segmentierung mit graph-cut-methoden
TRANSCRIPT

Segmentierung mit Graph-Cut-Methoden
Diplomarbeit im Fach Informatik
vorgelegtvon
Erik Rodner
Geboren am 22.05.1983 in Konigs Wusterhausen
Angefertigt am
Lehrstuhl fur Digitale Bildverarbeitung
Fakultat fur Mathematik und Informatik
Friedrich-Schiller-Universitat Jena.
Betreuer: Prof. Dr.Ing. J. Denzler, Dr. rer. nat. habil. H. Suße, Dipl.Inf. O. Kahler
Beginn der Arbeit: 4. Februar 2007
Abgabe der Arbeit: 6. Juli 2007

ii

iii
Ich versichere, dass ich die Arbeit ohne fremde Hilfe und ohne Benutzung anderer als der
angegebenen Quellen angefertigt habe und dass die Arbeit in gleicher oderahnlicher Form noch
keiner anderen Prufungsbehorde vorgelegen hat und von dieser als Teil einer Prufungsleistung
angenommen wurde. Alle Ausfuhrungen, die wortlich oder sinngemaß ubernommen wurden,
sind als solche gekennzeichnet.
Die Richtlinien des Lehrstuhls fur Studien- und Diplomarbeiten habe ich gelesen und aner-
kannt, insbesondere die Regelung des Nutzungsrechts.
Jena, den 5. Juli 2007

iv
Ubersicht
Die vorliegende Arbeit beschreibt die Verwendung von sogenannten Graph-Cut-Methoden
in der Bildverarbeitung. Diese Methoden losen Segmentierungsprobleme mit Verfahren der dis-
kreten Optimierung. Notwendige theoretische Grundlagen aus der Bayesschen Bildanalyse, Gra-
phentheorie, diskreten Optimierung und theoretischen Informatik werden dargestellt und in ei-
nem gemeinsamen Kontext erlautert. Einen Schwerpunkt bildet dabei eine klare Eingrenzung
der Moglichkeiten von Graph-Cut-Verfahren. Ausgehend von diesen Untersuchungen werden
im weiteren Verlauf der Arbeit zwei Problemstellungen der Bildverarbeitung bearbeitet. Die Lo-
kalisierung des Kennzeichenrandes ist ein wichtiger Schritt im Gesamtsystem eines Kennzei-
chenlesers und kann effizient durch einen Graph-Cut-Ansatz gelost werden. Weiterhin werden
Verfahren zur Verbesserung der Ebenendetektion entwickelt, welche es unter anderem ermogli-
chen, Tiefeninformationen und Grauwertinformationen aktueller Spezialkameras in einem Opti-
mierungsschritt zu kombinieren. Die Auswertung der vorgestellten Verfahren erfolgt anhand von
Experimenten und dem Vergleich mit Ground-Truth Daten.
Abstract
The following work describes the potential of graph cut methods in computer vision. These me-
thods solve segmentation problems with discrete optimization techniques. Theoretic fundamen-
tals from bayesian image analysis, graph theory, discrete optimization and theoretical computer
science are presented and explained in a common framework. Thereby the main focus is the study
of well defined limitations of graph cut methods. Based on these results it is possible to develop
new solutions for two applications. The localization of a license plate border is an important step
in a license plate recognition system and can be solved efficiently with a graph cut approach.
Furthermore different methods to refine planar patch detection are developed, which are able to
combine depth and intensity information from 3-D imaging sensors in a single optimization step.
Evaluation of all proposed algorithms is done by experiments and comparision with ground truth
data.

Inhaltsverzeichnis
1 Einfuhrung 1
1.1 Literaturuberblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Verwendete Notationen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.3 Aufbau der Arbeit. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Markov Random Fields 7
2.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 Satz von Hammersley-Clifford. . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3 Schatzung mittels MRF. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10
2.3.1 MAP-Schatzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .10
2.3.2 Annahmen der Schatzung . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3.3 Vereinfachungen der Schatzung . . . . . . . . . . . . . . . . . . . . . . 11
2.3.4 Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .12
3 Schatzung von MRF-Zustanden mit minimalen Schnitten 17
3.1 Minimale Schnitte in Graphen. . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.1 Problemdefinition. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .18
3.1.2 Zusammenhang zur Bestimmung des maximalen Flusses. . . . . . . . . 19
3.2 Algorithmen zur Bestimmung des minimalen Schnittes. . . . . . . . . . . . . . 23
3.2.1 Der Algorithmus von Dinic . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.2 Der Algorithmus von Kolmogorov und Boykov. . . . . . . . . . . . . . 24
3.3 Diskrete Optimierung mit Graph-Cut. . . . . . . . . . . . . . . . . . . . . . . . 25
3.3.1 Das Optimierungsproblem und die Funktionsklassen F2 und F3. . . . . 25
3.3.2 Regularitat und Graphkonstruktion fur F2 . . . . . . . . . . . . . . . . . 26
3.3.3 Vollstandige Charakterisierung. . . . . . . . . . . . . . . . . . . . . . . 31
3.3.4 Der Zusammenhang zu submodularen Funktionen. . . . . . . . . . . . 33
v

vi INHALTSVERZEICHNIS
3.4 alpha-Expansion-Algorithmus. . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4.1 Beschreibung des Algorithmus. . . . . . . . . . . . . . . . . . . . . . . 37
3.4.2 Eigenschaften des Algorithmus. . . . . . . . . . . . . . . . . . . . . . 39
3.4.3 Anforderungen an Zielfunktionen der Funktionsklasse F2. . . . . . . . 41
3.4.4 Beziehung zur Schatzung von MRF-Zustanden . . . . . . . . . . . . . . 42
4 Anwendungen 45
4.1 Interaktive Segmentierung. . . . . . . . . . . . . . . . . . . . . . . . . . . . .45
4.1.1 Aufgabenstellung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .45
4.1.2 Festlegung der unabhangigen Kosten einzelner Pixel. . . . . . . . . . . 46
4.1.3 Wahl der Cliquen-Potentiale 2. Ordnung. . . . . . . . . . . . . . . . . . 46
4.2 Kennzeichenlokalisierung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
4.2.1 Einfuhrung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .48
4.2.2 Kennzeichenlokalisierung als binares Segmentierungsproblem. . . . . . 48
4.3 Ebenendetektion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .50
4.3.1 Problemstellung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .51
4.3.2 Ebenendetektion durch Bewegungssegmentierung. . . . . . . . . . . . . 51
4.3.3 Ebenendetektion mit zusatzlicher Tiefeninformation . . . . . . . . . . . 55
5 Experimente 59
5.1 Kennzeichenlokalisierung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .59
5.1.1 Experiment. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .59
5.1.2 Auswertung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .61
5.2 Ebenendetektion. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .62
5.2.1 Experimentaufbau. . . . . . . . . . . . . . . . . . . . . . . . . . . . .62
5.2.2 Auswertung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .65
6 Ausblick 67
6.1 Allgemeine Ansatze fur die weitere Forschung. . . . . . . . . . . . . . . . . . . 67
6.2 Verbesserung der Kennzeichenerkennung durch Graph-Cut-Verfahren. . . . . . 68
6.3 Erweiterung der Ebenendetektion mit Graph-Cut. . . . . . . . . . . . . . . . . 68
7 Zusammenfassung 69
A Mathematische Details 71
A.1 Zusammenhang zwischen binarer Bildrestaurierung und Medianfilter. . . . . . . 71

INHALTSVERZEICHNIS vii
A.2 Details zum Algorithmus von [BK04] . . . . . . . . . . . . . . . . . . . . . . . 72
A.3 Minimierung von F2-Funktionen ist NP-schwer. . . . . . . . . . . . . . . . . . 74
A.4 Verifikation der Graph-Konstruktion bei F2-Funktionen. . . . . . . . . . . . . . 75
B Details zu den Experimenten 79
B.1 Verwendete Parameter bei der Kennzeichenlokalisierung. . . . . . . . . . . . . 79
B.2 Problemfalle bei der Kennzeichenlokalisierung. . . . . . . . . . . . . . . . . . 79
B.3 Verwendete Parameter bei der Ebenendetektion. . . . . . . . . . . . . . . . . . 80
B.4 Weitere Beispielbilder der Ebenendetektion. . . . . . . . . . . . . . . . . . . . 80
Literaturverzeichnis 83
Verzeichnis der Bilder 91
Verzeichnis der Tabellen 93

viii INHALTSVERZEICHNIS

Kapitel 1
Einf uhrung
Die folgende Arbeit beschaftigt sich mit den Moglichkeiten der Verwendungdiskreter Opti-
mierungsverfahrenbei Segmentierungsaufgaben in der Bildverarbeitung. Dabei bezeichnet der
Begriff der Segmentierungeines Bildes allgemein die Zusammenfassung von Pixeln aufgrund
von gewissen Kriterien zu inhaltlich zusammenhangenden Regionen. Diese Definition wirft zwei
Fragestellungen auf: Wie lassen sich anwendungsspezifische Kriterien definieren und wie lasst
sich aufgrund dieser Kriterien eine Segmentierung durchfuhren?
Bisherige Segmentierungsansatze verwenden meistens eine Folge von einzelnen Operatio-
nen und Verarbeitungsschritten wie etwa Kantendetektion und anschließende Kontursuche. Eine
klare mathematische Formulierung der Segmentierungskriterien kann bei dieser Staffelung oft
nicht verwendet werden und ist auch nicht implizit gegeben.
Ein komplett anderer Zugang ist die Segmentierung mit mathematischen Optimierungsver-
fahren wie bei der Bayessche Bildanalyse. Kriterien fur die Segmentierung werden dort anhand
eines Optimierungsproblems angegeben. Der Schwerpunkt dieser Arbeit ist dabei die Verwen-
dung von diskreten Optimierungsproblemen. Als Segmentierungsverfahren kann nach der Ent-
wicklung anwendungsspezifischer Kriterien, im weiteren Verlauf der Arbeit auch alsModell
bezeichnet, ein passendes numerisches Verfahren aus der mathematischen Optimierung gewahlt
werden.
So genannteGraph-Cut-Methodenbesitzen ihren Ursprung in der mathematischen Optimie-
rung. Grundidee ist die Abbildung eines Optimierungsproblems in ein Problem der Graphentheo-
rie. Die Formulierung des Problems in der Sprache der Graphentheorie ermoglicht es, ein breites
Spektrum von Forschungsergebnissen in diesem Bereich zu verwenden. Vor allem die Resultate
der theoretischen Informatik bieten diesbezuglich klar definierte Grenzen der Berechenbarkeit
und Losungsansatze fur die Ermittlung approximierter Losungen.
1

2 KAPITEL 1. EINFUHRUNG
Ziel dieser Arbeit soll es daher unter anderem sein, theoretische Moglichkeiten der Anwen-
dung von Graph-Cut-Verfahren in der Bildverarbeitung aufzuzeigen. Weiterhin werden konkrete
algorithmische Losungen fur ein Problem der industriellen Bildverarbeitung (Kennzeichenloka-
lisierung) sowie des Rechnersehens (Ebenendetektion) entwickelt und durch Experimente veri-
fiziert.
1.1 Literatur uberblick
Bereits in den fruhen Jahren der Bildverarbeitung wurden Segmentierungsprobleme mit ma-
thematischen Optimierungsverfahren gelost. Ausgangspunkt ist stets die MAP-Schatzung von
Zufallsvariablen mit einem zugrunde liegendenMarkov Random Field(MRF) Modell (MRF-
Zufallsvariable). Die fur die Schatzung notwendige Optimierung wird dabei im ursprunglichen
Standardwerk [GG84] der Bayesschen Bildanalyse [Win06] mit dem Gibbs Samplerdurch-
gefuhrt. Dieser Algorithmus ist ein Spezialfall zum allgemeinerenMetropolis-Hasting Algorith-
musbeziehungsweise der Optimierung mitSimulated Annealing. Diese Verfahren konnen auf
allgemeine Zielfunktionen angewendet werden, daher ist es zum Beispiel nicht moglich obere
Schranken fur die Laufzeit anzugeben.
Als weiteres iteratives Verfahren aus den Anfangen sei derIterated Conditional Modes(ICM)
Algorithmus aus dem Beitrag [Bes86] erwahnt. Eine Anmerkung in der dazugehorigen veroffent-
lichten Diskussion [GPS86] legt als erstes die Verbindung zur diskreten Optimierung [PR75,
Cun85] offen und ermoglicht so die exakte MAP-Schatzung von MRF-Zufallsvariablen bei bi-
naren Segmentierungsproblemen [GPS89]. Grundidee ist dieUbertragung auf das Problem des
minimalen Schnittes (Min-Cut) aus der Graphentheorie.
Die Einschrankung auf binare Probleme galt lange Zeit als unuberwindbare Einschrankung1.
Die Arbeiten [IG98, IG99, Ish03] untersuchen daher Bedingungen an die Zielfunktion, fur wel-
che auch bei nicht-binaren Problemen ein globales exaktes Minimum gefunden werden kann.
In [Fer95] wird hingegen versucht, eine Losung des allgemeinen Segmentierungsproblems mit
mehreren Klassen durch eine Aufteilung in binare Probleme zu finden. Die Arbeiten von Boy-
kov, Zabih und Veksler [BVZ98a, BVZ01] 2 verfolgen eineahnliche Grundidee, welche zumα-
Expansion-Algorithmus fuhrt und die Grundlage bildet fur viele weitere Anwendungen. Der Al-
gorithmus ist ein Approximationsalgorithmus3, der nur ein lokales Minimum des NP-schweren
1Diese Ansicht ist auch noch in”aktuellen“ Werken der Bayesschen Bildanalyse vorhanden [Win06].
2Zur Vollstandigkeit seien hier die Arbeiten [BVZ98b, BVZ99a, BVZ99b, Vek99] als verwandte Publikationenaufgefuhrt, die manche Details naher beschreiben.
3Es sei an dieser Stelle erwahnt dass der Algorithmus unabhangig von der Anwendung und dem Ursprung in der

1.1. LITERATURUBERBLICK 3
Ursprungsproblems [DJP*94] sicherstellen kann. Zusammen mit der Abbildung der MAP-Schatz-
ung bei binaren Problemen auf dasMin-Cut-Problemder kombinatorischen Optimierung nach
[GPS86] werden diese Ansatze in der neueren Literatur oft zusammengefasst alsGraph-Cut-
Methodenbezeichnet. Dieser Begriff kann durchaus zu ungewollten Mehrdeutigkeiten fuhren,
da im Bereich der Segmentierung auch andere Definitionen von Schnitten in einem Graphen ver-
wendet werden. Hervorzuheben ist an dieser Stelle der verwandte Begriff desNormalized-Cut
(N-Cut), welcher nur durch einenUbergang von der diskreten zur kontinuierlichen Optimierung
ermittelt werden kann [SM00, SM97, SM98, CWC06].
Als wichtigste Anwendungsgebiete desα-Expansion-Algorithmus sind die Bestimmung von
dichten Tiefenkarten [KZ02, KKZ03, Kol03], die Segmentierung mit einer Teilfixierung der La-
bels bei der interaktiven Segmentierung [BJ00, BJ01a, BJ01b, FZ05, BFL06, RMBK06, YS06],
die Segmentierung von beliebigen Bildern [Vek00] ohne A-Priori-Information, die Segmentie-
rung bei Bildern bestimmter Objektkategorien [KTZ05], Phase Unwrapping [BDV07] und die
Segmentierung auf der Grundlage von Bewegungsinformationen [BT99, XS05, SC06] zu nen-
nen.
Fur die Verwendung von Graph-Cut-Methoden in der Bildverarbeitung als reines Werk-
zeug ist es unerlasslich, theoretische Grenzen der Modellierungsmoglichkeiten bei der Anwen-
dung von Graph-Cut-Methoden aufzuzeigen. Einschrankungen bei der Modellierung liegen dar-
in begrundet, dass die Zielfunktion nur einer beschrankten Funktionsklasse angehoren kann. In
[KZ04] wird f ur eine große Klasse von Zielfunktionen eine allgemeine Graph-Konstruktion an-
gegeben. Die Ausfuhrungen [FD05] sind eine reine theoretische Abhandlunguber die Erweiter-
barkeit dieser beschriebenen Funktionsklasse.
Aufgezeigte theoretische Grenzen konnen in der Praxis naturlich nicht umgangen werden.
Dennoch ist es moglich, durch die Verwendung desQuadratic Pseudo-Boolean Optimization
(QPBO) Algorithmus [RK06, RSZ06] eine partielle Losung allgemeinerer Optimierungsproble-
me zu erhalten.
Neue Ideen, um Graph-Cut-Methoden auch algorithmisch zu verbessern, umfassen die Ver-
besserung der Laufzeit mit neuen fur die Bildverarbeitung angepassten Algorithmen der Opti-
mierung [BK04] sowie die traditionelle Beschleunigung durch Auflosungshierarchien [LSGX05,
SG06, JB06]. Die Moglichkeit, ein Maß fur die Unsicherheit eines Segmentierungsergebnisses
zu erhalten, wird durch [KT06] untersucht.
Die Arbeiten [BK03, KB05] ziehen direkte Verbindungen zu anderen Standardansatzen in
der Bildverarbeitung wie etwalevel-setMethoden.
Bildverarbeitung in der kombinatorischen bzw. diskreten Optimierung anzusiedeln ist.

4 KAPITEL 1. EINFUHRUNG
Trotz der Entwicklung neuer Verfahren fur die MAP-Schatzung von MRFs wie etwaLoopy
Belief Propagation[YFW00] sind Graph-Cut-Methoden bezuglich ihrer Geschwindigkeit und
der Gute des gefundenen Optimums fuhrend [KR06, SZS*06].
1.2 Verwendete Notationen
Pr(X = X) Fur diskrete ZufallsvariablenX sei damit die Wahrscheinlichkeit des Ereignisses
X = X bezeichnet. Bei stetigen Zufallsvariablen hingegen steht diese Notation fur
die Dichte vonX in Abhangigkeit vonX. Abkurzend kann auch die NotationPr(X) in
eindeutigen Situationen verwendet werden. Hingegen impliziert die SchreibweisePr(X )
eindeutig die Dichte oder Wahrscheinlichkeit als Funktion.
E(X ) bezeichnet den Erwartungswert der ZufallsvariablenX .
δ(x) bezeichnet die Delta-Funktion.x kann eine reelle Zahl oder ein Pradikat sein:
δ(x)def=
1 x ist wahr, oderx = 1
0 sonst.(1.1)
P(A) ist eine Notation fur die Potenzmenge einer MengeA..
]A bezeichnet fur endliche MengenA die Kardinalitat oder Anzahl der Elemente der MengeA.
R+ ist die Menge der nicht-negativen reellen Zahlen.
‖ · ‖ = ‖ · ‖2, ‖ · ‖∞ aufRn definierte euklidische Norm und Maximum-Norm.
Ei(·), Ei,j(·), EC(·) sind Bezeichnungen fur einzelne nummerierte Funktionen, welche fur jedes
i, j oderC verschieden gewahlt werden konnen.
1.3 Aufbau der Arbeit
Bei der Strukturierung der folgenden Arbeit wurde auf klare Abgrenzung von bekannten theore-
tischen Ergebnisse zu neuen direkten Anwendungen dieser Ergebnisse bei Problemen der Bild-
verarbeitung geachtet. Dabei zeigen die theoretischen Ausfuhrungen auch Moglichkeiten auf,
welcheuber den Horizont der hier besprochenen praktischen Problemlosungen hinausgehen.

1.3. AUFBAU DER ARBEIT 5
In Kapitel 2 werdenMarkov Random Fieldsvorgestellt, welche die Grundlage der Bayes-
schen Bildanalyse bilden. Das darauf folgende Kapitel3 prasentiert wichtige Ergebnisse der dis-
kreten Optimierung bei Graph-Cut-Methoden und schlagt im letzten Abschnitt die Brucke zur
Bayesschen Bildanalyse. Ausgehend von den ausfuhrlich beschriebenen Moglichkeiten der Opti-
mierungsverfahren ist es moglich, in Kapitel4 verschiedene Anwendungsmoglichkeiten prazise
und vollstandig vorzustellen. Eine Verifikation der im Rahmen dieser Arbeit entstandenen prak-
tischen Ergebnisse und Neuerungen wird in Kapitel5 durch verschiedene Experimente vorge-
nommen.
Die Arbeit schließt in den Kapiteln6 und7 mit einemUberblickuber Verbesserungsmoglich-
keiten und Ansatze fur eine weitere Forschung auf dem behandelten Gebiet sowie mit einer Zu-
sammenfassung der vorgestellten Ergebnisse. KapitelA im Anhang bietet dem interessierten Le-
ser zusatzliche mathematische Details in Form von Beweisen und Zusammenhangen. Verwende-
te Parameter bei den Experimenten und zusatzliche Beispielbilder konnen KapitelB entnommen
werden.

6 KAPITEL 1. EINFUHRUNG

Kapitel 2
Markov Random Fields
In diesem Kapitel soll zunachst der fur diese Arbeit notwendige Begriff des Markov Random
Field (MRF) motiviert und erklart werden. Im zweiten Teil des Kapitels wird die Problemstellung
der”Schatzung“ verborgener Bildinformationen mittels MRFs erlautert. Wie diese Schatzung
effizient mit so genannten minimalen Schnitten durchgefuhrt werden kann, ist Bestandteil der
folgenden Kapitel und zentraler theoretischer Schwerpunkt dieser Arbeit.
2.1 Definition
Grundlage fur die Definition von MRFs bildet eine Nachbarschaftsstruktur oder allgemeiner ein
Graph. Ein Graph besteht aus einer Knotenmenge und einer auf dieser Menge definierten Rela-
tion (Nachbarschaftsrelation, Kantenmenge):
Definition 2.1 Ein Graph1 S ist ein Tupel(V, N) bestehend aus einer abzahlbaren MengeV
und einer irreflexiven RelationN ⊆ V × V .
Ein typischer Graph in der Bildverarbeitung ist zum BeispielZn mit den folgenden Relatio-
nen:
N1def=(p, q) | ‖p− q‖2 = 1; p, q ∈ Zn (2.2)
N2def=(p, q) | ‖p− q‖∞ = 1; p, q ∈ Zn. (2.3)
1Im Folgenden wird nicht der Begriff der Nachbarschaftsstruktur verwendet, da keine Symmetrie der Relationgefordert sein soll [KR04]. Dem Leser sei hiermit dennoch empfohlen, den Begriff der Nachbarschaft und derNachbarschaftsstruktur damit zu assoziieren, um den direkten Bezug zur Bildverarbeitung herzustellen.
7

8 KAPITEL 2. MARKOV RANDOM FIELDS
Fur n = 2 werden diese Relationenublicherweise als 4er- und 8er-Nachbarschaft bezeichnet.
Fur eineubersichtlichere Schreibweise ist es von Vorteil den Begriff der (gerichteten) Nachbar-
schaft eines Knoten (Punktes) zu definieren:
Definition 2.4 Die (gerichtete) NachbarschaftNS(p) oder abkurzendN(p) eines GraphenS =
(V, N) bezuglich eines Knotenp ∈ V ist auf folgende Weise definiert:NS(p)def= q | (p, q) ∈ N.
Zugehorig zu einem speziellen Graphen lassen sich stochastische Felder betrachten:
Definition 2.5 Eine MengeXp | p ∈ V heißtstochastisches Feld, allgemeiner stochastischer
Prozessoder Random Fieldeines GraphenS = (V, N), wenn fur alle p ∈ V : Xp eine
Zufallsvariable2 ist.
Definition 2.6 (Multiindex-Konvention)
EineEinschrankungXM einer MengeXp | p ∈ V ist wie folgt definiert:XMdef= Xp | p ∈
V ∩M. Analog soll dieser Begriff fur Vektoren(Xp)p∈V verwendet werden.
Die Definition eines stochastischen Feldes verlangt nicht die Unabhangigkeit der Zufalls-
variablenXp voneinander. Die Abhangigkeit der Zufallsvariablen ist ein entscheidender Aspekt.
Allgemein ist eine beliebige ZufallsvariableXp immer von allen anderen ZufallsvariablenXq mit
q 6= p abhangig. Um diese starke Abhangigkeit zu schwachen und die Modellierung einfacher
zu gestalten, ist es moglich zu fordern, dass eine ZufallsvariableXp nur von ihren NachbarnXq
mit q ∈ N(p) abhangt und von allen anderen unabhangig ist. Diese Forderung fuhrt zu der neuen
Definition eines Markov Random Fields:
Definition 2.7 Eine MengeXp | p ∈ V heißtMarkov Random Fieldeines GraphenS, wenn
sie ein stochastisches Feld ist und folgender Bedingung genugt:
∀p ∈ V : Pr(Xp | XV \p ) = Pr(Xp| XNS(p) ). (2.8)
Anschaulich kann diese Definition in der Bildverarbeitung folgendermaßen betrachtet wer-
den: Wenn die ZufallsvariablenXp die Pixelwerte eines Bildes sind und der Graph wie im obigen
Beispiel eine Gitterstruktur mit der 8er Nachbarschaft darstellt, dann hangen die Pixelwerte eines
einzelnen Punktes nur von den Pixelwerten seiner Umgebung ab.
2Auf die genaue Definition einer Zufallsvariable bezuglich eines Wahrscheinlichkeitsraumes soll an dieser Stelleverzichtet werden.

