introduction to biocomputing - Åbo akademi · computing with dna (and other molecules) •...
TRANSCRIPT

Introduction to Biocomputing
Lecture 5: September 20, 2004Computing with bioComputing with bio--moleculesmolecules
http://http://www.abo.fi/~ipetre/biocompwww.abo.fi/~ipetre/biocomp//
September 21, 2004 1

Computing with DNA (and other molecules)
• Biomolecules: DNA, RNA, protein• Bio-tools: construct, measure, multiply, manipulate molecules• Use these tools for computing
September 21, 2004 2

Why molecular computing ?
• Objective reasons: very small, very precise, very specific, very cheap, and very energy efficient
– Energy efficiency • On the scale of 1019 ligations/J vs. a scale of 109 operations /J in electronic
computers• On the edge of what is thermodinamically possible
– Huge density of stored information• 1g DNA can store more than one trillion CDs
– Massive parallelism– Self-healing, self-sustained systems
September 21, 2004 3

Other reasons for molecular computing
• Physical boundaries for the performances of the electronic computers• Fast development of biotechnologies, genetics, and pharmaceutics• (Theoretical) Understanding the essence of computation
September 21, 2004 4

1. A METHOD FOR STORING INFORMATION
Computing is EasyComputing is Easy
2. A FEW SIMPLE OPERATIONS FOR ACTING ON INFORMATION
September 21, 2004 5

1. A METHOD FOR STORING INFORMATION
Computing is EasyComputing is Easy
2. A FEW SIMPLE OPERATIONS FOR ACTING ON INFORMATION
September 21, 2004 6

Demonstrating the potential of molecular computations
• Can DNA compute “everything” ?• Theoretical models – e.g., splicing systems
– Universality results: equivalence with Turing machines– Consequence: any algorithm can be implemented using biomolecular tools
in principle – How about in practice?
September 21, 2004 7

Demonstrating the potential of molecular computations
• Practical demonstrations– Adleman’s experiment– Satisfiability of logical formulas– Cryptanalyzing DES– Chess problems– Tic-tac-toe– Databases– DNA-based logical circuits– …
September 21, 2004 8

The beginning: Adleman’s experiment (1994)
• L.M. Adleman: Molecular computation of solutions to combinatorial problems. Science, 226, 1021-1024, 1994.
• Showed how DNA can be used to solve difficult math problems• The problem of choice: the Hamiltonian Path Problem (HPP)
September 21, 2004 9

Hamiltonian paths
• Directed graphs: set of nodes and edges (arrows) among them• Hamiltonian path from a node s to a node e: start in the node s and follow
the edges to arrive in node e, such that all the other nodes have been visited on the way exactly once
– Some graphs have Hamiltonian paths, others do not• Hamiltonian path problem (HPP): for a given graph, decide if there exists
a Hamiltonian path– Special case of the traveling salesman problem (TSP)
• Example: Adleman’s graph• Several algorithms are known, but they all have exponential complexity
in the worst case• HPP is NP-complete
September 21, 2004 10
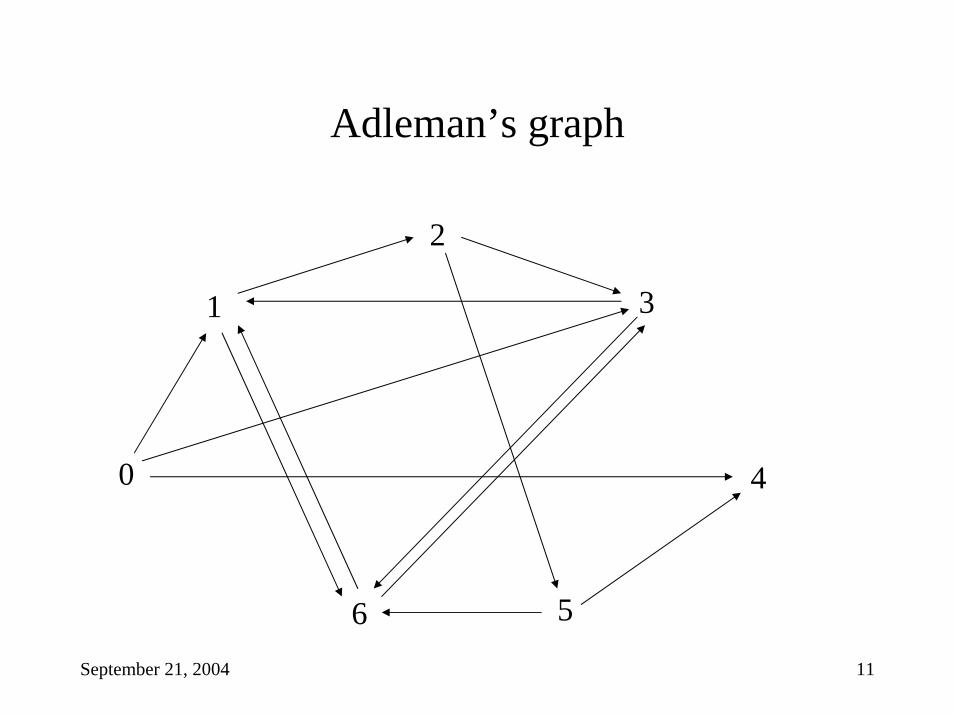
Adleman’s graph
0
1
2
3
5
September 21, 2004 11
4
6

