imperial college of science - citeseerx
TRANSCRIPT

Imperial College of Science, Technology and Medicine
(University of London) Department of Computing
Discovery in the Gene Ontology by
George Traganidas (GT)
Submitted in partial fulfilment of the requirements for the MSc
Degree in Advanced Computing of the University of London and for the Diploma of Imperial College of
Science, Technology and Medicine.
September 2003

I
Abstract The Gene Ontology (GO) is a shared, structured vocabulary for the annotation of molecular characteristics across organisms. The concepts contained in GO are called GO terms and are related with each other with (isa) or (partof) relationships. Most GO terms have a set of genes associated with them. For example, bile acid biosynthesis has five genes1, which are associated with it in some way, whereas steroid biosynthesis has one hundred and three genes1. It may be possible to use the HR program to make discoveries in this vocabulary of GO terms. The HR program was created to perform theory formation in mathematical domains. It has been expanded since then and can be used to form theories in many other domains too. Empirical evidence contained in the vocabulary will be used to make discoveries that will link various parts of the ontology. HR works by forming concepts and using the examples of those concepts to hypothesise links between new and old concepts. It is possible that the application of HR to this dataset would yield no statistically significant conjectures. That is, none of the conjectures are sufficiently supported by the empirical evidence to make it more than a coincidence that two concepts were linked by the conjecture. This project is a feasibility study that will try to decide if HR can be used to perform statistically significant discoveries in the Gene Ontology. The project consists of three phases. Initially, we will develop a program that the user will use to select GO terms from the Gene Ontology. The program will find the selected GO terms and save them together with their corresponding genes in a specially formatted file to be used in HR. In the second phase, we will provide this file as input to HR and we will use the program to try to discover statistically significant conjectures between the genes associated with the GO terms. In the end, we will enhance the features of HR, in order to increase the yield of such discoveries. In this project, we will not be worrying about whether the conjectures are interesting or not to biologists.
1 This information is taken from GO http://www.geneontology.org/, using the data files of May 2003

II
Acknowledgements A number of people have helped me during the development of this project. First of all I would like to thank Dr. Simon Colton for his support during the whole project. He has provided me with the HR program. He has assisted me in using it, analysing the results and implementing some additional features. In addition, he has provided valuable help in understanding the Gene Ontology. I would like to thank Alexei Grigorievich Yavlinsky for his assistance in the design and implementation of RMI and his insight about the performance issues of the project. Moreover, I would like to thank my fellow students in DOC for helping me generate random test cases for the project and our informal discussions about the project. Last, but not least, I would like to thank Irene Papatheodorou for the time she spent proof reading this report.

III
Contents Abstract I Acknowledgements II Contents III List of Figures V List of Tables VI 1 Introduction 1 2 Background Information 3
2.1 Gene Ontology (GO) 3 2.1.1 Ontology Types 3 2.2.2 Ontology Structure 5
2.2 GO Browsers 7 2.3 HR 9 2.3.1 Concept Representation 9 2.3.2 Production of new Concepts 10
2.3.3 Conjecture Formation 11 3 GO Search Program (GOSP) Design 13
3.1 Project Requirements 13 3.2 Design Decisions 14 3.3 Use Case Diagram 14
3.3.1 Use Case Descriptions 15 3.4 UML Diagrams 16 3.5 Object Interaction Model 17 3.6 Client Server Object Interaction 17
4 GO Search Program (GOSP) Implementation 19
4.1 Implementation Environment 20 4.2 GOSP Classes and Methods 20
4.2.1 ComputeEngine Class 21 4.2.2 Connection Class 22 4.2.3 GeneOntologies Class 22 4.2.4 Indexes Class 22 4.2.5 MainFrame Class 23 4.2.6 MainFrame_AboutBox Class 23

IV
4.2.7 TermData Class 23 4.2.8 Compute Interface 26 4.2.9 Task Interface 26
4.3 GOSP Java Class Details 17 5 GO Search Program (GOSP) Testing 28
5.1 Functionality Testing 28 5.1.1 Test Plan 28 5.1.2 Test Cases 29 5.1.3 Results and Analysis 33
5.2 Correctness Testing 34 5.3 Performance Testing 36
6 Experiments with HR on the Gene Ontology 37
6.1 Setting up HR to be Used in Discoveries in GO 38 6.2 Problems and Limitations of HR 40
7 Experiment Results and Evaluation 41
7.1 Random GO Term Tests 41 7.2 Localised GO Term Tests 43 7.3 Evaluation of Hypothesis 45
8 Conclusion and Future Work 46
8.1 Future Work 47 8.1.1 Extensions to GOSP 47 8.1.2 Extensions to HR 48
8.2 Summary 49 Bibliography 50 Appendix A: GO Search Program (GOSP) UML Diagrams 51 Appendix B: GO Search Program (GOSP) JavaDocs 56 B.1 Indexes JavaDoc 56
B.2 Connection JavaDoc 59 B.3 TermData JavaDoc 61 B.4 ComputeEngine JavaDoc 67
Appendix C: GO Search Program (GOSP) Output File 70 Appendix D: Notes on the Gene Ontology 78 Appendix E: HR Results 80 E.1 Test Results 80 E.2 Localised GO Term Near-conjecture Results 83 Appendix F: User Guide 90
F.1 Compiling GOSP 90 F.2 Using GOSP 91

V
List of Figures Figure 2.1 Gene Product Relationships 4 Figure 2.2 GO Terms Associated with S10A_HUMAN by GenNav 7 Figure 2.3 GenNav Direct Acyclic Graph (DAG) Legend 8 Figure 2.4 GO Terms Associated with S10A_HUMAN by AmiGO 8 Figure 3.1 GOSP Use Case Diagram 15 Figure 3.2 Object Interaction Model 17 Figure 3.3 Client Server odel of GOSP 18 Figure 4.1 Screenshot of GOSP version 1.0 19 Figure 6.1 Screenshot of HR Program version 2.2.1 37 Figure A.1 UML diagram of Task Interface 51 Figure A.2 UML Diagram of Compute Interface 52 Figure A.3 UML Diagram of Connection Class 52 Figure A.4 UML Diagram of ComputeEngine Class 53 Figure A.5 UML Diagram of TermData Class 54 Figure A.6 UML Diagram of Indexes Class 55 Figure A.7 UML Diagram of GeneOntologies Class 55 Figure F.1 GOSP User Guide 92
VI
List of Tables Table 5.1 Functionality Test Plan Results 34 Table 7.1 Random GO Term Tests with Relations 42 Table 7.2 Localised GO Term Tests with Relations 44 Table E.1 All Random GO Term Tests 80 Table E.2 All Localised GO Term Tests 82

1
Chapter 1 Introduction One of the biggest discoveries of the last century was the structure of the double-stranded DNA helix. The latter contains the genetic material of the organism in a coded form. Each helical strand is made up of bases i.e. Adenine (A), Guanine (G), Cytosine (C) and Thymine (T), as well as other chemical entities. Each base forms a complementary pairing interaction with the base in the opposite strand. These interactions are Hydrogen bonds and can occur only between A and T or C and G. The information encoded in DNA exists in the form of genes. These are usually sequences between 600 to 1200 bases. The information represented in them is very complex and its size makes it difficult for human analysis. As a consequence, a lot of time and effort is required for data retrieval and analysis. This suggests the automation of both processes, through the use of computers. The outcome of that was the formation of a new multidisciplinary scientific field called Bioinformatics, which in essence is a joint discipline between biology and computer science. The information that biologists have discovered so far is stored in many different databases. Most of the time, the data is represented in a database specific format. The storing of data in different formats makes sharing of knowledge a complicated process. For example, when a researcher wants to exchange data with a second one, the representation of data must first be appropriately changed and then stored in the database of the second researcher. An agreement on a common representation would make this exchange easier. The Gene Ontology (GO) is a shared and structured vocabulary, which can be used for the annotation of molecular characteristics across organisms. The terms that are stored in the ontology are called GO terms and fall into one of following three categories: molecular function, biological process and cellular component. Each term is linked with other ones in two ways: one term can be a specialisation of another (an “isa” relationship), or a property of another (a “part of ” relationship). Most of the GO terms have genes associated with them. The HR program can use the empirical evidence provided by the genes, to find relationships between GO terms. It performs automated theory formation, and maybe it can be used to find interesting conjectures in the Gene Ontology, which people (may not) have thought to link yet. HR can make either conjectures or near-conjectures. Near-conjectures are a type of conjecture that is true only for a portion of the data. We will study the ability of the current version of the program to find

2
statistically significant conjectures, linking parts of the Gene Ontology. This project consists of three phases. Initially, we will develop an application that will be used to select GO terms out of the ontologies, based on criteria that the user will specify. The application will search the database of the ontologies, select the GO terms and save them together with their corresponding genes to a file. This file will have a special format in order to be used as an input to HR. The second and the third phase are closely related and have to do with the ability of HR to find statistically significant conjectures which relate the given GO terms. During the second phase, we will run HR with sample input files and observe the results it yields. Based on these results, we will need to adjust the search parameters of HR to maximise the number of interesting conjectures. The final phase will be the expansion of HR with more search options in order to make the program more effective when forming a theorem about the GO terms. In the next chapters, we will provide more information about GO and HR, show the development of the Gene Ontology Search Program (GOSP) application, discuss our experience of using HR and discuss some extension to the project. In Chapter 2 we present more information about the Gene Ontology and the HR program. In Chapters 3, 4 and 5 we discuss the design, implementation and testing of the GOSP application, respectively. Chapter 6 contains the configuration of HR that we used in searching GO and we give a detailed overview of the tests that we run in HR in Chapter 7. Finally, in Chapter 8 we conclude on the work we have done and discuss future improvements to the project.

3
Chapter 2 Background Information In this chapter we provide some background information about the Gene Ontology (GO), two existing browsers for GO and the HR program. We discuss the information that makes up the ontology and the structure of the files that hold this information. Then we look at AmiGO2 and GenNav3, which are browsers for GO. These browsers will be used at the testing phase in Section 5.2 in order to check the results we get from the Gene Ontology Search Program (GOSP). Finally, we present the HR program in some detail and discuss the features that we used for this project. 2.1 Gene Ontology (GO) In the last few years there have been many discoveries in biology. The new information that has been discovered is stored in databases run by various organisations or research institutes. These databases store information using internal formats that are usually incompatible with each other. Thus, exchange of information is difficult and queries that span multiple databases are hard to run. These difficulties in information sharing are an obstacle to further discoveries. The Gene Ontology (GO) Consortium [7] was formed to develop shared, structured vocabularies adequate for the annotation of molecular characteristics across organisms [3]. These vocabularies are used to describe gene products of organisms. The common ontology helps to explore the functional aspects of the genomes in databases that represent different organisms. In addition, it provides an aid to discover new sequences [4]. Each term in the Gene Ontology represents a particular concept from genetics, and has a unique identity number. The identity begins with the letters GO, followed by a semicolon and a seven-digit number. For example, GO:0008384 is the GO identity of ‘IkappaB kinase activity’. 2.1.1 Ontology Types Three ontologies are currently under development. These ontologies are molecular function, biological process and cellular component. A gene product has one or more
2 AmiGO can be found at http://www.godatabase.org/cgi-bin/go.cgi. 3 GenNav can be found at http://etbsun2.nlm.nih.gov:8000/perl/gennav.pl.

4
molecular functions and is used in one or more biological processes; it may or may not be associated with one or more cellular components [5]. Gene products are physical entities. For example, it might be a protein or an RNA fragment. Figure 2.1 shows an example of a gene product. It has three molecular functions; it is used in two biological processes and is associated with two cellular components. The relations between gene products and molecular functions, biological processes and cellular components are all many to many.
Figure 2.1: Gene Product Relationships A molecular function is what a gene product does at the biochemical level. It does not specify the cellular location or at which point in the cell cycle the gene product will be used. An example of a molecular function is “alcohol dehydrogenase” (GO:0004022). A biological process is a biological objective to which a gene product contributes. One or more ordered molecular functions accomplish it. It often involves transformation in the sense that the input is changed when it comes out. An example of a biological process is “signal transduction” (GO:0007165). A cellular component is just that, a component of a cell but with the proviso that it is part of some larger object, which may be an anatomical structure (e.g. rough endoplasmic reticulum or nucleus) or a gene product group (e.g. ribosome, proteasome or a protein dimer). An example of cellular component is “nucleus” (GO:0005634).

5
2.1.2 Ontology Structure The ontologies are structured vocabularies in the form of directed acyclic graphs (DAGs), which differ from hierarchies in that a child (more specialized term) can have many parents (less specialized terms). The relationships between parents and children can be either of type “is a” or of type “part of”. The “is a” type signifies that a child is an instance of its parent (e.g. ‘calcium binding’ is an instance of ‘ligand binding or carrier’). The “part of ” type represents that a child is a component of the parent (e.g. ‘neurogenesis’ is part of ‘ectoderm development’). A child can have a different type of relation with each of its parents. In order for the Gene Ontologies to be consistent, certain rules have been followed in their construction [3]:
• All paths in the ontologies are considered true, based on the knowledge discovered so far.
• Terms should not be species specific. • All attributes of GO must be accompanied by appropriate citations
(where this is possible). • All annotations of gene products to GO terms must incorporate
controlled statements of the type of evidence that supports the relationship, as well as appropriate citations.
Each one of the GO terms in the ontologies may have certain genes associated with it. Discovery of new genes and new relations between GO terms may cause the invalidation of the current paths. In this case, the ontologies need to be redesigned in order to maintain the validity of the paths that connect the GO terms. The ontologies are stored in files. There are three different files that store the biological process ontology, the molecular function ontology and the cellular component ontology. A standard is followed in the storing of information. In particular, lines that start with ‘!’ are comment lines. Lines in which the first non-space character is a ‘$’ either reflect the domain and aspect of the ontology or the end of file. In the first lines of every file, there is version information, date of last update, the name of the database and other information. The parent-child relationships are represented by indentation. parent_term child_term1 | [child_term2] The “is a” relationship is represented by %. The following example shows that child_term is an instance of parent_term1 and also an instance of parent_term2. %parent_term1 %child_term %parent_term2

6
The “part of ” relationship is represented by <. The following example shows that child_term1 is an instance of parent_term1 and part of parent_term2 and parent_term3. %parent_term1 %child_term1 < parent_term2 < parent_term3 Here follows a sample of the process.ontology text file. Moreover, there is a version of the ontologies in XML format. %behavior ; GO:0007610 %adult behavior ; GO:0030534 %adult behavior (sensu Insecta) ; GO:0008044 %response to cocaine (sensu Insecta) ; GO:0008341 % response to cocaine ; GO:0042220 %response to ethanol (sensu Insecta) ; GO:0045473 % response to ethanol ; GO:0045471 %response to ether (sensu Insecta) ; GO:0045474 % response to ether ; GO:0045472 %adult feeding behavior ; GO:0008343 % feeding behavior ; GO:0007631 %adult feeding behavior (sensu Insecta) ; GO:0030535 %adult locomotory behavior ; GO:0008344 % locomotory behavior ; GO:0007626 %adult walking behavior ; GO:0007628 %flight behavior ; GO:0007629 %jump response ; GO:0007630 %behavioral fear response ; GO:0001662 % fear response ; GO:0042596 In addition to the ontology files, there is a database4 that stores more detailed biological information about the GO terms, for example citations and evidence about the findings of the GO terms. This database can be downloaded and built locally using mySQL. Moreover, the same information is contained in flat text files for processing. We will use these flat text files in our project. The analysis of the detailed biological information contained in the database is out of the scope of this project. We are interested in the associations between the GO terms and the association between the genes and the GO terms. There are three files that are of particular interest to us. These files are:
• Association.txt - This file contains an association database id and information about the association between genes and GO terms.
• Term.txt - This file contains a GO term database id and more detailed information about the GO terms.
• Gene_product.txt - This file contains a gene database id and additional information about the gene products.
The ontology is updated every day when new information is added. The database and the flat files are updated once a month with the new information and new associations between genes and GO terms. This constant updating has caused some inconsistencies and difficulties in analysing the results of the project that are described in more detail in Chapter 8.
4 The database can be found at http://www.godatabase.org/dev/database/.
7
2.2 GO Browsers Many tools already exist that can help the user to browse GO. Some of them produce graphical representations of the GO term relationships, like GenNav. Others display these relationships like a tree, for example AmiGO. We will only use these two tools. This choice is made based on their ease of use and their user friendly interface. These tools have existed for a number of years and are used by people who want to get information about GO. We will employ these two tools in the end to check the correctness of our results.
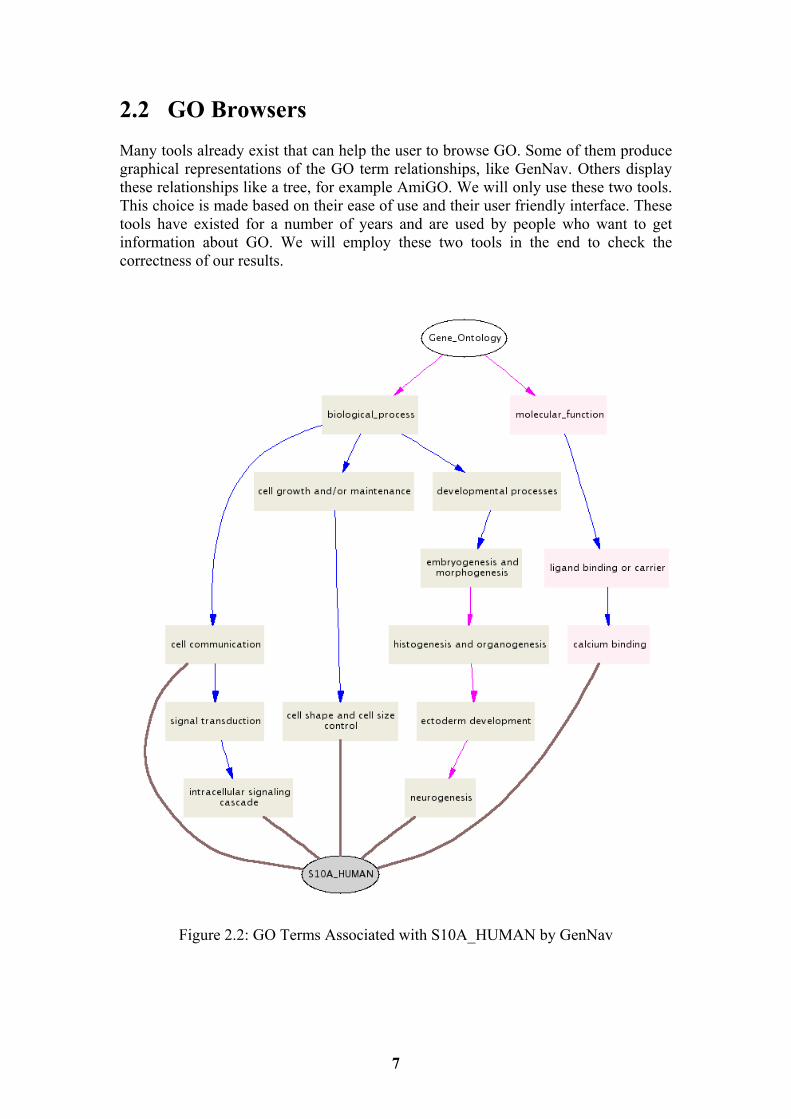
Figure 2.2: GO Terms Associated with S10A_HUMAN by GenNav

8
Figure 2.3: GenNav Direct Acyclic Graph (DAG) Legend GenNav is a GO browser, which can search GO terms and annotated gene products, and provides a graphical display of a term's position in the GO Direct Acyclic Graph (DAG). Figure 2.2 and Figure 2.3 show an example DAG and its legend as it is generated by the GenNav system. Figure 2.2 shows the GO terms that are associated with gene product S10A_HUMAN. From the figure we can see that ‘biological_process’ and ‘molecular_function’ are both children of ‘gene_ontology’ and the relationship with their parent is a “part of ” relationship. In addition, we can see that the gene ‘S10A_HUMAN’ is active in ‘cell communication’, ‘intracellular signaling cascade’, ‘cell shape and cell size control’, ‘neurogenesis’ and ‘calcium binding’. Using AmiGO, the user can search for a GO term and view all gene products annotated to it, or search for a gene product and view all its associations. In addition, the user can browse the ontologies to view relationships between terms as well as the number of gene products annotated to a given term. Figure 2.4 show the search result from AmiGO for terms that are associated with gene S10A_HUMAN.
Figure 2.4: GO Terms Associated with S10A_HUMAN by AmiGO

9
2.3 HR The HR5 program [6] was created to perform theory formation in mathematical domains [1]. The program has been expanded since then and can be used to form theories in other domains. HR is named after mathematicians Hardy and Ramanujan and takes a number of concepts and uses production rules to form new ones. It uses the model generator MACE and the theorem prover OTTER to prove or disprove conjectures it has created. In the next sections we will discuss the way that the input concepts are represented in HR, how HR derives new concepts from the existing ones and the way that it makes conjectures. 2.3.1 Concept representation HR starts with a user supplied collection of concepts that it will combine in order to form new ones. The concepts consist of definitions and a datatable. We will present an example input to HR that is based on the gene ontology. This example will form the basis for the examples that follow in the next sections of the chapter. For instance, this is a concept definition. GO:0008384 = [G]: gene (G) ∧ involved_in_GO_term(G, GO:0008384) This is the HR definition of the GO term GO:0008384. This definition states that it contains elements G, such that G is a gene and G is involved in the GO term GO:0008384. Each concept has a table of values. This is an example of a datatable5 for the above concept definition.
ik2 ird5 Key
IKKA_HUMANIkbke
The datatable contains examples of genes that are associated with GO term GO:0008384. Let us now define a second GO term together with its corresponding datatable. GO:0007252 = [G]: gene (G) ∧ involved_in_GO_term(G, GO:0007252)
IKKA_HUMANPDX4_HUMAN
Chuk Ikbkb
These concept definitions will be stored in an ASCII text file that the HR program will read in. The genes contained in the datatables will also be stored in the same text file, but the representation is different. They are not given in the format of a table, but 5 All the genes of the GO Terms in this chapter were taken from GenNav in April 2003.