2.2. SATZ VON HAMMERSLEY-CLIFFORD 9
Die Definition des MRF ist nichts anderes als dasn-dimensionale Analogon einer einfachen
Markov-Kette. Die Abhangigkeit einer Markov-Kette wird meist bezuglich der Zeit veranschau-
licht: Eine ZufallsvariableXp ist dann nur vom vorherigen ZeitpunktXp−1 abhangig. Durch den
zugrunde liegenden Graphen eines MRF kann die Abhangigkeit der ZufallsvariableXp ortlich
betrachtet werden.Xp ist durch die Markov-Einschrankung (2.8) nicht mehr global abhangig,
sondern nur lokal.
Abschließend noch zwei kleine Definitionen, welche in der Formulierung weiterer Resultate
von Vorteil sind:
Definition 2.9 Die Gibbs-Darstellungeiner VerteilungPr(X = X), ist die bijektive Transfor-
mation einer Verteilung in eineEnergiefunktion EX (X)def= − log(Pr(X = X)). Dabei bildet
die FunktionEX in die MengeR ∪ ∞ ab.
Bei einer Likelihood-Verteilung wird oft auch in diesem Zusammenhang von der log-Likeli-
hood-FunktionE gesprochen. Es wurde an dieser Stelle bewusst der Begriff der Gibbs-Verteilung
vermieden, da jede beliebige Verteilung eine Gibbs-Darstellung besitzt und daher auch in die-
sen Sinne eine Gibbs-Verteilung ist. Die FunktionEX wird im Folgenden auch einfach alsE
bezeichnet, falls der Zusammenhang zur zugehorigen Zufallsgroße eindeutig ist.
2.2 Satz von Hammersley-Clifford
Ein wichtiger und anschaulicher Begriff aus der Graphentheorie ist der Begriff der Clique in
einem Graphen:
Definition 2.10 Eine TeilmengeC ⊆ V von Knoten eines GraphenS = (V, N) heißtClique,
wenn∀p ∈ C : C \ p ⊆ NS(p).
Definition 2.11 Die maximale Cliquengroßeω(S) ist definiert durch:ω(S)def= max
C ist Clique inS]C.
Aus der Definition der Clique geht hervor, dass die leere Menge sowie jeder einzelne Knoten
Cliquen bilden. Entscheidend fur die Charakterisierung von MRFs ist das folgende verbluffende
Resultat von Hammersley, Clifford aus dem Jahr 1968:
Satz 2.12Es seiX = Xp p∈V ein stochastisches Feld eines GraphenS = (V, N). Dann gilt:
X ist ein MRF ⇐⇒ Pr(X = X) ist eine Verteilung mit der Gibbs-Darstellung:
E(X) =∑
C ist eine Clique inS
EC(XC). (2.13)

10 KAPITEL 2. MARKOV RANDOM FIELDS
Beweis zu 2.12: Ein Beweis kann in [Pol] gefunden werden.
Die einzelnen FunktionEC in der Zerlegung (2.13) werden auch oft als Cliquen-Potentiale
bezeichnet. Durch diesen Satz kann die Maximierung der Wahrscheinlichkeit eines MRFs zu
einer Minimierung der Energiefunktion umformuliert werden. Im Folgenden wird die Schatzung
zunachst allgemein beschrieben. Wie sich Funktionen des Typs (2.13) fur bestimmte Annahmen
minimieren lassen, ist Bestandteil des Abschnittes3.4.4.
2.3 Schatzung mittels MRF
2.3.1 MAP-Schatzung
Zunachst ein paarubliche Notationen aus der Bildverarbeitung: Das BildI ist ein (Zufalls-)
Vektor der Form( Ip )p∈P . Die einzelnen WerteIp reprasentieren dabei die Pixeleigenschaften
des Pixelsp ∈ P wie etwa Grauwert, Farbinformationen oder andere Maße. Im Folgenden wird
mit der NotationI das Bild als Zufallsvariable betrachtet und eine Auspragung davon mitI
bezeichnet. Die MengeP ist die Menge aller Punkte des Bildes. Weiterhin sei darauf ein Graph
S = (P , N) definiert.
I ist im hier behandelten Kontext die Beobachtung bei einer Zustandsschatzung. Ziel ist es,
die grundlegenden Informationen des Bildes zu extrahieren. Im speziellen Fall der Segmentie-
rung, ist dies die Einteilung des Bildes in verschiedene beschriftete (mit Zahlen von1 bis K)
Bereiche. Jeder Pixel besitzt demnach die Information der Zugehorigkeit zu einem Bildbereich.
Sei deshalb mitL, beziehungsweise der AuspragungL = ( Lp )p∈P mit Lp ∈ 1, . . . , K die
Beschriftung eines Bildes dargestellt. Einzelne WerteLp der Beschriftung werden alsLabel oder
Zustandbezeichnet
Ganzahnlich zu der Modellierung bei Hidden-Markov-Modellen (siehe Zusammenhang von
MRF und Markov-Ketten) ist nur das BildI beobachtbar. Die eigentlichen ZustandeLp des
Markov-Modells bleiben unsichtbar und mussen aus der Beobachtung und den zugrunde lie-
genden Abhangigkeiten geschatzt werden. Mit Abhangigkeiten sind hier die stochastischen Ab-
hangigkeiten der einzelnen ZufallsvariablenLp gemeint. Bei Hidden-Markov-Modellen werden
diese durch eine einfache stationare3 Markov-Kette alsUbergangswahrscheinlichkeiten und Zu-
standswahrscheinlichkeiten reprasentiert. Allgemein gesehen ist dies eine Modellierung der A-
Priori-Wahrscheinlichkeit vonL.
3stationar, homogen⇐⇒ Ubergangswahrscheinlichkeiten sind zeitunabhangig

2.3. SCHATZUNG MITTELS MRF 11
Die hier vorgestellte Schatzung mittels MRF ist eine MAP-Schatzung:
LMAP = argmaxL
Pr(L = L | I = I) = argmaxL
Pr(L = L , I = I) =
= argmaxL
Pr(I = I|L = L)Pr(L = L). (2.14)
Die VerteilungenPr(I = I | L = L) undPr(L = L) werden in diesem Kontext auch oft
als Likelihood-Verteilung beziehungsweise A-Priori-Verteilung bezeichnet. Abkurzend sollen im
weiteren Verlauf dafur die BezeichnungenPr(I|L) undPr(L) verwendet werden.
2.3.2 Annahmen der Schatzung
In vielen Arbeiten der Bayesschen Bildanalyse [Win06, BVZ98a] werden folgende Modellie-
rungsannahmen vorgenommen:
A1. Die Likelihood-Verteilung lasst sich zerlegen durch:Pr(I|L) =∏p∈P
Pr(Ip|Lp).
A2. L ist ein MRF auf dem GraphenS.
Die Annahme A1 ist aber fur die Praxis ungenugend (siehe Abschnitt4 und [KTZ05]). Aus
diesem Grund soll im weiteren Verlauf anstatt 1 und 2 auch die Annahme A1’ untersucht werden:
A1’ . Pr(L|I) ist ein MRF auf dem GraphenS4
2.3.3 Vereinfachungen der Schatzung
Aus den bisher gewonnenen Erkenntnissen und Annahmen kann die Schatzung in ein entspre-
chendes diskretes Optimierungsproblem umformuliert werden. Es sei zunachst noch einmal die
MAP-Schatzung als Minimierung der Energiefunktion vonPr(L|I) formuliert:
LMAP = argminL
(− logPr(L|I)) = argminL
(− logPr(I|L)− logPr(L)). (2.15)
4Genauer gesagt definiert man hier eine ZufallsvariableY(I) abhangig vom ParameterI mit der VerteilungPr(L|I). Die Forderung ist daraufhiin, dassY(I) ein MRF ist.

12 KAPITEL 2. MARKOV RANDOM FIELDS
Untersuchung von A1 und A2
Durch Annahme A2 und den Satz von Hammersley-Clifford2.12 lasst sich− log(Pr(L)) in
die Form von Gleichung (2.13) bringen. Als Vereinfachung lasst sich fur die zu minimierende
Funktion (proportional zur Energiefunktion vonPr(L|I)) E(L) schreiben:
E(L) = − log(Pr(I|L)) +∑
C ist eine Clique inS
EC(LC). (2.16)
Annahme A1 ergibt eine weitere Vereinfachung zu:
EA1,2(L) = − log
(∏p∈P
Pr(Ip|Lp)
)+
∑C ist eine Clique inS
EC(LC)
= −∑p∈P
log(Pr(Ip|Lp)) +∑
C ist eine Clique inS
EC(LC)
=∑p∈P
EpLikelihood(Lp) +
∑C ist eine Clique inS
EC(LC). (2.17)
Untersuchung von A1’
Annahme A1’ ergibt hingegen eine verallgemeinerte Form:
EA1’ (L) =∑
C ist eine Clique inS
EIC(LC). (2.18)
In beiden Fallen bestimmt die maximale Cliquengroßeω(S) die Anzahl der Argumente der
FunktionenEC undEIC .
2.3.4 Beispiele
Es sollen im Folgenden ein paar Beispiele fur die Schatzung mittels MRFs vorgestellt werden.
In diesen Beispielen wird deutlich wie die Verteilungen modelliert werden konnen und welche
Energiefunktionen sich daraus ergeben.

2.3. SCHATZUNG MITTELS MRF 13
Binare Bildrestaurierung
Gegeben sei ein verrauschtes Binarbild. Ziel ist es, ausgehend von einer Modellierung des Rau-
schens und einer Modellierung der A-Priori-BildinformationPr(L) das Originalbild”moglichst
gut“ zu rekonstruieren.
Die moglichen Werte der PixelIp sowie die Werte der LabelsLp (Pixelwerte des Original-
bildes) seien−1 und 1. Analog zu [Win06] sei das RauschenN als multiplikatives Rauschen
modelliert, welches einer Bernoulli-Verteilung unterliegt:
Pr(Np = v) =
q v = −1
1− q v = +1. (2.19)
Die Beobachtung ergibt sich durch die komponentenweise Multiplikation vonN undL:
∀p ∈ P : Ip = Np · Lp (2.20)
Das Modell erfullt demnach Annahme A1 und A2. Fur die Likelihood-FunktionPr(Ip|Lp)
einzelner Pixel gilt:
Pr(Ip|Lp) =
q Ip = −Lp
1− q Ip = Lp
(2.21)
Die Energiefunktion der VerteilungPr(I|L) kann daher folgendermaßen geschrieben werden
(ein Term aus Gleichung (2.17)):
− logPr(I|L) = −]p | Ip = −Lp log q − ]p | Ip = Lp log(1− q). (2.22)
Aus
δ(Ip = Lp) =1
2(IpLp + 1) (2.23)
δ(Ip = −Lp) = 1− δ(Ip = Lp) (2.24)
= −1
2(IpLp − 1) (2.25)
folgt unmittelbar mit der Konstantec = ]P log(
q1−q
), welche bei der Optimierung ver-
nachlassigt werden kann:

14 KAPITEL 2. MARKOV RANDOM FIELDS
− logPr(I|L) = −1
2log
(1− q
q
)∑p∈P
IpLp + c. (2.26)
Als A-Priori-Modell sei ein Spezialfall (homogene Gewichtung mitα > 0) des so genannten
Ising-Modells [Isi25] verwendet mit der Energiefunktion:
− logPr(L) = −α∑
(p,z)∈N
LpLz. (2.27)
Anschaulich kann man sich Gleichung (2.27) als Bewertung von homogenen Flachen vor-
stellen. Die Energiefunktion des A-Priori-Modells hat dabei zwei mogliche Minima:L ≡ −1
undL ≡ 1. Generell liefert ein Bild mit großen zusammenhangenden homogenen Flachen eine
niedrigeren Funktionswert als ein Bild mit vielen Objektgrenzen.
Der Parameterα dient dazu, in der Praxis die Gewichtung zwischen der A-Priori-Information
und dem Einfluss der Beobachtung einzustellen. Die zu minimierende EnergiefunktionEA 1,2 =
E1(L) besitzt dann, bis auf eine additive Konstante, die folgende Form:
E1(L) = −1
2log
(1− q
q
)∑p∈P
IpLp − α∑
(p,z)∈N
LpLz. (2.28)
Diese Art von Energiefunktionen lasst sich effizient und global mit Graph-Cut-Methoden op-
timieren (siehe Abschnitt3.3). Abbildung2.1 zeigt ein Beispiel der binaren Bildrestaurierung.
Das entstandene rechte restaurierte Bild ist eine MAP-Schatzung vonL und wurde mit den in Ka-
pitel 3 beschriebenen Graph-Konstruktionen und Algorithmen durchgefuhrt. Das dazugehorige
ProgrammtestImageRestoration ist Bestandteil der zu dieser Arbeit gehorenden Soft-
ware. Es sei abschließend darauf hingewiesen, dass fur die binare Bildrestaurierung ebenfalls
ein normaler Medianfilter angewendet werden kann, welcherahnliche Ergebnisse liefert. Eine
theoretische Verbindung zwischen beiden Ansatzen wird in AbschnittA.1 erlautert. Die obige
Darstellung als Anwendung von Graph-Cut dient demnach ausschließlich zur Vorstellung der
theoretischen Ergebnisse und ist fur die Praxis als gering zu bezeichnen.

2.3. SCHATZUNG MITTELS MRF 15
Bild 2.1: Binare Bildrestaurierung (Links) Originalbild, (Mitte) verrauschtes Originalbild,(Rechts) MAP-Schatzung des Originalbildes mit Graph-Cut (α = 0.3, p = 0.4)
Das verallgemeinerte Potts-Modell
Das Potts-Modell kann als Verallgemeinerung des speziellen Ising-Modells (2.27) angesehen
werden. Das einfache Potts-Model
− logPr(L) = α∑
(p,q)∈N
δ(Lp 6= Lq). (2.29)
ist dabei nicht auf binare Werte vonL beschrankt, sondern kann bei einer beliebigen An-
zahl von Labels verwendet werden. Wie auch beim Ising-Modell wird hier die Existenz großer
homogener Flachen (bzgl.L) belohnt.
Das verallgemeinerte Potts-Modell wurde von [BVZ98a] vorgestellt. Vergleichbare Ansatze
fur die Bildverarbeitung lassen sich aber bereits schon fruher in den Arbeiten von Graffigne
[Gra87] finden. Wie beim ursprunglichen Ising-Modell werden hier Kanten zwischen Punkten
mit verschiedenen Labels (Grenze zwischen zwei Regionen) nicht homogen mit einer Konstante
α bewertet, sondern mit einer ortsabhangigen GewichtungEp,q ≥ 0:
∑(p,q)∈N
Ep,q δ(Lp 6= Lq) (2.30)
In [BJ01b, BFL06] wird Ep,q mit einer Funktion abhangig von der BeobachtungI gewahlt,
daher kann bei diesen Arbeiten Modell (2.30) nicht als A-Priori-Modell verwendet werden. Eine
Interpretation im Sinne von Annahme A1’ (Abschnitt2.3.2) ist in diesem Fall hingegen moglich
und sinnvoll. Fur eine ausfuhrliche Beschreibung der Gewichtung aus [BJ01b, BFL06] sei an
dieser Stelle auf Abschnitt4.1 verwiesen. Es wird sich im weiteren Verlauf der Arbeit heraus-
stellen, dass eine Schatzung mittels MRFs mit einem verallgemeinerten Potts-Modell effizient
mit minimalen Schnitten in Graphen gelost werden kann.

16 KAPITEL 2. MARKOV RANDOM FIELDS

Kapitel 3
Schatzung von MRF-Zustanden mit
minimalen Schnitten
Dieses Kapitel bildet den theoretischen Kern der vorliegenden Arbeit. Zunachst soll hier das Prin-
zip des”minimalen Schnittes“ (Min-Cut, Graph-Cut) in Graphen vorgestellt werden. Ausgehend
von einer klar definierten Problembeschreibung werden einige Spezialfalle, Verallgemeinerun-
gen und Zusammenhange zu anderen Problemen der diskreten Optimierung hergestellt. Die No-
tation und die Darstellung der Resultate folgt dem Buch von Schrijver [Sch04]. An dieser Stelle
sei ebenfalls das Buch von Kleinberg und Tardos [KT05] empfohlen. Abschnitt3.2 beschreibt
anschließend mogliche effiziente Algorithmen zur Bestimmung von minimalen Schnitten in Gra-
phen.
Welche diskreten Optimierungsprobleme lassen sich mit minimalen Schnitten losen? Diese
Frage ist der Ausgangspunkt der Arbeiten [PR75, KZ04, FD05, RK06] und entscheidend fur die
Anwendung in der Bildverarbeitung. Ziel ist es, eine entsprechende Charakterisierung von Ziel-
funktionen zu erreichen. So kann bei einem gegebenen Optimierungsproblem der Bildverarbei-
tung erkannt werden, ob eineUbertragung auf das Problem eines minimalen Schnittes moglich
ist. Die Resultate dieser Arbeiten werden in Abschnitt3.3naher erortert.
Ausgehend von den erarbeiteten Grundlagen aus Kapitel2 wird weiterhin in Abschnitt3.4
die Schatzung mittels MRFs mit demα-Expansion-Algorithmus vorgestellt.
17

18 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
3.1 Minimale Schnitte in Graphen
3.1.1 Problemdefinition
Im Folgenden sollen gewichtete GraphenG = (V, N, w) mit der nicht-negativen Kantengewich-
tungw : N → R+ betrachtet werden. Diese Einschrankung auf nicht-negative Gewichte ist eine
wichtige Forderung, um im weiteren Verlauf effiziente Algorithmen zu entwickeln.
Allgemein lasst sich auf der Kantengewichtung eine Erweiterungw : P(N) → R+ definie-
ren (A ⊆ N ):
w(A)def=∑e∈A
w(e). (3.1)
Definition 3.2 Mit ϑout(v) und ϑin(v) sei der Outdegree bzw. Indegree eines Knotensv ∈ V
bezeichnet. Diese Bezeichnung soll an dieser Stelle gleich fur Knotenmengen erweitert werden:
1. ϑout(v)def= (v, q) ∈ N
2. ϑout(A)def= (p, q) ∈ N | p ∈ A, q ∈ V \ A
3. ϑin(v)def= (q, v) ∈ N
4. ϑin(A)def= (q, p) ∈ N | p ∈ A, q ∈ V \ A.
Definition 3.3 Ein s, t-Schnitt oders, t-Cut C eines GraphenG = (V, N) mit s, t ∈ V ist eine
ZerlegungS, V \ S der KnotenmengeV mit S ⊂ V , s ∈ S und t ∈ V \ S. Die SymbolikCsteht sowohl fur die Zerlegung der Knotenmenge als auch fur die darauf induzierte Kantenmenge
(p, q) | p ∈ S undq ∈ V \ S. Fur die zu einem SchnittC gehorende KnotenmengeS wird die
BezeichnungS(C) verwendet.
Definition 3.4 Die Kosteneiness, t-SchnittesC sind gemaß der obigen Vereinbarungen mit
w(C), w(ϑout(S(C))) oder abkurzend|C| bezeichnet.
Offensichtlich gibt es im allgemeinen Fall mehreres, t-SchnitteC, daher ist es von Interesse
den1 Schnitt zu finden, der minimale Kosten besitzt:
argminC ist eins,t-Schnitt inG
w(C). (MinCut)
1Genauer gesagt, wirdein minimaler Schnitt gesucht, da auch das Problem des minimalen Schnittes nicht immereine eindeutige Losung besitzt.

3.1. MINIMALE SCHNITTE IN GRAPHEN 19
Das Problem des minimalen Schnittes, oft als Min-Cut oder auch Graph-Cut bezeichnet,2
ist daher von den Knotens und t abhangig und wird durch diese parametrisiert. Die Knotens
und t werden aus diesem Grund alsTerminalsbezeichnet. Wichtig ist, dass die Kosten eines
Schnittes abhangig von der Richtung sind: Es werden nur Kanten vonS nachV \S gezahlt. Eine
Formulierung des Problems ohne Terminals ist eine wenig sinnvolle Aufgabe und wurde immer
zu der trivialen ZerlegungV, ∅ fuhren.
3.1.2 Zusammenhang zur Bestimmung des maximalen Flusses
Grundlage fur die folgenden Definitionen ist ein GraphG = (V, N). Der Begriff des Flusses
eines Graphen lasst sich am besten anhand eines Rohrsystems erlautern. Jede Kantee eines Gra-
phen reprasentiert eine Rohrverbindung mit der Kapazitat w(e). Ausgehend von einem Knoten
s fließt nun Wasser zu einem Knotent. Ein Fluss ist ein moglicher Zustand der Rohre wahrend
solch eines Vorganges. Dabei gilt das 1. Kirchhoffsche Gesetz, welches sicherstellt, dass an Rohr-
verbindungsstellen (Knoten im Graphen) die Menge des hinfließenden Wassers gleich der Men-
ge des abfließenden Wassers ist. Der Wert eines Flusses ist die transportierte Wassermenge von
Knotens zu Knotent in einem”Zeitpunkt“. Das Rohrsystem (Graph) legt weiterhin die maxi-
male Wassermenge oder den maximalen Fluss fest, der bei solch einem Vorgang vons nacht
transportiert werden kann. Diese Beschreibung wird im Folgenden mathematisch formuliert.
Definition 3.5 Eine Abbildungf : N → R+ (Verallgemeinerung auff : P(N) → R+ analog
zuw) ist eins, t-Fluss oder vereinfachendFluss ⇐⇒
1. ∀ e ∈ N : f(e) ≥ 0
2. ∀ v ∈ V \ s, t : f(ϑout(v)) = f(ϑin(v)).
Definition 3.6 Der Wert eines Flussesf ist |f | def= f(ϑout(s))− f(ϑin(s)), oder|f | def
= f(ϑout(s))
fur den hier behandelten Spezialfall mitf(ϑin(s)) = 0.
Definition 3.7 f ist zulassigbezuglichw ⇐⇒ ∀ e ∈ N : f(e) ≤ w(e).
An dieser Stelle ist es schon moglich das Problem des maximalen Flusses zu definieren:
argmaxf ist ein zulassigers,t-Fluss inG
|f |. (MaxFlow)
2Der Begriff Graph-Cut ist eigentlich ein allgemeinerer Begriff, da es viele verschiedene Moglichkeiten gibteinen Schnitt in einem Graph zu definieren [SM00, GS06].

20 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Der folgende Begriff derUberschussfunktion ist ein praktisches Werkzeug im Beweis des
Min-Cut-Max-Flow-Theorems3.26.
Definition 3.8 Die Uberschussfunktion∆f : P(V ) → R ist definiert als:
∆f (U)def= f(ϑin(U))− f(ϑout(U)). (excess)
Konvention∀ v ∈ V : ∆f (v)def= ∆f (v).
Beispiel 3.9 Aus der Definition derUberschussfunktion∆f folgt sofort, dass fur alle Knotenv,
ausgenommen die Knotens undt, ∆f (v) = 0 gilt.
Lemma 3.10 ∀ U ⊆ V : ∆f (U) =∑v∈U
∆f (v).
Beweis zu 3.10: Es sei zunachst die rechte Seite der Gleichung betrachtet:∑v∈U
∆f (v) =∑v∈U
f(ϑin(v))− f(ϑout(v))
=∑v∈U
∑(p,v)∈N
f((p, v))−∑
(v,p)∈N
f((v, p))
. (3.11)
In der letzten Summe existiert fur jede Kantee ∈ N zwischen zwei Knotenx, y ∈ U der Term
f(e) und der Term−f(e) als Summand (ahnlich wie bei Teleskopsummen). Daher vereinfacht
sich die Gleichung zu:
=∑v∈U
∑p∈V \U, (p,v)∈N
f((p, v))−∑
p∈V \U, (v,p)∈N
f((v, p))
. (3.12)
Die linke Seite der Gleichung kann durch Anwendung der Definitionen zu einemaquivalen-
ten Ergebnis umgeformt werden:
∆f (U) = f(ϑin(U))− f(ϑout(U))
=∑
p∈U, q∈V \U,(q,p)∈N
f((q, p))−∑
p∈U, q∈V \U,(p,q)∈N
f((p, q)). (3.13)

3.1. MINIMALE SCHNITTE IN GRAPHEN 21
Lemma 3.14 Seif ein beliebiger zulassigers, t-Fluss undC ein beliebigers, t-Schnitt, dann
gilt3:
|f | ≤ |C| = w(ϑout(S(C))). (3.15)
Weiterhin gilt die Gleichheit bei dieser Ungleichung⇐⇒
1. ∀ e ∈ ϑout(S(C)) : f(e) = w(e) und
2. ∀ e ∈ ϑin(S(C)) : f(e) = 0.
Beweis zu 3.14: Die Uberlegung aus Beispiel3.9 liefert:
∆f (S(C)) =∑
v∈S(C)
∆f (v) =
=∑
v∈S(C)\s
f(ϑin(v))− f(ϑout(v))+ ∆f (s) =
= ∆f (s). (3.16)
Aus dieserUberlegung folgt nahezu unmittelbar der Beweis des Lemmas:
|f | = −∆f (s)
= −∆f (S(C))
= f(ϑout(S(C)))− f(ϑin(S(C)))
≤ w(ϑout(S(C))) = |C|. (3.17)
Der zweite Teil der Aussage ist aus der obigen Abschatzung ersichtlich.
Der Begriff des Residual-Graphen ist entscheidend fur den Beweis des Satzes3.26sowie fur
die Beschreibung der Algorithmen.
Definition 3.18 Sei e = (p, q) ∈ N eine Kante. Mite−1 sei im Folgenden die Kante(q, p)
bezeichnet. Fur eine KantenmengeS ⊆ N ist weiterhinS−1 def= e−1|e ∈ S.
Definition 3.19 Seif ein zulassiger Fluss. Eine Kantee ∈ G heißtgesattigt (bezuglichf ), wenn
f(e) = w(e).
3Diese Ungleichung wird auch oft als”schwache Dualitat“ bezeichnet um den Zusammenhang zur linearen
Optimierung zu verdeutlichen.

