register packing exploiting narrow-width operands for reducing register file pressure oguz ergin*,...
Post on 20-Dec-2015
228 views
TRANSCRIPT

Register PackingRegister Packing Exploiting Narrow-Width Exploiting Narrow-Width Operands for Reducing Operands for Reducing Register File PressureRegister File Pressure
OOgguz Ergin*, Deniz Balkan, Kanad uz Ergin*, Deniz Balkan, Kanad Ghose, Dmitry PonomarevGhose, Dmitry PonomarevDepartment of Computer ScienceDepartment of Computer Science
State University of New York - BinghamtonState University of New York - Binghamton
*currently with Intel Barcelona Research Center*currently with Intel Barcelona Research Center

OutlineOutline
Introduction and motivationsIntroduction and motivations Register Packing: Register Packing:
Conservative PackingConservative PackingSpeculative PackingSpeculative Packing
Results and discussionsResults and discussions ConclusionConclusion

IntroductionIntroduction
Implications of larger instruction windowsImplications of larger instruction windows Increases register pressureIncreases register pressure Generally dealt with by using large register Generally dealt with by using large register
filesfiles Large register files have:Large register files have:
Higher access time or require multi-cycle Higher access time or require multi-cycle accessaccess
Higher energy dissipationHigher energy dissipation Need to decrease the register file Need to decrease the register file
pressurepressure

MotivationsMotivations
Many generated results have a lot of Many generated results have a lot of leading zeros or onesleading zeros or ones Fewer bits are needed to represent the Fewer bits are needed to represent the
valuevalue Register files are thus not used Register files are thus not used
efficientlyefficiently

““Narrow” ValuesNarrow” Values Prefixes of all 1s can be replaced with a Prefixes of all 1s can be replaced with a
single 1 and the prefixes of all 0s can be single 1 and the prefixes of all 0s can be replaced with a single 0.replaced with a single 0. 1111111111111111→→ 1 1 (width = 1)(width = 1) 0000000000000000→→ 0 0 (width = 1)(width = 1) 0000000100000001→→ 01 01 (width = 2)(width = 2) 1111110111111101→→ 101 101 (width = 3)(width = 3) 1010100110101001→→ 10101001 10101001 (width = 8)(width = 8)
Narrow width operands do not use the full Narrow width operands do not use the full width of a registerwidth of a register

Distribution of WidthsDistribution of Widths
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
bzi
p2
ga
p
gcc
gzi
p
mcf
pa
rse
r
two
lf
vpr
am
mp
ap
plu
ap
si art
eq
ua
ke
me
sa
mg
rid
swim
wu
pw
ise
INT
Ave
rag
e
FP
Ave
rag
e
To
tal A
vera
ge
16 bits 32 bits 48 bits 64 bits

Exploiting Narrow Exploiting Narrow ValuesValues
Packing multiple results into a single Packing multiple results into a single physical register improves physical register improves performance as the effective number performance as the effective number of physical registers go upof physical registers go up
64
32
16
48
32
64
32
1648
32

Main ChallengesMain Challenges
Value widths are not known until the Value widths are not known until the results are actually producedresults are actually produced Register allocation made to a result can Register allocation made to a result can
change if the value turns out to be change if the value turns out to be narrownarrow
Consumers of the result have to be Consumers of the result have to be informed if it is reallocated to a different informed if it is reallocated to a different register based on its widthregister based on its width
If multiple results are packed into a If multiple results are packed into a common register some means must be common register some means must be provided to locate them provided to locate them unambiguouslyunambiguously

Detecting Value WidthsDetecting Value Widths
Have to quantize the widths to simplify Have to quantize the widths to simplify implementationimplementation Chunks of bytes or double bytesChunks of bytes or double bytes
Width detection logic is embedded into Width detection logic is embedded into the final stages of an execution unitthe final stages of an execution unit Techniques for detecting widths are well Techniques for detecting widths are well
known – Leading Zero Detectors in known – Leading Zero Detectors in floating point unitsfloating point units

Storing Narrow Values in Storing Narrow Values in RegistersRegisters
Parts of a result do not need to be Parts of a result do not need to be stored contiguously. stored contiguously.
Upper half of narrow result A
Lower half of narrow result A
Upper half of narrow result B
Lower half of narrow result B
P7