10
as instances of corresponding GO term. The GO terms and the genes are represented in the file as first order logic concepts, similar to Prolog. For example, GO:0008384 GO:0008384 (G) ascii: @G@ is a gene product associated with GO:0008384 GO:0008384 (“ik2”). GO:0008384 (“ird5”). GO:0008384 (“Key”). GO:0008384 (“IKKA_HUMAN”). GO:0008384(“Ikbke”). 2.3.2 Production of new concepts HR uses ten production rules to form new concepts [2]. These rules combine the old concept definitions and the corresponding datatables to produce new definitions and new datatables. Of course, these ten production rules will not discover all the concepts in the particular domain, but they may produce some interesting ones to investigate further. The ten production rules that HR uses are: exists, match, forall, negate, conjunct, size, split, compose, disjunct and equals. Based on the two example concepts of GO terms we have given above, we will now combine them using the compose and disjunct production rules to derive two new concepts. Let us call the new term generated DGO:001. This is how the compose would work with of the above definitions and the corresponding datatables. Here is the new concept and the new datatable: DGO:001 = [G]: (gene(G) ∧ involved_in_GO_term(G, GO:0008384)) ∧ (gene (G) ∧ involved_in_GO_term(G, GO:0007252))
IKKA_HUMAN The datatable of the new concept DGO:001 contains only genes that are associated with both the previous GO terms. We will now combine the two old GO terms with the disjunct production rule and also show the corresponding datatable: DGO:002 = [G]: (gene(G) ∧ involved_in_GO_term(G, GO:0008384)) ∨ (gene (G) ∧ involved_in_GO_term(G, GO:0007252))
ik2 ird5 Key
IKKA_HUMANPDX4_HUMAN
Chuk Ikbkb

11
The datatable of the new concept DGO:002 contains the genes that are associated with either of the previous two GO terms. Using the production rules, the old concepts will be combined and new ones will be formed. This will help in discovering knowledge in the input domain that is not visible at first. 2.3.3 Conjecture formation HR combines the concepts that the user has input to the program and produces new concepts. This procedure is repeated many times and each time it compares the newly generated concepts with the old ones and makes conjectures. This process is called empirical conjecture making [1]. There are three types of conjectures: implication, equivalence and non-existence. The new concepts that are formed are checked against every one of the old ones to form the conjectures. Then the conjectures are added to the knowledge of the program. HR uses measures of interest to judge which concepts to combine. Therefore, HR will make conjectures using the most interesting of the concepts first. We now look at the two new concepts that we have created above. We compare the GO term DGO:001 and the original GO term GO:0008384. The examples of the new concept (DGO:001) are a subset of the old one (GO:0008384). HR will make an implication conjecture: DGO:001 → GO:0008384 ∀G : gene(G) ∧ involved_in_GO_term(G, GO:0008384) ∧
involved_in_GO_term(G, GO:0007252) → gene(G) ∧ involved_in_GO_term(G, GO:0008384)
HR can also form an implication conjecture when the old concept (GO:0008384) is a specialisation of the new one (DGO:002). DGO:002 ← GO:0008384 ∀G : gene(G) ∧ (involved_in_GO_term(G, GO:0008384) ∨
involved_in_GO_term(G, GO:0007252)) ← gene(G) ∧ involved_in_GO_term(G, GO:0008384)
The above two conjectures will actually be discarded by HR because they are obviously true. None the less, they still demonstrate the way HR makes implication conjectures. There is a possibility that one of the newly created concepts is the same as an old one, if they share the same datatable. In the case of concepts with equal datatables, HR makes an equivalence conjecture. The next example shows the tables of an old concept (GO:0008384) and a new one (DGO:078) that has just been created. In this case, HR would make an equivalence conjecture.

12
GO:0008384 DGO:078 ik2 ird5 Key
IKKA_HUMANIkbke
GO:0008384 ↔ DGO:078 If the datatable of the new concept is empty then a non-existence conjecture is made. The conjectures that are discussed above match the whole datatable of one concept to the second concept. There is another type of conjecture that is called a near-conjecture. This type of conjecture matches only a part of the datatable. For example, HR can make a seventy percent implication conjecture. This means that the conjecture is true for seventy percent of the entries in the datatables. For example, suppose that we have the following two GO terms: DGO:004 DGO:005
ik2 ird5 Key
PDX4_HUMANChuk
Then, HR based on the genes that are common on both datatables would make a forty percent near-conjecture. When HR is used to prove theorems in mathematical domains, the conjectures that have been generated by HR are passed to OTTER to prove them. The automatic creation of examples using MACE can disprove conjectures. This functionality will not be used in the project. In addition, the project will use only some of the production rules to create new concepts.
ik2 ird5 Key
IKKA_HUMAN Ikbke
ik2 Ikbkb Key
IKKA_HUMAN Ikbke

13
Chapter 3 GO Search Program (GOSP) Design In this Chapter we describe the requirements of the project and the way we designed GOSP. We discuss our design decisions and provide the documents that were used to build the GOSP program. In the end, we look at the use of RMI to connect to a remote server that provides two indexed lists. One of them contains the association between the GO terms and their genes and the other contains a list with more information about the genes. 3.1 Project Requirements This project is a feasibility study that will try to determine if HR can be used to find statistically significant discoveries in the Gene Ontology. The user will choose GO terms from GO and investigate if these terms have related genes. If the GO terms or some concepts that are derived from them, have a lot of genes in common, then that would lead to the hypothesis that these GO terms may be related. This process is done in two stages. In the beginning, the GOSP program is used to select the GO terms, their corresponding genes and the GO term’s relatives and save them in a specially formatted file. The relatives are chosen based on the criteria the user inputs. The user will be able to select the levels of parents and children he/she wants to search for. For example, if the user specifies a GO term GO id and chooses to search for two levels of parents then the program will search for the GO term’s parents (level one) and its grandparents (level two). The same is done for the children. Then the HR program is used to read this file and try to discover relationships between the GO terms. These relationships can be of two types: GO terms or related concepts can have all or a percentage of their genes occur in other GO terms. We try to investigate whether HR can produce any statistically significant relationships. In addition, we try to improve the occurrence of these relationships and increase the percentage of the associated genes in them.

14
3.2 Design Decisions The language that we used to implement this project was Java 1.2. One of the biggest benefits of using Java is its cross platform ability. The code that we wrote runs on any platform that has the same version of Java installed. We chose Java because it is an Object Oriented language and therefore we could split our projects in individual classes that are more flexible and easier to maintain. HR is also written in Java. Therefore, in case we wanted to merge GOSP with it, the process of merging would be easier if both applications were written in the same language. Moreover, Java allows us to use RMI to implement a client-server model for our application. One drawback of Java is its speed. The user will use GOSP to select certain GO terms from GO. The selection can be done in two ways. The user can manually type all the GO terms he/she wants to investigate in the program or the program can read a file that contains all the GO terms. The GO terms are selected based on their GO identifier. In addition, the user will select the number of children and parents of the GO term that he/she wants to be included. For example, the user might select GO:0045174 and all parents on two levels above it and all children at one level below it. All the GO terms that the user selects, their relatives and their genes will be saved in the output file. In order to find the information that the user has requested we would need to search the ontology files and the text files of the database. The association.txt and the gene_products.txt files are two hundred and eighty four megabytes and seventy megabytes respectively. Searching through them serially many times would have a great impact on the performance of the program. Therefore, we are going to build indexes that will speed up the access to these two files. The size of the files that will be indexed is big (two hundred and eighty four megabytes and seventy megabytes) and therefore the indexes themselves will need a lot of memory to be stored. During the testing phase the memory needed turned out to be 961MB. We will offer a choice to the user to either build the indexes locally or on a separate server. This would allow users whose machines do not have a lot of memory to be able to use the program. 3.3 Use Case Diagram The Use Case diagrams provide an unambiguous scenario of interaction between an actor and the software [8]. An actor is an entity outside the system that is modelled. It can be a human or another system. In our project the actor is the user of the program.

15
Figure 3.1: GOSP Use Case Diagram 3.3.1 Use Case Descriptions These are the descriptions of the Use Case diagram. These descriptions explain the interactions of the actor with the program in more detail. In the end there is a description of the actor. Name: Enter GO Terms Type: Use Case Description: The user will be able to input to the program the GO ids of GO terms and the levels of parents and children that he/she wants to search for. The GO terms can be input in two ways. The user can type the GO ids of the terms directly to the program in the table that is provided and then enter the levels of parents and children for them. Alternatively, the user can specify the path and the name of a filename that will contain the GO ids of the GO terms. In this case the GO ids will appear on the table for the user to see and the levels of parents and children will be set to zero. Then the user can change the levels if he/she wants.

16
Name: Build File Indexes Type: Use Case Description: The user will have to build two indexes in order to search for the GO terms. These indexes can either be built locally or on a remote server. If the user wants to build the indexes locally, then he/she will need to specify the path of the files that will be used to build the indexes. If the user wants to connect to a server that contains the indexes then he/she needs to specify the IP address of the server and the path of the files. The server does not have to be run by the user, but he/she must know its IP and the path of the files. Name: Search for GO Terms Type: Use Case Description: The user will be able to search for the GO terms that he/she has input to the program. Based on the levels of parents and children the user has specified the corresponding relatives are included in the search. Name: Write HR file Type: Use Case Description: The user will be able to write the results of the search to a file. The data that will be written to the file is a list of all the genes that are contained in all the GO terms and their relatives, the GO terms specified and all their relatives. Name: Start New Search Type: Use Case Description: The user will be able to clear the current data and start a new search. This is done when the user wants to search for more GO terms or in the event of an error, for example if one of the GO terms was misspelled. The user can clear all the data and start a new search or he/she can only clean the level of parents and children. In the second case the user will be able to use the same GO terms, but specify different level for his/her search. Name: User Type: Actor Description: Many users can use the program. The users can be biologists who are interested in specific GO terms or users who want to explore GO. 3.4 UML Diagrams The UML diagrams for the major classes of GOSP are included in Appendix A. The UML diagrams of the Graphical User Interface classes (MainFrameAboutBox and MainFrame) are not included, because all of their methods and variables have to do with drawing graphics on the screen.
17
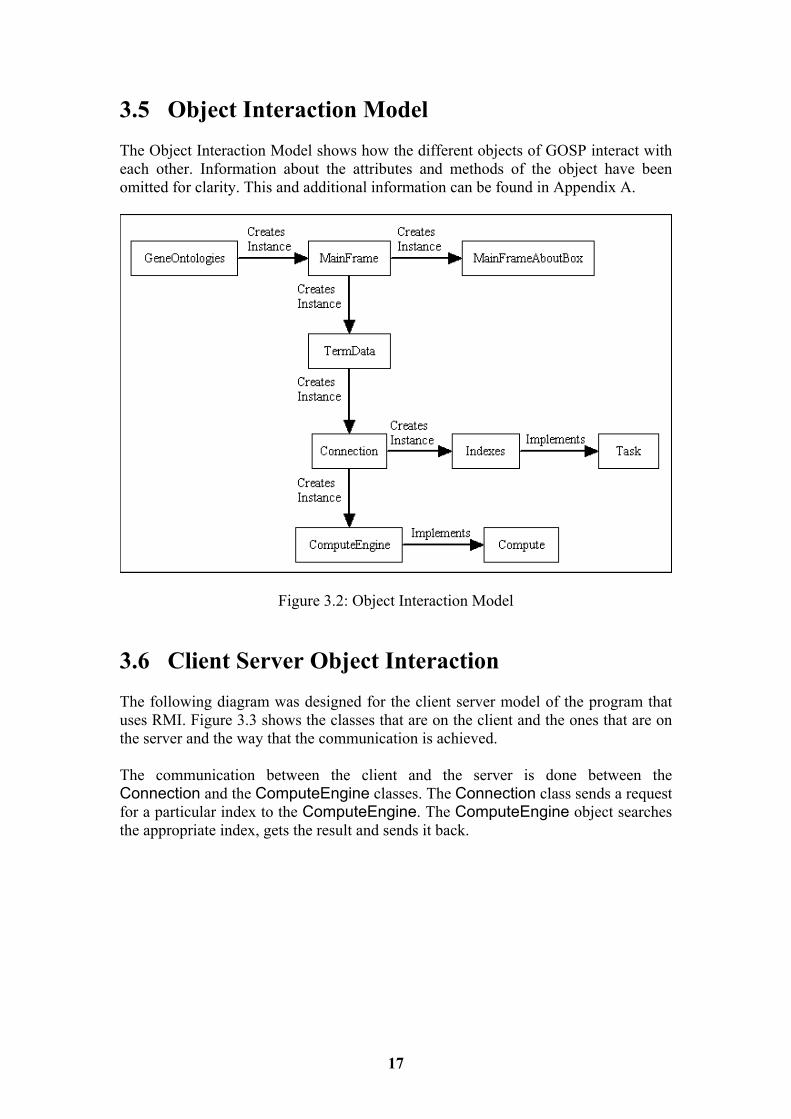
3.5 Object Interaction Model The Object Interaction Model shows how the different objects of GOSP interact with each other. Information about the attributes and methods of the object have been omitted for clarity. This and additional information can be found in Appendix A.
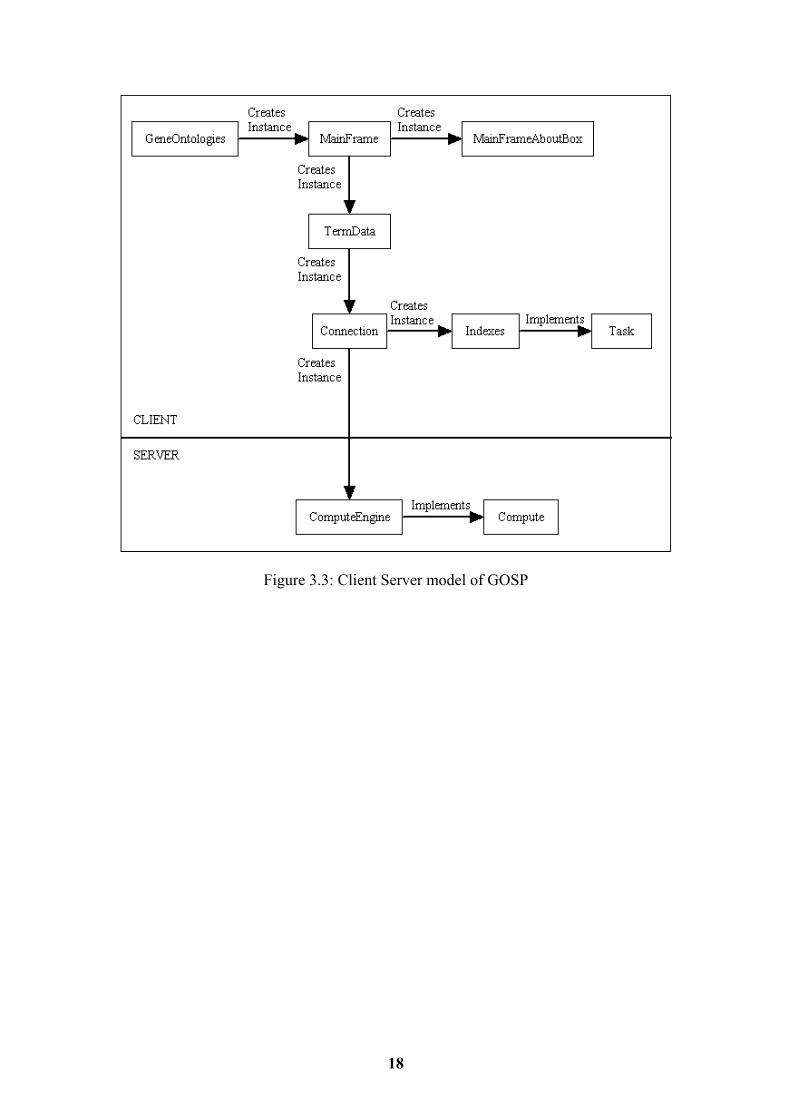
Figure 3.2: Object Interaction Model 3.6 Client Server Object Interaction The following diagram was designed for the client server model of the program that uses RMI. Figure 3.3 shows the classes that are on the client and the ones that are on the server and the way that the communication is achieved. The communication between the client and the server is done between the Connection and the ComputeEngine classes. The Connection class sends a request for a particular index to the ComputeEngine. The ComputeEngine object searches the appropriate index, gets the result and sends it back.
18
Figure 3.3: Client Server model of GOSP

19
Chapter 4 GO Search Program (GOSP) Implementation The implementation of GOSP is presented in this chapter. We discuss the development of the Java classes and their methods. The functionality of the main methods of the program will be presented in pseudo code. In addition, we include in Appendix B the JavaDoc documentation for further reference.
Figure 4.1: Screenshot of GOSP version 1.0

20
4.1 Implementation Environment The whole program was developed and run on Linux, Windows 2000 and Windows 2003. The transition between the operating systems did not cause any problems, thus demonstrating the power of Java as a cross platform language. The program was written in JavaTM 2 1.4.1_02-b06 and we used Jbuilder 9.0 Personal6 to assist with the development of the code and the JavaDoc documents. The existence of two versions of JBuilder allowed us to use Linux and Windows platforms for the development. At the end of the project, we installed an evaluation copy of Jbuilder 9.0 Enterprise6 in order to help us generate the UML diagrams of the classes. We developed the RMI functionality of the project under JBuilder but we used the standard Java command line commands to run it. This was done because we needed to start the server on the remote site manually and in addition we had to specify a java policy file that defined the access permissions. 4.2 GOSP Classes and Methods The GOSP application consists of three packages that contain seven classes and two interfaces. These are the following:
• engine Package 1. ComputeEngine Class
• geneontologies Package 1. Connection Class
2. GeneOntologies Class 3. Indexes Class 4. MainFrame Class 5. MainFrame_AboutBox Class 6. TermData Class
• server package 1. Compute Interface 2. Task Interface
The engine package contains the class that will be run on the server. The classes on the geneontologies package make up the client. Finally, the server package contains the two interfaces. These classes and interfaces together with their data structures and methods will be described in more detailed in the following sections. After the description of the main methods in each class, we will present their functionality in pseudo code.
6 Jbuilder is developed by Borland. The Personal Edition is free and an evaluation copy of Enterprise is available for download at “www.borland.com”.

