exploiting hpc for hep workloads - cern indico
TRANSCRIPT

1
Exploiting HPC for HEP workloads
● ATLAS centric view● Short-term: this and maybe next generation HPC
- Rod Walker, LMU Munich15th July 2016

2
Why HEP on HPC?
● Recent HPC are linux clusters – x86, with or without accelerator(GPU/MIC)
● But HEP don`t need fancy hardware!– fast interconnect adds little to cost(10%)
– offset by saving on bulk purchase & manpower
● Then why not Cloud? – currently no large public cloud resource in DE
– meanwhile, tiny share of SuperMUC's 230kcores is useful

3
Questions for strategy
● To what extent can HPC resources contribute to HEP computing requirements?– which workloads can run on HPC?
● What changes to HPC hardware and policy does this demand?
● Place in the overall resource request?
4
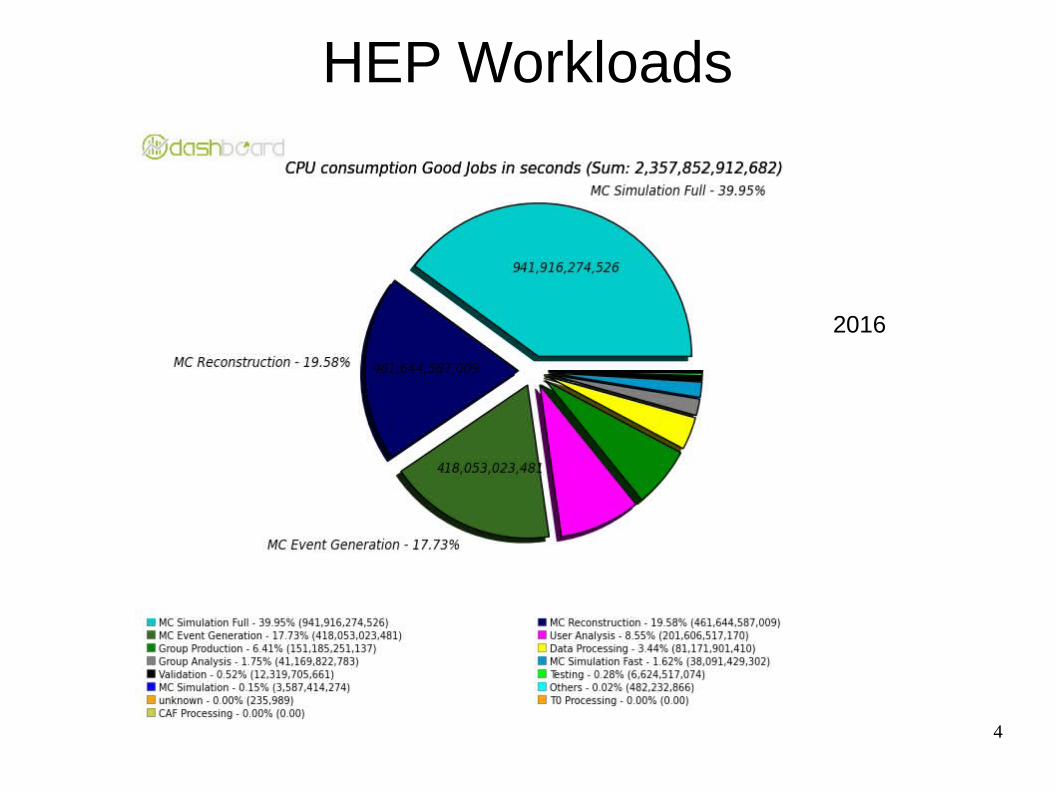
HEP Workloads
2016

5
Simulation: GEANT4
● Large mature code, deeply bound to experiment frameworks– not much customization for HPC possible outside the G4 project
efforts● Geant-MT will take advantage of many core arch(MIC)● no MPI planned
● Luckily it is easily parallelized– AthenaMP uses a whole node
– Yoda is MPI wrapper to use multiple nodes
● Low memory and IO requirements– can run this today with no special demands on HPC

6
Reconstruction
● Experiment specific– under our control, but large code base
– chosen dev path: Gaudi-hive multi-threaded● with MIC in mind
● Can also parallelize with AthenaMP/Yoda– not yet attempted for pile-up
● WAN transfers and job IO much higher– already see problems on shared-FS for pile-up
● Conditions data access is required– for data this needs outbound IP from WNs

7
Event Generators
● NLO are a large part of cpu usage (17%)● Typically stand-alone code
– some already support MPI
– potential to optimize for architectures and accelerators

8
Other workloads
● Group Production/Analysis– often IO intensive
– would need much customization of typical HPC
– some specific suitable use-cases: dyturbo
● EventService– bookkeeping of event ranges rather than files
– killed job loses only in-flight events● high-level checkpoint → preemptable jobs
– currently only G4 sim, but could add reco

