implantbench: characterizing and projecting representative - bioperf
TRANSCRIPT

........................................................................................................................................................................................................................................................
IMPLANTBENCH: CHARACTERIZINGAND PROJECTING REPRESENTATIVE
BENCHMARKS FOR EMERGINGBIOIMPLANTABLE COMPUTING
........................................................................................................................................................................................................................................................
HEALTHCARE WILL ADVANCE DRAMATICALLY WHEN MICRO- AND NANOSCALE
COMPUTING CHIPS, IMPLANTED IN THE HUMAN BODY, CAN ASSIST DIGITALLY IN CLINICAL
DIAGNOSIS AND THERAPY. TO DESIGN AND ENGINEER THE NECESSARY PROCESSOR AND
ACCELERATOR ARCHITECTURES, COMPUTER ARCHITECTS MUST FIRST UNDERSTAND THE
CURRENT AND POTENTIAL WORKLOADS. IMPLANTBENCH, THE FIRST ATTEMPT AT A
REPRESENTATIVE WORKLOAD TAXONOMY, INCLUDES REALISTIC, FULL-BLOWN WORKLOADS
SPANNING SECURITY, RELIABILITY, BIOINFORMATICS, GENOMICS, PHYSIOLOGY, AND HEART
ACTIVITY.
......The idea of implanting micro- andnanoscale electronic devices in the humanbody to collect, process, and communicatebiological data for clinical and augmentativeapplications provides an exciting example ofhow the confluence of information tech-nology, biotechnology, and nanotechnologycan revolutionize healthcare in the 21stcentury. For example, a retina implantcould restore vision to people with visualimpairment (see http://artif icialretina.energy.gov). Patients with spinal cord injuries whowould otherwise be permanently paralyzedcould regain the ability to move their limbsthrough functional electrical stimulation(FES) implants and other neural prosthetics.
Individuals with memory formation deficitscould recover the ability to form newmemories using an artificial hippocampus.Implanted radio-frequency identificationchips (RFIDs) could let emergency roomcaregivers retrieve physiological characteris-tics and perform health diagnosis for uncon-scious arrivals to speed their treatment andperhaps save their lives.
The deployment status of these bioim-plantable devices is at various stages. Some,such as deep brain stimulation (DBS), FES,cochlear, and RFID implants, have beenclinically adopted or approved by the USFood and Drug Administration (FDA);others, such as retina implants and the
Zhanpeng Jin
Allen C. Cheng
University of Pittsburgh
0272-1732/08/$20.00 G 2008 IEEE Published by the IEEE Computer Society
........................................................................
71

artificial hippocampus, are still in researchand clinical-trial phases. Despite their varieddeployment status, these bioimplantabledevices share one thing: very limitedcomputing power.
As was the case with many electronicdevices in their early stages (televisions,phones, cameras, audio and video playersand recorders, and even computers), thecomputational ability of the current bioim-plantable device is very crude. This compu-tational crudeness falls broadly into twocategories:
N The overall computational tasks thatthe implant device carries out areunderrealized.
N The actual implantable parts of thedevice have very limited computingpower, if any.
Some examples of the first category ofcomputational crudeness are RFID im-plants, whose main ‘‘computing’’ ability isto store a numeric identifier, usually 128bits or less, and to transmit it upon request;DBS and FES implants, which generate andregulate electrical pulses for stimulation;and cochlear and retina implants, whichhandle the basic signal processing ofauditory and optical input. Compared tothe computing power (and the concomitantfunctional sophistication) that most modernprocessors could offer, bioimplantable de-
............................................................................................................................................................................................................................................................................
Related Work on Benchmarks
Computer architects have long used benchmark programs representative
of real programs to assess the performance characteristics and power
consumption of their processor designs. Generally speaking, the currently
existing benchmark suites fall into three categories: general-purpose
computing benchmarks, embedded-system benchmarks, and other appli-
cation-specific benchmarks.1 Here, we briefly review some of the most
significant and widely adopted benchmark suites in industry and academia.
There is no doubt that benchmark suites released by the Standard
Performance Evaluation Corporation (SPEC) are the most popular and
widely used commercial evaluation tools. To date, the SPEC CPU-series
benchmark suite has been the incontestable source for benchmarking
general-purpose computing systems.2 However, although it has gone
through several generations—from SPEC CPU1989 to SPEC CPU2006 and
beyond—SPEC still can’t be applied to all application-specific domains
without introducing redundant or irrelevant programs. We draw this
conclusion from the study conducted by Vandierendonck and De Bosschere,
who used principal component analysis (PCA) to deduct that even the well-
established SPEC CPU2000 suite included some eccentric benchmarks; that
is, it is possible to speed up the benchmarks significantly by means of an
otherwise irrelevant optimization, because the execution time of some
benchmarks is determined to a large extent by one specific bottleneck.3
Owing to this situation, a mass of application-specific benchmark suites
have emerged in the last decade. Among them, MiBench, proposed by
researchers from the University of Michigan, establishes one of the most
representative evaluation criteria for benchmarking embedded systems.4
Following the model established by the EDN Embedded Microprocessor
Benchmark Consortium (EEMBC), the MiBench benchmarks are divided into
six categories of application domains—automotive and industrial control,
consumer devices, office automation, networking, security, and telecom-
munications. Other embedded application benchmark suites include
N EEMBC, MiBench’s predecessor, which covers automotive, consumer and
digital entertainment, networking, office automation, and telecommuni-
cation applications;5
N CommBench, NetBench, and NpBench for network applications;6–8 and
N MediaBench, proposed by researchers at UCLA, for multimedia
applications.9
In addition to these, various other benchmark suites have been developed
to evaluate specific applications. Nazhandali, Minuth, and Austin developed
the SenseBench suite to facilitate evaluation of wireless sensor network
processors.10 For simulation-based computer architecture research, KleinO-
sowski and Lijia proposed the MinneSPEC benchmark workload,11 which
they derived from the standard SPEC CPU2000 workload. Other benchmark
suites include 3DMark for 3D applications,12 PacketBench for implementing
network processing applications and obtaining an extensive set of workload
characteristics,13 and PennBench for embedded Java programs.14
For the emerging interdisciplinary field of bioinformatics, two separate
research groups are proposing benchmark suites: Albayraktaroglu et al.
have proposed BioBench;15 and Bader, Li, et al. have developed BioPerf.16
Both benchmark suits are composed of bioinformatics workloads such as
DNA/RNA sequence comparison, phylogenetic reconstruction, protein
structure prediction, and sequence homology.
Thus, although numerous benchmark suites have been developed and
proposed to meet the different needs of specific application domains, to
the best of our knowledge there is no prior effort that attempts to
construct a comprehensive, representative workload taxonomy for
emergent bioimplantable computer systems. Without this workload
taxonomy, we as a community do not have the necessary exploration
vehicle with which to assess the requirements for future bioimplantable
systems. This is what led us to develop ImplantBench.
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
72 IEEE MICRO

