prioritetskøers teoretiske og praktiske effektivitet
DESCRIPTION
Prioritetskøers teoretiske og praktiske effektivitet. Speciale af Claus Jensen Juni 2006. Samarbejdspartnere. Specialet består af tre separate dele, der er fremstillet i samarbejde med følgende personer: Jyrki Katajainen Amr Elmasry Fabio Vitale. Program. Introduktion til prioritetskøer - PowerPoint PPT PresentationTRANSCRIPT

Prioritetskøers teoretiske og praktiske effektivitet
Speciale af
Claus Jensen
Juni 2006

Samarbejdspartnere
• Specialet består af tre separate dele, der er fremstillet i samarbejde med følgende personer:– Jyrki Katajainen– Amr Elmasry– Fabio Vitale

Program
• Introduktion til prioritetskøer
• An extended truth about heaps
• An experimental evaluation of navigation piles
• A framework for speeding up priority-queue operations
• Konklusion

Introduktion til prioritetskøer
• En prioritetskø er en datastruktur, som vedligeholder et sæt af elementer, til hvert element er der knyttet en nøgle (et sådant par kaldes efterfølgende for et element)
• En minimumsprioritetskø understøtter følgende operationer:– find-min– insert– delete-min
• Minimumsprioritetskøen udvides nogle gange til også at understøtte operationer:– delete– decrease (også kaldet decrease-key)

An extended truth about heaps
• To artikler (LaMarca og Ladner 1996 og Sanders 2000) har beskrevet en eksperimentel afprøvning af hobe, men de to beskrevne eksperimenter nåede frem til forskellige resultater
• Et af formålene med de eksperimenter, der er beskrevet i specialets kapitel 2, er derfor at afdække, hvorfor denne forskel i resultaterne fremkommer
• Der er fremstillet et framework (en ramme) til at måle effektiviteten af de forskellige hobe. Dette er gjort for bedre at kunne afdække grunden til modstriden i resultaterne fra de tidligere eksperimenter
• For at få en så bred afprøvning som muligt er der brugt forskellige typer inddata og ordensfunktioner

Hobe
• En hob er et venstrekomplet træ
• Det gælder for hver gren i træet, at elementerne i en knudes børn, ud fra en given ordensfunktion, er mindre end knudens element (max hob)

Multivejshob
• Binære hobe er den type hobe, som kendes fra tekstbøgerne. En binær hob kaldes også en 2-vejs hob, og man siger, at den har en grad (degree) lig med 2 (Williams 1964)
• Det er muligt at generalisere begrebet hob til også at omfatte hobe med grader højere end 2 (Floyd 1964)
• Der er i forbindelse med specialets kapitel 2 implementeret og eksperimenteret med hobgraderne: 2-3-4
• De implementerede hobe er implicitte hobe, det betyder at elementerne opbevares i et resizable array, og der bruges indeksberegninger til navigering i hoben

Operationer
• push_heap– Basic– Two levels at a time– Binary search– Exponential binary search– Move saving

Operationer
• pop_heap– Top-down
• Basic• One-sided binary search
– Bottom-up• Basic• Two levels at a time• Binary search• Exponential binary search• Move saving

Framework
• Hobimplementeringerne er bygget op omkring et framework, dette framework er opdelt i tre moduler:– Et hobmodul, der indeholder de overordnede
funktioner. Interfacet for disse funktioner afspejler hobinterfacet i C++ standardbiblioteket
– Et utility modul med funktioner, der udfører shift up og shift down i hoben

Framework
– Et policy-baseret modul, der indeholder layout-funktioner og ”top”-funktioner
– Policy-modulets funktioner findes i to udgaver:• En generaliseret udgave• En specialiseret udgave (for en bestemt hobgrad)

