enabling collective communications between components
TRANSCRIPT

Enabling Collective Communications between Components
Julien Bigot Christian Perez
INRIA/IRISA
{Julien.Bigot,Christian.Perez}@inria.fr
Abstract
Existing high performance component models mainly fo-
cus on the efficiency of the composition of two components,
tackling also the special case of parallel components that en-
able N ×M communications. The implementation of paral-
lel components is usually assumed to be done thanks to some
external communication paradigms like MPI. However, as of
today, collective communication operations like broadcast,
reduction, gather, etc. are not supported by component mod-
els. Programmers should develop such operations on top of
point-to-point communication operations provided by com-
ponent models. This paper studies how collective operations
between components can be provided from an user and de-
veloper point of view. The result is an abstract component
model that allows the implementation of collective commu-
nications. Software components are then able to use collec-
tive communications between several instances. To be effec-
tive on hierarchical resources such as grids, the model is hi-
erarchical and relies on the concept of replicating component
implementation. Last, the paper deals with the projection of
such an abstract model onto existing models. It is validated
through some very preliminary experiments.
Categories and Subject Descriptors D.3.2 [Language
Classifications]: Concurrent, distributed, and parallel lan-
guages
General Terms Languages, Algorithms, Experimentation.
Keywords Component model, collective communications.
1. Introduction
High performance computing is a major challenging is-
sue. In order to handle scalability on very large machines,
like massively parallel machines, the SPMD1 programming
1 Single Program Multiple Data
Permission to make digital or hard copies of all or part of this work for personal orclassroom use is granted without fee provided that copies are not made or distributedfor profit or commercial advantage and that copies bear this notice and the full citationon the first page. To copy otherwise, to republish, to post on servers or to redistributeto lists, requires prior specific permission and/or a fee.
HPC-GECO/CompFrame’07, October 21–22, 2007, Montréal, Québec, Canada.Copyright c© 2007 ACM 978-1-59593-867-1/07/0010. . . $5.00
model has proved to be a very efficient paradigm. Its success
relies on letting the number of processes to be a parameter of
the application while providing a well founded communica-
tion model based on collective communications. PVM[14]
and MPI[6] are the two most used communication APIs that
provide collective communications.
However, the overall structure of an application remains
mainly hidden into the code. Hence, in order to face the in-
creasing software complexity of applications and to ease
code reuse, the software component approach was pro-
posed [15]. Component models like CCM[12], Fractal[5]
and CCA[2] provide mechanisms to let a component express
what it provides and what it requires. This provides/uses
port mechanism implies a one-to-one relationship between
components. Some component models, like CCM, support
multicast relationship through event oriented ports. GCM
proposes gather and scatter relationships between compo-
nents [7]. However, these models do not enable SPMD pro-
gramming style as the source and the destination of the oper-
ation are implied by the composition. They enable a N-to-M
communication (1-to-M for the event communication).
So far, collective communications à la MPI are only pos-
sible inside the implementation of parallel components pro-
vided by parallel component models such as CCA [2] and
GridCCM [13]. Moreover, such components models take
care of the N × M communication between parallel com-
ponents and let the user implement the parallel component
freely, for example by using MPI. While it provides an in-
teresting solution for embedding legacy parallel codes into a
component, it is a limited solution. First, it provides a dual
layer model: a lower layer made of MPI for example and
an upper layer to handle the component interactions. Hence,
a developer has to learn two models. Second, the collective
communications are not seen at the component level. This
is a limitation for code reuse and application deployment
as some requirements of the component are not expressed.
Last, and most important, it seems difficult to use collective
operations between any kind of components. It is very im-
portant for hierarchical component models, as hierarchy is
a powerful technique for improving code reuse. However,
constraining the usage of collective communications to only
the lowest level of the hierarchy seriously limits code-reuse.
121

The contribution of this paper is to propose an extension
to existing component models to support collective com-
munications between components. Consequently, the model
will increase code reuse, simplify developer live by provid-
ing a coherent model without impacting the performance.
The remainder of this paper is organized as follows. Sec-
tion 2 analyzes the requirements from the user and devel-
oper points of view. A generic component model support-
ing collective communications between component is intro-
duced and mapped on an existing model in Section 3. An
implementation of the broadcast operation using this model
is presented and evaluated in Section 4. Section 5 concludes
the paper and presents some perspectives.
2. User and developer points of views
2.1 Motivations
The goal of our model is to combine the advantages of col-
lective communications and component models under three
constraints.
First, the model should not introduce a noticeable over-
head. For example, the performance of a collective operation
should be comparable with the performance obtained from
that operation in MPI. In order to achieve that, it is impor-
tant to be able to select an adequate implementation of the
collective operation depending on the available resources.
Second, the model should maintain the abstraction level
of collective communications and component models. In a
library such as MPI, the user does not have to deal with the
way operations are implemented. Component models also
bring abstraction as components appears as black boxes.