vices currently lag behind by at least severalorders of magnitude.
The second category of computationalcrudeness is best illustrated by the trend ofloose decoupling between the control andI/O devices. For many bioimplantabledevices, only simple analog sensors oractuators are implanted within the humanbody; the critical control and processingcomponents (which are usually bulky andtethered) are left outside the body. Thisdetachment of the computational controland processing unit from the sensor oractuator peripherals can leave the entireimplant device vulnerable to many potentialmalfunctions that can considerably hinderits effectiveness, efficiency, and usability.
To address the computational crudenessof bioimplantable devices, we must answer
two important research questions: First,how can we increase total computingpower, so that a bioimplantable device notonly meets basic functional control andprocessing demands but also addressescritical issues such as reliability, security,and upgradability? Second, how can weintegrate this increased level of computingpower into the bioimplantable device whilestill satisfying the more constrained designrequirements associated with this stringentimplant platform, such as power, energy,size, thermal characteristics, and bio-com-patibility? Answering these two questionsrequires a paradigm shift; we need toholistically redesign the processor andaccelerator architectures we know todayinto forms better suited to this high-impact,high-reward domain.
References
1. J.J. Yi and D.J. Lijia, ‘‘Simulation of Computer Architec-
tures: Simulators, Benchmarks, Methodologies, and Rec-
ommendations,’’ IEEE Trans. Computers, vol. 55, no. 3,
Mar. 2006, pp. 268-280.
2. J. Henning, ‘‘SPEC CPU 2000: Measuring CPU Perfor-
mance in the New Millennium,’’ Computer, vol. 33, no. 7,
July 2000, pp. 28-35.
3. H. Vandierendonck and K. De Bosschere, ‘‘Eccentric and
Fragile Benchmarks,’’ Proc. Int’l Symp. Performance
Analysis of Systems and Software (ISPASS 04), IEEE CS
Press, 2004, pp. 2-11.
4. M.R. Guthaus et al., ‘‘MiBench, A Free, Commercially
Representative Embedded Benchmark Suite,’’ Proc. IEEE
Int’l Workshop Workload Characterization (WWC 01), IEEE
CS Press, 2001, pp. 3-14.
5. A. Weiss, ‘‘The Standardization of Embedded Benchmark-
ing: Pitfalls and Opportunities,’’ Proc. Int’l Conf. Computer
Design (ICCD 99), IEEE CS Press, 1999, pp. 492-498.
6. T. Wolf and M. Franklin, ‘‘Commbench—A Telecommuni-
cations Benchmark for Network Processors,’’ Proc. Int’l
Symp. Performance Analysis of Systems and Software
(ISPASS 00), IEEE CS Press, 2000, pp. 154-162.
7. G. Memik, W. Mangione-Smith, and W. Hu, ‘‘NetBench: A
Benchmarking Suite for Network Processors,’’ Proc. Int’l
Conf. Computer-Aided Design (ICCAD 01), IEEE CS Press,
2001, pp. 39-42.
8. B. Lee and L. Kurian John, ‘‘NpBench: A Benchmark Suite
for Control Plane and Data Plane Applications for Network
Processors,’’ Proc. Int’l Conf. Computer Design (ICCD 03),
IEEE CS Press, 2003, pp. 226-233.
9. C. Lee, M. Potkonjak, and W.H. Mangione-Smith, ‘‘Med-
iaBench: A Tool for Evaluating and Synthesizing Multimedia
and Communications Systems,’’ Proc. 30th Ann. Int’l
Symp. Microarchitecture (MICRO 97), IEEE CS Press,
1997, pp. 330-335.
10. L. Nazhandali, M. Minuth, and T. Austin, ‘‘SenseBench:
Toward an Accurate Evaluation of Sensor Network Proces-
sors,’’ Proc. Int’l Symp. Workload Characterization (WWC
05), IEEE CS Press, 2005, pp. 197-203.
11. A.J. KleinOsowski and D.J. Lijia, ‘‘MinneSPEC: A New
SPEC Benchmark Workload for Simulation-Based Comput-
er Architecture Research,’’ IEEE Computer Architecture
Letters, vol. 1, no. 1, Jan. 2002, pp. 7-10.
12. 3DMark05 Whitepaper, Futuremark, 2006; http://www.
futuremark.com/products/3dmark05.
13. R. Ramaswamy and T. Wolf, ‘‘PacketBench: A Tool for
Workload Characterization of Network Processing,’’ Proc.
Int’l Workshop Workload Characterization (WWC 03), IEEE
CS Press, 2003, pp. 42-50.
14. G. Chen et al., ‘‘PennBench: A Benchmark Suite for
Embedded Java,’’ Proc. Int’l Workshop Workload
Characterization (WWC 02), IEEE CS Press, 2002, pp. 71-
80.
15. K. Albayraktaroglu et al., ‘‘BioBench: A Benchmark Suite of
Bioinformatics Applications,’’ Proc. Int’l Symp. Perfor-
mance Analysis of Systems and Software (ISPASS 05),
IEEE CS Press, 2005, pp. 2-9.
16. D.A. Bader et al., ‘‘BioPerf: A Benchmark Suite to Evaluate
High-Performance Computer Architecture on Bioinfor-
matics Applications,’’ Proc. Int’l Symp. Workload Charac-
terization (WWC 05), IEEE CS Press, 2005, pp. 163-
173.
........................................................................
JULY–AUGUST 2008 73

Designing processor and accelerator ar-chitectures for modern computer systemsrelies heavily on the use of benchmarks.This design process typically involves mak-ing balanced trade-offs between the desiredsystem performance characteristics (speed,functionality, security, reliability, and so on)and costs (power, area, time to market,nonrecurring engineering, and so on). Thedesigner does this by iteratively ‘‘walkingthrough’’ the design space constituted bythe workload characteristics of the targetbenchmarks and the different system con-figurations and design options to beexplored. As a result, this benchmark-drivenarchitecture innovation process has madethe selection of proper benchmarks a criticalpart of the overall system design flow.
One of the biggest obstacles to architec-ture innovation in bioimplantable comput-ing is that there is currently no compilationof adequate workloads that can best repre-sent the requirements of this emergingdomain. Indeed, a variety of benchmarkshave been proposed in the past, includingDhrystone, Linpack, Whetstone, Media-Bench, MiBench, and, the most widelyused, the SPEC CPU benchmark suites.(The ‘‘Related Work on Benchmarks’’sidebar discusses these and others.) Unfor-tunately, most of these benchmark suitestarget traditional desktop and laptop, sci-entific, embedded, or multimedia systems.Although they have provided good vehiclesfor exploring conventional computer systemresearch, they do not offer representativeand significant biomedical workloads tocapture the essential evaluation milestonesto guide architecture innovation for futurebioimplantable systems. Without this rep-resentative bioimplant benchmark suite, it ispractically infeasible to make the appropri-ate performance and cost trade-offs.
The ImplantBench initiative is our firstattempt at filling this gap. Unlike tradition-al benchmark suites that aim to establish thegold-standard set of applications for whichnew architectures must be optimized, Im-plantBench is a workload taxonomy thataims to provide a higher level of abstractionfor reasoning about bioimplantable work-load requirements. Our goal is to delineateworkload requirements in a manner that is
not overly specific to individual applica-tions, so that we can draw broader conclu-sions about architecture requirements forbioimplantable processors and accelerators.Thus, we propose a set of computationalkernels, each of which captures a pattern ofcomputation common to a class of impor-tant applications that either already exist ormost likely will appear in the domain ofbioimplantable computing. To make ourworkload taxonomy approach more con-crete and tangible, we also provide somerepresentative code examples for each classof computational kernel. These codes areexamples rather than standards; we providethem mainly to reach out across thecomputer architecture community andbroaden participation in the field. Ourprojection is that many future bioimplant-able applications will combine these com-putational kernels in various ways.
In this article, we describe our compre-hensive study, characterization, compilation,and projection of a representative set ofopen-source algorithms and workloads thatare currently in use or will most likely beadopted by future bioimplantable systems.We have undertaken the necessary technicaltasks of converting, rewriting, implementing,and debugging the ImplantBench workloadsto enhance their portability from variousplatforms into the widely adopted Linux and386 research platforms. The benchmarksuite we propose can be convenientlyaccessed and used by researchers within andacross all relevant disciplines, free of charge.
We also conducted a realistic case studythat captures the essential workload charac-teristics of the included computationalkernels and demonstrates their usage withthe popular GNU development infrastruc-ture and SimpleScalar tool chains. Ourinsights and findings from the case studysuggest important design criteria that archi-tects should consider when designing pro-cessor and accelerator architectures foremerging bioimplantable systems.
ImplantBench components and descriptionsAll ImplantBench applications are coded
in high-level standard C programminglanguage and are thus compilable in mostcompiling platforms. In addition, we have
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
74 IEEE MICRO

