scaling rdbms on aws- clustrixdb @aws meetup 20160711
TRANSCRIPT

© 2014 CLUSTRIX © 2016 CLUSTRIX
Scaling RDBMS on AWS: Strategies, Challenges, & A Better Solution
Dave A. Anselmi @AnselmiDave Director of Product Management
Clustrix
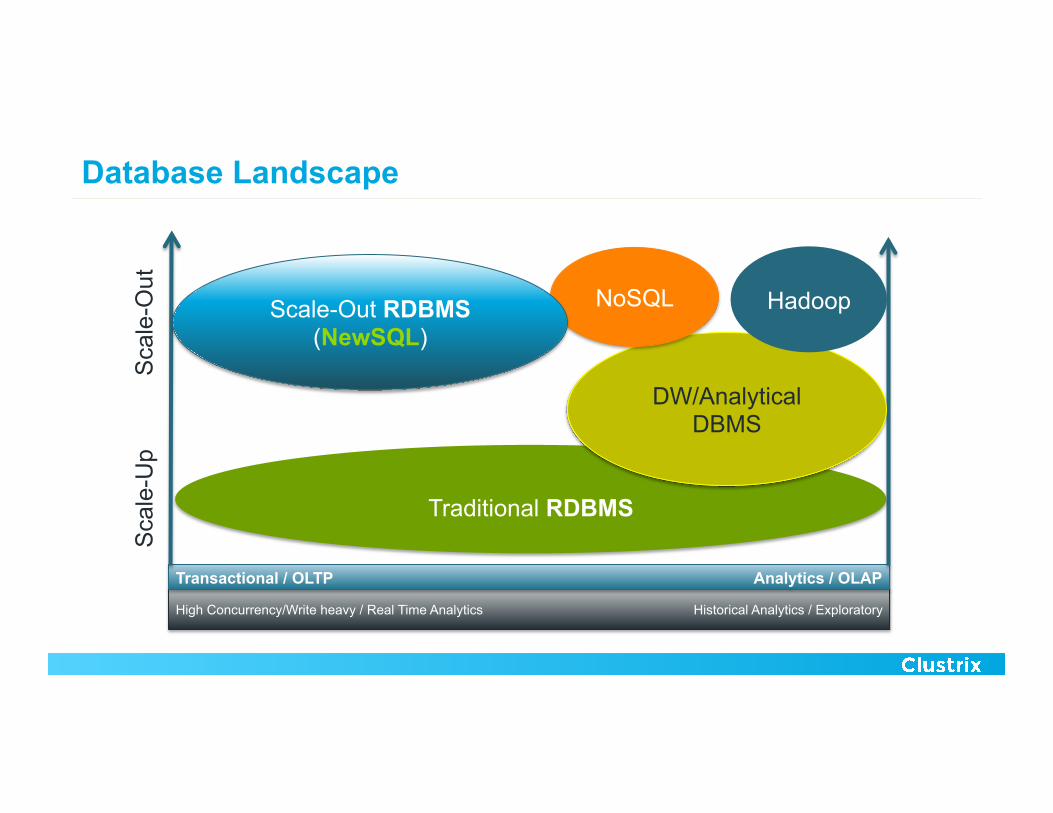
Database Landscape
Splice Machine Proprietary and Confidential
High Concurrency/Write heavy / Real Time Analytics Historical Analytics / Exploratory
Transactional / OLTP Analytics / OLAP
Traditional RDBMS
DW/Analytical DBMS
Hadoop
Sca
le-O
ut
Sca
le-U
p
NoSQL Scale-Out RDBMS (NewSQL)

RDBMS Scale-Out Dimensions
3
Resiliency
Capacity
Elasticity Enterprise RDBMS Scale

RDBMS Scale-Out Considerations Relational Database Scaling Is Very Hard (c.f. “SQL Databases Don’t Scale”, 2006)
• Data Consistency
• Read vs. Write Scale • ACID Properties
• Throughput and Latency
• Application Impact
4

RDBMS Scale-Out Dimensions
5
Resiliency
Capacity
Elasticity
SCALE § Data, Users, Session
THROUGHPUT § Concurrency, Transactions
LATENCY § Response Time
The ‘Promise of the Cloud’ – Scaling RDBMS Up/Down like a Web Node