Third, the model should well integrate with existing com-
ponent models and it should provide collective communica-
tions in a way that complies with the general collective com-
munication understanding. For example, it should be quite
straightforward for an MPI user to make use of this model.
Let us analyze possible solutions from the user and de-
veloper points of view that fulfill these requirements.
2.2 The user point of view
A first approach is to consider the standard provides/uses
port. One can notice that collective communications are usu-
ally provided through a set of methods. Therefore, they can
be grouped into an interface which could be very close of the
MPI API for example. Then, this interface has to be provided
by a component through a provides ports. User components
only need to declare a uses port to access such a service.
Thus, all components willing to behave collectively need to
connect to the same provider component. An assembly based
on such a solution with two communication groups, g1 and
g2 is shown in Figure 1.
However, collective communications are a special case.
They represent a service offered to the user code, but are
also a way of communicating between component instances.
In standard component models, the ports are used to connect
Figure 1. Collective communications provided by a compo-
nent through a provides port.
Figure 2. Collective communications provided by a specific
kind of port.
components. To express that component instances are com-
municating through collective operations, they would then
have to be connected to each other by ports. This relationship
is however not any longer of the provides/uses kind. Hence,
a second solution is to define a new kind of port, collective
ports carrying a new contract type. An assembly based on
such ports with two communication groups, g1 and g2 is
shown in Figure 2.
However, both solutions have serious drawbacks. In the
first one, communication groups are created at runtime, as
in MPI. Creation of communication groups is however a
decision that should be made at the same time as the creation
of component instances, i.e. at composition time. In the
second solution, there is no entity encapsulating collective
communications. Furthermore, if the instance acting as root
in operations is specified in the port, this port cannot share
the same interface on every instance. Hence they can not
be instances of the same component and the strict SPMD
paradigm is not respected.
Hopefully, a third solution that combines the advantages
of the two solutions exists. The underlying idea is to en-
capsulate the implementation of collective communications
into a component but to define communication groups at de-
ployment time. To fulfill both requirements, the collective
122

Figure 3. Collective communications provided by instances
of the collective provider with groups defined at deployment
time.
communications operations are provided by a component
through a simple provides port. A communication group is
then defined as the set of instances using this port on a given
instance of the collective communications provider. A com-
ponent instance has to be connected to one provider instance
for each group it belongs to. This behavior is described in
Figure 3.
2.3 The developer point of view
The second question is about the way collective commu-
nications could be implemented. A solution involving an
unique instance of the collective communication provider
means that every instance participating to a given operation
would have to call a method on this instance. Since a com-
ponent instance runs in a given process, located on given
node, this means that a centralized implementation could not
be avoided. This is simply unacceptable under high perfor-
mance constraints.
This problem does not arise in collective communications
libraries such as MPI since the library is instantiated in every
process using collective communications. The communica-
tions between these instances of the library are then hidden
to the user. Both the algorithms used and the communication
medium are chosen without any operation of the user code.
To obtain a similar behavior with components, a com-
ponent instance should be able to be instantiated in every
process where collective communications are used. These
instances then have to be connected to each other so as to
allow them to implement the algorithm that has to be used.
An assembly of such interconnected instances is presented
in Figure 4.
Hierarchical environment The previous solution is well
suited for homogeneous environments. However, it is not
the case for heterogeneous environments, like grids. For
such environments, specialized algorithms for implementing
collective communications have been proposed to enhance
performance [9, 11]. Such algorithms take into account the
Figure 4. Component instances in every processes used to
provide a library-like behavior.
heterogeneity and in particular the network hierarchy: the
bandwidth and the latencies between component instances
are different whether they are located on the same process,
same node, same cluster or none of these. Those algorithms
generally make use of sub communication groups, one for
each level of the hierarchy. They are usually made of a
sequence of other algorithms, each one involving a given
communication group.
An efficient broadcast algorithm for grid architectures,
proposed in [11], is representative. In this algorithm, a scat-
ter operation is first executed inside the cluster where the
root is. Then data are copied to every other cluster – this
step is in fact a broadcast operation at cluster level. Finally,
an allgather operation is made inside every cluster.
The choice of an algorithm has to be made at runtime
depending on the resource properties. However, this would
mean that the component implementing it would have to em-
bed an implementation of every operation that could possi-
bly be used. Such a large component implementing every-
thing would go against the component model philosophy
where a reusable part has to be encapsulated in a component.
Therefore, an algorithm should be encapsulated in the
implementation of a component. An algorithm using other
collective communication operations would then have to de-
clare uses ports to specify this dependency. This even allows
to choose the best algorithm to provide these operations in-
dependently. However this leads to an assembly following
the hierarchical structure of resources.
3. A component model with replicating
component
The discussion followed in Section 2 shows two different
visions. For the user, collective communications represent a
unique service per communication group and should there-
fore be provided by a unique component instance. On the
other hand, to provide an efficient implementation, a com-
ponent needs to be present in every process where these op-
erations are used. Therefore, to allow an efficient use of col-
123

lective communications between component instances with-
out needing the user to deal with implementation concerns,
the user described assembly has to be transformed to match
the developer point of view. One can note that the developer
point of view is close to the execution model.
