prototyping novel collaborative multimodal systems: simulation, data collection and analysis tools...
TRANSCRIPT

Prototyping Novel Collaborative Multimodal Systems: Simulation, Data Collection and Analysis Tools
for the Next Decade Alexander M. Arthur1 Rebecca Lunsford1,2 Matt Wesson1 Sharon Oviatt1,2,3
1Natural Interaction Systems LLC 999 Third Ave, 38th Floor
Seattle, WA 98104 +1 206 505 5813
2Dept. of Computer Science Oregon Health & Science Uni.
20,000 NW Walker Road Beaverton, OR, 97006
+1 206 223 0086
3University of Washington 14 Loew Hall, Box 352195 Seattle, WA 98195-2195
+1 206 505 5814
{Alex.Arthur, Rebecca.Lunsford, Matt.Wesson, Sharon.Oviatt}@naturalinteraction.com
ABSTRACT To support research and development of next-generation multimodal interfaces for complex collaborative tasks, a comprehensive new infrastructure has been created for collecting and analyzing time-synchronized audio, video, and pen-based data during multi-party meetings. This infrastructure needs to be unobtrusive and to collect rich data involving multiple information sources of high temporal fidelity to allow the collection and annotation of simulation-driven studies of natural human-human-computer interactions. Furthermore, it must be flexibly extensible to facilitate exploratory research. This paper describes both the infrastructure put in place to record, encode, playback and annotate the meeting-related media data, and also the simulation environment used to prototype novel system concepts.
Categories and Subject Descriptors H.5.2 [Information Interfaces and Presentation (e.g., HCI)]: User Interfaces – prototyping. H.5.3 [Information Interfaces and Presentation (e.g., HCI)]: Group and Organization Interfaces – collaborative computing, computer-supported cooperative work.
General Terms Design, Human Factors, Experimentation, Measurement
Keywords Multimodal interfaces, data collection infrastructure, multi-party, meeting, simulation studies, annotation tools, synchronized media.
1. INTRODUCTION Prototyping novel multimodal interfaces for collaborative use is a major interest both in our group and around the world [3, 12, 24]. A wide range of domains benefit from the rigorous analysis of naturalistic multimodal corpora. Examples include open microphone engagement for multi-party field settings, modeling human performance during complex group problem-solving, and the creation of supportive educational interfaces for students. We currently are analyzing meetings in which the participants not only work collaboratively with each other, but also with a computer assistant [12]. Such studies call for simulation-based methods, which are quick to implement, easily adaptable, and reveal realistic user performance as well as expected system design tradeoffs [21]. The ability to observe and monitor all user input as the session is in progress is a mandatory requirement for simulation data collection and prototyping. A further constraint is that the data collection infrastructure be unobtrusive so human interaction is naturalistic and the data valid.
Multimodal research frequently requires semantic and temporal information of high fidelity. For example, high-quality semantic signals are necessary for accurate acoustic-prosodic measurements, gaze estimation, and annotation of face gestures and hand gestures. In addition, accurate temporal information and fine-grained synchronization is essential for research on multimodal fusion and the development of a new generation of time-critical multimodal systems [8, 22]. To facilitate exploratory research on computer-assisted collaborative multimodal interaction, we have developed and used a suite of applications to record, encode, playback, and annotate multimodal data during group meetings. System simulation software is at the heart of this suite because it enables collection of realistic data while exploring users’ existing work practices and rapid reconfiguration of the multimodal interface. In summary, our functional requirements for this environment include:
• Capture of multiple heterogeneous data streams and the ability to observe them during data collection
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. ICMI’06, November 2–4, 2006, Banff, Alberta, Canada. Copyright 2006 ACM 1-59593-541-X/06/0011...$5.00.
