reconnaissance de l'écriture vietnamienne manuscrite par hmm
TRANSCRIPT

UNIVERSITÉ DE DANANG
ÉCOLE POLYTECHNIQUE
DÉPARTEMENT D’INFORMATIQUE
Tel. (84-511) 3736 949, Fax. (84-511) 3842 771
Website: itf.dut.edu.vn, E-mail: [email protected]
MÉMOIRE DE FIN D’ÉTUDES
CODE FILIÈRE : 05115
SUJET:
RECONNAISSANCE DE L’ÉCRITURE VIETNAMIENNE
MANUSCRITE PAR MODÈLE DE MARKOV CACHÉS
Code sujet : 09T4-029
Date de soutenance : 17/06/2014
Étudiant : LE Hoang Long
Classe : 09T4
Directeur: Dr. HUYNH Huu Hung
Danang, 06/2014

REMERCIEMENTS
Tout d’abord, je tiens à adresser mes remerciements sincères à mon directeur
du mémoire, Dr. HUYNH Huu Hung, qui est en grande partie à l’origine de mon
intérêt et de mon engouement pour le traitement d’image et sur tout ce qui touche
à la reconnaissance de l’écriture vietnamienne manuscrite. Il m’a donné les
orientations et m’a transmis des connaissances tout au long de mon travail.
Je voudrais également exprimer mes remerciements à tous les professeurs du
Département de l’Informatique de l’École Polytechnique de Danang et l’équipe de
CNF de Danang (AUF), qui m’ont soutenue tout au long de cette période dans les
meilleures conditions qui soient. Les connaissances que j’ai acquises constituent
une base solide pour que j’entreprenne travail de fin d’études et que j’aie aussi
confiance en moi-même pour être au contact des savoirs toujours renouvelés dans
le développement intense de l’Informatique.
Enfin, je voudrais à exprimer ma reconnaissance profonde à ma famille et
tous mes amis pour leur soutien et leur encouragement tout au long de mes études
et ainsi que dans la vie.
Danang, juin 2014
Le Réalisateur
LE Hoang Long

ENGAGEMENT
Je déclare sur l’honneur que :
1 Les contenus dans ce mémoire ont été réalisés par moi-même
sous la direction du Dr. HUYNH Huu Hung.
2 Tous les documents utilisés dans ce mémoire sont référencés:
auteurs, ouvrages, publications, dates.
3 Je me porte responsable de toutes les copies non conformes,
d’infraction au règlement de formation ou des mensonges .
Le Réalisateur
LE Hoang Long

OBSERVATION DU DIRECTEUR DE
MÉMOIRE
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………

OBSERVATION DU RAPPORTEUR
(PROFESSEUR CONTRADICTEUR)
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………
………………………………………………………………………………………

i
TABLE DES MATIÈRES
INTRODUCTION ................................ ................................ .....1
1. Contexte du mémoire ................................................................................................. 1
2. Objectifs....................................................................................................................... 2
3. Méthodologie .............................................................................................................. 2
3.1. Méthodologie .................................................................................................... 2
3.2. Résultats ............................................................................................................ 2
4. Plan du développement .............................................................................................. 3
5. Plan du mémoire ......................................................................................................... 3
BASES THÉORIQUES ................................ ..............................4
1. Reconnaissance de l’écriture manuscrite................................................................. 4
1.1. Méthodes de la reconnaissance ...................................................................... 4
1.1.1. Réseau Bayésiens (Bayesian Network) ...................................................... 4
1.1.2. Machine à vecteurs de support (Support Vector Machine)..................... 4
1.1.3. Modèles de Markov Cachés (Hidden Markov Models) ........................... 5
1.1.4. Réseaux de neurones artificiels (Artificial Neural Networks) ................ 5
1.2. Quelles problèmes de la reconnaissance de l’écriture vietnamienne
manuscrite ................................................................................................................. 6
1.2.1. Problème par personne ................................................................................ 6
1.2.2. Problème par les signes du vietnamien ..................................................... 7
2. Introduction aux modèles de Markov cachés.......................................................... 8
2.1. Introduction ....................................................................................................... 8
2.2. Chaîne de Markov ............................................................................................ 8
2.2.1. Introduction ................................................................................................... 8
2.2.2. Définition ....................................................................................................... 8
2.3. Modèle de Markov cachés ............................................................................10
2.3.1. Probabilité d'une séquence d'observations .............................................12
2.3.2. Séquence d'états la plus probable.............................................................13

TABLE DES MATIÈRES ii
2.3.3. Maximiser la probabilité d'une séquence d'observations......................14
2.4. Algorithme du modèle Markov cachés........................................................16
2.4.1. Algorithme Forward-Backward ................................................................16
2.4.2. Algorithme de Baum-Welch.......................................................................18
2.4.3. Algorithme de Viterbi .................................................................................21
2.5. Conclusion.......................................................................................................22
SYSTÈMES DE LA RECONNAISSANCE DE L’ÉCRITURE
VIETNAMIENNE MANUSCRITE ................................ ............ 24
1. Aperçu du système ...................................................................................................24
2. Base de données........................................................................................................26
2.1. EVM en ligne..................................................................................................26
2.2. EVM hors ligne ..............................................................................................26
3. Prétraitement .............................................................................................................27
3.1. EVM en ligne..................................................................................................27
3.2. EVM hors ligne ..............................................................................................27
4. Extraction de caractéristiques .................................................................................30
4.1. EVM en ligne..................................................................................................30
4.2. EVM hors ligne ..............................................................................................32
5. Apprentissage des HMMs .......................................................................................33
5.1. Initialisation des HMMs ................................................................................33
5.2. Apprentissage .................................................................................................36
6. Reconnaissance .........................................................................................................38
RÉSULTATS ................................ ................................ .......... 39
1. Implémentation .........................................................................................................39
1.1. Outils et le langage de programmation........................................................39
1.2. Construction du programme de démo..........................................................39
2. Base de données........................................................................................................39
3. Résultats et Interprétation ........................................................................................40
3.1. Taux de reconnaissance .................................................................................40

TABLE DES MATIÈRES iii
3.2. Évaluation de performance obtenue.............................................................40
4. Quelques figures du système...................................................................................41
4.1. La reconnaissance en ligne ...........................................................................41
4.2. Reconnaissance hors ligne ............................................................................43
CONLUSIONS ................................ ................................ ........ 45
1. Conclusion .................................................................................................................45
1.1. Avantages ........................................................................................................45
1.2. Désavantages ..................................................................................................45
2. Perspectives ...............................................................................................................45

iv
LISTE DES FIGURES
Figure 1: Exemple de réseau bayésien ..............................................................................4
Figure 2: Projection des données d’entrée dans un espace où elles sont linéairement
séparables..............................................................................................................................5
Figure 3: Hyper-plan optimal et marge maximale ..........................................................5
Figure 4: Le neurone biologique........................................................................................6
Figure 5: Deux exemples aléatoires de l’écriture qui démontre ces différences .........7
Figure 6: 178 caractères vietnamiens ................................................................................7
Figure 7: 50 lettres et 7 signes vietnamiens .....................................................................8
Figure 8: Chaîne de Markov simple avec 2 états.............................................................9
Figure 9: Chaîne de Markov suivant le temps .............................................................. 10
Figure 10: Modèle de Markov cachés avec 2 états ...................................................... 11
Figure 11: Modèle de Markov cachés suivant le temps .............................................. 12
Figure 12: L’observation et l’état cachés séquences .................................................... 13
Figure 13: Sesquenes d’états les plus probables ........................................................... 13
Figure 14: Sesquences de l’état cachés suivant le temps ............................................. 15
Figure 15: Modèles de l’algorithme Forward ............................................................... 16
Figure 16: Modèle de l’algorithme Backward .............................................................. 17
Figure 17: Modèle de l’algorithme de Baum-Welch ................................................... 19
Figure 18: Modèle de l’algorithme de Viterbi .............................................................. 21
Figure 19: Les applications du HMM ............................................................................ 22
Figure 20: L’écriture manuscirte en ligne et hors ligne ............................................... 24
Figure 21: Le système de la reconnaissance ................................................................. 25
Figure 22: Cinq caractères vietnamiens manuscrits en ligne ...................................... 26
Figure 23: Caratère « a » manuscrite en ligne été écrit cinq fois .............................. 26
Figure 24: Les modèles d’écriture manuscrite .............................................................. 26
Figure 25: Supprimer coups excès ................................................................................. 27
Figure 26: Mode de prétraitement .................................................................................. 28
Figure 27: Image RGB Image Gris Image binaire............................................ 28

