linguistics international journal
TRANSCRIPT

LIJ
Paul Robertson and Lucas Kohnke Editors
Linguistics International Journal
Volume 15 Issue 1, September 2021
ISSN: 2799-1113

The Linguistics International Journal
Volume 15 Issue 1
September 2021
Editors: Paul Robertson and Lucas Kohnke
Published by the Academic Education International Journals
A Division of AEIJ
Part of TESOL One
https://www.academics.education/journal/lij/
© The Linguistics International Journal 2021
This e-book is in copyright. Subject to statutory exception no reproduction of any part may
take place without the written permission of the Academics Education International
Journals.
No unauthorized photocopying
All rights reserved. No part of this book may be reproduced, stored in a retrieval system
or transmitted in any form or by any means, electronic, mechanical, photocopying or
otherwise, without the prior written permission of Academics Education International
Journals.
Editors: Dr. Paul Robertson and Dr. Lucas Kohnke
Chief Editor: Dr. Lucas Kohnke
Senior Advisor: Dr. John Adamson
Associate Editor for Production: Japhet E. Manzano
ISSN: 2799-1113 (Online)

ii
Table of Contents
Frankie Har ………………………….……………………………………………………... 1
Language Choices between Government Sector Colleagues: A Hong Kong Case Study of
English Language Adult Learners’ Plurilingual Practices in Computer-Mediated
Communication
Sujeewa Hettiarachchi ……...………………………………………………......................... 20
A Syntactic Analysis of Sinhala Relative Clauses
Leonardo O. Munalim and Cecilia F. Genuino ……………………...…............................ 41
Chair-like Turn-taking Features in a Faculty Meeting: Evidence of Local Conditions and
Collegiality
Yunisrina Qismullah Yusuf, Stefanie Pillai, W.A. Wan Aslynn and
Roshidah Binti Hassan …………...……………………………………………….................
61
Vowel Production in Standard Malay and Kedah Malay Spoken in Malaysia
Noreen E. Pontillas and Melanie D. Cayabyab ……………………………………….......... 88
Production of American English Phonemes and Adjustments in Connected Speech among
Filipino-English Bilingual Students
Rezvan Rasouli and Zahra Nouri …………………………………………………………... 110
Task Type and Fluency Aspect of the Productive Skills, Investigating the Probable Effects
Andres A. D. Labra ………………………………………………………………………… 130
Linguistic and social factors conditioning coda /s/ variation in the Spanish of Mendoza,
Argentina

1
Har, F. (2021). Language choices between government sector colleagues: A
Hong Kong case study of English language adult learners’ plurilingual
practices in computer-mediated communication. Linguistics International
Journal, 15(1), 1-20.
Language Choices between Government Sector Colleagues: A Hong Kong Case
Study of English Language Adult Learners’ Plurilingual Practices in
Computer-Mediated Communication
Frankie Har
English Language Centre, The Hong Kong Polytechnic University,
Hung Hom, Kowloon, Hong Kong SAR, China
Abstract
Early studies on practices of Cantonese-English code-mixing focused on university students in
Hong Kong and in the late 1970s. These tended to focus on face-to-face interactions (Gibbons,
1979, 1983, 1987), but with the rapid proliferation of computer-mediated communication
(CMC) in the past three decades, it has been observed that chat participants switch between
English and Cantonese in online chats such as on Signal, WhatsApp, Telegram etc. (e.g., Lee,
2002, 2007a, 2007b). As Cantonese characters and romanized forms of Cantonese words are
often mixed into their online discourse where English is the dominant language, attention has
gradually shifted to the emergence of this English-Cantonese mixed code. Such phenomenon
can also be seen among Chinese Hongkongers in the workplace, especially in instant-
messaging (IM) communication. This study examines the linguistic phenomena of Cantonese-
English code-switching and code-mixing in an unexplored domain- the government sector. The
findings suggest that, in plurilingual contexts like Hong Kong, the development of an English
language pedagogy that recognizes the need for the constructive but judicious use of
translanguaging and plurilingual practices as English learners are engaged in workplace
communication is justified.
Keywords: Code-mixing, code-switching, English language pedagogy, instant-messaging
(IM) communication, plurilingual practices, translanguaging
Introduction

2
Earlier studies on practices of Cantonese-English code-mixing between university
students in Hong Kong can be dated back to the late 1970s. These tended to focus on face-to-
face interactions (e.g., Gibbons, 1979, 1983, 1987), but with the rapid proliferation of
computer-mediated communication1 (CMC) in the past two decades, it has been observed that
chat participants alternate, or switch between English and Cantonese in online chats such as
ICQ, MSN Messenger or WhatsApp (e.g., Lee, 2002, 2007a, 2007b). As Cantonese characters
and Romanized forms of Cantonese words are often mixed into online discourse where English
is the dominant language, attention has gradually shifted to the emergence of such a mixed
code2 – the English-Cantonese mixed code. In addition, such phenomenon can also be seen
among Chinese Hongkongers beyond the education sector, especially in instant-messaging3
(IM) communication. The aim of this study is to examine the linguistic phenomena of
Cantonese-English code-switching and code-mixing in an unexplored domain – the
government sector.
Despite a variety of research on analyzing Cantonese-English code-switching and code-
mixing made in ESL classrooms (Ariffin & Husin, 2011; Tien & Li, 2014), the linguistic
phenomena of Cantonese-English code-switching and code-mixing in Hong Kong’s
government sector, with regard to the differences in educational background of the
interlocutors, have not been explored and elucidated. It is therefore instructive to see how the
practices of code-switching and code-mixing differ in the government domain of Hong Kong
and may be affected by the speaker’s educational background. Thus, the present study attempts
to observe another facet of the linguistic phenomena – whether practices of code-switching and
code-mixing differ according to the civil servants varied educational background. With the
proposed theoretical framework, the investigation into the research issue provides a
comprehensive guide for understanding the practices of code-switching and code-mixing in
Hong Kong. In particular, code-mixing among local civil servants who use instant messaging
applications for communication in their everyday life.
1 Traditionally, computer-mediated communication (CMC) refers to synchronous or asynchronous
communication via computer-mediated formats. There are electronic mail systems and bulletin board systems in
delay communication (asynchronous) and ICQ, MSN Messenger, WhatsApp and chatrooms in real-time
communication (synchronous). 2 Mixed code per se does not have a unified notion, but it is often discussed as the Hong Kong-style mixed code.
Generally speaking, Cantonese interspersed with English elements is referred to as the Cantonese-English mixed
code, which is the focus of the present study. Another variety of mixed code is the English-Cantonese mixed code,
where English interspersed with Cantonese linguistic elements. 3 Instant messaging (IM) allows participants to communicate in a nearly synchronous setting; and it is a type of
online chat (e.g., mobile apps) that offers asynchronous/synchronous exchanges over the smartphone.

3
Earlier studies on the practices of code-switching and code-mixing in text-messaging4
mode are insufficient as earlier studies (e.g., Friermuth, 2001; Lam, 2004; Tepper, 1997)
mainly investigated synchronous online chatting as a distinctive form of communication in the
virtual world (Wei, 2014) such as online chat rooms. Given that the ‘language of CMC’ is
relatively similar to the language used in mobile instant messaging (Baron, 2003), the linguistic
features identified in CMC was used in the present study, and was further elaborated in the
Findings Section-Code choice in WhatsApp chats.
In the following section, the literature on language use in the CMC context was
reviewed, focusing on studies which have addressed the most common language choices in
(near) synchronous communication among computer users, as well as literature on the extra-
linguistic motivations of Cantonese-English code-mixing.
Literature Review
What is Code-Switching?
Code-switching has been examined extensively in the past few decades. The term
“code-switching” has been defined in different ways by many scholars (Bell, 1976; Blom &
Gumperz, 1972; Hudson, 1980; Wang & Kirkpatrick, 2019). However, it is important to clearly
define the term “code-switching” used in this paper. According to Li (1999), code-switching
can be defined as “a phenomenon in which Cantonese and English are mixed within sentences
(English words are always used as signal word)” (cited in Chan, 2019). In this paper, the above
definition suggested by Li (1999) was chosen to be the working definition of code-switching
that underlies the analyses which were conducted. I hold the belief that this definition can be
used effectively to refer to “intra-sentential code-switching typical of Hong Kong bilinguals’
informal language use both in speech and in print” (Li, 2000).
Language Use in the CMC Context in Hong Kong
Lee (2002, 2007a) claims ‘standard written English’, ‘attempted standard English’,
‘standard written Chinese’, ‘character representation of Chinese’, ‘coined Cantonese
Romanization’ and ‘morpheme-for morpheme translation’, which are also referred to as the
Six Forms of Codes, are the most common language choices among his study participants’
4 Text-messaging, also called SMS (short message service), was one of the most prevalent forms of
communication. It is a service for sending short messages (of up to 160 characters) with mobile devices, which
usually charge mobile phone users. Instant-messaging (IM), on the other hand, have now become a new way of
communication for smartphone users because most IM apps are free to use, and it is SMS over the internet as
opposed to a phone network. However, both text-messaging and instant-messaging are similar in terms of
accessibility as these two types of communication are accessed from a portable device (e.g., smartphones) for
everyday communication among teenagers and adults.

4
emails and online chats such as with MSN Messenger and FB Messenger texts. All his study’s
participants were either possessed a university qualification when the study was conducted.
Conclusions were drawn on the basis of Lee’s (ibid) study that both ‘standard written English’
and ‘attempted Standard English’ are common linguistic features in the CMC context.
Motivations of Cantonese-English code-mixing in Hong Kong
As noted by Yau (1993), bilingual speakers code-mix differently as their proficiency in their
second language can vary. The varied proficiency levels of Cantonese-English bilinguals tend
to make consistent errors in grammar or lexical choice in their second language, which
functions as the embedded language. In other words, Cantonese-English bilinguals insert
syntactic elements of English – the language that Hongkongers usually learn as their second
language through education – into their discourse when they speak in their mother-tongue –
Cantonese, also known as the matrix language (Chan, 1998). Following Yau’s studies, a
substantial amount of research has been done on the study of Cantonese-English code-mixing
by bilingual speakers in Hong Kong. Chan (ibid) applied the Matrix Language Frame Model
as explained above, to his analysis and has documented the main features of Cantonese-English
code-mixing. The major findings of Chan’s studies include (Chan, 1998, pp.195-196):
(1) English nouns are inserted into Cantonese sentences
(2) Code-mixed English verb is treated like a Cantonese verb
(3) English adjectives are treated like Cantonese stative verbs
(4) English phrases function as whole units in Cantonese utterances
The Present Study
Certain perceived functions of code-mixing should receive more detailed and in-depth
analysis as previous researchers believe that bilingual speakers code-mix because the
proficiency level of their second language (‘standard written English’ and spoken English) is
lower than their native language (‘standard written Chinese’ and spoken Cantonese). As a
result, two research questions are formed for the present study:
1. What types of code-mixing could be found in civil servants’ WhatsApp chats?
2. Do the practices of code-switching and code-mixing differ (in the government
domain of Hong Kong) according to the speaker’s educational background?

5
Methodology
In order to examine the code-switching phenomena found among civil servants in the
context of Instant Messaging applications, the research was divided into two stages: 1)
WhatsApp chat histories were collected to study the practices of code-switching and code-
mixing between civil servants and; 2) some participants were invited for follow-up interviews,
in which they were asked about their language background, education level, as well as details
about their WhatsApp chat episodes and their habitual online practices (see Table 1). A few of
the participating subjects’ chat partners were also asked to do follow-up interviews, resulting
in a more in-depth analysis on the practices of code-mixing for this study.
Participants
Initially, twenty participants were invited for the research. However, the collected data
from two subjects cannot be used for analysis because informed consent was not obtained from
their chat partners, and the chat data provided by eight other subjects contained insufficient
instances of code-mixing. Hence, the WhatsApp chat database consisted of merely chat
histories from ten civil servants (five males and five females) from the Tuen Mun District
Leisure Service Office of the Leisure and Cultural Services Department of the Government of
the Hong Kong.
To control the confounding factors which would interfere with the findings, the Chinese
inputting methods were taken into consideration. As a few participants noted that some of the
examples in their WhatsApp chat episodes were inadequate because they had chosen not to
code-mix as they experienced much inconvenience when switching from a Chinese inputting
method to inputting English characters and vice versa. Consequently, an overall of 16 ‘chat
history’ records between a total of 39 chat participants were selected for analysis, forming an
approximate of 6,000 word mini-corpus of code-mixed text collated from WhatsApp.
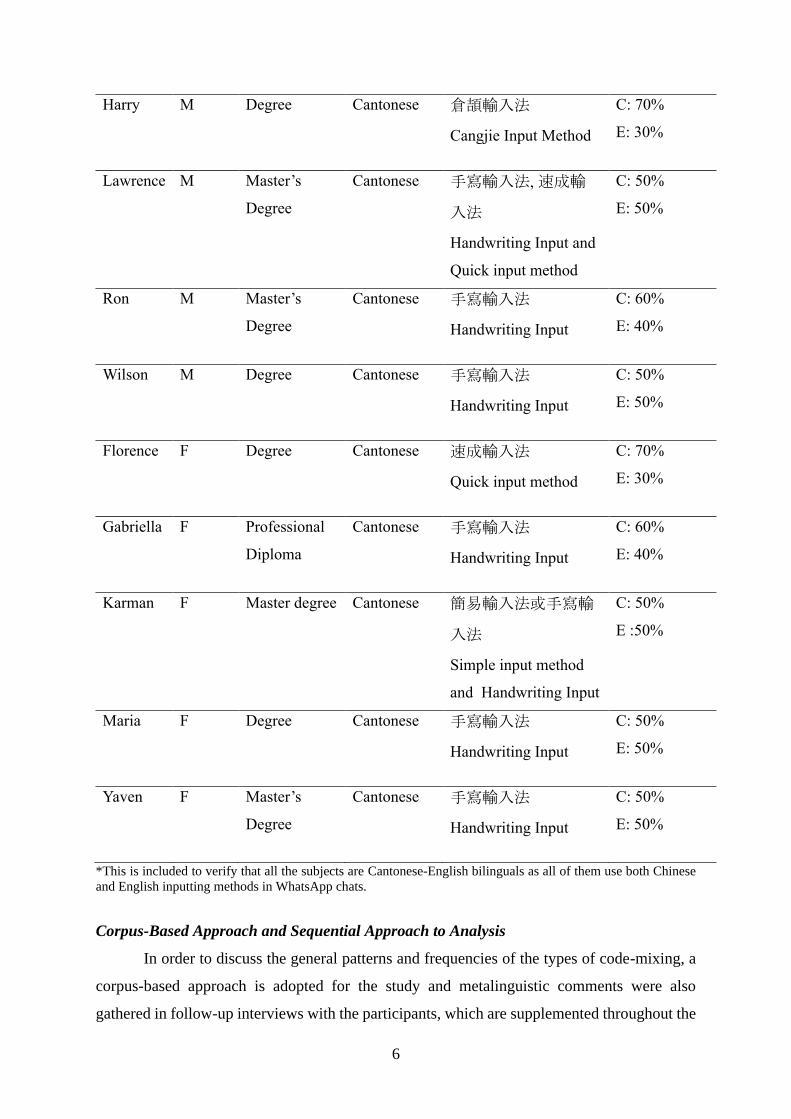
Table 1. Profile of Ten-Participating Subjects in the Study
Gender Educational
Level
Mother-
Tongue
Selected Chinese
Character Inputting
Method(s) in IM
Percentage of
Inputting
Languages in
IM*
Fred M Professional
Diploma
Cantonese 手寫輸入法
Handwriting Input
C: 60%
E: 40%
6
Harry M Degree Cantonese 倉頡輸入法
Cangjie Input Method
C: 70%
E: 30%
Lawrence M Master’s
Degree
Cantonese 手寫輸入法, 速成輸
入法
Handwriting Input and
Quick input method
C: 50%
E: 50%
Ron M Master’s
Degree
Cantonese 手寫輸入法
Handwriting Input
C: 60%
E: 40%
Wilson M Degree Cantonese 手寫輸入法
Handwriting Input
C: 50%
E: 50%
Florence F Degree Cantonese 速成輸入法
Quick input method
C: 70%
E: 30%
Gabriella F Professional
Diploma
Cantonese 手寫輸入法
Handwriting Input
C: 60%
E: 40%
Karman F Master degree Cantonese 簡易輸入法或手寫輸
入法
Simple input method
and Handwriting Input
C: 50%
E :50%
Maria F Degree Cantonese 手寫輸入法
Handwriting Input
C: 50%
E: 50%
Yaven F Master’s
Degree
Cantonese 手寫輸入法
Handwriting Input
C: 50%
E: 50%
*This is included to verify that all the subjects are Cantonese-English bilinguals as all of them use both Chinese
and English inputting methods in WhatsApp chats.
Corpus-Based Approach and Sequential Approach to Analysis
In order to discuss the general patterns and frequencies of the types of code-mixing, a
corpus-based approach is adopted for the study and metalinguistic comments were also
gathered in follow-up interviews with the participants, which are supplemented throughout the
7
study for further analysis. In addition, observations on how chat participants use mixed code
or switch from one code to another to meet their interactional needs by analyzing with the
sequential approach.
Findings
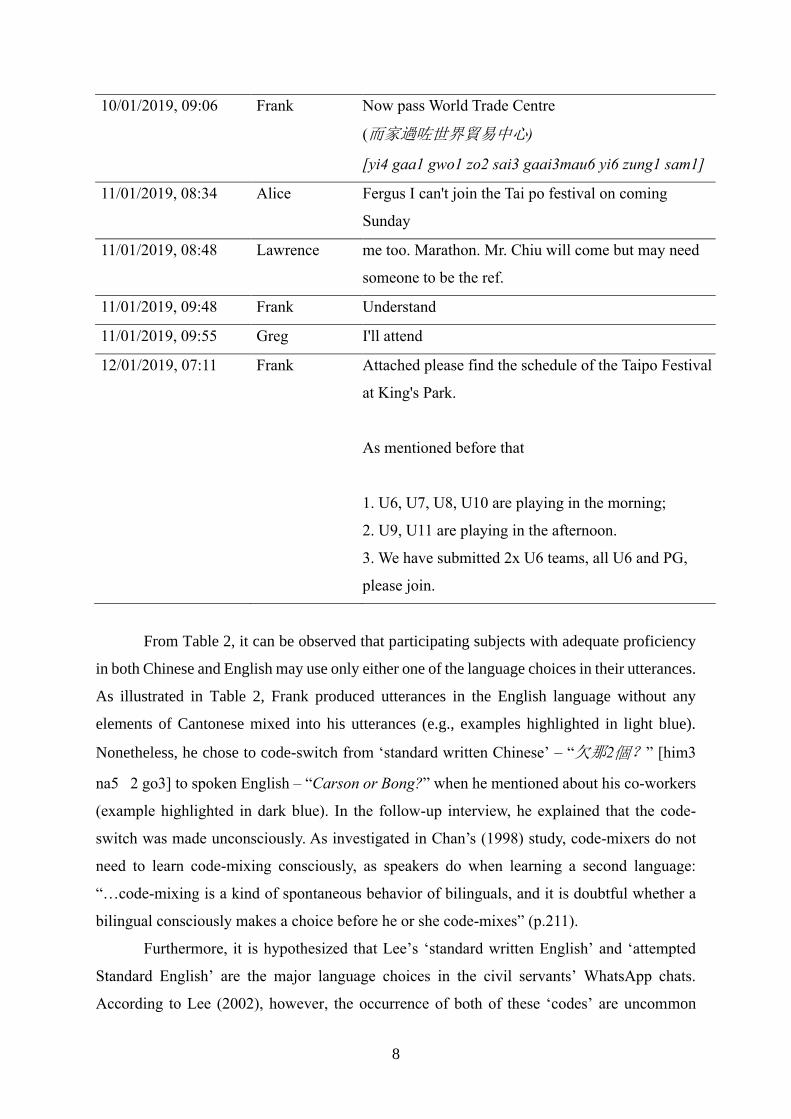
Table 2 shows the details of WhatsApp chat episode made by Lawrence including the
date, time, participants involved and verbatim.
Discussion on Lee’s Six Forms of Codes
Table 2. Lawrence’s WhatsApp Chat Episode
Date and Time Participant Verbatim I
10/01/2019, 08:49 Frank Coming now
10/01/2019, 08:51 Alice 👌
10/01/2019, 08:51 Frank Now go to SH.
10/01/2019, 08:53 Greg Thanks
10/01/2019, 08:57 Frank Leave SH going to Tin Hau.
10/01/2019, 09:02 Lawrence TH到了8個
8 have arrived in Tin Hau.
10/01/2019, 09:03 Frank 欠那2個?Carson or Bong?
[him3 na5 2 go3]
still owe 2 people, Carson or Bong?
10/01/2019, 09:03 Lawrence Peter
10/01/2019, 09:04 Alice 佢地自己去
[keui5 dei6 ji6 gei2 heui3]
They will go there themselves.
10/01/2019, 09:05 Alice 會跟車返
[wui6 gan1 che1 faan1]
(They) will take the return journey by car.
10/01/2019, 09:05 Frank Ok. He just told you?
10/01/2019, 09:06 Lawrence told Edwin
10/01/2019, 09:06 Frank Tks
8
10/01/2019, 09:06 Frank Now pass World Trade Centre
(而家過咗世界貿易中心)
[yi4 gaa1 gwo1 zo2 sai3 gaai3mau6 yi6 zung1 sam1]
11/01/2019, 08:34 Alice Fergus I can't join the Tai po festival on coming
Sunday
11/01/2019, 08:48 Lawrence me too. Marathon. Mr. Chiu will come but may need
someone to be the ref.
11/01/2019, 09:48 Frank Understand
11/01/2019, 09:55 Greg I'll attend
12/01/2019, 07:11 Frank Attached please find the schedule of the Taipo Festival
at King's Park.
As mentioned before that
1. U6, U7, U8, U10 are playing in the morning;
2. U9, U11 are playing in the afternoon.
3. We have submitted 2x U6 teams, all U6 and PG,
please join.
From Table 2, it can be observed that participating subjects with adequate proficiency
in both Chinese and English may use only either one of the language choices in their utterances.
As illustrated in Table 2, Frank produced utterances in the English language without any
elements of Cantonese mixed into his utterances (e.g., examples highlighted in light blue).
Nonetheless, he chose to code-switch from ‘standard written Chinese’ – “欠那2個?” [him3
na5 2 go3] to spoken English – “Carson or Bong?” when he mentioned about his co-workers
(example highlighted in dark blue). In the follow-up interview, he explained that the code-
switch was made unconsciously. As investigated in Chan’s (1998) study, code-mixers do not
need to learn code-mixing consciously, as speakers do when learning a second language:
“…code-mixing is a kind of spontaneous behavior of bilinguals, and it is doubtful whether a
bilingual consciously makes a choice before he or she code-mixes” (p.211).
Furthermore, it is hypothesized that Lee’s ‘standard written English’ and ‘attempted
Standard English’ are the major language choices in the civil servants’ WhatsApp chats.
According to Lee (2002), however, the occurrence of both of these ‘codes’ are uncommon

9
language choices in CMC. These two varieties could be found in Frank’s speech repertoire
when he interacted with his colleagues. While he informed his co-workers about the schedule
of the upcoming Tai Po Festival at King’s Park, ‘standard written English’ was used by him
such as “Attached please find…” and “As (I) mentioned before…”. Generally, the marked
choice takes place in a formal situation because the speaker feels the need to address the matter
officially and therefore, he uses ‘standard written English’ to communicate with his chat
participants and by doing so, he is trying to alert the colleagues about the timetable for the
various sport teams competing on the day of the festival.
‘Attempted Standard English’ refers to the phenomenon where a chat participant tries
to type an utterance in Standard English, but fails to do so due to the speaker’s lack of
proficiency in English. “Now pass World.trade (centre)” is an example that shows how English
is used and constructed into a Cantonese syntactic structure, which can also be understood as
a ‘morpheme-for-morpheme translation’; it is very likely that Hongkongers who lack English
proficiency to produce English utterances that are generated word by word from Cantonese to
English, also known as morpheme-to-morpheme translation.
Discussion on the Types of Cantonese-English Code-Mixing
It is observable how a civil servant code-switches from ‘Standard written Chinese’ to
spoken English without knowing one made the switch automatically, and how some language
choices that may not be used between university students are in fact used among civil servants
due to their varied language abilities or the purpose of using a code to achieve a certain effect;
consequently both ‘written Standard English’ and ‘attempted Standard English’ can be found
in their WhatsApp chats with English being the matrix language, but in some cases, Cantonese
is the matrix language among other chat participants (see Table 3).
Table 3. Fred’s WhatsApp Chat Episode
Date and Time Participant Verbatim Two
29/10/2019, 19:55 Brooke 昨天黎到FSB由Hall1行到Hall11,淨睇唔問都未
睇晒。今日只有半日睇,見到D新嘢,入去問
野,1個鐘只睇到2/3個booths. 康體世界太大,
香港太細了。

10
[jok6 tin1 lai4 dou3 FSB yau4 Hall1 hang4 dou3
Hall11,jing6 tai2 m4 man6 dou1 mei6 tai2 saai3。
gam1 yat6 ji2 yau5 bun3 yat6 tai2, gin3 dou2D san1
ye5,yap6 heui3 man6 ye5,1 go3 jung1 ji2 tai2
dou3 2/3 go3 booths. hong1 tai2 sai3 gaai3 taai3
daai6,heung1 gong2 taai3 sai3 liu5。]
Yesterday, (I) went to FSB and went from Hall 1 to
Hall 11, but I just walked around the hall without
entering any shops. Today I only had a half-day visit.
I saw some new things in booths so I went inside. I
only visited 2/3 booths in an hour. The world of
sports is too big, and Hong Kong is too small.
29/10/2019, 19:55 Brooke D play equipment不知幾好玩
[bat1 ji1 gei2 hou2 waan2]
There’s lot of fun if you play such equipment.
29/10/2019, 19:57 Brooke 現在潮流興玩tramp. 可考慮係新場裝翻個
[yin6 joi6 chiu4 lau4 hing1 waan2 tramp. ho2
haau2 leui6 hai6 san1 cheung4 jong1 faan1 go3]
Now the trend is to play tramp. Consider installing
one in a new outfit.
29/10/2019, 19:59 Brooke 好感慨,以前政府都會用歐洲靚野,自從鬥
平,用D土炮,不停要維修
[hou2 gam2 koi3, yi5 chin4 jing3 fu2 dou1 wui6
yung6 au1 jau1 leng3 ye5,ji6 chung4 dau3
peng4, yung6 D tou2 paau3,bat1 ting4 yiu3
wai4 sau1]
I’m very impressed. The government used to import

11
European made items. Since there is a cut-throat
competition, the government started using many
locally produced items, and they need to be repaired
frequently.
29/10/2019, 20:02 Brooke Schelde 真係好好,點會斷或跌板
[jan1 hai6 hou2 hou2,dim2 wui5 tyun5 waak6
dit3 baan2]
Schelde is really good. It won’t break or fall.
29/10/2019, 20:04 Hayden Oversea training 😁大開眼界
[daai6 hoi1 ngaan5 gaai3]
Oversea Training can broaden your horizon.
29/10/2019, 20:06 Brooke 報告住咁多,現在去睇pool d 野。然後再去睇
fitness equipment.
[bou3 gou3 jyu6 gam3 do1,yin6 joi6 heui3 tai2
pool d ye5。yin4 hau6 joi3 heui3 tai2 fitness
equipment]
So this is what I want to report so far. Now, (I) go to
the pool to have a look. Then (I will) go to check
fitness equipment.
30/10/2019, 08:14 Fred 要俾啲料訓練組,等佢哋安排同事參觀相關展
覽以增進知識。
[yiu3 bei2 di1 liu6 fan3 lin6 jou2,dang2 keui5
dei6 on1 paai4 tung4 si6 chaam1 gun1 seung1
gwaan1 jin2 laam5 yi5 jang1 jeun3 ji3 sik1。]
It is necessary to provide information to the training
team and wait for them to arrange colleagues to visit
related exhibitions to enhance their knowledge.

12
30/10/2019, 20:13 Brooke 我知道十幾年前,部門曾經安排過想當年既
development 的LSM同事睇依個展覽。唔知係
咪,後來development執笠,所以失傳。其實應
該SLM/CLM grade既同事要去之外,ASD做新
project既同事更應該去。我去咗一個專起
stadium既architect company既booth八卦。香港唔
幫襯,聽吓人地講都好。
[ngo5 ji1 dou6 sap6 gei2 nin4 chin4, bou6 mun4
chang4 ging1 on1 paai4 gwo3 seung2 dong1 nin4
gei3 development dik1 LSM tung4 si6 tai2 yi1 go3
jin2 laam5。m4 ji1 hai6 mai6,hau6 loi4
development jap1 lap1, so2 yi5 sat1 chyun4。kei4
sat6 ying1 goi1 SLM/CLM grade gei3 tung4 si6 yiu3
heui3 ji1 ngoi6,ASD jou6 san1 project gei3 tung4
si6 gaang1 ying1 goi1 heui3。ngo5 heui3 jo2 yat1
go3 jyun1 hei2 stadium gei3 architect company gei3
booth baat3 gwa3。heung1 gong2 m4 bong1
chan3, teng1ha5 yan4 dei6 gong2 dou1 hou2。]
I know that more than ten years ago, the Department
had arranged an exhibition for LSM developmental
colleagues in the past. I was not so sure if such
practice was lost because of the closure of the
developmental team. In fact, not just SLM/CLM
grade colleagues should visit the exhibition, but also
those colleagues who are in charge of the new
projects in ASD. I'm going to visit a booth in the
exhibition hall held by an architectural company,
specializing in building stadiums. (We) won’t do

13
business with Hong Kong-based firms, but it's good
to listen to their presentations.
30/10/2019, 20:13 Brooke 我仲去咗幾個專做artificial turf既 in-fill 的booths,
問佢d rubber係點?US話驚有毒,開始轉用
organic in-fill,佢地都update咗我—D資料。可
以俾多個角度我地睇依件事。唔用歐洲野,了
解吓行情也好?
[ngo5 jung6 heui3 jo2 gei2 go3 jyun1jou6 artificial
turf gei3 in-fill dik1 booths, man6 keui5 d rubber
hai6 dim2?US wa6 geng1 yau5 duk6, hoi1 chi2
jyun3 yung6 organic in-fill,keui5 dei6 dou1 update
jo2 ngo5—Dji1 liu2。ho2 yi5 bei2 do1 go3 gok3
dou6 ngo5 dei6 tai2 yi1 gin6 si6。m4 yung6 au1
jau1 ye5,liu5 gaai2 ha5 hong4 ching4 ya5
hou2?]
I have been to a few booths that specialize in both
artificial turf and in-fill, and I asked them what to do
with rubber? The US-based company was worried
about the rubber is poisonous, so it started to switch
to organic in-fill, and the company updated me some
information about the quality of rubber. So, we can
see things from multiple angles. Even though we
don't use the European products, it's okay to
understand the market trend.
30/10/2019, 20:20 Bowie 攞多啲資料返來給training unit,等佢知道好有
用,下次可以派人去學習下。不過.……近年機
會都係微啲啦!因為部門冇錢。
[lo2 do1 di1 ji1 liu2 faan1 loi4 kap1 training unit,

14
dang2 keui5 ji1 dou6 hou2 yau5 yung6,ha6 chi3
ho2 yi5 paai3 yan4 heui3 hok6 jaap6 ha6。bat1
gwo3…… gan6 nin4 gei1 wui6 dou1 hai6 mei4 di1
la1!yan1 wai6 bou6 mun4 mou5 chin2。]
(Try to) get as much information as possible to the
training unit. When the training unit knows it is
useful, someone will be sent to explore it next time.
But there have been few opportunities in recent years
because the department has no surplus.
1/11/2019, 16:21 Hayden 坪石遊樂場
[ping4 sek6 yau4 lok6 cheung4]
Ping Shek Playground
1/11/2019, 17:13 Bowie 咿,第一次見,好似幾好玩。不過我覺得消防
梯挑戰性大啲。多謝分享。👍
[yi1,dai6 yat1 chi3 gin3,hou2 chi5 gei2 hou2
waan2。bat1 gwo3 ngo5 gok3 dak1 siu1 fong4 tai1
tiu1 jin3 sing3 daai6 di1。do1 je6 fan1 heung2。]
Huh, seeing you for the first time, it seems like a lot
of fun. But I think the fire ladder is very challenging.
Thanks for sharing.
1/11/2019, 17:31 Brooke 以前我地都有依Dslide, 不過後來SE唔敢用,淘
汰晒。聽聞最後一條係HKP,早幾年都無埋。
[yi5 chin4 ngo5 dei6 dou1 yau5 yi1 D slide, bat1
gwo3 hau6 loi4 SE m4 gam2 yung6],tou4 taai3
saai3。teng1 man4 jeui3 hau6 yat1 tiu4 hai6

15
HKP, jou2 gei2 nin4 dou1 mou4 maai4。]
We used to have some slides, but then SE didn’t dare
to use it and eliminated it. I heard that the last one is
HKP, and it has not been used for a few years.
1/11/2019, 17:33 Brooke 小朋友真係要挑戰. That's why we are
professional. We need to strike the balance of safety
and challenge.
[siu2 pang4 yau5 jan1 hai6 yiu3 tiu1 jin3]
Children really have to face challenges. That's why
we are professional. We need to strike the balance
of safety and challenge.
From the above table, it can be realized that while Fred, one of our participating
subjects, communicated in a comparatively ‘standard written Chinese’ manner, his chat
partners tended to code-mix in a greater amount, except Bowie. With Chinese being the matrix
language in this chat episode, “Schelde真係好好,點會斷或跌板” “Schelde [jan1 hai6 hou2
hou2,dim2 wui5 tyun5 waak6 dit3 baan2]” is an example of an English noun inserted into a
Cantonese sentence, as identified as a type of code-mixing in Chan’s study (1998). There are
many other examples of this particular type of code-mix that can be found in the above example
(e.g., “ASD做新project既同事更應該去” [ASD jou6 san1 project gei3 tung4 si6 gaang1 ying1
goi1 heui3。], but an English letter can also be seen in Table 3, where ‘D’ is borrowed to
represent a Cantonese plural morpheme, in which些 is the Standard Chinese character
equivalent of the borrowed English letter ‘D’. For instance, “以前我地都有依D slide…” [yi5
chin4 ngo5 dei6 dou1 yau5 yi1 Dslide] is a Cantonese utterance, where ‘D’ functions as the
plural marker for ‘slide’. As a result, ‘letters of the English alphabet are borrowed into written
Cantonese for their phonetic values’ because they are ‘homophonous with the Cantonese
morpheme’ (Bauer, 1988).
Moreover, the participant who has the habit of code-mixing on WhatsApp chats, also
made an unpredicted code-switch in Table 3 (example highlighted in dark blue). Through

16
interviewing her, it can be comprehended that she wanted to establish a strong stance, signaling
to her colleagues that it is indeed important to continue selecting play equipment that is
challenging enough for children to play, but that its safety should be guaranteed as well.
Therefore, she chose to code-switch to English in order to show her stance point to her co-
workers, regarding the selection of play equipment for public parks in Hong Kong.
The present result is consistent with Sumartono and Tan’s (2018) work that deals with
the Malay-English Bilinguals’ Code-switching Behavior in Singapore, pinpointing that code-
switching between bilinguals is treated as means of communication, and not a linguistic
incompetence. It is important to note that the occurrence of code-mixing in this particular
WhatsApp chat episode is relatively higher when compared to Table 2.
Conclusion
The present study used quantitative data to explore the code-switching linguistic
phenomena in an unexplored domain- the government sector. In the present study, key
concepts have been developed in studies of language choices among Cantonese-English
bilingual speakers, including the classification of varieties in the Six Forms of Codes in online
chats and the main features of Cantonese-English code-mixing with the support of the Matrix
Language Frame Model, which are proposed by Yau (1993) and Chan (1998), respectively.
From the collected data, ‘character representation of Chinese’, ‘coined Cantonese
Romanization’ are the only two codes that have not been identified in the civil servants’
WhatsApp exchanges. Despite the overwhelming evidence of its occurrence in university
students’ online chats, this study found that ‘attempted Standard English’ and ‘standard written
Chinese’ are the most common codes in IM communication in the government domain.
Regarding the first research question, the data suggests that ‘attempted Standard
English’ is the most used variety by participants, who have relatively lower educational
background. Participating subjects who have at least obtained a Master’s degree would use
more ‘Standard written English’ codes than those limited English proficiency subjects who
tend to have the habit of inputting Chinese. Most of the participating subjects with relatively
higher academic attainment, however, would choose to code-mix Cantonese and English from
time to time.
There are limitations to the current study, for example, even though confounding extra-
linguistic factors such as the inconvenience of converting between Chinese and English
inputting methods were controlled, age and gender should also be considered as they are other
sociolinguistic variables which may affect the code-mixing patterns of the participating

17
subjects. In addition, further research to explore WhatsApp chats in other domains (e.g.,
vendors/buyers, doctors/nurses and insurance agents/clients) to gain a better understanding of
patterns of Chinese-English code-mixing in other Hong Kong speech community can be made
in future.
References
Ariffin, K. & Husin, M.S. (2011). Code-switching and Code-mixing of English and Bahasa
Malaysia in Content-Based Classrooms: Frequency and Attitudes. Linguistics Journal,
5, 220-247.
Baron, N. S. (2003). “Language of the Internet,” in A. Farghali (Ed.), The Stanford Handbook
for Language Engineers (pp. 59-127). CSLI Publications (Stanford Center for the Study
of Language and Information), distributed by the University of Chicago Press.
Bauer, R.S. (1988). Written Cantonese of Hong Kong. Cahiers de Linguiste Asie Orientale,
17, 245-293.
Bell, R. (1976). Sociolinguistics. B.T. Batsford.
Blom, J. P., & Gumperz J. (1972). Social meaning in linguistic structure: Code-switching in
Norway. In J. Gumperz, & D. Hymes (Eds.), Directions in sociolinguistics. Holt,
Rinehart and Winston.
Chan, B. (1998). How does Cantonese-English code-mixing work? In M. Pennington (Ed),
Language in Hong Kong at Century’s End (pp. 191-216). Hong Kong University Press.
Chan, K.L. R. (2019). Trilingual code-switching in Hong Kong. Applied Linguistics Research
Journal, 3 (4), 1-14.
Freiermuth, M.R. (2001). Features of electronic synchronous communication: a comparative
analysis of online chat, spoken and written texts. [Unpublished Master’s Dissertation].
Oklahoma State University, Stillwater.
Gibbons, J. (1979). Code-mixing and koineizing in the speech of students at the University of
Hong Kong. Anthropological Linguistics, 21(3), 113-23.
Gibbons, J. (1983). Attitudes towards languages and code-mixing in Hong Kong. Journal of
Multilingual and Multicultural Development, 4(2/3), 129-47.
Gibbons, J. (1987). Code-mixing and code choice: A Hong Kong case study. Multilingual
Matters.
Hudson, R. (1980). Sociolinguistics. Cambridge University Press.
Lam, W.S. (2004). Second language socialization in a bilingual chat room: Global and local
considerations. Language Learning Technology, 8(3), 44-65.

18
Lee, C.K.M. (2002). Literacy practices in computer-mediated communication in Hong Kong.
The Reading Matrix, 2(2), 1-25.
Lee, C.K.M. (2007a). Linguistic features of email and ICQ instant messaging in Hong Kong.
In B. Danet, & S.C. Herring (Eds.), The multilingual Internet language, culture and
communication online (pp.184-208). Oxford University Press.
Lee, C.K.M. (2007b). Text-making practices beyond the classroom context: Private instant
messaging in Hong Kong. Computers and Composition, 24, 285-301.
Li, David C. S. (1999). Linguistic Convergence: Impact of English on Hong Kong Cantonese.
Asian Englishes, 2(1), 5-36.
Li, David C.S. (2000). Cantonese‐English code‐switching research in Hong Kong: a Y2K
review. World Englishes. 19(3), 312–317. https://doi.org/10.1111/1467-971x.00181
Sumartono, F. & Tan, Y.Y. (2018). Juggling Two Languages: Malay-English Bilinguals’
Code-
switching Behavior in Singapore. Linguistics Journal, 12(1), 108-138.
Tien, C.Y. & Li, D. C. S. (2014). Codeswitching: Taiwan. In R. Barnard and J. McLellan (eds.),
Codeswitching in university English classrooms: Case studies and perspectives from
Asian contexts (pp. 24-42). Multilingual Matters.
Tepper, M. (1997). Usenet communities and the cultural politics of information. In D. Porter
(Ed.), Internet culture (pp.39-54). Routledge.
Wang, L., & Kirkpatrick, A. (2019). Trilingual education in Hong Kong primary schools.
Springer International Publishing.
Wei, M. (2014). Code-Switching in a Virtual English Community in China: An International
Perspective. Linguistics Journal, 8(1), 115-135.
Yau, M.S. (1993). Functions of two codes in Hong Kong Chinese. World Englishes, 12(1), 25-
33.