Framework
• Hvorfor opbygge et framework?– Framework opbygningen gør det muligt at
sammenligne forskellige hobgrader og forskellige hobstrategier på en mere reel måde
• I forbindelse med hobgraderne ligger forskellene kun i, hvordan policy funktionerne er implementeret
• I forbindelse med hobstrategierne ligger forskellene kun i implementeringen af utility funktionerne
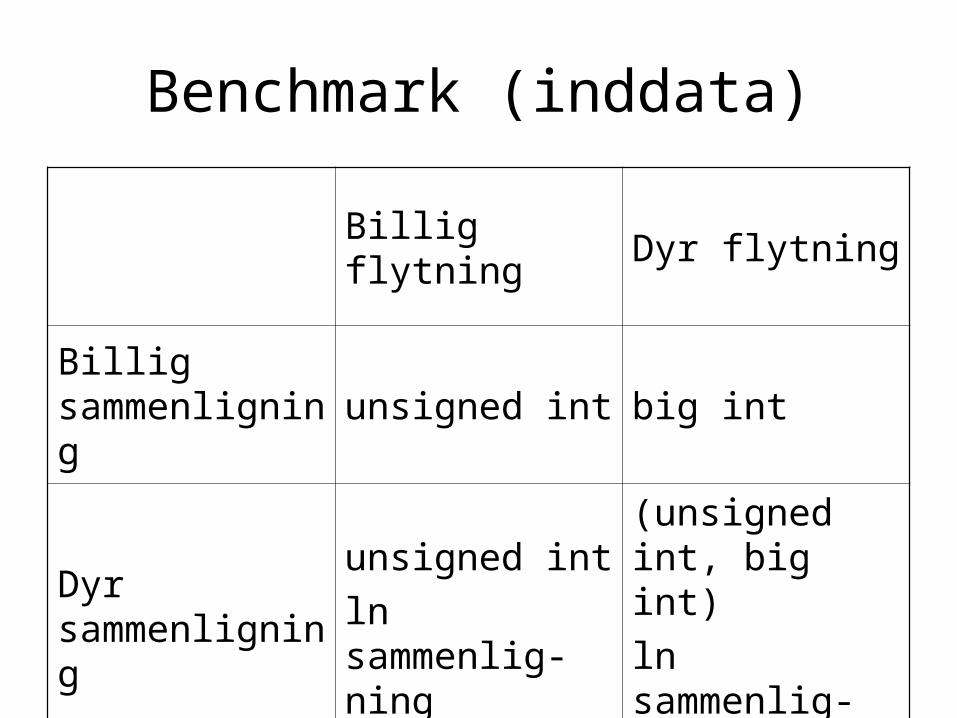
Benchmark (inddata)
Billig flytning Dyr flytning
Billig sammenligning
unsigned int big int
Dyr sammenligning
unsigned int
ln sammenlig-ning
(unsigned int, big int)
ln sammenlig-ning

Benchmark
• De implementerede hoboperationer push_heap og pop_heap blev sammenlignet med de tilsvarende operationer i C++ standardbiblioteket
• Inddata består af tilfældigt genererede tal/strenge• Sort modellen blev brugt til de eksperimentelle forsøg
(en make_heap operation efterfulgt af en serie af pop_heap operationer)
• Der blev målt CPU tid for hver operationssekvens • Miljø
– Computer: Intel Pentium 4 (1,5 GHz)– Cache level 2, 246 KB– C++ compiler, g++ 3.0.4

Benchmark (Intel P4 - 1,5 GHz)

Resultater
• De eksperimentelle resultater viser, at de modstridende resultater fra tidligere eksperimenter først og fremmest skyldes forskelle ved den måde, eksperimenterne blev gennemført
• Et andet resultat af eksperimenterne viser, at der ikke var nogen hobstrategi, som var bedst for alle inddatatyper og ordensfunktioner, men bottom-up strategien var generelt det bedste valg

