means++ clustering (studi kasus - usd repository
TRANSCRIPT

i
PENGELOMPOKAN SEKOLAH MENENGAH PERTAMA
BERDASARKAN DISTRIBUSI USIA GURU DENGAN ALGORITMA K-
MEANS++ CLUSTERING
(STUDI KASUS : DATA GURU SEKOLAH MENENGAH PERTAMA DI
PULAU KALIMANTAN)
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh
Gelar Sarjana Komputer
Program Studi Informatika
Oleh:
Bagas Dhitya Taufiqqi
165314093
PROGRAM STUDI INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ii
CLUSTERING OF JUNIOR HIGH SCHOOLS BASED ON AGE
DISTRIBUTION OF TEACHERS WITH K-MEANS++ CLUSTERING
ALGORITHM
(CASE STUDY : DATA OF JUNIOR HIGH SCHOOL TEACHERS IN
KALIMANTAN)
UNDERGRADUATE THESIS
Presented as Partial Fullfillment of the Requirement
to Obtain Sarjana Komputer Degree
in Informatics Study Program
By:
Bagas Dhitya Taufiqqi
165314093
INFORMATICS STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2020
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

HALAMAN PERSEMBAHAN
v
“The Greater Our Knowledge Increases
The More Our Ignorance Unfolds”
John F. Kennedy, 35th President of United
States of America
Karya Dipersembahkan Oleh Penulis Untuk :
Allah SWT
Orangtua
Keluarga
Teman-teman
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ABSTRAK
vii
Menurut data DAPODIK tahun 2018, pulau Kalimantan memiliki Sekolah
Menengah Pertama (SMP) sebanyak 1210 sekolah yang tersebar di berbagai
provinsi. Berdasarkan banyaknya SMP tersebut, seringkali menimbulkan
ketidakseimbangan pada perbandingan jumlah guru berusia muda dengan guru
berusia lanjut. Guru berusia lanjut yang akan memasuki masa pensiun, tentu sudah
tidak seproduktif guru yang masih berusia muda. Namun, guru berusia lanjut
mempunyai pengalaman dan pengetahuan lebih banyak dari guru yang berusia
muda. Maka, perbandingan antara guru muda dan guru berusia lanjut sebaiknya
harus seimbang, supaya dapat saling berkolaborasi dalam meningkatkan mutu
sekolah. Pengelompokan merupakan solusi tepat untuk mengatasi permasalahan
tersebut, dengan metode ini diharapkan pemerintah dapat memeriksa SMP yang
memiliki kemiripan jumlah guru muda dan berusia lanjut, agar dapat dilakukan
upaya lanjutan untuk melakukan pemerataan.
Dalam penelitian ini, penulis mengimplementasikan metode clustering
dengan algoritma K-Means++ Clustering menggunakan bahasa pemrograman Java
untuk mengelompokkan SMP yang memiliki kemiripan dalam distribusi usia guru.
Jumlah cluster terbaik ditentukan dengan metode Elbow. Hasil dari metode Elbow
berupa grafik yang menggambarkan nilai Sum of Square Error dari setiap
penambahan cluster pada proses clustering.
Dalam hasil akhir penelitian, metode clustering dengan algoritma K-
Means++ Clustering telah berhasil diimplementasikan pada Sistem
Pengelompokan Sekolah Menengah Pertama Berdasarkan Distribusi Usia Guru.
Nilai Sum of Square Error dapat divisualisasikan dengan menggunakan grafik
Elbow yang berfungsi untuk menentukan jumlah cluster terbaik. Dari pengujian
data yang berjumlah 1204 record, didapatkan hasil bahwa jumlah cluster terbaik
berada di k = 6.
Kata Kunci : SMP, Distribusi, Guru, Usia, Clustering, K-Means++ Clustering, Metode Elbow, Nilai Sum of Square Error
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

ABSTRACT
viii
Based on DAPODIK year of 2018, Kalimantan island has 1212 Junior High
School spread across various provinces. Based on amount of Junior High Schools,
it often creates an imbalance in the amount comparison between young teachers
with older teachers. Older teachers who are about to retire are certainly not as
productive as teachers who are still young. However, older teachers have more
experience and knowledge than younger teachers. So, the comparison between
young teachers and elderly teachers should be balanced, so that they can collaborate
with each other in improving the quality of schools. Clustering is the right solution
to overcome these problems, with this method the government is expected to be
able to examine junior high schools that have similar amounts of young and elderly
teachers, so that further efforts can be made to make equity.
In this research, the authors implemented the clustering method with K-
Means++ Clustering algorithm using Java programming language to clustering
Junior High School that have similarities in the distribution of teachers age. The
best number of cluster was determined by the Elbow method. The results of the
Elbow method in the form of a graph that illustrates the value of Sum of Square
Error of each additional cluster in the clustering process.
In the final result, the clustering method with K-Means++ Clustering
algorithm has been succesful implemented in the Junior High School Clustering
Based on Teachers Age Distribution System. The value of Sum of Square Error can
be visualized using the Elbow graphic which serves to determine the best number
of clusters. From testing data totaling 1204 records, the result show that the best
cluster number is at k = 6.
Key Words : Junior High School, Distribution, Teacher, Age, Clustering,
Clustering, K-Means++ Clustering, Elbow method, Sum of Square Error value
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xii
DAFTAR ISI
HALAMAN JUDUL ............................................................................................... I
TITLE PAGE ........................................................................................................... II
HALAMAN PERSETUJUAN .............................................................................. III
HALAMAN PENGESAHAN ............................................................................... IV
HALAMAN PERSEMBAHAN............................................................................. V
PERNYATAAN KEASLIAN KARYA ............................................................... VI
ABSTRAK ........................................................................................................... VII
ABSTRACT ......................................................................................................... VIII
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN AKADEMIS ................................................................. IX
KATA PENGANTAR ........................................................................................... X
DAFTAR ISI. ...................................................................................................... XII
DAFTAR TABEL ............................................................................................... XV
DAFTAR GAMBAR. ........................................................................................ XVI
BAB I PENDAHULUAN ....................................................................................... 1
1.1 Latar Belakang ............................................................................................. 1
1.2 Rumusan Masalah ........................................................................................ 2
1.3 Tujuan .......................................................................................................... 3
1.4 Batasan Masalah ........................................................................................... 3
1.5 Manfaat ........................................................................................................ 3
1.6 Sistematika Penulisan ................................................................................... 3
BAB II LANDASAN TEORI ................................................................................. 6
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiii
2.1 Data .............................................................................................................. 6
2.1.1 Pengertian Data .................................................................................... 6
2.1.2 Jenis Data ............................................................................................. 6
2.2 Data Mining ................................................................................................. 6
2.2.1 Pengertian Data Mining ....................................................................... 6
2.2.2 Tahapan Knowledge Discovery Database............................................ 7
2.2.2 Karakteristik Data Mining ................................................................... 8
2.2.3 Tugas-tugas Data Mining ..................................................................... 9
2.3 Clustering ..................................................................................................... 9
2.3.1 Pengertian Clustering ........................................................................... 9
2.3.2 K-Means Clustering ........................................................................... 10
2.3.3 K-Means++ Clustering ...................................................................... 11
2.3.3.1 Randomized Seeding Technique ................................................. 12
2.3.4 Flowchart K-Means++ Clustering .................................................... 12
2.3.5 Tinjauan Pustaka ................................................................................ 14
2.4 Metode Elbow ........................................................................................... 15
BAB III METODE PENELITIAN ....................................................................... 18
3.1 Gambaran Umum ....................................................................................... 18
3.2 Bahan Riset/Data ........................................................................................ 20
3.2.1 Pemrosesan Awal ............................................................................... 22
3.2.1.1 Pembersihan Data(Data Cleaning) ............................................ 22
3.2.1.2 Integrasi Data(Data Integration) ................................................ 23
3.2.1.3 Seleksi Data(Data Selection) ..................................................... 23
3.2.1.4 Transformasi Data(Data Transformation) ................................. 24
3.3 Peralatan Penelitian .................................................................................... 24
3.4 Desain Alat Uji ........................................................................................... 24
3.5 Model Fungsi Sistem .................................................................................. 26
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

xiv
3.5.1 Diagram Usecase ................................................................................ 26
3.5.2 Diagram Class .................................................................................... 27
3.5.3 Desain Algoritma ................................................................................ 27
BAB IV IMPLEMENTASI SISTEM DAN ANALISIS HASIL ......................... 31
4.1 Implementasi Sistem .................................................................................. 31
4.1.1 Menu Cari File ................................................................................... 32
4.1.2 Menu Tambah .................................................................................... 33
4.1.3 Menu Hitung Cluster .......................................................................... 33
4.1.4 Menu Hitung Nilai SSE ..................................................................... 34
4.1.5 Jumlah Cluster .................................................................................... 35
4.2 Analisis Hasil Implementasi Algoritma K-Means++ Clustering ............... 36
4.2.1 Uji Validasi ........................................................................................ 36
4.2.1.2 Perhitungan Manual ................................................................... 37
4.2.1.3 Perhitungan Perangkat Lunak .................................................... 48
4.2.2 Evaluasi Hasil Perhitungan Manual dan Perangkat Lunak ................. 50
4.3 Analisis Penentuan Jumlah Cluster terbaik ................................................ 51
BAB V PENUTUP ................................................................................................ 56
5.1 Simpulan .................................................................................................... 56
5.2 Saran ........................................................................................................... 56
DAFTAR PUSTAKA ........................................................................................... 57
Lampiran 1 : Desain Algoritma ............................................................................ 58
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

DAFTAR TABEL
xv
Tabel 3.1 . Sampel Data Dapodik 2018. ................................................................. 20
Tabel 3.2 . Keterangan Atribut ................................................................................ 21
Tabel 3.3 . Keterangan Noise .................................................................................. 22
Tabel 3.4 . Atribut Yang Tidak
Digunakan Pada Data Dapodik Tahun 2018........................................................... 23
Tabel 3.5 . Keterangan Fungsi................................................................................ 25
Tabel 5.1 . Dataset Uji Validasi .............................................................................. 38
Tabel 5.2 . Hasil Perhitungan
Randomized Seeding Technique ............................................................................ 40
Tabel 5.3 . Iterasi Pertama ....................................................................................... 42
Tabel 5.4 . Iterasi Kedua ......................................................................................... 45
Tabel 5.5 . Iterasi Ketiga......................................................................................... 47
Tabel 5.6 . Hasil Perhitungan MATLAB. ............................................................... 48
Tabel 5.7 . Hasil Akhir Perhitungan Manual, Perangkat Lunak, dan MATLAB. .. 50
Tabel 5.8 . Nilai SSE (Sum of Square Error) ........................................................ 52
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

DAFTAR GAMBAR
xvi
Gambar 2. 1 . Tahapan Dalam Data Mining (Fayyad,1996). ................................. 8
Gambar 2. 2 . Flowchart Algoritma K-Means++ Clustering .................................. 13
Gambar 3. 1 . Gambaran Umum Sistem.................................................................. 19
Gambar 3.2 . Prototype Sistem .............................................................................. 24
Gambar 3.3 . Diagram Usecase............................................................................... 26
Gambar 3.4 . Diagram Class................................................................................... 27
Gambar 4.1 . Tampilan Halaman Masuk. ............................................................... 31
Gambar 4.2 . Tampilan Halaman Utama ................................................................. 32
Gambar 4.3 . Menu Cari File .................................................................................. 32
Gambar 4.4 . Menu Tambah................................................................................... 33
Gambar 4.5 . Tabel Data......................................................................................... 33
Gambar 4.6 . Menu Hitung Cluster......................................................................... 34
Gambar 4.7 . Tempat Output Hasil K-Means++ Clustering. ................................... 34
Gambar 4.8 . Menu Hitung Nilai SSE ..................................................................... 34
Gambar 4.9 . Tabel Output Nilai SSE .................................................................... 35
Gambar 4.10 . Menu Jumlah Cluster....................................................................... 35
Gambar 4.11 . Menu Lihat Grafik. ......................................................................... 35
Gambar 4.12 . Tampilan Grafik Elbow .................................................................. 36
Gambar 4.13 . Nilai Random Pada Excel ................................................................ 42
Gambar 4.14 . Hasil Clustering Pada Perangkat Lunak. .......................................... 49
Gambar 4.15 . Grafik Elbow Data Dapodik Tahun 2018........................................
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Indonesia merupakan negara kepulauan yang memiliki luas wilayah
membentang dari Sabang sampai Merauke. Menurut data dari Perserikatan Bangsa-
Bangsa(PBB) pada tahun 2005, total luas keseluruhan wilayah Indonesia mencapai
1910931 km2, dengan perkiraan penduduk mencapai 261.115.456 orang pada tahun
2016. Dengan wilayah luas dan penduduk yang mencapai ratusan juta tersebut,
seringkali membuat pemerintah daerah mengalami kesulitan dalam memperhatikan
kualitas pendidikan di daerahnya masing-masing, khususnya Pulau Kalimantan.
Menurut data yang bersumber dari Data Pokok Pendidikan (DAPODIK)
tahun 2018, Pulau Kalimantan memiliki sekolah baik negeri maupun swasta
berjumlah 1824 yang tersebar di berbagai provinsi, dengan rincian Sekolah
Menengah Pertama(SMP) negeri/swasta sebanyak 1204 sekolah. Salah satu faktor
yang mempengaruhi kualitas suatu SMP ialah jumlah guru yang berusia muda,
karena usia muda dianggap lebih produktif untuk diterjunkan sebagai tenaga
pengajar.
Berdasarkan paragraf sebelumnya, dapat digali pokok-pokok permasalahan
yang ditimbulkan dari banyaknya jumlah SMP di Pulau Kalimantan. Jumlah SMP
yang sebanyak itu seringkali menimbulkan ketidakseimbangan pada jumlah guru
berusia muda, dengan guru berusia lanjut. Guru berusia lanjut yang akan memasuki
masa pensiun, tentu sudah tidak seproduktif guru yang masih berusia muda.
Namun, guru berusia lanjut memiliki pengalaman dan pengetahuan lebih banyak
dari guru yang berusia muda. Maka, perbandingan antara guru muda dan guru
berusia lanjut sebaiknya memiliki jumlah yang seimbang, supaya dapat saling
berkolaborasi dalam meningkatkan kualitas sekolah. Berdasarkan fakta yang
ditemukan, terdapat beberapa sekolah tidak memiliki jumlah guru muda dan guru
berusia lanjut yang seimbang. Akibat yang ditimbulkan dari ketidakseimbangan
tersebut, tentu mempengaruhi kualitas antara satu SMP dengan SMP yang lain.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

