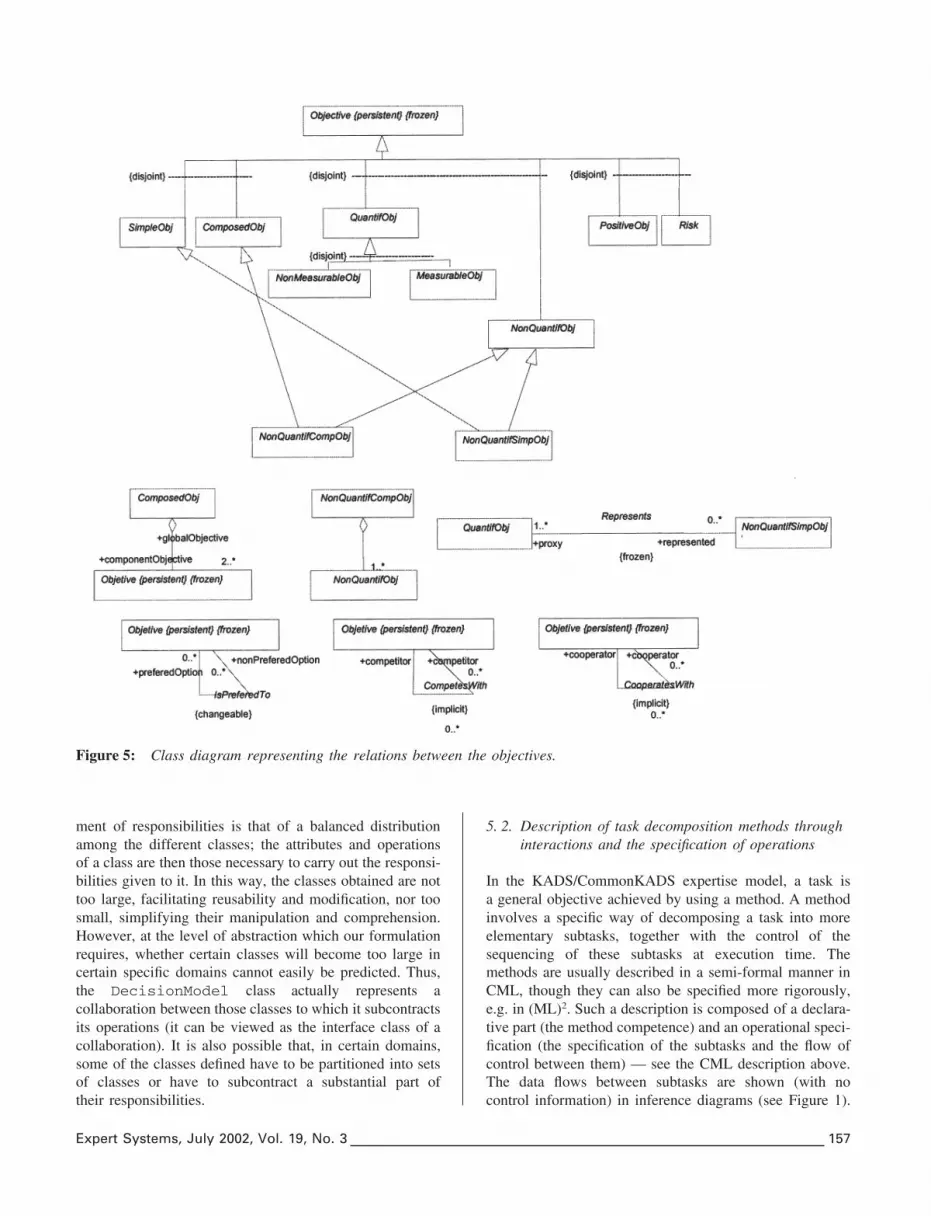
Figure 5: Class diagram representing the relations between the objectives.
ment of responsibilities is that of a balanced distributionamong the different classes; the attributes and operationsof a class are then those necessary to carry out the responsi-bilities given to it. In this way, the classes obtained are nottoo large, facilitating reusability and modification, nor toosmall, simplifying their manipulation and comprehension.However, at the level of abstraction which our formulationrequires, whether certain classes will become too large incertain specific domains cannot easily be predicted. Thus,the DecisionModel class actually represents acollaboration between those classes to which it subcontractsits operations (it can be viewed as the interface class of acollaboration). It is also possible that, in certain domains,some of the classes defined have to be partitioned into setsof classes or have to subcontract a substantial part oftheir responsibilities.
Expert Systems, July 2002, Vol. 19, No. 3 157
5. 2. Description of task decomposition methods throughinteractions and the specification of operations
In the KADS/CommonKADS expertise model, a task isa general objective achieved by using a method. A methodinvolves a specific way of decomposing a task into moreelementary subtasks, together with the control of thesequencing of these subtasks at execution time. Themethods are usually described in a semi-formal manner inCML, though they can also be specified more rigorously,e.g. in (ML)2. Such a description is composed of a declara-tive part (the method competence) and an operational speci-fication (the specification of the subtasks and the flow ofcontrol between them) — see the CML description above.The data flows between subtasks are shown (with nocontrol information) in inference diagrams (see Figure 1).

Figure 6: Other relations between the key elements of the decision model.
These resemble classic data flow diagrams except for theabstract character of the data flows represented: the so-called ‘domain roles’, as explained in the previous section,do not denote data structures but rather refer to roles thatdiverse data structures could assume in the inferencescheme described. As has also been observed above, therestrictions on such abstract data structures increase as thesubtasks are recursively decomposed into more elementarysubtasks — hence the use of the term ‘metaclasses’ for thedomain roles in the first versions of KADS/CommonKADS(they describe a common abstract structure for the differentdata structures which could assume a given role). The
158 Expert Systems, July 2002, Vol. 19, No. 3
methods may be more or less generic, i.e. oriented to agreater or lesser degree towards specific tasks and/ordomains. When the description of a solution method for asubtask necessarily involves domain knowledge which istoo specific to be found in the available libraries, the levelof primitive tasks or inferences is considered to havebeen reached.
We reiterate that domain, task and method are not clearlyseparated in an object-based modelling perspective. Weobserved previously that in the class and object diagramsthe structuring of a domain into classes and the specifi-cation of their relations cannot be separated from the defi-

nition of interfaces and the specification of collaborations.The type of knowledge that in KADS/CommonKADS isdescribed in the task part is here specified via both static(interface operation signatures and static aspects of usecases) and dynamic (dynamic aspects of the use cases)UML elements. The type of knowledge described in themethod part, on the other hand, is here mainly describedusing dynamic elements (implementation methods of theoperations and interactions), though it is also representedto some extent in the collaborations, considered structuralUML elements.