6
RDBMS SCALING STRATEGIES

Scaling-Up: Reads + Writes • Keep increasing the size of the (single) database server • Pros
– Simple, no application changes needed. ‘Click to Scale-up’ on AWS console – Best solution for Capacity, if it can handle your workload
• Cons – Capacity Limit. Most clouds provide up to 36 ‘vcpu’s at most for a single server – Leave the cloud=Expensive. Soon, you’re often paying 5x for 2x the performance
Eventually you ‘hit the wall’, and you literally cannot scale-up anymore
7

Scaling Reads: Master/Slave • Add a ‘Slave’ read-server(s) to your ‘Master’ database server • Pros
– Simple to implement, lots of automation available. AWS has ‘Read Replicas’ – Read/write fan-out can be done at the proxy level
• Cons – Best for read-heavy workloads- only adds Read performance – Data consistency issues can occur, especially if the application isn’t coded to
ensure read-consistency between Master & Slave (not an issue with RDS)
8

Scaling Reads + Writes: Master/Master • Add additional ‘Master’(s) to your ‘Master’ database server • Pros
– Adds Reads + Write scaling without needing to shard – Depending on workload (e.g. non-serialized), scaling can approach linear
• Cons – Adds Write scaling at the cost of read-slaves, which would add even more latency – Application changes are required to ensure data consistency / conflict resolution – AWS: Not available on RDS console; ‘roll-your-own’ with EC2
9

Examples: Master/Master Replication Solutions
• Replication-based synchronous COMMIT solutions: – Galera (open-source library) – Percona XtraDB Cluster (leverages Galera replication library) – Tungsten
• Pros – Good for High-Availability – Good for Read scaling
• Cons – Provides variable Write scale, depending on workload – Replication has inherent potential consistency and latency issues.
High-transaction workloads such as OLTP (e.g. E-Commerce) are exactly the workloads that replication struggles the most with
10

Scaling Reads & Writes: Horizontal (‘Regular’) Sharding • Partitioning tables across separate database servers
• Pros – Adds both Read and Write scaling, depending on well-chosen sharding keys and low skew – Most common way to scale-out both Reads and Writes
• Cons – Loses the ability of an RDBMS to manage transactionality, referential integrity and ACID;
Application must ‘re-invent the wheel’ – Consistent backups across all the shards are very hard to manage – Data management (skew/hotness) is ongoing significant maintenance – AWS: Not available on RDS console; ‘roll-your-own’ with EC2
11
SHARDO1 SHARDO2 SHARDO3 SHARDO4
A - K L - O P - S T - Z

Examples: Horizontal Sharding Solutions MySQL Fabric • Pros
– Elasticity: Can add nodes using Python scripts or OpenStack, etc – Resiliency: Automated load-balancing, auto slave promotion, & master/promotion-
aware routing, all transparent to the application • Cons
– Application needs to provide sharding key per query – JOINs involving multiple shards not supported – Data rebalancing across shards is manual operation
ScaleArc • Pros
– Capacity: Rule-based range or key-based sharding. Automatic read-slave promotion – Resiliency: Automatically manages MySQL replication, managing Master/Master,
promotion, and fail-over • Cons
– All queries need to route through ‘smart load balancer’ which manages shards – Data rebalancing across shards is manual operation
12

Scaling Reads & Writes: Vertical Sharding • Separating tables across separate database servers (used by Magento eCommerce 2, etc)
• Pros – Adds both write and read scaling, depending on well-chosen table distribution – Much less difficult than ‘regular’ sharding, and can have much of the gains
• Cons – Loses the ability of an RDBMS to manage transactionality, referential integrity and ACID;
Application must ‘re-invent the wheel’ – Consistent backups across all the shards are very hard to manage – Data management (skew/hotness) is ongoing significant maintenance – AWS: Not available on RDS console; ‘roll-your-own’ with EC2
13
SHARDO1 SHARDO2 SHARDO3 SHARDO4
Table 1,2
Table 3,4
Table 5,6
Table 7,8

