Новая аналитика на платформе oracle endeca · etl,...
TRANSCRIPT

Новая аналитика на платформе Oracle Endeca
Ольга Горчинская
Директор по исследовательским проектам
ФОРС
Oracle Big Data & BI Forum

Компания ФОРС Более 20 лет на рынке ИТ - технологий
Платиновый партнер Oracle
Официальный дистрибутор Oracle
Более 500 сотрудников, признанных на международном рынке специалистов в области технологий Oracle
Успешно реализовано свыше 600 масштабных ИТ- проектов
Около 1500 клиентов, работа во всех сегментах экономики
Сертифицированный Центр технической поддержки «первой линии» продуктов Oracle
Авторизованный Oracle Учебный Центр ФОРС
Большой опыт в BI&DW

ФОРС и Большие данные
Развитие экспертизы в области технологий Больших данных
Исследовательские проекты на основе платформы Oracle
Продвижение технологий для решения практических задач
Подготовка демо-стендов с индустриальными примерами
Проведение внутренних и внешних семинаров для распространения идей, методов и подходов к использованию Больших данных

Проекты в области больших данных
Проекты по Big Data
Две категории проектов
Повышение производительности
Новые данные, новая аналитика
Технологии и продукты Hadoop
NoSQL
Статистика, предиктивная аналитика
Data Discovery

Большие данные в России
Интерес или востребованность?
Эксперименты или промышленные внедрения
Наиболее активные индустрии
Банки и финансовые организации
Телеком
Госсектор
Недвижимость
Ритейл

Типовой проект для «новой аналитики»
Анализ неструктурированных текстов
Интернет-источники
Внутренние архивы
Совместный анализ текстов и «реляционных» данных
Цели - расширение состава данных для клиентской аналитики, смысловой поиск в неструктурированном контенте, поддержка аналитических исследований

Особенности задачи
Сбор данных из интернета
Обогащение текстов
Лингвистическая обработка
Извлечение фактов
Преобразования
Статистические исследования
Интерфейс пользователя – от бизнес-анализа к интуитивному исследованию
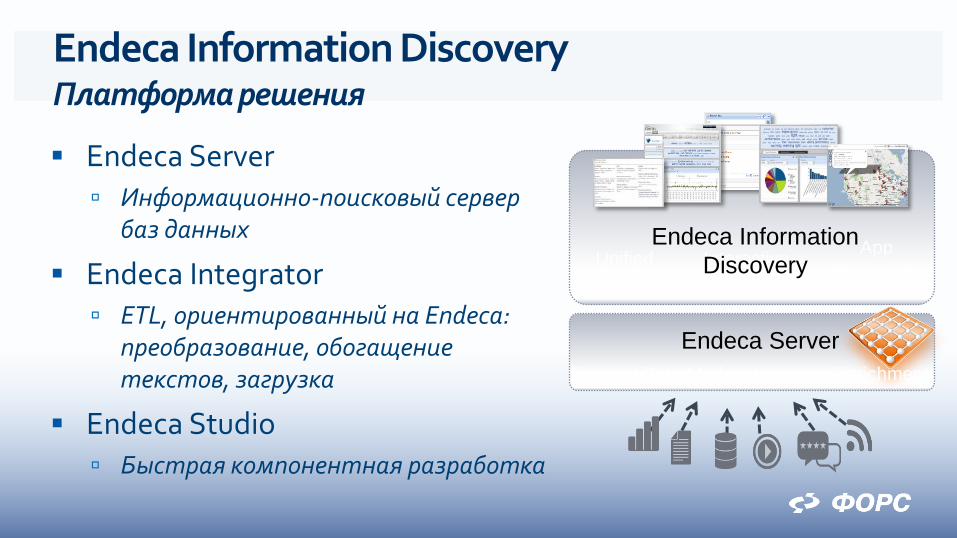
Endeca Information Discovery Платформа решения
Endeca Server Информационно-поисковый сервер
баз данных
Endeca Integrator ETL, ориентированный на Endeca:
преобразование, обогащение текстов, загрузка
Endeca Studio Быстрая компонентная разработка
Faceted Data Model Integration Enrichment
Unified
Querying
Interactive
Exploration
App
Compositio
n
Endeca Information
Discovery
Endeca Server