published all the applications as eitheropen-source code or under a general publiclicense (GPL), which makes this benchmarksuite easily and publicly available to a wideuser community.
ImplantBench consists of 23 specificapplications grouped into six importantcategories: security, reliability, bioinfor-matics, genomics, physiology, and heartactivity. We based this selection on howcommonly categories of applications areused in academia, and how likely they are tobe used in the future. Moreover, Implant-Bench is flexible enough to be adjusted andimproved when new applications becomeavailable and extendable. Table 1 lists themain categories and corresponding bench-mark components, which we explain inmore detail in the following sections.
SecurityWhen smart chips are implanted in the
human body for clinical purposes, certainsensitive medical information may need tobe transferred secretly—safe from inadver-tent invasion or from deliberate access byunauthorized parties. Thus, security be-comes the first important characteristic withwhich bioimplant researchers should beconcerned.
Haval (hash algorithm with variablelength of output) is a one-way hashingalgorithm that supports 15 different levelsof security.1 Haval can produce hashes ofdifferent lengths in 128, 160, 192, 224, and256 bits, and also lets users specify thenumber of rounds to be used to generate thehash. The algorithm is very efficient andparticularly suited for real-time applica-tions.
Khazad is an iterated 64-bit block cipherwith 128-bit keys.2 It comprises eightrounds: Each round consists of eight byte-to-byte S-box parallel lookups, a lineartransformation (multiplication by a con-stant MDS diffusion matrix), and round-key addition. (MDS is an Internet authen-tication protocol.) Khazad makes heavy useof involutions as subcomponents; thisminimizes the difference between the algo-rithms for encryption and decryption,making its hardware implementation moreunified.
SHA2 functions are used to generate acondensed representation of a messagecalled a message digest, suitable for use asa digital signature.3 The SHA2 functions areconsidered more secure than those ofSHA1, with which they share a similarinterface. For this benchmark suite, wechose SHA-256 from the SHA2 functionfamily, which includes SHA-224, SHA-256, SHA-384, and SHA-512.
ReliabilityFor chips implanted in the human body,
data communication should rely chiefly onwireless techniques rather than wired con-nection, which is impractical and awkwardin this context. Information communicatedfrom and to the implanted processors mustbe checked and confirmed as correct. Thus,our benchmark suite integrates simple butalso effective reliability algorithms.
Cyclic redundancy check (CRC) is a typeof hash function that has the ability todetect errors caused by data transmission.The check increases the overall reliability ofdata transmissions to ensure that data beingstreamed has not been altered or misread.CRC-CCITT, an algorithm standardizedby the International Telephone and Tele-graph Consultative Committee (CCITT), ispreferred over many other error-checkingalgorithms because of its easy realization inbinary hardware.4
The Luhn algorithm, also known as the‘‘mod 10’’ algorithm, is a simple checksumformula used to validate a variety ofidentification numbers.5 It was created byIBM scientist Hans Peter Luhn and isdescribed in US patent 2,950,048. Its lowhardware complexity makes it suitable forlow-power implementations.
Table 1. Categories and benchmark components in ImplantBench.
Category Benchmark components
Security Haval, Khazad, SHA2
Reliability CRC-CCITT, Luhn, Hamming, Reed-Solomon, Alder-32
Bioinformatics ELO, LM-GC, UPGMA, Unger-Moult
Genomics Jensen-Shannon, HMM, Nussinov-Jacobson, Smith-Waterman
Physiology AFVP, EVAL_ST, ECGSYN, RRGen
Heart activity Activity, pNNx, CO
........................................................................
JULY–AUGUST 2008 75

Hamming code is another error-checkingand -correcting algorithm.6 Useful forinformation streaming between nodes,Hamming codes come in a variety of forms.The algorithm works for several different bitcounts. It operates by using a varied paritybit; when a parity bit is incorrect uponreading, a flag is thrown. The error is eithersimply identified, or it is corrected as well.
Reed-Solomon error correction is an error-checking and -correcting algorithm thatuses a polynomial to keep track of data.7
Similar to other error-checking and-correcting algorithms, Reed-Solomon codeis useful for data transmission and datastorage and recovery.
Adler-32, invented by Mark Adler, is achecksum algorithm for transmission errordetection.8 Compared to a CRC of the samelength, it trades reliability for speed. Adler-32 uses relatively simple processes to checkdata integrity. It was designed to overcomesome of the inadequacies of simply sum-ming all the bytes, as the original checksumdid.
BioinformaticsAs the genomics field progresses, having
accessible computational methods withwhich to extract, view, and analyze genomicinformation becomes essential. Bioinfor-
matics lets researchers sift through themassive biological data and identify infor-mation of interest. Algorithms and applica-tions in this new computational field ofbiology are now expected to be used in vivowith limited computing resources as en-hanced diagnosis assistance methods.
Evolution simulation algorithm (ELO) isan implementation of Dawkins’ program,which simulates evolution of strings andcounts the number of generations necessaryto converge to a given target string.9,10 Thealgorithm forms mutant copies of a sourcestring by changing each of its characterswith a certain probability, and then replacesthe source with one copy that agrees mostwith the target string.
Lagrange multipliers for optimality ofgenetic code (LM-GC) is a program thatuses Lagrange multipliers, a method forfinding the extrema of a function of severalvariables subject to one or more constraints,to estimate the optimization level ofstandard genetic code—an approach firsttaken by DiGiulio.10 It creates a distancematrix, whose (i, j )th entry is the fourthpower of the difference between polarrequirement of the ith amino acid andpolar requirement of the jth amino acid.
The clustering algorithms program suiteimplements variants of the unweighted pairgroup method with arithmetic mean (UP-GMA) clustering algorithm for phylogenytrees.10,11 This program suite allows thecomputation of both UPGMA andWPGMA (unweighted and weighted forms)and also implements the Farris transformeddistance method. UPGMA is a straightfor-ward method of tree construction, with theoriginal purpose of constructing taxonomicphenograms. Widely adopted in the studyof bacterial population biology, the methoduses a sequential algorithm, in which localhomology between operational taxonomicunits (OTUs) is identified in order ofsimilarity.
The Unger-Moult protein-folding algo-rithm models the physical process by whicha polypeptide folds into its characteristic 3Dstructure, shown in Figure 1.10 Unger-Moult is a genetic algorithm (with hybridMetropolis steps) implemented by Schubertand Buchetmann, for folding a protein on a
Figure 1. Schematic energy landscape for protein folding (courtesy of
Christopher M. Dobson and Nature).12
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
76 IEEE MICRO

