métodos de decomposição de domínios para a solução ...guilherme/pesq/tcc_galante.pdf · ano...
TRANSCRIPT

Unioeste – Universidade Estadual do Oeste do Paraná
CENTRO DE CIÊNCIAS EXATAS E TECNOLÓGICASColegiado de Informática
Curso de Bacharelado em Informática
Métodos de Decomposição de Domínios para a SoluçãoParalela de Sistemas de Equações Lineares
Guilherme Galante
CASCAVEL
Fevereiro/2004
ANO LETIVO
2003

GUILHERME GALANTE
MÉTODOS DE DECOMPOSIÇÃO DE DOMÍNIOS PARA A SOLUÇÃOPARALELA DE SISTEMAS DE EQUAÇÕES LINEARES
Trabalho apresentado como requisitoparcial para obtenção do grau deBacharel em Informática.Curso de Bacharelado em Informática.Centro de Ciências Exatas eTecnológicas. Universidade Estadual doOeste do Paraná - Campus de Cascavel.
Orientador: Prof. Dr. Rogério Luis RizziCo-Orientador: André Luis Martinotto
Cascavel
Fevereiro/2004
Ano Letivo
2003

GUILHERME GALANTE
MÉTODOS DE DECOMPOSIÇÃO DE DOMÍNIOS PARA A SOLUÇÃOPARALELA DE SISTEMAS DE EQUAÇÕES LINEARES
Trabalho apresentado como requisito parcial para obtenção do Título de Bacharel emInformática, pela UNIOESTE - Universidade Estadual do Oeste do Paraná, Campus de
Cascavel, aprovada pela Comissão composta pelos professores:
Prof. Dr. Rogério Luis Rizzi (Orientador)Colegiado de Matemática, UNIOESTE
Prof. Francisco Sérgio SambattiColegiado de Informática, UNIOESTE
Prof. MSc. Ivonei Freitas da SilvaColegiado de Informática, UNIOESTE
Cascavel, 17 de Fevereiro de 2004.

iv
“ Do you believe in fate or chancesDesign or coincidencesWould you say that all the peopleLive their life for good and evilSome have reached the end of patienceStart to play with God's creationThey know youControl youIn a game we shouldn't playCorrupt your heartAnd make you partOf a game we shouldn't play”
Andi Deris

v
AGRADECIMENTOS
Gostaria de agradecer primeiramente a minha família, em especial meus pais
Sinval e Luiza, que sempre me incentivaram nos estudos... É graças a eles que pude vencer mais
esta etapa da minha vida.
Agradeço também a minha namorada Juliana pelos bons momentos que
passamos juntos, pelo carinho e compreensão.
Gostaria de agradecer também:
Todos colegas que compartilharam suas horas de trabalho, de risadas e de
preocupações, em especial o pessoal do LSDP e do GMCPAR.
Meus amigos que sempre estiveram comigo tanto nas difíceis e nas horas de lazer.
Os professores do Colegiado de Informática pelos conhecimentos que me foram
transmitidos. Um agradecimento especial ao professor Rogério por me orientar neste trabalho e em todos
os demais, que passaram e que estão por vir.
O meu co-orientador André Martinotto pelas muitas ajudas ao longo deste trabalho.
Os funcionários Carin e Nelson, por serem sempre prestativos em seu trabalho.

vi
LISTA DE FIGURAS
FIGURA 2.1: CLASSIFICAÇÃO DE FLYNN ..................................................................................................... 16FIGURA 2.2: PANORAMA GERAL DAS CLASSIFICAÇÕES DAS ARQUITETURAS PARALELAS........................... 18FIGURA 2.3: RESUMO DAS ARQUITETURAS PARALELAS (DEROSE, 2001)................................................... 19FIGURA 2.4: CARACTERÍSTICAS DO MCR LINUX CLUSTER (TOP500)....................................................... 21FIGURA 2.5: CARACTERÍSTICAS DO CLUSTER CORPORATE (TOP500)........................................................ 22FIGURA 2.6: CARACTERÍSTICAS DO CLUSTER LABTEC UFRGS................................................................. 22FIGURA 2.7: MODELO DE EXECUÇÃO OPENMP........................................................................................... 28FIGURA 2.8: NÍVEIS DA BIBLIOTECA BLAS ................................................................................................ 29FIGURA 2.9: ORGANIZAÇÃO DA BIBLIOTECA PETSC.................................................................................. 30FIGURA 3.1: REPRESENTAÇÃO PARA FASES DO PARADIGMA MESTRE-ESCRAVO ........................................ 33FIGURA 3.2: REPRESENTAÇÃO PARA FASES DO PARADIGMA SPMD........................................................... 34FIGURA 3.3: REPRESENTAÇÃO PARA FASES DO PARADIGMA PIPELINE......................................................... 34FIGURA 3.4: REPRESENTAÇÃO PARA FASES DO PARADIGMA DIVISÃO E CONQUISTA .................................. 35FIGURA 3.5: ESTRUTURA DA METODOLOGIA PCAM (FOSTER, 1995)........................................................ 37FIGURA 4.1: DOMÍNIO (AZUL) E RESPECTIVA MALHA. ................................................................................ 41FIGURA 4.2: GRAFO REFERENTE À MALHA DA FIGURA 4.1.......................................................................... 41FIGURA 4.3: (A) DOMÍNIO INICIAL . (B) DOMÍNIO PARTICIONADO APÓS UM PASSO DO RCB. (C) DOMÍNIO
APÓS DOIS PASSOS DO RCB................................................................................................................. 43FIGURA 4.4: EXEMPLO DE REFINAMENTO POR KL ...................................................................................... 44FIGURA 4.5: ESQUEMA MULTINÍVEL (KUMAR, 2003)................................................................................. 45FIGURA 5.1: ESTÊNCIL DE 5-PONTOS (MOLÉCULA COMPUTACIONAL) ......................................................... 49FIGURA 5.2: GERAÇÃO DE SISTEMAS DE EQUAÇÕES................................................................................... 49FIGURA 5.3: ALGORITMO DO GRADIENTE CONJUGADO.............................................................................. 52FIGURA 6.1: ILUSTRAÇÃO PARA O ESQUEMA GERAL DE MDDS .................................................................. 55FIGURA 6.2: DOMÍNIO FORMADO PELA UNIÃO DE UM DISCO E UM RETÂNGULO. ......................................... 56FIGURA 6.3: ESQUEMA DE TROCA DE DADOS ENTRE AS FRONTEIRAS.......................................................... 58FIGURA 6.4: EXEMPLO DE MATRIZ ARMAZENADA NO FORMATO CSR......................................................... 59FIGURA 6.5: ALGORITMO DO MDD ADITIVO DE SCHWARZ........................................................................ 60FIGURA 6.6: PARTICIONAMENTO DE DOMÍNIO............................................................................................. 60FIGURA 6.7: DOMÍNIO PARTICIONADO COM SOBREPOSIÇÃO........................................................................ 60FIGURA 6.8: MATRIZ GERADA A PARTIR DO SUBDOMÍNIO S1 DA FIGURA 6.7.............................................. 61FIGURA 6.9: ARQUIVO DE ENTRADA DA MATRIZ ILUSTRADA NA FIGURA 6.8.............................................. 61FIGURA 6.10: ESQUEMA DE NUMERAÇÃO DO MÉTODO DO COMPLEMENTO DE SCHUR ............................... 62FIGURA 6.11: MATRIZ GERADA A PARTIR DO DOMÍNIO DA FIGURA 6.10..................................................... 63FIGURA 6.12: CÁLCULO DE D NO MÉTODO DO COMPLEMENTO DE SCHUR.................................................. 67FIGURA 6.13: CÁLCULO DE Q NO MÉTODO DO COMPLEMENTO DE SCHUR........................................... 67FIGURA 6.14: CÁLCULO DE X NO MÉTODO DO COMPLEMENTO DE SCHUR.................................................. 68FIGURA 8.1: NÚMERO DE ITERAÇÕES DO MDD ADITIVO DE SCHWARZ: 11.506 INCÓGNITAS .................... 72FIGURA 8.2: NÚMERO DE ITERAÇÕES DO MDD ADITIVO DE SCHWARZ: 184.096 INCÓGNITAS .................. 73FIGURA 8.3: TEMPO DE EXECUÇÃO DO MDD ADITIVO DE SCHWARZ: 11.506 INCÓGNITAS........................ 74FIGURA 8.4: TEMPO DE EXECUÇÃO DO MDD ADITIVO DE SCHWARZ: 184.096 INCÓGNITAS...................... 74FIGURA 8.5: SPEEDUP DO MDD ADITIVO DE SCHWARZ: 11.506 INCÓGNITAS ........................................... 75FIGURA 8.6: SPEEDUP DO MDD ADITIVO DE SCHWARZ: 184. 096 INCÓGNITAS......................................... 76FIGURA 8.7: EFICIÊNCIA DO MDD ADITIVO DE SCHWARZ: 11.506 INCÓGNITAS........................................ 77FIGURA 8.8: EFICIÊNCIA DO MDD ADITIVO DE SCHWARZ: 184.096 INCÓGNITAS...................................... 77FIGURA 8.9: EXECUÇÃO DO MDD ADITIVO DE SCHWARZ.......................................................................... 78FIGURA 8.10: TEMPOS DE EXECUÇÃO: IMPLEMENTAÇÕES COM E SEM BLAS ............................................. 79FIGURA 8.11: SPEEDUP: IMPLEMENTAÇÕES COM E SEM BLAS .................................................................. 79FIGURA 8.12: PROCESSOS VERSUS THREADS NO MDD ADITIVO DE SCHWARZ ........................................... 80FIGURA 8.13: DECOMPOSIÇÃO DE DOMÍNIOS VERSUS DECOMPOSIÇÃO DE DADOS: TEMPO DE EXECUÇÃO 82FIGURA 8.14: EXECUÇÃO DO MDD ADITIVO (A) EXECUÇÃO DO GC PARALELO (B).................................. 83FIGURA 8.15: TEMPO DE EXECUÇÃO DO MÉTODO DO COMPLEMENTO SCHUR............................................ 83FIGURA 8.16: SPEEDUP DO MÉTODO DO COMPLEMENTO DE SCHUR........................................................... 84FIGURA 8.17: EFICIÊNCIA ........................................................................................................................... 84FIGURA 8.18: ERROS DO MDD ADITIVO DE SCHWARZ............................................................................... 86

vii
LISTA DE SIGLAS E ABREVIATURAS
ATLAS Automatically Tuned Linear Algebra Software
BLAS Basic Linear Algebra Subprograms
CC Condições de Contorno
CSR Compressed Sparse Row
EDP Equação Diferencial Parcial
GC Gradiente Conjugado
GMCPAR Grupo de Matemática Computacional e Processamento Paralelo
GMRES Método do Resíduo Mínimo Generalizado
KL Kernigham-Lin
LabTec Laboratório de Tecnologia em Clusters
MDD Métodos de Decomposição de Domínio
MIMD Multiple Instruction Multiple Data
MISD Multiple Instruction Simple Data
MPI Message Passing Interface
MPP Massively Parallel Processors
NORMA Non-Remote Memory Access
NOW Network of Workstations
NUMA Non-Uniform Memory Access
ORB Ortogonal Recursive Bisection
PC Computador Pessoal
PCAM Partitioning, Communication, Agglomeration e Mapping
PETSc Portable, Extensible Toolkit for Scientific Computation
POSIX Portable Operating System Interface
PVP Parallel Vector Processor
PVM Parallel Virtual Machine
RCB Recursive Coordinate Bisection
SCI Scalable Coherent Interface
SDP Simétrica-Definida Positiva
SEL Sistema de Equações Lineares
SIMD Simgle Instruction Multiple Data
SISD Simgle Instruction Simple Data
SMP Symmetric Multiprocessors
SOR Successive Overrelaxation
UFRGS Universidade Federal do Rio Grande do Sul
UMA Uniform Memory Access

viii
SUMÁRIO
1. INTRODUÇÃO ................................................................................................................................ 11
1.1 Organização do Trabalho........................................................................................................... 13
2. AMBIENTE DE COMPUTAÇÃO PARALELA: HARDWARE E SOFTWARE ..................... 15
2.1 Classificação das Arquiteturas Paralelas.................................................................................... 152.1.1 Modo de controle............................................................................................................... 152.1.2 Compartilhamento de memória.......................................................................................... 16
2.2 Tendências de Sistemas Paralelos.............................................................................................. 182.2.1 Clusters de PCs.................................................................................................................. 20
2.3 Bibliotecas.................................................................................................................................. 242.3.1 Bibliotecas de troca de mensagem..................................................................................... 242.3.2 Bibliotecas de threads........................................................................................................ 262.3.3 Bibliotecas de álgebra linear e resolução de sistemas........................................................ 28
2.4 Conclusão................................................................................................................................... 31
3. PROCESSAMENTO PARALELO ................................................................................................ 32
3.1 Paradigmas de Programação...................................................................................................... 323.1.1 Mestre-Escravo................................................................................................................... 333.1.2 Single-Program Multiple-Data (SPMD)............................................................................. 333.1.3 Pipeline de dados................................................................................................................ 343.1.4 Divisão e conquista............................................................................................................ 34
3.2 Estratégias para a Extração do Paralelismo................................................................................ 353.2.1 Técnicas para a solução paralela de sistemas de equações................................................. 36
3.3 Metodologia de desenvolvimento de programas paralelos......................................................... 363.4 Métricas para Avaliação de Desempenho Computacional......................................................... 38
3.4.1 Tempo de execução............................................................................................................ 383.4.2 Speedup.............................................................................................................................. 383.4.3 Eficiência............................................................................................................................ 39
3.5 Conclusão................................................................................................................................... 39
4. PARTICIONAMENTO DE DADOS E DE DOMÍNIO ................................................................ 40
4.1 Malhas e Grafos......................................................................................................................... 404.2 O Problema de Particionamento de Grafos................................................................................ 414.3 Heurísticas e Métodos de Particionamento................................................................................ 42
4.3.1 Métodos globais................................................................................................................. 424.3.2 Métodos locais................................................................................................................... 43
4.4 Métodos Multiníveis.................................................................................................................. 454.5 Pacotes de Particionamento........................................................................................................ 46
4.5.1 METIS................................................................................................................................ 464.6 Critérios para Escolha do Algoritmo.......................................................................................... 474.7 Conclusão................................................................................................................................... 47
5. SISTEMAS DE EQUAÇÕES.......................................................................................................... 48
5.1 Geração de Sistemas de Equações.............................................................................................. 485.2 Métodos Diretos e Métodos Iterativos....................................................................................... 50
5.2.1 Métodos iterativos do subespaço de Krylov....................................................................... 505.3 Métricas para Avaliação da Qualidade da Solução em Paralelo................................................ 525.4 Conclusão................................................................................................................................... 53
6. MÉTODOS DE DECOMPOSIÇÃO DE DOMÍNIO .................................................................... 55
6.1 Métodos de Schwarz.................................................................................................................. 566.1.1 MDD Aditivo de Schwarz.................................................................................................. 576.1.2 Implementação do MDD Aditivo de Schwarz................................................................... 58
6.2 Métodos do Complemento de Schur.......................................................................................... 626.2.1 Implementação do Método do Complemento de Schur..................................................... 65

ix
6.3 Conclusão................................................................................................................................... 68
7. METODOLOGIA DE DESENVOLVIMENTO ........................................................................... 69
8. RESULTADOS OBTIDOS ............................................................................................................. 71
8.1 Método MDD Aditivo de Schwarz: Análise de Desempenho Computacional........................... 718.1.1 Número de iterações........................................................................................................... 718.1.2 Tempo de execução............................................................................................................ 738.1.3 Speedup do MDD Aditivo de Schwarz.............................................................................. 758.1.4 Eficiência............................................................................................................................ 768.1.5 Comportamento do MDD Aditivo de Schwarz.................................................................. 788.1.6 MDD Aditivo de Schwarz: BLAS...................................................................................... 788.1.7 MDD Aditivo de Schwarz: processos versus threads........................................................ 808.1.8 MDD Aditivo de Schwarz versus decomposição de dados................................................ 81
8.2 MDD do Complemento de Schur: Análise de Desempenho Computacional............................. 838.3 Análise da Qualidade Numérica................................................................................................. 858.4 Conclusão................................................................................................................................... 86
9. CONCLUSÕES................................................................................................................................ 88
9.1 Contribuições............................................................................................................................. 889.2 Trabalhos Futuros....................................................................................................................... 89
REFERÊNCIAS BIBLIOGRÁFICAS ................................................................................................... 90
APÊNDICE A ........................................................................................................................................... 96

x
RESUMO
As soluções de sistemas de equações lineares estão entre os problemas
mais comuns encontrados em Computação Científica. Tais sistemas são gerados pela
discretização de equações diferenciais parciais (EDPs), e são parte integrante de
modelos matemáticos de fenômenos físicos e tecnológicos. Geralmente, tais sistemas de
equações são de grande porte e esparsos e demandam soluções a cada passo de tempo.
Requerem abordagens e estratégias numérico-computacionais eficientes, de tal modo
que é imprescindível o uso de computação de alto desempenho, que é oferecida, por
exemplo, por arquiteturas de memória distribuída não compartilhada. O objetivo deste
trabalho é a obtenção de soluções em paralelo para sistemas de equações lineares
esparsos e de grande porte. As soluções são obtidas empregando decomposição de
domínio, de modo que, ao explorar o paralelismo em clusters de PCs multiprocessados,
tais soluções possam ser atingidas em tempo significativamente menor do que aquele
obtido com abordagens seqüenciais. Foram implementados dois métodos de solução:
Método de Decomposição de Domínio Aditivo de Schwarz e o Método do
Complemento de Schur. Os resultados do Método Aditivo foram satisfatórios tanto no
que diz respeito ao desempenho quanto a qualidade numérica. Já o Método de Schur
apresentou resultados apenas regulares.
Palavras-chave: Clusters de PCs, Decomposição de Domínio, Sistemas de Equações lineares.

11
1. INTRODUÇÃO
Através de modelagem computacional é possível realizar simulações
computacionais de fenômenos naturais, tecnológicos e industriais, que seriam irrealizáveis ou
antieconômicos se efetivados por métodos experimentais. Tais fenômenos podem, em geral, ser
modelados de modo acurado através de equações diferenciais parciais (EDPs), que são definidas
sobre domínios contínuos, necessitando que sejam discretizadas, para poderem ser tratadas
computacionalmente.
Conforme o esquema de discretização empregado na aproximação de uma
determinada EDP, pode-se originar sistemas de equações que são lineares. Estes sistemas são,
de modo geral, esparsos e de grande porte, onde as incógnitas podem ser da ordem de milhares,
ou até mesmo de milhões (Canal, 2000).
Considerando tais características, uma solução com alta qualidade numérica
pode requerer grande capacidade de processamento e de armazenamento, o que torna
imprescindível o uso de ambientes computacionais de alto desempenho. Sob tais ambientes,
simulações computacionais podem ser realizadas com um nível de detalhe que não seria viável
em abordagens computacionais seqüenciais (Rizzi, 2002).
Tais ambientes podem ser oferecidos por clusters de PCs, que têm se
mostrado uma opção acessível e eficiente para se ter os recursos computacionais requeridos à
solução dos problemas, de modo a reduzir o tempo de processamento. Um cluster de PCs pode
ser definido como sendo um conjunto de computadores (homogêneos ou não) conectados em
rede, e que servem à execução de processamento em paralelo.
O processamento paralelo (ou paralelismo) é uma técnica usada em tarefas
grandes e complexas para obter resultados mais rápidos, dividindo-as em tarefas pequenas que
serão distribuídas em vários processadores para serem executadas simultaneamente. Esses
processadores se comunicam entre si para que haja sincronização na execução das diversas
tarefas executadas em paralelo (Cenapad, 2003).
Os sistemas de equações lineares, que são resolvidos utilizando-se de
paralelismo, estão presentes em várias aplicações como, por exemplo: programação linear;
dinâmica dos fluidos computacional; modelagem climática; previsão meteorológica; etc. (Saad,
1996). Para a solução desses sistemas de equações lineares, existem duas classes de métodos: a
classe dos métodos diretos e a classe dos métodos iterativos.
Os métodos diretos apresentam solução exata, exceto por erros de
arredondamento devido às operações de ponto flutuante, em um número finito de passos.
Métodos iterativos, por sua vez, utilizam-se de sucessivas aproximações dos valores das
incógnitas para obter uma solução cada vez mais acurada. Estas aproximações são feitas até que
se obtenha um limite de erro aceitável ou um número máximo de iterações (Martinotto, 2002).