LISTE DES FIGURES v
Figure 28: Filtrage du lissage et épaississement........................................................... 28
Figure 29: Segmentation, redimensionner et squelette ................................................ 29
Figure 30: Les caractères « u » ....................................................................................... 29
Figure 31: Les caractères « A » ...................................................................................... 29
Figure 32: L’angle entre deux vecteurs (pt, pt+1) .......................................................... 31
Figure 33: Diviser le système de coordonnées cartésiennes en 12 zones.................. 31
Figure 34: Diviser l'image d'entrée en 36 régions ........................................................ 32
Figure 35: Les séquences vecteurs de caractéristique de caractères « a » manuscrite
en ligne ............................................................................................................................... 41
Figure 36: Résultat de la reconnaissance du caractère « a » en ligne ........................ 41
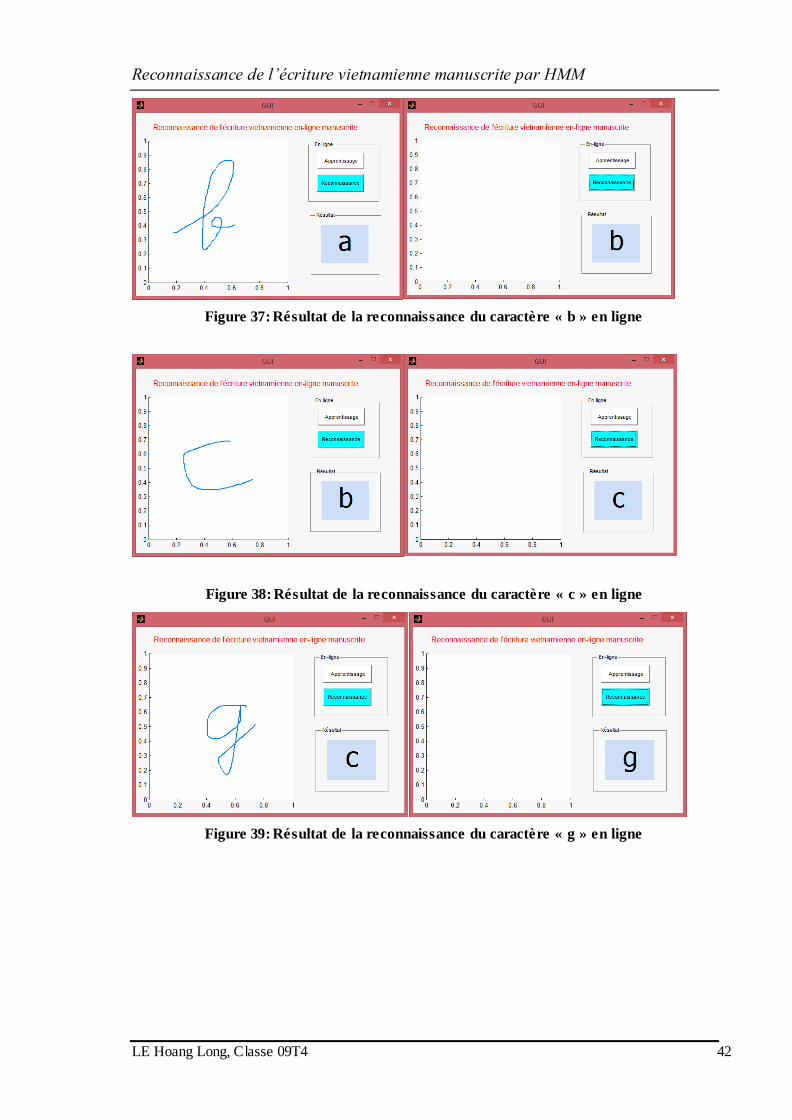
Figure 37: Résultat de la reconnaissance du caractère « b » en ligne ........................ 42
Figure 38: Résultat de la reconnaissance du caractère « c » en ligne ........................ 42
Figure 39: Résultat de la reconnaissance du caractère « g » en ligne ........................ 42
Figure 40: Résultat de la reconnaissance du caractère « n » en ligne ........................ 43
Figure 41: Résultat de la reconnaissance du caractère « A » hors ligne.................... 43
Figure 42: Résultat de la reconnaissance du caractère « C » hors ligne .................... 43
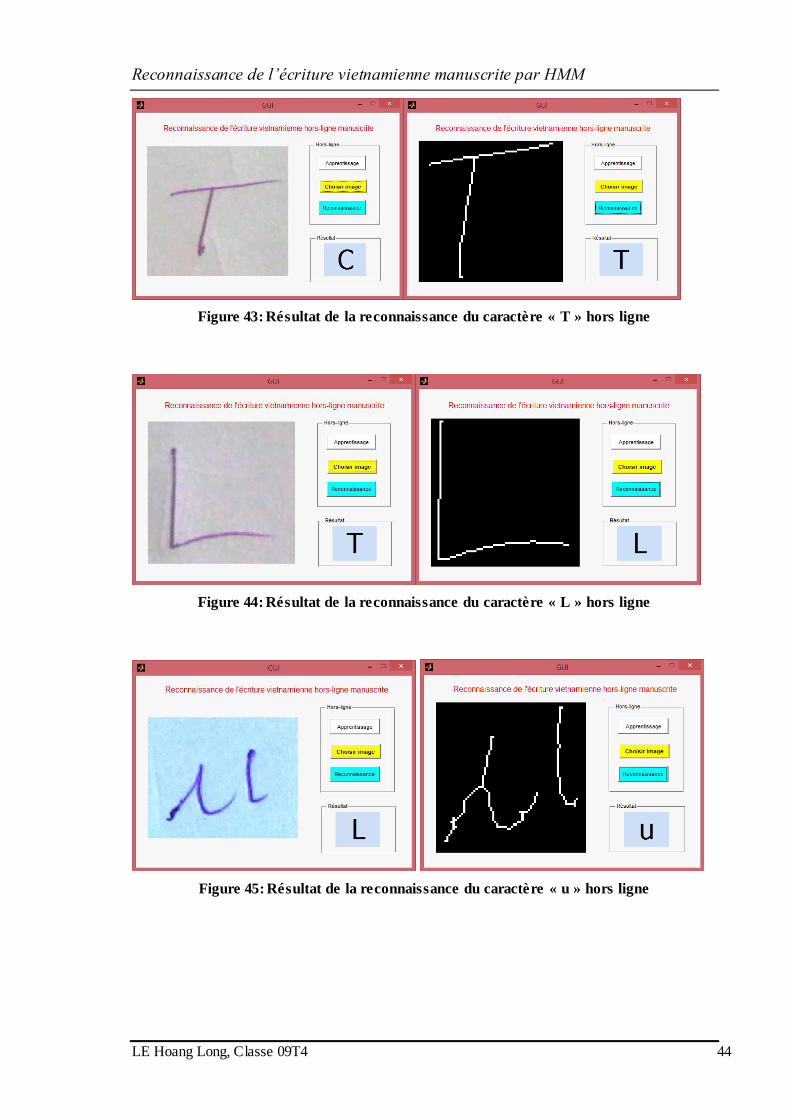
Figure 43: Résultat de la reconnaissance du caractère « T » hors ligne .................... 44
Figure 44: Résultat de la reconnaissance du caractère « L » hors ligne .................... 44
Figure 45: Résultat de la reconnaissance du caractère « u » hors ligne .................... 44

vi
LISTE DES TABLEAUX
Table 1: Le taux de la reconnaissance caractères manuscrite en ligne. ..................... 40
Table 2: Le taux de la reconnaissance caractères manuscrite hors ligne. ................. 40

vii
LISTE DES ABRÉVIATIONS
HMM Hidden Markov Model
EVM D’écriture vietnamienne manuscrite
SVM Support Vertor Machine

LE Hoang Long, Classe 09T4 1
INTRODUCTION
1. Contexte du mémoire
Dans le développement de la société humaine, l’écriture joue un rôle très grand
et très important. L'écriture est un moyen de sauvegarde des informations. Sans
l'écriture, on ne peut pas avoir les livres, les inventions. De plus, les réalisations des
ancêtres ne peuvent pas être transmises.
L'écriture manuscrite est un mode de communication primordial chez l'homme.
Il est à la fois universel, mais aussi très personnel. Chacun élabore son propre style
d'écriture qui va évoluer en permanence tout au long de sa vie. À l’heure actuelle,
l'informatisation a eu jusqu'à présent plutôt tendance à diminuer la place que tenait
l'écriture manuscrite dans la communication: le périphérique clavier/souris remplace
progressivement le stylo et cela au détriment de l'écriture manuscrite. Plus
récemment encore, l'utilisation courante du courrier électronique et des « SMS » n'a
fait qu'amplifier ce phénomène en le systématisant de plus en plus tôt dans la vie
courante.
Depuis peu, de nouvelles technologies orientées «stylo» arrivent à maturité:
téléphone mobile de nouvelle génération (Smartphone), ordinateur tablette (Tablet)
ou encore tableau blanc interactif (TBI). La tendance s'infléchit donc
progressivement en repositionnant l'écriture manuscrite au centre de la
communication personne-machine. Les recherches sur la reconnaissance
automatique de l'écriture manuscrite à fait des progrès considérables depuis une
dizaine d'années. Même si tous les problèmes ne sont pas encore résolus, les
moteurs de reconnaissance d'écriture en ligne et hors-ligne progressent et
bénéficient aujourd'hui de plus de puissance de calcul; ils sont maintenant
suffisamment performants pour envisager une interaction directe avec la machine
par le biais de l'écriture manuscrite.
Bien entendu, il ne s'agit pas non plus de supprimer les périphériques
traditionnels (clavier/souris) qui s'avèrent très efficaces dans de nombreux contextes
d'utilisation. Dans certains contextes de mobilité et dans de nombreux cas de
composition de document, écrire et dessiner à main levée sont les modalités d'entrée
les plus naturelles et les plus efficaces. Par exemple, l'utilisateur va pouvoir écrire
ses « SMS » directement sur l'écran de son téléphone portable (Smartphone).