Adleman’s graph: one path from 0 to 4 visiting all other nodes
0
1
2
3
5
September 21, 2004 12
4
6

Adleman’s graph: a Hamiltonian path from 0 to 4
0
1
2
3
5
September 21, 2004 13
4
6

Adleman’s approach to HPP
• Input: a directed graph with n nodes, vin, vout
• 1. Randomly generate paths in G• 2. Reject all paths that do not begin in vin
and do not end in vout
• 3. Reject all paths that do not involve exactly n nodes
• 4. For each node v of G, reject all paths that do not pass through v
• Output: YES if any paths remain, NO otherwise
September 21, 2004 14

Main idea
• Exhaustive search through all possible paths in G• Background engine: the massive parallelism of bio-operations
September 21, 2004 15

1. A METHOD FOR STORING INFORMATION
Computing is EasyComputing is Easy
2. A FEW SIMPLE OPERATIONS FOR ACTING ON INFORMATION
September 21, 2004 16

Experiment design: encoding the nodes
• A node: 20-mer DNA single strands2 = TATCGGATCGGTATATCCGAs3 = GCTATTCGAGCTTAAAGCTAs4 = GGCTAGGTACCAGCATGCTT
September 21, 2004 17

Experiment design: Encoding the edges
• Examples:s2 = 5’-TATCGGATCG GTATATCCGAs3 = 5’-GCTATTCGAG CTTAAAGCTAs4 = 5’-GGCTAGGTAC CAGCATGCTT
e2 3 = 3’-CATATAGGCT CGATAAGCTCe3 2 = 3’-GAATTTCGAT ATAGCCTAGCe3 4 = 3’-GAATTTCGAT CCGATCCATG
September 21, 2004 18

Experiment design: Encoding the edges
• Watson-Crick morphism h: a mapping applied on strings over the alphabet {A,C,T,G}
h(A)=T, h(T)=A, h(C)=G, h(G)=C• For a given string u, h(u) is the Watson-Crick complement of u (the single
strands u and h(u) can form a perfect duplex DNA molecule)• Note: h changes the orientation to 3’-5’• Example:
h(5’-CATTAG)=3’-GTAATC
September 21, 2004 19

Experiment design: Encoding the edges
• Each of the 7 strands for the nodes aresi=s’is”i
• Edge from i to j: 20-mer DNA strandh(s”is’j)
(i=0: s0 instead of s”0; j=6: s6 instead of s’6)
September 21, 2004 20