2
Solusi untuk menyelesaikan persoalan tersebut salah satunya ialah
pengelompokan menggunakan algoritma K-Means++ Clustering yang ditemukan
oleh David Arthur dan Sergei Vassilvitski pada tahun 2007 silam. Dalam jurnalnya,
David Arthur dan Sergei Vassilvitski mengemukakan bahwa algoritma temuannya
ini mempunyai performa lebih baik dalam hal kecepatan dan akurasi dibandingkan
pendahulunya (Arthur dan Vassilvitski, 2007). Selain itu, dalam jurnal yang
berjudul Pengelompokan Kualitas Kerja Pegawai Menggunakan Algoritma K-
Means++ Dan COP-Kmeans Untuk Merencanakan Program Pemeliharaan
Kesehatan Pegawai Di PT. PLN P2B JB Depok, (Chandra dkk., 2017) juga
dibuktikan bahwa algoritma K-Means++ Clustering mampu memberikan hasil
yang lebih mendekati kebenaran dibandingkan K-Means Clustering, walaupun
kecepatan perhitungan algoritma K-Means++ Clustering lebih lambat.
Dengan berbagai permasalahan yang ada di latar belakang ini, maka penulis
tertarik untuk mengangkat tema Pengelompokan Sekolah Menengah Pertama
Berdasarkan Distribusi Usia Guru Dengan Algoritma K-Means++ Clustering.
Penelitian ini diharapkan dapat membantu dinas pendidikan daerah di Pulau
Kalimantan dalam mengelompokkan SMP berdasarkan distribusi usia guru guna
meningkatkan kualitas sekolah. Data yang digunakan mengacu kepada data jumlah
guru muda dan guru berusia lanjut yang mengajar pada SMP yang terletak di Pulau
Kalimantan.
1.2 Rumusan Masalah
1. Bagaimana algoritma K-Means++ Clustering dapat mengelompokkan
SMP berdasarkan distribusi usia guru?
2. Bagaimana menentukan jumlah cluster terbaik dalam proses clustering
dengan metode Elbow?
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

3
1.3 Tujuan
1. Menerapkan algoritma K-Means++ Clustering dalam melakukan
pengelompokan SMP berdasarkan distribusi usia guru
2. Menentukan jumlah cluster terbaik dalam proses clustering dengan
menggunakan metode Elbow
1.4 Batasan Masalah
1. Implementasi menggunakan Netbeans
2. Data yang digunakan adalah data rentang usia guru SMP di Pulau
Kalimantan yang berasal dari Data Pokok Pendidikan (DAPODIK)
Tahun 2018
1.5 Manfaat
1. Membantu dinas pendidikan daerah dalam memperhatikan kualitas
pendidikan, khususnya di pulau Kalimantan, dengan mengidentifikasi
SMP mana saja yang memiliki kemiripan dalam hal distribusi usia guru.
2. Memberikan gambaran pengklasteran mengenai SMP mana saja yang
memiliki kemiripan distribusi usia guru.
1.6 Sistematika Penulisan
1. Bab I, berisi tentang latar belakang, rumusan masalah, tujuan, manfaat,
batasan masalah, dan sistematika penulisan
2. Bab II, memaparkan teori yang digunakan sebagai dasar penelitian, serta
mendukung perancangan dan implementasi selama penelitian
berlangsung.
3. Bab III, membahas mengenai metodologi penelitian yang terdiri dari
rumusan masalah, tahap perencanaan, observasi dan pengumpulan data,
studi literatur, serta algoritma K-Means++ Clustering
4. Bab IV, membahas mengenai pemrosesan awal, implementasi sistem
dan analisis hasil, terdiri dari teknik atau model analisis yang disebutkan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

4
di bab metodologi penelitian. Dalam bab ini juga dipaparkan mengenai
bagian-bagian dalam sistem(GUI) yang akan digunakan untuk
melakukan clustering dengan algoritma K-Means++ Clustering, dan
pengujian terhadap data beserta hasil ujinya.
5. Bab V, membahas mengenai penutup yang terdiri dari kesimpulan dan
saran. Kesimpulan merupakan jawaban atas permasalahan yang telah
dirumuskan pada latar belakang, sedangkan saran berisi tentang
himbauan penulis kepada pihak pembaca untuk mengatasi
permasalahan yang belum sempat diselesaikan karena tidak ada
relevansi dengan pokok bahasannya secara langsung.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

BAB II
LANDASAN TEORI
2.1 Data
2.1.1 Pengertian Data
Menurut pendapat Drs.Jhon J Longkutoy (1996), data merupakan istilah
majemuk dari fakta yang menyimpan arti dan dihubungkan dengan simbol, angka,
huruf, gambar maupun kenyataan yang membuktikan suatu objek,ide, atau kondisi.
Selain itu, seorang ahli yang bernama Vercellis (2009) juga mengemukakan bahwa
data merupakan sebuah penggambaran fakta yang tersusun secara terstruktur.
Dalam pendapat lain, data merupakan sebuah rekaman dari konsep,fakta, atau
instruksi pada media penyimpanan untuk hubungan perolehan, dan pemrosesan
dengan cara otomatis sebagai informasi yang dapat dipahami oleh manusia
(Inmon,2005)
2.1.2 Jenis Data
Data yang digunakan dalam penelitian ini merupakan kombinasi antara data
kuantitatif dan data kualitatif. Data kuantitatif merupakan salah satu jenis data yang
berisi informasi berupa bilangan atau angka sehingga dapat dihitung maupun diukur
secara langsung, sedangkan data kualitatif merupakan data yang berupa kata,
gambar, alur skema. (Sugiyono,2015). Data kuantitatif dalam penelitian ini adalah
jumlah guru pada rentang usia tertentu, sedangkan data kualitatifnya berupa nama
sekolah dan nama provinsi.
2.2 Data Mining
2.2.1 Pengertian Data Mining
Data Mining merupakan disiplin ilmu yang mengkaji metode dalam
menggali informasi atau mendapatkan pola dari suatu data (Han dan Kamber,
6
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

7
2006). Data Mining juga menggambarkan proses semi otomatik yang
memanfaatkan teknik Machine Learning, Artificial Intelligence, statistik, dan
matematika dalam mengenali serta mengekstraksi informasi yang berguna dan
bermanfaat pada database besar (Turban dkk., 2005). Data Mining sering disebut
sebagai Knowledge Discovery in Database (KDD), yaitu kegiatan yang mencakup
pemakaian data,pengumpulan data, historis untuk mendapatkan keteraturan, pola
maupun hubungan dalam set data berukuran besar (Santoso, 2007).
2.2.2 Tahapan Knowledge Discovery Database
Data Mining merupakan bagian dari proses Knowledge Discovery in
Database (KDD). Sebagai bagian dari proses KDD, Data Mining berkaitan erat
dengan penghitungan pada pola suatu data. Adapun beberapa tahapan dalam KDD
adalah sebagai berikut (Fayyad, 1996) :
1. Data Selection
Seleksi data dikerjakan dari suatu himpunan data operasional. Sebelum
memasuki tahap penggalian informasi dalam KDD, tahapan ini perlu
dikerjakan. Data hasil seleksi akan disimpan pada berkas yang terpisah dari
database operasional
2. Preprocessing/Cleaning
Dalam tahapan ini, terjadi proses pembuangan data yang
mempunyai duplikasi, data yang inkonsisten, serta memperbaiki kesalahan
pada data. Dilakukan pula proses enrichment untuk memperkaya data yang
telah ada dengan data/informasi lain yang tentunya harus relevan.
3. Transformation
Coding merupakan proses transformasi yang sesuai untuk
pengerjaan Data Mining pada data yang telah dipilih. Coding dalam KDD
sangat dipengaruhi oleh jenis atau pola informasi yang akan dicari dalam
database.
4. Data Mining
Proses dalam mencari sebuah pola atau informasi yang menarik
dalam data terpilih dengan metode tertentu disebut sebagai Data Mining.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

8
Data Mining mempunyai algoritma, teknik, ataupun metode yang
bervariasi. Proses KDD pun sangat dipengaruhi oleh pemilihan algoritma
dan metode yang tepat.
5. Interpretation/Evaluation
Proses untuk membawakan pola informasi yang dihasilkan dari
kegiatan Data Mining oleh pihak yang berkepentingan, disebut sebagai
Interpretation/Evaluation. Interpretation/Evaluation mencakup
pengecekan terhadap informasi atau pola yang ditemukan supaya tidak
berseberangan dengan hipotesis atau fakta yang ada sebelumnya. Penjelasan
diatas dapat diilustrasikan pada gambar 2.1
Gambar 2. 1 . Tahapan dalam Data Mining (Fayyad,1996)
2.2.2 Karakteristik Data Mining
Adapun beberapa karakteristik Data Mining sebagai berikut (Davies, 2004) :
1. Data Mining sering digunakan pada data yang jumlahnya sangat besar.
Hal ini dilakukan agar mendapatkan hasil yang lebih dipercaya.
2. Data Mining berasosiasi dengan penciptaan sesuatu yang masih
tersembunyi dan pola data tertentu yang belum diketahui sebelumnya.
3. Data Mining bermanfaat dalam pembuatan keputusan yang kritis,
terutama strategi.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

9
2.2.3 Tugas-tugas Data Mining
Data Mining dibagi ke dalam beberapa tugas, antara lain (Fayyad dan Usama,
1996):
1. Klasifikasi (Classification)
Menyamaratakan model yang diketahui untuk diterapkan pada data
yang baru. Misalkan, klasifikasi penyakit ke dalam sejumlah jenis.
2. Regresi (Regression)
Menciptakan fungsi yang memodelkan data dengan kesalahan prediksi
sesedikit mungkin.
3. Klastering (Clustering)
Menggolongkan data, yang belum diketahui label kelasnya, ke dalam
beberapa golongan tertentu sesuai dengan presentase kemiripannya.
2.3 Clustering
2.3.1 Pengertian Clustering
Clustering atau pengelompokan data memperhitungkan sebuah pendekatan
dalam menyelidiki kesamaan dalam data dan meletakkan data yang memiliki
kesamaan ke berbagai kelompok. Algoritma ini membagi himpunan data ke dalam
beberapa kelompok dimana kesamaan dalam sebuah kelompok lebih besar daripada
kelompok yang lain (Wunsch II dan Xu, 2009). Algoritma Clustering dipergunakan
secara menyeluruh, tidak hanya terpaut pada masalah pengkategorian data, namun
juga dapat menangani kompresi data maupun struktur model (Dubes dan Jain,
1988).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

10
2.3.2 K-Means Clustering
Algoritma Clustering ini mempunyai beberapa metode, salah satu
diantaranya ialah K-Means Clustering. Cara kerja K-Means Clustering berpatokan
pada pemilihan jumlah awal kelompok dengan menginterpretasikan nilai centroid
awalnya (Madhulatha, 2012). Dalam prosesnya, K-Means Clustering akan
memproduksi titik centroid yang dijadikan target atau tujuan dari K-Means
Clustering itu sendiri. Saat iterasi K-Means Clustering berhenti, dataset sudah terisi
oleh objek yang menjadi anggota dari suatu cluster. Nilai cluster dihasilkan dengan
mencari seluruh objek untuk mengidentifikasi cluster dengan jarak terdekat ke
objek. K-Means Clustering mengumpulkan item data dalam suatu dataset ke suatu
cluster berdasarkan jarak terdekat (Bangoria dkk., 2013). Adapun algoritma K-
Means Clustering sebagai berikut (Arthur dan Vassilvitski, 2007) :
1. Pilih secara acak k pusat awal C = {c1, . . . , ck}.
2. Untuk setiap i ∈ {1,...,k} , atur cluster Ci menjadi himpunan poin
di X yang lebih dekat ke ci daripada mereka untuk cj untuk semua
jz�
3. Untuk setiap i ∈ {1,...,k} , atur ci menjadi pusat massa semua titik
dalam
Ci: ci = 1/ ¨Ci ¨6 x� Cix
4. Ulangi langkah 2 dan 3 hingga C tidak berubah
Dalam machine learning dan statistik, clustering K-Means merupakan
metode analisis kelompok yang mengarah kepada pembagian N objek pemantauan
ke dalam cluster dimana setiap objek pemantauan dimiliki oleh kelompok dengan
mean terdekat, dimana keduanya berupaya untuk mendapatkan centroid dari dalam
data sebanyak iterasi yang dilakukan. Pengukuran jarak dengan Euclidean
menggunakan formula:
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