22 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Definition 3.20 Seif ein zulassiger Fluss. DerResidual-GraphDf = (V, Nf ) besitzt die glei-
che Knotenmenge wieG und die Kantenmenge:
Nfdef= e | e ∈ N, f(e) < w(e) ∪ e−1 | e ∈ N, f(e) > 0. (3.21)
Lemma 3.22 Seif ein zulassiger Fluss. Wenn der Residual-GraphDf keinens, t-Pfad besitzt,
dann gelten fur die KnotenmengeS = x ∈ V | ∃Weg von s nach x in Df folgende
Aussagen:
1. C mit S(C) = S ist ein minimaler Schnitt.
2. |f | = w(ϑout(S)) = |C|.
3. f ist ein maximaler Fluss.
Beweis zu 3.22: Alle Kanten an der Grenzevon S mussen gesattigt sein, ansonsten ware es
moglichS zu erweitern (Widerspruch zur Definition vonS):
∀e ∈ ϑoutG (S) : e /∈ Nf (3.23)
Fur alle Kanten an der GrenzezuS gilt analog:
∀e ∈ ϑinG(S) : e−1 /∈ Nf (3.24)
Daraus folgt nach Definition vonNf : f(ϑoutG (S)) = w(ϑout
G (S)) und f(ϑinG(S)) = 0). Die
obige Konstruktion vonC lasst sofort erkennen, dass durchs ∈ S undt ∈ V \ S die Zerlegung
C ein Schnitt ist. Es gelten daher folgende Schlussfolgerungen analog zu Lemma3.14:
|f | = f(ϑout(S))− f(ϑin(S))
= w(ϑout(S)) (3.25)
Annahme: Der SchnittC ist nicht minimal.
Dann gibt es einen SchnittC ′ mit |C ′| < |C|. Daraus folgt aber unmittelbar die Verletzung
von Lemma3.14 durch |C ′| < |f | und man erhalt einen Widerspruch. Die letzte Teilaussage
folgt ebenfalls aus Lemma3.14und Teilaussage 1.
Der folgende Satz ist das essentielle theoretische Fundament fur die effiziente Berechnung
eines minimalen Schnittes. Der Beweis wurde von Ford und Fulkerson im Jahre 1954 fur un-
gerichtete Graphen sowie 1956 von Dantzig und Fulkerson fur gerichtete Graphen gefuhrt. Die

3.2. ALGORITHMEN ZUR BESTIMMUNG DES MINIMALEN SCHNITTES 23
konstruktive Art des Beweises liefert sofort den ersten Ansatz zur Berechnung eines maximalen
Flusses, welcher zum Algorithmus der”erhohenden“ Pfade von Dinic fuhrt. Dieser Algorithmus
wird in Abschnitt3.2.1noch naher dargestellt.
Satz 3.26Min-Cut=Max-Flow Theorem
Sei f eine Losung von(MaxFlow) und C eine Losung von(MinCut)4. Dann gilt: |C| = |f |.Die Kosten eines minimalen Schnittes sind demnach gleich dem Wert des maximalen Flusses
(bezuglich der Terminalss undt).
Beweis zu 3.26: Seif ein maximaler Fluss. Nach Lemma3.14genugt es zu zeigen, dass es einen
s, t-SchnittC mit Kosten|f | gibt.
Annahme: Im Residual-GraphDf gibt es einens, t-PfadP .
Dann sei die FunktionχP wie folgt definiert:
χP (e)def=
1 e ∈ P
−1 e−1 ∈ P
0 sonst
. (3.27)
Diese Definition ist gultig, da man sich auf kreisfreie PfadeP beschranken kann (entwedere ∈ P
odere−1 ∈ P ). Fur geeignetesε > 0 ist dann
f ′def= f + εχP (3.28)
wieder ein zulassiger Fluss mit|f ′| = |f | + ε. Dies ist allerdings ein Widerspruch zur Ma-
ximalitat vonf . Es gibt demnach im Residual-GraphDf keinens, t-Pfad. Dann kann man nach
Lemma3.22einen SchnittC konstruieren mit|C| = |f |.
Bemerkung 3.29 Der Satz3.26 ist ein Spezialfall der Dualitat bei der linearen Optimierung.
Das Problem des minimalen Schnittes ist dual zum Problem des maximalen Flusses.
3.2 Algorithmen zur Bestimmung des minimalen Schnittes
Satz3.26zeigt, dass sich eine Berechnung des minimalen Schnittes in einem Graphen auf die Be-
stimmung des maximalen Flusses eines Graphen zuruckfuhren lasst: Der Residualgraph besitzt
am Ende der Berechnung mindestens zwei Zusammenhangskomponenten. Aufgrund der nicht
4Beide Probleme mussen keine eindeutige Losung besitzen

24 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
gesicherten Eindeutigkeit konnen auch mehr als zwei Zusammenhangskomponenten entstehen.
Dadurch ergibt sich der minimale Schnitt als eine der Moglichkeiten, die Zusammenhangskom-
ponenten in zwei entsprechende Gruppen einzuteilen.
3.2.1 Der Algorithmus von Dinic
Der Algorithmus von Dinic gehort zur Gruppe der Augmenting Path (erhohender Pfad) Algorith-
men. Diese Algorithmen verwenden die Idee des Beweises von Satz3.26und versuchen solange
s, t-Pfade im Residualgraphen zu finden und diese zu erhohen, bis durch die Nichtexistenz sol-
cher Pfade ein maximaler Fluss gefunden ist (siehe Lemma3.22). Der Begriff”erhohen“ bedeutet
dabei die Aktualisierung vonf im Sinne von Gleichung (3.28).
Der Algorithmus von Dinic verwendet eine Breitensuche und verarbeitet in einem Zyklus
Stuck fur Stuck alle kurzesten Wege mit einer festen Langek. Die Laufzeit betragtO(mn2).
3.2.2 Der Algorithmus von Kolmogorov und Boykov
Der Algorithmus von Kolmogorov und Boykov [BK04] kann die asymptotische Laufzeit der
bisherigen Max-Flow-Algorithmen nicht verbessern. Der dort vorgestellte Algorithmus besitzt
sogar eine wesentlich schlechtere asymptotische Laufzeit. Es hat sich jedoch in den Experimen-
ten von [BK04] gezeigt, dass fur die Aufgaben der Bildverarbeitung dieser Algorithmus bessere
durchschnittliche empirische Laufzeiten liefert.
Grundlage fur eine Beschleunigung der bisherigen Algorithmen ist die spezielle Struktur der
Graphen bei Bildverarbeitungsproblemen, welche durch Graph-Cut gelost werden konnen:
1. Der GraphG ist bezogen auf die KnotenmengeV \s, tmeistk-regular (lokale homogene
Nachbarschaft).
2. Es existieren viele Verbindungen zu den Terminals.
Der Algorithmus von [BK04] gehort wie der Algorithmus von Dinic zu den Augmenting
Path Algorithmen. Der Algorithmus von Dinic hat bei der Anwendung auf Probleme der Bild-
verarbeitung ein entscheidendes Problem. In jedem Schritt mussen fast alle Pixel (Knoten) neu
verarbeitet werden, um den entsprechenden Suchbaum zu konstruieren.
Der Algorithmus von [BK04] umgeht dieses Problem, in dem von der Quelles und von der
Senket jeweils ein Suchbaum konstruiert wird, welcher in den nachsten Schritten der Pfadsuche
weiterverwendet werden kann. Der Algorithmus liefert eine asymptotische Worst-Case Laufzeit
vonO(mn2|C|).

3.3. DISKRETE OPTIMIERUNG MIT GRAPH-CUT 25
Dinic O(mn2)Boykov und Kolmogorov O(mn2|C|)
Goldberg und Tarjan O(nm log(n2
m))
Tabelle 3.2: Laufzeiten verschiedener Max-Flow Algorithmen
3.3 Diskrete Optimierung mit Graph-Cut
Ziel des folgenden Abschnittes ist es, Klassen von binaren Optimierungsproblemen zu definie-
ren, welche effizient mit minimalen Schnitten in Graphen gelost werden konnen. Dabei besitzt
das Attribut”effizient“ zwei Bedeutungen: polynomielle Laufzeit des Algorithmus und Optimie-
rung mit Zusicherungen fur die Gute des gefundenen Optimums. Eine Charakterisierung dieser
Optimierungsprobleme lasst sich in aller Ausfuhrlichkeit in der Arbeit [KZ04] finden. Die dort
beschriebenen Resultate und Konstruktionen sollen in diesem Abschnitt erlautert und diskutiert
werden.
3.3.1 Das Optimierungsproblem und die FunktionsklassenF2 und F3
Eine klare Definition der Optimierungsprobleme ist Ausgangspunkt der Untersuchung. Allge-
mein soll das folgende diskrete Optimierungsproblem behandelt werden:
L = argminL∈0,1n
F (L). (BinF )
Die FunktionF : 0, 1n → R ist Element einer speziellen Funktionsklasse. Folgende allge-
meine Funktionsklassen werden in [KZ04] vorgestellt:
Definition 3.30 Eine Funktion5 F ist Element der FunktionsklasseF2 ⇐⇒F besitzt eine Darstellung6 mit FunktionenEi undEi,j der folgenden Form
F (L) =n∑
i=1
Ei(Li) +∑i<j
i,j∈1,...,n
Ei,j(Li, Lj). (3.31)
Definition 3.32 Eine FunktionF ist Element der FunktionsklasseF3 ⇐⇒ F besitzt eine
5Diese Definition ist nicht auf binare Funktionen beschrankt.6Die Darstellung (3.31) ist nicht eindeutig.

26 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Darstellung7 mit FunktionenEi, Ei,j undEi,j,k der folgenden Form
F (L) =n∑
i=1
Ei(Li) +∑i<j
i,j∈1,...,n
Ei,j(Li, Lj) +∑
i<j<ki,j,k∈1,...,n
Ei,j,k(Li, Lj, Lk). (3.33)
Dem aufmerksamen Leser, der bereits einen Blick in Kapitel2und den Satz von Hammersley-
Clifford 2.12geworfen hat, wird die Analogie zu der Darstellung (2.13) auffallen. Tatsachlich
sind bis auf eine additive Konstante die FunktionsklassenF2 undF3 als Gibbs-Darstellung ei-
nes MRF mitω(S) ≤ 2 undω(S) ≤ 3 deutbar. Dieser Zusammenhang schlagt eine Brucke zu
der Schatzung mittels MRFs, welche in Abschnitt3.4.4naher erlautert wird. In den weiteren Ab-
schnitten werden aus diesem Grund die FunktionenEi, Ei,j, Ei,j,k (und spater allgemeinerEβ)
ebenfalls als Cliquen-Potentiale bezeichnet.
3.3.2 Regularitat und Graphkonstruktion f ur F2
Die Minimierung allgemeinerF2-Funktionen ist NP-schwer. Ein Beweis dafur ist in [KZ04]
aufgefuhrt und in AbschnittA.3 erlautert. Diese Tatsache ist Ausloser fur eine Untersuchung
der Fragestellung, welche echten Untermengen vonF2-Funktionen auf das Min-Cut-Problem
reduziert werden konnen.
Eine Verbindung zum Problem des minimalen Schnittes lasst sich bereits an der binaren
Darstellung eines SchnittesC erkennen:
Definition 3.34 SeiL ∈ 0, 1n ein binarer Vektor undG ein Graph mitV = s, t, v1, . . . , vn.Dann istCL der Schnitt des Graphen, der durch die ZerlegungS, T entsteht mit:
1. s ∈ S
2. t ∈ T
3. vi ∈ S, wennLi = 0
4. vi ∈ T , wennLi = 1
Analog lasst sich anhand eines Schnittes in eineindeutiger Weise ein VektorL(C) angeben.
Bemerkung 3.35 Es konnen auch Graphen mit mehr alsn + 2 Knoten betrachtet werden. Ein
SchnittC definiert dann zwar in eindeutiger Weise einen Vektor bzw. eine BeschriftungL(C),
7Die Darstellung (3.33) ist ebenfalls nicht eindeutig.

3.3. DISKRETE OPTIMIERUNG MIT GRAPH-CUT 27
jedoch ist die Umkehrung nicht mehr moglich. Ein SchnittCL lasst sich dennoch, konsistent zur
obigen Definition, als Minimum aller moglichen Schnitte definieren:
CL = argminC ist ein Schnitt mit den Eigenschaften aus Definition3.34
|C|. (3.36)
Zunachst sei die etwas umstandliche Ziel-Beschreibung der Reduktion auf das Min-Cut-
Problem formalisiert und mit einem entsprechenden Begriff versehen:
Definition 3.37 Eine FunktionF heißt graph-darstellbar ⇐⇒ Das zuF gehorende Opti-
mierungsproblem(BinF ) lasst sich auf das Problem(MinCut) des minimalens, t-Schnittes auf
folgende Weise zuruckfuhren:
Zu (BinF ) gibt es einen GraphG = (V, N) mit Knoten (Terminals)s und t sowie eine
Kantengewichtungw : N → R+, so dass gilt:
∃κ : ∀L ∈ 0, 1n : F (L) = |CL|+ κ (3.38)
Da durch|CL| alle Schnitte im GraphenG dargestellt werden konnen, gilt :L = L(C)
Wie lassen sich Funktionen ausF2 charakterisieren, die graph-darstellbar sind? Diese Fra-
gestellung wird durch einen Satz von [KZ04] beantwortet. Vor der Formulierung des Satzes, sei
aber zuerst der entscheidende Begriff der Regularitat eingefuhrt und erlautert:
Definition 3.39 Eine FunktionE : 0, 12 → R heißtregular oder submodular⇐⇒
E(0, 0) + E(1, 1) ≤ E(0, 1) + E(1, 0) (Reg2)
Eine FunktionF ∈ F2 sei ebenfalls als regular bezeichnet⇐⇒ alle FunktionenEi,j einer
F2-Darstellung sind regular.
Beispiel 3.40Die einzelnen Summanden des Ising-Modells(2.27) sind regular (α ≥ 0):
E(0, 1) + E(1, 0) = −α− α ≤ α + α = E(0, 0) + E(1, 1)
Satz 3.42Die Summe von zwei graph-darstellbaren Funktionen ist wieder graph-darstellbar.
Beweis zu 3.42: Siehe Anhang von [KZ04].

28 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Satz 3.43F is graph-darstellbar ⇐⇒ Jeder TermEi,j in der Darstellung(3.31) vonF ist
regular.
Bemerkung 3.44 Es sei bemerkt, dass die Darstellung einer FunktionF in der Form (3.31)
nicht eindeutig ist, die Regularitat davon aber nicht beeinflusst wird.
Die TermeEi(Li) konnen zum Beispiel komplett in die TermeEi,j(Li, Lj) einfließen:
∑i
Ei(Li) +∑i<j
Ei,j(Li, Lj) =∑i<j
(Ei,j(Li, Lj) +
1
n− i− 1Ei(Li) +
1
j − 1Ej(Lj)
)=∑i<j
Ei,j(Li, Lj)
Die Regularitat ist aber invariant bezuglich derAnderung der Darstellung(3.31):
Ei,j(0, 0) + Ei,j(1, 1) = Ei,j(0, 0) + Ei,j(1, 1) +1
n− i− 1
(Ei(0) + Ei(1)
)+
+1
j − 1
(Ej(0) + Ej(1)
)≤ Ei,j(0, 1) + Ei,j(1, 0) + . . .
= Ei,j(0, 1) + Ei,j(1, 0)
Beweis zu 3.43: Die Ruckrichtung soll anhand einer Konstruktion des entsprechenden Graphen
gezeigt werden. In Folge der konstruktiven Art des Beweises ist damit implizit auch ein Algorith-
mus beschrieben, welcher regulareF2-Funktionen minimiert. Die andere Richtung wird spater
allgemeiner bewiesen durch Satz3.53. Fur einen formaleren Beweis des Satzes sei auf Satz (1.8)
im Anhang verwiesen.
Durch Satz3.42ist es moglich, die Konstruktion des Graphen fur die einzelnen Summanden
getrennt vorzunehmen und danach den Gesamtgraphen zusammenzusetzen. Dabei werden die
Kanten zu einer Kantenmenge vereinigt und die Kantengewichte bei gleichen Kanten summiert8 Sei mit V
def= s, t, v1, . . . , vn die Knotenmenge des Graphen bezeichnet. Wichtig bei der
Konstruktion ist die Sicherstellung von nicht-negativen Kantengewichten.
Konstruktion von Ei: Ein TermEi entspricht den Kosten fur Zuweisung vonLi zu den
einzelnen Klassen0 (symbolisiert durch Terminals) und 1 (Terminal t) ohne Beachtung der
Abhangigkeiten zu den anderen Komponenten vonL. Fur jeden TermEi wird daher eine Kante
8Satz3.42sichert eigentlich nur die Aussage des Satzes, aber nicht, dass der zusammengesetzte Graph wirklicheine geeignete Konstruktion des Gesamtproblems ist.

3.3. DISKRETE OPTIMIERUNG MIT GRAPH-CUT 29
Bild 3.1: Konstruktion des Graphen fur F2 Funktionen mit den verwendeten Abkurzungen ausTabelle (3.45) (Quelle [KZ04])
e zu einem Terminal hinzugefugt. BeiEi(1) − Ei(0) ≥ 0 ergibt sich die Kantee = (s, vi) mit
GewichtEi(1) − Ei(0) (Abbildung3.1 a). Ansonsten wird die Verbindunge von Knotenvi zu
Terminalt mit GewichtEi(0)− Ei(1) gesetzt (Abbildung3.1b). Diese Konstruktion findet auf
folgende Weise ihre plausible Begrundung: Die BedingungEi(1)−Ei(0) ≥ 0 bedeutet, dass die
Kosten fur die Zuweisung vonLi zu Klasse0 (Terminals) großer sind als bei Klasse1. Wenn
nach der OptimierungLi mit 1 belegt ist, gehort die Kantee zum minimalen Schnitt, da die
Knotenvi unds getrennt werden. Die”zusatzlichen“ Kosten der Zuweisung vonLi zu Klasse0
werden demnach beim Optimalwert berucksichtigt.
Konstruktion von Ei,j:
Fur die Konstruktion des Graphen dienen folgende Abkurzungen:(Ei,j(0, 0) Ei,j(0, 1)
Ei,j(1, 0) Ei,j(1, 1)
)=
(A B
C D
)(3.45)

30 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Term Bedingung Kante GewichtEi Ei(1)− Ei(0) ≥ 0 (s, vi) Ei(1)− Ei(0)
Ei(1)− Ei(0) ≤ 0 (vi, t) Ei(0)− Ei(1)Ei,j (vi, vj) B + C − A−DEi,j C − A ≥ 0 (s, vi) C − A
C − A ≤ 0 (vi, t) A− CC −D ≥ 0 (vj, t) C −DC −D ≤ 0 (s, vj) D − C
Tabelle 3.4:Ubersichtuber die Graph-Konstruktion fur regulareF2-Funktionen
Die FunktionEi,j lasst sich in die folgenden additiven Bestandteile zerlegen:
D +
(A− C A− C
0 0
)+
(C −D 0
C −D 0
)+
(0 B + C − A−D
0 0
)(3.46)
Der erste Summand wird bei der Konstruktion vernachlassigt, da es sich nur um eine additive
Konstante handelt. Die beiden folgenden Summanden hangen von einer einzigen Variable ab und
konnen daher analog zu denEi Termen konstruiert werden. Die KostenB + C −A−D zahlen
nur, bei einer Zuordnung von Knotenvi zu Terminals und von Knotenvj zu Terminalt. Daher
kann der letzte Summand in der Zerlegung (3.46) durch eine Kantee = (vi, vj) mit Gewicht
w(e) = B + C −A−D reprasentiert werden (Abbildung3.1c,d). Die Nicht-Negativitat dieser
Kante ist durch die Regularitatsbedingung (Reg2) sichergestellt.
Bemerkung 3.47 An der Zerlegung vonEi,j in Gleichung(3.46) lassen sich auch prinzipielle
Einschrankungen des Modells erkennen. Die Darstellung der FunktionenEi,j lasst sich immer
auf folgendes Modell reduzieren:
Ei,j(Li, Lj) =
Ei,j Lj > Li
0 sonst(3.48)
Diese Darstellung sei im Folgenden als gerichtetes Potts-Modell bezeichnet.
Die Abbildungen3.3und3.2zeigen ein einfaches Beispiel fur die Segmentierung mit Graph-
Cut. Dieses Beispiel soll dieAhnlichkeit von Segmentierungsproblemen und dem Min-Cut-
Problem offenlegen. Ziel ist es, das Originalbild in3.3zu segmentieren. Der konstruierte Graph3.2
enthalt Kanten zwischen Pixelknoten (Knoten im Graphen, die einem Pixel im Bild entsprechen)

3.3. DISKRETE OPTIMIERUNG MIT GRAPH-CUT 31
Bild 3.2: Schema der Konstruktion des Graphen fur das Beispielbild3.3 und Darstellung desminimalen Schnittes
und den Terminals um die Kosten einzelner Pixel zu kodieren (Ei). Die Kantengewichte zwi-
schen zwei Pixelknoten werden hingegen entsprechend der FunktionenEi,j belegt. Fur diese
beispielhafte Darstellung wird das Potts-Modell verwendet undEi,j so gewahlt, dass bei gerin-
gen Grauwertdifferenzen|Ii − Ij| hohe Kosten in der Zielfunktion entstehen9. Weiterhin soll
die linke obere (bzw. rechte untere) Ecke des 9 Pixel großen Bildes mit hohen Kosten fur den
Vordergrund (bzw. Hintergrund) belegt werden. Bei der anschließenden Optimierung wird da-
her eine optimale Kante zwischen den gegenuberliegenden Ecken gefunden. Eine allgemeinere
Darstellung des Zusammenhangs zur Segmentierung befindet sich in Abschnitt3.4.4.
3.3.3 Vollstandige Charakterisierung
Der Begriff der Regularitat kann wie folgt erweitert werden:
Definition 3.49 Seiα eine Indexmenge mitα ⊆ 1, . . . , n. Fur eine feste BelegungLfix = Lα
9Ein Beispiel fur eine solche Wahl vonEi,j ist die Festlegung von Gleichung4.3 in Abschnitt4.1.3.

32 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Bild 3.3: (Links) Originalbild, (Rechts) Segmentierung aufgrund des minimalen Schnittes inAbbildung3.2
ist dieProjektionFαproj : 0, 1n−]α → R gegeben durch:Fα
proj(B)def= F (L) mit
Lidef=
Lfixγ(i) i ∈ α
Bτ(i) sonst(3.50)
und entsprechenden Funktionenγ undτ fur die Zuordnung der Indizes.
Definition 3.51 SeiF : 0, 1n → R eine Funktion.
1. Fur n = 1 (nur ein Argument) ist jede FunktionF regular.
2. Fur n = 2 ist die FunktionF regular, wenn sie die Bedingung(Reg2) erfullt.
3. Fur n > 2 ist die FunktionF regular ⇐⇒ jede Projektion vonF mit zwei Argumenten
ist regular.
Bemerkung 3.52 Es ist nicht sofort offensichtlich, dass diese Definition wirklich eine Erweite-
rung von Definition3.39darstellt. Grundlage fur die Definition3.39bildete die entsprechende
Darstellung als Summe vonEi und Ei,j. Die obige Charakterisierung ist hingegen direkt un-
abhangig von der Darstellung. Wie in Bemerkung3.44 bereits schon erwahnt, ist der Begriff
der Regularitat 3.39ebenfalls vollstandig von der Darstellung(3.31) unabhangig. Ein genau-
er Beweis fur diesen Sachverhalt und derAquivalenz der beiden Definitionen befindet sich in
[KZ04].
Der folgende Satz ist ein Resultat aus [KZ04]:
Satz 3.53Jede graph-darstellbare Funktion ist regular.