12
Os métodos iterativos são os mais apropriados na solução de sistemas de
equações esparsos de grande porte, pois estes métodos trabalham apenas sobre os elementos não
nulos da matriz de coeficientes, não destruindo, portanto, a sua esparsidade. Essa questão é
importante, pois esse fato permite que se possa fazer otimizações no armazenamento, nas
estratégias de solução e de comunicação, de modo que se obtém soluções eficientes.
Uma das abordagens encontradas na literatura técnica para a solução de
sistemas de equações em paralelo é aquela que emprega métodos de decomposição de domínio
(MDDs). Os MDDs são baseados no particionamento do domínio computacional em
subdomínios, de modo que a solução global do problema é obtida pela combinação apropriada
das soluções obtidas em cada um dos subdomínios.
Uma vez que diferentes subdomínios podem ser tratados independentemente,
exceto nos pontos de sincronismo, tais métodos são atrativos para ambientes computacionais de
memória distribuída, como é o caso dos clusters de PCs. Os MDDs podem ser divididos em
duas grandes classes: métodos de Schwarz, onde os subdomínios apresentam uma região de
sobreposição, e métodos de Schur, onde os subdomínios não apresentam região de
sobreposição.
Na paralelização dos métodos numéricos para serem executados em clusters
de PCs multiprocessados, pode-se explorar dois níveis de paralelismo. Em um primeiro nível
explora-se o paralelismo intra-nodal, onde a memória é compartilhada e o paralelismo é
explorado usando threads ou processos escalonados pelo sistema operacional. Já em um
segundo nível explora-se o paralelismo inter-nodal através da troca de mensagem, utilizando
uma biblioteca de troca de mensagens.
Assim, o objetivo deste trabalho é desenvolver e analisar o desempenho
computacional e a qualidade numérica das soluções paralelas resultantes de dois métodos de
decomposição de Domínio, com e sem sobreposição. Especificamente, são desenvolvidas
estratégias, estruturas de dados e implementações para o MDD Aditivo de Schwarz, e para o
Método do Complemento de Schur.
As aplicações utilizam para teste arquivos de dados gerados no modelo
HIDRA e pelo software GERATRIZ. HIDRA é o modelo computacional paralelo bi e
tridimensional, com balanceamento dinâmico de carga para a hidrodinâmica e para o transporte
de substâncias desenvolvido por Rogério Luis Rizzi (Rizzi, 2002) e Ricardo Vargas Dorneles
(Dorneles, 2003). GERATRIZ é um software desenvolvido pelo Grupo de Matemática
Computacional e Processamento Paralelo (GMCPAR) (Perlin, 2003) para a geração de dados de
entrada a partir de domínios estabelecidos pelo usuário.
Outros trabalhos exploraram a paralelização de métodos de solução de
sistemas lineares. Dentre esses, estão aqueles realizados pelo Grupo de Processamento Paralelo
e Distribuído da UFRGS:

13
• Ana Paula Canal, que desenvolveu a dissertação intitulada de
“Paralelização de Métodos de Solução de Sistemas Lineares
Esparsos com o DECK em Clusters de PCs”, onde foram
implementadas versões paralelas do Método do Gradiente
Conjugado (GC) e do Método de Thomas para matrizes do tipo
banda.
• Delcino Picinin Junior, que desenvolveu o trabalho individual de
mestrado sobre a paralelização do GC utilizando MPI e threads e em
sua dissertação implementou e analisou a paralelização do método
do GC e do Método do Resíduo Mínimo Generalizado (GMRES),
utilizando MPI, DECK e Pthreads.
• André Luis Martinotto, desenvolveu o Trabalho de Conclusão de
Curso intitulado “Paralelização de Métodos Numéricos de Solução
de Sistemas Esparsos de Equações Utilizando MPI e Pthreads” e o
trabalho individual de mestrado sobre a paralelização de pré-
condicionadores para o GC.
Além destes, outros trabalhos relativos a este assunto foram desenvolvidos
pelos bolsistas Guilherme Galante e Jeysonn I. Balbinot, do GMCPAR, como pode ser visto na
bibliografia mencionada.
1.1 Organização do Trabalho
Este texto está organizado em sete capítulos. Nesse inicial, é realizada uma
introdução do trabalho.
No segundo capítulo, apresenta-se o ambiente de programação paralela,
abordando os quesitos de hardware e software.
No terceiro capítulo aborda-se os paradigmas, técnicas e metodologias para o
desenvolvimento de aplicações paralelas. Também são apresentadas algumas métricas para
avaliação de desempenho de programas paralelos.
O quarto capítulo refere-se ao problema de particionamento de dados e de
domínios, onde são mostrados alguns algoritmos e heurísticas existentes, e os softwares
disponíveis no mercado.
O capítulo 5 refere-se as questões relativas aos sistemas de equações
lineares. Inicialmente é dada uma introdução aos sistemas de equações lineares, em seguida é
mostrado como são gerados, e quais são os métodos pelos quais podem ser resolvidos. Ao final

14
do capítulo são apresentadas métricas para a avaliação da qualidade numérica dos métodos de
solução.
O capítulo 6 abrange os métodos de decomposição de domínio, suas
características, funcionalidades e aplicações, além de um panorama geral das implementações
contidas neste trabalho, com explicações dos algoritmos, estruturas de dados empregadas e
exemplos dos mesmos.
A metodologia empregada na implementação e testes dos algoritmos deste
trabalho é mostrada no capítulo 7.
No capítulo 8 apresentam-se os resultados obtidos com os testes das
implementações feitas neste trabalho. Os resultados são mostrados através de gráficos de tempo
de execução, speedup, eficiência e número de iterações. Ainda são mostrados alguns gráficos do
comportamento dos algoritmos obtidos com a ferramenta de perfilamento Jumpshot.
No capítulo 9 capítulo são discutidas as conclusões do trabalho, e algumas
contribuições e propostas para trabalhos futuros.

15
2. AMBIENTE DE COMPUTAÇÃO PARALELA: HARDWARE ESOFTWARE
Este capítulo refere-se ao ambiente utilizado no desenvolvimento de
aplicações paralelas. A descrição desse ambiente está dividida em duas partes: a primeira se
refere à parte física (hardware) e a segunda se refere à parte lógica (software).
Na primeira parte deste capítulo, são apresentados critérios de classificação
das máquinas paralelas e as tendências em sua construção, dando maior ênfase aos clusters de
PCs. Em um primeiro momento, é dado um panorama geral, apresentando uma definição de
cluster, os tipos de arquiteturas existentes e as principais redes de interconexão. Em um segundo
momento serão colocados exemplos de clusters de alto desempenho do ranking do Top500
(TOP500, 2003), e também o cluster LabTec do Instituto de Informática da UFRGS.
Na segunda parte, são abordadas as bibliotecas de troca de mensagens, de
threads, de álgebra linear e de resolução de sistemas de equações.
2.1 Classificação das Arquiteturas Paralelas
Existem, uma grande variedade de arquiteturas paralelas, que diferem tanto
nas características do hardware, quanto nos propósitos para que foram projetadas. Para
classificar estas arquiteturas existem vários critérios, dentre os quais aborda-se, neste trabalho, o
modo de controle e o compartilhamento de memória.
2.1.1 Modo de controle
Para se classificar as arquiteturas quanto ao modo de controle, pode-se
utilizar a classificação genérica de Flynn (Flynn, 1972). Esta classificação baseia-se no número
de fluxos de dados (data stream) e de fluxos de instruções (instruction stream). Segundo esta
abordagem, os computadores são divididos em quatro classes: SISD, SIMD, MISD E MIMD,
conforme visto na Figura 2.1.
• SISD (Single Instruction Single Data): São as máquinas convencionais,
que processam uma instrução operando sobre itens de dados simples.
Nesta categoria incluem-se os computadores seriais convencionais, que
executam instruções de modo seqüencial, não havendo nenhum tipo de
paralelismo.

16
SD ( )Single Data MD ( )Multiple Data
SI ( )Single Instruction
MI ( )Multiple Instruction
SISD
MISD
SIMD
MIMD
Figura 2.1: Classificação de Flynn
• SIMD (Single Instruction Multiple Data): São os chamados sistemas de
processamento vetorial, com uma mesma instrução operando
simultaneamente sobre dados distintos. Nesta classe, estão enquadradas
as máquinas Array CM-2 e MasPar (Hwang, 1993).
• MISD (Multiple Instruction Single Data): São máquinas que executam
diversos fluxos de instruções sobre itens de dados simples. Esta
arquitetura não existe na prática, sendo incluída apenas para tornar a
classificação de Flynn completa.
• MIMD (Multiple Instruction Multiple Data): Sistema paralelo de
processamento com diversas instruções operando simultaneamente sobre
dados distintos. É nesta classe que se encontram os computadores
paralelos. São representantes desta classe as máquinas CM-5 (Hwang,
1993), nCUBE, Intel Paragon e Cray T3D (Culler, 1999).
2.1.2 Compartilhamento de memória
As máquinas do tipo MIMD podem ser classificadas pelo critério de
compartilhamento de memórias em três classes: máquinas com memória compartilhada,
máquinas com memória distribuída e máquinas híbridas. São classificadas apenas as máquinas
MIMD, porque é nesta classe que estão as máquinas paralelas, que são o foco deste capítulo.
2.1.2.1 Memória compartilhada
Neste tipo de máquinas todos os processadores compartilham um único
espaço de endereçamento de memória. Máquinas deste tipo, também são chamadas de
multiprocessadores.

17
Levando em consideração o tipo de acesso à memória, os multiprocessadores
podem ser classificados como em (Hwang, 1993):
• UMA (uniform memory acess): a latência de acesso à memória é
uniforme para todos os processadores.
• NUMA (non-uniform memory acess): a latência de acesso à memória
depende da localização do processador em relação ao endereço de
memória.
Ainda quanto ao modo de acesso à memória, é importante ressaltar a
importância da coerência de cache. Mais informações podem ser encontradas em (Hwang,
1993).
2.1.2.2 Memória distribuída
Estas máquinas também são chamadas de multicomputadores. Inclui-se nesta
classe máquinas formadas por várias unidades de processamento, cada qual com sua memória
local, não acessível a outras máquinas. A troca de informações é efetuada pelo envio de
mensagens através da rede de interconexão.
O tipo de acesso à memória utilizada pelos multicomputadores é conhecido
como NORMA (non-remote memory access). Como todos os componentes de uma arquitetura
tradicional foram replicados na construção deste tipo de máquinas, cada nodo não tem acesso a
endereçamentos remotos de memória.
2.1.2.3 Memória híbrida
São máquinas que possuem tanto memória distribuída quanto memória
compartilhada simultaneamente. Um exemplo deste tipo de máquinas são os clusters com nodos
multiprocessados. Clusters são tratados detalhadamente na seção 2.3.1.
A Figura 2.2 mostra um panorama geral das classificações das arquiteturas
paralelas.

18
Arquiteturas de computadores
SISD SIMDMISD MIMD
Computadores Seriais
Computadores Vetoriais
Multiprocessadores Multicomputadores
Figura 2.2: Panorama geral das Classificações das arquiteturas paralelas
2.2 Tendências de Sistemas Paralelos
Segundo (De Rose, 2001), as principais tendências para a construção dos
sistemas paralelos baseiam-se em máquinas da classe MIMD. A seguir são apresentados os
modelos e suas respectivas características:
• PVP (Parallel Vector Processor): Sistemas constituídos de máquinas
paralelas com processadores vetoriais, que se comunicam através de
memória compartilhada. A desvantagem desta classe de máquinas é o
alto custo de seus processadores.
• SMP (Symmetric Multiprocessors): Sistemas constituídos de
processadores comerciais1. São conectados a uma memória
compartilhada através de um barramento de alta velocidade. O adjetivo
simétrico (symmetric) refere-se ao fato de que todos os processadores
têm igual acesso à memória, não ocorrendo nenhum privilégio por parte
do sistema operacional. No entanto o uso de um único barramento
impede a construção de uma máquina com grande quantidade de
processadores, já que o canal é compartilhado por todos os
processadores, e conseqüentemente o desempenho global das máquinas
é afetado pela contenção do mesmo.
• MPP (Massively Parallel Processors): Máquinas paralelas com grande
número de processadores comerciais, variando desde algumas dezenas
até milhares de unidades de processamento, e memória distribuída. O
uso de memória distribuída torna factível a construção de máquinas com
grande número de processadores.
1 Processadores para uso comum, não tendo como principal finalidade o uso em arquiteturas paralelas.

19
• NOW (Network of Workstations): São sistemas constituídos por várias
estações de trabalho comuns interligadas com tecnologia tradicional,
como por exemplo, redes Ethernet e ATM. Uma rede local pode ser vista
como uma máquina paralela, onde existem vários processadores, cada
qual com seu espaço de endereçamento de memória local, interligados
por uma rede, formando uma máquina NORMA de baixo custo. O
principal problema das NOWs é que as redes tradicionais não são
otimizadas para as comunicações de uma aplicação paralela, resultando
em uma alta latência nas operações, comprometendo o seu desempenho.
Uma evolução das NOWs são os Clusters de PCs. Estes possuem
hardware e software otimizados para a execução de aplicações paralelas.
É possível observar um resumo das características dos modelos apresentados
na Figura 2.3.
Tipo PVP SMP MPP NOW Clusters
Estrutura MIMD MIMD MIMD MIMD MIMD
Comunicação Memóriacompartilhada
Memóriacompartilhada
Troca demensagens
Troca demensagens
Troca demensagens
Número deNodos ~10 ~50 100 a 5000 2 a 5000 2 a 1000
Processador Específico Comum Comum Comum Comum
Acesso àmemória UMA UMA NORMA NORMA NORMA
Figura 2.3: Resumo das arquiteturas paralelas (DeRose, 2001)
É importante salientar que o paralelismo é explorado também no nível de
instrução, onde diversas instruções são executadas simultaneamente por meio da sobreposição
dos diferentes estágios do ciclo de execução de cada instrução (pipelining), e também pelo uso
de processadores superescalares, onde as unidades funcionais do processador são duplicadas de
modo que várias instruções são processadas ao mesmo tempo. Maiores detalhes sobre pipelining
e processadores superescalares podem ser encontrados em (Stallings, 1996), (Tanenbaum, 1999)
e (Patterson, 1998).

20
2.2.1 Clusters de PCs
Um cluster de PCs é um conjunto de computadores (heterogêneos ou não)
conectados em rede para o desenvolvimento de processamento paralelo. Ou seja, as máquinas
são conectadas via rede para formar um único computador.
O projeto pioneiro em clusters de PCs foi desenvolvido no CESDIS (Center
of Excellence in Space Data and Information Sciences) em 1994 (Pitanga, 2002). Contava com
16 máquinas 486 rodando GNU/Linux.
O uso de clusters é uma alternativa ao uso de supercomputadores e
mainframes. Entre as principais vantagens do uso de clusters pode-se citar:
• Ótima relação custo x benefício: possui um dos menores custos por
Mflops/s em comparação a outras arquiteturas paralelas, devido à sua
composição feita basicamente por componentes comuns (De Rose,
2001);
• Alto Desempenho: possibilidade de se resolver problemas muito
complexos através de processamento paralelo;
• Escalabilidade: possibilidade de que novos componentes sejam
adicionados ou trocados conforme a necessidade (Pitanga, 2002);
• Disponibilidade: se um nodo falhar, os outros podem continuar
fornecendo serviços (Carvalho, 2002).
Um cluster é dito homogêneo quando todos os nodos de um cluster possuem
as mesmas características (processador, memória, discos rígidos), e mesma rede de
comunicação interligando os nodos. Se o cluster possui nodos com diferentes características ou
diferentes redes de comunicação entre grupos de nodos, o cluster é dito heterogêneo.
Segundo (Dorneles, 2001), os nodos de um cluster podem ser
monoprocessados quando possuem apenas um processador ou multiprocessados, quando
possuem mais de um processador.
Segundo (Buyya, 1999 apud Martinotto, 2003), em clusters
multiprocessados, o paralelismo intra-nodal e inter-nodal pode ser explorado das seguintes
formas:
• Troca de mensagens: troca de mensagens são um padrão no
desenvolvimento de aplicações para clusters. Quando usado em
clusters multiprocessados, os processadores de um mesmo nodo
comunicam-se entre si através do uso de troca de mensagens.
• Memória compartilhada: mecanismos DSM, implementados em
software ou hardware, são uma alternativa ao uso de troca de
mensagens em clusters. Mecanismos DSM permitem simular

21
ambientes de memória compartilhada em ambientes com memória
distribuída. A comunicação inter-nodos é implícita ao programador.
Esse tipo de mecanismos introduz um custo adicional para o
gerenciamento de endereços e coerência de dados.
• Troca de mensagens em conjunto com memória compartilhada: para
uma melhor exploração do paralelismo em clusters
multiprocessados é adequado explorar as vantagens de ambas as
arquiteturas. Para a exploração do paralelismo inter-nodos o utiliza-
se troca de mensagens e para a exploração do paralelismo intra-
nodos utiliza-se multithreading.
Bibliotecas de threads e troca de mensagens são abordadas na seção 2.3.
2.2.1.1 Exemplos de clusters de PCs
Atualmente, diversas empresas e instituições de pesquisa possuem clusters
com o número de nodos que variam de dois até alguns milhares. No site
http://clusters.top500.org é possível encontrar os clusters de maior capacidade de processamento
do mundo. Nas Figuras 2.4 e 2.5 são mostrados detalhes de dois clusters pertencentes à lista
Top 500.
MCR Linux ClusterProprietário Lawrence Livermore National LaboratoryPaís e Localização Livermore, CA – USANúmero de Nodos 1.152Processadores 2.304 Intel Xeon 2.4 GHzTotal de Processadores 2.304Performance (Gflops) 11.174Memória Total (GB) 4.600Disco Rígido Total (GB) 100.000Sistema Operacional LinuxRede de Conexão QsNetAno de Instalação 2002Área de Aplicação Pesquisa Científica
Figura 2.4: Características do MCR Linux Cluster (TOP500)

22
CorporateProprietário GX Technology CorporationPaís e Localização Houston, Texas – USANúmero de Nodos 1792Processadores 528 Sun U-2 450 MHz
112 AMD Thunderbird 1.0 GHz84 AMD Palomino 1.2 GHz254 Intel Pentium III 1.1 GHz1726 Intel Pentium III 1.4 GHz880 Intel Pentium IV 2.4 GHz
Total de Processadores 3.264Performance (Gflops) 5.091Memória Total (GB) 3.084Disco Rígido Total (GB) 237.952Sistema Operacional LinuxRede de Conexão Gigabit EthernetAno de Instalação 2003Área de Aplicação Simulações Sísmicas
Figura 2.5: Características do Cluster Corporate (TOP500)
Na vigésima primeira edição da lista (2002), 80 clusters encontram-se entre
os 500 computadores mais rápidos do mundo.
Para os testes das aplicações desenvolvidas é utilizado o cluster LabTec do
Instituto de Informática da UFRGS. As características são mostradas na Figura 2.6.
LabTeC UFRGS – DELLNúmero de Nodos 21Processadores 40 Intel Pentium III 1.1 GHz
2 Intel Pentium Xeon IV 1.8 GHzTotal de Processadores 42Performance (Gflops) ~24Memória Total (GB) 21Disco Rígido Total (GB) 396Sistema Operacional LinuxRede de Conexão Gigabit/Fast EthernetAno de Instalação 2002Área de Aplicação Pesquisa Científica e Acadêmica
Figura 2.6: Características do Cluster LabTec UFRGS

23
2.2.1.2 Redes de interconexão
A adoção de uma tecnologia de rede com baixa latência2 e grande largura de
banda3 é muito importante para o desempenho final do sistema como um todo. Dentre as
possibilidades de redes de interconexão utilizadas em cluster, destacam-se:
• Gigabit Ethernet : é uma extensão dos padrões de rede Ethernet e Fast-
Ethernet, tendo sido definido em junho de 1998 pelo padrão IEEE
802.3.3z (Gigabit Ethernet Alliance, 1997). O padrão Gigabit Ethernet
oferece alta performance, e boa escalabilidade a baixos custos.
Apresenta boa largura de banda, mas uma alta latência.
• Myrinet: desenvolvida pela empresa Myricom (Myricom, 2003), tem
como objetivo ser uma tecnologia de interconexão, baseada em
chaveamento e comunicação por pacotes, de baixo custo e de alta
performance. As características que distinguem a Myrinet das demais
são especialmente links full-duplex alcançando 2 Gbps para cada um,
pacotes de tamanho variável (permitindo qualquer tipo de pacote),
controle de fluxo, de erro, monitoramento contínuo dos links, baixa
latência, suporte a qualquer configuração de topologia.
• SCI (Scalable Coherent Interface): definido pelo padrão IEEE/ANSI
1596-1992 (SCI, 2003), foi a primeira tecnologia de rede a ser
desenvolvida especialmente para propósitos de computação em clusters.
O padrão oferece baixa latência e alta taxa de transmissão de dados
(cerca de 8 Gbps). A comunicação em SCI pode ser feita através de troca
de mensagens e memória compartilhada distribuída, implementada em
um espaço de endereçamento físico de 64 bits que permite operações de
escrita e leitura. O desempenho é garantido pelo acesso à memória que é
feito por instruções LOAD/STORE implementadas em hardware (SCI,
2003).
• QsNet: Produzida pela Quadrics, é uma tecnologia para computadores
com multiprocessamento simétrico, oferece largura de banda nominal de
400Mbps e baixa latência (Petrini, 2002).
• Infiniband : tecnologia de interligação apoiada por fabricantes como
Intel, IBM, Sun, HP e Microsoft, e que especifica uma arquitetura de
2 A latência é dada pelo tempo necessário para transmitir uma mensagem de uma máquina origem a umdestino.3 É o número máximo de bits que podem ser transmitidos por segundo pela rede.

24
hardware para a interligação de alto desempenho intra e inter-nodal
(Infiniband Trade Association, 2003).
2.3 Bibliotecas
Como visto na seção 2.2, muitos sistemas paralelos são formados por
computadores independentes interligados por uma rede veloz. Estas máquinas são ditas de
memória distribuída. Nestes sistemas, pode-se executar tarefas de modo paralelo, e
eventualmente estas tarefas necessitam de mecanismos de compartilhamento de dados e
sincronização.
Sendo que cada processo possui acesso somente a sua memória local, a
comunicação entre os processos é feita através do envio e recebimento de mensagens, onde os
dados são enviados da memória local de um processo para a memória local de um processo
remoto. A distribuição dos dados entre os processos é feita de forma explícita pelo programador.
2.3.1 Bibliotecas de troca de mensagem
A utilização de compartilhamento de dados via troca de mensagens é
bastante popular e são encontradas na bibliografia diversas ferramentas disponibilizando estes
recursos de programação. Entre elas podemos citar o PVM e o MPI, que serão descritos nas
seções 2.4.1.1 e 2.4.1.2, respectivamente.
Pode-se relacionar dois principais fatores que justificam a grande aceitação
do paradigma de troca de mensagens:
• Pode ser executado em uma grande variedade de plataformas, inclusive
em arquiteturas multiprocessadas com memória compartilhada ou ainda
em um único processador;
• Adequa-se naturalmente a arquiteturas ampliáveis, ou seja, a capacidade
de aumentar o poder computacional proporcionalmente ao aumento de
componentes do sistema (boa escalabilidade);
A principal limitação do paradigma é a sobrecarga causada pela
comunicação entre os processos e pela sincronização entre eles. O custo da comunicação entre
processos pode tornar inviável o uso de troca de mensagens em determinados ambientes (Palha,
2000).