209

• Use of minimally obtrusive data recording devices that don’t alter natural communication patterns, so existing work practices can be documented
• Collection of synchronized, high fidelity semantic and temporal data to support performance analyses, including modeling of users’ multimodal integration patterns
• Development of system simulation software that supports rapid prototyping of different types of multimodal interface
• Development of analysis tools that support easily configurable and accurate annotation, as well as playback of multiple high-resolution data streams
Current worldwide research activity is focused on collecting data to support the design of systems for meeting understanding and post-meeting browsing. For example, the M4 project (Multimodal Meeting Manager) addresses multimodal meeting analysis using statistical techniques for people tracking [6], group action recognition [16], and meeting phase segmentation [2]. The instrumented meeting room used to record meeting data for many of these projects was developed at IDIAP [19]. Videos are captured with CCTV cameras recording at 720x576. Many of the recorded meetings were brief and scripted [2, 16] because the main purpose of the media recordings has been statistical analysis of low-level signals to improve speech and vision-based recognition. The AMI project (Augmented Multi-party Interaction), an overlapping successor of the M4 project, also has been researching multimodal technologies for supporting multi-person meetings. The smart meeting rooms at IDIAP and Edinburgh are being used to collect data for this project, to improve people tracking [4], meeting event segmentation [23], time-compression of speech [26], and detection of group interest level [5]. Again, the focus of most of this work has been improvement of engineering-level signal processing. As such, the data collected has involved brief and sometimes scripted human meetings with no computer assistance. The University of Twente, another partner of the AMI Project, has a separate instrumented meeting room for exploring the effects of different embodiments of computer meeting assistants [24]. Unlike the passive infrastructure at IDIAP, this environment includes interactive computer feedback to the meeting participants. To quickly prototype different forms of pro-active assistants, their data collection infrastructure included a simulation environment. Infrastructure in their room is described in [11]. There is a single camera and single microphone used by the “wizard” for observation during studies, and simulated computer feedback to the meeting participants was provided by a monitor and speakers. Since the assistant was performing complicated tasks requiring judgment, such as warning a speaker of being off-topic, unfortunately most of the participants realized that the system was a simulation [11] so the method itself did not support system credibility. On the CHIL project (Computers in the Human Interaction Loop), there is an instrumented seminar room at Universität Karlsruhe, in which audio and video are recorded during seminar presentations given by students [14, 28]. A presenter’s speech is recorded with a close-talking microphone and several microphone arrays. Video is recorded using four cameras, one in each corner of the meeting room. Most of the studies performed
with this corpus involve speech processing and recognition of monologues. Video processing for face recognition or lip reading would be difficult, because the videos are 640x480 and the presenter’s face is comprised of a fraction of those pixels. Another CHIL study used audio-visual data to identify intended addressee in human-human-robot interactions [9]. In this work, audio-visual data were recorded using a single camera and two microphones during interactions involving two humans. The National Institute of Standards and Technology (NIST), under the Smart Space project [20], has developed and made available both hardware and software components for the collection of audio-visual meeting data. Our group uses the Smart Flow data transport system. NIST also has an instrumented meeting room [17] in which seven high-resolution videos and over a dozen audio streams are recorded and synchronized. However, the NIST infrastructure does not include a simulation suite for prototyping novel system concepts. In reviewing the data collection and simulation systems, there was no single existing solution that satisfied our functional requirements as mentioned earlier, since each of these systems was built to achieve somewhat different goals. In the following sections, we describe our unique suite of prototyping, data collection, and analysis tools.
2. DATA COLLECTION SYSTEM The purpose of the data collection infrastructure is to capture several heterogeneous media streams in high fidelity to create a rich corpus of collaborative multimodal interactions. The infrastructure is designed to be an extensible and unobtrusive platform for capturing data that is semantically rich and precise. Additionally, it must allow the media streams to be observable as a session progresses to enable Wizard of Oz studies as well as the validation of different aspects of collected signal data.
Figure 1. Room layout of the meeting participants, computer assistant, and hardware components during data collection. During the summer of 2005, the data collection system was used to record the Peer-Tutoring Math Education Study corpus [12]. See Figure 1 for the room layout. The data collection system recorded five high-resolution videos, four audio sources, and three digital pens. The videos were captured using Pt. Grey
210

Scorpion firewire cameras with resolutions of 1024x768 at a frame-rate of 15 Hz. See Figure 2 for a collage of video frames taken at the same moment in time during an actual study. In addition, each of the three participants was fitted with a close-talking Countryman Isomax hypercardioid microphone. The fourth audio stream was from a room microphone hanging above the group. Digital ink was recorded with Nokia digital pens.