3.3. DISKRETE OPTIMIERUNG MIT GRAPH-CUT 33
Beweis zu 3.53: Siehe [KZ04].
Eine Verallgemeinerung der Definitionen3.30und3.32ist nahe liegend und wird in der Ar-
beit [FD05] f ur eine vollstandige Charakterisierung der graph-darstellbaren Funktionen verwen-
det. Damit ist [FD05] eine direkte Erweiterung der Ausfuhrungen von [KZ04]. Zur Definition
der KlasseFk soll die Multiindex-Konvention2.6aus Abschnitt2.1verwendet werden:
Definition 3.54 Eine FunktionF ist Element der FunktionsklasseFk ⇐⇒ F besitzt eine
Darstellung mit FunktionenEβ (β ⊆ 1, . . . , n, ]β ≤ k) der folgenden Form:
F (L) =∑
β⊆1,...,n]β≤k
Eβ(Lβ). (3.55)
Ziel der Arbeit [FD05] ist es erneut eine Charakterisierung der Klasse der graph-darstellbaren
Funktionen vorzunehmen. Folgendes Resultat kann fur die KlasseFk aufgestellt werden:
Satz 3.56Die Mengenα undβ seien Indexmengen mitα, β ⊆ 1, . . . , n Weiterhin sei fur eine
beliebige binare FunktionF mit n-Argumenten die NotationFβ mit Fβ = F (L) und (Li =
1 ⇐⇒ i ∈ β) erklart.
Wenn eine FunktionF ∈ Fk die Bedingung
∀α, 2 ≤ ]α ≤ k :∑β⊆α
(−1)]α−]βFβ ≤ 0 (FReg)
erfullt, dann ist sie graph-darstellbar.
Beweis zu 3.56: Siehe [FD05].
Bemerkung 3.57 Die Bedingung(FReg) reduziert sich fur k = 2 und k = 3 auf die Regula-
rit atsbedingung3.51.
3.3.4 Der Zusammenhang zu submodularen Funktionen
Als Einstieg sei gleich die Definition einer submodularen Funktion gegeben:
Definition 3.58 Eine (Mengen-)Funktionf : P(U) → R ist submodular10 ⇐⇒
∀A, B ⊆ U : f(A ∪B) + f(A ∩B) ≤ f(A) + f(B) (SubMod)
10Analog lassen sich die Begriffe supermodular (≥) und modular (=) mit einer entsprechendenAnderung derRelation in BedingungSubModdefinieren.

34 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Der Zusammenhang von Mengenfunktionenf und binaren FunktionenF kann in folgender
Weise dargestellt werden:
SeiM eine endliche Menge mitn Elementenxi fur 1 ≤ i ≤ n. Fur jede Mengenfunktion
f : P(U) → R kann eine entsprechende binare FunktionFf mit Ff (χA)def= f(A) definiert wer-
den.χA ist eine Schreibweise der charakteristischen Funktion vonA als binarer Vektor. Diese
Zuordnung ist bijektiv, denn zu jeder binaren FunktionF kann in analoger Weise eine Mengen-
funktion fF deklariert werden. Diese Bijektivitat liegt in derAquivalenz der Darstellung einer
Menge in Mengenschreibweise und als charakteristische Funktion begrundet. Aus diesem Grund
sei im Folgenden der Begriff der Submodularitat (SubMod) und Regularitat3.51fur binare Funk-
tionen und Mengenfunktionen gleichermaßen verwendet.
Eine Bemermerkunguber den Zusammenhang zwischen submodularen Funktionen und graph-
darstellbaren Funktionen findet sich bereits in [KZ04]. Schon in der Arbeit von Cunningham
[Cun85] konnte gezeigt werden, dass das Problem des minimalen Schnittes (MinCut) als Mini-
mierung einer submodularen Funktion umformuliert werden kann.
Satz 3.59Jede submodulare Funktionf ist regular im Sinne von Definition3.51.
Beweis zu 3.59: Die Ubertragung, bezuglich der obigen Beschreibung der bijektiven Zuordnung
zwischen Mengenfunktionen und binaren Funktionen, der Definition3.39fuhrt zu der folgenden
Bedingung:
∀x, y ∈ M, x 6= y ∀D ⊆ M \ x, y :
f(D) + f(D ∪ x, y) ≤ f(D ∪ x) + f(D ∪ y) (3.60)
Es bleibt also zu zeigen, dass submodulare Funktionenf die Bedingung (3.60) erfullen. Seien
D, x, y so gewahlt wie es Bedingung (3.60) vorschreibt. MitAdef= D ∪ x undB
def= D ∪ y
folgt unmittelbar:
f(A ∪B) = f(D ∪ x, y) (3.61)
f(A ∩B) = f(D) (3.62)
Damit folgt aus der Submodularitat (SubMod) mit A, B die Regularitatsforderung (3.60).
Satz 3.63Jede regulare Funktionf im Sinne von Bedingung3.51ist submodular.

3.3. DISKRETE OPTIMIERUNG MIT GRAPH-CUT 35
Literatur Resultate Funktionsklasse[Cun85, PR75] graph-darstellbare Funktionen sind
submodularsubmodulareFunktionen,
”cut
functions“[KZ04] F2-regular⊂ F3-regular⊆ graph-
darstellbar⊆ regular= submodularregulare Funktio-nen
[FD05] Satz3.56 Fk-Funktionenmit der Eigen-schaft (FReg)
Tabelle 3.6: Literaturverweise: Charakterisierung der graph-darstellbaren Funktionen
Beweis zu 3.63: Zu zeigen ist, dass aus der Bedingung (3.60) die Submodularitat der Funktionf
folgt. In [KZ04] wird die Bedingung (3.60) als alternative Charakterisierung der Submodularitat
angefuhrt. Daraus folgt unmittelbar der Beweis des Satzes.
Korrolar 3.64 Die Begriffe regular und submodular sindaquivalent.
Die Kriterien der Graph-Darstellbarkeit sind demnach vielfaltig und fallen bei den FallenF2
undF3 komplett zusammen. Abbildung3.4 versucht diese Zusammenhange zu verdeutlichen.
In Tabelle3.6 werden noch einmal die Literaturverweise mit den entsprechenden Resultaten
dargestellt.
Bild 3.4: Darstellungen der Beziehungen der einzelnen Funktionsklassen: (Links) fur Fk-Funktionen, (Rechts) fur die SpezialfalleF2 undF3. Die Freedman-Drineas Bedingung verweistauf die hinreichende Bedingung (FReg) von [FD05].

36 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
3.4 α-Expansion-Algorithmus
Bisher wurden Resultate vorgestellt, welche es ermoglichen, das binare Optimierungsproblem
(BinF ) fur Funktionen mit gewissen Einschrankungen (Regularitat, Fk) zu losen.Ubertragen
auf die Zuweisung zu bestimmten Klassen wurden daher nur Zweiklassen-Probleme gelost. Bei
der ursprunglichen Zielsetzung der Schatzung mittels MRFs wird aber die Einteilung inK un-
terschiedliche Klassen benotigt (siehe Abschnitt2.3.1):
L = argminl∈1,...,Kn
F (L) (OptF )
Ein Ansatz mit Blick auf die bisherige Vorgehensweise ware es, wieder zusatzliche Ein-
schrankungen fur die Zielfunktionen zu suchen, so dass auch dieses nicht-binare Problem auf
das Problem des minimalen Schnittes zuruckgefuhrt werden kann. Die Arbeiten von Ishikawa et
al. [IG98, IG99, Ish03] verfolgen diese Idee und gelangen zu einer FunktionsklasseK ⊂ F2.
Diese Funktionsklasse beinhaltet alle Funktionen mit konvexen11 Cliquen-PotentialenEi,jK der
Form:
Ei,j(Li, Lj)def= Ei,j
K (Li − Lj) (3.65)
Diese Funktionsklasse schrankt die Modellierung stark ein. So genugt zum Beispiel das Potts-
Modell (2.29) nicht diesen Bedingungen.
Eine weitere Ansatzmoglichkeit ist die Erweiterung des Min-Cut-Problems (MinCut) auf
ein ahnliches Problem mit mehr als zwei Terminals. Diese Formulierung wird als”Minimum-
Multiway-Cut“ bezeichnet. Die Minimierung ist fur beliebige Graphen leider NP-schwer [DJP*94].
Die Suche nach einem exakten Algorithmus, welcher in polynomieller Zeit lauft, kann daher op-
timistischeren Forschernuberlassen werden.
In der Bildverarbeitung ist die Suche nach”exakten“ Algorithmen oft gar nicht wesent-
lich. Typische Einschrankungen bei Anwendungen sind der Informationsverlust des Aufnah-
meprozesses, gravierende Modellannahmen und haufig auftretende Problemformulierungen, die
aufgrund ihrer Komplexitat generell nicht exakt gestellt werden konnen. Daher sind ohne Be-
schrankung der Allgemeinheit, die Auswirkungen der Approximation bei der Optimierung im
Gegensatz zu anderen Einflussen vernachlassigbar.
Die Arbeiten [Vek99, BVZ99a] stellen daher ein Algorithmus vor, welcher nicht immer das
globale Optimum berechnet, sondern eine Art lokales Optimum. Dabei erfolgt die Berechnung
11Die Konvexitat beschrankt sich bei Funktioneng : N → R auf∀x ∈ N : g(x + 1)− 2g(x) + g(x− 1) ≥ 0.

3.4. ALPHA-EXPANSION-ALGORITHMUS 37
Bild 3.5: Auswirkungen einer Iteration desα-Expansion-Algorithmus (α-Erweiterungsschritt)am Beispiel der Klasse der weißen Pixel [KZ04].
der Losung auf iterative Weise. Ein Teil des Gesamtproblems wird in jeder Iteration auf ein
binares Problem abgebildet und mit denublichen Algorithmen (siehe Abschnitt3.2) gelost.
3.4.1 Beschreibung des Algorithmus
Ziel soll es sein, Probleme der Form (OptF ) zu losen. In Abschnitt3.4.3 wird anschließend
gezeigt, welche Bedingungen dabei an die Zielfunktion geknupft werden mussen.
Anschaulich geht der Algorithmus folgendermaßen vor: Am Anfang ist eine Startlosung
L = L(0) gegeben. In jeder Iteration wird nun ein Labelα fest gewahlt. Alle Komponenten
(Punkte) vonL, welche bereits mitα beschriftet sind, werden in der aktuellen Iteration nicht
geandert. Ziel der Iteration ist es, fur alle anderen Komponenten (Punkte) vonL folgende binare
Entscheidungsfrage zu losen:
Soll die aktuelle Beschriftung der Komponente geandert und aufα gesetzt werden ?
Dies fuhrt zu einer Erweiterung (Expansion) der Klasseα. Ein Beispiel fur die Auswirkungen
einer Iteration ist in Abbildung3.5dargestellt.
Grundlage fur die mathematische Formulierung bilden so genannte zulassige Schritte im
RaumSKdef= 1, . . . , Kn. Diese definieren eine UmgebungU(L) eines VektorL ∈ SK . In
jeder Iteration kann durchUbertragung auf das schon anschaulich beschriebene binare Problem
ein Minimum in einer Umgebung gefunden werden. Es ist moglich, dieses Verfahren als ei-
ne Art dynamische lokale Suche in einem Graphen zu betrachtet. Die Arbeiten [Vek99, KT05]
bezeichnen es direkt als Spezialfall derublichen lokalen Suche. Ausgehend von den direkten
Beschreibungen des Algorithmus in [BVZ99a, SZS*06] sei aber darauf hingewiesen, dass der
konkrete Ablauf nicht direkt dem Konzept der”Lokalen Suche“ entspricht. Dieser Unterschied
wird nach der Beschreibung des Algorithmus deutlich.
In [Vek99, BVZ99a] wurden zwei unterschiedliche Konzepte (α-Expansion undα, β-Swap)

38 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
fur zulassige Schritte definiert und getestet, von denen an dieser Stelle nur das empirisch beste
Konzept derα-Expansion vorgestellt werden soll:
Definition 3.66 Ein Schritt im RaumSK ist ein Paar(L1, L2) mit L1, L2 ∈ SK .
(L1, L2) ist ein zulassigerα-Erweiterungsschritt⇐⇒
∀i ∈ 1, . . . , n : (L2i = L1
i ) ∨ (L2i = α). (3.67)
Die Menge der durch diese zulassigen Schritte definierten VektorenL2 definieren eine Umgebung
Uα(L1).
Der bereits skizzierte Ablauf des Algorithmus kann jetzt exakt formuliert werden: In jeder
Iterationk erfolgt die Auswahl eines festen Labelα(k). Ausgehend von dieser Wahl wird das
folgende allgemeine Teilproblem gelost:
L(k+1) = argminL ∈ Uα(k)(L(k))
F (L). (3.68)
Durch die Wahl der Umgebung kann das Problem folgendermaßen als binares Problem be-
schrieben werden: Zunachst ist durch die aktuelle BeschriftungL(k) und die Wahl des Labels
α(k) die Zielfunktion in der passenden Umgebung nur noch von einem binaren VektorB abhangig.
Dieser kodiert die Information, ob ein Punkt seine Beschriftung beibehalt oder die Beschriftung
aufα gesetzt wird. Daher lasst sich fur die neue binare ZielfunktionEbink schreiben:
Ebink (B)
def= F (L(B)) (3.69)
mit
Li(B)def=
α(k) Bi = 1
L(k)i Bi = 0
. (3.70)
Nicht jeder binare VektorB kodiert hingegen einen zulassigen”Nachbarn“ vonL(k). Es gilt
die Einschrankung:∀i mit L(k)i = α(k) : Bi = 1. Alle bisherigenα-Beschriftungen werden
dadurch fixiert. Durch diese Festlegung ergibt sich folgendes binare Teilproblem:
L(k+1) = Γ (L(k), argminB∈0,1n
∀L(k)i =α(k):Bi=1
Ebink (B)). (Subα)

3.4. ALPHA-EXPANSION-ALGORITHMUS 39
Die FunktionΓ dient dazu, die Information des binaren VektorsB zu”dekodieren“ und es
gilt
Γ (L(k), B)def= L(B) (3.71)
mit der Festlegung vonL(B) durch Gleichung (3.70).
Das in die Gleichung (Subα) eingebettete Optimierungsproblem ist ein bekanntes Optimie-
rungsproblem der Form (BinF ), welches unter den beschriebenen Anforderungen auf das Pro-
blem des minimalen Schnittes in einem Graphen reduziert werden kann. DieUbertragung die-
ser Anforderungen auf die ZielfunktionF werden im Abschnitt3.4.3naher untersucht. Weiter-
hin fuhrt die zusatzliche Nebenbedingung lediglich auf eine Minimierung einer Projektion von
Edef= Ebin
k :
argminB∈0,1n
∀i∈ω:Bi=1
E(B) = argminB∈0,1n−]ω
Eωproj(B) (3.72)
Die Indexmengeω umfasst alle fixierten Komponenten:ω = ω(k)def= i | L(k)
i = α(k). Der
fixierte Vektor der Projektion istBω ≡ 1.
Es gibt verschiedene Moglichkeiten die Funktionα(k) und damit die Wahl des fixierten La-
bels vorzunehmen. In den Arbeiten [Vek99, BVZ99b, BVZ01] wird vorgeschlagen, alle mogli-
chen Labels nacheinander durch eine Iteration abzuarbeiten. Solch ein Zyklus wird dann solange
wiederholt, bis eine weitere Minimierung des Funktionswertes vonF nicht mehr moglich ist. Die
Reihenfolge der Labels in einem Zyklus kann eine zu Beginn des Zyklus zufallig gewahlte Per-
mutation sein. In bisher bekannten Beschreibungen desα-Expansion-Algorithmus sind weitere
Details ausgespart. Der Algorithmus ist diesbezuglich noch einmal in der Pseudocodebeschrei-
bung3.1zusammengefasst und richtet sich nach der konkreten Implementierung von Olga Veks-
ler, auf die in der Arbeit [SZS*06] verwiesen wird. Der genaue Ablauf zeigt den Unterschied zur
”Lokalen Suche“: Die Nachbarschaft einer Beschriftung hangt explizit vom ausgewahlten fixier-
ten Labelα(k) ab. Sie ist daher vom genauen Weg der Suche abhangig. Dies steht im Kontrast
zu der fixierten Nachbarschaft bei derublichen”Lokalen Suche“.
3.4.2 Eigenschaften des Algorithmus
Die Terminierung des Algorithmus ist aus folgenden Grunden gesichert. Die ZielfunktionF ist
auf der MengeSK offensichtlich nach unten beschrankt, da die MengeSK endlich ist. Da in
jedem erfolgreichen Zyklus der Zielfunktionswert reduziert wird :F (L(k)) < Fold, konnen nur
endlich viele Zyklen durchlaufen werden. Unter ein paar zusatzlichen Annahmen ist es sogar

40 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
Pseudocode 3.1:α-Expansion-AlgorithmusWaehle eine Anfangsbeschriftung L(0)
k := 0Fold := ∞do
success := 0π = Zufaellige oder fest gewaehlte Permutation von 1, . . . , Kfor i := 1 . . . K do
α := π(i)
L(k+1) = Loesung des Unterproblems (Subα)k := k + 1
endif F (L(k)) < Fold then
success := 1Fold := F (L(k))
endwhile ( success and k < maxIterations )
moglich, die Terminierung inO(n) Zyklen zu beweisen [Vek99].
Der α-Expansion-Algorithmus erzeugt, wie bereits angesprochen, nicht notwendigerwei-
se ein globales Minimum. Der Algorithmus liefert hingegen immer ein Art lokales Minimum
bezuglich der moglichenα-Expansionsschritte. Eine wichtige Fragestellung in diesem Zusam-
menhang ist die”Entfernung“ des Resultates des Algorithmus vom globalen Minimum. Dies
mundet in der so genannten Approximationsgute (relative approximation):
Satz 3.73SeiL das globale Minimum vonF ∈ F2, L das Resultat desα-Expansion-Algorithmus
und o.B.d.A.F (L) ≥ 0. Dann gilt folgende Abschatzung:
F (L) ≤ F (L) ≤ 2
maxi,j
maxα 6=β
Ei,j(α, β)
minα 6=β
Ei,j(α, β)
F (L) (3.74)
Beweis zu 3.73: Siehe Veksler [Vek99] (Originalarbeit) oder Kleinberg und Tardos [KT05].
Korrolar 3.75 Sei L das globale Minimum vonF ∈ F2 mit F (L) ≥ 0 und L das Resultat
desα-Expansion-Algorithmus. Dann gilt fur das verallgemeinerte Potts-ModellEi,j(Li, Lj) =
Ei,j δ(Li 6= Lj) mit Ei,j ≥ 0:
F (L) ≤ F (L) ≤ 2F (L) (3.76)
Beweis zu 3.75: Es gilt:
maxα 6=β
Ei,j(α, β) = minα 6=β
Ei,j(α, β)
und nach Satz3.73folgt sofort Aussage (3.76).

3.4. ALPHA-EXPANSION-ALGORITHMUS 41
3.4.3 Anforderungen an die Zielfunktion beiF ∈ F2
In Abschnitt3.3 wurden die Anforderungen an eine binare Funktion untersucht, so dass diese
mit einer Reduzierung auf das Problem des minimalen Schnittes optimiert werden kann. Im
Folgenden seien FunktionenF : SK → R ausF2 betrachtet:
F (L) =n∑
i=1
F i(Li) +∑i<j
i,j∈1,...,n
F i,j(Li, Lj)
Die in jeder Iteration desα-Expansion-Algorithmus auftretende Zielfunktion des binaren
Teilproblem (Subα) seiEdef= Eω
proj. Die Definition vonE induziert die folgende Darstellung der
Funktion mitL(B) nach Gleichung3.70:
E(B) =∑i∈ω
F i(α) +∑i/∈ω
F i(Li(B))+
+∑
i<j, i∈ω, j∈ω
F i,j(α, α) +∑
i<j, i/∈ω, j∈ω
F i,j(Li(B), α)+
+∑
i<j, i∈ω, j /∈ω
F i,j(α, Lj(B)) +∑
i<j, i/∈ω, j /∈ω
F i,j(Li(B), Lj(B)) (3.79)
Die FunktionE besitzt daher ebenfalls eineF2-Darstellung miti, j /∈ ω:
E(B) =∑
i
Ei(B) +∑i<j
Ei,j(Bi, Bj) + C
und
Ei,j(Bi, Bj) = F i,j(Li(B), Lj(B))
Ei(Bi) = F i(Li(B)) +n∑
j=i+1
F i,j(Li(B), α) +i−1∑j=1
F j,i(α, Li(B))
C =∑i∈ω
F i(α) +∑
i<j, i∈ω, j∈ω
F i,j(α, α).
C ist eine vonB unabhangige Konstante und kann daher bei der Optimierung vernachlassigt
werden. Um die Minimierung in einer Iteration durchzufuhren, muss die FunktionE regular

42 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN
sein:
∀i, j ∈ ω : Ei,j(0, 0) + Ei,j(1, 1) ≤ Ei,j(0, 1) + Ei,j(1, 0). (3.81)
Diese Bedingungubertragt sich aufF in folgender Weise:
∀i, j mit L(k)i 6= α 6= L
(k)j :
F i,j(L(k)i , L
(k)j ) + F i,j(α, α) ≤ F i,j(L
(k)i , α) + F i,j(α, L
(k)j ) (3.82)
Damit wird aber nur die Regularitat in einer Iteration fur ein speziellesL(k) gefordert. Ein
notwendiges12 Kriterium fur die Regularitat in einer beliebigen Iteration ist daraufhin im folgen-
den Satz dargestellt.
Satz 3.83SeiF : SK → R die Zielfunktion des Problems(OptF ) undF ∈ F2. Wenn fur alle
FunktionenF i,j aus derF2-Darstellung vonF folgende Bedingung erfullt ist:
∀α, β, γ mit β 6= α 6= γ : F i,j(β, γ) + F i,j(α, α) ≤ F i,j(β, α) + F i,j(α, γ) (3.84)
dann lasst sich die FunktionF mit demα-Expansion-Algorithmus minimieren und es gelten
die in Abschnitt3.4.2angefuhrten Eigenschaften des gefundenen (lokalen) Optimums.
Beispiel 3.85Das verallgemeinerte Potts-Modell mitEi,j ≥ 0 (siehe Abschnitt2.3.4) genugt der
Bedingung(3.84):
F i,j(β, α) = F i,j(α, γ) = Ei,j (3.86)
F i,j(α, α) = 0 (3.87)
F i,j(β, γ) = Ei,j δ(β 6= γ). (3.88)
Daraus folgt unmittelbar:
Ei,j δ(β 6= γ) + 0 ≤ Ei,j + Ei,j (3.89)
3.4.4 Beziehung zur Schatzung von MRF-Zustanden
Die Beziehung der besprochenen Optimierungsprobleme zur Schatzung von MRF-Zustanden
(siehe Kapitel2) lasst sich ziemlich schnell erkennen. Die zu minimierende ZielfunktionE bei
12Dieses Kriterium kann nur als notwendig bezeichnet werden, daL(k) beliebig ist aber nicht zwangsweise jedeKomponente wahrend des Algorithmus jedes mogliche Label annehmen muss.

3.4. ALPHA-EXPANSION-ALGORITHMUS 43
der MAP-Schatzung (siehe Gleichung (2.16), Abschnitt2.3.3) hat im allgemeinen Fall (Annah-
me A1’) die Form:
E(L) =∑
C ist eine Clique inS
EIC(LC). (3.90)
Aus dieser Darstellung lasst sich erkennen, dassE zur FunktionsklasseFω(S) gehort. Bei der
4er-Nachbarschaft (siehe Abschnitt2.1) genugt daher eine Betrachtung vonF2-Funktionen mit
der ursprunglichen Definition der Regularitat 3.39:
E(L) =∑
i
Ei(Li) +∑
(i,j)∈N
Ei,j(Li, Lj) (3.91)
Die Anforderungen an die einzelnen SummandenEi,j ubertragen sich damit auf naturliche
Weise auf die CliquenpotentialeEIC
13.
Bei einemUbergang von der 4er-Nachbarschaft auf die 8er Nachbarschaft ist es bereits not-
wendigF4-Funktionen zu betrachten. Da diese in der Konstruktion des entsprechenden Graphen
unhandlich sowie die Anforderungen der Regularitat im Gegensatz zuF2-Funktionen nicht so
leicht nachzuprufen sind, ist esublich sich auf eine Approximation durchF2-Funktionen zu
beschranken.
13Zur Erinnerung sei an dieser Stelle angemerkt, dass die NotationEI die Abhangigkeit von der BeobachtungIausdruckt.