• Фасетная модель данных
• Набор записей, каждая из которых имеет собственную «структуру»
• Многозначные поля • Неструктурированные поля (тексты)
• Один из видов «Key Value» модели
• Модель состоит из • Записей • Атрибутов
• Каждая запись – это набор пар (атрибут, значение)
• Нет никакого разбиения на таблицы
• Нет понятия схемы данных
Endeca Server Информационно-поисковая NoSQL база данных

Endeca Integrator Загрузка данных в Endeca Server
ETL-среда для загрузки данных в базу данных Endeca Server
При загрузке выполняются преобразования и извлечение из текстов фактов – упоминание персон, географических объектов, событий, определение тональности и др.
Для семантической обработки русскоязычных текстов используются инструменты компании RCO

Endeca Studio Интерфейс пользователя
Быстрая компонентная разработка, возможность расширения
Поиск + Фасетная навигация + Визуальный анализ
• Поиск и выбор атрибутов в стиле вэб сайтов
• Уточнение критерия поиска
• Быстрое вычисление статистики
• Текстовый поиск
Интеграция с географическими картами
Интерактивные исследования
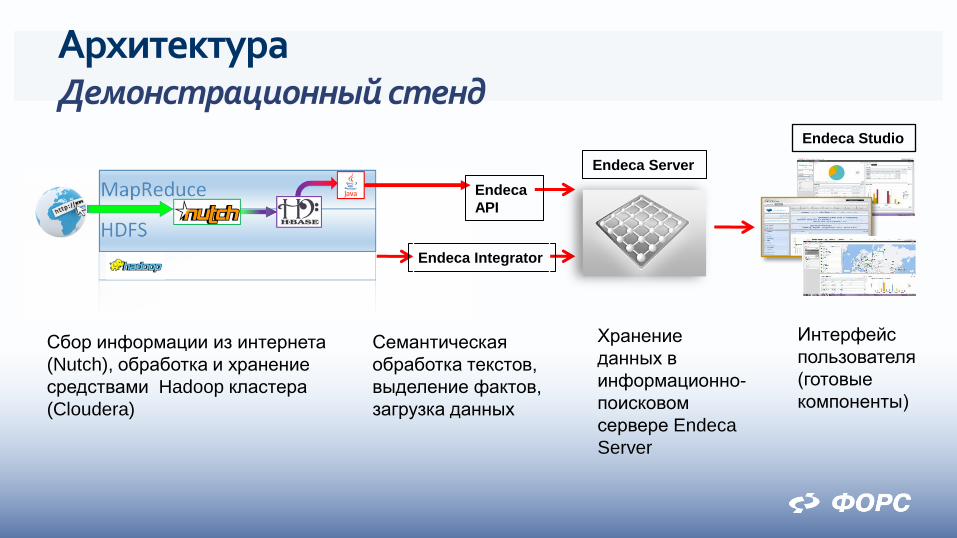
Архитектура Демонстрационный стенд
Хранение
данных в
информационно-
поисковом
сервере Endeca
Server
Интерфейс
пользователя
(готовые
компоненты)
Семантическая
обработка текстов,
выделение фактов,
загрузка данных
Сбор информации из интернета
(Nutch), обработка и хранение
средствами Hadoop кластера
(Cloudera)
Endeca Server
Endeca Studio
Endeca Integrator
Endeca
API

Индустриальные демо-примеры
Решение для HR
Анализ интернет-источников (для ФСК)
Решение для центра обучения
Большие данные в области недвижимости (Hadoop + Endeca + Oracle R Enterprise)
. . .

