statistical generation of 3d facial animation models
TRANSCRIPT

Statistical Generation of 3d Facial Animable Models
Isaac Rudomin1 Adriana Bojórquez1 Héctor Cuevas2
1Computer Science Department at ITESM-CEM 2 Visualization Lab at DGSCA-UNAM [email protected] [email protected]
Abstract This article reports results of a modeling system that is
part of a larger project which seeks to achieve perceptually realistic animations of 3D models driven by speech. This system generates individualized animatable 3D face models driven by “muscles” and compatible with MPEG-4. Our main contribution is in the use of an extensive facial database and statistical techniques to generate plausible facial models from limited data: from a single image using eigenface-like statistical recognition techniques, from descriptions (identikit) or randomly within the parameters of the population represented in the facial database. An interactive module and a muscle-based animation player are also part of the system. Keywords: facial modeling and animation
1. Introduction
The human face is the part of the body that allows us to recognize people and detect their emotions. For this reason the face has attracted the attention of different disciplines as varied as psychology, criminalistics and computer graphics. There are several kinds of facial models that have been used in the literature. Following [17] loosely we can classify them in two basic kinds depending on how they are to be animated:
1. Geometric 2. Muscle-based
Geometric models e most commonly used. They usually consist of a polygon mesh with an attached texture and are usually animated by interpolating or morphing between different meshes created for different expressions. Their appearance is usually realistic, but the animation looks artificial. Simple muscle-based models use the same polygon mesh, but interpret it as a particle-spring mesh with added springs that work as “muscles” that drive the facial mesh by contracting or expanding in a manner similar to real muscles.
There are other, more anatomically correct ways of developing a muscle-based system, but even the simplest
system described above allows for significantly more realistic animation.
Once a specific underlying model is chosen, there are many ways to generate facial models. A face model can be constructed from photographs [1, 2, 3, 4, 5] or video [6, 7, 8, 9, 10]; from a verbal description such as that normally used by police for generating portraits, also called identikit [11, 12, 13, 14] or randomly within certain restrictions [1, 11].
Systems that reconstruct facial models from photographs are very common. They can beclassified as either interactive or automatic. In the first type, user intervention is required in order to mark or adjust some points [3, 8, 15]. Automatic systems use recognition techniques in order to detect faces and extract points, some systems require two images [5, 6], while others use only a frontal image and additional data [1, 2].
In this paper we describe a system which constructs MPEG-4 compatible animatable 3D facial models based on muscles, from descriptions, at random or from a single image, using a facial database and recognition techniques. The models can be animated with speech data as described elsewhere [16]. 2. Related Work
The system described by Blanz and Vetter in [1] uses a 3D facial database of laser scans, a generic textured face and minimization techniques to synthesize texture and shape of a 3D face simultaneously, using intermediate rendered images as a guide in this process. Although they report good results, the construction process of a 3D face model from an image takes about 50 minutes on a SGI R1000 processor.
Cuevas and Rudomin [2] follow the shape by texture synthesis idea; they describe an automatic system that uses a 2D/3D facial database and principal component analysis (PCA) also known as eigenfaces. They use the eigenfaces obtained by image analysis to derive a set of 3D pseudo-eigenfaces, which are then used to quickly (in a few seconds) synthesize a 3D face model by linear combination. In order to allow the system to function,
they require all the 3D faces in the face database to have the same underlying generic mesh, which restricts the applicability of the method somewhat. The facial database used was rather small (13 faces), and although it was enough to give a preview of the possibilities, it is too small to give conclusive evidence of the potential of the technique. In the system we describe now, we have dealt with many of these issues in generating a 3D face model from a single image, using a more complete facial database. We have also used the underlying database, representation and statistical techniques to add the capabilities of the other modules to build a complete system we will now describe.