19
Appendix
Glossing Scheme
Some English examples are given in the following two-line glossing:
1. Cantonese Characters (italicized and in parenthesis).
2. Cantonese Romanization (italicized and in square brackets).
Example:
I don’t know!
(我唔知)
[ngo5 m4 zi1]
In this article, the Cantonese romanizations provided follow the Linguistic Society of Hong
Kong (LSHK) Cantonese Romanization Scheme (2004), also known as Jyutping “粤语粤拼”.

20
Hettiarachchi, S. (2021). A syntactic analysis of Sinhala relative clauses.
Linguistics International Journal, 15(1), 21-42.
A Syntactic Analysis of Sinhala Relative Clauses
Sujeewa Hettiarachchi
International Center for Multidisciplinary Studies,
University of Sri Jayewardenepura, Sri Lanka
Abstract
This paper provides a generative syntactic analysis of the relative clause (RC) construction in
Sinhala, the Indo-Aryan isolate spoken in Sri Lanka. The goal is to analyze Sinhala and
determine its place in the typology of human languages as characterized by a Minimalist theory
of principles and parameters. Thus, while using diagnostics standard in literature on relative
clauses from English and head-final languages such as Japanese and Korean, (Cinque, 2020;
Fukui & Takano, 2000; Kuno, 1973; Kwon, 2008; Murasugi, 2000; Saito, 1985), we present
evidence that favor a non-movement analysis of Sinhala RCs. We propose that the gap in a
Sinhala RC, unlike in English, is not a copy/trace left by head movement or operator
movement. Rather, it is a null pronominal (pro) base-generated inside the RC and A-bar bound
by a null operator base-generated at the specifier of the Complementizer Phrase. Evidence is
provided from subjacency, idiom chunks, adjectival modification and case marking. The paper
contributes to the discussion on the typology of relative clauses in generative grammar.
Keywords: Sinhala, relative clauses, null operator, null pronominal, pro
Introduction
A Relative Clause (RC) is a complex construction in which a Determiner Phrase (DP)
or Noun Phrase (NP) is modified by a Complementizer Phrase (CP) that is embedded inside it
(see Chomsky, 1977). A relative clause is generally characterized by at least two properties
(Alexiadou et al., 2000, p. 2):

21
(1) a. Non-canonical complementation (the clause is not an argument of a lexical
predicate)
b. Non-canonical wh-movement: (a) the clause contains a wh-dependency which is
not associated with interrogative semantics, (b) serves to link a position inside the
clause and an item outside that clause.
This is illustrated below with two examples from English.1
(2) a. This is DP [the boy CP [whoi___i kicked the ball.]] (Subject Relative Clause)
b. This is DP [the balli CP [which the boy kicked___i.]] (Object Relative Clause)
A noun that receives modification in an RC is called the ‘head’ of the relative
clause: e.g., the boy in (2a). It forms an agreement dependency with the relative pronoun
who that it precedes: its failure to agree with the relativizer results in ungrammaticality:
(3) a. * This is the book who pleased everyone.
b. There are guests who I am curious about what they are going to say.
(Prince (1990)
Cross-linguistically, there are two main structural types of relativization: ‘gap strategy’
and ‘resumptive strategy’ (e.g., Keenan & Comrie, 1977). As we have already observed in (2),
English relative clauses are formed via the ‘gap strategy:’ a relative clause contains a gap that
could be associated with the relative pronoun or the head of the RC. However, in the resumption
strategy, a pronominal element fills the gap of the RC, and it is bound by the element that would
have otherwise bound the gap (McCloskey, 2017, p. 2). As Chomsky (1982) observes, even
though English relative clauses are generally derived through syntactic movement, the
resumptive strategy is also not completely absent in English:
(4) a. the man whoi John saw himi.
b. There are guests whoi I am curious about what theyi are going to say. (Prince, 1990)
Meanwhile, a typical relative clause in Sinhala is illustrated in (5) below. As assumed
in Chandralal (2010), Henadeerage (2002) and Walker (2006), Sinhala RCs, similar to
those in English, are formed using the ‘gap strategy.’
1 English is one language that allows the relativization of all points on the Noun Phrase Accessibility Hierarchy
(2) proposed in Keenan and Comrie (1977). Subjects >Direct Obj > Indirect Obj > Obliques > Genitives > Object
of Comparatives.
a. This is the child who drew the picture of a unicorn. [Subject]
b. This is a poem which Mary wrote. [Direct Object]
c. This is the girl to whom John gave a present. [Indirect Object]
d. This is the brush that Kevin drew the painting with. [Oblique]
e. This is the manager whose decision nobody liked. [Genitive]
f. This is the drama which Macbeth is more interesting than. [Object Complement]

22
(5) [siri-tǝ ___i magǝ-di hamu-unǝ] minihai
siri-DAT way-on met.pst man.NOM
The man who Siri met on the way
There are three main properties that characterize Sinhala relative clauses. First, unlike
in English, relative clauses are pre-nominal in Sinhala, i.e., the clause precedes the noun that it
modifies. Second, an overt relativizer is absent in Sinhala RCs (Chandralal, 2010; Walker,
2006). Finally, the verb of the relative clause, which takes the form of a verbal adjective
(glossed as ADN=adnominal) modifies the head noun of the RC (Henadeerage, 2010, p.184).
In terms of the typology of relative clauses, these properties have been found to be common
with pre-nominal relative clauses in SOV languages (see e.g., Alexiadou et al., 2000; Comrie,
1989; Kwon, 2009; Larson & Takahashi 2007, Mahajan, 2000).
Earlier, we observed that English allows the relativization of any point on Keenan and
Comrie’s (1977) Noun Phrase Accessibility Hierarchy (NPAH). The same is observed in
Sinhala (see Chandralal, 2010; Henadeerage, 2002; Walker, 2006).
(6) a. [unicorn-ge pinthure ændəpu] laməya me inne. [Subject]
unicorn-GEN picture.ACC draw.PST child this is
This is the child who drew the picture of a unicorn.
b. [meri liyəpu] kawiya me thiyenne. [Direct Obj]
Mary.NOM write.PST poem.NOM this is
This is poem that Mary wrote.
b. [siri thægga-k dipu] laməya me inne. [Indirect Obj]
Siri.NOM present.INDEF-ACC give.PST child this is
This is the girl to whom Siri gave a present.
c. [kevin pinthure ændəpu] brashekə me thiyenne. [Oblique]
Kevin.NOM painting.OBL draw.PST brush this is
This is the brush that Kevin drew the painting with.
d. [kauruwath thirənəyə-tə akamæthi-wechchə] mænejər me inne. [Genitive]
nobody.NOM decision-DAT dislike.ADN manager this is
This is the manager whose decision nobody liked.
e. [Macbeth-tə wada rasawath] drama-ekə me thiyenne. [Object
Comparative]

23
Macbeth-DAT than interesting drama.NOM-DEF this is
This is the drama which Macbeth is more interesting than.
Also, Sinhala does not make a distinction between restrictive and descriptive relative
clauses (Chandralal, 2010). Finally, one important observation (see Chandralal, 2010) is that
Sinhala, similar to Japanese (e.g., Kuno 1973; Murasugi, 2000) and Korean (e.g., Han & Kim,
2004; Kwon, 2008), allows double relativization: one RC is embedded inside a second RC.
The following example is adapted from Chandralal (2010, p. 134):
(7) [RC1[RC2 ti tj igənə-gattə] paadəməj amətəkə-wechchə] lamaii
learn.PST.ADN lesson.ACC forgot.PST.ADN children-NOM
Children who forgot the lesson that (they) learnt.
Even though Sinhala relative clauses are formed through the gap strategy, similar to
Korean and Japanese (Kim, 1998), Sinhala also has gapless relative clauses as illustrated in (8)
below.
(8) a. rode karəkæwenə sadde
wheel.NOM turn.PRE sound
The sound of wheel turning
Even though the Sinhala relative clause construction has received some attention in
scarce syntactic literature on the language, the discussion of this phenomenon in current
literature is limited to providing descriptive generalizations. As far as we are aware, no
theoretical syntactic analysis has previously been proposed for relative clauses in Sinhala, the
gap that this paper intends to fill in literature. Thus, this paper, based on theoretical constructs
from Minimalism (Chomsky, 1993 and thereafter), provides a generative syntactic analysis of
Sinhala RCs. The goal is to analyze Sinhala and determine its place in the typology of human
languages, as characterized by a Minimalist theory of principles and parameters. While
drawing insights from discussions on the phenomenon in syntactic literature (e.g., Bhatt, 2002,
2015; Cinque, 2020; Fukui & Takano, 2000; Kang, 1986; Kuno, 1973; Kwon, 2008; Murasugi,
1991; Radford, 2019; Saito, 1985), we present evidence that favor a non-movement analysis
of Sinhala RCs. We provide evidence to show that the gap in a Sinhala RC is not a copy/trace
left by head movement or operator movement. Rather, it is a null pronominal (pro) element
base-generated inside the RC.

24
The rest of this paper is organized as follows. Section 2 provides a review of formal
approaches to the analysis of relative clauses, in light of the work by Chomsky (1977), Bhatt
(2002), Browning (1991), Cinque (2020), Kayne (1994), Schachter, (1973) and Vergnaud
(1974). Based on the approaches presented in Section 2, Section 3 provides an analysis of
Sinhala relative clauses. Finally, Section 4 presents the summary and conclusion.
Formal Approaches to the Analysis of Relative Clauses
How relative clauses are syntactically derived in English (and other languages) is a
debated issue in generative syntactic literature (see e.g., Alexiadou et al., 2000; Bhatt, 2000,
Cinque, 2020 for a review of different proposals). Starting from the early GB era (see e.g.,
Chomsky, 1977; Schachter, 1973; Vergnaud, 1974), three main analyses have been proposed
to account for English relative clauses: Head raising analysis (see e.g., Bhatt, 2002; Kayne,
1994; Schachter, 1973; Vergnaud, 1974) and External head/(wh-) operator movement analysis
(see e.g., Browning, 1991; Chomsky, 1977; Jackendoff, 1977; Safir, 1981) and Matching
analysis.
Head Raising Analysis
According to the Raising analysis (Bhatt, 2002, 2015; Brame, 1968; Kayne, 1994;
Radford, 2016; Schachter, 1973; Szczegielniak, 2012; Vergnaud, 1974), the modified NP, e.g.,
ball in (2b), is first merged as part of a DP inside the relative clause (i.e., as the object of
kicked). The surface word order in (2b) is created when the NP the ball undergoes syntactic
movement within its DP (i.e., which ball) inside the RC, after which the DP moves into the
Spec-CP position, as shown in Error! Reference source not found.). The relative clause CP,
meanwhile, is assumed to be a complement to the head of the Determiner Phrase (under
Kayne’s, 1994 analysis). By overt syntactic movement, the NP poem forms a chain with its
trace inside the RC, and its reconstruction at LF allows it to be interpreted in its base-position.
The proposed structure for English relative clauses under this approach (based on Kayne, 1994)
is illustrated in Error! Reference source not found.).
One source of evidence often cited in favor of head raising analyses such as the one
illustrated Error! Reference source not found.) is binding (Schachter, 1973). Notice that in
the following example Error! Reference source not found.), if the NP containing the anaphor
(the picture of himself) is not first merged inside the RC, the sentence is expected to be a
violation of the Binding Principle A (10) (Chomsky, 1981), i.e. the anaphor is not bound inside
its local domain. However, assuming that the binding principle applies at LF, raising analyses

25
would predict that the anaphor is bound in this context through reconstruction to its first merged
position inside the RC.
(9) The picture of himself that the child saw was on the table.
(10) An anaphor must be A-bound in its governing category.
(The governing category for an element α is the minimal XP containing α, its governor
and an accessible subject.)
(11)
Raising analyses of RCs in English are also supported by the movement of idiom
chunks (Bhatt, 2002; Schachter, 1973; Vergnaud, 1974). First consider the following example,
as discussed in Schachter (1973):
(12) a. We made headway.
b. The headway that we made was satisfactory.
If idioms are stored in the mental lexicon as syntactic/semantic units, constituent
elements of an idiom are required to be in a local relation at LF, i.e., in the corresponding
structure 0), the verb made and its complement headway must be in a sisterhood relation. This
is observed in 0a). Given this, 0b) can be grammatical only if headway is first generated as the
complement of the verb made inside the RC, before it is displaced to occupy the Spec-CP
position. If not, the two constituent elements of the idiom fail to be in a local relation at LF.
Thus, the grammaticality of 0b) provides further evidence for a head raising analysis in English
RCs.
As first discussed in Bhatt (2002), additional evidence for the head raising analysis in
English relative clauses comes from adjectival modifiers. Bhatt (2002) observes that the

26
following English example is ambiguous between high and low readings for the adjectival
modifier.
(13) The first book that John said that Tolstoy had written
Low reading: X is the first book that Tolstoy wrote.
High reading: X is the first book about which John said that Tolstoy had written (it).
As Bhatt (2002) argues, this ambiguity in 0) arises from a chain created by the
movement of the DP the first book from its base position (inside the RC) to the surface position
(matrix Spec-CP). The low reading for the DP the first book is obtained when the lower copy
inside the embedded TP2 receives an interpretation. The high reading is possible when the copy
in the intermediate position (TP1) is interpreted. Thus, if the DP the first book was not
generated inside the lower TP, this ambiguity would remain unexplained.
(14) [DP [ CP [DP The first book] that [TP1 John said [CP ti that [TP2 Tolstoy had written ti]]]]
Other evidence for the head raising analysis of RCs comes from sub-categorization,
scopal reconstruction and variable binding (see Alexiadou et al., 2000 and Bhatt, 2002 for a
review of these arguments).
External Head/Operator Movement Analysis
Despite the evidence for the head raising analysis reviewed in the previous section, the
dominant view in generative syntax has been that relative clauses in English (and many other
languages) are derived through wh-movement, following Chomsky (1977). This proposal (see
also Browning, 1991; Jackendoff, 1977; Safir, 1982; Webelhuth et al., 2018; Zhang, 2008) is
primarily based on three main assumptions: (i) the NP head of a relative clause is base-
generated outside the CP, (ii) the relativizer is first merged inside the relative clause, and it
subsequently undergoes wh-movement2 to occupy the Spec-CP position, and (iii) the NP and
the wh-phrase are linked through some form of co-indexation. Further, in the absence of an
overt relativizer, a null operator (OP) undergoes the same kind of movement. The proposed
2 Under Minimalism, it is generally assumed (though arguably) that wh-movement in English relative clauses is
not different from canonical wh-movement: in both instances, the movement is driven by an uninterpretable edge
feature (uwh*) in C (see Chomsky, 2001). Still, wh-movement in RCs is different from canonical wh-movement
at least in two respects (e.g., Alexiadou et al., 2000, p. 2). Wh-dependency in RCs: it (a) is not associated with
interrogative semantics and (b) serves to link a position inside the clause and an item outside that clause.

27
structure for an English RC under this approach is illustrated in Error! Reference source not
found.) below.
(15)
Evidence for the wh-movement analysis of English RCs comes from at least two
observations (see Alexiadou et al., 2000). Similar to canonical wh-movement, relative clauses
also allow LD dependency formation, as illustrated in the following example:
(16) a. This is the story which his father read yesterday.
c. This is the story which the child said his father read yesterday.
d. This is the story which Mary believes that the child said that his father read
yesterday.
Moreover, relative clauses, similar to canonical wh-dependencies, are subject to
island constraints in English (Ross, 1967): Complex NP constraint 0a), Relative clause island
0b), and Wh-island 0c).
(17)
a. *This is the story which the child made the claim that his father read yesterday.
b. *This is the story that the horse kicked the man who read.
c. *This is the book that Mary wondered how Max read.
Matching Analysis
Matching analysis, as proposed in Chomsky (1965), Catasso (2013), Citko (2001), Lees
(1961), Salzmann (2006) and Sauerland (1998) is a combination of some elements of both head
raising and operator movement analyses. This analysis assumes that the NP head in a relative
clause is base generated outside the CP; however, an identical representation of the NP is also

28
generated inside the CP, which is phonologically deleted: only the external copy receives
phonological interpretation. The two NPs are co-indexed, but they are not part of a movement
chain. This is illustrated below:
(18)
Evidence for the matching comes from the absence of condition C violations in relative
clauses, in contrast to wh-movement (Safir 1998; Sauerland, 2003; Sauerland, 2000). This is
illustrated with following examples from Sauerland (2000, p. 4):
(19) (a) Which is the picture of Johni that hei likes?
(b) ∗Which picture of Johni does hei like?
The example Error! Reference source not found.a) shows that a referential
expression in the head of an RC does not cause a condition C violation in the trace position
inside the CP: heads of RCs with referential expressions are not subject to obligatory
reconstruction in English. Thus, the absence of Condition C violations in relative clauses such
as in Error! Reference source not found.a) shows that there is no direct movement
relationship established between the external NP head and the trace inside the CP, which
provides evidence against a head raising analysis but favors a matching analysis of English
RCs. Other evidence for the matching analysis comes from idiom chunks (Brame, 1968;
Sauerland, 2000) and scope interpretation (Sauerland, 2000).
To sum up, how relative clauses are derived in English (and other languages) is an
unsettled issue in generative syntax. The first two approaches that we have reviewed at least
converge on the assumption that they are derived in English through some form of syntactic
movement. The disagreement is on whether it is the relativizer/operator or the head NP that
undergoes movement. In both approaches, the movement is sensitive to subjacency violations.

29
While there is compelling evidence for both these approaches (see e.g., Bhatt, 2003), the
matching analysis remains less supported in literature. However, in this study, following the
standard view in generative syntax literature (Chomsky, 1977 and thereafter), we assume that
RCs in English are derived through wh-movement. This movement, similar to canonical wh-
movement, involves an agreement dependency between an uninterpretable syntactic feature
(uwh*) in C and its interpretable counterpart on the relativizer/wh-phrase.
Analysis of Sinhala Relative Clauses
In this section, we extend the proposals/approaches discussed in the previous section to
Sinhala in an attempt to determine to what extent they can account for Sinhala relative clauses.
Against Movement and Matching Analyses
Let us first consider movement approaches to English relativization. Recall that the External
head analysis assumes that a relative clause in English is derived when the relativizer/operator
raises from its first merged position (inside the TP) to the Spec-CP position. The
operator/relative pronoun, thus displaced, can be reconstructed at LF for interpretation. In
contrast, under head raising analyses, it is the NP head that undergoes syntactic movement
from its base position (inside the TP) to Spec-CP position. However, both analyses can
accurately account for the subjacency violation in the following English example—i.e.,
regardless of whether it is the head NP or the null operator that moves to occupy the spec-CP
position: this movement of the head/operator corresponding to ‘the story’ has to cross more
than one bounding node at a time (TP and NP):
(20) *This is [NP the storyj [CP that [TP the horse kicked [NP the man [CP whoi [TP ti read tj]]
Given what we have observed in English, one possibility to consider is whether Sinhala
relative clauses, similar to those in English, can be generated by syntactic movement, namely
wh-movement or head raising. Given that Sinhala does not have overt relativizers, the wh-
movement approach would predict that RCs in Sinhala are derived through null operator
movement to Spec-CP. In contrast, head raising analysis would predict that the head of a
relative clause is first merged inside the RC in Sinhala, before it raises to Spec-CP. If operator
movement or head raising were indeed responsible for the generation of Sinhala relative
clauses, they would be expected to be sensitive to island constraints, an observation that we
have already made for English. However, this prediction is not borne out in Sinhala. As we

30
have observed in (7), Sinhala allows instances of double relativization which would involve an
island violation for the operator or the head NP that raises from inside the lower RC to a
position in the higher RC — i.e. no matter whether it is the operator or the head that raises, it
has to cross more than one bounding node at a time.3 We illustrate this in Error! Reference
source not found.) (a partial structure of Sinhala with English words). In Sinhala, grammatical
counterparts of subjacency violations in RCs are not limited to instances of double
relativization. They are also found in regular relative clauses in the language, with different
types of islands, as shown in Error! Reference source not found.), Error! Reference source
not found.),4 and Error! Reference source not found.).
(21) [thatha __i kiyewwa kiyənə prakasəyə laməya karəpu] katawəi
father.NOM read.PST that claim child.NOM make.PST.ADN story
*the story which the child made the claim that his father read
(22) [siri __i kohomə də kiyewwe kiyəla geeta kalpana-karəpu] potə
Siri.NOM how Q read.PST that Geeta.NOM wonder.PST.ADN book
*the book that Geetha wondered how Siri read.
(23) siri kanə koʈə] Ravi pudumə-unə piza
Siri.NOM eat when Ravi.NOM surprise.PST.ADN pizza
*the pizza which Ravi was surprised when Siri ate.
(24)
3 Following Kariyakarawana (1998), we assume that Sinhala, similar to English, has the same bounding nodes
(TP and NP (DP). 4 However, similar to English, the Coordinate Structure Constraint cannot be violated in Sinhala RC.
(1) a. laməya-tə amathəkə-unə potə saha pænə.
child-DAT forget.REL book.ACC and pen.ACC
The book and the pen that the child forgot
b. [*laməya-tə potə saha amathəkə-unə] pænə
child-DAT book.ACC and forget.ADN pen.ACC

31
The absence of subjacency effects that we have observed here is problematic for any
movement analysis of Sinhala relative clauses. Further, a head raising analysis cannot be
maintained for Sinhala RCs at least for three additional reasons, elaborated below. Next, let us
consider the argument about idiom chunks. In the English example in Error! Reference
source not found.) (repeated from 0b), the idiomatic reading is retained because the head NP
(headway) can be reconstructed to its first-merged position so that the two constituent elements
of the idiom are in a local relation at LF (Vergnaud, 1974). This reconstruction evidence
suggests that the head NP has undergone syntactic movement from a position inside the RC to
its surface position in the structure.
(25) The headway that we made was satisfactory.
But in some languages, such as Korean (Kwon, 2008), it has been observed that idiom
chunks cannot be relativized, i.e., an idiom loses its idiomatic reading under relativization. The
same observation holds in Sinhala. We illustrate this with the following Sinhala example, in
which the idiom is italicized. Notice that in contrast to Error! Reference source not found.a),
the relativized version in Error! Reference source not found.b) can only convey a literal
meaning.
(26) a. samaharə minissu ævilenə ginnə-tə piduru danəwa.
some people.NOM burning fire-DAT straw.ACC put.PRE
Some people contribute to the destruction of others/things.
b. samaharə minissu __i ævilenə ginnə-tə danə pidurui
some people.NOM burning fire-DAT put.PRE.ADN straw
Straw that some people put into the bonfire [only the literal meaning]
Thus, unlike in English, the head of a relativized idiom is not subject to LF
reconstruction in Sinhala, which is evident from the absence of the idiomatic reading in Error!
Reference source not found.b). This also disfavors a head raising analysis of RCs in Sinhala.
Moreover, the test of adjectival modification (Bhatt, 2002) that we reviewed for English shows
different results in Sinhala. Recall that the following sentence is ambiguous in English, given
that the head NP could either be interpreted in the higher clause (high reading) or the lower
clause (low reading). But its Sinhala counterpart only Error! Reference source not found.)
has the ‘high reading,’ implying that a head movement analysis is problematic for Sinhala RCs.
(27) [[Tolstoy liwwa kiyǝla] siri kiyǝpu ] palǝmu potǝ
Tolstoy.NOM write.PAST that Siri.NOM say.PST.ADN first book

32
The first book about which Siri said that Tolstoy had written.
Finally, anaphor binding also does not show evidence for head raising in Sinhala RCs.
As we discussed earlier, in the following English example, the LF reconstruction of the head
DP accounts for the satisfaction of the Binding Principle A. But a similar example in Sinhala
is degraded in grammaticality.5
(28) The picture of himself that the child saw was on the table.
(29) ??[laməya ti dækəpu] thaman-ge pinthure
child.NOM see-ADN self-GEN picture
Self’s book that the child forgot.
Observations that we have made above with regard to idiom chunks and adjectival
modification in Sinhala also disfavor a matching analysis of Sinhala RCs. If the RC has an
identical representation of the NP inside its CP, the idiomatic reading is expected even in the
relativized version in Error! Reference source not found.b): the local relation of the two
constituent elements of the idiom is not disrupted at LF. Further, as far as the argument on
adjectival modification (Bhatt, 2002) is concerned, the matching analysis predicts both higher
and lower readings for the adjectival modifier. But the fact that Sinhala allows only a higher
reading for the modifier implies that an exact representation of the head NP inside its CP is not
a plausible assumption in Sinhala.
Null Pronominal Analysis
Summarizing our discussion so far, the absence of subjacency effects along with the
results from idiomatic chunks, adjectival modification and anaphor binding disfavor a
movement or matching analysis of Sinhala relative clauses. Given this, following what has
been proposed for some other SOV/wh-in-situ languages, in which relative clauses bear similar
properties, mainly Japanese and Korean (Fukui & Takano, 2000; Kang, 1986; Kuno, 1973;
Kwon, 2008; Murasugi, 1991; Saito, 1985), we propose that relative clauses in Sinhala are not
derived through syntactic movement. Therefore, the gap in a Sinhala RC is not a copy/trace
left by head movement or operator movement. Rather, it is a null pronominal (pro) element
base-generated inside the RC. This element is A-bar bound by a null operator base-generated
in the Spec-CP position. Further, the head NP, as assumed in wh-movement analyses for
5 This has also been observed for e.g., Japanese (Hoshi, 1995) and Swedish (Platzack, 2000).

33
English (Chomsky, 1977), is also base-generated in its surface position. Under this proposal, a
relative clause in Sinhala Error! Reference source not found.) has a non-movement structure
as illustrated in Error! Reference source not found.) below.
(30) [CP Opi [TP proi paadəmə amətəkə-wechchə] lamaii
lesson.ACC forget.ADN children
Children who forgot the lesson
(31)
This analysis immediately accounts for the absence of island effects in Sinhala. If either
the operator or the NP head does not undergo movement, island effects are not predicted in
Sinhala RCs. On the other hand, if the NP were generated inside an RC and subsequently
underwent movement into its surface position, reconstruction effects would be observed in
binding, idioms and adjectival modification in Sinhala relative clauses, contrary to fact.
Evidence for this null argument analysis in other languages comes from a common observation
that pro in a relative clause can be replaced with an overt pronoun (resumptive pronoun), as
illustrated below with examples from Japanese (Kuno, 1973) and Korean (Kwon, 2008),
respectively.
32) [NP [S watasi-ga karei-no name-o wasurete shimatta] okyakusanj
I -NOM he-gen name-ACC have-forgotten guest
The guest who I have forgotten his name

34
(33) [Opi [Mary-ka [Tom-i proi / kui –lul kosohay-ss-tako] sayngkakha-n ] wuncensa
Mary-NOM [Tom-NOM he-ACC] sue-PAST-COMP] think-ADN driver
the driver who Mary thought that Tom sued
However, As Kwon (2008) observes in Korean, such replacement is limited to complex
relative clauses: the replacement of the gap in a simple clause with an overt pronoun yields
ungrammaticality:
(34) *[RC hyengsa-ka ku-luli enceyna sinloyha-n] kicai
detective-NOM he-ACC always trust-REL reporter
the reporter who the detective always trusted
The same observations hold in Sinhala too. The replacement of the gap with a
pronominal in a simple clause yields ungrammaticality Error! Reference source not found.).
However, a different result is observed in complex clauses in 0) and 0) below6:
(35) *[CP Opi [TP eyai irichchə ændumak ændan-innə]] hingannai
he.NOM torn shirt.ACC wear.AND.PRE beggar
the beggar who is wearing a torn-shirt
(36) [CP Opi [proi /eyai kege yaluwek da kiyala] api danne-nathi] aganthukəyai
he-NOM who.GEN friend.ACC Q that we.NOM don’t know-AND visitor
The visitor that we don’t know whose friend he is.
(37) [RC1[RC2 thaman tj igənə-gattə] paadəməj amətəkə-wechchə] lamaii
self.NOM learnt.PST lesson.ACC forget.ADN children
Children who forgot the lesson that (they) learnt.
If the gap inside a Sinhala RC were a trace/copy left by movement, 0) and 0) would be
expected to be ungrammatical in Sinhala. According to the copy theory of movement
(Chomsky, 1993, 2000), any trace is a copy of the moved element which is deleted in the
phonological component but available for semantic interpretation at LF. Once the syntactic
derivation is complete, language specific PF conditions determine which copy of the derivation
receives pronunciation. Thus, in minimalist terms, if a relative clause is derived through
syntactic movement, a gap is not really a gap but an invisible copy of the moved element.
Hence, a gap in a relative clause derived through movement cannot be occupied by an overt
6 However, the example is 37 is more natural when the gap is filled with an anaphor than a pronoun. This is an
observation that has been made for Korean by HYE HAN (2013).

35
pronominal. Thus, the resumptives in 0) and 0) confirm that that gap in a Sinhala relative clause
is not a copy of a moved element, another challenge for a non-movement analysis of Sinhala
relative clauses.
Additional evidence for the null argument analysis comes from case marking in Sinhala
relative clauses. Notice that in the example given in Error! Reference source not found.), the
resumptive pronoun occupying the gap is sensitive to specific case marking requirements
imposed by the semantics of the verb: the sentence is grammatical when the pronoun bears
dative case marking but not nominative case marking. Meanwhile, the head NP bears
nominative case marking.
(38) [CP Opi [TP proi/thaman-tə/*thaman paadəmə amətəkə-wechchə] lamaii
self-DAT / self.NOM lesson.ACC forget.ADN children.NOM
Children who forgot the lesson
This dichotomy in case marking observed on the resumptive pronoun in the above
example results from a semantic distinction in Sinhala verbs. It is well-known in literature that
Sinhala has a semantic classification of verbs known as volitives and involitives (see Beavers
& Zubair 2008, 2010, 2013; Chou & Hettiarachchi 2015, 2016; Gair 1991; Gair & Paolillo
1997; Gunasekara 1999; Henadeerage 2002; Hettiarachchi, 2015a, 2015b; Inman 1993 Kahr
1989). While a volitive verb denotes volitional or intentional action, an involitive verb denotes
non-volitional, unintentional or unplanned action. This is illustrated with the following
example from Chou and Hettiarachchi (2016):
(39) a. lal natənəwa
Lal.NOM dance.VOL
‘Lal (actively/voluntarily) dances.’
b. lal-ʈə nætenəwa.
Lal-DAT dance.INVOL
‘Lal (involuntarily) dances.’
As the example shows, the case marking on the subject in Error! Reference source
not found.) depends on the volitivity/involitivity of the verb: with a volitive verb the subject
by default takes a nominative case7 while it takes a dative case with an involitive verb. Chou
and Hettiarachchi (2016), based on a series of empirical tests, argue that in a volitive
construction, the subject receives nominative case (structural) from T while in an involitive
7 However, this is not without exceptions. See for example, Gair (1990) and Beavers and Zubair (2010, 2016) for
details.

36
construction, the subject receives a non-nominative case (inherent case) from the verb. This
explains why the relative clause in Error! Reference source not found.) is grammatical with
dative case marking on the resumptive pronoun but not with a nominative case marking on the
anaphor in the gap position: the involitive verb amətəkə-wenəwa requires non-nominative case
marking on the anaphor. However, this observation has a strong implication for the derivation
of relative clauses in Sinhala. From a theoretical point of view, the absence of the DAT case
on the head noun would be problematic if it indeed started inside the RC and underwent
syntactic movement—i.e., it would be expected to receive inherent dative case from the verb
before it raises to occupy a higher position. Its absence, thus, favors a non-movement analysis
of Sinhala RCs.
Summary and Conclusion
Even though the relative clause construction in Sinhala has received some attention in scarce
syntactic literature on the language, the discussion of this phenomenon in current literature is
limited to providing descriptive generalizations. Given this, in this paper, we have provided a
generative syntactic analysis of Sinhala relative clauses, with a goal to analyze Sinhala and
determine its place in the typology of human languages, as characterized by a Minimalist theory
of principles and parameters. While drawing insights from discussions on the phenomenon in
syntactic literature (Fukui & Takano, 2000; Kang, 1986; Kuno, 1973; Kwon, 2008; Murasugi,
1991; Saito, 1985), we have argued that Sinhala relative clauses, unlike in English, are not
derived through syntactic movement. Evidence mainly comes from the absence of island
effects in Sinhala RCs, idiom chunks, adjectival modification and case marking. Hence, the
gap in a Sinhala RC is not a copy/trace left by head movement or operator movement. Rather,
it is a null pronominal (pro) element base-generated inside the RC. This pro is bound by the
operator in Spec-CP position in a relative clause and the head of the RC is an element bese-
generated in its PF position. Thus, Sinhala RCs are parametrically different from those in
English in terms of the absence of syntactic movement and the existence of a null pronominal
(pro) in its grammar.
References
Alexiadou, A., Law, P., Meinunger, A., & Wilder, C. (Ed.) (2000). The syntax of relative
clauses (Vol. 32). John Benjamins Publishing.
Beavers, J., & C. Zubair (2008). Non-nominative subjects and the involitive construction in

37
Sinhala. Paper presented at the 82nd annual meeting of the Linguistic Society of
America,
Chicago, IL, January 3-6.
Beavers, J., & C. Zubair (2010). The interaction of transitivity features in the Sinhala involitive.
In P. Brandt & M. Garcia (eds.), Transitivity: Form, meaning, acquisition, and
processing (pp. 69–92). Benjamins.
Beavers, J., & C. Zubair (2013). Anticausatives in Sinhala: Involitivity and causer supression.
Natural Language and Linguistic Theory 31, 1-46.
Bhatt, R. (2002). The raising analysis of relative clauses: Evidence from adjectival
modification. Natural language semantics, 10(1), 43-90.
Bhatt, R. (2015). Relative clauses and correlatives. In A. Alexiadou & T. Kiss (eds.), Syntax –
theory and analysis. An international handbook (pp. 708-749). Mouton de Gruyter.
Brame, M. K. (1968). A new analysis of the relative clause: Evidence for an interpretive theory.
Unpublished manuscript.
Browning, M. (1991). Bounding Conditions on Representation. Linguistic Inquiry, 22, 541-
562.
Cattaso, N. (2013). For a headed analysis of free relatives in German and English: The ‘Free
Relative Economy Principle.’ The Linguistics Journal, 7(1), 273-293.
Chandralal, D. (2010). Sinhala (Vol. 15). John Benjamins Publishing.
Chomsky, N. (1973). Conditions on Transformations. In S. Anderson & P. Kiparsky (Eds.), A
Festschrift for Morris Halle (pp. 232-286). Holt, Rinehart & Winston.
Chomsky, N. (1977). “On wh-movement” in Peter Culicover, Thomas Wasow, and A
Drian Akmajian, eds. Formal Syntax. pp. 71–132. New York: Academic Press.
Chomsky, N. (1982). Some concepts and consequences of the theory of government and
binding (Vol. 6). MIT press.
Chomsky, N. (1993). A minimalist program for linguistic theory. In K. Hale, & S. J. Keyser
(Eds.), The view from building 20. MIT Press.
Chomsky, (N. 2000). Minimalist inquiries: The framework. In R. Martin, D. Michaels, & J.
Uriagereka (Eds.), Step by step: Essays on minimalist syntax in honor of Howard Lasnik
(pp. 89–155). MIT Press.
Chomsky, N. (2000). Derivation by phase. In M. Kenstowicz (Ed.), Ken Hale: a life in
language (pp. 1–52). MIT Press.
Chou, C.T. & Hettiarachchi, S. (2016). On Sinhala subject case marking and A-movement.
Lingua, 177, 17- 40.

38
Chou, C.-T. T. & Hettiarachchi, S (2012). Sinhala Case-marking, Modality and Amovement.
Paper presented at GLOW in Asia IX, Mia University, Japan, 1–9.
http://faculty.human.mie-u.ac.jp/~glow_mie/IX_Proceedings_
Cinque, G. (2020). The syntax of relative clauses: A unified analysis. Cambridge University
Press.
Citko, B. (2000). Deletion under identity in relative clauses. In Proceedings of the North East
Linguistic Society (NELS) 31, ed. Minjoo Kim and Uri Strauss, 131–145. Graduate
Linguistic Student Association.
Fukui, N., & Takano, Y. (2000). Nominal structure: An extension of the symmetry principle.
The derivation of VO and OV, 219-254.
Gair, J. W. (1990). Studies in south Asian linguistics: Sinhala and other south Asian languages.
Oxford University Press.
Gair, J. W.& J. C. Paolillo. (1997). Sinhala. Lincom Europa.
Gair, J., & Sumangala, L. (1991). What to focus in Sinhala. Paper presented at the ESCOL’:
Proceedings of the Eighth Eastern States Conference on Linguistics. Ohio State
University Working Papers.
Gunasekara, D. M. (1999). A comprehensive grammar of the Sinhalese language. Asian
Educational Services.
Han, C.-h., & Kim, J.-B. (2004). Are there “double relative clauses” in Korean? Linguistic
inquiry, 35(2), 315-337.
Han, C. (2013). On the syntax of relative clauses in Korean. Canadian Journal of Linguistics,
58(2), 319–347.
Henadeerage, D. K. (2002). Topics in Sinhala syntax. [Doctoral dissertation]. Australian
National University.
Hettiarachchi Gamage, S. (2015). Syntactic competence and processing: Constraints on long-
distance A-bar dependencies in Bilinguals. [Doctoral dissertation]. University of
Michigan, Ann arbor.
Hettiarachchi, S. (2015). Sinhala object scrambling revisited. In proceedings from the
Pennsylvania Lingustics Conference 39, University of Pennsylvania Working Papers
in Linguistics, 21 (1), article 13.
Inman, M. (1994). Semantics and pragmatics of Sinhala involitives. [Doctoral dissertation].
Stanford University.
Jackendoff, R. (1977). X syntax: A study of phrase structure. Linguistic Inquiry Monographs
Cambridge, Mass,2, 1-249.

39
Kahr, J.C. (1989). Discourse functions of the Sinhala passive. [Doctoral dissertation]. Harvard
University.
Kariyakarawana, S. M. (1998). The syntax of focus and wh-questions in Sinhala. Karunaratne
& Sons Limited.
Kang, Y. (1986). Korean syntax and universal grammar. [Doctoral dissertation]. Harvard
University
Kayne, R. S. (1994). The antisymmetry of syntax. MIT Press.
Keenan, E. L., & Comrie, B. (1977). Noun phrase accessibility and universal grammar.
Linguistic Inquiry, 63-99.
Kim, J. B. (1998b). A head-driven and constraint-based analysis of Korean relative clause
constructions. Language Research, 34, 767–808.
Kuno, S. (1973). The structure of the Japanese language (Vol. 3). MIT Press.
Kwon, N. (2008). Processing of Syntactic and Anaphoric Gap-Filler Dependencies in Korean:
Evidence from Self-Paced Reading Time, ERP and Eye-Tracking Experiments.
University of California, San Diego.
Larson, R. K. & Takahashi, N. (2007). Order and interpretation in pre-nominal relative
clauses, vol. 54, 101-120. MITWPL.
Lees, Robert B. (1961). The constituent structure of noun phrases. American Speech 36(3):
159–168.
Mahajan, A. (2000). Relative asymmetries and Hindi correlatives. The syntax of relative
clauses, 201-229.
Mahajan, A. K. (1990). The A/A-bar distinction and movement theory. [Doctoral dissertation].
Massachusetts Institute of Technology.
McCloskey, J. (2017). Resumption. In Martin Everaert, H. v. R., editor, The Wiley Blackwell
Companion to Syntax. John Wiley & Sons.
Murasugi, K. (2000). An antisymmetry analysis of Japanese relative clauses. The syntax of
relative clauses, 231-263.
Nishigauchi, T. (1986). Quantification in syntax. University of Massachusetts.
Radford, A. (2019). Relative Clauses: Structure and variation in everyday English. Cambridge
University Press.
Radford, A. (2016). Analysing English Sentences (2nd ed.). Cambridge University Press.
Ross, J. R. (l967). Constraints on variables in syntax. [Unpublished Ph. D. Dissertation].
Massachusetts Institute of Technology.

