hdfs deep dive
TRANSCRIPT


Hadoop File Systems• Local file://
• HDFS hdfs://
• S3 s3://
• Azure wasb://
• FTP ftp://
• WebHDFS, SecureWebHDFS (swebhdfs://)

HDFS Design• It is a distributed file system
• Should handle very large files
• Streaming Data Access: Write once, read many times
• Able to run on commodity Hardware Fault tolerance

Concepts
• Replication3 nodes by default, configurable
• Block basedBig blocks: Unix: 4kb, HDFS: 64-256MB

Blocks• Makes data abstraction simpler
• Enables storing files that only fit on more disks
• Makes replication easier
• Blocks are not filled up with empty space
• Mappers usually work at 1 block at a timeBig blocks -> fewer mappers -> might be slow

Permissions• Permissions like in UNIX
rwxrwxrwx
• x is ignored by files, used for directory listing
• Hadoop Security can be enabled Off by default, hdfs user = client’s username

Directory structure
• /tmp
• /user/<username>
• /var/log
• … It’s up to you
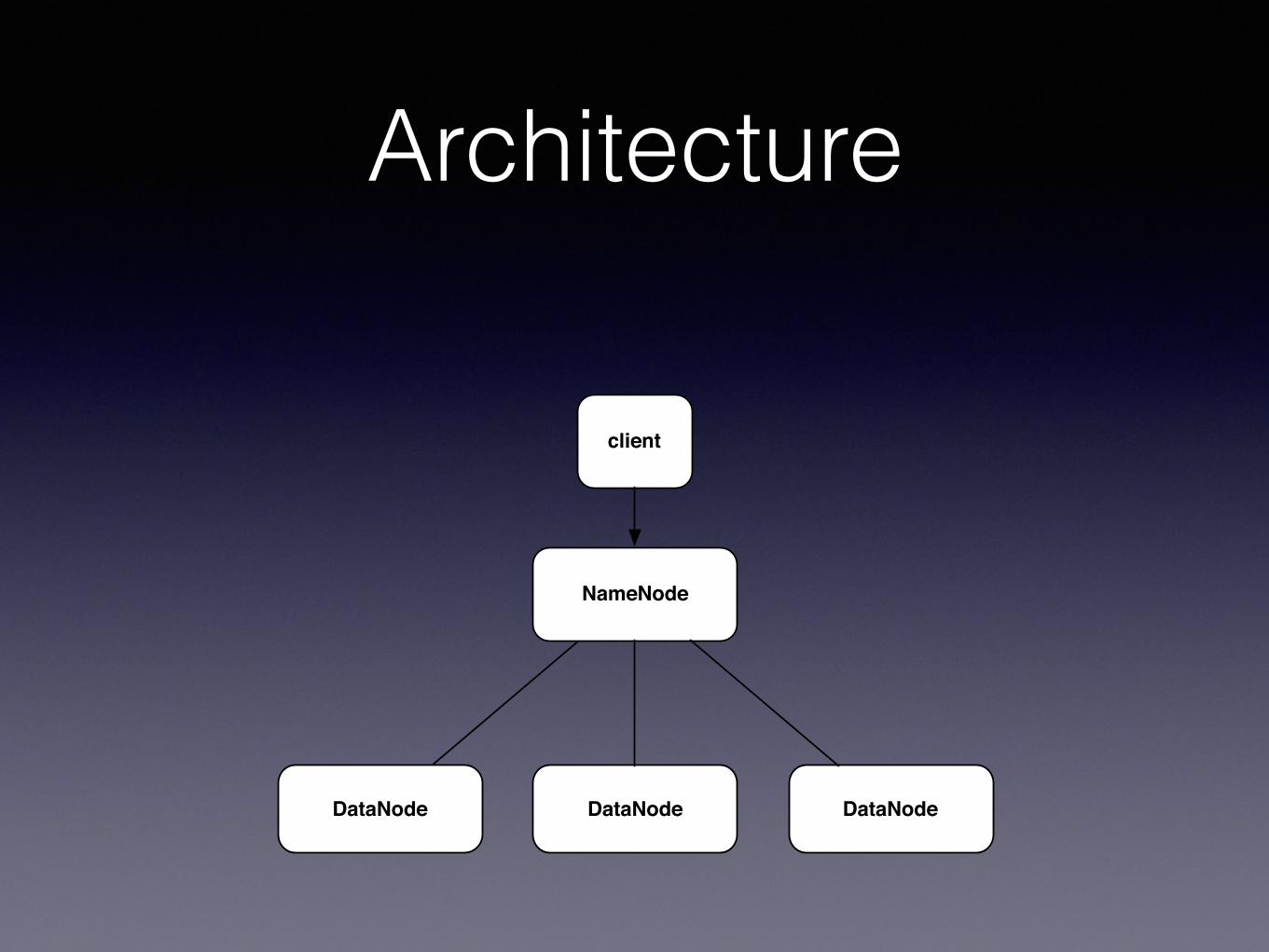
Architecture
DataNode
NameNode
DataNode DataNode
client