11
$%!
𝐷(푋! , 푋") = '∑# (푋! − 푋")"……………………….(2.1)
D merupakan jarak antara data X2 dengan X1 adalah nilai mutlak (Manvreet
dan Usvir, 2013) dimana X merupakan sebuah titik centroid.
2.3.3 K-Means++ Clustering
Algoritma K-Means Clustering pun mengalami perkembangan dari tahun
ke tahun. Pada tahun 2007, David Arthur dan Sergei Vassilvitski menemukan
algoritma K-Means++ Clustering. Dalam jurnalnya, David Arthur dan Sergei
Vassilvitski membuktikan bahwa K-Means++ Clustering lebih unggul daripada
pendahulunya, yaitu K-Means Clustering, dalam hal akurasi dan kecepatan.
Adapun algoritma K-Means++ Clustering sebagai berikut (Arthur dan Vassilvitski,
2007) :
1. Pilih satu centroid secara acak dari antara titik data.
2. Untuk setiap titik data x , hitung D ( x ), jarak antara x dan centroid
terdekat yang telah dipilih.
3. Pilih satu titik data baru secara acak sebagai centroid baru,
menggunakan distribusi probabilitas tertimbang di mana titik x
dipilih dengan probabilitas sebanding dengan D ( x ) 2 .
4. Ulangi Langkah 2 dan 3 sampai k centroid telah dipilih.
5. Sekarang setelah centroid awal telah dipilih, lanjutkan
menggunakan pengelompokan standar k -means
Meskipun algoritma ini membutuhkan waktu yang lebih lama dalam
pencarian centroid awal, bagian K-Means Clustering itu sendiri menyatu secara
cepat setelah algoritma ini dieksekusi, dengan demikian algoritma tersebut
sebenarnya menurunkan waktu komputasi. Algoritma ini diuji dengan dataset nyata
maupun buatan dengan hasil diperoleh peningkatan lebih cepat dua kali lipat dalam
hal kecepatan daripada K-Means Clustering biasa (Kanungo, T. dkk., 2004).
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

12
2.3.3.1 Randomized Seeding Technique
Masing-masing anggota mempunyai peluang untuk terpilih menjadi
centroid sehingga setiap anggota dihitung nilai peluang untuk terpilih dan yang
paling mendekati adalah yang paling tepat. Berikut formula randomized seeding
technique:
Dengan keterangan :
!(#’)!
∑#�' !(#’)!
……………………(2.2)
X = titik centroid
x = cluster
D(x’)2 = Jarak Euclidean Distance
¦x�XD(x’)2 = Jumlah Jarak Euclidean Distance Rumus Randomized Seeding Technique akan menghasilkan sebuah
angka yang dijadikan sebagai acuan semakin jauh nilai objek, maka
semakin besar kemungkinan nilai objek akan menjadi nilai C
berikutnya
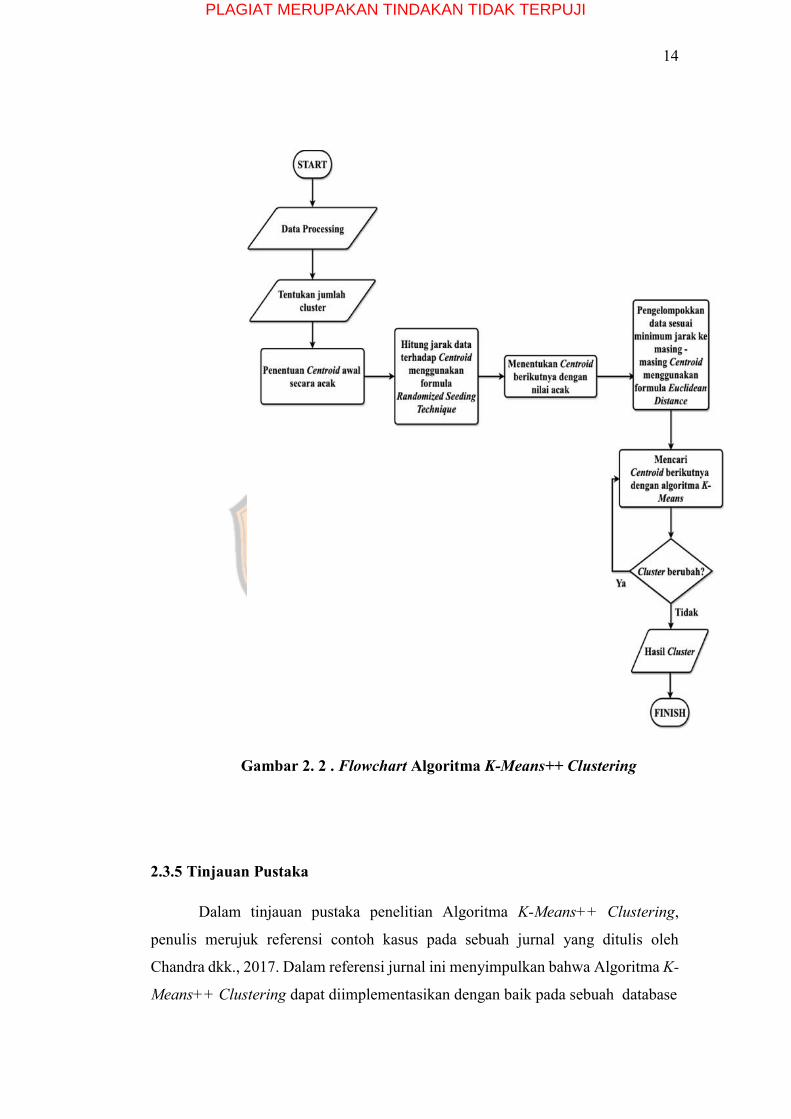
2.3.4 Flowchart K-Means++ Clustering
Pada Gambar 2.2 akan dijelaskan mengenai alur algoritma K-Means++
Clustering ke dalam bentuk flowchart. Alur dimulai dari tahapan memproses data
(Data Processing), dimana tahapan ini meliputi pemilihan atribut data, jumlah data,
dll. Setelah itu memasuki tahap penentuan jumlah cluster yang akan dipatok, lalu
dilanjut dengan menentukan centroid awal secara acak. Kemudian, melakukan
penghitungan jarak data terhadap masing-masing centroid menggunakan formula
Randomized Seeding Technique.
Langkah selanjutnya ialah menentukan nilai centroid kembali secara acak,
hingga setelahnya dilakukan pengelompokan data sesuai minimum jarak ke
masing-masing centroid menggunakan formula Euclidean Distance. Setelah
pengelompokan data, maka dimulai mencari centroid selanjutnya dengan algoritma
K-Means, dari tahap ini akan diketahui perubahan cluster. Jika cluster berubah,
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

13
maka akan mengulang kembali pencarian centroid dengan algoritma K-Means. Jika
cluster tetap, maka hasil cluster telah diperoleh.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
14
Gambar 2. 2 . Flowchart Algoritma K-Means++ Clustering
2.3.5 Tinjauan Pustaka
Dalam tinjauan pustaka penelitian Algoritma K-Means++ Clustering,
penulis merujuk referensi contoh kasus pada sebuah jurnal yang ditulis oleh
Chandra dkk., 2017. Dalam referensi jurnal ini menyimpulkan bahwa Algoritma K-
Means++ Clustering dapat diimplementasikan dengan baik pada sebuah database
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

15
)%!
kesehatan. Hal tersebut telah dibuktikan sebagaimana yang dikatakan oleh Chandra
dkk., 2017 pada akhir kesimpulan bahwa dalam hasil perhitungan akhir menyatakan
kualitas kerja pegawai dapat dikelompokkan menjadi 5 kelompok serta tidak ada
pegawai yang sama dengan kelompok lain.
2.4 Metode Elbow
Metode Elbow adalah sebuah metode yang diaplikasikan untuk membentuk suatu
informasi dalam menentukan jumlah cluster terbaik dengan cara melihat persentase
hasil perbandingan antara jumlah cluster yang akan membentuk siku pada sebuah
titik. Berikut merupakan algoritma dari metode Elbow dalam menentukan jumlah
cluster terbaik (Merliana, N.P.E. dkk.,2015) :
1. Mendeklarasikan awal nilai k;
2. Menaikkan nilai k;
3. Menghitung hasil dari SSE (Sum of Square Error) dari tiap nilai k;
4. Menganalisa hasil SSE dari nilai k yang mengalami penurunan secara
signifikan;
5. Cari dan tetapkan nilai k yang berbentuk siku;
Dalam metode Elbow, nilai cluster terbaik diambil dari nilai SSE yang mengalami
penurunan signifikan serta membentuk sebuah siku. Berikut merupakan formula
untuk menghitung SSE (Kodinariya & Makwana, 2013)
𝑆𝑆𝐸 = ∑) ∑$∈'! || 푋$ − 𝐶(||"……………... (2.3)
Keterangan :
K = jumlah cluster
S = K-cluster yang telah terbentuk
푋$ = data x pada indeks ke - i
𝐶( = rata-rata K-cluster pada nilai k (k=1,2,...K)
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

16
Sum of Square Error (SSE) adalah formula yang sering dimanfaatkan untuk
melakukan pengukuran terhadap data yang diperoleh dengan model prediksi yang
telah dilakukan sebelumnya. SSE sering digunakan acuan dalam menentukan
cluster yang optimal.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