25
2.3.1.1 PVM
PVM (Parallel Virtual Machine), é um conjunto integrado de bibliotecas e
ferramentas de software, que permitem que um conjunto de máquinas heterogêneas conectadas
em rede seja utilizado como uma arquitetura paralela de memória distribuída, formando uma
máquina paralela virtual.
PVM foi desenvolvida pelo Oak Ridge National Laboratory em conjunto
com diversas universidades. A intenção inicial era facilitar a implementação de programas
científicos de alto desempenho explorando o paralelismo sempre que possível.
O PVM é constituído por dois componentes: um daemon4 residente (pvmd) e
a biblioteca de comunicação (libpvm). Ambos devem estar disponíveis em cada nodo da
máquina virtual paralela. O primeiro componente, pvmd, é a interface de troca de mensagens
entre a aplicação de cada máquina local e o restante da máquina virtual. O segundo componente,
libpvm fornece à aplicação local todas as funcionalidades que necessita para que possa
comunicar-se com os outros nodos.
O download do PVM, e informações adicionais podem ser encontrados em:
http://www.csm.ornl.gov/pvm/pvm_home.html.
2.3.1.2 MPI
O MPI (Message Passing Interface) é um padrão, e não uma biblioteca,
criado em um fórum aberto constituído de aproximadamente 80 pessoas, representando 40
organizações. É importante ressaltar que, enquanto o PVM é uma implementação, o MPI é
apenas uma especificação sintática e semântica de rotinas constituintes da biblioteca de
comunicação (Cenapad, 2003).
O principal objetivo do MPI é garantir a portabilidade de aplicações que
utilizem troca de mensagens para diferentes arquiteturas de computadores. Isso permite que
aplicações desenvolvidas em MPI sejam executadas em diferentes arquiteturas sem a
necessidade de alterações. O documento que define o padrão "MPI: A Message-Passing
Standard" foi publicado pela Universidade de Tennesee e encontra-se em
http://www.mcs.anl.gov/mpi/.
A versão 1.1 de MPI possui ao todo 129 funções, mas com um número
reduzido (6) é possível resolver uma grande variedade de problemas (Pacheco, 1997). O MPI
define funções para:
4 Serviço permanentemente ativo em um sistema que aguarda instruções para disparar ações específicas.

26
• Comunicação ponto a ponto;
• Comunicação coletiva (de grupo);
• Grupos de processos;
• Gerenciamento de processos.
Atualmente o MPI possui diversas implementações comerciais ou de
domínio público. Neste trabalho utilizou-se a implementação de domínio público MPICH (MPI
Chameleon), do Argonne National Laboratory. Seu download e documentação completa pode
ser encontrada em: http://www-unix.mcs.anl.gov/mpi/mpich/download.html.
2.3.2 Bibliotecas de threads
Um thread pode ser definido como um fluxo de execução dentro de um
processo e consiste em um contador de instruções, um conjunto de registradores e um espaço de
pilha (Silberschatz, 2001).
Devido ao alto custo envolvido na criação de novos processos, a utilização
de múltiplos threads, ou multithreading, em um programa pode apresentar vantagens. Na
criação de um novo processo o sistema operacional copia todos os atributos do processo
corrente para o processo que está sendo criado. Já os threads compartilham os atributos do
processo. Deste modo a criação de um novo thread é menos custosa pois não é necessário
efetuar uma cópia dos atributos, bastando inicializar seus ponteiros de modo que referenciem os
atributos do processo (Picinin, 2001) (Silberschatz, 2001).
Além disso, os programas com múltiplos threads podem ter ganhos de
desempenho significativos tirando partido de arquiteturas multiprocessadas, de modo que
diferentes threads podem ser executados simultaneamente em diferentes processadores.
Mais informações sobre uso de threads e ganhos de desempenho com seu
uso podem ser encontrados em (Martinotto, 2001), (Picinin, 2001) e (Picinin, 2002).
Pode-se notar também o aumento do throughput5 do sistema. A execução de
um programa com um só thread resulta freqüentemente em tempo de CPU livre. Isto ocorre
quando o programa faz alguma chamada ao sistema operacional e tem que esperar que o serviço
esteja totalmente atendido antes de poder continuar. Em um programa multithread, se um thread
faz uma chamada ao sistema e fica bloqueado à espera que este seja totalmente atendido, outro
thread pode executar. Esta sobreposição permite uma melhor utilização da CPU mesmo em
máquinas monoprocessadas.
5 Quantidade de tarefas completadas por unidade de tempo.

27
Embora existam bons argumentos para o uso de múltiplos threads nas
aplicações, a adição de threads também introduz complexidade e a possibilidade de encontrar
uma nova classe de erros (deadlock, starvation, etc.) que não fazem parte dos problemas da
programação com thread único. Também se pode fazer necessário o uso de sincronização intra-
nodal, que pode ocasionalmente acarretar em sobrecarga extra, podendo afetar o desempenho da
aplicação.
Existem vários modelos de programação com threads. Nas plataformas
originárias do UNIX predominam Pthreads e o OpenMP.
2.3.2.1 Pthreads
O Pthreads (Lewis, 1998) é especificado pelo padrão POSIX 1003.1c. Esta
especificação define uma API para o desenvolvimento de ferramentas de suporte à programação
utilizando threads.
Em Pthreads, os threads são criados e eliminados dinamicamente, conforme
a necessidade. Além disso, o padrão oferece mecanismos de sincronização, como semáforos,
mutexes e variáveis condicionais.
Para utilizar a biblioteca Pthreads no Linux não é necessária a instalação de
nenhum componente, já que a mesma é padrão para este sistema operacional.
2.3.2.2 OpenMP
OpenMP (OpenMP, 2003) é uma especificação para um conjunto de
diretivas de compilador, biblioteca de rotinas e variáveis de ambiente que podem ser usadas
para especificar paralelismo em memória compartilhada.
O padrão OpenMP foi definido por um grupo de empresas que inclui:
Compaq, IBM, Intel, Silicon Graphics, Kuck & Associates, Sun Microsystems e US Department
of Energy ASCI Program.
OpenMP foi desenvolvido para ser um padrão flexível e de fácil
implementação em diferentes plataformas. Sua API pode ser dividida em 6 categorias: regiões
paralelas, compartilhamento de trabalho, sincronização, ambiente de dados, biblioteca de
funções e variáveis de ambiente.

28
O modelo de execução paralelo adotado em OpenMP é o fork-join. Como
mostrado na Figura 2.7, o programa inicia a execução com uma simples thread, chamado de
mestre. Quando esta atinge um construtor paralelo, ela cria um conjunto de n threads e o
trabalho continua em paralelo ao longo destas. Ao sair do construtor paralelo os threads
sincronizam e se juntam ao thread mestre, que segue sozinha a execução.
Para o uso do OpenMP é necessário o uso de um compilador especial, já que
compiladores comuns não suportam as diretivas do OpenMP.
Um compilador disponível gratuitamente para OpenMP é o OMNI. O pacote
disponibiliza um compilador e todas as bibliotecas necessárias. O compilador OMNI e sua
documentação podem ser obtido em http://phase.etl.go.jp/Omni/.
serial serial serialparalelo paralelo
thread 0
thread 1
thread 2
thread 0
thread 1
thread 2
início fim
Figura 2.7: Modelo de execução OpenMP
2.3.3 Bibliotecas de álgebra linear e resolução de sistemas
Sistemas de equações lineares e problemas que utilizam álgebra linear para
sua solução estão entre os maiores consumidores de tempo de processamento dos programas
científicos. No intuito de tornar a resolução desses sistemas cada vez mais rápidos e eficientes,
foram desenvolvidas diversas bibliotecas com diversas operações e métodos para a resolução
dos mesmos.
Esta seção tem como objetivo mostrar as características e funcionalidades de
duas bibliotecas gratuitas, uma para operações de álgebra linear e a outra para solução de
sistemas de equações, que são as mais utilizadas atualmente no meio científico: BLAS e PETSc,
respectivamente.

29
2.3.3.1 BLAS
BLAS (Basic Linear Algebra Subroutines) é um conjunto de rotinas de
operações vetoriais e matriciais básicas. É muito usada como camada em diversos softwares
matemáticos, como por exemplo, a biblioteca PETSc.
A versão inicial da BLAS destinava-se ao uso da linguagem Fortran.
Atualmente pode ser utilizada com C e C++ em diversas arquiteturas. A biblioteca BLAS
consiste em 3 níveis, cujas funcionalidades podem ser vistas na Figura 2.8.
BLAS utiliza convenção de nomes para identificar uma operação e o tipo de
dado envolvido na mesma. Exemplos desta convenção são:
• CSUM: soma de dois vetores (SUM) de números complexos (C);
• DTRMM: multiplicação de matrizes (MM) entre duas matrizes
triangulares (TR) de dupla precisão (D).
Uma completa referência das operações disponível na BLAS pode ser
encontrada em http://padmin2.ncsa.uiuc.edu/auxdocs/mkl/mklqref/index.htm.
Nível Complexidadedas Operações Exemplos de operações
BLAS 1 O vetores, produto escalar, norma de vetores
BLAS 2 O(n2) Multiplicação matriz-vetor, transposição de matrizes,solução de sistemas tridiagonais
BLAS 3 O(n3) Multiplicação matriz-matriz, fatorização LU
Figura 2.8: Níveis da biblioteca BLAS
Segundo (Dongarra, 2000), os ganhos de desempenho no nível 1 da BLAS
são de no máximo 15%. Neste nível os ganhos de desempenho ficam a cargo das otimizações
das operações de ponto flutuante e estruturas de repetição. Já nos níveis 2 e 3 os ganhos de
desempenho variam entre 10 e 300%. Esse fato se deve às otimizações de laços de repetição e
técnicas de acessos rápidos de memória, além da otimização das operações de ponto flutuante,
também presente no nível 1.
Várias implementações da BLAS estão disponíveis no mercado, muitas delas
são versões otimizadas para uma arquitetura específica. A versão utilizada é parte integrante do
pacote ATLAS6 (Automatically Tuned Linear Algebra Software). Este pacote fornece os 3
níveis com uma importante funcionalidade: no início da instalação, é feita a verificação da
arquitetura hospedeira e o pacote é otimizado automaticamente (Automatically Tuned).
6 math-atlas.sourceforge.net

30
2.3.3.2 PETSc
PETSc (The Portable, Extensible Toolkit for Scientific Computation) (Balay,
2003) é um conjunto de bibliotecas para a solução em paralelo de problemas relacionados à
discretização de equações diferenciais parciais e afins. Permite resolver sistemas de equações
lineares e não-lineares, tanto densos como esparsos, além de possuir um abrangente controle de
erros e funções para gráficos simples.
As estruturas de dados básicas e operações relacionadas são transparentes ao
usuário, sendo apenas acessadas através de tipos genéricos e funções. PETSc também fornece
um grande número de opções que podem ser selecionadas em tempo de execução.
Um exemplo destas opções é a seleção do resolvedor em tempo de execução.
Qualquer resolvedor de sistemas lineares poderá ser escolhido através da opção de linha de
comando -ksp_type seguido pela opção desejada. No exemplo a seguir o método escolhido é o
gradiente conjugado (GC).
mpirun -np 2 program_name –ksp_type cg
Esta característica é extremamente útil no desenvolvimento de programas de
propósito geral, que podem ser usados para resolver uma variedade de tipos diferentes de
problemas simplesmente escolhendo um resolvedor para cada uma delas.
PETSc utiliza MPICH em todas as comunicações de troca de mensagens, e
BLAS e LAPACK7 para operações de álgebra linear. A organização do pacote PETSc é
mostrado na Figura 2.9.
Figura 2.9: Organização da Biblioteca PETSc
O pacote e a documentação podem ser obtidos em: http://www-
unix.mcs.anl.gov/petsc/.
7 www.netlib.org/lapack

31
2.4 Conclusão
Neste capítulo foram tratados as questões referentes ao hardware e software
utilizado para a implementação de aplicações paralelas.
Em relação ao hardware, os clusters têm se mostrado uma opção acessível de
ambiente paralelo. Atualmente, com o avanço dos processadores comuns e das redes, pode-se
obter desempenho equivalente ao de PVPs e MPPs por um custo muito menor.
Em clusters, pode-se explorar o paralelismo intra-nodal e o inter-nodal,
fazendo-se necessário o uso de bibliotecas threads e de troca de mensagens respectivamente.
Nesse contexto, foram apresentadas duas bibliotecas de troca de mensagens: MPICH e PVM, e
para multithreading: Pthreads e OpenMP.
Buscou-se também proporcionar uma visão geral da biblioteca de álgebra
linear BLAS e da biblioteca de resolução de sistemas PETSc, mostrando suas principais
características.

32
3. PROCESSAMENTO PARALELO
O paralelismo em nível de programa pode ser explorado tanto
explicitamente, como implicitamente. A exploração do paralelismo explícito tem como principal
desvantagem o fato de requerer um projeto (e/ou um projetista) mais sofisticado do que o
necessário para explorar o paralelismo implícito. Porém, possui como principal vantagem à
obtenção de melhor desempenho, já que o projeto pode atentar às peculiaridades da arquitetura e
do algoritmo.
De fato, a programação paralela explícita requer que o projetista do
algoritmo paralelo especifique como os processadores devem operar e interagir para resolver um
problema específico. A tarefa do compilador é, nesses aspectos, apenas gerar as instruções
especificadas pelo programador, pois todo trabalho na paralelização das tarefas fica a cargo do
programador.
Já a programação paralela implícita emprega uma programação seqüencial, e
utiliza um compilador que insira automaticamente as instruções necessárias para executar o
programa de forma paralela. Essa abordagem é, sob o ponto de vista da programação, mais fácil.
Porém, a conversão automática de programas seqüenciais para paralelos é, via de regra, mais
satisfatória em arquiteturas vetoriais do que em arquiteturas com memória distribuída.
Além disso, em clusters multiprocessados, como o utilizado para executar os
experimentos computacionais desenvolvidos neste trabalho, tem-se memória compartilhada e
memória distribuída e, assim, pode-se explorar os dois níveis de paralelismo, o intra e o inter-
nodal. Então, neste trabalho, emprega-se a abordagem explícita, já que inexistem ferramentas
apropriadas para extrair o paralelismo implicitamente desse tipo de arquitetura (Picinin, 2001).
3.1 Paradigmas de Programação
Sob o ponto de vista de programação, os paradigmas de programação
paralela podem ter diversas classificações, e estas divergem de autor para autor. Uma
classificação é aquela de (Silva, 2003), onde se têm os seguintes paradigmas:
• Mestre-Escravo;
• Single Program Multiple Data;
• Pipeline de Dados;
• Divisão e Conquista.

33
3.1.1 Mestre-Escravo
O paradigma Mestre-Escravo, como o próprio nome sugere, consiste em
duas entidades: mestre e múltiplos escravos. O mestre é responsável pela decomposição do
problema em pequenas tarefas, em distribuir estas tarefas entre os escravos, e reunir os
resultados parciais obtidos. Estes resultados quando reunidos geram a solução total do
problema. Os processos escravos recebem as mensagens com a tarefa, processam esta tarefa e
enviam o resultado ao mestre. Geralmente a comunicação é efetuada apenas entre mestre e
escravos. Uma representação deste paradigma pode ser encontrada na Figura 3.1.
Figura 3.1: Representação para fases do paradigma Mestre-Escravo
Este paradigma pode alcançar bons speedups, (ver seção 3.5), e uma boa
escalabilidade. No entanto, o controle centralizado para um número elevado de processadores
pode tornar o processo mestre um gargalo para a aplicação. Isso pode ser resolvido estendendo o
controle para um conjunto de mestres, onde cada mestre controla um conjunto de escravos
distintos.
3.1.2 Single-Program Multiple-Data (SPMD)
O paradigma SPMD é o paradigma mais comumente utilizado. Cada
processo executa basicamente o mesmo trecho de código, mas em diferentes partes dos dados.
Isso envolve a divisão dos dados da aplicação entre os processadores disponíveis. Após a
divisão, os processos podem necessitar de comunicação ou/e sincronização. Os dados podem ser
inicializados pelo próprio processo ou podem ser lidos de um disco durante o estágio de inicial.
Veja uma representação na Figura 3.2.
As aplicações SPMD podem ser muito eficientes se tiverem seus dados bem
distribuídos e o sistema hospedeiro for homogêneo. Se os processos apresentam diferentes

34
cargas de trabalho ou capacidades, então o paradigma pode exigir algum esquema de
balanceamento de carga capaz de adaptar a distribuição de dados em tempo de execução.
Figura 3.2: Representação para fases do paradigma SPMD
3.1.3 Pipeline de dados
Neste paradigma, os processos são organizados em um pipeline, onde cada
processo corresponde a um estágio do pipeline e é responsável por uma tarefa específica, como
representado na Figura 3.3.
Figura 3.3: Representação para fases do paradigma pipeline
O padrão de comunicação neste paradigma é simples, de modo que pode ser
visto como um fluxo dos dados de um processo para o outro. Por este motivo este tipo de
paralelismo é referenciado como paralelismo de fluxo. A eficiência deste paradigma depende
diretamente do balanceamento de carga entre os estágios do pipeline.
3.1.4 Divisão e conquista
O paradigma de divisão e conquista é bem conhecido no desenvolvimento de
algoritmos seqüenciais. Um problema é dividido em dois ou mais subproblemas. Cada um
destes subproblemas é resolvido independentemente e seus resultados são combinados para se

35
chegar ao resultado final. Muitas vezes, os subproblemas são instâncias do problema original,
dando origem a uma execução recursiva.
No paradigma de divisão e conquista paralelos, os subproblemas podem ser
resolvidos simultaneamente de forma paralela. Além disso, pouca ou nenhuma comunicação
entre processos é necessária, já que os subproblemas são independentes. Veja uma
representação na Figura 3.4.
Figura 3.4: Representação para fases do paradigma Divisão e Conquista
Em algumas aplicações, pode-se misturar elementos de diferentes
paradigmas. Métodos híbridos podem combinar elementos de diversos paradigmas em
diferentes partes de um mesmo programa.
3.2 Estratégias para a Extração do Paralelismo
A construção de aplicações paralelas pode ser orientada por duas estratégias
principais, como segue:
1. Paralelismo de dados: onde as tarefas possuem a mesma função
operando sobre porções de dados diferentes, ou seja, utilizam-se do
paradigma de programação SPMD ou mestre-escravo;
2. Paralelismo funcional: onde as tarefas da aplicação possuem
diferentes funções, cada uma responsável por uma etapa do trabalho.
O paralelismo funcional pode ser implementado utilizando tanto o
paradigma mestre-escravo, quanto pipeline de dados.
Em geral, a decomposição funcional reduz a complexidade de projeto. Um
exemplo disso é o caso de modelos computacionais de sistemas complexos, que podem ser
estruturados como conjuntos de modelos mais simples, conectados por interfaces. Veja um

36
exemplo em (Foster, 1994) do emprego do paralelismo funcional para um modelo
meteorológico, que contém como “sub-modelos” o modelo hidrológico, oceânico e o da
superfície da Terra.
Neste trabalho, as estratégias de implementações para a obtenção da solução
em paralelo enfocam o paralelismo de dados, cujos modelos mais utilizados são a decomposição
ou particionamento de dados, onde as operações e os dados são distribuídos entre os processos
disponíveis e são resolvidos em paralelo, e a decomposição de domínio, onde se obtém a
solução do problema global combinando as soluções de subproblemas locais.
3.2.1 Técnicas para a solução paralela de sistemas de equações
Para a solução de sistemas de equações em paralelo são duas as abordagens
mais exploradas: a paralelização de métodos numéricos, e o emprego de métodos de
decomposição de domínio. É importante frisar que ambas abordagens se encaixam na estratégia
de paralelismo de dados. Na primeira abordagem gera-se um único sistema de equações para
todo o domínio, que é resolvido através de um método numérico paralelizado. Na segunda
abordagem emprega-se um método de decomposição de domínio (MDDs). MDDs designam um
conjunto de técnicas matemáticas e computacionais que fornece a solução global do problema
pela combinação apropriada das soluções obtidas em cada um dos subdomínios (Rizzi, 2003).
Neste trabalho são empregados métodos de decomposição de domínio. Uma
vez que diferentes subdomínios podem ser tratados independentemente, exceto nos pontos de
sincronismo, tais métodos são atrativos para ambientes computacionais de memória distribuída,
como é o caso dos clusters de PCs. Tais MDDs podem ser divididos em duas grandes classes:
métodos de Schwarz, onde os subdomínios apresentam uma região de sobreposição, e métodos
de Schur, onde os subdomínios não apresentam região de sobreposição (Smith, 1996). Mais
detalhes sobre os métodos são apresentados e discutidos no capítulo 6.
3.3 Metodologia de desenvolvimento de programas paralelos
A metodologia PCAM (Partitioning, Communication, Agglomeration e
Mapping) proposta por Foster (Foster, 1995), constitui um bom método para o desenvolvimento
de programas paralelos. O objetivo declarado desta proposta é projetar algoritmos
independentes de uma arquitetura particular fornecendo estratégias para maximizar as