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 2
Les grandes qualités de recherches de la reconnaissance ont été faite
sur l’anglais, l’arabe, et le japonaise, telles que la reconnaissance d’écriture
manuscrite par utiliser le réseau de neurones artificiels, machine à vecteurs de
support (en anglais Support Vector Machine)... Cependant, la reconnaissance de
l’écriture vietnamienne manuscrite est en train de trouver les problèmes avec des
résultats limités.
Dans ce mémoire de fin d’études, je propose une méthode de la reconnaissance
de l’écriture vietnamienne manuscrite par modèle Markov cachés . J’espère
qu’avec cette nouvelle technique, on pourra tenter d’améliorer les faiblesses des
autres méthodes, d’augmenter la performance et également la vitesse de la
reconnaissance de l’écriture vietnamienne manuscrite.
2. Objectifs
Rechercher des modèles Markov cachés pour l’apprentissage et
l’identification.
Construction d’un système qui peut reconnaître de l’écriture vietnamienne
manuscrite par modèles Markov cachés.
3. Méthodologie
3.1. Méthodologie
Rechercher les méthodes qu’on a appliquées dans le processus du
prétraitement d’images, de l'extraction de caractéristiques, du traitement et de
la reconnaissance.
Étudier des outils appropriés pour servir au travail de programmation.
3.2. Résultats
La construction d’un programme qui marche sur l’ordinateur ayant les fonctions
ci-dessous:
L’utilisateur peut écrire les lettres sur l’écran pour reconnaître de l’écriture
vietnamienne manuscrite en ligne.
L’utilisateur peut choisir le type de la source d’entrée: des images (hors
ligne).
Le système est capable d’identifier des lettres vietnamiennes.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 3
4. Plan du développement
Pour parvenir aux buts prémentionnés, il faut réaliser les tâches suivantes:
Rechercher les méthodes qu’on a appliquées dans le processus du
prétraitement d’images, de l'extraction de caractéristiques, de traitement et de
la reconnaissance
Créer une base de données pour les démonstrations
Construire le programme en Matlab
Tirer des conclusions
5. Plan du mémoire
Le mémoire comprend des parties suivantes:
Introduction: Présentation générale du contexte du mémoire, ses objectifs,
sa méthodologie, ses résultats escomptés, plan du développement et plan du
mémoire
Chapitre 1 – Bases Théoriques: Présentation du la l’écriture vietnamienne
manuscrite, de la reconnaissance de l’écriture vietnamienne manuscrite en
ligne et hors-ligne, des modèles Markov cachés
Chapitre 2 – Système de la reconnaissance de l’écriture vietnamienne
manuscrite: reconnaissance de l’écriture vietnamienne manuscrite en ligne,
reconnaissance de l’écriture vietnamienne manuscrite hors ligne
Chapitre 3 – Résultats: L’analyse et l’interprétation des résultats du
programme
Conclusion : Évaluation et Perspectives

LE Hoang Long, Classe 09T4 4
CHAPITRE 1
BASES THÉORIQUES
Ce chapitre présentera des bases théoriques de la reconnaissance de l’écriture
manuscrite, des modèles Markov cachés.
1. Reconnaissance de l’écriture manuscrite
1.1. Méthodes de la reconnaissance
1.1.1. Réseau Bayésiens (Bayesian Network)
Un réseau bayésien [1] est un système représentant la connaissance et
permettant de calculer des probabilités conditionnelles apportant des solutions à
différentes sortes de problématiques.
La structure de ce type de réseau est simple: un graphe dans lequel les nœuds
représentent des variables aléatoires, et les arcs (le graphe est donc orienté) reliant
ces dernières sont rattachées à des probabilités conditionnelles.
Figure 1: Exemple de réseau bayésien
1.1.2. Machine à vecteurs de support (Support Vector Machine)
Les SVMs [2] sont une classe d’algorithmes d’apprentissage qui ont été utilisés
avec succès dans plusieurs tâches d’apprentissage. Ils permettent de construire un
classifieur à valeurs réelles qui découpent le problème de classification en 2 sous-
problèmes: transformation non-linéaire des entrées et choix d’une séparation
linéaire optimale.
Le premier sous-problème à traiter est donc celui de travailler dans un espace où les
données soient linéairement séparables. Les données sont alors projetées dans un
espace de grande dimension par une transformation basée sur un noyau (voir
figure 1).

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 5
Figure 2: Projection des données d’entrée dans un espace où elles sont linéairement
séparables
Le deuxième sous-problème est traité dans cet espace transformé. Les classes y sont
séparées par des classifieurs linéaires qui déterminent un hyper-plan optimal.
L’hyper-plan optimal est celui qui sépare correctement toutes les données et qui
maximise la marge, la distance du point le plus proche à l’hyper-plan (représentée
par d dans la figure 2)
Figure 3: Hyper-plan optimal et marge maximale
1.1.3. Modèles de Markov Cachés (Hidden Markov Models)
Un modèle de Markov caché est un modèle statistique dans lequel le système
modélisé est supposé être un processus markovien de paramètres inconnus.
Les modèles de Markov cachés sont massivement utilisés notamment en
reconnaissance de formes, en intelligence artificielle ou encore en traitement
automatique du langage naturel.
1.1.4. Réseaux de neurones artificiels (Artificial Neural Networks)
Les réseaux de neurones [3] sont composés d’éléments simples (ou neurones)
fonctionnant en parallèle. Ces éléments ont été fortement inspirés par le système
nerveux biologique. Comme dans la nature, le fonctionnement du réseau (de
neurone) est fortement influencé par la connexion des éléments entre eux. On peut
entraîner un réseau de neurones pour une tâche spécifique (reconnaissance de

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 6
caractères par exemple) en ajustant les valeurs des connections (ou poids) entre les
éléments (neurones).
Figure 4: Le neurone biologique
Les réseaux de neurones ont été trainés pour exécuter des fonctions complexes
dans divers champs, incluant la reconnaissance des formes, l’identification, la
classification, la parole, la vision, et les systèmes de commande.
1.2. Quelles problèmes de la reconnaissance de l’écriture
vietnamienne manuscrite
1.2.1. Problème par personne
De nombreux chercheurs ont mené des recherches dans la reconnaissance de
l'écriture manuscrite dans les dernières années. Bien que de nombreux problèmes
ont été résolus, il y a encore beaucoup de problèmes à la main. Malgré la
disponibilité de la puissance de calcul et les progrès réalisés jusqu'à présent, la
capacité d'un système de reconnaissance d'écriture est toujours incomparable à la
reconnaissance humaine.
Il n'y a pas deux êtres humains qui ont exactement la même écriture et même si
une personne écrit le même mot deux fois, l’écriture n’est pas toujours semblable .
Entre les personnes, la variabilité peut comprendre la pente, la taille des caractères,
la forme et la manière dont cursive ou disjointe les caractères de l'écriture sont.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 7
Figure 5: Deux exemples aléatoires de l’écriture qui démontre ces différences
1.2.2. Problème par les signes du vietnamien
Un caractère vietnamien se compose de 2 parties: la lettre et le signe.
L'ensemble des caractères en vietnamien: 178 caractères
Figure 6: 178 caractères vietnamiens
Si on apprend tous les 178 caractères, donc on va perdre beaucoup de temps et
d'espace mémoire. Et plus, les taux de reconnaissance corrects ne sont pas bien.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 8
Si on sépare des lettres et des signes, on a 50 lettres et 7 signes. C’est mieux.
Figure 7: 50 lettres et 7 signes vietnamiens
2. Introduction aux modèles de Markov cachés
2.1. Introduction
Modèle de Markov cachés (en anglais Hidden Markov Model) est un modèle
mathématique statistique dérivé des Chaînes de Markov. Un HMM peut servir à de
multiples applications, l'une des plus connues étant la reconnaissance vocale, mais
également la reconnaissance de caractères. Un HMM peut aussi être "entraîné" à
reconnaître "quelque chose " puis déterminer si "autre chose" y ressemble ou pas, et
s’il y ressemble, à quel point?
2.2. Chaîne de Markov
Avant de passer à la description d'un modèle de Markov caché, voyons d'abord
ce qu'est une chaîne de Markov.
2.2.1. Introduction
Chaîne de Markov est un modèle statistique composé d'états et de transitions.
Une transition matérialise la possibilité de passer d'un état à un autre.
Une chaîne de Markov est de manière générale un processus de Markov à
temps discret, ou bien un processus de Markov à temps discret et à espace d'états
discret.
2.2.2. Définition
En mathématiques, un processus de Markov est un processus stochastique
possédant la propriété de Markov: de manière simplifiée, la prédiction du futur,
sachant le présent, n'est pas rendue plus précise par des éléments d'informations
supplémentaires concernant le passé; toute l'information utile pour la prédiction du
futur est contenue dans l'état présent du processus. Les processus de Markov portent
le nom de leur découvreur, Andreï Markov; qui est un mathématicien russe. Ses
travaux sur la théorie des probabilités l'ont amené à mettre au point les chaînes de

