modeling relational data with graph convolutional networks
TRANSCRIPT

Modeling Relational Data with Graph Convolutional Networks
Michael Schlichtkrull1 Thomas N. Kipf1 Rianne van den Berg1 Ivan Titov 1 Max Welling1
Peter Bloem2
1 University of Amsterdam
2 VU Amsterdam余文麒 2019 7/16

Overviewl模型:Relational Graph Convolutional Networks (R-GCNs)
An adaption of previous work on GCNs for large-scale and highly multi-relational data.
l 问题: Incomplete knowledge bases.
Predicting missing information in knowledge bases is the
main focus of statistical relational learning (SRL).
l任务:Two standard knowledge base completion tasks.
1.Entity classification 2. Link prediction
7/16/2019 东南大学计算机学院万维网数据科学实验室 2

任务描述l Entity classification Link prediction assigning types or categorical properties to entities. recovery of missing triples.
l Intution missing information can be expected to reside within the graph encoded through the neighborhood structure
l Solution an encoder model for entities in the relational graph and apply it to both tasks.
7/16/2019 东南大学计算机学院万维网数据科学实验室 3
Mikhail Baryshnikov was educated at the Vaganova Academy
(Mikhail Baryshnikov, label ,person) (Mikhail Baryshnikov, lived in, Russia)
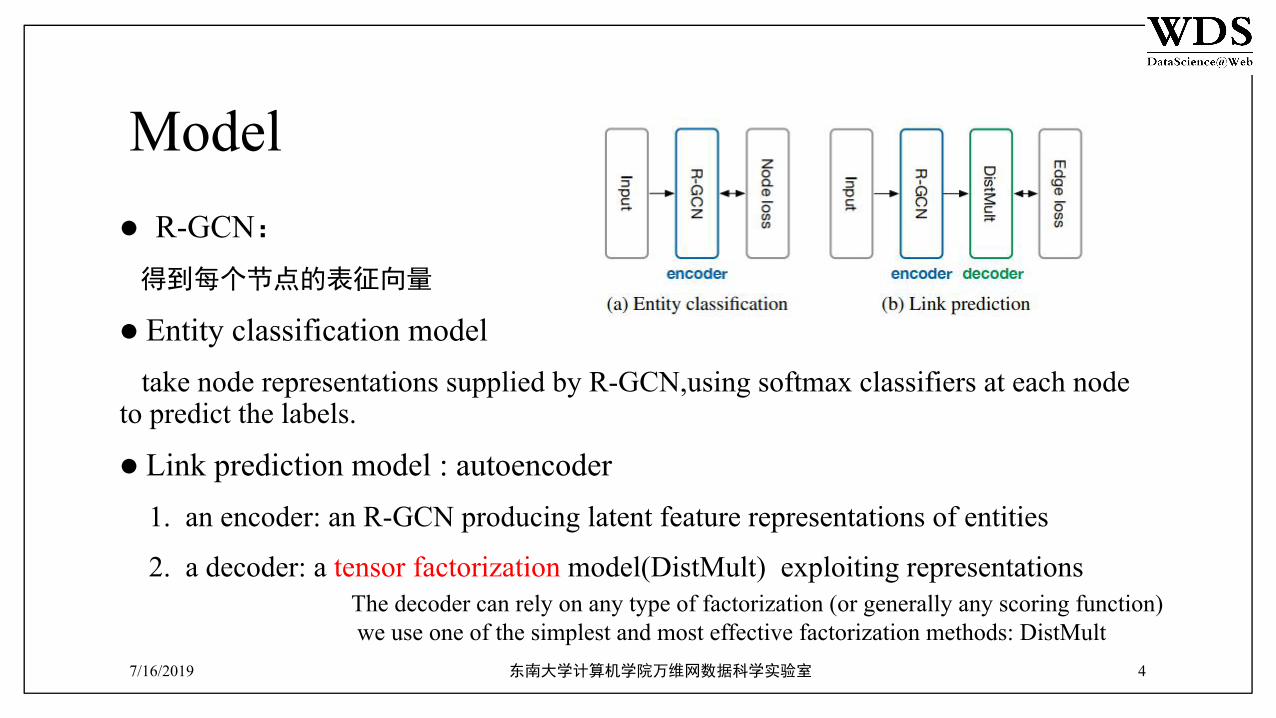
Modell R-GCN:
得到每个节点的表征向量
l Entity classification model take node representations supplied by R-GCN,using softmax classifiers at each node to predict the labels.
l Link prediction model : autoencoder 1. an encoder: an R-GCN producing latent feature representations of entities
2. a decoder: a tensor factorization model(DistMult) exploiting representations
7/16/2019 东南大学计算机学院万维网数据科学实验室 4
The decoder can rely on any type of factorization (or generally any scoring function) we use one of the simplest and most effective factorization methods: DistMult