Application Workload Partitioning • Partition entire application + RDBMS stack across several “pods” • Pros
– Adds both Write and Read scaling – Flexible: can keep scaling with addition of pods
• Cons – No data consistency across pods (only suited for cases
where it is not needed) – Queries / Reports across all pods can be very complex – Complex environment to setup and support
14
APP
APP
APP
APP
APP
APP
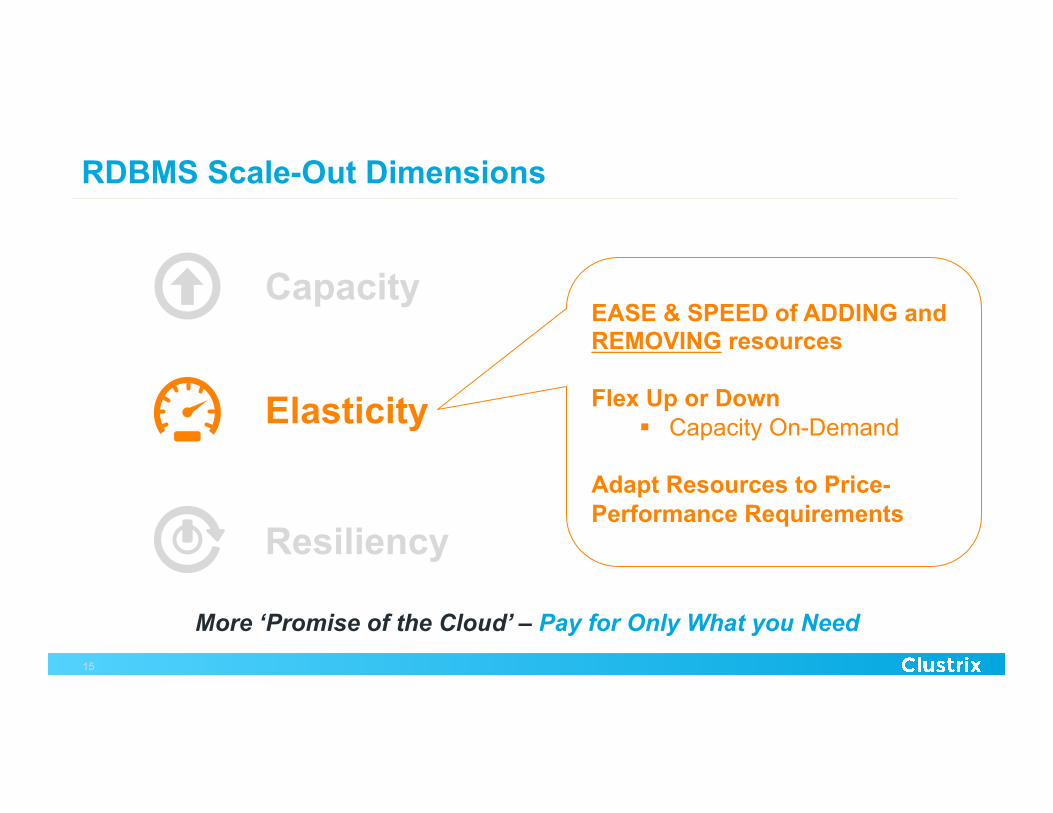
RDBMS Scale-Out Dimensions
15
Resiliency
Capacity
Elasticity
EASE & SPEED of ADDING and REMOVING resources
Flex Up or Down
§ Capacity On-Demand
Adapt Resources to Price-Performance Requirements
More ‘Promise of the Cloud’ – Pay for Only What you Need

Elasticity – Flexing Up and Down
• Application (for reference)
• Scale-up
• Master – Slave
• Master – Master
• Sharding
• Application Partitioning
16
Scaling Options Flex UP Flex DOWN
o Easy: Add more web nodes o Easy: Drop web nodes
o RDS: Easy. EC2: Expensive and awkward
o RDS: Easy. EC2: Difficult and awkward
o Easy: add read Replicas or slave(s)
o Easy: Drop read Replicas or slave(s)
o Involved o Involved
o Expensive and complex o Infeasible &/or untenable
o Expensive and complex o Expensive and complex

RDBMS Scale-Out Dimensions
17
Resiliency
TRANSPARENCY to Failures § Hardware or Software
Fault Tolerance and High Availability
Capacity
Elasticity
Who Needs High-Availability? – How Far do you Want to Walk?