40
Safir, K. (1982), Syntactic Chains and the Definiteness Effect. PhD dissertation, MIT.
Distributed by MIT Working Papers in Linguistics.
Saito, M. (1985). Some asymmetries in Japanese and their theoretical implications. Doctoral
dissertation. NA Cambridge.
Salzmann, M. (2006). Resumptive prolepsis. Utrecht: LOT Publications
Sauerland, U. (1998). On the making and meaning of chains. [Doctoral dissertation].
Massachusetts Institute of Technology.
Sauerland, U. (2000). Two structures for English restrictive relative clauses. Proceedings of
the Nanzan GLOW, 351–366.
Schachter, P. (1973). Focus and relativization. Language, 19-46.
Walker, B. (2006). Relative clauses in Sinhala. Santa Barbara Papers in Linguistics 17.
Vergnaud, J.-R. (1974). French relative clauses. Massachusetts Institute of technology.
Zhang, N.N. (2008). Existential coda constructions as internally headed relative clause
constructions. The Linguistics Journal, 3(3), 8-54.

41
Munalim, L.O., & Genuino, C.F. (2021). Chair-like turn-taking features in a
faculty meeting: Evidence of local condition and collegiality. Linguistics
International Journal, 15(1), 43-64.
Chair-like Turn-taking Features in a Faculty Meeting: Evidence of Local
Conditions and Collegiality
Leonardo O. Munalim
Philippine Women’s University
Cecilia F. Genuino
College of Graduate Studies and Teacher Education Research
Philippine Normal University Manila
Abstract
This paper is an attempt to describe the sequential features of corpus-driven features culled
from faculty meetings. Two corpus-driven features such as ‘all right, let’s move’, and ‘anyway,
anyway, which we coined as chair-like turn-taking features, were described microscopically
using Conversation Analysis. These features were further described based on the local
conditions of the speakers and the concept of collegiality in the academe. Data were five faculty
meetings conducted bilingually, that is, Tagalog and English, from three different departments
of a private university in the Philippines. The meetings lasted for five hours and fifty minutes.
The features were analyzed through the lens of socio-pragmatics to look at the local conditions
that afforded these features. The concept of collegiality was also discussed. Results show that
Chair possesses the default power, distance and ranking, but the subordinate possesses better
epistemic knowledge as regards the accreditation process; more years of teaching; and is older
than the Chair. Overall, it is argued that the chair-like features are supportive and collegial
rather than competitive or disruptive in nature, thus are socially appropriate. Recommendations
for a longitudinal and cross-linguistic collection of more (subordinate) chair-like turn-taking
features are offered.
Keywords: Chair-like, collegiality, faculty meeting, socio-pragmatics, turn-taking
Introduction

42
Conversation Analysis (CA) is situated in two sets of theoretical underpinning: ‘pure
science’ and ‘applied science’ (Ten Have, 1999). Heritage (2008) underlines that as “pure” CA,
all conversations are structured by practices and procedures that participants normatively
employ in the conduct of human activity. These practices and procedures are not influenced by
the participants’ characteristics, attitudes, motivation, psychological state, and other
sociological attributes such as class and gender. As ‘pure’ science, Ten Have (1999) maintains
that this enterprise wishes to discover both basic and general aspects of sociality of human
interactions. On the one hand, “applied” CA sets a distinction between “ordinary” and “non-
ordinary conversation” which is more commonly termed as “institutional talk (Heritage, 2008;
Schegloff, 1995). It intends to discover how institutional interactions are capable of organizing
social interactions. “The expression ‘applied CA’ can also be used to denote the implicit or
even explicit use of CA-inspired studies to support efforts to make social life ‘better’ in some
way, to provide data-based analytic suggestions for, or critiques of, the ways in which social
life can be organized” (Ten Have, 1999, p. 8).
The institutional type of talk is set off to illuminate routine institutional work in
conversation in contrast to the elements sui generis proposed in “pure” CA (Antaki 2011).
Sociological studies on asymmetrical relationships, gender, social class, accent, ethnicity, age,
sexual orientation, profession and individual personality (Itakura & Tsui, 2004; Kress, 2001;
Tannen, 1992; Young, 2008) can also shed light on the institutionality of the talk. Gibson
(2003) maintains that people hold different conversational entitlements and obligations in
discourse. For instance, the thrust of Ethnomethodology as the sister discipline of CA (Gibson,
2009; Jaworksi & Coupland, 1999) demonstrates that people’s behaviors are governed by
certain rules and roles that conversationalists assume when talking (O’Sullivan, 2010) in order
to produce an intelligible meaning-making of the utterances, which is determined by those
practical tasks and activities they need to perform and pursue (Drew & Sorjonen, 1997).
This present article is situated within the second theoretical underpinning, and is
subsequently coursed through socio-pragmatics where the social order reflects the immediate
local conditions of the talk (Leech, 1983). Foremost, “sociopragmatics, the end of the
pragmatic continuum closest to society and the world, is related to sociolinguistic knowledge
and refers to what constitutes socially appropriate linguistic behavior” (Bou-Franch & Garcés-
Conejos, 2003, p. 2). Since pragmatics is closely associated with sociolinguistics, the enterprise
of pragmatics also centers from the point of view of user and his conditions of language use,
knowledge of appropriateness, social status, and social power (Blum-Kulka, 1997; Chen,
Geluykens, & Choi, 2006; Félix-Brasdefer, 2012). Moreover, because pragmatics requires the

43
use of linguistic and social context, the flow of the conversation depends on how the utterances
are understood, inferred and oriented to by the hearers. In short, CA captures pragmatics in
conversational social interaction as CA describes stable systemic action sequences (Huth &
Taleghani-Nikazm, 2006). For the purpose of this present study, the local conditions (Leech,
1983) of the meeting talk have been anchored on the tripartite politeness domains such as
power, ranking, and distance (Brown & Levinson 1987), and the selected social variables of
the Chair and the subordinate such as age, knowledge as an accreditor and years of teaching
experience (see Table 1).
CA method is both “practical, robust” (Raymond, 2003, p. 942) and is selective in
nature (ten Have, 1999). Since it is geared toward talk examination as a constitutive site of
culture (Schegloff, 1997), this discipline seeks to explicate some shared and interesting features
that participants employ in the production of meaningful social action (Liddicoat, 2007). CA
researchers have to divulge some recurrent, interesting, constitutive, and regulative elements
in the conversations, and describe in great detail even the smallest discourse marker or particle
(Clifton, 2006; Kress, 2001; Psathas & Anderson, 1990; Raymond, 2003; Schegloff, 1987; Ten
Have, 1999; Walters, 2007; Wong & Olsher, 2000; Wooffitt, 2005). In like manner, the
“unmotivated looking” (Clifton, 2006) is acceptable with the assurance in mind that:
One of the key tasks of researchers is not to sacrifice the detailed examination of single
cases on the altar of broad claims… to examine the detailed analysis of single cases as
episodes with their own reality, deserving of their own rigorous analysis without respect
to their bearing on the larger argument for which they are being put forward (Schegloff,
2010, p. 42).
Specifying the phenomenon, showing its variants, showing that the participants are
oriented to it, etc.—all return to case-by-case analysis; … One does not go to work on
a corpus of data to conduct quantitative or statistical analysis and arrive at findings;
rather, one works up to the data case by case (Schegloff, 2009, p. 389).
The corpus of this present study is a faculty meeting. Although business and
professional meetings have been the focus of many CA studies (Allen et al., 2014; Kangasharju,
2002; Kurtic et al., 2009; Lai et al., 2013; van Kruiningen, 2013; Saft, 2001; Saft, 2004), no
studies, to the knowledge of these authors, have described chair-like turn-taking features in the
meeting. Another assurance is that even if these features have already been described, the local
Filipino context of these features may provide another vantage point of appreciation of the

44
analysis. Brown (2010) supports that languages vary massively within the spheres of linguistic
structures, cultural orientations and socio-pragmatic functions of any of the speech acts under
study. In fact, one has to examine the context-dependent aspects of the language structure and
language use (Dairo, 2010; Grice, 1967; Levinson, 1983) to understand the sequential
environments of the features of the talk.
In other words, the meaning does not lie on the formal structure or properties of the
language, but based on the immediate context where the utterances are produced, including
how the utterances were made to convey a particular meaning. The idea of context augers well
with the idea of speech act that may be characterized as a multi-faceted endeavor with different
intended meanings (Bach, 1994; Green, 1996; Searle, 1997), thus vary cross-linguistically. In
essence, using socio-pragmatic analysis of the microscopic features under study is a vantage
point in understanding why such features are tolerated in a faculty meeting where the Chair has
the default turn to move from one agenda to another.
With all these appropriate backdrops related to CA, this article describes
microscopically the corpus-driven features coined as chair-like turn-taking mechanisms. These
are further described socio-pragmatically in order to shed light on the reasons the subordinate
employs these seemingly presumptuous features that may encroach into the default territory of
the Chair. The discussion of collegiality is described through the concept of inferences and
orientations to the chair-like speech act features. Overall, it is axiomatic that there is differential
access to workplace power (Elliott & Smith, 2004), and that the Chair holds the default power
to move from one agenda to another and the overall next-relevant turns in the meeting talk.
Methodology1
The chair-like turn-taking features were culled from five meetings from three different
departments in a private university in Manila, Philippines. The meetings lasted for 5 hours and
50 minutes. The duration of these meetings is comparably the same with other studies (cf.
Duncan, 1972; Cohen et al., 2005; Cervantes & Olson, 2013; Huisman, 2001; Itakura & Tsui,
2004; Gibson, 2003; Goodwin & Heritage, 1990; Mondada, 2012; O’Sullivan, 2010; Park,
1 This article has been extracted from a larger study. There may be little information in this present article that is
identical to the authors’ previously published (Munalim & Genuino, 2019a, 2019b) and under-review articles, for
example, for the methodology section and the profile of the respondents. In such a case, that may not be
tantamount to self-plagiarism.

45
2009; Schegloff, 1998; Ten Have, 1999; Vettin & Todt, 2004). The major agendum of these
meetings was the plan for the department accreditation from a renowned accrediting body for
the higher educational institutions in the Philippines. The meetings were composed of a mix of
34 male and female part-time and full-time faculty members. In particular, School A has 8
faculty members; School B with 6; and School C with 20 faculty members.
They granted that the meetings would be audio-video recorded by the two official
videographers. Cameras were positioned to capture the non-verbal cues of the participants to
provide a rich source of contextual information in the analysis, and capture some non-vocal
cues that naturally accompany the vocal exchanges, especially that the features under study
were also investigated based upon the Chair’s orientations, either positive or negative (cf.
Goodwin, 1981; Goodwin & Heritage, 1990; Fujiwara & Daibo, 2014; Olsher, 2004; Pillet-
Shore, 2011; Pomerantz & Fehr, 2011; Tolins & Fox Tree 2014). Members from School A
formed the first meeting with the Chair in front, facing the faculty members who were sitting
on arm chairs. In the second and third meetings, the Chair was still sitting in front, while the
members were arranged in a semi-circle.
School B formed their meetings as illustrated in Figure 1. School C on the one hand
formed their meeting with the Chair standing in front of the members who were sitting on the
armchairs, facing the Chair. Data were originally transcribed using Jefferson’s (2004) selected
transcription conventions given that they are robust and useful (Liddicoat, 2007). The Leipzig
Glossing Rules have been followed to assist the non-Tagalog readers of this article. Deletion
of the original transcription conventions by Gail Jefferson, in no way, affects the data analysis
(cf. ten Have, 1999; Drew, 2001). Moreover, it should be found out that the glossing is not
exhaustive because the language of the meeting is mixing (mix-mix) or code switching from
English to Pilipino, or colloquially known as Taglish (Bautista, 2004; Munalim, 2019b;
Sibayan, 1985).

46
Figure 1. Spatial Arrangement of Meeting Members from School B
Meanwhile, the names of the Chair and the subordinate were anonymized to safeguard
their dignity (DeCosta, 2015; Ten Have, 1999). Overall, all ethical qualms including the
possible ‘observer’s paradox’ (Bowern, 2008; Labov, 1984) were considered. Most
importantly, the rather limited chair-like turn-taking features were described through the socio-
pragmatic domains of the speakers and the lens of collegiality within the Philippine cultural
background.
Results and Discussion
The ensuing section reports the microscopic analysis of the chair-like turn-taking
features employed by a subordinate. These features are described through the socio-pragmatic
lens and the lens of collegiality in a faculty meeting in the Philippine cultural backdrop.
The Environments of Chair-like Turn-Taking Features
Corpus 2, Extract 35, School A
(556) Reg lahat ng documents na e-exhibit mo ay (.)
All ART documents COMP- YOU
(557) pa-Xerox mo para may duplicate ka lagi triplicate
to-xerox you to there is you always
‘You have to photocopy so you have always the duplicate, triplicate’
(558) Chair yes Ma’am
(559) Reg-> All right, let’s move ((smiling)) a(h) ((sips some beverage))
(560) Chair Okay, so exam natin non-graduating: June 19 to 23 po.
our
(561) Reg Yes Ma’am.
(562) Chair Okay na Ma’am po, ano?
ADV POLITENESS TAG

47
‘It is already okay, right?’
(563) Graduating June 19 to 20, opo.
POLITENESS
Line 559 of Extract 35 shows that Reg attempts to move the agenda to the next after
commanding the Chair to photocopy all the documents to exhibit. The use of ‘all right’ as a
discourse marker signals that the prior talk should be the last. ‘All right, let’s move’ shows a
peculiarity for a member to say this. This formulaic expression is commonly available as a
discourse marker among the Chairs who control and manage the meeting.
Let us assume that Reg did not use this chair-like turn-taking feature starting at line
558. It was possible that the Chair could still elaborate and maintain her speaking turn by
clarifying things that are related to the documents to photocopy. Had the Chair clarified, Reg
could have not employed this chair-like turn-taking feature because she had to respond to the
clarification or to the question because she was made accountable by either clarifying or
answering the first utterance from the Chair, thus possibly suspending this chair-like discourse
marker.
To support this claim, a question can produce sequential relevant next turns where the
hearer becomes accountable to the obligatory answers (Schegloff & Sacks, 1973). A question
itself is a turn-taking yielding system that obligates the hearer to take the next relevant turn to
satisfy the first part of the pair, “either by providing an answer or by accounting for non-answer
responses” (Stivers & Rossano, 2010, p. 7). Moreover, questions are obligating speech acts
because they place constraints and restrictions on the recipient (Boyd & Heritage, 2006).
Chair-like Turn-Taking Features as Manifestation of Collegiality
Conceding at line 560, the Chair demonstrates the air of collegiality. In fact, as the
Chair of the meeting, she could have wrestled to this chair-like talk by either asking another
question to Reg or other members of the meeting in order to make Reg’s speech act to move to
the next agenda to downplay the perlocutionary effects on her end. In respect to the older
subordinate, the Chair offers a short submissive next-relevant turn at 558, thereby providing
Reg the chance to move to the next agenda. The Chair concedes to the directive at line 560,
utters ‘okay’, and then declares the next agenda at line 560 which is the exams for non-
graduating students scheduled from June 19 to 23. Overall, this validates that Reg’s turn at talk
to move to the next agenda is acknowledged and valued, thus may be considered as a legitimate
move from a subordinate. The Chair at line 562 again acknowledges the subordinate.

48
In like manner, Reg’s intention may be considered as a manifestation of collegiality.
The chair-like discourse marker at line 559 is nested with a beaming smile. Looking at the non-
verbal cues, it could be seen that Reg smiles intentionally before sipping some beverage.
Positive paralinguistic cues such as intonation are, in fact, consistent all throughout the meeting
talk. After all, the positive paralinguistic resources are able to establish the kind of framing that
her linguistic behavior accords with what a professional community should act and behave.
The strategic and supportive ways of handling the meeting are collegial and collaborative. The
Chair accommodates her subordinate by tolerating this chair-like turn-taking discourse marker.
Corpus 2, Extract 41, School A
(668) Chair Bedrest siya Ma’am si Dr. Yellow.
PR.3.SING ART
‘Dr. Yellow is having bedrest, Ma’am.’
(669) hindi malaman kung saan nakuha
NEG known if where gotten-PASSIVE
‘yong viral infection ng paa
ART ART feet
‘It is not known where the infection of the feet was
gotten.’
(670) hindi makalakad Ma’am eh=
NEG walk VOC
‘(She) cannot walk, Ma’am eh.’
(671) Villa =Baka naulanan Ma’am.
Perhaps, rained-PASSIVE
‘Perhaps, she got rained on.’
(672) Chair Oo
‘Yes.’
(673) Fil ((inaudible))
(674) Reg A(h)h(h)a(h) ((laughing))
(675) Chair Okay, we’ll continue na po tayo
ADV POLITENESS us
‘Okay, we’ll continue…’
[para matapos]
So that finish
‘so that we can finish’
(676) Reg -> [Anyway, anyway ]
(677) Chair1 Okay, so thank you Dr. Reg
(678) maganda po ‘yong wisdom niyo Ma’am,
Beautiful POLITE ART your
‘Your wisdom is beautiful, Ma’am.’
(679) Oh we will implement that.
(680) Candidates for Graduation: June 23.
The same person Reg employs a chair-like discourse marker such as ‘Anyway,
anyway,’ at line 676. On the onset, ‘anyway, anyway’ may not be used to move from one

49
agenda to another. In this context, by contrast, it attempts to signal the Chair to move to the
next topic. Arguably, it is not the usual nor plain Filipino or English expression. It constitutes
a chair-like talk because this marker can stop the next speaker to elaborate or deflect the course
of the talk. At the same time, this chair-like feature is supportive in nature. Looking back, the
Chair already signals that the next relevant turn is in the offing because she says, ‘Okay, we’ll
continue…’ This turn may be Reg’s intentional chair-like feature because Fil injects jokes at
line 673. Although Reg finds this joke healthy, Reg believes that the cracking of the jokes can
lead to the digression of the topic. Fil is known as a philosophical joker in the department
having taught logic and philosophy subjects. Entertaining Fil’s jokes would lead to the
elaboration of turns at talk, thus will lead to more competitions for turn-taking.
This ‘anyway, anyway’ feature that indicates an intention to continue (Fox Tree, 2000)
is related to the explicit topical shift phrases such as ‘this is the background…’ (Pälli &
Lehtinen, 2013) that is to turn to another part of the meeting. Consequently, the Chair welcomes
this initiative when she proceeds to line 677, thanking Reg for her wisdom, with a positive
coloring of her voice (Neiberg, 2012). It should be noted, however, that the commendation is
not tied with Reg’s line at 676. This commendation refers to the previous utterance about her
suggestion that leads to this next relevant talk on jokes. Nevertheless, this acknowledgement
prepares her for the next agenda at line 680. Reg enacts being in a higher relationship with the
Chair. At an elevated level, she claims an almost identical institutional identity with the Chair
in a subtle way.
The air of collegiality does not largely center on the discourse marker of ‘anyway,
anyway’ but on the positive pragmatic inference and orientation displayed by the Chair. As
demonstrated at line 676, Reg uses ‘anyway, anyway’ to signal the Chair to move to another
item as demonstrated at line 680 when the Chair moves to another agendum. The Chair
welcomes this initiative when she proceeds to line 677, thanking Reg for her wisdom. This
mechanism has unveiled some kind of orchestration of the framing of a lax and freewheeling
institutional talk which is different from other institutional talk such as courtroom interaction
and news interviews where there is a strong constraint of turn-taking on definite sets of
protocols and procedures (Heritage & Greatbatch, 1991). It is seen as a deliberate framing to
maximize solidarity (Arminen, 1996) where various ensembles of members co-construct in real
time with various practices (Schegloff, 1999) and the linguistic feature like ‘anyway, anyway’.
Socio-Pragmatic Conditions that Hasten the Production of Chair-Like Turn-Taking
Features
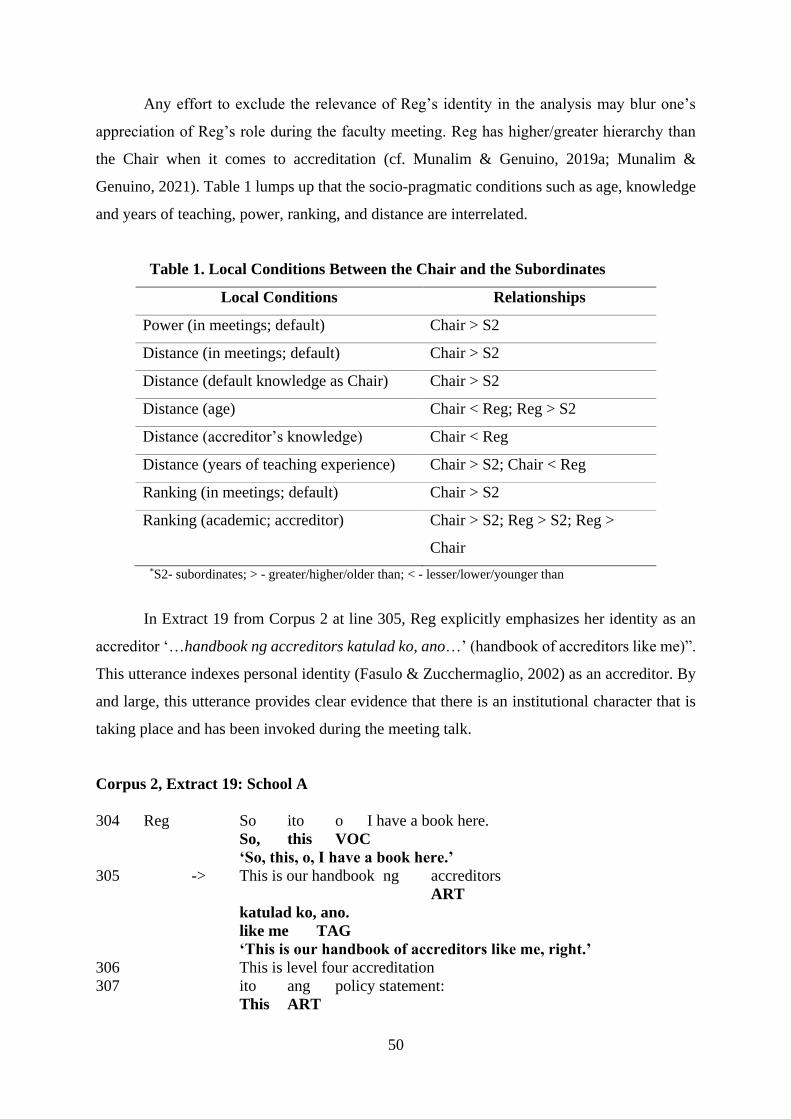
50
Any effort to exclude the relevance of Reg’s identity in the analysis may blur one’s
appreciation of Reg’s role during the faculty meeting. Reg has higher/greater hierarchy than
the Chair when it comes to accreditation (cf. Munalim & Genuino, 2019a; Munalim &
Genuino, 2021). Table 1 lumps up that the socio-pragmatic conditions such as age, knowledge
and years of teaching, power, ranking, and distance are interrelated.
Table 1. Local Conditions Between the Chair and the Subordinates
Local Conditions Relationships
Power (in meetings; default) Chair > S2
Distance (in meetings; default) Chair > S2
Distance (default knowledge as Chair) Chair > S2
Distance (age) Chair < Reg; Reg > S2
Distance (accreditor’s knowledge) Chair < Reg
Distance (years of teaching experience) Chair > S2; Chair < Reg
Ranking (in meetings; default) Chair > S2
Ranking (academic; accreditor) Chair > S2; Reg > S2; Reg >
Chair
*S2- subordinates; > - greater/higher/older than; < - lesser/lower/younger than
In Extract 19 from Corpus 2 at line 305, Reg explicitly emphasizes her identity as an
accreditor ‘…handbook ng accreditors katulad ko, ano…’ (handbook of accreditors like me)”.
This utterance indexes personal identity (Fasulo & Zucchermaglio, 2002) as an accreditor. By
and large, this utterance provides clear evidence that there is an institutional character that is
taking place and has been invoked during the meeting talk.
Corpus 2, Extract 19: School A
304 Reg So ito o I have a book here.
So, this VOC
‘So, this, o, I have a book here.’
305 -> This is our handbook ng accreditors
ART
katulad ko, ano.
like me TAG
‘This is our handbook of accreditors like me, right.’
306 This is level four accreditation
307 ito ang policy statement:
This ART

51
‘This is the policy statement’:
Discussion
The meeting is seen to have a social order with the use of chair-like turn-taking
mechanisms which are the product of the local academic conditions such as power, distance,
ranking, age and knowledge. These chair-like features are a systematically distinctive form of
turn-taking that is allowable within the local conditions of the talk, that is, Reg happens to have
a higher epistemic power, distance, and ranking than the Chair of the meeting. The case of
Reg’s chair-like talk is tied to her institutional identity as an accreditor. She tailors her
utterances that go well with her identity with a more knowledgeable persona as regards the
purpose and agenda of the meeting. Phoenix (2007) posits that the identities within the social
categorization allow the individuals to tailor their actions to those that are considered
appropriate for specific or general individuals with identified identities. This is supported by
the reticence from the rest of the meeting members who are not knowledgeable about the
dynamics of the accreditation process. Consequently, the non-knowledgeable (K-) personas
remain as a semi-ratified audience (Goffman, 1981) when Reg is reading the policy statements
from the accrediting body for higher educational institutions in the Philippines.
According to Foucault (1994), knowledge power is neither positive nor negative. In this
context, Reg’s chair-like turn-taking mechanisms may be considered positive because the
mechanisms have been neutralized with the positive paralinguistic cues, facial expressions and
gazes (Barraja-Rohan, 2011). These sets of paralinguistic machinery are instrumental to the
alleviation of Reg’s chair-like turn-taking discourse markers. In conflictual settings, for
example, Maemura and Horita (2012) find out that “humour can be used to improve cohesion,
signal cooperation, cope with a difficult situation, and release tension” (p. 837). These non-
verbal cues are interactional and intentional resources that are meant to show camaraderie,
solidarity, and even downplaying the seriousness of the matter. Therefore, Reg with the higher
power in terms of knowledge as an accreditor seeks to balance the use of power, thereby,
simultaneously demonstrating a sense of collegiality. This collegiality also redounds to the
concept pakikisama or smooth interpersonal relationship prevalent in the Philippine academic
and cultural backdrop (Andres, 1981) even if a speech act for a faculty meeting may appear
impolite, disruptive or competitive.
Seen from this light, the chair-like turn-taking features should not be considered as a
mechanism for the members to wrestle with the normative structure and the default role of the
Chair who controls the length of speaking turn for each agenda. These features are in fact

52
supportive and collegial in nature rather than competitive or disruptive. The subordinate may
be well cognizant of the fact that the granting of such a chance to act like a Chair using these
discourse markers is not absolute. The granting of this power is not enduring because the Chair
has to subtly “dodge the bullet” and go back to the normal course of the meeting to oversee the
“smoothness, effectiveness, and the hitchlessness” (Goffman, 1959, p. 98) of the interaction.
Overall, all these linguistic features may be considered socially appropriate.
Conclusion
The subordinate’s chair-like turn-taking mechanisms such as ‘all right, let’s move,’ and
‘anyway, anyway,’ illustrate that these discourse markers may not be only exclusive to the
Chair of the meeting. The non-exclusivity of these features to the Chair is hastened due to the
immediate local and academic conditions and the sense of collegiality invoked during the
meeting talk. At a more profound level, the re-alignment of the roles and the modifications of
footing may have influenced the levity of the pattern of negotiation and modification of roles
as demonstrated in these chair-like features and positive paralinguistic resources captured
during the meeting.
Even at the microscopic and case analytic discussion (cf. Vázquez Carranza, 2019),
these chair-like features hashed out important implications for teaching and learning pragmatic
competence (Abrams, 2013; Cohen, 2008; Filipi & Barraja-Rohan, 2015; Huth & Taleghani-
Nikazm, 2006), interactional competence (Kramsch, 1986), crosslinguistic understanding (cf.
Nkemleke, 2007), and socialization (Ahlund, 2015) to mention a few. Studies pinpoint the
positive effects of socio-pragmatic knowledge that can be beneficial in conversation-analytical
studies (cf. Bardovi-Harlig et al., 2015; Bou-Franch & Garcés-Conejos, 2003; Roever, 2011;
Wu, 2013). Students should be made aware of the marked behavioral patterns in interactions
as these illuminate insights into how a talk is organized by professionals who are considered
as the model of communicative competence. Such understanding is a crucial component as
students will also master themselves when participating in professional interactions in the
future. Van Bramer (2003) reminds, however, that “only highly trained and skilled teachers
who are thoughtful about instructional discourse can begin to provide these complex models
of instructional interaction” (p. 37).
This study is not without limitations. For this study, we intentionally excluded the
analysis on how the agenda of this meeting had inherent consequences on the manner the
subordinate attempted to deployed these chair-like turn-taking features. We suspect that the
agenda and even the number of agenda in a particular meeting may precipitate the need for any

53
official members of the meeting to behave like the Chair of the meeting. This important aspect
in the meeting should be studied accordingly using the same methodological orientation of CA.
In term of agenda, it will fruitful to look into these chair-like turn features when members of
the meeting come from multicultural and multilinguistic origins given that this university,
where the data came from, is multicultural (cf. Munalim, 2019a) in order to further analyze
chair-like tur-taking features within the terrain of intercultural competence (cf. Hwang, 2008).
Needless to say, the analysis is microscopic in nature that serves as the locus of the
social order in the faculty meeting. While the analysis is acceptable given that “a single
fragment serves to launch a proposal about how a certain mechanism operates in ordinary
conversation” (Schegloff, 1988, p. 442), or even in institutional talks, important
recommendations for a longitudinal collection of more instances of these types of chair-like
features are imperative. Doing so will subsequently allow CA researchers to produce a more
refined and robust characterization of these features and their sequential environments, and will
therefore provide an avenue for cross-linguistic comparisons (cf. Brown, 2010; Enfield, 2010;
Englert, 2010; Hayashi, 2010; Heinemann, 2010; Hoymann, 2010; Levinson, 2010; Rossano,
2010; Schegloff, 2009; Stivers, 2010; Stivers & Enfield, 2010; Yoon, 2010). These
comparisons can then be used to generalize the chair-like turn-taking features beyond the
specific domain of faculty meeting and beyond the Tagalog-English cultural-linguistic
landscape where these features were described.
References
Abrams, Z. (2013). Say what?! L2 sociopragmatic competence in CMC: Skill transfer and
development. CALICO Journal, 30(3), 423-445.
Ahlund, A. (2015). Swedish as multiparty work: Tailoring talk in a second language
classroom. A published dissertation from Stockholm University.
Allen, J.A., Lehmann-Willenbrock, N., & Landowski, N. (2014). Linking pre-meeting
communication to meeting effectiveness. Journal of Managerial Psychology, 29(8),
1064-1081.
Andres, T.D. (1981). Understanding Filipino values: A management approach. New Day
Publishers.
Antaki, C. (2011). Six kinds of applied conversation analysis. In C. Antaki (Ed.), Applied
conversation analysis. 1–14. Palgrave Macmillan.
Arminen, I. (1996). The construction of topic in the turns of talk at the meeting of alcoholics
anonymous. International Journal of Sociology and Social Policy 16(5-6), 88-130.

54
Bach, K. (1994). Meaning, speech acts, and communication. In R.M. Harnish (Ed.), Basic
Topics in the Philosophy of Language (pp. 3-18.). Prentice-Hall.
Bardovi-Harlig, K., Mossman, S., & Vellenga, H.E. (2015). The effect of instruction on
pragmatic routines in academic discussion. Language Teaching Research, 18(3), 324-
350.
Barraja-Rohan, A.N. (2011). Using conversation analysis in the second language classroom to
teach interactional competence. Language Teaching Research, 15(4), 479-507.
Bautista, M.L.S. (2004). Tagalog-English code switching as a mode of discourse. Asia Pacific
Education Review, 5, 226-233.
Blum-Kulka, S. (1997). Discourse pragmatics. In T.A. van Dijk (Ed.), Discourse as social
interaction (pp. 38-63). Sage Publications.
Bou-Franch, P., & Garcés-Conejos, P. (2003). Teaching linguistic politeness: A
methodological proposal. International Review of Applied Linguistics in Language
Teaching, 41(1), 1-22.
Bowern, C. (2008). Linguistic fieldwork: A practical guide. Palgrave Macmillan.
Boyd, E., & Heritage, J. (2006). Taking the history: Questioning during comprehensive history-
taking. In J. Heritage & D. W. Maynard (Eds.), Communication in medical care (pp.
151–184). Cambridge University Press.
Brown, P. (2010). Questions and their responses in Tzeltal. Journal of Pragmatics, 42, 2627-
2648.
Brown, P., & Levinson, S. (1987). Politeness: Some universals in language use. Cambridge
University Press.
Cervantes, S. E., & Olson, R. C. (2013). Using applied conversation analysis for professional
development. In N. Sonda & A. Krause (Eds.), JALT2012 Conference Proceedings.
Tokyo: JALT.
Chen, S., Geluykens, R., & Choi, C.J. (2006). The importance of language in global teams: A
linguistic perspective. Management International Review, 46(6), 679-695.
Clifton, J. (2006). Conversation analytical approach to business communication: Case of
leadership. Journal of Business Communication, 43, 202-219.
Cohen, A.D. (2008). Teaching and assessing L2 pragmatics: What can we expect from
learners? Language Teaching, 41(2), 213-235.
Cohen, L., Mancon, L., & Morrison, K. (2005). Research methods in education. Routledge
Falmer.

55
Dairo, L.A. (2010). A speech-act analysis of selected Yoruba proverbs. Journal of Cultural
Studies, 8(1-3), 431-442.
DeCosta, R. (Ed.). (2015). Ethics in applied linguistics research: Language researcher
narratives. Routledge.
Drew, P., & Sorjonen, M.L. (1997). Institutional dialogue. In T.A. van Dijk, Discourse as
social interaction, (pp. 92-118). Sage Publications.
Drew, P. (2001). Conversation analysis. In R. Mesthrie (Ed.). Concise encyclopedia of
sociolinguistics, (pp. 110-116). Elsevier.
Duncan, S. (1972). Some signals and rules for taking speaking turns in conversations. Journal
of Personality and Social Psychology 23(2). Retrieved from
http://www.justinecassell.com/discourse/pdfs/duncan_some_signals_and_rules_.pdf
Elliott, J.R., & Smith, R. A. (2004). Race, gender, and workplace power. American
Sociological Review, 69(3), 365-386.
Enfield, N. J. (2010). Questions and responses in Lao. Journal of Pragmatics, 42, 2649-2665.
Englert, C. (2010). Questions and responses in Dutch conversations. Journal of Pragmatics,
42, 2666-2684.
Fasulo, A., & Zucchermaglio, C. (2002). My selves and I: Identity markers in work meeting
talk. Journal of Pragmatics, 34, 1119-1144.
Félix-Brasdefer, C. (2012). Email openings and closings: pragmalinguistic and gender
variations in learner-instructor cyber consultations. Utrecht Studies in Language and
Communication, 24, 223-248.
Filipi, A., & Barraja-Rohan, A.M. (2015). An interaction-focused pedagogy based on
conversation analysis for developing L2 pragmatic competence. In Gesuato, S., F.
Bianchi, & W. Cheng. Teaching, learning and investigating pragmatics: Principles,
methods and practices. Chapter 10, (pp. 231-251). Cambridge Scholars Publishing.
Foucault, M. (1994). The subject and power. In Rubinow, P. & N. Rose (Eds.), The essential
Foucault, (pp. 47-63). New Press.
Fox Tree, J.E. (2000). Coordinating spontaneous talk. In L. Wheeldon (Ed.), Aspects of
language production, (pp. 375-406). Taylor & Francis.
Fujiwara, K., & Daibo, I. (2014). The extraction of nonverbal behaviors: Using video images
and speech-signal analysis in dyadic conversation. Journal of Nonverbal Behavior, 38,
377-388.
Gibson, D.R. (2003). Participation shifts: Order and differentiation in group conversation.
Social Forces, 81(4), 1335-1381.

56
Gibson, W. (2009). Intercultural communication online: Conversation analysis and the
investigation of asynchronous written discourse. Forum: Qualitative Social Research,
10(1).
Goffman, E. (1959). The presentation of self in everyday life. Doubleday Anchor Books.
Goffman, E. (1981). Footing: Forms of talk. University of Pennsylvania Press.
Goodwin, C. (1981). Conversational organization: Interaction between speakers and hearers.
Academic Press.
Goodwin, C., & Heritage, J. (1990). Conversation analysis. Annual Review of Anthropology,
19, 283-307.
Green, G.M. (1996). Pragmatics and natural language understanding. Lawrence Erlbaum
Associates Publishers.
Grice, H.P. (1967). Williams James Lectures: Logic and conversation. In P. Cole & J.L.
Morgan (Eds.), Syntax and semantics, (pp. 41-58). Academic Press.
Hayashi, M. (2010). An overview of the question-response systemin Japanese. Journal of
Pragmatics, 42, 2685-2702.
Heinemann, T. (2010). The question-response system in Danish. Journal of Pragmatics, 42,
2703-2725.
Heritage, J. (2008). Conversation analysis as social theory. In B. Turner (Ed.), The New
Blackwell Companion to Social Theory. Blackwell.
Heritage, J., & Greatbatch, D. (1991). On the institutional character of institutional talk: The
case of news interviews. In Boden, D., & D.H. Zimmerman (Eds.), Talk and social
structure: Studies in ethnomethodology and conversation analysis, (pp. 93-137).
Cambridge, Polity Press.
Hoymann, G. (2010). Questions and responses in Akhoe Hailom. Journal of Pragmatics, 42,
2726-2740.
Huisman, M. (2001). Decision-making in meetings as talk-in-interaction. International Studies
of Management and Organization, 31(3), 69-90.
Huth, T., & Taleghani-Nikazm, C. (2006). How can insights from conversation analysis be
directly applied to teaching L2 pragmatics? Language Teaching Research, 10(1), 53-
79.
Hwang, C.C. (2008). Pragmatic Conventions and Intercultural Competence. Linguistics
Journal, 3(2), 31-48.
Itakura, H., & Tsui, A.B.N. (2004). Gender and conversational dominance in Japanese
conversation. Language in Society, 33, 223-248.

57
Jaworski, A., & Coupland, N. (1999). The discourse reader. Routledge.
Jefferson, G. (2004). Glossary of transcript symbols with an introduction. In G. H. Lerner (Ed).
Conversation analysis: Studies from the first generation, (pp. 13-31). John Benjamins.
Kangasharju, H. (2002). Aligning in disagreement: Forming oppositional alliances in
committee meetings. Pragmatics, 34, 1447-1471.
Kramsch, C. (1986). From language proficiency to interactional competence. The Modern
Language Journal, 70, 366–372.
Kress, G. (2001). Critical sociolinguistics. In R. Mesthrie (Ed.). Concise encyclopedia of
sociolinguistics, (pp. 542-545). Elsevier.
Kurtic, E., Brown, G. J., & Wells, B. (2009). Fundamental frequency height as a resource for
the management of overlap in talk-in-interaction. In Barth-Weingarten, D., N. Dehe´,
& A. Wichmann (Eds.), Where prosody meets pragmatics: Studies in pragmatics, 8.
Emerald Group Publishing.
Labov, W. (1984). Field methods of the project on linguistic change and variation. In Baugh,
J., & J. Sherzer (Eds.), Language in use, (pp. 28-53). Prentice Hall.
Lai, C., Carletta, J., & Renals, S. (2013). Modelling participant affect in meetings with turn-
taking features. In Proceedings of WASSS. Available on
homepages.inf.ed.ac.uk/clai/laic2013affect.pdf
Leech, G.N. (1983). Principles of pragmatics. Longman.
Levinson, S.C. (1983). Pragmatics. Cambridge University Press.
Levinson, S.C. (2010). Questions and responses in Yélî Dnye, the Papuan language of Rossel
Island. Journal of Pragmatics, 42, 2741-2755.
Liddicoat, A.J. (2007). An introduction to conversation analysis. AC Black.
Maemura, Y., & Horita, M. (2012). Humour in negotiations: A pragmatic analysis of humour
in simulated negotiations. Group Decision Negotiation, 21, 821-838.
Mondada, L. (2012). The dynamics of embodied participation and language choice in
multilingual meetings. Language in Society, 41, 213-235.
Munalim, L.O. (2019a). Micro and macro practices of multicultural education in a Philippine
University: Is it global integration ready? The Asia-Pacific Education Researcher,
https://link.springer.com/article/10.1007/s40299-019-00497-7
Munalim, L.O. (2019b). Subject-auxiliary inversion in embedded questions in spoken
professional discourses: A comparison of Philippine English between 1999 and 2016-
2019. Journal of English as an International Language, 14(1), 40-57.