An experimental evaluation of navigation piles
• Da navigation piles er en ny og eksperimentelt uafprøvet datastruktur, er det oplagt at foretage en eksperimentel afprøvning som den, der er beskrevet i specialets kapitel 3
• Samtidig er det muligt at implementere navigation piles på flere forskellige måder, hvilket gør det muligt at sammenligne forskellige strategier, som f.eks. at pakke data kontra ikke at pakke data

Navigation piles
Struktur for (statiske) navigation piles• Form
– En navigation pile er et venstrekomplet binært træ af størrelse N (kapaciteten), hvor N ≥ n (n er lig med antallet af elementer)
• Blade– Bladene bruges til at opbevare elementerne– De første n blade opbevarer et element hver, mens resten er
tomme
• Indre knude:– En indre knude indeholder en reference til det blad, der
indeholder top-elementet for den gruppe af bladene, som dækkes af den indre knude

Operationer
• Make– En navigation pile konstrueres ved at
”besøge” (visit) de indre knuder bottom-up depth-first
• Push– Et nyt element indsættes i det første tomme
blad, hvorefter de indre knuder opdateres fra det nye blad og op til roden (hvis nødvendigt).
• En binær søgestrategi kan bruges til denne opdatering

Operationer
• Top– Der returneres en reference til top-elementet for hele
datastrukturen (refereret fra roden)
• Pop– Top-elementet slettes, og en række
elementreferencer opdateres– Opdateringen kan foregå på tre forskellige måder
afhængig af de omstændigheder, som eksisterer i datastrukturen på det givne tidspunkt. Som noget nyt bruges first ancestor teknikken i forbindelse med opdateringen

Programmer
• Navigation pile datastrukturen er blevet implementeret i tre forskellige versioner– En version, der bruger en vektor til at opbevare
indeksreferencer til bladene i de indre knuder– En version, der pakker offsets på samme måde, som
det blev foreslået i den originale artikel om navigation piles (Katajainen og Vitale 2003)
– En version, der er implementeret vha. konkrete knuder, og hvor navigationen mellem knuderne foregår vha. pointere

Benchmark (inddata)
Billig flytning Dyr flytning
Billig sammenligning
unsigned int big int
Dyr sammenligning
unsigned int
ln sammenlig-ning

Benchmark
• Navigation piles blev sammenlignet med prioritetskø-implementeringen fra C++’s standardbibliotek (binær hob) og en implementering, der vha. en adapter til C++ standardbiblioteksprioritetskøen gør det muligt at understøtte referentiel integritet
• Inddata består af tilfældigt genererede tal/strenge• Der er blevet brugt følgende operationsgenerende
modeller til de eksperimentelle forsøg– Insert, peak, sort og hold
• Der blev målt CPU tid for hver operationssekvens• Miljø
– Intel Pentium 4 (3 GHz)– Cache level 2: 1 MB– C++ Compiler: g++ 3.3.4

Benchmark (Intel P4 - 3 GHz)

Resultater
• Navigation piles er et godt alternativ, hvis flytning af elementer er dyrt
• Man bør være forsigtig med at bruge pladsbesparende strategier, hvis dette giver en forøgelse af antallet af instruktioner

A framework for speeding up priority-queue operations
• Der bliver præsenteret følgende nye datastrukturer i specialets kapitel 4:– two-tier binomial queue – multipartite binomial queue– multipartite relaxed binomial queue
• Deres hovedformål er at reducere antallet af elementsammenligninger, der foretages i forbindelse med prioritetskøoperationerne (værstefaldsomkostning)

Binomiale træer
• Binomiale træer er de basale byggekloder i frameworket
• Et binomialt træ Bk hvor k ≥ 0 er et ordnet træ, der kan defineres rekursivt på følgende måde:– For k = 0 består B0 af en knude
– For k > 0 består Bk af roden og dennes k binomiale subtræer B0,…, Bk-1 i denne orden

