on the optimal ordering of multiple-field tables
TRANSCRIPT

ELSEVIER Data & Knowledge Engineering 14 (1994) 27-44
DATA & KNOWLEDGE ENGINEERING
On the optimal ordering of multiple-field tables Pao lo Ciaccia*, Dar io Ma io
DEIS, University of Bologna, CIOC C.N.R., Viale Risorgimento, 2, 40136 Bologna, Italy
Received 4 February 1994; revised manuscript received 16 May 1994; accepted 25 July 1994
Abstract
Consider a table of n d-dimensional records, grouped into b buckets, and a set .~ = {(Qh, Wh)} of weighed partial-match conditions, where w h is the relative frequency of Qh" Let n(Qh) be the number of records which satisfy Qh, and b(Qh) the number of buckets in which these records are found. The problem we consider is the individuation of the optimal ordering field which minimizes the sum of accessed buckets, B(-~ ) = E h w h × b(Qh). An exact solution requires the records to be sorted according to the values of each of the d fields in turn with an overall time complexity, evaluated as a function of bucket accesses, of O(d x b log b). We present an approximate O(b) algorithm which estimates the optimal ordering without the need to sort the table at all. The algorithm makes use of a probabilistic counting technique, known as linear counting, which requires a single scan of the table. Experimental results show that in most cases the approximate solution agrees with the exact one.
Keywords: Relational databases; Physical design; Cost models; Linear counting; Optimal ordering
1. Introduction
Consider a table of n d-dimensional records, with fields F 1 , . . . , F ~ , . . . , Fd, grouped into b buckets, and a set .~ = { ( Q h , Wh)) ( h = 1 , . . . , q ) of weighed boolean conditions which are used to select records from the table. Let n(Qh)<~ n be the number of records which satisfy Qh, and b(Qh)<~ b the number of buckets on which these records are found, and B ( ~ ) = •h Wh × b(ah)" We are interested in determining the optimal ordering field, F~., which guarantees that when records are stored in the table according to increasing (or decreasing) values of F~,, B ( ~ ) attains its minimal value over all the d possible ordering criteria.
A more intuitive formulat ion of the problem, in (relational) database terminology, is i l lustrated by the following example. Consider a relation (table) SUPPLIES(Supp ,Par t ,P ro j ) , where each tuple (record) is a triple (i.e. d = 3) of the form (s, p , j ) , meaning that supplier s
* Corresponding author. Email: [email protected]
0169-023X/94/$07.00 ~) 1994 Elsevier Science B.V. All rights reserved SSDI: 0169-023X(94)00022-0

28 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
has supplied part p to project j. We can access relation SUPPLIES in order to know, say, which projects use part Pl, which parts supplier s 3 has supplied to project J2, etc. Relation SUPPLIES is organized into buckets (i.e. blocks, pages) and stored on a secondary memory device. In order to speed up retrieval of relevant information, access paths, such as indexes and links, are built on some of the attributes (fields). These can avoid sequential scans of the relation by allowing the retrieval into main memory of the only buckets containing at least one qualifying record.
Given indexes on the three attributes Supp, Part, and Proj, we would like to determine which is the ordering criterion that minimizes access costs, by considering a workload of relevant queries (conditions) together with their relative frequencies of execution.
The determination of optimal ordering is a special case of the more general problem of optimally clustering the records into buckets. Intuitively, given a set of queries, one can reduce the number of buckets to be accessed if records which are likely to be used together in one condition are allocated in as few buckets as possible [10]. It should be observed that if no limitation is imposed on the clustering strategy, the problem gets very difficult, since it is known to be NP-hard [1]. In this sense, the determination of an optimal ordering is a heuristic approach to the problem of record clustering that allows the application of polynomial time algorithms. Nonetheless, in practical applications with very large tables, such algorithms may still require a considerable computational effort, since they have to evaluate costs by sorting the table on each field in turn. For this reason, database designers typically resort to even more simple criteria. Database relations with a single-attribute key, that uniquely identifies records, are usually physically stored by clustering records according to the values of the key. This well-known heuristics accounts for the relevant role assumed by keys in retrieving information. Examples are sequential processing in order of key values, and join operations on key fields. For relations with composite keys, such as those originating from the translation of many-to-many relationships among entities of a conceptual schema, the heuristics breaks down, and other criteria are needed. This is the case, for instance, of relation SUPPLIES. A more general accepted heuristic criterion consists in sorting records according to the values of the attribute which is most used to retrieve records [4]. This criterion is usually extended by taking into account also data and indexes maintenance costs, to be paid when updates to values of the ordering field occur [9].
In this paper, we propose an approximate algorithm which estimates optimal ordering without the need to sort the table at all. Estimates are based on a set of parameters which can be collected by means of a single scan of the table. This makes it feasible to consider the effects of alternative ordering fields, without limiting the choice to pre-wired criteria, which can result in poor design choices.
The rest of the paper is organized as follows. In the next Section we first introduce an exact algorithm to determine the optimal ordering field, and provide a simple yet comprehensive example. In Section 3 we introduce the approximate algorithm, together with a brief description of the linear counting technique, introduced in [13], which is basilar to our work. Section 4 presents some experimental results. Section 5 shows how the algorithm can be extended to cover the case where updates to records are considered, and, finally, Section 6 briefly concludes.

P. Ciaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44 29
2. An exact algorithm
In this Section we precisely describe our working hypotheses and an exact algorithm to solve the optimal ordering problem on these hypotheses.
Let r = ( r l , . . . , ri, . . . , rd) be a record where r i is the value of field F` is the value of field F` in r, and let Qh be a condition. The scope of Qh is the set of fields that Qh uses to select records. In this work we consider conjunctive conditions in which the fields in the scope are restricted to match single values (these are also known as partial-match conditions). Thus, r is selected by Qh iff ri = v~, for each F~ in the scope of Qh, where D i is the value specified by Qh for field F r Rather than deal with conditions having specific values to be matched, we consider stochastic conditions, where constants are substituted by random variables, Vii. This is the usual way in which the workload of both local and distributed storage organizations is specified. In the case of partial-match conditions it follows that Qh is equivalent to its scope in that, say, ((F~ = V1) and ( F 2 = V2) ) can be more simply written a s FIF2 .1 With a slight abuse of notation, we write F /E Qh if F` is in the scope of Qh" Furthermore, we speak of a value of Qh to refer to a combination of values of the fields which are in (the scope of) Qh" We sometimes use the term instance of Qh t o mean a value of Qh used to select records.
Let f//stand for the cardinality, i.e. number of distinct values, of field F/. For any scope Qh"
1-I Fi~Qh
denotes the cardinality of the Cartesian product of the field domains in Qh" When condition Qh is issued, we assume that each of the possible cp(Qh ) instances of Qh is equally likely to be specified.
An exact algorithm for determining the optimal ordering field has to evaluate the cost arising from each possible alternative. Let E[B(~ )IF,] be the expected cost with respect to the ordering field F` for processing all the conditions in workload ~. This can be written as:
b %(ahlF`) E[B(~ )IF`] = ~', Wh X E[b(Qh)IF`] = ~ w h × ~',
h h j=, cp(Qh) (1)
where %(Qh[Fi) is the number of distinct values of Qh which are found in bucket j. This is also called the cardinality of Qh in bucket j. The term 7r/(Qh[F`)/cP(Qh) is just the fraction of instances of Qh which need to access bucket j and coincides with the probability that a random instance of Qh selects at least one record in bucket j. The sum Ej %(QhlFi)/cp(Qh) is therefore the (unweighed) expected cost due t o Qh (see also [11]). Note that, at this point, we do not consider maintenance costs at all. These have to be paid when some records in the table have the values of some fields (possibly including also the ordering field) to be modified.
F o r sets of fields we adopt , for the sake of conciseness , a list no ta t ion , wri t ing F~ for {Fi}, and X Y for X O Y.

30 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
We will detail in Section 5 how these costs can be taken into account in the present framework.
Example 1. Consider a table SUPPLIES(Supp,Part,Proj), storing information about the parts supplied by suppliers to projects. The sample instance shown in Fig. 1 is made up of n = 12 records, grouped into b = 4 buckets. Fig. 1 shows the placement of records into buckets, when they are sorted according to the values of the fields Supp, Part, and Proj, respectively. Field cardinalities are, respectively, fsupp = 4, &art = 6, a n d fProj = 3.
Consider now the workloads {(Supp, wsupp), (Part, Wpart), (Proj, Wproj), ({Part,Proj}, W(p,rt,Proj))}, where records are either selected by specifying a value for one of the three fields, or by a pair of {Part,Proj} values. Sample conditions are therefore: which are the supplies for project ]2 ? who has supplied part P5 to project j~?, etc. By assigning specific values to the w h
weights, the relative relevance of the above conditions can be specified. We consider the following three specific workloads:
Workload
Query on ( Q h )
Supp Part Proj {Part,Pro j}
~1 0.4 0.2 0.3 0.10 ~2 0.4 0.2 0.05 0.35 ~3 0.1 0.1 0.70 0.10
For each candidate ordering field, and for each scope, one can evaluate, by looking at Figure 1, the expression Ej Irj(QhlFi) that appears in Equation (1), that is, the sum over the (four) buckets of table SUPPLIES of the number of distinct values of Qh when the ordering field is F~. For our example, we obtain:
Supp Par t Proj
sl Pl 21
81 P2 33 81 P4 32
sl Pl 33 s2 Pl 31 s2 P5 32 s2 P6 32 S3 P3 33 s3 Pl 31
S4 P2 33 s4 P4 32
s4 P6 32
Fig. 1. The table
Supp Part
81 S3 82
81 81 84 83 84 81
82 82 84
SUPPLIES sorted on
Proj
Pl 31 Pl 31 Pl 31
Pl Y3 P2 33 P2 33
P3 33 P4 32 p4 32
P5 32 P6 32 P6 32
fields Supp, Part,
Supp Part Proj
Sl pl j l
s2 pl J1 s3 pl 31
s4 p6 32
s2 P5 32 s4 P4 32
81 P4 32 s2 P6 32 Sl Pl 33
84 P2 33 sl Pl 33 83 P3 33
and Pro j, respectively.

P. Ciaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44 31
Ordering field (F~)
Query on
(Qh)
Supp Part Proj {Part,Pro j}
Supp Part Proj
6 10 10 11 7 10 11 5 5 12 7 10
By combining these values and the weights of the conditions, workload costs can be evaluated by means of Eq. (1). This is done for each candidate ordering field and for each of the three considered workloads. Results are as follows:
Workload "@1 "@2 "@3
Ordering field
Supp Part Proj
2.13 1.77 1.89 1.38 1.45 1.61 2.97 1.57 1.64
Let us briefly comment on these results. As to workload "@1, where queries on field Supp are prevalent, it can be seen that the best choice is to order on Part, that, almost strikingly, is the field less frequently used for record selection. Workload ~z differs from "@1 only in the frequencies of conditions on Proj and on the pair {Part,Proj}. Nonetheless, the net effect is that the optimal ordering field is now Supp. This can be qualitatively explained as follows. Sorting on Part has the beneficial effect of leading to very low costs for processing queries on Proj, as it can be seen from the above table. When queries on Proj are less frequent, as it is the case in workload "@2, the advantage of sorting the table on Part diminishes, and the alternative of having Supp as ordering field becomes more convenient. Finally, in workload "@3 it is more clearly evidentiated that ordering on the field which is most frequently used to retrieve records does not necessarily lead to an optimal design.
The cost of evaluating E[B(.~ )[F~] is computed as a function of the number of buckets which have to be accessed to obtain the relevant information. Assuming that field cardinalities are given, the only unknowns are the %.(QhlF,.) cardinalities. These can be determined by reading into main memory a bucket, with access cost O(1), and sorting its records.
The following algorithm summarizes the steps to determine the optimal ordering field, F~.. It is termed 'exact counting' (EC) in that it works with the exact values of the ~(Qh[F~) cardinalities. The procedure Count(], C) (step 1.3.1), returns the C vector, whose hth component, Ch, is the cardinality of Qh in bucket j.
Algorithm EC: Optimal Ordering Field by Exact Counting
Input: A table with n records with fields F1,. . . , F d, stored in b buckets;

32 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
Output:
1 1.1 1.2 1.3 1.3.1 1.3.2.1 1.3.3 2.
A set ~ of q weighed boo&an conditions (Qh, Wh); The optimal ordering field F/..;
For each field F/, i = 1 . . . . , d do: Sort the tab& on Fi; Set E[B(~ )IF/] = 0; For each bucket j = 1 , . . . , b do:
Call Count(j, C); For each condition Qh do:
Set E[B(~ )IF/] = E[B(~ )lFi] + w h × Ch/cp(Qh); Set F/, to the field with the minimum expected cost;
The time complexity of algorithm EC is dominated by step 1.1, and is O(d x b log b). As noticed above, step 1.3 has O(b) time complexity, since each bucket is accessed just once. Nonetheless, O(d × b log b) is still unsuitable for large tables (with many buckets and, possibly, many fields), thus motivating the investigation of a cheaper, approximate, algorithm.
3. An approximate algorithm
The approximate algorithm we introduce is essentially based on the idea of estimating the number of distinct values of Qh in a bucket, 75(QhIF~), without sorting the table on F/. More precisely, we provide estimates for the sum E/zr/(Qh[F/), since this is all that is needed for our purposes, as should be clear from Eq. (1).
The probabilistic arguments we apply necessitate a set of measures of cardinalities over the whole table (rather than on single buckets). All these cardinalities are independent of the ordering criterion and can be estimated with good accuracy from a single scan of the table. This makes it possible to develop an approximate algorithm with O(b) time complexity.
Let 7r(Qh) be the number of distinct values of Qh which are actually in the table, that is, the cardinality of Qh in the table. Note that ~'(Qh), unlike %(QhlF/), is independent of the ordering field. In order to account for the effects of different ordering alternatives, we need the 7r(Qh) as well as the 7r(F/Qh) cardinalities, where FiQ h is shorthand for the set {Fi} tO Qh"
Example 2. Let us consider Example 1. Given the 3 candidate ordering fields Part, Supp, and Proj, and the scopes Part, Supp, Proj, and {Part,Proj}, the following measures of cardinalities are needed: 7r(Part), 1r({Part,Supp}), 7r({Part,Proj}), 7r(Supp), 7r({Supp,Proj}), 7r( {Supp,Part,Proj } ), 7r(Proj).
Of course, the above measures cannot be obtained by means of sorting, because they refer to the whole table, and each would cost O(b log b). As an alternative, probabilistic counting techniques may be considered. In particular, linear counting, which is fully described in [13], is a hash-based technique which allows accurate estimation of the number of distinct values of a set of fields without requiring excessive space overhead for the hash table, which is simply a binary vector. For instance, in the case of very large cardinalities, 1% of error may be
P. Ciaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44 33
obtained by using vectors with as few as k/12 bits, where k is the cardinality to be estimated. We briefly describe the linear counting technique by means of a simple example. For a more formal treatment, as well as for precise guidelines concerning quality of estimation versus bit vector size, we refer the reader to [13].
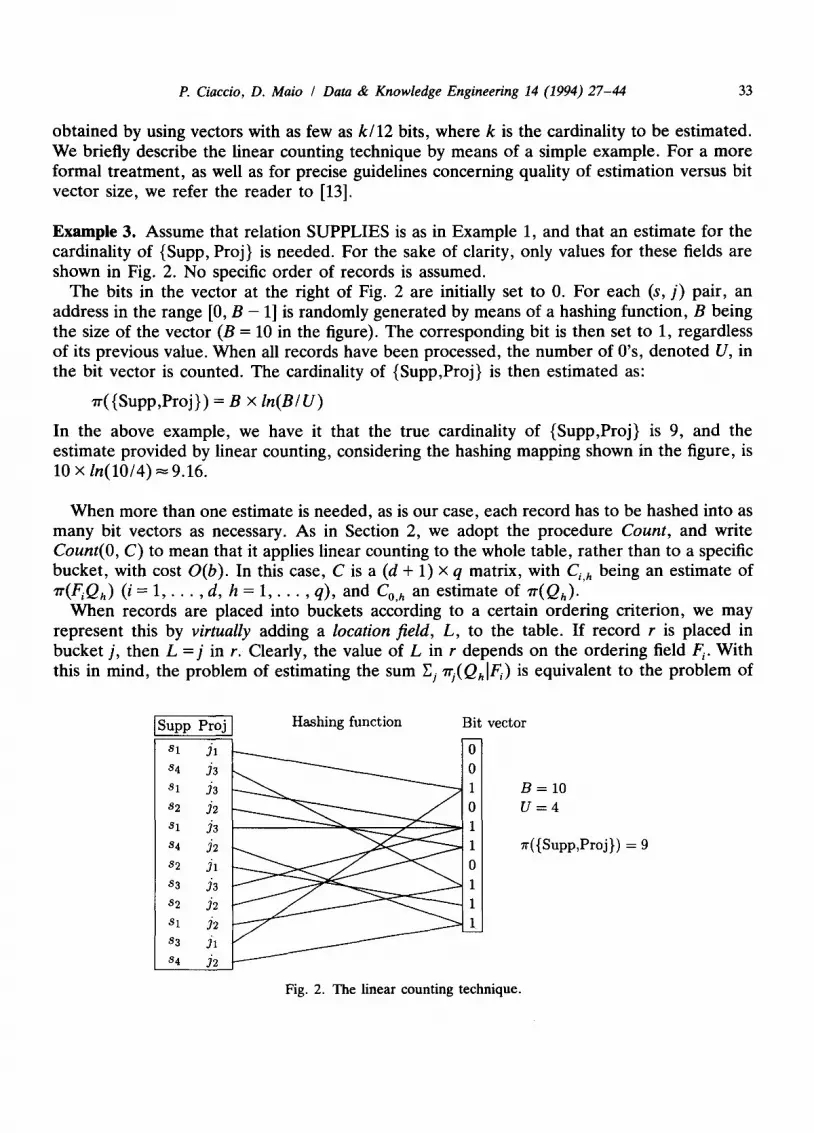
Example 3. Assume that relation SUPPLIES is as in Example 1, and that an estimate for the cardinality of {Supp, Proj} is needed. For the sake of clarity, only values for these fields are shown in Fig. 2. No specific order of records is assumed.
The bits in the vector at the right of Fig. 2 are initially set to 0. For each (s, ]) pair, an address in the range [0, B - 1] is randomly generated by means of a hashing function, B being the size of the vector (B = 10 in the figure). The corresponding bit is then set to 1, regardless of its previous value. When all records have been processed, the number of O's, denoted U, in the bit vector is counted. The cardinality of {Supp,Proj} is then estimated as:
7r({Supp,Proj}) = B x ln (B/U)
In the above example, we have it that the true cardinality of {Supp,Proj} is 9, and the estimate provided by linear counting, considering the hashing mapping shown in the figure, is 10 x l n ( 1 0 / 4 ) ~ 9.16.
When more than one estimate is needed, as is our case, each record has to be hashed into as many bit vectors as necessary. As in Section 2, we adopt the procedure Count, and write Count(O, C) to mean that it applies linear counting to the whole table, rather than to a specific bucket, with cost O(b). In this case, C is a (d + 1) × q matrix, with Ci, h being an estimate of ~'(FiQh) (i = 1 , . . . , d, h = 1 , . . . , q), and Co. h an estimate of 7r(Qh).
When records are placed into buckets according to a certain ordering criterion, we may represent this by virtually adding a location field, L, to the table. If record r is placed in bucket j, then L = ] in r. Clearly, the value of L in r depends on the ordering field F~. With this in mind, the problem of estimating the sum Zj 7~(QhlFi) is equivalent to the problem of
[Supp Proj [ Hashing function Bit vector
7, y s4 J3 0
sl J3 1 B = 10
s2 j2 0 U = 4
sl j3 1 s4 j2 1 r({Supp,Proj}) = 9 s2 jl 0 s3 ja 1 s2 j2 1 81 j~ 1 s3 jl s4 j2
Fig. 2. The linear counting technique.