58
Munalim, L.O., & Genuino, C.F. (2019a). Subordinate's imperatives in faculty meetings:
Pragmalinguistic affordances in Tagalog and local academic conditions. The New
English Teacher, 13(2), 85-100.
Munalim, L.O., & Genuino, C.F. (2019b). "Through-produced" multiple questions in Tagalog-
English faculty meetings: Setting the agenda dimension of questions. Language Art,
4(2), 105-122.
Munalim, L.O., & Genuino, C.F. (2021). Subordinate’s imperatives in a faculty meeting:
Evidence of social inequality and collegiality. The New English Teacher. In press.
Neiberg, D. (2012). Modelling paralinguistic conversational interaction: Towards social
awareness in spoken human-machine dialogue. Published doctoral thesis. Sweden:
KTH School of Computer Science and Communication.
Nkemleke, D. (2007). “You will come when?” The pragmatics of certain questions in
Cameroon English. Linguistics Journal, 2(1), 128142.
O’Sullivan, T. (2010). More than words? Conversation analysis in arts marketing research.
International Journal of Culture, Tourism and Hospitality Research 4(1), 20-32.
Odermatt, I., König, C.J., & Kleinmann, M. (2015). Meeting preparation and design
characteristics. In in J.A. Allen, N. Lehmann-Wilenbrock, & S.G. Rogelberg (Eds.),
The Cambridge handbook of meeting science (pp. 49-69). Cambridge University Press.
Olsher, D. (2004). Talk and gesture: The embodied completion of sequential actions in spoken
interaction. In R. Gardner & J. Wagner (Eds.), Second language conversation, (pp. 221-
245). Continuum.
Pälli, P., & Lehtinen, E. (2013). How organizational strategy is realized in situated interaction:
A conversation analytical study of a management meeting. LSP Professional
Communication Knowledge Management Cognition, 4(2), 4-20.
Park, J.E. (2009). Turn-taking organization for Korean conversation: With a Conversation
Analysis proposal for the research and teaching of Korean learners of English. A
doctoral dissertation from University of California, Los Angeles. Available on Proquest
Theses and Dissertation Databases. (UMI 3388123).
Phoenix, A. (2007). Intragroup processes: Entitativity. In Langdridge, D., & S. Taylor (Eds.),
Critical readings in social psychology, (pp. 103-132). Open University Press.
Pillet-Shore, D. (2010). Making way and making sense including newcomers in interaction.
Social Psychology Quarterly, 73(2), 152-175.
Pomerantz, A., & Fehr, B.J. (2011). Conversation analysis: An approach to the study of social
action as sense making practices. In Teun A. van Dijk. Discourse as social interaction:

59
Discourse studies: A multidisciplinary introduction, Vol. 2 (pp. 64-91). New Delhi:
Sage.
Psathas, G., & Anderson, T. (1990). The 'practices' of transcription in conversation analysis.
Semiotica, 78, 75-99.
Raymond, G. (2003). Grammar and social organization: Yes/no interrogatives and the structure
of responding. American Sociological Review, 68(6), 939-967.
Roever, C. (2011). Testing of second language pragmatics: Past and future. Language Testing,
28(4), 463-481.
Rossano. F. (2010). Questioning and responding in Italian. Journal of Pragmatics, 42, 2756-
2771.
Saft, S. (2004). Conflict as interactional accomplishment in Japanese: Arguments in university
faculty meeting. Language in Society, 33, 549-584.
Saft, S. (2001). Displays of concession in university faculty meetings: Culture and interaction
in Japanese. Pragmatics, 11(3), 223-262.
Schegloff, E.A. (2010). Commentary on Stivers and Rossano: "Mobilizing response". Research
on Language & Social Interaction, 43(1), 38-48.
Schegloff, E.A. (2009). One perspective on conversation analysis: Comparative perspectives.
In Sidnell, J. (Ed.), Conversation analysis: Comparative perspectives, (pp. 357-406).
Cambridge University Press.
Schegloff, E.A. (1999). Discourse, pragmatics, conversation analysis. Discourse Studies, 1(4),
405-435.
Schegloff, E.A. (1998). Discourses as an interactional achievement II: An exercise in
conversation analysis. In D. Tannen (Ed.), Linguistic in context: Connecting
observation and understanding, (pp. 135-159). Ablex.
Schegloff, E.A. (1997). Whose text? Whose context? Discourse and Society, 8(2), 165-187.
Schegloff, E.A. (1995). Discourse as an interactional achievement III: The omnirelevance of
action. Research on Language and Social Interaction, 28(2), 185-211.
Schegloff, E.A. (1988). Presequences and indirection: Applying speech act theory to ordinary
conversation. Journal of Pragmatics, 12, 55–62.
Schegloff, E.A. (1987). Between macro and micro: Contexts and other connections. In J.
Alexander, B. Giesen, R. Munch, & N. Smelzer (Eds.), The micro-macro link, (pp. 207–
234). University of California Press.
Schegloff, E.A. & Sacks, H. (1973). Opening up closings. Semiotica, 8, 289–327.
Searle, J.R. (1997). Expression and meaning. Cambridge University Press.

60
Sibayan, B.P. (1985). Reflections, assertions and speculations on the growth of Pilipino.
Southeast Asian Journal of Social Sciences, 13, 40-51.
Stivers, T. (2010). An overview of the question-response system in American English
conversation. Journal of Pragmatics, 42, 2772-2781.
Stivers, T., & Enfield, N.J. (2010). A coding scheme for question-response sequences in
conversation. Journal of Pragmatics, 42, 2620-2626.
Stivers, T., & Rossano, F. (2010). Mobilizing response. Research on Language and Social
Interaction, 43, 3–31.
Tannen, D. (1992). Interactional sociolinguistics. In W. Bright (Ed.), Oxford international
encyclopedia of linguistics, Vol. 4. Oxford University Press.
Ten Have, P. (1999). Doing conversation analysis: A practical guide. Sage Publications.
Tolins, J., & Fox Tree, J.E. (2014). Addressee backchannels steer narrative development.
Journal of Pragmatics, 70, 152-164.
Van Bramer, J. (2003). Conversation as a model of instructional interaction. Literacy Teaching
and Learning, 8(1), 19-46.
van Kruiningen, J.F. (2013). Educational design as conversation: A conversation analytical
perspective on teacher dialogue. Teaching and Teacher Education, 29, 110-121.
Vázquez Carranza, A. (2019). The Spanish particle eh in talk-in-interactions. Linguistics
Journal, 13(1), 7-29.
Vettin, J., & Todt, D. (2004). Laughter in conversation: Features of occurrence and acoustic
structure. Journal of Nonverbal Behavior, 28(2), 93-115.
Walters, F.S. (2007). A conversation-analytic hermeneutic rating protocol to assess L2 oral
pragmatic competence. Language Testing, 24(2), 155-183.
Wong, J., & Olsher, D. (2000). Reflections on conversation analysis and nonnative speaker
talk: An interview with Emanuel A. Schegloff. Issues in Applied Linguistics, 11(1),
111-128.
Wooffitt, R. (2005). Conversation analysis & discourse analysis: A comparative and critical
introduction. Sage Publications.
Wu, Y. (2013). Conversation analysis-A discourse approach to teaching oral English skills.
International Education Studies, 6(5), 87-91.
Yoon, K.E. (2010). Questions and responses in Korean conversation. Journal of Pragmatics,
42, 2782-2798.
Young, F.R. (2008). Language and interaction: Advanced resource book. Routledge.

61
Yusuf, Y.Q., Pillai, S., Aslynn, W.A.W., & Hassan, R.B. (2021). Vowel
production in standard Malay and Kedah Malay spoken in Malaysia.
Linguistics International Journal, 15(1), 65-93.
Vowel Production in Standard Malay and Kedah Malay Spoken in Malaysia
Yunisrina Qismullah Yusuf
Faculty of Teacher Training and Education
Universitas Syiah Kuala, Indonesia
Stefanie Pillai
Faculty of Languages & Linguistics
Universiti Malaya, Malaysia
W.A. Wan Aslynn
Kulliyyah of Allied Health Sciences
International Islamic University Malaysia, Malaysia
Roshidah Binti Hassan
Faculty of Languages and Linguistics
Universiti Malaya, Malaysia
Abstract
This study investigates and compares the production of vowels by speakers of Standard Malay
(SM) and the Kedah Malay dialect (KD). Previous acoustic studies on the Malay vowels
concentrated largely on SM, and there is a dearth of acoustic studies on how these vowels are
produced in other Malay dialects. The findings indicate that the vowels /i/, /e/, /ə/ and /o/ were
similarly produced by these two groups of speakers, whilst, the vowels /a/ and /o/ were
produced higher in the vowel space by the KD speakers compared to those produced by the
SM speakers. Further, the SM speakers produced the diphthong vowels /ai/ and /oi/ with larger
movements in the vowel space compared to the KD speakers. Despite the small samples
presented in this study, it shows the similarities and variances of vowel production between

62
SM and the KD speakers in Malaysia that are useful for the documentation of languages spoken
in this multi-ethnic and multilingual country.
Keywords: Standard Malay, Kedah Malay, vowels, Malay dialects, formant frequencies
Introduction
Bahasa Melayu or Malay belongs to the Austronesian language family. Standard Malay
(SM), the national language of Malaysia, is based on the Johor-Riau Malay dialect. According
to Asmah (1977, p. 2), “in Malaysia, there are two varieties accepted as the norms for good
language usage”. The main variances between the two accepted SM varieties are the realisation
for orthographic a in a word-final position as /a/ and /ə/. For example, the word baca ‘read’ as
[batʃə] mainly in the central and southern parts of Peninsular Malaysia, and as [batʃa] in the
northern states of Penang, Kedah, and Perlis, as well as the East Malaysian states of Sabah and
Sarawak (Asmah, 1977). Another difference is in the realisation of the word-final r, for
example in the word kotor ‘dirty’, which tends to be produced in the Malay used in East
Malaysia, but not in the Peninsular.
Previous research on SM and Malay dialects tended to be based on impressionistic
descriptions (i.e., visual), and the few acoustic characteristics of Malay vowels tended to focus
on SM (e.g., Asmah, 2008; Shaharina & Shahidi, 2012). Acoustic studies can capture the slight
differences that can only be identified through acoustic measurements (Bao, 2013; Salem &
Pillai, 2020). This study aims to look at the acoustic characteristics of SM and a Malay dialect
spoken in a state situated in the northwest of Peninsular Malaysia, which is Kedah. Acoustic
studies on dialects of Malay are important as they help to document these languages, which in
turn can help to maintain them in a multi-ethnic and multilingual country such as Malaysia.
Standard Malay Vowels
Seminal contributions made by Chaiyanara (2001), Yunus (1980), Asmah (2008), Teoh
(1994), and Indirawati and Mardian (2006) noted that there are six monophthongs in SM, which
are /i/, /e/, /ə/, /a/, /u/ and /o/. The main characteristics of SM vowels are that phonetically the
back vowel is usually rounded, the front and central vowels are usually unrounded (Yunus,
1980). Moreover, phonologically Malay does not have vowel length contrast, and therefore,
there are no phonemically long or short vowels in the Malay language unless the speakers
shorten or lengthen them intentionally for specific purposes. Table 1 illustrates some examples
of minimal pairs of Malay monophthongs that are taken from Indirawati and Mardian (2006).

63
Table 1. Examples of minimal pairs for SM monophthongs*
Vowels Examples
/i/ - /e/ bila [bila] ‘when’ - bela [bela] ‘defend/defence’
/i/ - /a/ bila [bila] ‘when’ - bala [bala] ‘disaster’
/e/ - /a/ bela [bela] ‘defend/defense’ - bala [bala] ‘disaster’
/ə/ - /i/ beri [bəri] ‘give’ – biri-biri [biri-biri] ‘sheep’
/ə/ - /e/ bela [bəla] ‘care/breed’ - bela [bela] ‘defend/defence’
/ə/ - /a/ entah [əntah] ‘unknown’ – antah [antah] ‘remaining in the rice paddy’
/ə/ - /o/ bela [bəla] ‘care/breed’ - bola [bola] ‘ball’
/ə/ - /u/ sekat [səkat] ‘ban/block’ - sukat [sukat] ‘measure’
/o/ - /u/ borong [boroŋ] ‘wholesale’ - burung [buruŋ] ‘bird’
*Source: Indirawati & Mardian, 2006, pp. 145-146
As has been previously reported in the literature based on auditory descriptions, there
are three diphthongs in SM, which are /ai/, /au/ and /oi/ (Asmah, 2008; Indirawati & Mardian
2006; Teoh, 1994). They occur in the second syllable of the following words: pandai [pandai]
‘smart’, kerbau [kərbau] ‘buffalo’, and sepoi [səpoi] ‘blowing softly’ (Asmah, 2008). In
borrowed words, the diphthongs /ai/ and /au/ typically occur in the first syllable of a word; for
examples: aulia [aulija] ‘holy’, hairan [hairan] ‘astonished’, and taulan [taulan] ‘associate,
colleague’.
In an acoustic study of Malay vowels, Mardian (2005) measured the first (F1) and
second formant (F2) values in Hertz (Hz) across the SM vowels of one speaker. The methods
of data collection and the gender of the subjects, however, were not specified. Shaharina and
Shahidi (2012) also investigated Malay vowels acoustically. They used a wordlist comprising
90 words to be recorded by ten respondents, who were five Malay males and five Malay
females. Each of these words was repeated five times by each respondent. However, details
about the words in the wordlist were not provided. Based on the F1 and F2 values, /a/, /u/ and
/i/ from Mardian (2005) and Shaharina and Shahidi (2012) are somewhat similar. However, a
greater variability for the F1 values can be observed for /e/ and /ə/ in both of the studies. Some
variability can also be seen for the F2 values of /o/ between these two studies. There are a few
possibilities for the variability in the F1 and F2 values in these studies. Some of the reasons
that could have influenced the vowels analysed are the effect of neighbouring sounds, speakers’
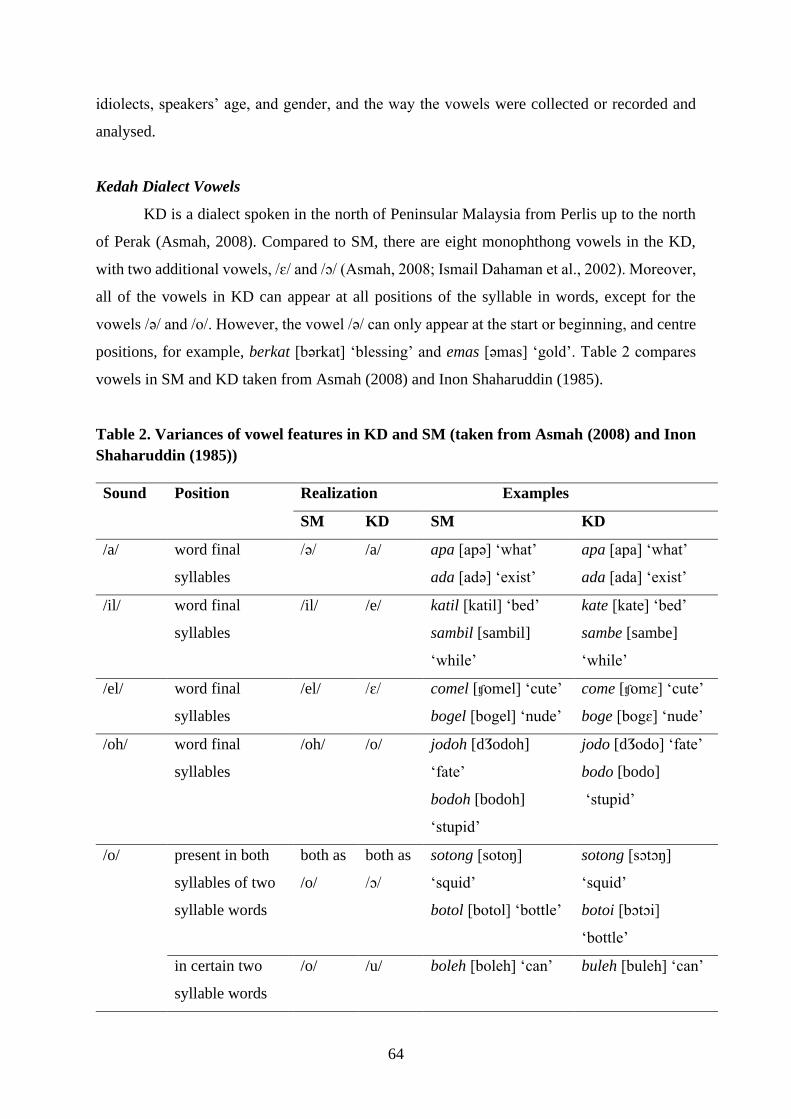
64
idiolects, speakers’ age, and gender, and the way the vowels were collected or recorded and
analysed.
Kedah Dialect Vowels
KD is a dialect spoken in the north of Peninsular Malaysia from Perlis up to the north
of Perak (Asmah, 2008). Compared to SM, there are eight monophthong vowels in the KD,
with two additional vowels, /ɛ/ and /ɔ/ (Asmah, 2008; Ismail Dahaman et al., 2002). Moreover,
all of the vowels in KD can appear at all positions of the syllable in words, except for the
vowels /ə/ and /o/. However, the vowel /ə/ can only appear at the start or beginning, and centre
positions, for example, berkat [bərkat] ‘blessing’ and emas [əmas] ‘gold’. Table 2 compares
vowels in SM and KD taken from Asmah (2008) and Inon Shaharuddin (1985).
Table 2. Variances of vowel features in KD and SM (taken from Asmah (2008) and Inon
Shaharuddin (1985))
Sound Position Realization Examples
SM KD SM KD
/a/ word final
syllables
/ə/ /a/ apa [apə] ‘what’
ada [adə] ‘exist’
apa [apa] ‘what’
ada [ada] ‘exist’
/il/ word final
syllables
/il/ /e/ katil [katil] ‘bed’
sambil [sambil]
‘while’
kate [kate] ‘bed’
sambe [sambe]
‘while’
/el/ word final
syllables
/el/ /ɛ/ comel [ʧomel] ‘cute’
bogel [bogel] ‘nude’
come [ʧomɛ] ‘cute’
boge [bogɛ] ‘nude’
/oh/ word final
syllables
/oh/ /o/ jodoh [dӠodoh]
‘fate’
bodoh [bodoh]
‘stupid’
jodo [dӠodo] ‘fate’
bodo [bodo]
‘stupid’
/o/ present in both
syllables of two
syllable words
both as
/o/
both as
/ɔ/
sotong [sotoŋ]
‘squid’
botol [botol] ‘bottle’
sotong [sɔtɔŋ]
‘squid’
botoi [bɔtɔi]
‘bottle’
in certain two
syllable words
/o/ /u/ boleh [boleh] ‘can’ buleh [buleh] ‘can’

65
where /o/ occurs
in the first
syllable
tonggeng [toŋgeŋ]
‘bend’
toreh [toreh]
‘scratch, cut’
tungging [tuŋgiŋ]
‘bend’
tureh [tuᴚeh]
‘scratch, cut’
/i/ and
/a/
following the
other in a
syllable
/i/ and
/a/
a single
/a/ or
/ε/
siapa [siapə] ‘who’
biasa [biasə] ‘usual’
biawak [biawaʔ]
lizard
sapa [sapa] ‘who’
besa [bεsa] ‘usual’
bewak [bɛwaʔ]
‘lizard’
/u/ and
/a/
following the
other in a
syllable
/u/ and
/a/
a single
/ɔ/ or
/o/
kualə [kuala]
‘estuary’
laut [laut] ‘sea’
kola [kɔla]
‘estuary’
laut [lot] ‘sea’
There are four KD diphthongs; they are /ai/, /ui/, /oi/ and /au/ (Ismail Dahaman, et al.,
2002; Asmah, 2008). These diphthongs occur in KD words in the following situations:
▪ The diphthongs /ai/ and /au/ can appear at the final syllable of a word, between the
stops /p/, /t/, and the fricative /h/. For examples: the word lepas [ləpas] ‘after’ in
SM is pronounced lepaih [ləpaih] ‘after’ in KD, the word pahit [pahit] ‘bitter of
taste’ in SM is pronounced pait [pait] ‘bitter of taste’ in KD.
▪ The diphthong /oi/ only appears at the final position of a word, for example: boroi
/bɔrɔi/ ‘pot-bellied, having a big stomach’. Meanwhile, /ui/ occurs before stops and
before /t/ and /h/. For examples: tikus [tikus] ‘mouse’ in SM is pronounced tikuih
[tikuih] ‘mouse’ in KD, and the word kuit [kuit] ‘to touch lightly’ in SM is
pronounced kuit [kuit] ‘to touch lightly’ in KD.
Method
The Speakers
To examine the acoustic characteristics of SM and KD vowels, the production of
vowels by three female speakers for SM and three female speakers for KD were recorded. All
of these six speakers consented to participate in this study. Only female speakers were selected
for this study. The reason for doing so is to reduce the influence of specific speaker effects
(Jacobi, 2009). Research has shown that the length of the vocal tracts for adult females and
males are different. The length of adult female vocal tracts is around 13 cm each, meanwhile,
the length of adult male vocal tracts can differ up to over 18 cm (Maragakis, 2008). In addition,

66
the vocal tracts of females also have higher resonance frequencies compared to the vocal tracts
of males (Flynn, 2011), which makes females to have formant frequencies of about 10% to
15% higher compared to males (Simpson, 2009; Wang & van Heuven, 2003).
Based on the information obtained via a questionnaire (refer to Appendix A), the SM
speakers had acquired Malay as their mother tongue or first language (L1) at home. Until the
age of fifteen, these speakers resided in the Klang Valley, Malaysia. The age of these speakers
ranged from 25-38 years old (with an average of 31.6 years). Meanwhile, the KD speakers
acquired the KD dialect as their L1. They were born and bred in Kedah (specifically in the
areas of Alor Setar, Kulim, and Pendang), and had lived there until the age of 15. The age of
the KD speakers ranged from 24-25 years old (with an average of 24.6 years). All the speakers,
who were either university students or administrative officers in government departments had
completed their secondary education, in the case of the latter.
Word List
Word lists are commonly used to obtain the target vowels in acoustic studies. In some
studies, speakers read the words in the list and repeat each word several times (e.g., Leemann,
2008; Man, 2007; Maxwell & Fletcher, 2010; Yusuf, 2013). Meanwhile, in other studies, these
words with the target vowels are embedded in a carrier sentence such as “Say ___ again” to be
said by the speakers repeatedly (e.g., Pillai, Zuraidah, Knowles & Tang, 2010; Verhoeven &
van Bael, 2002; Yusuf, Fata & Karwinda, 2021). The advantage of using a word list where
words are embedded in a carrier phrase is that the target tokens can occur within similar
phonetic surroundings (King, 2006; Verhoeven & van Bael, 2002). Furthermore, placing the
target words in a carrier sentence allows for a more naturalistic production. In addition, words
where nasals, liquids, and approximants that appear before or after these vowels tend to be
excluded to avoid the effects of adjoining sounds as they have similar acoustic properties to
the vowels. On the other hand, stops and fricatives are preferred because they have little
influence on the vowel qualities (King, 2006). Examples are words that occur in the contexts
of [hVt] or [hVd] (e.g., Maxwell & Fletcher, 2010), [hVd] (e.g., Clopper, Pisoni & de Jong,
2005; Ferragne & Pellegrino, 2010; Pillai, et al., 2010), and [sV] (e.g., Morrison, 2003).
For the wordlist, the target words for SM (see Appendix B) were selected based on the
reference to word samples available in the Malay dictionary, Kamus Dewan (2005). Then, the
target words for KD (see Appendix C) were selected based on the reference to word samples
in Ismail Dahaman et al. (2002). The target vowels for both dialects were inserted in words
within a CVCV context, and C in this case is a stop consonant. The words were placed in a

67
carrier sentence where the speakers were asked to read each sentence three times in sequential
order: Sebut CVCV tiga kali ‘Say CVCV three times’.
Data Collection and Analysis
The data from both groups were recorded in a quiet room situated at Universiti Malaya
using a recording device, the Marantz PMD661 Solid State Sound Recorder and an Audio-
Technica ATM73 head-worn microphone. The recordings were sampled at 44,100 Hz at a 16-
bit sample rate to ensure quality recordings. For annotation and measurement (i.e., analysis),
PRAAT version 4.6.12 software was used (Boersma & Weenink, 2007). The target vowels in
the audio files in .WAV format were then segmented, labelled, and measured using the
TextGrid function in PRAAT. Since the range of frequency that is commonly selected for
female speakers is 5500 Hz, this range of frequency was fixed for the spectrographic
presentation of the data in PRAAT (Chen, 2008; Ladefoged, 2003; Nowak, 2006). The window
length of 0.005 seconds and the spectral analysis at 40 dB were fixed for the dynamic range
that determines the energy thresholds of the recordings.
To measure the monophthong of the SM and KD vowels, the Linear Predictive Coding
(LPC) analysis overlaid on digital spectrograms in PRAAT was used to measure the F1 and F2
of the target vowels (Yusuf & Pillai, 2016). These two formants were measured at a middle
point of the vowel where the formants were at their most steady state (Ladefoged, 2003;
O’Rourke, 2010). These formants were measured because “the frequencies of F1 and F2
relative to one another are thought to provide the human speech perception system with the
cues necessary for the recognition of individual vowel qualities” (Watt and Tillotson, 2010, p.
210) although there are shortcomings to this formant frequency model as the formant plots can
offer an estimated representation of the qualities of individual vowels. In this model, F1 tends
to correspond to vowel height (i.e., quality), while F2 tends to correspond to tongue
advancement/retraction. This model is commonly used in the acoustic analysis of vowels (e.g.,
Hawkins & Midgley, 2005; Islam & Ahmed, 2020; Watt & Tillotson, 2001). Normalization of
data measurements was not performed since all of the speakers were adult females in this study
(Konopka & Pierrehumbert, 2014; Yusuf, 2013).
The numbers from the measurements in Hertz were transferred to Excel and converted
to Bark. The formula used for this conversion is as shown below, where Zc is the critical-band
rate in Bark, arctan applies to numbers in radians, and F is the frequency in kHz (Zwicker &
Terhardt, 1980, p. 1524):

68
Zc = 13 arctan (0.76*F) + 3.5 arctan (F/7.5 )2
The size of the vowel inventory shapes the acoustic vowel space; in this case, a large
vowel inventory produces a large vowel space (Al-Tamimi & Ferragne, 2005; Bradlow, 1995).
Accordingly, the Euclidean Distance (or ED) is the distance between two points on a two-
dimensional plot. It can be used to calculate the dispersion of the vowels from the midpoint in
the vowel space. In this study, ED was also calculated to see the spread of the Malay vowels
from the centre of the vowel space. The purpose was to determine whether they are more central
or peripheral (Harrington, 2010). The calculation that provides the midpoint of the vowel space
is as follows; in the formula, the values of F1and F2 are in Bark (Harrington, 2010, p. 191):
= SQRT(((5.35-F1)^2) + ((11.81-F2))^2)
From the formula, (5.35) and (11.81) is the midpoint of the vowel space. When this has
been done, it can be used to calculate the dispersion of the vowels from the midpoint.
Meanwhile, for diphthongs, the formants for these vowels are expected to not be stable for the
reason that the vowel quality from the beginning or onset of the vowel to the ending or offset
of the vowel changes (Ladefoged, 2006). Therefore, to describe this change in the vowel quality
of the SM and KD vowels, the Rate of Change (ROC) was measured by using the formula
(Deterding, 2000, p. 94):
F1end –F1onset/duration in seconds= ROC (Hz/s)
The values of the F1 and F2 ROC were both computed for the diphthongs (see Yusuf
and Pillai, 2013). Furthermore, the F1 and F2 of every diphthong were measured at 20% for
the onset point and 80% for the offset point of the vowels to minimize the effect from
neighbouring sounds (Tsukada, 2008). Consequently, the average values of F1 and F2 in Bark
at the onset and offset of each diphthong were plotted in a vowel chart to get visual illustrations
of its trajectory (see Mayr & Davies, 2011).
Findings
For the SM and KD vowels, there were a total of 189 tokens measured and analysed.
From these tokens, 81 tokens were from nine SM vowels: 54 tokens from the six monophthongs
and another 27 tokens from the three diphthongs. Another 108 tokens were from twelve KM
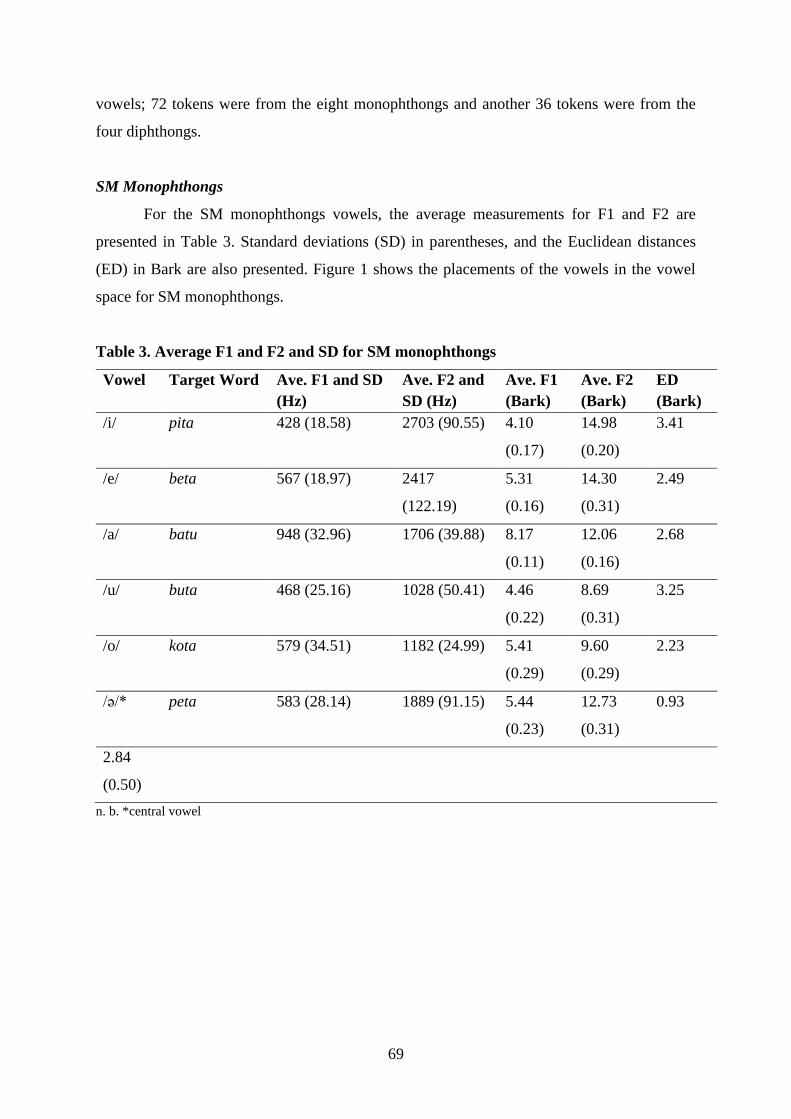
69
vowels; 72 tokens were from the eight monophthongs and another 36 tokens were from the
four diphthongs.
SM Monophthongs
For the SM monophthongs vowels, the average measurements for F1 and F2 are
presented in Table 3. Standard deviations (SD) in parentheses, and the Euclidean distances
(ED) in Bark are also presented. Figure 1 shows the placements of the vowels in the vowel
space for SM monophthongs.
Table 3. Average F1 and F2 and SD for SM monophthongs
Vowel Target Word Ave. F1 and SD
(Hz)
Ave. F2 and
SD (Hz)
Ave. F1
(Bark)
Ave. F2
(Bark)
ED
(Bark)
/i/ pita 428 (18.58) 2703 (90.55) 4.10
(0.17)
14.98
(0.20)
3.41
/e/ beta 567 (18.97) 2417
(122.19)
5.31
(0.16)
14.30
(0.31)
2.49
/a/ batu 948 (32.96) 1706 (39.88) 8.17
(0.11)
12.06
(0.16)
2.68
/u/ buta 468 (25.16) 1028 (50.41) 4.46
(0.22)
8.69
(0.31)
3.25
/o/ kota 579 (34.51) 1182 (24.99) 5.41
(0.29)
9.60
(0.29)
2.23
/ə/* peta 583 (28.14) 1889 (91.15) 5.44
(0.23)
12.73
(0.31)
0.93
2.84
(0.50)
n. b. *central vowel

70
Figure 1. Formant plots for average SM monophthongs
Figure 1 displays the positions of the SM vowels, and this is found to be similar to the
descriptions of these vowels in the previous studies by Chaiyanara (2001), Yunus (1980),
Asmah (2008), and Teoh (1994). Moreover, Figure 2 further displays the scatter plots of these
vowels as produced by the SM speakers of this study.

71
Figure 2. Scatter plot of SM monophthongs
Nevertheless, from the findings of this study, several variances were found compared
to the findings in studies by Mardian (2005) and Shaharina and Shahidi (2012) on the Malay
vowels. Figure 3 displays the placements in the vowel space of their SM monophthong vowels
versus the SM monophthong vowels in this study. It is important to note that only results from
the female speakers were chosen from Shaharina and Shahidi (2012) for comparison with the
present study.
Figure 3. Formant plots for SM monophthongs from this present study,
Shaharina and Shahidi (2012), and Mardian (2005)
Figure 3 shows that the speakers from this study produced the vowels /i/ and /a/ lower
than the speakers in the study conducted by Mardian (2005) and the study by Shaharina and
Shahidi (2012). However, the speakers from the latter study produced the vowels /e/ and /ə/
higher than the speakers in this present study, but these vowels are produced lower by the
speakers in Mardian’s study. Meanwhile, for the vowel /u/, it was produced more back by the
speakers in this study compared to the other studies. Finally, when compared to the speakers
of this present study, the vowel /o/ was produced lower by the speakers from Shaharina and
Shahidi (2012) but higher by the speakers from Mardian’s study. The variances in qualities are
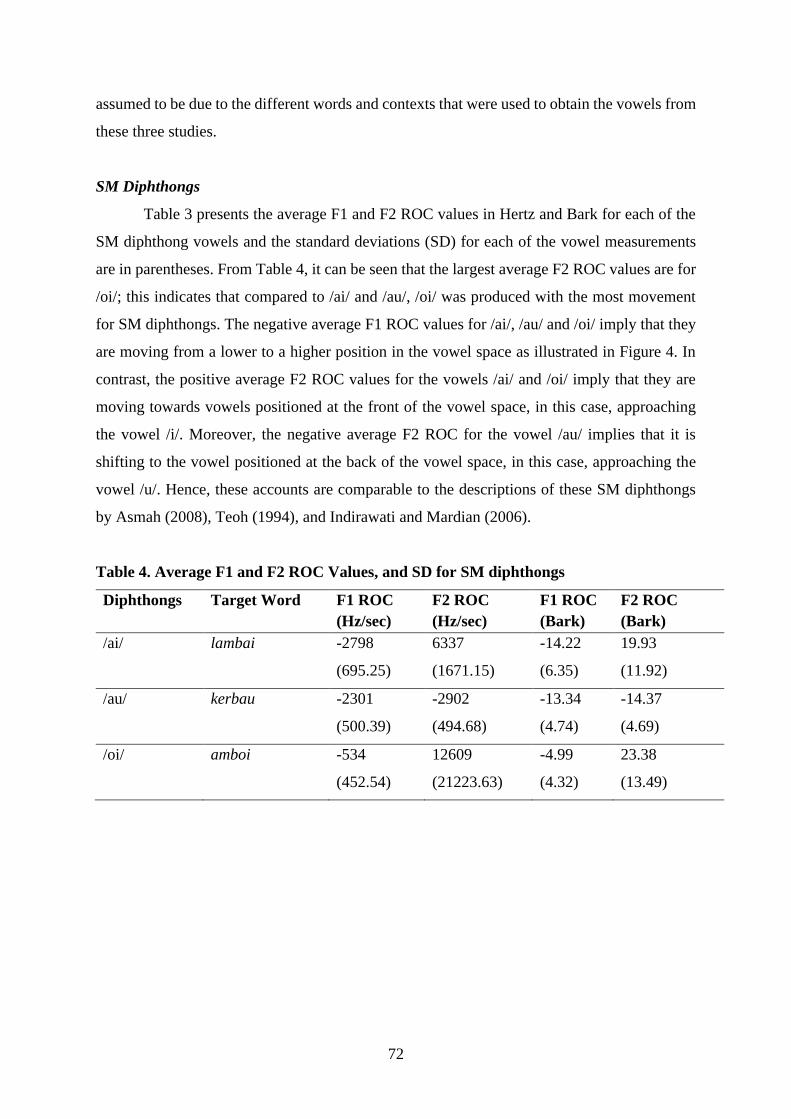
72
assumed to be due to the different words and contexts that were used to obtain the vowels from
these three studies.
SM Diphthongs
Table 3 presents the average F1 and F2 ROC values in Hertz and Bark for each of the
SM diphthong vowels and the standard deviations (SD) for each of the vowel measurements
are in parentheses. From Table 4, it can be seen that the largest average F2 ROC values are for
/oi/; this indicates that compared to /ai/ and /au/, /oi/ was produced with the most movement
for SM diphthongs. The negative average F1 ROC values for /ai/, /au/ and /oi/ imply that they
are moving from a lower to a higher position in the vowel space as illustrated in Figure 4. In
contrast, the positive average F2 ROC values for the vowels /ai/ and /oi/ imply that they are
moving towards vowels positioned at the front of the vowel space, in this case, approaching
the vowel /i/. Moreover, the negative average F2 ROC for the vowel /au/ implies that it is
shifting to the vowel positioned at the back of the vowel space, in this case, approaching the
vowel /u/. Hence, these accounts are comparable to the descriptions of these SM diphthongs
by Asmah (2008), Teoh (1994), and Indirawati and Mardian (2006).
Table 4. Average F1 and F2 ROC Values, and SD for SM diphthongs
Diphthongs Target Word F1 ROC
(Hz/sec)
F2 ROC
(Hz/sec)
F1 ROC
(Bark)
F2 ROC
(Bark)
/ai/ lambai -2798
(695.25)
6337
(1671.15)
-14.22
(6.35)
19.93
(11.92)
/au/ kerbau -2301
(500.39)
-2902
(494.68)
-13.34
(4.74)
-14.37
(4.69)
/oi/ amboi -534
(452.54)
12609
(21223.63)
-4.99
(4.32)
23.38
(13.49)