There are four points that need to be changed in the
user described assembly to obtain the assembly that will
effectively be deployed.
• The user level collective component instance must be
replaced by a set of instances,
• these instances must have location constraints to be de-
ployed in the same process as instances using them,
• connections must be made between those instances so
that they can communicate,
• the type of those instances is not the same as the one of
the user deployed instance, at least one more port needs
to be present, so that instances can be connected to each
other.
The parameters used to determine how these transforma-
tions are made belong to two categories. The first category of
parameters comes from the user assembly. These parameters
are important to determine how many instances of the collec-
tive communications provider must be created. The second
category of parameters comes from the resources where the
application is to be deployed. These parameters are useful
to determine the algorithm that should be used and therefore
the component implementation to use. They are also useful
to determine where the collective communications provider
instances must be created.
The proposed solution to take these parameters into ac-
count and to allow an automatic assembly transformation is
the concept of replicating component implementation. The
implementation of such a component is another component,
the replicate. Each instance of the component is replaced by
a set of instances of the replicate. The number of replicate
instances to be created is specified in the description of the
replicating implementation. If the replicate has alltoall ports,
these can be connected in the replicating implementation so
that replicate instances can communicate with each other.
The next section will specify the behavior of such an
implementation within a generic component model mainly
inspired by CCM.
3.1 Definition of the elements of the model
Let us now define the elements of the model before examin-
ing how the assembly transformation algorithm works.
Component A component is an entity that encapsulates
services. It is the atomic unity of assembly. A component
is identified by its definition and it must provide at least
one implementation. If a component provides more than
one implementation, it must also provides the parameters to
choose between them.
Component definition A component definition is its type.
It specifies how instances of this component can interact
with their environment, this means the way they communi-
cate. This is expressed through ports, so in fact the definition
of a component is a list of named ports.
Port A port is a point of interaction between components.
There are at least three kinds of ports: provides ports, uses
ports and alltoall ports. These ports have a type which is an
interface. provides and uses ports have the usual meaning
of providing and requiring a service. An alltoall port means
that a service is used and provided by a component. Any
number of alltoall port can be connected to each other. It is
possible for the implantation to enumerate connected alltoall
ports and to sort them, so that each alltoall port has a rank in
a connection.
Component implementation A component implementa-
tion provides the services declared as provided in the def-
inition and can for that use the services declared as used.
There are at least three kinds of implementations: primi-
tive, composite and replicating. A primitive implementation
of a component is a binary. This binary is created with a
programming model such as FORTRAN, C++, JAVA, etc.
It offers an entry point for each services provided by the
component and is able to call methods associated with used
services. A composite implementation is composed of an
abstract assembly and of a port mapping definition. When
an assembly containing an instance whose implementation
is composite is expanded, the instance is replaced by the
corresponding assembly and the connections to the ports
of this instance are replaced by connections to the mapped
ports. Those mappings must ensure that any valid assem-
bly containing such an instance remains valid after it has
been expanded. A replicating implementation is composed
of a component, the replicate, of a replication level, of a
port mapping definition and of inner connections. When an
assembly containing an instance whose implementation is
replicating is deployed, the instance is replaced by a set of
instances of the replicate. A replicate instance is created in
every group of the replication level where the initial instance
was used. These replicate instances have location constraints
to ensure that they are created in the same group as the in-
stances using them. The connections to the ports of the initial
instance are replaced by connections to the mapped ports of
the replicate instances. The connections to provides ports
are connected to the port of the replicate instance located in
the same group as the using instance. Connections to other
kind of ports are replaced by connections to the port of ev-
ery replicate instance. Alltoall ports of the replicate may
be declared as inner connections. In this case, a connec-
tion is made between this port on every replicate instances.
The transformation of an assembly containing a component
whose implementation is replicating is shown in Figure 5.
124

Figure 5. Expansion of an assembly with a replicating component.
Figure 6. Component servers and server groups on a com-
putational grid made of two clusters of three dual nodes.
Assembly The model specifies three types of assembly: ab-
stract, concrete and deployable. An abstract assembly de-
scribes a set of component instances and links between the
ports of those instances that have to be created when the ap-
plication is deployed. It only specifies the definition of com-
ponents to be created, not their implementation. This is typi-
cally the assembly described by a user. A concrete assembly
is similar to an abstract one, except for the fact that for ev-
ery component instance described in such an assembly, only
primitive implementations can be chosen. A concrete assem-
bly may contain location constraints. A deployable assem-
bly is an assembly in which the exact implementation of ev-
ery component instance has been chosen and the component
server where each instance will be deployed has been deter-
mined.
Component instance A component instance is an instance
of the selected implementation of the component. An in-
stance is located in a process called a component server.
There is no instance of composite or replicating component
instances since those instances are replaced by instances of
other components when the assembly is expanded.