BAB III
METODE PENELITIAN
3.1 Gambaran Umum
Penelitian ini bertujuan untuk membantu dinas pendidikan daerah masing-
masing provinsi di Pulau Kalimantan dalam mendapatkan informasi mengenai
persebaran SMP mana saja yang memiliki jumlah guru seimbang dan belum
seimbang dengan mengacu pada perbandingan antara guru muda dengan guru yang
berusia lanjut menggunakan algoritma K-Means++ Clustering. Dari hasil
pengklasteran tersebut nantinya akan dihasilkan pengelompokan ke dalam beberapa
cluster sekolah-sekolah yang memiliki kemiripan jumlah distribusi usia guru.
Dengan penelitian ini, diharapkan dapat membantu dinas pendidikan daerah dalam
meningkatkan kualitas pendidikan di masing-masing daerah dengan melakukan
pengelompokan terhadap sekolah-sekolah yang mempunyai kemiripan jumlah guru
muda dan guru berusia lanjut. Dalam Gambar 3.1 berikut merupakan rancangan
umum penggunaan sistem dari penelitian ini :
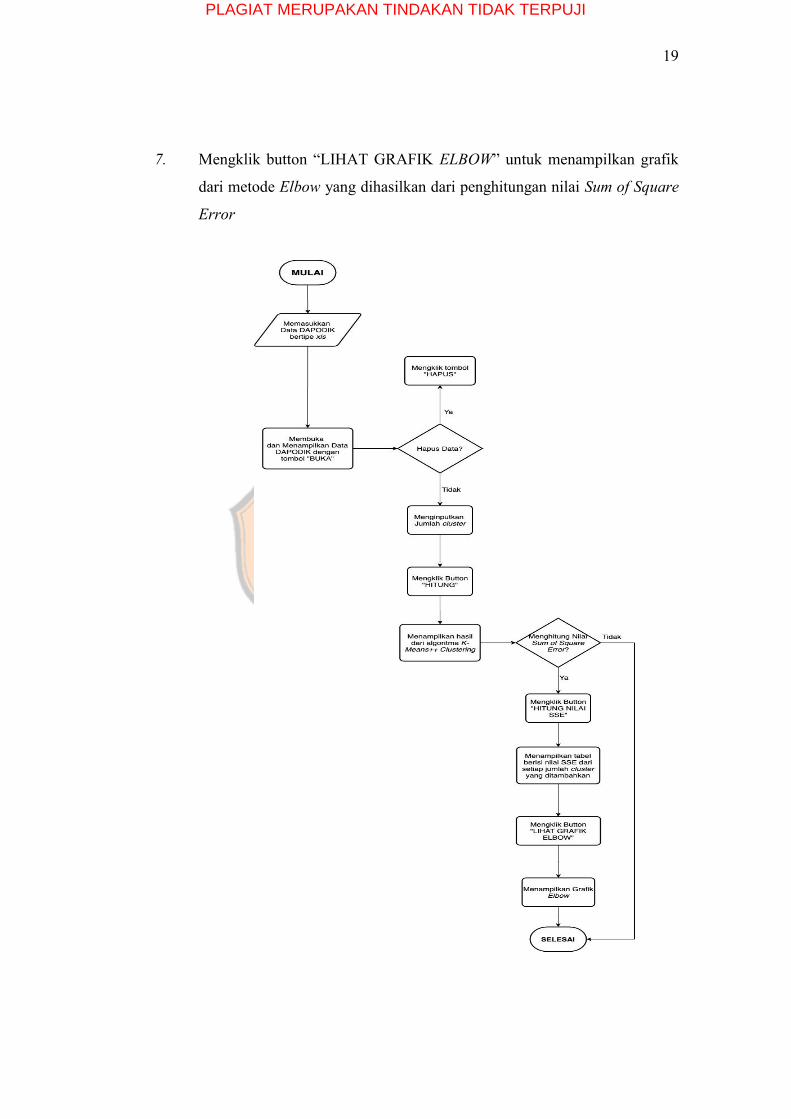
1. Menekan tombol “Masukan File untuk memasukkan DAPODIK yang
bertipe xls
2. Mengklik button “BUKA” untuk membuka data yang sudah diinputkan
sebelumnya ke dalam Tabel Data
3. Mengklik button “HAPUS” bila ingin menghapus isi tabel
4. Menginputkan jumlah cluster yang diinginkan sebelum melakukan
clustering
5. Mengklik button “HITUNG” untuk menghitung hasil clustering dari
algoritma K-Means++ Clustering dan menampilkan hasilnya
6. Mengklik button “HITUNG NILAI SSE” untuk menghitung nilai Sum of
Square Error dan menampilkan hasilnya
18
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
19
7. Mengklik button “LIHAT GRAFIK ELBOW” untuk menampilkan grafik
dari metode Elbow yang dihasilkan dari penghitungan nilai Sum of Square
Error
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
20
Gambar 3. 1 . Gambaran Umum Sistem
3.2 Bahan Riset/Data
Penelitian ini menggunakan Data Pokok Pendidikan (DAPODIK) tahun
2018. Total data sejumlah 1204 record dengan 9 atribut. Isi DAPODIK berupa
data Sekolah Menengah Pertama yang berstatus Negeri ataupun Swasta dari
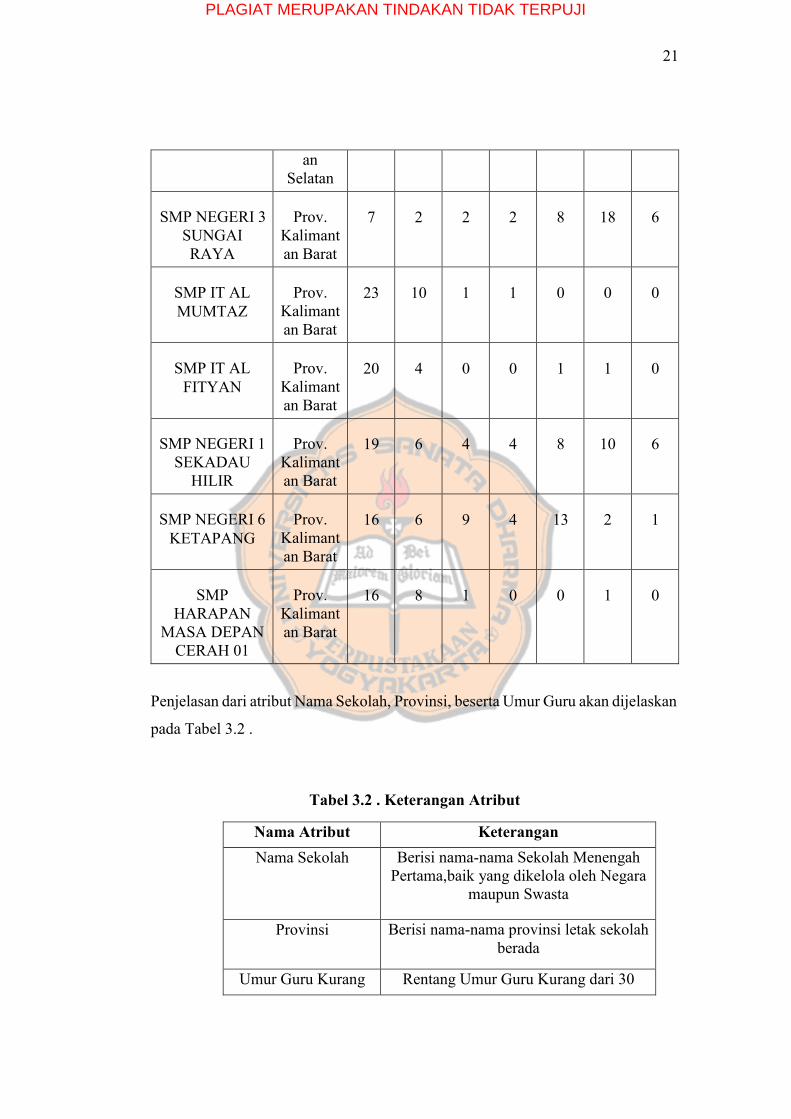
seluruh provinsi di Pulau Kalimantan. Pada Tabel 3.1. berikut merupakan 10
sampel record data yang diambil pada DAPODIK tahun 2018 dalam bentuk
excel :
Tabel 3.1 . Sampel data DAPODIK 2018
Nama Sekolah
Provinsi
Um ur Gur u < 30
Um ur Gur u 31 - 35
Um ur
Gur u 36 - 40
Um ur Gur u 41 - 45
Um ur Gur u 46 - 50
Um ur Gur u 51 - 55
Um ur Gur u > 55
SMP NEGERI 6 PALANGKAR
AYA
Prov.
Kalimant an
Tengah
3
2
7
5
8
27
10
SMP NEGERI 1 TENGGARON
G
Prov.
Kalimant an Timur
1
1
3
3
8
26
8
SM NEGERI 2 SAMARINDA
Prov.
Kalimant an Timur
0
1
6
3
16
20
19
SMP NEGERI 1 BANJARBARU
Prov.
Kalimant
5
13
4
3
7
19
7
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
21
an Selatan
SMP NEGERI 3
SUNGAI RAYA
Prov.
Kalimant an Barat
7
2
2
2
8
18
6
SMP IT AL MUMTAZ
Prov.
Kalimant an Barat
23
10
1
1
0
0
0
SMP IT AL
FITYAN
Prov.
Kalimant an Barat
20
4
0
0
1
1
0
SMP NEGERI 1
SEKADAU HILIR
Prov.
Kalimant an Barat
19
6
4
4
8
10
6
SMP NEGERI 6
KETAPANG
Prov.
Kalimant an Barat
16
6
9
4
13
2
1
SMP
HARAPAN MASA DEPAN
CERAH 01
Prov.
Kalimant an Barat
16
8
1
0
0
1
0
Penjelasan dari atribut Nama Sekolah, Provinsi, beserta Umur Guru akan dijelaskan
pada Tabel 3.2 .
Tabel 3.2 . Keterangan Atribut
Nama Atribut Keterangan Nama Sekolah Berisi nama-nama Sekolah Menengah
Pertama,baik yang dikelola oleh Negara maupun Swasta
Provinsi Berisi nama-nama provinsi letak sekolah berada
Umur Guru Kurang Rentang Umur Guru Kurang dari 30
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

22
dari 30 Tahun tahun Umur Guru 31-35
Tahun Rentang Guru 31-35 tahun
Umur Guru 36-40 Tahun
Rentang Umur Guru 36-40 tahun
Umur Guru 41-45 Tahun
Rentang Umur Guru 41-45 tahun
Umur Guru 46-50 Tahun
Rentang Umur Guru 46-50 tahun
Umur Guru 51-55 Tahun
Rentang Umur Guru 51-55 tahun
Umur Guru Lebih dari 55 Tahun
Rentang Umur Guru Lebih dari 55 tahun
3.2.1 Pemrosesan Awal
3.2.1.1 Pembersihan Data(Data Cleaning)
Data cleaning merupakan proses awal dalam data mining yang dilakukan
untuk menghilangkan noise. Dalam data yang diujikan pada penelitian ini terdapat
beberapa noise berupa data sekolah yang berbeda jenjang. Peneliti menghilangkan
noise tersebut karena tidak sesuai dengan fokus penelitian. Tabel 3.3 berikut
berisikan keterangan mengenai noise yang ada di dalam data.
Tabel 3.3 . Keterangan Noise
Nama Sekolah Keterangan Noise SD – SMP Negeri Satu Atap 1 Pangkalan Banteng
Beberapa institusi yang memiliki sistem satu atap (gabungan lintas
jenjang) menyebabkan tidak jelasnya informasi mengenai
jumlah rentang usia guru yang mengajar di masing-masing
SD – SMP Negeri Satu Atap 1 Laung Tuhup SD SMP Negeri Satu Atap 3 Arut Utara SMP NEGERI 3 MUARA KOMAM(SD-SMP Satap 02 Muara Kom SD SMP NEGERI SATU ATAP 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

23
MARIKIT jenjang sekolah tersebut SD SMP NEGERI SATU ATAP 2 ARUT UTARA
Dalam melakukan pembersihan data, peneliti menelusuri cell di dalam data excel,
kemudian menghapus noise secara langsung tanpa menggunakan tools khusus.
3.2.1.2 Integrasi Data(Data Integration)
Peneliti tidak melakukan tahap ini dikarenakan data tersebut berasal dari
sumber referensi yang sama, yaitu data excel DAPODIK tahun 2018 bertipe xls.
3.2.1.3 Seleksi Data(Data Selection)
Sebelum melakukan penggalian informasi dalam KDD, diperlukan tahap
penyeleksian data terhadap sekumpulan data operasional. Seleksi data merupakan
tahap menganalisis data yang relevan dari database. Atribut yang tidak digunakan
pada data DAPODIK tahun 2018 akan dijelaskan dalam tabel 3.4
Tabel 3.4 . Atribut yang tidak digunakan pada data DAPODIK tahun 2018
DATA ATRIBUT TIDAK DIGUNAKAN
Data DAPODIK tahun 2018 Kepala Sekolah Akreditasi Status
Akses Internet NPSN Jenjang
Kurikulum
Atribut yang terdapat dalam tabel 4.1 tidak dibutuhkan untuk proses
pengelompokan di penelitian ini. Proses pengelompokan hanya membutuhkan
atribut nama sekolah, provinsi, dan rentang usia guru.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