73
Figure 4. Diphthongal movements for the SM diphthongs
KD Monophthongs
A number of 108 elicitation tokens in total were measured for the KD vowels. Only the
first vowel in the target words was measured. From this number, 72 tokens were for the eight
monophthongs and another 36 tokens were for the four diphthongs. The average F1 and F2
values for the monophthongs are shown in Table 5. Standard deviations (SD) in parentheses
and the Euclidean distances (ED) in Bark are also presented. Figure 5 displays the formant
plots for the average KD vowels and shows the positions of the vowels in the vowel space.
Table 5. F1 and F2 averages, and SD for KD monophthongs
Vowel Target
Word
Ave. F1 and
SD (Hz)
Ave. F2 and SD
(Hz)
Ave. F1
(Bark)
Ave. F2
(Bark)
ED
(Bark)
/i/ pita 404 (37.64) 2782 (120.17) 3.89
(0.34)
15.16
(0.25)
3.65
/e/ beta 516 (25.10) 2576 (67.02) 4.87
(0.22)
14.69
(0.16)
2.92
/ɛ/ bebeh 599 (18.00) 2520 (49.01) 5.58
(0.15)
14.56
(0.12)
2.76
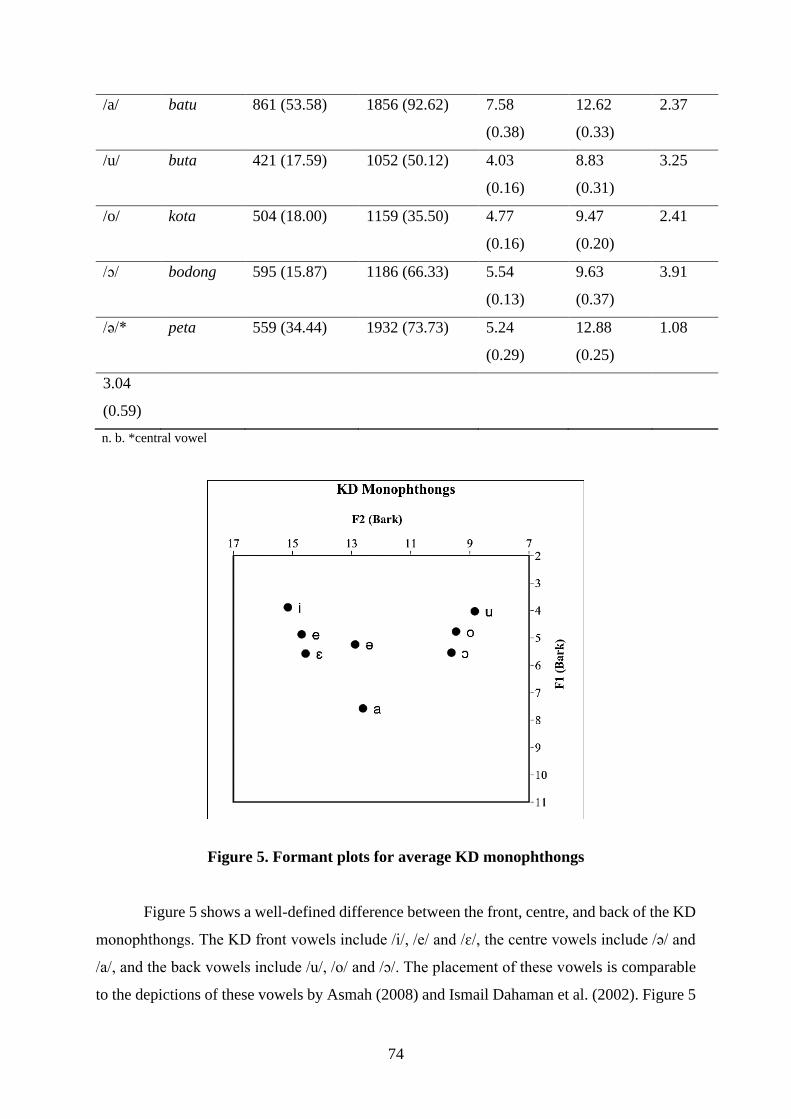
74
/a/ batu 861 (53.58) 1856 (92.62) 7.58
(0.38)
12.62
(0.33)
2.37
/u/ buta 421 (17.59) 1052 (50.12) 4.03
(0.16)
8.83
(0.31)
3.25
/o/ kota 504 (18.00) 1159 (35.50) 4.77
(0.16)
9.47
(0.20)
2.41
/ɔ/ bodong 595 (15.87) 1186 (66.33) 5.54
(0.13)
9.63
(0.37)
3.91
/ə/* peta 559 (34.44) 1932 (73.73) 5.24
(0.29)
12.88
(0.25)
1.08
3.04
(0.59)
n. b. *central vowel
Figure 5. Formant plots for average KD monophthongs
Figure 5 shows a well-defined difference between the front, centre, and back of the KD
monophthongs. The KD front vowels include /i/, /e/ and /ɛ/, the centre vowels include /ə/ and
/a/, and the back vowels include /u/, /o/ and /ɔ/. The placement of these vowels is comparable
to the depictions of these vowels by Asmah (2008) and Ismail Dahaman et al. (2002). Figure 5
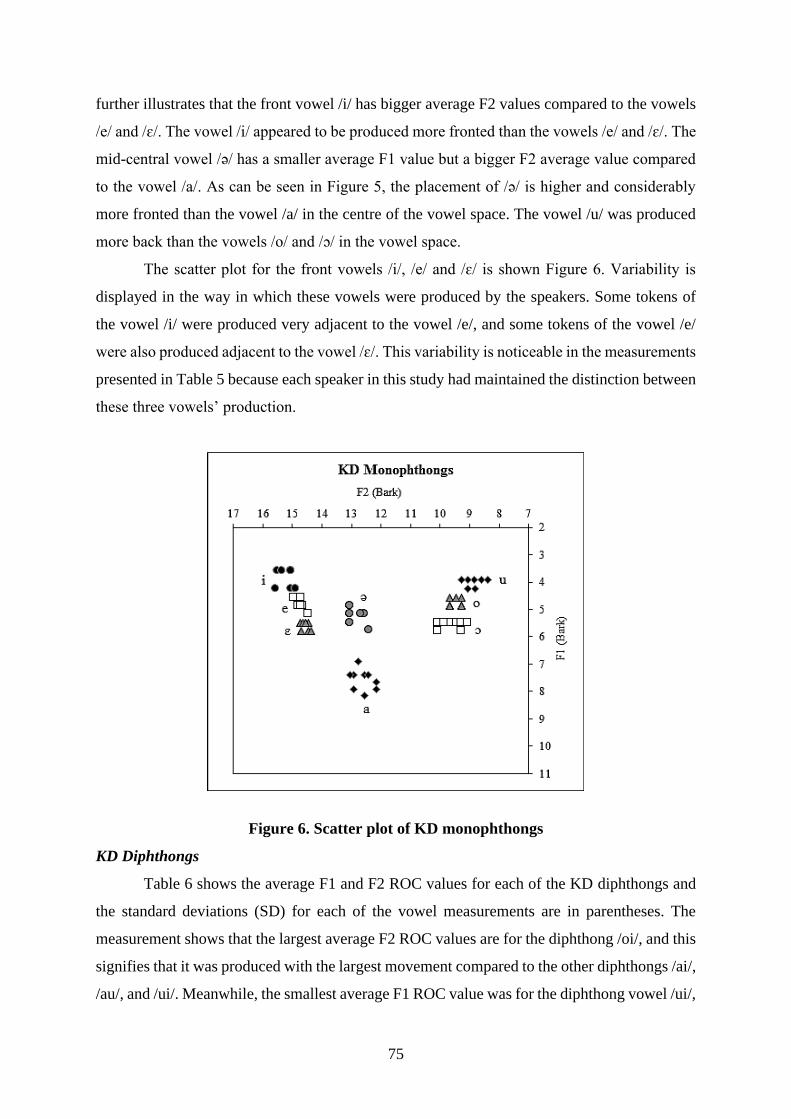
75
further illustrates that the front vowel /i/ has bigger average F2 values compared to the vowels
/e/ and /ɛ/. The vowel /i/ appeared to be produced more fronted than the vowels /e/ and /ɛ/. The
mid-central vowel /ə/ has a smaller average F1 value but a bigger F2 average value compared
to the vowel /a/. As can be seen in Figure 5, the placement of /ə/ is higher and considerably
more fronted than the vowel /a/ in the centre of the vowel space. The vowel /u/ was produced
more back than the vowels /o/ and /ɔ/ in the vowel space.
The scatter plot for the front vowels /i/, /e/ and /ɛ/ is shown Figure 6. Variability is
displayed in the way in which these vowels were produced by the speakers. Some tokens of
the vowel /i/ were produced very adjacent to the vowel /e/, and some tokens of the vowel /e/
were also produced adjacent to the vowel /ɛ/. This variability is noticeable in the measurements
presented in Table 5 because each speaker in this study had maintained the distinction between
these three vowels’ production.
Figure 6. Scatter plot of KD monophthongs
KD Diphthongs
Table 6 shows the average F1 and F2 ROC values for each of the KD diphthongs and
the standard deviations (SD) for each of the vowel measurements are in parentheses. The
measurement shows that the largest average F2 ROC values are for the diphthong /oi/, and this
signifies that it was produced with the largest movement compared to the other diphthongs /ai/,
/au/, and /ui/. Meanwhile, the smallest average F1 ROC value was for the diphthong vowel /ui/,
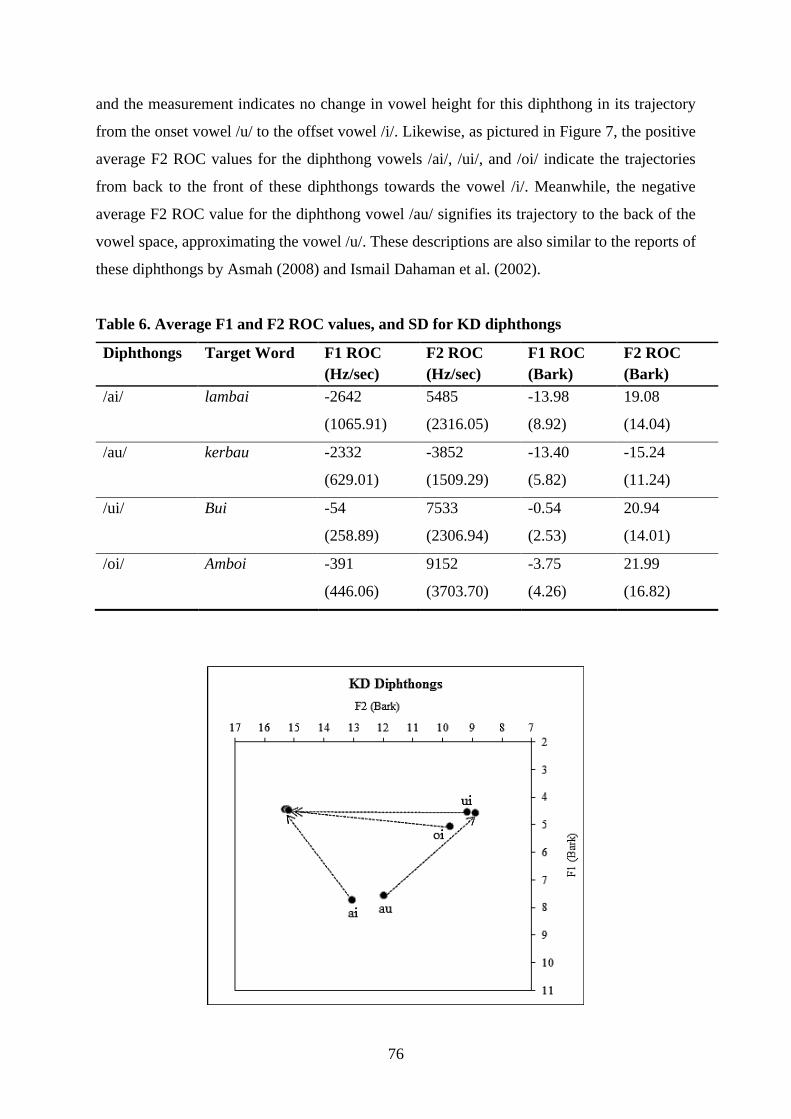
76
and the measurement indicates no change in vowel height for this diphthong in its trajectory
from the onset vowel /u/ to the offset vowel /i/. Likewise, as pictured in Figure 7, the positive
average F2 ROC values for the diphthong vowels /ai/, /ui/, and /oi/ indicate the trajectories
from back to the front of these diphthongs towards the vowel /i/. Meanwhile, the negative
average F2 ROC value for the diphthong vowel /au/ signifies its trajectory to the back of the
vowel space, approximating the vowel /u/. These descriptions are also similar to the reports of
these diphthongs by Asmah (2008) and Ismail Dahaman et al. (2002).
Table 6. Average F1 and F2 ROC values, and SD for KD diphthongs
Diphthongs Target Word F1 ROC
(Hz/sec)
F2 ROC
(Hz/sec)
F1 ROC
(Bark)
F2 ROC
(Bark)
/ai/ lambai -2642
(1065.91)
5485
(2316.05)
-13.98
(8.92)
19.08
(14.04)
/au/ kerbau -2332
(629.01)
-3852
(1509.29)
-13.40
(5.82)
-15.24
(11.24)
/ui/ Bui -54
(258.89)
7533
(2306.94)
-0.54
(2.53)
20.94
(14.01)
/oi/ Amboi -391
(446.06)
9152
(3703.70)
-3.75
(4.26)
21.99
(16.82)
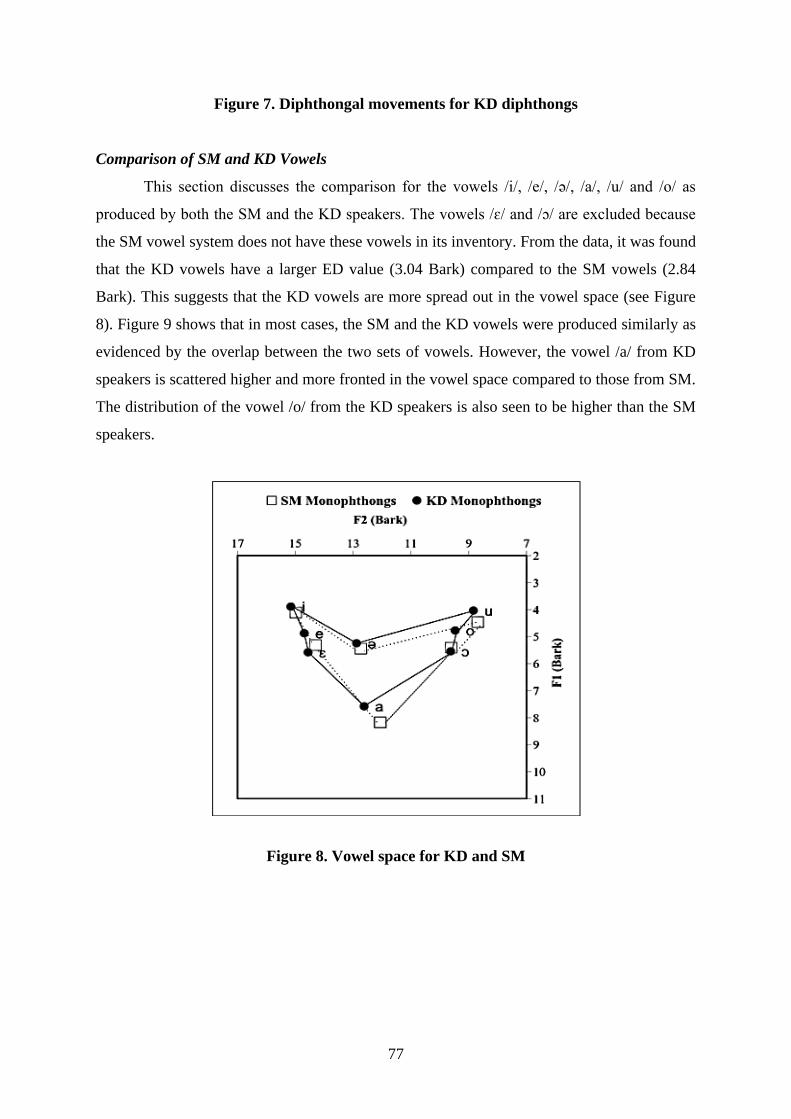
77
Figure 7. Diphthongal movements for KD diphthongs
Comparison of SM and KD Vowels
This section discusses the comparison for the vowels /i/, /e/, /ə/, /a/, /u/ and /o/ as
produced by both the SM and the KD speakers. The vowels /ɛ/ and /ɔ/ are excluded because
the SM vowel system does not have these vowels in its inventory. From the data, it was found
that the KD vowels have a larger ED value (3.04 Bark) compared to the SM vowels (2.84
Bark). This suggests that the KD vowels are more spread out in the vowel space (see Figure
8). Figure 9 shows that in most cases, the SM and the KD vowels were produced similarly as
evidenced by the overlap between the two sets of vowels. However, the vowel /a/ from KD
speakers is scattered higher and more fronted in the vowel space compared to those from SM.
The distribution of the vowel /o/ from the KD speakers is also seen to be higher than the SM
speakers.
Figure 8. Vowel space for KD and SM
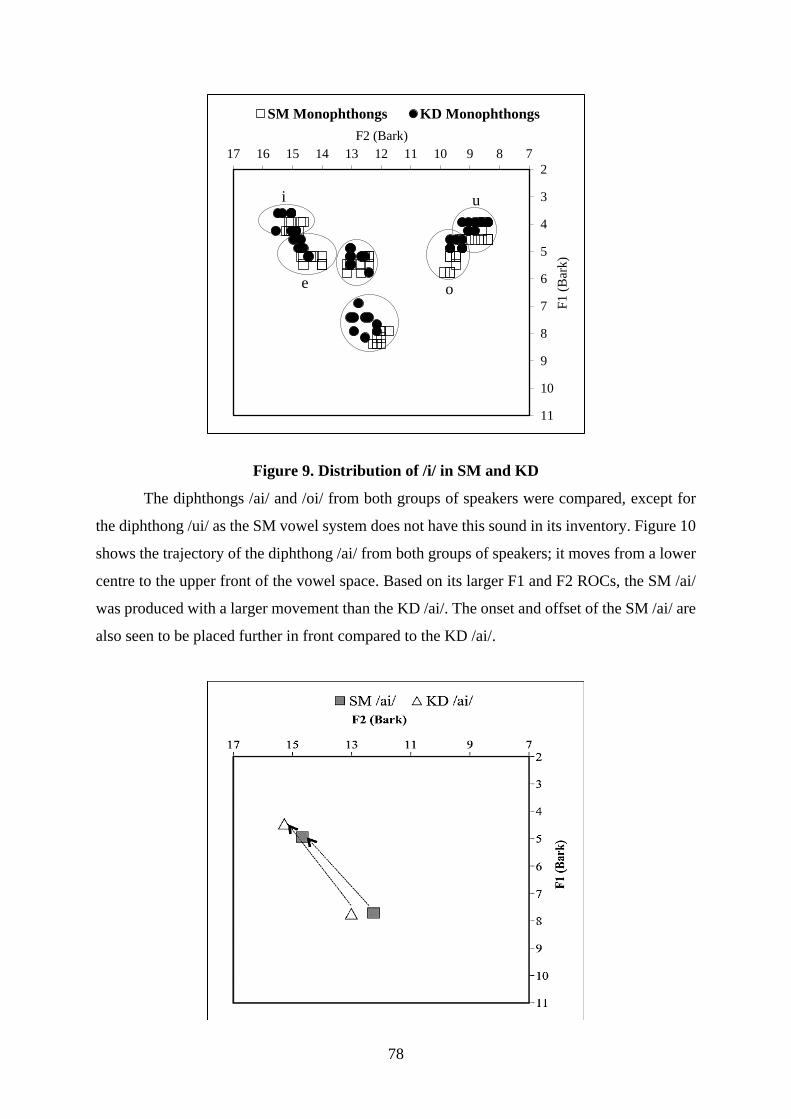
78
Figure 9. Distribution of /i/ in SM and KD
The diphthongs /ai/ and /oi/ from both groups of speakers were compared, except for
the diphthong /ui/ as the SM vowel system does not have this sound in its inventory. Figure 10
shows the trajectory of the diphthong /ai/ from both groups of speakers; it moves from a lower
centre to the upper front of the vowel space. Based on its larger F1 and F2 ROCs, the SM /ai/
was produced with a larger movement than the KD /ai/. The onset and offset of the SM /ai/ are
also seen to be placed further in front compared to the KD /ai/.
2
3
4
5
6
7
8
9
10
11
7891011121314151617
F1
(B
ark
)
F2 (Bark)
SM Monophthongs KD Monophthongs
i
e o
u
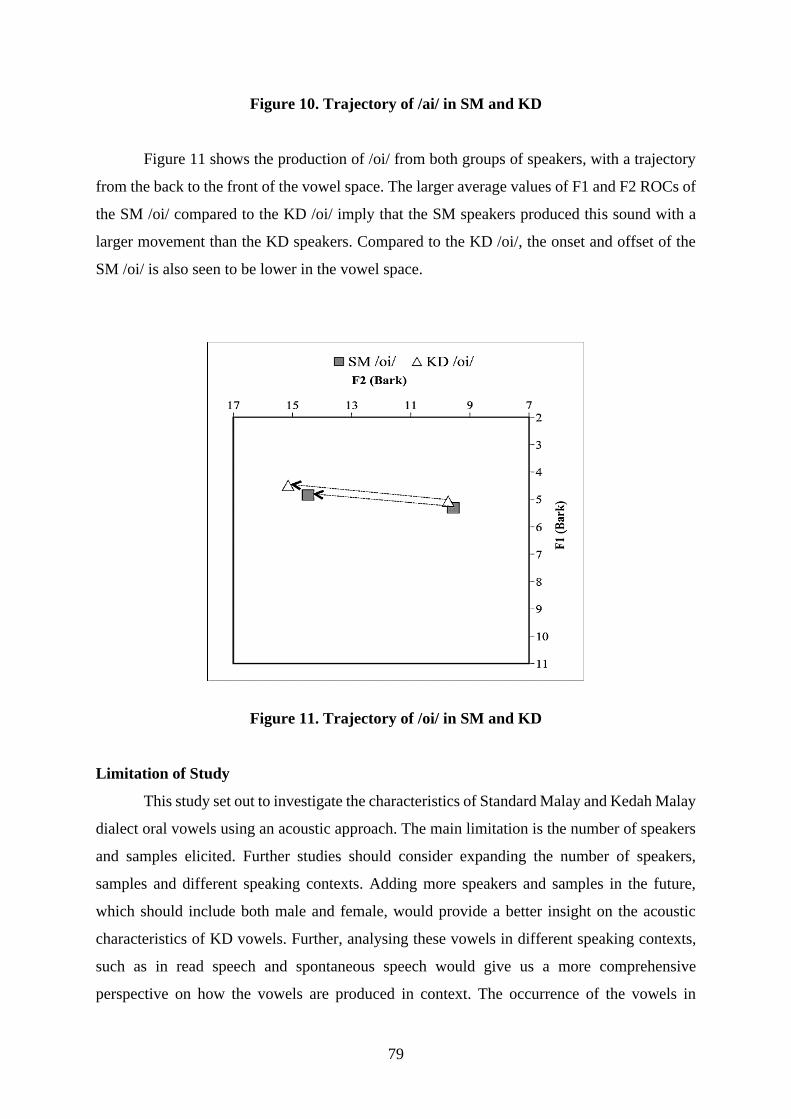
79
Figure 10. Trajectory of /ai/ in SM and KD
Figure 11 shows the production of /oi/ from both groups of speakers, with a trajectory
from the back to the front of the vowel space. The larger average values of F1 and F2 ROCs of
the SM /oi/ compared to the KD /oi/ imply that the SM speakers produced this sound with a
larger movement than the KD speakers. Compared to the KD /oi/, the onset and offset of the
SM /oi/ is also seen to be lower in the vowel space.
Figure 11. Trajectory of /oi/ in SM and KD
Limitation of Study
This study set out to investigate the characteristics of Standard Malay and Kedah Malay
dialect oral vowels using an acoustic approach. The main limitation is the number of speakers
and samples elicited. Further studies should consider expanding the number of speakers,
samples and different speaking contexts. Adding more speakers and samples in the future,
which should include both male and female, would provide a better insight on the acoustic
characteristics of KD vowels. Further, analysing these vowels in different speaking contexts,
such as in read speech and spontaneous speech would give us a more comprehensive
perspective on how the vowels are produced in context. The occurrence of the vowels in

80
different phonetic environments should also be investigated to ascertain the effect of co-
articulation which can affect the formant patterns of vowels (Paillereau, 2016). Other sounds,
such as the nasals and consonants should also be investigated to build a complete profile of
KD.
Implication of Study
The study supports previous descriptions of KM which were mainly based on auditory
impressions. The findings can also be used in comparative studies of the acoustic properties of
the sounds of the various varieties of Malay spoken in Malaysia. In a clinical setting, the data
gathered from this study is beneficial particularly for KD speakers with hearing impairment
and/or speech disability to lead a better quality of life. According to Kent (1997), listeners
distinguish between the two vowel sounds based on their formant differences, and hence the
formant values obtained from this study would help the audiologists to set the hearing aid (HA)
accordingly. The hearing-impaired person fitted with a proper frequency range on their HA
would have an improved listening quality particularly in a KD speaking environment.
Furthermore, among others, the data from this study also can be used as the basis of comparison
when diagnosing patients with dysarthria (a neurological disorder which affects the production
of speech). The vowel space area of the patients is usually reduced compared to those speakers
who are healthy (Lansford & Liss, 2014).
Conclusion
In conclusion, the monophthong vowels of /i/, /e/, /ə/ and /o/ were produced similarly by
both groups of speakers, the SM speakers, and the KD speakers, except for the vowels /a/ and
/o/, which were produced higher in the vowel space by the KD speakers compared to the SM
speakers. As for the vowels /ɛ/ and /ɔ/, no comparison was done as these sounds do not occur
in the SM vowel system. Furthermore, the SM speakers produced the diphthong vowels /ai/
and /oi/ with larger movements in the vowel space compared to the KD speakers. Despite the
small samples presented in this study, it shows the similarities and variances of vowel
production between the SM and the KD speakers in Malaysia. Nonetheless, further research
with more data is needed to establish a better description and comparison of vowel qualities
from both varieties.
Acknowledgment
This research was supported by a grant from Universiti Malaya (PS021/2008C).

81
References
Al-Tamimi, J-E., & Ferragne, E. (2005). Does vowel space size depend on language vowel
inventories? Evidence from two Arabic dialects and French. Proceedings of
Interspeech (pp. 2465-2468). Lisbon, Portugal.
Asmah Haji Omar. (1977). The phonological diversity of the Malay dialects. Dewan Bahasa
dan Pustaka.
Asmah Haji Omar. (2008). Susur galur Bahasa Melayu (2nd. ed) [Malay language lineage].
Dewan Bahasa dan Pustaka.
Bao, M. (2013). Acoustic evidences for glottalization of word-initial vowels in Shughni.
Linguistics Journal, 7(1), 250-272.
Boersma, P., & Weenink, D. (2007). PRAAT: doing phonetics by computer (Version 4.6.12)
[Computer software]. http://www.praat.org/
Bradlow, A. R. (1995). A comparative acoustic study of English and Spanish vowels. Journal
of the Acoustical Society of America, 97(3), 1916-1924.
Chaiyanara, P. M. (2001). Fonetik dan fonologi Bahasa Melayu [Malay phonetics and
phonology]. Wespac Consult Centre.
Chen, Y. (2008). The acoustic realization of vowels of Shanghai Chinese. Journal of Phonetics,
36, 629-648.
Clopper, C. G., Pisoni, D. B., & Jong, K. d. (2005). Acoustic characteristics of the vowel
systems of six regional varieties of American English. Journal of Acoustical Society of
America, 118(3), 1661–1676.
Deterding, D. (2000). Measurements of the /eɪ/ and /əʊ/ vowels of young English speakers in
Singapore. In A. Brown, D. Deterding & L. E. Ling (Eds.). The English language in
Singapore: Research on pronunciation (pp. 93-99). Singapore Association for Applied
Linguistics.
Ferragne, E., & Pellegrino, F. (2010). Vowel systems and accent similarity in the British Isles:
Exploiting multidimensional acoustic distances in phonetics. Journal of Phonetics 38,
526–539.
Flynn, N. (2011). Comparing vowel formant normalisation procedures. York Paper in
Linguistics, 2(11), 1-28.
Harrington, J. (2010). Phonetic analysis of speech corpora. Blackwell Publishing.
Hawkins, S., & Midgley, J. (2005). Formant frequencies of RP monophthongs in four age
groups of speakers. Journal of the International Phonetic Association 35(2), 183-199

82
Indirawati Zahid & Maridian Shah Omar (2006). Fonetik dan fonologi [Phonetics and
phonology]. PTS Professional Publishing Sdn. Bhd.
Inon Shaharuddin Abdul Rahman (1985). Two dalangs: A comparison of styles and dialect.
Sari, 3(1), 49-73.
Islam, M. J., & Ahmed, I. (2020). Mid-front and back vowel mergers in Mymensingh Bangla:
An acoustic investigation. Linguistics Journal, 14(1), 206-232.
Ismail Dahaman., Abdul Jalil bin Haji Anuar., Nor Hazizan bin Talib., Haji Ab. Halim bin Haji
Salleh., & Haji Ismail bin Saleh. (2002). Kosa kata dialek: Glosari dialek Kedah
[Dialect vocabulary: Glossary of Kedah dialects]. Dewan Bahasa dan Pustaka.
Jacobi, I. (2009). On variation and change in diphthongs and long vowels of spoken Dutch.
[Ph.D. dissertation]. University of Amsterdam, Amsterdam.
Kamus Dewan. (2005). Dewan dictionary (4th ed.). Dewan Bahasa dan Pustaka.
Kent, R. D. (1997). The speech sciences. Singular Publishing Group.
King, P. (2006). An acoustic description of central vowels in three Austronesian languages of
New Ireland. SIL Electronic Working Papers 2007, 1-21.
Konopka, K., & Pierrehumbert, J. B. (2014). Vowel dynamics of Mexican Heritage English:
Language contact and phonetic change in a Chicago community. Papers from the 46th
Annual Meeting of the Chicago Linguistic Society, 1-15.
Ladefoged, P. (2003). Phonetic data analysis: An introduction to fieldwork and instrumental
techniques. Blackwell Publishing.
Ladefoged, P. (2006). A course in phonetics (5th ed.). Thomson Wadsworth.
Lansford, K. L., & Liss, J. M. (2014). Vowel acoustics in dysarthria: Speech disorder diagnosis
and classification. Journal of Speech Language and Hearing Research, 57(1),
57. https://doi.org/10.1044/1092-4388(2013/12-0262)
Lee, E. M., & Lim, L. (2000). Diphthongs in Singaporean English: Their realizations across
different formality levels, and some attitudes of listeners towards them. In A. Brown,
D. Deterding & L. E. Ling (Eds.). The English language in Singapore: Research on
pronunciation (pp. 101-111). Singapore Association for Applied Linguistics.
Leemann, A. (2008). Vowel quality of Swiss EFL speakers. In Ewa Waniek-Klimczak (Ed.).
Issues in accents of English (pp. 16-32). Cambridge Scholars Publishing.
Man, C. D. (2007). An acoustical analysis of the vowels, diphthongs and triphthongs in Hakka
Chinese. Proceedings of the International Congress of Phonetic Sciences 2007 (ICPhS
XVI) (pp. 841-844). Saarbrücken, Germany.

83
Maragakis, M. G. (2008). Region-based vocal tract length normalization for automatic speech
recognition. [Master’s thesis]. Technical University of Crete, Crete.
Mardian Shah Omar (2005). Perbezaan bunyi vokal dan konsonan: Suatu analisis spektografik
[Vocal and consonant sound differences: A spectrographic analysis]. Proceedings of
the Seminar Kebangsaan Linguistik (SKALI 2005) (pp. 1-9). Bangi, Malaysia.
Maxwell, O., & Fletcher, J. (2010). The acoustic characteristics of diphthongs in Indian
English. World Englishes, 29(1), 27-44.
Mayr, R., & Davies, H. (2011). A cross-dialectal acoustic study of the monophthongs and
diphthongs of Welsh. Journal of the International Phonetic Association, 41(1), 1-25.
Morrison, G. S. (2003). Perception and production of Spanish vowels by English speakers. In
M.-J. Solé, D. Recasens & J. Romero (Eds.). Proceedings of the 15th International
Congress of Phonetic Sciences Barcelona 2003 (pp. 1533-1536). Causal Productions.
Nowak, P. M. (2006). Vowel reduction in Polish. [Ph.D. dissertation]. University of California,
Berkeley.
O’Rourke, E. (2010). Dialect differences and the bilingual vowel space in Peruvian Spanish.
In Marta Ortega-Llebaria (Ed.). Selected Proceedings of the 4th Conference on
Laboratory Approaches to Spanish Phonology (pp. 20-30). Somerville, MA: Cascadilla
Proceedings Project.
Paillereau, N., M. (2016). Do isolated vowels represent vowel targets in French? An acoustic
study on coarticulation. SHS Web of Conferences, 27, 09003.
https://doi.org/10.1051/shsconf/
20162709003
Pillai, S., Don, Z. M., Knowles, G., & Tang, J. (2010). Malaysian English: An Instrumental
Analysis of Vowel Contrasts. World Englishes, 29(2), 159-172.
Salem, N. M., & Pillai, S. (2020). An acoustic analysis of intonation in the Taizzi variety of
Yemeni Arabic. Linguistics Journal, 14(1), 154-182.
Shaharina Mokhtar and Shahidi Abdul Hamid (2012). Analisis akustik terhadap forman bunyi
vokal Bahasa Melayu: Satu perbandingan antara gender [Acoustic analysis of formant
vocal sounds of Malay: A comparison between gender]. Proceedings of the
International Conference on Social Sciences & Humanities 2012 (pp. 301-313). Bangi,
Malaysia.
Simpson, A. P. (2009). Phonetic differences between male and female speech. Language and
Linguistics Compass, 3(2), 621–640.
Teoh, B. S. (1994). The sound system of Malay revisited. Dewan Bahasa dan Pustaka.

84
Verhoeven, J., & Van Bael, C. (2002). Acoustic characteristics of monophthong realisation in
southern standard Dutch. In J. Verhoeven (Ed.), Phonetic work in progress (pp. 149-
164). University of Antwerp.
Wang, H., & Heuven, V. J. v. (2006). Acoustical analysis of English vowels produced by
Chinese, Dutch and American speakers. Linguistics in the Netherlands, 23, 237–248.
Watt, D., & Tillotson, J. (2001). A spectrographic analysis of vowel fronting in Bradford
English. English World-Wide, 22(2), 269-302.
Yunus Maris (1980). The Malay sound system. Penerbit Fajar Bakti Sdn. Bhd.
Yusuf, Y. Q. (2013). A comparative study of vowels in the Acehnese language spoken in Kedah,
Malaysia and Aceh, Indonesia. [Doctoral dissertation]. University of Malaya, Kuala
Lumpur.
Yusuf, Y. Q., Fata, I. A., & Karwinda, S. (2021). Oral monophthong vowel qualities of the
Jamee language in Aceh. Indonesian Journal of Applied Linguistics, 10(3), 793-803.
Yusuf, Y. Q., & Pillai, S. (2013). An acoustic description of diphthongs in two varieties of
Acehnese. Pertanika Journal of Social Sciences & Humanities, 21(S), 153–168.
Yusuf, Y. Q., & Pillai, S (2016). An instrumental study of oral vowels in the Kedah variety of
Acehnese. Language Sciences, 54, 14-25.
Zwicker, E., & Terhardt, E. (1980). Analytical expression for critical bandwidths as a function
of frequency. The Journal of the Acoustical Society of America, 68, 1523-25.

85
Appendix A
Please fill in the following questionnaire.
Personal details:
Name:
Age:
Ethnicity:
Gender:
Phone number and email:
Date of recording:
Questions:
Where are you from (hometown)? Please also explain where you grew up and lived until the
age of 15.
What was your first, second, and third language (and fourth, if any)?
What language/dialect do you speak at home with your family?
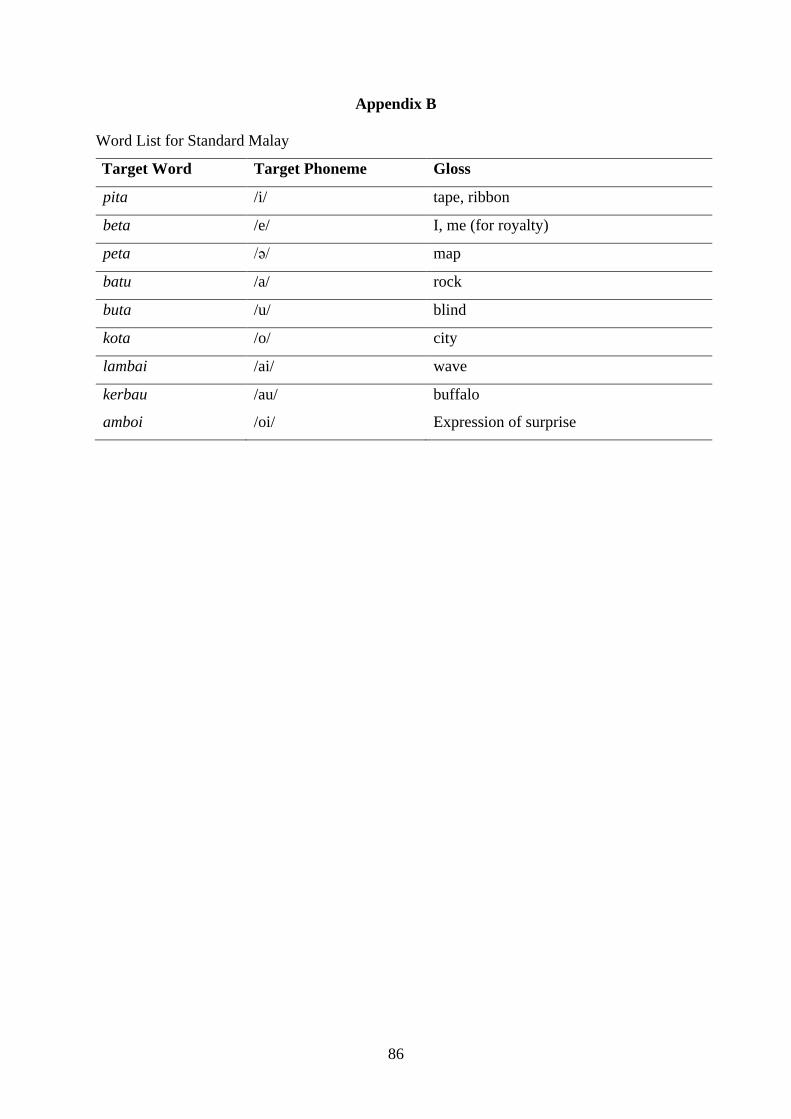
86
Appendix B
Word List for Standard Malay
Target Word Target Phoneme Gloss
pita /i/ tape, ribbon
beta /e/ I, me (for royalty)
peta /ə/ map
batu /a/ rock
buta /u/ blind
kota /o/ city
lambai /ai/ wave
kerbau /au/ buffalo
amboi /oi/ Expression of surprise
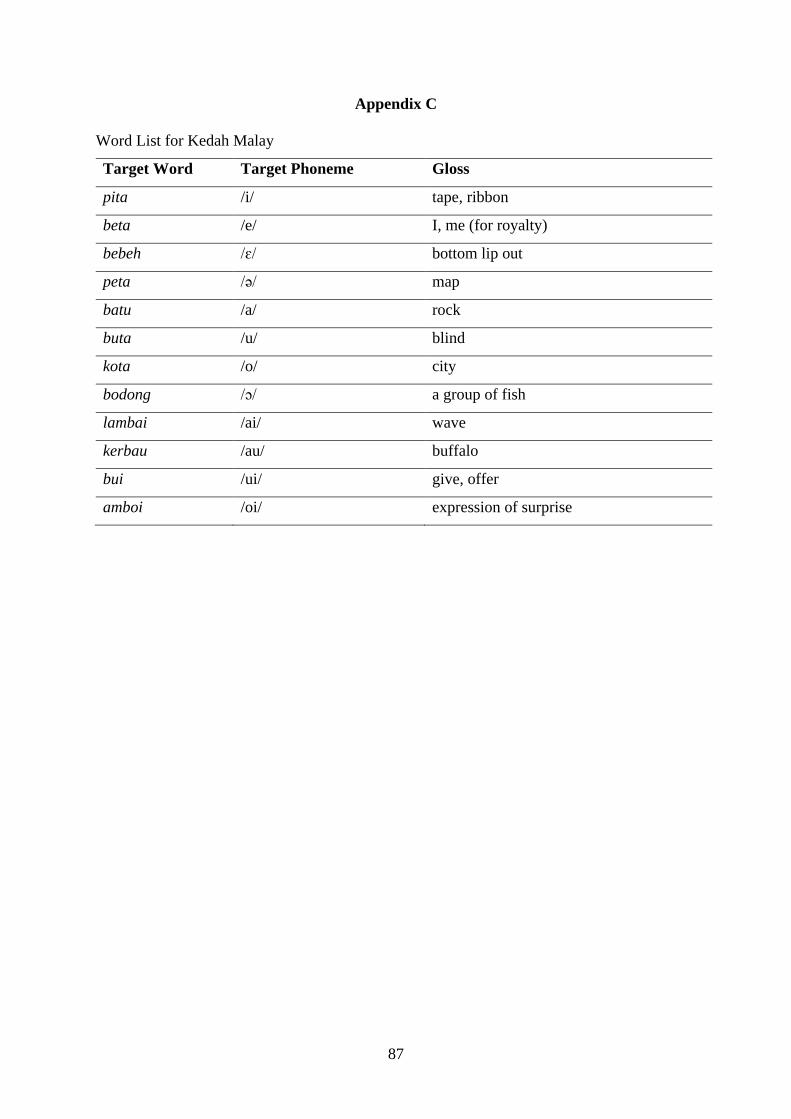
87
Appendix C
Word List for Kedah Malay
Target Word Target Phoneme Gloss
pita /i/ tape, ribbon
beta /e/ I, me (for royalty)
bebeh /ɛ/ bottom lip out
peta /ə/ map
batu /a/ rock
buta /u/ blind
kota /o/ city
bodong /ɔ/ a group of fish
lambai /ai/ wave
kerbau /au/ buffalo
bui /ui/ give, offer
amboi /oi/ expression of surprise

88
Pontillas, N.E., & Cayabyab, M.D. (2021). Production of American English
phonemes and adjustments in connected speech among Filipino-English
bilingual students. Linguistics International Journal, 15(1), 94-116.
Production of American English Phonemes and Adjustments in Connected Speech
among Filipino-English Bilingual Students
Noreen E. Pontillas
De La Salle University, Manila, Philippines
Capitol University, Cagayan de Oro City, Philippines
Melanie D. Cayabyab
De La Salle University, Manila, Philippines
Dr. Sixto Antonio Elementary School
Abstract
This study explored the production of phonemes and adjustments in connected speech among
Filipino-English bilingual students with American English as the referent. This study centered
on two adjustments in connected speech: linking (consonant-vowel linking and y-glides) and
assimilation (coalescent assimilation). Flege’s Speech Learning Model is applied to both
consonant phonemes and adjustments in connected speech. Qualitative and quantitative
method was utilized in this study. Ten (10) Bachelor of Secondary Education major in
English students was able to record both Avery and Ehrlich’s (2012) word list and a
diagnostic passage from Celce-Murcia et al. (1996) book. The reliability of the transcriptions
rates stood at 95.90% for the vowel and consonant phonemes and 94.28% for the adjustments
in connected speech. Participants produced a mean of 15.60 (N=20) for vowel sounds and 22.80
(N=24) for consonant sounds. Minimal instances of consonant-vowel linking with function
word beginning in a vowel reduced. None of them were able to produce y-glide linking and
coalescent assimilation adjustments in connected speech. There is a significant difference in
the production of vowels and in the adjustments in connected speech produced. This means
that the Filipino language can be said to influence the production of American English

89
phonemes and adjustments in connected speech among Filipino-English bilinguals. The results
of the study lead to two directions: Filipino-English bilinguals can continue to strive to
approximate American English; and a call for the standardization of Philippine English, in
terms of its phonetic and phonological features is desired.
Keywords: Linking, consonant-vowel linking, y-glides, assimilation, coalescent assimilation,
Flege’s Speech Learning Model
Introduction
Bilingualism stands at the center in multilingual communities. Where more than one
language exists in a community, bilingualism is inevitable due mostly to language contact.
Language contact happens given the multitude of languages existing in the world. Paul et al.
(2016) puts the number of languages between 6000 and 7000 languages. Several factors lead
to language contact and these are, but not limited to, politics, natural disaster, religion, culture,
economy, education and technology. Language contact allows bilingualism to blossom such
that at the current rate of technological advancement, for example, rare it is to find a strictly
monolingual community.
Bilingualism has been defined in numerous ways (Liddicoat, 1991). In 1933,
Bloomfield wrote that bilingualism is “native-like control of two languages” (p.56). An oft-
quoted definition of bilingual, his view represented an extreme definition of bilingualism.
Other scholars, however, have presented the viewpoint at the other end of the continuum. For
example, McNamara (as cited in Hamers & Blanc, 2000) describes a bilingual person as
someone who possesses a minimal degree of least one language skill in a second language. The
definition continuum of bilingualism continues up to this day, with one school espousing
complete control, i.e., proficiency, of more than one language while the other end accepting
minimal proficiency in more than one language. Despite the many definitions of bilingualism,
it is an accepted view that the term bilingualism pertains to having more than one language at
a person’s disposal, be at the native level or beginner level of proficiency.
The Philippines is ranked as the 12th country with the greatest number of first languages
(Paul et al., 2016). With nearly 200 languages, bilingualism permeates the Philippine society
with trilingualism even a norm outside Filipino-speaking communities. Ensuring such
pervasive bilingualism is the constitutional mandate that English is an official language while
Filipino is the national language. This translates to both languages, English and Filipino, being

90
taught in the elementary years and even as early as kindergarten in many private schools around
the country.
This paper embarked on a study of Filipino-English bilinguals who are senior education
students. One of the researchers taught the course on Language Research. Amidst the Language
Research classes, the students’ English sound inventories generated curiosity as to their nature.
As future English teachers, these students will become role models, consciously or
unconsciously, of their future students. Their English pronunciations will indelibly leave a
mark on their students as these students will be listening to them in the classroom on a regular
basis. With averred adherence to American English in the Philippines due to historical ties,
these students, however, failed to consistently produced American English pronunciation when
talking in the Language Research classes. Hence, this study was conceptualized.
This study focused on two phenomena of language sounds in American English:
phonemes and adjustments in connected speech. In the Philippines, as stated earlier, American
English is the referent given its historical role in the country. This study tried to illustrate the
differences in both phenomena when produced by Filipino-English bilinguals. It also tried to
establish the significance of these differences such that it may or may not be postulated that
Filipino as the first language prompts non-production of American English phonemes and
adjustments in connected speech.
Literature Review
Phonemes and Adjustments in Connected Speech
American English has 20 distinct vowel phonemes and 24 consonant phonemes (Avery
& Ehrlich, 2012). The American English vowel inventory includes four r-colored phonemes
and the schwa. The American English consonant phonemes, on the other hand, include the
glides and the liquids. On the other hand, Filipino has five vowel phonemes and 23 consonant
phonemes (Jose et al., 2013). The large discrepancy between the number of vowel phonemes
between American English (with 20 phonemes) and Filipino (with five phonemes) is
noteworthy given that second language acquisition theories posit a difficulty in producing
phonemes absent in the inventory of the first language (Hansen et al., 2008).
American English is a stress-timed language, which entails a rhythm where stressed
syllables appear in regular intervals with utterance length dependent on the number of stresses
(Richards & Schmidt, 2010). Filipino, however, is a syllable-timed language. Syllable-timed
languages have utterance length that is syllable-dependent and a rhythm wherein syllables recur
at regular intervals (Richards & Schmidt, 2010).