Resiliency – High-Availably and Fault Tolerance
• Application (for reference)
• Scale-up
• Master – Slave
• Master – Master
• Sharding
• Application Partitioning
18
Scaling Options
o No single point failure – failed node bypassed
Resilience to failures
o RDS: Easy if standby instance. EC2: One large machine à Single point failure
o RDS: Easy. EC2: Fail-over to Slave à Potential data consistency issue(s)
o RDS: Unavailable. EC2: Resilient to one of the Masters failing
o RDS: Unavailable. EC2: Multiple points of failures, without redundant hardware
o RDS: Unavailable. EC2: Multiple points of failures, without redundant hardware
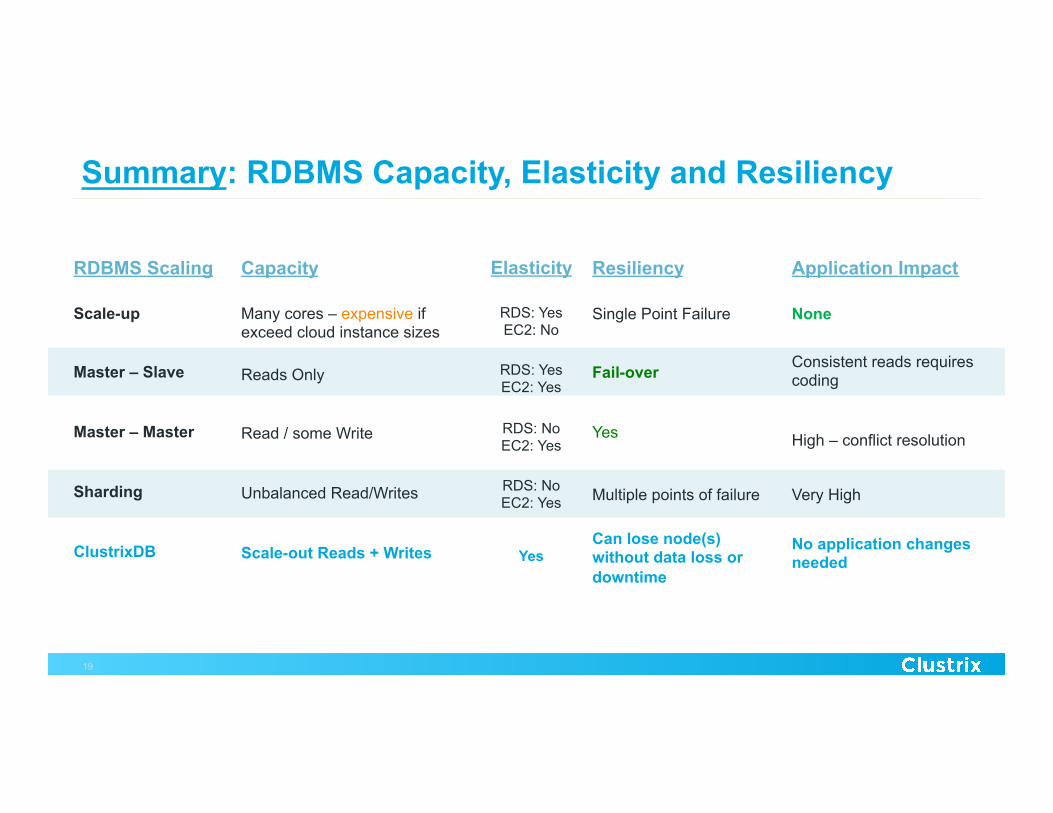
Summary: RDBMS Capacity, Elasticity and Resiliency
Scale-up
Master – Slave
Master – Master
Sharding
ClustrixDB
19
RDBMS Scaling
Many cores – expensive if exceed cloud instance sizes
Reads Only
Read / some Write
Unbalanced Read/Writes
Scale-out Reads + Writes
Capacity
Single Point Failure
Fail-over
Yes
Multiple points of failure
Can lose node(s) without data loss or downtime
Resiliency Elasticity
RDS: Yes EC2: No
RDS: Yes EC2: Yes
RDS: No EC2: Yes
RDS: No EC2: Yes
Yes
None
Consistent reads requires coding
High – conflict resolution
Very High
No application changes needed
Application Impact

20
ANOTHER APPROACH:
§ MYSQL-COMPATIBLE CLUSTERED DATABASE § LINEAR SCALE-OUT OF BOTH WRITES & READS § HIGH-TRANSACTION, LOW-LATENCY § ARCHITECTED FROM THE GROUND-UP TO ADDRESS:
CAPACITY, ELASTICITY AND RESILIENCY
CLUSTRIXDB