2.1 Video Data Processing The video data must be high resolution close-ups of the meeting participants to enable annotation of subtle cues such as direction of eye gaze, head nods, and facial expressions. Videos also needed to be tightly synchronized so that an annotation for one particular video segment would correspond to the same interval for all other video views during a given interaction. To accomplish this, the videos are recorded on three Unix machines with clocks synchronized via the Network Time Protocol (NTP). Each raw Bayer video frame is compressed by a method using Haar wavelet transformations with quadtree coding similar to
the technique in [27], resulting in about 50% compression. Every frame is timestamped and written to disk in an in-house media file format. A new output file is created every minute to avoid exceeding the maximum file size. The video collection software suite is composed of several software modules, each responsible for a particular task, e.g. frame-grabbing, color space conversion, video rendering, file writing, etc. Figure 3 is a flowchart illustrating the video capture process. The data streams are piped between modules using NIST Smart Flow [25]. Smart Flow is used to decompose the task of video collection into a number of specialized agents, each responsible for a specific task.
Essentially, Smart Flow is the infrastructure that permits agents to communicate with each other. It allows software modules to publish or subscribe to data flows of interest, such as RGB video or PCM audio. It effectively simplifies inter-process communication, especially for applications running on different machines.
Figure 2. A snapshot from each camera at the same moment during the meeting.
211

We are currently porting the video capture software to run on Windows because of a greater technical support base and increased code-reusability within our organization.
Figure 3. Data flow between video software components.
2.2 Ink Data Ink is an important modality to capture and process because it will support mobile multimodal interfaces, which exist outside of an instrumented room. Speech and ink bridge more easily to mobile applications, unlike video. A mobile user can use a digital pen and Bluetooth headset, whereas the availability of video sensors will be limited. Furthermore, ink is important for our current research because we aim to capture, process, and observe students’ existing work practice for geometry, which includes frequent diagramming and written symbols and digits. In our data collection, ink is captured by Nokia digital pens and is recorded and timestamped locally on the pen. When the pen is physically docked in a USB enclosure, the data is sent by Anoto components via COM to our software on the host machine, which saves it to disk in an XML file. Using Bluetooth, the pens also transmit ink data to workstations so that handwriting and sketches can be observed while data collection is in progress. We have not found any prior research that includes real-time ink for simulation-based studies. Unfortunately, there were frequent streaming ink failures during our first simulation study. Early in the meeting, some of the pens stopped transmitting for the rest of the session. We now believe these failures were caused by a weakening of the signal due to physical occlusions and distance.
Although our initial goal was to synchronize ink data with the audio and video streams, the pen-local timestamps were shown to be inaccurate by comparison with the other media streams and the PC clock of the host machine. We tested this by placing a camera inches from a sheet of digital paper to record a video of a pen stroke. The timestamp of the video frame when the pen nib touched the paper was compared with the timestamp taken by the pen for recording that stroke. The pen timestamps ranged from 60 to 100 seconds in the future. For these brief test recordings, the timestamps from the pen denote a later date than the creation date of the file that holds them, as timestamped by the operating system. This removes video recording from the loop and shows that the tests do not fail because of a bug in the video recording code. Further work will be required to effectively synchronize the ink with the other media streams. In future studies, we plan to use Logitech I/O pens since they offer
better synchronization than Nokia pens. Preliminary tests have indicated that no drift is present in the Logitech pens after one hour.
2.3 Audio Data It is important that we have high-quality audio signals with minimal cross-talk for studies we’re conducting on acoustic-prosodic changes during group communication (e.g, amplitude analyses [12]). We use Countryman Isomax close-talking microphones because they have a hypercardioid pickup pattern for noise-cancellation, and they are very light-weight and visually inconspicuous.