2D lattice to maximize the number ofhydrophobic-hydrophobic (HH) contacts atunit distance (http://www.cs.bc.edu/,clote/ComputationalMolecularBiology/ungerMoult.c).
GenomicsGenomic-related programs are usually
considered computation-intensive tasks.However, some simple and preliminarygenomic analysis could be shifted toimplantable devices and implemented toserve real-time or time-urgent therapeuticapplications that automatically adapt tochanging conditions.
Hidden Markov models (HMMs) arestatistical models that were initially devel-oped for speech recognition, and havesubsequently been used in numerous bio-logical-sequence analysis applications.10,13
Current applications of HMMs in compu-tational biology include protein familiesmodeling, gene finding, transmembranehelices prediction, tertiary structure predic-tion, and others. An HMM models abiological sequence—for example, a pro-tein, DNA, or RNA sequence—as anoutput generated by a stochastic processprogressing through discrete time steps. Ateach time step, the process outputs a symbol(an amino acid or a nucleotide) and movesfrom one of a finite number of states to thenext state.14
Jensen-Shannon divergence (JSD) is ameasure of the ‘‘distance’’ between twoprobability distributions, which can also begeneralized to measure the distance (simi-larity) between a finite number of distribu-tions.10,15 JSD is a natural extension of theKullback-Leibler divergence (KLD) to a setof distributions. This program computesthe Jensen-Shannon divergence D(U, V ) fora segmentation of the whole genome W intoleft segment U and right segment V.
A common problem for researchersworking with RNA is determining the 3Dstructure of a molecule, given just thenucleic acid sequence. The Nussinov-Jacob-son algorithm (N-J) uses dynamic program-ming and backtracking to determine theoptimal RNA secondary structure by find-ing the structure with the maximumnumber of base pairs.10,16 Here, base pair
means Watson-Crick or guanine-uracil(GU) base pair varied in the code.
Smith-Waterman (S-W) is a well-knownalgorithm for performing local sequencealignment;10,17 that is, it determines similarregions between two nucleotide or proteinsequences. Instead of looking at the totalsequence, the S-W algorithm comparessegments of all possible lengths and opti-mizes the similarity measurement. Besidesimplementing Smith-Waterman local se-quence alignment using similarity matrices,this S-W program also implements globalsequence alignment (Needleman-Wunsch, aglobal alignment on two sequences pro-posed by Needleman and Wunsch in197018).
PhysiologyOne of the most important applications
of implantable chips is to collect andanalyze intrinsic physiological signals—forexample, electrocardiogram (ECG or EKG),electromyogram (EMG), and electroen-cephalogram (EEG) signals. Many of theseapplications rely heavily on advanced signal-processing techniques to break these signalsinto segments to facilitate abnormalitydetection. For instance, a typical ECGtracing of a normal heartbeat can bedecomposed into a P wave, a QRS complex,and a T wave. (The letters P, Q, R, S, and Twere originally assigned to the variousdeflections by Willem Einthoven, a NobelPrize Laureate in physiology and medicine.)Another emerging research area is tosynthesize and simulate such intrinsicphysiological signals for artificial organsand prosthetics.
Atrial fibrillation and ventricular pacing(AFVP) is a realistic ventricular rhythmmodel of atrial fibrillation (AF), generatinga synthesized beat-to-beat interval sequenceof ventricular excitations with a realisticstructure.19 The model treats the atrialventricular junction (AVJ) as a lumpedstructure characterized by refractoriness andautomaticity. Bombarded by random AFimpulses, the AVJ can also be invaded bythe ventricular-pacing-induced retrogradewave. The model also considers electrotonicmodulation by blocked impulses. Withproper parameter settings, the model can
........................................................................
JULY–AUGUST 2008 77

account for most principal statistical prop-erties of the intervals between heartbeats(known as RR intervals) during AF. Figure 2illustrates the AFVP flow.
The EVAL_ST program was developed toevaluate and compare the performance androbustness of transient ST-episode detectionalgorithms, as well as to predict real-worldclinical performance and robustness.20 (AnST episode is a transient ST-segmentdepression or elevation of at least0.10 mV.) It provides first-order (record-by-record) and second-order (aggregate,gross, and average) performance statisticsfor evaluation and comparison of transientST-episode detection algorithms. EVAL_STlets us assess an algorithm’s accuracy in
N detecting transient ST episodes,N distinguishing between ischemic and
nonischemic heart-rate-related ST ep-isodes,
N measuring durations of ST episodesand ischemic ST episodes, and
N measuring ST segment deviations.
The ECGSYN program generates asynthesized ECG signal from user-settablemean heart rate, number of beats, samplingfrequency, waveform morphology (timing,amplitude, and duration of P, Q, R, S, andT), standard deviation of the RR interval,and LF/HF ratio (a measure of the relativecontributions of the low- and high-frequen-cy components of the RR time series to totalheart rate variability).21 Using a model based
on three coupled ordinary differentialequations, ECGSYN reproduces many ofthe features of the human ECG, includingbeat-to-beat variation in morphology andtiming, respiratory sinus arrhythmia, QTdependence on heart rate, and R-peakamplitude modulation.
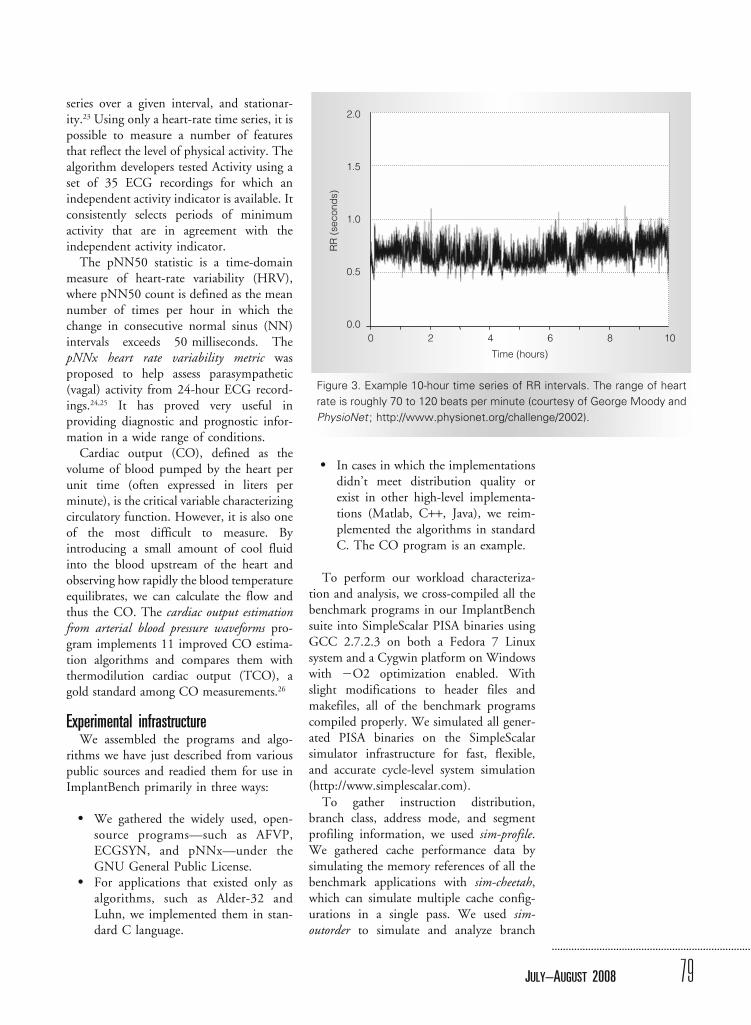
Physicians have long understood that ametronomic heart rate is pathological, andthat the healthy heart is influenced bymultiple neural and hormonal inputs thatresult in variations in heart interbeat (RR)intervals, at time scales ranging from lessthan a second to 24 hours. Given informa-tion about heart rate variability, RR Gener-ator (RRGen) was developed to simulate arealistic sequence of RR intervals.22 Al-though the intricate interdependencies ofvariations exist at different scales, RRGentries to create a simulation that is sufficient-ly realistic to mislead an experiencedobserver to some extent. Figure 3 shows a10-hour time series of RR intervals.
Heart activityCardiovascular disease claims more lives
yearly than cancer does. Thus, we selectedthree representative programs that record,analyze, evaluate, and diagnose heart activ-ity, and we set a separate category forcardiologic-relevant applications.
Activity, a tool for activity estimationfrom instantaneous heart rate, was devel-oped for deriving an ‘‘activity index’’ basedon measurements of mean heart rate, totalpower of the instantaneous heart-rate time
Figure 2. Schematic flow of AFVP model (courtesy of Jie Lian).
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
78 IEEE MICRO
series over a given interval, and stationar-ity.23 Using only a heart-rate time series, it ispossible to measure a number of featuresthat reflect the level of physical activity. Thealgorithm developers tested Activity using aset of 35 ECG recordings for which anindependent activity indicator is available. Itconsistently selects periods of minimumactivity that are in agreement with theindependent activity indicator.
The pNN50 statistic is a time-domainmeasure of heart-rate variability (HRV),where pNN50 count is defined as the meannumber of times per hour in which thechange in consecutive normal sinus (NN)intervals exceeds 50 milliseconds. ThepNNx heart rate variability metric wasproposed to help assess parasympathetic(vagal) activity from 24-hour ECG record-ings.24,25 It has proved very useful inproviding diagnostic and prognostic infor-mation in a wide range of conditions.
Cardiac output (CO), defined as thevolume of blood pumped by the heart perunit time (often expressed in liters perminute), is the critical variable characterizingcirculatory function. However, it is also oneof the most difficult to measure. Byintroducing a small amount of cool fluidinto the blood upstream of the heart andobserving how rapidly the blood temperatureequilibrates, we can calculate the flow andthus the CO. The cardiac output estimationfrom arterial blood pressure waveforms pro-gram implements 11 improved CO estima-tion algorithms and compares them withthermodilution cardiac output (TCO), agold standard among CO measurements.26
Experimental infrastructureWe assembled the programs and algo-
rithms we have just described from variouspublic sources and readied them for use inImplantBench primarily in three ways:
N We gathered the widely used, open-source programs—such as AFVP,ECGSYN, and pNNx—under theGNU General Public License.
N For applications that existed only asalgorithms, such as Alder-32 andLuhn, we implemented them in stan-dard C language.
N In cases in which the implementationsdidn’t meet distribution quality orexist in other high-level implementa-tions (Matlab, C++, Java), we reim-plemented the algorithms in standardC. The CO program is an example.
To perform our workload characteriza-tion and analysis, we cross-compiled all thebenchmark programs in our ImplantBenchsuite into SimpleScalar PISA binaries usingGCC 2.7.2.3 on both a Fedora 7 Linuxsystem and a Cygwin platform on Windowswith 2O2 optimization enabled. Withslight modifications to header files andmakefiles, all of the benchmark programscompiled properly. We simulated all gener-ated PISA binaries on the SimpleScalarsimulator infrastructure for fast, flexible,and accurate cycle-level system simulation(http://www.simplescalar.com).
To gather instruction distribution,branch class, address mode, and segmentprofiling information, we used sim-profile.We gathered cache performance data bysimulating the memory references of all thebenchmark applications with sim-cheetah,which can simulate multiple cache config-urations in a single pass. We used sim-outorder to simulate and analyze branch
Figure 3. Example 10-hour time series of RR intervals. The range of heart
rate is roughly 70 to 120 beats per minute (courtesy of George Moody and
PhysioNet ; http://www.physionet.org/challenge/2002).
........................................................................
JULY–AUGUST 2008 79