Сбор данных из интернет-источников
Открытые и закрытые источники
Для каждого источника – специализированный способ извлечения данных (особенности доступа очистка от рекламы, картинок и др.)
Большой объем разработки
Использование опыта специализированных компаний (IQ’MEN)
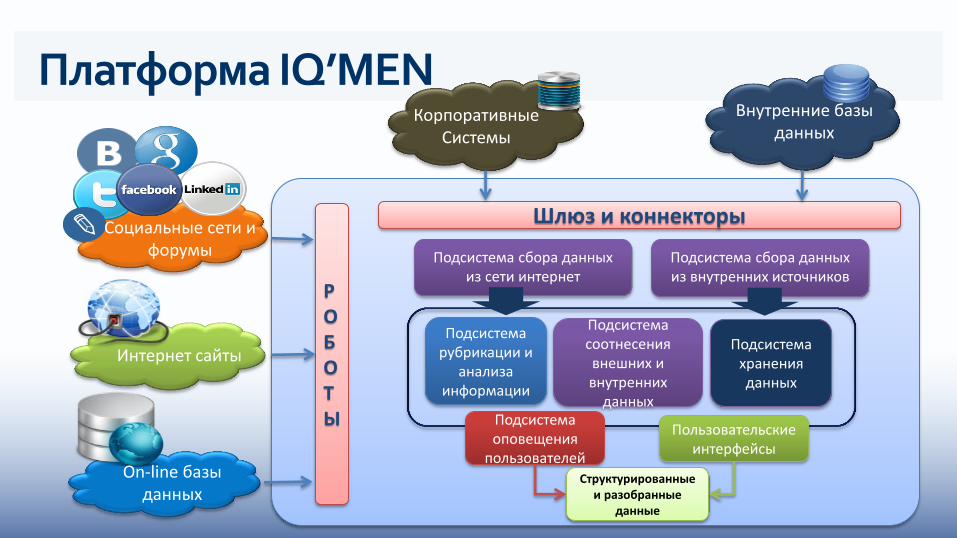
Платформа IQ’MEN Корпоративные
Системы
Внутренние базы данных
On-line базы данных
Интернет сайты
Социальные сети и форумы
РОБОТЫ
Подсистема сбора данных из сети интернет
Подсистема сбора данных из внутренних источников
Подсистема рубрикации и
анализа информации
Подсистема соотнесения внешних и внутренних
данных Подсистема оповещения
пользователей
Пользовательские интерфейсы
Подсистема хранения данных
Структурированные и разобранные
данные
Шлюз и коннекторы

Автоматическая обработка текстов
Поддержка русского языка
Использование лингвистических продуктов
Можно ли обойтись без глубокой лингвистики?
Инструментальные средства
Oracle Text + RCO
RCO for Oracle
ABBYY Comprena
Интеграция с Endeca

Возможности инструментов
Поиск с учетом морфологии, синтаксиса, семантики
Извлечение сущностей
Извлечение фактов
Классификация, рубрикация
Определение тональности, настроения
….

Oracle Text + RCO for Oracle Встроенная в базу данных лингвистика
Полнотекстовый поиск с учетом словоформ
Нечеткий поиск
Расширение поиска с помощью тезауруса
Поиск по темам
Формирование рефератов
Автоматическая классификация текстов
Кластеризация текстовых документов
Интеграция с Oracle Data Mining и Oracle R Enterprise

О компании
ООО «ЭР СИ О», www.rco.ru
Специализация – компьютерная лингвистика, информационный поиск
Коллектив – с 1996г.
до 12.2006 бизнес-подразделение ООО «Гарант-Парк-Интернет»
Более 60-ти публикаций, Диалог, RCDL, РОМИП
АналитЦентр при правительстве РФ, Банк России, Газпром, ГИБДД, Консультант+, Минюст, Первый канал, Роснано, Росфинмониторинг, Филип Моррис