Component server A component server is a process where
components can be executed. It embeds the component
framework and everything that is needed to execute com-
ponents. It may belong to some server groups.
Server group A server group is a group of component
servers. Server groups have a property called a level. Groups
are used to put together component servers sharing the prop-
erty associated with the group level. For example, one may
define a level of name cluster with the meaning that every
component servers in this group belong to the same cluster.
An example of the groups that can be used on a grid is pre-
sented in Figure 6.
3.2 An assembly expanding algorithm
A user is expected to describe his/her application as an ab-
stract assembly so as not to be bothered with resource is-
sues. However, it is the deployable assembly that needs to
be executed on the actual resources. Hence, an algorithm is
needed to transform an abstract assembly into a deployable
assembly. To be executed, such an algorithm needs an ab-
stract assembly and a description of the resources where the
assembly is to be deployed. The execution of the proposed
algorithm is done by applying the following rules until no
one can be applied.
• Select what kind of implementation (primitive, compos-
ite, or replicating) should be used for a given component
instance2;
• replace an instance whose implementation is composite
by the corresponding assembly and the links to its ports
by links to the mapped ports, transfer any location con-
straint to the instances of the assembly;
• replace an instance whose implementation is replicating
by instances of the replicate, replace the links to its ports
2 A component may have several implementations.
125

by links to the replicate instances, create the inner con-
nections and add location resources to the replicate in-
stances;
• choose the component server where to deploy an instance
whose implementation is primitive and choose which
primitive implementation should be used.
To be executed, the first rule requires that all the param-
eters used to determine which implementation of the com-
ponent must be used are set. The second rule can always be
executed. The third rule requires that the implementation of
every component instance using the replicating instance is
primitive. There must be no dependency cycle for an assem-
bly to be deemed as well formed. An example of dependency
cycle is an assembly containing two component instances
whose implementation is replicating, each one using a pro-
vides port of the other. In this case, the third rule could never
be applied to any of those instances and the assembly would
remain abstract.
The execution of the algorithm could also never end. This
is for example the case of an assembly formed of an unique
component whose only implementation is composite and
made of the same assembly. Assemblies where the execution
of the algorithm does never end are invalid.
This algorithm is not a scheduling algorithm: the first and
last rules assume that there is an external service which is
able to perform an efficient location selection.
3.3 Mapping on CCM
We have presented a generic component model that enables
the use of collective communications between component
instances. We now introduce its application to the CORBA
Component Model.
New kind of implementations The first concepts that need
to be mapped on CCM are composite and replicating im-
plementations of components. In CCM an implementation
is a file that is referenced in the “CORBA Software Descrip-
tor”. The only kind of implementation available in CCM are
primitive implementations. These can be provided by an ex-
ecutable, a shared library or a java class. Allowing two new
kinds of implementation means defining two new file types.
For a composite implementation, this new file type must
contain an assembly and a port mapping. Hence, this file
type is an XML file type based on the “CORBA Assembly
Descriptor” plus a portmapping element.
For a replicating implementation, the new file type must
describe the component used as a replicate, the level of
replication, internal links and port mapping. These elements
are described in an XML file with four main elements. A
basic example of such a file is described in Figure 7 and the
graphical equivalent is shown in Figure 8.
Alltoall ports Another concept that CCM lacks is alltoall
ports. Those can however be implemented using other kind
of ports. Since an alltoall port stands for a service that is
<replicating id="MyReplicating">
<replicate>
<fileinarchive name="Replicate.csd">
</replicate>
<replicationlevel>Process</replicationlevel>
<interconnect>
<alltoall>pairsport</alltoall>
</interconnect>
<portmapping>
<providesmapping>
<replicateport>userport</replicateport>
<replicatingport>user</replicatingport>
</providesmapping>
<usesmapping>
<replicateport>logport</replicateport>
<replicatingport>log</replicatingport>
</usesmapping>
</portmapping>
</replicating>
Figure 7. A basic Replicating Descriptor example.
Figure 8. A basic replicating implementation example.
both used and provided, it is mapped on a pair of ports with
the same interface, a provides port and a multiple uses port.
The uses port enables to list the connected ports, but there is
no guaranty that this enumeration is done in the same order
on every instance. To obtain this behavior, a base interface
InnerPort is defined. This interface provides a rank for
each port connected and allows to sort them.
Resources description model There is no resource de-
scription model in CCM. For component localization, the
only thing that can be expressed is the collocation in the
same component server of more than one component. For
this aspect of the work, we used the solution proposed for
the deployment tool Adage [10].
3.4 Conclusion
The originality of the proposed model relies on the con-
cept of replicating component. We have defined it within a
generic component model so as to be able to map it to several
component technologies. As it is based on a transformation
of the assembly description, its mapping on component mod-
els with ADL such as CCM and Fractal is quite straightfor-
ward. However, while it needs more work to map it to CCA,
126

it seems achievable as we prove that it was possible for the
master-worker paradigm [1]. The difficulty comes from the
fact that CCA specifications imply a component to be a con-
crete entity.