predictions and dynamic execution perfor-mance. We will distribute the detailedconfiguration information along with theImplantBench release.
As for the use of ImplantBench, Table 2provides an instruction summary for allImplantBench benchmarks, including thecommand line executables and their argu-ments. We will provide the detailed com-mand line usage in the source distribution.
Results and insightsHere, we offer both high-level qualitative
analyses and detailed quantitative evaluationto characterize the ImplantBench workloadsvia cycle-level system simulation.
Benchmark component analysisBecause we used the SimpleScalar simu-
lator to simulate the entire ImplantBench
suite, it is feasible to gather the full dynamicinstruction trace cycle by cycle. For ourbenchmark program simulation, we usedmoderate input data sets, striking a balancebetween dynamic runtime and how well thedata sets represent real workloads. Table 3shows that—except in the reliabilitygroup—the total number of dynamic in-structions simulated for the ImplantBenchprograms are in the range of hundreds ofmillions, with a maximum greater than twobillion dynamic instructions.
In the reliability group, because bioim-plantable systems should be ultralow-powerand energy efficient due to the extremelylimited energy provided by either batteriesor scavenge energy, our design objective isto maintain the necessary reliability as muchas possible with minimal power consump-tion overhead. That is, we attempted to
Table 2. Summary of ImplantBench execution commands.
Application Execution command
CRC-CCITT crc [options] ,filename.
Luhn luhn ,input value strings.
Hamming Hamming ,filename.
Reed-Solomon rs [options] ,filename.
Alder-32 Alder ,filename.
Haval haval [-c| -e| -s] ,filename.
Khazad khazad ,number.
khazad [options] ,filename.
SHA2 sha [options] ,filename.
ELO evolution ,strings. ,number of generations.
LM-GC digiulio ,polarity_vector_file. [v1|v2|v3|v4|v5]
UPGMA multipleGotoh ,filename.
phy5 ,filename. -t/u/w
Unger-Moult ungerMoult ,filename.
HMM markov ,filename.
hmm2 ,number.
Jensen-Shannon jensenShannon ,filename.
Nussinov-Jacobson rnaMaxNumBasePairs RNAnucleotideString
Smith-Waterman smithWaterman protein1 protein2 PAM gapPenalty
AFVP afvp ,config_file. ,random number seed.
EVAL_ST eval_st –r ,database._,algorithm..evl ,record. -[i|s]
eval_st –a ,database._,algorithm..evl –[i|s] [-e|-b [NR_TRIALS]]
ECGSYN ecgsyn [options] ,input values.
RRGen rrgenv3 seed [tmax] P,ectopy. P,noise.
Activity activity [options] ,‘len’ values. ,instantaneous heart rate file.
pNNx pNNx –r ,record name. -a ,annotator name. pnnlist , ,interval list.
Cardiac output evco ,input file.
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
80 IEEE MICRO

