comparative evaluation of automatic test case generation ppi utm
TRANSCRIPT

1st Technology, Education, and Science International Conference (TESIC) 2013
66
COMPARATIVE EVALUATION OF AUTOMATIC TEST CASE GENERATION METHODS Shayma Mustafa Mohi-Aldeen*1, Safaai Deris1, Radziah Mohamad1
1Faculty of Computing, Universiti Teknologi Malaysia, 81310 UTM Skudai, Johor, Malaysia
*e-mail address: [email protected]
ABSTRACT
Software testing is an inevitable activity in software development. It is a critical determinant of software quality and consumes approximately 50% of software development costs. Test case generation is a vital component of software testing and greatly influences the efficiency and effectiveness of any software test hence; it has been extensively studied and is regarded as an important subject area in software testing. Any guarantee of high software quality requires maximum test adequacy coverage using test cases during software testing. This paper presents a comparative study of the methods used for the automatic generation of test cases during software testing and explores the limitations of each method. Keywords: Software testing; Test case generation; automatic test case generation methods
Introduction
Software testing is a necessary and an integral section of software engineering development [1]. However, testing is an intensive work and costly. It is often account greater than 50% of total cost of the development. Therefore, it is important to decrease the cost and improve the software testing effectiveness by automate the process of testing [2]. Among the different testing activities, test case generation is one of the most mentally overwork and most critical, because it can have a powerful effect on the effectiveness and efficiency of total testing process [3][4]. It is not amazing that most of researches effort in the last decades has been expend on the automatic test case generation.
A perfect set of test cases is one that has high chance of discovering the previous unknown errors and a successful test run, which discovers these errors. To uncover all potential errors in program, detailed testing is required to examine all possible input and logical execution paths but it is neither possible nor economically feasible. Thus, the actual goal for software testing is to increase the finding errors probability using a limited number of test cases that perform in less time with less effort [5].
Various metrics have appeared, and applied, to evaluate the test cases generated quality like the cost, time, effort, and generation complexity as well as coverage criteria. Optimizing or even improving test cases quality can be intend of several researchers [6][7][8]. It can take many forms, like minimizing time or effort testing, minimizing the complexity or the generation algorithms cost, maximizing the coverage function as well as another reliability and quality matters. Also decreasing the test cases or test data generation can be an optimization form [9].
A test adequacy criterion provides a measurement of test suite quality and can be used to guide test generation. There are three widely applied kinds of coverage criteria namely mutation coverage (which evaluates the fault- revealing capability of a test suite) code coverage (which describes the extent to which source code program has been examined) and specification based coverage (which specify the percentage of testing requirements identified in a specification that have been covered by the test suite). Code coverage has branches which includes branch coverage, statement coverage and path coverage while specification based coverage includes types like requirements coverage, test data adequacy, boundary value analysis [10].
The present test case generation methods can be categorized into black-box testing and white-box testing depends on type of testing. Black-box test cases are specified from the description of the software under test [11]. White-box test cases are obtained from the inner software structure [12]. However, in both the cases it is difficult to achieve complete automation of the test case design [13].
This paper discusses an overview of different approaches that is used in generated test cases automatically which is the critical part in software testing process and the types of coverage that is used in these methods.
This comparative evaluation study helps the researchers to choose the suitable method that generate appropriate test cases with minimum test suite size and maximum coverage criteria as well as in minimum execution time. We described how to evaluate generated test cases, and introduce a classification of evaluation approaches.

1st Technology, Education, and Science International Conference (TESIC) 2013
67
Follow the introduction, this paper is organized as follows: In Section 2, present a short overview of current study that has been conducted on the automatic test case generation methods and justify its need rather than the comparison between methods. Section 3 describes the comparative evaluation of the previous methods and finally the discussion and Conclusions are presented in Section 4 and 5 respectively.
Classification of Automatic Test Case Generation Methods
This section provided a short background to automatic test case generation methods display the essence concepts, motivation and comparing between them.
There is no a single search method that exceed all other methods [14]. For that reason, when a new problem required being classified, several algorithms should be study and compared; this simplify more comprehension of the search problem, for that different suitable search algorithms have been discussed here. In this paper, the techniques presented are classified into Random-based methods, Search-based methods and Data mining-based methods. In these methods the problems of generating the test cases are considered as an optimization problem, and try to find optimize solution including best test set for the problem under test. They were selected since they perform good domain of different search methods, Speed reduce time, minimize cost, intelligent path search and optimize test cases generation.