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 9
Markov qui l'ont rendu célèbre. Il a publié les premiers résultats sur les chaînes de
Markov à espace d'états fini en 1906.
Un processus de Markov en temps discret est une séquence ... de
variables aléatoires. L'ensemble de leurs valeurs possibles est appelé l’espace
d'états, la valeur étant l'état du processus à l'instant n.
Si la loi conditionnelle de sachant le passé, sachant ( ) est
une fonction de seul, alors:
( ) ( ) (2.1)
Où x est un état quelconque du processus. L'identité ci-dessus identifie la
probabilité markovienne.
Dans la chaîne de Markov, les transitions sont unidirectionnelles: une
transition de l'état A vers état B ne permet pas d'aller de l'état B vers l'état A. Tous
les états ont des transitions vers tous les autres états, y compris vers eux-mêmes.
Chaque transition est associée à sa probabilité d'être empruntée et cette probabilité
peut éventuellement être nulle.
Voici la représentation d'une chaîne de Markov simple avec 2 états:
Figure 8: Chaîne de Markov simple avec 2 états
On note la présence d'un état "Début" qui sert à présenter les probabilités de
commencer dans chacun des états du modèle : ici on a 40% de chances (0.4) de
commencer dans l'état 1 et 60% de chances (0.6) de commencer dans l'état 2. Par
définition, on ne revient jamais à l'état de départ, raison pour laquelle il n'y a jamais
de transition vers cet état. On remarque également que la somme des probabilités
des transitions partant d'un état est toujours égale à 1 (100%). Par exemple, pour
l'état 1: 0.7 + 0.3 = 1

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 10
Cette propriété doit toujours être vraie ! En effet si la somme n'était pas égale à
1, cela signifierait qu'il existe une chance de ne pas opérer de transition, ce qui est
impossible dans une chaîne de Markov.
L'utilisation du modèle se fait en rapport avec le temps. A chaque "unité de
temps", on opère une transition, ce qui génère finalement une séquence d'états :
Figure 9: Chaîne de Markov suivant le temps
Sur cet extrait de séquence, on voit qu'au moment t-1 on était sur l'état 1, puis au
moment t sur l'état 2, puis au moment t+1 sur l'état 2. Comme il existe des
transitions d'un état vers lui même, il est possible que le même état soit plusieurs
fois d'affilée dans la séquence, ce qui est le cas dans notre exemple.
Dans le contexte d'une chaîne de Markov, on étudierait la séquence d'états
produite par le modèle, principalement sa probabilité d'apparition.
2.3. Modèle de Markov cachés
Les modèles de Markov cachés ont été introduits par Leonar E. Baum et ses
collaborateurs dans les années 1960-1970s[1][2]. Un HMM se définit par une
structure composée d’états et de transitions; par un ensemble de distributions de
probabilité sur les transitions.
Un modèle de Markov caché est basé sur une chaîne de Markov, sauf qu'on ne
peut pas observer directement la séquence d'états: les états sont cachés. Chaque état
émet des "observations" qui, elles sont observables. On ne travaille donc pas sur la
séquence d'états, mais sur la séquence d'observations générées par les états.
En mathématiquement, pour finir, un HMM se décrit par:
( ) (2.2)
- N: le nombre d'états
- M: le nombre d'observations
- : la matrice des probabilités de départ [1xN], c'est-à-dire les probabilités de
démarrer dans chacun des N états
- A: la matrice des probabilités de transition [NxN], c'est à dire les probabilités de
passer d'un état à l'autre:

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 11
[
] , avec ∑
- B : la matrice des probabilités d'émission [NxM], c'est-à-dire les probabilités
pour chaque état d'émettre chacune des observations possibles
Ces trois matrices ont la particularité d'avoir des lignes "stochastiques". Cela
signifie que chaque élément d'une ligne est une probabilité et que la somme des
éléments de la ligne est égale à 1.
Pour comprendre, reprenons la chaîne de Markov représenté plus haut et
transformons-le en modèle de Markov caché :
Figure 10: Modèle de Markov cachés avec 2 états
On retrouve bien le modèle de Markov : l'état "Début", les deux états "Etat 1"
et "Etat 2" et les transitions avec leur probabilité associée.
On y a ajouté deux observations : "A" et "B". Chaque état peut émettre chacune des
observations avec une certaine probabilité que nous appelons "probabilité
d'émission". Cette probabilité peut éventuellement être nulle, ce qui signifie que
l'état ne peut pas émettre l'observation concernée.
Dans notre exemple, l'état 1 a 50% de chances (0.5) d'émettre un "A" et 50%
de chances d'émettre un "B", tandis que l'état 2 a 90% de chances (0.9) d'émettre un
"A" et 10% (0.1) d'émettre un "B". Comme pour les transitions partant d'un état, la
somme des probabilités d'émission d'un état doit toujours être égale à 1.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 12
Comme le modèle de Markov, le modèle de Markov caché évolue dans le
temps. Mais cette fois, on ne peut pas observer la séquence d'états, on ne voit que la
séquence d'observations. Notez cependant que cette séquence d'états existe, elle est
simplement cachée. A chaque unité de temps, on opère une transition qui nous
amène dans un état. Cet état émet alors une observation selon les probabilités
d'émission. L'évolution dans le temps génère donc une séquence d'observations:
Figure 11: Modèle de Markov cachés suivant le temps
Ici la séquence d'états a généré la séquence d'observations "A","A","B". La
séquence d'états est représentée pour aider à la compréhension, mais on ne la
connait pas lors de l'utilisation du modèle.
Maintenant que nous savons à quoi ressemble un HMM, nous sommes en droit
de nous demander ce que nous pouvons en faire.
Il y a trois questions majeures que nous pouvons poser à un HMM, étant donnée
une séquence d'observations:
- Quelle est la probabilité d'apparition de cette séquence?
- Quelle est la séquence d'états la plus probable qui a généré cette séquence?
- Comment modifier le HMM pour que la probabilité d'apparition de cette
séquence soit maximale?
2.3.1. Probabilité d'une séquence d'observations
Nous avons un HMM dont nous connaissons tous les paramètres (nombre
d'états, nombre d'observations, probabilités de départ, probabilités de transition et
probabilités d'émission) ainsi qu'une séquence d'observations de longueur T. Nous
nous demandons alors quelle est la probabilité d'apparition de cette séquence. Dans
le cas d'un HMM "entraîné" à reconnaître "quelque chose" (la langue d'un texte, par
exemple), c'est cette question que nous nous posons pour déterminer si "autre
chose" est du même type ou non.
Cette question a une réponse unique. En effet, la probabilité de voir apparaître
la séquence d'observations se trouve en additionnant les probabilités de la voir
apparaître pour chacune des séquences d'états possibles.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 13
De façon naïve, nous pourrions écrire un algorithme qui parcourt toutes les
séquences d'états possibles en calculant la probabilité d'apparition de la séquence
d'observations, puis additionnerait tous les résultats pour trouver la réponse à la
question. Le problème de cet algorithme est qu'il y a NT séquences d'états
candidates (N états, T longueur de la séquence d'observations), ce qui donnerait une
complexité en O(NT). Autant dire incalculable, car T est souvent très grand.
Figure 12: L’observation et l’état cachés séquences
Heureusement, le forward-algorithme permet de trouver la solution avec une
bien meilleure complexité: O(N2T).
2.3.2. Séquence d'états la plus probable
Nous avons un HMM dont nous connaissons tous les paramètres (nombre
d'états, nombre d'observations, probabilités de départ, probabilités de transition et
probabilités d'émission) ainsi qu'une séquence d'observations de longueur T. Nous
nous demandons alors quelle était la séquence d'états génératrice. C'est la question à
laquelle nous souhaitons répondre dans le cadre de la reconnaissance vocale.
Figure 13: Sesquenes d’états les plus probables