24
3.2.1.4 Transformasi Data(Data Transformation)
Dalam penelitian ini tidak dilakukan normalisasi, keseluruhan data
memiliki interval yang sama, yaitu 0-4.
3.3 Peralatan Penelitian
Alat yang digunakan dalam penelitian ini adalah:
1) Laptop dengan Spesifikasi :
- Processor Intel Core i5 1.8 GHz
- RAM 8 GB 1600 MHz DDR3
2) Spesifikasi Software :
- MacOS Mojave 10.14.6
- Netbeans IDE 8.0.2
- Apache POI jar
3.4 Desain Alat Uji
Perencanaan sistem dilaksanakan untuk mendukung tahap awal
pembangunan sistem menggunakan bahasa pemrograman Java. Perencanaan
sistem menggambarkan tampilan atau interface dari sistem, proses algoritma K-
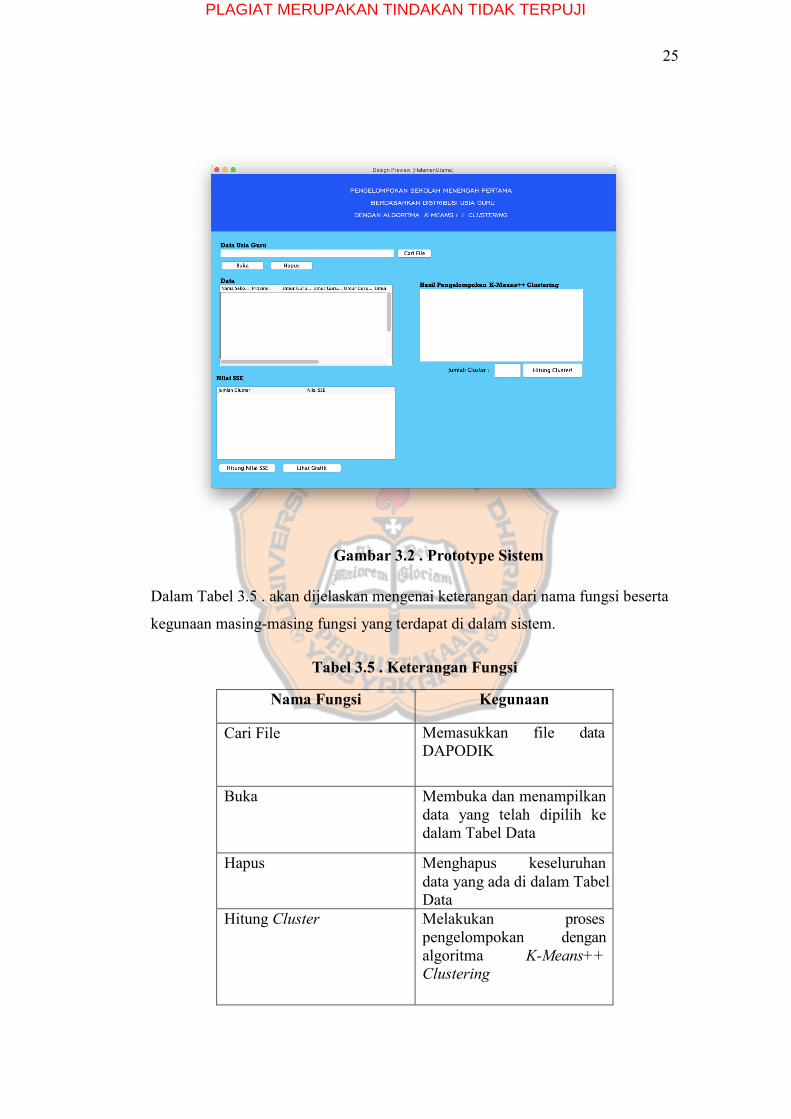
Means++ Clustering, hingga hasil akhir dari clustering. Pada Gambar 3.2
diperlihatkan prototype sistem yang akan digunakan dalam penelitian ini.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
25
Gambar 3.2 . Prototype Sistem
Dalam Tabel 3.5 . akan dijelaskan mengenai keterangan dari nama fungsi beserta
kegunaan masing-masing fungsi yang terdapat di dalam sistem.
Tabel 3.5 . Keterangan Fungsi
Nama Fungsi Kegunaan
Cari File Memasukkan file data DAPODIK
Buka Membuka dan menampilkan data yang telah dipilih ke dalam Tabel Data
Hapus Menghapus keseluruhan data yang ada di dalam Tabel Data
Hitung Cluster Melakukan proses pengelompokan dengan algoritma K-Means++ Clustering
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
26
Hitung Nilai SSE Melakukan penentuan jumlah cluster terbaik dari kinerja algoritma K- Means++ Clustering terhadap data yang digunakan menggunakan metode Elbow
Jumlah Cluster Menentukan jumlah cluster yang akan diujikan
Lihat Grafik Melihat grafik Elbow yang dihasilkan dari nilai SSE
3.5 Model Fungsi Sistem
3.5.1 Diagram Usecase
Pada sistem yang di dalam Gambar 3.3 ini terdapat satu pengguna yang
dapat memasukkan file data DAPODIK, menghapus data dalam tabel,
menampilkan hasil clustering dari algoritma K-Means++ Clustering, dan
menampilkan nilai cluster terbaik dari hasil clustering dengan algoritma K-
Means++ Clustering.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
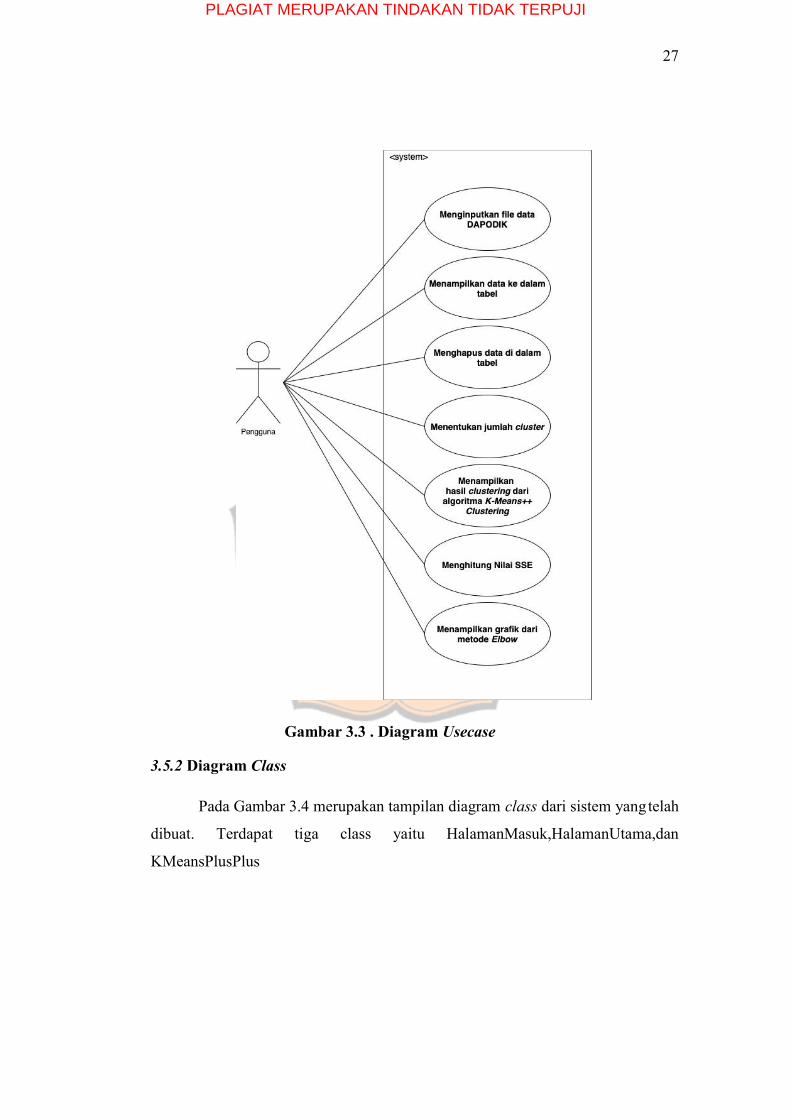
27
Gambar 3.3 . Diagram Usecase
3.5.2 Diagram Class
Pada Gambar 3.4 merupakan tampilan diagram class dari sistem yang telah
dibuat. Terdapat tiga class yaitu HalamanMasuk,HalamanUtama,dan
KMeansPlusPlus
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

28
Gambar 3.4 . Diagram Class
3.5.3 Desain Algoritma
Adapun desain algoritma metode-metode utama yang terdapat di dalam
class dapat dilihat pada Lampiran 1.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

BAB IV
IMPLEMENTASI SISTEM DAN ANALISIS HASIL
4.1 Implementasi Sistem
Pada gambar 4.1 berikut merupakan tampilan dari sistem untuk halaman
masuk ketika ingin menuju ke halaman utama. Kemudian, halaman utama yang
ditampilkan pada gambar 4.2 mempunyai beberapa fitur, diantaranya adalah menu
Cari File,menu Tambah,kolom Jumlah Cluster, menu Hitung Cluster,dan menu
Hitung Nilai SSE.
Gambar 4.1 . Tampilan halaman masuk
31
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

32
Gambar 4.2 . Tampilan halaman utama
4.1.1 Menu Cari File
Menu Cari File yang ditampilkan pada Gambar 4.3 ini merupakan menu
pertama untuk memulai melakukan clustering. Pada menu ini terdapat satu tombol
Cari File yang berfungsi untuk memilih file data DAPODIK bertipe xls yang akan
diolah oleh sistem.
Gambar 4.3 . Menu Cari File
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

33
4.1.2 Menu Tambah
Menu Tambah yang ditampilkan pada Gambar 4.4 ini berfungsi untuk
menampilkan data yang sudah melalui pemilihan kategori jenis SMP dan provinsi
pada sebuah tabel data. Tabel data ditunjukkan pada Gambar 4.5
Gambar 4.4 . Menu Tambah
Gambar 4.5 . Tabel Data
4.1.3 Menu Hitung Cluster
Menu yang ditunjukkan pada Gambar 4.6 mempunyai fungsi sebagai
penghitungan algoritma K-Means++ Clustering. Pada Gambar 4.7 akan
ditampilkan hasil pengelompokan dari penghitungan algoritma K-Means++
Clustering dalam bentuk Pane yang dilakukan oleh fungsi Menu Hitung Cluster.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

34
Gambar 4.6 . Menu Hitung Cluster
Gambar 4.7 . Tempat Output Hasil K-Means++ Clustering
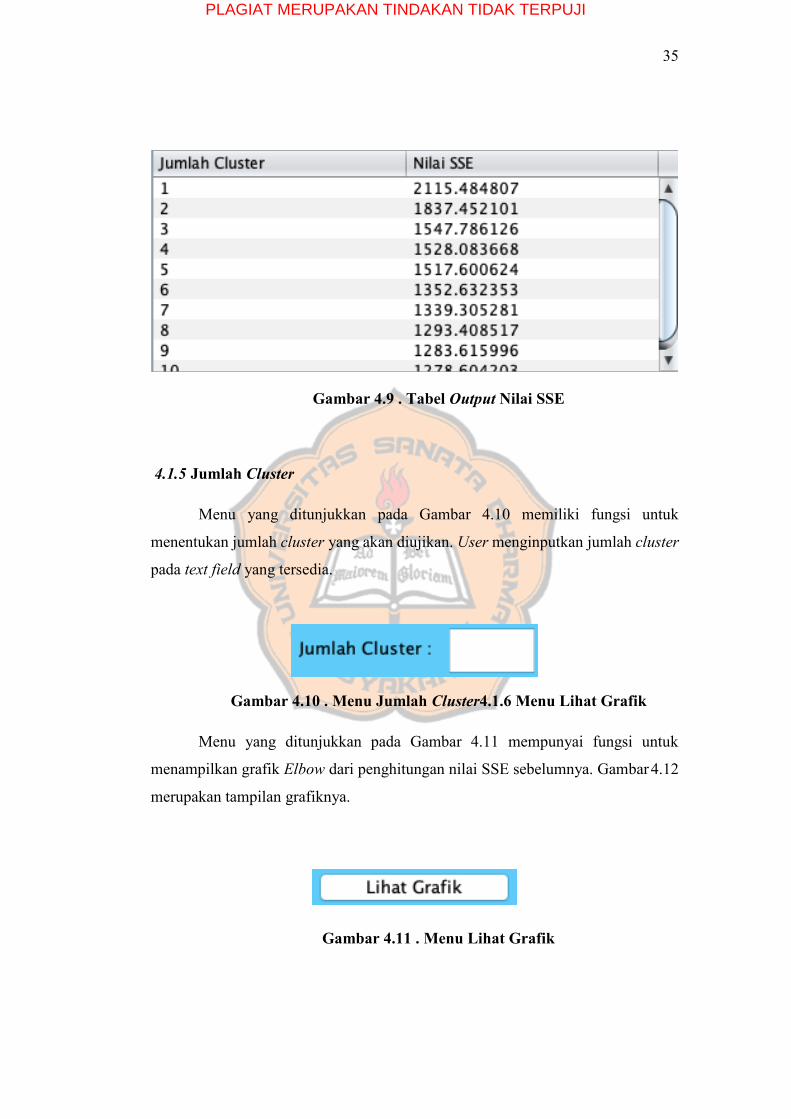
4.1.4 Menu Hitung Nilai SSE
Menu yang ditunjuk oleh Gambar 4.8 memiliki fungsi sebagai penghitungan
nilai SSE dari kinerja algoritma K-Means++ Clustering dengan metode Elbow
terhadap data yang digunakan. Adapun hasil dari perhitungan tersebut ditampilkan
dalam bentuk pada Gambar 4.9
Gambar 4.8 . Menu Hitung Nilai SSE
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
35
Gambar 4.9 . Tabel Output Nilai SSE
4.1.5 Jumlah Cluster
Menu yang ditunjukkan pada Gambar 4.10 memiliki fungsi untuk
menentukan jumlah cluster yang akan diujikan. User menginputkan jumlah cluster
pada text field yang tersedia.
Gambar 4.10 . Menu Jumlah Cluster4.1.6 Menu Lihat Grafik
Menu yang ditunjukkan pada Gambar 4.11 mempunyai fungsi untuk
menampilkan grafik Elbow dari penghitungan nilai SSE sebelumnya. Gambar 4.12
merupakan tampilan grafiknya.
Gambar 4.11 . Menu Lihat Grafik
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

36
Gambar 4.12 . Tampilan Grafik Elbow
4.2 Analisis Hasil Implementasi Algoritma K-Means++ Clustering
Pada tahap ini dilakukan pengujian program terhadap pengelompokan data
DAPODIK tahun 2018 dengan menggunakan algoritma K-Means++ Clustering.
Data yang akan diuji merupakan 15 sampel data rentang umur guru pada seluruh
Sekolah Menengah Pertama di Pulau Kalimantan dari jumlah 1204 record data
yang tersedia.
4.2.1 Uji Validasi
Uji validasi dilakukan dengan membandingkan perhitungan manual
menggunakan excel dan hasil akhir dari sistem. Dalam uji validasi yang dilakukan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
37
oleh peneliti menggunakan k (jumlah cluster) = 2 dengan sebanyak 15 data. Atribut
yang diuji meliputi seluruh rentang usia guru.
4.2.1.2 Perhitungan Manual
Pada tabel 5.1 berikut akan ditunjukkan dataset yang digunakan.
Tabel 5.1 Dataset Uji Validasi
Nama sekolah
Provinsi
Umu r Gur u < 30 Tah un
Umu r Gur u - 31- 35 Tah un
Umu r Gur u - 36- 40 Tah un
Umu r Gur u - 41- 45 Tah un
Umu r Gur u - 46- 50 Tah un
Umu r Gur u - 51- 55 Tah un
Umu r Gur u - Lebi h dari 55 Tah un
SMPIT AL MUMTAZ
Prov. Kaliman tan Barat
23
10
1
1
0
0
0
SMPIT AL- FITYAN
Prov. Kaliman tan Barat
20
4
0
0
1
1
0 SMP NEGERI 1 SEKADAU HILIR
Prov. Kaliman tan Barat
19
6
4
4
8
10
6 SMP HARAPAN MASA DEPAN CERAH 01
Prov. Kaliman tan Barat
16
8
1
0
0
1
0
SMP NEGERI 6
Prov. Kaliman
16
6
9
4
13
2
1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
38
KETAPANG tan Barat
SMP DARUL HIJRAH PUTERI
Prov. Kaliman tan Selatan
15
20
11
3
5
3
1 SMP ISLAM AL HASYIMIYY AH
Prov. Kaliman tan Tengah
15
3
3
3
5
0
0 SMP PLUS CITRA MADINATU L ILMI
Prov. Kaliman tan Selatan
15
2
1
1
1
0
0 SMP NEGERI 14 BANJARMA SIN
Prov. Kaliman tan Selatan
14
4
5
2
7
13
5 SMP NEGERI 1 PULAU SEMBILAN
Prov. Kaliman tan Selatan
14
2
5
0
2
0
0
SMP ISLAM NURUL IHSAN
Prov. Kaliman tan Tengah
14
2
5
0
4
0
0 SMP NEGERI 2 NUNUKAN
Prov. Kaliman tan Utara
13
10
4
9
8
4
0
SMP NEGERI 2 SENDAWAR
Prov. Kaliman tan Timur
13
5
1
4
7
14
2
SMP HASBUNAL LAH
Prov. Kaliman tan Selatan
13
4
3
0
1
0
2
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

