jitpr: a framework for supporting fast application's implementation onto fpgas
TRANSCRIPT

7
JITPR: A Framework for Supporting Fast Application’sImplementation onto FPGAs
HARRY SIDIROPOULOS and KOSTAS SIOZIOS, National Technical University of AthensPETER FIGULI, Karlsruhe Institute of TechnologyDIMITRIOS SOUDRIS, National Technical University of AthensMICHAEL HUBNER, Ruhr-University of BochumJURGEN BECKER, Karlsruhe Institute of Technology
The execution runtime usually is a headache for designers performing application mapping onto reconfig-urable architectures. In this article we propose a methodology, as well as the supporting toolset, targeting toprovide fast application implementation onto reconfigurable architectures with the usage of a Just-In-Time(JIT) compilation framework. Experimental results prove the efficiency of the introduced framework, as wereduce the execution runtime compared to the state-of-the-art approach on average by 53.5×. Additionally,the derived solutions achieve higher operation frequencies by 1.17×, while they also exhibit significant lowerfragmentation ratios of hardware resources.
Categories and Subject Descriptors: C.0 [Computer System Organization]: General—System architec-tures
General Terms: Algorithms, Design
Additional Key Words and Phrases: FPGA, just-in-time compilation, placement
ACM Reference Format:Sidiropoulos, H., Siozios, K., Figuli, P., Soudris, D., Hubner, M., and Becker, J. 2013. JITPR: A framework forsupporting fast application’s implementation onto FPGAs. ACM Trans. Reconfig. Technol. Syst. 6, 2, Article 7(July 2013), 12 pages.DOI: http://dx.doi.org/10.1145/2492185
1. INTRODUCTION
Field-Programmable Gate Arrays (FPGAs) have become the key implementationmedium for a large portion of digital circuits. However, as the complexity of targetcircuits and FPGAs increases, the effectiveness and efficiency of the employed CADtools become even more important. The complete end-to-end compile time of large FP-GAs is threatening to become so long that it may take a significant portion of a day tocompile, or even to declare failure of compilation.
Up to now, the task of application implementation onto FPGAs is mainly appliedduring the design phase of a project, since CAD algorithms impose mentionable runtimeoverhead. Techniques that accelerate core CAD algorithms can bring about important
Authors’ addresses: H. Sidiropoulos and K. Siozios (corresponding author), School of Electrical and ComputerEngineering, National Technical University of Athens, Greece; email: [email protected]; P. Figuli,Karlsruhe Institute of Technology, Karlsruhe, Germany; D. Soudris, School of Electrical and ComputerEngineering, National Technical University of Athens, Greece; M. Hubner, Ruhr-University of Bochum,Germany; J. Becker, Karlsruhe Institute of Technology, Karlsruhe, Germany.Permission to make digital or hard copies of part or all of this work for personal or classroom use is grantedwithout fee provided that copies are not made or distributed for profit or commercial advantage and thatcopies show this notice on the first page or initial screen of a display along with the full citation. Copyrights forcomponents of this work owned by others than ACM must be honored. Abstracting with credit is permitted.To copy otherwise, to republish, to post on servers, to redistribute to lists, or to use any component of thiswork in other works requires prior specific permission and/or a fee. Permissions may be requested fromPublications Dept., ACM, Inc., 2 Penn Plaza, Suite 701, New York, NY 10121-0701 USA, fax +1 (212)869-0481, or [email protected]© 2013 ACM 1936-7406/2013/07-ART7 $15.00
DOI: http://dx.doi.org/10.1145/2492185
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

7:2 H. Sidiropoulos et al.
PlacementRegion Finder
START
Proposed Framework (JITPR)
Configure FPGA
Bitstream Generation
Routing Update Utilized ResourcesInsert newapplication?
Execution phaseUtilized resources (XML) FastPR
Fig. 1. The proposed framework for performing fast application’s implementation onto FPGA devices.
changes in product design times for these applications, whereas many designers maybe willing to trade off some quality of the solution for an improved runtime of the CADtools. Towards this goal, a number of algorithms have been proposed in the last years,spanning from fast application’s placement [Wu and McElvain 2012], routing [Gort andAnderson 2011], as well as FPGA programming [Silva and Ferreira 2008].
Another challenging task for these algorithms affects the device fragmentation, as itintroduces constraints to the performance of upcoming applications. This task becomesfar more savage for high-density FPGAs since over the time, as a partially reconfig-urable device loads and unloads configurations, the hardware resources are likely tobecome fragmented. Existing approaches to this problem aim to identify a proper regionover the target architecture, with a sufficient amount of contiguous nonutilized hard-ware resources, in advance of placing a new configuration data [Siozios et al. 2010].Even though these solutions enable designers to adapt FPGA’s functionality underruntime constraints, the applications are handled as precomputed macroblocks, withfixed width and height, leading to increased fragmentation ratios. For this purpose,relevant approaches mainly incorporate techniques targeting to perform bitstreamreallocation [Flynn et al. 2009].