21
4.2.1 ComputeEngine Class This class implements the Compute Interface and is the server that will be used in RMI and it will build the two file indexes. The class contains three methods:
• main • executeTask • build_indexes
This class has an array of vectors that will hold the database id of the genes that are associated with each GO term. The database id of the GO terms is used to index that array. In addition, it contains a vector that stores the names of the genes. The database id of the genes is used to index this array. The main method installs a Security Manager that will control access to the server, if one does not already exist. Then it calls the build_indexes method to build the indexes on the server. Finally it creates a ComputeEngine object and binds it. if (not exist security manager) install a new one build the indexes create ComputeEngine object bind object to the IP of the server The build_indexes method builds the two file indexes that exist at a specific path on the server. First it builds the index for the association.txt file. It reads each line of the file and it splits it in seven columns. If the line does not have seven columns then there is an error in the line and we read the next one. It reads the second column that has the database id of the GO term and then if that position is null in the association array it creates a new vector. Then it reads the third column that is the database id of the gene and it adds it to the vector of the genes for that GO term. Then it builds the gene_product.txt index. It adds a random value at position zero of the vector, because it will not be used. It reads each line of the file and it splits it in columns. Then it adds the name of the gene with database id one to position one of the vector and it continues with the next line. read association.txt file while(we have not reached the end of the file) split line in columns if (there are seven columns) read GO term database id from second column and use as index if (association array at that index is null) create new vector read gene database id from third column store id at the vector of the genes of the GO term used as index read the next line of the file read gene_product.txt file while(we have not reached the end of the file) split line in columns read gene name from second column

22
add to the genes array read next line of the file The execute_Task method will receive a request from the client, retrieve the appropriate index and return it back to the client. 4.2.2 Connection Class The client uses this class to establish a connection to the server and request indexes from it. The class contains two methods:
• connectserver • getdata
The connectserver method installs a Security Manager that will control access to the server, if one does not already exist. Then it will connect to the IP of the server. The getdata method performs the communication between the client and the server. It creates an indexes object that contains the IP of the server to connect to, the file index that we want to use and the index we search for. Finally it calls the executeTask method of the ComputeEngine and gives it the Indexes object. 4.2.3 GeneOntologies Class This class will start the client and is used to initialise the user interface. We will not provide much detail about its functionality, because it is a standard class created by JBuilder and not specific to our program. 4.2.4 Indexes Class This class implements the Task Interface and is the object that the client will send to the server. It contains four methods:
• Indexes • choose_file • get_index • get_serverIP
The Indexes constructor will create a new class with the information that we want to get from the server. When the class arrives at the server, the server will use choose_file, get_index and get_serverIP to get the information from the class.

23
4.2.5 MainFrame Class This class is used to build the Graphical User Interface (GUI). We are not going to get into much detail about it, because it does not contain any information about our approach to solving the task. It only contains the elements that make up the GUI, user input validation and calls to the methods of the TermData class. 4.2.6 MainFrame_AboutBox Class This class is used to create the About box of the GUI. We will not provide much detail about its functionality, because this is also a standard class created by JBuilder and not specific to our program. 4.2.7 TermData Class This class holds all of the data structures with the information about the GO terms, their relatives and their genes. In addition, it has two data structures for the indexes in case the user wants to build them locally. The class contains thirteen methods:
• build_indexes • clearData • findchildren • findgenedata • findGOTerms • findparents • findrelatives • findrelativesgenes • getassociation_array • getgenes • loadfile • makeconnection • write_to_file
This class has an array of vectors that holds the database id of the genes that are associated with each GO term. The database id of the GO term is used to index that array. In addition, it contains a vector that stores the names of the genes. The database id of the genes is used to index this array. It has a vector that holds the GO ids of the GO terms, another vector for their database ids and another one to store their ontology. In addition, it has a vector to store the levels of parents and a vector to store the levels of children we want to search for. There is an array of vectors to store the GO ids of the relatives of the GO terms and one for the database ids of the relatives. A common index is used to index all these data structures. For example, if we look for the information of GO term with database id ten, we know that we have to look at all the vectors and all the arrays at position ten.

24
The class has two more vectors to store the GO terms and the genes that we will save to the output file. The reason that the second vector for GO terms exists is that we will not write to the output file GO terms that do not have any genes. The second vector is a vector that holds vectors that contain the genes for the GO terms. These two data structures use a common index to get the GO term GO id and the vector of its genes. The build_indexes method is called when the user wants to build the indexes local and not want to use RMI. The building of the indexes takes less that a minute and therefore we will not need to store them in a file. The indexes need to be built once when the program starts. The way the indexes are build is covered in section 4.2.1. The makeconnection method is used to connect to the server that holds the indexes. The loadfile method is called when the user wants to load a file that contains the GO terms and does not want to type them in the table provided in the GUI. It loads the file that is provided in the path and shows the GO terms in the table of the GUI. The findGOTerms receives a vector of GO terms that the user is interested in searching for and retrieve their information. First, it loads the term.txt file. Then it scans through the whole file to find the GO term that we look for. When it is found it retrieves its database id and its ontology and stores them in the data structures. for(each GO term) read term.txt file while(we are not at the end of the file read the next line) if(we found the GO term) store its database id store its ontology The getgenes method finds the genes for the GO terms. It goes trough the GO terms and retrieves its vector of genes from the association array. If the vector is null, then it create a new one. It then retrieves the names of the genes and concatenates the database id of the gene with its name. The reason of doing this is discussed in appendix D. In the end, if the genes are not included in the vectors of the ones that are going to be printed, they are added. for(each GO term) get its database id to use as index get the vector of genes from the association index array using the index if(the vector is null) we initialise it for(all the genes) get its name from the gene index array create a composite id if(the gene does not appear in the ones to be printed) add the GO term to the array for GO term printing add the gene to the array for gene printing

25
The findrelatives method is called if the user has specified a level for the parents and the children and wants to search for the relatives of a particular GO term. This method goes through the GO terms that we want to find and calls the findparents and findchildren methods to find the children and the parents of a GO term respectively. The findparents method finds the parents of a given GO term. It is given the number of the GO term we want to find (therefore we can also index the relatives array and store the information for the GO term in the correct position), the number of iterations we want (based on the levels of parents we want to search for) and the GO id of the GO term. This function is quite complicated and therefore we will present it only in pseudo code. get the ontology of the given GO term open the appropriate ontology file while(we are not at the end of the file read the next line) split the line based on characters ‘%’ and ‘<’ if (line contains relations and not comments) split the line based on character ‘ ; ‘ add the line read to the vector of read lines if(line has a GO term) split it again based on character ‘, ‘ // in case GO term has two GO ids if(line has a GO term and it is the one we look for) { get the number of spaces at start of line for(of the parent that are on the same line) split using ‘, ‘ to get their first GO id if(the vector of relatives for the GO term is null) create a new vector if(the GO term is not in the array and it is not the original GO term) add it to the relatives for(the number of levels we want to go up) call again findparents for this relative for(all the lines that we read) // loop from end to start split the line based on characters ‘%’ and ‘<’ if(line has a space less) split the line based on character ‘ ; ‘ if(line has a GO term) split it again based on character ‘, ‘ if(GO term is not contained in the relatives) add it for(the number of levels we want to go up) call again findparents for this relative break break } else if(line starts with white space) add the line read to the a vector of read lines then we fill the array with the relatives ids

26
The findchildren method finds the children of the GO term. Its functionality is very similar to the findparents method. The difference is that we not look for relatives up, but down. Moreover, when we find the GO term we looked for, the children are all the lines that follow that have one more space at start. If it finds a line with equal spaces again, it will stop to look any further, because the line contains a sibling. Then the findrelativesgenes is called to find the genes of the relatives. Its functionality is similar to the findgenes method. The difference is that first of all it has to initialise all the vectors in the relatives array and then find the genes. The clearData method clears all the data structures and reinitialises the program, so that the user can start a new search. If the user has built the indexes locally, the index data structures are not cleared. The MainFrame class uses the getgenes and getassociation_array methods to perform a check in the beginning, in case the user wants to search for GO terms and has forgotten to build the indexes. Finally the write_to_file method is used to output the HR file that contains the GO terms, their relative and all the genes in format suitable to be used by HR. First of all, the genes are written to the file. Then it goes through the GO terms that are to be printed and prints the GO term and its corresponding vector of genes. 4.2.8 Compute Interface This Interface represents the computation that we want to perform. It only contains one method:
• executeTask Details about this method can be found at Section 4.2.1 where they are implemented by the ComputeEngine class. 4.2.9 Task Interface This Interface represents the specific task we want to solve. It contains three methods:
• get_index • choose_file • get_serverIP
Details about these methods can be found at Section 4.2.4 where they are implemented by the Indexes class.

27
4.3 GOSP Java Class Details The JavaDoc document of the main classes of GOSP (Indexes, Connection, TermData and ComputeEngine) can be found at appendix B. They provide a more detailed overview of the classes and the methods of each class. In addition, details about the input and output parameters of the methods can be found.

28
Chapter 5 GO Search Program (GOSP) Testing The testing of the project was conducted in many stages during the development. Three aspects of the program were checked: functionality, correctness of results and search performance. First of all, we tested that the program provided the desired functionality that was agreed in the project specifications. Then the results of the GOSP program were checked against AmiGO and GenNav, to verify their correctness. We were interested in verifying that the relationship between the GO terms and the association between genes and GO terms that our program produced was the same as the one found in the existing browsers. Finally, we tested the performance of the two ways of building the indexes. We looked at the speed of the search and the memory used in the case that the indexes were built locally or when the indexes were built on a remote server. 5.1 Functionality Testing The following tests will check if the program provides the user with the functionality specified in the requirements. In addition, we are interested in the response time of the program. Search operations for a few GO terms should complete within reasonable amount of time (less than one minute). Longer ones will take more, but the user will know that already. For example, if the user is interested in searching for five hundred terms it is unlikely that the search will be conducted in less than one minute. But the time should still be reasonable. 5.1.1 Test Plan Purpose The purpose of this outline test plan is to test that the project provides the agreed functionality to the user. Also that it is stable and easy to use. Entry Criteria We will install GOSP on a stand-alone Pentium 4 PC with 512 Mbytes of memory running Windows 2000 (SP4). Exit Criteria The project passes tests 1 – n listed in Section 5.1.2.

29
Coverage: We will test the use of GOSP. This test will not check the correctness of the results or carry out any specific performance tests. The response times must be less than one minute. 5.1.2 Test Cases Test1 Purpose: To demonstrate that GOSP can be started on the target machine. Outline Script:
1. Install GOSP on the target computer. 2. Start GOSP and check that it throws no errors or warnings. 3. Quit GOSP.
Pass Criteria: GOSP starts with no errors or warnings. In addition, the program quits with no errors. Test2 Purpose: To demonstrate that we can build the indexes locally and search for one GO term and its parents and children at level one. Outline Script:
1. Run GOSP. 2. Enter the path where the data files are and build the indexes. 3. Enter a GO term id and set the parents and children level to one. 4. Find the relatives and the genes of the GO term. 5. Save the search results in the genes.hrd file in HR’s input syntax. 6. Quit GOSP. 7. Load the genes.hrd file in HR.
Pass Criteria: The indexes are built successfully and we are able to find the GO term, its relatives and the corresponding genes. Moreover, the file is saved successfully and has the desired format. HR manages to load the files successfully. Test3 Purpose: To demonstrate that we can build the indexes locally and search for four GO terms and their parents and children at level one. Outline Script:
1. Run GOSP. 2. Enter the path where the data files are and build the indexes. 3. Enter four GO term ids and set the parents and children levels to one. 4. Find the relatives and the genes of each GO term. 5. Save the search results in the genes.hrd file in HR’s input syntax. 6. Quit GOSP.

30
7. Load the genes.hrd file in HR. Pass Criteria: The indexes are built successfully and we are able to find the GO terms, their relatives and their corresponding genes. Moreover, the file is saved successfully and has the desired format. HR manages to load the files successfully. Test4 Purpose: To demonstrate that we can build the indexes locally and search for one GO term, its parents at level three and its children at level two. Outline Script:
1. Run GOSP. 2. Enter the path where the data files are and build the indexes. 3. Enter a GO term id, set the parents level to three and the children level
to two. 4. Find the relatives and the genes of the GO term. 5. Save the search results in the genes.hrd file in HR’s input syntax. 6. Quit GOSP. 7. Load the genes.hrd file in HR.
Pass Criteria: The indexes are built successfully and we are able to find the GO term, its relatives and the corresponding genes. Moreover, the file is saved successfully and has the desired format. HR manages to load the files successfully. Test5 Purpose: To demonstrate that we can start the remote server and connect to it. Outline Script:
1. Start the remote server. 2. Run GOSP. 3. Enter the IP of the remote server and connect to it. 4. Quit GOSP.
Pass Criteria: The remote server starts and the indexes are built successfully. GOSP is able to connect to the server with no errors or warnings. Moreover, we can shut down GOSP and the server with no errors. Test6 Purpose: To demonstrate that we can build the indexes at the remote server and search for one GO term and its parents and children at level one. Outline Script:
1. Start the remote server 2. Run GOSP. 3. Enter the IP and the path of the data files of the remote server and
connect to it. 4. Enter a GO term id and set the parents and children level to one.

31
5. Find the relatives and the genes of the GO term. 6. Save the search results in the genes.hrd file in HR’s input syntax. 7. Quit GOSP. 8. Load the genes.hrd file in HR.
Pass Criteria: The indexes are built successfully on the remote server and we are able to find the GO term, its relatives and the corresponding genes. Moreover, the file is saved successfully and has the desired format. HR manages to load the files successfully. Test7 Purpose: To demonstrate that we can build the indexes at the remote server and search for four GO term and its parents and children at level one. Outline Script:
1. Start the remote server 2. Run GOSP. 3. Enter the IP and the path of the data files of the remote server and
connect to it. 4. Enter four GO term ids and set the parents and children levels to one. 5. Find the relatives and the genes of each GO term. 6. Save the search results in the genes.hrd file in HR’s input syntax. 7. Quit GOSP. 8. Load the genes.hrd file in HR.
Pass Criteria: The indexes are built successfully on the remote server and we are able to find the GO terms, their relatives and their corresponding genes. Moreover, the file is saved successfully and has the desired format. HR manages to load the files successfully. Test8 Purpose: To demonstrate that we can build the indexes at the remote server and search for one GO term, its parents at level two and its children at level three. Outline Script:
1. Start the remote server 2. Run GOSP. 3. Enter the IP and the path of the data files of the remote server and
connect to it. 4. Enter a GO term id, set the parents level to two and the children level
to three. 5. Find the relatives and the genes of the GO term. 6. Save the search results in the genes.hrd file in HR’s input syntax. 7. Quit GOSP. 8. Load the genes.hrd file in HR.
Pass Criteria: The indexes are built successfully on the remote server and we are able to find the GO term, its relatives and the corresponding genes. Moreover, the file

32
is saved successfully and has the desired format. HR manages to load the files successfully. Test9 Purpose: To demonstrate that we can build the indexes at the remote server and search for four GO terms, their parents at level ten and their children at level ten. Outline Script:
1. Start the remote server 2. Run GOSP. 3. Enter the IP and the path of the data files of the remote server and
connect to it. 4. Enter four GO term ids and set the parents and children levels to ten. 5. Find the relatives and the genes of each GO term. 6. Save the search results in the genes.hrd file in HR’s input syntax. 7. Quit GOSP. 8. Load the genes.hrd file in HR.
Pass Criteria: The indexes are built successfully on the remote server and we are able to find the GO terms, their relatives and the corresponding genes. Moreover, the file is saved successfully and has the desired format. HR manages to load the files successfully. Test10 Purpose: To demonstrate that we can build the indexes at the remote server and load a file with one hundred GO terms with their parents and their children level at zero. Outline Script:
1. Start the remote server 2. Run GOSP. 3. Enter the IP and the path of the data files of the remote server and
connect to it. 4. Enter the full path of the file and load it. 5. Find the relatives and the genes of each GO term. 6. Save the search results in the genes.hrd file in HR’s input syntax. 7. Quit GOSP. 8. Load the genes.hrd file in HR.
Pass Criteria: The indexes are built successfully on the remote server, the file was loaded and we saw the GO terms on the table. Then we are able to find the GO terms, their relatives and the corresponding genes and save the file successfully with the desired format. HR manages to load the files successfully.