Addressing Narrow Addressing Narrow ValuesValues
Use a bit mask to specify partitions Use a bit mask to specify partitions holding components of the value holding components of the value along with the register addressalong with the register address
Upper half of narrow result A
Lower half of narrow result A
Address of A = P7, 1001
P7
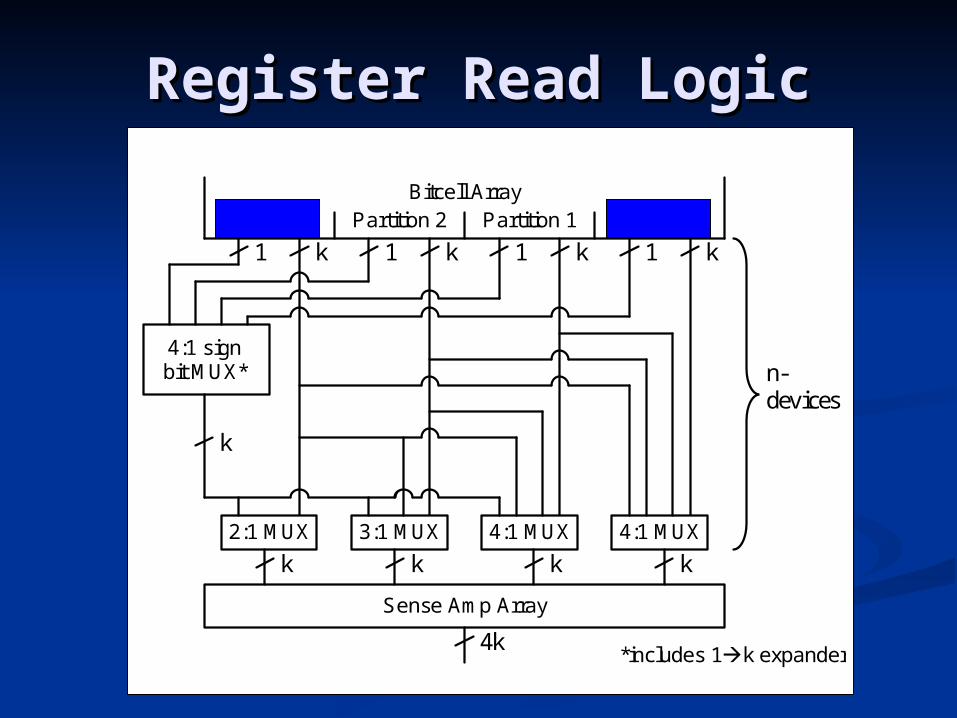
Register Read LogicRegister Read Logic
4:1 sign bit MUX* n-
devicess
1 1 k 1 k 1 k k
k
k k k k
4k
2:1 MUX 3:1 MUX 4:1 MUX 4:1 MUX
Sense Amp Array
Bitcell Array Partition 3 Partition 2 Partition 1 Partition 0
*includes 1k expander

Register Packing Register Packing AlternativesAlternatives
Conservative PackingConservative Packing Assume result to use the full width of a Assume result to use the full width of a
register at allocation timeregister at allocation time
Speculative PackingSpeculative Packing Predict the result width at allocation Predict the result width at allocation
time and allocate accordinglytime and allocate accordingly

Conservative PackingConservative Packing
Initially allocate a full-width Initially allocate a full-width registerregister
If the result turns out to be If the result turns out to be narrow:narrow: Release the unneeded parts to the Release the unneeded parts to the
free poolfree pool If there is a suitable partition: If there is a suitable partition:
reallocate.reallocate.