The Random-based search (RS) simply automatically generating a huge number of test cases randomly even the source code and specifications of the program under test are not available or incomplete, it is easy to implement with low cost and it is works well for simple programs [15]. Even though the RS is the most simple among the search methods, it might be give perfect coverage. The problem requires the definition of the sequences length that will be generated during the search. Since it does not set any bands on the length, the sequences can be very long [14]. Not only wasting time, but like long sequences will be do-nothing that
available information for test case generation and also the Structures that are only executed with a low probability are often not covered [16]. RS is commonly used as a base line for comparing and understanding the effectiveness of the other search algorithms.
In the search-based methods the problems of generating the test cases are considered as an optimization problem, and try to find optimize solution including best test set for the problem under test. These methods are classified into local search and global search based on the search space that they cover. Local search algorithms operate using a single current node and generally move only to the neighbors of that node. These methods have advantage in using little memory and converge to a solution in large or state spaces [17]. Three local search methods to automate test case generation are used: hill climbing (HC), simulated annealing (SA) and Tabu search (TS).
Global search methods aiming to outperform the local optimum problem in the space of the search and could thereby find further global optimal solutions. The complicated global search behavior makes it more difficult to understand its theoretical achievement. Local search might be restricting in local optima during the solution space, but it can be more efficiency in simple search problems. In software engineering, this give clear example of the classic differentiation between effectiveness and efficiency, one may expect global search to perform the branch coverage better than local search, but with great cost of computational
[18]. The global search based methods that used to automate test case generation are Genetic Algorithms (GA), Scatter Search (SS), Differential Evolution (DE), and swarm optimization techniques: Particle Swarm Optimization (PSO), Artificial Colony Optimization (ACO) and Artificial Bee Colony (ABC). Finally, the Memetic Algorithm (MA) is a hybrid method that combines local and global searches together. If the problem addressed in local search is not better than a global search constantly (or conversely), combine them may lead to better results.
Based on the methods used, intelligent path search that optimize test case generation and speed reduces time rather than minimize cost. However, these methods have large search spaces and also the fitness functions are an important factor in speed and efficiency, as well as, some methods are suffering from prematurity, which causes the convergence problem that effect on the speed and direction. Also, problems in updating pheromone in some methods as well as computational time and memory overheads.
In Data Mining based methods, the main goal is analyzing the I/O of SUT to decrease the test cases number by eliminating unimportant and infeasible test cases. Being more efficient, as a result of being more intelligent, decreasing the test cases number effect the saving of the

1st Technology, Education, and Science International Conference (TESIC) 2013
68
software testing resources directly [12], although these methods avoid redundancy and low time consumption but is high complexity and the efficiency of this method depends on number of available training samples [19]. Comparative Evaluation
This section discusses the comparison of above discussed methods with respect to some criteria. The existing work on automatic test case generation shows that the researches focus mostly on software test optimization by using the intelligent techniques and different various methods have been used to generate more efficiently test cases and decrease the time cost in the testing phase. The idea is to have enough test cases capable to test the software under test (SUT) with minimum number of test cases and maximum fault detection percentage. The automation of testing process has been desired to decrease the testing cost and improve the software quality. The test suite optimization process include generation of the effective test cases in the test suite that could be cover the given SUT within minimum time and minimum number of generation with maximum coverage percentage.
In this paper, the test adequacy criteria considered are reduced test suite size, fault detected capability, reduce testing time and cost as well as the coverage criteria.
Reduced Test Suite Size: Test suite size is the number of test cases that is
generated to test the software. Generated an efficiently test cases are the essential part for improving the test efficiency, for that reason most of Automation algorithms are used to optimize the test cases.
Fault Detected Capability: The effectiveness of test cases can be evaluated using fault injection techniques. That is meant that the faults are injected to the system to verify the efficiency of test cases.
Reduce time and Cost: Through the testing process, the cost can be increased due to unsuitable test cases. These unsuitable test cases caused resources wasted as well as time. For that reason, there is a need to reduce the time and cost for getting an efficient test method.
Coverage Criteria: A problem involved in generating test cases is to find a set of test cases that has the highest coverage to satisfy the test adequacy criteria that is given as input to the software under test. The type of coverage criteria depends on the type of testing, as described in section 1, which requires many algorithms to increase the coverage percentage.
