a hierarchical document clustering environment based on the induced bisecting k-means
TRANSCRIPT

A Hierarchical Document Clustering Environment based on the Induced Bisecting k-Means
F. Archetti1,2, P. Campanelli1,2, E. Fersini1, E. Messina1
1 DISCO, Università degli Studi di Milano Bicocca, Via Bicocca degli Arcimboldi, 8
20126 Milano, Italy {fersini, messina}@disco.unimib.it
2 Consorzio Milano Ricerche, Via Cicognara 7, 20129 Milano, Italy
{archetti,campanelli}@milanoricerche.it
Abstract. The steady increase of information on WWW, digital library, portal, database and local intranet, gave rise to the development of several methods to help user in Information Retrieval, information organization and browsing. Clustering algorithms are of crucial importance when there are no labels associated to textual information or documents. The aim of clustering algorithms, in the text mining domain, is to group documents concerning with the same topic into the same cluster, producing a flat or hierarchical structure of clusters. In this paper we present a Knowledge Discovery System for document processing and clustering. The clustering algorithm implemented in this system, called Induced Bisecting k-Means, outperforms the Standard Bisecting k-Means and is particularly suitable for on line applications when computational efficiency is a crucial aspect.
1. INTRODUCTION
Document search results are often presented to user as a flat list of documents, ranked by their relevancies to a given query, and users have to examine all the titles and snippets of the documents in the list. This is a time consuming process because multiple topics can be mixed together. The need of improving the browsability of search engine results has increased the interest in different clustering approaches most of which based on vector space document models, also known as bag-of-words models [11]. As far as unsupervised classification algorithms are concerned, several approaches have been proposed [5][19] which play an important role in providing intuitive navigation and browsing mechanisms by organizing large amounts of information into a small number of meaningful clusters. An interesting clustering approach has been proposed in [18], which provides a mechanism to group those documents whose snippets share similar phrases, by using suffix trees. This approach is well suited for clustering web search; the only drawback is that the clustering is flat, while a hierarchical structure is usually more suitable for browsing on line search results, in particular when queries are about general topics possibly belonging to

different domains. Clustering algorithms that build meaningful hierarchies out of large document collections are ideal tools for their interactive visualization and exploration as they provide data-views that are consistent, predictable, and at different levels of granularity. The Scatter/Gather system [9], is an interactive environment which supports the browsing, of both summaries and contents, of all the texts in a collection. It uses a hierarchical agglomerative clustering algorithm, known as Buckshot [3], which is a combination of two approaches: k-Means and hierarchical agglomerative clustering (HAC). HAC works by considering each data point as a separate cluster and then combining them in new clusters. This continues until there are only k clusters and finally, the centroids of the clusters are used as the initial centroids for the k-Means algorithm. Another important clustering system for web search results is proposed in WebACE Project [6], which uses an algorithm, named Principal Direction Divisive Partitioning [1]. It constructs a binary tree hierarchy of clusters by encompassing the entire document collection, and recursively split clusters on the bases of a linear discriminant function derived from the principal direction, until a desired number of clusters are reached. Recently, commercial products as Vivisimo (http://vivisimo.com) and iBoogie (http://www.iboogie.com/) are available on the web. They are meta-search engines that add to the flat list of query result a hierarchical structure of document clusters. Another approach, for improving browsability of web documents, returned by a search engine, consists in classifying these entities with a model built on an existing taxonomy, such as Yahoo! (http://www.yahoo.com) or the Open Directory Project (http://www.dmoz.org). In order to build such taxonomy model Naïve Bayes based method can be applied: it performs a hierarchical classification and constructs distinct classifiers at the internal nodes of the taxonomy using all the document in its child node as training data [8]. The classification is then applied at every node until a leaf is reached.
In this paper, we propose a system for searching and clustering large corpus of documents by using an experimental approach for on line text processing and hierarchical clustering. The clustering algorithm we propose in this paper, called Induced Bisecting k-Means, is an extension of the Standard Bisecting k-Means [14][15] which makes it more stable with respect to noisy data and applicable to web search results. Preliminary experiments and evaluations are conducted to investigate its effectiveness. Results obtained seem to be promising both in terms of accuracy and computational time. The basic outline of this paper is as follows. Section 2 presents our methodological approach together with a brief description of the system architecture. In Section 3 the datasets and the performance measures used for the validation of our approach are described. In Section 4 a set of preliminary experimental results are presented and, finally, in Section 5 conclusions are derived.
2. SYSTEM MODEL
We propose a Knowledge Discovery System able to satisfy the following requirements: • High Dimensionality: it can process documents with thousands of relevant terms