In order to address this limitation, throughout this article we introduce a novelmethodology targeting to perform fast application’s implementation onto FPGAs. Thegoal of this approach is to reduce considerably the runtime overhead with the minimumpossible performance degradation. Towards this direction rather than identifying loca-tions with sufficient empty area of contiguous nonutilized slices (as relevant approachesdo), where the precomputed at design-time configuration files will be assigned to, wepropose the usage of a Just-In-Time (JIT) compilation framework. Specifically, the con-figuration data for our framework is computed at runtime by performing application’splacement, routing, and bitstream generation.
The rest of the article is organized as follows: Section 2 describes the proposed JITPRframework, whereas the supporting algorithms are discussed in Section 3. Experimen-tal results that show the efficiency of the introduced solution are discussed in Section 4.Finally, conclusions are summarized in Section 5.
2. PROPOSED FRAMEWORK
This section describes the proposed framework, depicted in Figure 1, for supportingfast application implementation onto FPGA devices. Whenever a new application hasto be mapped onto the target architecture, its netlist is fed as input to our introducedJITPR framework. The first task in our framework deals with the application’s floorplantargeting to derive the most suitable region over the FPGA, where the new applicationwill be implemented. As we will discuss later, this is a critical step in order to preserveboth the minimum fragmentation ratio and the maximization of performance. Then,
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

JITPR: A Framework for Supporting Fast Application Implementation 7:3
application’s netlist is placed and routed (P&R) at the selected region. Since additionalapplications might be already mapped onto the reconfigurable device, our frameworkhas to be aware of the available (nonutilized) resources at the selected region. Forthis purpose, our framework takes as input an XML file that describes the occupiedresources (logic, I/O, or routing) over the FPGA device, whereas the granularity of thisdescription is at slice level.
At this step, we have all the necessary information to compute the partial bitstreamfile for the new application. However, in advance of proceeding to device reconfigura-tion, we appropriately annotate the XML file in order to represent the current stateof utilized resources by taking into account also the resources required by the newapplication. Finally the corresponding configuration file is generated and the FPGAis programmed with the new application. Additional details about how we apply thistechnique can be found in Hubner et al. [2011].
On the other hand, whenever an application has to be deallocated from the recon-figurable device, we appropriately update the XML file by eliminating these entries(mark these resources as nonutilized). Then, the corresponding slices are configured as“empty”. Different approaches could be employed for realizing this task (e.g., programthese slices with an empty bitstream file), whereas the selected approach has to takeinto consideration inherent constraints posed by the underline FPGA device. For in-stance, regarding our platform, it has to be able to provide reconfiguration at fine-grain(slice) level [Hubner et al. 2011].
The task of fast application implementation with the usage of JIT framework issoftware supported by an open-source toolset, named NAROUTO [Sidiropoulos et al.2012a]. Even though one might expect that application’s P&R and bitstream generationwill introduce mentionable overheads both in terms of execution runtime and thequality of derived results, such a conclusion is not derived based on the experimentalresults provided in Section 4. Moreover, the introduced JIT framework imposes theminimum possible fragmentation, since it does not require contiguous area of empty(nonutilized) hardware resources for performing application implementation.
3. SUPPORTING TOOLFLOW
This section describes in more detail the employed algorithms for supporting the fastapplication’s implementation onto the target architecture. Even though previous anal-ysis indicates that if the architectural parameters of underline FPGA are predefined,then placer is by far the most time-consuming algorithm [Sidiropoulos et al. 2012b],throughout this section we discuss three orthogonal approaches. More specifically,initially we introduce the RegionFinder tool, targeting to identify the most suitableregion of the FPGA for application realization. Next, we describe the improvement tothe placer targeting to reduce execution runtime, whereas the last subsection providesthe modifications to the employed router for balancing execution runtime with qualityof derived solutions.
3.1. JIT RegionFinder
The first tool in our proposed JITPR compilation framework is the RegionFinder.This tool is applied in advance of application’s placement in order to identify themost suitable spatial location over the device, where the new application has to bemapped.
In contrast to relevant approaches dealing with the floorplanning problem, the goalsof the introduced solution are twofold: (i) to achieve better utilization of available re-sources, and (ii) to reduce the execution runtime for performing application’s P&R.Towards this direction, instead of trying to identify regular (usually with rectangu-lar or square shape) regions of contiguous unutilized resources, similar to relevant
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

7:4 H. Sidiropoulos et al.
The seed area Bounding box (Seed 1)
Bounding box (Seed 2) Bounding box (Seed 3)
Seed 2
1:1
1:2
Seed 3
Seed 1
2:1
(b)(a)
Unutilized slice
(Seed 2)
Seed
(Seed 3)(Seed 1)
Utilized slice (from previous applications)
Fig. 2. Example of applying RegionFinder tool: (a) distribution of seeds; and (b) expansion of seeds.
approaches, the RegionFinder tool incorporates an advanced heuristic methodologytargeting to quantify simultaneously multiple candidate regions over the target archi-tecture.
The inputs to the RegionFinder tool are the application’s netlist, as well as twoXML files that describe the target architecture (e.g., array size, channel width, etc.)and the utilized resources (both logic and routing) from the designs already mappedonto the FPGA, respectively. Similarly, the output from this analysis is a region whichincludes only the necessary amount of hardware resources (e.g., logic and I/O blocks),leading to lower fragmentation ratios compared to relevant approaches. The introducedalgorithm, in contrast to relevant approaches, does not introduce any blockages tothe upcoming applications, since it reserves only the actually needed (for applicationimplementation) hardware resources, while it can also derive regions with irregularshapes.