Two-tier binomial queue
• En two-tier binomial queue består af tre komponenter:– Upper store, som er en binomial kø (Brown 1978),
hvis elementer er pointere til nuværende og evt. også til visse tidligere rødder i lower store
– Lower store, som indeholder de fleste af køens elementer
– Reservoir, som indeholder et binomialt træ, hvorfra der kan lånes knuder
• Alle de nævnte komponenter er i sig selv prioritetskøer

Two-tier binomial queue
• Node borrowing: En knude lånes fra træet i reservoiret ved, at rodens ældste barn fjernes, og den fjernede knudes børn (hvis der er nogle) sættes sammen med rodens andre børn
• Tree borrowing: Først findes træet med den højeste rang. Herefter fjernes (fraskæres) det subtræ, hvis rod er træets yngste barn. Dette træ indsættes herefter i reservoiret
• Lazy deletions: Der påsættes en markering på den valgte knude. Når antallet af ikke markerede knuder bliver lig med m/2 (hvor m er antallet af knuder), fjernes de markerede knuder vha. en trinvis global rebuilding

Two-tier binomial queue
• Find-min: De enkelte komponenters find-min operationer konsulteres, og det mindste element blandt disse vælges
• Insert: Operationen insert i lower store kaldes med det nye element. Hvis der før indsættelsen eksisterer et element med rang 0, og det nye element er mindre end dette, indsættes en pointer til elementet i upper store, og der foretages lazy delete af pointeren til den tidligere rod.

Two-tier binomial queue
• Delete-min: – Lower store: Efter roden er fjernet, lånes der en
knude, og træerne samles til et nyt træ– Upper store: Pointeren til den fjernede rod markeres
vha. lazy delete – Upper store: En pointer til den nye rod indsættes
• Delete: Knuden ombyttes (swap) op gennem træet, indtil den bliver rod i træet, derefter udføres de samme operationer som ved delete-min
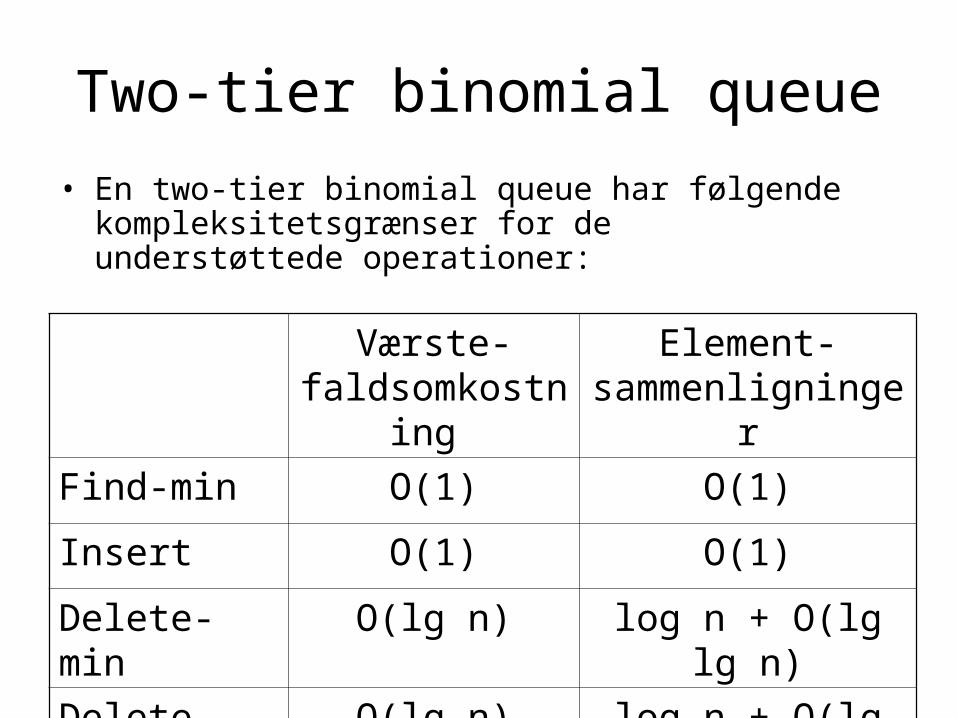
Two-tier binomial queue
• En two-tier binomial queue har følgende kompleksitetsgrænser for de understøttede operationer:
Værste-faldsomkostning
Element-sammenligninger
Find-min O(1) O(1)
Insert O(1) O(1)
Delete-min O(lg n) log n + O(lg lg n)
Delete O(lg n) log n + O(lg lg n)