• Modular and Extensible: the system is designed in a modular way, so that new functionalities could be easily added
• Speed: search and clustering features return relevant results in a few seconds • Non parametric: user does not need to specify any input parameters, such as the
desired number of clusters • Adaptability at different document formats: in the web world, documents in plain-
text format are diminishing, and in their place we increasingly find information presented in different physical formats, such as Microsoft Office document, HTML, XML, PDF format, etc…
• Accuracy: our clustering solution shows high intra-cluster similarity and low inter-cluster similarity, i.e., documents in the same cluster are very similar, but they are dissimilar to elements in other clusters.
• Easy Browsing: the hierarchical structure obtained with our approach is presented with a user interface, to provide document browsing. In order to meet simultaneously all the requirements listed above, we had to extend
and combine in an efficient way different methodologies of feature selection, information filtering and clustering. We give more details in the next sub-sections.
2.1 System Architecture
Our system is composed of the following modules: 1. Web Crawler and Freshness Manager 2. Indexing module 3. Searching and Data-Preparation 4. Clustering module 5. Presentation interface
The system is component-oriented designed around the inversion of control pattern and entirely written in Java; it offers document management and manipulation, adding functionalities of searching and clustering from unstructured text documents. Figure 1 illustrates a flow diagram relevant to the entire computational process.
Fig. 1. Computational Process

2.2 Web Crawler and Freshness Manager
The Crawler, implemented as multithread process, retrieves web pages following their hyperlinks, and downloads relating documents on the local disk. In order to maintain locally stored pages “fresh” the crawler has to update its web pages periodically. We implemented a Freshness Manager in order to decide how often to refresh the page and maximize the “freshness” of downloaded pages. According to [2] a document is considered “fresh” when the local copy is equal to the real-world remote data. This component is able to estimate how often a page changes and to decide, through an optimization model, how often the pages need to be refreshed.
2.3 Indexing
The main functionality of this module is to organize documents into a highly efficient cross-reference lookup. Such indexing is based on inverted index structures. During the indexing phase, a pre-processing activity is performed in order to make page cases insensitive, remove stop words, acronyms, non-alphanumeric characters, html tags and apply stemming rules, using Porter’s suffix stripping algorithm. This module, based on Lucene Library (http://lucene.apache.org/), is able to manage different document formats and it accommodates easily for user customization.
2.4 Searching and Data-Preparation
The searching function, provided by Lucene library, supports single and multiterm queries, phrase queries, wildcards, result ranking, and sorting. When a user submits a query about a topic of interest, this module retrieves matching documents. In order to prepare the input for the clustering module, the collection Q of returned documents is mapped into a matrix ]m[M ij= . Each row of M is represented by a document d , following the Vector Space Model [12]:
( )Vwwwd ,..., 21= (1)
where V it is the number of words shared from all documents belonging to Q and
jw is the weight of the thj term computed using the TFxIDF approach [13]:
)t(IDF)d,t(TFw jjj ∗= (2)
where ( )d,tTF j is the Term Frequency, i.e. the number of occurrences of term jt in d, and ( )jtIDF is the Inverse Document Frequency. ( )jtIDF is a factor which enhances the terms which appear in fewer documents, while downgrading the terms
occurring in many documents and is defined as ( ) ( )⎟⎟⎠
⎞⎜⎜⎝
⎛=
jj tDF
DlogtIDF , where D
represents the number of documents matching the query, and ( )jtDF is the number

