aws re:invent 2016| dat318 | migrating from rdbms to nosql: how sony moved from mysql to amazon...
TRANSCRIPT

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Nate Slater, Senior Manager AWS Solutions Architecture
Benedikt Neuenfeldt, Architect, SIE Inc.
Aki Kusumoto, VP of NPS Development Department, SIE Inc.
December 1, 2016
Migrating from RDBMS to NoSQL
How PlayStation™Network Moved
from MySQL to Amazon DynamoDB
DAT318

What to Expect from the Session
• Understand key differences between NoSQL and
RDBMS
• Learn the fundamentals of Amazon DynamoDB
• Identify suitable use cases for DynamoDB
• Plan and execute a migration from RDBMS to
DynamoDB
• Explore a customer use case: Sony’s migration from
MySQL to DynamoDB
2016 – A Dizzying Array of Choices for Data Storage and Analytics!
file:///.file/id=657136
7.22587195

Tame the Madness!
Despite a dizzying array of choices, most workloads are
well suited to a tiny subset of options, such as:
• RDBMS – The workhorse. Still as relevant today as it’s
ever been.
• NoSQL – The newcomer. Efficient and inexpensive for
high-volume, high-velocity data.

Why NoSQL?
• Horizontal Scaling – Achieve massive scale at a price
point lower than traditional RDMBS.
• High Concurrency – Locking and consistency models of
NoSQL allow for much higher concurrency than an
ACID-compliant RDBMS.
• Flexible Schema – Key-value pairs and JSON
documents stored in the same table do not need to be
identical in form.

Scaling RDBMS and NoSQL
Scale-Up = Vertical Scaling
• Higher costs for lower operational complexity
• At the top end, everything is proprietary
Scale-Out = Horizontal Scaling
• Lower cost through the use of commodity hardware and
software
• Operationally complex
• Sharding
• Replication

Introducing Amazon DynamoDB
DynamoDB is a fully managed, horizontally scaling
key/value and document data store:
• No infrastructure to manage
• Scaling handled transparently by the service
• Ideal for highly concurrent reads and writes of small
items

Suitable Workloads for DynamoDB
Ad-Tech
• Capturing browser cookie state
Mobile Applications
• Storing application data and session state
Gaming Applications
• Storing user preferences and application state
• Storing players’ game state
Large-Scale Websites
• Session state
• User data used for personalization
• Access control
Internet of Things
• Sensor data and log ingestion

Fundamentals of DynamoDB

Fundamentals of DynamoDB: Keys
• Partition Key – An attribute that defines how
DynamoDB will partition (i.e., shard) your data
• Sort Key – An attribute that defines how data in a
specific partition key space will be sorted on disk
• Primary Key – The partition key or combination of
partition key and sort key that uniquely identifies a single
item in a table

Fundamentals of DynamoDB: Indexes
• Local Secondary Index (LSI) – An alternate
combination of partition key and sort key that allows
atomic lookups and range queries. Stored on the same
set of partitions as the main table.
• Global Secondary Index (GSI) – An alternate partition
key or combination of partition key and sort key that
allows atomic lookups and range queries. Stored on a
different set of partitions than the main table.

Fundamentals of DynamoDB: Queries
Query – An expression for returning pages of items from a
table or index. Requires a partition key and sort key and
supports range operations (greater than, between, etc.) on
the sort key value.

Fundamentals of DynamoDB: Partitions and IOPS
Partition – A shard of data from a DynamoDB table. A
hash function is applied to the partition key values and the
value of the hash determines the partition.
The number of partitions is determined by taking the max
of the partitions required for storage, and the partitions
required for IO.

Migrating from RDBMS to DynamoDB
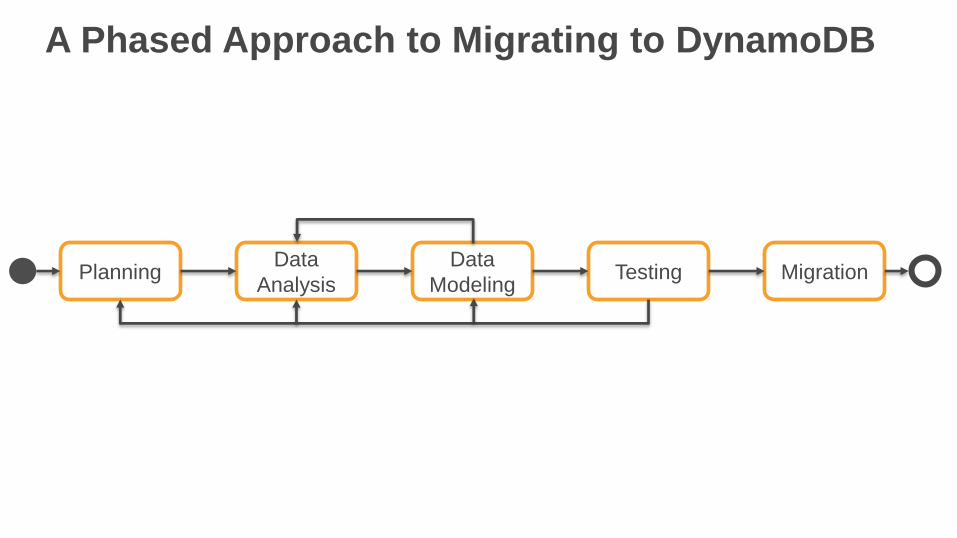
A Phased Approach to Migrating to DynamoDB
PlanningData
Analysis
Data
ModelingTesting Migration

Planning Phase
Overview
• Define goals of the migration
• Identify tables to migrate
• Document per-table challenges
• Define and document backup and restore strategies

Planning Phase
Migration goals should inform which tables to migrate:
• Look for tables with non-relational data as strong
candidates for migration
• Some examples
• Entity-Attribute-Value tables
• Application session state tables
• User preference tables
• Logging tables

Planning Phase
Clearly define and document the backup and recovery
process and the cutover and rollback procedures.
• As it relates to the migration cutover:
• If the migration strategy requires a full cutover from RDBMS
to DynamoDB, make sure to document the restore/rollback
process.
• If possible, run the workload on DynamoDB and the RDBMS
in parallel. The legacy RDBMS can be disabled after the
workload has been running on DynamoDB in production for a
suitable length of time.