NameNode• Responsible for managing the filesystem
filesystem treepermissionsfile-block mappingsblock-datanode mappings datanode location arbitrary metadata
• Namespace image and edit log fsimage, editsstores everything in-memory

NN Data protection
• No overwrite by default
• Safe Mode - read only mode In case of a failure or e.g. low free space

DataNode
• Stores and receives blocks
• Reports health to NN
• At startup: Reports block and file data to NN

DN Block Caching
• Stores frequently accessed files in memory
• ConfigurableE.g.: frequently accessed small files can replicated to all nodes and caches

Replica Management• Network distance metric
1. same node2. same rack3. same data center4. different data center this has to be configured
• NN keeps track of under replicated blocks
• Cluster can get unbalancedhadoop balancer
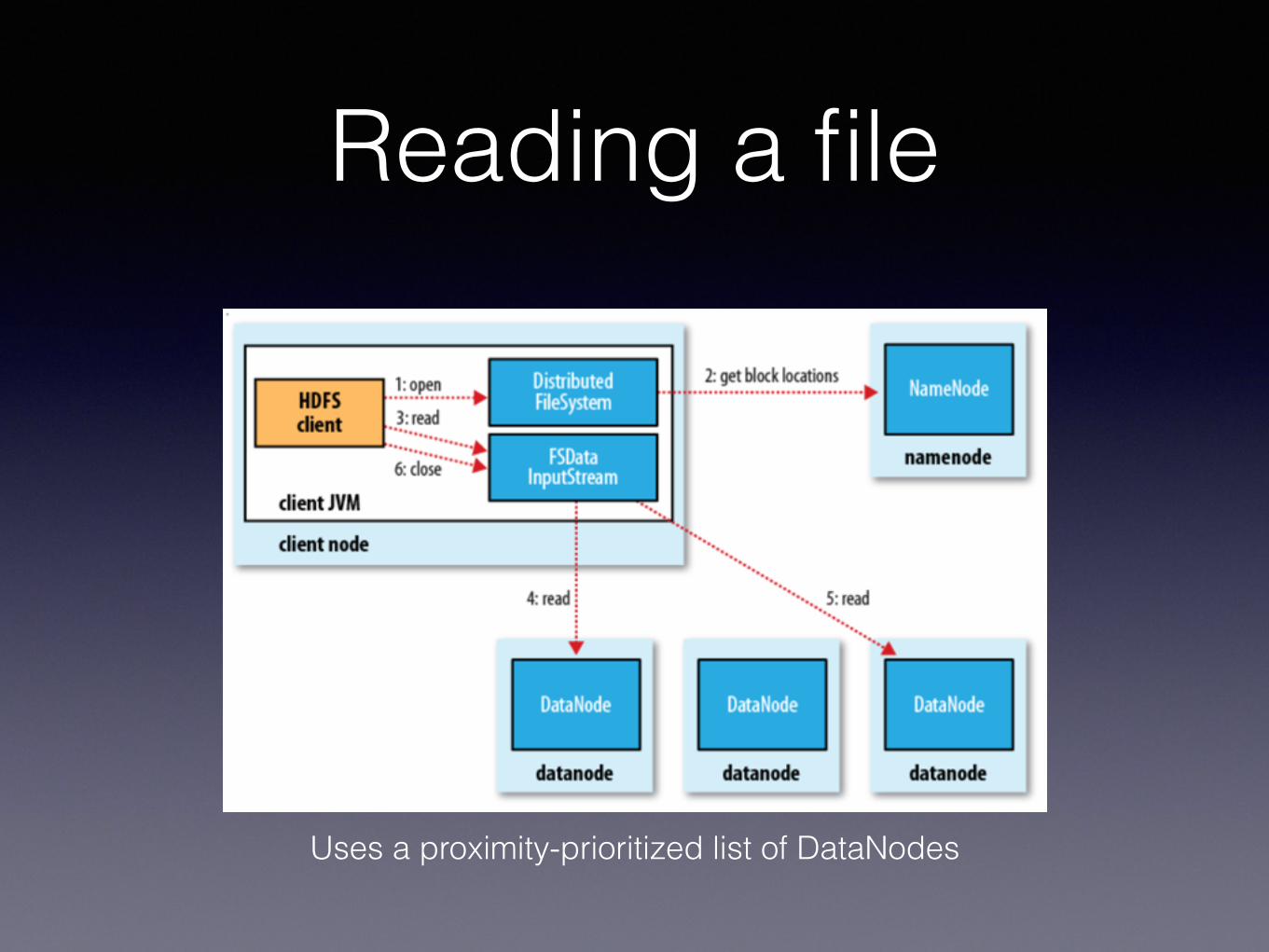
Reading a file
Uses a proximity-prioritized list of DataNodes
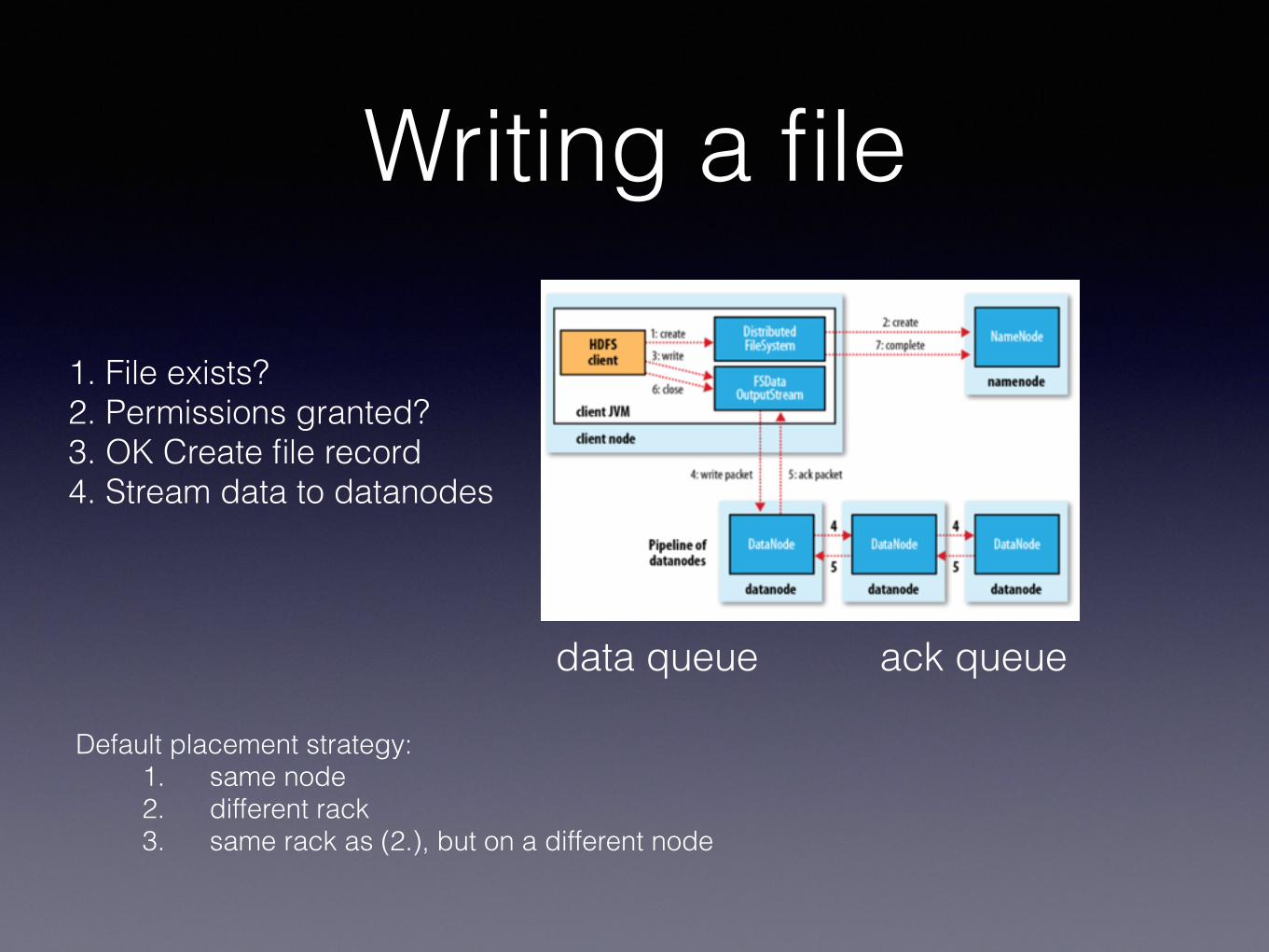
Writing a file
1. File exists? 2. Permissions granted? 3. OK Create file record 4. Stream data to datanodes
data queue ack queue
Default placement strategy: 1. same node 2. different rack 3. same rack as (2.), but on a different node

Moving a file
?A simple NameNode FS tree update

Interfaces• CLI
hdfs dfs -ls /
• JavaConfiguration conf = new Configuration(); FileSystem fs = FileSystem.get(URI.create(“hdfs://…”), conf);
• libhdfs#include "hdfs.h"
• FuseFilesystem mount

Problems

HDFS weaknesses• Not suitable for low latency data access
• Slow if you have lots of small filesfile access overhead
• No arbitrary file modification it’s append-only
• NameNode if a single point of failure
• Everything in the NN’s memory: Scalability issues

Secondary NameNode
• Store the namespace image and edit log on NFS
• Secondary NameNode (Not a NameNode) Stores the namepsace image and merges it with edit log periodically

High Availability NN• Active-standby configuration of 2 NameNodes
• Failover is usually managed by ZooKeeper
• HA shared storage for the edit log - NFS (disfavoured due to multiple writers) - Quorum Journal Manager (QJM): 3 nodes store each edit (confugurable)
Each edit must be written to the majority of the journal nodes

HDFS federation
• One NN manages on namespace volume, e.g.:NN-1: /user NN-2: /data
• Configuration must be done on the client’s side NN’s don’t know about each other

Thanks!Zoltan Toth