There is an immediate correspondence between therelation of the tasks to the solution methods in KADS/CommmonKADS and that of the operations in the classinterfaces to the methods — OO paradigm terminology forexecutable algorithms — that implement them. In theinheritance hierarchy according to which the classes arestructured, frequently the high-level classes are purelyabstract, for which reason they do not have instances andin some cases their operations are not associated to anyconcrete implementation method. At a high level of abstrac-tion, an operation is an abstraction of analogous behaviourin different classes of objects. Each child class thendeclares its own methods for implementing its operations.
Thus, the link between the methods and the data models,which in KADS is treated in the assumptions, is inherentin the model. The assumptions about the type of datastructures which a method manipulates are implicit in theclass hierarchy in which the method is used. The inherit-ance mechanism facilitates both method and data structurereuse. In an OO model, the data structure hierarchy is ident-ical to the method inheritance hierarchy: in the OOapproach there is a single unified hierarchy. Any methodassociated to a class can be applied in any of its subclassesunless this subclass redefines it. This possibility of redefin-ing the methods of a superclass gives rise to polymorphism.In many OO languages, the correct implementation methodof an operation is selected automatically as a function ofthe name of the operation and the class of the object beingmanipulated (this feature being known as dynamicbinding). Each object knows how to carry out its own oper-ations, and the user of an operation does not need to beconscious of the number of existing methods whichimplement a given polymorphic operation. The user doesnot need to identify the type in order to invoke the correctprocedure. This simplifies the maintenance of systemsdeveloped using OAD, since the code which invokes theoperations does not need to be modified when new classesare added.
Similarly, a collaboration demands that the participantentities can assume the roles involved. However, thespecialization of the OO pattern in specific domains doesnot pose any problem with respect to the roles in a collabor-ation since any instance of a class may assume the rolesthat any of its superclasses play in a collaboration
Expert Systems, July 2002, Vol. 19, No. 3 159
(polymorphism), implementing the inherited operationswith specialized methods.
The implementation of the operations is modelled inUML via mechanisms which do not correspond to the con-cept of task solution method of KADS/CommonKADSstyle AI development methodologies. The interaction dia-grams (in the form of collaboration and sequence diagrams)of the UML models show how the functionality derivesfrom the organization of entities (classes and actors) whichcooperate (collaborations represented in the class diagrams)and from their interrelations and interactions. The dynamicbehaviour of the different objects of the system is specifiedusing state diagrams, while activity diagrams are a basicallyfunctional view of the global dynamic behaviour. As in theKADS/CommonKADS methodology, the methods can bespecified recursively, i.e. described at different abstrac-tion levels.
Interaction diagrams The counterpart of the basicdecision methods previously described from the KADS/CommonKADS perspective are the interaction mechanismspresented in the interaction diagrams (see Figures 7–10).These diagrams are very high level, given the generality ofthe task being tackled. Thus, we have identified only twocollaborations. In the case of the collaboration diagrams,the order of the messages is indicated by prefixing a numberto each message, where the numbering of each flow isnested according to the Dewey decimal numbering system.
In the case of the sequence diagrams (Figures 8 and 9)the graphical notation for messages which involve subcon-tracting of tasks has been used (filled arrowheads) toexpress that the flow of control is procedural. We have notjudged it pertinent to consider ‘active objects’ (objectswhich initiate control activities), since in our case there isonly one flow of control. The nesting of the message invo-cations corresponds, roughly speaking, to the functionaldecomposition of a functional analysis methodology. Wehave used the usual convention of locating on the left theobjects which initiate the interactions, and on the right themost subordinate objects. The messages represent operationinvocations (call), values returned by operations (return)and the creation of objects (create); no signals (send) areinvolved in this specification.
To express an iteration condition in the sending ofmessages, a particular use has been made of the OCL,though note that it is not possible to use the iteration con-struct of OCL in this context.
Spatial and temporal restrictions, as well as pre- andpost-conditions, can be associated to the messages but wehave not considered it necessary to repeat the OCLexpressions attached to the class diagrams, given the sim-plicity of the interaction scheme shown.
Activity diagrams In Figure 11 the functional perspectiveof the solution of the decision task is shown using an
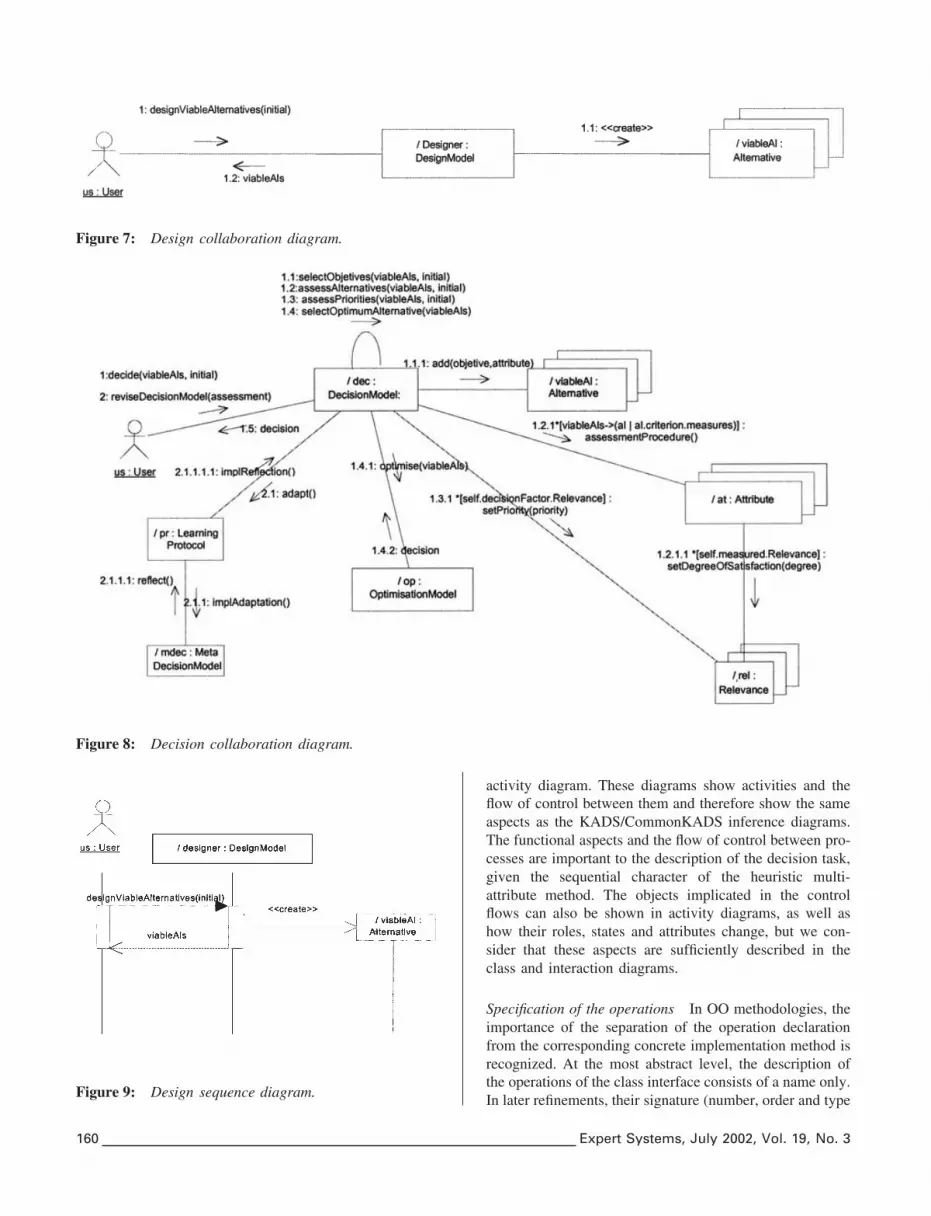
Figure 7: Design collaboration diagram.