FaceGen 2[11], which includes identikit and random generation modules, and also promises generating a facial model from a single image, is a system that has recently become available that we have found to be very similar to ours in functionality and philosophy. There is not much information available, since it is a commercial product, but their web page advertises the versatility of their multiple modules and their statistical techniques.
In their words, “The shape and color controls are generated from hundreds of actual color 3D scans of people of many ages and races using advanced statistical methods. The main advantages of statistical controls over artist-created controls are greater realism, realistic random face creation, and the ability to construct almost any human face. The mathematical terms for these advantages are, respectively, Precision, Orthogonality and Basis Spanning.”
In this respect, the system we have been building and will describe here has similar power. One difference with FaceGen 2 is that the module that generates a facial model automatically from a single image is already available. Another difference is that they use a propietary format and we use MPEG-4. Lastly, the models we generate are muscle driven rather than mesh-based, permitting the creation of more realistic animations by using simulation rather than morphing. 3. System Overview
We have implemented four modules for generating 3D facial models, and a module for animating these models from speech data. The modeling modules are:
1. Generating a 3D facial model from a single image by using a statistical recognition technique;
2. Generating a face randomly within the statistical parameters of the population represented in the facial database;
3. Generating a face from verbal descriptions (Identikit);
4. Generating a face from the interactive analysis of a 2D facial image.
In the following sections we will describe the new facial database as well as the different modules and their theoretical basis. 3.1. Database
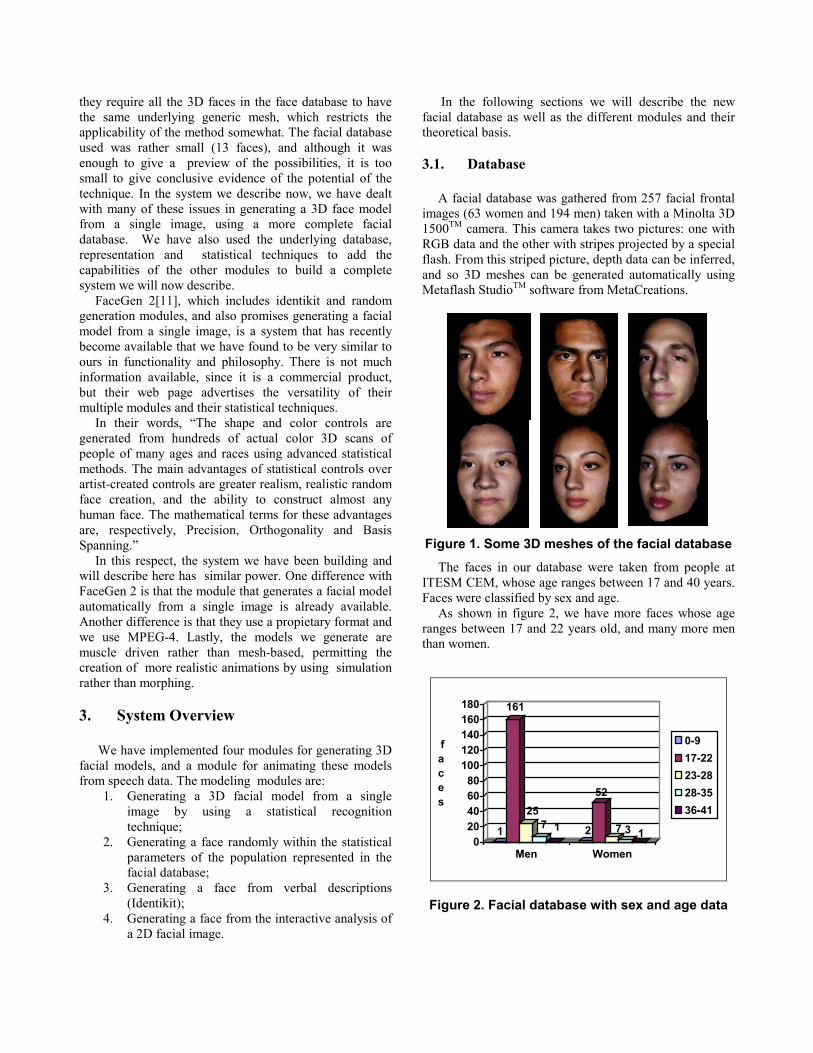
A facial database was gathered from 257 facial frontal images (63 women and 194 men) taken with a Minolta 3D 1500TM camera. This camera takes two pictures: one with RGB data and the other with stripes projected by a special flash. From this striped picture, depth data can be inferred, and so 3D meshes can be generated automatically using Metaflash StudioTM software from MetaCreations.