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 14
Cette question n'a pas qu'une seule réponse. Si le HMM étudié ne présente
aucune probabilité d'émission nulle, n'importe quelle séquence d'états de longueur T
peut générer n'importe quelle séquence d'observations de longueur T. Même avec
certaines probabilités d'émission nulles, il reste plusieurs réponses à cette question.
Puisqu'il y a plusieurs séquences d'états possibles pour une séquence
d'observations donnée, nous ne pouvons pas dire avec certitude laquelle a généré
nos observations. En revanche, puisque nous connaissons les paramètres du HMM,
nous pouvons dire quelle est la plus probable.
De façon naïve, nous pourrions encore écrire un algorithme qui parcourt toutes
les séquences d'états possibles en calculant la probabilité d'apparition de la séquence
d'observations, trouvant ainsi la séquence d'états qui a le plus probablement généré
notre séquence d'observations. Le problème est à nouveau la complexité : il y a NT
séquences d'états candidates (N états, T longueur de la séquence d'observations) et
donc une complexité en O(NT).
L'algorithme de Viterbi permet de trouver la solution avec une bien meilleure
complexité : O(N2T). On en verra un exemple commenté dans la partie exemples
d'utilisation.
2.3.3. Maximiser la probabilité d'une séquence d'observations
Nous avons un HMM, dont nous connaissons le nombre d'états N et le nombre
d'observations M, et une séquence d'observations de longueur T. Nous nous
demandons alors quelles sont les matrices , A et B (respectivement probabilités de
départs, de transitions et d'émissions) qui maximisent la probabilité d'apparition de
notre séquence d'observations. C'est à cette question qu'il nous faut répondre
lorsque nous souhaitons entraîner un HMM à reconnaître "quelque chose".
Cette question a une réponse unique. Il existe bien 3 matrices , A et B pour
lesquelles la probabilité d'apparition de notre séquence d'observations est maximale.
Malheureusement, si la résolution mathématique de ce problème est déjà difficile, il
n'existe aucun algorithme permettant de le résoudre (à ce jour du moins). Il existe,
par contre, un algorithme permettant d'approcher la solution.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 15
Figure 14: Sesquences de l’état cachés suivant le temps
Cet algorithme, appelé algorithme de Baum-Welch, présente cependant le
défaut de ne pas toujours converger vers la même solution, voire même de ne pas
converger du tout sous certaines conditions. Ces problèmes surviennent surtout
lorsque nous n'avons aucune idée des probabilités du HMM que nous recherchons
(pas même approximative) et que nous commençons donc avec un HMM quasiment
équiprobable (ce qui signifie que les probabilités de départ et de transition sont
toutes égales à ~1/N et les probabilités d'émission à ~1/M). "Quasiment"
équiprobable justement pour minimiser le risque d'échec de l'algorithme, qui ne
converge presque jamais en cas d'équiprobabilité parfaite.
L'idée de l'algorithme est la suivante:
1. Nous initialisons le HMM avec des probabilités presque équivalentes ou des
approximations de ce à quoi nous nous attendons
2. Nous réévaluons le HMM par rapport à la séquence d'observations sur
laquelle nous voulons l'entraîner
3. Nous calculons la probabilité d'apparition de la séquence d'observations avec
le "nouveau" HMM
4. Si la probabilité d'apparition augmente, nous recommençons en 2
L'algorithme tourne donc jusqu'à ce que la réévaluation fasse baisser la probabilité
d'apparition.
La complexité de cet algorithme est O(N2T), mais attention, il est beaucoup
plus long à exécuter que les deux premiers. En effet, il y a d'une part la présence de
la boucle (entre 100 et 500 itérations en général lors de mes tests sur une séquence
de 50 000 observations) et d'autre part, à l'intérieur même de la boucle on a déjà une
constante multiplicative de 4. En résumé, il y a un facteur de l'ordre de 1 000 qui est
masqué dans cette complexité.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 16
2.4. Algorithme du modèle Markov cachés
2.4.1. Algorithme Forward-Backward
1. Algorithme Forward
Considérons la variable forward ( ) définie par :
t(j) = ( )
∑ ( )
= ∑ ( ) ( ) (2.3)
Qui exprime la probabilité d’avoir généré la séquence en partant de
l’état start et d’être s à l’instant t. Cette variable peut être calculée de manière
inductive :
1. Initialisation:
0(i) = ( ) 1 N (2.4)
2. Induction
t(j) = ∑ ( ) bj( ) 2 T, 0 N (2.5)
3. Résiliation
P[X| ] = ∑ ( ) (2.6)
Figure 15: Modèles de l’algorithme Forward
Examinons la complexité de cet algorithme. La phase d’initialisation requiert
une opération pour chaque état du HMM, donc au total O(N) opérations. Pour la
phase d’induction, pour chaque instant et chaque état, on réalise O(N) opérations.
Somme sur l’ensemble des états et la totalité des instants, la phase d’induction
requiert donc O( T) opérations. Une fois les ( ) calcules, le calcul de P(X| )
suivant la formule (2.6) demande une opération pour chaque état, donc au total
O(N) opérations. Le calcul de P(X| ) a l’aide de l’algorithme forward ne requiert
donc au total que O( T) opérations.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 17
2. Algorithme Backward
L'algorithme Backward est conçu de manière similaire à l'algorithme Forward.
Une seule chose diffère : l'ordre des lignes. On utilise alors la variable backward
t(i) = ( )
∑ ( )
∑ ( ) t+1(j) (2.7)
Figure 16: Modèle de l’algorithme Backward
Cette variable peut être calculée de manière inductive :
1. Initialisation:
T(i) = 1 1 N (2.8)
2. Induction
t(i) = ∑ bj( ) ( )
avec 1 N, t = T-1, T-2, .., 1 (2.9)
3. Résiliation
P[X| ] = ∑ ( ) (2.10)
La complexité de l’algorithme backward est, comme pour l’algorithme
forward, O( T)

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 18
2.4.2. Algorithme de Baum-Welch
L’algorithme de Baum-Welch est un cas particulier d’une généralisation de
l’algorithme espérance-maximisation(EM). Un des problèmes liés aux modèles de
Markov cachés est de trouver un modèle ̅ = ( ̅ ̅ ̅) qui maximise la probabilité
d’une séquence d’observations X ; c’est-à-dire, de déterminer le modèle qui
explique le mieux la séquence. Le problème est qu'il n'est pas possible de trouver
un tel modèle de façon analytique. L'algorithme de Baum-Welch est un algorithme
itératif, qui permet d'estimer les paramètres du modèle qui maximisent la probabilité
d'une séquence d'observables. C’est un algorithme à apprentissage.
Définissons d'abord ( ) la probabilité d'être dans l'état i à l'instant t et dans
l'état j à l'instant t+1, étant donné une observation X et le modèle .
( ) = P( )
( ) = ( )
( ) =
( ) ( ) ( )
( )
( ) = ( ) ( ) ( )
∑ ∑ ( ) ( ) ( )
(2.11)
avec la probabilité de transition de l'état i vers l'état j, et ( ) la probabilité
d'observer x lorsque l'on est dans l'état j, et où les valeurs ( ) et ( ) définies ci-
après peuvent se calculer simplement avec l'algorithme forward-backward.
( ) = ( )
( ) = ( )
La figure montre une vue schématique partielle des éléments nécessaires pour
le calcul de ( ).

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 19
Figure 17: Modèle de l’algorithme de Baum-Welch
Nous définissons aussi ( ) la probabilité d'être dans l'état i à l'instant t,
( ) = ∑ ( ) (2.12)
En sommant ( ) sur le temps, on obtient le nombre prévu de transitions d'un
état i dans l'observation X
∑ ( )
Et en faisant la même chose avec ( ), nous obtenons le nombre prévu de
transitions d'un état i à l'état j dans l'observation X
∑ ( )
Le fonctionnement de la procédure itérative est la suivante :
Partir d'un modèle initial qui peut être choisi aléatoirement.
Réaliser le calcul des transitions et symboles émis qui sont les plus
probables selon le modèle initial.
Construire un nouveau modèle dans lequel la probabilité des transitions et
des observations déterminée à l'étape précédente augmente. Pour la
séquence des observables en question, le modèle aura désormais une
probabilité plus élevée que le modèle précédent.
Ce processus de formation est répété plusieurs fois jusqu'à ce qu'il n'y ait plus
d'amélioration entre le modèle recalculé et l'ancien.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 20
Probabilité d'être dans l'état i à l'instant t=1:
= ( ) , (2.13)
Re-estimation des probabilités de transition. Le numérateur correspond au
nombre attendu de transitions de i à j, et le dénominateur représente le nombre
attendu de transitions de i:
= ∑ ( )
∑ ( )
, , (2.14)
Re-estimation des probabilités d'émission. Le numérateur correspond au
nombre de fois où l'on est passé dans l'état j et que l'on a observé , et le
dénominateur représente le nombre de fois où l'on est passé dans l'état j:
( ) = ∑ ( )
∑ ( )
, , (2.15)