4. Evaluation
4.1 Implementation of a broadcast algorithm
To validate the proposed model, the broadcast operation has
been implemented in this model. Two distinct algorithms
have been implemented to provide this operation. These
algorithms are provided by two implementations of the same
component.
The first choice to make is the ports used and provided
by this component. There is no need for any uses port.
Only one port is provided, the userbroadcast port. Its
interface is BroadcastPort that contains three methods: a
rank method, a communicator size method and the broadcast
method itself.
A first solution to implement this algorithm is to reuse
an existing library such as an MPI implementation. In this
case, the library must be instantiated in every processes. To
allow to instantiate the library in each process, a replicating
component implementation is used. Since a primitive imple-
mentation of a component in the CCM model can be a shared
library it can easily embed the MPI library. The only thing
to do when a method is called on the component instance is
to call the corresponding procedure of the MPI library.
It is however interesting to see how this model can be
used to develop new implementations of the collective com-
munication operations. We therefore exhibit two possible
implementations of the broadcast algorithm and evaluate the
performance obtained with them.
A binomial implementation The first implementation of
this component is based on a binomial tree. To provide this
implementation, there is a need to communicate between
processes. This is what replicating implementation is de-
signed for. This kind of implementation is therefore used.
The replicate needs at least one port of BroadcastPort
type to be mapped on the replicating component port. It also
needs a way to send data from one instance to another. An
alltoall port (pairs), whose interface (Sender) contains a
single method (send) is used and this port is defined as an
inner connection. This component is obviously replicated at
process level. The resulting replicate is presented in Figure 9.
The implantation of this replicate is primitive. When a
broadcast is started, the first task is to compute the tree. This
is done by simply using the rank provided by the alltoall
port. Then, each process waits the send method to be called,
and when data has been received, it forward it to its children.
On hierarchical resources, this algorithm may however
not be very effective. The rank of the replicate instances is
not linked to the hierarchy of resources. So in the worst case,
on a grid, the father of a process can always be on another
Figure 9. A binomial broadcast implementation.
Figure 10. A unfavorable binomial tree on two clusters with
four nodes each.
Figure 11. The hierarchical broadcast algorithm executed
on two cluster with four nodes each.
cluster. Such an unfavorable binomial tree is presented in
Figure 10.
An implementation for hierarchical resources An effi-
cient broadcast algorithm for hierarchical resources was pro-
posed in [11]. So, we will see how to provide an implemen-
tation of the broadcast provider component using this algo-
rithm. As described in Section 2.3, this algorithm is com-
posed of three steps as described in Figure 11.
The step at the highest hierarchy level consist in copying
data between clusters, so this is how the implementation is
first split. A replicating implementation whose replicating
level is cluster is used. The replicate needs to provide a
port of BroadcastPort type and to have a way of sending
data between instances. These are the same needs as those of
the BinomialBroadcast replicate, so the definition of the
replicate is the same as the one shown in Figure 9.
127
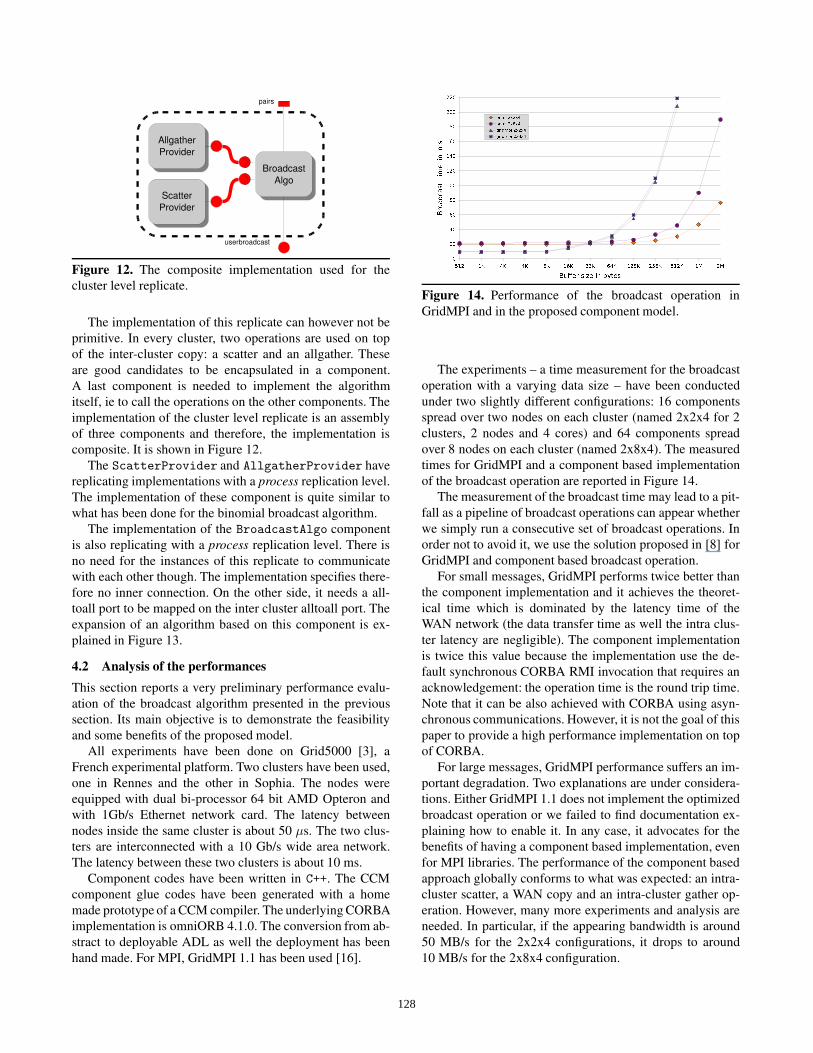
Figure 12. The composite implementation used for the
cluster level replicate.