The functionality of RegionFinder tool can be described as follows: Initially, thealgorithm assigns a number of uniformly distributed seeds across the FPGA, as theyare depicted with red color boxes in Figure 2(a). The number of seeds, the seeds’ size,as well as the distance between two consecutive seeds are tuned at runtime, sincetheir selection is affected by the availability of hardware resources onto the targetarchitecture and the performance requirements (more seeds lead to higher performancebut with increased computational cost).
Then, each of the seeds is expanded towards x and y directions following three ratios(1:1, 1:2, and 2:1). This expansion is applied repeatedly until the seeds include sufficientamount of hardware resources for performing application’s implementation. Note thatduring this task, the RegionFinder tool is aware of the utilized resources from previousdesigns. For demonstration purposes, Figure 2(b) shows how the RegionFinder toolretrieves three candidate regions (depicted with different colors) by expanding thecorresponding seeds with ratios 1:1, 1:2, and 2:1, respectively. At this figure, we havealso highlighted the bounding box for these candidate regions.
The selection of most suitable region is performed by quantifying the efficiency ofalternative seeds, based on the cost function depicted in Eq. (1). We have
Cost = a × (URSeed Area) + (1 − a) × (URBounding Box), (1)
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

JITPR: A Framework for Supporting Fast Application Implementation 7:5
where
URSeed Area =(
Utilized CLBsTotal CLBs at Seed Area
+ Utilized IOsTotal IOs at Seed Area
)(2)
URBounding Box =(
Utilized CLBs at Bounding BoxTotal CLBs at Bounding Box
+ Utilized IOs at Bounding BoxTotal IOs at Bounding Box
).
(3)The weighting factor a balances the effort for optimizing either the implementation
of current, or the up-coming applications, onto the reconfigurable architecture. Morespecifically, whenever the framework is tuned with a high a value, then the applica-tion’s implementation is as compact as possible, leading to the maximum performanceenhancement; however, there are some penalties in terms of resource fragmentation.On the other hand, lower value of a parameter corresponds to designs with the min-imum possible bounding box, which in turn improves the routability of up-comingapplications that will be mapped onto the target architecture, but it imposes a control-lable penalty at the application’s performance. We have to clarify that the boundingbox corresponds to the minimum box that surrounds all the utilized resources fromprevious designs, as well as the resources belonging to the seed area. Consequently,by appropriately selecting the value of a factor, it is possible to provide an acceptabletrade-off between these two competitive implementation scenarios. For the scopes ofthis article, the value of weighting factor a is set to 0.7.
Another parameter that has to be studied for the new tool affects its runtime over-head. The complexity of RegionFinder is O(n × √ n
m), where n denotes the numberof slices found in the target architecture and m is the number of slices required forapplication implementation.
3.2. JIT Placer
The next task in our framework involves the JIT placer, which assigns the applica-tion’s functionalities to specific spatial locations inside the region already derived fromRegionFinder tool, in a way that these blocks can be successfully interconnected witha subsequent routing step given the available routing resources. For this purpose, ourplacer incorporates also a technique to rapidly estimate localized routability inside aregion [Betz et al. 1999].
The functionality of our placer is based on a fast simulated annealing approach,similar to the one employed at the VPR tool [Betz et al. 1999]. An initial logic blockplacement is progressively optimized by swapping pairs of blocks, having as goal tofind an intermediate placement with lower overall cost. Greedy acceptance of costimprovements frequently leads to intermediate placements that, while locally optimal,are dependent on the order in which blocks are swapped and may be far from theglobally optimal solution. Annealing algorithms are characterized by their acceptanceof not only lower-cost permutations of logic blocks but also by their acceptance of apercentage of higher-cost permutations at various points in the progression of thealgorithm to avoid premature convergence to local placement minima.
Figure 3 gives the execution runtime for placing alu4 benchmark with the VPRtool onto a given FPGA device. As we can conclude from this figure, the “try swap”function is by far the most time-consuming kernel, as it takes almost 89.5% of the totalexecution time. Even though the inherent computational complexity of this function islow enough, it is called almost 36 × 106 times.
All the public available placers based on simulated annealing perform b × NRblocks
swaps per temperature value, where Nblocks is the number of blocks (logic and I/O)
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

7:6 H. Sidiropoulos et al.
89.53% of the totalexecu�on run-�me
main
100.00%
place_and_route
99.94%
10.10%
try_route
89.65%
try_place
try_�ming_driven_route
9.30% 86.53%
try_swap
8.79%
update_bb
5.92%
get_net_cost get_non_updateable_bb
6.07%
comp_td_point_to_point_delay
15.00%
�ming_driven_route_net
9.27%
Fig. 3. Profiling results for placing alu4 benchmark with VPR tool.
employed by the design, whereas b = 10 and R = 4/3. In Betz et al. [1999], Betzsuggests that the constant factor of 10 can be scaled to balance placer’s runtime withquality, while complementary approaches towards this goal include the reduction of theannealing start temperature and the change of the annealing schedule [Tessier 2002].