select useful and efficient algorithms withminimum energy consumption require-ments. We chose the programs for thereliability category from a large pool ofcandidates, some of which might offerbetter protection than those included. Theprimary reason for not including such otherprograms at this point is that the powerrequirement they impose is simply largerthan we can afford. Therefore, the totalnumber of dynamic instructions simulatedfor each respective category is sufficient forthe purpose of our workload characteriza-tion analyses.
Instruction class distribution analysisThere are four main classes of instruc-
tions: memory (load and store), integeroperations, floating-point operations, andcontrol (unconditional and conditionalbranches). Control-intensive applicationsspend many more operations on branchcontrol, and correspondingly execute morebranch-related instructions. Similarly, inI/O-intensive applications, frequent dataaccess and transmission from memory aredominant in all operations, so load andstore instructions occupy the largest portionin the instruction distribution. Computa-tion-intensive programs have a larger per-centage of integer or floating-point ALUoperations for specific applications. Fig-ure 4 shows the instruction distribution ofall the ImplantBench programs.
This figure demonstrates some distinctivecharacteristics of the benchmark suite. Thesecurity benchmarks spent more than 70percent of their total runtime in executinginteger computations. This is because mostof the processing required for secureencryption and decryption consists ofrepeated computational operations on thesame set of integer data. However, securitybenchmarks also have the least branchcontrol operations among all the programs,because of their relatively easier programcontrol structure.
Compared with the security programs,the reliability benchmarks have more loadand store operations: Memory access oper-ations account for approximately 40 percentof all executed instructions. This is becausemost of these programs must frequently
obtain an input data stream from memory,perform data integrity checks and correc-tions, and then write results back tomemory. Both the security and reliabilitycategories have very few floating-pointoperations, because their emphasis is onprocessing integer data.
On the other hand, the floating-pointinstructions in the heart activity andphysiology groups have a stronger presence.Most programs in these categories mustsample or process ECG data, heart activitydata streams, and blood pressure wave-forms, which typically are nonintegralnumeric data. The different instructiondistributions of these benchmark programsreflect a strong correlation to their real-world applications in the biomedical field.
Figure 4 also brings to light the similarinstruction distributions among all pro-grams within the respective categories. Forexample, the three programs in heartactivity category—Activity, pNNx, andCO—have a very similar instruction distri-
Table 3. Benchmark program sizes.
Category
Benchmark
program
Dynamic
instructions (no.)
Reliability CRC-CCITT 12,231
Luhn 6,333
Hamming 984,576
Reed-Solomon 767,125
Alder-32 8,995
Security Haval 430,413,126
Khazad 14,355,628
SHA2 428,459,652
Bioinformatics ELO 48,173,094
LM-GC 1,849,203
UPGMA 3,928,748
Unger-Moult 2,475,136,094
Genomics Jensen-Shannon 57,432,567
HMM 37,471,844
Nussinov-Jacobson 473,967
Smith-Waterman 58,139,042
Physiology AFVP 246,568,756
EVAL_ST 414,258,851
ECGSYN 1,813,104,873
RRGen3 87,291,436
Heart activity Activity 441,153,291
pNNx 246,456,300
CO 387,740,186
........................................................................
JULY–AUGUST 2008 81

bution. This intragroup similarity applies tothe other four groups as well. In contrast,when we consider all the programs from theentire benchmark as a whole, they showgreat variation in instruction distribution.For example, across the entire suite, theinteger instructions range from 30 percentto nearly 90 percent. Load and storeoperations also vary from 10 percent tomore than 50 percent, and so on. Theobvious variation between programs fromdifferent categories and the notable similar-ity among programs within the samecategory convince us that the selection andgrouping strategies we used to composeImplantBench are reasonable and logical.
Branch analysisImplantBench also shows a great varia-
tion in program control flow. First, let’slook at the dynamic branch class distribu-tion, shown in Figure 5. This figure showsthe distinct similarity among programswithin their respective categories. Addition-ally, it shows that conditional direct branch
operations are dominant among all thebranch types, taking up at least 40 percentof total branch instructions executed acrossthe entire benchmark suite, and for someprograms as much as 90 percent. The threeother significant branch types are uncondi-tional direct mode, call direct mode, andunconditional indirect mode. These threemodes together account for approximately40 percent of total branch instructions. Theremaining two modes—conditional indirectand call indirect—are rarely used by themajority of the ImplantBench programs.
Another important issue we considered isthe effectiveness of different branch predic-tion schemes. How well program branchescan be predicted is an important criterion inmodern computer architecture design. Weused four schemes provided by SimpleScalarto simulate and compare branch predictionefficiency: a not-taken prediction scheme,an 8-Kbyte gshare two-level adaptive pre-dictor, an 8-Kbyte bimodal predictor, andan 8-Kbyte combined bimodal and two-level predictor. We configured all the
Figure 4. Dynamic instruction distribution.
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
82 IEEE MICRO

predictors, except the not-taken strategy,with a 2-Kbyte branch target buffer (BTB).Figure 6 shows the detailed mispredictionrates, expressed in mispredictions per thou-sand instructions. Increasing the sophistica-tion of the predictor strategy results in aremarkable decrease in misprediction rates:a rate of up to 400 mispredictions per 1,000instructions for the simple, not-taken pre-dictor can be reduced to as few as 10mispredictions per 1,000 instructions.
As for the remaining three predictorschemes, there is no obvious differenceamong their effects on improving branchprediction rates. Like SPEC, MiBench, andMediaBench benchmarks, ImplantBenchhas well over a 90 percent prediction successrate, and most branches in every benchmarkprogram are predictable. However, someprograms still have a slightly higher mis-prediction rate, such as those in thegenomics and reliability categories. This isdue to massive relative random data streamthat these applications must transfer andprocess. In contrast, the security group has aslightly lower misprediction rate than the
other categories, which is a result of therelatively more regular data-access pattern ofthese programs’ integer-intensive opera-tions.
Address mode analysisAddress mode is another important
criterion we need to inspect. Figure 7provides a detailed distribution for everyaddress mode, including constant (const),global-pointer with constant (gp + const),stack-pointer with constant (sp + const),frame-pointer with constant (fp + const),general-purpose register with constant (reg+ const), and general-purpose register withgeneral-purpose register (reg + reg). Thesesix addressing modes can be classified intothree categories: constant only (const),register plus displacement with pre or postincrement or decrement (gp, sp, fp, and reg+ const), and registers only (reg + reg).
Figure 7 shows that the displaced ad-dressing mode shows benchmark-widedominance. Examining the displaced ad-dressing mode in greater detail, Figure 7shows that the order of dominance is reg +
Figure 5. Branch class distribution.
........................................................................
JULY–AUGUST 2008 83

Figure 7. Address mode distribution.
Figure 6. Branch prediction rates for several schemes.
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
84 IEEE MICRO

const, followed by sp + const, and then fp +const—with some variation. Programs suchas CRC-CCITT, Adler-32, Haval, andSmith-Waterman have a strongly dominantuse of reg + const mode, with up to 90percent of address mode use. On the otherhand, fp + const dominates address modeuse (up to 70 percent) in Reed-Solomon,Unger-Moult, and HMM. Khazad, whichmainly uses the const address mode, is anexception within the suite.
The dominance of displaced addressmode use, as shown in Figure 7, indicatesthe potential of using two-address operandsinstead of the common three-address oper-ands when designing the instruction setarchitecture for bioimplantable applica-tions.
Load and store segment analysisA segment is a section of a program in an
object file or in memory that contains theglobal variables that are initialized by theprogrammer. A program has four basicmemory regions: data, stack, heap, and text.A data segment relates to the amount of
memory used to store initialized data. Aheap segment relates to the amount ofmemory currently being used for datacreated at runtime. A stack segment meansthe amount of memory used by thecurrently executing procedures or functioncalls and all the subroutines that have beeninvoked. A text segment refers the amountof memory used to store the actual machinecode instructions. Thus, to understand thememory access characteristics of bioimplan-table device applications, it is useful andsignificant to explore the segment distribu-tion of all the memory references (loads andstores) in ImplantBench. Figure 8 gives thedistribution details.
From Figure 8, we could conclude thatbenchmark programs with considerableruntime allocated to intermediate- andfinal-result data that must be written backto the main memory—such as CRC-CCITT, Luhn, Adler-32, UPGMA, andSmith-Waterman—have the biggest distri-bution in the heap segment. Khazad andEVAL_ST have the most data to beinitialized at the beginning of program
Figure 8. Load and store segment distribution.
........................................................................
JULY–AUGUST 2008 85