37
alternativas de paralelismo visando minimizar os problemas que podem ocorrer nas etapas do
desenvolvimento do projeto.
A estrutura metodológica de Foster é composta por quatro fases: o
particionamento, a comunicação, a aglomeração e o mapeamento. Nas primeiras duas fases, são
enfocadas a concorrência e a escalabilidade e procura-se descobrir algoritmos que tenham estas
qualidades; no terceiro e quarto estágios, os enfoques são a localidade e outros aspectos
relacionados ao desempenho. Estes quatro estágios podem ser sintetizados como representado
na Figura 3.5 e, como detalhado a seguir.
Figura 3.5: Estrutura da Metodologia PCAM (Foster, 1995)
• Particionamento: a computação a ser executada e o seu respectivo
conjunto de dados, devem ser decompostos em pequenas tarefas.
Como a abordagem é genérica, ignoram-se questões como o número
de processadores e características específicas de máquinas em
particular. O enfoque neste passo é reconhecer as oportunidades para
execução paralela. Existem duas formas de gerar partições: através
da divisão dos dados ou das funções, tal como mostrado na seção
3.2;
• Comunicação: deve-se determinar a comunicação necessária para
coordenar a execução das tarefas e as estruturas mais apropriadas
para a realização desta tarefa;
• Aglomeração: deve-se avaliar as estruturas das tarefas e das
comunicações, definidas nos dois primeiros estágios do projeto, com
respeito às exigências de desempenho e aos custos de
implementação. Se necessário, as tarefas podem ser combinadas em

38
tarefas maiores para aumentar o desempenho e/ou reduzir os custos
de projeto/implementação;
• Mapeamento: cada tarefa é endereçada para um processador na
tentativa de satisfazer os objetivos de maximizar a utilização de cada
um deles e minimizar os custos de comunicação. Este mapeamento
pode ser especificado de forma estática, ou determinado em tempo
de execução, por algoritmos de balanceamento de carga.
Assim, o projeto metodológico PCAM para desenvolvimento de programas
paralelos é estruturado, ou seja, inicia com uma especificação do problema; depois se
desenvolve uma estratégia de particionamento; em seguida se determinam as necessidades de
comunicação e aglomeração de tarefas e realiza-se mapeamento destas para os processadores.
3.4 Métricas para Avaliação de Desempenho Computacional
O desempenho de um programa em uma arquitetura pode ser mensurado de
diversos modos. As medidas mais utilizadas são: tempo de execução, speedup e eficiência.
3.4.1 Tempo de execução
O tempo de execução de um programa paralelo é o tempo que decorrido
desde o primeiro processador iniciar a execução do programa até o último terminar. A fórmula
para determinar o tempo de execução é dada por:
inicialfinalexec TTT −=
3.4.2 Speedup
O Speedup (S) obtido por um algoritmo paralelo executando sobre p
processadores é a razão entre o tempo levado por aquele computador executando o algoritmo
serial mais rápido (Ts) e o tempo levado pelo mesmo computador executando o algoritmo
paralelo usando p processadores (Tp). Esta definição é representada pela expressão:
S Ts Tp=
À medida que o número de processadores é incrementado, o speedup de uma
aplicação também é incrementado. No entanto, pode ocorrer em alguns casos a saturação do
sistema. A partir desse ponto a adição de novos processadores não resulta em ganho de

39
desempenho, podendo acontecer até mesmo o reverso (speeddown). Isso se deve a sobrecarga
causada pelo aumento de comunicação entre os processadores e o aumento de tarefas de
sincronização.
3.4.3 Eficiência
A eficiência (E) é a razão entre o speedup obtido com a execução com p
processadores e p. Esta medida mostra o quanto o paralelismo foi explorado no algoritmo.
Quanto maior a fração inerentemente seqüencial menor será a eficiência.
E S p=
3.5 Conclusão
Apesar da literatura ser um tanto confusa em relação aos paradigmas de
programação, apresentou-se neste trabalho alguns deles de acordo com a abordagem de (Silva,
2003). Segundo o autor, podemos citar os paradigmas Mestre-Escravo, Single Program Multiple
Data, Pipeline de Dados e Divisão e Conquista.
Num segundo momento, foram abordadas as estratégias para a extração do
paralelismo e as técnicas, paralelização de métodos numéricos e decomposição de domínio, para
a Solução Paralela de Sistemas de Equações.
Ainda neste capítulo, apresentou-se a metodologia PCAM (Partitioning,
Communication, Agglomeration e Mapping) proposta por Foster (Foster, 1995).
Finalizando o capítulo encontram-se algumas métricas de avaliação de
desempenho computacional, que são utilizadas para avaliar os ganhos de desempenho de uma
determinada aplicação em relação ao seu algoritmo seqüencial. Com isso pode-se saber se a
paralelização foi vantajosa ou não.

40
4. PARTICIONAMENTO DE DADOS E DE DOMÍNIO
Para a solução em paralelo de um determinado sistema de equações
utilizando-se da abordagem de decomposição de domínio ou da abordagem de paralelização de
métodos numéricos (estratégias discutidas no capítulo 3), é necessário que o domínio global ou
os dados do problema sejam “divididos” em partes menores, e cada parte atribuída a um
processo. Desse modo, o processo pode ser resolvido de modo simultâneo por uma coleção de
processadores.
O domínio computacional deve ser particionado entre os processadores
disponíveis atendendo pelo menos dois requisitos básicos (Dorneles, 2001):
• A carga de trabalho deve ser bem balanceada entre os processadores;
• A comunicação entre os processadores deve ser minimizada;
Uma distribuição desigual do domínio entre os processadores faz com que
alguns terminem antes sua tarefa, permanecendo ociosos até que os outros processadores
cheguem nos pontos de sincronização e os primeiros recebam os dados necessários para
executar uma nova carga de tarefas, o que resulta em redução da eficiência. Para minimizar a
comunicação entre os processos deve-se diminuir o número de células nos contornos dos
subdomínios, visto que as aplicações paralelas são, geralmente, síncronas, e as comunicações
são restritas às essas fronteiras dos subdomínios.
O problema de particionamento de domínio em subdomínios, considerando-
se a arquitetura disponível e exigindo o balanceamento de carga e a minimização da
comunicação dos processos, durante tempo de execução, é uma das etapas mais importantes da
Computação Científica Paralela (Rizzi, 2002). No entanto, apesar de ser um fator de grande
relevância na paralelização de uma aplicação, não existe um algoritmo que determine um
particionamento ótimo, pois este é um problema NP-difícil (Garey; Johnson, 1979). Assim, para
se ter aproximações razoavelmente boas, são empregados algoritmos heurísticos, como os
apresentados e discutidos na seção 4.3.
4.1 Malhas e Grafos
O domínio para aplicações paralelas é, geralmente, representado por uma
malha bi ou tri-dimensional, como mostrado na Figura 4.1. A execução eficiente da aplicação
requer um mapeamento da malha entre os processadores, de forma que cada processador receba
uma quantidade de nodos (ou células computacionais) proporcional a sua capacidade de
processamento, e de tal modo que a comunicação entre os processadores seja minimizada.

41
Figura 4.1: Domínio (azul) e respectiva malha.
Para que seja possível particionar uma malha, utilizando-se de algoritmos de
grafos, é preciso antes transformá-la em um grafo. Em diversos tipos de aplicações os nodos
representam as coordenadas em um espaço bi ou tridimensional, ou seja, as células
computacionais, e as arestas representam a comunicação ou dependência entre nodos vizinhos,
ou seja, a dependência de dados entre as células computacionais.
4.2 O Problema de Particionamento de Grafos
O problema de particionamento de domínio pode ser modelado como um
problema de particionamento de grafos (Rizzi, 2002). Uma aplicação pode ser vista como um
grafo G=(V, A, pv, pa), onde: V = 0,...,n-1) é o conjunto dos n vértices; A ⊆ V×V é o conjunto
de arestas; pv é o peso dos vértices, e; pa é o peso das arestas.
Sob esse ponto de vista, o domínio mostrado na Figura 4.1 pode ser
representado por grafo (ou, uma malha cartesiana regular) como mostrado na Figura 4.2.
Figura 4.2: Grafo referente à malha da Figura 4.1.
Note-se que se pode ter distintos significados para a terminologia “nodos” e
“arestas”. Por exemplo, nodos podem descrever processos ou dados, arestas podem significar
dependências de dados ou necessidades de comunicação.
Sob o ponto de vista de grafos o problema do particionamento de dados ou
de domínio conhecido como o “problema de k-particionamento de grafos”, que consiste em

42
dividir um grafo em k subgrafos, de modo que cada subgrafo contenha um número semelhante
de vértices, e que o número arestas entre os subgrafos seja o menor possível (Karypis, 1996).
4.3 Heurísticas e Métodos de Particionamento
Sendo o problema de k-particionamento um problema NP-difícil sua solução
pode ser aproximada por algoritmos heurísticos. Existem, pelo menos, duas grandes classes de
heurísticas, dependendo das informações disponíveis sobre o grafo, que são as geométricas e as
combinatórias (Santos, 2001). Note-se que existem outras abordagens para o particionamento de
grafos, mas estas fogem do escopo do trabalho. Entre elas pode-se citar redes neurais e
algoritmos genéticos (Bhargava, 1993).
A primeira classe é utilizada quando estão disponíveis informações sobre as
coordenadas de cada vértice do grafo. Isto ocorre freqüentemente em grafos derivados da
discretização de um domínio físico. Os algoritmos geométricos são bastante rápidos, mas
tendem a gerar partições de qualidade relativamente inferiores, pois calculam as mesmas
baseadas nas coordenadas dos vértices (juntando aqueles que estão mais perto no espaço) e não
na sua conectividade.
Já a segunda classe é utilizada quando o grafo não possui coordenadas
associadas aos vértices, isto é, não há identificação de um nodo com um ponto físico no espaço.
Estes algoritmos calculam as partições baseadas nas adjacências do grafo, juntando vértices que
são altamente conectados, sem se importar com sua localização. Estes tipos de algoritmos são
mais lentos que os geométricos, mas geram partições com corte de arestas menor, sendo menos
provável que haja subdomínios desconexos.
Além disso, as heurísticas de particionamento ainda podem ser divididas em
métodos globais, locais ou multiníveis (Dorneles, 2001).
4.3.1 Métodos globais
Métodos globais são algumas vezes chamados de heurísticas de construção,
uma vez que utilizam a descrição do grafo como entrada e geram várias partições.
Existem diversos algoritmos, baseados nas heurísticas, para realizar o
particionamento global de um grafo. Destes podemos citar o particionamento em faixas, o
particionamento em blocos, a bissecção recursiva ortogonal (ORB), a bissecção recursiva por

43
coordenada (RCB), a bissecção inercial, as curvas de preenchimento do espaço, a bissecção
espectral, e a bissecção nivelada.
Neste trabalho será discutido apenas o RCB, por ser um dos algoritmos
utilizados no particionamento no modelo HIDRA. Os demais algoritmos são detalhados em
(Dorneles, 2001) e (Santos, 2001).
4.3.1.1 Bissecção recursiva por coordenada (RCB)
Nestes algoritmos, as divisões (bissecções) são feitas recursivamente e
sempre de modo ortogonal à sua maior dimensão, como ilustrado na Figura 4.3. Desse modo,
objetiva-se diminuir o número de elementos das fronteiras e gerar subdomínios com carga
aproximadamente equivalentes.
(a) (b) (c)
Figura 4.3: (a) Domínio Inicial. (b) Domínio Particionado após um passo do RCB. (c) Domínio apósdois passos do RCB.
O algoritmo consiste basicamente nos seguintes passos: a) determinar a
maior dimensão do domínio (direção x, y ou z); b) atribuir metade dos vértices para cada
subdomínio; c) repetir recursivamente até que seja alcançado o número de partições requerido.
O RCB é um método rápido, requer pouca memória, e segundo (Schloegel,
2000 e Santos, 2001) é fácil de ser paralelizado. Note-se, porém, que o algoritmo RCB usado
neste trabalho é o implementado no modelo HIDRA que é empregado de modo seqüencial.
4.3.2 Métodos locais
Apesar de alguns dos métodos globais produzirem bons cortes,
freqüentemente há um potencial grande de melhora através de rearranjos locais. Os métodos
locais são os responsáveis por esta melhora. Estes métodos recebem como entrada um grafo e

44
suas respectivas partições e fazem um refinamento destas através da troca de vértices (nodos)
entre elas. Por isso as heurísticas dessa classe são, também, são chamadas de heurísticas de
melhoramento.
Desta classe, destacam-se os algoritmos Kernighan-Lin (Kernigham, 1970) e
Fiduccia-Mattheyses (Fiduccia, 1982).
O método Kernighan-Lin (KL) consiste em selecionar pares de vértices, que
quando trocados entre os subdomínios resultem na melhora da qualidade das partições. O ganho
é calculado pela redução do corte de arestas. Quanto menos arestas cortadas, maior o ganho
obtido. Se o ganho sobre um par de vértices é positivo, claramente é desejável fazer a troca, mas
em alguns casos pode-se mover vértices com ganhos negativos, pois estes podem trazer
benefícios nas próximas iterações do algoritmo, por exemplo, movendo a partição de um
mínimo local.
O principal inconveniente deste método é sua complexidade: requer O(N3)
operações por iteração. Porém, este método merece destaque por ser utilizado na fase de
refinamento nos métodos multinível, descrito na seção 4.4. O método Fiduccia-Mattheyses
(FM) é uma modificação do algoritmo KL. Este algoritmo move apenas um vértice por vez
entre os subdomínios, ao invés de um par, como no KL.
Na Figura 4.4 se ilustra a aplicação do algoritmo KL. Na parte (a) mostra-se
uma partição gerada de modo não apropriado, dado que os vértices que estão em destaques na
Figura 4.4(a) devem ser trocados entre os subdomínios, mas sobre estes é associada uma
quantidade excessiva de comunicação. Já na Figura 4.4(b) mostra-se o refinamento que pode ser
feito empregando o algoritmo KL.
Figura 4.4: Exemplo de refinamento por KL
Pode-se notar, que em (a) os subdomínios necessitam comunicar-se seis
vezes entre si. Em (b), após a execução do algoritmo KL, as comunicações necessárias foram
reduzidas pela metade.

45
4.4 Métodos Multiníveis
Estes métodos podem ser vistos como uma combinação de algoritmos
globais e locais. É o principal método utilizado pelo pacote de particionamento METIS, que é
empregado no modelo HIDRA e pelo software GERATRIZ para fazer o particionamento. O
pacote METIS é discutido na seção 4.5.1.
A idéia básica dos algoritmos multiníveis de particionamento de grafos
consiste basicamente de três fases:
• Encolhimento: o grafo é reduzido a um grafo menor através da contração
de arestas (agrupamento de vértices) até que o número de vértices do
grafo seja um múltiplo pequeno do número buscado de partições;
• Particionamento inicial: o grafo menor é particionado utilizando alguma
técnica como bissecção inercial ou espectral. Este particionamento é
bastante rápido, pois é realizado no grafo reduzido;
• Fase de refinamento e crescimento: o grafo é expandido, e suas partições
são melhoradas através de um método local.
Figura 4.5: Esquema Multinível (Kumar, 2003)
Os métodos multinível apresentam bons resultados por duas razões: a
primeira é que com um número reduzido de arestas, é mais fácil calcular uma partição com boa
qualidade. A segunda e devido ao fato de que os métodos locais se tornam muito mais
poderosos, porque movendo um único vértice é como se mover um grande número deles no
grafo original, porém só que de forma muito mais rápida.
Uma grande variedade de alternativas e esquemas de encolhimento,
particionamento inicial e refinamento foram estudados e avaliados em (Karypis, 1996).

46
4.5 Pacotes de Particionamento
Dentre os pacotes e bibliotecas para particionamento de grafos, os mais
conhecidos e utilizados são: o METIS, JOSTLE (Walshaw, 2000), CHACO (Hendrickson,
1995), SCOTCH (Pellegrini, 1996).
O METIS, por ser o pacote mais popular e um dos softwares utilizados no
particionamento no modelo HIDRA e no software GERATRIZ, receberá uma descrição mais
detalhada. O pacote METIS está disponível no endereço http://www.cs.umn.edu/~karypis/metis,
não sendo necessária licença de uso.
4.5.1 METIS
O software METIS é um pacote de particionamento de grafos e
reordenamento de matrizes esparsas desenvolvido na University of Minessota por George
Karypis e Vipin Kumar (Karipys, 1998). O pacote é composto por vários programas diferentes,
cada qual com uma finalidade específica:
• pmetis e kmetis, para o particionamento de grafos;
• partnmesh e partdmesh, para o particionamento de malhas;
• oemetis e onmetis, para ordenação de matrizes esparsas;
• mesh2nodal, mesh2dual, graphchk e mtest, programas auxiliares.
Destes programas, os de relevância para este trabalho são o pmetis e o
kmetis.
O pmetis utiliza um algoritmo de particionamento baseado em bissecção
recursiva multinível, como mostrado na seção 3.4, e o kmetis é baseado em um algoritmo de k-
particionamento multinível, descrito em (Karipys, 1998). O pmetis garante um balanceamento
perfeito a cada nível da recursão, enquanto o kmetis permite um desbalanceamento de até 3%.
Segundo (Karipys, 1998) o kmetis mais é indicado para particionamento de
um grafo em mais de 8 partes. Já o pmetis é mais rápido que o kmetis em particionamento de um
grafo em um número pequeno de partes (menor que 8).
Além de ser usado como programa independente, o METIS pode ser
utilizado como biblioteca. Através da biblioteca metislib, o usuário pode acessar todos os
algoritmos de particionamento do METIS. A biblioteca metislib está disponível para C e
Fortran.

47
4.6 Critérios para Escolha do Algoritmo
Vários fatores devem ser levados em consideração na escolha de um
algoritmo para o particionamento. Estes fatores estão relacionados tanto coma aplicação como
com a arquitetura onde os algoritmos serão executados.
Segundo (Bhargava, 1993), dentre os aspectos mais importantes que podem
ser analisados, destacam-se:
• Custo x qualidade: quanto maior o custo de um algoritmo, em relação a
tempo de execução, melhor a qualidade das partições geradas. Uma boa
estratégia é aquela que possui custo e qualidade equilibrados.
• Paralelizabilidade: este fator é muito importante quanto são considerados
grafos de grande porte.
• Custo de implementação: similarmente ao custo de execução, os
algoritmos que geram partições melhores também são mais complexos
de implementar. Deve-se ponderar muito este fator, pois muitas vezes
aplicações não exigem uma alta qualidade, sendo mais adequado a
implementação de um método mais simples.
4.7 Conclusão
Neste capítulo abordou-se o particionamento de dados e domínio. O
particionamento de domínio pode ser tratado como um problema de particionamento de grafos.
Por ser um problema NP-difícil, não existe um algoritmo que defina um particionamento ótimo,
assim faz-se necessário o uso de heurísticas para se ter aproximações razoavelmente boas.
As heurísticas podem ser classificadas como métodos globais, locais e
multiníveis. Os métodos globais tomam um grafo e geram um particionamento. Já os métodos
locais servem para o refinamento de grafos já particionados. Os métodos multiníveis são uma
combinação de métodos globais e locais.
A escolha de um algoritmo de particionamento é muito importante, pois a
divisão do domínio influencia na carga de trabalho para cada processo, e na quantidade de
comunicação entre eles, afetando diretamente o tempo de solução do problema.

48
5. SISTEMAS DE EQUAÇÕES
Um sistema de equações lineares pode ser definido como um conjunto de n
equações com m variáveis independentes entre si, na forma genérica, como:
11 1 12 2 1 1
21 1 22 2 2 2
1 1 2 2
n n
n n
m m mn n m
a x a x a x b
a x a x a x b
a x a x a x b
+ + + =+ + + =
+ + + =
⋯⋯⋮ ⋮ ⋱ ⋮ ⋮⋯ (5.1)
na qual ija (i,j = 1, 2, 3, ..., n) são os coeficientes do sistema de equações ix (i = 1, 2, 3, ..., n)
são as n incógnitas e ib (i = 1, 2, ...,m) são os termos independentes (Shigue, 2003).
As equações representadas em (5.1) podem ser descritas na forma matricial
como:
Ax b= (5.2)
para o qual se tem:
11 12 1 1 1
21 22 2 2 2
1 2
, ,
m
m
n n nm m m
a a a x b
a a a x bA x b
a a a x b
= = = ⋯⋯⋮ ⋮ ⋱ ⋮ ⋮ ⋮⋯A solução de um sistema de equações lineares é obtida através do cálculo de
um vetor x, formado por valores que satisfaçam a igualdade (5.2) (Steinbruch, 1999).
O estudo de sistemas de equações é de grande importância, pois estes
resultam de modelos discretos provenientes de vários tipos de aplicação, como programação
linear, dinâmica dos fluídos, modelagem do clima e previsão meteorológica, etc. (Saad, 1996).
5.1 Geração de Sistemas de Equações
Um modelo matemático que não possui solução analítica deve ser resolvido
numericamente. Além disso, tais modelos são, algumas vezes, definidos em uma região cujo
porte obriga o emprego de computação de alto desempenho. O processo de transformação do
modelo contínuo em um modelo discreto, que pode ser construído considerando-se um
determinado método de aproximação e um dado domínio de definição, gera sistemas de
equações que podem ser lineares ou não lineares (Galante, 2002).