Технологии RCO Содержательный портрет текста
Упоминания персон и организаций
Упоминания особых объектов
Распознавание ситуаций в тексте
Отношение к объекту в тексте
Разбор частично-структурированного текста
Тематическое рубрицирование текстов
Кластеризация новостей
Поиск документов
Выявление заимствований и поиск похожих текстов
…

Высокая точность анализа текстов и полнота поиска фактов ABBYY Fact Extractor основан на уникальной технологии лингвистического анализа текстов
ABBYY Compreno
ABBYY Fact Extractor
Выполняя полный семантико-синтаксический разбор текстов, ABBYY Compreno определяет значения слов и выделяет все связи между ними в тексте. Это позволяет компьютеру лучше «понимать» тексты и точнее находить в них необходимые данные.
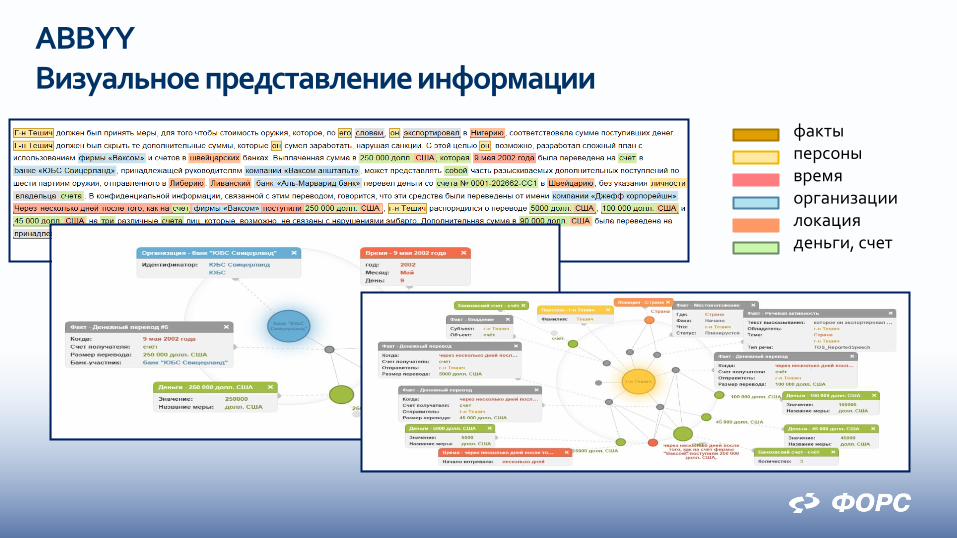
ABBYY Визуальное представление информации
факты персоны время организации локация деньги, счет

Статистические исследования Oracle R Enterprise
Распространенный язык статистических исследований R -- open source
Встроен в Oracle Database – R-вычисления транслируются и выполняются в Oracle Database
Широкий спектр функций, возможность расширения, «научная» визуализация, высокая производительность Oracle R Enterprise
R

Решение в области недвижимости Цель – оценка стоимости объектов недвижимости на
основе исследования данных рынка
Проблемы – отсутствие единого источника информации по сделкам и объектам, низкое качество данных
Особенности – использование методик, основанных на статистическом анализе, алгоритмах data mining, итеративность исследований
Требования к системе – сбор данных из интернет-источников, стандартизация, извлечение атрибутов, построение моделей, оценка