Neural relational modelingl Definition:
l Simple message-passing framework (Gilmer et al. 2017):
: hidden state of node vi in the l-th layer of the neural network.
Mi: the set of incoming messages for vi, often chosen to be the set of incoming edges.
gm: typically chosen to be a (message-specific) neural network-like function or simply
a linear transformation with a weight matrix W.
7/16/2019 东南大学计算机学院万维网数据科学实验室 5

Neural relational modelingRelational Graph convolutional networksl R-GCN
:the set of neighbor indices of node i under relation ci,r : a problem-specific normalization constant that can either be learned or chosen in advance (such as )
7/16/2019 东南大学计算机学院万维网数据科学实验室 6
a single self-connection of a special relation type to each node
Figure 2: Diagram for computing the update of a single graph node/entity (red) in the R-GCN model.
riN Rr
特点:introduce relation-specific transformations, i.e. depending on the type and direction of an edge

R-GCNRegularizationl Issue: applying (2) to highly multi-relational data is the rapid growth in number of parameters with the number of relations in the graph.l Method: basis decomposition and block-diagonal-decomposition.l Concept: 1. direct sum
2. block-diagonal matrix
7/16/2019 东南大学计算机学院万维网数据科学实验室 7

R-GCNRegularization1. basis decomposition:
7/16/2019 东南大学计算机学院万维网数据科学实验室 8
2. block-diagonal decomposition:
作用:a sparsity constraint on the weight matrices for each relation type.
输入向量:The input can be chosen as a unique one-hot vector for each node in the graph if no other features are present. For the block representation, we map this one-hot vector to a dense representation through a single linear transformation
B是指基函数的数量
作用:effective weight sharing between different relation types(Vb
l 不依赖r 因此同一层不同的relation可以共享Vbl)
Wr(l) : block-diagonal matrices

Entity classification
7/16/2019 东南大学计算机学院万维网数据科学实验室 9
l Stack R-GCN layers of the form (2), with a softmax activation (per node) on the output of the last layer.
l Loss function
Y: the set of node indices that have labels hik
( L): the k-th entry of the network output for the i-th labeled node. tik : its respective ground truth label.

Link predictionTask: G = . given only an incomplete subset assign scores f(s,r,o) to possible edges (s,r,o), determine how likely those edges are to belong to E.Approach: graph auto-encoder model:entity encoder + a scoring function (decoder) 实现效果:scores (s,r,o) triples through a function s : 特点:reliance on an encoder our work: compute representations through an R-GCN encoder with ei = hi
(L)
previous work: use a single, real-valued vector ei for every vi optimized directly in training
7/16/2019 东南大学计算机学院万维网数据科学实验室 10
tensor and neural factorization DistMult factorization

Link predictionDistMult (Bilinear-Diag) factorization: Concept:
7/16/2019 东南大学计算机学院万维网数据科学实验室 11
arg
brg
l Method: every relation r is associated with a diagonal matrix a triple is scored as
a basic linear transformation a bilinear transformation

Link predictionModel Trainingl Negative sampling: For each observed example we sample w negative ones. We sample by randomly corrupting either the subject or the object of each positive example. l Objective function:
7/16/2019 东南大学计算机学院万维网数据科学实验室 12
T: total set of real and corrupted triples, l : logistic sigmoid function, y : an indicator, y = 1 for positive triples, y = 0 for negative ones.

Entity classification experimentsDatasets (RDF format)
7/16/2019 东南大学计算机学院万维网数据科学实验室 13
dataset description classification objectiveAIFB research institute affiliation of people
AM artifacts in the Amsterdam Museum
category of artifacts
BGS eological measurements in Britain
lithogenesis property of named rock units
MUTAG molecular graphs mutagenic
Remove relations that were used to create entity labels: employs and affiliation for AIFB, isMutagenic for MUTAG,hasLithogenesis for BGS, objectCategory and material for AM.

Entity classification experiments
Results
7/16/2019 东南大学计算机学院万维网数据科学实验室 14
参数选择:
2-layer model with 16 hidden units (10 for AM), basis function decomposition.50 epochs using a learning rate of 0.01. normalization constant

Entity classification experimentDiscussion: 1. MUTAG(分子图数据集)
relations either indicate atomic bonds or merely the presence of a certain feature. 2. BGS(具有分层特征描述的岩石类型数据集) relations encode the presence of a certain feature or feature hierarchy. Reason: 1. labeled entities in MUTAG and BGS are only connected via high-degree hub nodes that encode a certain feature. 2. solution for fixed choice of normalization constant :
7/16/2019 东南大学计算机学院万维网数据科学实验室 15
introduce an attention mechanism to replace the normalization constant1/ci,r .with data-dependent attention weights ai,j,r, where 1
,,,
rjrjia

Link prediction experimentsDatasets1. FB15k: a subset of the relational database Freebase.
2. WN18: a subset of WordNet containing lexical relations between words.
7/16/2019 东南大学计算机学院万维网数据科学实验室 16
Flaw in both datasets: 有大量互逆三元组 分别一个出现在训练集一个出现在测试集中,This reduces a large part of the prediction task to memorization of affected triplet pairs.
3. FB15k-237:all such inverse triplet pairs removed.