of documents containing the thj term. The TF values are used to perform a feature selection procedure based on the Term Frequency Variance (TFV) index [4]:
( )2
1 11
21 11∑ ∑
= =⎥⎦
⎤⎢⎣
⎡−=
n
i
n
iiij f
nftq
(3)
where 1n is the number of documents in Q containing jt at least once. Now, let R
be the set, with VrR ×= and 1≤r , containing the terms with highest quality, then
only terms jt having ( )jtq greater than a given threshold parameter μ will be considered as columns of M, where
( )( )jRtqtqmin
j ∈=μ . In our system we set 050.r = .
This feature selection technique is suitable for the unsupervised requirement and requires lower computational cost compared to other feature selection techniques. Finally, in order to account for document of different lengths, each document vector is normalized so that it is of unit length.
2.5 Hierarchical Clustering
The approaches proposed in the literature for hierarchical clustering where mostly statistical with a computational complexity which is quadratic with respect to Q . A novel approach, Bisecting k-Means was proposed in [14][15], has a linear complexity and is relatively efficient and scalable.
It starts with a single cluster of all documents and works in the following way: 1. Pick a cluster S to split 2. Select two random seeds which are the initial centroids 3. Find 2 sub-clusters 1S and 2S using the basic k-Means algorithm. 4. Repeat step 2 and 3 for ITER times and take the split that produces the clustering
with the highest Intra Cluster Similarity (ICS)
( )∑∈
∈
=
k'
k
k
SdSd
'
k
S d,dcosS
ICS2
1 (4)
5. Repeat steps 1, 2 and 3 until the desired number of clusters is reached. The major disadvantage of this algorithm is that it requires the a priori
specification of K and ITER parameters. An incorrect estimation of K and ITER may lead to poor clustering accuracy. Moreover, the algorithm is sensitive to the noise which may affect the computation of cluster centroids. For any given cluster let N be the number of documents belonging to that cluster and R the set of their indices. In fact, the thj element of a cluster centroid is computed as:
∑∈
=Rr
rjj mN
c 1 (5)

where N represents the number of documents belonging to the cluster. The centroid C may contain also the contribution of noisy terms contained in the
documents which the pre-processing phase and feature selection phase have not been able to remove. To overcome these two problems we propose an extended version of the Standard Bisecting k-Means, named Induced Bisecting k-Means, whose main steps are described as follows: 1. Set the Intra Cluster Similarity (ICS) threshold parameter τ. 2. Build a distance matrix A, of dimension QxQ , whose elements are given by the
Euclidean distance between document
∑=
−=V
kjkikij )mm(a
1
2 (6)
where Qj,i ∈ . 3. Select, as centroids, the two documents i and j s.t.
{ } lmQ,...,m,lj,i Amaxa1=
= .
The splitting is also different from the Standard Bisecting k-Means and is performed according to the following 3 steps: 4. Find 2 sub-clusters 1S and 2S using the basic k-Means algorithm. 5. Check the ICS of 1S and 2S as
• If the ICS value of a cluster is smaller than τ, then reapply the divisive process to this set, starting form step 2.
• If the ICS value of a cluster is over a given threshold, then stop. 6. The entire process will finish when there are no sub-clusters to divide.
The main differences of this algorithm with respect to the Standard Bisecting k-Means consist in: − how the initial centroids are chosen: as centroids of the two child clusters we select
the documents of the parent cluster having the greatest distance between them − the cluster splitting rule: a cluster is split in two if its Intra Cluster Similarity is
smaller than a threshold parameter τ. Therefore, the “optimal” number of cluster K is controlled by the parameter τ, τhe main advantages being that no input parameters K and ITER must be specified by the user.
Computational results seem to be very promising as it is shown in section 4.
2.6 Visualization
Our algorithm outputs a binary tree of documents, where each node represents a document collection about the same topic. This structure has been processed, in order to obtain a meaningful taxonomy, according to [7]. The new hierarchical structure is a tree-like structure presented by a simple GUI, where each internal node represents a higher-level concept that semantically includes all of its child concepts. Labels are assigned to each node of the taxonomy, by using the top H weighted values of the centroid vector and determine the terms which contribute to the top H terms. Other