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 21
2.4.3. Algorithme de Viterbi
Le problème que l’on se pose ici est de trouver, étant donné une séquence de
symboles X= et un HMM ( ), la séquence d’états du
HMM qui a la probabilité maximale de générer X. Ce qui nous préoccupe n’est pas
la valeur de la probabilité maximale, mais le chemin (appelé chemin de Viterbi) qui
permet de générer la séquence X avec cette probabilité. De manière similaire à
l’approche utilisée pour le calcul de P(X| ), l’approche directe pour résoudre ce
problème consiste à calculer la probabilité de génération suivante tous les chemins
possibles et de choisir parmi ces chemins celui qui a la probabilité la plus élevée.
Cette approche a, comme pour le calcul de P(X| ), une complexité en O(T ) et est
donc également inapplicable. L’algorithme de Viterbi est un algorithme de
programmation dynamique très similaire à l’algorithme forward et qui permet de
résoudre efficacement ce problème.
Figure 18: Modèle de l’algorithme de Viterbi
Considérons la varibale ( ) définie par
( ) = ( ) ( ) (2.16)
( ) = ( ) (2.17)
1. Initialisation:
( ) = ( ), (2.18)

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 22
( ) = 0 (2.19)
2. Récursivité:
( ) = ⌊ ( ) ⌋ bj(Xt+1), , (2.20)
( ) = ( ) (2.21)
3. Résiliation:
P* = ⌊ ( )⌋ (2.22)
= ⌊ ( )⌋ (2.23)
4. Rétro-propagation :
= (
), i = T-1, T-2, … , 1 (2.24)
On notera que, mise à part la phase de rétro-propagation, l’algorithme de Viterbi
est très similaire à l’algorithme forward. La principale différence résulte de la
maximisation des probabilités attachées aux états précédents au lieu du calcul de la
somme de ces probabilités dans le cas de l’algorithme forward.
2.5. Conclusion
Les HMM sont des modèles statistiques très puissants qui trouvent des
applications dans de multiples domaines.
Nous avons déjà évoqué la reconnaissance vocale: il s'agit de faire
correspondre une séquence de phonèmes (la séquence d'observations) avec une
séquence de mots (la séquence d'états cachés).
Figure 19: Les applications du HMM

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 23
De façon générale, un HMM permet de retrouver des informations cachées que
l'on sait liées à des informations observables. Voici quelques exemples
d'applications:
- L'analyse cryptographique
- La traduction automatique
- La recherche de virus polymorphe
- La reconnaissance d'écriture manuscrite
- La bio-informatique
- L'analyse financière
Et bien d'autres...

LE Hoang Long, Classe 09T4 24
CHAPITRE 2
SYSTÈMES DE LA RECONNAISSANCE DE
L’ÉCRITURE VIETNAMIENNE
MANUSCRITE
1. Aperçu du système
Le système de la reconnaissance de l’écriture vietnamienne manuscrite compose 2
parties :
- Reconnaissance de l’écriture vietnamienne manuscrite en ligne :
Ce mode de reconnaissance s'opère en temps réel (pendant l'écriture). Il est
réservé généralement à l'écriture manuscrite, c'est une approche «signal» où la
reconnaissance est effectuée sur des données à une dimension. L'écriture est
représentée comme un ensemble de points dont les coordonnées sont en fonction du
temps. L'acquisition de l'écrit est généralement assurée par : téléphone mobile de
nouvelle génération (Smartphone), ordinateur tablette (Tablet PC ou UMPC) ou
encore tableau blanc interactif (TBI).
- Reconnaissance de l’écriture vietnamienne manuscrite hors ligne
Ce mode peut être considéré comme le cas le plus général de la reconnaissance
de l'écriture. Il se rapproche du mode de la reconnaissance visuelle. Après
l'acquisition par une image, l’écriture est représentée comme une matrice de pixel.
Figure 20: L’écriture manuscirte en ligne et hors ligne
Chaque partie compose 4 éléments principaux ci-dessous:
Collection de la base de données : construction de données d'entrée fixe pour
le processus de formation et le processus d'identification. Les données
d'entrée, y compris des photos et des lettres manuscrites, vecteur contenant

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 25
les coordonnées de la séquence de dessin en ligne a été extraites
caractéristiques.
Extraction de caractéristiques : identifier des caractéristiques différentes
pour les différents personnages. La première caractéristique est dans le
processus de formation et de caractère processus de reconnaissance .
Apprentissage : créer le modèle optimal pour chaque vecteur de
caractéristique de caractère masqué. Le modèle optimal sera utilisé dans le
processus de reconnaissance.
Reconnaissance : basé sur le modèle caché de Markov était optimale
formation réussie et la séquence de vecteurs de caractéristiques de
reconnaissance de caractères, nous allons résoudre le problème de l'identité .
Le système de la reconnaissance de l'écriture manuscrite est représenté sur la figure
16 ci-dessous:
Figure 21: Le système de la reconnaissance

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 26
2. Base de données
2.1. EVM en ligne
Créer une base de données de formation enregistrée par la séquence de
vecteurs de caractéristiques avec chaque classe de lettres. Synthèse de cette
séquence de vecteurs de caractéristiques servira de base pour le système d'entrée
d'apprentissage.
Figure 22: Cinq caractères vietnamiens manuscrits en ligne
Figure 23: Caratère « a » manuscrite en ligne été écrit cinq fois
2.2. EVM hors ligne
Dans ce mémoire, j’utilise des modèles d'écriture manuscrite de cinq personnes
pour l’apprentissage et la reconnaissance.
Figure 24: Les modèles d’écriture manuscrite

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 27
3. Prétraitement
3.1. EVM en ligne
Un des problèmes de reconnaissance de l’EVN en ligne est de supprimer coups
excès. Cela aidera à normaliser l'écriture, joue un rôle important, grandement
affecter l'efficacité d’apprentissage et de reconnaissance.
Coups excès apparaissent souvent au début ou à la fin du processus d'écriture
d'un caractère. Nous allons nous concentrer sur l'étude de la forme de l'action de
dessin et de prendre pour les éliminer.
Figure 25: Supprimer coups excès
3.2. EVM hors ligne
Après avoir obtenu de la caméra, les images peuvent être un bruit et la
distorsion. Par conséquent, elles doivent être pris en prétraitement pour améliorer la
qualité de l'image.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 28
Figure 26: Mode de prétraitement
Figure 27: Image RGB Image Gris Image binaire
Figure 28: Filtrage du lissage et épaississement

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 29
Figure 29: Segmentation, redimensionner et squelette
L'ensemble des images après le processus de prétraitement:
Figure 30: Les caractères « u »
Figure 31: Les caractères « A »

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 30
4. Extraction de caractéristiques
Extraction de caractéristique est un processus très important dans le problème
général de la classification et de la reconnaissance de l'écriture manuscrite en
particulier.
4.1. EVM en ligne
Pour le problème de la reconnaissance de l'écriture en ligne, la direction de
chaque paire de points est une base principale pour construire le vecteur de
caractéristique.
Après les caractères ont été écrit, on va obtenir les coordonnées des pixels de
coups de pinceau. Effectuez les étapes suivantes en parallèle avec le processus
d'écriture des caractères :
- Étape 1: Les coordonnées qui passent par le dessin seront enregistrées à leur
tour dans le sens du dessin lors de ce processus. Ici, nous considérons chaque
paire de points consécutifs pt et pt+1 dans le sens des traits de pinceau.
- Étape 2: Appelez θ est l’angle entre deux vecteurs (pt, pt+1), c’est-à-dire le
vecteur original est pt et pt+1 en tête, avec vecteur Ox dans le système de
coordonnées cartésiennes, avec la valeur de domaine correspondant est [0o,
360o]. La valeur de θ est défini par:
(
√
)
Avec:
Si le vecteur (pt, pt+1) a la direction à la baisse, la valeur de l’angle θ dépasse
180o. Toutefois, la fonction arccos retourne juste la valeur qui se situe dans
l’intervalle [0o, 180
o]. En effet, l’angle θ devrait être défini comme suit:

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 31
Figure 32: L’angle entre deux vecteurs (pt, pt+1)
- Étape 3: Caractéristiques de vecteurs (pt, pt+1) est déterminée en fonction de
l'ordre de valeur de l’angle θ:
Figure 33: Diviser le système de coordonnées cartésiennes en 12 zones
Ce processus est répété sur toutes les paires de points consécutifs dans le trajet.
Ensuite, nous avons caractérisé le vecteur de caractères correspondant à
l'observation d'un modèle Markov caché.
Par exemple, une forme de vecteur caractéristique du caractère " " écrit après le
processus d'extraction comme suit:

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 32
4.2. EVM hors ligne
Pour le problème de la reconnaissance de l'écriture hors ligne, l'extraction de
caractéristiques devient plus difficile. Caractérisé principalement pris de la structure
statistique des pixels de caractères. Nous ne suit :
Diviser l'image d'entrée en 36 régions et chaque région de pixel sous test.
Examen et approbation de l'ordre de gauche à droite, de haut en bas, et sauvegarder
chaque valeur caractéristique. La séquence des valeurs est vecteurs des
caractéristiques des images.
Figure 34: Diviser l'image d'entrée en 36 régions
Par exemple, une forme de vecteur caractéristique du caractère "A" écrit après
le processus d'extraction comme suit:
[3 2 3 2 3 2 3 2 3 2 3 8 9 8 9 8 10 8 10 8 10 8 10 8 10 8 10 8 10 8 10 8 10 8 10 14
16 14 16 14 16 14 16 14 16 14 16 14 16 14 16 14 16 14 17 14 17 14 17 20 23 20 21 22 23 20 21 23 20 23 19 23 19 23 19 23 19 23 19 23 19 23 19 23 19 24 25 30 25 30
25 30 25 30 25 30 25 30 25 30 25 30 25 30 25 30 25 30 25 30 31 36 31 ]