ClustrixDB: Scale-Out, Fault-tolerant, MySQL-Compatible
21
ClustrixDB
ACID Compliant
Transactions & Joins
Optimized for OLTP
Built-In Fault Tolerance
Flex-Up and Flex-Down
Minimal DB Admin
Also runs GREAT in the Data Center
Built to run GREAT
in the Cloud

Linear Scale-Out: Sysbench OLTP 90:10 Mix (bare metal)
• 90% Reads + 10% Writes – Very typical workload mix
• 1 TPS = 10 SQL – 9 SELECT + 1 UPDATE – a.k.a 10 operations/sec
• Linearly scales TPS by adding servers:
– Oak4 = 4x 8core (32 cores) – Oak16 = 16x 8core (128 cores) – Oak28 = 28x 8core (224 cores)
22
800,000 SQL/sec @ 20 ms

ClustrixDB vs. RDS_db1 vs. RDS_db2 (AWS)
• 90% Reads + 10% Writes – Very typical workload mix
• 1 TPS = 10 SQL – 9 SELECT + 1 UPDATE – a.k.a 10 operations/sec
• Shows scaling TPS by adding servers:
– Aws4 = 4x 8vcpu ClustrixDB – Aws16 = 16x 8vcpu ClustrixDB – Aws20 = 20x 8vcpu ClustrixDB
23
ClustrixDB scaling TPS 4X past RDS_db2’s largest instance (db.r3.8xlarge) at 20ms
RDS_db1 (8XL)
RDS_db2 (8XL)
ClustrixDB
>400,000 SQL/sec @ 20 ms
ClustrixDB (20x c3.2XL)

24
CLUSTRIX RDBMS
Production Customer Workload Examples

Example: Heavy Write Workload (AWS Deployment)
25
The ApplicationInserts 254 million / day
Updates 1.35 million / day
Reads 252.3 million / day
Deletes 7,800 / day
The DatabaseQueries 5-9k per sec
CPU Load 45-65%
Nodes - Cores 10 nodes - 80 cores
Application Sees a Single RDBMS Instance

Example: Very Heavy Update Workload (Bare-Metal)
26
The ApplicationInserts 31.4 million / day
Updates 3.7 billion / day
Reads 1 billion / day
Deletes 4,300 / day
The DatabaseQueries 35-55k per sec
CPU Load 25-35%
Nodes - Cores 8 nodes - 160 cores
Application Sees a Single RDBMS Instance

27
CLUSTRIX RDBMS
§ MYSQL COMPATIBLE SHARED-NOTHING CLUSTERED RDBMS § FULL TRANSACTIONAL ACID COMPLIANCE ACROSS ALL NODES § ARCHITECTED FROM THE GROUND-UP TO ADDRESS:
CAPACITY, ELASTICITY AND RESILIENCY
TECHNICAL OVERVIEW

ClustrixDB Overview
Fully Distributed & Consistent Cluster • Fully Consistent, and ACID-compliant database
– Cross-node Transactions & JOINs – Optimized for OLTP – But also supports reporting SQL
• All servers are read + write
• All servers accept client connections • Tables & Indexes distributed across all nodes
– Fully automatic distribution, re-balancing & re-protection
– All Primary and Secondary Keys
28
Private N
etwork
ClustrixDB on commodity/cloud servers
HW or SW Load Balancer�
SQL-based Applications�
High Concurrency�
Custom: PHP, Java, Ruby, etc
Packaged: Magento, etc�

ClustrixDB – Shared Nothing Symmetric Architecture
• Database Engine: – all nodes can perform all database operations (no
leader, aggregator, leaf, data-only, special nodes)
• Query Compiler: – distribute compiled partial query fragments to the
node containing the ranking replica
• Data: Table Slices: – All table slices auto-redistributed by the
Rebalancer (default: replicas=2)
• Data Map: – all nodes know where all replicas are
29
Each Node Contains
ClustrixDB
Compiler Map
Engine Data
Compiler Map
Engine Data
Compiler Map
Engine Data