Data Analysis Phase
Analysis of both the source data and application access
patterns is key to understanding the cost and performance
of running the workload on DynamoDB.
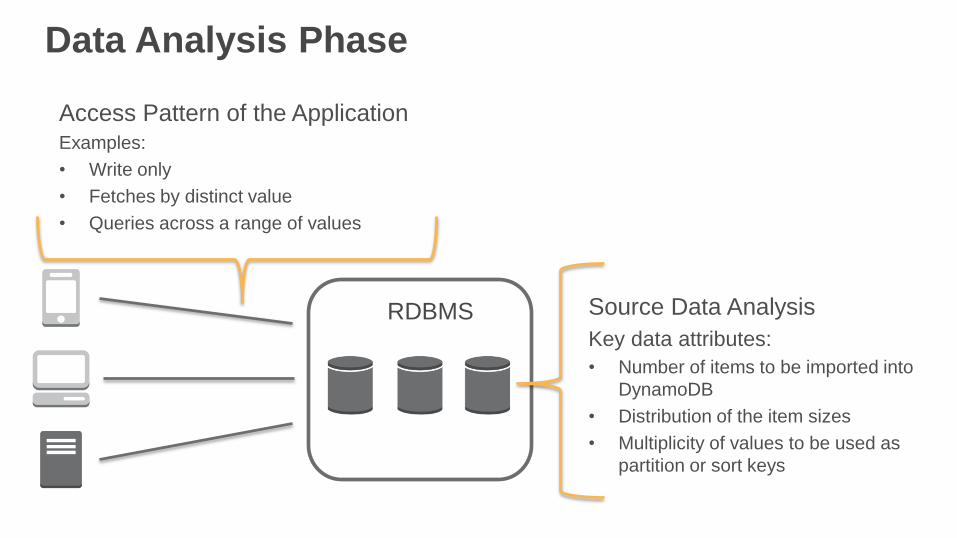
Data Analysis Phase
RDBMS Source Data Analysis
Key data attributes:
• Number of items to be imported into
DynamoDB
• Distribution of the item sizes
• Multiplicity of values to be used as
partition or sort keys
Access Pattern of the ApplicationExamples:
• Write only
• Fetches by distinct value
• Queries across a range of values
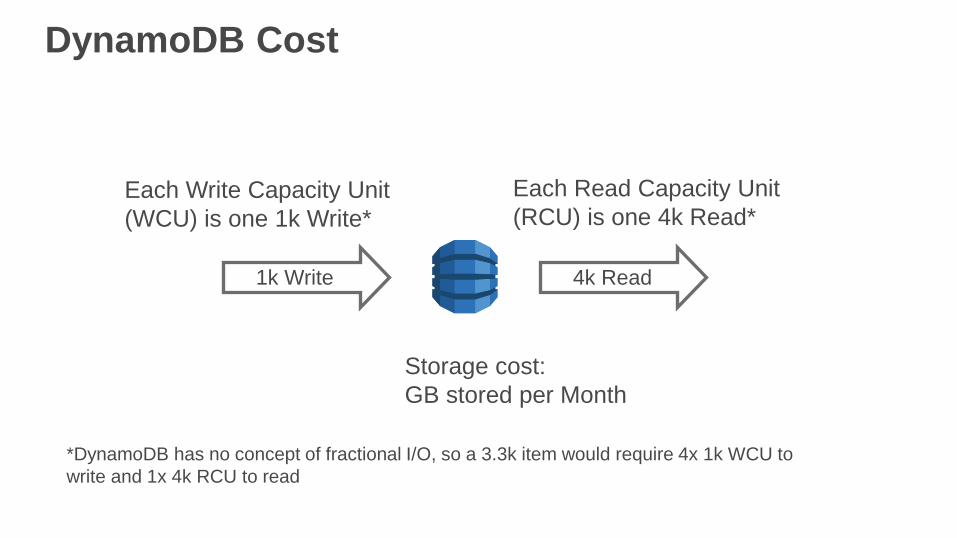
DynamoDB Cost
4k Read1k Write
Each Write Capacity Unit
(WCU) is one 1k Write*
Each Read Capacity Unit
(RCU) is one 4k Read*
Storage cost:
GB stored per Month
*DynamoDB has no concept of fractional I/O, so a 3.3k item would require 4x 1k WCU to
write and 1x 4k RCU to read

Data Modeling Phase
Choosing a good primary key for a table is crucial for
performance:
• While it is tempting to use the primary key on the source RDBMS
table, this is often not a good practice.
• For example, an RDBMS user table might have a numeric primary
key, but that key is meaningless to the application.
• In this case, the email address would be a better choice for the
DynamoDB table.