and more efficient way of choosing representative cluster labels can be implemented as reported in [7][16]. This will be one of the subjects of our future developments.
3. DATASETS AND PERFORMANCE EVALUATION
In this section we compare the Induced Bisecting k-Means, against the k-Means and Standard Bisecting k-Means algorithms. To evaluate clustering performance we used several benchmarks using all the terms of the dataset vocabulary, i.e. without TFV feature selection. More details are given in the next sub-sessions.
3.1 Datasets
The summary description of data sets used in this paper is shown in the table 1 #classes Average Class Size #docs #words re0 13 115,7 1504 11465 re1 25 663 1657 3758 Wap 20 78 1560 8460 tr31 7 132,4 927 10128 tr45 10 69 690 8261
Table 1. Dataset description
Datasets re0 and re1 are from Reuters-21587 test collection [10]. Dataset wap is from WebAce project [6]. Datasets tr31 and tr45 are from TREC-5 , TREC-6, and TREC-7 [17]. We collected documents that have relevance judgments and then selected documents that have just a single relevance judgment.
3.2 Evaluation of cluster quality
In order to evaluate the cluster quality, we used the widely adopted F-Measure. It combines the Precision and Recall measure which are computed as follows:
j
ij
i
ij
nn
)j,i(ecisionPr nn
)j,i(callRe == (7)
where, jn is the number of elements of cluster Jj ∈ , in is the number of
elements of class Ii ∈ , and ijn denotes the number of elements of class i in cluster j. The F Measure of cluster j and class i is given by:
))j,i(callRe)j,i(ecision(Pr))j,i(ecisionPr*)j,i(callRe*()j,i(F
+=
2 (8)
The overall quality of the clustering is given by a scalar F computed as:

{ }∑∈
=i Jj
i jiFnn
F ),(max (9)
As pointed out in section 2.6, both the Standard Bisecting k-Means and the Induced Bisecting k-Means generate binary trees that are subsequently transformed in a taxonomy. Then, there are two different ways of computing F which depend on the definition of J. In fact, given a binary tree, if we denote E as the set of all its nodes, and EL ⊂ as the set of its leaf nodes, then the F-measure can be computed either setting EJ = or LJ = .
4. EXPERIMENTAL RESULTS
We ran the Induced Bisecting k-Means with different values of τ: 0.20, 0.10 and 0.05. Table 2-4 reports the F-measure computed using both J=E and J=L.
τ = 0.20
J=E J=L # of cluster re0 0.5895 0.3534 88 re1 0.6537 0.3867 124 wap 0.7706 0.3489 62 tr31 0.7282 0.4920 54 tr45 0.6214 0.2699 239
Table 2. Induced Bisecting k-Means performance with τ = 0.20
τ = 0.10 J=E J=L # of cluster re0 0.5076 0.3467 26 re1 0.6148 0.4480 39 wap 0.7648 0.5944 14 tr31 0.6644 0.6644 15 tr45 0.6174 0.3980 84
Table 3. Induced Bisecting k-Means performance with τ = 0.10
τ = 0.05 J=E J=L # of cluster re0 0.4472 0.4129 4 re1 0.5242 0.4973 12 wap 0.6552 0.6552 4 tr31 0.4840 0.4840 4 tr45 0.5547 0.5340 21
Table 4. Induced Bisecting k-Means performance with τ = 0.05