33
5.1.3 Results and Analysis The tests run verified that the project had the desired functionality. The user could either put as many GO terms as he/she wanted by hand in the table or type them in a file and then load the file to GOSP. In addition, the ability to select the number of parents and children proved useful. The further up that we moved on the GO tree then the more generalised the GO terms got and the more genes they had. The further down we went on the tree the GO terms got more specialised and they had fewer genes. Therefore, the user could perform the search exactly the way he/she wanted and even not include any parents or children in the search at all. This could be useful in the case the user was only interested in the GO terms themselves and did not want their relatives in the search. One limiting factor to the usability of the program that was discovered during the testing was the amount of time that some searches took to complete. For example, tests four, eight and nine took around eight minutes each to be completed. That was due to the fact that the parent GO terms contained too many genes. Therefore, moving up the GO tree would slow the searching. On the other hand, test ten, where we have specified one hundred GO terms but no parents or children, was not as slow as the previous three ones. Even though it had a large number of GO terms to search for, it took about five minutes. That was because the GO terms that we have input had less that one hundred genes each and we did not look for any relatives. One other factor that had to be taken into account was the size of the file that GOSP produced. The bigger the file, the slower HR would run. For example, a file with eight GO terms and four hundred and eleven genes was twenty four kilobytes. A file with seven GO terms and sixty two thousand nine hundred and fourteen genes was three megabytes.
34
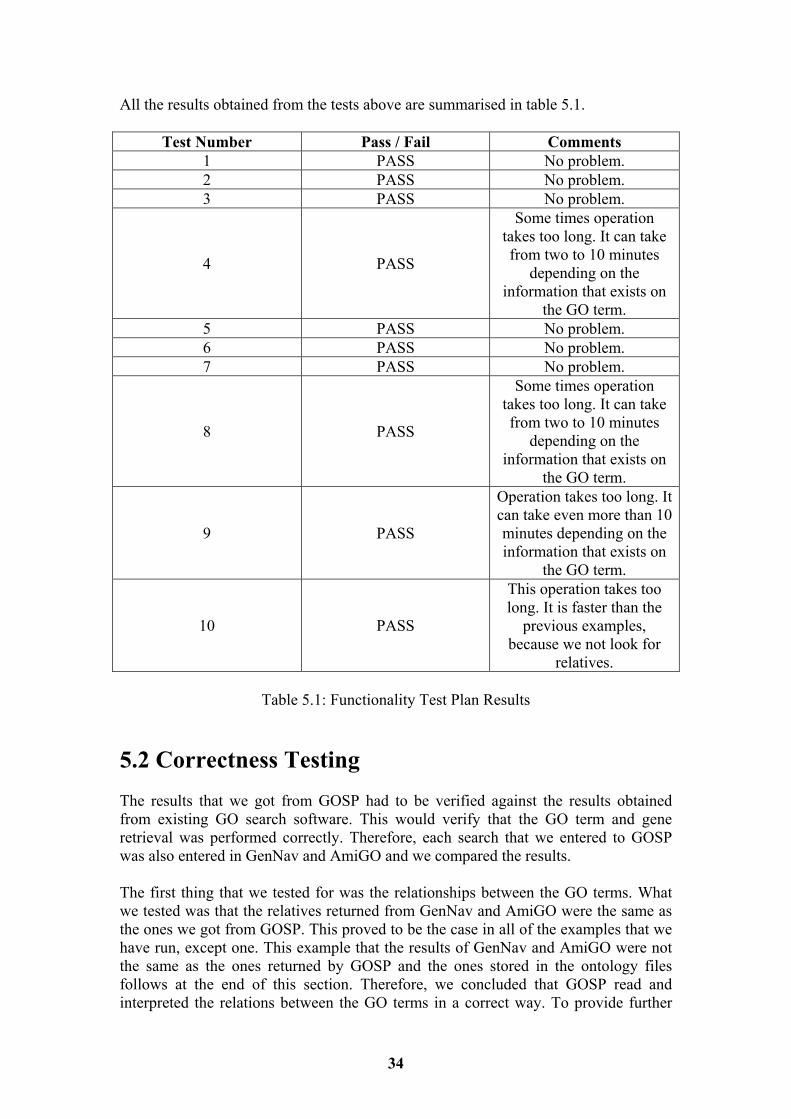
All the results obtained from the tests above are summarised in table 5.1.
Test Number Pass / Fail Comments 1 PASS No problem. 2 PASS No problem. 3 PASS No problem.
4 PASS
Some times operation takes too long. It can take from two to 10 minutes
depending on the information that exists on
the GO term. 5 PASS No problem. 6 PASS No problem. 7 PASS No problem.
8 PASS
Some times operation takes too long. It can take from two to 10 minutes
depending on the information that exists on
the GO term.
9 PASS
Operation takes too long. It can take even more than 10 minutes depending on the information that exists on
the GO term.
10 PASS
This operation takes too long. It is faster than the
previous examples, because we not look for
relatives.
Table 5.1: Functionality Test Plan Results 5.2 Correctness Testing The results that we got from GOSP had to be verified against the results obtained from existing GO search software. This would verify that the GO term and gene retrieval was performed correctly. Therefore, each search that we entered to GOSP was also entered in GenNav and AmiGO and we compared the results. The first thing that we tested for was the relationships between the GO terms. What we tested was that the relatives returned from GenNav and AmiGO were the same as the ones we got from GOSP. This proved to be the case in all of the examples that we have run, except one. This example that the results of GenNav and AmiGO were not the same as the ones returned by GOSP and the ones stored in the ontology files follows at the end of this section. Therefore, we concluded that GOSP read and interpreted the relations between the GO terms in a correct way. To provide further

35
evidence, the ontology files were also read manually and the hierarchy was constructed on paper for the GO terms that we searched for. This further supported that the result we received were correct. One problem that we encountered was in the number and the identity of genes the GO terms contained. The number of genes that were returned for a given GO term by GenNav and AmiGO were less than the ones that we got from GOSP. Most of the times we discovered more genes than the two programs and sometimes we discovered the same number of genes. The amount of genes that were discovered by GenNav and AmiGO, sometimes were not the same. For example, GenNav removed the duplicate genes from the GO terms, while AmiGO did not. Then we had a look at the association.txt file and we found out that it confirmed the findings of GOSP. There were many relations between genes and GO terms in that file that were not shown either by GenNav or AmiGO. This has lead us to suspect that GenNav and AmiGO might use some other information to find the genes of the GO terms. This hypothesis needed to be investigated further. One specific problem that we found was the results returned for the children of GO:0007612 (‘learning’). AmiGO and GenNav returned the following four children: GO:0008306 (‘associative learning’) GO:0008355 (‘olfactory learning’) GO:0008542 (‘visual learning’) GO:0042297 (‘vocal learning’) But GOSP returned five children: GO:0008306 (‘associative learning’) GO:0008355 (‘olfactory learning’) GO:0008542 (‘visual learning’) GO:0042297 (‘vocal learning’) GO:0046958 (‘nonassociative learning’) In addition, the process.ontology file7 showed these five GO terms to be the children of GO:0007612. When we enter the fifth child (GO:0046958) to GenNav or AmiGO then they both reply that this GO term does not exist. In addition, GO:0046958 does not exist in term.txt8, even though it exists in the process.ontology file. An explanation for this might be that AmiGO and GenNav used old files from the ontology. Something else that was noted was that GenNav removes genes that appear twice in a GO term but AmiGO does not. For example, in GO:0007612 (learning) GenNav returns eighteen genes, AmiGO twenty and GOSP eighty. Here follows the difference in genes of AmiGO and GenNav but not GOSP. The reason for excluding the difference in genes with GOSP is that it is a list of sixty genes.
7 This ontology file was downloaded on the 20 of August 2003. Later ontology files might be different. 8 This refers to the database files of July 2003.

36
GenNav AmiGO FYN_HUMAN FYN_HUMAN FYN_HUMAN DLG4_HUMAN DLG4_HUMAN DLG4_HUMAN 5.3 Performance Testing In the end of the project we performed some performance testing between the two ways of building the indexes. The indexes can either be built locally or they can be built on a server and use RMI to fetch the data we want. The performance testing was based on the amount of memory used and the time it took GOSP to find the GO terms given by the user. When the program was run and we built the indexes locally, we needed 961 MB of memory on the client. This was because of the big size of the files9 that we indexed. Having the indexes locally speeded up the retrieval of information, but slowed down the general performance of the client machine, due to the fact that we were using most of its memory. This could not be such an issue on a machine that has a lot of physical memory and does not have to use the swap file. When we built the indexes on the server and we used RMI to get the search results memory usage at the client side improved. The client needed only 45MB of memory, which is significantly less than previously. This time the program took slightly longer to retrieve the information requested. This occurred, because every time an index was requested form the server, the communication had first to be established and then the data was exchanged. This caused a small delay to the response time. For example, if we built the indexes locally and perform a search for five GO terms that have in total eight hundred genes, it could take about twenty seconds. The same search with the indexes built remotely could take about twenty six seconds. The more GO terms we want to search for though, the bigger the time difference would get. Thus, we had the following trade-off. If the indexes were built locally, the client machine used much more memory but information retrieval was faster. In the case that we used RMI to connect to a server with the indexes, then the client machine used less memory but information retrieval took a little longer.
9 The association.txt and gene_product.txt files used for the test were from the July 2003 database.

37
Chapter 6 Experiments with HR on the Gene Ontology When we finished using GOSP to find the information about the GO terms and the genes, we used HR to try to discover relationships between them. In this chapter, we describe the features we used from HR in order to search and perform discoveries in GO. In addition, we discuss a few of the problems and limitations we encounter during the use of the program. A sample output file from GOSP that we used in HR can be found in Appendix C.
Figure 6.1: Screenshot of HR Program version 2.2.1

38
6.1 Setting up HR to be Used for Discoveries in GO The HR program was developed to perform theory formation in mathematical domains. Therefore, many of its features will not be used in our project. We turned these features off and only kept the ones that would help us find statistically significant results in GO. The tweaking of the features was a continuing process and was performed during the whole running of the tests. In the next paragraphs we will discuss the final configuration that we think produces optimal results. The tests that were ran that lead us to the tweaking of the options will be discussed in Chapter 7. The words in parenthesis are the actual options that appear in HR. First of all, we defined the way that the search would be performed in GO. The options that define the characteristics of the search that HR will carry out are at the Search tab on the first drop-down list on the left. This tab has many options and they are mainly used for mathematical domains. We are interested in a biological domain and not a mathematical one; therefore we turned most of these options off. We changed the options that defined the methods of the search. These are under the heading Methods. One search method that we enabled was the near implications by subsume and we set the percentage to fifty (make near-imps by sub 50). The implications by subsume will find relations in the event that one GO term is contained in another one. Another search method we enabled was the near equivalences and we set the percentage that we are interested in to fifty percent (make near-equivs 50). This will try not only to find equivalences between the GO terms, but also near equivalences between terms that have more than fifty percent of their datatables in common. HR is capable of performing near equivalences on both the negative and the positive examples. In our case, positive examples are the genes that belong to that concept and negative ones are the genes that do not. We are trying to prove that there exist some statistically significant relations between the GO terms and it would not be helpful to create relations based on the negative examples. Therefore, the near equivalences we are interested in will only be based on the positive examples of the concept (base on positives only). Then we removed all the Unary Production Rules. These rules are the following:
• embed_algebra • embed_graph • equal • entity_disjunct • exists • match • record • size • split

39
These rules will not be useful, because we are interested in relations between the GO terms and not between the genes that are contained in them and therefore we turn all of them off. Then we changed the Binary Production Rules. We enabled the compose production rule (compose). This would create new concepts and new conjectures by combining the previous ones with the AND logical operator. Thus, the positive examples of a new concept would be based on positives examples that were on all of the previous concepts. We turned off the disjunct and the negate rules. The disjunct rule would form new concepts and new conjectures based on the OR logical operator. Thus, the positive examples of the new concepts would be based on the positive examples of any of the previous concepts. For example, the creation of a new concept C that has positive examples that are based on A OR B would not be of much interest to us in this stage. This is because a biologist would be needed to analyse the importance of the result that C might be associated with A or B based on the genes that they share. Maybe at a later stage we would turn this operator on again. In addition, the negate operator would produce new concepts that are based on the NOT logical operator. Again this would not produce interesting results in our search. For example, it would discover that a new concept B has no genes in common with A. At this stage this is not something we are interested in, because we try to prove the existence of new relationships and not to disprove the existing ones. Moreover, we altered how the results were presented to us. We tried to eliminate many of the trivial results and we kept only the most interesting ones. This helped us to speed up the analysis of the results, by not having to go through many trivial ones. We changed the option in the Store tab at the first drop down list. We did not want to keep the non-existence conjectures that were found after the search (keep non-exists). There were many conjectures that were discovered that were of the following form: not exists a s.t. (a is a gene product & a is a gene product associated with GO:0006665 & a is a gene product associated with GO:0006643 ) Again this type of conjecture was not of any interest to us. We were interested in discovering new relationships and not verifying that the relationships did not exist. In addition, we changed the options we that were associated with viewing the conjectures that were formed in the Conjectures tab in the third drop down list. We did not want HR to show us the positive and negative examples of the left hand concept (lh_concept) and the right hand one (rh_concept). Moreover, we wanted to sort the near equivalences on the percentage of positive examples (percentage_match). We could also sort them on their surprisingness.

40
6.2 Problems and Limitations of HR During our use of HR and the running of the searches on GO, we came across some of its limitations. These limitations created a few problems in our searching and we had to find ways to bypass them. In the next paragraphs, we explain these problems and also present the ways that we used to overcome them. One of the problems that we encountered with HR was the use of the special character ‘@’ in the input files. This character was used to define variables that would be substituted by the examples when HR ran. For example two typical lines in a HR file are the following: ascii: @G@ is a gene product geneproduct("807974~~~YHY5_YEAST"). This would produce the positive example that: 807974~~~YHY5_YEAST is a gene product Many of the genes that were in the gene_product.txt file had as their name the character ‘@’. This caused a problem when genes with that name were stored in the output file of GOSP, because HR got confused between the gene name and the special character. Therefore, we had to substitute this character in the file. When it occurred for the name of the gene we rename the gene to ‘!AT!’. This change lead to a small inconsistency in the naming of the genes, but when the substitute characters are met, we knew that the original name was ‘@’. A second limitation of HR is the size of the input files that it accepts. File sizes of more than five hundred kilobytes were too big for HR to handle in an efficient way. These files contained many GO terms and each of the GO terms had many associated genes. With files bigger than that size HR did not crashed and could perform the searching. However, the searching took very long time to complete and so did the visualisation of the concepts and the conjectures. Therefore, some of the output files were not used as input to HR because of their size. These files were kept though to be used in future versions of HR where size would not be a limiting factor.

41
Chapter 7 Experiment Results and Evaluation In this chapter we describe the tests we ran with HR. We have used the output files of GOSP in HR in order to find statistically significant results. There were two kinds of tests that we ran in HR. The first test contained GO terms that were picked randomly from GO. The second one contained GO terms that were near each other in GO and therefore had more chances of sharing genes. When we ran HR we were interested in finding new concepts, conjectures and near-conjectures. The most interesting of these three were the new concepts HR created. Based on the setup of HR that is discussed on Chapter 6, a new concept would be formed if two or more of the old concepts shared any genes. This would lead us to discover relationships between the GO terms that are not obvious at the start. The conjectures would be used to verify the new concepts that were discovered. The near-conjectures would help to find relationships between the GO terms based on a percentage of the genes that they share. We have speculated that HR can find statistically significant relationships between terms in GO. To test this hypothesis, we have run the following tests. The next two sections will show the tests that we ran and the results that we obtained. The third section will comment on these results and evaluate our hypothesis. 7.1 Random GO Term Tests The first group of tests that we ran contained GO terms that were picked in random from GO. We did not use any domain information about the particular GO terms or the way that they might be related to each other. For example, we did not look for GO terms that were close in the hierarchy or that had similar names. We just picked random GO terms from the terms.txt file and we got their genes. In addition, the number of relatives was picked randomly; even though we made sure we did not pick a large number. The reason for that is that it would create big input files for HR. The details of the problem with big input files are discussed in section 6.2. The findings of the tests that we ran were not very interesting. We ran eighty-two tests and only in eleven of them did HR find relationships. We used GOSP to find the GO terms and their relatives and then HR to discover relationships between them. Many of the files that GOSP produced were too big in size and we could not use them in
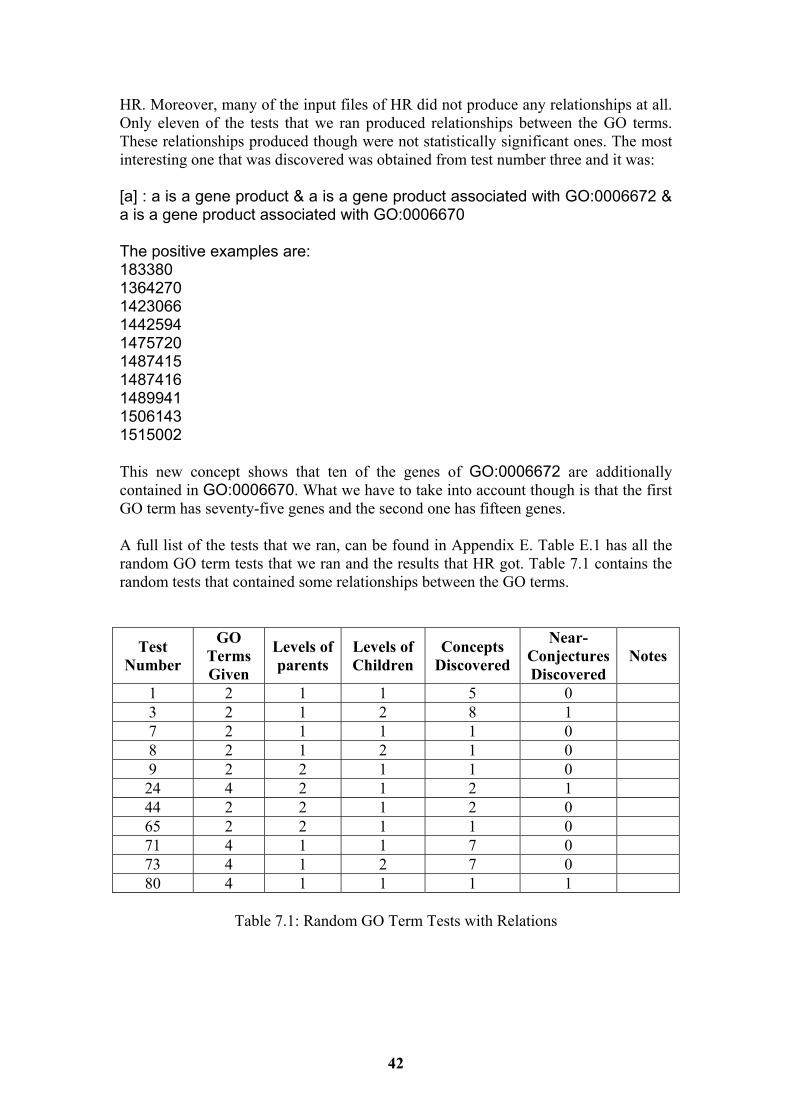
42
HR. Moreover, many of the input files of HR did not produce any relationships at all. Only eleven of the tests that we ran produced relationships between the GO terms. These relationships produced though were not statistically significant ones. The most interesting one that was discovered was obtained from test number three and it was: [a] : a is a gene product & a is a gene product associated with GO:0006672 & a is a gene product associated with GO:0006670 The positive examples are: 183380 1364270 1423066 1442594 1475720 1487415 1487416 1489941 1506143 1515002 This new concept shows that ten of the genes of GO:0006672 are additionally contained in GO:0006670. What we have to take into account though is that the first GO term has seventy-five genes and the second one has fifteen genes. A full list of the tests that we ran, can be found in Appendix E. Table E.1 has all the random GO term tests that we ran and the results that HR got. Table 7.1 contains the random tests that contained some relationships between the GO terms.
Test Number
GO Terms Given
Levels of parents
Levels of Children
Concepts Discovered
Near-Conjectures Discovered
Notes
1 2 1 1 5 0 3 2 1 2 8 1 7 2 1 1 1 0 8 2 1 2 1 0 9 2 2 1 1 0 24 4 2 1 2 1 44 2 2 1 2 0 65 2 2 1 1 0 71 4 1 1 7 0 73 4 1 2 7 0 80 4 1 1 1 1
Table 7.1: Random GO Term Tests with Relations