44 KAPITEL 3. SCHATZUNG VON MRF-ZUSTANDEN MIT MINIMALEN SCHNITTEN

Kapitel 4
Anwendungen
Die allgemeine abstrakte Beschreibung von Graph-Cut-Methoden ermoglicht eine vielseitige
Anwendung in unterschiedlichen Gebieten der Bildverarbeitung. Die folgenden Abschnitte die-
nen der Beschreibung der Problemstellungen, welche im Kontext dieser Arbeit mit Graph-Cut
gelost werden konnten.
Die Beschreibung der”interaktiven Segmentierung“ in Abschnitt4.1 dient dazu, einen ent-
scheidenden Grundansatz bei der Modellierung vorzustellen, welcher spater bei der Kennzei-
chenlokalisierung4.2effektiv angewendet werden kann.
Anschließend werden Grundaspekte der Bewegungssegmentierung vorgestellt, welche zu der
Ebenensegmentierung mit Tiefeninformationen fuhren.
4.1 Interaktive Segmentierung
Im Folgenden soll das Prinzip der Teilfixierung bei der Anwendung von Graph-Cut-Methoden
vorgestellt werden. Der Begriff”Interaktive Segmentierung“ wird hier verwendet, da diese Art
von Segmentierung hauptsachlich bei der benutzerunterstutzten Segmentierung von medizini-
schen Bild- oder Voxeldaten zum Einsatz kommt. Es sei aber explizit darauf hingewiesen, dass
die Grundidee auch bei automatischen Segmentierungen (siehe Abschnitt4.2) anwendbar ist und
daher an dieser Stelle vorgestellt wird.
4.1.1 Aufgabenstellung
Ziel soll es sein, ein Bild in eine fest vorgegebene AnzahlK von Regionen zu unterteilen. Da-
bei muss eine Region nicht zwangslaufig nur eine Zusammenhangskomponente bilden. Im Ge-
45

46 KAPITEL 4. ANWENDUNGEN
gensatz zu der Segmentierung von allgemeinen Bildern ohne Zusatzinformationen in Gebiete,
wie etwa bei der Verwendung von Normalized-Cuts [GS06, SM00], ist bei dieser Aufgaben-
stellung zusatzlich eine Teilauswahl von Punkten allerK Regionen gegeben. Im Folgenden soll
die Formulierung”Teilfixierung“ verwendet werden. Dieser Unterschied ist das Analogon zur
Unterscheidung vonuberwachten und unuberwachten Lernverfahren.
4.1.2 Festlegung der unabhangigen Kosten einzelner Pixel
Eine Teilfixierung im Bild (n-dimensional)I ist eine FolgeΩ = PiKi=1 von paarweise dis-
junkten PunktemengenPi ⊂ Zn. Analog zu Abschnitt2.3.1soll wieder eine BeschriftungL des
Bildes I geschatzt werden. Ein paar Komponenten dieser Beschriftung sind bereits durch die
Teilfixierung festgelegt:xi ∈ Pk → Li = k.
Die WahrscheinlichkeitPr(Li = k|Ii) fur diese Punkte ist demnach1 fur xi ∈ Pk und0 fur
alle anderen moglichen Werte aus1, . . . , K. Ubertragen auf die dazugehorige ZielfunktionE
ergibt sich fur dieEi Terme mitxi ∈ Pk:
Ei(Li)def=
∞ Li 6= k
0 Li = k.(4.1)
Bei der Implementierung kann die fur die Optimierungaquivalente Variante mit
Ei(Li)def=
−H Li = k
0 Li 6= k.(4.2)
verwendet werden. Der WertH ist dabei ein praktisch genugend großer Wert. Eine andere
Moglichkeit ist es, denα-Expansion-Algorithmus so anzupassen, dass alle Knotenvi des Gra-
phen mitxi ∈ Pk mit den entsprechenden Terminals vereinigt1 werden.
4.1.3 Wahl der Cliquen-Potentiale 2. Ordnung
Entscheidend fur die Beschriftung der anderen Pixel ist die Festlegung der Cliquen Potentiale
2. Ordnung (TermeEi,j). Diese Funktionen bestimmen die Grenzen der Regionen und werden
daher oft alssmoothness costoderNachbarschaftsbewertungbezeichnet.
1Eine Vereinigung von Knotenv und Knotenw eines Graphen ist ein Knotenq mit N(q) = (N(v) ∪N(w)) \v, w.
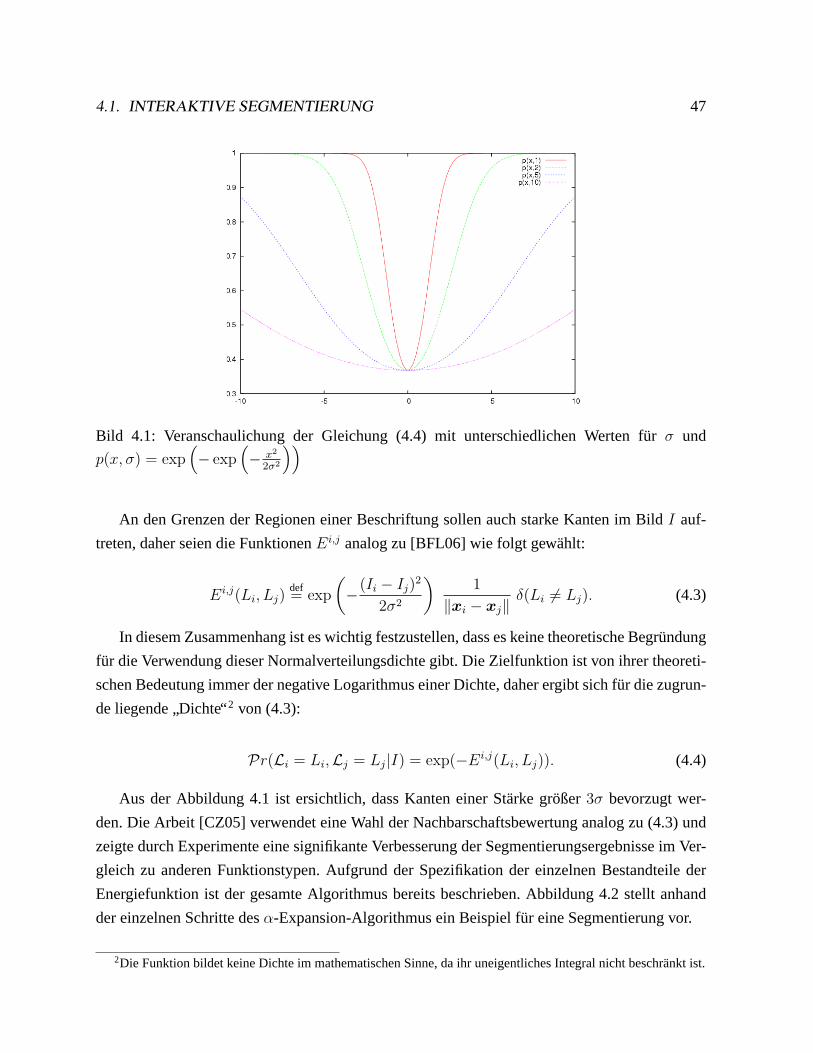
4.1. INTERAKTIVE SEGMENTIERUNG 47
Bild 4.1: Veranschaulichung der Gleichung (4.4) mit unterschiedlichen Werten fur σ und
p(x, σ) = exp(− exp
(− x2
2σ2
))
An den Grenzen der Regionen einer Beschriftung sollen auch starke Kanten im BildI auf-
treten, daher seien die FunktionenEi,j analog zu [BFL06] wie folgt gewahlt:
Ei,j(Li, Lj)def= exp
(−(Ii − Ij)
2
2σ2
)1
‖xi − xj‖δ(Li 6= Lj). (4.3)
In diesem Zusammenhang ist es wichtig festzustellen, dass es keine theoretische Begrundung
fur die Verwendung dieser Normalverteilungsdichte gibt. Die Zielfunktion ist von ihrer theoreti-
schen Bedeutung immer der negative Logarithmus einer Dichte, daher ergibt sich fur die zugrun-
de liegende”Dichte“2 von (4.3):
Pr(Li = Li,Lj = Lj|I) = exp(−Ei,j(Li, Lj)). (4.4)
Aus der Abbildung4.1 ist ersichtlich, dass Kanten einer Starke großer3σ bevorzugt wer-
den. Die Arbeit [CZ05] verwendet eine Wahl der Nachbarschaftsbewertung analog zu (4.3) und
zeigte durch Experimente eine signifikante Verbesserung der Segmentierungsergebnisse im Ver-
gleich zu anderen Funktionstypen. Aufgrund der Spezifikation der einzelnen Bestandteile der
Energiefunktion ist der gesamte Algorithmus bereits beschrieben. Abbildung4.2 stellt anhand
der einzelnen Schritte desα-Expansion-Algorithmus ein Beispiel fur eine Segmentierung vor.
2Die Funktion bildet keine Dichte im mathematischen Sinne, da ihr uneigentliches Integral nicht beschrankt ist.

48 KAPITEL 4. ANWENDUNGEN
Bild 4.2: Bildreihenfolge von links nach rechts bzw. oben nach unten: (1) Originalbild, (2) Aus-wahl der Teilfixierung, (3)-(8) Die einzelnen Iterationen desα-Expansion-Algorithmus im erstenZyklus (Die nachsten Iterationen fuhren zu keiner weiteren Verbesserung des Zielfunktionswer-tes, daher bricht der Algorithmus ab).
4.2 Kennzeichenlokalisierung
4.2.1 Einfuhrung
Die moderne Verkehrssicherheitstechnik in Form von automatischen Geschwindigkeitsmesssy-
stemen ist ohne die automatische Detektion und Erkennung von KFZ-Nummernschildern in Bild-
aufnahmen undenkbar geworden. Ein so genannter Kennzeichenleser muss dabei viele Teilpro-
bleme losen: Detektion der Nummernschilder, Ausrichtung, Buchstabensegmentierung, Buch-
stabenerkennung, SyntaktischeUberprufung.
Die Ausrichtung der Nummernschilder kann dabei anhand der Ausrichtung des Nummern-
schild-Randes erfolgen. In einem dafur notwendigen ersten Schritt ist es moglich, die Hypothese
des Nummernschildes mittels anderer Bildverarbeitungsmethoden zu finden. Diese Hypothese
im EingabebildI sei im Folgenden mitxh bezeichnet.
4.2.2 Kennzeichenlokalisierung als binares Segmentierungsproblem
Die Segmentierung des Randes kann als ein binares Segmentierungsproblem aufgefasst werden.
Ziel ist es, das BildI in eine Kennzeichenregion1 (begrenzt durch den gesuchten Rand) und eine
Hintergrundregion0 aufzuteilen.
Die Große des Nummernschildes ist a priori nicht bekannt. Im Folgenden soll aber von einer
maximalen Breitewx und maximalen Hohewy ausgegangen werden.

4.2. KENNZEICHENLOKALISIERUNG 49
Bild 4.3: Ausgeschnittener Bildbereich um die gefundene Hypothese des Nummernschildes
Bild 4.4: Festlegung der fixierten Labels fur das optimale”Region Growing“ mit Graph-Cut:
(roter Bereich in der Mitte)Ei(1) = −∞, (gruner Bereich am Rand)Ei(0) = −∞
Die Idee der Kennzeichenlokalisierung istaquivalent zum Grundgedanken der interaktiven
Bildsegmentierung wie sie in Abschnitt4.1 vorgestellt wurde. Fur eine korrekte Beschreibung
des Algorithmus reicht es daher, eine Teilfixierung des Bildes anzugeben. Die Zielfunktion lasst
sich analog zu den Gleichungen (4.2) und (4.3) aufstellen.
In einem gewissen Bereich um die Hypothesexh wird eine Fixierung der Beschriftung der
Kennzeichenregion (Li = 1) vorgenommen:
P1def= x | |x1 − xh
1 | ≤ux
2∨ |x2 − xh
2 | ≤uy
2. (4.5)
Die Parameterux und uy sollten so gewahlt werden, dass die entstehende RegionP1 min-
destens einen Hintergrundpixel des Nummernschildes enthalt, auch wenn die Hypothese direkt
auf einem Zeichen des Nummernschildes liegt. Die Großeux ist somit indirekt abhangig von der
maximalen Breite eines Zeichens.
Ausgehend von der Angabe der maximalen Große eines Nummernschildes erfolgt die Fest-

50 KAPITEL 4. ANWENDUNGEN
Bild 4.5: Ergebnis der Segmentierung des Nummernschildes von Beispielbild4.3. Der rot-gestreifte Bereich markiert das gefundene Nummernschild.
legung, dass auf dem maximalen Rand alle Pixel dem Hintergrund angehoren:
P0def= x | |x1 − xh
1 | =wx
2∨ |x2 − xh
2 | =wy
2 (4.6)
Eine Veranschaulichung dieser Festlegungen ist in Abbildung4.4dargestellt. Da ausgehend
von einem Punkt eine optimale Kontur (im Sinne des Bildgradienten senkrecht zur Kontur) ge-
sucht wird, kann das Verfahren als”optimales Region-Growing“ bezeichnet werden.
4.3 Ebenendetektion
Die Detektion von Ebenen ist in vielen Anwendungen der 3D-Bildverarbeitung ein wichtiger
Teilschritt. Ziel ist es raumlich planare Teilstucke in einer Szene zu erkennen.
Eine Moglichkeit ist es, aus einer gegebenen Folge von Aufnahmen verfolgte Punktmerkma-
le so zu gruppieren, dass sie jeweils einer gemeinsamen Homographie unterliegen [KD07]. In
der Arbeit [KD07] wurde weiterhin gezeigt, dass aus dieser Gruppierung nur dann auf planare
Teilstucke geschlossen werden kann, wenn die Kamerabewegung eine Translation beinhaltet.
Neue Kameras mit Echtzeit-Tiefeninformationen [Lan00] ermoglichen es hingegen, einen
ganz anderen Zugang zu wahlen. Die Detektion planarer Teilstucke kann dadurch Standardver-
fahren verwenden, welche auf 3D-Punktewolken arbeiten [vH06, CZ01]. Eine Moglichkeit ist es
zum Beispiel, eine Art Region Growing durchzufuhren. Dabei wird, wenn der Abstand zur bisher
geschatzten Ebene einen gewissen Schwellwert unterschreitet, ein Punkt zur Region hinzugefugt.
Eine Verbesserung der Schatzung erfolgt daraufhin Schritt fur Schritt durch neue Punkte.
In den folgenden Abschnitten wird eine Verbesserung beider Ansatze vorgestellt. Zunachst
kommt ein beliebiges Verfahren der Ebenendetektion3 zur Anwendung, um eine Startschatzung
3Fur eine Beschreibung dieser Verfahren sei an dieser Stelle auf die Originalarbeiten [KD07, vH06, CZ01] oder

4.3. EBENENDETEKTION 51
zu erhalten. Diese Schatzung wird danach durch eine Graph-Cut-Segmentierung verbessert.
4.3.1 Problemstellung
SeiRπ die Menge der abgebildeten Punkte im BildI einer Ebeneπ im Raum. Die Anwendung
eines Verfahrens der Ebenendetektion [CZ01, KD07] liefert eine StartschatzungS der Menge
Rπ. Beim Verfahren von [KD07] kann zum Beispiel eine Auswahl von zufalligen Punkten in
der konvexen Hulle der Punktmerkmale verwendet werden. Um die Schatzung zu verbessern,
kann das zugrunde liegende Segmentierungsproblem wieder als binares Optimierungsproblem
formuliert werden. Die BeschriftungLi = 1 bedeutet dann, dass der Punktxi zuRπ gehort.
4.3.2 Ebenendetektion durch Bewegungssegmentierung
Um ausgehend von verfolgten Punktmerkmalen eine vollstandige Segmentierung einer Bildse-
quenz durchzufuhren, wurde in [XS05] Graph-Cut verwendet. Der Begriff”vollstandig“ bezieht
sich auf die Gruppierung der Pixel: Jeder Pixel in jedem Bild wird genau einer Komponente
zugeordnet, die wahrend der Sequenz eine gemeinsame Bewegung durchfuhrt.
Ein Hauptbestandteil der Arbeit [XS05] ist die Erweiterung von verfolgten Punktmerkmale
mit Graph-Cut. Dieser Ansatz kann effizient fur die Ebenensegmentierung verwendet werden.
Gegeben seien die StartschatzungS der Ebenenpunkte sowie die bereits ermittelte Bewe-
gung der Ebene als HomographieH vom aktuellen BildIt zu einem fruheren Bild der Sequenz
It−ν . H ist eine 3x3 Matrix, die homogene Bildkoordinaten ineinander abbildet. Im Folgenden
sei die SchreibweiseH(x) verwendet, um die resultierende nicht-lineare Abbildung direkt in
Bildkoordinaten auszudrucken.
Ausgehend von diesen Informationen lasst sich nun das Differenzbild∆ berechnen:
∆idef= |It(xi)− It−ν(H(xi))|. (4.7)
Unter der Annahme einer perfekten Abbildung verschwindet∆ auf dem gesuchten Ebe-
nenstuck sowie in homogenen Gebieten. Bei realen Aufnahmen ist diese Annahme naturlich
unhaltbar und eine Optimierung mit Graph-Cut erscheint sinnvoll. Dadurch kann ein kompaktes
Gebiet ermittelt werden, welches gewisse Bedingung am Rand und im Inneren erfullen muss.
Diese Bedingungen werden im Folgenden durch die Bewertung einzelner PixelEi und die
auf die Zusammenfassung in [KRD07] verwiesen.

52 KAPITEL 4. ANWENDUNGEN
Bewertung der ObjektgrenzeEi,j ausgedruckt:
F (L) =n∑
i=1
Ei(Li) +∑i,j∈N
Ei,j δ(Li 6= Lj). (4.8)
Wieder dient das verallgemeinerte Potts-Modell dazu, die Bewertung der Objektgrenze zu
modellieren. In [XS05] werden folgende Bedingungen an das Innere der Ebenenregion gestellt:
1. geringe Werte von∆i
2. beschrankter”Abstand“ zur Anfangsschatzung.
Die zweite Bedingung kann durch die Verwendung einer sogenannten Level-Set-Darstellung4
erreicht werden. Fur die AnfangsschatzungS lasst sich dazu ein BildmaskeM erstellen:
Midef=
1 xi ∈ S
0 sonst.(4.9)
Die Level-Set-Darstellungϑ ergibt sich anschließend aus einer zweidimensionalen Gaußfil-
terung des BildesM :
ϑdef= Gσ ∗M. (4.10)
Gσ ist in diesem Fall ein uniformer zweidimensionaler Gaußkern mit”großer“ Varianzσ. Das
Bild ϑ fuhrt zu einer Glattung der Grenzen vonM . Die Werte vonϑ fallen monoton orthogonal
zu der Objektgrenze inM . Dies wird in der Kostenfunktion dazu verwendet, einen plausiblen
Abstand zur Anfangsschatzung zu definieren. Abbildung4.6zeigt ein Beispiel fur die Funktion
ϑ. An den dort abgebildeten Hohenlinien ist die Grundform der Anfangsschatzung erkennbar.
Geringe Werte von∆i mit kleinen Kosten zu belegen, kann durch eine speziell gewahlte
Funktions erzielt werden. Analog zu [XS05] ergibt sich insgesamt folgende Kostenfunktion:
Eihomography(l)
def=
s(∆i, αh, βh) l = 1
(1− s(∆i, αh, βh))ϑi l = 0(4.11)
4Der Begriff Level-Set bezeichnet eigentlich Hohenlinien, bzw. eine Menge von Punkte mit gleicherz-Koordinate.
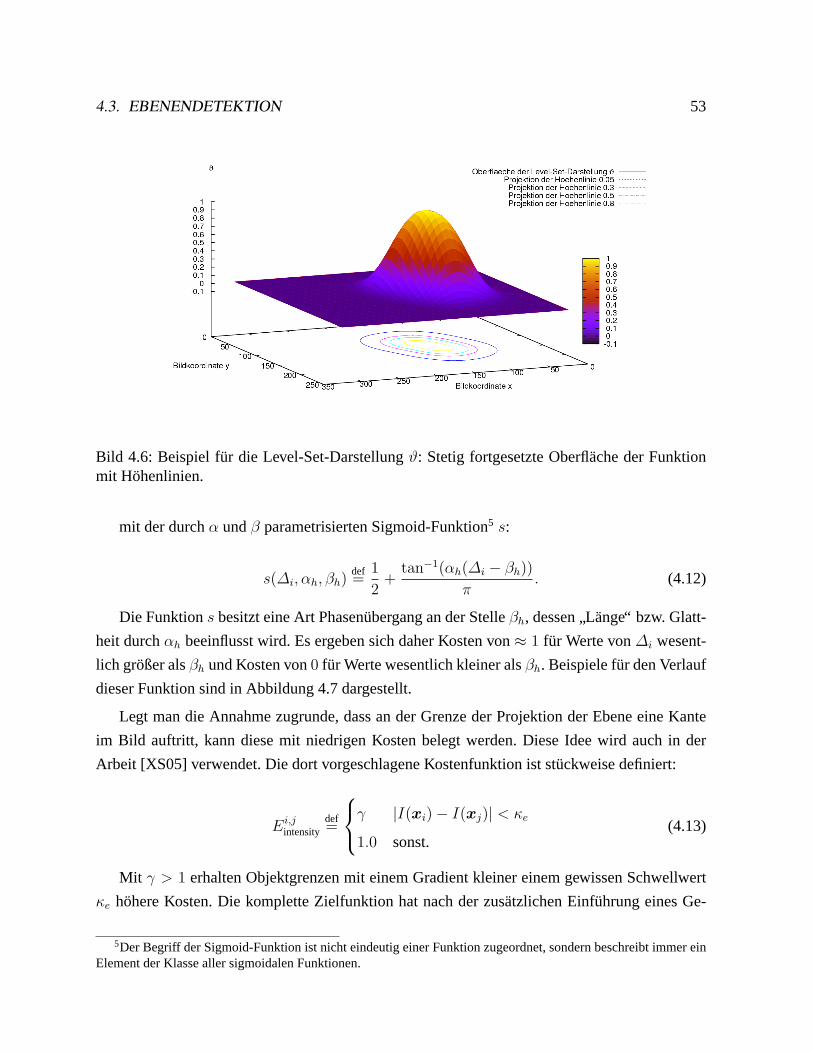
4.3. EBENENDETEKTION 53
Bild 4.6: Beispiel fur die Level-Set-Darstellungϑ: Stetig fortgesetzte Oberflache der Funktionmit Hohenlinien.
mit der durchα undβ parametrisierten Sigmoid-Funktion5 s:
s(∆i, αh, βh)def=
1
2+
tan−1(αh(∆i − βh))
π. (4.12)
Die Funktions besitzt eine Art Phasenubergang an der Stelleβh, dessen”Lange“ bzw. Glatt-
heit durchαh beeinflusst wird. Es ergeben sich daher Kosten von≈ 1 fur Werte von∆i wesent-
lich großer alsβh und Kosten von0 fur Werte wesentlich kleiner alsβh. Beispiele fur den Verlauf
dieser Funktion sind in Abbildung4.7dargestellt.
Legt man die Annahme zugrunde, dass an der Grenze der Projektion der Ebene eine Kante
im Bild auftritt, kann diese mit niedrigen Kosten belegt werden. Diese Idee wird auch in der
Arbeit [XS05] verwendet. Die dort vorgeschlagene Kostenfunktion ist stuckweise definiert:
Ei,jintensity
def=
γ |I(xi)− I(xj)| < κe
1.0 sonst.(4.13)
Mit γ > 1 erhalten Objektgrenzen mit einem Gradient kleiner einem gewissen Schwellwert
κe hohere Kosten. Die komplette Zielfunktion hat nach der zusatzlichen Einfuhrung eines Ge-
5Der Begriff der Sigmoid-Funktion ist nicht eindeutig einer Funktion zugeordnet, sondern beschreibt immer einElement der Klasse aller sigmoidalen Funktionen.
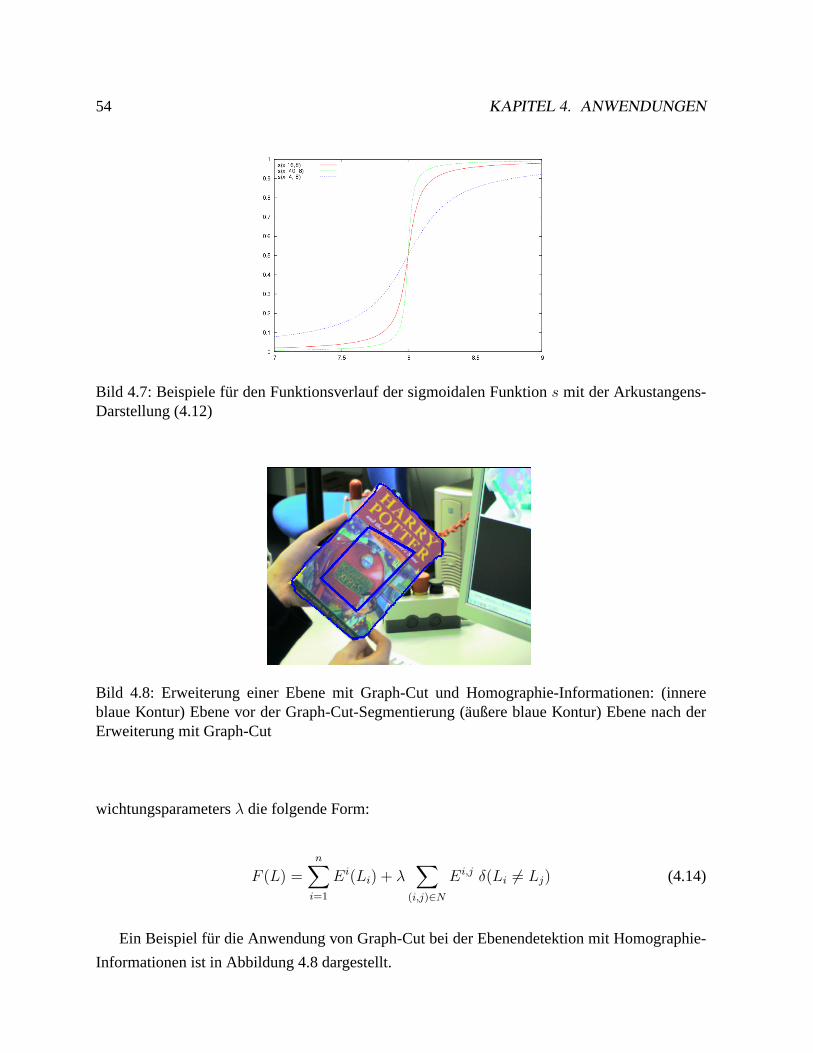
54 KAPITEL 4. ANWENDUNGEN
Bild 4.7: Beispiele fur den Funktionsverlauf der sigmoidalen Funktions mit der Arkustangens-Darstellung (4.12)
Bild 4.8: Erweiterung einer Ebene mit Graph-Cut und Homographie-Informationen: (innereblaue Kontur) Ebene vor der Graph-Cut-Segmentierung (außere blaue Kontur) Ebene nach derErweiterung mit Graph-Cut
wichtungsparametersλ die folgende Form:
F (L) =n∑
i=1
Ei(Li) + λ∑
(i,j)∈N
Ei,j δ(Li 6= Lj) (4.14)
Ein Beispiel fur die Anwendung von Graph-Cut bei der Ebenendetektion mit Homographie-
Informationen ist in Abbildung4.8dargestellt.