49
No caso específico de sistemas gerados pela discretização de equações
diferenciais parciais (EDPs), pode-se aproximar cada uma das derivadas parciais do modelo
usando métodos de discretização como, por exemplo, o de diferenças finitas. Para essas
aproximações deve-se considerar, em geral, ao valores das células adjacentes. E nesse caso, o
nível de dependência de dados entre as células da malha, após a discretização, pode ser
representada usando um estêncil (molécula computacional). O estêncil empregado é aquele de
5-pontos, representado na Figura 5.1.
Figura 5.1: Estêncil de 5-pontos (molécula computacional)
Com a discretização usando o estêncil de 5-pontos, o valor de cada célula
depende da sua posição e dos quatro vizinhos. Ou seja, o valor de uma célula no domínio
depende de seu valor central (C) e do valor de seus quatro vizinhos, que são: esquerdo (E),
direito (D), superior (S) e fundo (F). O estêncil computacional define a posição e valor de cada
elemento na matriz e a estrutura e regularidade da mesma (Picinin, 2002). A Figura 5.2 mostra a
construção de uma matriz a partir da aplicação do estêncil ao domínio (cinza).
Figura 5.2: Geração de Sistemas de Equações

50
A geometria do domínio ou dos subdomínios determina a localidade dos
elementos não-nulos da matriz. Na Figura 5.2, pode-se notar que um domínio não-retangular
gerou consequentemente uma matriz irregular. Da mesma forma um domínio retangular geraria
uma matriz regular, cujos elementos estão posicionados em forma de diagonais.
5.2 Métodos Diretos e Métodos Iterativos
Para a solução de sistemas de equações lineares, existem, basicamente, duas
classes de métodos que os resolvem: a classe dos métodos diretos e a classe dos métodos
iterativos.
Os métodos diretos apresentam a solução exata em um número finito de
passos, exceto por erros de arredondamento, que surgem devido a operações de ponto flutuante.
Métodos iterativos, por sua vez, utilizam-se de sucessivas aproximações dos valores das
incógnitas para obter uma solução cada vez mais acurada. Estas aproximações são feitas até que
se obtenha um limite de erro aceitável ou um número máximo de iterações (Martinotto, 2002).
Os métodos iterativos são os mais apropriados na solução de sistemas de
equações esparsos de grande porte, pois estes métodos trabalham apenas sobre os elementos não
nulos da matriz de coeficientes, não destruindo, portanto, a sua esparsidade. Essa questão é
importante, pois esse fato permite que se possa fazer otimizações no armazenamento, nas
estratégias de solução e de comunicação, de modo que se obtém soluções computacionalmente
eficientes.
5.2.1 Métodos iterativos do subespaço de Krylov
Os métodos iterativos podem ser classificados em estacionários ou não
estacionários. Nos estacionários, cada iteração não envolve informações da iteração anterior e
manipulam variáveis do sistema de equações lineares durante a resolução, através de operações
elementares entre linhas e colunas da matriz. Alguns exemplos são Jacobi, Gauss-Seidel e SOR
(Diverio, 1990). Os não estacionários trabalham sob a ótica da minimização da função
quadrática ou por projeção, manipulando os vetores e matrizes inteiros, e incluem a
hereditariedade em suas iterações, a cada iteração. Desse modo calcula-se um resíduo que é
usado na iteração subseqüente (Canal, 2000).
Dentre os métodos não estacionários, a classe mais promissora é a dos
métodos do subespaço de Krylov, pois são robustos e computacionalmente eficientes em

51
ambientes paralelos. Essa eficiência decorre do fato de que esses métodos são construídos sobre
operações básicas de álgebra linear e, portanto, são altamente paralelizáveis (Rizzi, 2002).
O método do subespaço de Krylov mais proeminente é o gradiente
conjugado (GC), que objetiva encontrar uma aproximação da solução para o sistema de
equações lineares (5.2) num subespaço de Krylov de k-dimensões. Considerando uma solução
inicial dada por x0 uma solução aproximada é obtida através de: 0kx K+ , onde kK é o
subespaço de Krylov de k-dimensões formado a partir de do subespaço gerado como:
10 0 0( , ,..., )k kK gerado r Ar A r−= , para k ≥ 1. O vetor r0 corresponde ao resíduo inicial e é
calculado a partir de 0 0r b Ax= − .
5.2.1.1 Método do gradiente conjugado
Para sistemas de equações cujas matrizes são simétricas e definidas-positivas
(SDP), o método do subespaço de Krylov mais eficiente é o gradiente conjugado (GC)
(Shewchuk, 1994).
O método baseia-se na minimização de uma dada função quadrática, e não
na interseção de hiperplanos como os métodos iterativos clássicos. Parte do princípio de que o
gradiente, que é um campo vetorial, aponta sempre na direção mais crescente da função
quadrática. Assim, as direções de procura devem buscar a solução na direção oposta do
gradiente.
Levando em consideração a característica SDP da matriz, o algoritmo do
GC, ao buscar minimizar essa função quadrática, tem a importante característica de calcular o
gradiente da função quadrática, )(xf∇ , que se pode mostrar ser definido por Axbxf −=∇ )( .
Então, como o objetivo é minimizar )(xf∇ , deve-se determinar o vetor solução x tal que
Axbxf −=∇ )( , ou seja o sistema de equações (5.2). Isso significa que ao encontrar a solução
do GC encontra-se a solução do sistema de equações a ele associado.
Existem diferentes algoritmos do GC que apresentam algumas modificações
em relação ao algoritmo original (Picinin, 2002). Neste trabalho a versão do algoritmo do GC
adotada é a apresentada em (Shewchuk, 1994), mostrado na Figura 5.3.
Nesse algoritmo, como entrada tem-se a matriz dos coeficientes A, o vetor b,
uma aproximação inicial de x0, o número máximo de iterações itmax e a tolerância do erro ε
(critério de parada). A idéia do Gradiente Conjugado é, então, ir efetuando novas iterações na
direção oposta à do gradiente (campo vetorial), de tal forma que as direções já pesquisadas não
seja repetidas, até encontrar o mínimo global. A minimização ocorre sobre certos espaços de

52
vetores, chamados de subespaço de pesquisa (espaço de Krylov), gerados a partir dos resíduos
(r) de cada iteração (Canal, 2000).
it ⇐ 0 (inicialização das iterações)r ⇐ b − Ax (subtração de vetores (produto matriz vetor))d ⇐ rδ_novo ⇐ rTr (produto escalar)δ_o ⇐ δ_novoenquanto I< itmax e δ_novo >ε2δ_o façaq⇐ Ad (produto matriz vetor)α ⇐ δ_novo / d
Tq (divisão (produto escalar))x ⇐ x + αd (adição de vetores (multiplicação escalar vetor))r ⇐ r − αq (subtração de vetores (multiplicação escalarvetor))δ_velho ⇐ δ_novoδ_new ⇐ rTr (produto escalar)β ⇐ δ_velho / δ_novod ⇐ r + βd(adição de vetores (multiplicação escalar vetor))it ⇐ it + 1
Figura 5.3: Algoritmo do Gradiente Conjugado
5.3 Métricas para Avaliação da Qualidade da Solução em Paralelo
Soluções numéricas são obrigatoriamente aproximadas relativamente às
soluções exatas. Essas soluções têm, além dos erros que podem eventualmente ser introduzidos
na etapa de programação, três tipos de erros que surgem de forma sistemática (Rizzi, 2002):
• erros de modelagem: que são os erros que surgem da diferença entre
o problema real e a solução exata do modelo matemático, que quase
sempre é aproximado;
• erros de discretização: que são aqueles de aproximação ou de
truncamento, e que surgem da diferença entre a solução exata das
equações na forma analítica, e a solução exata do sistema de
equações algébricas obtida quando da discretização das equações
analíticas;
• erros de arredondamento: que são os erros introduzidos nos cálculos
que são constantemente arredondados quando do uso de aritmética
de ponto flutuante.
Pode-se analisar e avaliar a qualidade da aproximação do modelo discreto e
os erros de arredondamento gerados pela solução desse modelo discreto, através do emprego de
métricas apropriadas. Essas métricas verificam a conservatividade de determinadas propriedades

53
físicas e/ou numéricas do esquema numérico e, em geral, consideram a diferença entre o valor
arredondado e o valor exato.
Assim, se i
*ϕ e e
iϕ são, respectivamente, a solução numérica e a solução discreta
exata, define-se o erro absoluto AE como * eA i iE = −ϕ ϕ e o erro relativo RE como
* *eR i i iE = −ϕ ϕ ϕ , se *
0i
ϕ ≠ , para calcular o erro relativo à solução exata, ou como
* e eR i i iE = −ϕ ϕ ϕ , se 0
e
iϕ ≠ , para calcular o erro relativo à solução numérica.
Erros relativos são mais apropriados já que é mais significativo saber se o erro
relativo é pequeno ou grande comparando-o com, por exemplo, 1,0 pois nesse caso 1,0RE = significa
que o erro absoluto é da mesma magnitude que o número que está sendo aproximado. Por exemplo, se o
erro relativo de i
*ϕ é da ( )5O 10− , diz-se que i
*ϕ tem precisão (ou acurácia) de cinco dígitos decimais.
Neste trabalho a solução exata, não disponível, será substituída na métrica do
erro relativo por aquela solução numérica fornecida pelo MATLAB, que servirá como um
benchmark. Assim serão calculados os erros relativos entre a solução fornecida pelo benchmark
MATLAB e a solução numérica fornecida pela versão seqüencial (monoprocessada) do
algoritmo do Gradiente Conjugado implementado. Essa abordagem indicará a qualidade
numérica entre a solução “exata” e a solução numérica. Agora, para avaliar a qualidade
numérica da solução seqüencial (monoprocessada) em relação à solução numérica obtida em
paralelo, será feita uma avaliação, usando a métrica do erro relativo, entre a solução gerada pela
versão seqüencial e a solução gerada versão biprocessada. Essa abordagem é suficiente dado
que a abordagem empregada neste trabalho para se obter o paralelismo é aquela que usa o
método de decomposição de domínio Aditivo de Schwarz. Nessa abordagem as trocas de dados
são restritas às fronteiras e, desse modo, basta avaliar as diferenças entre as soluções seqüencial
e paralela nas células adjacentes às fronteiras artificiais geradas pelo algoritmo ou pacote de
particionamento.
Note-se que, além das métricas destacadas nessa seção, existem outras mais
que podem ser adotadas e podem ser encontradas em (Rizzi, 2002).
5.4 Conclusão
Conforme o esquema de discretização empregado na transformação do
modelo contínuo para o modelo discreto, podem se originar sistemas de equações que são
lineares, esparsos e SDP. Os sistemas de equações lineares estão entre os mais freqüentes
problemas que são abordados pela computação científica.

54
Uma vez gerados, os sistemas de equações podem ser resolvidos
empregando dois tipos de métodos: os diretos e os iterativos. Os métodos iterativos são os mais
apropriados na solução de sistemas de equações esparsos de grande porte, pois estes métodos
trabalham apenas sobre os elementos não nulos da matriz de coeficientes, não destruindo a sua
esparsidade. Neste trabalho será utilizado um método iterativo do subespaço de Krylov, o
Gradiente Conjugado, dada as características intrínsecas da matriz dos coeficientes.
Para avaliar a acurácia das soluções numéricas encontradas pode-se utilizar
métricas específicas, conforme mostrado na seção 5.3.

55
6. MÉTODOS DE DECOMPOSIÇÃO DE DOMÍNIO
Métodos de decomposição de domínio (MDD) designam um conjunto de
técnicas e métodos matemáticos, numéricos e computacionais para resolver problemas em
computadores paralelos. Um MDD é caracterizado pela divisão do domínio computacional, que
é particionado em subdomínios empregando algoritmos de particionamento. A solução global
do problema é, então, obtida através da combinação dos subproblemas que são resolvidos
localmente. Cada processador é responsável por encontrar a solução local de um ou mais
subdomínios, que a ele são alocados e, então, essas soluções locais são combinadas para
fornecer uma aproximação para a solução global. No caso da resolução de sistemas de equações
de a combinação das soluções resume-se em intercalar corretamente o vetor de solução.
Uma ilustração para o emprego de métodos de decomposição de domínio na
solução de sistemas de equações lineares (SELs) é como mostrado na Figura 6.1.
Figura 6.1: Ilustração para o esquema geral de MDDs
Abordagens paralelas via decomposição de domínio baseiam-se no fato de
que cada processador pode fazer grande parte do trabalho de forma independente (Saad, 1994).
E, uma vez que os subdomínios podem ser tratados independentemente, tais métodos são
atrativos para ambientes de memória distribuída.
De fato, alguns dos principais atrativos para o uso de MDDs são: a
necessidade de pouca comunicação, a qual, em geral, fica restrita às fronteiras dos subdomínios;
a versatilidade para trabalhar com distintos modelos matemáticos que são definidos em
diferentes subregiões do domínio global; e o fato de que podem ser utilizados para a construção
de pré-condicionadores para métodos iterativos (Smith, Bjorstad e Gropp, 1996).
Os MDDs podem ser divididos em duas classes: os métodos de Schwarz,
onde os subdomínios apresentam uma região de sobreposição, que pode variar de acordo com o
tipo de aproximação empregada para resolver os modelos matemáticos já discretizados, e
métodos de Schur, onde os subdomínios não apresentam região de sobreposição.

56
6.1 Métodos de Schwarz
O uso pela primeira vez de decomposição do domínio como método de
solução foi aquele proposto por Hermann Amandus Schwarz em 1869. Schwarz empregou essa
abordagem para resolver analiticamente uma EDP elíptica definida em um domínio não
retangular, formado pela união de dois subdomínios regulares sobrepostos, como, por exemplo,
os domínios formados pela união de um disco e de um retângulo como mostrado na Figura 6.2.
O método desenvolvido por Schwarz foi o de obter a solução do problema
global de modo alternado em cada subdomínio, sendo que os valores calculados em um
subdomínio, em uma determinada iteração, são utilizados como condição de contorno para o
outro subdomínio na iteração seguinte. Este algoritmo é conhecido na literatura como MDD
Alternado de Schwarz (Flemish, 2001).
Em 1936 Sobolov propõe uma formulação matemática abstrata para o
método original de Schwarz colocando-o em rigorosas bases matemáticas. Com essa nova
formulação matemática, o método original de Schwarz, passou a ser conhecido na literatura
técnica como MDD multiplicativo de Schwarz. Posteriormente, Dryja e Widlund (Dryja, 1987)
ao analisarem as características matemáticas do MDD multiplicativo de Schwarz,
desenvolveram um novo MDD, o Aditivo de Schwarz. Tal abordagem será abordada neste
trabalho para resolver EDPs em paralelo, dado que tem maior potencial de paralelismo (Müller,
2003).
Figura 6.2: Domínio formado pela união de um disco e um retângulo.
A notação empregada na Figura 6.2 decorre do fato que os MDDs de
Schwarz caracterizam-se pela decomposição do domínio global Ω em N subdomínios
sobrepostos iΩ , tal que ii 1,s
Ω Ω=
=∪ com i jΩ Ω ≠∩ ∅ . As fronteiras artificiais são denotadas
por iΓ , e ∂Ω denota a fronteiras reais de Ω . A fronteira artificial iΓ é parte de iΩ que é
interior do domínio Ω , e \∂Ω Γ i são os pontos de ∂Ω que não estão em iΓ .

57
6.1.1 MDD Aditivo de Schwarz
No MDD Aditivo de Schwarz os subdomínios utilizam condições de
contorno do tipo Dirichlet (Rizzi, 2002), que são obtidas através do conhecimento dos valores
das células adjacentes aos subdomínios vizinhos na iteração anterior. Assim, os subdomínios,
durante uma iteração, podem ser resolvidos independentemente. O método Aditivo de Schwarz
pode ser escrito, na forma discreta, como:
1
,
, \
,
ni i i i
ni i
n ni
Lu f u
u g u
u g u−
= ∈Ω = ∈∂Ω Γ = ∈Γ (6.1)
onde em (6.1), ,ni i i iL u f u= ∈Ω representa a solução no interior de Ω ; , \n
i iu g u= ∈ ∂Ω Γ
representa a solução na fronteira real de Ω ; e 1n niu g −= solução na fronteira artificial Γ de Ω .
Note-se que para resolver (6.1) no nível de tempo n é necessário o
conhecimento dos valores das células de contorno no nível de tempo anterior (n-1), como pode
ser visto em 1n niu g −= . Assim, para resolver o problema em paralelo em arquiteturas de
memória distribuída deve-se trocar informações entre os subdomínios. A forma de como é feita
a troca dessas informações, que são chamadas de condições de contorno (CC), entre as
fronteiras artificiais geradas pelo particionamento determinam o particular MDD.
Na versão aditiva, utilizada neste trabalho, todos os subdomínios usam a
solução da última iteração em cada subdomínio como CC para os subdomínios adjacentes, de
modo que cada um deles pode ser resolvido independentemente, ficando as comunicações
restritas às fronteiras. Além disso, supondo que Ωi∩Ωj∩Ωk≠∅, ∀i≠j≠k, pode-se mostrar que o
algoritmo converge, e a presença de regiões sobrepostas assegura a continuidade da solução e de
suas derivadas (Debreu, 1998).
O nível de sobreposição mínima requerida depende do particular método
usado para aproximar as EDPs, e o uso do MDD Aditivo de Schwarz requer troca de
informações a cada iteração do método de Schwarz (ciclo de Schwarz), a fim de estabelecer CC
homogêneas. Como as matrizes locais são simétricas definidas positivas (SDP) empregou-se
como resolvedor local o GC seqüencial, de modo que a cada ciclo do método de Schwarz
trocam-se as CCs até que seja satisfeito um determinado critério de convergência global. Essas
questões serão melhores discutidas na seção 6.1.2. Na Figura 6.3 é mostra-se um exemplo de
como são feitas as trocas de dados entre os subdomínios.

58
Figura 6.3: Esquema de troca de dados entre as fronteiras
Este esquema de troca de dados permite que um sistema de equações
Ax b= possa ser escrito como extAx b b= + , onde extb denota a contribuição dada pelos
subdomínios vizinhos.
Pode-se notar na Figura 6.3 a presença de uma região diferenciada (em azul),
esta área é chamada de região de sobreposição, que é a área sobreposta entre dois domínios.
Observa-se que esta área é numerada após as demais células.
6.1.2 Implementação do MDD Aditivo de Schwarz
Para que possa ser resolvido em paralelo o domínio computacional deve ser
particionado, conforme discutido no capítulo 4. O particionamento de domínios e o processo de
geração dos arquivos de dados referente a cada subdomínio são feitos pelo modelo HIDRA.
Uma vez que os sistemas de equações gerados são de grande porte e
esparsos, pode-se economizar um espaço significativo de memória se forem armazenados
apenas os termos diferentes de zero. Desse modo, os arquivos de entrada para cada subdomínio
utilizam-se do formato CSR (Compressed Sparse Row) (Saad, 1996). O formato CSR armazena
apenas os elementos não nulos de uma matriz esparsa e sua estrutura é baseada em quatro
vetores, como pode ser visto no exemplo ilustrado pela Figura 6.4 onde dois vetores são de
ponto flutuante e dois vetores são de inteiro, de modo que:

59 4800
0520
0193
00110
Figura 6.4: Exemplo de matriz armazenada no formato CSR
1. diag: armazena os valores da diagonal principal da matriz;
2. elems: armazena os demais valores da matriz;
3. cols: armazena a coluna da qual os valores contidos em “elems” foram
obtidos na matriz;
4. ptrs: armazena os ponteiros que indicam quantos valores não nulos cada
linha possui. A primeira posição desse vetor recebe “0”, a segunda posição
recebe o valor da posição anterior somado com o número de elementos não
nulos da primeira linha do vetor (exceto os elementos da diagonal) e assim
sucessivamente.
O formato CSR não considera qualquer informação sobre a estrutura da
matriz, armazenando os elementos não nulos em posições contíguas na memória. Com a
utilização deste formato de armazenamento ao invés de se armazenar N2 elementos, são
necessários apenas n+N+1 posições (onde N é a dimensão da matriz e n é o número de
elementos não nulos). Note-se, porém, que o formato CSR não é computacionalmente eficiente
para matrizes de dimensões pequenas, pois necessita de endereçamento indireto para quaisquer
operações.
O arquivo de dados possui ainda os vetores x e b e algumas estruturas
auxiliares necessárias para a comunicação entre subdomínios vizinhos. Estas estruturas
consistem da identificação dos subdomínios vizinhos, sendo que para cada vizinho são
armazenadas duas listas. A primeira armazena as posições do vetor das incógnitas x a serem
enviadas. A segunda armazena as posições em que serão recebidos os valores enviados pelos
subdomínios vizinhos. Uma vez lidos, os dados dos arquivos de entrada são armazenados em
memória através de vetores alocados dinamicamente. Na seqüência, cada processo calcula
independentemente a solução do sistema de equações referente ao seu subdomínio, conforme o
algoritmo da Figura 6.5.
diag 10 9 5 4elems 1 3 1 2 8cols 1 0 2 1 2ptrs 0 1 3 4 5

60
Figura 6.5: Algoritmo do MDD Aditivo de Schwarz
Faz-se a seguir um exemplo para ilustrar os detalhes para uma
implementação efetiva do MDD Aditivo em paralelo. Na Figura 6.6 o domínio D1 é
particionado em dois subdomínios S1 e S2. Neste trabalho esta etapa é feita no modelo HIDRA,
que emprega o pacote de particionamento de grafos como METIS, conforme visto no capítulo 4.
Figura 6.6: Particionamento de domínio
Como no MDD Aditivo de Schwarz é necessário criar uma região de
sobreposição entre os subdomínios, gera-se esta sobreposição de uma célula para cada
subdomínio, representado por O1 e O2, como pode ser visto na Figura 6.7. A região O1
corresponde à região de sobreposição de S1 em S2 e a região O2 é a região de sobreposição de S2
em S1.
Figura 6.7: Domínio particionado com sobreposição
Inicialização: escolha uma solução inicial 0( )
iu em cada subdomínio iΩ ;
Resolva o sistema com a solução inicial 0( )
iu ;
k=1;faça
enviar dados das fronteiras da iteração 1−(k )
iu para os vizinhos;
receber dados das fronteiras da iteração 1−(k )
iu dos vizinhos;
resolver via GC o sistema utilizando os novos valores da fronteirarecebidos;
obter (k )
iu ;
k++;até que ( )1 2 2−− ≤(k) (k ) (k)
i i imax u u u ε ,onde ε é a acurácia desejada.