Link prediction experiments
7/16/2019 东南大学计算机学院万维网数据科学实验室 17
Metricsl Mean Reciprocal Rank (MRR) and Hits at n (H@n).
1. MRR:把标准答案最终排序的倒数作为它的准确度,再对所有结果取平均。
2. Hits@n: the proportion of correct triples ranked in the top n.
l Both metrics in a filtered setting(Bordes et al. (2013))These metrics can be flawed when some corrupted triplets end up being from training set.In this case, those may be ranked above the test triplet, but this should not be counted as an error. To avoid this, we propose to remove from the list of corrupted triplets all the triplets that appear either in the training, validation or test set.

Link prediction experiments
7/16/2019 东南大学计算机学院万维网数据科学实验室 18
Parameter: 1. Normalization constant
2. For FB15k and WN18,basis decomposition with two basis functions, and a single encoding layer with 200-dimensional embeddings.
3. For FB15k-237, block decomposition, two layers with block dimension 5 × 5 and 500-dimensional embeddings.
4. L2 regularization to the decoder with a penalty of 0.01.

Link prediction experiments
Baselinel ComplEx(2016) and HolE(2015), two state-of-the-art link prediction models for FB15k
and WN18. ComplEx facilitates modeling of asymmetric relations by generalizing DistMult to the complex domain. HolE replaces the vector-matrix product with circular correlation.l CP (1927) and TransE (2013) : two classic algorithms.l LinkFeat: simple neighbor-based algorithm.l DisMult+fixed entity embeddings in place of the R-GCN encoder .
7/16/2019 东南大学计算机学院万维网数据科学实验室 19

Link prediction experiments
R-GCN+
l In Figure 4 the FB15k performance of the best R-GCN model and the baseline (DistMult) as functions of degree of nodes corresponding to entities in the considered triple.
l RGCN performs better for nodes with high degree where contextual information is abundant.The two models are complementary suggests combining them into a single model, RGCN+
l On FB15k and WN18 where local and long distance information can both provide strong solutions, we expect R-GCN+ to outperform each individual model. On FB15k-237 where local information is less salient, we do not expect R-GCN+ to outperform a pure R-GCN model significantly.
l (R-GCN+) with a trained R-GCN model and a separately trained DistMult factorization model:
f(s, r,o)R-GCN+ = αf(s, r,o)R-GCN + (1 − α)f(s,r,o)DistMult, with α = 0.4
7/16/2019 东南大学计算机学院万维网数据科学实验室 20

Link prediction experiments
7/16/2019 东南大学计算机学院万维网数据科学实验室 21
A simple baseline LinkFeat employing a linear classifier on top of sparse feature vectors of observed training relations was shown to outperform existing systems.

Link prediction experiments
7/16/2019 东南大学计算机学院万维网数据科学实验室 22
Our R-GCN model outperforms the DistMult baseline by a large margin of 29.8%, highlighting the importance of a separate encoder model.

Conclusion
Contribution1. We are the first to show that the GCN framework can be applied to modeling relational data, specifically to link prediction and entity classification tasks.
2. We introduce techniques for parameter sharing and to enforce sparsity constraints, and use them to apply R-GCNs to multigraphs with large numbers of relations.
3. Performance of factorization models(DistMult) can be significantly improved by enriching them with an encoder model.
7/16/2019 东南大学计算机学院万维网数据科学实验室 23

Conclusion
Future work1. The graph autoencoder model could be considered in combination with other factorization models, such as ComplEx,which can be better suited for modeling asymmetric relations.
2. Integrate entity features in R-GCNs, which would be beneficial both for link prediction and entity classification problems.
3. Replace the current form of summation over neighboring nodes and relation types with a data-dependent attention mechanism.
7/16/2019 东南大学计算机学院万维网数据科学实验室 24

报告预告
吕琛晖:Inductive Representation Learning On Large Graphs
“ Network Embedding 旨在为图中的每个顶点学习特征表示。近年的Deepwalk,LINE, node2vec, SDNE, DNGR等模型能够高效地、直推式(transductive)地得到节点的特征表示。然而,这些方法无法有效适应动态图中新增节点的特性, 往往需要从头训练或至少局部重训练。斯坦福Jure教授组提出一种适用于大规模网络的归纳式(inductive)学习方法-GraphSAGE,能够为新增节点快速生成embedding,而无需额外训练过程。”
7/16/2019 东南大学计算机学院万维网数据科学实验室 25

Thank you!
7/16/2019 东南大学计算机学院万维网数据科学实验室 26