Data Modeling Phase
Primary key examples:
• For other data access patterns, such as “write only,” using a
randomly generated numeric ID will work well for the Partition key
• RDBMS tables that contain a unique index on two key values are
good candidates for a Partition + Sort key
• Time series tables often use the time as the Sort key
• For example a table tracking visits to different URLs could use the URL as
the hash key and the date as the range
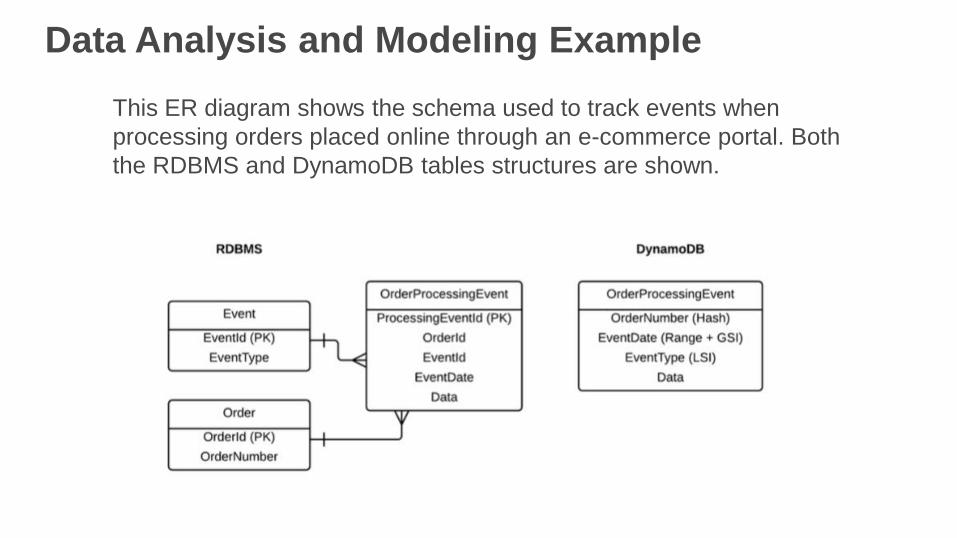
Data Analysis and Modeling Example
This ER diagram shows the schema used to track events when
processing orders placed online through an e-commerce portal. Both
the RDBMS and DynamoDB tables structures are shown.

Data Analysis Example
The statistical sampling yields a 95th percentile size of 6.6 KB
• Minimum WCU: 𝑐𝑒𝑖𝑙𝑖𝑛𝑔(6.6𝐾𝐵 𝑝𝑒𝑟 𝑖𝑡𝑒𝑚 1𝐾𝐵 𝑝𝑒𝑟 𝑤𝑟𝑖𝑡𝑒 𝑢𝑛𝑖𝑡)=7 𝑤𝑟𝑖𝑡𝑒 𝑢𝑛𝑖𝑡𝑠 𝑝𝑒𝑟 𝑖𝑡𝑒𝑚
• Minimum RCU: 𝑐𝑒𝑖𝑙𝑖𝑛𝑔(6.6𝐾𝐵 𝑝𝑒𝑟 𝑖𝑡𝑒𝑚 4𝐾𝑏 𝑝𝑒𝑟 𝑟𝑒𝑎𝑑 𝑢𝑛𝑖𝑡)=2 𝑟𝑒𝑎𝑑 𝑢𝑛𝑖𝑡𝑠 𝑝𝑒𝑟 𝑖𝑡𝑒𝑚
This particular workload is write-heavy, and we need enough IO to write 1000 events for
500 orders per day. This is computed as follows:
• 500 𝑜𝑟𝑑𝑒𝑟𝑠 𝑝𝑒𝑟 𝑑𝑎𝑦 × 1000 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 𝑜𝑟𝑑𝑒𝑟 = 5 ×105 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 𝑑𝑎𝑦
• 5 × 105 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 𝑑𝑎𝑦/86400 𝑠𝑒𝑐𝑜𝑛𝑑𝑠 𝑝𝑒𝑟 𝑑𝑎𝑦 = 5.78 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 𝑠𝑒𝑐𝑜𝑛𝑑
• 𝑐𝑒𝑖𝑙𝑖𝑛𝑔(5.78 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 𝑠𝑒𝑐𝑜𝑛𝑑 × 7 𝑤𝑟𝑖𝑡𝑒 𝑢𝑛𝑖𝑡𝑠 𝑝𝑒𝑟 𝑖𝑡𝑒𝑚) = 41 𝑤𝑟𝑖𝑡𝑒 𝑢𝑛𝑖𝑡𝑠 𝑝𝑒𝑟 𝑠𝑒𝑐𝑜𝑛𝑑

Data Analysis Example
Reads on the table happen only once per hour, when the previous hour’s data is
imported into an Amazon EMR cluster for ETL.
• This operation uses a query that selects items from a given date range (which is why
the EventDate attribute is both a range key and a global secondary index).
• The number of read units (which will be provisioned on the global secondary index)
required to retrieve the results of a query is based on the size of the results returned
by the query:
5.78 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 𝑠𝑒𝑐𝑜𝑛𝑑 × 3600 𝑠𝑒𝑐𝑜𝑛𝑑𝑠 𝑝𝑒𝑟 h𝑜𝑢𝑟 = 20808 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 h𝑜𝑢𝑟
20808 𝑒𝑣𝑒𝑛𝑡𝑠 𝑝𝑒𝑟 ℎ𝑜𝑢𝑟 × 6.6𝐾𝐵 𝑝𝑒𝑟 𝑖𝑡𝑒𝑚
1024𝐾𝐵= 134.11MB per hour

Data Analysis Example
To support this particular workload, 256 read units (GSI) and 41 write units (Table & GSI)
will be required. From a practical standpoint, the write units would likely be expressed in
an even number, like 48. We now have all of the data we need to estimate the
DynamoDB cost for this workload:
These can be run through the Amazon Simple Monthly Calculator to derive a cost estimate.
Table
1. Number of items (108)
2. Item size (7KB)
3. Write units (48)
4. Read units (2)
GSI
1. Number of items (108)
2. Item size (7KB)
3. Write units (48)
4. Read units (256)

Testing Phase
“A good programmer is someone who
looks both ways before crossing a one-
way street.” – Doug Linder

Testing Phase
During this phase, the entire migration process should be tested end-to-end.
These tests should be run and developed during the other phases because our
migration strategy is iterative. The outcome of a round of tests will often result
in revisiting a previous phase.
Testing Overview
• Basic Acceptance Test
• Functional Tests
• Non-Functional Tests
• User Acceptance Tests

Data Migration Phase
By this time, the end-to-end data migration process will have been
tested and vetted thoroughly. The steps of the process should be fully
documented and automated as much as possible. This should be a
familiar process that has been repeated numerous times in the testing
phase.
• If the migration fails for any reason, execute the rollback procedure,
which also should be well documented and tested.
• After the rollback, a root cause analysis of the failure should be
done. After the issue is identified and resolved, the migration should
be rescheduled.