Bill
ions
of R
ows
Database Tables
S1 S2 S2 S3
S3 S4 S4
S5 S5
Intelligent Data Distribution • Tables auto-split into slices • Every slice has a replica on another server
– Auto-distributed and auto-protected
30
S1
ClustrixDB
S1
S2
S3
S3
S4
S4
S5
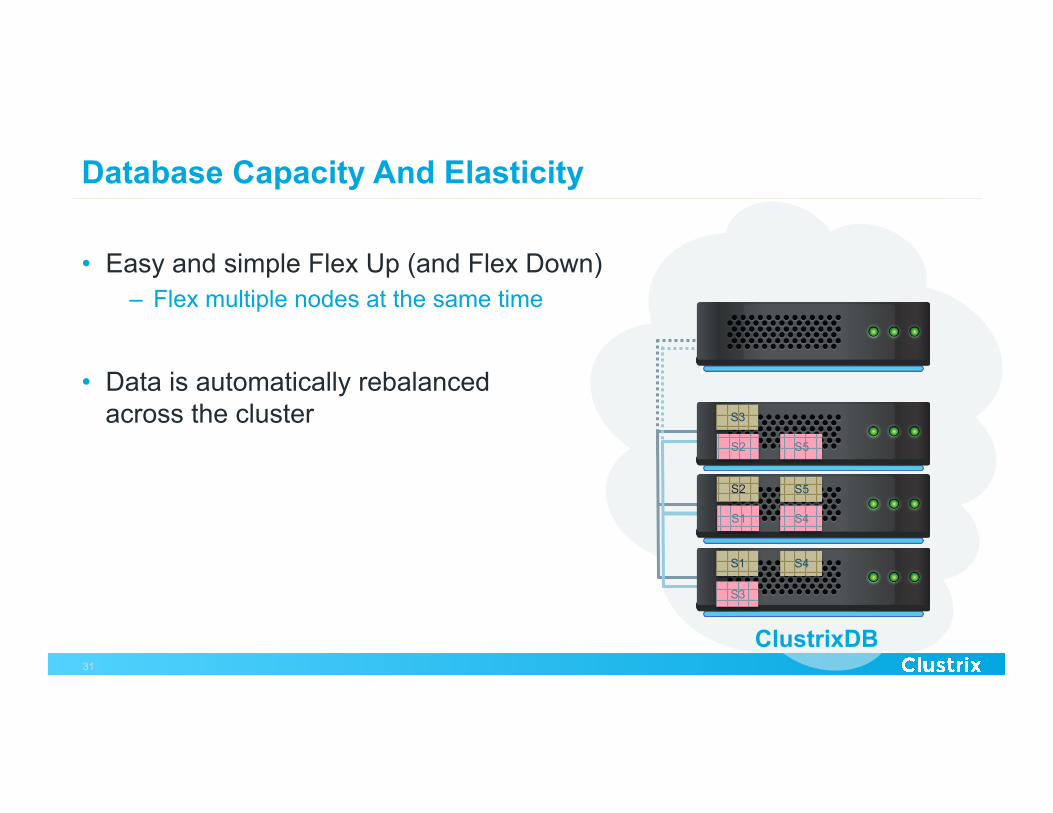
Database Capacity And Elasticity
• Easy and simple Flex Up (and Flex Down) – Flex multiple nodes at the same time
• Data is automatically rebalanced
across the cluster
31
S1
ClustrixDB
S2
S5

S1
S2
S3
S3
S4
S4
S5
Built-in Fault Tolerance
• No Single Point-of-Failure – No Data Loss – No Downtime
• Server node goes down… – Data is automatically rebalanced across
the remaining nodes
32
S1
ClustrixDB
S2
S5

Query
Distributed Query Processing • Queries are fielded by any peer node
– Routed to node holding the data
• Complex queries are split into fragments processed in parallel – Automatically distributed for optimized performance
33
ClustrixDB Load
Balancer
TRX TRX TRX

Automatic Cluster Data Rebalancing
The ClustrixDB Rebalancer:
• Initial Data: Distributes the data into even slices across nodes
• Data Growth: Splits large slices into smaller slices
• Failed Nodes: Re-protects slices to ensure proper replicas exist
• Flex-Up/Flex-Down: Moves slices to leverage new nodes and/or evacuate nodes
• Skewed Data: Re-distributes the data to even out across nodes
• Hotness Detection: Finds hot slices and balances then across nodes
Patent 8,543,538 - Systems and methods for redistributing data in a relational database Patent 8,554,726 - Systems and methods for reslicing data in a relational database