The audio signals from close-talking microphones worn by each meeting participant are transmitted wirelessly with a Shure UHF transmitter. The Shure receiver is connected to a MobilePre M-Audio USB external analog/digital converter. Using an external analog/digital converter, as opposed to an internal soundcard, eliminates electrical interference noise introduced by the machine. All audio streams are recorded with a single Windows XP machine using DirectSound into the same in-house file format as video. We record audio on Windows because of better soundcard support and the benefits of DirectSound, such as the automatic recognition of a range of sound cards and USB analog/digital converters, and the automatic buffering of incoming audio data. USB analog/digital converters allow us to record multiple audio streams on a single machine without having to install additional hardware.
2.4 Integration and Synchronization Upon completion of a session, the saved audio and video files are encoded to universally viewable MPEG-4 media streams. A video stream is paired with an audio stream to form a single media stream (e.g., for a close-up of a given meeting participant), and the different audio-visual streams all are synchronized for the entire meeting session.
The network of computers running the data collection software suite is comprised of machines running both Windows and Unix. The fundamental feature enabling this heterogeneous network of machines to work together as a single data collecting unit is that all machines periodically synchronize their clocks with NTP.
By recording data in our in-house file format, with a header containing rich meta-data for every frame, the streams can be synchronized with any input source which has a clock synchronized via NTP. This also means our infrastructure is extensible, and in the future could incorporate data from touch-sensitive white-boards, computer screenshots, slideshow presentations, sensors such as accelerometers, and other sources.
To estimate video-to-video synchronization fidelity, we examined manual contact with physical artifacts during videotaped data recordings, including different pair-wise combinations of cameras and also videos recorded on separate machines. We also took estimates both at the beginning and end of every recorded session, in order to estimate possible drift in synchronization. Videos were shown to be synchronized with a mean departure of 0.025 seconds, and to within one frame or 0.067 seconds for 100% of the cases. To estimate audio-to-video synchronization fidelity, we examined speakers producing
212

utterance-initial consonants (e.g., ‘p’). The audio and video signal were shown to be synchronized with a mean departure of 0.077 seconds, and to within two frames or 0.12 seconds for 80% of cases.
2.5 Unobtrusiveness of Data Collection Unobtrusiveness was a key characteristic for selecting the recording hardware to use in our infrastructure. The Pt. Grey Scorpion cameras have a 50mm x 50mm x 40mm form factor, which can be easily hidden on bookshelves or from the ceiling. The Countryman Isomax microphones are “flesh-colored” and are very thin and light. The audio is transmitted wirelessly to the computer, so participants are free to interact without being tethered by a wire. As shown in Figure 2, the participants’ shared tabletop workspace is completely free of recording devices, except for the calculators and digital pens and paper that mimic non-digital familiar materials used to solve math problems. Figure 4 shows the form factors for the camera, pen, and microphone used to capture multimodal data capture used for each participant.
Figure 4. Integration of data capture from each
participant’s video, audio, and ink input.
3. SIMULATION TOOLS A good simulation tool provides a flexible way to rapidly prototype new interfaces for human-computer interaction. Simulations allow the collection of empirical data to reveal performance tradeoffs for systems that have not yet been developed. Advance data is particularly important for prototyping collaborative teamwork applications, since evaluation of performance can be very challenging. Almost all previous simulation-based studies have involved individual user-computer interaction, rather than group collaborations. In any simulation, it’s important that subjects believe they are interacting with an automated system so their collaborations are natural and engaged, resulting in realistic data. To simulate a
real system in a credible way, the Wizard of Oz environment must permit the wizard to react quickly and accurately to participants’ actions. Furthermore, the system must not appear to be flawless. If it performs tasks known to be unsolved in commercial applications, such as perfect speech recognition and interpretation, then the participants will be suspicious that they are not interacting with a computer. During the simulation data collection sessions, the programmer assistant is able to monitor thirteen rich input streams, including six video streams, four audio streams, and three digital ink streams. For studies conducted to date, the wide-angle camcorder view of the whole room was most helpful to the programmer assistant during data collection in responding to human-human interactions, because it provided the best contextual information about the whole interaction. Likewise, the room microphone was most useful for following the group conversation, and the leader’s close-talking microphone was valuable for tracking specific requests to the system. The primary value of the real-time digital ink was off-line data analysis.