Towards this direction, it could be possible to alleviate the runtime overhead duringplacement by reducing the amount of times that this function is called; however, in sucha case we have to study the impact of this selection to the performance degradation.More specifically, the proposed placer uses b = 1.0 and R = 1.0 (performs Nblocksswaps of logic blocks per temperature value). Regarding the alu4 benchmark depictedin Figure 3, such a selection leads to reduce the number of calling the “try swap”function about 30×. Additionally, based on results summarized in up-coming section,the previously mentioned reduction of swaps per temperature value leads to significantlower execution runtime without sacrificing the quality of derived placements.
3.3. JIT Router and Bitstream Generation
Apart from the placer, our JIT framework incorporates a router for creating con-nected paths from net sources to net destinations. The employed router is based onthe PathFinder negotiated congestion algorithm [McMurchie and Ebeling 1995], usedin VPR tool, however, it was tuned for faster execution times. Specifically two parame-ters of the router’s algorithm were tuned towards this direction.
—We have changed the cost for channel overuse. Specifically, we have replaced thedefault value found in original VPR (equals to 0.5) with an excessively high value(10,000). This selection forces the algorithm to derive a legal routing from the firstpass, and consequently in most of the cases, the router does not have to rip andreroute this path.
—We have restricted the algorithm to search for valid routing paths only inside thebounding box (includes area equal to Bx × By slices), instead of the original VPR,where a net could be routed inside an area of (Bx + 3) × (By + 3) slices. This selectionreduces the exploration space during routing by a factor of Bx×By
(Bx+3)×(By+3) , where Bx
and By are the horizontal and vertical dimensions, respectively, of bounding box fora given network.
By incorporating these differentiations, we force the employed algorithm to improveconsiderably the execution runtime, but with an expected penalty in performancedegradation, due to the lower effort for optimizing the routing path (e.g., it is formedwith more interconnection resources). After successful application’s P&R, we have
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

JITPR: A Framework for Supporting Fast Application Implementation 7:7
Fig. 4. Impact of R to the placer’s execution runtime and maximum frequency for the alu4 benchmark.
available all the necessary input files for computing configuration data. However, sincethe task of bitstream generation involves also a number of device-oriented parametersto be defined, the FPGA programming is beyond the scopes of this article. Additionaldetails about the employed bitstream generator can be found in Siozios et al. [2010].
4. EXPERIMENTAL RESULTS
This section provides a number of comparisons that prove the efficiency of the proposedJIT framework, as compared to relevant approaches. Since the most time-consumingtask at this procedure affects the application’s placement [Sidiropoulos et al. 2012b],throughout this article the emphasis is to quantify the two complementary tools,named RegionFinder and FastPR (dealing with application’s placement, routing, andbitstream generation), against state-of-the-art VPR tool [Betz et al. 1999]. Unfortu-nately, it is not possible to provide comparisons against the relevant tools discussed inrelated work, since they are not publicly available. For this analysis, we employ the20 biggest MCNC benchmarks [Yang 1991], which are widely accepted in the FPGAcommunity. Regarding the target architecture, it is an island-style FPGA consisting ofan array of 150×150 slices and 50 tracks per routing channel.
Figure 4 plots the variation of execution runtime for performing application’s place-ment as a function of the power “R” (discussed in Section 3.2). Even though the resultssummarized in this figure affect the alu4 benchmark, they are similar for the entirebenchmark suite. Based on this figure, we can conclude that the gradient of executionruntime is almost zero for values of R up to 1.0, whereas for larger values of R, there isan exponential increment. Specifically, the introduced placer (R = 1.0) achieves about10× lower execution runtime as compared to the VPR tool (where R = 1.33).
Even though one might assume that such a speedup comes with mentionableperformance degradation, this is not depicted in Figure 4, where the maximumoperation frequency is almost constant between the two alternative tools. Morespecifically, based on our exploration we found that for R values higher than 0.9, thereis a saturation effect in maximum operation frequency, since the placer does not leadto higher-quality solutions.
In order to quantify the impact of the proposed framework to the application’s perfor-mance, Table I provides the execution runtime for performing placement, routing, and
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.
7:8 H. Sidiropoulos et al.