Replication and Disaster Recovery
35
Asynchronous multi-point MySQL 5.6 Replication
ClustrixDB Parallel Backup up to 10x faster
Replicate to any cloud, any datacenter, anywhere
Patent 9,348,883 - Systems and methods for replication replay in a relational database

36
FINAL THOUGHTS

ClustrixDB
37
Capacity
Massive read write scalability
Very high concurrency
Linear throughput scale
Elasticity
Flex UP in minutes
Flex DOWN easily
Right-size resources on-demand
Resiliency
Automatic, 100% fault tolerance
No single point of failure
Battle-tested performance
Cloud
Cloud, VM, or bare-metal
Virtual Images available
Point/click Scale-out

Thank You.
facebook.com/clustrix
www.clustrix.com
@clustrix
linkedin.com/clustrix
38

39
SUPPLEMENTARY SLIDES

40
CLUSTRIX RDBMS
GRAPHICAL USER INTERFACE

New UI – Enhanced Dashboard
41

New UI – Workload Comparison
42

New UI – FLEX Administration
43

44
CLUSTRIX RDBMS
SCALE-OUT BENCHMARKS

Sysbench OLTP 100% Reads (bare metal)
• 100% Reads – Max throughput test
• 1 TPS = 10 SQL – 10 SELECT – a.k.a 10 operations/sec
• Linearly scales TPS by adding servers:
– Oak6 = 6 servers – Oak18 = 18 servers – Oak30 = 30 servers
45
>1 Million SQL/sec @ 20 ms
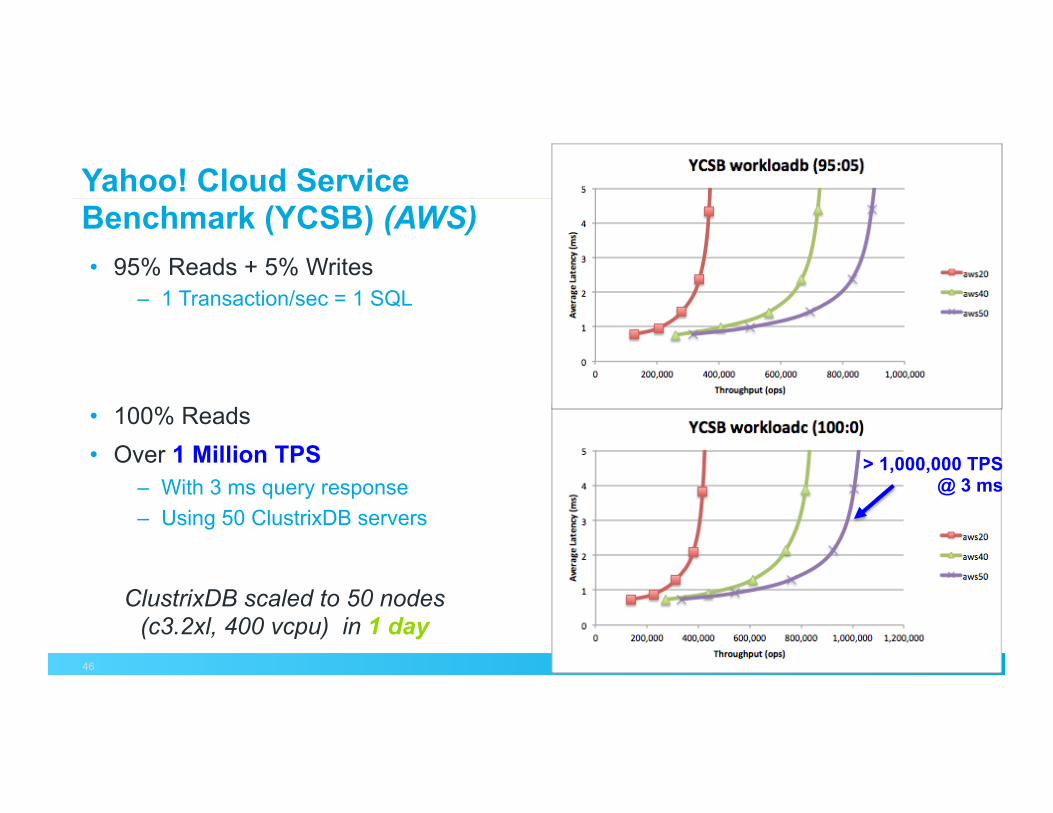
Yahoo! Cloud Service Benchmark (YCSB) (AWS) • 95% Reads + 5% Writes
– 1 Transaction/sec = 1 SQL
• 100% Reads • Over 1 Million TPS
– With 3 ms query response – Using 50 ClustrixDB servers
46
> 1,000,000 TPS @ 3 ms
ClustrixDB scaled to 50 nodes (c3.2xl, 400 vcpu) in 1 day

