mini projet: résolveur de problèmes
TRANSCRIPT

NAWAR Oussema & SKHIRI Adel GL 4 GROUPE2 |
Mini projet: Résolveur de problèmes INTELLIGENCE ARTIFICIELLE

Avant-propos Les buts de ce projet étaient d'implémenter :
Un résolveur de problème de logique des prédicats d’ordre 1 pouvant fonctionner avec n'importe quelle base de connaissances en entrée.
un algorithme de recherche de solution sur un arbre en profondeur limité itérative
un algorithme de recherche de solution sur un arbre (ou graphe) de type A*
utiliser différentes heuristiques de façon à pouvoir comparer leur efficacité.
Réalisation Base de connaissances
La réalisation du projet résolveur nécessite tout d’abord de préparer la structure de données permettant de représenter le problème : base de règles, base de faits… Ainsi que de préparer les fonctions permettant de charger la base de connaissances du problème en mémoire dans notre structure de données.
L’approche adoptée pour représenter la base de connaissance :
La structure de données développées pour représenter la base de connaissance était conçus comme
suit :
Remarque : un attribut complexe doit être formé comme suit : x+(y-(3+z))
cruchesAetB (?x, ?y) et ?x + ?y ≥ 4 et ?y > 0 alors cruchesAetB (4, ?y − (4 − ?x))
Conditions (type : ensemble de GenericPredicats)
Résultat (type : predicat)
cruchesAetB (?x, ?y) et ?x + ?y ≥ 4
Predicat Item
?x , ?x + ?y
Attribut Simple Attribut
complexe
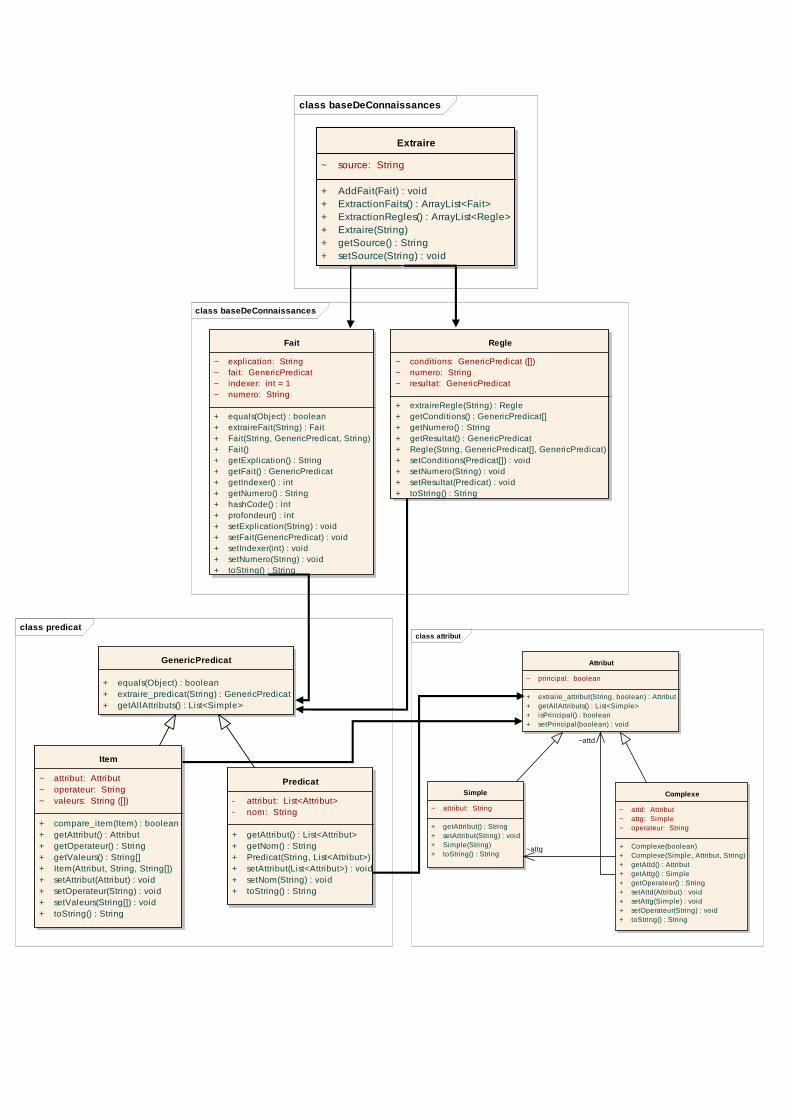
class baseDeConnaissances
Fait
~ explication: String
~ fait: GenericPredicat
~ indexer: int = 1
~ numero: String
+ equals(Object) : boolean
+ extraireFait(String) : Fait
+ Fait(String, GenericPredicat, String)
+ Fait()
+ getExplication() : String
+ getFait() : GenericPredicat
+ getIndexer() : int
+ getNumero() : String
+ hashCode() : int
+ profondeur() : int
+ setExplication(String) : void
+ setFait(GenericPredicat) : void
+ setIndexer(int) : void
+ setNumero(String) : void