Figure 5. Screenshot of wizard client interface in which the answer and example solution for a geometry problem are
presented. The simulation suite is composed of a client and a server application. The client is the simulated front-end which serves as the interface with the meeting participants. The server is controlled by the programmer assistant, or “wizard”, and determines what is displayed by the client. Communication between the applications is facilitated by the Adaptive Agent Architecture [10]. When this simulation infrastructure was used to support the study in [12], the client simulated the interface to a computational math assistant that displayed geometry problems and their answers, as well as allowing participants to query the system for math terms, equations, example solutions, and so forth (for details see [12]). See Figure 5 for a screenshot of the client application as presented to a high school geometry student. The client displays problem bitmaps as dictated by the server, and it forwards participants’ requests to the server which allows the wizard to interact with them. See Figure 6 for a screenshot
213
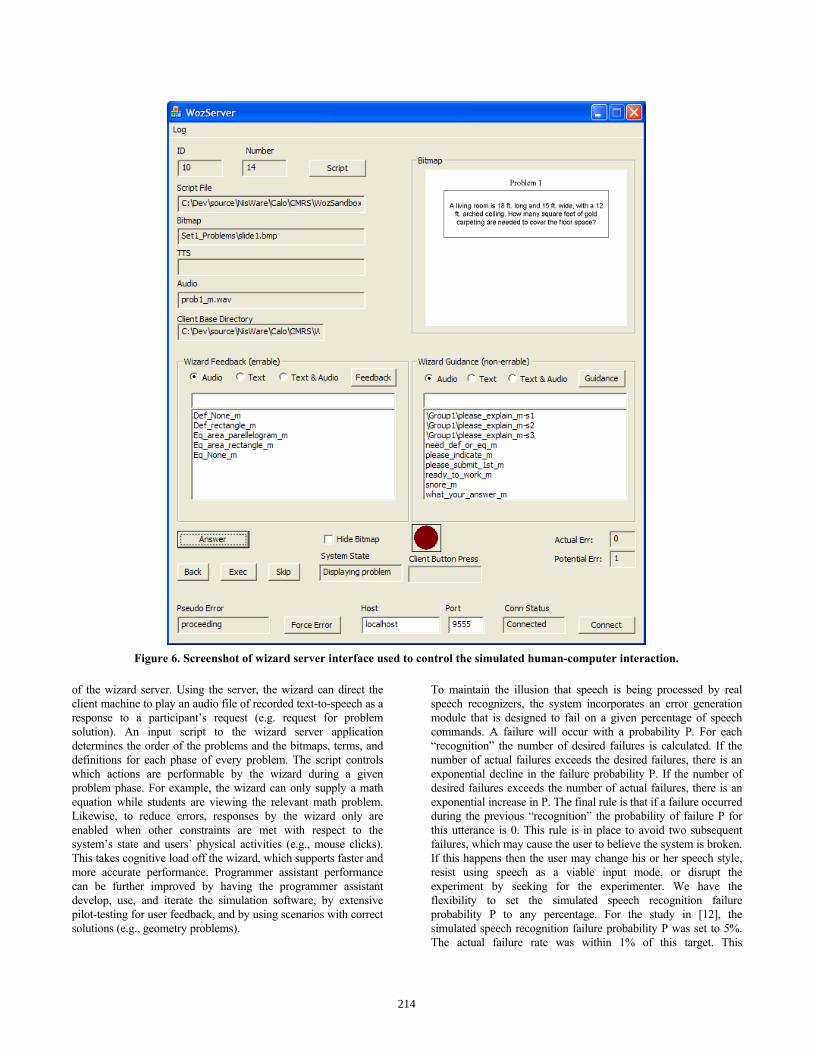
of the wizard server. Using the server, the wizard can direct the client machine to play an audio file of recorded text-to-speech as a response to a participant’s request (e.g. request for problem solution). An input script to the wizard server application determines the order of the problems and the bitmaps, terms, and definitions for each phase of every problem. The script controls which actions are performable by the wizard during a given problem phase. For example, the wizard can only supply a math equation while students are viewing the relevant math problem. Likewise, to reduce errors, responses by the wizard only are enabled when other constraints are met with respect to the system’s state and users’ physical activities (e.g., mouse clicks). This takes cognitive load off the wizard, which supports faster and more accurate performance. Programmer assistant performance can be further improved by having the programmer assistant develop, use, and iterate the simulation software, by extensive pilot-testing for user feedback, and by using scenarios with correct solutions (e.g., geometry problems).