Conclusion
Keys to Success
• Select a workload that is a good fit for DynamoDB
• Understand the source data and access patterns
• Test thoroughly and often
• Plan on an iterative migration process

What is PSN?
Digital entertainment service platform for PlayStation® devices
• Launched in 2006
• Features and Services
• PlayStation®Store: Online content distribution
• Online multi-play
• Social/Community
• User to user communications
• Etc.

Strategy & Principle
Always-onServices must always be available without downtime
ScalabilityNeeds to be able to scale rapidly to increase consumer demand
TestabilityEverything needs to be testable
Backwards compatibilityMust still work with legacy platforms and old clients
Establishing a common patternCreate a guiding framework migrating other services

Friends

About friends?
Friend/Social graph in PSN
Bi-directional friend relationship
• Request Friendship/Accept Request
System Characteristics
• Core system in PSN social features• Have many sub systems
• Heavy READ access
• Supporting List/Pagination in Web API• Up to 2000 friends per user
• Multi platform supports• PlayStation®4, PlayStation®3, PlayStation®Vita, PSP®, iOS, Android, and PC web
Pain points/Bottleneck of current architecture• Hard to scale out (Fixed sharding)
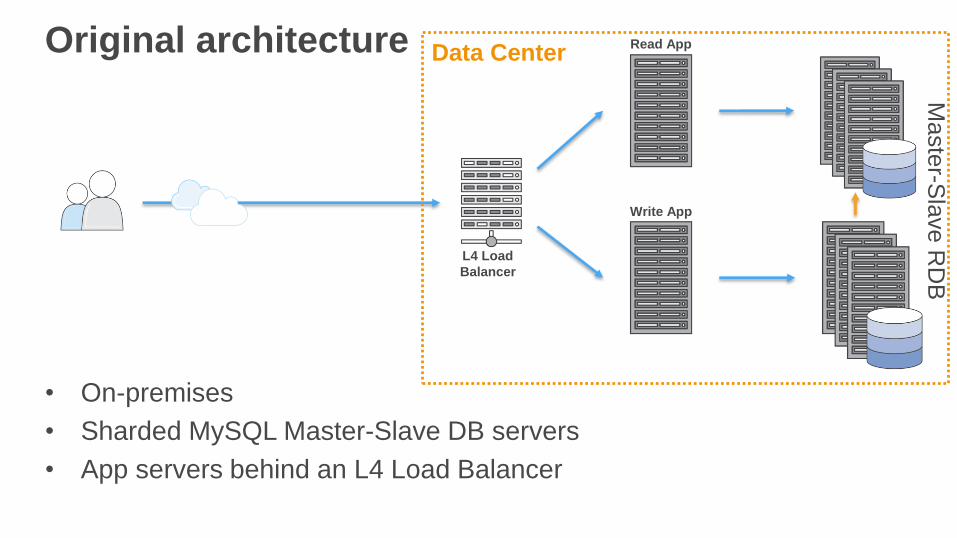
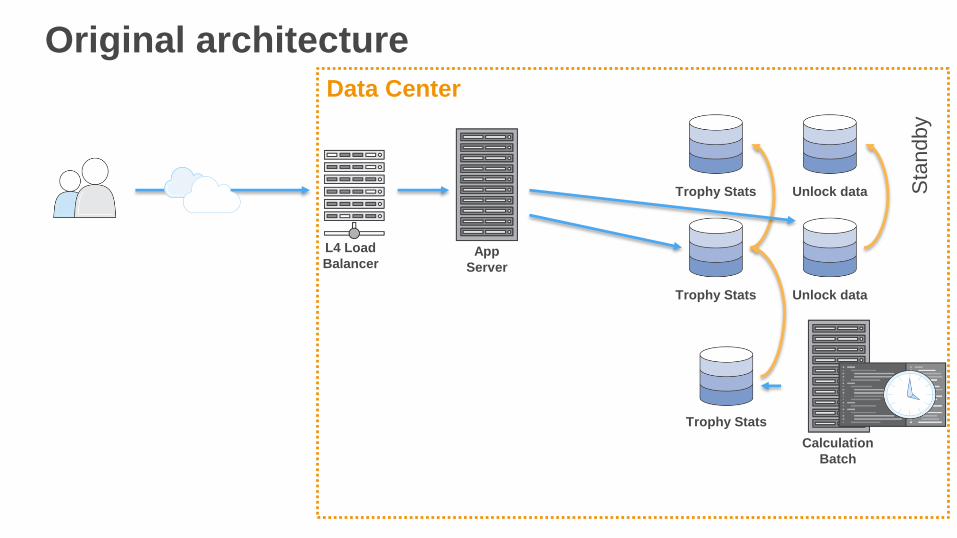
Original architectureM
aste
r-Sla
ve R
DB
Read App
Write App
L4 Load
Balancer
• On-premises
• Sharded MySQL Master-Slave DB servers
• App servers behind an L4 Load Balancer
Data Center
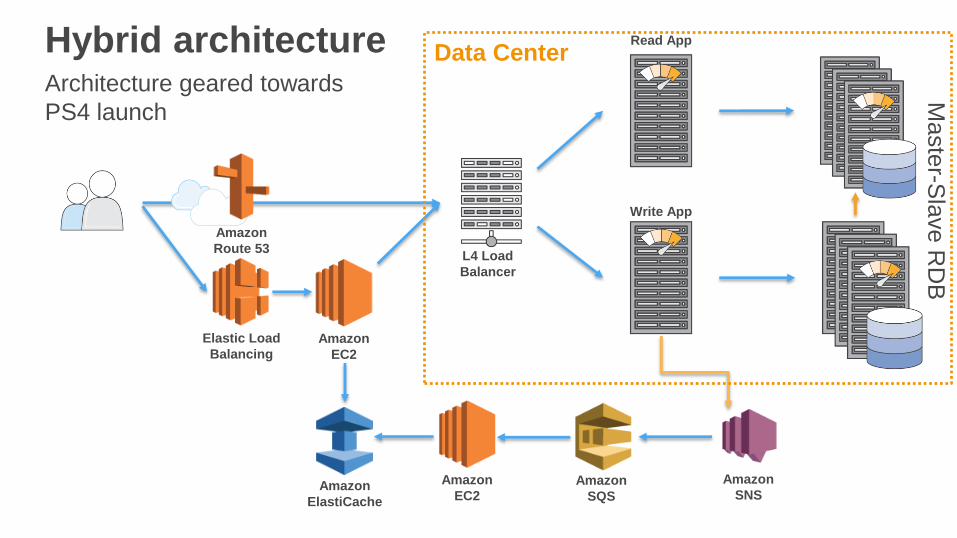
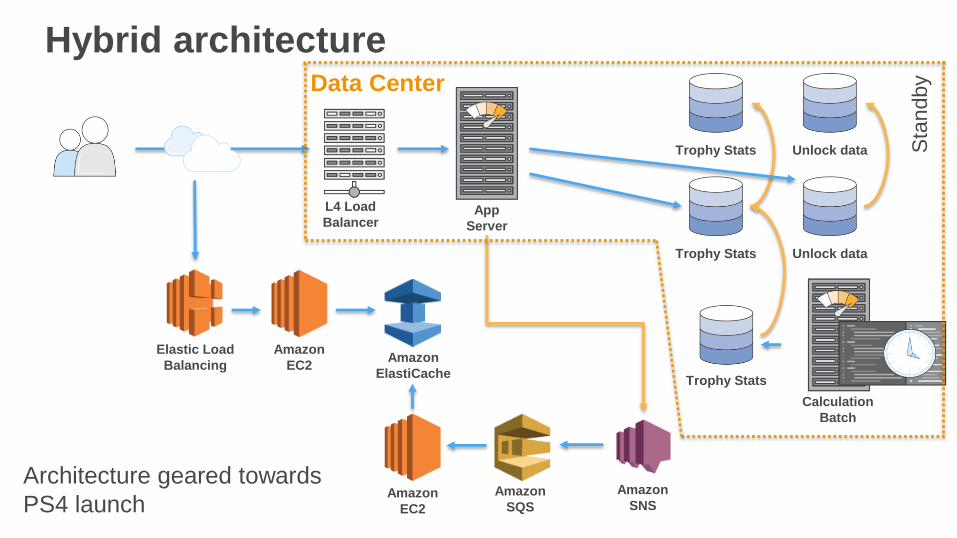
Hybrid architecture
Amazon
SNS
Maste
r-Sla
ve R
DB
Amazon
EC2
Amazon
ElastiCache
Amazon
SQS
Amazon
EC2
Elastic Load
Balancing
Read App
Write App
L4 Load
Balancer
Amazon
Route 53
Data Center
Architecture geared towards
PS4 launch
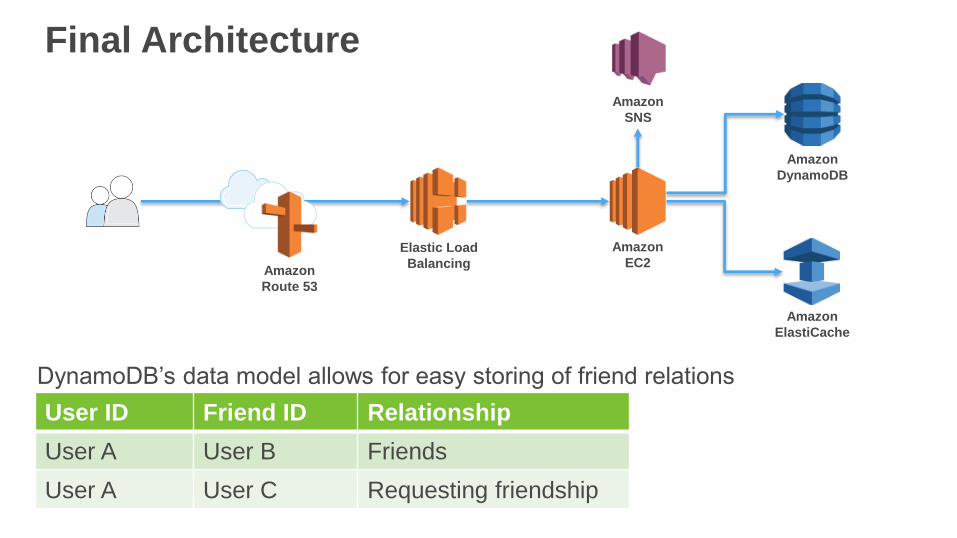
Final Architecture
Elastic Load
Balancing
Amazon
EC2
Amazon
DynamoDB
Amazon
ElastiCache
Amazon
SNS
Amazon
Route 53
User ID Friend ID Relationship
User A User B Friends