Figure 8: Decision collaboration diagram.
Figure 9: Design sequence diagram.
160 Expert Systems, July 2002, Vol. 19, No. 3
activity diagram. These diagrams show activities and theflow of control between them and therefore show the sameaspects as the KADS/CommonKADS inference diagrams.The functional aspects and the flow of control between pro-cesses are important to the description of the decision task,given the sequential character of the heuristic multi-attribute method. The objects implicated in the controlflows can also be shown in activity diagrams, as well ashow their roles, states and attributes change, but we con-sider that these aspects are sufficiently described in theclass and interaction diagrams.
Specification of the operations In OO methodologies, theimportance of the separation of the operation declarationfrom the corresponding concrete implementation method isrecognized. At the most abstract level, the description ofthe operations of the class interface consists of a name only.In later refinements, their signature (number, order and type

Figure 10: Decision sequence diagram.
of parameters and type returned), their functionality andother properties (stereotypes, restrictions) are specified.
The functionality of an operation — both its input–outputrelation and the side-effects associated with its appli-cation — can be specified in different ways, e.g. varioustypes of formal methods, pseudo-code or natural language.A formal approach which is well suited to use with classinterfaces is that of specifying pre- and post-conditions, aswell as invariants, on operations. In the case of the UML,any type of specification is allowed for specifying the func-tionality of operations. The OCL, however, has been speci-ally devised for joint use with the UML and is in fact exten-sively used in defining the UML metamodel. In OCL thefollowing three types of assertions can be defined:
� operation post-conditions: statements concerningmodelling entities reachable from the owning objectwhich must be satisfied after any execution of theoperation. They define the effect of the operation onthe system state and with respect to what is to be con-sidered correct output: what a client of that operationcan expect as a result of invoking it.
� operation pre-conditions: statements about modellingentities reachable from the owning object which mustbe satisfied before any execution of the operation.They define the initial assumptions of the operation
Expert Systems, July 2002, Vol. 19, No. 3 161
concerning the system state and with respect to whatis to be considered correct input: what the operationexpects of the state and of the data supplied by theclient who invokes it. This clarifies responsibilitiesand avoids absence or duplication of error-checkingcode.
� class invariants: statements about modelling entitiesreachable from the object which must be satisfied forany object of the class whose operations can beinvoked, both initially and after the invocation of anythese operations.
Assertions can be used in OO software development forspecification (cf. design by contract), documentation,support for testing, debugging and quality assurance, andsupport for software fault tolerance (Meyer, 1999). The lasttwo uses imply run-time assertion monitoring whichinvolves raising an exception if, on invocation of an oper-ation, its pre-condition is not satisfied, or if on invocationof an operation its pre-condition is satisfied but after itsinvocation its post-condition, or a class invariant, is not.
The operations of simple objects are identified withprimitive inferences of the KADS/CommonKADS libraries.This is the case of the generic, low-level operations and ofoperations of classes which are very specific to a domain.These operations generally have no argument other than the

Figure 11: Global activity diagram.
implicit one of the object to which they belong and do notsubcontract any of their responsibilities by invokingoperations of another object nor produce side-effects in anyother object. The operations of the more complex classesusually correspond to high-level tasks of the expertisemodel. As mentioned previously, there is often a directcorrespondence between the levels of nesting of KADS/CommonKADS tasks and the use relations (client–server)between operations of the object model.
Generally speaking, one of the input roles of the taskdescribed in the expertise model can be identified as theclass which owns the corresponding operation in the UMLmodel, while the rest are identified with classes linked tothe former by some relation, or with parameters or localvariables of the operation. That is, when a class plays aninput role for a task, it is either responsible for the operationcorresponding to that task or subcontracted as part of carry-ing out that operation. The class responsible is a client ofthe rest (servers) since it uses them to carry out the oper-ation, generally by invoking some of their operations
162 Expert Systems, July 2002, Vol. 19, No. 3
(which correspond to subtasks). Strictly speaking, in theUML operations of an object can be invoked in the courseof executing an operation without that object being an argu-ment of the operation, if the appropriate visibility con-ditions are satisfied (in which case the object is an implicitargument). For high-level, abstract specification purposes,it is preferable, however, to make dependences explicitwhere possible. In order to identify which of the input andoutput domain roles of an expertise model task is to beidentified with the class which owns the correspondingoperation, we use the following rules, based on thedistribution of responsibility criteria suggested by Rum-baugh et al. (1991).
1. If a role is both input and output, then the operationbelongs to the class corresponding to this role.
2. Otherwise, if at least one of the input roles is asupport role (see Section 5.3), then the operationbelongs to the class corresponding to one of theseroles.
3. Otherwise, if the output role is a support role, thenthe operation belongs to this role.
4. Otherwise, if an input or an output role is an actor(in the KADS/CommonKADS cooperation model)then the operation belongs to the class whichrepresents this role (possibly also of actor type).
5. Otherwise, if an output role represents part of aninput role then the operation belongs to the classcorresponding to the input role.
6. Otherwise, if an output role is created from partsrepresented by input roles then the operation involvesobject creation.
On occasions, the support role in rule 2 or 3 has not beenmade explicit in the KADS/CommonKADS model. In allcases, it will be made explicit in the class diagram as theclass which encapsulates the operation.