+ toString() : String
Regle
~ conditions: GenericPredicat ([])
~ numero: String
~ resultat: GenericPredicat
+ extraireRegle(String) : Regle
+ getConditions() : GenericPredicat[]
+ getNumero() : String
+ getResultat() : GenericPredicat
+ Regle(String, GenericPredicat[], GenericPredicat)
+ setConditions(Predicat[]) : void
+ setNumero(String) : void
+ setResultat(Predicat) : void
+ toString() : String
class predicat
GenericPredicat
+ equals(Object) : boolean
+ extraire_predicat(String) : GenericPredicat
+ getAllAttributs() : List<Simple>
Item
~ attribut: Attribut
~ operateur: String
~ valeurs: String ([])
+ compare_item(Item) : boolean
+ getAttribut() : Attribut
+ getOperateur() : String
+ getValeurs() : String[]
+ Item(Attribut, String, String[])
+ setAttribut(Attribut) : void
+ setOperateur(String) : void
+ setValeurs(String[]) : void
+ toString() : String
Predicat
- attribut: List<Attribut>
- nom: String
+ getAttribut() : List<Attribut>
+ getNom() : String
+ Predicat(String, List<Attribut>)
+ setAttribut(List<Attribut>) : void
+ setNom(String) : void
+ toString() : String
class attribut
Attribut
~ principal: boolean
+ extraire_attribut(String, boolean) : Attribut
+ getAllAttributs() : List<Simple>
+ isPrincipal() : boolean
+ setPrincipal(boolean) : void
Complexe
~ attd: Attribut
~ attg: Simple
~ operateur: String
+ Complexe(boolean)
+ Complexe(Simple, Attribut, String)
+ getAttd() : Attribut
+ getAttg() : Simple
+ getOperateur() : String
+ setAttd(Attribut) : void
+ setAttg(Simple) : void
+ setOperateur(String) : void
+ toString() : String
Simple
~ attribut: String
+ getAttribut() : String
+ setAttribut(String) : void
+ Simple(String)
+ toString() : String~attg
~attd
class baseDeConnaissances
Extraire
~ source: String
+ AddFait(Fait) : void
+ ExtractionFaits() : ArrayList<Fait>
+ ExtractionRegles() : ArrayList<Regle>
+ Extraire(String)
+ getSource() : String
+ setSource(String) : void