User A User C Requesting friendship
DynamoDB’s data model allows for easy storing of friend relations
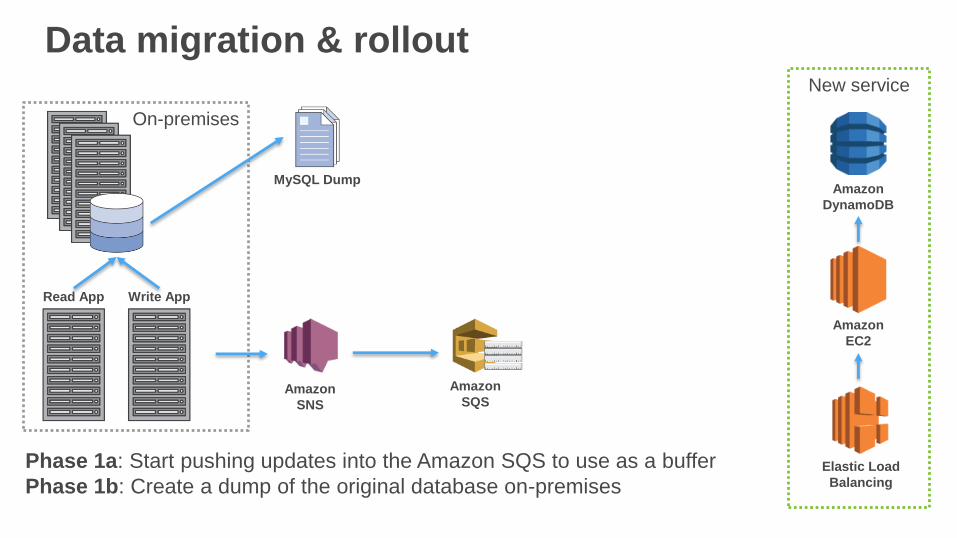
Data migration & rollout
Amazon
SNS
Amazon
SQS
Amazon
DynamoDB
Amazon
EC2
Elastic Load
Balancing
Write AppRead App
On-premises
New service
MySQL Dump
Phase 1a: Start pushing updates into the Amazon SQS to use as a buffer
Phase 1b: Create a dump of the original database on-premises
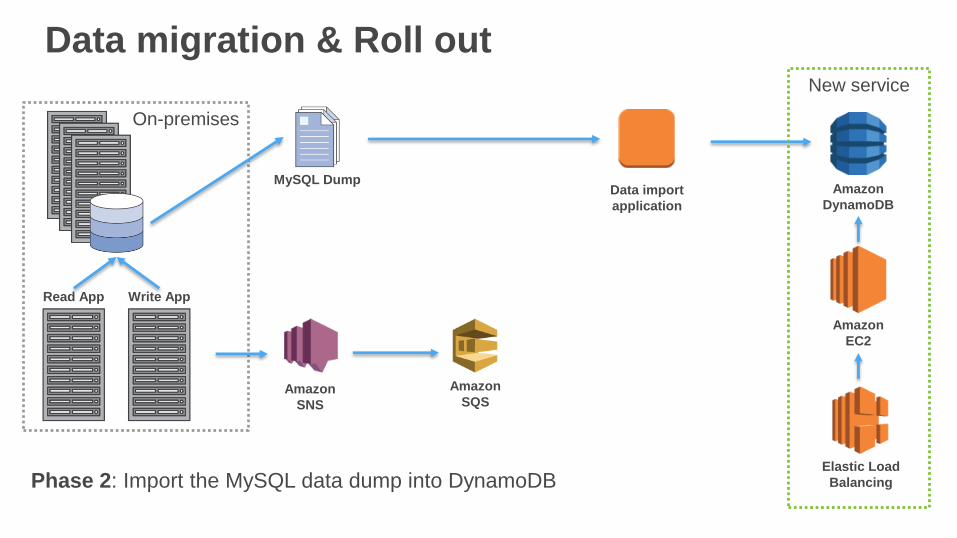
Data migration & Roll out
Amazon
SNS
Amazon
SQS
Data import
application
Amazon
DynamoDB
Amazon
EC2
Elastic Load
Balancing
Write AppRead App
On-premises
New service
MySQL Dump
Phase 2: Import the MySQL data dump into DynamoDB
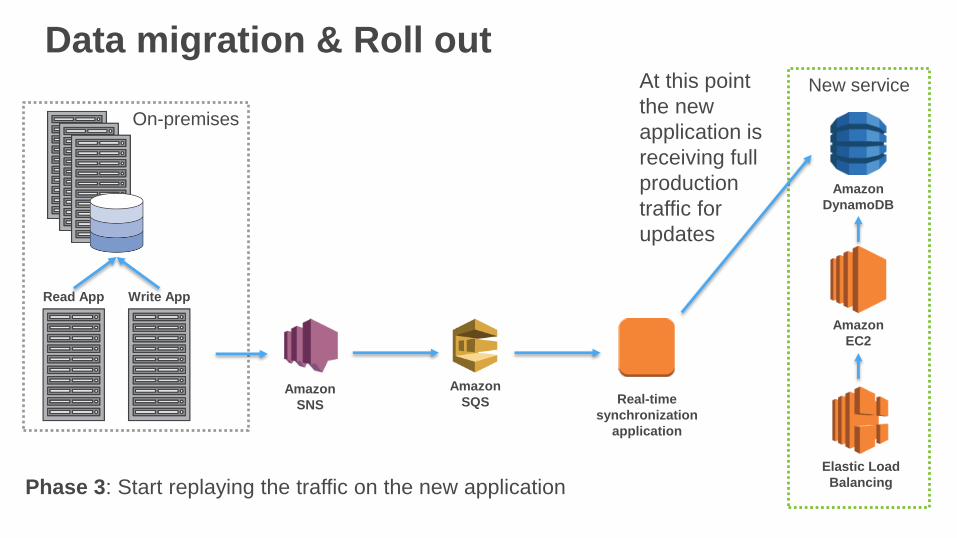
Data migration & Roll out
Amazon
SNS
Amazon
SQS
Amazon
DynamoDB
Amazon
EC2
Elastic Load
Balancing
Write AppRead App
On-premises
New service
Real-time
synchronization
application
Phase 3: Start replaying the traffic on the new application
At this point
the new
application is
receiving full
production