Experiment design: encoding paths: double strands
• A strand encoding si fuses together (annealing) with a strand encoding ei j: double strand with sticky ends
• A strand encoding sj then fuses along forming the path from i to j• It follows a strand corresponding to ej k, and one corresponding to sk,
etc.
September 21, 2004 21

Adleman’s solution to HPP
• Input: a directed graph G with n nodes, vin, vout
• 1. Generate all paths in G• 2. Reject all paths that do not begin in vin
and do not end in vout
• 3. Reject all paths that do not involve exactly n nodes
• 4. For each node v of G, reject all paths that do not pass through v
• Output: YES if any paths remain, NO otherwise
September 21, 2004 22

Step 1: Generate (all) paths in the graphs
• For each node i (except i=0,4) and each edge i j: mix large quantities of si and ei j in one single ligation reaction
• Result: DNA molecules encoding random paths– Having enough oligos we ensure having all paths with high probability
• Note: in the 1994 experiment huge scale was used (much larger than needed): each oligo present in 1013 copies
September 21, 2004 23

Step 2: Start in s0 and end in s4
• Multiply the result of Step 1• PCR with s0 and s4 as primers• Result: amplify those paths beginning in node 0 and ending in node 4
September 21, 2004 24

Step 3: Exactly 7 nodes on the path
• Run the result of Step 2 through gel electrophoresis• The 140 bp band (7 nodes on the path) excised and DNA recovered• Gel-purification and PCR• Result: paths of 7 vertices from 0 to 4
September 21, 2004 25

Step 4: All nodes are on the path
• Denature the product of Step 3: single stranded DNA• Testing: test for molecules s0
• Repeat the testing for s1, …, s4
• Amplify by PCR and run on gel• Result: molecules encoding Hamiltonian paths from 0 to 4molecules encoding Hamiltonian paths from 0 to 4
September 21, 2004 26

Discussion
• 7 days of work – the last step most time consuming (one full day)• The molecular algorithm used here is rather primitive and inefficient• The steps can be described in algorithmic way (bio-algorithm): easy to
reason
September 21, 2004 27

Scaling up the algorithm
• Quantity of oligos needed in the experiment: difficult issue• More edges: more oligos (linear growth)• More vertices: more oligos (exponential growth)• Errors: due to incorrect ligation, pseudo-paths may be formed; unlikely to
survive Step 4– One must be careful in the experiment design: choose oligos (encoding vertices)
without “too many common nucleotides” – Math: high Hamming distance• Other errors: losing the Hamiltonian path in Step 4 and getting some non-
Hamiltonian ones
September 21, 2004 28

Other practical demonstrations
• In this lecture– SAT– DES– Chess problems
• Others– Tic-tac-toe– Poker– Logical gates– Databases– Arithmetic – …
September 21, 2004 29

The SAT problem
• A logical formula u built from variables x1, x2, …, and the connectives ~, OR, &(negation, disjunction, conjunction)
– Example: u=(~x1 OR ~x2 OR x3) & (x2 OR x3) & (~x1 OR x3) & ~x3
• Truth-value assignment: f:{x1, x2, …} {0,1}• Given u, one can compute f(u)• u is satisfiable if there is a truth-value assignment f such that f makes u TRUE:
f(u)=1
September 21, 2004 30

Example
u=(~x1 OR ~x2 OR x3) & (x2 OR x3) & (~x1 OR x3) & ~x3
• f(x1)=FALSE, f(x2)=TRUE, f(x3)=FALSE– f(u)=TRUE
• f(x1)=TRUE, f(x2)=TRUE, f(x3)=TRUE– f(u)=FALSE
September 21, 2004 31

The SAT problem
• Problem: for a given logical formula u decide if u is satisfiable or not– In other terms, decide if there exists a truth assignment that makes u
TRUE• Complexity: NP-complete problem
– There is no solution essentially better than exhaustive search through all 2k possible truth assignments (k variables)
– Exponential-time complexity for the best known algorithms
September 21, 2004 32