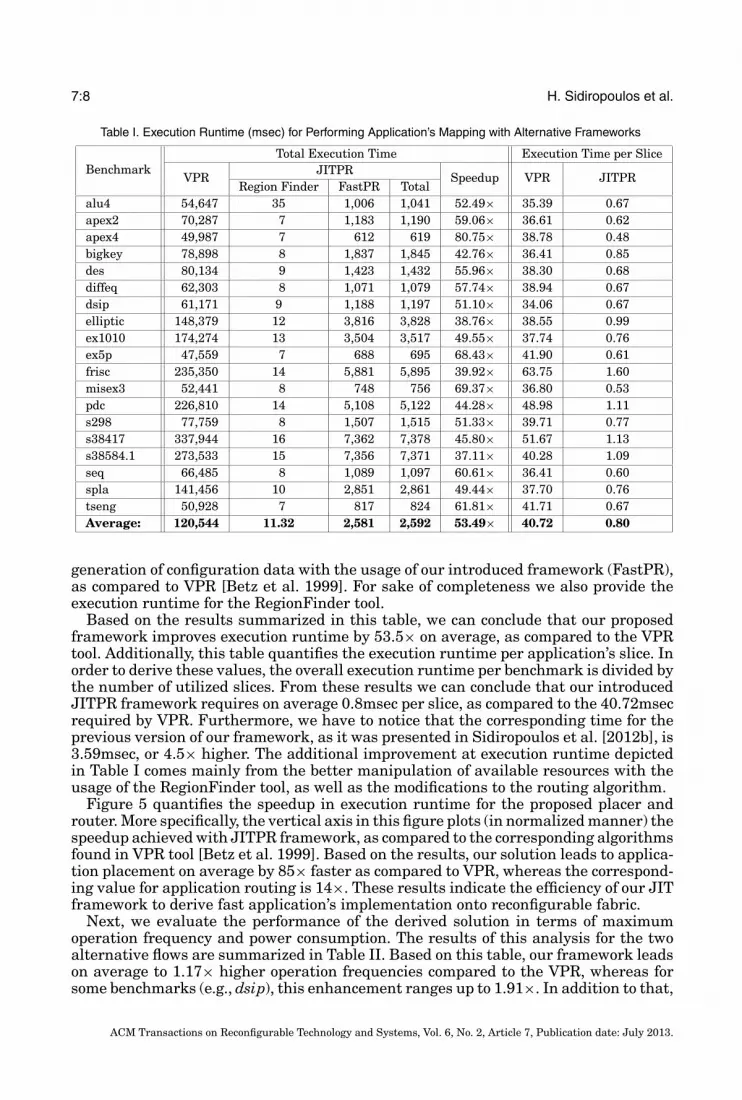
Table I. Execution Runtime (msec) for Performing Application’s Mapping with Alternative Frameworks
BenchmarkTotal Execution Time Execution Time per Slice
VPRJITPR
Speedup VPR JITPRRegion Finder FastPR Total
alu4 54,647 35 1,006 1,041 52.49× 35.39 0.67apex2 70,287 7 1,183 1,190 59.06× 36.61 0.62apex4 49,987 7 612 619 80.75× 38.78 0.48bigkey 78,898 8 1,837 1,845 42.76× 36.41 0.85des 80,134 9 1,423 1,432 55.96× 38.30 0.68diffeq 62,303 8 1,071 1,079 57.74× 38.94 0.67dsip 61,171 9 1,188 1,197 51.10× 34.06 0.67elliptic 148,379 12 3,816 3,828 38.76× 38.55 0.99ex1010 174,274 13 3,504 3,517 49.55× 37.74 0.76ex5p 47,559 7 688 695 68.43× 41.90 0.61frisc 235,350 14 5,881 5,895 39.92× 63.75 1.60misex3 52,441 8 748 756 69.37× 36.80 0.53pdc 226,810 14 5,108 5,122 44.28× 48.98 1.11s298 77,759 8 1,507 1,515 51.33× 39.71 0.77s38417 337,944 16 7,362 7,378 45.80× 51.67 1.13s38584.1 273,533 15 7,356 7,371 37.11× 40.28 1.09seq 66,485 8 1,089 1,097 60.61× 36.41 0.60spla 141,456 10 2,851 2,861 49.44× 37.70 0.76tseng 50,928 7 817 824 61.81× 41.71 0.67Average: 120,544 11.32 2,581 2,592 53.49× 40.72 0.80
generation of configuration data with the usage of our introduced framework (FastPR),as compared to VPR [Betz et al. 1999]. For sake of completeness we also provide theexecution runtime for the RegionFinder tool.
Based on the results summarized in this table, we can conclude that our proposedframework improves execution runtime by 53.5× on average, as compared to the VPRtool. Additionally, this table quantifies the execution runtime per application’s slice. Inorder to derive these values, the overall execution runtime per benchmark is divided bythe number of utilized slices. From these results we can conclude that our introducedJITPR framework requires on average 0.8msec per slice, as compared to the 40.72msecrequired by VPR. Furthermore, we have to notice that the corresponding time for theprevious version of our framework, as it was presented in Sidiropoulos et al. [2012b], is3.59msec, or 4.5× higher. The additional improvement at execution runtime depictedin Table I comes mainly from the better manipulation of available resources with theusage of the RegionFinder tool, as well as the modifications to the routing algorithm.