39
SMP IT QARDHAN HASANA
Prov. Kaliman tan Selatan
13
3
1
1
0
0
0
Proses clustering dengan mengimplementasikan algoritma K-Means++ Clustering,
dilakukan dengan tahapan-tahapan sebagai berikut :
1. Dalam awal proses clustering, dilakukan pemilihan satu centroid awal.
Pada algoritma K-Means++ pemilihan dilakukan secara random
Centroid 1 : SMP IT AL MUMTAZ
2. Penentuan centroid kedua dan seterusnya. Dalam proses penentuan ini
diawali dengan melakukan penghitungan jarak tiap data ke centroid yang
telah terpilih, lalu mencari jarak centroid terdekat dari setiap data dan hitung
kuadrat dari jarak terdekat tersebut. Langkah selanjutnya dengan
menggunakan formula randomized seeding technique, hitung probabilitas
dan probabilitas secara kumulatif pada setiap data. Hasil penghitungan
ditampilkan pada tabel 5.2 berikut :
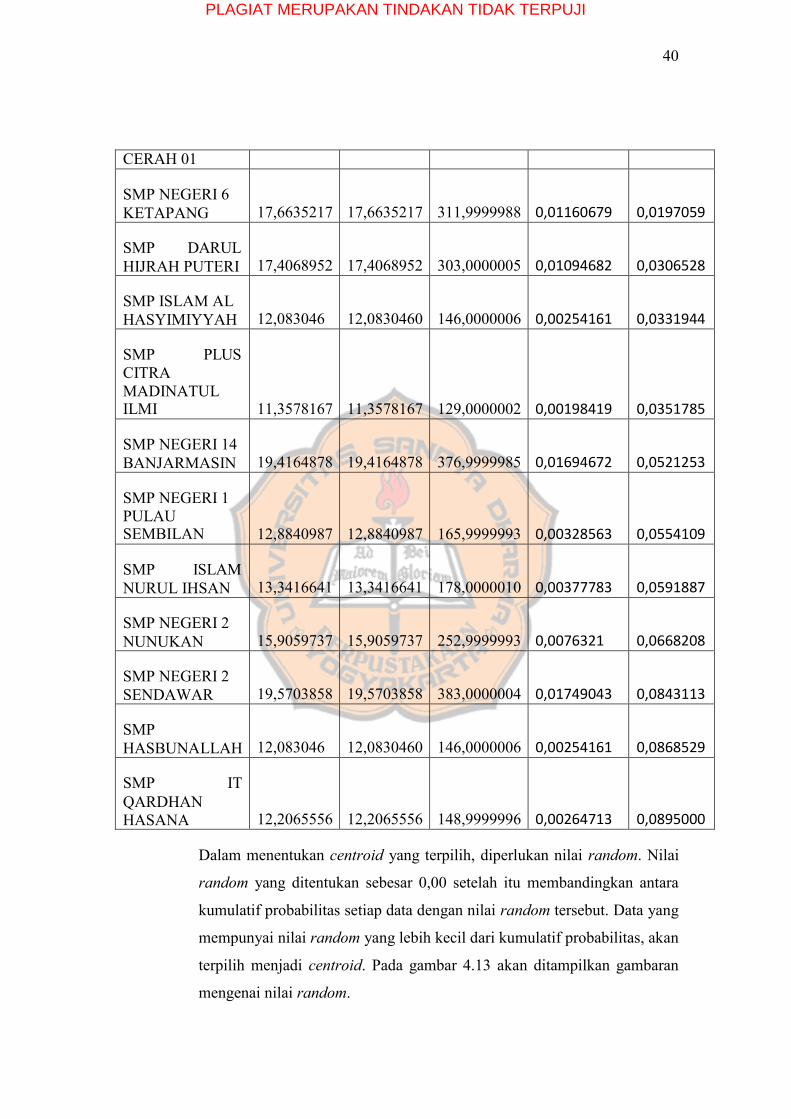
Tabel 5.2 Hasil Penghitungan Randomized Seeding Technique
Nama Sekolah
D1
Min
Min2
D(x)2/∑D(x)2
Kumulatif
SMPIT AL MUMTAZ
0
0
0
0
0
SMPIT AL- FITYAN
7
7
49
0,00028628
0,0002863
SMP NEGERI 1 SEKADAU HILIR
15,8113883
15,8113883
250
0,00745217
0,0077385 SMP HARAPAN MASA DEPAN
7,41619849
7,4161985
55
0,00036069
0,0080991
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
40
CERAH 01
SMP NEGERI 6 KETAPANG
17,6635217
17,6635217
311,9999988
0,01160679
0,0197059
SMP DARUL HIJRAH PUTERI
17,4068952
17,4068952
303,0000005
0,01094682
0,0306528
SMP ISLAM AL HASYIMIYYAH
12,083046
12,0830460
146,0000006
0,00254161
0,0331944
SMP PLUS CITRA MADINATUL ILMI
11,3578167
11,3578167
129,0000002
0,00198419
0,0351785
SMP NEGERI 14 BANJARMASIN
19,4164878
19,4164878
376,9999985
0,01694672
0,0521253
SMP NEGERI 1 PULAU SEMBILAN
12,8840987
12,8840987
165,9999993
0,00328563
0,0554109
SMP ISLAM NURUL IHSAN
13,3416641
13,3416641
178,0000010
0,00377783
0,0591887
SMP NEGERI 2 NUNUKAN
15,9059737
15,9059737
252,9999993
0,0076321
0,0668208
SMP NEGERI 2 SENDAWAR
19,5703858
19,5703858
383,0000004
0,01749043
0,0843113
SMP HASBUNALLAH
12,083046
12,0830460
146,0000006
0,00254161
0,0868529
SMP IT QARDHAN HASANA
12,2065556
12,2065556
148,9999996
0,00264713
0,0895000
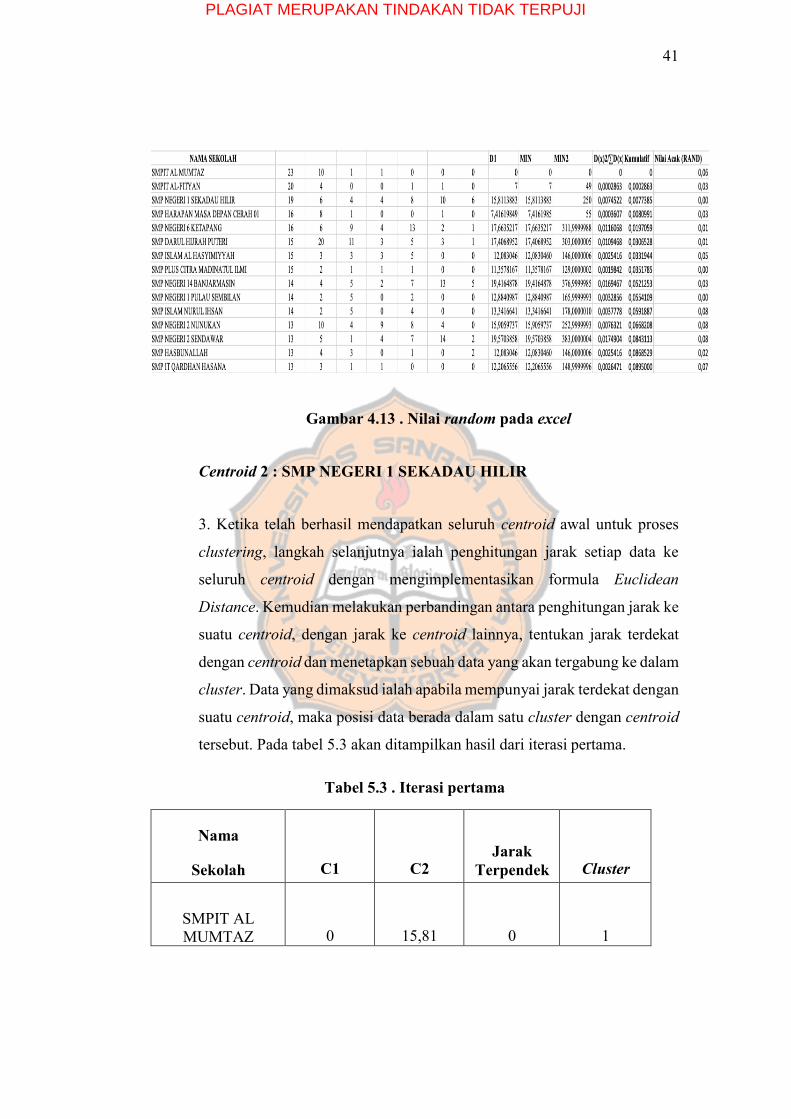
Dalam menentukan centroid yang terpilih, diperlukan nilai random. Nilai
random yang ditentukan sebesar 0,00 setelah itu membandingkan antara
kumulatif probabilitas setiap data dengan nilai random tersebut. Data yang
mempunyai nilai random yang lebih kecil dari kumulatif probabilitas, akan
terpilih menjadi centroid. Pada gambar 4.13 akan ditampilkan gambaran
mengenai nilai random.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
41
Gambar 4.13 . Nilai random pada excel
Centroid 2 : SMP NEGERI 1 SEKADAU HILIR
3. Ketika telah berhasil mendapatkan seluruh centroid awal untuk proses
clustering, langkah selanjutnya ialah penghitungan jarak setiap data ke
seluruh centroid dengan mengimplementasikan formula Euclidean
Distance. Kemudian melakukan perbandingan antara penghitungan jarak ke
suatu centroid, dengan jarak ke centroid lainnya, tentukan jarak terdekat
dengan centroid dan menetapkan sebuah data yang akan tergabung ke dalam
cluster. Data yang dimaksud ialah apabila mempunyai jarak terdekat dengan
suatu centroid, maka posisi data berada dalam satu cluster dengan centroid
tersebut. Pada tabel 5.3 akan ditampilkan hasil dari iterasi pertama.
Tabel 5.3 . Iterasi pertama
Nama
Sekolah
C1
C2
Jarak Terpendek
Cluster
SMPIT AL MUMTAZ
0
15,81
0
1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
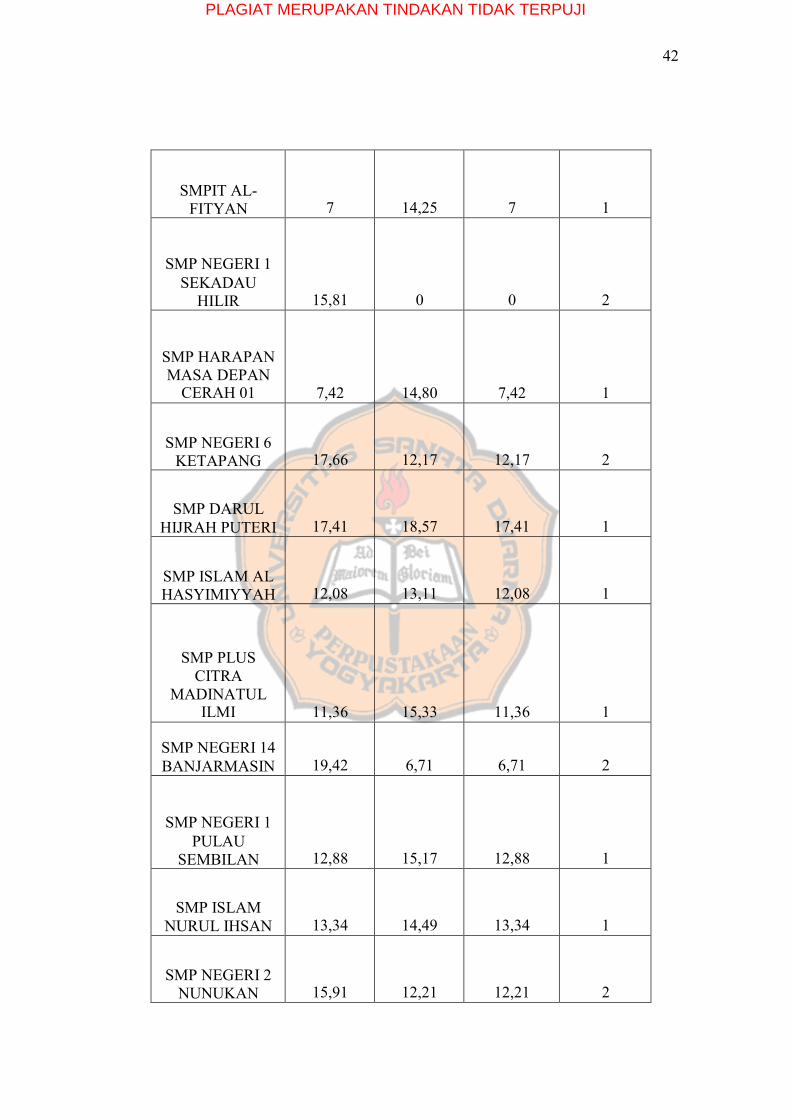
42
SMPIT AL- FITYAN
7
14,25
7
1
SMP NEGERI 1 SEKADAU
HILIR
15,81
0
0
2
SMP HARAPAN MASA DEPAN
CERAH 01
7,42
14,80
7,42
1
SMP NEGERI 6
KETAPANG
17,66
12,17
12,17
2
SMP DARUL
HIJRAH PUTERI
17,41
18,57
17,41
1
SMP ISLAM AL HASYIMIYYAH
12,08
13,11
12,08
1
SMP PLUS CITRA
MADINATUL ILMI
11,36
15,33
11,36
1
SMP NEGERI 14 BANJARMASIN
19,42
6,71
6,71
2
SMP NEGERI 1 PULAU
SEMBILAN
12,88
15,17
12,88
1
SMP ISLAM
NURUL IHSAN
13,34
14,49
13,34
1
SMP NEGERI 2
NUNUKAN
15,91
12,21
12,21
2
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