61
Uma vez particionado o domínio computacional, e com suas regiões de
sobreposição já criadas, as EDPs são discretizadas via métodos de discretização e de
aproximação. O resultado desse procedimento pode ser representado por um estêncil
computacional, como visto na seção 5.1. Nesta representação utilizou-se como estêncil o valor 4
para a célula central e –1 para as demais.
Nas Figuras 6.8 e 6.9 são mostrados a matriz gerada pela discretização do
domínio S1 e o arquivo de entrada gerado a partir dela, respectivamente. Note que no arquivo de
entrada a matriz está armazenada em formato CSR e que já estão inclusos os dados adicionais
necessários para a comunicação entre os subdomínios vizinhos.
4 -1 0 -1 0 0 0 0 0-1 4 -1 0 -1 0 0 0 00 -1 4 0 0 -1 0 0 0-1 0 0 4 -1 0 -1 0 00 -1 0 -1 4 -1 0 -1 00 0 -1 0 -1 4 0 0 -10 0 0 -1 0 0 4 -1 00 0 0 0 -1 0 -1 4 -10 0 0 0 0 -1 0 -1 4
Figura 6.8: Matriz gerada a partir do subdomínio S1 da Figura 6.7
Figura 6.9: Arquivo de entrada da matriz ilustrada na Figura 6.8
Domínio S1Ordem9Número de Elementos24Ponteiros0 2 5 7 10 14 17 19 22 24Colunas1 3 0 2 4 1 5 0 4 6 1 3 5 7 2 4 8 3 7 4 6 8 5 7Diagonal4 4 4 4 4 4 4 4 4Valores-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 –1Qtde Vizinhos1ID do Vizinho2Índices a enviar2 5 8Índices a receber3 6 9Vetor X0 0 0 0 0 0 0 0 0Vetor B1 1 1 1 1 1 1 1 1

62
Após a geração do arquivo, cada processo carrega o arquivo pelo qual é
responsável e calcula a solução utilizando o algoritmo mostrado na Figura 6.4.
6.2 Métodos do Complemento de Schur
Métodos de Schur são empregados em computação científica paralela para o
desenvolvimento de soluções para aplicações nas quais a malha numérica é não estruturada, ou
não ocorre o emparelhamento das submalhas entre os diversos subdomínios, ou ainda, quando
os diferentes subdomínios possuem diferentes modelos matemáticos (Martinotto, 2003).
Os métodos de Schur foram desenvolvidos na década de 70. Nestes MDDs o
domínio Ω é particionado em subdomínios sem sobreposição, da forma que:
ii 1,s
Ω Ω=
=∪ com i jΩ Ω = ∅∩A continuidade da solução entre os subdomínios é garantida através da
solução de um sistema de interface (sistema correspondente às células pertencentes às fronteiras
artificias criadas pelo particionamento). O sistema de interface é conhecido na literatura como
complemento de Schur (Smith, 1996).
Existem diversas variantes do Método do Complemento de Schur, cada uma
diferencia-se de outra pela forma de particionamento. Neste trabalho será utilizada o
particionamento feito através de cortes nos nodos fronteiras (Saad, 1996). Neste tipo de
particionamento células locais de todos os domínios são numeradas primeiro. Em seguida todas
as células de fronteira são numeradas, conforme pode ser visto na Figura 6.10.
Figura 6.10: Esquema de numeração do Método do Complemento de Schur
Com este esquema de numeração, o domínio da Figura 6.10 gera uma matrizmostrada na Figura 6.11.

63
Figura 6.11: Matriz gerada a partir do domínio da Figura 6.10
Para explicar as notações introduzidas na Figura 6.11, considere um sistema
de equações escrito na forma matricial como Ax b= , onde A é a matriz dos coeficientes, x é
o vetor das incógnitas e b o vetor dos termos independentes. Um modo de escrever a matriz A
é como:
i ii
i i
B FA
E C
=
onde iB é uma matriz associada às células internas do subdomínio, iE e iF representam as
interações das células internas com as células da fronteira e iC representa as interações entre as
células de fronteira.
De modo análogo, o vetor das incógnitas x também pode ser particionado
em duas partes:
ii
i
xx
y
=
onde ix representa as incógnitas referentes ao interior do subdomínio e iy representa as
incógnitas das fronteiras. E, da mesma forma, o vetor dos termos independentes b pode ser
particionado como:
ii
i
fb
g
=

64
Com isso, as equações locais podem ser escritas, para 1,..,i n= processos,
como:
i i i i i
i i i i i
B x F y f
E x C y g
+ = + =Isolando-se o termo ix na primeira equação do sistema acima obtém-se:
1( )i i i i ix B f F y−= − (6.2)
Através da substituição da variável ix na segunda equação obtém-se
1 1 1
1 1
( ( ))i i i i i i i i i i i i i i i i i i
i i i i i i i i i i
E B f F y C y g E B f E B F y C y g
C y E B F y g E B f
− − −
− −
− + = ⇒ − + =⇒ − = −
Fazendo 1i i i i iS C E B F−= − , onde essa matriz iS é conhecida na literatura
como complemento de Schur, tem-se que o sistema acima pode ser escrito na forma compacta
como:
1i i i i i iS y g E B f−= − (6.3)
Resolvendo (6.3) encontra-se o valor das incógnitas do vetor iy , que são as
incógnitas das regiões de fronteira. Desse modo substituindo iy pelos valores encontrados em
(6.2) pode-se encontrar os valores de ix em (6.1), que são os valores das incógnitas referentes à
parte interna dos subdomínios.
Note-se, porém, que para a construção da matriz de complemento de Schur
e, também para o cálculo do lado direito da equação (6.3) é necessário o cálculo de inversas
locais de matrizes. Essa necessidade é o principal obstáculo do método do complemento de
Schur, pois se efetivado acabaria destruindo a esparsidade das submatrizes, além de que têm um
alto custo computacional (Charão, 2003).
Para contornar o problema da inversão das matrizes locais iB , serão
utilizadas métodos para obter apenas aproximações para 1iB− , onde tais métodos possuem custo
computacional reduzido (Rizzi, 2002). Note-se, porém, que decorre dessa abordagem que a
acurácia numérica não é suficientemente boa para simulações computacionais que requerem alta
qualidade numérica. No entanto, neste trabalho a opção foi privilegiar o desempenho
computacional às custas da qualidade numérica. Em trabalho futuro outras aproximações
(Cholesky incompleto, etc.) pode ser empregadas para se obter soluções mais acuradas.
O métodos empregados neste trabalho baseiam-se na série de Neumann para
obter uma aproximação 1iM − para 1
iB− . Truncando-se a série com 1k = , tem-se:
1 1 1 1( )TM D D L L D− − − −= − +

65
onde, 1D− é a inversa da diagonal principal, L é a parte inferior à diagonal principal e TL é
denota a transposta de L . Neste caso o método é chamado de polinomial.
Se a série é truncada com 0=k , o método é chamado de diagonal (ou
Jacobi), e é dado por:
1 1M D− −=O método diagonal apresenta um menor custo computacional que o
polinomial, no entanto sua aproximação possui pior qualidade numérica.
6.2.1 Implementação do Método do Complemento de Schur
Levando em consideração o esquema de numeração mostrado no início da
seção 6.2, e consequentemente o formato das matrizes e sua divisão em blocos, optou-se por
armazenar as submatrizes iB , iE e iF em estruturas CSR distintas e a submatriz iC no
formato diagonal, onde cada diagonal é armazenada em um vetor, já que a mesma possui a
característica de ser sempre uma matriz tridiagonal. Os subvetores ix , iy , if e ig também são
armazenados em estruturas separadas. Dessa forma cada processo receberá um arquivo
contendo os seus respectivos iB , iE e iF , ix e if . A matriz iC e os vetores iy e ig são
carregadas apenas pelo processo 0.
É importante salientar que os domínios para o Método do Complemento de
Schur não serão gerados pelo modelo HIDRA como no MDD Aditivo, já que uma inclusão do
MDD de Schur no modelo HIDRA acarretaria a necessidade de desenvolver um algoritmo
paralelo mais geral, que extrapolaria o objetivo deste trabalho. Desse modo, os domínios e o
respectivos sistemas de equações são gerados pelo software GERATRIZ, desenvolvido pelo
GMCPAR (Perlin, 2003).
Uma vez divididos as submatrizes e subvetores entre os i processadores
disponíveis, o primeiro passo é calcular o lado direito da equação (6.3) fazendo
1i i i id g E B f−= − . Primeiramente cada processador encontra seu 1
iB− através do método
diagonal ou polinomial, e na seqüência calcula-se 1i i iE B f− . A subtração é feita centralizada no
processador 0, após uma comunicação para informar os valores encontrados da operação
1i i iE B f− .
Agora, com o valor de d calculado pode-se calcular o complemento de
Schur. O cálculo do complemento de Schur é feito utilizando o método do gradiente conjugado
(GC) já que a matriz do complemento de Schur é SDP. A matriz complemento de Schur é

66
calculada no passo q Ad= do método GC, onde a matriz A corresponde ao complemento de
Schur iS , e d é o valor calculado anteriormente. Sendo 1i i i i iS C E B F−= − , tem-se que
1i i i iq C d E B Fd−= − , que é calculado de forma análoga a d , sendo que iC d é calculado no
processo 0 e os termos 1i i iE B Fd− são calculados em seus respectivos processos. Como saída do
algoritmo do GC tem-se iy .
Conhecendo-se o valor de iy pode-se retornar ao sistema (6.2), de modo que
por substituição encontra-se os valores dos elementos ix , que são a solução desejada do
sistema. Fazendo-se:
1( )i i i i ix B f F y−= −
e tomando i i i iw f F y= − , tem-se:
iii wxB =
o qual é um sistema de equações, e pode ser também resolvido localmente por um GC
seqüencial.
Este procedimento é repetido até que se alcance a precisão desejada (ε ), da
mesma forma feita no MDD Aditivo de Schwarz.
6.2.1.1 Exemplo de resolução do Método do Complemento de Schur
Dado o domínio apresentado na Figura 6.10 e a respectiva matriz resultante
na Figura 6.11, o primeiro passo para a solução é distribuir os arquivos de entrada para os
respectivos processos, conforme descrito na seção 6.2.1.
Após a distribuição dos dados deve-se calcular 1i i i id g E B f−= − , mais
especificamente para este exemplo com apenas dois subdomínios deve-se calcular
1 10 0 0 1 1 1id g E B f E B f− −= − − . Os processo 0 e 1 devem calcular inicialmente o valor de 1
iB−
através do método diagonal ou polinomial. O valor de 1iB− será utilizado para o cálculo de
1i i iE B f− .
Uma vez 10B− e 1
0 0 0E B f− calculados pelo processo 0 e 11B− e
11 1 1E B f− calculados pelo processo 1, o processo 1 deve enviar o resultado de 1
1 1 1E B f− para o
processo 0, para que possa ser calculado o valor de d , conforme mostrado na Figura 6.12.

67
Processo 0 Processo 1
Cálculo de
Cálculo de 11B-
11 1 1E B f-1
0 0 0E B f-Cálculo de
10B-Cálculo de
1 10 0 0 1 1 1id g E B f E B f- -= - -Cálculo de
Figura 6.12: Cálculo de d no Método do Complemento de Schur
Na seqüência é necessário o emprego do método do GC para encontrar o
valor de iy . Para isso ao invés de se utilizar Ax b= , utiliza-se Sy f= . Desse modo, no passo
q Ad= do método do GC, tem-se que 1i i i i iA S C E B F−= = − e d é o valor calculado
anteriormente.
Assim, pode-se obter o valor de q , calculando-se
1 10 0 0 1 1 1iq C d E B F d E B F d− −= − − . Os cálculos de q , iC d e 1
0 0 0E B F d− são efetuados no
processo 0 e 11 1 1E B F d− é calculado no processo 1. A subtração dos termos também é feita no
processo 0. O cálculo de q é ilustrado na Figura 6.13.
Cálculo de
Processo 0 Processo 1
iC d
Cálculo de 10 0 0E B F d-
1 10 0 0 1 1 1iq C d E B F d E B F d- -= - -Cálculo de
Cálculo de 1
1 1 1E B F d-
Figura 6.13: Cálculo de q no Método do Complemento de Schur
É importante salientar que este processo do cálculo de q é necessário para
cada iteração do método do GC, ou seja, deverá ser calculado várias vezes. Os demais passos do
GC são calculados no processo 0 e são idênticos ao apresentado na seção 5.2.1.1.
Finalizado o cálculo do GC, como resultado obtém-se o vetor iy , que será
utilizado para o cálculo de ix , ou seja, a solução final do sistema de equações. E, para que se
calcule ix , o processo 0 envia o vetor iy para os demais processos. Estes por sua vez devem
calcular i i iB x w= através de um GC local, onde i i i iw f F y= − , como mostrado na Figura 6.14.

68
Processo 0 Processo 1
Cálculo de Envia
Cálculo de 0 0 0 iw f F y= -iy
1 1 1 iw f F y= -
0 0 0B x w=Cálculo via GC de Cálculo via GC de 1 1 1B x w=
Solução final encontrada Solução final encontrada
Figura 6.14: Cálculo de x no Método do Complemento de Schur
6.3 Conclusão
Este capítulo apresentou uma visão geral dos métodos de decomposição de
domínios. A ênfase foi dada aos métodos implementados neste trabalho: o método Aditivo de
Schwarz e o Método do Complemento de Schur. Para cada método apresentou-se a idéia geral
do método, seu funcionamento e questões relativas à implementação, como estruturas de dados,
estratégias de comunicação, distribuição de processamento, entre outros.
Esta seção foi escrita de maneira didática, contendo alguns exemplos e
ilustrações, para que sirva como material de apoio para os integrantes do GMCPAR.

69
7. METODOLOGIA DE DESENVOLVIMENTO
Esta seção tem o objetivo de mostrar a metodologia empregada durante o
desenvolvimento das implementações contidas neste trabalho. No Apêndice A, encontram-se os
endereços de todas as ferramentas utilizadas.
Todas as implementações foram desenvolvidas em linguagem C, sobre o
sistema operacional Mandrake GNU/Linux 8.1.
7.1 Metodologia de Desenvolvimento
Foram implementadas 3 versões para o MDD Aditivo de Schwarz:
1. MDD Aditivo com MPI;
2. MDD Aditivo com MPI e threads;
3. MDD Aditivo com MPI e BLAS.
Para a primeira implementação foi necessário instalar a biblioteca de troca
de mensagens MPICH 1.2.5. A sua instalação é simples, bastando seguir os passos contidos no
arquivo README que vem junto ao pacote.
O próximo passo foi implementar o MDD Aditivo de Schwarz, como
descrito na seção 6.1.2. Para compilar utiliza-se a linha de comando:
mpicc –o aditivo aditivo.c –lm
O comando segue a mesma sintaxe do compilador gcc. É importante
salientar a necessidade de incluir a biblioteca math.h (-lm).
Para a execução de um programa que utiliza MPICH, usa-se a linha de
comando:
mpirun –np 2 aditivo
onde mpirun é a instrução para a execução do programa, e -np <num_procs> é o parâmetro que
informa a quantidade de processos a ser utilizada.
Para adicionar threads à aplicação, utilizou-se OpenMP. Como os
compiladores padrão do Linux não suportam suas diretivas, foi necessário instalar um
compilador especial. Após pesquisa efetuada para descobrir compiladores disponíveis optou-se
pelo Omni 1.4a, por ser de distribuição gratuita.
A instalação do compilador Omni também é muito simples, seguindo os
passos descritos em seu arquivo README, no entanto este compilador necessita de um
compilador Java instalado, e com seu classpath configurado corretamente.
Para compilar as aplicações utilizando OpenMP, utiliza-se a linha de
comando:

70
mpicc –cc=omcc –o aditivo aditivo_opmp.c –lm
onde o parâmetro –cc=omcc define a utilização do compilador Omni. Para a execução das
aplicações com OpenMP, o processo é o mesmo das aplicações sem OpenMP.
Para a terceira implementação, foi necessário a instalação da biblioteca
BLAS. A distribuição escolhida foi a oferecida no pacote ATLAS. A sua instalação segue o
mesmo padrão anteriormente citado, no entanto a compilação da biblioteca é demorado,
podendo demorar aproximadamente 3 horas. Todo este tempo é utilizado para a otimização da
biblioteca.
Para compilar utilizando a biblioteca BLAS, utiliza-se a linha de comando:
mpicc –cc=omcc –o aditivo aditivo_blas.c –lm –cblas -latlas
Para a execução, utiliza-se o mesmo procedimento das demais.
Em relação ao processo de depuração, pode-se dizer que é a parte mais
complexa do processo, já que não existem ferramentas eficientes de depuração paralela todo
processo é feito através da impressão de mensagens na tela.
A metodologia empregada na implementação do Método do Complemento
de Schur é análoga à utilizada no MDD Aditivo de Schwarz utilizando apenas MPICH.
7.2 Metodologia dos Testes
Uma vez terminado a etapa de implementação, faz-se os testes de
desempenho e qualidade numérica dos algoritmos.
Todos os testes foram efetuados no cluster LabTec apresentado na seção
2.2.1.1.
A análise de desempenho é feita avaliando-se o tempo de execução, o
speedup e a eficiência do algoritmo.
A tomada de tempo é feita tomando-se o tempo de dez execuções,
eliminando-se o maior e menor tempo obtido, de modo a eliminar possíveis anomalias nos
tempos. O tempo considerado é a média aritmética das oito tomadas de tempos restantes.
Tendo-se os tempos de execução é possível calcular o speedup e a eficiência
de cada algoritmo.
Os resultados dos testes efetuados são encontrados no capítulo 8.
Em relação a qualidade numérica, utiliza-se o erro relativo e a norma do sup.
Mais informações e exemplo da utilização podem ser encontradas na seção 8.3.

71
8. RESULTADOS OBTIDOS
Neste capítulo são apresentados os resultados obtidos com as paralelizações
desenvolvidas.
Já para o Método do Complemento de Schur utilizou-se um domínio
quadrado de 128x128 células, que resulta em sistemas de equações com 16.384 incógnitas.
Para a solução dos sistemas locais, ou seja, em cada subdomínio, utilizou-se
o método iterativo do GC usando como critério de parada a norma do resíduo kr , tal que
0kr r≤ ε , onde 610−≃ε e 0r é o resíduo inicial. Para a solução global via MDD Aditivo
de Schwarz utilizou-se como critério de parada a norma do sup, ou seja,
( )1 1
2 2sup n n n
i i ix x x− −− ≤ ε , onde nix denota a solução na i-ésima célula do domínio no n-
ésimo passo de tempo, e ε a acurácia que foi tomada como 0,1, 0,01 e 0,001. Para os métodos
de Schur utilizou-se acurácia de 0,01. Tais acurácias foram escolhidas de modo empírico, de
modo a avaliar a influência das mesmas sobre os desempenho dos algoritmos.
A tomada de tempo foi feita tomando-se o tempo de dez execuções,
eliminando-se o maior e menor tempo obtido, de modo a eliminar possíveis anomalias nos
tempos. O tempo considerado é a média aritmética das oito tomadas de tempos restantes.
Primeiramente são mostrados os resultados da paralelização do MDD
Aditivo de Schwarz, e em seguida são mostrados resultados referentes ao Método do
Complemento de Schur. Apresenta-se ainda, uma comparação entre paralelizações do método
do GC, utilizando as abordagens de decomposição de domínio e decomposição de dados.
8.1 Método MDD Aditivo de Schwarz: Análise de Desempenho Computacional
Para a análise de desempenho do MDD Aditivo considerou-se o número de
iterações, tempo de execução, speedup e eficiência, conforme visto na seção 3.4. Os resultados
são mostrados para o MDD Aditivo com acurácia de 0,1, 0,01 e 0,001. O uso de tal acurácia é
mostrada na Figura 6.5 e é referenciada como ε .
8.1.1 Número de iterações
Na Figura 8.1 e 8.2 pode-se ver o número de iterações do MDD Aditivo com
acurácia de 0,1, 0,01 e 0,001, para domínio de 11.506 e 184.096 incógnitas, respectivamente.
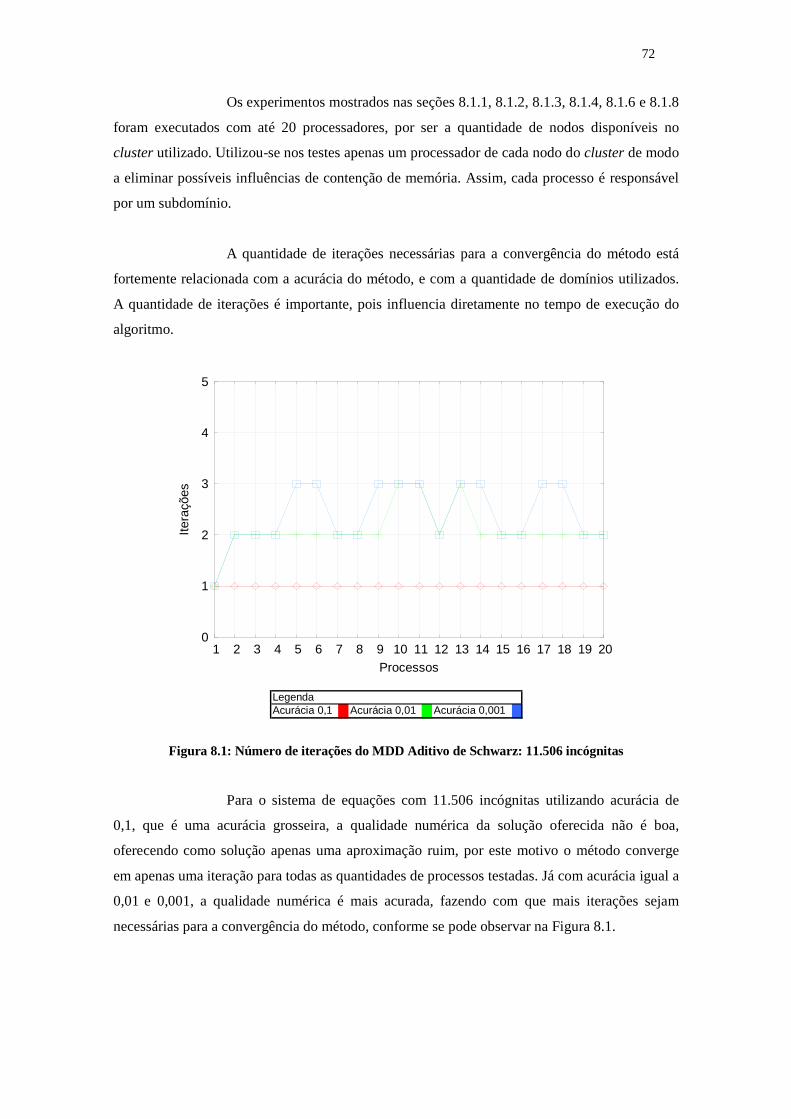
72
Os experimentos mostrados nas seções 8.1.1, 8.1.2, 8.1.3, 8.1.4, 8.1.6 e 8.1.8
foram executados com até 20 processadores, por ser a quantidade de nodos disponíveis no
cluster utilizado. Utilizou-se nos testes apenas um processador de cada nodo do cluster de modo
a eliminar possíveis influências de contenção de memória. Assim, cada processo é responsável
por um subdomínio.
A quantidade de iterações necessárias para a convergência do método está
fortemente relacionada com a acurácia do método, e com a quantidade de domínios utilizados.
A quantidade de iterações é importante, pois influencia diretamente no tempo de execução do
algoritmo.
0
1
2
3
4
5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Itera
ções
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.1: Número de iterações do MDD Aditivo de Schwarz: 11.506 incógnitas
Para o sistema de equações com 11.506 incógnitas utilizando acurácia de
0,1, que é uma acurácia grosseira, a qualidade numérica da solução oferecida não é boa,
oferecendo como solução apenas uma aproximação ruim, por este motivo o método converge
em apenas uma iteração para todas as quantidades de processos testadas. Já com acurácia igual a
0,01 e 0,001, a qualidade numérica é mais acurada, fazendo com que mais iterações sejam
necessárias para a convergência do método, conforme se pode observar na Figura 8.1.