Discussion
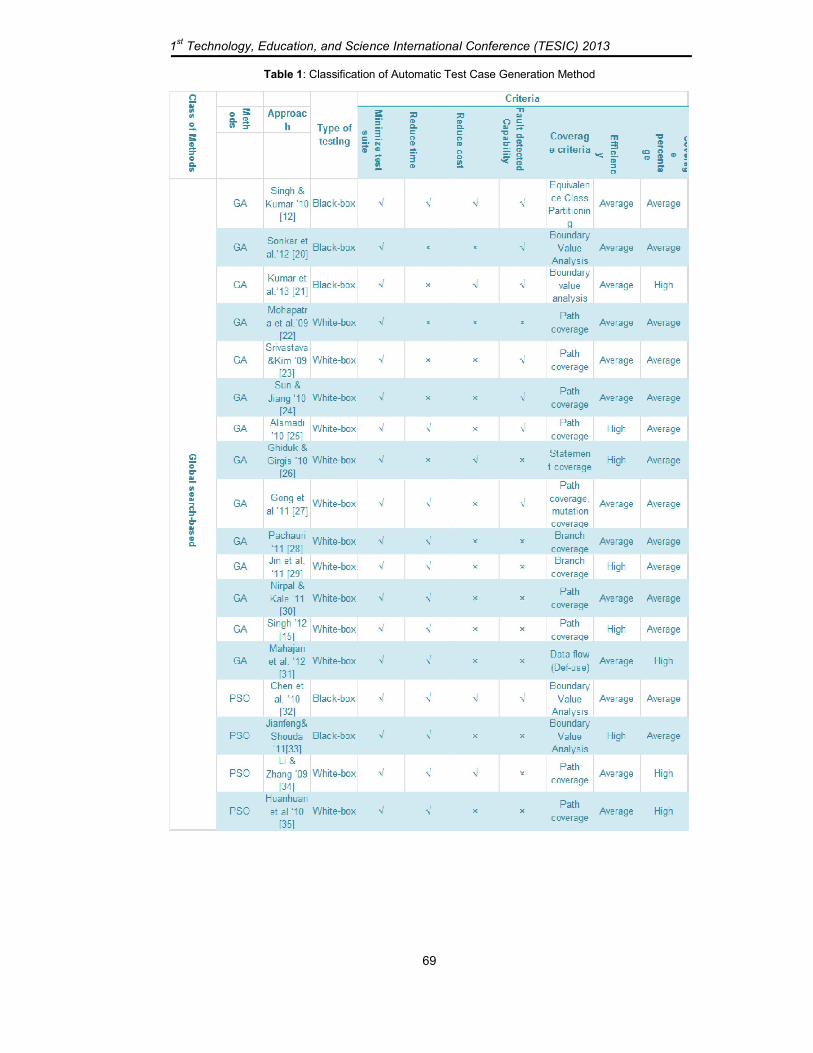
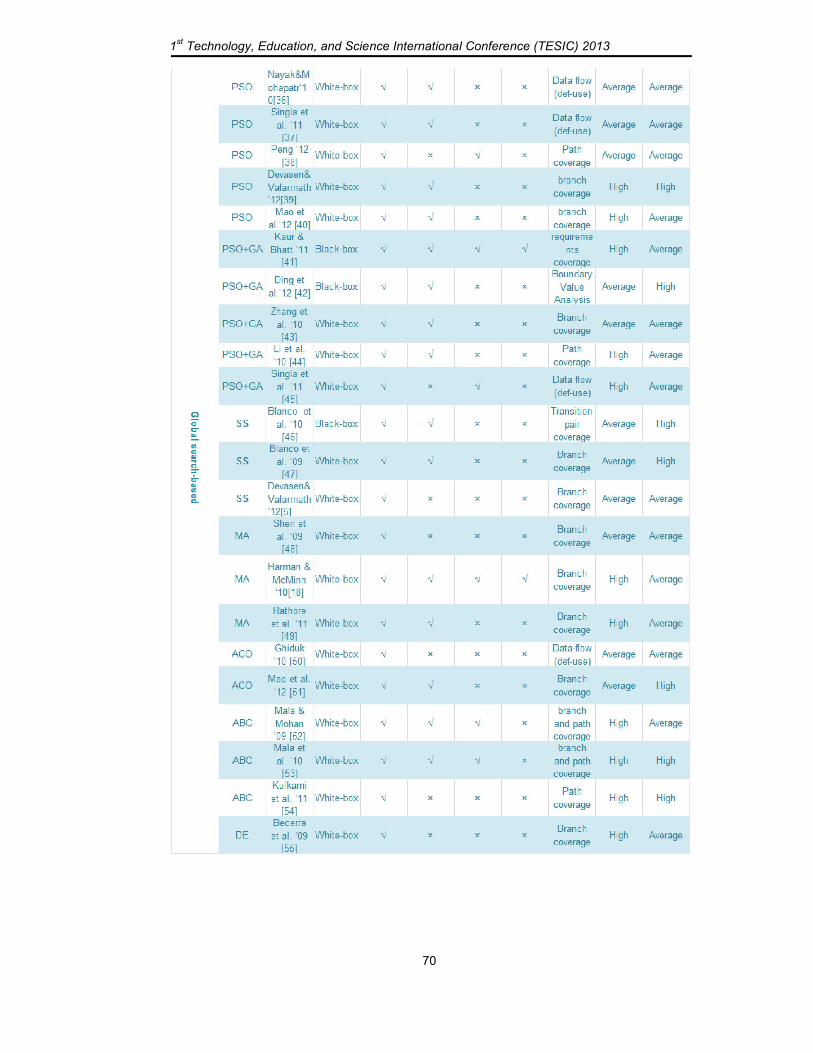
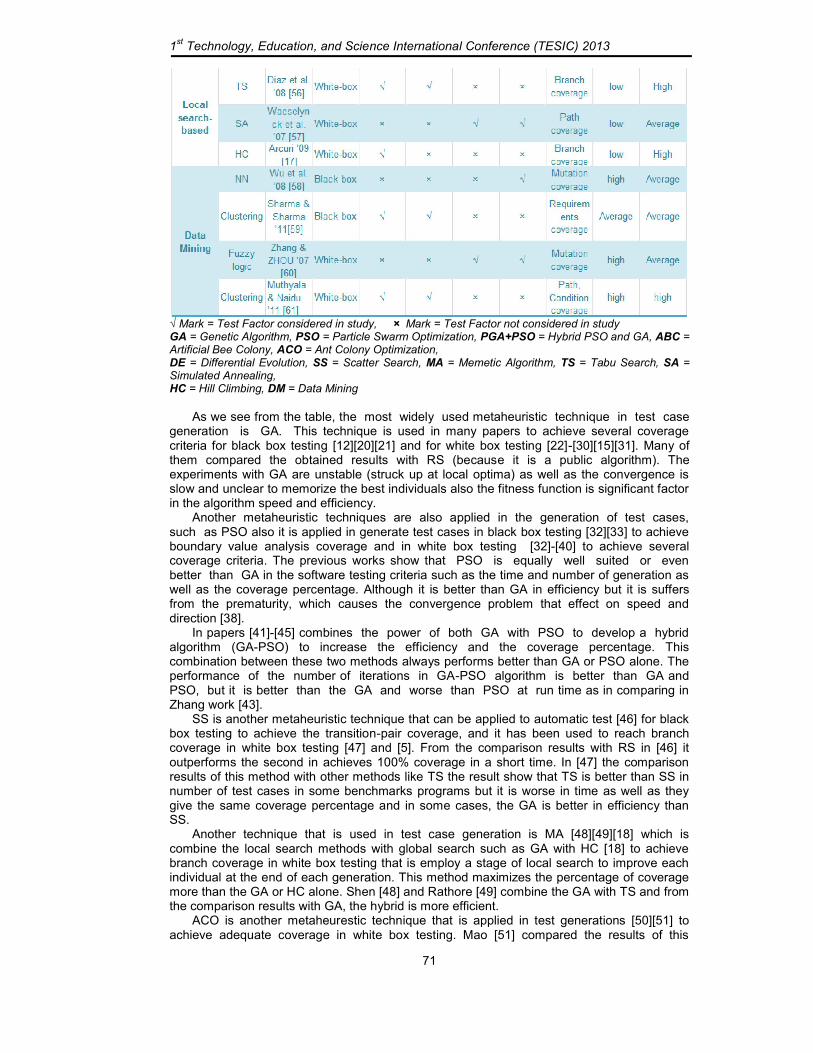
Table 1 shows the results of the comparison of automated test case generation approaches for the previous works with respect to the proposed classification of test adequacy criteria in software testing. Each row in the table is labeled with the reference of the work for which its data are shown. The first column displays the class of search method, the second, third and fourth columns show the metaheuristic technique used and the approach as well as the type of testing respectively. The following four columns show the test adequacy criteria that are used in evaluate the method. The next column shows the coverage criterion that is used for test generation; this criterion is depending on the type of testing. The black box criterion is (Equivalence Class Partitioning, Boundary Value Analysis, Transition-pair coverage or Requirements coverage). The structural criterion is subdivided into the control-flow criteria (in which the statement, branch, condition and path coverage) and data-flow
depending on the criteria that is used and the last column represent the percentage of coverage (success) achieved in these methods.