Conservative PackingConservative Packing
Instruction I is dispatched:Instruction I is dispatched:
P2
P5
Free Partition Allocated Partition

Conservative PackingConservative Packing
Instruction I is dispatched:Instruction I is dispatched:
P2 is allocatedP2 is allocated
P2
P5
Free Partition Allocated Partition

Conservative PackingConservative Packing
Instruction I is dispatched:Instruction I is dispatched:
Width of result = 2 slotsWidth of result = 2 slots
P5’s upper half is allocated and P2 is P5’s upper half is allocated and P2 is releasedreleased
P2
P5
Free Partition Allocated Partition

Taking Care of Taking Care of ReassignmentsReassignments
Two broadcasts are neededTwo broadcasts are needed First broadcast uses old tag (=originally First broadcast uses old tag (=originally
assigned register id) to inform dependents assigned register id) to inform dependents that the result will be available shortlythat the result will be available shortly
Second broadcast drives the old tag and Second broadcast drives the old tag and the new tag (= newly-assigned register id the new tag (= newly-assigned register id + “parts” bits)+ “parts” bits) old tag is used to locate dependentsold tag is used to locate dependents new tag picked up by matching entries and new tag picked up by matching entries and
used later to read out source value from the used later to read out source value from the register fileregister file
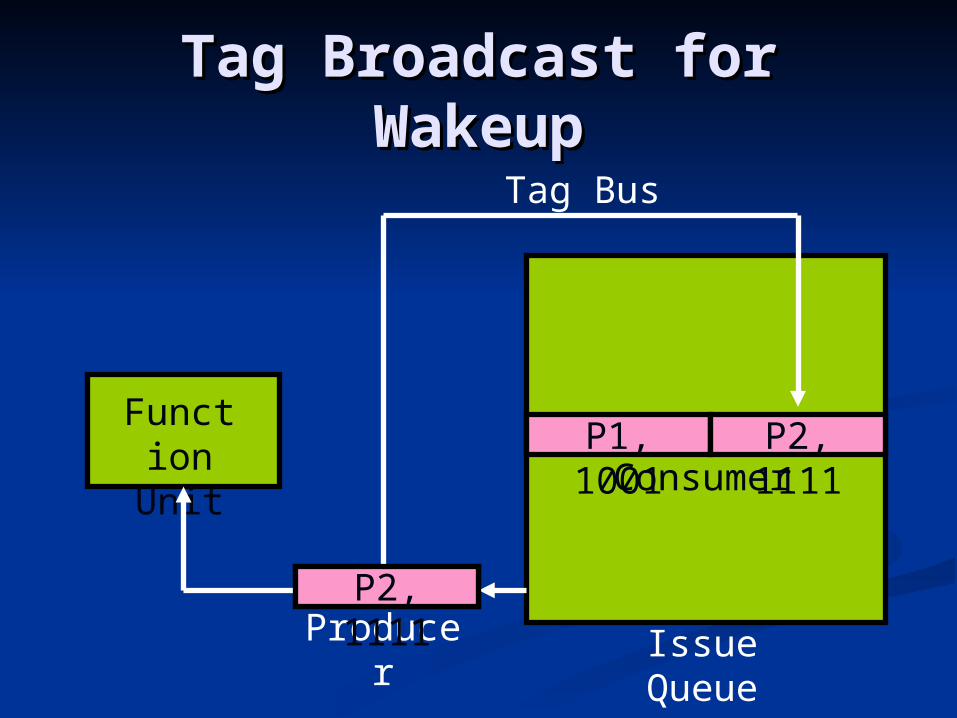
Tag Broadcast for Tag Broadcast for WakeupWakeup
P1, 1001
P2, 1111Consumer
Issue Queue
P2, 1111Produce
r
Function
Unit
Tag Bus
P2, 1111
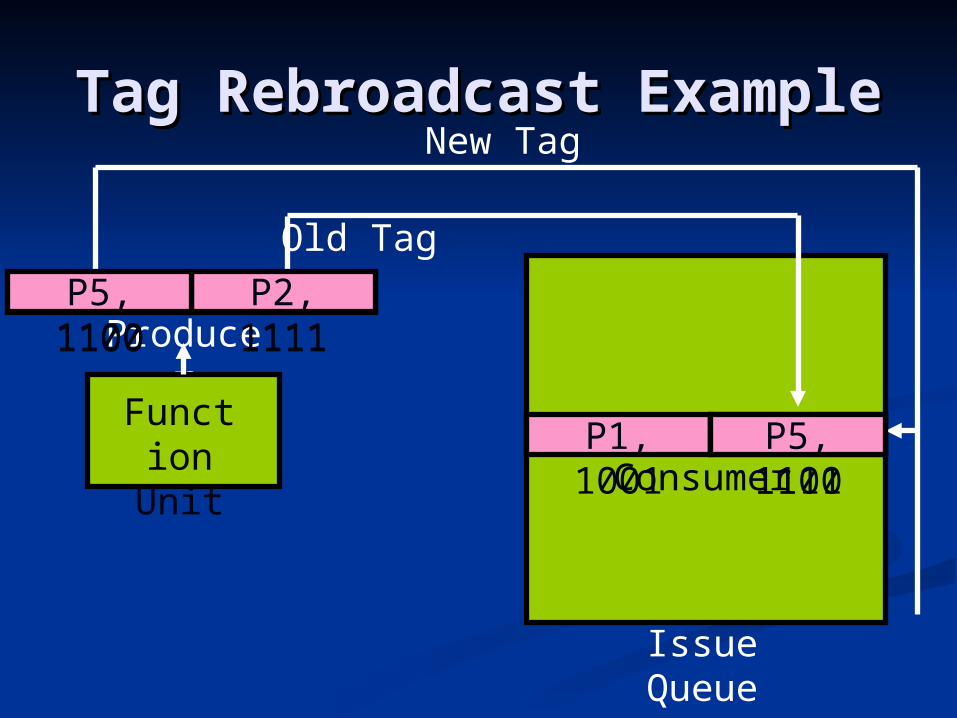
Tag Rebroadcast Tag Rebroadcast ExampleExample
P1, 1001
P2, 1111Consumer
Issue Queue
P2, 1111Produce
rFuncti
on Unit
Old Tag
P5, 1100
New Tag
P2, 1111
P5, 1100
P5, 1100
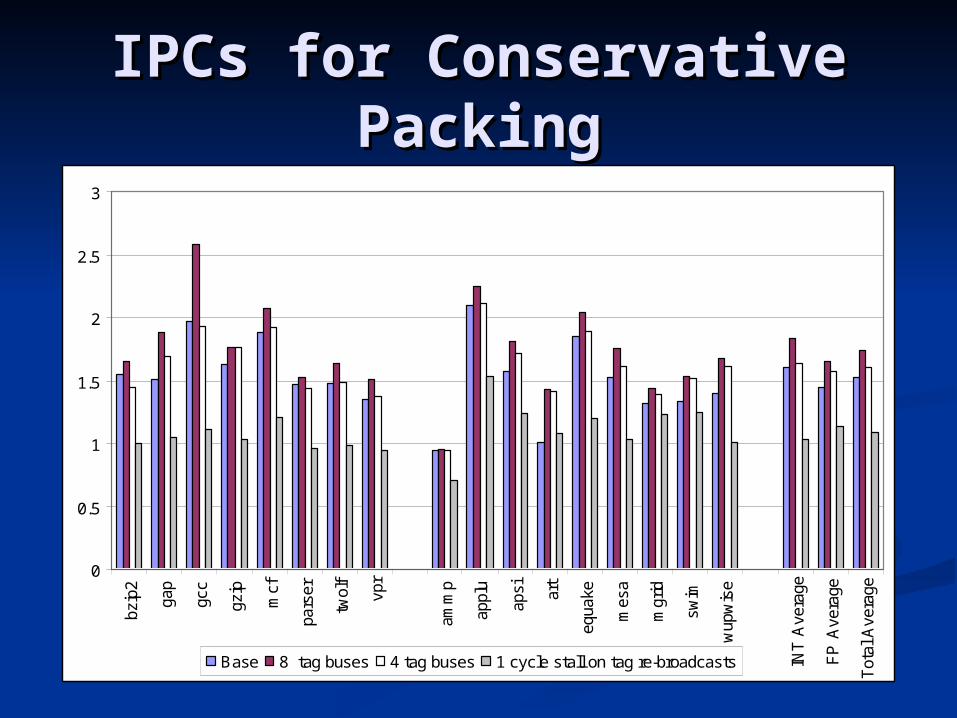
IPCs for Conservative IPCs for Conservative PackingPacking
0
0.5
1
1.5
2
2.5
3
bzip
2
gap
gcc
gzip
mcf
pars
er
twol
f
vpr
amm
p
appl
u
apsi art
equa
ke
mes
a
mgr
id
swim
wup
wis
e
INT
Ave
rage
FP
Ave
rage
Tot
al A
vera
ge
Base 8 tag buses 4 tag buses 1 cycle stall on tag re-broadcasts