4.3. EBENENDETEKTION 55
4.3.3 Ebenendetektion mit zusatzlicher Tiefeninformation
Filterung der Tiefeninformation
Eine Filterung der Eingabedaten ist bei jeder Anwendung der Bildverarbeitung ein wichtiger
Schritt. Tiefeninformationen aktueller Kameras, wie etwa der PMD 19k (Abbildung5.1), sind
oft stark verrauscht und liefern viele Ausreißer in den Tiefenwerten.
Um diese Ausgangssituation zu verbessern, wurden zwei Filterungen durchgefuhrt. Die Ka-
mera liefert Kamera zusatzlich die Amplitudenwerte der Infrarot-Wellen in einem Sensor. Eine
geringe Amplitude lasst auf eine geringe Abstrahlung der aktiven Beleuchtung in der Szene
schließen. An diesen Stellen ist eine robuste Tiefenschatzung schwierig [Lan00] und die Wahr-
scheinlichkeit eines Ausreißers im Tiefenbild hoch. Die erste Filterung loscht daher die Tiefen-
information in Pixeln, bei denen der Amplitudenwert unter einem gewissen Schwellwert (z.B.
2.0) fallt. Anschließend erfolgt eine zweite Filterung mit einem 3x3 Median-Filter.
Verwendung der Tiefeninformation
Durch die Tiefeninformationen der Kamera (Abbildung5.1) und deren vorher bestimmte int-
rinsische Kameraparameter ist es moglich, fur jeden Punktx des Bildes den Punktx(3D) im
Raum relativ zum Kamerazentrum zu bestimmen. In Abschnitt4.3.2wurde als Maß fur die Zu-
gehorigkeit einzelner Pixel zur Ebeneπ ein Differenzbild berechnet. Ausgehend von den bereits
ermittelten 3D-Punkten lasst sich ein anderes Maß definieren, welches die exakte mathematische
Zugehorigkeit zur Ebene im Raum betrachtet.
Zunachst ist eine Bestimmung der Ebenenparameter notwendig. Unter Verwendung der Punk-
teS lasst sich eine allgemeine Schatzung im Sinne von M-Estimation [Hub80] anwenden:
n = argminn
∑x∈S
ρ(nT x(3D) − 1). (4.15)
Dabei istρ eine geeignete robuste Fehlerfunktion wie etwa die Huber-Funktion [Hub80]. Die
Losung des Optimierungsproblems (4.15) fuhrt auf eine iterative gewichtete Kleinste-Quadrate
Schatzung (IRLS). Es ist relativ leicht zu sehen, dass bei der Schatzung keine Ebene ermit-
telt werden kann, die durch den Ursprung (Kamerazentrum) verlauft. Diese mathematische Ein-
schrankung spielt in der Praxis keine Rolle, da jede Ebene, die das Kamerazentrum schneidet,
nur eine Gerade in der Bildebene bildet.
Ein geeignetes Maß fur die Zugehorigkeit eines Punktes zur Ebene lasst sich durch den Ab-

56 KAPITEL 4. ANWENDUNGEN
stand zur geschatzten Ebene definieren:
∆idef=|nT x(3D)
i − 1|‖n‖
. (4.16)
Dieser Abstand liefert die entscheidende Information bei der Aufstellung der passenden Ener-
giefunktionen.
Definition der Energiefunktionen
Bei der Pixelbewertung (Cliquen-Potentiale 1. Ordnung) ist es notwendig, folgende Sonderbe-
handlungen vorzunehmen:
1. Teilfixierung des Bildrandes auf die Hintergrundbeschriftung
2. Stellen an denen keine Tiefeninformationen verfugbar sind, konnen nur durch die Infor-
mationen der Nachbarn ( KostenEi,j ) beschriftet werden.
Die Bildrandbehandlung ist ein nicht zu unterschatzendes Problem bei der Graph-Cut-Segmentierung:
Fur Objektgrenzen am Bildrand entstehen im Gegensatz zu Grenzen im Bild keine Kosten. Dies
kann oft zu einer falschen Segmentierung fuhren. Die Annahme von Hintergrundpixeln am Rand
behebt dieses Problem.
Pixel ohne Tiefeninformationen entstehen durch die angewendeten Filteroperationen aus Ab-
schnitt4.3.3. Eine mathematische Beschreibung dieser Sonderfalle als Energiefunktion ist die
Folgende:
Eiplane(Li)
def=
0 keine Tiefeninformation an Positionxi verfugbar
−∞ Li = 0 ∧ xi liegt am Bildrand
Eiplane(Li) sonst.
(4.17)
Analog zu der Bewertung des Differenzbildes in Abschnitt4.3.2lasst sich der restliche Teil
der Funktion definieren:
Eiplane(Li)
def=
s(∆i, αp, βp) Li = 1
1− s(∆i, αp, βp) Li = 0.(4.18)
Die Bewertung von Objektgrenzen kann auf zwei verschiedene Arten durchgefuhrt werden.
Eine Moglichkeit ist es, Kanten im Distanzbild∆ zu betrachten. Wird zum Beispiel eine Ebene

4.3. EBENENDETEKTION 57
Bild 4.9: Beispiel fur eine Ebenensegmentierung: (Links) Startebene, (Mitte) Verfeinerung mitGraph-Cut und reiner Tiefeninformation, (Rechts) Verfeinerung mit Graph-Cut unter Verwen-dung von Tiefen- und Grauwertinformationen
vor einem weiter entfernten Hintergrund segmentiert, so ist klar ersichtlich, dass sich in∆ an den
Objektgrenzen eine klare Kante abzeichnet. Die Angabe der Kosten fur die Objektgrenze erfolgt
dabei wieder analog zu Abschnitt4.3.2mit einer stuckweise definierten Funktion:
Ei,jplane
def=
γ |∆i −∆j| < κp
1.0 sonst.(4.19)
Insgesamt ergibt sich wieder folgende Zielfunktion fur das Segmentierungsproblems:
F depth(L) =∑
i
Eiplane(Li) + λ
∑(i,j)∈N
Ei,jplane δ(Li 6= Lj). (4.20)
Fusion mit Grauwertinformationen
Zusatzlich zur Tiefe liefert die Kamera ein Infrarot-Bild der Szene. Die Verwendung der bis-
her beschriebenen Zielfunktion (4.20) fuhrt hingegen zu einer Segmentierung, die lediglich auf
den Tiefeninformationen basiert. Aus diesem Grund ist es Ziel des folgenden Abschnittes, eine
Fusion der Informationen aus Infrarot-Bild, im Folgenden allgemein als Grauwertinformation
bezeichnet, mit den Tiefeninformationen wahrend der Segmentierung zu erreichen.
Ein Ansatz ist es, die Bewertung der Objektgrenze im Infrarot-BildI anstatt im Distanzbild∆
vorzunehmen. Dabei kann wieder die Festlegung (4.13) aus Abschnitt4.3.2verwendet werden.
Die Kombination aus den beiden unterschiedlichen Kostenfunktionen ergibt daraufhin die fur
die Fusion verwendete ZielfunktionF fusion:
F fusion(L) =∑
i
Eiplane(Li) + λ
∑(i,j)∈N
Ei,jintensity δ(Li 6= Lj). (4.21)

58 KAPITEL 4. ANWENDUNGEN
Abbildung 4.9 zeigt auf anschauliche Weise wie diese Fusion zu besseren Ergebnissen bei
der Segmentierung fuhren kann. Bisherige Ebenen-Segmentierungsalgorithmen basierten entwe-
der auf reinen 3D-Informationen oder auf Grauwertinformationen. Durch die Kombination von
einzelnen Optimierungskriterien in einer Zielfunktion ist es moglich geworden, beide Informati-
onsquellen in einem Prozess effektiv zu nutzen.
Die Verwendung der Homographie-Information als dritte Informationsquelle ist leider bei
der heutigen gangigen Auflosung der Kameras von 19k Bildpunkten noch nicht nutzbar. Die
Schatzung der Homographie und die Bestimmung eines Differenzbildes ist leider nur bei große-
ren Auflosungen robust moglich.
An dieser Stelle sei weiterhin angemerkt, dass im ermittelten Infrarot-Bild der verwendeten
PMD-Kamera oft Phasensprunge auftreten konnen, die abhangig von den Oberflachen der Ob-
jekte in der Szene sind. Eine Modellierung dieser Effekte, wie sie in”normalen“ Grauwertbilder
nicht auftreten, wurde bisher nicht vorgenommen.

Kapitel 5
Experimente
Das folgende Kapitel soll die Moglichkeiten von Graph-Cut-Verfahren durch Experimente auf-
zeigen. Dabei werden unterschiedliche Ansatze gegenuber gestellt und die Auswirkungen der
Parameter aufgezeigt. Im Vordergrund bei der Auswahl der Experimente stand die Verwendung
von realen Bildmaterial.
So wurde fur die Kennzeichenlokalisierung das in Abschnitt4.2 beschriebene Verfahren in
das GesamtsystemlprJ des an der Universitat Jena entwickelten Kennzeichenlesers zusatzlich
integriert. Die Auswertung erfolgte anschließend auf der Grundlage der Gesamterkennungsrate.
Bei der Ebenendetektion wurden Ground-Truth Informationen fur verschiedene Szenen er-
stellt, welche eine quantitative Auswertung der in Abschnitt4.3vorgestellten Algorithmen ermoglich-
ten.
5.1 Kennzeichenlokalisierung
Im Rahmen einer Kooperation mit der FirmaROBOT Visual Systems GmbHentwickelte der
Lehrstuhl fur digitale Bildverarbeitung an der Universitat Jena den KennzeichenleserlprJ. Dieses
bereits existierende Gesamtsystem wurde um zusatzliche Komponenten der Graph-Cut-Optimierung
erweitert.
5.1.1 Experiment
Die Auswertung erfolgte auf unterschiedlichen Testreihen von Straßenszenen. Die Charakteristik
der einzelnen Sequenzen ist in Tabelle5.1aufgelistet.
Die Lokalisierung von Nummernschildrandern wie in Abschnitt4.2vorgestellt, wird fur jede
59
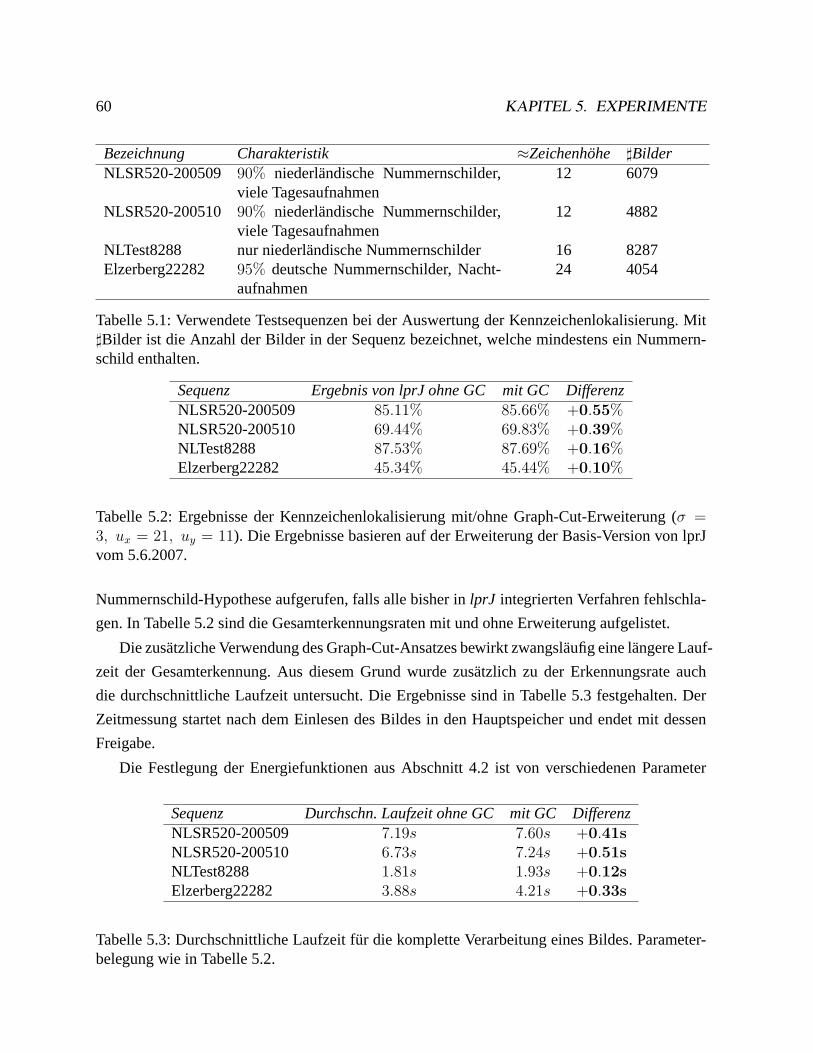
60 KAPITEL 5. EXPERIMENTE
Bezeichnung Charakteristik ≈Zeichenhohe ]BilderNLSR520-200509 90% niederlandische Nummernschilder,
viele Tagesaufnahmen12 6079
NLSR520-200510 90% niederlandische Nummernschilder,viele Tagesaufnahmen
12 4882
NLTest8288 nur niederlandische Nummernschilder 16 8287Elzerberg22282 95% deutsche Nummernschilder, Nacht-
aufnahmen24 4054
Tabelle 5.1: Verwendete Testsequenzen bei der Auswertung der Kennzeichenlokalisierung. Mit]Bilder ist die Anzahl der Bilder in der Sequenz bezeichnet, welche mindestens ein Nummern-schild enthalten.
Sequenz Ergebnis von lprJ ohne GC mit GC DifferenzNLSR520-200509 85.11% 85.66% +0.55%NLSR520-200510 69.44% 69.83% +0.39%NLTest8288 87.53% 87.69% +0.16%Elzerberg22282 45.34% 45.44% +0.10%
Tabelle 5.2: Ergebnisse der Kennzeichenlokalisierung mit/ohne Graph-Cut-Erweiterung (σ =3, ux = 21, uy = 11). Die Ergebnisse basieren auf der Erweiterung der Basis-Version von lprJvom 5.6.2007.
Nummernschild-Hypothese aufgerufen, falls alle bisher inlprJ integrierten Verfahren fehlschla-
gen. In Tabelle5.2sind die Gesamterkennungsraten mit und ohne Erweiterung aufgelistet.
Die zusatzliche Verwendung des Graph-Cut-Ansatzes bewirkt zwangslaufig eine langere Lauf-
zeit der Gesamterkennung. Aus diesem Grund wurde zusatzlich zu der Erkennungsrate auch
die durchschnittliche Laufzeit untersucht. Die Ergebnisse sind in Tabelle5.3 festgehalten. Der
Zeitmessung startet nach dem Einlesen des Bildes in den Hauptspeicher und endet mit dessen
Freigabe.
Die Festlegung der Energiefunktionen aus Abschnitt4.2 ist von verschiedenen Parameter
Sequenz Durchschn. Laufzeit ohne GC mit GC DifferenzNLSR520-200509 7.19s 7.60s +0.41sNLSR520-200510 6.73s 7.24s +0.51sNLTest8288 1.81s 1.93s +0.12sElzerberg22282 3.88s 4.21s +0.33s
Tabelle 5.3: Durchschnittliche Laufzeit fur die komplette Verarbeitung eines Bildes. Parameter-belegung wie in Tabelle5.2.

5.1. KENNZEICHENLOKALISIERUNG 61
Parameterσ Ergebnis von lprJ mit Graph-Cut1.0 85.54%2.0 85.56%3.0 85.66%4.0 85.66%5.0 85.59%6.0 85.51%
Tabelle 5.4: Auswertung des Parametersσ (Bewertung der Objektgrenzen) bei der Kennzeichen-lokalisierung anhand der Sequenz NLSR520-200509 (ux = 21, uy = 11)
Parameterux Ergebnis von lprJ mit Graph-Cut15 85.51%17 85.54%19 85.54%20 85.54%21 85.54%23 85.52%25 85.52%
Tabelle 5.5: Auswertung des Parametersux (Große der fixierten Region) bei der Kennzeichenlo-kalisierung anhand der Sequenz NLSR520-200509 (σ = 1, uy = 11)
abhangig. Die Untersuchung der Auswirkung dieser Parameter wurde ebenfalls anhand der Ge-
samterkennungsrate durchgefuhrt.
Der Parameterσ (Tabelle5.4) steuert den Einfluß der Bewertung der Objektgrenze. Durch
ux (Tabelle5.5) wird hingegen die Große der inneren fixierten Region festgelegt.
5.1.2 Auswertung
Durch die Kennzeichenlokalisierung mit Graph-Cut-Methoden konnte eine Verbesserung der
Gesamterkennungsrate (siehe Tabelle5.2) des Kennzeichenlesers erzielt werden. Die verwende-
ten Testsequenzen beinhalten eine Vielzahl von herausfordernden Problemstellungen (Schatten,
Buchstabensegmentierung mit Kontextinformation, Detektion), welche nur durch eine Vielzahl
von Algorithmen und Ansatzen losbar sind. Eine Verbesserung von durchschnittlich0.3% ist
daher in diesen Bereichen der Erkennungsrate ein wichtiger Schritt.
Die Auswertung der Laufzeit in Tabelle5.3 zeigt, dass die Verwendung des Graph-Cut-
Ansatzes eine Verlangerung der Laufzeit um durchschnittlich340 msec bewirkt. Diese zusatz-

62 KAPITEL 5. EXPERIMENTE
Bild 5.1: Verwendete Kamera fur Echtzeit-Tiefeninformationen: PMD Kamera 19k
liche Zeit ist im Verhaltnis zur Gesamtzeit der Erkennung vernachlassigbar. Dennoch ist es
abhangig vom Anwendungsgebiet, ob eine leichte Verbesserung der Gesamterkennung durch
eine solche Erhohung der Laufzeit sinnvoll ist.
Die Auswertung der Parameter in den Tabellen5.4und5.5zeigt außerdem, dass deren Wert
den Erkennungsprozess nicht signifikant beeinflusst. Eine rein heuristische Festlegung vonσ und
ux ist demnach zulassig.
5.2 Ebenendetektion
5.2.1 Experimentaufbau
Als Kamera mit Echtzeit-Tiefeninformation wurde die PMD 19k (Abbildung5.1) mit einer Auflosung
von 160x120 Bildpunkten verwendet.
Die quantitative Auswertung wurde anhand von drei Bildsequenzen durchgefuhrt. Die dabei
verwendete Szene stellt eine Art raumliches Kalibriermuster dar, welches gute Punktmerkma-
le fur die Verfolgung liefert. Fur die Sequenzen wurden Ground-Truth Informationen erstellt.
Diese Ground-Truth Informationen beinhalteten die Anzahl der ebenen Teilstucke im Bild so-
wie zugehorige Bildpunkte. Die Generierung dieser Informationen erfolgte ausgehend von einer
manuellen Startauswahl mit Hilfe der Ebenenverfolgung und zusatzlicher manueller Korrekturen
innerhalb der Sequenz.
Der Fehler bzw. Abstand zwischen zwei ebenen Teilstucken (Regionen) wurde anhand des
folgenden Verhaltnisses berechnet:
e(A, B) =](A \B) + ](B \ A)
]A + ]B. (5.1)

5.2. EBENENDETEKTION 63
Bild 5.2: Versuchsaufbau fur Beispiel5.5
Dieses Fehlermaß ist0 genau dann, wenn die RegionenA undB identisch sind und1 falls
es sich um disjunkte Mengen handelt. Der Zahler wird auch oft als symmetrische Differenz
von A mit B bezeichnet. In jedem Bild der Sequenz mussen mehrere Ground-Truth Regionen
und geschatzte Regionen miteinander verglichen werden. Da die Zuordnung zueinander nicht
gegeben ist, erfolgt die Bestimmung des minimalen Fehlerse zwischen zwei Regionen1:
e = minGround-Truth RegionA,
Berechnete RegionB
e(A, B). (5.2)
Dadurch ist es moglich, fur ein Bild mit einzigen Wert eine quantitative Aussage bezuglich
der Genauigkeit der Segmentierung zu erhalten. Fur jede Sequenz konnten daraufhin Durch-
schnittswerte vone gebildet werden. Die ermittelten Werte sind in Tabelle5.6 dargestellt. Die
Bewegung der Kamera in den verwendeten Sequenzen beinhaltet zu jedem Zeitpunkt eine Trans-
lation. Daher wurde der in der Arbeit [KD07] vorgestellte Translations-Test nicht benotigt. Ver-
wendete Modellparameter sind in TabelleB.2 des AbschnittesB.3 aufgelistet.
Abbildung 5.3 zeigt beispielhaft den Fehlere bei jedem erfolgreichen Detektionsschritt in
der Sequenzseq1 . Aus Grunden derUbersichtlichkeit wurden nur die auf [KD07] basierenden
Verfahren in der Abbildung verglichen. Das Verfahren von [KD07] kann nicht in jedem Bild der
Sequenz eine Gruppe von Punktmerkmale finden, welche der gleichen Homographie unterliegen.
Daher erfolgte nur an den in Abbildung5.3markierten Stellen eine Detektion.
Eine ahnliche Darstellung der Resultate fur die Ebenendetektion auf der Grundlage von
1Analog wurde auch die Auswertung der Kennzeichenerkennung beilprJ durchgefuhrt. Der dort verwendeteAbstand ist die Levenshtein-Distanz zwischen den Kennzeichen-Strings.
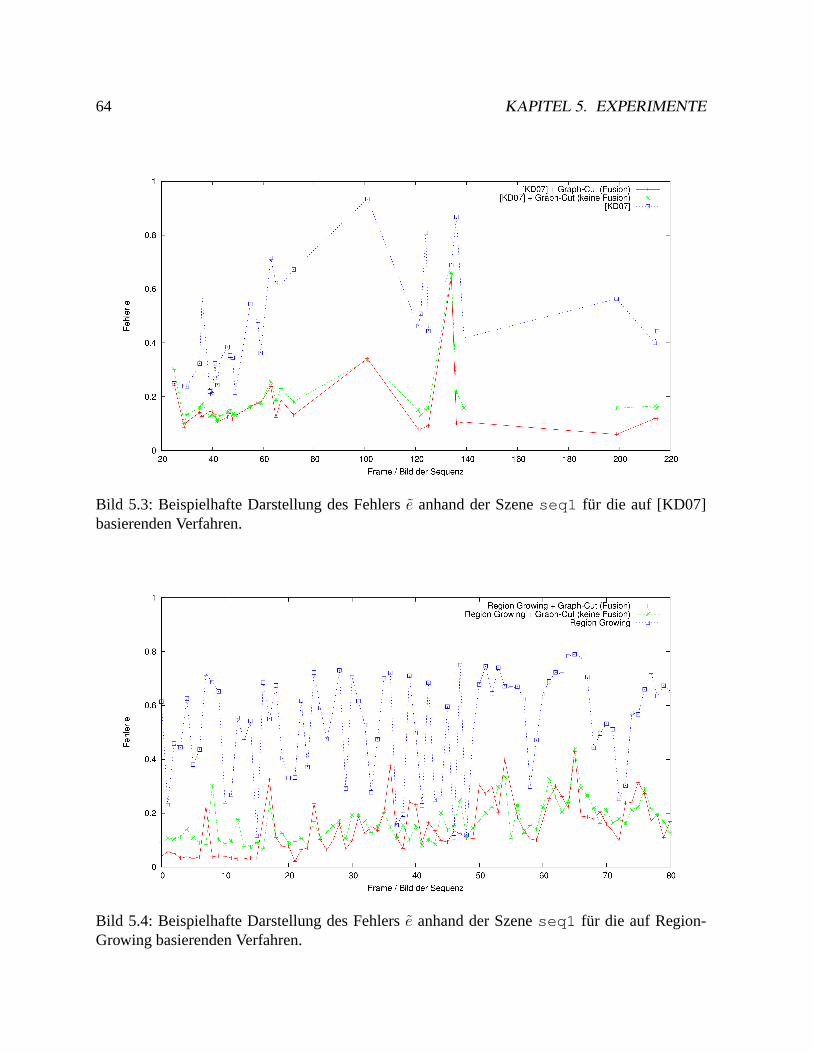
64 KAPITEL 5. EXPERIMENTE
Bild 5.3: Beispielhafte Darstellung des Fehlerse anhand der Szeneseq1 fur die auf [KD07]basierenden Verfahren.
Bild 5.4: Beispielhafte Darstellung des Fehlerse anhand der Szeneseq1 fur die auf Region-Growing basierenden Verfahren.