43
SMP NEGERI 2
SENDAWAR
19,57
8,89
8,89
2
SMP HASBUNALLAH
12,08
14,90
12,08
1
SMP IT QARDHAN HASANA
12,21
16,22
12,21
1
4. Ketika anggota dari tiap cluster telah diketahui, tahap selanjutnya yang
dilakukan ialah penghitungan centroid baru berdasarkan anggota cluster
x Centroid 1
Umur Guru Kurang dari 30 Tahun
(23+20+16+15+15+15+14+14+13+13) / 10 = 15,8
Umur Guru 31 – 35 Tahun
(10+4+8+20+3+2+2+2+4+3) / 10 = 5,8
Umur Guru 36 – 40 Tahun
(1+0+1+11+3+1+5+5+3+1) / 10 = 3,1
Umur Guru 41 – 45 Tahun
(1+0+0+3+3+1+0+0+0+1) / 10 = 0,9
Umur Guru 46 – 50 Tahun
(0+1+0+5+5+1+2+4+1+0) / 10 = 1,9
Umur Guru 51 – 55 Tahun
(0+1+1+3+0+0+0+0) / 10 = 0,5
Umur Guru Lebih dari 55 Tahun
(0+0+0+1+0+0+0+0+2+0) / 10 = 0,3
x Centroid 2
Umur Guru Kurang dari 30 Tahun
(19+16+14+13+13) / 5 = 15
Umur Guru 31 – 35 Tahun
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
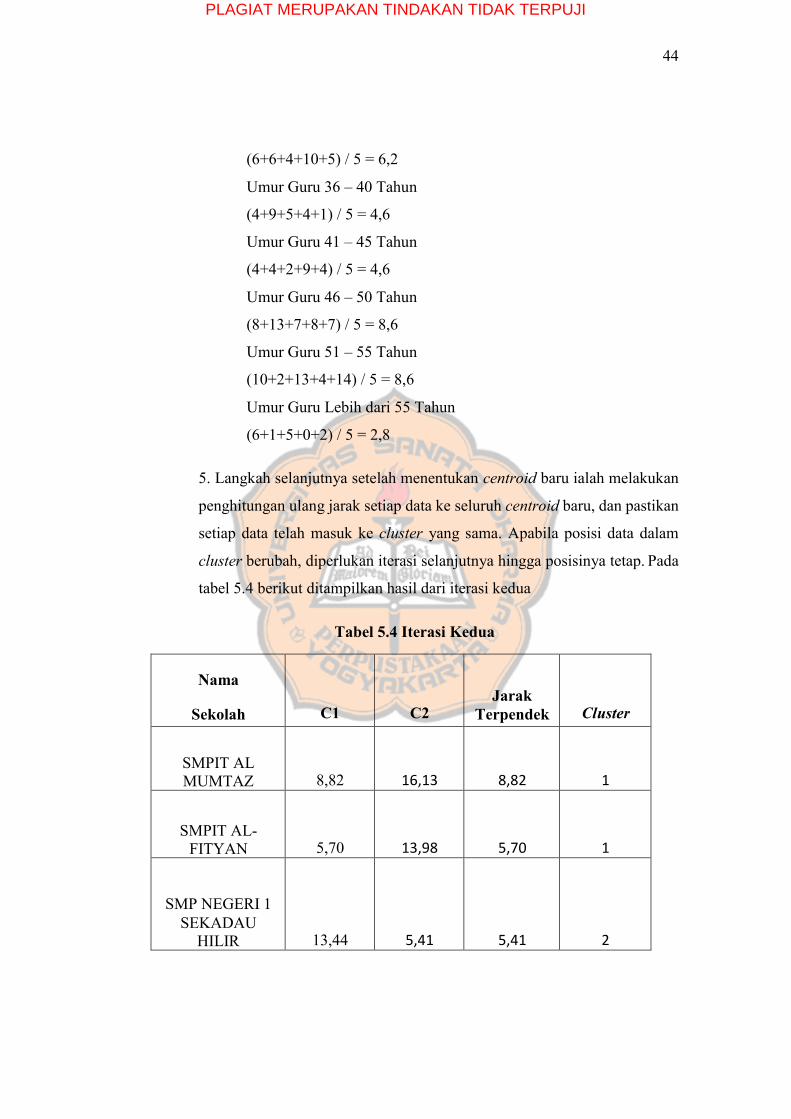
44
(6+6+4+10+5) / 5 = 6,2
Umur Guru 36 – 40 Tahun
(4+9+5+4+1) / 5 = 4,6
Umur Guru 41 – 45 Tahun
(4+4+2+9+4) / 5 = 4,6
Umur Guru 46 – 50 Tahun
(8+13+7+8+7) / 5 = 8,6
Umur Guru 51 – 55 Tahun
(10+2+13+4+14) / 5 = 8,6
Umur Guru Lebih dari 55 Tahun
(6+1+5+0+2) / 5 = 2,8
5. Langkah selanjutnya setelah menentukan centroid baru ialah melakukan
penghitungan ulang jarak setiap data ke seluruh centroid baru, dan pastikan
setiap data telah masuk ke cluster yang sama. Apabila posisi data dalam
cluster berubah, diperlukan iterasi selanjutnya hingga posisinya tetap. Pada
tabel 5.4 berikut ditampilkan hasil dari iterasi kedua
Tabel 5.4 Iterasi Kedua
Nama
Sekolah
C1
C2
Jarak Terpendek
Cluster
SMPIT AL MUMTAZ
8,82
16,13
8,82
1
SMPIT AL- FITYAN
5,70
13,98
5,70
1
SMP NEGERI 1 SEKADAU
HILIR
13,44
5,41
5,41
2
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
45
SMP HARAPAN MASA DEPAN
CERAH 01
3,75
13,34
3,75
1
SMP NEGERI 6
KETAPANG
13,06
9,32
9,32
2
SMP DARUL
HIJRAH PUTERI
16,90
16,78
16,78
2
SMP ISLAM AL HASYIMIYYAH
4,78
10,49
4,78
1
SMP PLUS CITRA
MADINATUL ILMI
4,54
13,53
4,54
1
SMP NEGERI 14 BANJARMASIN
14,69
6,29
6,29
2
SMP NEGERI 1 PULAU
SEMBILAN
4,74
12,86
4,74
1
SMP ISLAM
NURUL IHSAN
5,18
11,95
5,18
1
SMP NEGERI 2
NUNUKAN
11,89
8,22
8,22
2
SMP NEGERI 2
SENDAWAR
15,29
7,15
7,15
2
SMP HASBUNALLAH
3,98
12,84
3,98
1
SMP IT
4,90 14,00 4,90 1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

46
QARDHAN HASANA
6. Pada iterasi kedua telah terjadi pergeseran posisi data, sehingga
menyebabkan data berpindah cluster. Maka diperlukan untuk melakukan
iterasi selanjutnya, dan didapatkan hasil iterasi pada tabel 5.5 berikut :
Tabel 5.5 Iterasi Ketiga
Nama
Sekolah
C1
C2
Jarak Terpendek
Cluster
SMPIT AL MUMTAZ
9,38
15,11
9,38
1
SMPIT AL- FITYAN
4,83
13,99
4,83
1
SMP NEGERI 1 SEKADAU
HILIR
14,06
6,54
6,54
2
SMP HARAPAN MASA DEPAN
CERAH 01
4,39
12,51
4,39
1
SMP NEGERI 6
KETAPANG
13,96
8,82
8,82
2
SMP DARUL
HIJRAH PUTERI
18,77
13,98
13,98
2
SMP ISLAM AL HASYIMIYYAH
4,51
10,64
4,51
1
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
47
SMP PLUS CITRA
MADINATUL ILMI
2,78
13,75
2,78
1
SMP NEGERI 14 BANJARMASIN
15,13
7,93
7,93
2
SMP NEGERI 1 PULAU
SEMBILAN
4,12
12,79
4,12
1
SMP ISLAM
NURUL IHSAN
4,77
11,98
4,77
1
SMP NEGERI 2
NUNUKAN
13,05
7,11
7,11
2
SMP NEGERI 2
SENDAWAR
15,63
8,92
8,92
2
SMP HASBUNALLAH
3,60
12,58
3,60
1
SMP IT
QARDHAN HASANA
3,74
14,01
3,74
1
7. Setelah mendapatkan hasil dari iterasi ketiga, dapat dilihat tidak ada
pergeseran posisi data yang menyebabkan berpindahnya ke cluster lain.
Oleh karenanya, maka iterasi dihentikan. Sehingga hasil akhir dari proses
clustering ini terpampang di iterasi ketiga pada tabel 5.5
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

48
4.2.1.2 Perhitungan Perangkat Lunak
Pada gambar 4.14 berikut akan ditampilkan hasil dari proses clustering
yang berjalan pada perangkat lunak.
Gambar 4.14 . Hasil Clustering Pada Perangkat Lunak
Pada output yang dihasilkan oleh perangkat lunak, ditampilkan baris array (dari
atas ke bawah) untuk cluster pertama, kedua, dan seterusnya. Apabila ingin
menambahkan jumlah cluster, maka baris array akan bertambah secara otomatis.
Dalam suatu struktur array menggambarkan data usia guru dari sebuah SMP.
Kumpulan angka pada struktur array merupakan jumlah orang dari masing-masing
rentang usia guru yang terdapat dalam suatu SMP.
4.2.1.3 Perhitungan MATLAB
Pada perhitungan menggunakan software MATLAB, didapatkan hasil
dalam tabel 5.6 berikut :
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