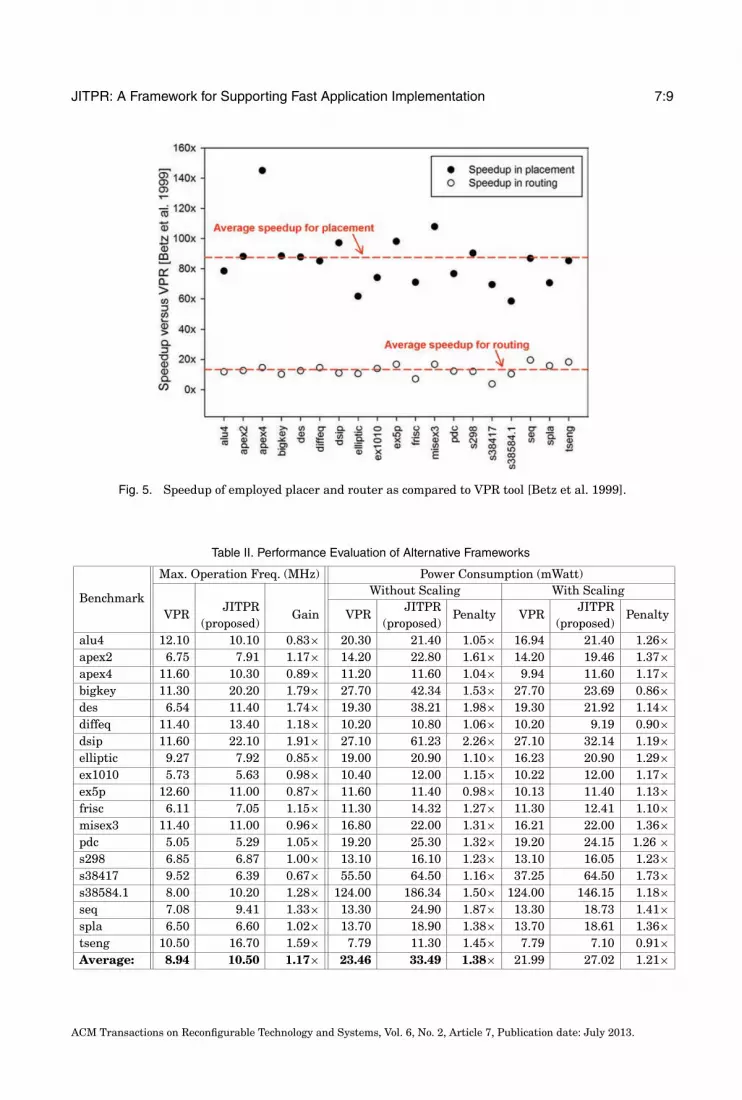
Figure 5 quantifies the speedup in execution runtime for the proposed placer androuter. More specifically, the vertical axis in this figure plots (in normalized manner) thespeedup achieved with JITPR framework, as compared to the corresponding algorithmsfound in VPR tool [Betz et al. 1999]. Based on the results, our solution leads to applica-tion placement on average by 85× faster as compared to VPR, whereas the correspond-ing value for application routing is 14×. These results indicate the efficiency of our JITframework to derive fast application’s implementation onto reconfigurable fabric.
Next, we evaluate the performance of the derived solution in terms of maximumoperation frequency and power consumption. The results of this analysis for the twoalternative flows are summarized in Table II. Based on this table, our framework leadson average to 1.17× higher operation frequencies compared to the VPR, whereas forsome benchmarks (e.g., dsip), this enhancement ranges up to 1.91×. In addition to that,
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.
JITPR: A Framework for Supporting Fast Application Implementation 7:9
Fig. 5. Speedup of employed placer and router as compared to VPR tool [Betz et al. 1999].
Table II. Performance Evaluation of Alternative Frameworks
Benchmark
Max. Operation Freq. (MHz) Power Consumption (mWatt)Without Scaling With Scaling
VPRJITPR
Gain VPRJITPR
Penalty VPRJITPR
Penalty(proposed) (proposed) (proposed)
alu4 12.10 10.10 0.83× 20.30 21.40 1.05× 16.94 21.40 1.26×apex2 6.75 7.91 1.17× 14.20 22.80 1.61× 14.20 19.46 1.37×apex4 11.60 10.30 0.89× 11.20 11.60 1.04× 9.94 11.60 1.17×bigkey 11.30 20.20 1.79× 27.70 42.34 1.53× 27.70 23.69 0.86×des 6.54 11.40 1.74× 19.30 38.21 1.98× 19.30 21.92 1.14×diffeq 11.40 13.40 1.18× 10.20 10.80 1.06× 10.20 9.19 0.90×dsip 11.60 22.10 1.91× 27.10 61.23 2.26× 27.10 32.14 1.19×elliptic 9.27 7.92 0.85× 19.00 20.90 1.10× 16.23 20.90 1.29×ex1010 5.73 5.63 0.98× 10.40 12.00 1.15× 10.22 12.00 1.17×ex5p 12.60 11.00 0.87× 11.60 11.40 0.98× 10.13 11.40 1.13×frisc 6.11 7.05 1.15× 11.30 14.32 1.27× 11.30 12.41 1.10×misex3 11.40 11.00 0.96× 16.80 22.00 1.31× 16.21 22.00 1.36×pdc 5.05 5.29 1.05× 19.20 25.30 1.32× 19.20 24.15 1.26 ×s298 6.85 6.87 1.00× 13.10 16.10 1.23× 13.10 16.05 1.23×s38417 9.52 6.39 0.67× 55.50 64.50 1.16× 37.25 64.50 1.73×s38584.1 8.00 10.20 1.28× 124.00 186.34 1.50× 124.00 146.15 1.18×seq 7.08 9.41 1.33× 13.30 24.90 1.87× 13.30 18.73 1.41×spla 6.50 6.60 1.02× 13.70 18.90 1.38× 13.70 18.61 1.36×tseng 10.50 16.70 1.59× 7.79 11.30 1.45× 7.79 7.10 0.91×Average: 8.94 10.50 1.17× 23.46 33.49 1.38× 21.99 27.02 1.21×
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.