Concerning the decision pattern, at this level of ab-straction it is not relevant to assign methods to the oper-ations, so that these have been specified exclusively throughtheir signatures and, in some cases, by adding stereotypes(�scale conversion procedures�) to characterize them orpre- and post-conditions to describe some aspects of theirfunctionality. Thus, for example, for the operationdesignViableAlternatives, the following con-straints have been specified in OCL:
-- The operation assumes: current state-- problematic, resources compatible with-- it unknown, viable alternatives not-- calculated. The operation calculates-- the compatibility relation between the-- input state and the resources-- (non-empty) and returns all the-- alternatives (non-empty) that can be-- designed from the resources which

-- compose the decision model satisfying:-- * they only use resources which are-- compatible with the input state-- * they only use resources that can be-- combined with each other-- * they are applicable to the input
state-- * on application to this state, they
cause it to evolve to an acceptablestate
-- (a,b).c is our shorthand for-- a.c-intersection(b.c)-- (ternary relation)
context DesignModel::designViableAlternatives(initial:State):
Set�Alternative�
pre: initial.problematic = trueand initial.resource-�isEmptyand Alternative.allInstances-�isEmpty
post: initial.resource-�notEmptyand self.resource.alternative-�notEmptyand result =
self.resource.alternative-�asSet-�select( al � initial.resource-�
includesAll(al.resource)and al.resource-�forAll(r1,r2�
r1.canbeCombinedWith-�includes(r2))and al.initialState-�includes(problem)and (problem,al).finalState.problematic
=false )
Note that the symbols preceding the names of operationsin the class diagrams of Figures 3, 4 and 6 serve to indicatetheir ‘visibility’. We only use two visibility categories:
� private: the operation is used internally by a class toimplement its responsibilities;
� public: the operation is offered as a service for otherclasses to use directly, hiding from them theimplementation details.
5. 3. Representing support knowledge using persistentobjects
The so-called support roles of KADS/CommonKADS referto the roles which the domain entities play in theaccomplishment of a task. In general, two types of rolesare distinguished:
� static roles: those domain entities which are used inthe reasoning process solving a task, but which arenot affected by this process. The term support roles
Expert Systems, July 2002, Vol. 19, No. 3 163
is generally used when they refer to data which arenot entered at execution time. Frequently the supportroles are not made explicit, being considered part ofthe inference specification involved in the solutionmethod.
� dynamic roles: those domain entities manipulated inthe reasoning process.
Given the assumptions linking task, method and domain,the structure of the domain entities condition the methodsapplicable for the solution of a task.
The definition of type is coherent with the OO analysisphilosophy. Logically, if adequate criteria for structuring adomain into classes, coherent with a suitable distributionof responsibilities, are followed, a single class shouldencapsulate all the data which participate in a given rolein the inferential process. The domain models in the OOperspective are ‘responsibility oriented’ rather than ‘dataoriented’, as is appropriate for a cooperative view of com-putation. In methodologies such as KADS/CommonKADS,on the other hand, since the functionality and the data aremodelled independently, on occasions different data struc-tures participate in a domain role. This implies the need foran analysis of the correspondence between ontologies androles, whose translation to implementations is not alwaystrivial.
The circumstance could arise, however, in which thesame domain role can be played by very different entities,for which it is impossible to find a common structure. Insuch cases, generic classes will naturally arise in thedomain. A generic class is a class which is defined in termsof generic parameters instantiated, in turn, with otherclasses.
The distinction between static and dynamic roles can beestablished in the specification of operations (by specifyingwhether the parameters are in, out or inout andattaching pre- and post-conditions).
The extent to which an operation affects the state of theobjects involved is represented principally in the class andobject state diagrams, these belonging to the dynamic partof the UML model. In Section 5.2 some basic rules weregiven for determining which domain role corresponds tothe class to which the operation will belong.
The support knowledge is represented in this specifi-cation as so-called persistent objects (using the taggedvalue annotation {persistence = persistent},abbreviated here to {persistent}), as opposed totransitory objects, entities which do not transcend theexecution time of the applications in which they figure. Inour model, a reflexive perspective is taken and learningimplies the modification of the metamodels of only someof the persistent classes (those involved in theDecisionModel) and their structural relations(IsPreferableTo, InfluencesInPriorityOf,%). Note that the class DesignModel assumes the

responsibility of designing the alternatives and as suchplays a support role which is not made explicit in the infer-ence diagram of the decision task, according to the criterionof representing only the support knowledge which is sus-ceptible to modification in the learning process. In theobject model, on the other hand, a class which can assumethe responsibility for designing the alternatives must bemade explicit.
5. 4. Potential collaborations conditioned by thestructural relations
Figures 7 and 8 show the most relevant collaborationdiagrams. The relations are lines of communication alongwhich messages are sent: the functionality of the collabor-ations derives from the class structure. This means that theclasses which collaborate in a given behaviour are necessar-ily related. This aspect of OAD is particularly evident inthis specification, since the class diagrams, together withthe attached constraints expressed in OCL, describe anappreciable part of the global functionality (the interactiondiagrams in reality add very little). The relations define thepotential collaborations in which the objects of a classparticipate and the tasks which they subcontract, in short,the roles or responsibilities of the different objects in thecooperation.
The diagrams show how the potential collaborationsbetween classes are conditioned by their structural re-lations. Although the relations imply communication chan-nels for sending messages, the specification is not behav-iour oriented (Booch et al., 1998), in view of the fact thatthey are also used as navigation routes. In fact, we haveassumed the criterion of not making explicit as parametersthose classes which are accessible for the operation by navi-gation from the owning class. The pre- and post-conditionsspecified for some of the operations reflect the use of therelations for navigation; e.g.
-- The operation assumes that, for each-- alternative viable in the current-- state, the objectives to be used to-- assess it have been chosen but that-- the consequences of choosing it-- have not been calculated.-- The operation calculates these-- consequences.
context DecisionModel::AssessAlternatives(viableAls:Set�Alternative�,init:State)
pre: viableAls-�forAll(al �al.criterion-�notEmpty andal.effect-�isEmpty)
and al.effect-�notEmpty)post: viableAls-�forAll (al �
al.effect-�notEmpty)
164 Expert Systems, July 2002, Vol. 19, No. 3
5. 5. Formalizing assumptions by means of OCLannotations
In the KADS/CommonKADS methodologies, the infor-mation which completes the modelling tasks, denominatedassumptions, is structured in Benjamins and Pierret-Golbreich (1996) into different types:
� epistemological assumptions: these define the knowl-edge required by the solution method. They aredivided into assumptions concerning the availabilityof entities, in the application domain, which can beplaced in correspondence with the concepts of themethod, and assumptions about properties of theseentities.
� pragmatic assumptions: these relate to the physicalcontext or external environment in which the systemoperates.
� teleologic assumptions: these relate to the goal the sol-ution method has to achieve.
With respect to the availability assumptions, they make nosense in an OO model, in which the domain entities andthe functionality are integrated.