43
The lack of statistically significant results using random GO terms could have two meanings. Either the way that we picked the test data was not appropriate, or HR could not find statistically significant results. We tested further the abilities of HR by changing the method we were selecting GO terms from GO. The GO terms were picked based on their location in GO and the number of genes they contained. 7.2 Localised GO Term Tests After we ran the initial group of tests, we used some of our knowledge of GO and HR to pick GO terms. We did not choose them at random but we picked them based on the observations of the previous tests. First of all, we picked GO terms that had less than one hundred genes. This would reduce the size of the files that GOSP produced and additionally reduce the time that HR took to produce results. Out of these GO terms, we picked the ones that were close to each other in GO. This would increase the chances that these GO terms were related with each other and therefore HR would produce more relations. Finally, in most tests we did not search for relatives in order to avoid getting ones with many genes that would slow the search. In the case that we searched for relatives, we searched for children of the GO terms. This would also avoid the risk of going too high on the tree and getting terms with many genes. The results we obtained this time were better than the random selection of GO terms. We ran eighteen tests and sixteen of them produced new concepts. This is a great improvement from the random tests that we ran. On the other hand, the results again are not statistically significant. Not many of the genes of the original concepts are present in the newly formed ones. A full list of the localised tests that we ran can be found in Appendix E. Table E.2 has all the localised GO term tests that we ran and the results of HR. Table 7.2 contains the localised tests for which we found some relationships between the GO terms.
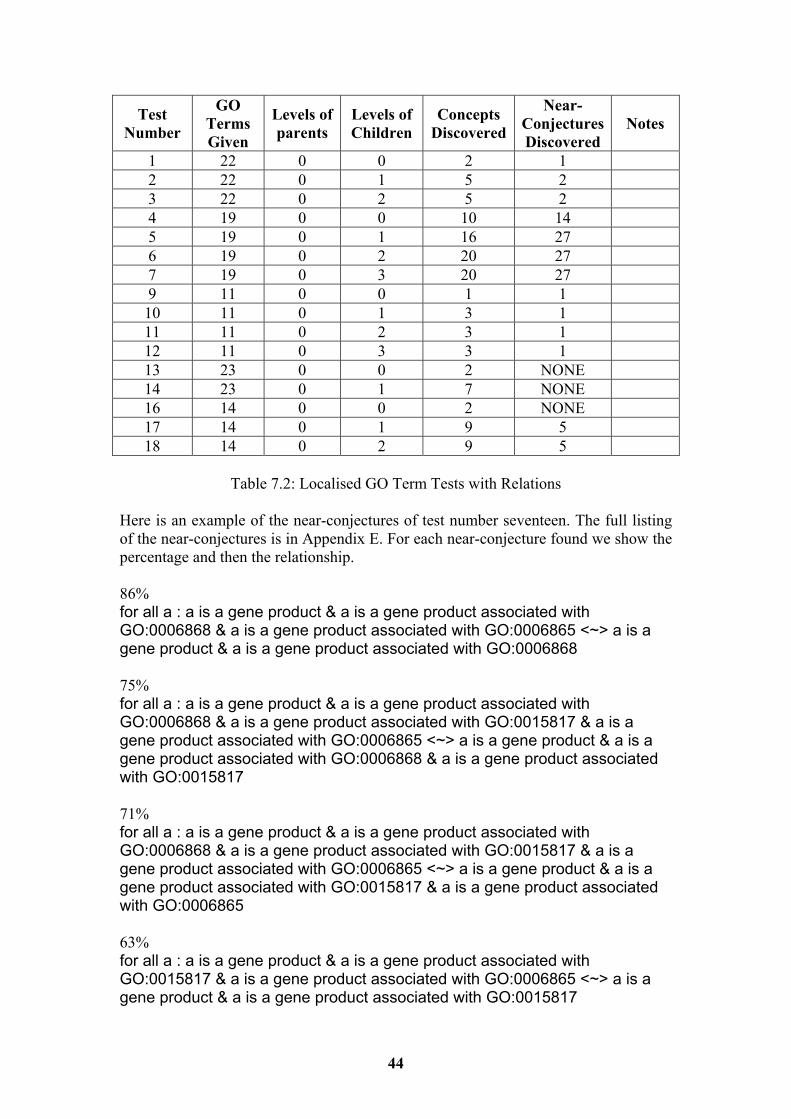
44
Test Number
GO Terms Given
Levels of parents
Levels of Children
Concepts Discovered
Near-Conjectures Discovered
Notes
1 22 0 0 2 1 2 22 0 1 5 2 3 22 0 2 5 2 4 19 0 0 10 14 5 19 0 1 16 27 6 19 0 2 20 27 7 19 0 3 20 27 9 11 0 0 1 1 10 11 0 1 3 1 11 11 0 2 3 1 12 11 0 3 3 1 13 23 0 0 2 NONE 14 23 0 1 7 NONE 16 14 0 0 2 NONE 17 14 0 1 9 5 18 14 0 2 9 5
Table 7.2: Localised GO Term Tests with Relations
Here is an example of the near-conjectures of test number seventeen. The full listing of the near-conjectures is in Appendix E. For each near-conjecture found we show the percentage and then the relationship. 86% for all a : a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0006868 75% for all a : a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817 71% for all a : a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 63% for all a : a is a gene product & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0015817

45
56% for all a : a is a gene product & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817 Our choice to select GO terms from GO that were not picked at random, but using some domain knowledge, was backed up by better search results. HR produced more new concepts and conjectures and the time required to produce them was reduced. There is however still space for improvement. A biologist who can pick GO terms based on his/her detailed knowledge of GO, might be able to select and create tests that produce even more interesting results. This is something that we could not test, but it is worth testing in the future. 7.3 Evaluation of Hypothesis The tests that we ran will be used to evaluate the hypothesis that HR can be used to find statistically significant discoveries in the Gene Ontology. The number of tests ran is not adequate to prove or disprove the hypothesis. On the other hand, a number of interesting observations can be made. First of all, HR can find relations between GO terms in GO. Even though HR was not designed for such a task, it can perform it. Its ability to perform such discoveries is based on the existing options of the program that were used. We presented a sample configuration for HR in Section 6.1 that is adequate in producing results, but it is not proven that it is the optimal one. Other configurations might be able to give better results. In addition, HR could be extended with features that are specific to this biological domain. These extensions might improve the results even further. Secondly, biologists can help to select tests based on their expert knowledge of GO. We showed that moving from random selections from GO to selecting related terms gave better results. The knowledge of biologists might help to get even better ones. Finally, the results that we have obtained from HR might not be statistically significant, but that does not mean that they might not be important for biologists. For example, the fact that two GO terms do not share ninety percents of their genes but only two percent must not be overlooked. Even this small percent might be a very important discovery. Thus, HR managed to produce results that we (as computer scientists) are not suitable to analyse further.

46
Chapter 8 Conclusion and Future Work This project was a feasibility study to test whether HR could discover statistically significant relations between GO terms in the Gene Ontology. Initially, the project was split into three phases, but then the last two were combined into one. The first phase, was to develop a program that would allow us to extract the GO terms and other information from GO. The second one and then third one consisted of using HR to perform the discoveries and then extending it to receive better results. The main focus of the project was on the use of HR to perform the discoveries. A few problems with the Gene Ontology lead us to spend an equal amount of time in the two phases. The main problem was the real-time updating of the ontology and the databases. This caused some inconsistencies in analysing GO. For example, not all of the GO terms that existed in the ontology files existed in the term.txt. In addition, the updating of the ontology files and the databases caused our search results not to be consistent. For, example relations between GO terms that did not exist in the database files in July appeared in August. The inconsistencies of GO are presented in more detail in Appendix D. The design, implementation and testing of GOSP took longer that was expected, but in the end the functionality is enhanced. The user has the ability to choose as many GO terms and their relatives as he/she wants. Moreover, he/she can search for more general GO terms (parent) or more specialised ones (children). On the other hand, the user can type the GO terms in a text file and input it to GOSP. The performance testing lead us to allow the user to choose the way he/she wants to build the indexes with the information about the GO terms and the genes. In the end, the correctness of the results was compared to GenNav and AmiGO. The differences in the results based on the number of genes that the GO terms have, made us believe that these search programs use some other information to build the association between the GO terms and the genes. In our case, we built this association based on the association.txt file and the ontology files. Many tests were run in order to conclude on a configuration of HR that would eliminate many of the trivial results and produce interesting ones. HR was capable of performing discoveries in GO and producing new concepts, conjectures and near-conjectures. The tests that we ran in HR were split into two groups. The first one, used files that contained GO terms picked at random from GO. The second one contained GO terms that were selected from GO based on their locality and the

47
number of their genes. The second group of tests produced a greater number of results and more interesting ones. Using HR we came across two problems. The first one was the use of the special character ‘@’ as a gene name in the file would cause the program not to work. We overcame that by replacing the character with the characters ‘!AT!’ The second was the size of the input file. If the size was bigger than five hundred kilobytes then HR ran very slowly. In order to overcome this problem we selected GO terms that had few genes and thus produced smaller output files. 8.1 Future Work The results that we got from HR might not be statistically significant, but on the other hand it does not mean that they are not important. Cooperation with biologists may increase the number of discoveries that HR makes and it is also essential to provide them with the existing results for further analysis. The configuration that we used is not proven to be the optimal one. The selection of the near-conjectures and near implications by subsume have returned a few results. We set their percentage to fifty in order to observe if the search methods could find any examples and they did. Lowering the percentage would produce more examples and it might find some interesting ones that we have eliminated before. In addition, after we have proven that new concepts can be formed, it would be appropriate to turn the disjunct rule on to observe if it can produce more results that are interesting. Biologists know more about the structure and the biological information in GO than computer scientists. Therefore, they can provide better input samples for HR. Based on their knowledge, they can select GO terms that they know (or suspect) they have relationships. This may increase the number of discoveries made. The results that we have obtained so far are not statistically significant. But that does not mean that there is no useful information hidden in them. The results have to be checked with biologists in order to verify that the relations discovered are of any use or not. There might be occasions that very few genes are shared between GO terms. The few genes on the other hand, might provide a great insight to biologist that they have never thought of. Thus, cooperation with biologists is needed to judge the impact of the results obtained from HR. 8.1.1 Extensions to GOSP The main use of GOSP is to select the given GO terms, their relatives and the corresponding genes from GO. A few things can be improved in the program to extend its usability. When GOSP writes the output file, it reports to the user the number of duplicate genes that exist in the file. This is used to measure how interesting the data collected is. For example, if there are no duplicate genes between the GO terms, then are no chances

48
that HR will find any relation between the given GO terms. This duplicate counter though, does not take into account that the duplicate genes must appear in different GO terms. Therefore, even if you have one GO terms and it has a few genes associated with it more than once then the counter will show it. But this again would not produce any results in HR. This counter needs to be redesigned to take into account and count only genes that appear in different GO terms. Another issue that has to be looked at more carefully is the implementation of RMI. At the moment, the communication between the client and the server is done each time a new index is requested. This leads to many communications and poor performance. Index requests could be grouped together and then sent to the server. This will result in a lower communication cost, because the time spent on communication initialisation would decrease. Another feature that will be useful to add to GOSP is the ability to run in the command line without the GUI. It will take as input a file that has the GO terms and their relatives, and then it will build the indexes, perform the search and output the file. An even better feature would be to enable the user to specify the number of genes that he/she wants to be contained in the GO terms and not the GO terms themselves. Therefore, the user might ask to find all the GO terms that have between ten to one hundred genes. This will provide the user with another way of searching GO. It would be very interesting to model the known ‘isa’ and ‘part of’ relationships between the GO terms in the output file. This extra information that will be stored in the file may help HR in producing more statistically significant results. 8.1.2 Extensions to HR After we have used HR to make discoveries in GO and analysed the results, we propose an extension to the program that will improve the analysis of the results returned. This extension will not improve the number of the results returned, but it would make it easier to distinguish between the trivial and the interesting ones. HR uses a measure of interest to judge which of the concepts to combine. Therefore, it will make conjectures using the most interesting of the concepts first. A new measure of interest would speed the production of interesting results. Each GO term has a number of genes associated with it. A new concept formed will share some of the genes of the existing concept. The new measure of interest will be the sum of the genes of the new concept that are shared with the old one divided by the number of genes that each of the old concepts has. For example, assume that we have three GO terms A, B and C and they have fifty, sixty and seventy genes respectively. Then, two new concepts are created. One of them is D that has ten genes in common with A and B and the other is E that has eight genes in common with A and C. Their measure of interest is calculated as follows:

49
Interest of D = (genes of D)/(genes of A) + (genes of D)/(genes of B) = 10/50 + 10/60 = 0.2 + 0.16 = 0.36 Interest of E = (genes of E)/(genes of A) + (genes of E)/(genes of C) = 8/50 + 8/70 = 0.16 + 0.11 = 0.27 Thus, the newly formed concept D is more interesting than concept E. This measure will allow HR to use the more interesting concepts to create new ones. Moreover, when the results are displayed, we could sort them based on this measure of interest. The most interesting ones will be at the top and that would help in the analysis. 8.2 Summary The area of Bioinformatics is a very interesting one, because biologists and computer scientist are using the power of computers to perform discoveries that were not possible in the past. This project tried to achieve a similar goal. It used the power of a machine-learning program (HR), to try to perform discoveries in a biological domain. This type of search is something that had not occurred before in GO and it produced interesting results. This project needs to be continued even further. The results that we got were interesting, but we think that we did not take advantage of the full potential of the HR program. This is because of the lack of time to fully explore its potential. Further testing needs to be performed and based on the results that we already got, we are confident that it will produce even better ones. In addition, we should involve biologists in the project and steer the testing using their domain knowledge. In addition, their help in the analysis of the results will be very valuable.

50
Bibliography [1] Simon Colton, The HR Program for Theorem Generation, Proceedings of CADE'02, Copenhagen, Denmark, 2002 [2] Simon Colton, Alan Bundy and Toby Walsh, Automatic Concept Formation in Pure Mathematics, Proceedings of IJCAI-99, Stockholm, Sweden, 1999 [3] Creating the Gene Ontology Resource: Design and Implementation, Genome Reaserach, Vol. 11, Issue 8, 1425-1433, August 2001 http://genome.org/cgi/content/full/11/8/1425 [4] Michael Ashburner, On the representation of gene function in genetic databases, http://www.ebi.ac.uk/~ashburn/ontology_discussion.html [5] Gene Ontology General Documentation, http://www.geneontology.org/doc/GO.doc.html [6] S. Colton, Automated Theory Formation in Pure Mathematics (Distinguished Dissertations Series), Springer Verlag, 2002 [7] Gene Ontology Consortium http://www.geneontology.org/ [8] Roger S. Pressman, Software Engineering A Practitioner’s Approach, Fourth Edition, New York, McGraw-Hill, European Adaptation, 1997

51
Appendix A GO Search Program (GOSP) UML Diagrams This Appendix contains the UML diagrams of the major classes of the GOSP program. The UML diagrams of the classes that construct the GUI (MainFRame and MainFrameAboutBox class) are not included.
Figure A.1: UML diagram of Task Interface
52
Figure A.2: UML Diagram of Compute Interface
Figure A.3: UML Diagram of Connection Class
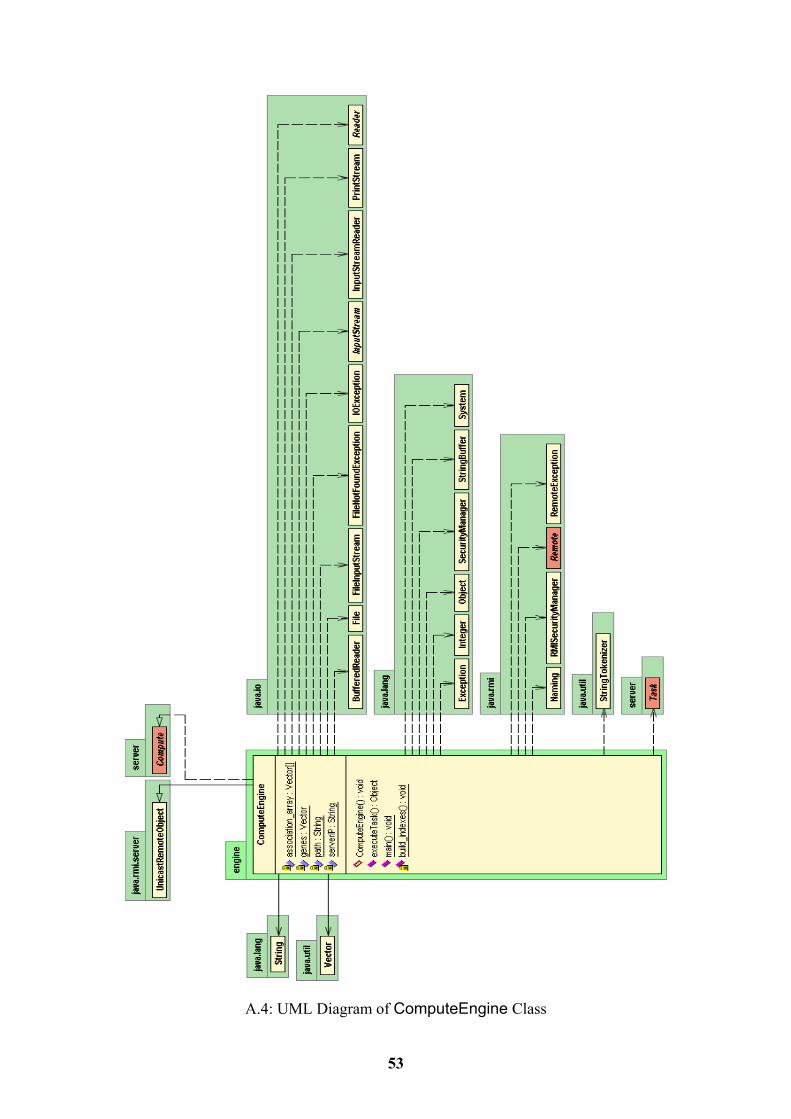
53
A.4: UML Diagram of ComputeEngine Class
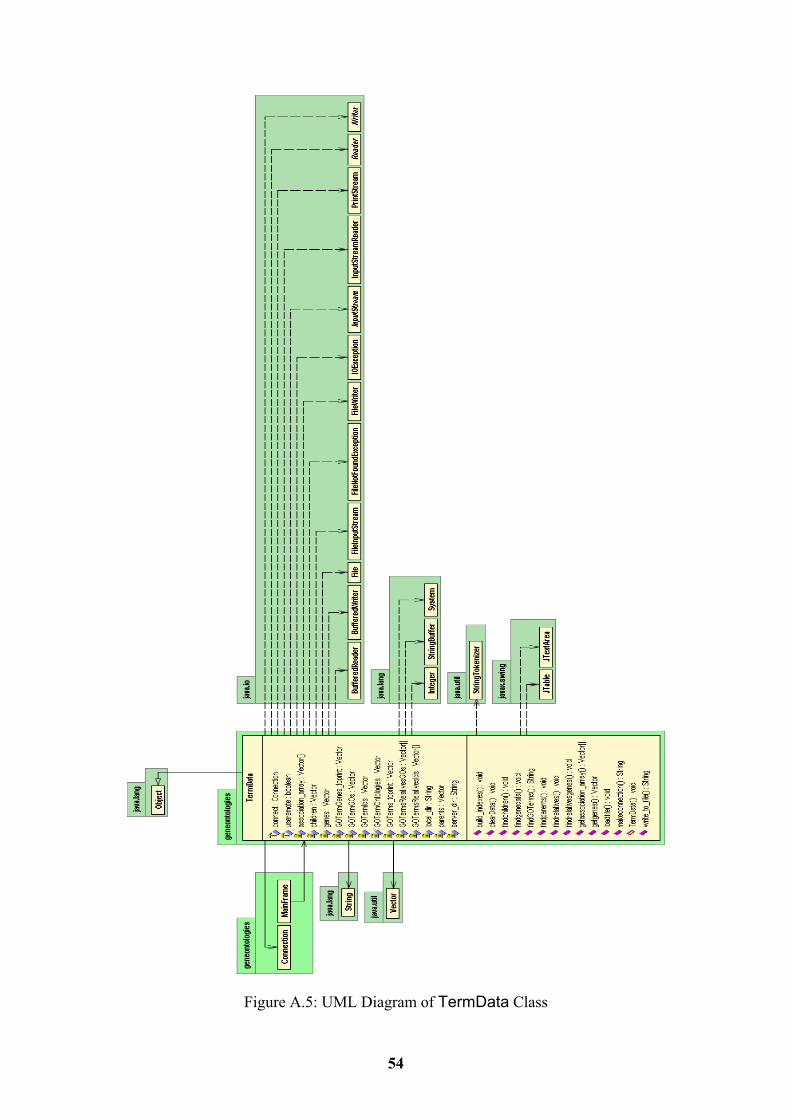
54
Figure A.5: UML Diagram of TermData Class
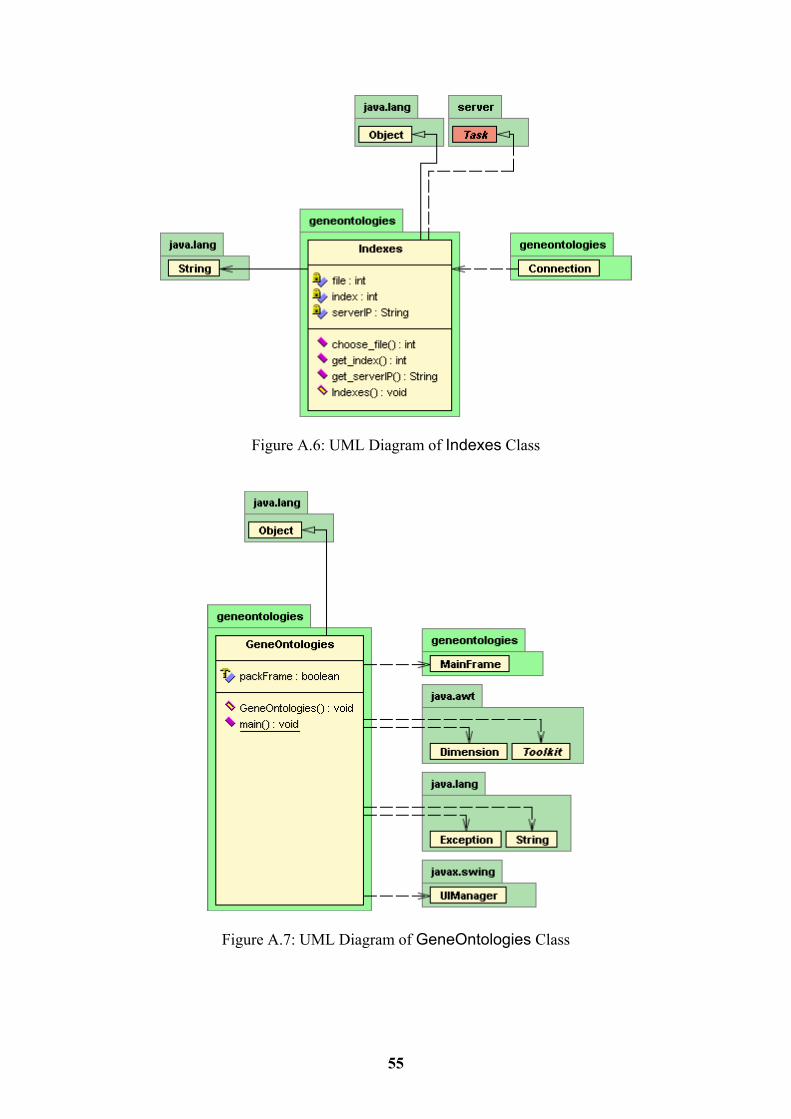
55
Figure A.6: UML Diagram of Indexes Class
Figure A.7: UML Diagram of GeneOntologies Class