7:10 H. Sidiropoulos et al.
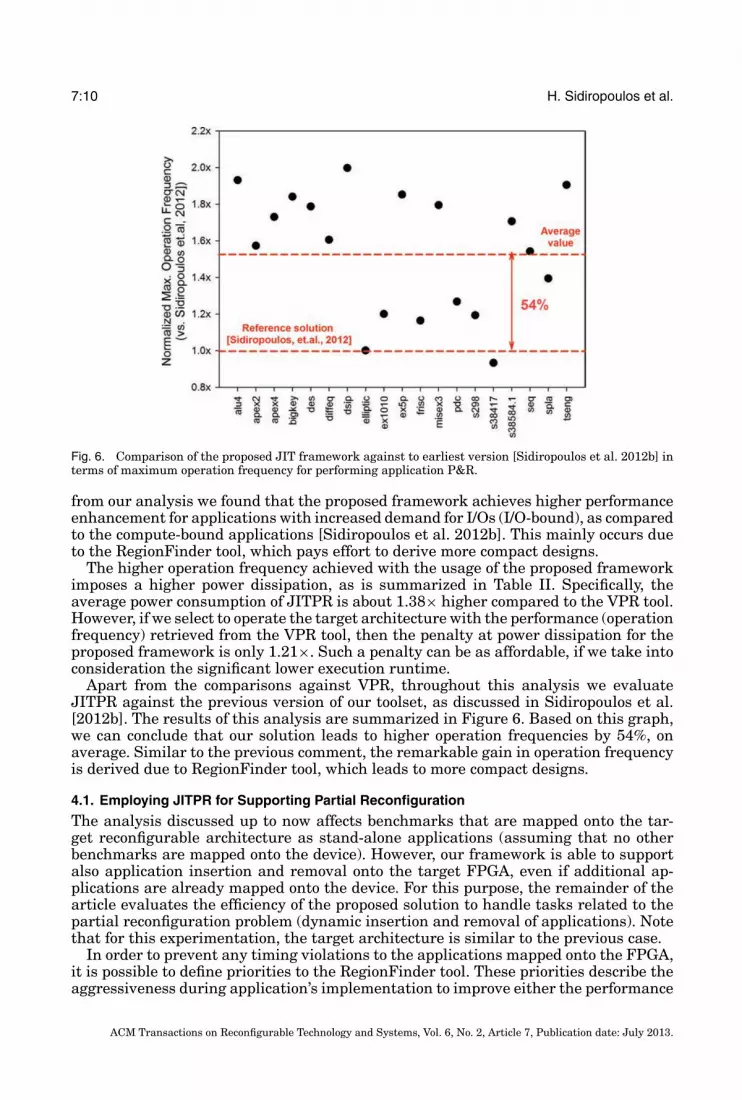
Fig. 6. Comparison of the proposed JIT framework against to earliest version [Sidiropoulos et al. 2012b] interms of maximum operation frequency for performing application P&R.
from our analysis we found that the proposed framework achieves higher performanceenhancement for applications with increased demand for I/Os (I/O-bound), as comparedto the compute-bound applications [Sidiropoulos et al. 2012b]. This mainly occurs dueto the RegionFinder tool, which pays effort to derive more compact designs.
The higher operation frequency achieved with the usage of the proposed frameworkimposes a higher power dissipation, as is summarized in Table II. Specifically, theaverage power consumption of JITPR is about 1.38× higher compared to the VPR tool.However, if we select to operate the target architecture with the performance (operationfrequency) retrieved from the VPR tool, then the penalty at power dissipation for theproposed framework is only 1.21×. Such a penalty can be as affordable, if we take intoconsideration the significant lower execution runtime.
Apart from the comparisons against VPR, throughout this analysis we evaluateJITPR against the previous version of our toolset, as discussed in Sidiropoulos et al.[2012b]. The results of this analysis are summarized in Figure 6. Based on this graph,we can conclude that our solution leads to higher operation frequencies by 54%, onaverage. Similar to the previous comment, the remarkable gain in operation frequencyis derived due to RegionFinder tool, which leads to more compact designs.
4.1. Employing JITPR for Supporting Partial Reconfiguration
The analysis discussed up to now affects benchmarks that are mapped onto the tar-get reconfigurable architecture as stand-alone applications (assuming that no otherbenchmarks are mapped onto the device). However, our framework is able to supportalso application insertion and removal onto the target FPGA, even if additional ap-plications are already mapped onto the device. For this purpose, the remainder of thearticle evaluates the efficiency of the proposed solution to handle tasks related to thepartial reconfiguration problem (dynamic insertion and removal of applications). Notethat for this experimentation, the target architecture is similar to the previous case.