Le chargement de la structure suit l’ordre suivant :
Trace d’exécution lors du chargement de la base de connaissances en mémoire :
Moteur d’inférence : Algorithme de recherche
Le moteur d’inférence développé implémente 2 algorithmes de recherche :
algorithme de recherche en profondeur limité itérative
algorithme de recherche A*
Les algorithmes de recherche font appel aux fonctions d’unifications
Declenchable.OperateursApplicables(regles, fait_a_applique) qui retourne une liste de
régles instanciées à partir du fait sélectionner
Exemple : OperateursApplicables (pbCruches, cruchesAetB(0, 0)) donne {R1(x/0,y/0),
R2(x/0,y/0)}
Elle fait appel à la méthode unifier(Predicat,Predicat) pour générer les opérateurs
applicables
ExtractionFaits()
Classe « Extraire »
ExtraireFait()
ExtraireRegles()
Classe « Fait » ExtrairePredicat()
Classe « GenericPredicat »
ExtraireAttribut()
Classe « Attribut »

InstancierFait.instancier_Fait(regle_instanciee, regles, parent) qui retourne un fait construit
en remplaçant les variables de la conclusion de la régle séléctionnée avec celles définies
dans la régle regle_instanciee
Exemple instancier_Fait(R1(x/0,y/0), regles, ‘’R2(x/2,(y/0)’’) donne Fait :{ numéro :F3,
Fait=cruchesAetB(2,0), explication=R1(x/0,y/0);R2(x/2,(y/0) }
Algorithme de recherche en profondeur limité itérative :
Stratégie: étendre un nœud jusqu’à une limite de profondeur d'exploration L puis passer au suivant
approfondissement itératif = répéter pour toutes les valeurs possibles de L = 0, 1, 2 ⋯
Implémentation:
o Les nœuds de profondeur L n'ont pas de successeurs
o Insertion des successeurs en tête de la file d'attente
Pour éviter les boucles infinies, on élimine les nœuds déjà rencontrés.
function Iterative-Deepening-Search (problem) returns a
solution
for depth = 0 to infinity do
result = Depth-Limited-Search (problem, depth)
if result != cutoff then return result
end
Construction de l’arbre de recherche :
Trace d’exécution :

Remarque : L’explication du fait contient la description du chemin emprunté pour atteindre cet état.
Algorithme de recherche A* :
L'algorithme A* est un algorithme de recherche de chemin dans un graphe entre un nœud initial
et un nœud final. Il utilise une évaluation heuristique f() sur chaque nœud pour estimer le
meilleur chemin y passant, et visite ensuite les nœuds par ordre de cette évaluation heuristique.
f(n) = g(n) + h(n)
où n est un nœud représentant un état dans l`espace d`états du problème et g(n) et h(n) ont les significations utilisées dans le cas de ces deux algorithmes. Cette heuristique estime le coût total du chemin entre l`état initial et l`état solution qui passe par n. On remarque qu`il s`agit d`une estimation f(n) obtenue par la somme d`une valeur exacte g(n) issue du chemin parcouru de l`état initial jusqu`au nœud n et d`une estimation h(n) du coût du chemin optimal qui lie le nœud n avec au nœud solution.
Pour chaque nœud exploré n on va étendre le successeur x qui minimise la fonction heuristique f()
f(x) = min { f(s) / s dans Successeurs( n ) }
Algorithme général :
function A*(start,goal) closedset := the empty set openset := set containing the initial node g_score[start] := 0 h_score[start] := heuristic_estimate_of_distance(start, goal) f_score[start] := h_score[start] while openset is not empty
x := the node in openset having the lowest f_score[] value if x = goal
return reconstruct_path(came_from,goal) remove x from openset add x to closedset foreach y in neighbor_nodes(x)
if y in closedset continue
tentative_g_score := g_score[x] + dist_between(x,y) tentative_is_better := false if y not in openset
add y to openset h_score[y] := heuristic_estimate_of_distance(y, goal) tentative_is_better := true
elseif tentative_g_score < g_score[y] tentative_is_better := true
if tentative_is_better = true came_from[y] := x g_score[y] := tentative_g_score f_score[y] := g_score[y] + h_score[y]
return failure