1st Technology, Education, and Science International Conference (TESIC) 2013
69
Table 1: Classification of Automatic Test Case Generation Method
1st Technology, Education, and Science International Conference (TESIC) 2013
70
1st Technology, Education, and Science International Conference (TESIC) 2013
71
Mark = Test Factor considered in study, × Mark = Test Factor not considered in study
GA = Genetic Algorithm, PSO = Particle Swarm Optimization, PGA+PSO = Hybrid PSO and GA, ABC = Artificial Bee Colony, ACO = Ant Colony Optimization, DE = Differential Evolution, SS = Scatter Search, MA = Memetic Algorithm, TS = Tabu Search, SA = Simulated Annealing, HC = Hill Climbing, DM = Data Mining
As we see from the table, the most widely used metaheuristic technique in test case
generation is GA. This technique is used in many papers to achieve several coverage criteria for black box testing [12][20][21] and for white box testing [22]-[30][15][31]. Many of them compared the obtained results with RS (because it is a public algorithm). The experiments with GA are unstable (struck up at local optima) as well as the convergence is slow and unclear to memorize the best individuals also the fitness function is significant factor in the algorithm speed and efficiency.
Another metaheuristic techniques are also applied in the generation of test cases, such as PSO also it is applied in generate test cases in black box testing [32][33] to achieve boundary value analysis coverage and in white box testing [32]-[40] to achieve several coverage criteria. The previous works show that PSO is equally well suited or even better than GA in the software testing criteria such as the time and number of generation as well as the coverage percentage. Although it is better than GA in efficiency but it is suffers from the prematurity, which causes the convergence problem that effect on speed and direction [38].
In papers [41]-[45] combines the power of both GA with PSO to develop a hybrid algorithm (GA-PSO) to increase the efficiency and the coverage percentage. This combination between these two methods always performs better than GA or PSO alone. The performance of the number of iterations in GA-PSO algorithm is better than GA and PSO, but it is better than the GA and worse than PSO at run time as in comparing in Zhang work [43].
SS is another metaheuristic technique that can be applied to automatic test [46] for black box testing to achieve the transition-pair coverage, and it has been used to reach branch coverage in white box testing [47] and [5]. From the comparison results with RS in [46] it outperforms the second in achieves 100% coverage in a short time. In [47] the comparison results of this method with other methods like TS the result show that TS is better than SS in number of test cases in some benchmarks programs but it is worse in time as well as they give the same coverage percentage and in some cases, the GA is better in efficiency than SS.
Another technique that is used in test case generation is MA [48][49][18] which is combine the local search methods with global search such as GA with HC [18] to achieve branch coverage in white box testing that is employ a stage of local search to improve each individual at the end of each generation. This method maximizes the percentage of coverage more than the GA or HC alone. Shen [48] and Rathore [49] combine the GA with TS and from the comparison results with GA, the hybrid is more efficient.
ACO is another metaheurestic technique that is applied in test generations [50][51] to achieve adequate coverage in white box testing. Mao [51] compared the results of this

1st Technology, Education, and Science International Conference (TESIC) 2013
72
method with GA and SA, the ACO is faster than GA but it is little slower than SA that is mean the ACO cost more time, but it is outperforms them in coverage percentage as well as in number of test case generation. This method also need to updating pheromone.
In [52][53][54] applied ABC method in generating test cases to generate an efficient test suit that can cover several coverage in minimum time. From the comparison results with GA in [52] ABC is outperforms GA in efficiency and in coverage percentage. Mala [53] compare this method with RS, GA and with ACO the results show that ABC is need less time and reduce the number of test case generation that is more efficient and maximize the coverage than the other. This method can be added more factors to increase its efficiency and give more optimized test suite.
DE is another algorithm that is used in generate test cases [55] to cover all the branches in source code, in comparison this method with GA and SS the results show that DE is better than the first and the second in efficiency and coverage percentage but in some cases SS is better than DE in these criteria.
TS, SA and HC are local search methods that have been used to generate test cases to achieve path and branch coverage criteria [56][18]. TS and HC methods have been used to obtain branch coverage [56][17]. SA has been used to generate path coverage [57]. From these papers, we found that local search algorithms have better runtime than RS. Although, TS performs better than RS in efficiency and coverage percentage, it requires more memory allocation in expression of long-term memory to prevent strike up at local optima and the short-term memory, to retrieve all test cases in current search. In SA, repeatedly annealing with a schedule is very slow, especially if the function cost is high to compute and the method cannot inform whether it has detect an optimal solution [57].
Data mining technique [58][59][60][61] is also used to generate test cases automatically to achieve both black and white box testing criteria as well as the mutation coverage, the efficiency of this technique is high also the percentage coverage is high, but it is complex.