Реализованная методика Оценка качества данных
Степень однородности
Выявление зависимостей
Построение моделей
Регрессионная модель
Самоорзанизующиеся карты Кохонена
Кластеризация карт
Применение моделей для оценки стоимости
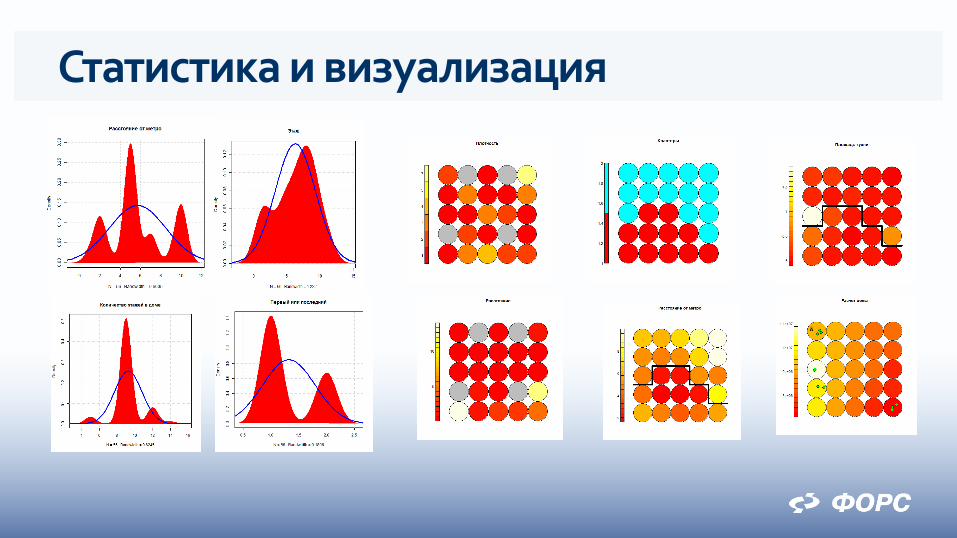
Статистика и визуализация
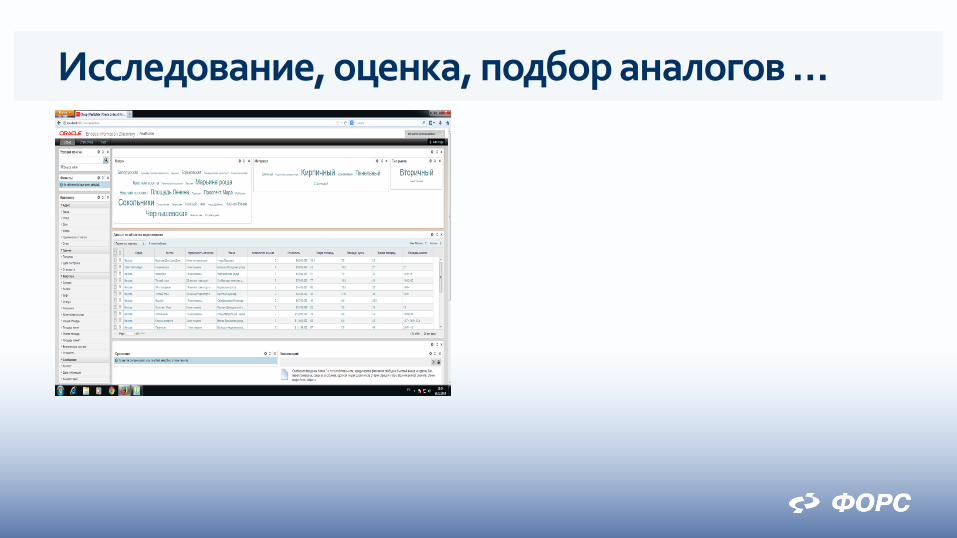
Исследование, оценка, подбор аналогов …

Подводя итоги Oracle Endeca можно успешно использовать в качестве платформы
для задач, связанных с анализом текстов
Сбор данных из интернет-источников нетривиальная задача, лучше использовать опыт специализированных компаний
Обязательна интеграция с внешними инструментами автоматической обработки текстов
Для фасетного поиска важно иметь функцию извлечения сущностей и фактов
Endeca Studio ориентирована на интерфейсы интуитивного исследования (поиск, формирование гипотез, быстрая проверка идей)

Спасибо за внимание!