To maintain the illusion that speech is being processed by real speech recognizers, the system incorporates an error generation module that is designed to fail on a given percentage of speech commands. A failure will occur with a probability P. For each “recognition” the number of desired failures is calculated. If the number of actual failures exceeds the desired failures, there is an exponential decline in the failure probability P. If the number of desired failures exceeds the number of actual failures, there is an exponential increase in P. The final rule is that if a failure occurred during the previous “recognition” the probability of failure P for this utterance is 0. This rule is in place to avoid two subsequent failures, which may cause the user to believe the system is broken. If this happens then the user may change his or her speech style, resist using speech as a viable input mode, or disrupt the experiment by seeking for the experimenter. We have the flexibility to set the simulated speech recognition failure probability P to any percentage. For the study in [12], the simulated speech recognition failure probability P was set to 5%. The actual failure rate was within 1% of this target. This
Figure 6. Screenshot of wizard server interface used to control the simulated human-computer interaction.
214

simulation suite was employed successfully by Lunsford and colleagues [12]. All participants thought they were interacting with a real automated system. The tool minimized cognitive load on the wizard, which allowed the wizard to successfully imitate a real system for sessions lasting as long as 81 minutes. In future work, the interaction between the Wizard of Oz environment and the data capture software will be more tightly coupled to allow system response decisions based on real-time signal analyses for simulating a user-adaptive multimodal assistant. To support these real-time analyses, we anticipate implementing a dual-wizard environment, in which one wizard monitors features of the signal (i.e. head position or vocal pitch), while the other wizard performs the traditional role of responding to the users’ interactions with the system. This will allow the system simulation to more efficiently mimic a mutually adaptive interface, in which the system recognizes and leverages each user’s natural interaction patterns. Prior work with dual-wizard systems can be found in [22].
4. ANALYSIS TOOLS The requirements for developing an effective annotation tool become more challenging as the number, variety, and fidelity of input sources increase. For example, if the annotation tool cannot play multiple high-resolution videos such that they remain synchronized then the benefits of capturing high fidelity videos are lost. As background, there are a number of annotation tools written in Java, such as MockBrow [1], NOMOS [7], TASX [18], Anvil [15], etc. Many of these tools use the Java Media Framework (JMF) for playing media. The JMF, the standard API for playing media in Java, does not have the performance to play several high resolution videos simultaneously without jittering or asynchrony. Unfortunately, most existing annotation tools have this shortcoming.
To enable the playback of multiple high-resolution videos, our group has created a general purpose media playback library. The Java interface to our library extends the JMF, so an annotation tool using the JMF needs few or no modifications to use our library. The client application makes the same calls it would to the JMF, but calls are redirected through the Java Native Interface (JNI) to control media players running on DirectX technology. DirectX is closer to the hardware than JMF (i.e. not platform-independent) and is better optimized for media playback.
This library has been successfully integrated into MockBrow, resulting in an application named MockBrowDS. The first version of MockBrowDS replaced the JMF with our DirectX video player. We have since augmented the MockBrow user interface to include a navigation bar which allows for slow/fast motion, frame-by-frame, and improved selection playback. Slow motion and frame-by-frame are useful for identifying the precise beginning of an event (e.g., an utterance). The playback of a selected clip of media was enhanced to maintain better synchrony with the annotator’s desired start and end times. If playback isn’t tight, then the beginning of an utterance can be cut off, for example. This augmented tool has been used to annotate selected utterances and interlocutor as reported in [12]. Our future plans for annotations include performance measures and physical gestures.
The media player library also has supported a second study [13], which examined human perception of an intended interlocutor
based on audio-visual cues. The library was integrated into an application which was used by subjects to identify intended addressee. Each session was driven by an XML file which determined the clips to play and the available modes (audio, video or both).