In order to compare our approach with the k-Means and the Standard Bisecting k-Means we set k equal to the number of clusters obtained by performing our approach.
Tables 5-9 show the F-measure obtained by running the k-Means algorithm on different datasets. Since the k-Means algorithm produces a flat clustering, we considered J=L.
Tables 10-14 show the F-Measure obtained by running the Standard Bisecting k-
Means, setting ITER=5 for every run, considering both J=E and J=L. For the wap dataset the F-Measure coefficient with K=129 are not available because the algorithm is not able to produce this number of clusters.
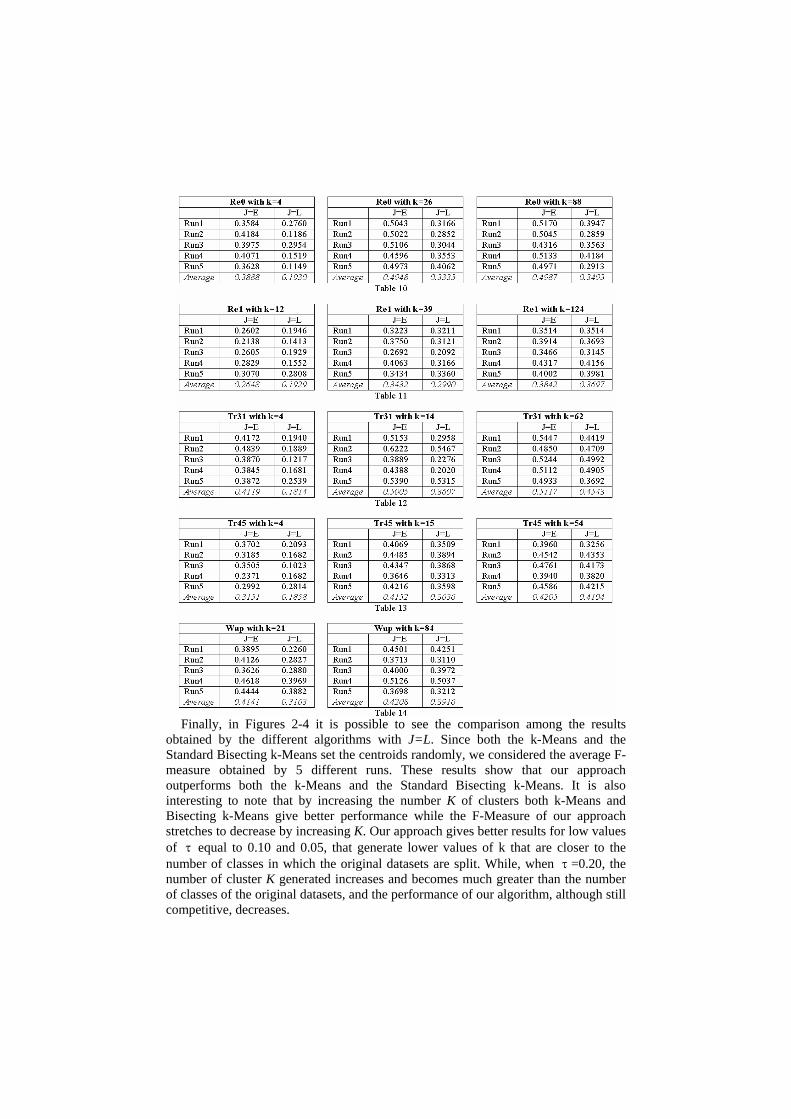
Finally, in Figures 2-4 it is possible to see the comparison among the results
obtained by the different algorithms with J=L. Since both the k-Means and the Standard Bisecting k-Means set the centroids randomly, we considered the average F-measure obtained by 5 different runs. These results show that our approach outperforms both the k-Means and the Standard Bisecting k-Means. It is also interesting to note that by increasing the number K of clusters both k-Means and Bisecting k-Means give better performance while the F-Measure of our approach stretches to decrease by increasing K. Our approach gives better results for low values of τ equal to 0.10 and 0.05, that generate lower values of k that are closer to the number of classes in which the original datasets are split. While, when τ =0.20, the number of cluster K generated increases and becomes much greater than the number of classes of the original datasets, and the performance of our algorithm, although still competitive, decreases.