49
Tabel 5.6 Perhitungan Matlab
Nama Sekolah
C1
C2
Min.
Distance
Cluster
SMP ISLAM AL HASYIMIYYAH
6,73
8,91
6,73
1 SMP HARAPAN MASA DEPAN CERAH 01
5,88
11,47
5,88
1
SMP IT AL MUMTAZ
13,45
15,10
13,45
1
SMP IT AL FITYAN
8,22
12,34
8,22
1
SMP ISLAM NURUL IHSAN
5,56
12,21
5,56
1 SMP NEGERI 1 PULAU SEMBILAN
8,39
11,90
8,39
1 SMP PLUS CITRA MADINATUL ILMI
4,20
10,98
4,20
1
SMP HASBUNALLAH
5,33
12,09
5,33
1
SMP NEGERI 14 BANJARMASIN
14,26
8,28
8,28
2
SMP NEGERI 2 NUNUKAN
12,03
9,47
9,47
2
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
50
SMP IT QARDHAN HASANA
5,71
12,40
5,71
1
SMP NEGERI 2 SENDAWAR
15,70
4,23
4,23
2
SMP NEGERI 6 KETAPANG
14,34
9,77
9,77
2
SMP DARUL HIJRAH PUTERI
16,07
15,89
15,89
2 SMP NEGERI 1 SEKADAU HILIR
13,66
5,67
5,67
2
4.2.2 Evaluasi Hasil Perhitungan Manual, Perangkat Lunak, dan MATLAB
Berdasarkan hasil pengujian, didapatkan kesimpulan bahwasanya proses
clustering pada penghitungan perangkat lunak dan manual memiliki hasil akhir
yang sama. Tabel 5.7 berikut merupakan hasil akhir dari kedua percobaan
penghitungan yang dilakukan oleh peneliti.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
51
Tabel 5.7 . Hasil Akhir Perhitungan Manual, Perangkat Lunak, dan
MATLAB
Perhitungan Manual Perhitungan Perangkat
Lunak
Perhitungan
MATLAB
C1 C2 C1 C2 C1 C2
SMP IT SMP SMP SMP SMP SMP
AL NEGERI 1 NEGERI 1 DARUL ISLAM AL NEGERI
MUMTAZ SEKADA PULAU HIJRAH HASYIMI 14 U HILIR SEMBILA PUTERI YYAH BANJAR N MASIN
SMP IT SMP SMP SMP SMP SMP
AL NEGERI 6 ISLAM AL NEGERI 1 HARAPA NEGERI 2
FITYAN KETAPA HASYIMI SEKADA N MASA NUNUKA NG YYAH U HILIR DEPAN N CERAH 01
SMP SMP SMP SMP SMP IT SMP
HARAPA DARUL HASBUN NEGERI 2 AL NEGERI 2
N MASA HIJRAH ALLAH NUNUKA MUMAZ SENDAW
DEPAN PUTERI N AR
CERAH 01
SMP SMP SMP IT SMP SMP IT SMP
ISLAM AL NEGERI AL NEGERI 6 AL NEGERI 6
HASYIMI 14 MUMTAZ KETAPA FITYAN KETAPA
YYAH BANJAR NG NG MASIN
SMP PLUS SMP SMP SMP SMP SMP
CITRA NEGERI 2 HARAPA NEGERI 2 ISLAM DARUL
MADINAT NUNUKA N MASA SENDAW NURUL HIJRAH
UL ILMI N DEPAN AR IHSAN PUTERI
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
52
CERAH 01
SMP
NEGERI 1
PULAU
SEMBILA
N
SMP
NEGERI 2
SENDAW
AR
SMP PLUS
CITRA
MADINAT
UL ILMI
SMP
NEGERI
14
BANJAR
MASIN
SMP
NEGERI 1
PULAU
SEMBILA
N
SMP
NEGERI 1
SEKADA
U HILIR
SMP
ISLAM
NURUL
IHSAN
SMP IT
QARDHA
N
HASANA
SMP PLUS
CITRA
MADINAT
UL ILMI
SMP
HASBUN
ALLAH
SMP IT
AL
FITYAN
SMP
HASBUN
ALLAH
SMP IT
QARDHA
N
HASANA
SMP
ISLAM
NURUL
IHSAN
SMP IT
QARDHA
N
HASANA
4.3 Analisis Penentuan Jumlah Cluster terbaik
Dalam sistem ini mengimplementasikan metode Elbow sebanyak k = 15
untuk mencari jumlah cluster terbaik. Pada tabel 5.8 ditampilkan nilai SSE (Sum of
Square Error) pada data DAPODIK tahun 2018
Tabel 5.8 . Nilai SSE (Sum of Square Error) pada data DAPODIK tahun
2018
K Sum of Square Error
1 2115,484807
2 1837,452101
3 1547,786126
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
53
4 1528,083668
5 1517,600624
6 1352,632353
7 1339,305281
8 1293,408517
9 1283,615996
10 1278,604203
11 1274,176775
12 1271,171150
13 1268,638885
14 1264,930056
15 1263,207481
Pada gambar 4.15 menampilkan gambar grafik Elbow untuk data DAPODIK tahun
2018. Sumbu X merepresentasikan jumlah cluster, sedangkan sumbu Y
merepresentasikan nilai Sum of Square Error. Pada gambar 4.15 terjadi penurunan
nilai SSE secara signifikan saat k = 1 menuju k = 3, hingga k = 6.
Grafik Elbow 2500,000000
2000,000000
1500,000000
1000,000000
500,000000
0,000000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

54
Gambar 4.15 . Grafik Elbow data DAPODIK tahun 2018
Metode Elbow menyatakan bahwa jumlah cluster terbaik memiliki ciri-ciri
berupa grafik membentuk siku dan tidak ada penurunan maupun kenaikan nilai
Sum of Square Error yang signifikan. Berdasarkan persyaratan tersebut, didapati
bahwa jumlah cluster terbaik terletak pada k = 3, karena pada jumlah cluster ini
grafik membentuk siku, dan setelahnya tidak ada penurunan nilai Sum of Square
Error secara signifikan. Oleh karenanya, k = 3 direkomendasikan sebagai jumlah
cluster yang terbaik.
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

BAB V
PENUTUP
5.1 Simpulan
Penelitian tugas akhir dengan judul “Pengelompokan Sekolah Menengah
Pertama Berdasarkan Distribusi Usia Guru dengan Algoritma K-Means++
Clustering” menghasilkan beberapa kesimpulan sebagai berikut :
1. Sistem Pengelompokan Sekolah Menengah Pertama Berdasarkan Distribusi Usia
Guru berhasil dibangun dengan mengimplementasikan algoritma K-Means++
Clustering.
2. Pengujian metode Elbow yang dilakukan dengan jumlah cluster sebanyak 1
hingga 15 menghasilkan nilai k = 3 sebagai jumlah cluster yang terbaik/optimal di
dalam proses clustering, dikarenakan grafik menunjukkan bahwa k = 3 mendekati
bentuk sudut siku.
5.2 Saran
Pengembangan sistem sangat dibutuhkan untuk penelitian mendatang, supaya
sistem dapat melakukan :
1. Menerima input dari berbagai macam tipe file.
2. Menyimpan hasil clustering
3. Menampilkan hasil clustering dengan informasi yang detail
4. Menguji kualitas suatu cluster dengan metode Silhouette Coefficien
56
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

57
DAFTAR PUSTAKA
Arthur, D.; Vassilvitskii, S. (2007). "k-means++: the advantages of careful seeding" (PDF). Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics Philadelphia, PA, USA. pp. 1027–1035.
Bangoria, B., Mankad, N., dan Pambhar, V., 2013, A Survey on Efficient Enhanced
K-Means Clustering Algorithm, International Journal for Scientific Research & Development, vol. 9, hal 1698-700.
Chandra, M., Fenty, E., dan Fitri, M., 2017, Pengelompokan Kualitas Kerja
Pegawai Menggunakan Algoritma K-Means++ dan COP-Kmeans Untuk Merencanakan Program Pemeliharaan Kesehatan Pegawai di PT. PLN P2B JB Depok, Jurnal Pseudocode, vol. 4, hal 16-17.
Davies, and Paul Beynon.2004. Database Systems Third Edition. New York:
Palgrave Macmillan.
Dubes dan Jain, A, (1988), Algorithm for Clustering Data, New Jersey: Prentice Hall.
Efraim Turban, dkk. 2005. “Decision Support Systems and Intelligent Systems” .
Yogyakarta:ANDI.
Fayyad, U. M, 1996, Advances in Knowledge Discovery and Data Mining. Camberidge, MA: The MIT Press
Han, J. dan M.Kamber. 2006. “Data Mining Concepts and Techniques Second
Edition” . San Francisco: Morgan Kaufmann.
Inmon, William H. 2005. “Building The Data Warehouse (4th ed.)” . Indianapolis :Wiley Publishing, Inc..
Izenman AJ. 2008. “Modern Multivariate Statistical Techniques: Regression,
Classification, and Manifold Learning” . New York (US): Springer.
John. J. Longkutoy. 1989. “Pengenalan Komputer” : Cetakan Keenam. Jakarta: PT. Mutiara Sumber Widya.
Kanungo, T.; Mount, D.; Netanyahu, N.; Piatko, C.; Silverman, R.; Wu, A. (2004),
"A Local Search Approximation Algorithm for k-Means Clustering" (PDF), Computational Geometry: Theory and Applications, 28 (2–3): 89–112,
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

58
doi:10.1016/j.comgeo.2004.03.003, archived from the original (PDF) on 2006-02-09.
Kodinariya, T. M., & Makwana, P. R. (2013). Review on determining number of
cluster in K-Means Clustering. . International Journal of Advance Research in Computer Science and Management Studies,I(6),90-95.
L. Kaufman and P.J. Rousseuw, “Finding Groups in Data” , New York: John
Wiley & Sons, 1990.
Madhulatha, T.S., 2012, “An Overview On Clustering Methods” , IOSR Journal of Engineering, II(4), pp.719-25.
Manvreet dan Usvir (2013). “Comparison Between K-Mean and Hierarchical
Algorithm Using Query Redirection” . India: Department of CSE, Sri Guru Granth Sahib World University, Fatehgarh Sahib, Punjab.
Rui Xu dan Donald C. Wunsch II, 2009, “Clustering” , A John Wiley & Sons, Inc.,
Publication.
Santoso, Budi. 2007. “Data Mining : Teknik Pemanfaatan data untuk keperluan bisnis” . Yogyakarta:Graha Ilmu.
Sugiyono (2015). “Metode Penelitian Kombinasi (Mix Methods)” . Bandung:
Alfabeta
Vercellis, Bernadth. (2009). “Sistem Informasi” . Yogyakarta: Lokomedia
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI
59
LAMPIRAN 1
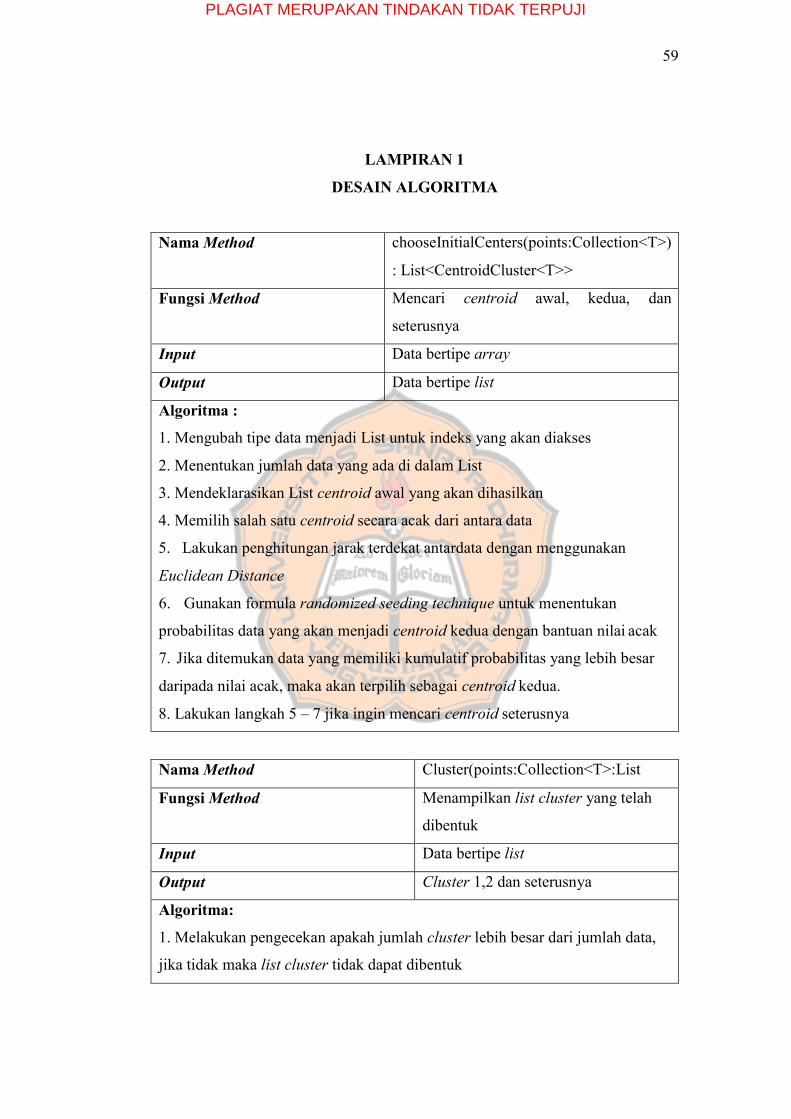
DESAIN ALGORITMA
Nama Method chooseInitialCenters(points:Collection<T>)
: List<CentroidCluster<T>>
Fungsi Method Mencari centroid awal, kedua, dan
seterusnya
Input Data bertipe array
Output Data bertipe list
Algoritma :
1. Mengubah tipe data menjadi List untuk indeks yang akan diakses
2. Menentukan jumlah data yang ada di dalam List
3. Mendeklarasikan List centroid awal yang akan dihasilkan
4. Memilih salah satu centroid secara acak dari antara data
5. Lakukan penghitungan jarak terdekat antardata dengan menggunakan
Euclidean Distance
6. Gunakan formula randomized seeding technique untuk menentukan
probabilitas data yang akan menjadi centroid kedua dengan bantuan nilai acak
7. Jika ditemukan data yang memiliki kumulatif probabilitas yang lebih besar
daripada nilai acak, maka akan terpilih sebagai centroid kedua.
8. Lakukan langkah 5 – 7 jika ingin mencari centroid seterusnya
Nama Method Cluster(points:Collection<T>:List
Fungsi Method Menampilkan list cluster yang telah
dibentuk
Input Data bertipe list
Output Cluster 1,2 dan seterusnya
Algoritma:
1. Melakukan pengecekan apakah jumlah cluster lebih besar dari jumlah data,
jika tidak maka list cluster tidak dapat dibentuk
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI

60
Nama Method hitungSSE
Fungsi Method Menampilkan nilai Sum of Square
Error
Input double [][] points, double[][] centroids
Output Nilai Sum of Square Error
Algoritma:
1. Mendeklarasikan variabel “sse” dengan tipe data double
2. Mendeklarasikan variabel “assignedClust” dengan tipe data int
3. Looping sebanyak cluster yang telah ditentukan
4. Variabel “assignedClust” untuk menampung cluster sebanyak looping
sebelumnya
5. Variabel “sse” untuk menjumlahkan hasil perhitungan selisih jarak data
dengan centroid dari sejumlah cluster pada langkah 4
2. Jika jumlah cluster lebih besar dari jumlah data, maka buat array berisi list
cluster yang telah terbentuk.
3. Lakukan iterasi untuk mengetahui banyaknya list cluster yang akan ditampung
terhadap array
4. Jika tidak ada lagi perubahan terhadap list cluster, maka iterasi dihentukan
PLAGIAT MERUPAKAN TINDAKAN TIDAK TERPUJI