Conservative Packing: Conservative Packing: ObservationsObservations
Extra broadcast is needed for all Extra broadcast is needed for all results that don’t use all of the results that don’t use all of the partitions within a registerpartitions within a register
Performance is heavily constrained Performance is heavily constrained by the number of broadcast busesby the number of broadcast buses 6% for 4 buses6% for 4 buses 14% for 8 buses14% for 8 buses -26% for 4 buses assuming an extra -26% for 4 buses assuming an extra
cycle delay for width estimationcycle delay for width estimation

Speculative PackingSpeculative Packing Predict the width of the result and Predict the width of the result and
allocate accordinglyallocate accordingly Width overprediction: two choices Width overprediction: two choices
herehere Release unused parts of register – Release unused parts of register –
rebroadcast only the parts bitsrebroadcast only the parts bits Do not release unused parts – no Do not release unused parts – no
rebroadcast is neededrebroadcast is needed Width underprediction: requires Width underprediction: requires
reallocation and an update broadcastreallocation and an update broadcast

Width PredictorWidth Predictor
Width prediction bits are maintained Width prediction bits are maintained within the L1 I-Cachewithin the L1 I-Cache
Prediction bits do no percolate down Prediction bits do no percolate down the memory hierarchy from L1the memory hierarchy from L1
Default prediction is full widthDefault prediction is full width Prediction bits are updated only on Prediction bits are updated only on
mispredictionsmispredictions

Width Prediction is Width Prediction is Accurate !Accurate !
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
bzip
2
gap
gcc
gzip
mcf
pars
er
twol
f
vpr
amm
p
appl
u
apsi art
equa
ke
mes
a
mgr
id
swim
wup
wis
e
INT
Ave
rage
FP
Ave
rage
Tot
al A
vera
ge
Prediction accuracy when counting the overpredictions as mispredictionsPrediction accuracy when counting the overpredictions as correct predictions

Deadlock AvoidanceDeadlock Avoidance
If there is a misprediction and there are no If there is a misprediction and there are no free register parts available:free register parts available: Stall writeback and waitStall writeback and wait
This can still cause a deadlock if the instruction is the This can still cause a deadlock if the instruction is the oldest in the pipelineoldest in the pipeline
Create an exception and squash all instructions Create an exception and squash all instructions younger than the instruction (including itself)younger than the instruction (including itself)
Steal a register from a younger instruction and Steal a register from a younger instruction and squash all instructions coming after the ownersquash all instructions coming after the owner