9
HPC in use for ATLAS
● Nordugrid utility HPC– pledged resources so accommodating to ATLAS
● allow single core jobs, cvmfs, conditions Db access● but limited connectivity, no pilots, data via gateway
● US leadership facilities– Titan, Mira, Cori, Edison at NERSC & Oakridge
– N HPC, N integration strategies, 2N FTEs
– winning large allocations and high level support
● EU & China x86 – common integration strategy
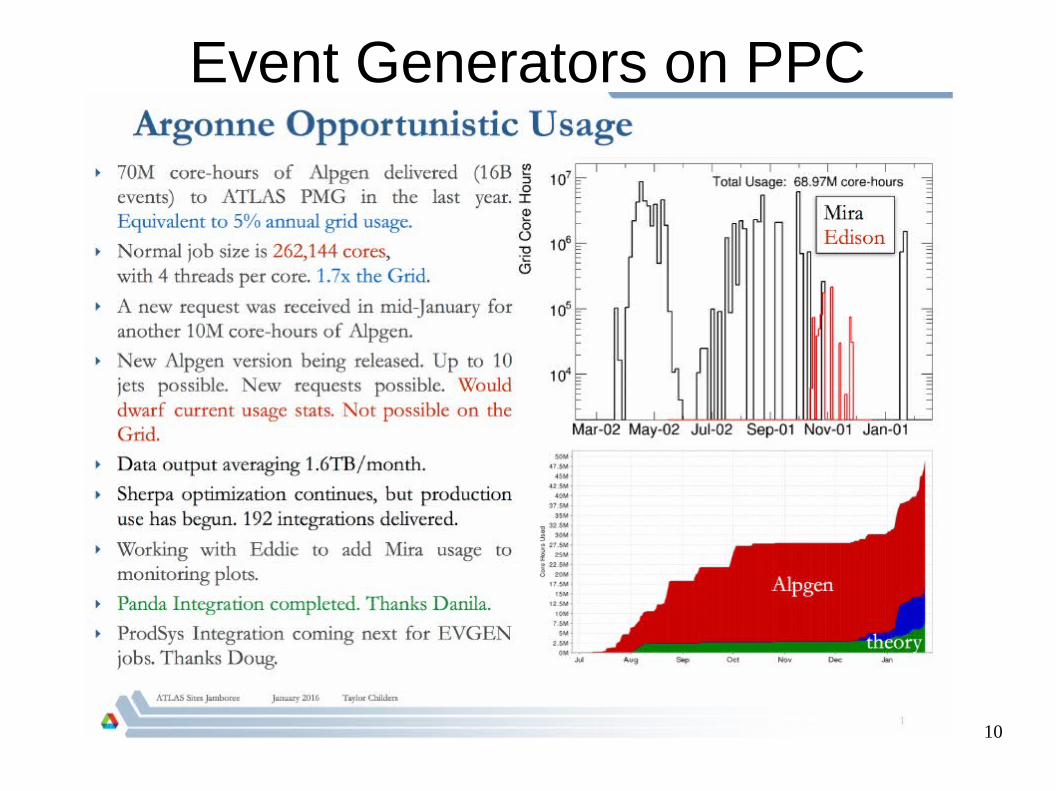
10
Event Generators on PPC

11
EU & China HPC
● LRZ SuperMUC– Phase 1: 150k cores, Sandybridge
– Phase 2: 86k cores, Haswell
– 19Mcore hours used from 20M allocation● effectively open-ended allocation if preempt-only
● Max Planck Institute computer centre: Hydra– 83k core Sandybridge + 28k core extension
● UK Supercomputer - Edinburgh● China – various
– start small and move up

12
ATLAS ProdSys integration
● Benefit from Nordugrid middleware and experience● Pilot model no longer flies – no IP
– submit real jobs(pre-loaded pilots)
● ARC CE designed for non-intrusive integration– stage-in/out data on shared FS, BS interface(LoadLeveler)
– added ability to have remote CE access cluster via ssh
● ATLAS SW available by rsync of cvmfs and relocation, more recently via parrot-cvmfs.– no outbound IP → no Frontier → only sim
– only whole-node scheduled → AthenaMP

13
HEP requirements
● Gatekeeper to receive jobs and move data– integration to production system: no manual submission
● Outbound connectivity– low volume, e.g. Frontier,wget
● SW via cvmfs– automation and standardization
● Local storage and io– WAN bandwidth: high in/out volume vs job length
– job posix io rate(pile-up)

14
Expt. Manpower
● Custom integration per HPC– therefore manpower intensive
– common approaches depend on accommodation by HPC admin● eg. ARC CE
● HEP support at planning stage would ease integration– mostly policy: IP connectivity, single core jobs,...
– also WAN, FS io, storage, Containers(for SL)
● Planned-in HEP support reduces expt. integration and operation manpower– common HEP strategy would reduce it further – not to zero!

15
Current usage
● Geant4 on x86 HPC– MUC running 300 whole-node jobs (4800 cores)
● negotiating increased limit: usually >1000 nodes idle● used 20M core hours, running standard production G4
– MPI Hydra also running in production ~60 nodes
– Titan ORNL 2M hours/month in backfill
● Event generator on PowerPC(Mira in US)– multi-node jobs submitted manually
● integration to prodsys ongoing: can only run few large jobs
● Can continue, extend and repeat for Next Generation– never more than opportunistic add-on, or ….?

16
The trade-off
● Not all core-hours are equally useful– restricted mem/io/workloads, opportunistic
– still need dedicated resources
● Provide N HS06s pledge cpu with:– 1. $$$ for T2 + HPC core-hours budget
– 2. or more $$$$ for T2
● Obviously we want (2) for control & flexibility– but interesting when (1) gives much more HS06s
– (1) also give backfill/opportunistic use

17
Conclusion
● Current HPC inflexibility partially overcome– management and admins are often positive and helpful
● but feel inhibited by funding and tradition
● HEP stake in next generation HPC service– input to design and policy decisions
● make clusters useful for more workloads
– 'stake' means more than opportunistic usage● part of the pledge is from HPC allocation?
– some fraction of G4 done on HPC, is conservative.