Some of the so-called property assumptions are implicitin the class model itself. For example, given the wide appli-cability of the decision task, the nature of concepts such asalternative, objective or attribute is very diverse, thisassumption translating simply as a high degree of abstrac-tion of the associated classes, of which no attribute is madeconcrete. Another basic assumption of the decision model,the measurable character of the objectives and thepossibility of measuring them using different attributes,is also implicit in the multiplicity of the roles of therelation PredictsTheDegreeOfSatisfactionOf.Other property assumptions can be included in the patternby formalizing them as OCL constraints. Thus, in the con-text of the operation designViableAlternatives,the assumptions about the mutual exclusion of the alterna-tives designed (no other intermediate or combined designis possible (problem.resource -� includesAll(al.resource))), about the existence of at least onevalid alternative (self.resource.alternative-�notEmpty) and about the compatibility of the re-sources used by an alternative (self.resource-�forAll(r1,r2�r1.canBeCombinedWith -�includes(r2)) are expressed in the OCL presentedpreviously.
The possibility of assessing each viable alternative withrespect to at least one of the prespecified objectives throughsome attribute is specified in the context of the operationSelectObjectives:
-- The operation assumes that, for each-- alternative viable in the current-- state, the objectives to be used to

-- assess it have been chosen but that-- the consequences of choosing it-- have not been calculated.-- The operation calculates these-- consequences.
context DecisionModel::AssessAlternatives
(viableAls:Set�Alternative�,init:State)pre viableAls-�forAll )al �
al.criterion-�2notEmptyand al.effect-�isEmpty)
post:viableAls-�forAll(al �al.effect-�notEmpty
-- The operation assumes that the-- objectives to be used to assess-- each alternative have not been-- selected and consequently neither-- have the attributes which will be-- used to measure each of these-- objectives for each of these-- alternatives, though there are-- known to be one or many attributes-- which can be used to preict the-- degree of satisfaction of any one-- of them, either directly, or-- indirectly (proxies). It also-- assumes that the current state is-- problematic. The operation selects-- for each alternative those objectives-- of the decision model satisfying:-- * they are relevant for that-- alternative-- * there is at least one attribute-- that can be used to assess them-- * they are relevant for the problem-- state-- and creates the links “Asessess”-- between each alternative and the-- objectives selected for it and the-- links “Measures” between each-- selected objective for each-- alternative and an attribute chosen-- to measure it.
context DecisionModel::selectObjectives(viableAls:set�Alternative�,init:State)
pre: self.decisionFactor-�forAll (ob �and ob.assessed-�isEmpty)
and init.problematic = truepost: viableals-�forall ( al �
(self.decisionFactor-�select (ob �al.criterion-�includes (ob)
and ob.measure-�notEmpty) )
Expert Systems, July 2002, Vol. 19, No. 3 165
= (self.decisionFactor-�select (ob �al.goal-�includes (ob)
and ob.degree-�notEmptyand ob.State-�includes (initial)))
5. 6. The modelling of learning based on reflectivetheories
It is of interest to comment on the presence of the classesstereotyped �Metaclass� (see Figure 12) which revealthe reflective character of the proposed architecture. In AIdevelopment methodologies such as KADS/CommonKADS,the so-called ‘support knowledge’ refers to the domain enti-ties which play a role in the reasoning process which solvesa task without being affected by it. This knowledge, whichcan be understood to ‘parameterize’ the tasks, is usuallyconsidered implicit in the solution methods and is not madeexplicit in the analysis. Part of this knowledge was alreadymade explicit in the expertise model in order to show howit is modified by a ‘learning task’. If a perspective of learn-ing as ‘a reflective task which modifies a self model’ istaken, such knowledge is modified from a metalevel wherethe solution model of the task is ‘reified’.
In the decision pattern which we present, this perspectiveimplies a metalevel architecture where learning is translatedas modification of some of the objects involved in thedecision model and of their structural relations. Theclasses associated to these objects have been stereotyped{persistent}. They have also been stereotyped{frozen} with the idea of putting emphasis on the factthat their objects can only be modified via their associatedmetaclasses, by mediation of a metaobject protocol whichwe have specialized in the class ‘learning protocol’. In thisway, the structural character of the learning tasks of AI is
Figure 12: Learning class diagram.

brought to the fore. Usually, the constraint ‘frozen’ refersonly to attributes and relations. When we characterize anabstract class as frozen, we are stereotyping as frozen allthe possible attributes of its possible subclasses.
The elements of the DecisionModel susceptible to bemodified by learning effects thus appear reified in the formof metaclasses. We have concluded that these elements willgenerally be the solution methods of the operationsdecide, selectObjectives, assessAlterna-tives, assessPriorities, selectOptimumAlternative, optimise, scaleValues, andevaluationProcedure, as well as some relationswhich involve objectives, namely the aggregation relationsand the relations IsRelevantfor, InfluencesIn-ThePriorityOf, Quantifies, Represents,CooperatesWith, CompetesWith and IsPrefer-ableTo.
The user of the decision system (a human user or anothersoftware system) has been modelled as an actor whichinteracts with it. We have supposed that the task assessingthe adopted decision (called assess decision in the ExpertModel) is undertaken by this actor. The result of this evalu-ation is thus communicated (we are therefore dealing withsupervised learning) in the message reviseDecision-Model which, on invoking the operation of the same namein the DecisionModel, results in the modification of themetamodel. The appropriate modifications are carried outwith the mediation of the LearningProtocol, whichaccesses the DecisionMetaModel navigating throughthe Reify relation, which connects each model with itsmetamodel. The way in which the modifications of a meta-model are reflected in the corresponding model depends onthe particular design chosen for the reflective architecture.
5. 7. Representing the creation of relations in interactiondiagrams
Concerning the representation of the creation of associ-ations between objects in interaction diagrams as aconsequence of the invocation of operations, having foundno satisfactory solution we in the end adopt the criterionsuggested by Booch et al. (1998): for each relation thatcan be dynamically created we assume the existence of animplicit class operation in one of the related classes whichstores the reference or reference list (depending on themultiplicity) of the objects related by this relation. Theclass designated as the relation owner will, in general, bethe one having the higher multiplicity, though we do notexclude the possibility that representing the relation in theclass with lower multiplicity, or even in all the classesinvolved in the relation, may sometimes be more appropri-ate. In this respect, the specification is oriented toward animplementation in which relations are implemented as ref-erences, a constraint which is not really appropriate at theanalysis level we are tackling.
166 Expert Systems, July 2002, Vol. 19, No. 3
The specification also includes predefined and non-modifiable relations (stereotyped as {persistent,frozen}). We have used the constraint {implicit} for‘conceptual relations’, i.e. relations which are not used bythe solution method but which may be useful for checkingpurposes (for instance, the relation CooperateWithbetween two objectives implies that their evaluations arepositively correlated, i.e. they change in the same sensewhen any two decision instances are compared).