Figure 1. Some 3D meshes of the facial database
The faces in our database were taken from people at ITESM CEM, whose age ranges between 17 and 40 years. Faces were classified by sex and age.
As shown in figure 2, we have more faces whose age ranges between 17 and 22 years old, and many more men than women.
1
161
257 1 2
52
7 3 10
20406080
100120140160180
faces
Men Women
0-917-2223-2828-3536-41
Figure 2. Facial database with sex and age data

3.2. Generic face model
A generic face model was developed from a basic pseudo-muscle based model by Parke and Waters [17]. This model uses a facial particle-spring mesh with 28 extra springs that work like “muscles” that pull on the facial mesh.
This basic model was modified in order to make it MPEG-4 compatible by specifying 64 feature point locations. These modifications allow us:
1. the construction of a new face by modifying the generic face by changing the feature point coordinates that define the facial features
2. animating this face by changing other feature points
This mesh has 876 triangles and 28 muscles to allow expressions and movement. Our generic face and some of the associated MPEG-4 feature points can be seen in figure 3.
Figure 3. Generic face mesh. MPEG-4 feature points
Each of the 28 muscles of the generic face has at least
one MPEG-4 feature point associated to it (as a head or tail), a predetermined area (vertices to modify) and a stiffness constant. Muscles behave as springs, where muscle contraction is obtained by changing it’s length. The force vector is calculated by :
f�
= -[ks(|I|-r)] I/|I| where ks is stiffness constant, |I|: actual length , r: rest length, I: length vector. The muscle contraction c is obtained by:
fff zyxc222
++=
Given new contractions, displacement for muscle
related vertices is calculated. The amount of displacement is calculated to be relative to the muscle contraction, and
the surface distance of the vertex to the muscle’s tail and the angle between it and the muscle vector (see figure 4).
head
muscletail
surfacedistance
vertex i
θ
Figure 4. Diagram showing muscle structure and
distance from vertex
3.3. Principal Component Analysis
Principal Component Analysis (PCA) is a statistical method for data restatement, although it can be used for lossy and lossless data compression. Its chief advantage is that it doesn’t require a model of the data being analyzed; it also treats all variables similarly, without choosing a dependent one. An informal explanation using face images follows:
Any image can be generated by the following linearly independent set of images, which can be seen as vectors (see figure 5):
Figure 5. Generating basis for image space
For faces this is clearly redundant and inconvenient: for example, since faces are round we could drop the images in our general basis that represent corners pixels. Since each face image is a trivial linear combination of itself, for representing a set of M face images we need just M elements. A non-trivial generating basis for that set would then have at most M elements; we would like them to be as orthogonal as possible and to be capable of generating faces outside our original set reasonably well. This is exactly what PCA accomplishes. See figure 6 for PCA applied to faces.
Figure 6. PCA applied to faces (eigenfaces)

Here each element of the new generating basis is a new coordinate axis for our existing data; thus we have restated our data. These axes are also called principal components (PC).
More formally, we ask a PC to satisfy three important conditions: 1. To be a linear function of the original variables 2. To be perpendicular to any PC chosen before. 3. Of all possible functions satisfying the previous
conditions, we choose as the first/new PC the one who explains as much as possible the variation of the original data points. This is why PCs resemble faces, specially the first one.