Conclusion
Software testing is an important activity and a critical determinant of software quality. Test case generation is vital component of the testing process required to determine the test quality. This paper presents the comparative study for automatic test case generation methods using previous researches and summarizes the critical problems involved in using these methods. The automatic test case generation methods were then classified and some criteria related to adequacy of testing compared. However, it cannot be claimed that this comparison is comprehensive and exhaustive. The considered criteria can be used as reference to generally help in evaluating or selecting test case generation methods. However, the results show indicate the absence of a single efficient method that fulfils all the criteria. Any solution depends on coverage percentage and efficiency in order to decide the method to be selected.
Acknowledgements
The authors acknowledge the Universiti Teknologi Malaysia (UTM) for sponsoring and providing the facilities and support for the research.
References
[1] Young, M. (2008). Software testing and analysis: process, principles, and techniques.
John Wiley & Sons. [2] Anand, S., Burke, E., Chen, T. Y., Clark, J., Cohen, M. B., Grieskamp, W., & Zhu, H.
(2013). An Orchestrated Survey on Automated Software Test Case Generation. Journal of Systems and Software.
[3] Bertolino, A. (2007, May). Software testing research: Achievements, challenges, dreams. In Future of Software Engineering, 2007. FOSE'07 (pp. 85-103). IEEE.
[4] Pezz`e, M. and Young, M., 2007. Software Testing and Analysis - Process, Principles and Techniques. Wiley.
[5] Devasena, M. G., & Valarmathi, M. L. (2012). Search based Software Testing Technique for Structural Test Case Generation. International Journal of Applied Information Systems (IJAIS), 1(6).
[6] Farooq, U., & Lam, C. P. (2009, April). Evolving the Quality of a Model Based Test Suite. In Software Testing, Verification and Validation Workshops, 2009. ICSTW'09. International Conference on (pp. 141-149). IEEE.

1st Technology, Education, and Science International Conference (TESIC) 2013
73
[7] Kosindrdecha, N., & Daengdej, J. (2010). A Black-Box Test Case Generation Method. International Journal of Computer Science and Information Security (IJCSIS).
[8] Harman, M., Kim, S. G., Lakhotia, K., McMinn, P., & Yoo, S. (2010, April). Optimizing for the number of tests generated in search based test data generation with an application to the oracle cost problem. In Software Testing, Verification, and Validation Workshops (ICSTW), 2010 Third International Conference on (pp. 182-191). IEEE.
[9] Boghdady, P. N., Badr, N., Hashem, M., & Tolba, M. F. (2011). Test Case Generation and Test Data Extraction Techniques. Inter. J. Electr. Comput. Sci, 11(3), 87-94.
[10] ZHENG, W. (2011). Automatic Software Testing Via Mining Software Data, PhD thesis, The Chinese University of Hong Kong.
[11] Parnami, S., Sharma, K. S., & Chande, S. V. (2012). A Survey on Generation of Test Cases and Test Data Using Artificial Intelligence Techniques , UACEE International Journal of Advances in Computer Networks and its Security, pp. 16-18.
[12] Singh, K., & Kumar, R. (2010). Optimization of Functional Testing using Genetic Algorithms. International Journal of Innovation, Management and Technology, 1(1), 2010-0248.
[13] Geetha Devasena, M. S., & Valarmathi, M. L. (2012).Meta Heuristic Search Technique for Dynamic Test Case Generation. International Journal of Computer Applications. 39 (12)
[14] Arcuri, A., & Yao, X. (2008). Search based software testing of object-oriented containers. Information Sciences, 178(15), 3075-3095.
[15] Singh, B. K. (2012). Automatic efficient test data generation based on genetic algorithm for path testing. International Journal of Research in Engineering & Applied Sciences, 2(2), pp. 1460-1472.
[16] McMinn, P. (2004). Search based software test data generation: a survey. Software Testing, verification and Reliability, 14(2), 105-156.
[17] Arcuri, A. (2009). Theoretical analysis of local search in software testing. In Stochastic Algorithms: Foundations and Applications (pp. 156-168). Springer Berlin Heidelberg.
[18] Harman, M., & McMinn, P. (2010). A theoretical and empirical study of search-based testing: Local, global, and hybrid search. Software Engineering, IEEE Transactions on, 36(2), 226-247.
[19] Anbarasu, I. (2012). A Survey on Test Case Generation and Extraction of Reliable Test Cases. International Journal of Computer Science & Applications, 1(10).
[20] Sonkar, S. K., Malviya, A. K., Lal, D. G., & Chandra, G. (2012). Software Testing using Genetic Algorithm. International Journal of Computer Sci ence And Technology (IJCST), 3 (1), 183-187.
[21] Kumar, R., Singh, S., & Gopal, G. (2013). Automatic Test Case Generation Using Genetic Algorithm. International Journal of Scientific & Engineering Research (IJSER), 4(6), 1135-1141.