Concerning the meaning of the composition relations(between State and StateVariable), as opposed toaggregation, we comment that it indicates a strong pos-session of the parts by the whole; their lifetimes coincideunless they are explicitly destroyed. A part can only belongto one whole at any given moment.
5. 8. Attributes
We comment also that we have decided not to includeoperations to instantiate values of attributes, consideringthem not to be relevant in a high-level specification exceptfor the two operations of the class Relevance which wereintroduced in order to be able to show their explicit invo-cation in the sequence diagrams. Thus, in Figure 3, aderived attribute problematic, whose values charac-terize states of the objects, is defined. Generally speaking,the states condition the roles which an object can play inrelations and the operations which are applicable to it.Thus, for example, in the previous OCL specification,initial.problematic = true is a pre-condition ofthe designViableAlternatives operation.
The dependence of the derived attribute problematicon the state variables is expressed as an invariant of theState class via the following OCL constraint:
-- The value of the attribute-- “problematic” of a state is true-- according to whether the value-- of one of the state variables is-- not acceptable.context State invself.problematic=self.StateVariable
�exists(var �var.isAcceptable(var.value)=false)
The specification also shows how the operations inducechanges of state (e.g. the post-conditions of the operationdesignViableAlternatives include finalState.problematic = false).
The calculation of the value of the derived attributevalues of each Consequence of the class diagram ofFigure 6 is expressed via the following OCL constraint (inthe absence of tuples in OCL, we have to assume aniteration order):
-- The attribute ‘values’ of the

-- consequence of an alternative is-- the sequence of values of degrees-- of satisfaction, one for each of-- the objectives used to assess that-- alternativecontext Consequence invself.values = self.cause.relevance-�iterate(rel:Relevance ;vals:Sequence(Degree) = Sequence{} �vals-�append(rel.degreeOfSatisfaction) )
6. Conclusions
In this paper we plant objections to the most commonlyused AI task analysis and problem-solving methodapproaches, in particular that of the widely known KADS/CommonKADS expertise model. We argue that reuse inthis context — based on a task/method/domain trichotomyarising, in part, from a functional modelling perspective —is unnecessarily complex and impractical, difficulties whicha more formal approach to reuse does little to solve. Wealso point to the inadequacies of this approach as regardsmodelling those AI tasks in which the dynamic behaviouris of some importance, particularly interactive systems (e.g.decision support systems, intelligent tutoring systems) andstrongly reactive systems (e.g. robots).
We then discuss the utility of formal or semi-formalspecification notations to facilitate incremental refinementof models and model reuse, from high-level analysisthrough to implementation.
These arguments lead us to the use of the OOcomputational paradigm in the analysis of AI tasks and, inparticular, to the formulation of generic knowledge modelsas OO analysis patterns. A library of these patterns (a ‘pat-tern language’) could then constitute the counterpart of thewidespread task, method, domain, adapter libraries ofKADS/CommonKADS.
We introduced the idea of using UML (in conjunctionwith its associated constraint language OCL) as a descrip-tion language for AI analysis patterns in Pickin andManjarres (2000), where we proposed a ‘decision pattern’in analogy to the decision expertise model we discussed inManjarres et al. (1999, 2000). It should be noted at thispoint that while design patterns have become almostubiquitous in the OO literature in the last decade, the verydefinition of analysis patterns remains tentative and is stillan emerging research topic, as is the use of UML fordescribing such patterns.
In the present paper, we give an explicit comparison ofthe expertise model and the OO analysis pattern approachesto formalizing a simplified decision theory. In so doing,we demonstrate the potential of the UML for adequatelyrepresenting the entities commonly modelled in theKADS/CommonKADS expertise model. The decision taskwas chosen because of its importance as the basic task of
Expert Systems, July 2002, Vol. 19, No. 3 167
the ‘intelligent’ agent, inspired in the original concept of‘intentional agent’ proposed by Newell. This task and theassociated heuristic multi-attribute method are of wideapplicability, particularly in the development of decisionsupport systems, notably in fields such as medicine andeconomics.
In this paper, then, we have demonstrated the promiseof the research avenues we have begun to explore aimedat the compilation of a library of AI analysis patterns, asa counterpart to the widespread KADS/CommonKADStask/method/ontology/adapter libraries, and the definition ofa reuse methodology based on such patterns. Such a meth-odology promises to be significantly less complex and moreeasily applicable than KADS/CommonKADS approachessuch as that using adapters. Carrying out this program hasalready involved us in other research topics of significantinterest, concerning the use of different formal and semi-formal notations in AI, and concerning the adequacy ofUML for defining analysis patterns, particularly in the AIfield. As the next step, we are carrying on the refinementof the proposed UML decision pattern and its specializationto different AI domains.
References
Akkermans, H., F. van Harmelen, G. Schreiber and B.Wielinga (1993) A formalisation of knowledge-level modelfor knowledge acquisition, International Journal of IntelligentSystems, 8, 169–208.
Alexander C., S. Ishikawa and M. Silverstein (1977) APattern Language, Oxford: Oxford University Press.
Angele J., D. Fensel, D. Landes and R. Studer (1998)Developing knowledge-based systems with MIKE, Journal ofAutomated Software Engineering, 5 (4), 389–418.
Benjamins, V.R. (1995) Problem-solving methods for diagnosisand their role in knowledge acquisition, International Journalof Expert Systems: Research and Applications, 8 (2), 93–120.
Benjamins, V.R. and C. Pierret-Golbreich (1996) Assump-tions of problem-solving methods, in Advances in KnowledgeAcquisition, Lecture Notes in Artificial Intelligence 1076, N.Shadbolt, K. O’Hara and G. Schreiber (eds), Berlin: Springer,1–16.
Benjamins, V.R., E. Plaza, E. Motta, D. Fensel, R. Studer,B. Wielinga, G. Schreiber and Z. Zdrahal (1998) An intel-ligent brokering service for knowledge-component reuse on theWorld-Wide-Web, in Proceedings of the 11th Workshop onKnowledge Acquisition, Modeling and Management (KAW‘98), Banff, Canada.
Bernaras, A. and W. Van de Velde (1994) The commonKADS library for expertise modelling, in CommonKADSLibrary for Expertise Modelling: Reusable Problem-solvingComponents, J.A. Breuker and W. Van de Velde (eds), Amster-dam: IOS Press, 175–196.
Bobrow, D.G. and T. Winograd (1977) An overview of KRL,a knowledge representation language, Cognitive Science, 1 (1),3–46.
Booch, G. (1994) Object-oriented Analysis and Design;with Applications, 2nd edn, Redwood City, CA: BenjaminCummings.
Booch, G., J. Rumbaugh and I. Jacobson (1998) Unified

Modeling Language User Guide, Object Technology Series,Reading, MA: Addison-Wesley.