91
Given the stress-timed feature of English, adjustments in connected speech occur.
Celce-Murcia, Brinton and Goodwin (1996) identified five major adjustments in connected
speech: linking, assimilation, dissimilation, deletion and epenthesis. Of the five major
adjustments in connected speech, two were given focus in this paper. These are linking and
assimilation. Linking has five subtypes; however, only two were included in the study:
consonant-vowel linking and y-glides. Meanwhile, assimilation has three subtypes and one was
included in the study: coalescent assimilation.
In this study, consonant-vowel linking focused on function words starting with a vowel
that follows a word ending in either a single consonant or consonant clusters. Function words
in American English pronunciation are reduced to a schwa-sound (Celce-Murcia et al., 1996).
In consonant-vowel linking with functions words starting with vowel phonemes, there is a re-
syllabification where the schwa sound become part of the word ending in a consonant or
intervocality occurs “as if the consonant sound belonged to both syllables” (Celce-Murcia,
Brinton & Goodwin, 1996, p. 158). An example is the have + a, which in linking as an
adjustment in connected speech becomes /havə/. The /y/ glide linking, on the other hand, occur
when one word ending in a tense vowel or a diphthong and the next word or syllable starts with
a vowel (Celce-Murcia, Brinton & Goodwin, 1996). A common example of this the /iy/ +
vowel in be able wherein a /y/ sound links both words as in beyable.
Coalescent assimilation occurs when two sequential sounds create a third sound. This
often occurs when final alveolar sounds or sound sequences are followed by /y/ such that the
new sound produced are palatalized fricatives or affricates (Celce-Murcia, Brinton & Goodwin,
1996). A few examples are as follows: (1) /s/ + /y/ in this year becomes /ʃ/ and (2) /t/ + /y/ in
that your becomes /tʃ/. Adjustments in connected speech do not occur in syllable-timed
Filipino. In Filipino utterances, each syllable or each phoneme is distinctly pronounced, be they
part of a content word or a functions word. As such, Filipino-English bilinguals may tend to
produce utterances in English following the syllable-timed nature of Filipino. Hence,
phonological transfer occurs in the English utterances of Filipino-English bilinguals.
Phonology and Bilingualism
Marinova-Todd et al. (2010) examined the effects of bilingual exposure on the
development of phonological awareness in both languages of Mandarin-English bilingual
children. Only one significant interaction, between the phonological awareness test and group,
was found. Across both age groups, the bilingual children had higher scores than the

92
monolingual English-speaking children on elision and blending. Aoki and Nishihara (2013),
meanwhile, studied the sound feature interference between two second languages. They
concentrated on recordings of three groups of speakers. The results show that the experience
of Chinese contributed to the production of English voice-onset time. This means that the
acquired category in Chinese (i.e., aspiration) helped in distinguishing aspiration in English
pronunciation.
The acquisition of phonetic and phonological realization of word stress by Arabic
speaking second language learners of English was investigated by Almbark et al. (2014). The
phonology of stress differs across spoken Arabic dialects. In addition, phonetic realization of
stress may also vary across dialects. In the study, no differences were found in the phonetic
realization of stress between the two Arabic dialects under consideration; however, differences
are found between the realization of stress in Arabic as compared to English. In the L2 English
production data, the results show a clear pattern of L1 transfer in the phonetic realization of
stress; particularly, in the lack of vowel reduction in unstressed syllables, which contrasts with
minimal errors in word‐stress placement.
Major (2008) critically examined research on transfer in second language (L2)
phonology over the past half century, starting with the psychological studies on language
transfer in the 1940s to the current theories. Some key theories examined is the contrastive
analysis hypothesis, optimality theory in phonology and markedness. Methodological issues
on transfer research were explored, with emphasis on the definition and conditions of transfer.
Lastly, Major presented directions for future research. Two of which are the inadequacy of
transfer to completely explain interlanguage and transfer’s interaction with other factors in
phonology in second language learning.
The evolution of contrastive analysis hypothesis was described in Zampini’s 2008
article. Despite being published a half century ago, the Contrastive Analysis Hypothesis (CAH)
presented by Lado (as cited in Zampini, 2008) continues to be invoked in much second
language (L2) speech acquisition research today. She noted recognizable phenomena in second
language phonology through the years: (1) many adult learners speak their L2 with a foreign
accent and (2) a learner’s first language (L1) can play an inhibitive role in L2 speech
perception, processing, and production. The CAH highlights this role in its simplest form by
predicting that those aspects of the L2 sound system that are similar to the L1 will be easy to
acquire, while those aspects that are different from the L1 will be difficult. However, later
research has shown that the role of the first language (L1) in L2 phonological acquisition is not
as straightforward as hypothesized in CAH. Some L2 sounds not in the L1 sound inventory

93
may rather be easier to acquire, while the opposite could be true, i.e., L2 sounds similar to L1
sounds may be more challenging to acquire. Furthermore, other factors have been found to
affect L2 phonological acquisition that may mitigate or heighten the role of the L1, such as
age, markedness, and social factors.
Research Questions
Towards the goal of exploring the English phone production and adjustments in
connected speech among Filipino-English bilinguals, this study attempted to answer the
following questions:
1. What differences in pronunciation are manifested by the Filipino-English bilingual
students among the American English vowel and consonant phonemes?
2. What differences in pronunciation are manifested by the Filipino-English bilingual
students in terms of the following American English adjustments in connected
speech:
a. linking
b. coalescent assimilation
3. Is there a significant difference between the standard American pronunciation and
the pronunciation of the Filipino-English bilingual students in the following areas:
a. phonemes
b. adjustments in connected speech?
Theoretical Framework
In the areas of phonetics and phonology under bilingualism, the idea of cross-language
similarity provides the core foundation in many theories. In other words, cross-language
similarity has often been cited in predicting difficulties and ease among adult second language
learners “in mastering the production and perception of nonnative phonetic segments and
sequences” (Strange, 1999, p. 2513). This concept posits that the more similar L2 sounds are
to L1 sounds, the more likely the L1 will influence how L2 sounds are produced. Theories
invoking cross-language similarity potentially face the problem of circularity in its arguments.
However, this concept has continued for decades to be the pillar in many second language
research and theories, particularly in the field of phonology.

94
One theory that posits cross-language similarity is Flege’s Speech Learning Model,
which underpins this study. Flege first advanced this model in his 1995 article. Subsequent
articles by Flege further strengthened the model. The latest addition has been in his 2015 paper
wherein Flege refined his ideas with respect to his Speech Learning Model. Flege (1995) aimed
to understand how speech learning changes over the life span and to explain why "earlier is
better" as far as learning to pronounce a second language (L2) is concerned. One assumption
made is that the phonetic systems used in the production and perception of vowels and
consonants remain adaptive over the life span, and that phonetic systems reorganize in response
to sounds encountered in an L2 through the addition of new phonetic categories, or through the
modification of old ones. In this regard. Flege came up with three phonetic categories in L2
with respect to L1: new, similar and same.
The Speech Learning Model generates several hypotheses. One is that “L2 vowels rated
as phonetically similar to an existing L1 vowel will be produced fairly well in early stages of
L2 acquisition” (Flege, 2015, p. 100). A second prediction is that L2 vowels dissimilar from
L1 vowels will be produced unsuccessfully in the early stages of L2 acquisition. However,
long-term L2 acquisition would see such vowels produced more successfully than the
phonetically similar vowels. Hence, the Speech Learning Model advances the idea that in the
long-run, similar sounds are more difficult to produce since they are perceived to be similar to
the sounds in L1 while the dissimilar sounds are easier to produce due to their salient
characteristics that deviates from the sounds in L1.
In this study, the Speech Learning Model is also extended to both consonant phonemes
and adjustments in connected speech, i.e., the Speech Learning Model also applies in both
linguistic phenomena. With the participants in the study exposed to English since their early
years in school or for more than a decade, the Speech Learning Model assumes that these
participants would find L2 sounds and phonological segments dissimilar from L1 easier to
produce than similar sounds and phonological segments in L2 and L1.
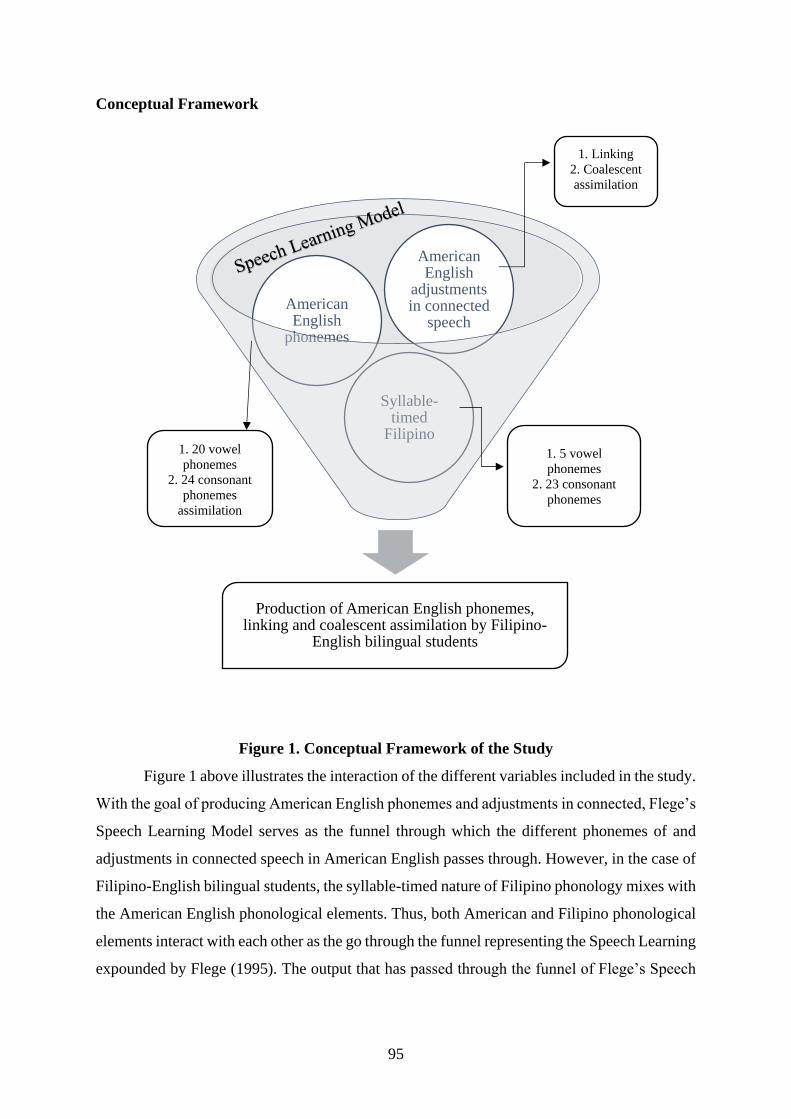
95
Conceptual Framework
Figure 1. Conceptual Framework of the Study
Figure 1 above illustrates the interaction of the different variables included in the study.
With the goal of producing American English phonemes and adjustments in connected, Flege’s
Speech Learning Model serves as the funnel through which the different phonemes of and
adjustments in connected speech in American English passes through. However, in the case of
Filipino-English bilingual students, the syllable-timed nature of Filipino phonology mixes with
the American English phonological elements. Thus, both American and Filipino phonological
elements interact with each other as the go through the funnel representing the Speech Learning
expounded by Flege (1995). The output that has passed through the funnel of Flege’s Speech
Production of American English phonemes, linking and coalescent assimilation by Filipino-
English bilingual students
Syllable-timed
Filipino
American English
phonemes
American English
adjustments in connected
speech
1. Linking
2. Coalescent
assimilation
1. 20 vowel
phonemes
2. 24 consonant
phonemes
assimilation
1. 5 vowel
phonemes
2. 23 consonant
phonemes

96
Learning Model is the production of the American English phonemes and adjustments of
connected speech by the Filipino-English bilingual students.
The expected production of the American English by the Filipino-English bilingual
students included the vowel and consonant phonemes as well as linking and coalescent
assimilation as adjustments in connected speech. Within the framework of the Speech Learning
Model represented by the funnel in Figure 1 above, American phonological elements dissimilar
to Filipino is expected to be produced more successfully than similar phonological elements
given that these Filipino-bilingual students have had long-term exposure to American English.
Significance of the Study
Although studies have been focused on English pronunciation among Filipino speakers
such that several textbooks addressing pronunciation needs have been formulated, a look at the
phonological aspects of English pronunciation with American English as a referent has been
missing. Hence, this study can add to the literature on Filipino-English bilinguals in terms of
pronunciation, particularly on the production of phonemes and adjustments in connected
speech. As whole, the results of the study contribute to the field of sociolinguistics, particularly
in the area of phonology under bilingualism. In addition, this study deepens the existing
knowledge and practice of Philippine English as distinct variety of its own. The results of the
study can serve as springboard to further studies on the phonological elements of Philippine
English such that a standard can be established for the phonological aspect of Philippine
English.
This study informs English teachers as well as future English teachers as to the nature
of the phonological outputs of Filipino-English bilinguals. Clear sets of phonological targets
can then be set in the English classrooms in the Philippines. Results on the adjustments in
connected speech can show whether there is a need for the explicit teaching of these
adjustments in connected speech in the Filipino classrooms. However, the choice of whether
the target is the attainment of an American English standard or a nascent phonological system
of Philippine English will depend on a variety of sociolinguistic factors.
Students can derive further knowledge in the areas of bilingualism and phonology from
the results of this study. The results of the study can heighten the awareness of the students on
phonological issues within a bilingual setting like the Philippines. For example, students can
recognize that despite the supposed adherence to American English standards, their first
language still influences their actual productions of the phonemes. Furthermore, appreciation

97
of the existence of adjustments in connected speech in a stress-timed language such as English
can be developed among bilingual students in the Philippines.
Future researchers in the fields of linguistics and education can build on the results of
the study, whether by extending the scope of the study or in varying the methodology. The
research scene in linguistics in the Philippines is marginal, at the least. Studies focusing on
phonetics and phonology in the Philippine setting can be taken to a higher level of engagement
such that a clear linguistic description of Philippine English can be derived in studies similar
to the present study.
Methodology
Research Design
This study made use of both qualitative and quantitative research methods. Qualitative
in part because of the phonemic transcriptions and quantitative due to the statistical tools
utilized to show differences and their significance. The sets of phonemic transcriptions serve
as qualitative data as it is being compared to the standard American English phonemic
transcriptions. The differences in the phonemic transcriptions are presented and form part of
the qualitative analysis. Additionally, basic statistical tools such frequencies and percentages
are presented to show a summary of the results in a numerical form. These numerical data allow
the derivation of trends in the results. Furthermore, inferential statistical tools, such as the two-
tailed t-test and Wilcoxon Signed Rank Test, show significance in the results.
Research Setting
The research setting was a Filipino-speaking community in the southern part of Luzon.
This Filipino-speaking community sits in the province of Cavite, adjacent to Metro Manila.
More specifically, a private university is research site for this study. Established in 2008,
Lyceum of the Philippines University – Cavite is the fifth campus under the Lyceum of the
Philippines University System. The Cavite campus has six colleges and offers a variety of
educational degrees. One of the degrees it offers is the Bachelor of Secondary Education major
in English. With Lyceum of the Philippines University- Cavite only eight years old, its
Bachelor of Secondary Education major in English was offered in its second year. Four batches
of Secondary Education major in English graduates had left the university and took the
Licensure Exam for Teachers with a 100% passing rate in its first batch of graduates. A young

98
degree program in the Lyceum of the Philippines University - Cavite, the Bachelor of
Secondary Education major in English has maintained a small population.
Participants
The participants in this study are ten (10) senior students taking Language Research as
a major course towards the completion of the degree, Bachelor in Secondary Education with
English as a major. These 10 students comprise the total population of senior students in the
university studying the said degree. They were selected as participants for several reasons. For
one, these students will embark on their practice teaching in the second semester of AY 2016-
2017. With this, they will be finding themselves in actual classrooms teaching English to high
school students. Their English pronunciation will be on display. This study then gauged their
American English pronunciation as they are about to enter real classrooms.
All ten participants are within the age range of 19-20 years old with a mean range of
19.5 years old. With two males and eight females, all the respondents have Filipino as their
first language. They went through the regular educational system in the Philippines. Half of the
participants had their first English class during kindergarten while the other had theirs in the
first grade. The school is where they first use English as a language. Six of the participants
indicated that they use English 41%-60% each day while three indicated 21%-40% and a sole
participant indicated 61%-80%. When asked who they usually speak English with on a day-to-
day basis, all ten participants indicated that it is with their teachers. All participants shared that
they do use pronunciation keys or guides in dictionaries to get an idea on how a word is
pronounced and that they are all familiar with the International Phonetic Alphabet.
The ten participants have asked for help with English pronunciation. Eight of the
participants that the help they got was through modeling, which then helped them produce the
correct pronunciation of a word. However, nine participants indicated areas of pronunciation
where they need to work on the most. Only one participant reported that there are no areas of
pronunciation that he/she needs to work on the most. The pronunciation difficulties include
long words, phonemes that are not in the Filipino inventory like θ, f and the schwa. Finally, all
participants claimed to have more experience with American English.
Instruments
Two research instruments were used in this study. The first one was a word list
containing the American English inventory of vowel and consonant phonemes (See Appendix
A). This word list is taken from the book, Teaching American English Pronunciation, written

99
by Avery and Ehrlich (2012). The vowel phone inventory consists of 20 phonemes including
the four r-colored vowels and the schwa. The consonant phone inventory, meanwhile, has 24
phonemes.
The second research instrument was a diagnostic passage presented in the 1996 book
of Celce-Murcia et al. (Refer to Appendix B). This study centered on two adjustments in
connected speech: linking and assimilation. The part on linking focused on two areas. One is
the /y/ glides and the other is the single consonant-vowel linking. In the diagnostic passage,
there are two y-glides and 21 single consonant-vowel linkings. The other adjustment in
connected speech included in the study is assimilation. There are four instances of coalescent
assimilation in the diagnostic passage.
Procedures
Permissions were first requested from the Education Coordinator of Lyceum of the
Philippines University Cavite. Once permission has been granted, the participants were
individually asked if they are willing to be participants in the study. They were given a brief
background of the study followed by a discussion on the instruments and procedures. These
were done before they made their decision either to participate or not to participate. The ten
participants all agreed to be part of the study.
A week later, the ten participants were asked to meet with one of the researchers in a
classroom with an approximate area of 168 square meters. The classroom was divided into two
areas. The first area is where the participants completed the background profile and practiced.
The second area is the recording area where the iPad is placed on a student desk. The
participants were given copies of both instruments along with a short profile questionnaire and
data permission sheet to complete. After the participants had completed both profile
questionnaire and data permission sheet, they were asked to practice reading aloud the word
list and diagnostic passage. The participants were given the right to decide when they were
ready to record. The practice period ranged from five minutes to 30 minutes.
The recording was done through an app in an iPad. Once the participants were ready to
record, they were shown how to work with the controls in the recording app. Each participant,
then, controlled their recording without the researcher hovering nearby. The participants were
asked to state their names twice: before reading the word list as well as before reading the
diagnostic passage. This way, ease in identifying the participants during the transcription stage
was ensured leading to accurate data identification. The ten participants were able to record
both word list and diagnostic passage in one mp3 file.

100
The recordings were then phonemically transcribed using the conventions in the Avery
and Ehrlich (2012) book. The two researchers independently transcribed the recordings to
ensure reliability of the transcriptions. The inter-reliability rates stood at 95.90% for the vowel
and consonant phonemes and 94.28% for the adjustments in connected speech. The word list
consisted of 20 vowel phonemes and 24 consonant phonemes while the diagnostic passage has
four instances of coalescent assimilation and 24 instances of linking. Thus, for each participant,
a total of 71 transcriptions were done. With 10 participants, the total transcriptions amounted
to 710 composed of 440 phonemes and 270 adjustments in connected speech. This number
represented the total number of transcriptions done in the study.
The numbers of appropriately produced phonemes and adjustments in connected speech
were encoded in the software, Statistical Package for the Social Sciences (SPSS) for data
treatment. Skewness ratio and Levene’s test for homogeneity were used to determine whether
the data can be subjected to parametric tests. After subjecting the three sets of data (vowel
phonemes, consonant phonemes and adjustments in connected speech) to the said tests, it was
found out that only the data sets for vowel phonemes and adjustments in connected speech
allow the assumption of a normal curve. Hence, both set of variables can be subjected to the
one-sample t-test using hypothesized and sample means. The data set for the consonant
phonemes was subjected to the nonparametric test, one-sample Wilcoxon Signed Rank Test.
Methods of Analysis
Data for the first research question on the differences between the standard American
English pronunciation and the study participant’s pronunciations of the phonemes are captured
in a table containing the number of correct phonemes produced by each participant with the
overall mean and standard deviation indicated for both vowel and consonant phonemes. The
phonemes incorrectly produced by each participant are then presented in a tabular form. The
second research question on the adjustments in connected speech entails the tabular
presentation of the number of appropriate adjustments in connected speech produced by each
participant as well as the phonetic transcriptions of each adjustments in connected speech. For
the third research question on significant differences, a two-tailed t-test was used at 0.05
significant level for the vowel phonemes and adjustments in connected speech. Wilcoxon
Ranked Sign Test was used for the consonant phonemes as the skewness ratio does not allow
the assumption of normally-distributed data set.

101
Results and Discussion
Production of Vowel and Consonant Phonemes
The differences in the production of vowel and consonant phonemes by the Filipino-
English bilinguals with respect to standard American English is the first question raised in this
study. Table 1 below shows the number of phonemes appropriately produced by the Filipino-
English bilingual students with a mean of 15.60 (N=20) for vowel sounds and 22.80 (N = 24)
for consonant sounds. For the vowel phonemes, the highest number is 19 (95%) appropriately
produced phonemes by one participant while the lowest is 13 (65%) produced by another
participant. On the other hand, one participant appropriately produced all the consonant
phonemes while another participant appropriately produced only 20 (83.33%) consonant
phonemes.
Table 1. Number of Phonemes Appropriately Produced by Filipino-English Bilinguals
Participant Vowel Consonant
f
(N=20)
% f
(N=24)
%
1 19 95 24 100.00
2 15 75 23 95.83
3 16 80 23 95.83
4 15 75 23 95.83
5 18 90 23 95.83
6 15 75 23 95.83
7 13 65 20 83.33
8 16 80 23 95.83
9 16 80 23 95.83
10 14 70 23 95.83
Mean & SD μ = 15.60, SD = 1.897 μ = 22.80, SD = 1.033
Interestingly, the lowest numbers in both vowel and consonant phonemes were
appropriately produced by the same participant. This could mean that among the participants,
this one participant produces American English sounds the least accurately. Observations in
the Language Research classroom by one of the researchers confirms this pronunciation
deviance from American English. In other words, this participant was observed to produce

102
sounds in English that is farthest from the American English variety. As noted by Zampini,
several factors can possibly explain this phenomenon, including but not limited to the
articulatory mechanism, exposure and social factors.
With the figures provided in Table 1, it can be safely said except for the one outlier
participant, most of the participants displayed differences in their production for less than 25%
of the vowel inventory and less than 5% in the consonant inventory. These results corroborate
with the Contrastive Analysis Hypothesis (Zampini, 2008). Given that Filipino consonant
inventory shares a larger number of phonemes that are the same, it has a lower percentage of
differences as produced by the ten participants. On the other hand, the vowel inventory of
American English and Filipino has 25:5 ratio, which means there is a large number of dissimilar
vowel phonemes between the two languages. In fact, the jump from five Filipino vowel
phonemes to 20 American English vowel phonemes lends itself to the Contrastive Analysis
Hypothesis. Hence, a larger percentage of differences have been produced by the participants
when compared to the consonant inventory.
Table 2. List of Phonemes Produced Differently by Filipino-English Bilinguals
Participant Vowel Phonemes Consonant
Phonemes
1 /a/ /ʒ/
2 /I/ /æ/ /ʌ/ /ə/ /uw/ /ʒ/
3 /I/ /æ/ /ə/ /uw/ /ʒ/
4 /I/ /æ/ /ʌ/ /ə/ /uw/ /ʒ/
5 /ə/ /uw/ /ʒ/
6 /æ/ /ə/ /uw/ /ur/ /or/ /ʒ/
7 /I/ /æ/ /ə/ /uw/ /ɔ/ /ʊ/ /er/ /ʒ/ /δ/ /θ/ /v/
8 /I/ /æ/ /ʌ/ /ə/ /ʒ/
9 /I/ /æ/ /ʌ/ /ə/ /ʒ/
10 /I/ /æ/ /uw/ /iy/ /ur/ /or/ /ʒ/
Table 2 summarizes the phonemes produced differently by the Filipino-English
bilingual participants. Aside from the single outlier (Participant 7), the nine participants were
not able to produce /ʒ/ in the word, pleasure. Given that /ʒ/ is not found in the Filipino
inventory, pleasure is produced with an /s/ sound. This /s/ pronunciation of /ʒ/ in pleasure is
common in the Philippines as experiences of both researchers who hail from Luzon and

103
Mindanao affirm. In line with Flege’s Speech Learning Model, similar phonemes are produced
less successfully by the participants in the long run.
Flege’s Speech Learning Model can account for the results in the vowel inventory
produced by the participants. More than half of the participants produced differently similar
phonemes in Filipino and American English. For example, the distinction between long and
short sounds for the letters i and u were mostly interchanged in the results. Thus, the
participants display a difficulty in producing the long and short sounds of the two vowels. In
addition, with Filipino having only one sound for the letter a, which approximates /a/ in
American English, the participants produced differently similar sounds like /æ/, /ʌ/ and the
schwa sound. Consistent with the hypothesis in the Speech Learning Model that dissimilar
sounds are produced successfully in the long run, most of the participants were able to produced
successfully the r-colored vowels, which are absent in the Filipino vowel inventory.
Adjustments in Connected Speech
This study attempted to extend the Speech Learning Model beyond Flege’s (1995)
original hypothesis concerning phoneme production. Hence, it is posited in this paper that the
Speech Learning Model can also explain American English adjustments in connected speech
as produced by Filipino-English bilinguals. The second research question on adjustments in
connected speech in this study concretizes this position. Table 3 shows the frequency and
percentage of adjustments in connected speech present in the data. As can be seen, the number
of adjustments in connected speech ranges from zero to four out of a total of 28 adjustments in
connected speech found in the diagnostic passage read by the participants. These results are
minimal at its best. It can be said then that the results of the study contradict the hypothesis in
the Speech Learning Model that dissimilar elements in the sound repertoire of two languages
is more successfully produced in the long run than in the short run.
Table 3. Adjustments in Connected Speech of Filipino-English Bilinguals
Participant Adjustments in
Connected Speech
Produced adjustments in connected speech
f
(N =28)
%
1 3 12.50 /mæstərdə/ /spiykɛrsəf/ /wIδəwtə/
2 2 8.33 /spiykərsəv/ /gIvap/
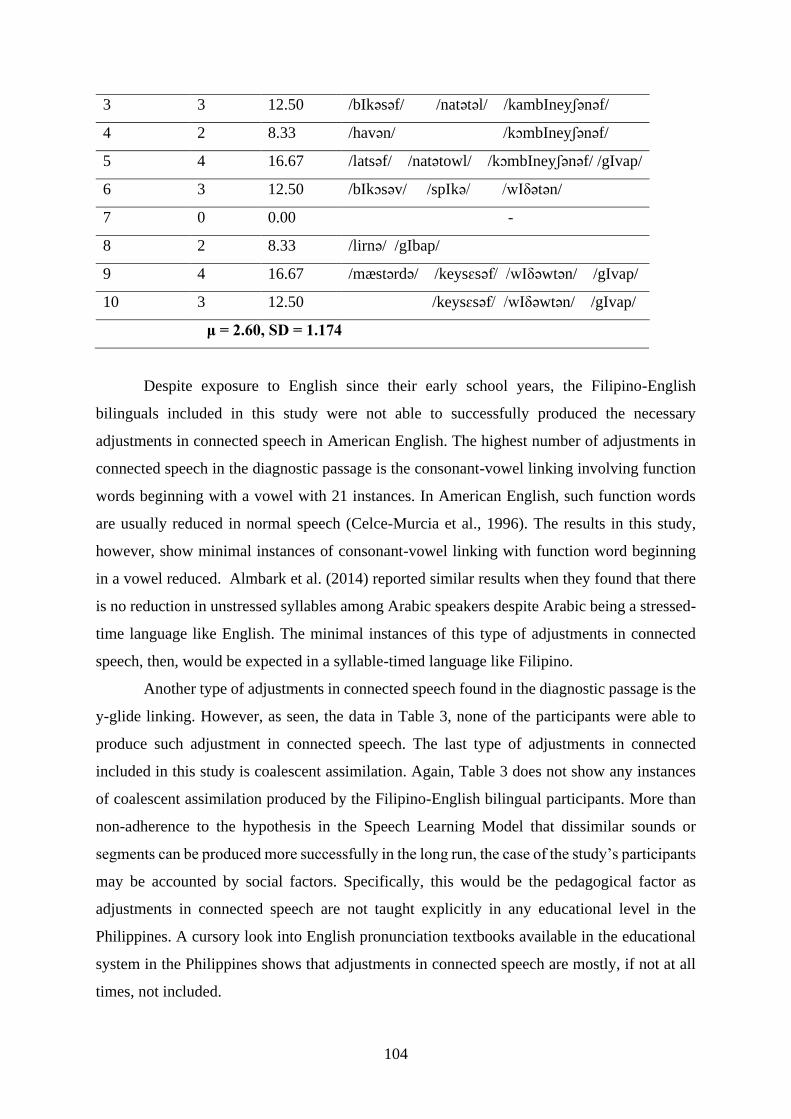
104
3 3 12.50 /bIkəsəf/ /natətəl/ /kambIneyʃənəf/
4 2 8.33 /havən/ /kɔmbIneyʃənəf/
5 4 16.67 /latsəf/ /natətowl/ /kɔmbIneyʃənəf/ /gIvap/
6 3 12.50 /bIkɔsəv/ /spIkə/ /wIδətən/
7 0 0.00 -
8 2 8.33 /lirnə/ /gIbap/
9 4 16.67 /mæstərdə/ /keysɛsəf/ /wIδəwtən/ /gIvap/
10 3 12.50 /keysɛsəf/ /wIδəwtən/ /gIvap/
μ = 2.60, SD = 1.174
Despite exposure to English since their early school years, the Filipino-English
bilinguals included in this study were not able to successfully produced the necessary
adjustments in connected speech in American English. The highest number of adjustments in
connected speech in the diagnostic passage is the consonant-vowel linking involving function
words beginning with a vowel with 21 instances. In American English, such function words
are usually reduced in normal speech (Celce-Murcia et al., 1996). The results in this study,
however, show minimal instances of consonant-vowel linking with function word beginning
in a vowel reduced. Almbark et al. (2014) reported similar results when they found that there
is no reduction in unstressed syllables among Arabic speakers despite Arabic being a stressed-
time language like English. The minimal instances of this type of adjustments in connected
speech, then, would be expected in a syllable-timed language like Filipino.
Another type of adjustments in connected speech found in the diagnostic passage is the
y-glide linking. However, as seen, the data in Table 3, none of the participants were able to
produce such adjustment in connected speech. The last type of adjustments in connected
included in this study is coalescent assimilation. Again, Table 3 does not show any instances
of coalescent assimilation produced by the Filipino-English bilingual participants. More than
non-adherence to the hypothesis in the Speech Learning Model that dissimilar sounds or
segments can be produced more successfully in the long run, the case of the study’s participants
may be accounted by social factors. Specifically, this would be the pedagogical factor as
adjustments in connected speech are not taught explicitly in any educational level in the
Philippines. A cursory look into English pronunciation textbooks available in the educational
system in the Philippines shows that adjustments in connected speech are mostly, if not at all
times, not included.

105
Significant Differences in the Production of Phonemes and Adjustments in Connected
Speech
A question on the significant differences in the production of phonemes and
adjustments in connected speech as produced by Filipino-English bilinguals vis-à-vis
American English completes the set of research questions in this study. To answer this
question, three data sets were subjected to tests of significance: vowel phonemes, consonant
phonemes and adjustments in connected speech.
Table 4. Test of Significant Difference in the Production of Vowel Phonemes
Test Value = 20
t df Sig. (2-tailed) Mean
Difference
95% Confidence Interval of
the Difference
Lower Upper
Vowels -7.333 9 .000 -4.400 -5.76 -3.04
Table 4 contains the test results for vowel phonemes using the one-sample t-test at 0.05
significant level. There is a significant difference in the production of vowel phonemes by
Filipino-English bilinguals (M =15.60, SD = 1.89), t(9) = -7.33, p=0.00. This means that the
production of Filipino-English bilinguals of the vowel phonemes is markedly different from
the standard set in Avery & Ehrlich (2012) for American English. This significant difference
is reinforced by the effect size of 2.31, which means that the difference is larger than two
standard deviations. Hence, there is a considerable deviation from standard American English
in the production of vowel phonemes by the ten Filipino-English bilinguals.
The data set for consonant phonemes was subjected to the one-sample Wilcoxon Signed
rank test. The test result indicated that there is a significant difference in the production of
consonant phonemes by the ten Filipino-English bilinguals (Mdn= 23), p=0.004. Similar to the
vowel phonemes, the production of the ten Filipino-bilinguals of the consonant phonemes
varies significantly from the standard set in Avery and Ehrlich (2012) for American English
consonant phonemes.
Table 5. Test of Significant Difference in the Adjustments in Connected Speech
Adjustments
in Connected
Speech
Test Value = 27
t df Sig. (2-tailed) Mean
Difference
95% Confidence Interval
of the Difference

106
Lower Upper
-65.736 9 .000 -24.400 -25.24 -23.56
For the adjustments in connected speech, the one-sample t-test indicated that there is a
significant difference in the adjustments in connected speech produced by the ten Filipino-
English bilinguals (M = 2.60, SD = 1.174), t(9) = -65.736., p=0.00 (See Table 5) with an effect
size of more than two standard deviations. As the data on adjustments in connected speech
showed earlier, the highest number of adjustments in connected speech among the study
participants stands at four as produced by two participants. This clearly shows that out of the
27 adjustments in connected speech, only a few were produced by the study participants. This
means that adjustments in connected speech is rarely produced among Filipino-English
bilinguals.
Conclusions and Implications to Language Teaching
This study explored the production of phonemes and adjustments in connected speech
among Filipino-English bilingual students with American English as referent. The results could
show the effect of Filipino on the production of English phonemes and adjustments in
connected speech. Focusing on senior education students who majors in English, this study
attempted to gauge their production of the two linguistic phenomena as they embark on their
practice teaching. A limitation of this study is the number of participants, which could be
increased in future studies. In addition, the linguistic community can be expanded to cover
other language groups in multilingual Philippines.
Key to this study are the implications to the language teaching milieu in the Philippines.
Despite the claim of the participants that their exposure is mostly to American English, the ten
participants in this study produced phonemes and adjustments in connected speech that are
markedly different from American English. One consonant phoneme, /ʒ/, were not produced
by all participants. More than lack of exposure, it could pedagogical as students in the
Philippines are mostly exposed to “pleasure” that is pronounced with an /s/. Here, the effect of
Filipino as an L1 can be deduced as the /ʒ/ phoneme is absent in the Filipino consonant
inventory.
Vowel phonemes follow the hypothesis in the Speech Learning Model, which states
that in the long run, it is the dissimilar sounds or sound segments that are produced more
successfully than similar sounds. Similar sounds, such as the long and short vowels in

107
American English, are produced less successfully as exhibited by the production of the ten
participants in this study. There seems to be an inability to distinguish between the short and
vowel sounds. Adjustments in connected speech is minimal in the data set analyzed in this
study. This points toward the absence of explicit teaching of the said phonological feature in
the Philippine classrooms.
While the results in the adjustments in connected speech do not conform with the
Speech Learning Model, the assumptions of model might not have been met in the situation
espoused in the study. For one, the concept of adjustments in connected speech, more often
than not, has been neglected in the English classrooms in the Philippines. In all these, the
Filipino language can be said to has an effect to the production of American English phonemes
and adjustments in connected speech among Filipino-English bilinguals.
The results of the study lead to two directions that can be taken in terms of the phonetic
and phonological aspects of English used in the Philippines. One, Filipino-English bilinguals
can continue to strive to approximate American English with its 20 vowel phonemes, 24
consonant phonemes and give types of adjustments in connected speech identified by Celce-
Murcia et al. (2010). This means to put all the effort needed to obtain an American English
accent. The other direction is the development and maintenance of the Philippine English
phonetics and phonology. This second direction calls for the standardization of Philippine
English, in terms of its phonetic and phonological features. The results of the current study can
contribute to the said standardization where, for example, adjustments in connected speech are
not called for.
The direction that will be taken will strongly influence and will have implications to
the pedagogy of language teaching in the Philippines. If the first direction is taken, i.e., to
approximate American English, then the concept of adjustments in connected speech has to
take center stage in any pronunciation class in Philippine classrooms. Philippine English
teachers would need to gain mastery in these adjustments in connected speech so they can be
appropriate models to their students. In addition, correct pronunciation of English words has to
be ensured so that wrong pronunciation would not be unintentionally spread, which has been
the case for the word, pleasure. Vowel discrimination needs to be intensified as well so that
most, if not all, students can correctly distinguish and produce the different English vowel
phonemes not found in Filipino.
On the other hand, the second direction requires aggressive measures toward the
standardization of the phonetic and phonological features of Philippine English. This direction
is not an easy task as has been illustrated in the struggles toward the acceptance of a world

108
where World Englishes abound. Although Philippine English has been recognized as one
variety of World Englishes, its standardization is still in progress up to the present. As with any
language standardization, it will take generations for it to be actualized. At the least, the
Philippines needs to make a choice between the two directions rather than continue the eclectic
practices in language teaching followed for decades in the country.
References
Almbark, R., Bouchhioua, N., & Hellmuth, S. (2014). Acquiring the phonetics and phonology
of English word stress: Comparing learners from different L1 backgrounds.
Proceedings of the International Symposium on the Acquisition of Second Language
Speech Concordia Working Papers in Applied Linguistics, 5.
Aoki, R., & Nichihara, F. (2013). Sound feature interference between two second languages:
An expansion of the feature hypothesis to the multilingual situation in SLA.
Proceedings of 37th Annual Meeting of the Berkeley Linguistics Society, 18-32.
http://dx.doi.org/10.3765/bls.v37i1.847
Avery, P. & Ehrlich, S. (2012). Teaching American English pronunciation. Oxford University
Press.
Bloomfield, L. (1933). Language. Holt, Rinehart and Winston.
Celce-Murcia, M., Brinton, D., & Goodwin, J. (1996). Teaching pronunciation: A reference
for Teachers of English to speakers of other languages. Cambridge University Press.
Flege, J. E. (1995). Second language speech learning: Theory, findings and problems. In
W. Strange (Ed.), Speech perception and linguistic experience: Issues in cross-
linguistic research (pp. 233-277). York Press.
Flege, J. E. (2015). Origins and development of the speech learning model.
http://www.jimflege.com/files/SLMvancouver_updated.pdf\
Hamers, J., & Blanc, M. (2000). Bilinguality and Bilingualism. Cambridge: Cambridge
University Press.
Hansen-Edwards, J., & Zampini, M. (Eds.), Phonology and second language acquisition. John
Benjamin Publishing Company.
Jose, L., Lemi, L., & Lalunio, L. (2013). Bagong Filipino tungo sa globalisasyon: Aklat sa
wika at pagbasa 1. VIBAL Group, Inc.
Lewis, M., Paul, G. & Fennig, C. (Eds.) (2016). Ethnologue: Languages of the world (19th ed.).
SIL International. https://www.ethnologue.com/guides/how-many-languages
Liddicoat, A. (1991). Bilingualism: An introduction. ERIC.