[22] Mohapatra, D., Bhuyan, P., & Mohapatra, D. P. (2009, July). Automated test case generation and its optimization for path testing using genetic algorithm and sampling. In Information Engineering, 2009. ICIE'09. WASE International Conference on (Vol. 1, pp. 643-646). IEEE.
[23] Srivastava, P. R., & Kim, T. H. (2009). Application of genetic algorithm in software testing. International Journal of software Engineering and its Applications, 3(4), 87-96.
[24] Sun, J. H., & Jiang, S. J. (2010, August). An approach to automatic generating test data for multi-path coverage by genetic algorithm. In Natural Computation (ICNC), 2010 Sixth International Conference on (Vol. 3, pp. 1533-1536). IEEE.
[25] Alsmadi, I. (2010, May). Using genetic algorithms for test case generation and selection optimization. In Electrical and Computer Engineering (CCECE), 2010 23rd Canadian Conference on (pp. 1-4). IEEE.
[26] Ghiduk, A. S., & Girgis, M. R. (2010). Using genetic algorithms and dominance concepts for generating reduced test data. Informatica: An International Journal of Computing and Informatics, 34(3), 377-385.
[27] Gong, D. W., Zhang, W. Q., & Zhang, Y. (2011). Evolutionary generation of test data for multiple paths coverage. Chinese Journal of Electronics, 19(2).
[28] Pachauri, A. (2011). Software Test Data Generation using Path Prefix Strategy and Genetic Algorithm. International Conference on Science and Engineering (ICSE 2011). pp. 131-140.
[29] Jin, R., Jiang, S., & Zhang, H. (2011, March). Generation of test data based on genetic algorithms and program dependence analysis. In Cyber Technology in Automation,

1st Technology, Education, and Science International Conference (TESIC) 2013
74
Control, and Intelligent Systems (CYBER), 2011 IEEE International Conference on (pp. 116-121). IEEE.
[30] Nirpal, P. B., & Kale, K. V. (2011). Using Genetic Algorithm for Automated Efficient Software Test Case Generation for Path Testing. International Journal of Advanced Networking and Applications, 2(6), 911-915.
[31] Mahajan, M., Kumar, S., & Porwal, R. (2012). Applying genetic algorithm to increase the efficiency of a data flow-based test data generation approach. ACM SIGSOFT Software Engineering Notes, 37(5), 1-5.
[32] Chen, X., Gu, Q., Qi, J., & Chen, D. (2010, July). Applying Particle Swarm optimization to Pairwise Testing. In Computer Software and Applications Conference (COMPSAC), 2010 IEEE 34th Annual (pp. 107-116). IEEE.
[33] Jianfeng, W., & Shouda, J. (2011, October). An Improved Algorithm for Test Data Generation Based on Particle Swarm Optimization. In Instrumentation, Measurement, Computer, Communication and Control, 2011 First International Conference on (pp. 404-407). IEEE.
[34] Li, A., & Zhang, Y. (2009, May). Automatic generating all-path test data of a program based on pso. In Software Engineering, 2009. WCSE'09. WRI World Congress on (Vol. 4, pp. 189-193). IEEE.
[35] Huanhuan, C., Li, C., Bian, Z., & Halei, K. (2010, March). An efficient automated test data generation method. In Measuring Technology and Mechatronics Automation (ICMTMA), 2010 International Conference on (Vol. 1, pp. 453-456). IEEE.
[36] Nayak, N., & Mohapatra, D. P. (2010). Automatic test data generation for data flow testing using particle swarm optimization. In Contemporary Computing (pp. 1-12). Springer Berlin Heidelberg.
[37] Singla, P., & Rai, H. M. (2011). An automatic test data generation for data flow coverage using soft computing approach. International Journal of Research and Reviews in Computer Science (IJRRCS), 2(2).
[38] Peng, N. (2012). A PSO Test Case Generation Algorithm with Enhanced Exploration Ability . Journal of Computational Information Systems, 8(14), 5785-5793.
[39] Devasena, G., & Valarmathi, M. L. (2012). Structural Test Suite Generation using Adaptive Particle Swarm Optimization [APSO]. European Journal of Scientific Research, 75(3), 361-369.
[40] Mao, C., Yu, X., & Chen, J. (2012, May). Swarm Intelligence-Based Test Data Generation for Structural Testing. In Computer and Information Science (ICIS), 2012 IEEE/ACIS 11th International Conference on (pp. 623-628). IEEE.
[41] Kaur, A., & Bhatt, D. (2011). Hybrid particle swarm optimization for regression testing. International Journal on Computer Science and Engineering, 3(5), 1815-1824.