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 33
5. Apprentissage des HMMs
5.1. Initialisation des HMMs
Chaque HMM se défini par:
( )
- : la matrice des probabilités de départ [1xN], c'est-à-dire les probabilités de
démarrer dans chacun des N états
- A: la matrice des probabilités de transition [NxN], c'est à dire les probabilités de
passer d'un état à l'autre:
[
] , avec ∑
- B : la matrice des probabilités d'émission [NxM], c'est-à-dire les probabilités
pour chaque état d'émettre chacune des observations possibles (il y a M
observations)
Ces trois matrices ont la particularité d'avoir des lignes "stochastiques", ne
dépendent que de l'état N et le nombre d'observations M dans chaque état. Cela
signifie que chaque élément d'une ligne est une probabilité et que la somme des
éléments de la ligne est égale à 1.
∑
∑
Pour le problème de la reconnaissance en ligne, ici, on choisit le nombre d'états
du modèle est 4 (N = 4). Chaque état dispose de 12 valeurs observées (M = 12, en
fonction du nombre de valeurs de vecteurs des caractéristiques ont été obtenues).
On initialise le modèle HMM pour des états et des observations comme suit:
[ ]

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 34
A = [
]
Avec chaque line de la matrice A, on a :
- Line 1 :
0.24235 + 0.1881 + 0.28482 + 0.28472 = 1
- Line 2 :
0 + 0.063019 + 0.62339 + 0.31359 = 1
- Line 3 :
0 + 0 + 0.16454 + 0.83546 = 1
- Line 4 :
0 + 0 + 0 + 1 = 1
B =
[
]
Avec chaque line de la matrice B, on a :
- Line 1 :
0.1033 + 0.087049 + 0.10929 + 0.12416 + 0.077467 + 0.080923 + 0.10253 +
0.055814 + 0.099059 + 0.074941 + 0.035953 + 0.049508 = 1
- Line 2 :
0.13381 + 0.054186 + 0.033558 + 0.014835 + 0.079703 + 0.093402 + 0.069234 +
0.17171 + 0.10735 + 0.042148 + 0.031216 + 0.16885 = 1
- Line 3 :
0.088103 + 0.10129 + 0.050119 + 0.12641 + 0.060769 + 0.11121 + 0.11039 +
0.11914 + 0.028256 + 0.11484 + 0.030966 + 0.058514 = 1
- Line 4 :
0.084413 + 0.035372 + 0.11712 + 0.14521 + 0.057348 + 0.14879 + 0.099745 +
0.10299 + 0.056393 + 0.03646 + 0.081563 + 0.034597 = 1

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 35
Pour le problème de la reconnaissance hors ligne, on choisit le nombre d'états
du modèle est 4 (N = 4). Chaque état dispose de 36 valeurs observées (M = 36). On
initialise le modèle HMM pour des états et des observations comme suit :
[ ]
A = [
]
B = [4x36]
Avec chaque line de la matrice B, on a :
- Line 1 :
0.022469 + 0.0094493 + 0.040017 + 0.011675 + 0.03927 + 0.0075782 + 0.051178 + 0.016845 + 0.011236 + 0.019911 +
0.02689 + 0.053077 + 0.0035743 + 0.059809 + 0.055248 + 0.047962 + 0.029281 + 0.047275 + 0.046643 + 0.013556 +
0.044637 + 0.040833 + 0.010832 + 0.0080343 + 0.0083751 + 0.049717 + 0.0073587 + 0.039241 + 0.0019486 +
0.048571 + 0.018748 + 0.01605 + 0.013665 + 0.050282 + 0.028682 + 8.0827e-05 = 1
- Line 2 :
0.02805 + 0.039641 + 0.039185 + 0.030994 + 0.028384 + 0.035278 + 0.017254 + 0.0063308 + 0.0048523 + 0.04557 +
0.032076 + 0.018251 + 0.016286 + 0.029019 + 0.040783 + 0.033625 + 0.047696 + 0.018605 + 0.027098 + 0.041128 +
0.016273 + 0.025689 + 0.020671 + 0.002462 + 0.033297 + 0.03805 + 0.042504 + 0.0043429 + 0.034754 + 0.027147 +
0.015311 + 0.035115 + 0.0040082 + 0.035496 + 0.037729 + 0.047043 = 1
- Line 3 :
0.011107 + 0.018233 + 0.046424 + 0.00021842 + 0.019707 + 0.0094885 + 0.0046188 + 0.042388 + 0.012213 +
0.032239 + 0.033182 + 0.045375 + 0.049508 + 0.020492 + 0.015558 + 0.029838 + 0.029721 + 0.02746 + 0.039297 +
0.054812 + 0.01652 + 0.050231 + 0.028817 + 0.038017 + 0.031242 + 0.030405 + 0.058784 + 0.0045261 + 0.0087337 +
0.022865 + 0.047557 + 0.0098722 + 0.0044651 + 0.045938 + 0.025601 + 0.034545 = 1
- Line 4 :
0.0042457 + 0.021189 + 0.020653 + 0.015615 + 0.054587 + 0.023991 + 0.030741 + 0.02682 + 0.0074376 + 0.013671 +
0.033618 + 0.0086492 + 0.020839 + 0.051222 + 0.015758 + 0.053412 + 0.027789 + 0.0073331 + 0.04405 + 0.016119 +
0.0093986 + 0.014758 + 0.043342 + 0.0016055 + 0.029949 + 0.015269 + 0.052025 + 0.010071 + 0.035101 + 0.045349
+ 0.027805 + 0.05084 + 0.042477 + 0.053055 + 0.052091 + 0.019124 = 1
C’est ainsi que nous avons fait le processus d'initialisation pour les modèles
HMM.

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 36
5.2. Apprentissage
Après l'étape de prétraitement et extrait les vecteurs de caractéristiques pour
chacun des modèles de caractères, nous allons obtenir le vecteur caractéristique du
participant. Le vecteur de caractéristiques contient la séquence des valeurs de
l’observées X de chaque lettres:
Nous utilisons l'algorithme de Baum Welch introduit dans la section 2.4.2 pour
créer le modèle optimal de les valeurs de l'observation séquences X et le modèle .
Ce modèle optimal est une base importante pour le processus d'identification.
Chaque modèle optimal différent représentera chacune différentes classes de
caractère.
Étant donné que le modèle HMM est initialisé initiale est aléatoire, quand on
crée un modèle optimal, la valeur de ce modèle est aléatoire et n’est pas en même
pour chaque création différente.
Les modèles optimaux (avec trois matrices) seront enregistrés pour leur
utilisation dans le processus de reconnaissance.
Un exemple pour le modèle optimal de caractère « a » d’écriture manuscrite en
ligne :
Matrice [ ]
Matrice A :
0.59122 0.40878 8.4574e-14 7.0634e-23
0 0.65435 0.34565 9.0244e-08
0 0 0.69514 0.30486
0 0 0 1
Matrice B :
[0 0 0.0064885 0.012977 0.051908 0.18168 0.62289 0.1172 0.006851 5.3971e-19 9.4725e-59
6.7494e-148 ;
2.9935e-66 7.0972e-156 0 7.8059e-63 0 2.9848e-38 1.371e-06 0.55927 0.4401 0.00062725
4.0343e-08 3.0287e-27 ;
0.04078 8.589e-05 6.2777e-19 2.6229e-08 4.1091e-60 1.1522e-110 4.0712e-60 1.2537e-06 0.017689 0.43412
0.12491 0.38242 ;
0.11955 0.15378 0.1343 0.18773 0.025993 0.0043322 0.0036102 0.0057763 0.024602 0.19219
0.070895 0.077239]