109
Major, R. (2008). Transfer in second language phonology: A review. In J. Hansen-Edwards, &
M. Zampini (Eds.), Phonology and second language acquisition (pp. 63-94). John
Benjamin Publishing Company.
Marinova-Todd, S., Zhao, J., & Bernhardt, M.(2010). Phonological awareness skills in the two
languages of Mandarin-English bilingual children. Clinical Linguistics and Phonetics,
24 (4-5), 387-400.
Richards, J., & Schmidt, R. (2010). Longman Dictionary of Language Teaching and Applied
Linguistics (4th ed). Pearson Education Limited.
Strange, W. (1999). Levels of abstraction in characterizing cross-language phonetic similarity.
In J.J. Ohala, Y. Hasegawa, D. Granville, & A. C. Bailey (Eds.), Proceedings of the
Fourteenth International Congress of Phonetic Sciences, 2513-2519. New York:
American Institute of Physics.
Speech Learning Model. (n.d.). Info-Sci Dictionary. http://www.igi-
global.com/dictionary/speech-learning-model/56245
Zampini, M. (2008). L2 speech production research: Findings, issues and advances. In Hansen-
J. Edwards, & M. Zampini (Eds.), Phonology and second language acquisition (pp.
219-250). John Benjamin Publishing Company.

110
Rasouli, R., & Nouri, Z. (2021). Task type and fluency aspect of the
productive skills, investigating the probable effects. Linguistics International
Journal, 15(1), 117-137.
Task Type and Fluency Aspect of the Productive Skills,
Investigating the Probable Effects
Rezvan Rasouli
Department of English, Tabriz Branch, Islamic Azad University, Tabriz, Iran
Zahra Nouri
Department of English, Faculty of Persian Literature & Foreign Languages,
University of Tabriz, Tabriz, Iran
Abstract
Performances in task-based activities playing a major role in SLA, are affected by particular
factors among which task type can be recalled. The present study is aimed at investigating the
probable effects of task type on fluency as an aspect of productive skills in general and writing
in particular in an educational area considering TBLT as the model. To set the scene for the
concluding remarks, 50 individuals were chosen through making use of available sampling
method who were given three different types of writing tasks including personal descriptive,
narrative and decision-making tasks, and were asked to write a composition of at least 100
words for each task in 30 minutes. The data analysis was carried out through estimating the
number of the T-units per text. The collected data was entered into the SPSS 16, and within-
subjects and between-subjects ANOVA were used to analyze the data. Considering the
foregoing, the results showed a higher writing fluency in the narrative task for the male
participants; while, a higher writing fluency in the personal descriptive and narrative tasks for
the female participants. The results of between-subjects ANOVA did not show any significant
differences in the writing fluency of both male and female EFL learners in the three task types.
The findings of the present research can be practically implicated in designing and utilizing
tasks for foreign language classroom settings, EFL testing, and SLA research.

111
Keywords: Task type, fluency, writing, TBLT.
Introduction
Starting with CLT (Communicative Language Teaching), it is an approach which has
made the most pervasive modifications to language teaching practice focusing mostly on
transferring messages as the means and eventual objective. One of the CLT’s subsequent
extensions has been Task-Based Language Teaching (TBLT), which is based on using tasks as
the core unit of planning and instruction of language teaching and learning. Nunan (2006)
defines task as a piece of classroom work through which the learners are involved in an
understanding, directing, producing or interacting way in the target language while the
students’ attention is focused on activating their grammatical knowledge in order to express
meaning. To put it simply, task is a teaching tool which can enhance EFL learners’ fluency
development (Albino, 2017). The mentioned tasks can be carried out in two productive skills
including speaking and writing, the latter being marginalized in comparison to the prior one.
Additionally, writing skill is often perceived as the most difficult language skill for majority of
ESL/EFL learners (Richards & Renandya, 2002) since it requires a higher level of productive
language control than other skills (Celce-Murcia & Olshtain, 2000). As Wolf-Quintero et al.
(1998) put, second language writers need to be proficient in a variety of skills in order to write
effectively. Although writing is one of the most important skills in SLA, there are still many
vague points about how to teach it or how to guide learners to become more proficient EFL
writers.
The tasks used in TBLT should be useful for teaching each of the skills, as well as for
writing as one of the main skills. Nunan (1989) believes that using tasks would be beneficial
in teaching writing because they create new and different situations for students and make
language experience easier and more interesting. Meanwhile, CLT as one of the most popular
approaches in the last decades, and TBLT as one of its main branches have instigated several
studies on the effect of different aspects of tasks (e.g., task complexity, task difficulty and task
condition) on EFL learners’ writing performance (Ellis, 2003, 2005, 2009; Long, 2007;
Rahimpour, 2010; Robinson, 2007). However, relatively few studies have been conducted to
investigate the role of different types of tasks in EFL learners’ writing performance (Foster &
Skehan, 1996, 1999; Kuiken & Vedder, 2008; Pourdana et al., 2011; Rimani-Nikou &
Eskandarsefat, 2012). Therefore, the effect of different task types has to be taken into
consideration. The present study aimed to find out the effect of three different types of task
including personal descriptive, narrative and decision-making tasks on fluency aspect of EFL

112
learners’ writing skill. The significance of this study lies in the importance of task type in
second language instruction and syllabus design. As Nunan (1989) constantly declares,
utilizing different types of task opens a window of opportunity for EFL learners to have real-
life interactions. The current research was an attempt to shed more light on the notion of
communicative tasks in EFL language teaching and learning with a specific attention to using
different types of tasks in one of the most complex and critical language skills that is writing.
One of the challenges in working on second language acquisition is to address the need for
maintaining fluency in EFL learners' language. Therefore, the major objective in this study was
to investigate whether different task types will have any significant effects on the fluency
aspect of EFL learners' writing performance.
Literature Review
Since the last decade of the 20th century, Task-Based Approach (TBA), as a new
approach within the communicative framework, has gained enormous popularity in the field of
language teaching and learning. Ellis (2003) declares that tasks hold a central place in current
second language acquisition research and also in language pedagogy. He also believes that
tasks provide evidence of learners’ ability to use their L2 knowledge in real time
communication.
Pourdana et al. (2011) examined the impact of three types of language task which were
topic writing, picture description, and text reconstruction on accuracy, fluency and complexity
aspects of EFL learners' writing performance. The results demonstrated a high degree of
accuracy and complexity in EFL learners' performance on topic writing tasks in comparison to
fluency which was higher in EFL learners' performance on picture description tasks. Rezazadeh
et al. (2011) investigated the effects of two task types on EFL learners’ written production.
Their study addressed the issue of how three aspects of language production (fluency,
complexity, and accuracy) vary among two different task types (i.e., argumentative writing task
and instruction writing task). The findings revealed that the participants in the instruction-task
group performed significantly better than those in argumentative-task group in terms of fluency
and accuracy. Rimani-Nikou and Eskandarsefat (2012) scrutinized the simultaneous effects of
task complexity and task types on EFL learners’ written performance regarding accuracy,
fluency, and complexity. The results of statistical analysis showed that in decision-making
tasks, task complexity had significant effect on accuracy and fluency of learners’ writing, but
it did not have any significant effect on syntactic complexity. Biria and Karimi (2015)
conducted a study on the effects of pre-task planning on the writing fluency of EFL Learners.

113
The results of their study indicated that the essays written by the male students revealed that
pre-task planning improved fluency. On the other hand, the comparison of the essays written
by the females revealed that they produced more fluent texts. Fakhraee Faruji and Ghaemi
(2016) examined the effect of task sequencing on the writing fluency of EFL Learners. The
findings of their study revealed no significant effect for sequencing tasks from simple to
complex on fluency in writing task performance.
Methodology
This is an experimental study with the independent variable being task type. In this
study, three different types of tasks including personal descriptive, narrative, and decision-
making tasks were used. Gender served as a moderating variable and the participants’ gender
was the criterion for grouping them. And writing fluency was a dependent variable. Fifty
intermediate EFL learners of English, from six EFL classes in Tabriz, Iran, were selected as
the participants in this study. They were selected on the basis of their scores in Nelson English
Proficiency test (Fowler & Coe, 1976) which yielded two (one all-male and another all-female)
homogeneous groups. The males’ average age was 21 with the youngest and oldest being 19
and 25, respectively. The females’ age ranged between 20 and 26, and the average age equaled
20. The tasks were piloted with a group of 12 EFL learners similar to the main participants of
the study in advance. Based on the results of piloting, (a) the minimum number of words was
found to be 100, so it was set as the acceptable minimum number of words; and (b) the
minimum and the maximum time needed for writing the tasks were found to be between 25 to
35 minutes, therefore, an average time of 30 minutes was set for the actual writing session.
The participants were selected from a pool of 96 Iranian EFL learners who had been
placed in the intermediate level of English class by either an institutional placement test or a
final examination composing of a written examination and oral interview. At the time of the
data collection, they were studying New Interchange 2 (Richards et al., 2005) and they have
been participating in English classes for at least two years.
Subsequently, 150 written texts were collected, photocopied and given to two raters to
be evaluated in terms of fluency. Both of the raters held MA in the field of ELT, and had
experience in rating EFL writing, they also have been teaching English in various institutes for
more than five years. The researcher had a meeting with the raters prior to giving them the
students’ compositions in order to train them in rating the compositions based on the guidelines
for counting the T-units, taken from Casanave (1994), Polio (1997), Sotillo (2000), and Ahour
et al. (2012). Also, the formula for measuring fluency, which included dividing the total

114
number of words in the written text by the total number of T-units, was explained to them. This
meeting was held in order to make sure that both raters knew exactly what T-units meant and
how to measure fluency, so that they had no difficulties in rating, and were able to rate the
compositions accurately.
The raters assessed the compositions, and returned them to the researcher when they
finished measuring T-units, error-free T-units, and subsequently the fluency for each
composition. Therefore, three scores were obtained by each rater as measures of T-units, error-
free T-units, and fluency. Afterwards, the inter-rater reliability between the two raters was
assessed using the Pearson product-moment correlation coefficient for each of the items (Table
1).
Table 1. Inter-rater Reliability for T-units, Error-free T-units, and Fluency in Three
Task Types
Factor TU EFTU F
Pearson Correlation .97 .83 .94
Sig. (2-tailed) .000 .000 .000
N 150 150 150
Note: TU=T-units, EFTU=Error-Free T-units, F=Fluency, *p<.05
The collected data were entered into SPSS 16.00 for further analysis. In order to test
the first and second null hypotheses, within-subjects ANOVA was used. In order to test the
third null hypothesis, between- subjects ANOVA was employed. The Alpha level for
significance testing was set at 0.05.
For this reason, the study is aimed at addressing the following research questions:
1. Does task type affect male EFL learners' writing fluency?
2. Does task type affect female EFL learners' writing fluency?
3. Is there any significant difference in the writing fluency of male and female EFL
learners in three task types?

115
Findings
The Results of the Proficiency Test
In order to ensure the homogeneity of the groups studied in terms of general
proficiency, the researcher administered Nelson English Proficiency test (Fowler and Coe,
1976). Table 2 shows the descriptive statistics of the participants’ scores on this test.
Table 2. Descriptive Statistics of the Participants’ Scores Using Nelson Test
Factor N Minimum Maximum Mean SD
Participants’ scores 96 27 48 38.38 5.31
Fifty participants whose scores fell between one SD (5.31) above or below the mean
(38.38) were randomly selected and divided into two groups based on their genders (25 males
and 25 females).
Ho 1: Task type does not affect the writing fluency of male EFL learners.
To test the first null hypothesis, the fluency of all the compositions written by male
participants was considered. There were three types of writing tasks, and all the 25 male
participants were required to accomplish each of them. Accordingly, the total number of raw
scores for fluency of the compositions written by male participants was 75 for the three task
types. Within-subjects ANOVA was used to compare their means. Table 3 shows the
descriptive statistics for the fluency of the male participants’ writing performance in the three
different task types.
Table 3. Descriptive Statistics for Fluency of the Male Participants’ Performance in the
Tasks
Fluency Mean SD N
Narrative 6.91 1.81 25
Personal 5.30 1.44 25
Decision 4.51 1.65 25
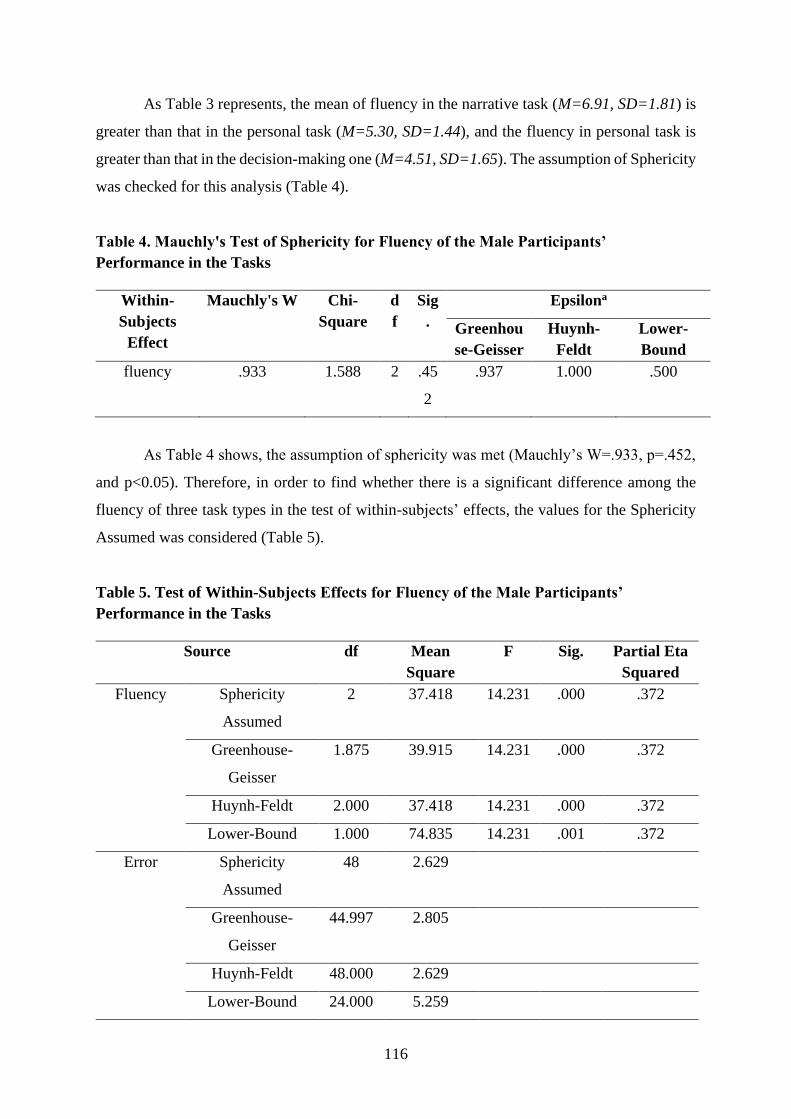
116
As Table 3 represents, the mean of fluency in the narrative task (M=6.91, SD=1.81) is
greater than that in the personal task (M=5.30, SD=1.44), and the fluency in personal task is
greater than that in the decision-making one (M=4.51, SD=1.65). The assumption of Sphericity
was checked for this analysis (Table 4).
Table 4. Mauchly's Test of Sphericity for Fluency of the Male Participants’
Performance in the Tasks
Within-
Subjects
Effect
Mauchly's W Chi-
Square
d
f
Sig
.
Epsilona
Greenhou
se-Geisser
Huynh-
Feldt
Lower-
Bound
fluency .933 1.588 2 .45
2
.937 1.000 .500
As Table 4 shows, the assumption of sphericity was met (Mauchly’s W=.933, p=.452,
and p<0.05). Therefore, in order to find whether there is a significant difference among the
fluency of three task types in the test of within-subjects’ effects, the values for the Sphericity
Assumed was considered (Table 5).
Table 5. Test of Within-Subjects Effects for Fluency of the Male Participants’
Performance in the Tasks
Source df Mean
Square
F Sig. Partial Eta
Squared
Fluency Sphericity
Assumed
2 37.418 14.231 .000 .372
Greenhouse-
Geisser
1.875 39.915 14.231 .000 .372
Huynh-Feldt 2.000 37.418 14.231 .000 .372
Lower-Bound 1.000 74.835 14.231 .001 .372
Error Sphericity
Assumed
48 2.629
Greenhouse-
Geisser
44.997 2.805
Huynh-Feldt 48.000 2.629
Lower-Bound 24.000 5.259
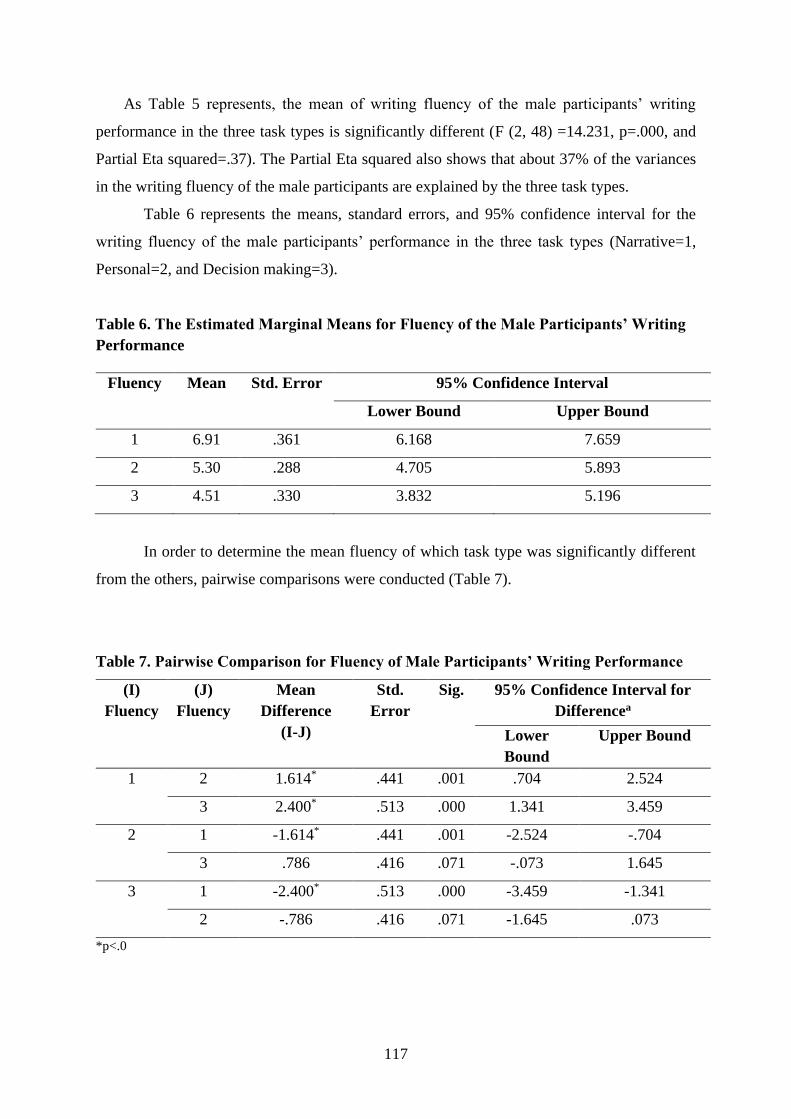
117
As Table 5 represents, the mean of writing fluency of the male participants’ writing
performance in the three task types is significantly different (F (2, 48) =14.231, p=.000, and
Partial Eta squared=.37). The Partial Eta squared also shows that about 37% of the variances
in the writing fluency of the male participants are explained by the three task types.
Table 6 represents the means, standard errors, and 95% confidence interval for the
writing fluency of the male participants’ performance in the three task types (Narrative=1,
Personal=2, and Decision making=3).
Table 6. The Estimated Marginal Means for Fluency of the Male Participants’ Writing
Performance
Fluency Mean Std. Error 95% Confidence Interval
Lower Bound Upper Bound
1 6.91 .361 6.168 7.659
2 5.30 .288 4.705 5.893
3 4.51 .330 3.832 5.196
In order to determine the mean fluency of which task type was significantly different
from the others, pairwise comparisons were conducted (Table 7).
Table 7. Pairwise Comparison for Fluency of Male Participants’ Writing Performance
(I)
Fluency
(J)
Fluency
Mean
Difference
(I-J)
Std.
Error
Sig. 95% Confidence Interval for
Differencea
Lower
Bound
Upper Bound
1 2 1.614* .441 .001 .704 2.524
3 2.400* .513 .000 1.341 3.459
2 1 -1.614* .441 .001 -2.524 -.704
3 .786 .416 .071 -.073 1.645
3 1 -2.400* .513 .000 -3.459 -1.341
2 -.786 .416 .071 -1.645 .073
*p<.0

118
As Table 7 demonstrates, the significance level in the case of fluency between the
narrative and personal descriptive tasks (p=.001), and between the narrative and decision-
making tasks (p=0.000) is lower than alpha level (𝛼 = 0.05). However, the significance level
in case of fluency in the personal and decision-making tasks is higher than alpha level (α =
0.05). Therefore, it can be concluded that task type affects the writing fluency of male EFL
learners’ writing performance.
The significant mean differences between the narrative (M=6.91, SE=.36), and
personal descriptive tasks (M=5.30, SE=.288); and the mean difference between the narrative
and decision-making tasks (M=4.51, SE=.330) are statistically confirmed. However, the mean
difference between the personal descriptive and decision-making tasks is not statistically
significant. Therefore, the first null hypothesis is rejected. Figure 1 illustrates the mean of
fluency of the male participants’ writing performance in the three task types (Narrative=1,
Personal descriptive=2, and Decision making=3).
Figure 1. The Estimated Marginal Means for Mean of Fluency of the Male Participants’
Writing Performance in the Three Task Types
Ho 2: Task type does not affect the writing fluency of female EFL learners.
To test the second null hypotheses, the fluency of all the compositions written by the
female participants was considered. There were three types of writing tasks, and all the 25
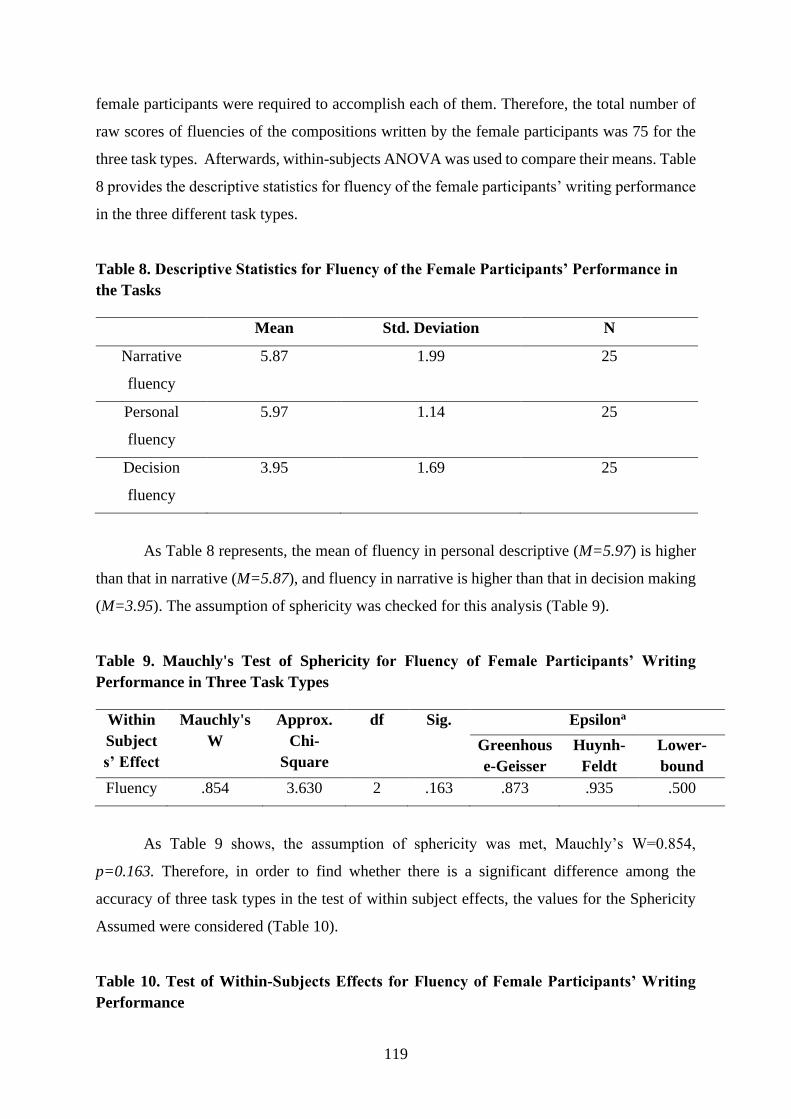
119
female participants were required to accomplish each of them. Therefore, the total number of
raw scores of fluencies of the compositions written by the female participants was 75 for the
three task types. Afterwards, within-subjects ANOVA was used to compare their means. Table
8 provides the descriptive statistics for fluency of the female participants’ writing performance
in the three different task types.
Table 8. Descriptive Statistics for Fluency of the Female Participants’ Performance in
the Tasks
Mean Std. Deviation N
Narrative
fluency
5.87 1.99 25
Personal
fluency
5.97 1.14 25
Decision
fluency
3.95 1.69 25
As Table 8 represents, the mean of fluency in personal descriptive (M=5.97) is higher
than that in narrative (M=5.87), and fluency in narrative is higher than that in decision making
(M=3.95). The assumption of sphericity was checked for this analysis (Table 9).
Table 9. Mauchly's Test of Sphericity for Fluency of Female Participants’ Writing
Performance in Three Task Types
Within
Subject
s’ Effect
Mauchly's
W
Approx.
Chi-
Square
df Sig. Epsilona
Greenhous
e-Geisser
Huynh-
Feldt
Lower-
bound
Fluency .854 3.630 2 .163 .873 .935 .500
As Table 9 shows, the assumption of sphericity was met, Mauchly’s W=0.854,
p=0.163. Therefore, in order to find whether there is a significant difference among the
accuracy of three task types in the test of within subject effects, the values for the Sphericity
Assumed were considered (Table 10).
Table 10. Test of Within-Subjects Effects for Fluency of Female Participants’ Writing
Performance
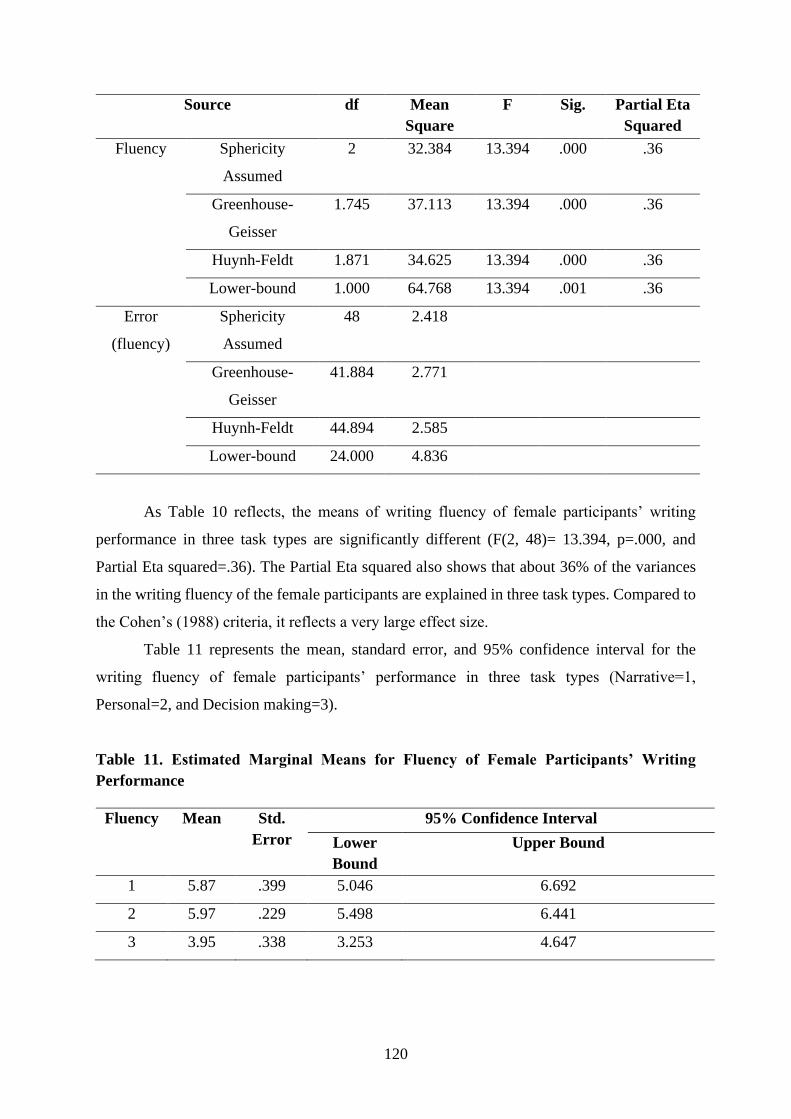
120
Source df Mean
Square
F Sig. Partial Eta
Squared
Fluency Sphericity
Assumed
2 32.384 13.394 .000 .36
Greenhouse-
Geisser
1.745 37.113 13.394 .000 .36
Huynh-Feldt 1.871 34.625 13.394 .000 .36
Lower-bound 1.000 64.768 13.394 .001 .36
Error
(fluency)
Sphericity
Assumed
48 2.418
Greenhouse-
Geisser
41.884 2.771
Huynh-Feldt 44.894 2.585
Lower-bound 24.000 4.836
As Table 10 reflects, the means of writing fluency of female participants’ writing
performance in three task types are significantly different (F(2, 48)= 13.394, p=.000, and
Partial Eta squared=.36). The Partial Eta squared also shows that about 36% of the variances
in the writing fluency of the female participants are explained in three task types. Compared to
the Cohen’s (1988) criteria, it reflects a very large effect size.
Table 11 represents the mean, standard error, and 95% confidence interval for the
writing fluency of female participants’ performance in three task types (Narrative=1,
Personal=2, and Decision making=3).
Table 11. Estimated Marginal Means for Fluency of Female Participants’ Writing
Performance
Fluency Mean Std.
Error
95% Confidence Interval
Lower
Bound
Upper Bound
1 5.87 .399 5.046 6.692
2 5.97 .229 5.498 6.441
3 3.95 .338 3.253 4.647
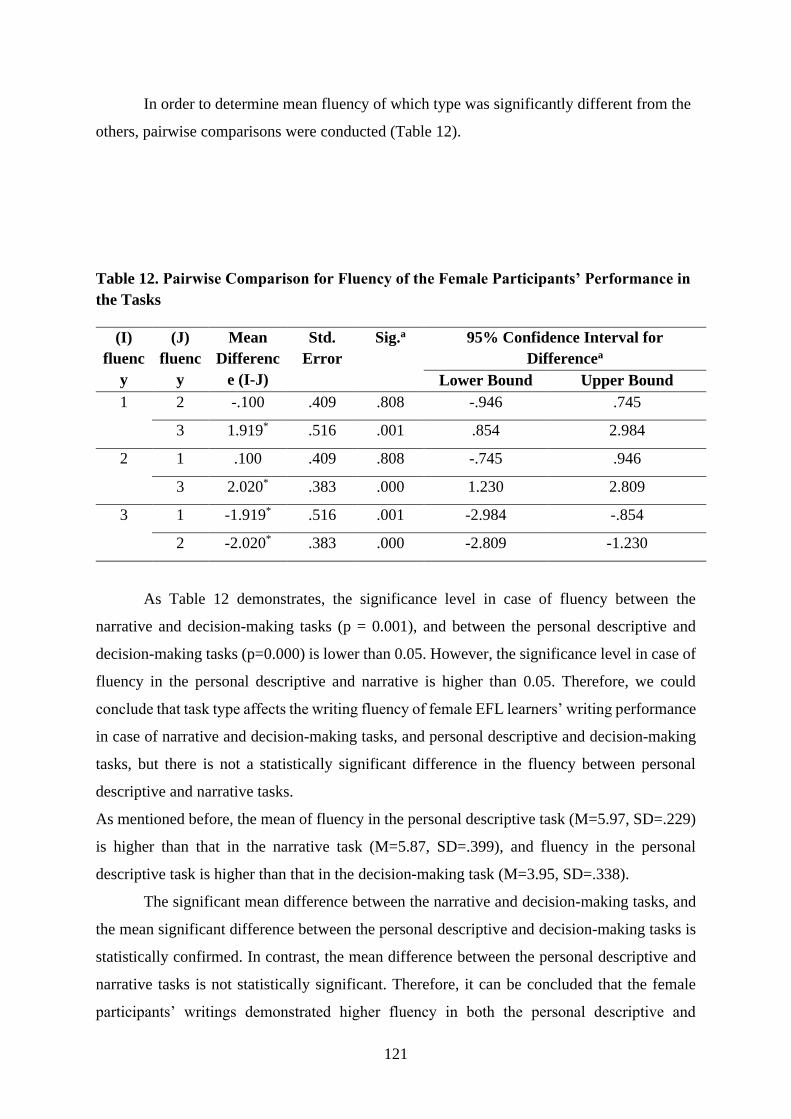
121
In order to determine mean fluency of which type was significantly different from the
others, pairwise comparisons were conducted (Table 12).
Table 12. Pairwise Comparison for Fluency of the Female Participants’ Performance in
the Tasks
(I)
fluenc
y
(J)
fluenc
y
Mean
Differenc
e (I-J)
Std.
Error
Sig.a 95% Confidence Interval for
Differencea
Lower Bound Upper Bound
1 2 -.100 .409 .808 -.946 .745
3 1.919* .516 .001 .854 2.984
2 1 .100 .409 .808 -.745 .946
3 2.020* .383 .000 1.230 2.809
3 1 -1.919* .516 .001 -2.984 -.854
2 -2.020* .383 .000 -2.809 -1.230
As Table 12 demonstrates, the significance level in case of fluency between the
narrative and decision-making tasks (p = 0.001), and between the personal descriptive and
decision-making tasks (p=0.000) is lower than 0.05. However, the significance level in case of
fluency in the personal descriptive and narrative is higher than 0.05. Therefore, we could
conclude that task type affects the writing fluency of female EFL learners’ writing performance
in case of narrative and decision-making tasks, and personal descriptive and decision-making
tasks, but there is not a statistically significant difference in the fluency between personal
descriptive and narrative tasks.
As mentioned before, the mean of fluency in the personal descriptive task (M=5.97, SD=.229)
is higher than that in the narrative task (M=5.87, SD=.399), and fluency in the personal
descriptive task is higher than that in the decision-making task (M=3.95, SD=.338).
The significant mean difference between the narrative and decision-making tasks, and
the mean significant difference between the personal descriptive and decision-making tasks is
statistically confirmed. In contrast, the mean difference between the personal descriptive and
narrative tasks is not statistically significant. Therefore, it can be concluded that the female
participants’ writings demonstrated higher fluency in both the personal descriptive and

122
narrative tasks than that in the decision-making task. Accordingly, the second null hypothesis
is rejected. Figure 2 illustrates the mean fluency of the female participants’ writing
performance in three task types (Narrative=1, Personal descriptive=2, and Decision making=3)
Figure 2. The Estimated Marginal Means for Mean of Fluency of Female Participants’
Writing Performance in Three Task Types
Ho 3: There is no significant difference in the writing fluency of male and female EFL learners
in three task types.
To test the third null hypothesis, between-subjects ANOVA was used to compare their
means. Table 13 shows the descriptive statistics for fluency of both male and female
participants’ written texts in three task types.
Table 13. Descriptive Statistics for Fluency of both Male and Female Participants’
Performance in the Tasks
Factor Group Mean SD N
Fluency
(Narrative)
Male 6.91 1.80 25
Female 5.87 1.99 25
Total 6.39 1.95 50
Fluency
(Personal)
Male 5.30 1.44 25
Female 5.97 1.14 25
Total 5.63 1.33 50

123
Fluency
(Decision-making)
Male 4.51 1.65 25
Female 3.95 1.69 25
Total 4.23 1.68 50
As Table 13 shows, the mean of fluency of the male participants’ narrative writing
(M=6.91,SD=1.80) is higher than that of the female participants’ narrative writing (M=5.87,
SD=1.99), and the mean of fluency of the female participants’ personal descriptive writing
(M=5.97, SD=1.14) is greater than that of the male participants’ descriptive writing (M=5.30,
SD=1.44), and the mean of fluency of the male participants’ decision making writing (M=4.51,
SD=1.65) is greater than that of female participants’ decision making writing (M= 3.95,
SD=1.69). The test of sphericity for this analysis is shown in Table 14.
Table 14. Mauchly’s Test of Sphericity for Fluency of both Male and Female Participants’
Performance in the Tasks
Within-
Subjects Effect
Mauchly's
W
Chi-
Square
df Sig. Epsilona
Greenhouse
-Geisser
Huynh
-Feldt
Lower-
Bound
fluency .899 4.994 2 .082 .908 .962 .500
As Table 14 shows, the assumption of sphericity was met (Mauchly’s W= 0.899,
P=0.082). For this reason, in tests of within-subjects’ effects, the values in Sphericity-Assumed
row are considered for the trial main effect (Fluency) and the interaction effects (Fluency &
Group).
Table 15. Tests of Within-Subjects Effects for Fluency of both Male and Female
Participants’ performance in The Tasks
Source Type III
Sum of
Squares
df Mean
Square
F Sig.
Fluency Sphericity
Assumed
120.051 2 60.025 23.785 .000
Greenhouse-
Geisser
120.051 1.817 66.076 23.785 .000
Huynh-Feldt 120.051 1.924 62.406 23.785 .000
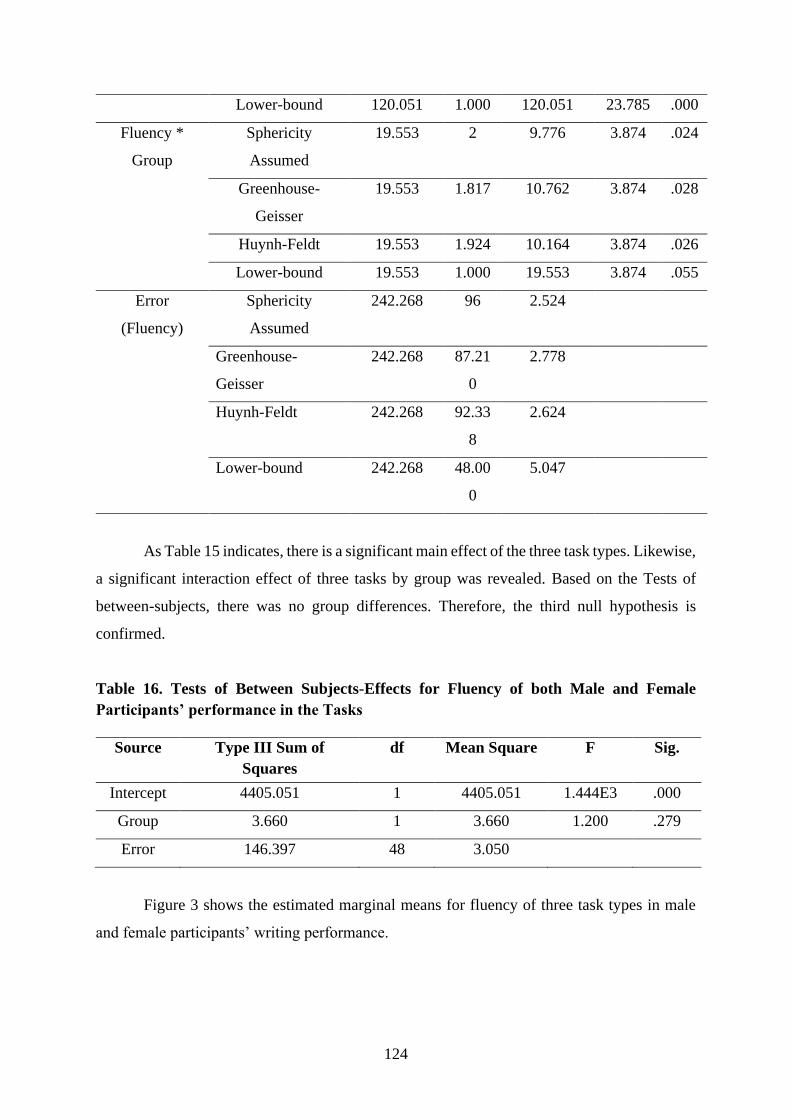
124
Lower-bound 120.051 1.000 120.051 23.785 .000
Fluency *
Group
Sphericity
Assumed
19.553 2 9.776 3.874 .024
Greenhouse-
Geisser
19.553 1.817 10.762 3.874 .028
Huynh-Feldt 19.553 1.924 10.164 3.874 .026
Lower-bound 19.553 1.000 19.553 3.874 .055
Error
(Fluency)
Sphericity
Assumed
242.268 96 2.524
Greenhouse-
Geisser
242.268 87.21
0
2.778
Huynh-Feldt 242.268 92.33
8
2.624
Lower-bound 242.268 48.00
0
5.047
As Table 15 indicates, there is a significant main effect of the three task types. Likewise,
a significant interaction effect of three tasks by group was revealed. Based on the Tests of
between-subjects, there was no group differences. Therefore, the third null hypothesis is
confirmed.
Table 16. Tests of Between Subjects-Effects for Fluency of both Male and Female
Participants’ performance in the Tasks
Source Type III Sum of
Squares
df Mean Square F Sig.
Intercept 4405.051 1 4405.051 1.444E3 .000
Group 3.660 1 3.660 1.200 .279
Error 146.397 48 3.050
Figure 3 shows the estimated marginal means for fluency of three task types in male
and female participants’ writing performance.