[42] Ding, R., Feng, X., Li, S., & Dong, H. (2012, June). Automatic generation of software test data based on hybrid particle swarm genetic algorithm. In Electrical & Electronics Engineering (EEESYM), 2012 IEEE Symposium on (pp. 670-673). IEEE.
[43] Zhang, S., Zhang, Y., Zhou, H., & He, Q. (2010, October). Automatic path test data generation based on GA-PSO. In Intelligent Computing and Intelligent Systems (ICIS), 2010 IEEE International Conference on (Vol. 1, pp. 142-146). IEEE.
[44] Li, K., Zhang, Z., & Kou, J. (2010). Breeding Software Test Data with Genetic-Particle Swarm Mixed Algorithm. Journal of computers, 5(2), 258-265.
[45] Singla, S., Kumar, D., Rai, H. M., & Singla, P. (2011). A Hybrid PSO Approach to Automate Test Data Generation for Data Flow Coverage with Dominance Concepts. International Journal of Advanced Science and Technology, 37, 15-26.
[46] Blanco, R., Fanjul, J. G., & Tuya, J. (2010). Test case generation for transition-pair coverage using Scatter Search. International Journal of Software Engineering and Its Applications, 4(4).
[47] Blanco, R., Tuya, J., & Adenso-Díaz, B. (2009). Automated test data generation using a scatter search approach. Information and Software Technology, 51(4), 708-720.
[48] Shen, X., Wang, Q., Wang, P., & Zhou, B. (2009, August). Automatic generation of test case based on GATS algorithm. In Granular Computing, 2009, GRC'09. IEEE International Conference on (pp. 496-500). IEEE.
[49] Rathore, A., Bohara, A., Prashil, R. G., Prashanth, T. S., & Srivastava, P. R. (2011, March). Application of genetic algorithm and tabu search in software testing. In Proceedings of the Fourth Annual ACM Bangalore Conference (p. 23). ACM.

1st Technology, Education, and Science International Conference (TESIC) 2013
75
[50] Ghiduk, A. S. (2010). A New Software Data-Flow Testing Approach via Ant Colony Algorithms. Universal Journal of Computer science and engineering Technology, 1(1), 64-72.
[51] Mao, C., Yu, X., Chen, J., & Chen, J. (2012, August). Generating Test Data for Structural Testing Based on Ant Colony Optimization. In Quality Software (QSIC), 2012 12th International Conference on (pp. 98-101). IEEE.
[52] Mala, D. J., & Mohan, V. (2009). ABC Tester Artificial Bee Colony Based Software Test Suite Optimization Approach. International Journal of Software Engineering, 2(2), 15-43.
[53] Jeya Mala, D., Mohan, V., & Kamalapriya, M. (2010). Automated software test optimisation framework-an artificial bee colony optimisation-based approach. Software, the Institution of Engineering and Technology (IET), 4(5), 334-348.
[54] Kulkarni, N. J., Naveen, K. V., Singh, P., & Srivastava, P. R. (2011). Test Case Optimization Using Artificial Bee Colony Algorithm. In Advances in Computing and Communications (pp. 570-579). Springer Berlin Heidelberg.
[55] Becerra, R. L., Sagarna, R., & Yao, X. (2009, May). An evaluation of Differential Evolution in software test data generation. In Evolutionary Computation, 2009. CEC'09. IEEE Congress on (pp. 2850-2857). IEEE.
[56] Diaz, E., Tuya, J., Blanco, R., & Javier Dolado, J. (2008). A tabu search algorithm for structural software testing. Computers & Operations Research, 35(10), 3052-3072.
[57] Waeselynck, H., Thévenod-Fosse, P., & Abdellatif-Kaddour, O. (2007). Simulated annealing applied to test generation: landscape characterization and stopping criteria. Empirical Software Engineering, 12(1), 35-63.
[58] Wu, L., Liu, B., Jin, Y., & Xie, X. (2008, August). Using back-propagation neural networks for functional software testing. In Anti-counterfeiting, Security and Identification, 2008. ASID 2008. 2nd International Conference on (pp. 272-275). IEEE.
[59] Sharma, S., & Sharma, A. Amalgamation of Automated Testing and Data Mining: A Novel Approach in Software Testing. IJCSI International Journal of Computer Science Issues, 8(5), 1694-0814.
[60] ZHANG Z.,& ZHOU Y. (2007). A FUZZY LOGIC BASED APPROACH FOR SOFTWARE TESTING. International Journal of Pattern Recognition and Artificial Intelligence. 21(4). Pp. 709 722.
[61] Muthyala, K., & Naidu, R. (2011). A novel approach to test suite reduction using data mining. Indian Journal of Computer Science and Engineering, 2(3), 500-505.