Comparison of Deadlock Comparison of Deadlock Avoidance SchemesAvoidance Schemes
0
0.5
1
1.5
2
2.5
3
bzip
2
gap
gcc
gzip
mcf
pars
er
twol
f
vpr
amm
p
appl
u
apsi art
equa
ke
mes
a
mgr
id
swim
wup
wis
e
INT
Ave
rage
FP
Ave
rage
Tot
al A
vera
ge
flush all steal from younger
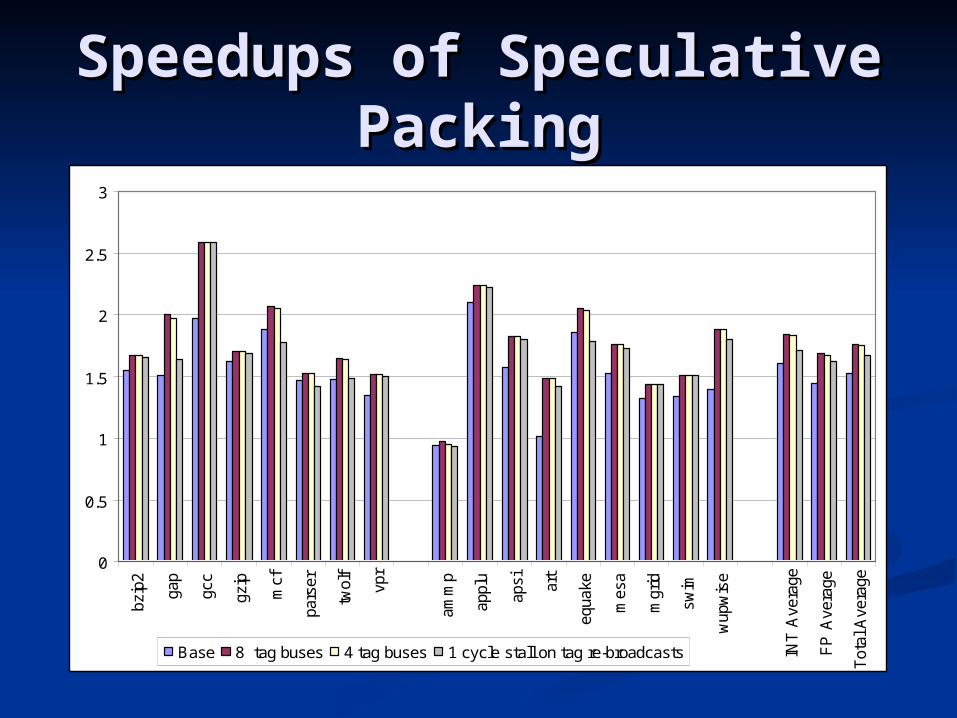
Speedups of Speculative Speedups of Speculative PackingPacking
0
0.5
1
1.5
2
2.5
3
bzip
2
gap
gcc
gzip
mcf
pars
er
twol
f
vpr
amm
p
appl
u
apsi art
equa
ke
mes
a
mgr
id
swim
wup
wis
e
INT
Ave
rage
FP
Ave
rage
Tot
al A
vera
ge
Base 8 tag buses 4 tag buses 1 cycle stall on tag re-broadcasts

Performance of Packing Performance of Packing
0
0.5
1
1.5
2
2.5
3
bzip
2
gap
gcc
gzip
mcf
pars
er
twol
f
vpr
amm
p
appl
u
apsi art
equa
ke
mes
a
mgr
id
swim
wup
wis
e
INT
Ave
rage
FP
Ave
rage
Tot
al A
vera
ge
Base 64+64 Register Packing 64+64 Base 128+128

ConclusionsConclusions
We proposed and evaluated two We proposed and evaluated two register packing schemesregister packing schemes
Because of the high number of tag Because of the high number of tag broadcasts Conservative Packing broadcasts Conservative Packing suffers in performancesuffers in performance
Speculative Packing results in 15% Speculative Packing results in 15% IPC improvement on the average IPC improvement on the average with 64 fp and 64 int registers (with with 64 fp and 64 int registers (with tag bus sharing)tag bus sharing)

Thank You !Thank You !Oguz ErginOguz Ergin
Department of Computer ScienceDepartment of Computer ScienceState University of New York - State University of New York -
BinghamtonBinghamtonwww.cs.binghamton.edu/www.cs.binghamton.edu/~~oguzoguz
Intel Barcelona Research CenterIntel Barcelona Research Center

64-bit Apps vs. 32-bit 64-bit Apps vs. 32-bit AppsApps
Can use fewer registers on 32-bit Can use fewer registers on 32-bit apps running on a 64-bit datapath: apps running on a 64-bit datapath: this this maymay result in some energy result in some energy savingssavings
See similar trends on data widths for See similar trends on data widths for 32-bit applications on 32 bit datapath32-bit applications on 32 bit datapath
Savings shown in running apps Savings shown in running apps retargeted for 64 bits PISA ISA does retargeted for 64 bits PISA ISA does have a fair number of 64 bit have a fair number of 64 bit operands in FP benchmarks, integers operands in FP benchmarks, integers holding addresses etc.holding addresses etc.

32-bit value widths32-bit value widths
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%am
mp
appl
u
art
bzip
2
equa
ke gcc
gzip
mcf
mes
a
mgr
id
pars
er
swim
twol
f
vpr
wup
wis
e
INT
FLO
AT
AV
G
32
24
16
8