Bowen, J. and M. Hinchey (1995) Ten commandments of formalmethods, IEEE Computer, 56–63.
Brazier, F.M.T., B.M. Dunin-Keplicz, N.R. Jennings and J.Treur (1997) DESIRE: modelling multi-agent systems in acompositional formal framework, International Journal ofCooperative Information Systems, Special Issue on FormalMethods in Cooperative Information Systems: MultiagentSystems, M. Huhns and M. Singh (eds), 6 (1), 67–94.
Bredeweg, B. (1994) Model-based diagnosis and prediction ofbehaviour, in CommonKADS Library for Expertise Modelling:Reusable Problem-solving Components, J. Breuker and W. Vande Velde (eds), Amstedam: IOS Press, 121–153.
Breuker, J. and W. Van de Velde (1994) CommonKADSLibrary for Expertise Modelling. Reusable Problem SolvingComponents, Amsterdam: IOS Press.
Breuker, J.A., B.J. Wielinga, M. Van Someren, R. De Hoog,A.T. Schreiber, P. de Greef, B. Bredeweg, J. Wielemaker,J.P Billaul, M. Davoodi and S.A. Hayward (1987) Modeldriven knowledge acquisition interpretation model, ESPRITProject P1098 Deliverable D1 (task A1), Amsterdam:University of Amsterdam and STL Ltd.
Buschman, F., R. Meunier, H. Rohnert, P. Sommerland andM. Stal (1996) A System of Patterns, Chichester: Wiley.
Chandrasekaran, B. (1987) Towards a functional architecturefor intelligence based on generic information processing tasks,in Proceedings of the 10th International Joint Conference onArtificial Intelligence (IJCAI ’87), San Mateo, CA: MorganKaufmann, 1183–1192.
Christodoulou, E. and E.T. Keravnou (1998) Metareasoningand meta-level learning in a hybrid knowledge-based architec-ture, Artificial Intelligence in Medicine, 14, 53–81.
Clancey, W.J. (1985) Heuristic classification, ArtificialIntelligence, 27, 289–350.
Davison, A. (1992) A survey of logic programming-based objectoriented languages, in Object-based Concurrency, P. Wegner,A. Yonezawa and G. Agha (eds), Reading, MA: Addison-Wesley, 3052.
Dennett, D.C. (1969) Content and Consciousness, London:Routledge and Kegan Paul.
Fayad, M. and D.C. Schmidt (1997) Object-oriented applicationframeworks Introduction, Communications of the ACM, 40(10), 32–38.
Fensel, D. (1997) An ontology-based broker: making problem-solving method reuse work, in Proceedings of a Workshop onProblem-solving Methods for Knowledge-based Systems(IJCAI-97), Nagoya, Japan.
Fensel, D. and R. Benjamins (1998) Key issues for automatedproblem-solving methods reuse, in Proceedings of the 13thEuropean Conference on Artificial Intelligence (ECAI-98), H.Prade (ed.), Brighton: Wiley, 63–67.
Fensel, D. and F. van Harmelen (1994) A comparison oflanguages which operationalise and formalise KADS models ofexpertise, Knowledge Engineering Review, 9, 105–146.
Fensel, D. and E. Motta (2001) Structured development ofproblem solving methods, IEEE Transactions on Knowledgeand Data Engineering, 13 (6), 913–932.
Fensel, D., V. R. Benjamins, E. Motta and R. Wielinga(1999) UPML: a framework for knowledge system reuse, inProceedings of an International Joint Conference on ArtificialIntelligence, Stockholm, Sweden.
Fikes, R. and T. Kehler (1985) The role of frame-based rep-resentation in reasoning, Communications of the ACM, 28 (9),904–920.
168 Expert Systems, July 2002, Vol. 19, No. 3
Fowler, M. (1997) Analysis Patterns: Reusable Object Models,Reading, MA: Addison-Wesley.
Fox, R. and G. Ochoa (1997) Routine decision making usinggeneric tasks, Expert Systems with Applications, 12, 109–117.
Gamma, E., R. Helm, R. Johnson and J. Vlissides (1995)Design Patterns: Elements of Reusable Object-oriented Soft-ware, Reading, MA: Addison-Wesley.
Ginsberg, A. (1988) Knowledge-based reduction: a newapproach to checking knowledge bases for inconsistency andredundancy, in Proceedings of the 7th National Conference onArtificial Intelligence (AAAI 88), St Paul, MN: AAAI Press,Vol. 2, pp. 585–589.
van Harmelen, F. and M. Aben (1996) Structure-preservingspecification languages for knowledge-based systems, Inter-national Journal of Human–Computer Studies, 44, 187–212.
van Harmelen, F. and J. Balder (1992) (ML)2: a formallanguage for KADS models of expertise, Knowledge Acqui-sition, 4, 127–161.
Heckerman, D.E. and E.J. Horvitz (1988) The myth of modu-larity in rule-based systems for reasoning with uncertainty(SMI-86-0150), in Proceedings of the 2nd Conference onUncertainty in Artificial Intelligence, J.F. Lemmer and L.N.Kanal (eds), New York: Elsevier, Vol. 2, pp. 23–24.
Ignizo, J.P. (1991) Review: the development and implementationof rule based expert systems (knowledge acquisition), inProceedings of Introduction to Expert Systems, University ofHouston, New York: McGraw-Hill.
Jacobson, I., M. Christerson, P. Jonsson and G. Overgaard(1992) Object-oriented Software Engineering: A Use Casedriven Approach, Reading, MA: Addison-Weley.
Jeron, T., J.M. Jezequel and A.L. Guennec (1998) Validationand test generation for object-oriented distributed software, inProceedings of PDSE ‘98, ICSE Workshop on Parallel andDistributed Software Engineering, Kyoto, B. Kramer, N.Uchihira, P. Croll and S. Russo (eds).
Kaindl, H. (1994) Object-oriented approaches in softwareengineering and artificial intelligence, Journal of Object-Oriented Programming, 21, 1–3.
Keeney, R. and H. Raiffa (1976) Decisions with Multiple Objec-tives: Preferences and Value Tradeoffs, Series in Probabilityand Mathematical Statistics, Chichester: Wiley.
Landes, D. (1994) Design KARL — a language for the designof knowledge-based systems, in Proceedings of the 6th Inter-national Conference on Software Engineering and KnowledgeEngineering (SEKE ’94), Jurmala, Lettland, pp. 78–85.
Manjarres, A., R. Martınez and J. Mira (1999) A new taskfor expert systems analysis libraries: the decision task and theHM method, Expert Systems with Applications, 16, 325–341.
Manjarres, A., R. Martınez and J. Mira (2000) A customis-able framework for the assessment of therapies in the solutionof therapy decision tasks, Artificial Intelligence in Medicine,18, 57–82.