Fig. 2. Performance comparison with τ = 0.05
Fig. 3. Performance comparison with τ = 0.10
Fig. 4. Performance comparison with τ = 0.20
This suggests that our algorithm is also able to generate an “optimal” number K of cluster in which the data set should be split.
5. CONCLUSION
The clustering algorithm implemented in this system is particularly suitable for on line applications when computational efficiency is a crucial aspect. Our results

indicate that Induced Bisecting k-Means is better than Standard Bisecting k-Means and k-Means both in terms of computational time and accuracy. More specifically, our approach produces significantly better clustering solutions quite consistently according to the F-measure. In addition, the run time of Induced Bisecting k-Means is lower than Standard Bisecting k-Means and k-Means, because it converges more quickly, i.e. it requires a lower number of iterations.
REFERENCES
1. D. Boley, Principal Direction Divisive Partitioning, Technical Report TR-97-056, Department of Computer Science and Engineering, University of Minnesota, Minneapolis
2. J. Cho, H. Garcia-Molina, Synchronizing a database to improve freshness, In Proc. of ACM International Conference on Management of Data, pp 117-128, 2000
3. D. R. Cutting, J. O. Pedersen, D. Karger, and J. W. Tukey, Scatter/gather: A cluster-based approach to browsing large document collections, In Proc. of 15th Annual ACM-SIGIR, pp. 318-329, 1992
4. I. Dhillon, J. Kogan, C. Nicholas, Feature selection and document clustering, Book chapter in Text Data Mining and Applications, 2002
5. P. Ferragina, A. Gulli, A personalized search engine based on web-snippet hierarchical clustering, Special interest tracks and posters of the 14th International Conference on WWW, pp 801-810, 2005
6. E. H. Han, D. Boley, M. Gini, R. Gross, K. Hastings, G. Karypis, V. Kumar, B. Mobasher, and J. Moore, WebACE: A web agent for document categorization and exploration, In Proc. of the 2nd International Conference on Autonomous Agents, pp 408-415, 1998
7. V. Kashyap, C. Ramakrishnan, C. Thomas, D. Bassu, T. C. Rindflesch, A. Sheth, TaxaMiner: An experiment framework for automated taxonomy bootstrapping, International Journal of Web and Grid Services 2005, Vol. 1, No.2 pp. 240-266
8. D. Koller, M. Sahami, Hierarchically classifying documents using very few words, In Proc. of the 14th International Conference on Machine Learning, pp 170-178, 1997
9. P. Pirolli, P. Schank, M. Hearst, C. Diehl, Scatter/Gather Browsing Communicates the Topic Structure of a Very Large Text Collection, In Proc. of CHI, pp 213-220, 1996
10. Reuters-21578, http://www.daviddlewis.com/resources/testcollections/reuters21578/ 11. G. Salton, M. J. McGill, Introduction to Modern Retrieval, McGraw-Hill Company, 1983 12. G. Salton, A. Wong, C. S. Yang, A vector space model for automatic indexing,
Communications of ACM, vol. 18, Issue 11, pp 613-620, 1975 13. G. Salton, C. Buckley, Term weighting approaches in automatic text retrieval, Information
Processing and Management, Vol. 24, Issue. 5, pp 513-523, 1988 14. M. Savaresi, D. L. Boley, On the performance of bisecting k-Means and PDDP, First
SIAM International Conference on Data Mining , pp 1-14, 2001 15. M. Steinbach, G. Karypis, V. Kumar, A comparison of Document Clustering Techniques,
In KDD Workshop on Text Mining, 2000 16. H. Toda, R. Kataoka, A search Result clustering Method using Informatively Named
Entities, In Proc. of the 7th annual ACM International Workshop on Web information and data management, pp 81-86, 2005
17. TREC: Text Retrieval Conference, http://trec.nist.gov 18. O. Zamir, O. Etzioni, O. Madani, R. M. Karp, Fast and intuitive Clustering of Web
document, In Proc. of KDD, pp 287-290, 1997 19. D. Zhang, Y. Dong. Semantic, Hierarchical, Online Clustering of Web Search Results. In
Proc. of the 6th Asia Pacific Web Conference, 2004