SAT
• Simplifications (?)– Conjunctive normal form:
• Any logical formula can be written as a sequence of conjunctions u1 & u2 & u3&…& un
• Each clause ui is a sequence of disjunctions ti,1 OR ti,2 OR … OR ti,ki, with each t being a variable or the negation of a variable
• Example: u=(~x1 OR ~x2 OR x3) & (x2 OR x3) & (~x1 OR x3) & ~x3
– 3-SAT• Each clause consists of exactly 3 variables or negation of variables• Example:
u=(~x1 OR ~x2 OR x3) & (x2 OR x3 OR x4) & (~x1 OR x3 OR x5 )• 3-SAT remains NP-complete
September 21, 2004 33

Bio-algorithm for SAT
• R.Lipton, 1995: Using DNA to solve NP-complete problems• Idea
– exhaustive search, made feasible by the massive parallelism of DNA strands
• Sketch of the algorithm – generate all possible truth assignments and reject those not satisfying the
formula
September 21, 2004 34

Lipton’s approach to SAT
• Take advantage of Adleman’s idea: reduce SAT to a graph problem• Major step forward: the initial “soup” is the same for all formulas with
the same number of variables– In Adleman’s solution, different graphs need different initial “soups”
September 21, 2004 35

Lipton’s graph
• Idea: looking for truth assignments is essentially the same as finding a path in a graph
• Example:u=(~x1 OR ~x2 OR x3) & (x2 OR x3) & (~x1 OR x3) & ~x3
vin
a1FALSE
a1TRUE
a2FALSE a3
FALSE
a2TRUE a3
TRUE
v1 v2 vout
September 21, 2004 36

Lipton’s graph
• Example:u=(~x1 OR ~x2 OR x3) & (x2 OR x3) & (~x1 OR x3) & ~x3
• Looking for a truth assignment is the same as looking for a path from vin to vout
• Picking a node from top is to give FALSE to the corresponding variable, node from the bottom is to give value TRUE
September 21, 2004 37
vin
a1FALSE
a1TRUE
a2FALSE a3
FALSE
a2TRUE a3
TRUE
v1 v2 vout

Experiment design
• Vertices (nodes) encoded in 20-mer single stranded DNA• Edges: 20-mer single stranded DNA designed as in Adleman’s
experiment• Lipton encoding: produce an initial “soup” of DNA that encodes all
paths from vin to vout
– As in Adleman’s experiment • mix all single strands• Allow them to hybridize• PCR with vin and vout as primers• Result: amplify those paths starting in vin and ending in vout
September 21, 2004 38

Experiment design
• Note: – The graph is the same for all formulas with the same number of variables– The initial soup is the same for all formulas over k variables– On the other hand, the exact algorithm changes from formula to formula
September 21, 2004 39

The SAT problem
• Example: z=(x1 OR x2) & (~ x1 OR ~ x2)• The associated graph
vin
a1FALSE
a1TRUE
a2FALSE
a2TRUE
v1 vout
September 21, 2004 40

Bio-implementation
• Example: z=(x1 OR x2) & (~ x1 OR ~ x2)• Initial test tube: all possible paths from vin to vout, i.e., all possible truth
assignments• Step 1: separate those strands which satisfy the first clause of the formula: (x1
OR x2)– Either x1 or x2 must be assigned TRUE– Separate from the initial soup those DNA strands containing the sequence a1
TRUE
– Separate from the initial soup those DNA strands containing the sequence a2TRUE
– Mix the two test tubes: all the strands in the result satisfy the first clause• Step 2: from the result of step 1 (amplified by PCR) separate those strands
satisfying the second clause (~ x1 OR ~ x2)– Either x1 or x2 must be FALSE– Separate those DNA strands containing the sequence a1
FALSE
– Separate those DNA strands containing the sequence a2FALSE
– Result: Sequence the remaining DNA sequences (if any) to get all possible truth assignments satisfying the original formula
September 21, 2004 41