Multipartite binomial queue
• En multipartite binomial kø er opbygget af fem komponenter:– Main store, der fungerer på samme måde
som lower store i two-tier binomial queue– Insert buffer, som er en binomial kø, der
vedligeholdes på en værstefalds-omkostningseffektiv måde
– Floating tree, der trinvist forenes med træerne i main store

Multipartite binomial queue
– Upper store er en cirkulær dobbelthægtet liste, der indeholder en knude pr. træ i main store. Hver knude indeholder en pointer til roden af det træ, som indeholder det mindste element blandt de elementer, der er indeholdt i træerne af mindre rang (inklusiv træet selv). Pointerne kaldes prefix-minimum pointere.
– Reservoir har samme struktur som tidligere, men ved genopfyldning hentes et træ af passende størrelse fra insert buffer

Multipartite binomial queue
• Find-min: Henter information fra forskellige komponenter: – I main store fra prefix-minimum pointeren, der
er tilknyttet træet med den største rang– Fra floating tree, hvis et sådant eksisterer– Fra insert buffer og reservoir
• Insert: Alle nye elementer indsættes i insert buffer, denne er en værstefalds-omkostningseffektiv binomial kø

Multipartite binomial queue
• Delete-min: Hvis minimum er i main store, lånes en knude fra reservoiret, og træets struktur genskabes. Herefter opdateres alle prefix-minimum pointere, der er tilknyttet træer med en rang det valgte træ
• Delete: Samme fremgangsmåde som delete-min, men knuden ombyttes (swap) med sin forælder, indtil den bliver rod i træet

Multipartite binomial queue
• Størrelsesforholdene mellem insert buffer og main store vedligeholdes i faser
• Hver fase består af:– en vedligeholdelsesoperation log n0 modificeringsoperationer
• Insert, delete-min og delete
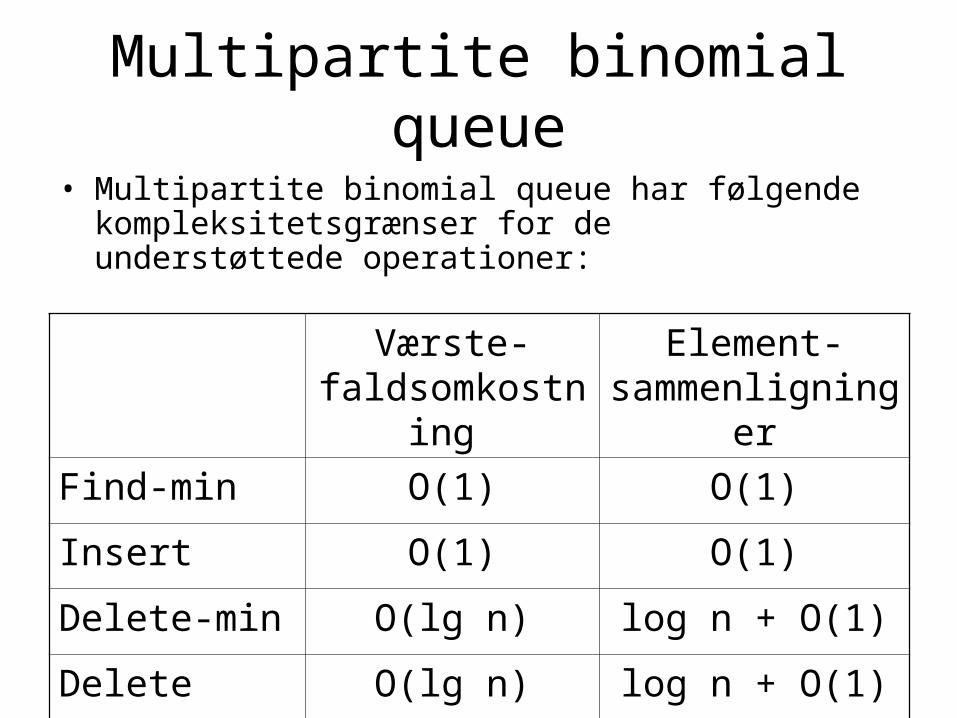
Multipartite binomial queue
• Multipartite binomial queue har følgende kompleksitetsgrænser for de understøttede operationer:
Værste-faldsomkostning
Element-sammenligninger
Find-min O(1) O(1)
Insert O(1) O(1)
Delete-min O(lg n) log n + O(1)
Delete O(lg n) log n + O(1)