34 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
estimating the cardinality 7r(QhL IF,.) of Oh L as induced by the ordering on Fi, as can be easily verified.
Let the density of Qh be defined as the ratio of the cardinality of Qh to the cardinality of its cartesian product, that is:
~r(ah) P ( a h ) - cp(Qh)
Note that P(ah) = ] if Qh contains a single field. The location-dependent density (L-density for short) of Qh, as determined by the ordering field Fi, is similarly defined as:
zr(QhLlFi) q ( a h l E ) - cp(Qh) x b
As long as 7r(QhLIF~) is a good estimate of Ej ¢rj(Qh[Fi), the expected cost given by equation (1) can be reliably approximated by:
E[B(~ )IF/] = ~ w h × E[b(Oh)lE ] = E Wh X b X e(QhlF~) (2) h h
Note that p(QhlF~) equals the probability, conditional on F i, that a value of Qh appears in a bucket. The different cases to be considered for L-density estimation are detailed in the following.
3.1. Estimation of L-densities
The probabilistic arguments to be applied in order to estimate the Q(Qh[Fi) L-densities require us to distinguish between four basic cases, which depend on the ratio f~/b and on whether F~ belongs to Qh or not.
(1) The first case is when f~ > b and Fi~Qh. Thus, the ordering field is not used to select records, and its cardinality is such that each bucket contains, on the average, f~/b > 1 values of F i. We consider that each value of Qh appears in the table in conjunction with P(FiOh) × f / ( = "n'(FiQh)/Cp(Qh)) values of F/. The following Lemma is the key to yield an approximate estimate of Q(Qh/Fi). For the sake of generality it is formulated in the context of urn models.
Lemma 1. Let x balls be placed in y urns, and let z be the number of possible colors of the balls. I f each urn contains v distinct colors, and w colors are chosen, then the expected number of urns containing at least one ball of one of the w colors is given by:
E[U(w)] = y × ( 1 - ( 1 - v/z) ~) (3)
Proof. The probability that a urn does not contain a color is 1 - v/z. The probability that it does not contain any of the selected w colors is (1 - v/z) ~. By complementing to 1 and summing over the urns we obtain the result. []
From Lemma 1 we can derive, by analogy, that:

P. Ciaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44 35
Q(ahlF~) = 1 - ( 1 - p(FiQh)) :,/b (4)
This holds since it is assumed that each value of Qh appears in conjunction with P(FiQh) × f / v a l u e s of F~. Thus, P(FiQh) is the probability that a value of Qh (i.e. a urn) appears together with (i.e. it contains) a value of F~ (i.e. a color). Since f~/b values of F,. are found in a bucket, the result follows. 2
(2) Let f/,. ~< b and Fiz~Qh. Thus , each value of F i spans b/fi buckets and n/fi i records, on the average. In order to estimate Q(QhlFi) consider one of the values, v h, of Qh which appears in conjunction with a value, vi, of F~. If the bucket j contains v;, the probability that it contains (v h, v~) can be evaluated as
1 ~n/b 1 \1 -- p(F~Qh ) X cp(Qh) /
where P(FiQh)X cP(Qh) is the expected number of values of Qh which appears in conjunction with v i, and ( 1 - 1/(p(FiQh)× cp(Qh)) ) is the probability that a given record in bucket j does not contain the value (v h, vi). To derive Q(QhIFi), that is, the probability that a bucket contains a given value of Qh, we have to normalize the above expression by multiplying by P(FiQh) × cp(Qh) and dividing by cP(Qh). This leads to:
1 "~,,;b'~ q(QhIF~)=P(F, Qh)X(1-(1 p(F, Qh)XCp(Q,)/ : (5)
(3) The case when F i E Qh and f~ > b is easily dealt with, in that each of the "rr(Qh) values of Qh actually present in the table is found in just one bucket. It follows that:
q(QhlF~) =P(Qh)/b (6)
Note that if F /= Qh we have, by definition, p(F,.) = 1 and o(F~IF~) = 1/b, as expected. (4) The final case arises when F / ~ Qh and f~ ~< b. By making use of what derived for case 2,
and noticing that the presence of F/simply introduces a factor I/f,., we obtain:
q(ahlF~) -- ~/ P(Qh) × cP(Qh)] } (7)
Where F,. = Qh we have p(F~)= 1 and the above expression correctly reduces to e(FilF,) = 1I f .
E x a m p l e 4. In this example we show how L-densities can be computed, and how they are used
2 Eq. (4) breaks down in the limit case when b = 1, in which Q(Qh[F~)= P(Qh). Although this has no practical relevance, this adjustment has been used in the simulation programs we present in the next section.

36 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
for cost estimation. Assume that the SUPPLIES table now consists of n = 10,000 records stored into b = 500 buckets, and that there a r e fPart = 200 distinct Part values, and fProj = 60 projects. Furthermore, let zr({Part ,Proj})=600, that is, each project, on the average, is furnished with 10 distinct parts. We want to evaluate the average cost of retrieving records of project j when the table is ordered on the Part field. To this end, we need an estimate for the L-density Q(Proj[Part), for which case 2 applies, since fPart < b. From Eq. (5), and observing that p({Part,Proj}) = 600/(200 × 60) = 0.05, we get:
( ( 1 ) 1°'°°°/5°° ) o(ProjlPart) = 0.05 × 1 - 1 0.05 x 60 ~ 5 × 10 -2
This value, times the number of buckets, yields the expected cost of processing a single instance query on the Proj field, that is, about 25. This result can be qualitatively explained as follows. Since each Part value, on the average, appears in 10,000/200 = 50 records, and each bucket stores 10,000/500 = 20 records, we have it that each Part value is found in 2.5 buckets (on the average). Because each Proj value is associated, on the average, with 10 distinct parts, the result follows.
We should point out that more simple estimates for access costs could, in principle, be applied here. Among these we consider those obtainable from the Cardenas' model [3]. Other possibilities are extensively described in [7]. Consider a condition that selects all the records using a value of scope Oh, when the ordering field Fi~ .Qh . Then, the expected cost is evaluated by the Cardenas' model as:
(1_1) ) (8)
Cardenas' model is based on the assumption that the selected records are randomly allocated into the buckets. This is because the model does not relate at all the scope Qh with the ordering field F~. For this reason, estimates are likely to be very far from actual values, as the following example demonstrates.
Example 5. We use the Cardenas' model to estimate the average cost when the scope is Pro j, and the ordering field is Part, as done in Example 4. By using Eq. (8) we obtain:
(1 (1 = × - 142
This result makes evident that, without taking into account that each project is furnished only with a small fraction of parts (10 out of 200), access costs can be exaggerately pessimistic.
Algorithm LD below details the steps for estimation of the optimal ordering field.
Algorithm LD: Optimal Ordering Field from L-Densities

P. Ciaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44 37
Input:
Output:
1 2 2.1 2.2 2.2L1 2.2.2 3.
A table with n records with fields F I , . . . , F d, stored in b buckets; A set ~ o f q weighed boolean conditions (Qh, Wh); A n estimate o f the optimal ordering field F/,;
Call Count(O,C); For each field F i, i = 1 , . . . , d do:
Set E[B(.~ )IF/] = 0; For each condition Qh do: Compute Q(QhIF/) in the appropriate way; Set E[B(~ )IF/] = E[B(~2)IF/] + w h x b x e(ahlFi);
Set F/, to the field with the minimum expected cost;
The time complexity of algorithm LD is O(b), because this is the complexity of procedure Count when applied to the whole table.
4. Experimental results
The experimental results we present refer to 4-field tables with 5,000 records stored in 500 buckets. Field cardinalities are 100, 150, 50, and 150, from fl to f4, respectively. Simulations differ in the way records are randomly generated in the workload. For a given workload, costs may change because of different values of the cardinalities of the scopes [8]. In order to analyze this we cannot sample records randomly, because this would permit no control over the (average) value of scope cardinalities. A simple yet effective way to exert such control is to lay down that each value of field F/, (i = 1, 2, 3) may appear in conjunction with only a subset of values of field F/÷I. The detailed steps to achieve this are summarized in the following procedure:
Procedure RTG: Random Table Generation
Input:
Ou~ut :
1 1.1 1.1.1 1.1.1.1 2 2.1 2.2 2.2.1 2.2.1.1 2.2.1.2
Field cardinalities f~ (i = 1 , . . . , d); Cardinality parameters s i ÷ 1 (i = 1 , . . . , d - 1); A table with n records with fields F 1 , . . . , Fa;
For each field F i, i = 1 , . . . , d - 1 do: For each value v i of F i do:
For each value vi+ 1 o f F/+ 1 do: Set Si(v i, vi+l) = 1 with probability Si÷l/f~+l;
Do n times: Sample v ~ ; For each field F/+ 1, i = 1 , . . . , d - 1 do:
Repeat: Sample v i + ~; Accept i f Si(v~, v~+l) = 1;

38 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
2 .2 .2
2 .3 Unti l accepted;
S tore ( V l , . . . , V i , . . . , V d ) ;
Step 1 actually builds the 'sample space' from which step 2 selects records. The si÷ 1
parameters represent limits to the values of the -n-(F,F~+~) cardinalities, as the number of records, n, goes to infinity. They influence the number of l 's which are present in the S i binary matrices at the end of step 1. When sampling a value of F~+I, given V l , . . . , v i (step 2.2.1.1), this is accepted only if the corresponding entry in the S i matrix is set to 1. It has to be remarked that the procedure influences the values of the ~-(FiF~+I) cardinalities without the need for a probability distribution other than the uniform one over the initial sample space. Indeed, it can be verified that all the d-dimensional values in the Cartesian product of field domains maintain the same a pr ior i probability to occur in the table [6].
Since the number of values of Fi+ 1 which may be sampled, given v,., is a binomial random variable, rather than a constant, the assumptions needed for the estimation of L-densities (that is, constancy of the number of associated values) are not satisfied. Nonetheless, experimental results show that this does not prevent algorithm LD from yielding quite accurate estimates.
In order to appreciate the effects of the si+ ~ parameters, in Fig. 3 we have plotted the expected costs yielded by algorithms EC and LD as functions of parameter s3, when s 2 = 10, s 4 = 3, and with the following workload:
Qh F~ F z F 3 F 4 F2F 3 F~F3F 4
w h 0.102 0.245 0.163 0.286 0.102 0.102
As it can be observed in Fig. 3, the optimal ordering fields is always correctly determined (this
35 Expected cost . =
= . . _ _ = . . . . . . . . . • iF1
25
. . . . . . . . . . . . . . . . . @ F 4
• A s s o c i a t i o n d e g r e e 10 ~ i i ~ i t L i
0 5 10 15 2 0 2 5 3 0 3 5 4 0
Fig. 3. Access costs versus parameter s3, which is an indicator of the 'association degree ' of fields F 2 and F 3. Solid lines refer to actual costs (algorithm EC), dotted lines to estimated costs (algorithm LD). Line markers are the same for a given ordering field.

P. Ciaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
Table 1 Performance of the LD algorithm on 200 randomly generated workloads (see text for further details).
39
Conditions Correct % Error % Max_Over % Exp_Over %
F 1 , F2, F3, F 4 80 5.24 92.28 28.94 F1, F2, F3, F4, F1F2, F3F 4 70 5.79 106.23 33.82 F~, F2, F3, F4, F1F2, FaF 4 62 5.46 106.69 39.82 FiF / (i #j) , FIF2F3, FIFEF4 92 1.25 18.28 5.21
is F 2 when s 3 = 1, and F 4 in the other cases). It is interesting to observe how the value of s 3 affects performance when the ordering field is F2. Consider sorting on F2 and using F 3 as condit ion, which corresponds to case 2 of Section 3.1 (since f2 < b and F 2,~ F 3). For this, we get p(FaF2) ~ 0.02 for 3' 3 ~--- 1, and p(FaF2) .~ 0.1 for S 3 -~- 5. Consequently, from Eq. (5) we get, respectively, Q(FaIF2)~0.02 and p(FaIF2)~O.09 . Multiplying these by w h x b = 8 1 . 5 we observe a cost increase of 5.7, which accounts for about half of the difference observed in Fig. 3. In Table 1 we summarize the results running algorithms EC and LD with 200 randomly generated workloads. There are 4 groups of 50 workloads each. Within a group, conditions are the same, and only weights are randomly varied. In the first two groups we have s 2 = 5, s 3 = 2, and 3'4 = 3, whereas in the last two s 2 = 10, 3'3 = 5, and s 4 = 3. The results in column Correct refer to the number of times algorithm LD determines the optimal ordering field. In case of failure, the average relative cost difference (as computed by algorithm EC) between the optimal field and the one selected by algorithm LD is reported (column Error). This is to examine whether sub-optimal choices may heavily affect performance or not. As can be noticed, when algorithm LD fails, the incurred overhead is really negligible (about 5% in the first three groups). If all the ordering alternatives led to a similar cost, any choice would suffice for practical purposes. In the cases we have incurred, however, this is not true, and dramatic consequences may arise from poor design choices. This is shown in column Max_Over , where the overhead due to sorting the table on the field leading to the highest cost, averaged over the cases for which algorithm LD misses the optimal choice, is considered. It can be observed that the sub-optimal choices of algorithm LD are extremely good if compared to the worst possible ones. Fur thermore , in no case does algorithm LD incur a cost overhead greater than 14%, as Fig. 4 shows. Finally, data in column Exp_Over shows the
20
15
10
5
0
N. of cases
!
I
0--3 3--6 6 - 9
Error %
9--12 12--14
Fig. 4. Error distribution for the cases where algorithm LD fails to determine the optimal ordering field.