The implementation of this replicate can however not be
primitive. In every cluster, two operations are used on top
of the inter-cluster copy: a scatter and an allgather. These
are good candidates to be encapsulated in a component.
A last component is needed to implement the algorithm
itself, ie to call the operations on the other components. The
implementation of the cluster level replicate is an assembly
of three components and therefore, the implementation is
composite. It is shown in Figure 12.
The ScatterProvider and AllgatherProvider have
replicating implementations with a process replication level.
The implementation of these component is quite similar to
what has been done for the binomial broadcast algorithm.
The implementation of the BroadcastAlgo component
is also replicating with a process replication level. There is
no need for the instances of this replicate to communicate
with each other though. The implementation specifies there-
fore no inner connection. On the other side, it needs a all-
toall port to be mapped on the inter cluster alltoall port. The
expansion of an algorithm based on this component is ex-
plained in Figure 13.
4.2 Analysis of the performances
This section reports a very preliminary performance evalu-
ation of the broadcast algorithm presented in the previous
section. Its main objective is to demonstrate the feasibility
and some benefits of the proposed model.
All experiments have been done on Grid5000 [3], a
French experimental platform. Two clusters have been used,
one in Rennes and the other in Sophia. The nodes were
equipped with dual bi-processor 64 bit AMD Opteron and
with 1Gb/s Ethernet network card. The latency between
nodes inside the same cluster is about 50 µs. The two clus-
ters are interconnected with a 10 Gb/s wide area network.
The latency between these two clusters is about 10 ms.
Component codes have been written in C++. The CCM
component glue codes have been generated with a home
made prototype of a CCM compiler. The underlying CORBA
implementation is omniORB 4.1.0. The conversion from ab-
stract to deployable ADL as well the deployment has been
hand made. For MPI, GridMPI 1.1 has been used [16].
�� �� �� �� �� � �� � �� � �� � �� � �� � �� � �
� � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � � �� ���� ������ � � !�� " # $ % & ' & ' (" # $ % & ' ) ' (* + % , # - % & ' & ' (* + % , # - % & ' ) ' (Figure 14. Performance of the broadcast operation in
GridMPI and in the proposed component model.
The experiments – a time measurement for the broadcast
operation with a varying data size – have been conducted
under two slightly different configurations: 16 components
spread over two nodes on each cluster (named 2x2x4 for 2
clusters, 2 nodes and 4 cores) and 64 components spread
over 8 nodes on each cluster (named 2x8x4). The measured
times for GridMPI and a component based implementation
of the broadcast operation are reported in Figure 14.
The measurement of the broadcast time may lead to a pit-
fall as a pipeline of broadcast operations can appear whether
we simply run a consecutive set of broadcast operations. In
order not to avoid it, we use the solution proposed in [8] for
GridMPI and component based broadcast operation.
For small messages, GridMPI performs twice better than
the component implementation and it achieves the theoret-
ical time which is dominated by the latency time of the
WAN network (the data transfer time as well the intra clus-
ter latency are negligible). The component implementation
is twice this value because the implementation use the de-
fault synchronous CORBA RMI invocation that requires an
acknowledgement: the operation time is the round trip time.
Note that it can be also achieved with CORBA using asyn-
chronous communications. However, it is not the goal of this
paper to provide a high performance implementation on top
of CORBA.