125
Figure 3. The Estimated Marginal Means for Fluency of Three Task Types in
Male and Female Participants’ Writing Performance
Discussion
The purpose of this study was to investigate whether the fluency of male and female
EFL learners’ writing performance is affected by the three different task types or not. To
explain and discuss the results of this study, first of all, Skehan’s (1996) criteria for task grading
need to be reviewed. Skehan's (1996) criteria for task grading consist of cognitive complexity
and code complexity. His first criterion, cognitive complexity, covers two areas: cognitive
familiarity and cognitive processing. Based on the criteria, we can categorize the three types of
task used in this study. The personal descriptive task can be considered to have the lowest
cognitive and linguistic demands compared with the narrative and decision-making tasks for
two reasons. First, the participants clearly knew their family members, their personality and
education. Second, the participants were more familiar with the structure of descriptive tasks
than they were with the structure of decision making and narrative writing tasks.
With respect to the second area, cognitive processing, which is the amount of on-line
computation that is required while doing the task (Skehan, 1996), the personal descriptive task
required a smaller amount of on-line computation than the decision making and narrative tasks
for the following reasons. First, the personal descriptive task did not require as many reasoning
operations as the narrative and decision-making tasks. For example, the personal descriptive
task only required the participants to describe their family members; whereas, the decision-
making task required them to come up with reasons to support their positions, and narrative

126
task asked them to understand the story based on the picture strips and explain it to the reader.
Second, regarding the nature of input material used in the task, when undertaking the personal
descriptive task, the participants simply drew on ready-made knowledge since they already
knew their family members. Also, the narrative task can be considered to have lower cognitive
and linguistic demands compared to the decision-making task. Because in the narrative task,
the participants just had to get the story from the picture strips; but in the decision-making task,
they had to consider all the five hotels’ good points and bad points, and finally a carefully
considered choice had to be made. Therefore, from the above discussion based on Skehan’s
(1996) criteria, we can conclude that personal descriptive and narrative tasks can be categorized
as low demanding tasks, and decision-making task can be categorized as high demanding task.
The first and second research questions addressed the effects of task type on the writing fluency
of male and female learners. Male EFL learners showed increased fluency on narrative writing
compared to the personal descriptive and decision-making writing, respectively.
Regarding female EFL learners, the results showed that their writing fluency is more in
both narrative and personal descriptive tasks than decision making task. This finding may be
explained on the basis of writing process. Participants could use more words and longer
sentences when they performed their writing for the low cognitive and linguistically demanding
tasks. This seems reasonable, given that these types of tasks require simpler language (i.e.,
vocabulary and grammatical structures) than decision making tasks. This finding is consistent
with the results of previous studies conducted by Foster and Skehan (1996). Furthermore, the
findings of this study are in agreement with the results the study carried out by Pourdana et al.
(2011) who examined the impact of three types of language on accuracy, fluency and
complexity aspects of EFL learners' writing performance and reported that EFL learners
perform differently in different writing task types. The results of their study demonstrated a
high degree of accuracy and complexity in EFL learners' performance on topic writing tasks
compared with fluency which was higher in EFL learners' performance on picture description
tasks. Considering Skehan’s (1996) criteria for task grading, we can categorize topic writing
and picture description tasks as low demanding than text reconstruction task.
Conclusion
The purpose of the present study was to provide insight into the effects of task type on
the fluency of EFL learners’ writing performance. The general finding of the study
demonstrates that there is statistically significant effect of task type on intermediate male and
female writing fluency. The results showed that different types of task lead to different

127
operations carried out within the tasks, and that these have an impact on performance.
Regarding gender, the findings of this study rejected any significant effect on intermediate EFL
learners’ writing performance. Taken together, the results of this study showed the significant
role of tasks on EFL writing and their usability in promoting writing fluency of intermediate
EFL learners. EFL teachers and syllabus designers are the people who can benefit from the
findings of this study. The findings provide insights on designing and implementation of tasks
in EFL classroom settings. Being aware of the effects of different task types on the learners
with different genders would enable the language teachers and syllabus designers to choose the
most appropriate task type to be implemented in second language classroom setting in order to
get better results in language learning. Moreover, in the case of enhancing intermediate female
EFL learners' writing fluency, both narrative and personal descriptive tasks would be
appropriate activities.
The writing performance of intermediate learners was scrutinized in this study.
Therefore, the writing performance of learners at other levels of proficiency can also be a
worthwhile issue to be examined, and it would be useful for future studies to examine other
aspects of performance such as complexity, concept load, and lexical density as well.
References
Ahour, T., Mukundan, J., & Rafik-Galea, Sh. (2012). Cooperative and individual reading: The
effects on writing fluency and accuracy. The Asian EFL Journal Quarterly, 14(1), 47-
99.
Albino, G. (2017). Improving speaking fluency in a task-based language approach: the case of
EFL learners at PUNIV-Cazenga. Sage Open, 2, 1-11.
Biria, R. & Karimi, Z. (2015). The Effects of Pre-task Planning on the Writing Fluency of
Iranian EFL Learners. Journal of Language Teaching and Research, 6(2), 357-365.
Casanave, C. P. (1994). Language development in students’ journals. Journal of Second
Language Writing, 3(3), 179-201.
Celce-Murcia, M. & Olshtain, E. (2000). Discourse and context in language teaching: A guide
for language teachers. Cambridge University Press.
Ellis, R. (2003). Task-based language learning and teaching. Oxford University Press.
Ellis, R. (2005). Planning and task-based research: Theory and research. In R. Ellis (Ed.),
Planning and task performance in a second language (pp. 3-34). John Benjamins.

128
Ellis, R. (2009). The differential effects of three types of task planning on the fluency,
complexity, and accuracy in L2 oral production. Applied Linguistics, 30(4), 474-509.
Fakhraee Faruji, L. & Ghaemi, F. (2016). The Effect of Task Sequencing on the Writing
Fluency of English as Foreign Language Learners. Journal of Language and
Translation, 6(12), 37-52.
Foster, P., & Skehan, P. (1996). The influence of planning on performance in task-based
learning. Studies in Second language Acquisition, 18(3), 299-324.
Kuiken, F., & Vedder, I. (2007). Task complexity and measures of linguistic performance in
L2 writing. International Review of Applied Linguistics, 45(3), 261-284.
Long, M. (Ed.) (2007). Problems in SLA. Erlbaum.
Larsen-Freeman, D. (2006). The emergence of complexity, fluency, and accuracy in the oral
and written production of 5 Chinese learners of English. Applied Linguistic, 27(4), 590-
619.
Nunan, D. (2006). Task-based language teaching in the Asia context: Defining ‘task’. Asian
EFL Journal, 8(3), 1-298.
Nunan, D. (1989). Designing tasks for the communicative classroom. Cambridge University
Press.
Pourdana, N., Karimi Behbahani, S. M., Safdari, M. (2011). The impact of task types on aspects
of Iranian EFL learners' writing performance: Accuracy, fluency, and complexity.
International Conferences on Humanities, Society and Culture, 2, 261-265.
Polio, C. G. (1997). Measures of Linguistic accuracy in second language writing research.
Language Learning, 47(1), 101-143.
Rimani-Nikou, F., & Eskandarsefat, Z. (2012). The simultaneous effects of task complexity
and task types on EFL Learners’ written performance. Australian Journal of Basic and
Applied Sciences, 6(7), 137-143.
Rahimpour, M. (2010). Current trends on syllabus design in FL instruction. Procedia Social
and Behavioral Sciences. Vol. 2. pp: 1660-64.
Rezazadeh, M., Tavakoli, M., & EslamiRasekh. A. (2011). The Role of Task Type in Foreign
Language Written Production: Focusing on Fluency, Complexity, and Accuracy.
International Education Studies, 4(2), 169-176.
Richards, J. C., Hull, J., Proctor. S. (2005). Interchanges (third edition). Cambridge University
Press.
Richards, J. C. and W. A. Renandya (2002). Methodology in Language Teaching: An
Anthology of. Current Practice. Cambridge University.

129
Robinson, P. (2007). Task complexity, theory of mind, and intentional reasoning: Effects on
L2 speech production, interaction, uptake and perceptions of task difficulty.
International Review of Applied Linguistics, 45(3), 193-213.
Storch, N. (2009). The impact of studying in a second language (L2) medium university on the
development of L2 writing. Journal of Second Language Writing, 18(2), 103-118.
Skehan, P. (1996). A framework for the implementation of task-based instruction. Applied
Linguistics, 17(1), 38-62.
Skehan, P. & Foster, P. (1999). The influence of task structure and processing conditions on
narrative retellings. Language Learning, 49(1), 93-120.
Sottilo, S. M. (2000). Discourse functions and syntactic complexity in synchronous and
asynchronous Communication. Language Learning and Teaching, 4(1), 82-119.
Wolf-Quinterio, K. Inagaki, S., & Kim, H.Y. (1998). Second Language Development in
Writing: Measuring of fluency, accuracy, and complexity. Hawaii University Press.

130
Labra, A.A.D. (2021). Linguistic and social factors conditioning coda /s/
variation in the Spanish of Mendoza, Argentina. Linguistics International
Journal, 15(1), 138-150.
Linguistic and social factors conditioning coda /s/ variation in the
Spanish of Mendoza, Argentina
Andres A. D. Labra
Saint Louis University
Abstract
Coda /s/ variation has been studied in diverse Spanish-speaking communities of Latin America,
namely Argentina, Chile, and Panama among others. Previous studies have proven that the
elision, aspiration, and retention of /s/ might be conditioned not only by the location of the
variable in the clause and the surrounding sounds, but also by extra-linguistic factors such as
sex, age, and education level. This study aims to provide a preliminary approach to coda /s/
variation of the Spanish of Mendoza, Argentina. Eight natives were interviewed on Zoom and,
through the reading of a passage, the results were encoded using the articulatory phonetic
technique (Diaz-Campos, 2014). Preliminary findings show both linguistic and social factors
condition the variable: Mendocinians prefer the aspirated variant in coda position within the
word, while its realization seems to be preferred by males and by younger generations.
Keywords: Coda /s/ variation, aspiration, elision, retention, Mendoza, Argentina, Spanish,
social factors, linguistic factors
Introduction
Coda /s/ variation has been explored in many Latin American cities from countries such
as Panama, Chile and Argentina among others, which has shown linguistic variation not only
in terms of the relationship between phoneme /s/ clause position and its phonological
surroundings, but also between the phoneme and extra linguistics factors such as age, sex, and
education level. Such a statement is confirmed through carefully designed research carried out
in those countries. Examining interviews with four participants, Cid-Hazard (2003) analyzes
the retention, aspiration, and deletion of the phoneme /s/ and the situational context in which

131
the phonetic occurrence takes place in the Spanish of Santiago, Chile. In terms of formal and
informal situations, the author comes to the conclusion that the elided form is the preferred
variant in informal situations, while formal situations favor the sibilant form. This study also
claims that the aspirated variant is preferred in all situations regardless of their degree of
formality. As for age and the use of the variable /s/, it is shown that adults prefer the sibilant
variant while the young participants choose the elided one. Men tend to elide the variable, while
women tend to aspirate and retain the variable. Retention and elision take place at the end of
the word in coda position, while the aspiration of /s/ is favored within the word in coda position.
As for the three possible /s/ variants in the Spanish of Panama, Diaz Campos (2014)
cites a study undertook by Cedergren aimed at explaining the occurrence of aspiration, elision
or sibilant pronunciation in relation to possible linguistic contexts -position of the variable,
phonetic context and morpheme- and social contexts -sex, age, socioeconomic level and origin
of the participant-. A correlation was found between the variants and sex (males use the elided
variant while females tend to produce aspiration), age (young people prefer aspiration over
elision while older people do the opposite) and socioeconomic level (the lower the social class
is, the more frequent the aspirated and elided variants are).
Similar social and linguistics factors were considered in several studies conducted in
cities such as Buenos Aires, Rosario, La Plata, Bahía Blanca in Argentina and Montevideo,
Uruguay (Correa & Couto, 2012). Participants with college education and those who belong to
upper social class exhibit a preference for the aspirated form in a restricted linguistic context
namely before a consonant in contrast to the sibilant preference found before vowels or pauses.
The realization of /s/ as the elided form at the end of a word before a pause may be restricted
to informal conversations between speakers with elementary education and yet not found in
speakers with higher education (Coloma & Colantoni, 2012)1.
Regarding Porteño Spanish (Terrell, 1978), it was shown that aspiration takes place
when the phoneme /s/ occurs inside the word, except when the phoneme is preceded by the
dental, voiceless /t/ sound. In the latter case, the phoneme is realized as the sibilant or elided
variant. According to the findings, it is more likely that both the sibilant and elided forms occur
when the variable is at the end of a word in coda position than when it is within the word; or
that the elided form takes place before a pause. Terrell did not find any correlation between the
1 The main focus of Coloma & Colantoni’s research is the study of two musical genres. Certain studies affirmed
that singers adapt themselves to the audience they want to identify with, being Tango a genre that prefers aspiration
while Rock tends to retain the sibilant. This shows that the Buenos Aires audience tend to use the aspirated variants
over the sibilant.

132
sex of the participants and the use of one variant over the other: “antes de llegar a conclusiones
sobre el efecto del sexo del hablante en la retención de la sibilante o su elisión en Argentina,
habrá que hacer estudios mucho más extensos que estos dos” [Before coming to conclusions
about the effect of the participant’s sex on the sibilant retention or its elision in Argentina, more
extensive studies than these two should be done] (Terrell 50). The author concludes there are
more aspirated instances than elided ones in the Porteño Spanish of Argentina.
Geographically speaking, Mendoza is located in the center of Argentina, between two
main cities of great importance in terms of population size and dialects: Santiago, Chile and
Buenos Aires. Mendoza natives constantly interact with Chileans as the border of the province
in the Andes serves as a gate for people to enter and leave the country for tourism, commerce,
and immigration purposes among other reasons. Mendoza also belongs to the Argentinian
territory in terms of its Italian heritage, which may also condition the use of the phoneme /s/
variants as stated by Lipsky: “In Argentina and Uruguay, elision of word-final /s/ was once
associated with the speech of Italian immigrants, who interpreted the weakly aspirated
Argentine and Uruguayan /s/ as the absence of a consonant, aided by the many cognate words
in Italian lacking a final /s/” (Lipski, 2011).
It is evident, through the lenses of the studies mentioned above, that the phoneme /s/ may
be realized as aspirated, sibilant, or elided in the syllabic position of coda, within a word or at
the end of the word and that other social factors may condition the use of one variant over the
other. It can be predicted that Mendoza Spanish also follows the /s/ aspiration rule within the
word, while the sibilant variant may be retained at the end of the word. Age, education level
and sex might also condition the variable. The purpose of this preliminary study based on the
Spanish of Mendoza, Argentina is to obtain general data and draw some conclusions about /s/
variation and possible correlation to linguistic and social factors: Which variant is most used
in the Spanish of Mendoza, Argentina? What linguistic or extralinguistic factors condition the
use of one variant over the other?
Methodology
Eight Mendocinian participants were chosen for this study, all of them born and
currently living in the province by the time the interview was done, five women and three men.
They were invited to participate by completing a Google form doc, in which it was briefly
explained to them what the research encompasses as well as the steps to take to participate.
They were also asked questions about their age, education level, and sex, and finally were asked
to agree to the terms of the study by submitting the form.

133
Based on the data collected, one participant was less than eighteen, two participants
between the age of nineteen and twenty-eight, three participants between twenty-nine and forty,
one participant between forty-one and fifty and one over fifty. As for their education level, two
participants completed elementary education, while four participants claimed to have finished
high-school and two earned a college degree.
The study consists of an individual and formal one-hour Zoom meeting in which each
participant is asked a few questions and are shown a text sample on the shared screen. The first
part of the interview aims to perceive the presence of /s/ aspiration through random questions
and to find out more about the participant’s background. The second part consists of reading a
text out loud while being recorded. Although some participants had the chance to practice the
text before the Zoom meeting, they were unaware of what sound was specifically under study
and were asked to read the text at a speed natural for them.
The text sample is a fragment of Argentine writer Manuel Puig’s novel’s El beso de la
mujer araña that contains a total of 299 /s/ occurrences. After recording all of the participants,
I proceeded to randomly select a few sentences -with a total of 151 tokens- for each of the
following independent variables as described below.
Under the linguistic umbrella, the position of the phoneme in the word and its
relationship with neighboring sounds will be studied. Some examples with the phoneme /s/
were selected to measure the sibilant [s], aspirated [h] and elided [Ø] variants within the word
or at the end of the word followed either by a vowel or a consonant such as:
“Es el minuto fatal, porque él sale y la espera y la espera y ella nunca más aparece”
“La noche debe terminar sin que él sepa quién es ella, y sin que ella sepa quién es él”
“Empezó su carrera en teatros de revistas”
The position of the phoneme in relation to the sentence itself will be also considered
for this study. It involves the phoneme /s/ followed by a pause (comma or period); a succession
of coda /s/ within a single nominal phrase without pauses; and a succession of /s/ as part of an
enumeration, within a nominal phrase and with pauses as shown below:
“Le dice que todos los hombres son iguales, que ella no es una cosa”
“[…] tomando champagne con un solitario rarísimo, ya no le queda duda de quién es.”
“De montones de pañuelos atados a la cintura”
“él le dice que se vaya con él, que deje todo, joyas, pieles, vestidos, magnate, y lo siga.”

134
Under the extralinguistic umbrella and based on the collected Google forms,
information about participants’ age, sex and education level could be gathered and organized
as followed:
▪ Age: less than 18, 19-28, 29-40, 41-50, Over 50
▪ Sex: male, female
▪ Education level: elementary, secondary, college
The data was collected and organized in an Excel doc. The sounds under study were
measured using the auditory method also known as the articulatory phonetic technique (Diaz
Campos, 300). Thus, the range of sounds perceived as sibilant and aspirated ([h][s]) or as
aspirated and elided ([Ø][h]) were encoded between parenthesis and were not counted for the
results as they still need to be measured through the acoustic phonetic technique in future
studies (Diaz Campos 300). There was one case in which the participant omitted the word that
contained the study variable. In this case, it was not counted for the results and is encoded and
represented by the symbol [x].
Finally, the data was collected, analyzed, and coded, comparing the data to previous
studies. After that, the conclusions were made based on the information collected, specific
implications for the field were mentioned, and areas that need further analysis are subsequently
explained.
Results
[s], [h] or [Ø]?
Table 1. Average Use of Variants
[s] [h] [Ø]
66 83 2
Total Tokens: 151
As shown in Table 1, there are more cases of the aspirated variant, but scarce samples
of elision in this study. If we consider the Zoom interview as a formal situation in which
participants read a previously rehearsed text, regardless of the degree of confidence between
the participants and the interviewer, then this result contrasts with Cid-Hazard’s findings about
the Spanish of Santiago, in which the sibilant variant was the most preferred form in formal
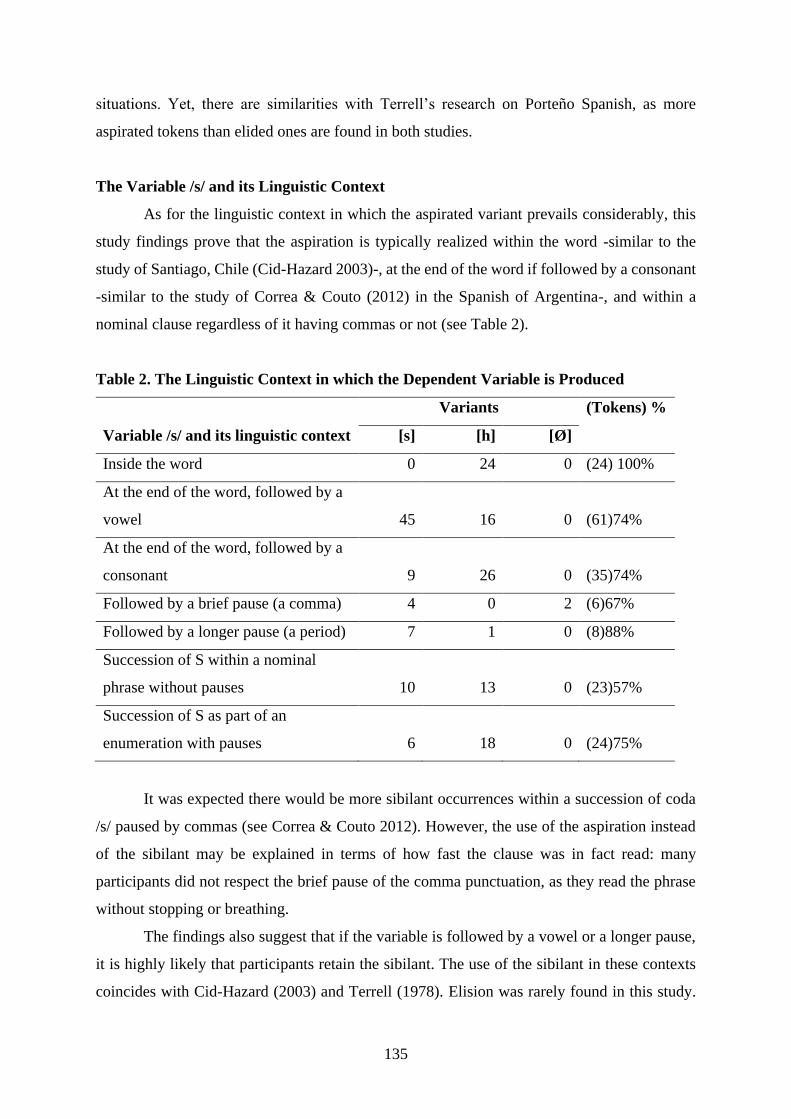
135
situations. Yet, there are similarities with Terrell’s research on Porteño Spanish, as more
aspirated tokens than elided ones are found in both studies.
The Variable /s/ and its Linguistic Context
As for the linguistic context in which the aspirated variant prevails considerably, this
study findings prove that the aspiration is typically realized within the word -similar to the
study of Santiago, Chile (Cid-Hazard 2003)-, at the end of the word if followed by a consonant
-similar to the study of Correa & Couto (2012) in the Spanish of Argentina-, and within a
nominal clause regardless of it having commas or not (see Table 2).
Table 2. The Linguistic Context in which the Dependent Variable is Produced
Variable /s/ and its linguistic context
Variants (Tokens) %
[s] [h] [Ø]
Inside the word 0 24 0 (24) 100%
At the end of the word, followed by a
vowel 45 16 0 (61)74%
At the end of the word, followed by a
consonant 9 26 0 (35)74%
Followed by a brief pause (a comma) 4 0 2 (6)67%
Followed by a longer pause (a period) 7 1 0 (8)88%
Succession of S within a nominal
phrase without pauses 10 13 0 (23)57%
Succession of S as part of an
enumeration with pauses 6 18 0 (24)75%
It was expected there would be more sibilant occurrences within a succession of coda
/s/ paused by commas (see Correa & Couto 2012). However, the use of the aspiration instead
of the sibilant may be explained in terms of how fast the clause was in fact read: many
participants did not respect the brief pause of the comma punctuation, as they read the phrase
without stopping or breathing.
The findings also suggest that if the variable is followed by a vowel or a longer pause,
it is highly likely that participants retain the sibilant. The use of the sibilant in these contexts
coincides with Cid-Hazard (2003) and Terrell (1978). Elision was rarely found in this study.

136
Still, there were seven barely perceptible tokens [([Ø][h]) or ([s][Ø])]. They cannot be included
as complete elision in this research results and cannot be studied through an auditory analysis
(See Appendix for more information).
The Variable /s/ and its Social Factors
Figure 1. Phoneme /s/ and Sex (Tokens)
Figure 1 illustrates how both female and male participants make frequent use of the
aspirated variant, though it is relevant to say that males correspond to the highest preference
group for aspiration, as there are fewer male participants than females. Only the female group,
however, seems to elide the sibilant when the phoneme is located at the end of the word. This
is the opposite of the Spanish of Chile (Cid-Hazard 2003) and the Spanish of Panama (Diaz
Campos 2014), where men prefer elision and women prefer aspiration and retention of the
sibilant. Still, the number of participants is limited in this study and more males and females
should be interviewed in order to generalize possible correlations, as Terrell also suggested in
his study of the Porteño Spanish.
Regarding age, participants that are in the fourteen (below eighteen-years of age) to
forty age range seem to have a preference for the aspirated variant, but it gradually descends
as age increases, the sibilant retention being the preferred realization for adults over forty years
old (see Figure 2 below). Young people corresponding to both “less than 18” and “19 to 28”
groups appear to have the highest usage of aspiration. Adults preferring sibilant retention seems
to coincide with the Spanish of Santiago (Cid-Hazard 2003), while young people preferring
aspiration relates to the study of the young speakers from Panama (Diaz Campos 2014).
0% 10% 20% 30% 40% 50% 60%
/s/
/h/
/Ø/
Female (92) Male (59)
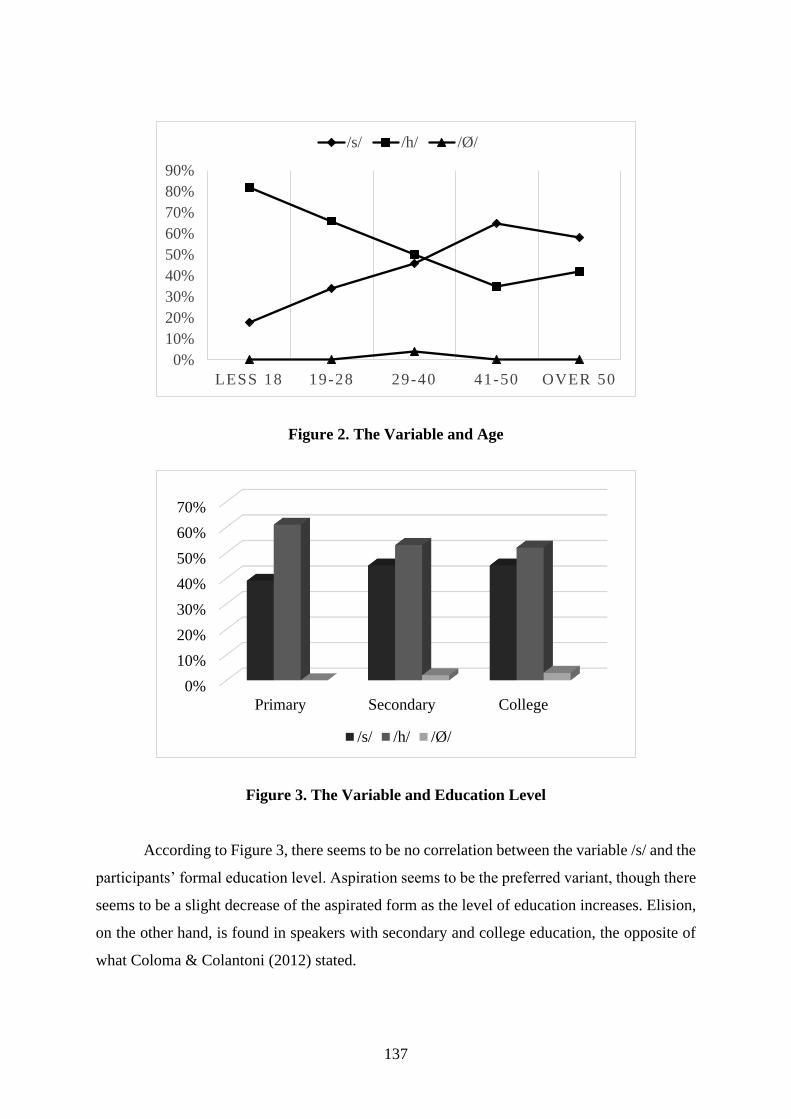
137
Figure 2. The Variable and Age
Figure 3. The Variable and Education Level
According to Figure 3, there seems to be no correlation between the variable /s/ and the
participants’ formal education level. Aspiration seems to be the preferred variant, though there
seems to be a slight decrease of the aspirated form as the level of education increases. Elision,
on the other hand, is found in speakers with secondary and college education, the opposite of
what Coloma & Colantoni (2012) stated.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
LESS 18 19-28 29-40 41-50 OVER 50
/s/ /h/ /Ø/
0%
10%
20%
30%
40%
50%
60%
70%
Primary Secondary College
/s/ /h/ /Ø/

138
Conclusion
This pilot study has shown that Spanish speakers from Mendoza use the aspirated
variant more frequently than the sibilant variant for coda /s/ in any clause position. As assumed
before carrying out this study, aspiration occurs within the word in coda position or at the end
of the word in coda position before a consonant. Elision seems not to be an important feature
of the Spanish of Mendoza. Social factors also play an important role when conditioning coda
/s/. Women tend to elide more than men, while men tend to realize aspirated tokens more
frequently than women. Young people prefer aspiration, while adults over forty tend to retain
the sibilant. Education level seems not to correlate with the three possible variants, though
aspiration is used at all levels.
These preliminary findings may contribute to the Sociolinguistics field as they seem to
explain not only the existence of /s/ variation in Mendoza, but it may also reveal that speakers
from different generations prefer variant α over variant β: “La observación del habla en
situaciones cotidianas permite que se pueda estudiar la variación linguística, su estratificación
social y entender los procesos de cambios linguísticos” [The observation of everyday speaking
situations allows us to study linguistic variation, social stratification and allows us to
understand linguistic change processes] (Diaz-Campos, 2014, p65). Besides, it seems there are
not available studies about /s/ variation specifically in Mendoza, Argentina, which
prospectively makes this pilot study be a great contribution in the field of Sociophonology. It
also gives Second Language instructors insight about how to teach the pronunciation and/or
production of coda /s/ aspiration in the classroom, and in what linguistic or social contexts it
may take place.
This study also has its limits: in order to generalize, more participants are needed. It
explored the variable realization through the reading of a text in a formal context, but other
contexts should be provided, such as a constant interaction with more participants through
social media -an informal context- that allows an analysis of spontaneous, non-rehearsed
tokens. More social factors should be taken into account, such as socioeconomic information
about the participants. As for the linguistic variables, besides analyzing the position of the
phoneme in the word, it should be specified other contexts such as the type of consonant or
vowel that follows the phoneme in both positions (within the word, at the end of the word), the
grammar category of word that carries the phoneme (is it a noun, a verb, an article, etc.?), as
well as word function (Terrell, 52) and frequency.

139
References
Cid-Hazard, S. M. (2003). Variación de estilo en relación a la variable fonológica/s/en el
español de Santiago de Chile. Southwest Journal of Linguistics, 22(2), 13-44.
Coloma, G., & Colantoni, L. (2012). Variación fonética y el efecto de la audiencia: el
debilitamiento de/s/en dos géneros musicales. RLA. Revista de lingüística teórica y
aplicada, 50(2), 121-143.
Correa, P., & Rebollo Couto, L. (2012). Sociolingüística rioplatense: principales fenómenos de
variación. Español actual, 161, 213.
Díaz-Campos, M. (2014). Introducción a la sociolingüística hispánica. John Wiley & Sons.
Lipski, J. M. (2011). Socio-phonological variation in Latin American Spanish. The handbook
of Hispanic sociolinguistics, 72-97.
Terrell, T. D. (1978). La aspiración y elisión de/s/en el español porteño. Anuario de Letras:
Lingüística y filología, (16), 41-66.
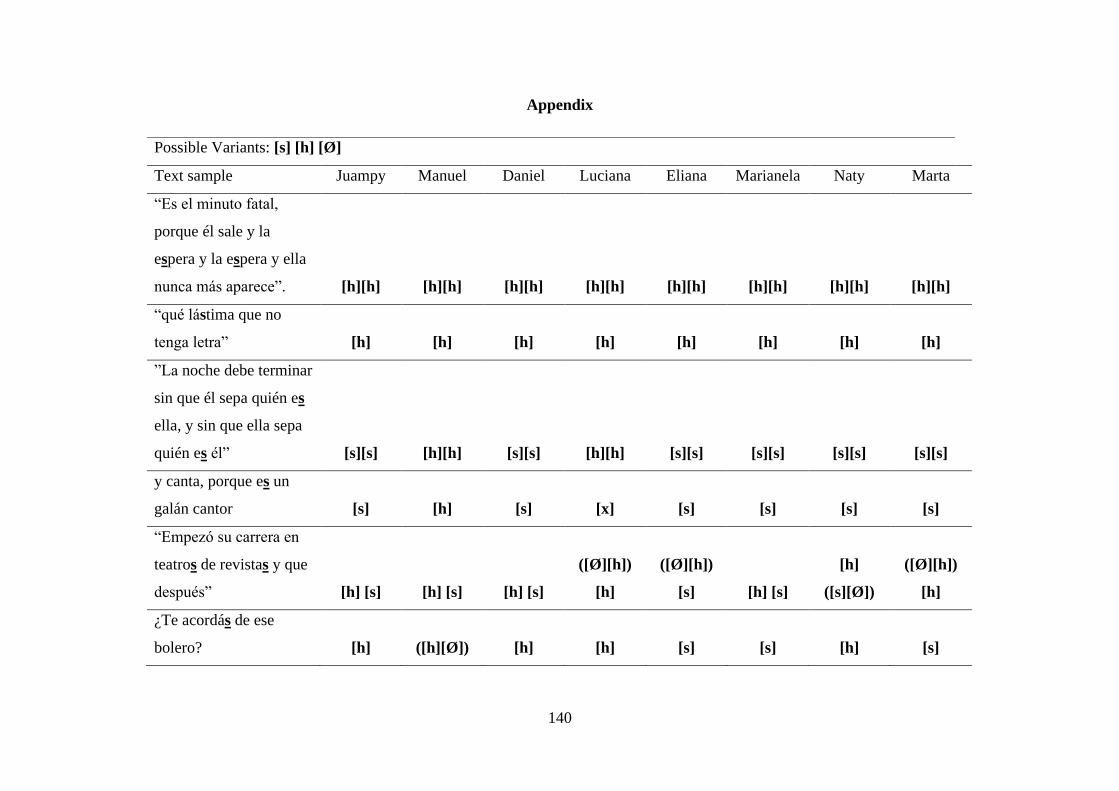
140
Appendix
Possible Variants: [s] [h] [Ø]
Text sample Juampy Manuel Daniel Luciana Eliana Marianela Naty Marta
“Es el minuto fatal,
porque él sale y la
espera y la espera y ella
nunca más aparece”. [h][h] [h][h] [h][h] [h][h] [h][h] [h][h] [h][h] [h][h]
“qué lástima que no
tenga letra” [h] [h] [h] [h] [h] [h] [h] [h]
”La noche debe terminar
sin que él sepa quién es
ella, y sin que ella sepa
quién es él” [s][s] [h][h] [s][s] [h][h] [s][s] [s][s] [s][s] [s][s]
y canta, porque es un
galán cantor [s] [h] [s] [x] [s] [s] [s] [s]
“Empezó su carrera en
teatros de revistas y que
después” [h] [s] [h] [s] [h] [s]
([Ø][h])
[h]
([Ø][h])
[s] [h] [s]
[h]
([s][Ø])
([Ø][h])
[h]
¿Te acordás de ese
bolero? [h] ([h][Ø]) [h] [h] [s] [s] [h] [s]

141
“Le dice que todos los
hombres son iguales,
que ella no es una cosa”
[h][h][s]
[s]
[h][h][s]
[s]
[h][s][s]
[s]
[h][h]
([Ø][h])
[h]
[h][s][Ø]
[s]
[h][s][Ø]
[s]
[h][s]
([Ø][h])
[s] [s][s][s][s]
“Cuando le ve en una
foto la mano tomando
champagne con un
solitario rarísimo, ya no
le queda duda de quién
es.” [s] [s] [s] [s] [s] [s] [h] [s]
“De montones de
pañuelos atados a la
cintura” [h][s][s] [h][h][h] [h][s][s] [h][s][s]
[h][h]
([h][s]) [h][s][s] [h][h][h] [h][s][s]
“pero entonces él le dice
que se vaya con él, que
deje todo, joyas, pieles,
vestidos, magnate, y lo
siga.” [h][h][h] [h][h][h] [s][s][s] [h][h][h] [h][h][s] [h][s][s] [h][h][h] [h][h][h]