In order to prevent any timing violations to the applications mapped onto the FPGA,it is possible to define priorities to the RegionFinder tool. These priorities describe theaggressiveness during application’s implementation to improve either the performance
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

JITPR: A Framework for Supporting Fast Application Implementation 7:11
(a)
(b)Fig. 7. Evaluation of the proposed framework when multiple applications are mapped onto the FPGA interms of: (a) maximum operation frequency and (b) power consumption.
(i.e., operation frequency, power consumption) or the execution runtime. For this article,we assume that all the benchmarks are of the same importance.
The results of this analysis are summarized in Figure 7. More specifically,Figures 7(a) and 7(b) plot the maximum operation frequency and power consumption,respectively, when multiple applications are mapped onto the FPGA. For demonstrationpurposes, both of these figures are plotted in normalized manner over the correspondingresults depicted at Table II (regarding a single application implementation).
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.

7:12 H. Sidiropoulos et al.
Based on the results summarized in these figures, we can conclude that the averagemaximum operation frequency and power consumption achieved by the introducedsolution is 0.86× and 0.90×, respectively, as compared to the corresponding valuesdiscussed previously in Table II. These penalties mainly occur due to the routingblockages posed by the applications that are already mapped onto the reconfigurabledevice. Even though these results indicate a performance degradation as compared toVPR tool, we have to take into consideration the significant lower fragmentation ratio,which in turn enables additional applications to be mapped onto the target FPGA.
5. CONCLUSIONS
A novel software-supported framework for performing Just-In-Time (JIT) compilationfor FPGA-based designs was introduced in this article. Rather than similar approaches,which deal mostly with precomputed configuration files, our introduced JITPR frame-work performs application implementation at runtime, leading to negligible fragmen-tation problems. Through our experimentation, we showed that the proposed solu-tion achieves an average speedup to the application’s P&R by 53.5×, as compared tothe state-of-the-art VPR tool, whereas for specific benchmarks this gain ranges up to80.75×. Even though someone might expect that these gains come with performancedegradation, the JITPR achieves on average 1.17× higher operation frequency.
REFERENCES
BETZ, V., ROSE, J., AND MARQUARDT, A., EDS. 1999. Architecture and CAD for Deep-Submicron FPGAs. KluwerAcademic Publishers, Norwell, MA.
FLYNN, A., GORDON-ROSS, A., AND GEORGE, A. 2009. Bitstream relocation with local clock domains for partiallyreconfigurable fpgas. In Proceedings of the Conference Exhibition on Design, Automation Test in Europe(DATE’09). 300–303.
GORT, M. AND ANDERSON, J. 2011. Reducing fpga router run-time through algorithm and architecture. InProceedings of the International Conference on Field Programmable Logic and Applications (FPL’11).336–342.
HUBNER, M., FIGULI, P., GIRARDEY, R., SOUDRIS, D., SIOZIOS, K., AND BECKER, J. 2011. A heterogeneous multicoresystem on chip with run-time reconfigurable virtual fpga architecture. In Proceedings of the IEEE Inter-national Symposium on Parallel and Distributed Processing Workshops and PhD Forum (IPDPSW’11).IEEE Computer Society, 143–149.
MCMURCHIE, L. AND EBELING, C. 1995. Pathfinder: A negotiation-based performance-driven router for fpgas. InProceedings of the 3rd ACM International Symposium on Field-Programmable Gate Arrays. (FPGA’95).ACM Press, New York, 111–117.
SIDIROPOULOS, H., SIOZIOS, K., AND SOUDRIS, D. 2012a. On supporting rapid exploration of memory hierarchiesonto fpgas. J. Syst. Archit. Embed. Syst. Des. 59, 2, 78–90.
SIDIROPOULOS, H., SIOZIOS, K., FIGULI, P., SOUDRIS, D., AND HUBNER, M. 2012b. On supporting efficient partialreconfiguration with just-in-time compilation. In Proceedings of the 26th IEEE International Paralleland Distributed Processing Symposium Workshops and PhD Forum (IPDPSW’12). 328–335.
SILVA, M. AND FERREIRA, J. 2008. Generation of partial fpga configurations at run-time. In Proceedings of theInternational Conference on Field Programmable Logic and Applications (FPL’08). 367–372.
SIOZIOS, K., SOUDRIS, D., AND THANAILAKIS, A. 2010. A novel allocation methodology for partial and dynamicbitstream generation of fpga architectures. J. Circ. Syst. Comput. 19, 3, 701–717.
TESSIER, R. 2002. Fast placement approaches for fpgas. ACM Trans. Des. Autom. Electron. Syst. 7, 2, 284–305.WU, Q. AND MCELVAIN, K. S. 2012. A fast discrete placement algorithm for fpgas. In Proceedings of the
ACM/SIGDA International Symposium on Field Programmable Gate Arrays (FPGA’12). ACM Press,New York, 115–118.
YANG, S. 1991. Logic synthesis and optimization benchmarks user guide version 3.0. Tech. rep., Microcenterof North Carolina.
Received September 2012; revised January 2013; accepted April 2013
ACM Transactions on Reconfigurable Technology and Systems, Vol. 6, No. 2, Article 7, Publication date: July 2013.