73
0
1
2
3
4
5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Itera
ções
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.2: Número de iterações do MDD Aditivo de Schwarz: 184.096 incógnitas
Para o sistema de equações com 184.096 incógnitas, o número de iterações
se manteve estável em uma iteração para os testes com acurácia 0,1 e em duas iterações para os
testes com acurácia 0,01. Já com acurácia 0,001 houveram alguns picos com a execução
utilizando 11, 13 e 14 processos.
8.1.2 Tempo de execução
Nas Figuras 8.3 e 8.4 são apresentados os resultados em relação ao tempo de
execução, utilizando acurácia de 0,1, 0,001 e 0,001, para sistemas de 11.506 e 184.096
incógnitas, respectivamente. O tempo de execução é dado em segundos.
Os resultados obtidos com a paralelização foram satisfatórios, apresentando
uma boa escalabilidade. Pode-se perceber a presença de picos. Estes picos são causados pelo
aumento da quantidade de iterações, como pode ser visto na seção 7.1.1.

74
0
0.005
0.01
0.015
0.02
0.025
0.03
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Tem
po d
e E
xecu
ção
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.3: Tempo de execução do MDD Aditivo de Schwarz: 11.506 incógnitas
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Tem
po d
e E
xecu
ção
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.4: Tempo de execução do MDD Aditivo de Schwarz: 184.096 incógnitas
Na Figura 8.3 observa-se que o melhor desempenho obtido foi com a
execução utilizando 16 processos. Com quantidades de processos superiores a 16 ocorre um
pequeno aumento de tempo de execução. Este aumento é causado pelo aumento da quantidade

75
de comunicação e pela redução do processamento necessário para cada subdomínio, já que os
domínios possuem um tamanho reduzido.
Já na Figura 8.4, que a relação comunicação/processamento melhora com
sistemas de equações de maior porte, apresentando uma melhor escalabilidade, e por
conseqüência a redução do tempo de execução do algoritmo.
Em geral, pode-se observar também que se utilizando acurácia igual a 0,1 o
tempo de execução é bem inferior aos apresentados utilizando-se acurácia 0,01 e 0,001, mas sua
qualidade numérica é ruim. Entretanto os resultados obtidos entre as execuções utilizando
acurácia de 0,01 e 0,001 são muito semelhantes, sendo é mais vantajoso utilizar acurácia de
0,001, já que oferece melhor qualidade numérica.
8.1.3 Speedup do MDD Aditivo de Schwarz
Nas Figuras 8.5 e 8.6 mostra a comparação dos speedups das execuções
utilizando-se acurácia de 0,1, 0,01 e 0,001.
Na seção 3.4.2, mostra-se speedup como a razão entre o tempo de execução
do algoritmo serial mais rápido e o algoritmo paralelo utilizando p processadores. No entanto
pela indisponibilidade deste algoritmo serial mais rápido utilizou-se na tomada de tempos a
versão paralela utilizando apenas um processador.
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Spe
edup
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.5: Speedup do MDD Aditivo de Schwarz: 11.506 incógnitas

76
Observa-se que com o aumento do domínio computacional e
consequentemente, da granularidade do problema ocorreu um aumento nos speedups obtidos.
Observa-se ainda nos gráficos pontos de quedas signicativas nos speedups. Esses pontos são
decorrentes do aumento no número de iterações para a convergência do método.
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Spe
edup
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.6: Speedup do MDD Aditivo de Schwarz: 184. 096 incógnitas
8.1.4 Eficiência
Nas Figuras 8.7 e 8.8 são apresentados os gráficos de eficiência do método
Aditivo de Schwarz.
Observa-se que a eficiência diminui com o aumento dos processos. Isso se
deve a sobrecarga causada pelo aumento na quantidade de comunicações efetuadas, pois quanto
mais forem as subdivisões do domínio computacional, cada subdomínio terá uma maior
quantidade de vizinhos, exigindo mais comunicações, além de cada subdomínio ter seu tamanho
reduzido, fazendo com que o processamento efetivo diminua.
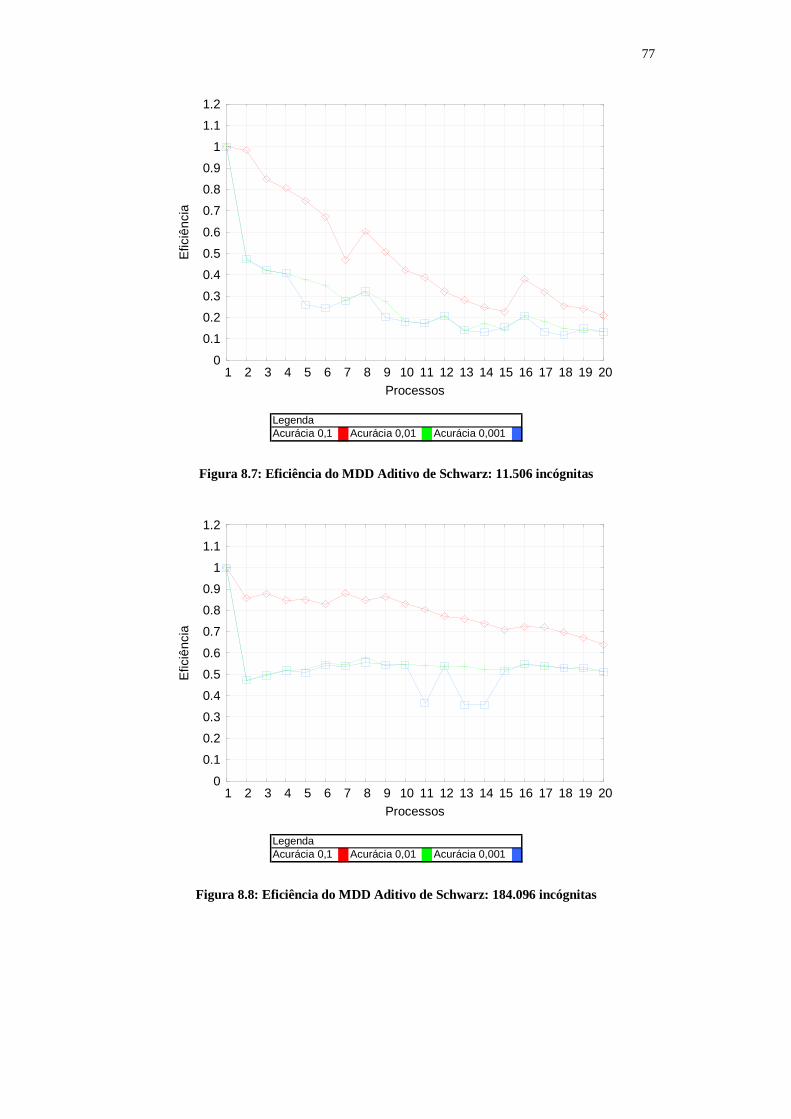
77
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Efic
iênc
ia
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.7: Eficiência do MDD Aditivo de Schwarz: 11.506 incógnitas
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Efic
iênc
ia
Processos
LegendaAcurácia 0,1 Acurácia 0,01 Acurácia 0,001
Figura 8.8: Eficiência do MDD Aditivo de Schwarz: 184.096 incógnitas

78
8.1.5 Comportamento do MDD Aditivo de Schwarz
Na Figura 8.9, ilustra-se a execução do MDD Aditivo de Schwarz com 8
processos para sistemas com 11.506 e 184.096 incógnitas respectivamente.
Para a geração da figura utilizou-se a biblioteca MPE (MultiProcessing
Environment) disponível com a distribuição MPICH. Essa contém rotinas que permitem a
geração de arquivos de registro, que descrevem as etapas de execução de um programa MPI
(Chan; Gropp; Lusk, 2003). Para a visualização dos arquivos de registro utilizou-se a ferramenta
Jumpshot-4 (Chan et al., 2003).
Nas figuras, as áreas cinzentas representam o processamento, as vermelhas
representam operações de envio de mensagens, as azuis representam operações de recebimento
de mensagens e as verdes representam operações de redução. A operação de redução é utilizada
no cálculo do critério de convergência do método.
(a) (b)(a) (b)
Legendaprocessamento envio recebimento redução
Figura 8.9: Execução do MDD Aditivo de Schwarz(a) sistema com 11.506 incógnitas (b) sistemas com 184.096 incógnitas
A partir da figura pode-se determinar a quantidade de processamento
efetuado por cada processo e também o tempo necessário para as comunicações. Note que em
(b) a proporção do tempo gasto com comunicação é muito menor que em (a). Isso justifica o
melhor desempenho obtido com as execuções utilizando como entrada o sistema com 184.096
incógnitas.
8.1.6 MDD Aditivo de Schwarz: BLAS
Nas Figuras 8.10 e 8.11 pode-se observar os resultados referentes ao tempo
de execução e speedup da implementação utilizando BLAS comparada aos resultados obtidos

79
com a implementação sem o uso da biblioteca. Para a comparação utilizou-se o sistema de
equações com 184.096 incógnitas e acurácia de 0,001.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Tem
po d
e E
xecu
ção
Processos
LegendaCom BLAS Sem BLAS
Figura 8.10: Tempos de execução: implementações com e sem BLAS
0 1 2 3 4 5 6 7 8 9
10 11 12 13 14 15
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Spe
edup
Processos
LegendaCom BLAS Sem BLAS
Figura 8.11: Speedup: implementações com e sem BLAS

80
Segundo (Dongarra, 2000), o uso do nível 1 da biblioteca BLAS, que é o
empregado na implementação deste trabalho, oferece no máximo 15% de ganho de
desempenho. Nos testes efetuados, foram obtidos, em média, ganhos de aproximadamente 10%,
ficando dentro das expectativas.
Melhores resultados poderiam ser obtidos se utilizados os níveis 2 e 3 da
biblioteca, no entanto o seu uso não é possível em matrizes esparsas, como as empregadas neste
trabalho.
8.1.7 MDD Aditivo de Schwarz: processos versus threads
A Figura 8.12 apresenta um comparativo entre as duas estratégias usadas na
exploração do paralelismo em clusters multiprocessados: o uso apenas de múltiplos processos
em um processador e o uso de múltiplos threads em um processador. Para estes testes ambas
estratégias utilizam os dois processadores das máquinas duais, portanto afetadas pelo problema
de contenção de memória.
Na execução destes testes foram utilizados até 10 nodos do cluster. Utilizou
as implementações com acurácia 0,001 e como entrada o sistema de 184.096 incógnitas.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
1 2 3 4 5 6 7 8 9 10
Tem
po d
e E
xecu
ção
(seg
s)
Nodos
LegendaProcessos Threads
Figura 8.12: Processos versus Threads no MDD Aditivo de Schwarz
Tem
po d
e E
xecu
ção

81
A Figura 8.12 mostra que a implementação que utiliza múltiplos threads
apresenta um desempenho melhor a que usa múltiplos processos. O pico observado quando se
utiliza sete nodos, deve-se ao aumento do número de iterações necessárias para a convergência
do método utilizando-se 14 processos, como pode ser visto na Figura 8.2.
Na estratégia de múltiplos processos o particionamento do domínio é feito de
acordo com o número de processadores disponíveis e a exploração do paralelismo intranodal
através da alocação de um processo para cada processador do nodo. Já na abordagem que usa
múltiplos threads o particionamento é feito de acordo com o número de nodos e a exploração do
paralelismo intranodal é obtida através da alocação de um thread para cada processador. Neste
trabalho, especificamente, utilizou-se dois processos e dois threads para cada nodo, já que cada
nodo é biprocessado.
Deste modo, na estratégia que usa apenas múltiplos processos, o número de
subdomínios é o dobro daquele número da estratégia que usa múltiplos threads. O aumento no
número de subdomínios afeta a convergência do método, provoca uma maior redundância de
cálculo (regiões de sobreposição) e um maior volume de comunicação. Isso justifica o melhor
desempenho obtido pela implementação que utiliza múltiplos threads, já que a mesma possui
uma quantidade reduzida de comunicação e menos redundância de cálculos.
Um outro fator a ser observado nestes testes é a contenção de memória. Ao
utilizar 2 processos em um nodo, deverá ser alocado dois subdomínios para o mesmo, ou seja,
uma maior quantidade de dados. Como pode-se notar existe o aumento no tempo de execução
do algoritmo, decorrente da competição entre os processadores por recursos de hardware
compartilhados, tais como barramento e memória principal. Coma disputa entre os
processadores a latência média de acesso a memória tende a ser maior. Desta forma, o
processador fica ocioso por uma número maior de ciclos (Martinotto, 2004).
8.1.8 MDD Aditivo de Schwarz versus decomposição de dados
Nessa seção é feito um estudo comparativo entre as abordagens de
decomposição de domínio e decomposição de dados. Mais especificamente são comparados os
tempos de execuções do MDD Aditivo de Schwarz, desenvolvido neste trabalho, e da
implementação o do método do GC paralelo desenvolvida em (Picinin, 2003).
Nos resultados obtidos, mostrados na Figura 8.15, o GC Paralelo apresentou
tempo de execução inferior ao MDD Aditivo. No entanto pode-se observar que a medida que a
quantidade de processos aumenta a diferença entre os tempos diminui. Isso ocorre porque o
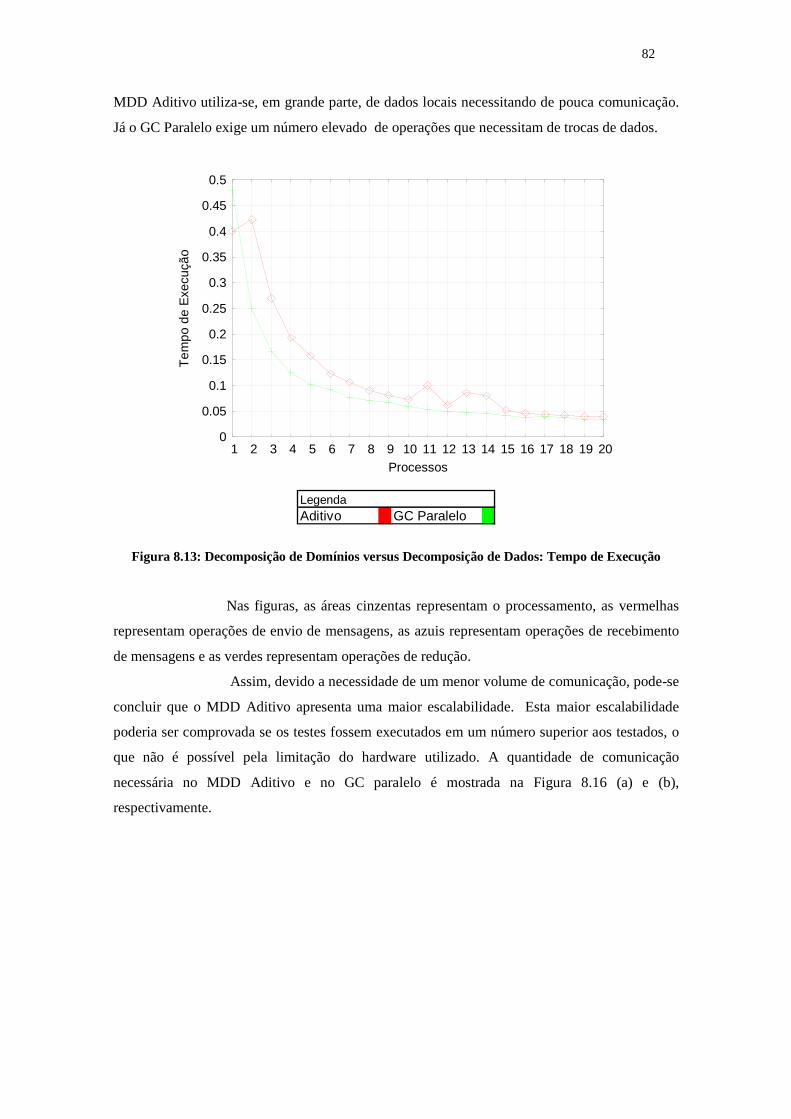
82
MDD Aditivo utiliza-se, em grande parte, de dados locais necessitando de pouca comunicação.
Já o GC Paralelo exige um número elevado de operações que necessitam de trocas de dados.
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
0.4
0.45
0.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Tem
po d
e E
xecu
ção
Processos
LegendaAditivo GC Paralelo
Figura 8.13: Decomposição de Domínios versus Decomposição de Dados: Tempo de Execução
Nas figuras, as áreas cinzentas representam o processamento, as vermelhas
representam operações de envio de mensagens, as azuis representam operações de recebimento
de mensagens e as verdes representam operações de redução.
Assim, devido a necessidade de um menor volume de comunicação, pode-se
concluir que o MDD Aditivo apresenta uma maior escalabilidade. Esta maior escalabilidade
poderia ser comprovada se os testes fossem executados em um número superior aos testados, o
que não é possível pela limitação do hardware utilizado. A quantidade de comunicação
necessária no MDD Aditivo e no GC paralelo é mostrada na Figura 8.16 (a) e (b),
respectivamente.

83
(a) (b)
Legendaprocessamento envio recebimento redução
Figura 8.14: Execução do MDD Aditivo (a) Execução do GC Paralelo (b)
8.2 MDD do Complemento de Schur: Análise de Desempenho Computacional
Para a análise de desempenho do Método do Complemento de Schur
considerou-se o número de iterações, tempo de execução, speedup e eficiência.
A Figura 8.16 mostra os resultados relativos ao tempo de execução do
método. Os testes mostraram um ganho razoável de desempenho. Melhores resultados não
puderam ser obtidos porque algumas operações foram centralizadas apenas em um nodo.
0.005
0.01
0.015
0.02
0.025
0.03
0.035
0.04
2 4 6 8 10 12 14 16
Tem
po d
e E
xecu
ção
(seg
s)
Processos
Figura 8.15: Tempo de Execução do Método do Complemento Schur
Tem
po d
e E
xecu
ção

84
1
1.5
2
2.5
3
3.5
4
4.5
5
2 4 6 8 10 12 14 16
Spe
edup
Processos
Figura 8.16: Speedup do Método do Complemento de Schur
Na Figura 8.16 encontra-se o resultado obtido em relação ao speedup do
Método do Complemento de Schur.
0
0.2
0.4
0.6
0.8
1
1.2
2 4 6 8 10 12 14 16
Efic
iênc
ia
Processos
Figura 8.17: Eficiência
Na Figura 8.17, mostra-se a eficiência do Método do Complemento de
Schur. Note que a eficiência cai conforme o número de processos aumenta. Isso se deve ao fato
da má distribuição das operações entre os processos, conforme mostrado na seção 6.2.1.