40 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
expected overhead in access costs if the ordering field is randomly chosen (each with the same probability).
5. Update costs
In this Section we describe how algorithm LD can be extended to cover the case where ma in t enance costs are present, due to updates that modify records in the table. 3
We therefore consider that workload ~ is now described by conditions of the form (Qh, Uh, Wh), where Qh is the set of fields used to select records, and U h is the (possibly empty) set of fields to be modified in the selected records. To simplify our arguments, we assume that all modifications are of the form F k = Ok, that is, for each selected record and each F k E Uh, the new value of F k is a constant. The case where the new value is computed through a general expression can be similarly dealt with.
In order to extend algorithm LD we first rewrite Equat ion (1) as:
E[B(~ )IF/] = ~ Wh X (E[b(Qh)IF~] + E[d(Qh, Uh)IF~] + E[X(Qh, Uh)IF~]) h
(9)
where E[d(Qh, Uh)IFi] is the expected cost to be paid for updating records, and E[X(Qh, Uh)lFi] accounts for the costs of updating the access structures (i.e. indexes) to the table.
For record update costs, we have the two following cases.
Fi~. Uh: The records selected for modification are rewritten in place, with a cost given by:
E[d(Qh, Uh)IEI = E[b(Qh)IF~]
F~ E Uh: Since the value of the ordering field is modified in the selected records, records have to be moved to new buckets. Since the new value is a constant, we have it that:
E[d(Qh, Uh)lFi] = E[b(Qh)lFi] + n(Qh)/(n/b)
where, as before, the first term accounts for the cost of rewriting the modified buckets, and the second one assumes that the n(Qh) selected records are packed into buckets of capacity (n/b). In the above Equat ion n(Qh) is estimated a s n/cp(Qh), because each value of Qh has the same probability to be specified in the condition. As a consequence, the second term equates b /cp(Qh ).
3 For the sake of conciseness we consider only update operations. Similar arguments apply in the case of insertion and deletion of records.

P. Oaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44 41
For index update costs, we only evaluate the component that is actually dependent on the specific ordering field. It is quite evident that a detailed analysis would necessitate of making specific assumptions on the way modifications are executed and indexes are organized [12]. 4 For the sake of generality, we do not make any specific hypothesis on index structure, that can be both hash- and tree-based, and simply consider that each entry of the index on field F k is a pair (ok, ptr), where o k is a value, and ptr is a pointer to a record. Index entries of F~ are then organized into bx k index (leaf) buckets. 5
As to the way modifications of indexes are executed, we consider the following abstract model . If F k E U h, then, for each record satisfying Qh, we have to replace (Vk, ptr) with (v' k, ptr). If the record has to be moved, because the value of the ordering field is modified (i .e. , F i E Uh) , then we replace (Ok, ptr) either with (Vk, ptr ' ) , if Fk~. Uh, o r with (V'k, ptr ') if F k ~_ U h, where ptr' refers to the new record position in the table. Index update costs are then evaluated as the number of index buckets that have to be read and written to perform the above operations. We again distinguish whether F~ E U h or not.
F~ ~ U h: If the ordering field is not modified, index update costs do not depend on F,., because the entries to be modified are determined only by Qh, that is, they depend on the selected records, but not on their placement in the table.
F i ~ Uh: Since records are to be moved to other buckets, all the indexes have to be modified. Indexes on fields F k E U h yield a cost that is again independent on F~. In fact, we have to pay the same cost as in the previous case, with the only difference that we substitute (V'k, ptr ' ) , rather than (v'~, ptr), for (v k, ptr).
Indexes on fields F k ~ Uh, on the other hand, pay a cost that is entirely due to reallocation of records and, therefore, dependent on the specific ordering field. The cost for updating the index on F k can be derived as follows. Since we have to modify all the entries (v k, ptr), where ptr refers to a record selected by the condition Qh = Oh, and since index entries are sorted by F k values, the number of index buckets to be accessed (and rewritten) is:
bx k x ek(Qh]F~) w h e r e Qk(QhlFk) is the probability that a pointer addressing a record with Qh = Oh is found in an index bucket. In other terms, the problem is analogous to the one of estimating the access costs due to Qh on a file of bx k buckets and ordered on F k. The estimation of Qk(QhlFk) can then be performed as described in Section 3.1. Therefore, the index update costs that depend on the ordering field F~ are given by:
f ~k:Fk~i~Uh 2 >( bXk X ~k(Qh]Fk) if F i ~ U h E[X( ah , U )IF,] [0 otherwise.
4 For instance, in [12] it is shown that index update costs are also dependent on the order records are accessed, as well as on the management policy of indexes. 5 Entries with the same value Ok can be more compactly stored as (o k, (ptr_list)), where (ptr_list) is the list of pointers addressing all the records that have value ok for field F~. This variant does not influence our analysis.