The set of PC components obtained is a generating basis for our original data, and, unless our face data wasn’t linearly independent, we have one PC for each original face. The key advantage is that since this new basis isn’t trivial, it can be used to create novel faces. Another advantage is that the contribution of each PC is measurable, so we can choose to drop some, reducing the size of our base to be less than the number of original faces.
Compression is achieved by storing a face as the group of coefficients which generate it by linear combination of the new basis. This obviously implies storing the generating faces, so compression is only suitable for large sets of data, or when an small representation is preferred. This compression is lossless unless we dropped some PCs.
PCA can be applied to any data which can be represented as a set of vectors, for example images (including faces [18]), and meshes. 3.4. 3D Facial model from a Single Image by
using PCA
Based on principal component analysis, this module allows the generation of a face model from a single frontal image. We use an improved version of the system we first outlined in [2] with our now larger facial database.
Facial generation systems using a single image depends heavily on the selection of feature points, as they are used to infer the face shape. Once good feature points are selected, the problem becomes the method of shape estimation. Many solutions have been tried and while they are good, they tend to focus only on image knowledge, setting aside the shape properties of the human face.
The original “3D eigenfaces” method as we described it in [2], applies a common PCA to the 2D faces in the face database. Once 2D eigenfaces are obtained, so called “3D eigenfaces” are analytically derived from them (technically they are not eigenfaces but the name helps us understand the process) as can be seen in figure 7.
Taking all 3D meshes and 2D encodings we solve for the 3D eigenmeshes.
3D Mesh = 2D Encoding ·3D eigenmeshes
FacialDatabase
FaceImages Create eigenfaces and encode
all face images.
3DMeshes
2D Encodings 2D Eigenfaces
3D eigenmeshes
Figure 7. Generating “3D eigen-meshes”
Although it is possible to create true 3D eigenmodels
from a mesh to create a 3D face model from an image we need what in [2] the authors call the interchangeable encoding property, which is illustrated in figure 8:
Apply 3D eigenmeshes:3D Mesh = 2D Encoding ·3D eigenmeshes
Normalized 2D Face
Encode using2D eigenfaces.
3D Mesh
2D Encoding
Figure 8. Obtaining a 3D face mesh from a single image
This property can only be guaranteed to hold by
deriving the 3D pseudo-eigenfaces from the 2D ones, and its name comes from the fact that we use the coefficients of a 2D face decomposition (also called encoding) to create by linear combination the corresponding 3D face.
This makes the facial database extremely important: this property holds by construction on it, but the facial database needs to be representative enough of face space to work on faces outside this database.
This method gave encouraging results, our facial database was small. Also, we synthesized only mesh vertices: normals and texture coordinates were left out, and they required the 3D faces in their database to use the same generic mesh model, so they could be linearly combined. The process we follow here incorporates MPEG-4 feature points and is similar to the original one. We are working on 3 different methods based on this principle. They are not finished yet, but preliminary results are encouraging. They are described next.

3.4.1. Enhanced Eigenmeshes. First, we convert all our models in the face database to the MPEG-4 generic model by sampling the existing face surface, obtaining normal and texture coordinate information from it. Using this face database, we apply the "3D eigenmeshes" method described in [2] and explained above to generate not only 3D vertices, but also normals and texture coordinates, so that the resulting face can be used immediately, while allowing for more comprehensive testing of the results. We are still working on this method.
3.4.2. Fit to MPEG-4 feature points. In a preliminary step, we obtain only the MPEG-4 feature points from the models on the database. Then we apply the method described in [2] to this data and obtain what we call “eigenfpointvectors”. Then, when a new image is entered, we project it to facial space and use this 2D encoding, together with the eigenfpointvectors to obtain a new feature point vector. This is then used to fit the other parts of the generic mesh (i.e. not the feature points) as a particle-spring system with forces. Texture is adjusted in a semi-automatic module.