Complexity of the algorithm
• m clauses in the formula: m steps• k variables: at most k merge and separate• Problem: cope with the errors
– Get the result with high probability• Recent advances
– Braich, Chelyapov, Johnson, Rothemund, Adleman (2002): 3-SAT problem with 20 variables – exhaustive search through more than 1 million possible solutions
September 21, 2004 42

DES
• DES= Data Encryption Standard, 1977• Secret key cryptography• Encripts a 64 bit message using a 56 bit key• Breaking DES = finding the secret key, knowing the encryption of a
certain text
September 21, 2004 43

Breaking DES
• Classical approaches: – Differential cryptanalysis (several days on an electronic computer, needs high
number of pairs)– Dedicated hardware (expensive, specific to DES, 7 hours)– Internet-based (massive parallelism !)
• Bio-approach: it is very general (applicable to any encryption on 64 bits), 1 day of work (with some preprocessing)
September 21, 2004 44

DES algorithm
• Plain text – 64 bits; encrypted text – 64 bits; key – 56 bits, expanded to 64 bits
• Composed of 16 rounds• Each round is based on
– XOR on 48 bits– P-box: permutes the bits of the input– S-box: maps 6 bits into 4 bits based on a given table
September 21, 2004 45

Plan of an attack on DES based on DNA
• Given a function f:{0,1}m {0,1}n (e.g., the DES encryption), construct a solution Tf containing all pairs (k,f(k))
– In other terms, for a given text, encrypt that text using all possible keys– Compare then with what the system encrypts (denote E that encryption) and find
the key it uses• Separate those molecules in Tf containing E
– Result: molecules encoding (k,E) – pairs (key, encryption)
• Sequence the first half of the molecule to find the key k
September 21, 2004 46

Notes on the DES attack
• Tf depends only on the plain text M0. Denote Tf by DES(M0)• DES(M0) contains 256 DNA strands: less than one liter of water !• Having DES(M0), Eve can break many DES systems with very little cost (one
day work): generate (M0,E0) and find the key as above– Eve must be able to use the cryptosystem to encrypt M0 and then she compares the
result with her DNA database to find the key
September 21, 2004 47

Constructing DES(M0)
• Encode all possible 56-bit string into a DNA solution: less than one liter of water – Done as in Adleman’s and Lipton’s experiments – Design oligos for each bit, separated by some spacers– Allow the oligos to hybridize with each other to form all possible 56-bit strings
• Implement the primitives of the DES circuit: XOR, S-box, P-box• Apply the algorithm on all 56-bit strings in parallel• Look for the encoded text E and read the key
September 21, 2004 48

Implementing XOR gates
• XOR = exclusive OR– Definition:
a XOR b = 1 iff either a=1, or b=1, but not botha XOR b = 0 iff a and b have the same value
• Easy to prove:x XOR y = (x OR y) & (~x OR ~y)
• Already implemented in SAT– We know how to implement disjunctions and conjunctions, see Lipton’s
experiment
September 21, 2004 49

Implementing S-boxes
• S-box: essentially a function f:{0,1}6 {0,1}4
– The function f is known from the specifications of DES• f has 16 possible values• Implementation: separation• Example:
– f(z)=0000 iff z=a or z=b; – Separate from the initial soup those strands containing the sequence a– Separate from the initial soup those strands containing the sequence b– Merge the two test tubes to get all strands giving value 0000 to the function f
September 21, 2004 50

Summary of the DES attack
• Construct the initial solution, based on annealing and separation – Difficult: 4 months of work (these are old estimates, possibly less time nowadays!)
• Find the (plain_text,encrypted_text) pair– One must be able to use the encryption system ONCE
• Apply separation and sequencing on the initial solution to find the key: less than 1 day work in the lab• Virtues
– General method: applicable to any 64 bits encryption– The initial soup may be used to break any DES– Possibility to build such an initial soup and then sell it to anyone interested
• Note: technical errors not taken into account
September 21, 2004 51