Multipartite relaxed binomial queue (Relaxed binomial queue)
• Et relaxed binomial tree er et næsten hobordnet binomialt træ, hvor nogle knuder kan være aktive (de er eller har været mindre end deres forælder)
• En relaxed binomial queue understøtter operationen decrease, og antallet af aktive knuder er maximalt log n (Driscoll, Gabow, Shrairman og Tarjan 1988)
• En singleton er en aktiv knude, hvis søskende ikke er aktive
• En run er en sekvens af på hinanden følgende aktive søskendeknuder

Multipartite relaxed binomial queue
• En multipartite relaxed binomial queue er opbygget af tre komponenter, der alle er modificerede relaxed binomial queues:– Upper store, hvis knuder indeholder pointere til
følgende knuder i main store og insert buffer: • nuværende rødder og nuværende aktive knuder• tidligere rødder og tidligere aktive knuder, der kun er
markeret som slettet i upper store
– Main store, som indeholder de fleste af køens elementer
– Insert buffer

Multipartite relaxed binomial queue
• Multipartite relaxed binomial queue operationerne fungere stort set på samme måde som operationerne i two-tier binomial queue, men nu understøttes også decrease
• Komponenternes relaxed binomial queue operationer er modificeret, så de passer til frameworkstrukturen
• Modificerede operationer:– (Insert)– Delete-min– Delete

Multipartite relaxed binomial queue
• Multipartite relaxed binomial queue har følgende kompleksitetsgrænser for de understøttede operationer:
Værste-faldsomkostning
Element-sammenligninger
Find-min O(1) O(1)
Insert O(1) O(1)
Decrease O(1) O(1)
Delete-min O(lg n) log n + O(lg lg n)
Delete O(lg n) log n + O(lg lg n)

Konklusion
• Mulige forbedringer af arbejde– De andre operationsgenerende modeller end sort modellen
kunne være blevet brugt i det eksperimentelle studie beskrevet i kapitel 2
– Weight biased leftist trees kunne have været brugt i en sammenligning med navigation piles
– Prioritetskøerne i kapitel 4 er for komplicerede og kunne simplificeres
• Fremtidigt arbejde– Simplificering af multipartite relaxed binomial queue data
strukturen ved brug af en zeroless repræsentation– Implementere prioritetskøerne beskrevet i kapitel 4 (A framework
for speeding up priority-queue operations) og foretage en eksperimentel afprøvning af disse

Konklusion
• Relateret arbejde– Amr Elmasry, Claus Jensen, and Jyrki Katajainen.
Relaxed weak queues: an alternative to run-relaxed heaps. CPH STL Report 2005-2.
– Amr Elmasry, Claus Jensen, and Jyrki Katajainen. On the power of structural violations in priority queues. CPH STL Report 2005-3.
– Claus Jensen, Jyrki Katajainen, and Fabio Vitale. Experimental evaluation of local heaps. CPH STL Report 2006-1.