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 37
Un exemple pour le modèle optimal de caractère «A» d’écriture manuscrite
hors ligne :
Matrice [ ]
Matrice A : [4x4]
0.89024 0.10976 2.486e-23 0
0 0.94156 0.058439 1.2914e-91
0 0 0.97546 0.024538
0 0 0 1
Matrice B : [4x36]
- Line 1 :
0.46342 0 0 0 0.024385 0.5122 5.8694e-07 0 0 0 3.7875e-27 4.0568e-09
6.3777e-120 0 0 0 6.4632e-126 3.4098e-40 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0
- Line 2 :
5.7046e-27 0 0 0 2.5886e-06 4.407e-13 0.4805 0.0064932 0 0 0.084412
0.42855 4.3829e-05 0 0 5.224e-103 4.56e-07 6.8032e-09 2.1723e-110 0 0 0 0
7.4628e-302 0 0 0 0 0 0 0 0 0 0 0 0
- Line 3 :
0 0 0 0 0 0 6.6851e-76 0 0 0 4.0714e-24 3.1818e-15 0.25075
1.6616e-253 0 2.5855e-09 0.10633 0.16631 0.22603 6.755e-12 0.0027264 0.068844 0.13469
0.043622 0.0007012 6.9062e-19 1.008e-17 1.2815e-06 1.0262e-06 1.4798e-238 8.1002e-243 1.4967e-103 2.5069e-
155 7.5266e-273 0 0
- Line 4 :
0 0 0 0 0 0 0 0 0 0 0 0 0.0054331 0.0053937
0 0.012585 1.1471e-21 2.418e-72 0.0055677 0.046745 1.9161e-195 0.035507 0.020853 2.6242e-15
0.069655 0.11686 0.05933 0.13664 0.086298 0.0071915 0.046745 0.11147 0.10608 0.11506
0.0089894 0.0035958

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 38
6. Reconnaissance
La reconnaissance d'un nouveau caractère est de rechercher la probabilité
P(X| ), qui est la plus probable, grâce aux modèles d'entrées ),,( BA , qui a été
entraîneur, et la séquence des valeurs de l’observées de l'identité de
caractère.
Nous utilisons l'algorithme Forward/Backward, qui a été présenté dans la
section 2.4.1, pour rechercher la probabilité d'occurrence de la séquence vecteur de
caractéristique X dans chaque modèle optimale HMM à la section 5.
Après avoir trouvé les valeurs de probabilité pour chaque modèle, on obtient
une séquence de probabilité correspondante. Si on avait 5 modèles optimaux, le
résultat de calculer le log-likehood pour chaque modèle est:
Nous allons appliquer l'algorithme recherché le plus grand dans une séquence
de valeurs pour trouver le plus probable P(X| ). Puis, nous reconnaissons l'identité
du modèle de caractère. C'est les états cachés correspondants de caractère que nous
devons reconnaître.
Si le modèle i-ème est la plus probable , alors déclarer la classe de la séquence
d'être la classe i.
Ici, on a i = 1. Le caractère est la classe i.

LE Hoang Long, Classe 09T4 39
CHAPITRE 3
RÉSULTATS
Système de la reconnaissance de l'écriture vietnamienne manuscrite est un ensemble
de processus. Donc, le test est également effectué avec chaque procès pour avoir
d’une vue d'ensemble pour le système.
1. Implémentation
1.1. Outils et le langage de programmation
Dans ce mémoire, on utilise langage Matlab pour faire un programme démo.
Malab (matrix laboratory) est un langage de programmation de quatrième
génération et un environnement de développement ; il est utilisé à des fins de calcul
numérique. Développé par la société The MathWorks, MATLAB permet de
manipuler des matrices, d'afficher des courbes et des données, de mettre en œuvre
des algorithmes, de créer des interfaces utilisateurs, et peut s’interfacer avec
d’autres langages comme le C, C++, Java, et Fortran. Les utilisateurs de MATLAB
sont de milieux très différents comme l’ingénierie, les sciences et l’économie dans
un contexte aussi bien industriel que pour la recherche. Matlab peut s’util iser seul
ou bien avec des toolbox (boîte à outils). On utilise une boîte à outils de HMM pour
supporter les fonctions et les algorithmes.
1.2. Construction du programme de démo
Le programme se compose de 2 parties: reconnaissance d’écriture
vietnamienne manuscrite en ligne et reconnaissance d’écriture vietnamienne
manuscrite hors ligne.
2. Base de données
Les données d'entrée pour l'étude comprennent:
La base de données de la reconnaissance en ligne : 350 patterns de 5
caractères a, b, c, g, n
La base de données de la reconnaissance hors ligne : 500 patterns de 5
caractères A, C, T, L, u

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 40
3. Résultats et Interprétation
3.1. Taux de reconnaissance
Table 1: Le taux de la reconnaissance caractères manuscrite en ligne.
TT Caractère
manuscrit
Nombre de
tests
Nombre de
correct
Taux
1 a 50 46 92%
2 b 50 48 96%
3 c 50 45 90%
4 g 50 46 92 %
5 n 50 43 86%
Table 2: Le taux de la reconnaissance caractères manuscrite hors ligne.
TT Caractère
manuscrit
Nombre de
tests
Nombre de
correct
Taux
1 A 50 43 86%
2 C 50 45 90%
3 T 50 43 86%
4 L 50 44 88 %
5 u 50 43 86%
3.2. Évaluation de performance obtenue
Dans ce mémoire, nous utilisons moyen de 80 échantillons pour
l’apprentissage. La performance moyenne atteinte 91,2% identifier correct pour

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 41
d’écriture manuscrite en ligne et 87,2% identifier correct pour d’écriture manuscrite
hors-ligne. C’est un très bon taux.
Les erreurs d'identification des échantillons sont principalement dues à
l'écriture bâclée et à la différence est trop grande par rapport à l'échantillon. Cela
rend le processus d'extraction de caractéristiques et de donnée des résultats inexacts.
4. Quelques figures du système
4.1. La reconnaissance en ligne
Figure 35: Les séquences vecteurs de caractéristique de caractères « a » manuscrite en ligne
Figure 36: Résultat de la reconnaissance du caractère « a » en ligne
Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 42
Figure 37: Résultat de la reconnaissance du caractère « b » en ligne
Figure 38: Résultat de la reconnaissance du caractère « c » en ligne
Figure 39: Résultat de la reconnaissance du caractère « g » en ligne

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 43
Figure 40: Résultat de la reconnaissance du caractère « n » en ligne
4.2. Reconnaissance hors ligne
Figure 41: Résultat de la reconnaissance du caractère « A » hors ligne
Figure 42: Résultat de la reconnaissance du caractère « C » hors ligne
Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 44
Figure 43: Résultat de la reconnaissance du caractère « T » hors ligne
Figure 44: Résultat de la reconnaissance du caractère « L » hors ligne
Figure 45: Résultat de la reconnaissance du caractère « u » hors ligne

Reconnaissance de l’écriture vietnamienne manuscrite par HMM
LE Hoang Long, Classe 09T4 45
CONLUSIONS
1. Conclusion
1.1. Avantages
Maîtriser le langage de programmation de Matlab et les boîtes à outils dans la
construction le programme de démo.
Proposer deux nouvelles méthodes de la recherche la séquence vecteur de
caractéristique.
Avoir la notion d’une théorie et de certaines méthodes de reconnaissance
d’écriture vietnamienne manuscrite : en ligne et hors-ligne.
Le programme de démo a bien traité la reconnaissance d’écriture vietnamienne
manuscrite par le modèle Markov cachés avec les taux très bien et rapidement.
1.2. Désavantages
Le nombre de classes d’apprentissage est limité (10 caractères).
Besoin de créer plusieurs classes d'apprentissage pour les caractères restants
dans le système de l'alphabet vietnamien pour pouvoir reconnaître l'écriture
vietnamienne manuscrite complète.
2. Perspectives
Continuer l’apprentissage les caractères
Lorsqu'il sera mis en pratique, nous devrons établir un seuil qui indiquera les
motifs de caractères sélectifs pour des résultats plus précis lorsque la différence
de probabilité entre les caractères est faible


RÉFERENCES [1] Res. Unit SAGE, Nat. Eng. Sch. of Sousse, Sousse, Tunisia, "Application of Bayesian
networks for pattern recognition: Character recognition case"
[2] Phạm Anh Phương, “Nghiên cứu lý thuyết SVM và mô hình ứng dụng cho bài toán nhận dạng
chữ viết tay hạn chế”, Đề tài Khoa học và Công nghệ cấp Bộ, 2007 – 2008
[3] Dept. of Electron. & Electr. Eng., IIT Guwahati, Guwahati, India, "Offline handwritten
character recognition using neural network"
[4] Baum, L. E.; Petrie, T.; Soules, G.; Weiss, N. (1970). "A Maximization Technique Occurring
in the Statistical Analysis of Probabilistic Functions of Markov Chains". The Annals of
Mathematical Statistics 41: 164.
[5] "A Revealing Introduction to Hidden Markov Models", Mark Stamp Associate, Professor
Department of Computer Science, San Jose State University September 28, 2012
[6] Hidden Markov Model (HMM) Toolbox for matlab,
http://www.cs.ubc.ca/~murphyk/Software/HMM/hmm.html
[7] http://igm.univ-mlv.fr/~dr/XPOSE2012/HiddenMarkovModel/
[8] Huỳnh Hữu Hưng, "Xử lý ảnh số", Khoa CNTT, Trường ĐHBK Đà Nẵng.
[9] Huỳnh Hữu Hưng, Nguyễn Trọng Nguyên(2014): "Nhận dạng dấu thanh và mũ trong ký tự
tiếng Việt viết tay".
[10] Procter,Surrey,Guildford, Illingworth: "Handwriting recognition using HMMs and a
conservative level building algorithm".