At the moment, a 3D face is generated, with correct vertical proportions, but more is needed in order to obtain correct horizontal and eye proportions, as can be seen figure 9:
Figure 9. Preliminary results of fitting to MPEG4
feature points (3D models have blue background)
3.4.3. Use Depth-maps. Depth data is another way of representing a non self-occluding surface, so, we can also apply the PCA coefficients to the depth map associated with the images in the database instead of to the meshes, thereby obtaining what we call “eigen-depthmaps”, as can be seen in figure 10.
Taking all depth maps and 2D encodings we solve for the depth maps.
Depth Maps = 2D Encoding ·eigendepthmaps
Facial Database
FaceImages Create eigenfaces and encode
all face images.
Depth Maps 2D Encodings 2D Eigenfaces
eigendepthmaps Figure 10. Generating “eigendepthmaps”
Analyzing a eigen-depthmap has the advantage of relaxing many of the restrictions in the original method, as long as depth values are obtained carefully (remember that those were obtained from a 3D camera). Reconstruction is applied to the depth-maps as well, as can be seen in figure 11.
Depthmaps = 2D Encoding ·Eigen-depthmaps
Normalized 2D Face
Encode using2D eigenfaces.
Depthmaps
2D Encoding
Figure 11. Obtaining a depthmap from a single
image
Finally, to generate an animatable model, we must fit
our generic MPEG-4 model to these depth-maps. This can be done either interactively or automatically. 3.5. Generating a face randomly
This module allows the construction of a random face, in case the user needs a representative face from some population and doesn’t care about specific appearance. The geometry generation uses PCA applied to the 3D coordinates of MPEG-4 feature points from the facial database. The database was pruned in order to select 112 faces with neutral expression and correct geometry, from those that had distortions and noise. From these faces a representative sample of 36 was selected in order to extract MPEG-4 feature point coordinates.
A face is described by a vector d of size n, where n stands for the number of feature points.
43nnnn222111d n3T)z,y,x,....,z,y,x,z,y,x( =∈= ℜ
Mean values are obtained by:
∑=
=m
1jiji xx ∑
=
=m
1jiji
yy ∑=
=m
1jiji zz
where i =1…n, j=1...m, and m is the number of faces in the database.
Mean vector is:
)z,y,x,....,z,y,x,z,y,x( nnn222111T
=µ
A new face is constructed from a weight vector b with limits between {-3σI, 3σI} where σσσσ stands for the standard deviation of each feature point. A new coordinate for feature point Xi is obtained from:
Pbxi +µ=

where P= (p1,...,pt) is the eigenvector matrix, b=(b1,...bt) is a weight vector of t eigenvectors, µ is the media vector.
After this process, a calibration file with feature point coordinates is generated. The generated face has a smooth appearance that can be changed with a textured one. Some results are depicted in figure 12. Resulting faces are plausible within the population represented by faces in the database.
Figure 12. Some faces generated by the random module
3.6. Generating a face from descriptions
(Identikit)
The identikit module has a graphic interface where the user enters a facial description with sliders. This description is then analyzed and encoded to model a new face.
Facial characteristics were classified in measurable and not measurable. The first ones can be directly related with MPEG-4 feature points and distances between them (i.e. face length, face width, nose length, mouth width, eyes’ separation). Non measurable characteristics are not directly related with MPEG-4 feature points, but are important to distinguish a face (i.e. skin and eye color, eyebrow thickness). Initially, the representative faces of our database were classified with the identikit criteria in order to obtain statistical data.
With this data, facial descriptions that can be directly related with MPEG-4 feature points were specified by using description rules. From the new description chosen by the user, each feature can be processed in two ways: If the feature is measurable, the slider selected value is scaled between minimum and maximum values in
database for that feature. A vector is created (geometry vector) with all faces that match this feature. If feature isn’t measurable a vector is created (appearance vector) with all possible matches. At the end the face with greater number of matches is selected.