Application dans le problème de cruches :
- La fonction g(n) n’existe pas car le cout chemin parcouru de l`état initial jusqu`au nœud n
n’est pas calculable.
- La fonction dist_between(x,y) return 1
- La fonction f(n) devient égale à h(n) : coût du chemin optimal qui lie le nœud n avec au nœud solution.
- La fonction heuristique est
Application : Jeu du Taquin (Optionel)
- dist_between(x,y) return1
- Chaque noeud possède un coût f=g+h, où f est la somme entre :
• g : le coût pour atteindre un noeud depuis l'état initial ;
• h : le coût pour atteindre l'état final à partir de ce même noeud.
• Le cout est une heuristique : les heuristiques choisies sont la distance de
Manhattan et Misplaced.
- distance de Manhattan : somme des distances entre chaque tuile et sa position finale.
- Misplaced : chaque pièce mal placée par rapport à son état final reçoit une pénalité, ici de 1
Remarque : L’algorithme de recherche en profondeur est à éviter avec le jeu de taquin car elle
nécessite un temps d’exécution infinie (n’est pas optimal).
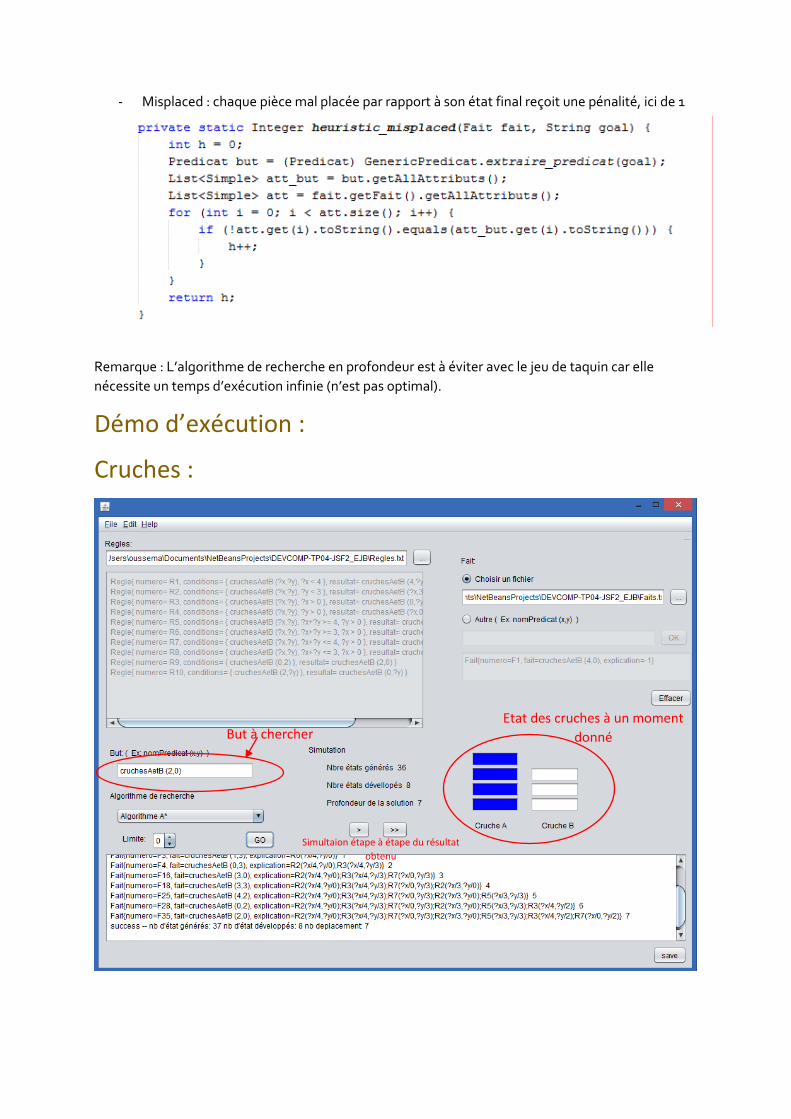
Démo d’exécution :
Cruches :
But à chercher Etat des cruches à un moment
donné
Simultaion étape à étape du résultat
obtenu

Taquin :
L’éxécution montre que l’heuristique manhattan est plus rapide MisPlaced.
Exemple :
:
Etat initial Manhattan MisPlaced