56
Appendix B GO Search Program (GOSP) JavaDocs Here is the JavaDoc documentation for the main classes of GOSP. These classes are Indexes, Connection, TermData and ComputeEngine. The rest of the classes are not included because they are used to draw the components of the GUI. The two interfaces are not included, because the classes that implement them explain their methods. B.1 Indexes JavaDoc Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD
geneontologies Class Indexes java.lang.Object | +--geneontologies.Indexes All Implemented Interfaces:
java.io.Serializable, Task
public class Indexes extends java.lang.Object implements Task
Title: Discovery in Gene Ontologies
Description: Indexes Class
Copyright: Copyright (c) 2003
Company: Imperial College

57
Version: 1.0
See Also: Serialized Form
Constructor Summary
Indexes(java.lang.String sIP, int f, int i) This function Creates a new Indexes object.
Method Summary int choose_file()
This function returns the file index we want to use. int get_index()
This function returns the index to look for. java.lang.String get_serverIP()
This function returns the IP of the server.
Methods inherited from class java.lang.Object clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
Indexes public Indexes(java.lang.String sIP, int f, int i)
This function Creates a new Indexes object. Parameters:
sIP - This variable contains the IP of the server. f - This variable holds the information about which of the two file indexes to use. i - This varibale holds the index that is going to be used for the search.
Method Detail
get_serverIP public java.lang.String get_serverIP()
58
This function returns the IP of the server. Specified by: get_serverIP in interface Task Returns: A String that contains the IP of the server.
get_index public int get_index()
This function returns the index to look for. Specified by: get_index in interface Task Returns: An integer that represents the index.
choose_file public int choose_file()
This function returns the file index we want to use. Specified by: choose_file in interface Task Returns: An integer that represents the file index to sue.
Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD
59
B.2 Connection JavaDoc Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD
geneontologies Class Connection java.lang.Object | +--geneontologies.Connection
public class Connection extends java.lang.Object
Title: Discovery in Gene Ontologies
Description: Connection
This class creates a connection to the server with the indexes.
Copyright: Copyright (c) 2003
Company: Imperial College
Version: 1.0
Constructor Summary
Connection() This function Creates a new Connection object.
Method Summary java.lang.String connectserver(java.lang.String sIP)
This function establishes the connection to the server. java.lang.Object getdata(int file, int index)
This function requests for the data of a given index.

60
Methods inherited from class java.lang.Object clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Constructor Detail
Connection public Connection()
This function Creates a new Connection object.
Method Detail
connectserver public java.lang.String connectserver(java.lang.String sIP)
This function establishes the connection to the server. Parameters: sIP - This variable holds the IP of the server. Returns: A String that will return the result of the operation.
getdata public java.lang.Object getdata(int file, int index)
This function requests for the data of a given index. Parameters: file - This variable holds the information about which of the two file indexes to use. 0 for the association index and 1 for the genes index. index - This varibale holds the index that is going to be used for the search. Returns: A String that will return the result of the operation.
Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD
61
B.3 TermData JavaDoc Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD
geneontologies Class TermData java.lang.Object | +--geneontologies.TermData
public class TermData extends java.lang.Object
Title: Discovery in Gene Ontology
Description: TermData
This class holds all the information about the GO terms and the genes.
Copyright: Copyright (c) 2003
Company: Imperial College
Version: 1.0
Field Summary (package private)
Connection
connect This variable holds the connection to the server that has the indexes.
(package private) boolean
useremote This variable is set when we want to use RMI.
Constructor Summary
TermData() This function creates a new TermData object.

62
Method Summary void build_indexes(java.lang.String dir)
This fuinction will build the indexes for the files association.txt and gene_product.txt localy.
void clearData() This function will clear all the data structures, so we can start a new search.
void findchildren(javax.swing.JTextArea output, int term, int iterations, java.lang.String goT) This function will find the children of a given GO Term.
void findgenedata() This function will find the information about the genes that are associatted with a given GO Term.
java.lang.String findGOTerms(javax.swing.JTextArea output, java.util.Vector g, java.util.Vector p, java.util.Vector c) This function will find the information for the GO Terms.
void findparents(javax.swing.JTextArea output, int term, int iterations, java.lang.String goT) This function will find the parents of a given GO Term.
void findrelatives(javax.swing.JTextArea output) This function will find the information about the relatives of the GO Terms.
void findrelativesgenes() This function will find the information about the genes of the relatives that are associatted with the GO Terms.
java.util.Vector[] getassociation_array() This function will return the association_array.
java.util.Vector getgenes() This function returns the genes.
void loadfile(java.lang.String full_path, javax.swing.JTextArea output, javax.swing.JTable table) This function loads a file that contains the GOs of the GO Terms.
java.lang.String makeconnection(java.lang.String serverIP, java.lang.String serverDIR) This function will connect to the remote server.
java.lang.String write_to_file() This function will output the genes.hrd files.

63
Methods inherited from class java.lang.Object clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait
Field Detail
useremote boolean useremote
This variable is set when we want to use RMI.
connect Connection connect
This variable holds the connection to the server that has the indexes.
Constructor Detail
TermData public TermData()
This function creates a new TermData object.
Method Detail
getassociation_array public java.util.Vector[] getassociation_array()
This function will return the association_array. Returns: An Array of Vectors that contains the associations between the GO Terms and the genes.
getgenes public java.util.Vector getgenes()
This function returns the genes. Returns: A Vector that contains all the information about the genes.
makeconnection public java.lang.String makeconnection(java.lang.String serverIP, java.lang.String serverDIR)
This function will connect to the remote server. Parameters:

64
serverIP - This is the parameter that contains the IP address of the server. serverDIR - This is the parameter that contains the direcotry of the server where the data files are stored. Returns: A String that will return the result of the operation.
clearData public void clearData()
This function will clear all the data structures, so we can start a new search.
build_indexes public void build_indexes(java.lang.String dir)
This fuinction will build the indexes for the files association.txt and gene_product.txt localy. Parameters: dir - This String will specify the local directory where the data files are stored.
findGOTerms public java.lang.String findGOTerms(javax.swing.JTextArea output, java.util.Vector g, java.util.Vector p, java.util.Vector c)
This function will find the information for the GO Terms. Parameters: output - This is the TextArea where the program will output the results. g - This parameter holds the GOs of the GO Terms. p - This parameter holds the level of parents of the corresponding GO Terms. c - This parameter holds the level of children of the corresponding GO Terms. Returns: A String that will return the result of the operation.
findgenedata public void findgenedata()
This function will find the information about the genes that are associatted with a given GO Term.
findrelatives public void findrelatives(javax.swing.JTextArea output)

65
This function will find the information about the relatives of the GO Terms. Parameters: output - This is the TextArea where the program will output the results.
findrelativesgenes public void findrelativesgenes()
This function will find the information about the genes of the relatives that are associatted with the GO Terms.
write_to_file public java.lang.String write_to_file()
This function will output the genes.hrd files. Returns: A String that will return the result of the operation.
findparents public void findparents(javax.swing.JTextArea output, int term, int iterations, java.lang.String goT)
This function will find the parents of a given GO Term. Parameters: output - This is the TextArea where the program will output the results. term - This Integer defines which of the four GO Terms the user is interested in. iterations - This Integer specifies how many levels up the user wants to search. goT - This String is the GO id of the GO Term.
findchildren public void findchildren(javax.swing.JTextArea output, int term, int iterations, java.lang.String goT)
This function will find the children of a given GO Term. Parameters: output - This is the TextArea where the program will output the results. term - This Integer defines which of the four GO Terms the user is interested in. iterations - This Integer specifies how many levels down the user wants to search. goT - This String is the GO id of the GO Term.

66
loadfile public void loadfile(java.lang.String full_path, javax.swing.JTextArea output, javax.swing.JTable table)
This function loads a file that contains the GOs of the GO Terms. Parameters: full_path - This parameter contains the full path (path and filename) of the file that contains the information. output - This is the TextArea where the program will output the results. table - This is the table that will be filled with the information read from the file.
Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD
67
B.4 ComputeEngine JavaDoc Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD
engine Class ComputeEngine java.lang.Object | +--java.rmi.server.RemoteObject | +--java.rmi.server.RemoteServer | +--java.rmi.server.UnicastRemoteObject | +--engine.ComputeEngine All Implemented Interfaces:
Compute, java.rmi.Remote, java.io.Serializable
public class ComputeEngine extends java.rmi.server.UnicastRemoteObject implements Compute
Title: Discovery in Gene Ontologies
Description: ComputeEngine
This class performs the building of the indexes on the remote server.
Copyright: Copyright (c) 2003
Company: Imperial College
Version: 1.0
See Also: Serialized Form
Field Summary
Fields inherited from class java.rmi.server.RemoteObject ref

68
Constructor Summary
ComputeEngine() Creates a new ComputeEngine object.
Method Summary java.lang.Object executeTask(Task t)
This function will receive a given task and execute it. static void main(java.lang.String[] args)
This function will start the execution of the ComputeEngine.
Methods inherited from class java.rmi.server.UnicastRemoteObject clone, exportObject, exportObject, exportObject, unexportObject
Methods inherited from class java.rmi.server.RemoteServer getClientHost, getLog, setLog
Methods inherited from class java.rmi.server.RemoteObject equals, getRef, hashCode, toString, toStub
Methods inherited from class java.lang.Object finalize, getClass, notify, notifyAll, wait, wait, wait
Constructor Detail
ComputeEngine public ComputeEngine() throws java.rmi.RemoteException
69
Creates a new ComputeEngine object. Throws:
java.rmi.RemoteException - This Exception is thrown in case there is a problem with the RMI communication.
Method Detail
executeTask public java.lang.Object executeTask(Task t)
This function will receive a given task and execute it. Specified by: executeTask in interface Compute Parameters: t - This variable holds the task that will be executed. Returns: This object is the result of the task execution.
main public static void main(java.lang.String[] args)
This function will start the execution of the ComputeEngine. Parameters: args - These are the command line arguments.
Overview Package Class Tree Deprecated Index Help
PREV CLASS NEXT CLASS FRAMES NO FRAMES All Classes SUMMARY: NESTED | FIELD | CONSTR | METHOD DETAIL: FIELD | CONSTR | METHOD

70
Appendix C GO Search Program (GOSP) Output File Here is a sample output from the GOSP program. We performed a search for the following GO terms: GO:0030476 GO:0015817 GO:0006868 GO:0015809 GO:0015828 GO:0015827 GO:0015801 GO:0015800 GO:0015837 GO:0006949 GO:0007153 GO:0030437 GO:0007152 We specified that we wanted zero levels of parents and children; therefore we did not get their relatives. At the beginning of the file, there is a list of all genes that are contained in all the GO terms. Then, there are lists of the GO terms with their corresponding genes. The genes are recognised by their database id number, followed by the characters ‘~~~’ and followed by their name. If the name of the gene is ‘@’, it is replaced by ‘!AT!’. This is done because in HR the ‘@’ character has a special meaning. This file will be the input to HR. genes geneproduct(G) ascii: @G@ is a gene product geneproduct("807974~~~YHY5_YEAST"). geneproduct("1371655~~~PFS1"). geneproduct("787540~~~SS10_YEAST"). geneproduct("793996~~~CP56_YEAST"). geneproduct("794016~~~DIT1_YEAST"). geneproduct("807381~~~YB30_YEAST"). geneproduct("807457~~~GIP1_YEAST"). geneproduct("807973~~~YHY4_YEAST"). geneproduct("810168~~~SMK1_YEAST"). geneproduct("819802~~~YNM8_YEAST"). geneproduct("841843~~~Q02651"). geneproduct("842725~~~Q03868"). geneproduct("843020~~~YMP7_YEAST"). geneproduct("843230~~~YMG6_YEAST"). geneproduct("843823~~~Q05610"). geneproduct("844539~~~CDA2_YEAST"). geneproduct("844540~~~CDA1_YEAST"). geneproduct("845224~~~Q07732"). geneproduct("845727~~~Q08550"). geneproduct("845779~~~Q08646"). geneproduct("847508~~~CHS5_YEAST"). geneproduct("847666~~~Q12379").

71
geneproduct("847685~~~Q12411"). geneproduct("1369178~~~ADY3"). geneproduct("1369610~~~CDA1"). geneproduct("1369611~~~CDA2"). geneproduct("1369613~~~CDC10"). geneproduct("1369682~~~CHS5"). geneproduct("1369969~~~DIT1"). geneproduct("1369970~~~DIT2"). geneproduct("1369992~~~DON1"). geneproduct("1370022~~~DTR1"). geneproduct("1370369~~~GIP1"). geneproduct("1371141~~~MPC54"). geneproduct("1372655~~~SMA1"). geneproduct("1372656~~~SMA2"). geneproduct("1372673~~~SMK1"). geneproduct("1372845~~~SPO20"). geneproduct("1372846~~~SPO21"). geneproduct("1372850~~~SPO71"). geneproduct("1372861~~~SPR3"). geneproduct("1372864~~~SPS100"). geneproduct("1372937~~~SSP1"). geneproduct("1372939~~~SSP2"). geneproduct("1373108~~~SWM1"). geneproduct("1373164~~~TEP1"). geneproduct("1496449~~~TIGR_TGI:Mouse_TC925877"). geneproduct("1517320~~~TIGR_TGI:S.cerevisiae_TC10842"). geneproduct("1517448~~~TIGR_TGI:S.cerevisiae_TC11024"). geneproduct("1517626~~~TIGR_TGI:S.cerevisiae_TC11233"). geneproduct("1517708~~~TIGR_TGI:S.cerevisiae_TC11340"). geneproduct("1518001~~~TIGR_TGI:S.cerevisiae_TC11793"). geneproduct("1518069~~~TIGR_TGI:S.cerevisiae_TC11884"). geneproduct("1518107~~~TIGR_TGI:S.cerevisiae_TC11929"). geneproduct("1518671~~~TIGR_TGI:S.cerevisiae_TC8525"). geneproduct("1519148~~~TIGR_TGI:S.cerevisiae_TC9125"). geneproduct("1519158~~~TIGR_TGI:S.cerevisiae_TC9138"). geneproduct("1519710~~~TIGR_TGI:S.cerevisiae_TC9920"). geneproduct("1525038~~~TIGR_TGI:S.pombe_TC6523"). geneproduct("808074~~~YES6_YEAST"). geneproduct("841193~~~SPR6_YEAST"). geneproduct("1371022~~~MEI4"). geneproduct("1372578~~~SHC1"). geneproduct("1372842~~~SPO14"). geneproduct("1372862~~~SPR6"). geneproduct("1372877~~~SPT3"). geneproduct("1518156~~~TIGR_TGI:S.cerevisiae_TC11998"). geneproduct("1518896~~~TIGR_TGI:S.cerevisiae_TC8811"). geneproduct("1519401~~~TIGR_TGI:S.cerevisiae_TC9492"). geneproduct("1519493~~~TIGR_TGI:S.cerevisiae_TC9644"). geneproduct("809165~~~IRR1_YEAST"). geneproduct("1370737~~~IRR1"). geneproduct("1373352~~~UBC1"). geneproduct("1419105~~~TIGR_TGI:Barley_TC78421"). geneproduct("1430609~~~TIGR_TGI:Cryptococcus_j5j22j2.r1"). geneproduct("1473523~~~TIGR_TGI:Maize_TC181814"). geneproduct("1501697~~~TIGR_TGI:Pine_AW011414"). geneproduct("1504395~~~TIGR_TGI:Potato_TC66896"). geneproduct("1513873~~~TIGR_TGI:Rice_TC127676"). geneproduct("1518121~~~TIGR_TGI:S.cerevisiae_TC11949"). geneproduct("1519378~~~TIGR_TGI:S.cerevisiae_TC9459"). geneproduct("1522571~~~TIGR_TGI:Soybean_TC147156"). geneproduct("440712~~~4262290").