execution, so they also have the largest datasegments—about 60 percent. In general,stack segment use is significant for all thebenchmark programs. The variation is dueto different layers of nested function callsand the total number of procedure callsinvoked. The percentage of stack segmentsranges from 10 percent (Smith-Waterman)to almost 100 percent (Haval, which has theleast initialized data as well as the leastintermediate data created during execution).Again we find interesting similarities withincertain categories. For example, physiology,heart activity, genomics (except S-W), andbioinformatics (except UPGMA) all showsimilar segment characteristics.
Memory analysisSimulations of memory performance
focus on both the instruction cache anddata cache, with various cache sizes (from256 bytes to 128 Kbytes) and associativityconfigurations (one-, two-, four-, and eight-way). We used the SimpleScalar built-incache simulators sim-cheetah and sim-cacheto measure the cache miss rates. To performthis detailed cache performance analysis, werandomly chose five programs—Jensen-Shannon, pNNx, Activity, Hamming, andKhazad.
Figure 9 shows instruction cache perfor-mance of the selected benchmark programs.Most miss rate values decrease to less than 1percent with associativity greater than four-way and cache size greater than 8 Kbytes.The variety of inner functionalities associ-ated with a proportional distribution ofinstructions including floating-point andinteger calculation, load and store, andbranch lead to a relatively higher instructioncache miss rate for pNNx and Activity,which are designed for cardio-activitymeasurement and monitoring. In the secu-rity group, Khazad’s miss rate dropsdrastically to less than 0.3 percent whencache size reaches 2 Kbytes, because of itsrelatively simple and symmetric computa-tion structure.
Figure 9 also shows that miss rates dropto less than 0.1 percent for every programwe simulated when we used the eight-wayassociativity scheme. That is, the eight-wayscheme provides sufficient degrees of asso-
ciativity to effectively converge the missrates to a satisfactory level. In comparison,miss rates for some of the SPEC2000benchmarks don’t fall below 2 percent untilcache size reaches around 16 to 32 Kbytes—8 to 16 times larger than that required byImplantBench for similar miss rates. Thus,ImplantBench provides more opportunitiesfor designs in the ultralow-power domainthan do traditional benchmark suites.
Figure 10 indicates the data cache per-formance for the selected benchmark pro-grams. As the cache size and the associativityincrease, all of the programs illustrate atrend of decreasing data cache miss ratessimilar to those of the instruction cache. Onaverage, miss rates for the data cacheconverge faster than those for the instruc-tion cache as the cache size and associativityincrease. The miss rates for all but one ofthe selected benchmarks become negligiblewith either associativity greater than four-way or cache size greater than 4 Kbytes.Khazad’s relatively higher miss rate comesfrom the large number of inputs and therandomness of test vectors. However, owingto the large number of iterative encryptionunits in the cipher, Khazad’s instructioncache performance remains stable because ofrelatively higher locality. Compared withtraditional general-purpose and scientificbenchmarks, ImplantBench has more easilycacheable instructions and data, againproviding opportunities for constrainedbiomedical implant applications.
Performance analysisTo assess the achievable target perfor-
mance for bioimplantable processor design,we need to determine the available instruc-tion-level parallelism (ILP) exhibited by theImplantBench programs. This led us toperform program throughput analyses onthe programs, measured in instructions percycle (IPC). Figure 11 gives the results ofour IPC simulation and analyses. Thegreatest IPC values come from securityapplications Khazad and SHA2, whichachieve up to 3 IPC. This is not surprising,because these programs feature more ILP-rich integer ALU operations and fewermemory and program controls. The lowestIPC values are for UPGMA, AFVP, and
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
86 IEEE MICRO

Figure 9. Instruction cache miss rates for various cache sizes and associativities.
........................................................................
JULY–AUGUST 2008 87

Figure 10. Data cache miss rates for various cache sizes and associativities.
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
88 IEEE MICRO
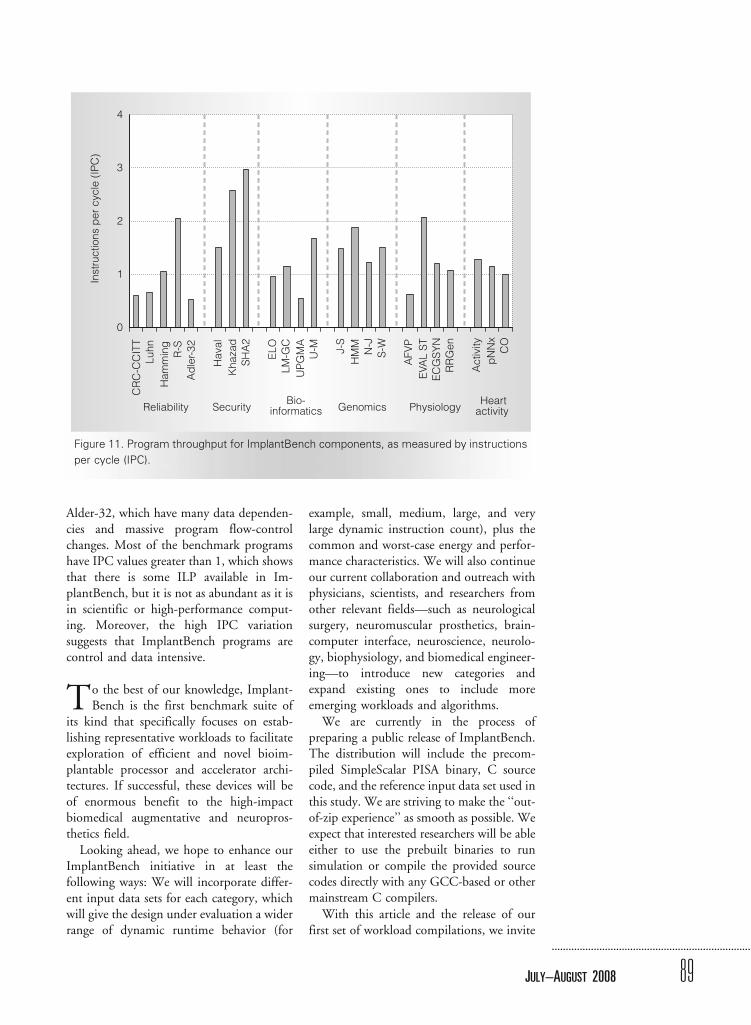
Alder-32, which have many data dependen-cies and massive program flow-controlchanges. Most of the benchmark programshave IPC values greater than 1, which showsthat there is some ILP available in Im-plantBench, but it is not as abundant as it isin scientific or high-performance comput-ing. Moreover, the high IPC variationsuggests that ImplantBench programs arecontrol and data intensive.
To the best of our knowledge, Implant-Bench is the first benchmark suite of
its kind that specifically focuses on estab-lishing representative workloads to facilitateexploration of efficient and novel bioim-plantable processor and accelerator archi-tectures. If successful, these devices will beof enormous benefit to the high-impactbiomedical augmentative and neuropros-thetics field.
Looking ahead, we hope to enhance ourImplantBench initiative in at least thefollowing ways: We will incorporate differ-ent input data sets for each category, whichwill give the design under evaluation a widerrange of dynamic runtime behavior (for
example, small, medium, large, and verylarge dynamic instruction count), plus thecommon and worst-case energy and perfor-mance characteristics. We will also continueour current collaboration and outreach withphysicians, scientists, and researchers fromother relevant fields—such as neurologicalsurgery, neuromuscular prosthetics, brain-computer interface, neuroscience, neurolo-gy, biophysiology, and biomedical engineer-ing—to introduce new categories andexpand existing ones to include moreemerging workloads and algorithms.
We are currently in the process ofpreparing a public release of ImplantBench.The distribution will include the precom-piled SimpleScalar PISA binary, C sourcecode, and the reference input data set used inthis study. We are striving to make the ‘‘out-of-zip experience’’ as smooth as possible. Weexpect that interested researchers will be ableeither to use the prebuilt binaries to runsimulation or compile the provided sourcecodes directly with any GCC-based or othermainstream C compilers.
With this article and the release of ourfirst set of workload compilations, we invite
Figure 11. Program throughput for ImplantBench components, as measured by instructions
per cycle (IPC).
........................................................................
JULY–AUGUST 2008 89