We are currently investigating a possible integration with NOMOS [7], a tool which stores annotations in a meeting ontology currently under active development by our collaborators. Re-usability such as this is a significant benefit of extending the JMF interface to implement our media player library.
5. CONCLUSION The suite of data collection, simulation, and analysis tools allows researchers in our group to perform collaborative multi-party, multimodal studies for the prototyping of future systems. The unobtrusiveness of the environment encourages natural and engaged interactions for prototyping multimodal adaptive systems that incorporate machine learning. To summarize, the highlights of our new suite of tools include:
• Simulation tool for prototyping a new generation of collaborative multimodal interaction
• Collection and analysis of multiple synchronized and high-fidelity media streams that represent heterogeneous information sources
• Inconspicuous and extensible data collection infrastructure for capturing video, audio, and ink without disturbing users’ existing work practice
• Media playback library for the synchronized playback of many high resolution videos
6. ACKNOWLEDGMENTS Thanks to Rachel Coulston, Xiao Huang, and Marisa Flecha-Garcia for experimental setup, to Erik Erikson for pen-related programming, to Steven Poitras and Barry Kliff for graphics, to Aaron Crandall and J.D. Harris for technical support, and to NIST for Smart Flow. This material is based upon work supported by NSF Grant No. IIS-0117868 and the Defense Advanced Research Projects Agency (DARPA) under Contract No. NBCHD030010. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the DARPA or the Department of Interior-National Business Center (DOI-NBC).
7. REFERENCES [1] Banerjee, S., Rose, C., & Rudnicky, A.I. The necessity of a
meeting recording and playback system and the benefit of topic-level annotations to meeting browsing. In Proceedings of the IFIP Interact'05: Human-Computer Interaction, 2005 (Rome, Italy). 3585, Springer Berlin/Heidelberg: 643-656.
[2] Dielmann, A. & Renals, S. Dynamic bayesian networks for meeting structuring. In Proceedings of ICASSP '04. 2004 (Montreal, Canada). 5, IEEE: V-629-32 vol.5.
[3] Falcon, V., Leonardi, C., Pianesi, F., Tomasini, D., & Zancanaro, M. Co-located support for small group meetings. Workshop on The Virtuality Continuum Revisited Workshop
215

held in conjunction with Computer-Human Interaction CHI2005 Conference, 2005 (Portland, OR).
[4] Gatica-Perez, D., Lathoud, G., Odobez, J.-M., & Mccowan, I. Multimodal multispeaker probabilistic tracking in meetings. In Proceedings of the 7th International Conference on Multimodal Interfaces, 2005 (Trento, Italy). ACM Press: 183-190.
[5] Gatica-Perez, D., Mccowan, I., Zhang, D., & Bengio, S. Detecting group interest-level in meetings. In Proceedings of ICASSP '05. 2005 (Philadelphia, PA). 1, IEEE: 489-492.
[6] Gatica-Perez, D., Odobez, J.-M., Ba, S., Smith, K., & Lathoud, G. Tracking people in meetings with particles. In Proceedings of the International Workshop on Image Analysis for Multimedia Interactive Services (WIAMIS), 2005, Instituto Superior Tecnico, Lisbon
[7] Gruenstein, A., Niekrasz, J., & Purver, M. Meeting structure annotation: Data and tools. In Proceedings of the 6th SIGdial Workshop on Discourse and Dialogue, 2005 (Lisbon, Portugal). 117-127.
[8] Huang, X., Oviatt, S., & Lunsford, R. Combining user modeling and machine learning to predict users’ multimodal integration patterns. In Proceedings of the 3rd Joint Workshop on Multimodal Interaction and Related Machine Learning Algorithms, 2006 (Washington DC, USA).
[9] Katzenmaier, M., Stiefelhagen, R., & Schultz, T. Identifying the addressee in human-human-robot interactions based on head pose and speech. In Proceedings of the 6th International Conference on Multimodal Interfaces, 2004 (State College, PA, USA). ACM Press: 144-151.
[10] Kumar, S., Cohen, P.R., & Levesque, H.J. The adaptive agent architecture: Achieving fault-tolerance using persistent broker teams. In Proceedings of the Fourth International Conference on Multi-Agent Systems (ICMAS 2000), 2000 (Boston, MA, USA). IEEE Press: 159-166.