McCarthy, J. and P.J. Hayes (1969) Some philosophicalproblems from the standpoint of artificial intelligence, inMachine Intelligence, B. Meltzer, D. Michie and M. Swann(eds), Edinburgh: Edinburgh University Press, Vol. 4, pp.463–502.
Meyer, B. (1999) Object-oriented Software Construction, UpperSaddle River, NJ: Prentice Hall.
Miller, L. A. (1990) Dynamic testing of knowledge bases usingthe heuristic testing approach, Expert Systems with Appli-cations, 1 (3), 249–269.
Minsky, M. (1975) A framework for representing knowledge, inThe Psychology of Computer Vision, P.H. Winston (ed.), NewYork: McGraw-Hill, 211–277.

Minsky, M. (1986) The Society of Mind, New York: Simonand Schuster.
Motta, E. (1998) Reusable components for knowledge models,PhD Thesis, Knowledge Media Institute, The Open Univer-sity, UK.
Newell, A. (1982) The knowledge level, Artificial Intelligence,18, 87–127.
Object Management Group (2000) OMG Unified ModellingLanguage Specification, Version 1.3, 2000, Framingham, MA:OMG, March.
Pickin, S. and A. Manjarres (2000) Describing AI analysispatterns with UML, in UML 2000 — The Unified ModelingLanguage: Advancing the Standard, Lecture Notes in ComputerScience 1939, A. Evans, S. Kent and B. Selic (eds), Berlin:Springer, 466–481.
Pierret-Golbreich, C. and X. Talon (1996) TFL: an algebraiclanguage to specify the dynamic behaviour of knowledge-basedsystems, in Proceedings of the 12th European Conference onArtificial Intelligence (ECAI-96), Budapest, Chichester: Wiley,1123–1127.
Plaza, E. and J.L. Arcos (1993) Reflection and analogy inmemory-based learning, in Proceedings of Multistrategy Learn-ing Workshop, R.S. Michalski and G. Tecuci (eds), 42–49.
Preece, A., R. Shinghal and A. Batarekh (1992) Principlesand practice in verifying rule-based systems, KnowledgeEngineering Review, 7, 115–141.
Putnam, H. (1960) Minds and machines, in Dimensions of Mind,S. Hook (ed.), London: Macmillan, 138–164.
Ram, A., M.T. Cox and S. Narayanan (1992) An architecturefor integrated introspective learning, in Proceedings of the ML‘92 Workshop on Computational Architectures for MachineLearning and Knowledge Acquisition.
Riehle, D. and H. Zullighoven (1996) Understanding andusing patterns in software development, Theory and Practiceof Object Systems, 2 (1), 3–13.
Roberts, R.B. and I.P. Goldstein (1977) The FRL Primer, MITMemo 408.
Rumbaugh, J., M. Blaha, W. Premerlani, F. Eddy and W.Lorensen (1991) Object-oriented Modeling and Design, UpperSaddle River, NJ: Prentice-Hall.
Schreiber, G., B. Wielinga and J. Breuker (eds) (1993)KADS — A Principled Approach to Knowledge-based SystemsDevelopment, London: Academic Press.
Schreiber, G., B. Wielinga, J. Akkermans, W. Van de Veldeand A. Anjewierden (1994a) CML: the CommonKADS con-ceptual modelling language, in Proceedings of the EuropeanKnowledge Acquisition Workshop EKAW ‘94, L. Steels, A. Th.Schreiber and W. Van de Velde (eds), Lecture Notes in Arti-ficial Intelligence 867, Berlin: Springer, 1–25.
Schreiber G., B. Wielinga, R. Hoog, H. Akkermans and W.Van de Velde (1994b) CommonKADS: a comprehensivemethodology for KBS development, IEEE Expert, 12, 28–36.
Smith, B.C. (1982) Reflection and semantics in a procedurallanguage, PhD Thesis, Technical Report TR-272, Laboratoryfor Computer Science, MIT.
Stuart, R. and P. Norvig (1995) Artificial Intelligence. AModern Approach, Englewood Cliffs, NJ: Prentice-Hall.
Studer, R., V. R. Benjamins and D. Fensel (1998) Knowledgeengineering: principles and methods, Data and KnowledgeEngineering, 25, 1–2.
Valente, A. and C. Lockenhoff (1993) Organization as guid-ance: a library of assessment models, in Proceedings of the7th European Knowledge Acquisition Workshop (EKAW ’93),243–262.
Van Eck, P., J. Engelfriet, D. Fensel, F. van Harmelen, Y.Venema and M. Willems (2001) A survey of languages for
Expert Systems, July 2002, Vol. 19, No. 3 169
specifying dynamics: a knowledge engineering perspective,IEEE Transactions on Knowledge and Data Engineering, 13(3), 462–496.
Waern, A. and S. Gala (1993) The CommonKADS AgentModel, KADS-II/M4/TR/SICS/005/2.0.
Warmer, J. B. and A. Kleppe (1999) The object constraintlanguage: precise modeling with UML, in The Object Con-straint Language: Precise Modeling with UML, G. Booch, I.Jacobson and J. Rumbaugh (eds), Reading, MA: Addison-Wesley.
Zimmermann, C. (ed.) (1996) Advances in Object-orientedMetalevel Architectures and Reflection, New York: CRC Press.
The authors
Angeles Manjarres
Angeles Manjarres received a degree in physics from theUniversidad Complutense de Madrid, in 1986. She spentover five years at the Alcatel, SESA’s research centre,working on abstract data types and on the integrationof object orientation and formal specification languages.Since 1992 she has been working as a researcher in theArtificial Intelligence Department of the Spanish OpenUniversity (UNED), while giving courses for theInformatics School of this university. In 2001 sheobtained a PhD degree from the UNED, with a thesisentitled ‘Modelado computacional de la decision coop-erativa: perspectivas simbolica y conexionista’. Her cur-rent research interests are mainly centred on the appli-cation of object-oriented techniques (particularly in thearea of patterns and reflective architectures) in knowl-edge engineering.
Simon Pickin
Simon Pickin received a Master’s degree in ComputerScience from Imperial College, London, in 1988 havingpreviously studied mathematics and theoretical physicsat Sussex University (BSc), Cambridge University(Maths Tripos, Part III) and King’s College, London(MSc). He spent over five years at France Telecom’sresearch centre, working on formal specification, proto-col engineering, telecom-service creation, and verifi-cation and validation. He then spent over five years inSpanish academic centres (DIT/UPM, IT/UCIIM andEUI/UPM), where his research concerned the use of for-mal techniques in object-based distributed systems, andlatterly, hybrid systems and cosimulation. Since 2001 hehas been working at IRISA in Rennes, France, on aUML-based test description formalism and test synthesisfor UML descriptions. His research interests includeverification and validation, formal methods in distributedsystems and component-based software.