72
geneproduct("773751~~~O95244"). geneproduct("2996~~~SPCC18.02"). geneproduct("3400~~~SPBC36.03C"). geneproduct("3401~~~SPBC36.02C"). geneproduct("3402~~~SPBC36.01C"). geneproduct("3658~~~SPBC1734.09"). geneproduct("3735~~~SPBC1683.05"). geneproduct("5569~~~HUT1"). geneproduct("1397025~~~BA0554"). geneproduct("1400759~~~BA5479"). geneproduct("1400942~~~BA5694"). geneproduct("21030~~~10242111"). geneproduct("681171~~~Q99624"). geneproduct("1395087~~~AAP2"). geneproduct("1412042~~~TIGR_TGI:Arabidopsis_TC183404"). geneproduct("1423547~~~TIGR_TGI:Cattle_TC175601"). geneproduct("1458419~~~TIGR_TGI:Human_THC1488744"). geneproduct("1458420~~~TIGR_TGI:Human_THC1488745"). geneproduct("1462928~~~TIGR_TGI:Human_THC1525776"). geneproduct("1465402~~~TIGR_TGI:Human_THC1554212"). geneproduct("1465403~~~TIGR_TGI:Human_THC1554215"). geneproduct("1465404~~~TIGR_TGI:Human_THC1554216"). geneproduct("1470251~~~TIGR_TGI:Ice_plant_TC5406"). geneproduct("1493711~~~TIGR_TGI:Mouse_TC898800"). geneproduct("1523140~~~TIGR_TGI:Soybean_TC153635"). geneproduct("808041~~~TAT2_YEAST"). geneproduct("1373145~~~TAT2"). geneproduct("1518354~~~TIGR_TGI:S.cerevisiae_TC8164"). geneproduct("1538120~~~SO4601"). geneproduct("1540684~~~VCA0160"). geneproduct("1535451~~~SO1074"). geneproduct("1536188~~~SO2065"). geneproduct("1541035~~~VCA0772"). geneproduct("177859~~~14588939"). geneproduct("460664~~~4653"). geneproduct("664807~~~RHEB_YEAST"). geneproduct("797057~~~RHEB_YEAST"). geneproduct("1365706~~~Slc7a3"). geneproduct("1372048~~~RHB1"). geneproduct("1398325~~~BA2281"). geneproduct("1441388~~~TIGR_TGI:Frog_TC125357"). geneproduct("1453145~~~TIGR_TGI:Human_THC1433453"). geneproduct("1453146~~~TIGR_TGI:Human_THC1433454"). geneproduct("1485316~~~TIGR_TGI:Mouse_TC815810"). geneproduct("1485841~~~TIGR_TGI:Mouse_TC821009"). geneproduct("1510648~~~TIGR_TGI:Rat_TC395276"). geneproduct("1517870~~~TIGR_TGI:S.cerevisiae_TC11602"). geneproduct("1524907~~~TIGR_TGI:S.pombe_TC5624"). geneproduct("1538707~~~VC0433"). geneproduct("1541023~~~VCA0757"). geneproduct("1541024~~~VCA0758"). geneproduct("1541025~~~VCA0759"). geneproduct("1541026~~~VCA0760"). geneproduct("98445~~~12832716"). geneproduct("585187~~~7406950"). geneproduct("615287~~~8926332"). geneproduct("1365670~~~Slc38a1"). geneproduct("1365671~~~Slc38a3"). geneproduct("1488967~~~TIGR_TGI:Mouse_TC852922"). geneproduct("1488968~~~TIGR_TGI:Mouse_TC852923"). geneproduct("1490426~~~TIGR_TGI:Mouse_TC865949").

73
geneproduct("1494478~~~TIGR_TGI:Mouse_TC905641"). geneproduct("1498151~~~TIGR_TGI:Mouse_TC941785"). geneproduct("1500201~~~TIGR_TGI:Pig_TC66005"). geneproduct("1507200~~~TIGR_TGI:Rat_TC365374"). geneproduct("1509994~~~TIGR_TGI:Rat_TC390580"). geneproduct("1510835~~~TIGR_TGI:Rat_TC397401"). geneproduct("782540~~~HIP1_YEAST"). geneproduct("1370531~~~HIP1"). geneproduct("1517538~~~TIGR_TGI:S.cerevisiae_TC11132"). GO:0030476 GO:0030476(G) ascii: @G@ is a gene product associated with GO:0030476 GO:0030476(G) -> geneproduct(G) GO:0030476("807974~~~YHY5_YEAST"). GO:0030476("1371655~~~PFS1"). GO:0007152 GO:0007152(G) ascii: @G@ is a gene product associated with GO:0007152 GO:0007152(G) -> geneproduct(G) GO:0007152("787540~~~SS10_YEAST"). GO:0007152("793996~~~CP56_YEAST"). GO:0007152("794016~~~DIT1_YEAST"). GO:0007152("807381~~~YB30_YEAST"). GO:0007152("807457~~~GIP1_YEAST"). GO:0007152("807973~~~YHY4_YEAST"). GO:0007152("810168~~~SMK1_YEAST"). GO:0007152("819802~~~YNM8_YEAST"). GO:0007152("841843~~~Q02651"). GO:0007152("842725~~~Q03868"). GO:0007152("843020~~~YMP7_YEAST"). GO:0007152("843230~~~YMG6_YEAST"). GO:0007152("843823~~~Q05610"). GO:0007152("844539~~~CDA2_YEAST"). GO:0007152("844540~~~CDA1_YEAST"). GO:0007152("845224~~~Q07732"). GO:0007152("845727~~~Q08550"). GO:0007152("845779~~~Q08646"). GO:0007152("847508~~~CHS5_YEAST"). GO:0007152("847666~~~Q12379"). GO:0007152("847685~~~Q12411"). GO:0007152("1369178~~~ADY3"). GO:0007152("1369610~~~CDA1"). GO:0007152("1369611~~~CDA2"). GO:0007152("1369613~~~CDC10"). GO:0007152("1369682~~~CHS5"). GO:0007152("1369969~~~DIT1"). GO:0007152("1369970~~~DIT2"). GO:0007152("1369992~~~DON1"). GO:0007152("1370022~~~DTR1"). GO:0007152("1370369~~~GIP1"). GO:0007152("1371141~~~MPC54"). GO:0007152("1372655~~~SMA1"). GO:0007152("1372656~~~SMA2"). GO:0007152("1372673~~~SMK1"). GO:0007152("1372845~~~SPO20"). GO:0007152("1372846~~~SPO21"). GO:0007152("1372850~~~SPO71"). GO:0007152("1372861~~~SPR3"). GO:0007152("1372864~~~SPS100").

74
GO:0007152("1372937~~~SSP1"). GO:0007152("1372939~~~SSP2"). GO:0007152("1373108~~~SWM1"). GO:0007152("1373164~~~TEP1"). GO:0007152("1496449~~~TIGR_TGI:Mouse_TC925877"). GO:0007152("1517320~~~TIGR_TGI:S.cerevisiae_TC10842"). GO:0007152("1517448~~~TIGR_TGI:S.cerevisiae_TC11024"). GO:0007152("1517626~~~TIGR_TGI:S.cerevisiae_TC11233"). GO:0007152("1517708~~~TIGR_TGI:S.cerevisiae_TC11340"). GO:0007152("1518001~~~TIGR_TGI:S.cerevisiae_TC11793"). GO:0007152("1518069~~~TIGR_TGI:S.cerevisiae_TC11884"). GO:0007152("1518107~~~TIGR_TGI:S.cerevisiae_TC11929"). GO:0007152("1518671~~~TIGR_TGI:S.cerevisiae_TC8525"). GO:0007152("1519148~~~TIGR_TGI:S.cerevisiae_TC9125"). GO:0007152("1519158~~~TIGR_TGI:S.cerevisiae_TC9138"). GO:0007152("1519710~~~TIGR_TGI:S.cerevisiae_TC9920"). GO:0007152("1525038~~~TIGR_TGI:S.pombe_TC6523"). GO:0030437 GO:0030437(G) ascii: @G@ is a gene product associated with GO:0030437 GO:0030437(G) -> geneproduct(G) GO:0030437("808074~~~YES6_YEAST"). GO:0030437("841193~~~SPR6_YEAST"). GO:0030437("1371022~~~MEI4"). GO:0030437("1372578~~~SHC1"). GO:0030437("1372842~~~SPO14"). GO:0030437("1372862~~~SPR6"). GO:0030437("1372877~~~SPT3"). GO:0030437("1518156~~~TIGR_TGI:S.cerevisiae_TC11998"). GO:0030437("1518896~~~TIGR_TGI:S.cerevisiae_TC8811"). GO:0030437("1519401~~~TIGR_TGI:S.cerevisiae_TC9492"). GO:0030437("1519493~~~TIGR_TGI:S.cerevisiae_TC9644"). GO:0007153 GO:0007153(G) ascii: @G@ is a gene product associated with GO:0007153 GO:0007153(G) -> geneproduct(G) GO:0007153("809165~~~IRR1_YEAST"). GO:0007153("1370737~~~IRR1"). GO:0007153("1373352~~~UBC1"). GO:0007153("1419105~~~TIGR_TGI:Barley_TC78421"). GO:0007153("1430609~~~TIGR_TGI:Cryptococcus_j5j22j2.r1"). GO:0007153("1473523~~~TIGR_TGI:Maize_TC181814"). GO:0007153("1501697~~~TIGR_TGI:Pine_AW011414"). GO:0007153("1504395~~~TIGR_TGI:Potato_TC66896"). GO:0007153("1513873~~~TIGR_TGI:Rice_TC127676"). GO:0007153("1518121~~~TIGR_TGI:S.cerevisiae_TC11949"). GO:0007153("1519378~~~TIGR_TGI:S.cerevisiae_TC9459"). GO:0007153("1522571~~~TIGR_TGI:Soybean_TC147156"). GO:0006949 GO:0006949(G) ascii: @G@ is a gene product associated with GO:0006949 GO:0006949(G) -> geneproduct(G) GO:0006949("440712~~~4262290"). GO:0006949("773751~~~O95244").

75
GO:0015837 GO:0015837(G) ascii: @G@ is a gene product associated with GO:0015837 GO:0015837(G) -> geneproduct(G) GO:0015837("2996~~~SPCC18.02"). GO:0015837("3400~~~SPBC36.03C"). GO:0015837("3401~~~SPBC36.02C"). GO:0015837("3402~~~SPBC36.01C"). GO:0015837("3658~~~SPBC1734.09"). GO:0015837("3735~~~SPBC1683.05"). GO:0015837("5569~~~HUT1"). GO:0015837("807381~~~YB30_YEAST"). GO:0015837("1370022~~~DTR1"). GO:0015837("1397025~~~BA0554"). GO:0015837("1400759~~~BA5479"). GO:0015837("1400942~~~BA5694"). GO:0015800 GO:0015800(G) ascii: @G@ is a gene product associated with GO:0015800 GO:0015800(G) -> geneproduct(G) GO:0015800("21030~~~10242111"). GO:0015800("21030~~~10242111"). GO:0015800("681171~~~Q99624"). GO:0015800("681171~~~Q99624"). GO:0015800("1395087~~~AAP2"). GO:0015800("1412042~~~TIGR_TGI:Arabidopsis_TC183404"). GO:0015800("1423547~~~TIGR_TGI:Cattle_TC175601"). GO:0015800("1458419~~~TIGR_TGI:Human_THC1488744"). GO:0015800("1458420~~~TIGR_TGI:Human_THC1488745"). GO:0015800("1462928~~~TIGR_TGI:Human_THC1525776"). GO:0015800("1465402~~~TIGR_TGI:Human_THC1554212"). GO:0015800("1465403~~~TIGR_TGI:Human_THC1554215"). GO:0015800("1465404~~~TIGR_TGI:Human_THC1554216"). GO:0015800("1470251~~~TIGR_TGI:Ice_plant_TC5406"). GO:0015800("1493711~~~TIGR_TGI:Mouse_TC898800"). GO:0015800("1523140~~~TIGR_TGI:Soybean_TC153635"). GO:0015801 GO:0015801(G) ascii: @G@ is a gene product associated with GO:0015801 GO:0015801(G) -> geneproduct(G) GO:0015801("808041~~~TAT2_YEAST"). GO:0015801("1373145~~~TAT2"). GO:0015801("1518354~~~TIGR_TGI:S.cerevisiae_TC8164"). GO:0015827 GO:0015827(G) ascii: @G@ is a gene product associated with GO:0015827 GO:0015827(G) -> geneproduct(G) GO:0015827("1538120~~~SO4601"). GO:0015827("1540684~~~VCA0160"). GO:0015828 GO:0015828(G) ascii: @G@ is a gene product associated with GO:0015828 GO:0015828(G) -> geneproduct(G) GO:0015828("1535451~~~SO1074"). GO:0015828("1536188~~~SO2065"). GO:0015828("1541035~~~VCA0772").

76
GO:0015809 GO:0015809(G) ascii: @G@ is a gene product associated with GO:0015809 GO:0015809(G) -> geneproduct(G) GO:0015809("177859~~~14588939"). GO:0015809("460664~~~4653"). GO:0015809("177859~~~14588939"). GO:0015809("664807~~~RHEB_YEAST"). GO:0015809("797057~~~RHEB_YEAST"). GO:0015809("1365706~~~Slc7a3"). GO:0015809("1372048~~~RHB1"). GO:0015809("1398325~~~BA2281"). GO:0015809("1441388~~~TIGR_TGI:Frog_TC125357"). GO:0015809("1453145~~~TIGR_TGI:Human_THC1433453"). GO:0015809("1453146~~~TIGR_TGI:Human_THC1433454"). GO:0015809("1485316~~~TIGR_TGI:Mouse_TC815810"). GO:0015809("1485841~~~TIGR_TGI:Mouse_TC821009"). GO:0015809("1510648~~~TIGR_TGI:Rat_TC395276"). GO:0015809("1517870~~~TIGR_TGI:S.cerevisiae_TC11602"). GO:0015809("1524907~~~TIGR_TGI:S.pombe_TC5624"). GO:0015809("1538707~~~VC0433"). GO:0015809("1541023~~~VCA0757"). GO:0015809("1541024~~~VCA0758"). GO:0015809("1541025~~~VCA0759"). GO:0015809("1541026~~~VCA0760"). GO:0006868 GO:0006868(G) ascii: @G@ is a gene product associated with GO:0006868 GO:0006868(G) -> geneproduct(G) GO:0006868("98445~~~12832716"). GO:0006868("585187~~~7406950"). GO:0006868("615287~~~8926332"). GO:0006868("98445~~~12832716"). GO:0006868("615287~~~8926332"). GO:0006868("585187~~~7406950"). GO:0006868("1365670~~~Slc38a1"). GO:0006868("1365671~~~Slc38a3"). GO:0006868("1488967~~~TIGR_TGI:Mouse_TC852922"). GO:0006868("1488968~~~TIGR_TGI:Mouse_TC852923"). GO:0006868("1490426~~~TIGR_TGI:Mouse_TC865949"). GO:0006868("1494478~~~TIGR_TGI:Mouse_TC905641"). GO:0006868("1498151~~~TIGR_TGI:Mouse_TC941785"). GO:0006868("1500201~~~TIGR_TGI:Pig_TC66005"). GO:0006868("1507200~~~TIGR_TGI:Rat_TC365374"). GO:0006868("1509994~~~TIGR_TGI:Rat_TC390580"). GO:0006868("1510835~~~TIGR_TGI:Rat_TC397401"). GO:0015817 GO:0015817(G) ascii: @G@ is a gene product associated with GO:0015817 GO:0015817(G) -> geneproduct(G) GO:0015817("98445~~~12832716"). GO:0015817("585187~~~7406950"). GO:0015817("615287~~~8926332"). GO:0015817("98445~~~12832716"). GO:0015817("615287~~~8926332"). GO:0015817("585187~~~7406950"). GO:0015817("782540~~~HIP1_YEAST"). GO:0015817("1365671~~~Slc38a3"). GO:0015817("1370531~~~HIP1").

77
GO:0015817("1498151~~~TIGR_TGI:Mouse_TC941785"). GO:0015817("1500201~~~TIGR_TGI:Pig_TC66005"). GO:0015817("1507200~~~TIGR_TGI:Rat_TC365374"). GO:0015817("1510835~~~TIGR_TGI:Rat_TC397401"). GO:0015817("1517538~~~TIGR_TGI:S.cerevisiae_TC11132").

78
Appendix D Notes on the Gene Ontology This Appendix contains some notes on the structure of the Gene Ontology. During the whole project, we found certain peculiarities in GO. We summarise our findings here, in order to help other people who might want to work with GO. One specific problem that we found was the results returned for the children of GO:0007612 (‘learning’). AmiGO and GenNav returned the following four children: GO:0008306 (‘associative learning’) GO:0008355 (‘olfactory learning’) GO:0008542 (‘visual learning’) GO:0042297 (‘vocal learning’) But GOSP returned five children: GO:0008306 (‘associative learning’) GO:0008355 (‘olfactory learning’) GO:0008542 (‘visual learning’) GO:0042297 (‘vocal learning’) GO:0046958 (‘nonassociative learning’) In addition, the process.ontology file showed these five GO terms to be the children of GO:0007612. When we enter the fifth child (GO:0046958) to GenNav or AmiGO then they both reply that this GO term does not exist. In addition, GO:0046958 does not exist in term.txt, even though it exists in the process.ontology file. An explanation for this might be that AmiGO and GenNav used old files from the ontology. Two more strange things we discovered had to do with the genes and their association to GO terms. The first one is that many genes share the same name. The genes have different database ids, but have the same name. In order to get unique ids in the GOSP output file we concatenated the name with the id of the gene. This composite id would provide a unique way to identify the genes with the same name, but different id numbers. An example of genes with the same name and different database id is the following, 696333 A 696335 A 696336 A