A chess problem
• Place knights on a chessboard so that no knight is threatening another• Princeton University (2000): a bio-implementation based on RNA (instead of
DNA as in the other experiments shown here)– Authors: Faulhammer, Cukras, Lipton, Landweber– The problem was considered for a 3X3 chess board
September 21, 2004 52

A chess problem
• The problem: can be reduced to SAT– Associate to each square a variable that is true if and only if you place a knight on
it– Once you decide to place a knight on a square, the sqaure which are menaced by it
must remain free– Clearly, one may write a logical formula to describe the connections:((~h & ~f) OR ~a) & ((~g & ~i) OR ~b) & ((~d & ~h) OR ~c) & ((~c & ~i) OR ~d)
& ((~a & ~g) OR ~f)
September 21, 2004 53

A chess problem
• Novelty of the implementation:– Use RNA instead of DNA– Destructive approach: destroy the unacceptable solutions, rather than
separate the acceptable ones (more accurate, more likely to automate)
September 21, 2004 54

RNA implementation
• 3X3 chessboard: 10 bit strings (one for backup, the other nine for the nine squares of the board)
• Encode in RNA all possible 10 bit strings as seen in the other experiments
• To destroy a string containing 1 on position a:– If it contains 1 on position a, then the RNA molecule contains the specific
sequence we have designed for that value– Add the complementary DNA sequence that sticks to the targeted RNA
sequence (!)– Use enzyme RnaseH: chews up RNA/DNA hybrids, leaves “normal” RNA
alone
September 21, 2004 55

RNA implementation
• Example: satisfy the formula ~a OR (a & ~h & ~f)
• Divide the solution into two tubes– Tube 1
• Destroy the strings which make first clause false: destroy the strings with 1 on position a
• Add a DNA strand complementary to the RNA strand encoding a=1• Add the enzyme to destroy the hybrids
– Tube 2• Destroy the strings which make the clause false: a=0, h=1, AND f=1• Add 3 DNA strands complementary to the RNA for a=0, f=1, h=1
September 21, 2004 56

RNA implementation - results
• Out of the final solutions, 43 molecules were randomly chosen and sequenced
• 42 were correct, 1 was wrong• Altogether, 126 knights placed correctly, 1 wrong: 97.7% success rate
September 21, 2004 57

RNA computer plays chess
September 21, 2004 58

Molecular Computing – perspectives
• Over-optimism, over-pessimism • What can we compute with DNA ?
– “Killer” application is needed – challenge for computer scientists– Better algorithms than exhaustive search – same comment– We need better biotech tools to control the molecules (do they exist
already?) – challenge for biotech– Cope with the errors: impact on the size of the solutions (in number of
strands)– How much can we compute – SAT up to 70-80 variables impact on the
size of the solutions (in number of strands)
September 21, 2004 59

Molecular Computing – perspectives
• Positive side– Applications to biotechnology: e.g., a SAT implementation used to
execute Boolean queries on a “wet” database, based on some tags (IDs)– Useful in specialized environments: e.g., extreme energy efficiency or
extreme information density required– Provide the means to control biochemical systems just like electronic
computers provide the means to control electromechanical systems
September 21, 2004 60

Molecular Computing – perspectives
• Bad news– At this moment, we cannot control the molecules with the precision the
physicists and electrical engineers control electrons– Need of a breakthrough in biotechnology: more automation, more precise
techniques– Example:
• HPP may be solved nowadays on electronic computers for graphs with 13 500 nodes
• Adleman’s approach scaled up for graphs with 200 nodes needs more DNA than the weight of the Universe
September 21, 2004 61

One last thought
• Adleman: “So here it is (the cell), the most amazing tool-chest you have ever seen. We know
it is a great tool-chest, because it was used to build you and me. And even though we are very clumsy in our use of the tools right now, and even though molecular biology has made only a small portion of them available to us so far, we can already use them to build a computer. And if you can build a computer, then presumably many other exciting things can be built.
So, this is the challenge of molecular science: take the tools and build something great.”
September 21, 2004 62