For large messages, GridMPI performance suffers an im-
portant degradation. Two explanations are under considera-
tions. Either GridMPI 1.1 does not implement the optimized
broadcast operation or we failed to find documentation ex-
plaining how to enable it. In any case, it advocates for the
benefits of having a component based implementation, even
for MPI libraries. The performance of the component based
approach globally conforms to what was expected: an intra-
cluster scatter, a WAN copy and an intra-cluster gather op-
eration. However, many more experiments and analysis are
needed. In particular, if the appearing bandwidth is around
50 MB/s for the 2x2x4 configurations, it drops to around
10 MB/s for the 2x8x4 configuration.
128
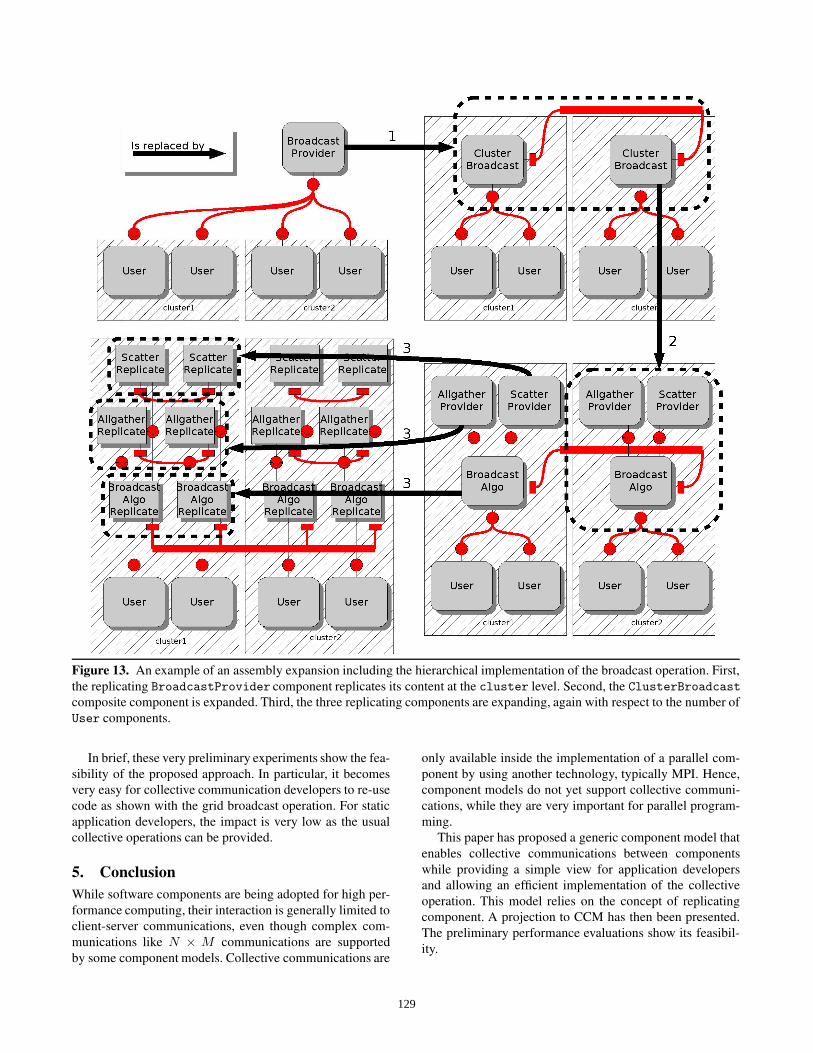
Figure 13. An example of an assembly expansion including the hierarchical implementation of the broadcast operation. First,
the replicating BroadcastProvider component replicates its content at the cluster level. Second, the ClusterBroadcast
composite component is expanded. Third, the three replicating components are expanding, again with respect to the number of
User components.
In brief, these very preliminary experiments show the fea-
sibility of the proposed approach. In particular, it becomes
very easy for collective communication developers to re-use
code as shown with the grid broadcast operation. For static
application developers, the impact is very low as the usual
collective operations can be provided.
5. Conclusion
While software components are being adopted for high per-
formance computing, their interaction is generally limited to
client-server communications, even though complex com-
munications like N × M communications are supported
by some component models. Collective communications are
only available inside the implementation of a parallel com-
ponent by using another technology, typically MPI. Hence,
component models do not yet support collective communi-
cations, while they are very important for parallel program-
ming.
This paper has proposed a generic component model that
enables collective communications between components
while providing a simple view for application developers
and allowing an efficient implementation of the collective
operation. This model relies on the concept of replicating
component. A projection to CCM has then been presented.
The preliminary performance evaluations show its feasibil-
ity.
129

The implementation of the model was quite straight-
forward as it was mainly ADL transformation. Hence, the
generic model should be easy to port on any component
model with ADL. For component models without ADL,
such as CCA, it would be more difficult but not impossi-
ble as we shown it for the master-worker paradigm [1].
This work need several improvements. More experiments
are needed to better understand why GridMPI does not be-
have as expected, to compare it to other MPI implemen-
tations and to better understand the behavior of the CCM
implementation. Moreover, the assembly transformation al-
gorithm needs to be integrated in a deployment tool [4] to
complete the proof of the model. Although it seems straight-
forward, it should be showed that MPI can be use as an im-
plementation for collective operations. Such a feature will
enable to have a straightforward implementation of collec-
tive communications for primitive components.
More fundamental questions concern the adaptation of
an application to this model as well as the management of
dynamic groups. For example, how to guaranty that a group
made of distinct components is valid? Such a guaranty seems
to require to define and attach some protocols3 to collective
port.