79
The second one is that the same gene is associated with the same GO term more than once. This is not due to a typing error, because it appears many times in the association.txt file. Here are two extracts from the association.txt file, Databse id GO term database id gene database id 14695 9 37889 240583 9 37889 146696 5088 37889 240584 5088 37889 Another peculiarity that was discovered in the ontology files of August 2003 was that some GO terms had two GO ids. The reasons behind this choice were not obvious to us. Here, is an extract from the component.ontology file, <flagellum ; GO:0019861, GO:0008223 These peculiarities of GO are not very obvious from the start and can cause problems when people search in GO. They are not included in the documentation about GO. The reason for the existence of duplicate names in different genes or the multiple associations of the same gene and a GO term might be obvious to biologists, but it is not made clear to people who are not familiar with biology. Moreover, the reason for the existence of to GO term ids for one cellular component is not obvious. These issues were discovered during the whole project. The lack of documentation of these peculiarities slows down the users from building tools for GO. We sent an email to the Gene Ontology consortium asking them for more detailed explanations about the structure of GO, but our request was not answered. The Gene Ontology consortium should be notified of these issues and they should provide better documentation of special cases that exist in GO.
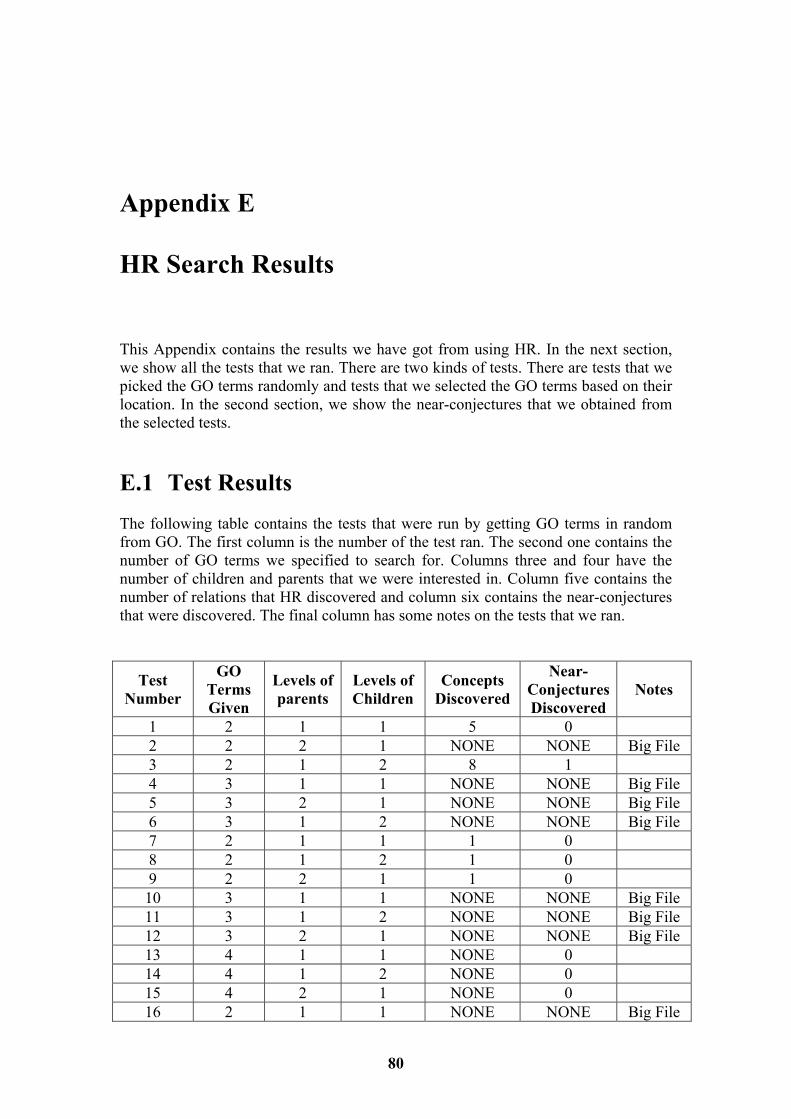
80
Appendix E HR Search Results This Appendix contains the results we have got from using HR. In the next section, we show all the tests that we ran. There are two kinds of tests. There are tests that we picked the GO terms randomly and tests that we selected the GO terms based on their location. In the second section, we show the near-conjectures that we obtained from the selected tests. E.1 Test Results The following table contains the tests that were run by getting GO terms in random from GO. The first column is the number of the test ran. The second one contains the number of GO terms we specified to search for. Columns three and four have the number of children and parents that we were interested in. Column five contains the number of relations that HR discovered and column six contains the near-conjectures that were discovered. The final column has some notes on the tests that we ran.
Test Number
GO Terms Given
Levels of parents
Levels of Children
Concepts Discovered
Near-Conjectures Discovered
Notes
1 2 1 1 5 0 2 2 2 1 NONE NONE Big File 3 2 1 2 8 1 4 3 1 1 NONE NONE Big File 5 3 2 1 NONE NONE Big File 6 3 1 2 NONE NONE Big File 7 2 1 1 1 0 8 2 1 2 1 0 9 2 2 1 1 0 10 3 1 1 NONE NONE Big File 11 3 1 2 NONE NONE Big File 12 3 2 1 NONE NONE Big File 13 4 1 1 NONE 0 14 4 1 2 NONE 0 15 4 2 1 NONE 0 16 2 1 1 NONE NONE Big File
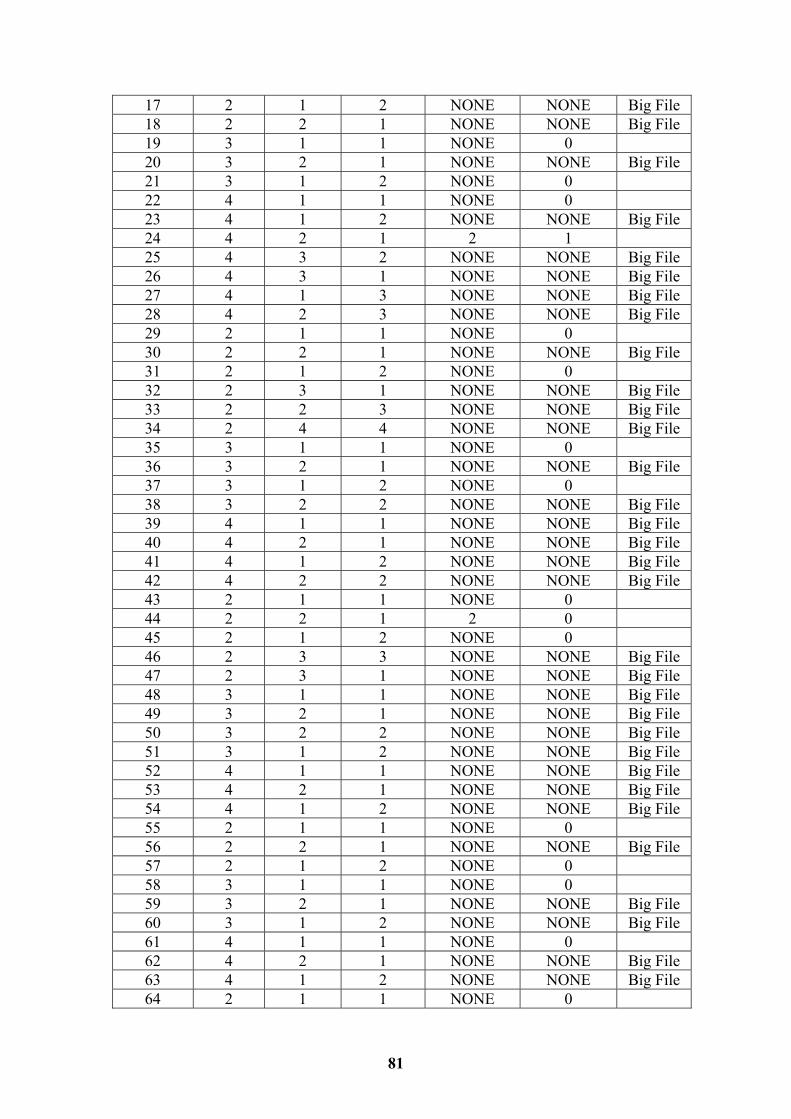
81
17 2 1 2 NONE NONE Big File 18 2 2 1 NONE NONE Big File 19 3 1 1 NONE 0 20 3 2 1 NONE NONE Big File 21 3 1 2 NONE 0 22 4 1 1 NONE 0 23 4 1 2 NONE NONE Big File 24 4 2 1 2 1 25 4 3 2 NONE NONE Big File 26 4 3 1 NONE NONE Big File 27 4 1 3 NONE NONE Big File 28 4 2 3 NONE NONE Big File 29 2 1 1 NONE 0 30 2 2 1 NONE NONE Big File 31 2 1 2 NONE 0 32 2 3 1 NONE NONE Big File 33 2 2 3 NONE NONE Big File 34 2 4 4 NONE NONE Big File 35 3 1 1 NONE 0 36 3 2 1 NONE NONE Big File 37 3 1 2 NONE 0 38 3 2 2 NONE NONE Big File 39 4 1 1 NONE NONE Big File 40 4 2 1 NONE NONE Big File 41 4 1 2 NONE NONE Big File 42 4 2 2 NONE NONE Big File 43 2 1 1 NONE 0 44 2 2 1 2 0 45 2 1 2 NONE 0 46 2 3 3 NONE NONE Big File 47 2 3 1 NONE NONE Big File 48 3 1 1 NONE NONE Big File 49 3 2 1 NONE NONE Big File 50 3 2 2 NONE NONE Big File 51 3 1 2 NONE NONE Big File 52 4 1 1 NONE NONE Big File 53 4 2 1 NONE NONE Big File 54 4 1 2 NONE NONE Big File 55 2 1 1 NONE 0 56 2 2 1 NONE NONE Big File 57 2 1 2 NONE 0 58 3 1 1 NONE 0 59 3 2 1 NONE NONE Big File 60 3 1 2 NONE NONE Big File 61 4 1 1 NONE 0 62 4 2 1 NONE NONE Big File 63 4 1 2 NONE NONE Big File 64 2 1 1 NONE 0
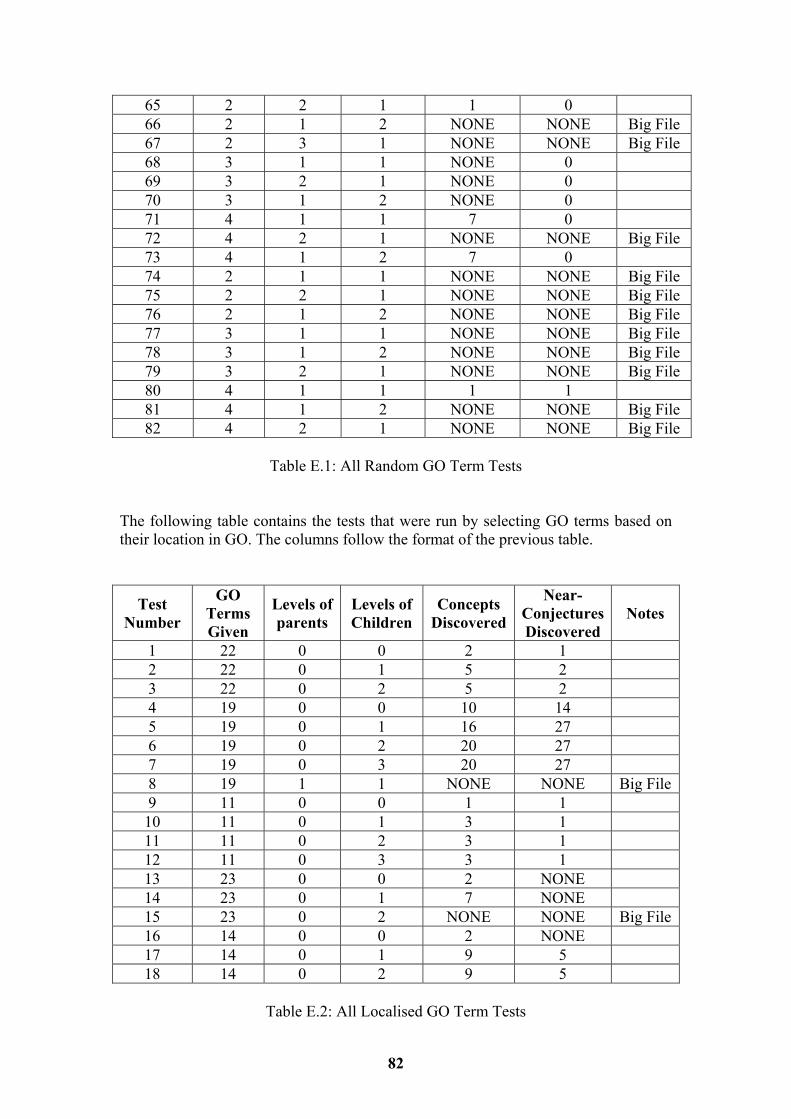
82
65 2 2 1 1 0 66 2 1 2 NONE NONE Big File 67 2 3 1 NONE NONE Big File 68 3 1 1 NONE 0 69 3 2 1 NONE 0 70 3 1 2 NONE 0 71 4 1 1 7 0 72 4 2 1 NONE NONE Big File 73 4 1 2 7 0 74 2 1 1 NONE NONE Big File 75 2 2 1 NONE NONE Big File 76 2 1 2 NONE NONE Big File 77 3 1 1 NONE NONE Big File 78 3 1 2 NONE NONE Big File 79 3 2 1 NONE NONE Big File 80 4 1 1 1 1 81 4 1 2 NONE NONE Big File 82 4 2 1 NONE NONE Big File
Table E.1: All Random GO Term Tests
The following table contains the tests that were run by selecting GO terms based on their location in GO. The columns follow the format of the previous table.
Test Number
GO Terms Given
Levels of parents
Levels of Children
Concepts Discovered
Near-Conjectures Discovered
Notes
1 22 0 0 2 1 2 22 0 1 5 2 3 22 0 2 5 2 4 19 0 0 10 14 5 19 0 1 16 27 6 19 0 2 20 27 7 19 0 3 20 27 8 19 1 1 NONE NONE Big File9 11 0 0 1 1 10 11 0 1 3 1 11 11 0 2 3 1 12 11 0 3 3 1 13 23 0 0 2 NONE 14 23 0 1 7 NONE 15 23 0 2 NONE NONE Big File16 14 0 0 2 NONE 17 14 0 1 9 5 18 14 0 2 9 5
Table E.2: All Localised GO Term Tests

83
E.2 Localised GO Term Near-conjecture Results This section contains the near-conjectures of the localised tests that we run. We have omitted the ones that contain no near-conjectures. In addition, we have not included the ones that contain the same GO terms and different amount of children but the results are the same. For each near-conjecture found we show the percentage and then the relationship. Test 1 72 % for all a : a is a gene product & a is a gene product associated with GO:0008296 & a is a gene product associated with GO:0008310 <~> a is a gene product & a is a gene product associated with GO:0008310 Test 2 72 % for all a : a is a gene product & a is a gene product associated with GO:0008296 & a is a gene product associated with GO:0008310 <~> a is a gene product & a is a gene product associated with GO:0008310 67% for all a : a is a gene product & a is a gene product associated with GO:0000702 & a is a gene product associated with GO:0008534 <~> a is a gene product & a is a gene product associated with GO:0000702 Test 4 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 <~> a is a gene product & a is a gene product associated with GO:0016297 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016297 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295

84
97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016297 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016295 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0004320 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016296 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016295 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0004320

85
79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016296 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 67% for all a : a is a gene product & a is a gene product associated with GO:0016293 & a is a gene product associated with GO:0016290 <~> a is a gene product & a is a gene product associated with GO:0016293 Test 5 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 <~> a is a gene product & a is a gene product associated with GO:0016297 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016297 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016297 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated

86
with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016297 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 97% for all a : a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016297 & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 87% for all a : a is a gene product & a is a gene product associated with GO:0016290 & a is a gene product associated with GO:0016289 <~> a is a gene product & a is a gene product associated with GO:0016293 & a is a gene product associated with GO:0016289

87
79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016295 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0004320 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016296 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016295 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0004320 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016296 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016295 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a

88
gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0004320 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016296 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 79% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 67% for all a : a is a gene product & a is a gene product associated with GO:0016293 & a is a gene product associated with GO:0016290 <~> a is a gene product & a is a gene product associated with GO:0016293 51% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 <~> a is a gene product & a is a gene product associated with GO:0016294 51% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 <~> a is a gene product & a is a gene product associated with GO:0016294 51% for all a : a is a gene product & a is a gene product associated with GO:0016295 & a is a gene product associated with GO:0004320 & a is a gene product associated with GO:0016296 & a is a gene product associated with GO:0016294 <~> a is a gene product & a is a gene product associated with GO:0016294

89
Test 9 80% for all a : a is a gene product & a is a gene product associated with GO:0015226 & a is a gene product associated with GO:0015227 <~> a is a gene product & a is a gene product associated with GO:0015227 Test 17 86% for all a : a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0006868 75% for all a : a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817 71% for all a : a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 63% for all a : a is a gene product & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0015817 56% for all a : a is a gene product & a is a gene product associated with GO:0015817 & a is a gene product associated with GO:0006865 <~> a is a gene product & a is a gene product associated with GO:0006868 & a is a gene product associated with GO:0015817

90
Appendix F User Guide GOSP consists of three packages. These are the engine, geneontologies and server package. Below we will provide details on how to compile and run the program. The instructions that follow are for compiling and running the server and the client under Linux. In order to compile and run under windows, the paths have to be changed to the windows style. F.1 Compiling GOSP To compile the server we need to go to the src directory and run the following commands: javac server/*.java jar cvf server.jar server/*.class cp server.jar ~/public_html/classes setenv CLASSPATH /homes/gt02/project/code/src:/homes/gt02/public_html/classes/server.jar javac engine/*.java rmic -d . engine.ComputeEngine cp engine/ComputeEngine_*.class ~/public_html/classes/engine cd ~/public_html/classes jar xvf server.jar This would compile our server and place the server.jar file at the public_html where it can be accessed by other users. In order to run the server we need to start the rmiregistry first and then run the following command: java -Xms256M -Xmx512M -Djava.rmi.server.codebase=http://www.doc.ic.ac.uk/gt02/classes -Djava.rmi.server.hostname=146.169.2.59 -Djava.security.policy=java.policy engine/ComputeEngine /vol/bitbucket/gt02/data_files/ The first two arguments increase the heap size of Java, so that there is space to build the indexes and not get OutOfMemory errors. The third argument is the address

91
where we have placed the classes of the server. The fourth one is the IP address of the server. The fifth one is the policy file that will control access to the server machine. The last ones are the name of the java class file and one command line argument. This argument is the directory of the server that has the ontology and the database text files. Here is an example of a java.policy file that gives full access target machine. grant { permission java.security.AllPermission; }; To compile the client we need to go to the src directory and run the following commands: setenv CLASSPATH /homes/gt02/project/code/src:/homes/gt02/public_html/classes/server.jar javac geneontologies/*.java cp geneontologies/Indexes.class ~/public_html/classes To run the client we need to run the following command: java -Xms256M -Xmx512M -Djava.rmi.server.codebase=http://www.doc.ic.ac.uk/gt02/classes -Djava.security.policy=java.policy geneontologies/GeneOntologies The first two arguments increase the heap size of Java, so that there is space to build the indexes and not get OutOfMemory errors. The third argument is the address that we have placed the classes of the server. The fourth one is the policy file that will control access to the client machine. The last one is the name of the java class file. F.2 Using GOSP Figure F.1 shows a screenshot of GOSP. We have annotated on the picture the buttons the user will use to interact with the program. The following paragraphs contain a description of the usability of these buttons. Once the GUI has been displayed, the user can start to use GOSP. First, he/she needs to build the indexes. This can be done locally or the user can connect to a server that has the indexes. If he/she wants to build the indexes locally (button 1) the user must supply the path of the ontology and the database text files. At the end of the path there must be the character ‘\’ or ‘/’ depending on the operating system used. If he/she wants to connect a server that holds the indexes, the user must specify the IP of the server and the path of the server that the ontology and database text files are stored (button 2). The path must end in ‘/’ or ‘\’. The user can input GO terms in two ways. The first one if to type the GO terms on the table provided and then specify how many levels of children and parents he/she is interested in. The square that selects the current cell must be placed at an empty cell, or that cell will not be taken into account in the searching. This could lead to errors.

92
The second way to input GO terms is to specify the full path of a file that contains the GO terms (button 3). The file must only contain the GO ids of the terms. The file will be loaded and the GO terms will appear on the table and their levels of parents and children will be set to zero. The button beneath the table will search to find all the GO terms, their relatives and their genes (button 6). Then the user can save the results in a file that has the HR syntax (button 7). The text area at the bottom right displays some information about the GO terms, during the search. There are two buttons that clear all the data structures and the GUI, in order for a new search to start. The ‘Clear All Fields and Data’ button clears everything (button 4). The ‘Clear Levels and Data’ clears all the data structures of the program and resets the GUI, apart from the GO term GO ids (button 5). This is useful in case the user wants to run many tests with the same GO terms but different levels of parents and children.
Figure F.1: GOSP User Guide