47
CLUSTRIX RDBMS
UNDER THE HOOD
§ DISTRIBUTION STRATEGY § REBALANCER TASKS § QUERY OPTIMIZER § EVALUATION MODEL § CONCURRENCY CONTROL

ClustrixDB key components enabling Scale-Out • Shared-nothing architecture
– Eliminates potential bottlenecks. • Independent Index Distribution
– Hash each distribution key to a 64-bit number space divided into ranges with a specific slice owning each range
• Rebalancer – Ensures optimal data distribution across all nodes. – Rebalancer assigns slices to available nodes for data capacity and access balance
• Query Optimizer – Distributed query planner, compiler, and distributed shared-nothing execution engine – Executes queries with max parallelism and many simultaneous queries concurrently.
• Evaluation Model – Parallelizes queries, which are distributed to the node(s) with the relevant data.
• Consistency and Concurrency Control – Using Multi-Version Concurrency Control (MVCC), 2 Phase Locking (2PL) on writes,
and Paxos Consensus Protocol
48

Rebalancer Process
• User tables are vertically partitioned in representations.
• Representations are horizontally partitioned into slices.
• Rebalancer ensures: – The representation has an appropriate number of slices. – Slices are well distributed around the cluster on storage devices – Slices are not placed on server(s) that are being flexed-down. – Reads from each representation are balanced across the nodes
49

ClustrixDB Rebalancer Tasks
• Flex-UP – Re-distribute replicas to new nodes
• Flex-DOWN – Move replicas from the flex-down nodes to other nodes in the cluster
• Under-Protection – when a slice has fewer replicas than desired – Create a new copy of the slice on a different node.
• Slice Too Big – Split the slice into several new slices and re-distribute them
50

ClustrixDB Query Optimizer
• The ClustrixDB Query Optimizer is modeled on the Cascades optimization framework. – Other RDBMS leverage Cascades are Tandem's Nonstop SQL and Microsoft's SQL Server. – Cost-driven - Extensible via a rule based mechanism – Top-down approach
• Query Optimizer must answer the following, per SQL query: – In what order should the tables be joined? – Which indexes should be used? – Should the sort/aggregate be non-blocking?
51

ClustrixDB Evaluation Model
• Parallel query evaluation
• Massively Parallel Processing (MPP) for analytic queries
• The Fair Scheduler ensures OLTP prioritized ahead of OLAP
• Queries are broken into fragments (functions).
• Joins require more data movement by their nature. – ClustrixDB is able to achieve minimal data movement – Each representation (table or index) has its own distribution map,
allowing direct look-ups for which node/slice to go to next, removing broadcasts.
– There is no a central node orchestrating data motion. Data moves directly to the next node it needs to go to. This reduces hops to the minimum possible given the data distribution.
52
COMPILATION
FRAGMENTS
FRAGMENT 1
FRAGMENT 2
VM
FRAGMENT 1 Node := lookup id = 15
<forward to node>
VM
FRAGMENT 2 SELECT id, amount
<return>
SELECT id, amount FROM donation WHERE id=15

Concurrency Control
• Readers never interfere with writers (or vice-versa). Writers use explicit locking for updates
• MVCC maintains a version of each row as writers modify rows
• Readers have lock-free snapshot isolation while writers use 2PL to manage conflict
53
Time
reader reader
writer
writer writer
row conflict one writer blocked
no conflict no blocking
Lock Conflict Matrix
Reader Writer
Reader None None
Writer None Row

Thank You.
facebook.com/clustrix
www.clustrix.com
@clustrix
linkedin.com/clustrix
54