After processing the features, we analyze both the geometry and appearance vector in order to take the face with more matches. The selected face from the geometry vector is the base for MPEG-4 coordinates. To obtain a calibration file, coordinates are modified with the desired data. The texture image is obtained as the face with more matches in the appearance vector, if the texture is not correctly placed in the resulting face.
Some results are depicted in figure 13. As can be seen, the module works as expected, and allows the user the generation of a face models with specific characteristics within a certain population.
Face shape round &chin shape round
Face shape
angular & chin shape angular
Face shape oval & chin
shape square
Face shape
square & chin shape square
Face shape triangular & chin shape
pointed
Face shape
square & chin shape
round
Figure 13. Some faces generated by the identikit module
3.7. Interactive module
This module allows the user to open a facial image and select feature point locations over it. The image must have a face facing forward and with a neutral expression.
This module can be used in case the user wants to generate a face that automatic analysis can’t classify or to paste and adjust texture to either the generic or another facial model.
Initially, the user points 10 feature points of the face contour, with this locations the relative position of the rest of feature points is displayed. Then the user has to adjust these points to the correct location. The coordinates are used to extract texture images and are transformed to adjust the generic face.

Figure 14. Some faces generated by interactive module next to the photographs of the models
As can be seen in figure 14, the module works as
expected, and permits the generation of a face models with specific characteristics interactively from a given image. 3.8. Animation
This module allows the facial model to be animated from speech data provided by the system described in [12]. In this article, an audiovisual system that learns the spatio-temporal relationship between speech acoustics and facial animation is described. The system obtains data containing 3D coordinates of MPEG-4 feature points operating at a sub-phonetic level and bypassing problems with phonetic recognition and the many-to-many relationships between phonemes and visemes. Data was sampled at 60 frames per second to capture even very short phonetic phenomena. Both 3D data and audio is sent to our animation system in order to synchronize it.
The 3D data provided is preprocessed in order to adjust it to the face model and modify it. With the new coordinates we are able to determine the appropriate muscle contraction, apply it to the muscle and modify the vertices within the muscle’s influence zone. Opening the mouth is handled as a special case; we obtain an aperture angle from the 3D data provided and apply a rotation for all vertices influenced by the jaw. Some results are depicted in figures 15 and 16.
This animation module provides movement at low level MPEG-4 (MPEG-4 feature points), allowing us to simulate coarticulation and bypass phonemes and visemes.
Figure 15. MPEG-4 basic expressions: joy, sadness, anger, fear, disgust, surprise.
Figure 16. Some frames of animation generated from MPEG-4 feature point data.
This module can display at a range between 3.43 and
58.82 frames per second on a Pentium II at 400 Mhz with no special graphics acceleration. Although results are encouraging the algorithm is still being adjusted in order to synchronize frame changes with the data at 60 frames per second. We are building a second player that in addition to muscles uses an ellipsoidal approximation to the skull and mandible in order to forbid their penetration during the animation and thus increase its realism. 4. Conclusions
Using statistical methods to generate faces is useful in many applications Generating animatable face models from a single image is very useful when one desires a specific face and has a frontal image of it, while using descriptions is useful when the user doesn’t have an image of the desired face, but can provide a description of it. On the other hand, generating faces randomly is useful when user doesn’t care about specific characteristics but desires a representative face from a population.

The system described in this article has many applications and provides the user with different ways to generate individualized animatable 3D face models.
Future work:
1. Facial database. Increase the number of useful faces in database for the statistical face model generation method, including more diversity of age and race.
2. Generic face model. Improve the calibration algorithm in order to generate smoother surfaces. Simulate circular muscles around eyes.
3. Identikit module. Increase the number of facial features to chose from. Explore the direct relationship between eigenvalue coefficients and distinguish facial features.