Acknowledgments
This work is supported by the French National Agency for
Research project DISCOGRID (ANR-05-CIGC-11), by the
CoreGRID European Network of Excellence. The authors
wish to thanks the Grid’5000 experimental testbed project.
References
[1] Gabriel Antoniu, Hinde Lilia Bouziane, Mathieu Jan, Chris-
tian Pérez, and Thierry Priol. Combining data sharing with
the master-worker paradigm in the common component ar-
chitecture. In Proc. Joint Workshop on HPC Grid program-
ming Environments and COmponents and Component and
Framework Technology in High-Performance and Scientific
Computing (HPC-GECO/CompFrame 2006), pages 10–18,
Paris, France, June 2006.
[2] D. E. Bernholdt, B. A. Allan, R. Armstrong, F. Bertrand,
K. Chiu, T. L. Dahlgren, K. Damevski, W. R. Elwasif,
T. G. W. Epperly, M. Govindaraju, D. S. Katz, J. A. Kohl,
M. Krishnan, G. Kumfert, J. W. Larson, S. Lefantzi, M. J.
Lewis, A. D. Malony, L. C. McInnes, J. Nieplocha, B. Norris,
S. G. Parker, J. Ray, S. Shende, T. L. Windus, and S. Zhou.
A component architecture for high-performance scientific
computing. International Journal of High Performance
Computing Applications, nov 2005. ACTS Collection special
issue.
[3] Franck Cappello, Eddy Caron, Michel Dayde, Fred-
eric Desprez, Emmanuel Jeannot, Yvon Jegou, Stephane
Lanteri, Julien Leduc, Nouredine Melab, Guillaume Mor-
net, Raymond Namyst, Pascale Primet, and Olivier Richard.
Grid’5000: a large scale, reconfigurable, controlable and
3 By protocol, we mean an order in collective operation invocation.
monitorable Grid platform. In Grid’2005 Workshop, Seattle,
USA, November 13-14 2005. IEEE/ACM.
[4] Massimo Coppola, Marco Danelutto, Sébastien Lacour,
Christian Pérez, Thierry Priol, Nicola Tonellotto, and
Corrado Zoccolo. Towards a common deployment model
for grid systems. In Sergei Gorlatch and Marco Danelutto,
editors, CoreGRID Workshop on Integrated research in
Grid Computing, pages 31–40, Pisa, Italy, November 2005.
CoreGRID, IST.
[5] E. Bruneton and T. Coupaye and J.B. Stefani. The Fractal
Component Model, version 2.0-3. Technical report, Ob-
jectWeb consortium, February 2004.
[6] William Gropp, Steven Huss-Lederman, Andrew Lumsdaine,
Ewing Lusk, Bill Nitzberg, William Saphir, and Marc Snir.
MPI: The Complete Reference – The MPI-2 Extensions,
volume 2. The MIT Press, 2 edition, September 1998. ISBN
0-262-57123-4.
[7] Institute on Programming Model. Basic features of the
grid component model (assessed). Deliverable D.PM.04,
CoreGRID Network of Excellence, mar 2007.
[8] N. T. Karonis and B. R. de Supinski. Accurately mea-
suring MPI broadcasts in a computational grid. In Eighth
International Symposium on High-Performance Distributed
Computing, May 1999.
[9] Nicholas T. Karonis, Brian Toonen, and Ian Foster. MPICH-
G2: a grid-enabled implementation of the message passing
interface. Journal of Parallel and Distributed Computing
(JPDC), 63(5):551–563, 2003.
[10] Sébastien Lacour, Christian Pérez, and Thierry Priol. A
network topology description model for grid application
deployment. In Rajkumar Buyya, editor, Proceedings of the
5th IEEE/ACM International Workshop on Grid Computing
(GRID 2004), pages 61–68, Pittsburgh, PA, USA, November
2004.
[11] M. Matsuda, T. Kudoh, Y. Kodama, R. Takano, and
Y. Ishikawa. Efficient MPI collective operations for clusters
in long-and-fast networks. In IEEE International Conference
on Cluster Computing, Barcelona, Spain, September 2006.
IEEE.
[12] Open Management Group (OMG). CORBA components
model specification (version 4.0). Document formal/06-04-
01, April 2006.
[13] Christian Pérez, Thierry Priol, and André Ribes. A parallel
corba component model for numerical code coupling. The
International Journal of High Performance Computing
Applications (IJHPCA), 17(4):417–429, 2003.
[14] Vaidy S. Sunderam. PVM: A framework for parallel dis-
tributed computing. Concurrency: Practice and Experience,
2(4):315–339, December 1990.
[15] Clemens Szyperski, Dominik Gruntz, and Stephan Murer.
Component Software - Beyond Object-Oriented Program-
ming. Addison-Wesley / ACM Press, 2 edition, 2002. ISBN
0-201-74572-0.
[16] AIST The Grid Technology Research Center. The gridmpi
website. http://www.gridmpi.org/.
130