[11] Kuperus, J. The effect of agents on meetings. In Proceedings of the The 4th Twente Student Conference on IT, 2006 (Enschede, The Netherlands). Twente University Press
[12] Lunsford, R., Oviatt, S., & Arthur, A. Toward open-microphone engagement for multiparty field interactions. In press, ICMI 2006.
[13] Lunsford, R. & Oviatt, S. Human perception of intended addressee in multiparty meetings. In press, ICMI 2006
[14] Macho, D., Padrell, J., Abad, A., Nadeu, C., Hernando, J., Mcdonough, J., Wölfel, M., Klee, U., Omologo, M., Brutti, A., Svaizer, P., Potamianos, G., & Chu, S.M. Automatic speech activity detection, source localization, and speech recognition on the CHIL seminar corpus. In Proceedings of the IEEE International Conference on Multimedia and Expo, 2005. ICME 2005., 2005 (Amsterdam, The Netherlands). IEEE: 876-879.
[15] Martin, J.-C. & Kipp, M. Annotating and measuring multimodal behaviour - tycoon metrics in the anvil tool. In Proceedings of the 3rd International Conference on
Language Resources and Evaluation (LREC 2002), 2002 (Las Palmas, Canary Islands, Spain).
[16] Mccowan, I., Gatica-Perez, D., Bengio, S., Lathoud, G., Barnard, M., & Zhang, D. Automatic analysis of multimodal group actions in meetings. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005 27, IEEE: 305-317.
[17] Michel, M. & Stanford, V. Synchronizing multimodal data streams acquired using commodity hardware. In submission.
[18] Milde, J.-T. & Gut, U. The TASX-environment: An xml-based corpus database for time aligned language data. In Proceedings of the IRCS Workshop on Linguistic Databases, 2001 (Pennsylvania, Philadelphia). 174-180.
[19] Moore, D., The IDIAP smart meeting room. IDIAP-COM 02-07, 2002.
[20] NIST smart space project. http://www.nist.gov/smartspace/ [21] Oviatt, S., Cohen, P., Fong, M., & Frank, M. A rapid semi-
automatic simulation technique for investigating interactive speech and handwriting. In Proceedings of the International Conference on Spoken Language Processing, 1992 (University of Alberta). 2, Quality Color Press, Edmonton, Canada: 1351-1354.
[22] Oviatt, S.L., Coulston, R., Tomko, S., Xiao, B., Lunsford, R., Wesson, M., & Carmichael, L. Toward a theory of organized multimodal integration patterns during human-computer interaction. In Proceedings of the International Conference on Multimodal Interfaces, 2003 (Vancouver, BC). ACM Press: 44-51.
[23] Reiter, S., Schreiber, S., & Rigoll, G. Multimodal meeting analysis by segmentation and classification of meeting events based on a higher level semantic approach. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005. Proceedings. (ICASSP '05). 2005 (Philadelphia, PA). 2, IEEE: 161-164.
[24] Rienks, R., Nijholt, A., & Barthelmess, P. Pro-active meeting assistants: Attention please. In Proceedings of the 5th Workshop on Social Intelligence Design, 2006 (Osaka, Japan).
[25] Stanford, V., Garofolo, J., Galibert, O., Michel, M., & Laprun, C. The NIST smart space and meeting room projects: Signals, acquisition annotation, and metrics. In Proceedings of ICASSP '03, 2003 4, IEEE: IV-736-9 vol.4.
[26] Tucker, S. & Whittaker, S. Novel techniques for time-compressing speech: An exploratory study. In Proceedings of ICASSP '05. 2005 (Philadelphia, PA). 1, IEEE: 477-480.
[27] White, R.L. & Percival, J.W. Compression and progressive transmission of astronomical images. The International Society for Optical Engineering, 2199: 703-713.
[28] Wölfel, M., Nickel, K., & Mcdonough, J. Microphone array driven speech recognition: Influence of localization on the word error rate. Joint Workshop on Multimodal Interaction and Related Machine Learning Algorithms, 2005 (Edinburgh). 3869: 320-331.
216