traffic for
updates
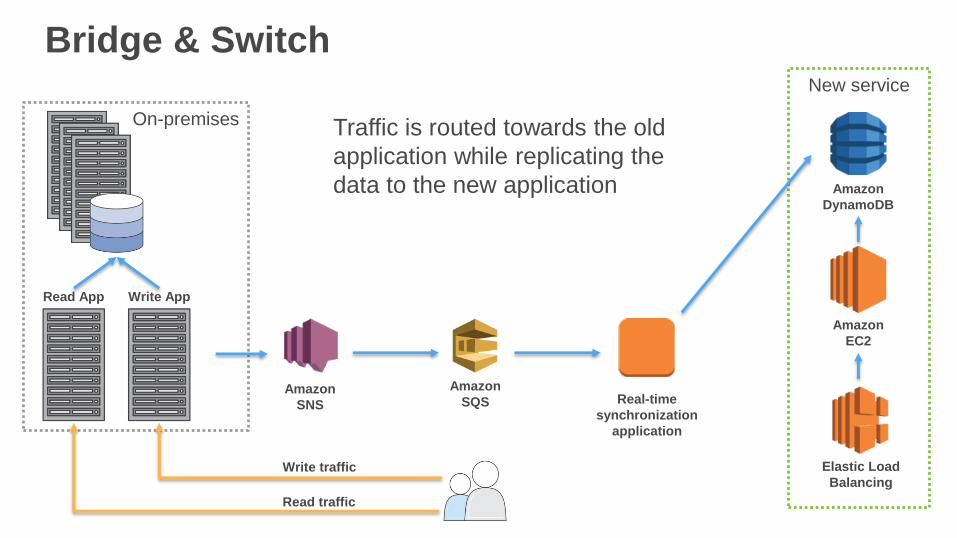
Bridge & Switch
Amazon
SNS
Amazon
SQS
Amazon
DynamoDB
Amazon
EC2
Elastic Load
Balancing
Write AppRead App
On-premises
New service
Real-time
synchronization
application
Traffic is routed towards the old
application while replicating the
data to the new application
Write traffic
Read traffic
Bridge & Switch
Amazon
SNS
Amazon
SQS
Amazon
DynamoDB
Amazon
EC2
Elastic Load
Balancing
Write AppRead App
On-premises
New service
Real-time
synchronization
application
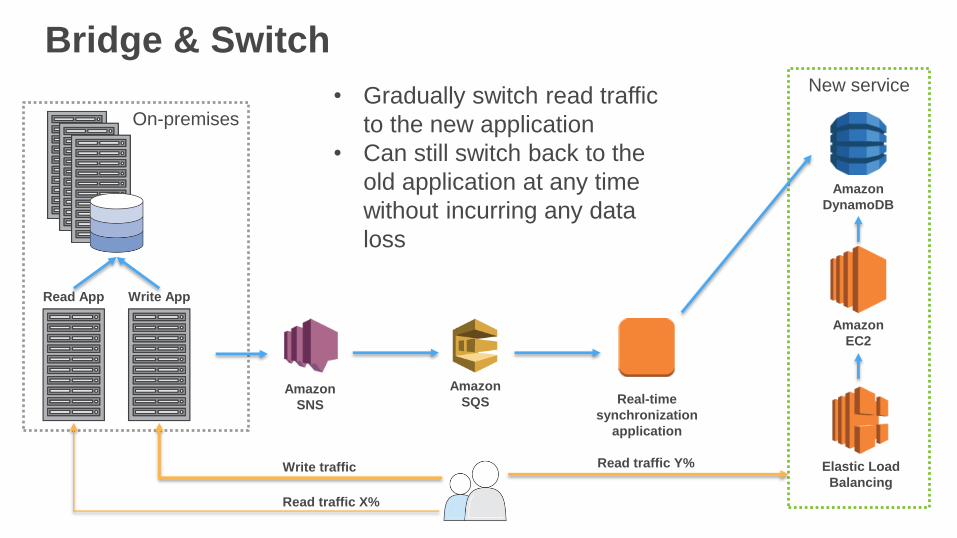
• Gradually switch read traffic
to the new application
• Can still switch back to the
old application at any time
without incurring any data
loss
Write traffic
Read traffic X%
Read traffic Y%
Bridge & Switch
Amazon
SNS
Amazon
SQS
Amazon
DynamoDB
Amazon
EC2
Elastic Load
Balancing
Write AppRead App
New service
Real-time
synchronization
application
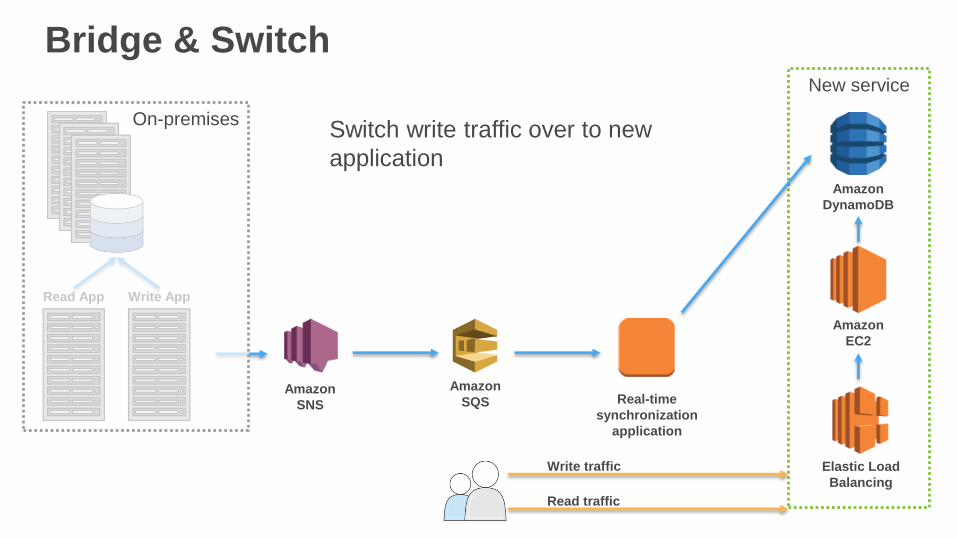
Switch write traffic over to new
application
Write traffic
Read traffic
On-premises