42 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
6. Conclusions
In this paper we have introduced an approximate probabilistic algorithm, called LD, for determination of the optimal ordering field of a table. The linear-time complexity of the algorithm is achieved by means of a technique (linear counting) which allows the cardinalities of many field sets to be estimated with good accuracy from a single scan of the table. Then, appropriate probabilistic arguments relate these cardinalities to access costs. Experimental results point out that the algorithm is quite reliable: even when the optimal ordering is missed, the sub-optimal choice introduces no appreciable cost overhead. The algorithm can also be applied when the workload includes operations that modify records in the table.
The problem of determining an optimal ordering field is a typical one in the physical design of a database, where it amounts to determine the primary attribute (and index) of a relation. 6 Selection of the primary index usually precedes the choice of a set of additional access paths (called secondary indexes) to be built on other attributes [2]. This is due to the fact that the choice of the primary attribute does not affect the cost estimates of processing queries on the other attributes, according to estimate models that do not correlate selection and ordering fields. For instance, this is the case if the Cardenas' model is used (see Section 3). On the other hand, if estimates provided by our approach are used, it makes sense to jointly consider the two problems, and, consequently, obtain a better design.
Algorithm LD, and the concepts on which it has been developed, can also be applied to other typical database problems. We just give suggestions for two of the many.
90
80
70
60
50
40
30
20
10
0
Expected cost
• " ' - - . F1
",, • F 2 " .
F3 " ' " •
number of buckets I I I I
10 1 O0 1000 10000
Fig. 5. Access costs versus number of buckets. Simulation parameters are the same as in Fig. 3, with s 3 = 5. The value of k is 0.02.
6 In the l i terature, sometimes the ordering field is also called the clustering attribute.

P. Ciaccio, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44 43
When the block size is a matter of choice, the function to be minimized, can be written as:
E[B(~)lEd x 1 + k x ~- (10)
where the second term in parentheses accounts for the cost of transferring the data of a bucket, and k depends on system (disk) characteristics. Fig. 5 shows how costs vary as a function of b, when k = 0.02. Again, the approximate algorithm always leads to reliable choices and can also be used to determine the optimal b value for a given ordering field.
In distributed databases, consider a relation to be partitioned across the database sites according to the values of one attribute. 7 When a query is issued, the sites which contain at least one qualifying record are activated. In this context the problem we have considered amounts to find a partitioning criterion that minimizes the number of sites activated by a query and, consequently, the communication start-up costs which are generally very high.
References
[1] D.A. Bell, Difficult data placement problems, Comput. J. 27(4) (1984). [2] A. Caprara, M. Fischetti and D. Maio, Exact and approximate algorithms for the index selection problem in
physical database design, to appear in IEEE Trans. Knowledge and Data Eng. [3] A.F. Cardenas, Analysis and performance of inverted database structures, Commun. ACM 18(5) (May 1975)
252-263. [4] S. Ceri,, ed., Methodology and Tools for Database Design (North-Holland, 1983). [5] S. Ceri and G. Pelagatti, Distributed Databases - Principles and Systems (McGraw-Hill Book Co., Singapore,
1985). [6] P. Ciaccia, Il trattamento delle dipendenze nei modelli di costo per basi di dati relazionali, PhD thesis,
Dipartimento di Elettronica Informatica e Sistemistica, Universita' degli Studi di Bologna, Bologna, Italy, 1991.
[7] P. Ciaccia and D. Maio, Access cost estimation for physical database design, Data Knowledge Eng. 11(2) (Oct 1993) 125-150.
[8] P. Ciaccia and D. Maio, Performance of database relations under alternative orderings: the role of attribute dependence, in: M. Baray and B. Ozguc, eds., Proc. 6th Int. Syrup. on Computer and Information Sciences (ISCIS VI), Nevshehir (1991) (Elsevier Science, 1991) 145-155.
[9] S. Finkelstein, M. Schkolnick and P. Tiberio, Physical database design for relational databases, ACM TODS, 13(1) (Mar. 1988) 91-128.
[10] M. Jakobbson, Reducing block accesses in inverted files by partial clustering, Informat. Syst. 5 (1980). [11] D. Maio, M.R. Scalas and P. Tiberio, On estimating access costs in relational databases, Informat. Processing
Letters 19(3) (Oct. 1984) 157-161. [12] M. Schkolnick and P. Tiberio, Estimating the cost of updates in a relational database, ACM TODS 10(2)
(June 1985) 163-179. [13] K.-Y. Whang, B.T. Vander Zanden and H.M. Taylor, A linear-time probabilistic counting algorithm for
database applications, ACM TODS 15(2) (June 1990) 208-229.
7 This is a case of non-overlapping horizontal fragmentation [5].

44 P. Ciaccia, D. Maio / Data & Knowledge Engineering 14 (1994) 27-44
Dario Maio was born in Napoli, Italy, on August 22, 1951. He is Full Professor at the Dipartimento di Elettronica, Informatica e Sistemis- tica, University of Bologna, Italy. He has published in the fields of infor- mation systems, computer perform- ance evaluation, database design, neural networks, autonomous sys- tems. Before joining the Dipar- timento di Elettronica, Informatica e Sistemistica, he received a fellowship from the C.N.R. (Italian National
Research Council) for the participation to the Air Traffic Control Project. He received a degree in Electronic En- gineering from the University of Bologna in 1975. He is an IEEE member.
.. Paolo Ciaccia was born in Peschiera del Garda (Verona), Italy, on April 16, 1959. He received both the Laurea degree in Electronic En- gineering (1985) and the PhD degree in Electronic and Computer En- gineering (1992) from the University of Bologna, Italy. For his Laurea thesis he was awarded the 'IBM- Italia Prize' in 1986. He is currently an Associate Professor at the Dipar- timento di Elettronica, Informatica e Sistemistica, University of Bologna,
teaching courses on DBMS for the Computer Science cur- riculum. From 1986 to 1988 he participated to the ESPRIT Project ADKMS (Advanced Data and Knowledge Manage- ment Systems). His research interests include database sys- tems, information retrieval systems, and learning algorithms.