5.2. EBENENDETEKTION 65
Bild 5.5: Beispiel fur eine Ebenensegmentierung: (Links) Startebene, (Mitte) Verfeinerung mitGraph-Cut und reiner Tiefeninformation, (Rechts) Verfeinerung mit Graph-Cut unter Verwen-dung von Tiefen- und Grauwertinformationen
Region-Growing [KRD07] l asst sich Abbildung5.4entnehmen. Das Startverfahren benotigt nur
die Information eines einzelnen Bildes und kann daher die Detektion von planaren Teilstucken
in jedem Bild der Sequenz vornehmen.
Bei der Anwendung des Verfahrens in realen Aufnahmen treten oft Probleme mit der Punkt-
verfolgung auf. Dies liegt in der niedrigen Auflosung des Infrarot-Bildes begrundet, welches die
zusatzliche Schwierigkeit von Phasensprungen aufweist. Eine qualitative Auswertung von realen
Sequenzen wurde daher immer mit dem Region-Growing Varianten durchgefuhrt. Abbildung5.5
zeigt ein Beispiel solch einer Szene. In AbbildungB.3 des Anhangs befindet sich eine, mit einer
anderen Kamera aufgenommene, Darstellung.
5.2.2 Auswertung
Die Entwicklung der Verfahren fur die Ebenensegmentierung basierten auf zwei Thesen, welche
im Folgenden anhand der Daten aus den Experimenten ausgewertet werden.
Die erste These ist, dass die Verfeinerung der bereits gefundenen ebenen Teilstucke durch
eine Segmentierung mit Graph-Cut zu einer Verbesserung der Ebenendetektion fuhrt. Die er-
mittelten Werte des Fehlerse in Tabelle5.6 bestatigen diese Vermutung. Der durchschnittliche
Fehler bei den zwei Varianten der Graph-Cut-Segmentierung liegt signifikant unterhalb des Feh-
Verfahren seq1 seq2 seq3[KD07] + Graph Cut mitF fusion 0.153 0.244 0.214[KD07] + Graph Cut mitF depth 0.184 0.252 0.217[KD07] 0.462 0.345 0.260Region Growing + Graph Cut mitF fusion 0.178 0.239 0.202Region Growing + Graph Cut mitF depth 0.213 0.249 0.205Region Growing 0.556 0.476 0.459
Tabelle 5.6: Durchschnittswerte vone fur verschiedene Szenen und die vorgestellten Verfahren.

66 KAPITEL 5. EXPERIMENTE
lers des ursprunglichen Verfahrens. Sowohl beim Region-Growing in den reinen 3D-Daten als
auch bei der Detektion von planaren Teilstucke nach [KD07] konnte daher durch einen Optimie-
rungsschritt mit Graph-Cut die Segmentierung verbessert werden.
Die Verwendung von Informationen aus dem Infrarot-Bild wurde motiviert durch eine zwei-
te These: Die Fusion von Tiefeninformation und Grauwertinformation kann zu einer weiteren
Verbesserung der Segmentierung fuhren. Auch diese These wird durch Tabelle5.6bestatigt. Der
Fehler beim Verfahren, welches die Fusion verwendet, ist bei allen 3 Sequenzen und beiden
Ansatzen geringer als bei der Verwendung reiner Tiefeninformation.
Beide Aussagen lassen sich ebenfalls in den Abbildungen5.3 und 5.4 erkennen. Die Kur-
ven der Graph-Cut-Ansatze liegen weit unterhalb der Verfahren, welche die Startlosung liefern.
Durch die Fusion kann daraufhin eine zweite Verbesserung erzielt werden.

Kapitel 6
Ausblick
Die Moglichkeiten der allgemeinen Erweiterung der vorgestellten Verfahren konzentrieren sich
auf die drei Kernbereiche: Modellerweiterungen, Theorie, Algorithmik. Weiterhin lassen sich
naturlich auch Verbesserungsansatze bei den im Rahmen dieser Arbeit vorgestellten Anwendun-
gen erkennen.
6.1 Allgemeine Ansatze fur die weitere Forschung
Ausgangspunkt fur die in dieser Arbeit verwendeten Modelle war immer das verallgemeiner-
te Potts-Modell. Dies lag vor allem an der Regularitatsforderung, die kaum eine andere Wahl
(siehe Abschnitt3.3.2, Bemerkung3.47) ermoglicht. Grundlegend stellt sich aber die Frage, ob
es nicht durch die Verallgemeinerung von [FD05] moglich ist, komplexere Modelle zu verwen-
den. Dabei wird es zwangslaufig notig sein, die richtige Balance zwischen der Gute des Modells
und der Komplexitat der entstehenden Graphen zu finden. Schon eine Verwendung von Cliquen-
Potentialen 3. Ordnung erzwingt die Einfuhrung zusatzlicher Knoten und Kanten.
Bisherige theoretische Untersuchung von Graph-Cut-Verfahren beschrankten sich oft auf die
Charakterisierung von graph-darstellbaren1 Funktionen. In der Arbeit [Vek00] wurden hinge-
gen”topologische“ Eigenschaften von Segmentierungsergebnissen untersucht, welche durch die
Anwendung von Graph-Cut-Verfahren entstehen. Eine Fortfuhrung dieser Untersuchungen fur
allgemeinere Modelle konnte generell zu theoretischen Richtlinien fuhren, welche die Entwick-
lung von geeigneten Zielfunktionen bei vielen anderen Anwendungen unterstutzen konnten. In
vielen Arbeiten wurden bereits verwendete Ansatze aus fruheren Arbeitenubernommen, ohne
1Graph-darstellbare Funktionen sind Zielfunktionen von Optimierungsproblemen, welche auf das Min-Cut-Problem abgebildet werden konnen (siehe Abschnitt3.3.2).
67

68 KAPITEL 6. AUSBLICK
die Moglichkeiten der Weiterentwicklung und Spezialisierung auf das aktuelle Problem voll aus-
zuschopfen.
Ein ahnliches Problem sind die vielen Parameter der Zielfunktion, welche nur durch empi-
risch ermittelte Richtwerte festgelegt werden. Die Arbeit [CG06] bietet an dieser Stelle erste
Ansatze, um Modelle bzw. Zielfunktionen anzulernen. Dadurch ware es moglich, eine Vielzahl
von Parametern automatisch zu bestimmen und sich von bisher gewahlten Heuristiken zu losen.
6.2 Verbesserung der Kennzeichenerkennung durch Graph-
Cut-Verfahren
Die Verwendung von diskreten Optimierungsproblemen und deren Losung in Form von Graph-
Cut-Verfahren ist in vielen Teilschritten der Kennzeichenerkennung denkbar. Im Rahmen dieser
Arbeit konnte ein weiteres Verfahren zur Kennzeichenlokalisierung entwickelt werden.
Welche Moglichkeiten sich bei der Segmentierung mit Graph-Cut-Methoden im Bereich der
Buchstabensegmentierung in einem gefundenen Kennzeichen ergeben, bleibt weiterhin offen.
Eine gezielte Modellierung dieser Anwendung, welche bezuglich der resultierenden Ergebnis-
se etablierter Standardverfahren entscheidende Vorteile aufweisen sollte,ubersteigt bislang die
theoretischen Moglichkeiten. Effizient losbare diskrete Optimierungsprobleme, welche komple-
xe Kontureigenschaften der Objektgrenze einfließen lassen, wurden eine Brucke schlagen zur
bisher weitaus praktikableren kontinuierlichen Optimierung [CKS03].
Ein weiterer moglicher Ansatz ware, das Problem der Trennung von Buchstabenkonturen mit
Graph-Cut zu losen. Dies ist ein wichtiger Nachbearbeitungsschritt, um Fehler bei der Kontursu-
che zu beheben. Die aktuelle Implementierung inlprJ verwendet horizontale Projektionen, um
eine geeignete Stelle zu finden.
6.3 Erweiterung der Ebenendetektion mit Graph-Cut
Die vorgestellte Verfeinerung der Ebenendetektion verwendet ein binares Optimierungsproblem.
Eine Erweiterung konnte die Verfeinerung mehrerer planarer Teilstucke durch denα-Expansion-
Algorithmus in einer Optimierung durchfuhren. Das noch vorhandene Problem vonuberlappen-
den Teilstucken ware damit gelost. Zusatzlich ware es in diesem Kontext sinnvoll, eine passende
Methode fur die Vereinigung von mehreren planaren Teilstucken als Teilschritt der Detektion zu
integrieren.

Kapitel 7
Zusammenfassung
Ziel der vorliegenden Arbeit war es, die Moglichkeiten von Graph-Cut-Methoden in der Bildver-
arbeitung theoretisch und an praktischen Beispielen darzulegen. Diese Verfahren ermoglichen
es, allgemeine Segmentierungsprobleme zu losen.
In den ersten beiden Kapiteln wurden getrennt voneinander die wichtigsten Resultate der
Bayesschen Bildanalyse und der diskreten Optimierung mit Graph-Cut vorgestellt. Auf der einen
Seite fuhrten die Ausfuhrungen zur Bayesschen Bildanalyse in Kapitel2zum Satz von Hammers-
ley und Clifford. Auf der anderen Seite konnte in Kapitel3 mit den Ergebnissen aktueller Arbei-
ten [KZ04, FD05] eine Klasse von effizient losbaren Optimierungsproblemen gefunden werden.
Die eindeutige Charakterisierung dieser Probleme und die Darstellung der Verbindungen zu an-
deren Gebieten ermoglichte eine umfassende Darstellung des aktuellen Forschungsstandes auf
diesem Gebiet. Weiterhin wurden Grenzen der Berechenbarkeit bei der diskreten Optimierung
aufgezeigt. Die Anwendung von Approximationsalgorithmen, wie etwa dem in Abschnitt3.4
vorgestelltenα-Expansion-Algorithmus, ermoglichte es dennoch ein Ergebnis zu finden, welche
klar definierten Optimalitatsanforderungen (siehe Abschnitt3.4.2) genugt.
Beide Hauptresultate der ersten Kapitel konnten in Abschnitt3.4.4zu einem praktikablen
Werkzeug fur die Anwendung in der Bildverarbeitung kombiniert werden.
In Kapitel 4 wurden anschließend verschiedene Problemstellungen vorgestellt, welche effi-
zient mit diskreter Optimierung gelost werden konnten. Im Kontext eines Industrieprojektes des
Lehrstuhls konnte die Kennzeichenlokalisierung des KennzeichenleserslprJ mit einem Graph-
Cut-Ansatz verbessert werden.
Bewegungssegmentierung im Sinne der Detektion planarer Teilstucken in einer Szene wur-
de in Abschnitt4.3.2 analog zu einem Ansatz von [XS05] realisiert. Eine zusatzliche Erwei-
terung dieser Idee fuhrte auf eine Losung dieser Problemstellung bei der Verwendung einer
69

70 KAPITEL 7. ZUSAMMENFASSUNG
Echtzeit-Tiefenkamera. Das dabei entwickelte Verfahren ermoglicht es, Tiefen und Grauwert-
Informationen effizient in einem Optimierungsschritt zu kombinieren.
Kapitel 5 zeigte durch Experimente, dass die vorgestellten Verfahren zur Losung ihrer Pro-
blemstellung beitragen. Die Untersuchung der Kennzeichenlokalisierung erfolgte durch die Aus-
wertung der Erkennungsrate des Gesamtsystems. Dabei wurden zusatzlich die Auswirkungen
verschiedener Parameteruberpruft. Insgesamt konnte die Erkennungsrate durch das zusatzliche
Graph-Cut basierende Verfahren um durchschnittlich0.3% Prozentpunkte gesteigert werden.
Die Leistungsfahigkeit des Graph-Cut-Ansatzes bei der Ebenensegmentierung wurde durch
den Vergleich mit Ground-Truth Daten demonstriert. Die Algorithmen fuhrten zu einer signi-
fikanten Verbesserung der initial gefundenen Ebenen. Im Vergleich zum Ansatz, welcher nur
Tiefen-Informationen verwendet, ermoglichte die Fusion mit Grauwert-Informationen eine zusatz-
liche Minimierung des Fehlers.

Anhang A
Mathematische Details
A.1 Zusammenhang zwischen binarer Bildrestaurierung und
Medianfilter
Die Ahnlichkeit der Ergebnisse zwischen einem binaren Medianfilter und der binaren Bildre-
staurierung wie sie in Abschnitt2.3.4vorgestellt wurde, werfen die Frage nach mathematischen
Zusammenhangen auf. Dieser Abschnitt versucht diesbezuglich, mogliche Querverbindungen
aufzuzeigen.
Betrachtet wird zunachst die vollstandige Energiefunktion der binaren Bildrestaurierung mit
der Konstanteβq :
E(L) = βq
∑p∈P
IpLp − α∑
(p,z)∈N
LpLz. (1.1)
Es gilt weiterhin ohne Beschrankung die folgende Aussage:
Die Beschriftung vonLp ist gleich1 ⇐⇒
βqIp − α∑
(p,z)∈N
Lz < −βqIp + α∑
(p,z)∈N
Lz. (1.2)
Dabei mussen nur die Summanden der Zielfunktion betrachtet werden, welche vonp abhangig
sind. Weitere Umformungen ergeben:
0 >
∑(p,z)∈N
Lz
− βq
αIp (GC)
71

72 ANHANG A. MATHEMATISCHE DETAILS
Es lasst sich leicht sehen, dass im Gegensatz dazu fur den Medianfilter die folgende Charak-
teristik gilt: Lp = 1 ⇐⇒
0 >
∑(p,z)∈N
Iz
+ Ip (Median)
Unter den folgenden Annahmen ergibt sich daraufhin dieAquivalenz der beiden Verfahren:
1. Die Beschriftung benachbarter Pixel weicht nicht von den Werten im Originalbild ab:Lz =
Iz.
2. Fur die Parameterβq undα gilt: −βq
α= 1.
Die erste Forderung ist naturlich bei beliebigen Bildern und beliebiger Positionp nicht ge-
geben. Betrachtet man hingegen eine homogene schwarze Flache mit einem weißen Punkt im
Inneren, welcher durch Rauschen erzeugt wurde, so kann sich bei beiden Verfahren nur dieser
Punkt in seiner Beschriftung verandern.
Die zweite Annahme lasst sich noch auf die Wahrscheinlichkeitq des Rauschens zuruckfuhren:
α = −βq =1
2log
(1− q
q
)(1.3)
q =1
exp (2α) + 1. (1.4)
Fur den Wertα = 0.3 aus Beispiel2.1 ergibt sich daher der Wertq ≈ 0.354, welcher un-
gefahr mit der gewahlten Wahrscheinlichkeitubereinstimmt. Aus Gleichung (GC) lasst sich die
Funktionsweise der binaren Bildrestaurierung deutlich erkennen. Der Einfluss der Beobachtung
im aktuellen Pixel wird durch den Parameterγ = −βq
αgesteuert. Dieser gewichtet sozusagen
den PixelwertIp in der Statistik der Umgebung. Die binare Bildrestaurierung im Sinne von Ab-
schnitt2.3.4kann daher als Verallgemeinerung des Median-Filters angesehen werden.
A.2 Details zum Algorithmus von [BK04]
Die Suchbaume ausgehend vom Knotens bzw.t seien mitS undT bezeichnet. Diese Suchbaume
sind disjunkt, bilden aber keine Zerlegung der KnotenmengeV (siehe AbbildungA.1). Fur den
BaumS gilt, dass jede Kante vom Elternknoten zum Kindknoten nicht gesattigt ist. Im BaumT
gilt das Gleiche fur Kanten von den Kindknoten zu den Elternknoten.

A.2. DETAILS ZUM ALGORITHMUS VON [?] 73
Bild A.1: Darstellung der Notation und Vorgehensweise des Algorithmus von [BK04].Suchbaume:S, T . A dient zur Beschriftung der aktiven Knoten (Blatter des Suchbaumes). Allemit P beschrifteten Knoten sind passive Knoten (innere Knoten des Suchbaumes).
Die Knoten der Suchbaume konnen zwei Zustande annehmen: aktiv (Grenzknoten, Blatter
oder Knoten mit nicht erfassten Nachbarn) und passiv (innere Knoten). Aktive Knoten konnen
einen Suchbaum erweitern. Wenn ein aktiver Knoten mit einem Nachbarn aus dem anderen Such-
baum verarbeitet wird, dann ist ein damit gesuchter erhohender (augumenting) Pfad gefunden.
Der Algorithmus lasst sich in folgende 3 Phasen aufteilen:
1. Wachstumsphase: Erweiterung vonS undT solange bis sie sich”beruhren“ und den ersten
s-t-Pfad bilden.
2. Erhohungsphase: Der entsprechende Pfad wird erhoht, dadurch zerfallenS undT in Walder.
3. Anpassungsphase: Die BaumeS undT werden wiederhergestellt.
Der Zerfall der BaumeS und T in Walder geschieht, wenn eine Kante vom Elternknoten
zum Kindknoten plotzlich nach der Erhohung gesattigt ist. In der Arbeit [BK04] werden diese
Kindknoten als”Orphans“ bezeichnet. Sie bilden die Wurzelknoten der neuen Teilbaume.
In der Anpassungsphase wird anschließend zu jedem Orphan ein neuer Elternknoten gesucht,
welcher sich im gleichen Suchwald befindet wie der Orphan selbst (sozusagen eine Wiederher-
stellung). Die neue Verbindung zum neuen Elternknoten darf nicht gesattigt sein. Falls es keine
solche Verbindung gibt, wird der Orphan frei gegeben (free node) und alle seine Kindknoten
werden selbst zu Orphans. Daraufhin beginnt der Prozess von neuem.
Der Algorithmus endet, wenn die Suchbaume nicht weiter wachsen konnen (keine aktiven
Knoten mehr) und die Baume durch gesattigte Kanten getrennt sind. Weitere algorithmische
Details konnen [BK04] und [Kol03] entnommen werden.

74 ANHANG A. MATHEMATISCHE DETAILS
A.3 Minimierung von F2-Funktionen ist NP-schwer
In [KZ04] wird der Beweisuber eine Reduktion des Problems der großten unabhangigen Menge
in einem Graphen gefuhrt. Dieses Problem ist bekanntermaßen NP-schwer.
Sei G = (V, N) ein beliebiger ungerichteter Graph mitn = ]V und m = ]N . Um die
großte unabhangige Menge1 in G zu finden, dient eine Umformulierung des Problems auf ein
Beschriftungsproblem. SeiL ∈ 0, 1n ein binarer Vektor, welcher als Reprasentation einer
Teilmenge von Knoten inG verwendet wird. Gesucht ist demnach ein binarer Vektor, welcher
einer großten unabhangigen Menge inG entspricht.
Dieser Vektor lasst sich mit einem Optimierungsproblem mit folgender Form der Zielfunkti-
on finden:
E(L) = − 1
2n
∑i
Li +∑
(i,j)∈N
LiLj. (MaxISet)
Diese Zielfunktion ist nicht mit dem in Abschnitt2.3.4beschriebenen Ising-Modell (2.27)
vergleichbar, da dieses Mal der VektorL mit 0, 1 kodiert wurde. Erkennbar ist ebenfalls, dass
diese Funktion nicht regular2 ist: 0 · 0 + 1 · 1 > 0 · 1 + 1 · 0.
Satz 1.5 Eine großte unabhangige Menge in einem ungerichteten GraphenG = (V, N) lasst
sich durch Minimierung von(MaxISet) finden.
Beweis zu 1.5: Sei L die Losung von (MaxISet). Im Folgenden seien binare VektorenL ∈0, 1n zusatzlich zur Vektordarstellung mit ihrer entsprechenden Menge von Knoten ausV
identifiziert.
Annahme 1: L ist keine unabhangige Menge.
Dann gibt es mindestens ein benachbartes Knotenpaar inL und es gilt demnach mitk = ]L:
E(L) ≥ − k
2n+ 1 > − 1
2n= E(v). (1.6)
mit einem beliebigen Knotenv ausV . Daher kannL nicht die Losung von (MaxISet) sein
und es ergibt sich der gewunschte Widerspruch zur Annahme1.
Annahme 2: Es gibt eine CliqueL in G mit ]L > ]L = k.
1A ⊆ V ist eine unabhangige Menge inG ⇐⇒ ∀v ∈ A : NG(v) ∩A = ∅2Aus der Regularitat vonE wurde sich folgende Argumentationskette ergeben:E regular→E graph-darstellbar
→ (MaxISet) ∈ P → Maximum Independent Set∈ P → P = NP → Fields Medal.

A.4. VERIFIKATION DER GRAPH-KONSTRUKTION BEI F2-FUNKTIONEN 75
Es ergibt sich sofort die Folgerung:
E(L) = −]L
2n< − k
2n= E(L). (1.7)
Damit waren Annahme1 und Annahme2 widerlegt und der Beweis vollstandig.
A.4 Verifikation der Graph-Konstruktion bei F2-Funktionen
Im Folgenden soll die Korrektheit der Graph-Konstruktion furF2-Funktionen bewiesen werden.
Als”Wegweiser“ dient Tabelle3.4. Mit ∝ sei die Gleichheit bis auf eine Konstante bezeichnet.
Satz 1.8 Die Graph-Konstruktion fur F2 Funktionen, wie in Tabelle3.4beschrieben, ist korrekt.
Beweis zu 1.8: Gegeben sei ein minimaler SchnittC im konstruierten Graphen. MitL sei die
darauf definierte Beschriftung bezeichnet. Die SchreibweiseLi = 0 als Index einer Summe
bedeutet, dassuber alle moglicheni summiert wird, fur dieLi = 0 gilt.
∑e∈C
w(e) =∑Li=0Lj=1
w((vi, vj)) +∑Li=1
w((s, vi)) +∑Li=0
w((vi, t)) (1.9)
Die einzelnen Kantengewichte konnen durch die verwendeten Werte bei der Konstruktion
(siehe Tabelle3.4) ersetzt werden. Dazu seien die AbkurzungenEi,jab
def= Ei,j(a, b) und Ei
adef=
Ei(a) verwendet. Fur die einzelnen Summanden der obigen Gleichung ergibt sich daraufhin:
∑Li=0Lj=1
w((vi, vj)) =∑Li=0Lj=1
(Ei,j
01 + Ei,j10 − Ei,j
00 − Ei,j11
)(1.10)
∑Li=1
w((s, vi)) =∑
Li=1,Ei1≥Ei
0
(Ei
1 − Ei0
)+∑Li=1
∑j, Ei,j
10 ≥Ei,j00
(Ei,j
10 − Ei,j00
)+ (1.11)
+∑Li=1
∑j, Ej,i
11≥Ej,i10
(Ej,i
11 − Ej,i10
)(1.12)

76 ANHANG A. MATHEMATISCHE DETAILS
∑Li=0
w((vi, t)) =∑
Li=0,Ei1≤Ei
0
(Ei
0 − Ei1
)+∑Li=0
∑j, Ei,j
10 ≤Ei,j00
(Ei,j
00 − Ei,j10
)+ (1.13)
+∑Li=0
∑j,Ej,i
11≤Ej,i10
(Ej,i
10 − Ej,i11
)(1.14)
Fur dieEi-Terme gelten folgende Vereinfachungen:
∑Li=1,Ei
1≥Ei0
(Ei
1 − Ei0
)+
∑Li=0,Ei
1≤Ei0
(Ei
0 − Ei1
)=
∑i, Ei(Li)≥Ei(1−Li)
(Ei(Li)− Ei(1− Li)
)(1.15)
=∑
i
Ei(Li)−∑
i
(min
x∈0,1Ei(x)
)(1.16)
∝∑
i
Ei(Li) (1.17)
Ziel ist es noch zu zeigen, dass der Ausdruck∑i,j
Ei,j(Li, Lj) und die folgende Summe bis
auf eine Konstanteaquivalent sind:
∑Li=0Lj=1
(Ei,j
01 + Ei,j10 − Ei,j
00 − Ei,j11
)+ (1.18)
+∑Li=1
∑j, Ei,j
10 ≥Ei,j00
(Ei,j
10 − Ei,j00
)+ (1.19)
+∑Lj=1
∑i, Ei,j
11 ≥Ei,j10
(Ei,j
11 − Ei,j10
)+ (1.20)
+∑Li=0
∑j, Ei,j
10 ≤Ei,j00
(Ei,j
00 − Ei,j10
)+ (1.21)
+∑Lj=0
∑i, Ei,j
11 ≤Ei,j10
(Ei,j
10 − Ei,j11
)(1.22)
An den Summanden (1.18) bis (1.22) lasst sich erkennen, dass es vollkommen legitim ist, die
einzelnen TermeEi,j getrennt voneinander zu betrachten. An dieser Stelle seien daher wieder

A.4. VERIFIKATION DER GRAPH-KONSTRUKTION BEI F2-FUNKTIONEN 77
die folgenden Abkurzungen und die Matrix-Notation der Funktion verwendet:
(Ei,j
00 Ei,j01
Ei,j10 Ei,j
11
)=
(A B
C D
)(1.23)
Bei einem TermEi,j ist es notwendig, 4 Falle3 zu untersuchen. Aus der obigen großen Sum-
me lassen sich daraufhin die Summanden angeben, welche voni und j gleichzeitig abhangig
sind. Diese Summanden seien mitSi,j bezeichnet und in der Matrix-Notation dargestellt. Ziel ist
es, zu zeigen, dassSi,j ∝ Ei,j gilt.
1. Fall C ≥ A undD ≥ C
Si,j =
(0 B + C − A−D + D − C
C − A C − A + D − C
)(1.24)
=
(0 B − A
C − A D − A
)∝
(0 B − A
C − A D − A
)+
(A A
A A
)= Ei,j (1.25)
2. Fall C ≥ A undD ≤ C
Si,j =
(C −D B + C − A−D
C − A + C −D C − A
)(1.26)
=
(C −D B + C − A−D
2C − A−D C − A
)+
(A− C + D A− C + D
A− C + D A− C + D
)= Ei,j
(1.27)
3. Fall C ≤ A undD ≥ C
Si,j =
(A− C B + C − A−D + A− C + D − C
0 D − C
)(1.28)
=
(A− C B − C
0 D − C
)∝
(A− C B − C
0 D − C
)+
(C C
C C
)= Ei,j (1.29)
3Die 4 Falle sind nicht disjunkt. Bei den jeweiligen Schnittmengen fallen aber die Argumentationen (Umfor-mungen) zu einer zusammen.