Trophies

About trophies?
Achievement system in PSN
System Characteristics• Simple data model
• Strict data retention
• Data aggregation required
Pain points/Bottleneck of current architecture• Limited write capacity/performance
• Complicated system architectures• Sharding/Replications
Original architecture
Sta
ndby
Unlock data
Unlock data
Trophy Stats
Trophy Stats
Calculation
Batch
L4 Load
BalancerApp
Server
Trophy Stats
Data Center
Hybrid architecture
Sta
ndby
Unlock data
Unlock data
Trophy Stats
Trophy Stats
Calculation
Batch
L4 Load
BalancerApp
Server
Amazon
SNS
Amazon
EC2Amazon
ElastiCache
Amazon
SQSAmazon
EC2
Elastic Load
BalancingTrophy Stats
Architecture geared towards
PS4 launch
Data Center
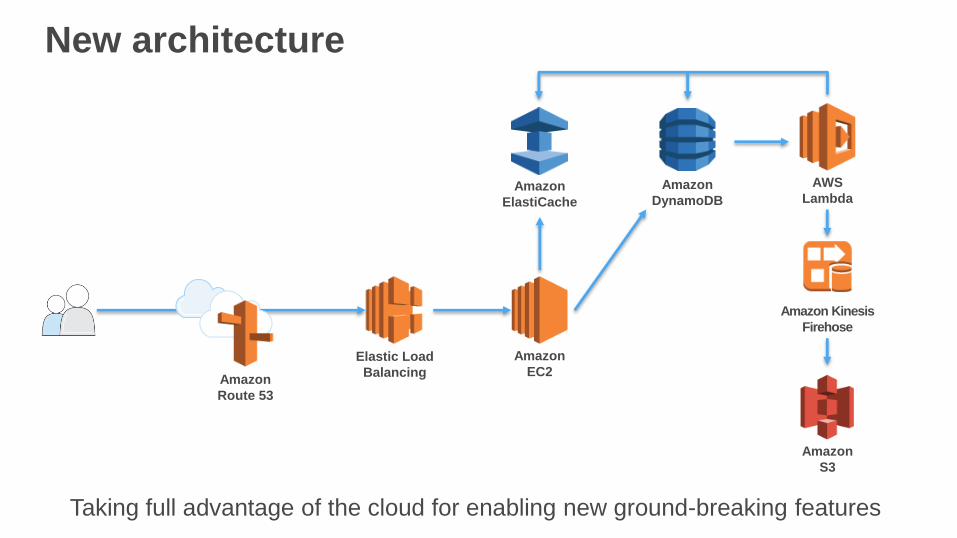
New architecture
Elastic Load
Balancing
Amazon
DynamoDBAmazon
ElastiCache
Amazon
Route 53
Amazon
EC2
AWS
Lambda
Amazon
S3
Amazon Kinesis
Firehose
Taking full advantage of the cloud for enabling new ground-breaking features
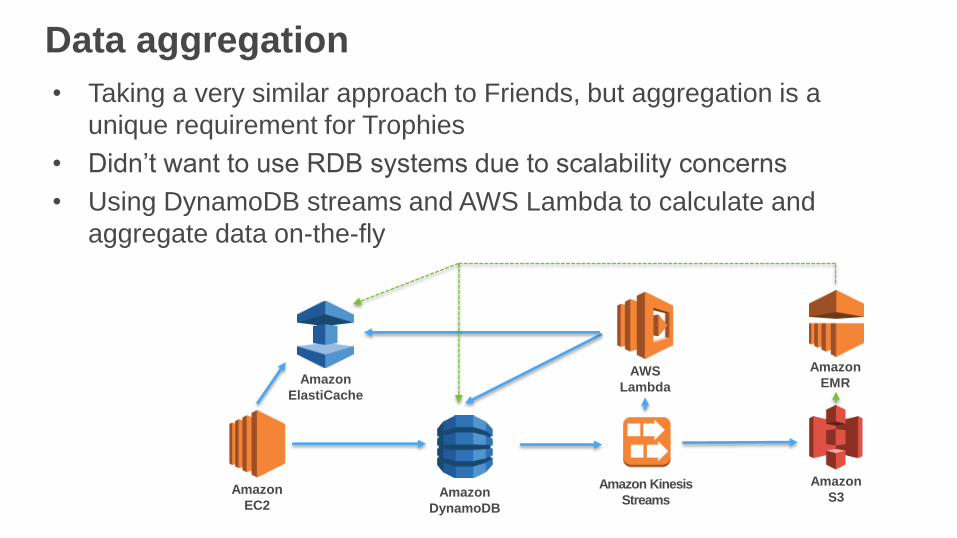
Data aggregation
• Taking a very similar approach to Friends, but aggregation is a
unique requirement for Trophies
• Didn’t want to use RDB systems due to scalability concerns
• Using DynamoDB streams and AWS Lambda to calculate and
aggregate data on-the-fly
Amazon
DynamoDB
Amazon
ElastiCache
AWS
Lambda
Amazon
EC2
Amazon Kinesis
Streams
Amazon
S3
Amazon
EMR

Challenges
• Data Integrity is a requirement
• Spent multiple days on reading back data from DynamoDB to
ensure data integrity
• DynamoDB key names
• Reducing key names from the full name (e.g. name) to a
single letter (e.g. ”n”) reduced costs by 3x times

Feature Requests
Multi-region support for DynamoDB
TTL support for DynamoDB
Redis Cluster support for ElastiCache
Multi-region support for RDS

Thank you!

We are hiring globally!

Remember to complete
your evaluations!