4. Animation module. Work on making the animation faster in order to animate at 60 frames per second. Work on making animation more realistic by using an ellipsoidal approximation to skull and mandible and avoid their penetration during animation.
5. Analysis of the effects of image resolution on 3D face generation.
6. Construct an algorithm for automatic adjustment of texture.
5. References [1] V. Blanz, T.A. Vetter, “Morphable Model for the
Synthesis of 3D Faces”, SIGGRAPH´99 Proceedings, 1999.
[2] H. Cuevas, I. Rudomin, “Generating a 3D Facial Model from a single image using principal component analysis”, Proceedings of Visual 2000, Sept. 2000.
[3] W. Lee, M. Escher, G. Sannier, N. Magnenat Thalmann, “MPEG-4 Compatible Faces from Orthogonal Photos”, Proceedings of the Computer Animation 1999, Geneva, Switzerland, 1999, p.186-194.
[4] F. Pighin, J. Hecker, D. Lischinski, R. Szeliski, D. Salesin, “Synthesizing Realistic Facial Expressions from Photographs”, SIGGRAPH´98 Proceedings, 1998, p. 75-84.
[5] T. Goto, S. Kshirsagar, N. Magnenat-Thalmann, “Automatic Face Cloning and Animation”, IEEE Signal Processing, 2001, Vol. 18, No. 3, p.17-25.
[6] M. Akimoto, Y. Suenaga, R.S. Wallace, “Automatic Creation of 3-D Facial Models”, IEEE Computer Graphics & Applications, 1993, Vol. 13, No. 5, p. 16-22.
[7] P. Fua, C. Miccio, “Animated Heads from Ordinary Images: A Least Squares Approach”, Computer Vision and Image Understanding, 1999.
[8] B. Guenter, C. Grimm, D. Wolf, H. Malvar, F. Pighin, “Making Faces”, SIGGRAPH´98 Proceedings, 1998, p. 55-66.
[9] Z. Liu, Z. Zhang, A. Jacobs, M. Cohen, “Rapid Modeling of Animated Faces From Video”, Proceedings of Visual 2000, Sept. 2000.
[10] S. Morishima, “Face Analysis and Synthesis”, IEEE Signal Processing, 2001, Vol. 18, No. 3, p. 26-34.
[11] FaceGen Modeller 2.0 from Singular Inversions Inc., http://www.FaceGen.com
[12] J.K. Wu, Y.H. Ang, P.C. Lam, S.K. Moorthy, A.D. Narasimhalu, “Facial Image Retrieval, Identification, and Inference System”, Proceedings of the conference on Multimedia '93, Ag. 2 - 6, 1993, Anaheim, CA USA, p. 47.
[13] R. Brunelli, O. Mich, “SpotIt! An Interactive Identikit System”, Computer Vision, Graphics and Image Processing: Graphical Models and Image Processing. 1996, Vol. 58, No. 5, p.399-404. SpotIt! from ITC-irst, http://spotit.itc.it/
[14] Facette from IDENTI.NET, http://www.facette.de/ [15] D. Decarlo, D. Metaxas, M. Stone, “An
Anthropometric Face Model using Variational Techniques”, SIGGRAPH´98 Proceedings, 1998, p. 67 - 74.
[16] P. Kakumano, R. Gutierrez-Osuna, A. Esposito, R. Bryll, A. Goshtaby, O.N. Garcia, “Speech Driven Facial Animation”, to be published at Workshop on Perceptive User Interfaces, November 2001.
[17] F.I. Parke, K. Waters, Computer Facial Animation, A. K. Peters, Wellesley, Massachusetts, 1996.
[18] A. Pentland, B. Moghaddam, T. Starner, “View-Based and Modular Eigenspaces for Face Recognition”, M.I.T. Media Laboratory Perceptual Computing Section Technical Report No. 245. Also appeared in IEEE Conference on Computer Vision & Pattern Recognition, 1994.