78 ANHANG A. MATHEMATISCHE DETAILS
4. Fall C ≤ A undD ≤ C
Si,j =
(A− C + C −D B + C − A−D + A− C
C −D 0
)(1.30)
=
(A−D B −D
C −D 0
)∝
(A−D B − C
C −D 0
)+
(D D
D D
)= Ei,j (1.31)
Setzt man diese Argumentation fur die gesamte Funktion zusammen, erhalt man das gewunsch-
te Resultat:
∑e∈C
w(e) ∝∑
i
Ei(Li) +∑i,j
Ei,j(Li, Lj) = F (L) (1.32)

Anhang B
Details zu den Experimenten
B.1 Verwendete Parameter bei der Kennzeichenlokalisierung
Sequenz vx vy
NLSR520-2005* 175 64NLTest8288 175 64
Elzerberg Testset 22282350 80
Tabelle B.1: Verwendete Parameter bei den Experimenten der Kennzeichenlokalisierung
TabelleB.1 zeigt die verwendeten Angaben fur die Maximalgroße eines Nummernschildes.
Als Nachbarschaft bei der Zielfunktion des Optimierungsproblems wurde die 8er-Nachbarschaft
(siehe Abschnitt2.1) verwendet.
B.2 Problemfalle bei der Kennzeichenlokalisierung
In AbbildungB.1 ist eine Schwierigkeit bei der Kennzeichenlokalisierung erkennbar. Deutsche
Trennungssymbole bewirken, dass der Graph-Cut Ansatz den Rand dieser Zeichen gegenuber
dem Rand des Nummernschildes bevorzugt. Dies kann zwar durch eine großere Teilfixierung des
Vordergrundes verhindet werden, fuhrt aber zu einer starkeren Abhangigkeit von der Hypothese.
79
80 ANHANG B. DETAILS ZU DEN EXPERIMENTEN
Bild B.1: Problemfall bei der Kennzeichenlokalisierung: Trennung entlang der deutschenTrennungssymbole: (Links) Origin albild, (Rechts) Segmentierung des Bildes in Interlaced-Darstellung
Parameter Wertγ 3λ 1
2
αp 4 · 103
βp 0.03 ∼= 3cmκp 0.03 ∼= 3cmκe 8
Tabelle B.2: Verwendete Parameter bei den Experimenten der Ebenensegmentierung
B.3 Verwendete Parameter bei der Ebenendetektion
In TabelleB.2 sind alle verwendeten Parameter bei den Verfahren der Ebenendetektion auf-
gefuhrt. Diese Werte wurden bei den Experimenten verwendet und orientieren sich an empirisch
gewahlten Werten und Angaben aus der Literatur wie etwa [XS05].
B.4 Weitere Beispielbilder der Ebenendetektion
Bild B.2: Beispiel fur eine Ebenensegmentierung: (Links) Startebene, (Mitte) Verfeinerung mitGraph-Cut und reiner Tiefeninformation, (Rechts) Verfeinerung mit Graph-Cut unter Verwen-dung von Tiefen- und Grauwertinformationen

B.4. WEITERE BEISPIELBILDER DER EBENENDETEKTION 81
Bild B.3: Originalbild von Beispiel5.5aufgenommen mit einer Sony Kamera
Die AbbildungB.3 zeigt eineubersichtliche Darstellung der verwendeten Szene von Bei-
spiel 5.5. Ein weiteres Beispiel fur das Ergebnis einer Ebenendetektion mit Graph-Cut ist in
AbbildungB.2 dargestellt.

82 ANHANG B. DETAILS ZU DEN EXPERIMENTEN

Literaturverzeichnis
[BDV07] J. M. Bioucas-Dias, G. Valadao:Phase Unwrapping via Graph Cuts, Image Pro-
cessing, IEEE Transactions on, Bd. 16, Nr. 3, March 2007, S. 698–709.
[Bes86] J. Besag:On the Statistical Analysis of Dirty Pictures, Journal of the Royal Stati-
stical Society, Bd. 48, 1986, S. 259–279.
[BFL06] Y. Boykov, G. Funka-Lea:Graph Cuts and Efficient N-D Image Segmentation, In-
ternational Journal of Computer Vision, Bd. 70, Nr. 2, 2006, S. 109–131.
[BJ00] Y. Boykov, M.-P. Jolly: Interactive Organ Segmentation Using Graph Cuts, in
MICCAI ’00: Proceedings of the Third International Conference on Medical Image
Computing and Computer-Assisted Intervention, Springer-Verlag, London, UK,
2000, S. 276–286.
[BJ01a] Y. Boykov, M. Jolly: Demonstration of segmentation with interactive graph cuts,
in Eighth IEEE International Conference on Computer Vision, 2001. ICCV 2001.
Proceedings, Bd. 2, 7-14 July 2001, S. 741–741.
[BJ01b] Y. Boykov, M.-P. Jolly: Interactive graph cuts for optimal boundary & region seg-
mentation of objects in N-D images, in Computer Vision, 2001. ICCV 2001. Procee-
dings. Eighth IEEE International Conference on, Bd. 1, 7-14 July 2001, S. 105–112.
[BK03] Y. Boykov, V. Kolmogorov:Computing geodesics and minimal surfaces via graph
cuts, in Computer Vision, 2003. Proceedings. Ninth IEEE International Conference
on, Bd. 1, 2003, S. 26–33.
[BK04] Y. Boykov, V. Kolmogorov:An experimental comparison of min-cut/max- flow algo-
rithms for energy minimization in vision, Pattern Analysis and Machine Intelligence,
IEEE Transactions on, Bd. 26, Nr. 9, Sept. 2004, S. 1124–1137.
83

84 LITERATURVERZEICHNIS
[BT99] S. Birchfield, C. Tomasi:Multiway cut for stereo and motion with slanted surfa-
ces, in Computer Vision, 1999. The Proceedings of the Seventh IEEE International
Conference on, Bd. 1, 20-27 Sept. 1999, S. 489–495.
[BVZ98a] Y. Boykov, O. Veksler, R. Zabih:Markov random fields with efficient approximati-
ons, in Computer Vision and Pattern Recognition, 1998. Proceedings. 1998 IEEE
Computer Society Conference on, 23-25 June 1998, S. 648–655.
[BVZ98b] Y. Boykov, O. Veksler, R. Zabih:Efficient Restoration of Multicolor Images with
Independent Noise, TR98-1712, Cornell University, 27, 1998.
[BVZ99a] Y. Boykov, O. Veksler, R. Zabih:Fast approximate energy minimization via graph
cuts, in Computer Vision, 1999. The Proceedings of the Seventh IEEE International
Conference on, Bd. 1, 20-27 Sept. 1999, S. 377–384.
[BVZ99b] Y. Boykov, O. Veksler, R. Zabih:A New Algorithm for Energy Minimization with
Discontinuities, in Energy Minimization Methods in Computer Vision and Pattern
Recognition, 1999, S. 205–220.
[BVZ01] Y. Boykov, O. Veksler, R. Zabih:Fast approximate energy minimization via graph
cuts, Pattern Analysis and Machine Intelligence, IEEE Transactions on, Bd. 23,
Nr. 11, Nov. 2001, S. 1222–1239.
[CG06] D. Cremers, L. Grady:Statistical Priors for Efficient Combinatorial Optimization
Via Graph Cuts., in Computer Vision - ECCV 2006, 9th European Conference on
Computer Vision, Graz, Austria, May 7-13, 2006, Proceedings, Part III, 2006, S.
263–274.
[CKS03] D. Cremers, T. Kohlberger, C. Schnorr: Shape Statistics in Kernel Space for Varia-
tional Image Segmentation, Pattern Recognition, Bd. 36, Nr. 9, 2003, S. 1929–1943.
[Cun85] W. H. Cunningham:Minimum Cuts, Modular Functions, and Matroid Polyhedra,
Networks, Bd. 15, 1985, S. 205–215.
[CWC06] W. Cai, J. Wu, A. Chung:Shape-Based Image Segmentation Using Normalized
Cuts, in IEEE International Conference on Image Processing (ICIP’06), 2006, S.
1101–1104.

LITERATURVERZEICHNIS 85
[CZ01] D. Cobzas, H. Zhang:Planar patch extraction with noisy depth data, in Proceedings
Third International Conference on 3-D Digital Imaging and Modeling, Quebec, Ca-
nada, May 2001, S. 240–245.
[CZ05] A. Y. S. Chia, V. Zagorodnov:Graph Cut Segmentation on Convoluted Objects,
IEEE International Conference on Image Processing, Bd. 3, 2005, S. 848–851.
[DJP*94] E. Dahlhaus, D. S. Johnson, C. H. Papadimitriou, P. D. Seymour, M. Yannakakis:
The Complexity of Multiterminal Cuts, SIAM J. Comput., Bd. 23, Nr. 4, 1994, S.
864–894.
[FD05] D. Freedman, P. Drineas:Energy Minimization via Graph Cuts: Settling What is
Possible, in CVPR ’05: Proceedings of the 2005 IEEE Computer Society Confe-
rence on Computer Vision and Pattern Recognition (CVPR’05) - Volume 2, IEEE
Computer Society, Washington, DC, USA, 2005, S. 939–946.
[Fer95] P. Ferrari:Fast Approximate MAP Restoration of Multicolor Images, Journal of the
Royal Statistical Society, Bd. 57, Nr. 3, 1995, S. 485–500.
[FZ05] D. Freedman, T. Zhang:Interactive graph cut based segmentation with shape priors,
in Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer
Society Conference on, Bd. 1, 2005, S. 755–762.
[GG84] S. Geman, D. Geman:Stochastic Relaxation, Gibbs Distributions, and the Bayesian
Restoration of Images, Pattern Analysis and Machine Intelligence, IEEE Transacti-
ons on, Bd. 6, Nr. 6, November 1984, S. 721–741.
[GPS86] Greig, Porteuous, Seheult:Discussion on On the statistical analysis of dirty pictures,
Journal of the Royal Society of Statistics, Series B, Bd. 48, 1986, S. 282–284.
[GPS89] Greig, Porteous, Seheult:Exact Maximum A Posteriori Estimation for Binary
Images, Journal of the Royal Statistical Society, Series B, Bd. 51, 1989, S. 271–
279.
[Gra87] C. Graffigne:Experiments in texture analysis and segmentation, PhD thesis, Brown
University, 1987.
[GS06] L. Grady, E. Schwartz:Isoperimetric graph partitioning for image segmentation,
Pattern Analysis and Machine Intelligence, IEEE Transactions on, Bd. 28, Nr. 3,
March 2006, S. 469–475.

86 LITERATURVERZEICHNIS
[Hub80] P. J. Huber:Robust Statistics, John Wiley and Sons, 1980.
[IG98] H. Ishikawa, D. Geiger:Segmentation by grouping junctions, in IEEE Computer So-
ciety Conference on Computer Vision and Pattern Recognition, 1998. Proceedings,
23-25 June 1998, S. 125–131.
[IG99] H. Ishikawa, D. Geiger:Mapping Image Restoration to a Graph Problem, in IEEE-
EURASIP Workshop on Nonlinear Signal and Image Processing, 1999, S. 20–23.
[Ish03] H. Ishikawa:Exact optimization for Markov random fields with convex priors, Pat-
tern Analysis and Machine Intelligence, IEEE Transactions on, Bd. 25, Nr. 10, Oct.
2003, S. 1333–1336.
[Isi25] E. Ising:Beitrag zur Theorie des Ferromagnetismus, Zeitschrift fuer Physik, Bd. 31,
1925, S. 253–258.
[JB06] O. Juan, Y. Boykov:Active Graph Cuts, in Computer Vision and Pattern Reco-
gnition, 2006 IEEE Computer Society Conference on, Bd. 1, 17-22 June 2006, S.
1023–1029.
[KB05] V. Kolmogorov, Y. Boykov: What metrics can be approximated by geo-cuts, or
global optimization of length/area and flux, in Computer Vision, 2005. ICCV 2005.
Tenth IEEE International Conference on, Bd. 1, 17-21 Oct. 2005, S. 564–571.
[KD07] O. Kahler, J. Denzler:Detecting Coplanar Feature Points in Handheld Image Se-
quences, in Proceedings Conference on Computer Vision Theory and Applications
(VISAPP 2007), Bd. 2, INSTICC Press, Barcelona, March 2007, S. 447–452.
[KKZ03] J. Kim, V. Kolmogorov, R. Zabih:Visual correspondence using energy minimiza-
tion and mutual information, in Computer Vision, 2003. Proceedings. Ninth IEEE
International Conference on, Bd. 2, 13-16 Oct. 2003, S. 1033–1040.
[Kol03] V. Kolmogorov: Graph-based Algorithms for Multi-camera Reconstruction Pro-
blem, PhD thesis, Cornell University, CS Department, 2003.
[KR04] R. Klette, A. Rosenfeld:Digital Geometry: Geometric Methods for Digital Picture
Analysis, Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2004.

LITERATURVERZEICHNIS 87
[KR06] V. Kolmogorov, C. Rother: Comparison of Energy Minimization Algorithms for
Highly Connected Graphs., in Computer Vision - ECCV 2006, 9th European Con-
ference on Computer Vision, Graz, Austria, May 7-13, 2006, Proceedings, Part II,
2006, S. 1–15.
[KRD07] O. Kahler, E. Rodner, J. Denzler:Fusion of Range and Intensity Information Using
Graph-Cut for Planar Patch Segmentation, (submitted to Dynamic 3D Imaging
Workshop 2007), 5 2007.
[KT05] J. Kleinberg, E. Tardos:Algorithm Design, Addison-Wesley Longman Publishing
Co., Inc., Boston, MA, USA, 2005.
[KT06] P. Kohli, P. H. S. Torr:Measuring Uncertainty in Graph Cut Solutions - Efficiently
Computing Min-marginal Energies Using Dynamic Graph Cuts., in Computer Vi-
sion - ECCV 2006, 9th European Conference on Computer Vision, Graz, Austria,
May 7-13, 2006, Proceedings, Part II, 2006, S. 30–43.
[KTZ05] M. P. Kumar, P. H. S. Torr, A. Zisserman:OBJ CUT, in CVPR ’05: Proceedings of
the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Re-
cognition (CVPR’05) - Volume 1, IEEE Computer Society, Washington, DC, USA,
2005, S. 18–25.
[KZ02] V. Kolmogorov, R. Zabih:Multi-camera Scene Reconstruction via Graph Cuts, in
European Conference on Computer Vision, 2002, S. 82–96.
[KZ04] V. Kolmogorov, R. Zabin:What energy functions can be minimized via graph cuts?,
Pattern Analysis and Machine Intelligence, IEEE Transactions on, Bd. 26, Nr. 2,
Feb 2004, S. 147–159.
[Lan00] R. Lange:3D Time-of-Flight Distance Measurement with Custom Solid-State Image
Sensors in CMOS/CCD-Technology, PhD thesis, University of Siegen, 2000.
[LSGX05] H. Lombaert, Y. Sun, L. Grady, C. Xu:A Multilevel Banded Graph Cuts Method for
Fast Image Segmentation, in ICCV ’05: Proceedings of the Tenth IEEE Internatio-
nal Conference on Computer Vision (ICCV’05) Volume 1, IEEE Computer Society,
Washington, DC, USA, 2005, S. 259–265.

88 LITERATURVERZEICHNIS
[Pol] D. B. Pollard: Hammersley-clifford theorem for markov ran-
dom fields. Handouts, Available at http://www, star.yale.edu/
pollard/251.spring04/Handouts/Hammersley-Clifford.pdf.
[PR75] Picard, Ratliff: Minimum cuts and related problems, Networks, Bd. 5, 1975, S.
357–370.
[RK06] C. Rother, V. Kolmogorov:Minimizing non-submodular functions with graph cuts
- a review, MSR-TR-2006-100, Microsoft Research, 2006.
[RMBK06] C. Rother, T. Minka, A. Blake, V. Kolmogorov:Cosegmentation of Image Pairs by
Histogram Matching - Incorporating a Global Constraint into MRFs, in CVPR ’06:
Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision
and Pattern Recognition, IEEE Computer Society, Washington, DC, USA, 2006, S.
993–1000.
[RSZ06] A. Raj, G. Singh, R. Zabih:MRF’s for MRI’s: Bayesian Reconstruction of MR
Images via Graph Cuts., in 2006 IEEE Computer Society Conference on Computer
Vision and Pattern Recognition (CVPR 2006), 17-22 June 2006, New York, NY, USA,
2006, S. 1061–1068.
[SC06] T. Schoenemann, D. Cremers:Near Real-Time Motion Segmentation Using Graph
Cuts., in DAGM-Symposium, 2006, S. 455–464.
[Sch04] A. Schrijver: Combinatorial Optimization : Polyhedra and Efficiency (Algorithms
and Combinatorics), Springer, July 2004.
[SG06] A. K. Sinop, L. Grady:Accurate Banded Graph Cut Segmentation of Thin Structures
Using Laplacian Pyramids., in Medical Image Computing and Computer-Assisted
Intervention - MICCAI 2006, 9th International Conference, Copenhagen, Denmark,
October 1-6, Proceedings, Part II, 2006, S. 896–903.
[SM97] J. Shi, J. Malik: Motion Segmentation and Tracking using normalized cuts, 962,
University of California, Berkeley, 1997.
[SM98] J. Shi, J. Malik:Motion segmentation and tracking using normalized cuts, in Pro-
ceedings of the Sixth International Conference on Computer Vision, 1998, S. 1154–
1160.

LITERATURVERZEICHNIS 89
[SM00] J. Shi, J. Malik: Normalized cuts and image segmentation, Pattern Analysis and
Machine Intelligence, IEEE Transactions on, Bd. 22, Nr. 8, Aug. 2000, S. 888–905.
[SRR07] W. Schorisch, H. Rodner, H.-J. Rodner:Thanks for everything, International Jour-
nal for Acknowledgements, Bd. 1, 2007, S. 1–10.
[SZS*06] R. Szeliski, R. Zabih, D. Scharstein, O. Veksler, V. Kolmogorov, A. Agarwala, M. F.
Tappen, C. Rother:A Comparative Study of Energy Minimization Methods for Mar-
kov Random Fields., in Computer Vision - ECCV 2006, 9th European Conference
on Computer Vision, Graz, Austria, May 7-13, 2006, Proceedings, Part II, 2006, S.
16–29.
[Vek99] O. Veksler:Efficient graph-based energy minimization methods in computer vision,
PhD thesis, Faculty of the Graduate School of Cornell University, 1999.
[Vek00] O. Veksler:Image Segmentation by Nested Cuts, in IEEE Conference on Computer
Vision and Pattern Recognition, Bd. 1, 2000, S. 339–344.
[vH06] W. von Hansen: Robust Automatic Marker-free Registration of Terrestrial Scan
Data, in Proceedings Photogrammetric Computer Vision 2006, Bd. 36, Bonn, Ger-
many, September 2006, S. 105–110.
[Win06] G. Winkler: Image Analysis, Random Fields and Markov Chain Monte Carlo Me-
thods, Springer-Verlag New York, Inc., 2006, ISBN 3540442138.
[XS05] J. Xiao, M. Shah:Motion layer extraction in the presence of occlusion using graph
cuts, Pattern Analysis and Machine Intelligence, IEEE Transactions on, Bd. 27,
Nr. 10, Oct. 2005, S. 1644–1659.
[YFW00] J. S. Yedidia, W. T. Freeman, Y. Weiss:Generalized Belief Propagation, in NIPS,
2000, S. 689–695.
[YS06] P. Yan, M. Shah:Segmentation of Neighboring Structures by Modeling Their In-
teraction, in CVPRW ’06: Proceedings of the 2006 Conference on Computer Visi-
on and Pattern Recognition Workshop, IEEE Computer Society, Washington, DC,
USA, 2006, S. 77.

90 LITERATURVERZEICHNIS

Verzeichnis der Bilder
2.1 Binare Bildrestaurierung. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .15
3.1 Konstruktion der Kanten fur F2-Funktionen. . . . . . . . . . . . . . . . . . . . 29
3.2 Graphkonstruktion fur ein einfaches Beispiel. . . . . . . . . . . . . . . . . . . 31
3.3 Einfaches Graph-Cut-Beispiel. . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.4 Beziehungen der Funktionsklassen. . . . . . . . . . . . . . . . . . . . . . . . . 35
3.5 Beispiel eines Alpha-Erweiterungsschrittes. . . . . . . . . . . . . . . . . . . . 37
4.1 Veranschaulichung von Gleichung (4.4) . . . . . . . . . . . . . . . . . . . . . . 47
4.2 Segmentierung mit Teilfixierung. . . . . . . . . . . . . . . . . . . . . . . . . . 48
4.3 Ausgangsbild fur die Kennzeichenlokalisierung. . . . . . . . . . . . . . . . . . 49
4.4 Veranschaulichung der fixierten Bereiche. . . . . . . . . . . . . . . . . . . . . 49
4.5 Ergebnis der Kennzeichenlokalisierung. . . . . . . . . . . . . . . . . . . . . . 50
4.6 Beispiel fur eine Level-Set Darstellung. . . . . . . . . . . . . . . . . . . . . . . 53
4.7 Beispiel fur die sigmoidale Funktion s. . . . . . . . . . . . . . . . . . . . . . . 54
4.8 Bewegungssegmentierung einer Ebene. . . . . . . . . . . . . . . . . . . . . . . 54
4.9 Ebenensegmentierung mit Graph-Cut-Verfeinerung. . . . . . . . . . . . . . . . 57
5.1 Kamera fur Echtzeit-Tiefeninformationen. . . . . . . . . . . . . . . . . . . . . 62
5.2 Versuchsaufbau fur Beispiel5.5 . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.3 Fehlere bei [KD07] Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
5.4 Fehlere bei Region-Growing Verfahren. . . . . . . . . . . . . . . . . . . . . . 64
5.5 Beispiel fur eine Ebenensegmentierung. . . . . . . . . . . . . . . . . . . . . . 65
A.1 Notation von [BK04] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .73
B.1 Problemfall bei der Kennzeichenlokalisierung. . . . . . . . . . . . . . . . . . . 80
B.2 Beispiel fur eine Ebenensegmentierung. . . . . . . . . . . . . . . . . . . . . . 80
91

92 VERZEICHNIS DER BILDER
B.3 Originalbild von Beispiel5.5 . . . . . . . . . . . . . . . . . . . . . . . . . . . .81

Verzeichnis der Tabellen
3.2 Laufzeiten von Max-Flow Algorithmen. . . . . . . . . . . . . . . . . . . . . . 25
3.4 Graph-Konstruktion fur F2-Funktionen. . . . . . . . . . . . . . . . . . . . . . . 30
3.6 Literaturverweise: Charakterisierung der graph-darstellbaren Funktionen. . . . . 35
5.1 Verwendete Testsequenzen. . . . . . . . . . . . . . . . . . . . . . . . . . . . .60
5.2 Ergebnisse der Kennzeichenlokalisierung. . . . . . . . . . . . . . . . . . . . . 60
5.3 Auswertung der Laufzeit. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .60
5.4 Auswertung des Parametersσ . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.5 Auswertung des Parametersux . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.6 Durchschnittswerte vone . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .65
B.1 Verwendete Parameter bei den Experimenten der Kennzeichenlokalisierung. . . 79
B.2 Verwendete Parameter bei den Experimenten der Ebenensegmentierung. . . . . 80
93