85
Outro fator a ser observado, que com o aumento do número de domínios, o
tamanho do sistema de interface a ser resolvido cresce, aumentando o custo computacional da
operação, o que reduz o seu desempenho.
Mais testes não puderam ser feitos devido ao fato da ferramenta GERATRIZ
ainda não estar plenamente desenvolvida, não podendo gerar mais casos de teste que os
apresentados. Testes mais efetivos poderiam ser efetuados se pudessem ser gerados domínios de
maior tamanho, e se este pudesse ser particionado em quantos domínios fossem necessários.
8.3 Análise da Qualidade Numérica
A análise da qualidade numérica do MDD Aditivo de Schwarz foi feita
utilizando o erro relativo * *eR i i iE ϕ ϕ ϕ= − , conforme descrito na seção 5.3, e uma adaptação
da norma do sup ( )* *
2 2sup( ) sup
defe
i i iE ϕ ϕ ϕ≡ − .
A forma de utilização das fórmulas utilizadas pode ser visto no exemplo,
como segue.
Dado os vetores contendo a solução exata (Se), solução aproximada
monoprocessada (Sm) e solução aproximada biprocessada (Sb), respectivamente:
Se = 5.0000 5.0000 8.0000 5.0000 5.0000
Sm = 4.9998 5.0001 8.0010 4.9997 5.0001
Sb = 4.9987 5.0005 8.0012 4.9989 5.0002
Utilizando o erro relativo, primeiramente compara-se a solução exata com a
solução aproximada monoprocessada, tomando-se *i eSϕ = e e
i mSϕ = , como resultado obtém-
se o vetor
E = 0.00004 0.00002 0.000125 0.00006 0.00002
Para se determinar o erro relativo toma-se o maior valor do vetor resultante,
logo o erro entre a solução exata e a solução monoprocessada é 0,00006RE = .
Para encontrar o erro relativo entre a solução monoprocessada e a
biprocessada repete-se o procedimento tomando-se *i mSϕ = e e
i bSϕ = .

86
Já para a determinação do erro utilizando a norma do sup, mais uma vez
toma-se *i eSϕ = e e
i mSϕ = , e aplicando-se a norma temos que 0,00008E = . Repete-se o
procedimento com *i mSϕ = e e
i bSϕ = para determinar o erro entre a solução monoprocessada
e biprocessada.
Os testes da qualidade numérica do MDD Aditivo de Schwarz foram feitos
de forma análoga ao exemplo. Os resultados podem ser vistos na Figura 8.17. Para os testes foi
utilizado um domínio 30x30 células, o que resulta em um sistema de equações com 900
incógnitas.
Erro Relativo Norma sup
Solução monoprocessada 0.000000196 0,000000114
Solução biprocessada 0.00652 0.00166
Figura 8.18: Erros do MDD Aditivo de Schwarz
Tanto nos testes utilizando erro relativo quanto utilizando a norma do sup, a
solução monoprocessada apresentou erro na sétima casa decimal, e a solução biprocessada erro
na terceira casa decimal.
Embora os resultados apresentados sejam satisfatórios, testes mais efetivos
não puderam ser feitos devido ao fato dos testes simularem apenas um passo de tempo do
modelo HIDRA. Melhores resultados quanto a acurácia do MDD Aditivo poderia ser obtidos se
o mesmo fosse acoplado ao modelo, podendo simular inúmeros passos de tempo do modelo.
O Método do Complemento de Schur apresentou erros a partir da segunda
casa decimal nas soluções monoprocessada e biprocessada. Esta baixa qualidade numérica se
deve aos algoritmos inversão de matrizes empregados que geram apenas aproximações
grosseiras para tais inversas.
8.4 Conclusão
Apresentou-se neste capítulo a avaliação dos resultados obtidos com as
implementações desenvolvidas neste trabalho.
Pode-se observar que o MDD Aditivo de Schwarz apresentou bons
resultados em relação e desempenho e qualidade numérica, mostrando-se uma boa alternativa
para este fim. Além disso se mostrou mais escalável que os métodos de decomposição de dados,
devido a sua menor quantidade de comunicação.

87
Nos testes de comparação entre múltiplos processos e múltiplos threads, a
abordagem de múltiplos threads apresentou um melhor desempenho. Este melhor desempenho
se deve principalmente às diferenças existentes no particionamento computacional, mais
favorável a esta abordagem.
Mostrou-se também que o uso da biblioteca BLAS pode apresentar
resultados satisfatórios, mesmo utilizando apenas seu nível 1.
Em relação ao método de Schur, pode-se observar que o mesmo apresentou
um desempenho computacional razoável, e uma baixa qualidade numérica. O desempenho
computacional ficou comprometido pela má distribuição das operações entre os processos.

88
9. CONCLUSÕES
O desenvolvimento de aplicações paralelas é hoje uma abordagem
indispensável em áreas que requerem grande capacidade de processamento. A disseminação do
uso de clusters de PCs, conseqüência direta do baixo custo do hardware e do desenvolvimento
de redes de alta velocidade, permite que problemas complexos anteriormente tratados em
supercomputadores, sejam resolvidos em plataformas de baixo custo.
Apresentou-se neste trabalho alguns aspectos do desenvolvimento de
aplicações paralelas. Mais especificamente estudou-se dois métodos de decomposição de
domínio: o MDD Aditivo de Schwarz e o Método do Complemento de Schur, utilizados na
solução de sistemas de equações lineares.
O MDD Aditivo de Schwarz apresentou resultados satisfatórios. Esse
método mostrou-se altamente paralelizável e com uma boa escalabilidade. Ainda apresentou
resultados satisfatórios com a inclusão de multithreads e da biblioteca BLAS às
implementações.
Já o método do complemento de Schur não apresentou resultados tão
satisfatórios, apresentando um desempenho computacional razoável, e soluções com baixa
qualidade numérica se comparado as soluções obtidas utilizando um método de Schwarz.
O desempenho foi afetado pela má distribuição de tarefas entre os nodos. Já
a baixa qualidade numérica se deve, principalmente, a erros numéricos introduzidos pelo uso de
aproximações polinomiais no cálculo das inversas locais.
9.1 Contribuições
Algumas contribuições deste trabalho são:
• Desenvolvimento de aplicações paralelas para a solução de sistemas
de equações;
• Estudo do uso de apenas múltiplos processos ou o uso de múltiplos
processos em conjunto com múltiplos threads na paralelização de
métodos de decomposição e domínio em clusters de PCs
multiprocessados;
• Estudo do uso da biblioteca BLAS na paralelização de métodos de
decomposição de domínio.
Os estudos realizados durante o desenvolvimento desse trabalho resultaram
na publicação de três resumos, que foram publicados em eventos regionais:

89
• SEMINC 2003 – Semana de Informática de Cascavel;
• ERMAC – Escola Regional de Matemática Aplicada
Computacional;
• ERAD 2004 – Escola Regional de Alto Desempenho.
Além das contribuições citadas, este texto tem como objetivo servir de
material didático para o GMCPAR.
9.2 Trabalhos Futuros
Dentro do escopo deste trabalho, seguem algumas sugestões para trabalhos
futuros, bem como, atividades que possam complementar os estudos realizados durante o
desenvolvimento deste trabalho, e que não puderam ser realizados:
• Estudo sobre técnicas para aproximações de matrizes, para melhorar
a qualidade das inversas locais exigidas no Método do Complemento
de Schur;
• Melhor distribuição das tarefas no Método do Complemento de
Schur, de modo a melhorar seu desempenho computacional;
• Uso de múltiplos threads para sobrepor comunicação e
processamento, de modo a melhorar o desempenho das aplicações;
• Adicionar múltiplos threads ao Método do Complemento de Schur;
• Utilizar a biblioteca BLAS no Método do Complemento de Schur.

90
REFERÊNCIAS BIBLIOGRÁFICAS
BALAY, S. et al. PETSc Users Manual. Argonne National Laboratory. 2003. Disponível em:
http://www-unix.mcs.anl.gov/petsc/petsc-2/documentation/index.html. Acessado em
08/08/2003.
BHARGAVA, R.; FOX, G. Scalable Libraries for Graph Partitioning. School of Computer Science.
Syracuse University. Scalable Libraries Conference. 1993. Disponível em
http://citeseer.nj.nec.com/bhargava93scalable.html. Acessado em 14/08/2003.
BLAS: Basic Linear Algebra Subprograms. Disponível em: www.netlib.org/blas/. Acessado em
10/07/03.
CAI, X-C, WIDLUND, O. Multiplicative Schwarz algorithms for nonsymmetric and indefinite Elliptic
Problems, SIAM J. Numer. Anal., v. 30, pp. 936-952. 1993.
CANAL, A. P. Paralelização de Métodos de Solução de Sistemas Lineares Esparsos com o DECK em
um Cluster de PCs. 117 p. Dissertação (Mestrado em Ciência da Computação) – Instituto de
Informática, UFRGS. Porto Alegre. 2000.
CARVALHO, E. C. A.; DIVERIO, T. A. Particionamento de Grafos de Aplicações e Mapeamento em
Grafos de Arquiteturas Heterogêneas. Dissertação de Mestrado. Instituto de Informática,
UFRGS. Porto Alegre. 2002.
CENAPAD Apostila de MPI. Unicamp. 2003. Disponível em
http://www.cenapad.unicamp.br/servicos/treinamentos/mpi.shtml. Acessado em 05/09/2003.
CHAN, T. F.; MATHEW, T. P. Domain Decomposition Algorithms. Acta Numerica, Los Angeles, p.
61-143, Aug. 1994.
CHAN, A.; GROPP,W.; LUSK, E. User's Guide for MPE: extensions for MPI programs. Disponível
em http://www-unix.mcs.anl.gov/mpi/mpich/. Acessado em 10/11/2003.
CHAN, A.; ASHTON, D.; LUSK, R.; GROPP, W. Jumpshot-4's User's Guide. Disponível em
http://www-unix.mcs.anl.gov/perfvis/software/viewers/. Acessado em 10/11/2003.
CHARÃO, A. S. Multiprogrammation Parallele Générique des Méthodes de Décomposition de
Domaine. 2001. Tese (Doutorado em Ciência da Computação) Institut National Polytechnique
de Grenoble.

91
CULLER, D. E.; PAL, S. J.; GUPTA A. Parallel Computer Architecture: a hardware/software
approach. Morgan Kaufmann Publishers. 1999.
DEBREU, L.; BLAYO, E. On the Schwarz Alternating Method for Oceanic Models on Parallel
Computers. Journal of Computational Physics, v. 141, p. 93-111. 1998.
DE ROSE, C. A. Arquiteturas Paralelas. Anais da Escola Regional de Alto Desempenho. Gramado.
2001.
DRYJA, M, WIDLUND, O. B. An Additive Variant of the Alternating Method for the Case of Many
Subregions, TR 339, Courant Institute, New York University. 1987.
DIVERIO, Tiarajú A. LEPMAC Material Didático de Apoio – Módulo SELAS. Porto Alegre: Instituto
de Informática. UFRGS. 1990.
DONGARRA, J; Petitet, A; Whaley, R. C. Automated Empirical Optimization of Software and the
ATLAS project. 2000. Disponível em:
http://www.netlib.org/utk/people/JackDongarra/papers.htm. Acessado em 07/08/2003.
DORNELES, R. Particionamento de Domínio e Balanceamento Dinâmico de Carga em Arquiteturas
Heterogêneas : Aplicação a Modelos Hidrodinâmicos e de Transporte de Massa 2-D e 3-D.
Proposta de Tese (Doutorado em Ciência da Computação) – Instituto de Informática, UFRGS,
Porto Alegre. 2001.
EDELMAN, A. Parallel Scientific Computing. Notas de Aula. Massachusetts Institute of Technology.
2002. Disponível em: http://beowulf.lcs.mit.edu/18.337/index.html. Acessado em 09/07/03.
FLYNN, M. J., Some Computer Organization and Their Effectiveness. In: IEEE Transactions on
Computers, v. c-21, n. 9, pp. 948-960. 1972.
FOSTER, I. T. Designing and Building Parallel Programs: Concepts and Tools for Parallel Software
Engineering. Addison-Wesley Publishing Company. 1994.
GALANTE, G. et al. Paralelização de Métodos Numéricos Utilizando Clusters de PCs. Anais da II
Mostra de Trabalhos Científicos em Computação. Cascavel. UNIOESTE. 2003.
GALANTE, G. et al. Processamento de alto desempenho aplicado a modelos computacionais de
dinâmica de fluidos ambiental. Revista SCIENTIA v.13 nº 2 Julho/Dezembro 2002, São
Leopoldo. 2002.

92
GEIST, A. et al. PVM: Parallel Virtual Machine: A Users' Guide and Tutorial for Networked Parallel
Computing. MIT Press. Massachusetts Institute of Technology. 1994. Disponível em:
http://www.netlib.org/pvm3/book/pvm-book.html. Acessado em 18/10/03.
GIGABIT ETHERNET ALLIANCE. Gigabit Ethernet White Pape. Disponível em:
http://www.10gea.org/Tech-whitepapers.htm. Acessado em 05/08/2003.
HWANG, K. Advanced Computer Architecture: Paralelism, Scalability, Programmability. McGraw-
Hill, 1993.
HENDRICKSON,B.; LELAND, R. The Chaco User’s Guide. Version 2.0. 1995. Disponível em
http://www.cs.sandia.gov/CRF/papers_chaco.html. Acessado em 13/08/2003.
KARIPYS G.; KUMAR V. Parallel Multilevel k-way Partitioning Scheme for Irregular Graphs.
University of Minnesota, Department of Computer Science. 1996. Disponível em http://www-
users.cs.umn.edu/~karypis/metis/metis/files/. Acessado em 13/08/2003.
KARIPYS G.; KUMAR V. METIS: A Software Package for Partitioning Unstructured Graphs,
Partitioning Meshes, and Computing Fill-Reducing Orderings of Sparse Matrices. University of
Minnesota, Department of Computer Science. 1998. Disponível em http://www-
users.cs.umn.edu/~karypis/metis/metis/files/. Acessado em 13/08/2003.
KERNIGHAN B. e LIN S. An effective heuristic procedure for partitioning graphs, The Bell System
Technical Journal, pp. 291 – 308. 1970.
KUMAR, Vipin; et al. Introduction to Parallel Computing: Design and Analysis of Algorithms.
California: The Benjamin/Cummings Publishing Company, Inc. 1994.
LEWIS, B.; BERG D. Multithreaded Programing with Pthreads. Sun Mycrosystems Press. Mountain
View.1998.
INFINIBAND TRADE ASSOCIATION. An InfiniBand Technology Overview. Disponível em:
www.infinibandta.org. Acessado em 08/08/2003.
MARTINOTTO, A. L, Paralelização de Métodos Numéricos de Solução de Sistemas Esparsos de
Equações Utilizando MPI e Pthreads. Trabalho de Conclusão de Curso (Bacharelado em
Ciência da Computação). Universidade de Caxias do Sul. 2001.
MARTINOTTO, A. L. Resolução de Sistemas de Equações Lineares Através de Métodos de
Decomposição de Domínio. 2003. 92 p. Dissertação (Mestrado em Ciência da Computação) –

93
Instituto de Informática. UFRGS, Porto Alegre.
MARTINOTTO, A. L, Estudo de Pré-condicionadores para Métodos Iterativos do Subespaço de
Krylov. Trabalho Individual de Mestrado. Trabalho Individual – Instituto de Informática
UFRGS. Porto Alegre. 2002.
MYRICOM. Myrinet Overview. Disponível em: http://www.myri.com/myrinet/overview/index.html.
Acessado em 07/08/2003.
MÜLLER, F. M.; CHARÃO, A. S.; SANTOS H. G. Aplicações de Alto Desempenho. Anais Escola
Regional de Alto Desempenho 2003. Santa Maria-RS. 2003.
OPENMP: Simple, Portable, Scalable SMP Programming. Disponível em http://www.openmp.org/.
Acessado em 07/07/2003.
PACHECO, P. S. Parallel Programing with MPI. Morgan Kaufmann Publishers Inc. Boston. 1997.
PALHA, M. A. K. Avaliação de Desempenho e Perfilamento de Código em Programas Paralelos.
Trabalho de Conclusão de Curso. Universidade de Caxias do Sul. 2000.
PATTERSON, A. D.; HANNESSY, J. L. Computer Organization & Design: The Hardware e
Software Interface. Morgan-Kaufmman. 1998.
PELLEGRINI, F. SCOTCH 3.1 User’s Guide. 1996. Disponível em
www.labri.fr/Perso/~pelegrin/scotch/.
PERLIN, H.; GALANTE, G.: GERATRIZ – Ferramenta Para Auxílio Na Geração De Sistemas De
Equações a partir de Domínios. Grupo de Matemática Computacional e Processamento
Paralelo. Anais ERMAC 2003. 2003.
PETRINI F. et al. The Quadrics Network: High-performance Clustering Technology. Los Alamos
National Laboratory. 2002. Disponível em: http://www.c3.lanl.gov/~fabrizio/quadrics.html.
Acessado em 07/08/2003.
PICININ, D. Jr. Paralelização do Algoritmo do Gradiente Conjugado Através da Biblioteca MPI e de
Threads. Trabalho Individual – Instituto de Informática UFRGS. Porto Alegre. 2001.
PICININ, D. Jr. Paralelização de Métodos de Solução de Sistemas Lineares em Clusters de PCs com
as Bibliotecas DECK, MPICH e Pthreads. Dissertação (Mestrado em Ciência da Computação) –
Instituto de Informática, UFRGS. Porto Alegre. 2002.

94
PITANGA, M. Construíndo Supercomputadores com Linux. Brasport. Rio de Janeiro. 2002.
RIZZI, R. L. Modelo Computacional Paralelo para a Hidrodinâmica e para o Transporte de
Substâncias Bidimensional e Tridimensional. Tese (Doutorado em Ciência da Computação) –
Instituto de Informática, UFRGS, Porto Alegre. 2002.
RIZZI, R. L. et al. Modelo Computacional Paralelo Com Balanceamento Dinâmico de Carga para a
Hidrodinâmica e para o Transporte de Substâncias. XXIV Iberian Latin-American Congress on
Computational Methods in Engineering. Universidade Federal de Rio Preto. 2003.
RUNTING, S. Parallel Computation of IncompleteCholesky Factorization. Disponível em:
http://media.cs.tsinghua.edu.cn/~shirunting/research.htm. Acessado em 08/07/2003.
SAAD, Y. Data Structures and Algorithms for Domain Decomposition and Distributed Sparse
Matrices. University of Minnesota. Department of Computer Science. 1994. Disponível em
http://citeseer.nj.nec.com/saad94data.html. Acessado em 05/11/2003.
SAAD, Y. Iterative Methods for Sparse Linear Systems. PWS Publishing Company. 1996.
SAAD, Y; SOSONKINA M.; ZHANG, J. Domain Decomposition and Multi-Level Type Techniques
for General Sparse Linear Systems. University of Minnesota. Department of Computer Science.
1998. Disponível em http://www.cs.umn.edu/~saad. Acessado em 10/12/2003.
SCHÜLE, J. Parallel Computing II – winter term 2002/2003. Notas de Aula. Disponível em:
http://cfgaussms.rz.tu-bs.de:2301/jschuele/vorlesung/WS00.html. Acessado em: 10/07/03.
SCI: The Scalable Coherent Interface. Disponível em: http://www.scizzl.com/. Acessado em
07/08/2003.
SHEWCHUCK, J. R. An Introduction to the Conjugate Gradient Method Without the Agonizing Pain.
School of Computer Science. Carnegie Mellon University. 1994. Disponível em:
<ftp://warp.cs.cmu.edu>. Acessado em: 20/06/2003.
SHYGUE, C. Y. Cálculo Numérico e Computacional. Notas de Aula. Disponível em:
geocities.yahoo.com.br/numericobr/apostila/sistema.pdf. Acessado em: 19/08/2003.
SILBERSCHATZ, A.; Galvin, P.; Gagne, G. Sistemas Operacionais: Conceitos e Aplicações. Campus.
2001.
SILVA, L. M.; BUYYA R. Parallel Programming Models and Paradigms. Departamento de

95
Engenharia Informática. Universidade de Coimbra. Coimbra. 2003. Disponível em:
www.cs.mu.oz.au/~raj/cluster/v2chap1.pdf.
SMITH, B.; BJORSTAD, P.; GROPP, W. Domain Decomposition: Parallel Multilevel Methods for
Elliptic Partial Differential Equations. Cambridge: Cambridge University. 1996.
STEINBRUCH, A; WINTERLE P. Álgebra Linear. Makron Books. 1999.
STALLINGS, W. Computer Organization and Architecture. Prentice Hall. 1996. Fourth Edition.
TALLEC, P. L. Domain Decomposition Methods in Computational Mechanics. Computational
Mechanics Advances, Le Chesnay Cedex, v. 1, p. 121-220, Oct. 1994.
TANENBAUM A. S. Structured Computer Organization. Prentice Hall. 1999. Fourth Edition.
TOP500. Supercomputer Site. Disponível em clusters.top500.org. Acessado em 29/09/03.
WALSHAW, C. The Jostle user manual: Version 2.2. 2000. Disponível em
www.gre.ac.uk/~c.walshaw/jostle/.

96
APÊNDICE A
Endereço eletrônico das ferramentas citadas neste trabalho:
Bibliotecas de Troca de Mensagens
PVM
http://www.csm.ornl.gov/pvm/pvm_home.html
MPICH
http://www-unix.mcs.anl.gov/mpi/mpich/download.html
Bibliotecas de Threads
OpenMP – Compilador OMNI e Bibliotecas
http://phase.etl.go.jp/Omni/
Bibliotecas Matemáticas
BLAS (ATLAS)
math-atlas.sourceforge.net
PETSc
http://www-unix.mcs.anl.gov/petsc/
Pacotes de Particionamento
METIS
http://www.cs.umn.edu/~karypis/metis
Pacotes de Visualização e Perfilamento
Jumpshot
http://www-unix.mcs.anl.gov/perfvis/software/viewers/