the entire community to take the first stridein promoting human healthcare with inno-vative and cutting-edge bioimplantablecomputing technologies. MICRO
AcknowledgmentsWe thank our collaborators in the
University of Pittsburgh School of Medi-cine—Robert Scalabassi and Mingui Sun inthe Department of Neurological Surgery,and Chia-Lin Chang in the Department ofPhysical Medicine and Rehabilitation—fortheir proactive support and insightfulconsultation in helping us start this inter-disciplinary bioimplantable computing ini-tiative. We also thank other group membersin the Advanced Computing TechnologyLaboratory—Yuan Sun for participating ininitial workload surveying, porting, andanalysis; and Timothy Sestrich for con-structing and maintaining the Implant-Bench website. We also gratefully acknowl-edge the original algorithm and applicationdevelopers of the workloads included in thisfirst version of ImplantBench. Finally, wethank the anonymous reviewers for theirhelpful feedback on improving this article.
................................................................................................
References1. Y. Zheng, J. Pieprzyk, and J. Seberry,
‘‘HAVAL—A One-Way Hashing Algorithm
with Variable Length of Output,’’ Proc. Int’l
Conf. Cryptology: Advances in Cryptology,
LNCS 718, Springer-Verlag, 1993, pp. 83-104.
2. P. Barreto and V. Rijmen, ‘‘The Khazad
Legacy-Level Block Cipher,’’ 1st Open
NESSIE Workshop 2000, pp. 13-14;
https://www.cosic.esat.kuleuven.be/nessie/
workshop.
3. H. Gilbert and H. Handschuh, ‘‘Security
Analysis of SHA-256 and Sisters,’’ Selected
Areas in Cryptography, LNCS 3006, Spring-
er-Verlag, 2003, pp. 175-193.
4. R.N. Williams, A Painless Guide to CRC
Error Detection Algorithms, Rocksoft Party,
1993.
5. H.P. Luhn, Computer for Verifying Num-
bers, US patent 2,950,048, Patent and
Trademark Office, 1960.
6. D.J.C. MacKay, Information Theory, Infer-
ence and Learning Algorithms, Cambridge
University Press, 2003.
7. S. Lin and D.J. Costello Jr., Error Control
Coding: Fundamentals and Applications,
2nd ed., Prentice Hall, 2005.
8. P. Deutsch, A. Enterprises, and J.-L. Gailly,
ZLIB Compressed Data Format Specifica-
tion, RFC 1950, Internet Engineering Task
Force, May 1996; ftp://ftp.rfc-editor.org/
in-notes/rfc1950.pdf.
9. R. Dawkins, The Blind Watchmaker: Why
the Evidence of Evolution Reveals a Uni-
verse Without Design, W.W. Norton & Co.,
1996.
10. P. Clote and R. Backofen, Computational
Biology: An Introduction, John Wiley &
Sons, 2000.
11. H.C. Romeburg, Cluster Analysis for Re-
searchers, Lifetime Learning Publications,
1984.
12. C.M. Dobson, ‘‘Protein Folding and Mis-
folding,’’ Nature, vol. 426, no. 6968, 18
Dec. 2003, pp. 884-890.
13. L.R. Rabiner, ‘‘A Tutorial on Hidden Markov
Models and Selected Applications in
Speech Recognition,’’ Proc. IEEE, vol. 77,
no. 2, Feb. 1989, pp. 257-286.
14. T.M. Przytycka, ‘‘Hidden Markov Models,’’
Nature Encyclopedia of the Human Ge-
nome, D. Cooper, ed., Nature Publishing
Group, 2003.
15. B. Fuglede and F. Topsoe, ‘‘Jensen-Shan-
non Divergence and Hilbert Space Embed-
ding,’’ Proc. Int’l Symp. Information Theory
(ISIT 04), IEEE Press, 2004, pp. 31-36.
16. R. Nussinov and A.B. Jacobson, ‘‘Fast
Algorithm for Predicting the Secondary
structure of Single Standard RNA,’’ Proc.
National Academy of Sciences, vol. 77,
no. 11, Nov. 1980, pp. 6309-6313.
17. T.F. Smith and M.S. Waterman, ‘‘Identifi-
cation of Common Molecular Subsequenc-
es,’’ J. Molecular Biology, vol. 147, 1981,
pp. 195-197.
18. S. Needleman and C. Wunsch, ‘‘A General
Method Applicable to the Research for
Similarities in the Amino Acid Sequence of
Two Proteins,’’ J. Molecular Biology,
vol. 48, 1970, pp. 443-453.
19. J. Lian, D. Mussig, and V. Lang, ‘‘Computer
Modeling of Ventricular Rhythm During
Atrial Fibrillation and Ventricular Pacing,’’
IEEE Trans. Biomedical Engineering,
vol. 53, no. 8, Aug. 2006, pp. 1512-1520.
.........................................................................................................................................................................................................................
ACCELERATOR ARCHITECTURES
.......................................................................
90 IEEE MICRO

20. F. Jager, A. Smrdel, and R.G. Mark, ‘‘An
Open-Source Tool to Evaluate Performance
of Transient ST Segment Episode Detec-
tion Algorithms,’’ Computers in Cardiology,
IEEE Press, 2004, pp. 585-588.
21. P.E. McSharry et al., ‘‘A Dynamical Model
for Generating Synthetic Electrocardiogram
Signals, ’’ IEEE Trans. Biomedical Engi-
neering, vol. 50, no. 3, Mar. 2003,
pp. 289-294.
22. G.D. Clifford, F. Azuaje, and P.E. McSharry,
Advanced Methods and Tools for ECG
Analysis, Artech House Publishing, 2006.
23. G.B. Moody, ‘‘ECG-Based Indices of Phys-
ical Activity,’’ Computers in Cardiology,
IEEE Press, 1992, pp. 403-406.
24. A.L. Goldberger et al., ‘‘PhysioBank, Physio
Toolkit, and PhysioNet Components of a
New Research Resource for Complex
Physiologic Signals,’’ Circulation, vol. 101,
no. 23, 13 June 2000, pp. e215-e220.
25. J.E. Mietus et al., ‘‘The pNNx Files: Re-
examining a Widely Used Heart Rate
Variability Measure,’’ J. Heart, vol. 88,
no. 4, Oct. 2002, pp. 378-380.
26. J.X. Sun et al., ‘‘Estimating Cardiac Output
from Arterial Blood Pressure Waveforms: A
Critical Evaluation Using the MIMIC II
Database,’’ Computers in Cardiology, IEEE
Press, 2005, pp. 295-298.
Zhanpeng Jin is a PhD student of electricaland computer engineering at the Universityof Pittsburgh. His research interests includecomputer architecture; biomedical andbioimplantable computing systems; ultralow-power, energy-efficient processors;VLSI and ASIC system design; and math-ematical modeling. He has a BS and an MSin computer science from the NorthwesternPolytechnical University in China. He is astudent member of IEEE and the IEEEComputer Society.
Allen C. Cheng is an assistant professor inthe departments of Electrical and ComputerEngineering, Computer Science, Neurolog-ical Surgery, and Neural Engineering in theMcGowan Institute for Regenerative Med-icine at the University of Pittsburgh, wherehe also serves as director of the AdvancedComputing Technology Laboratory (ACT).His research interests include the interdis-
ciplinary confluence of computer engineer-ing, computer science, electrical engineer-ing, neural engineering, biomedical engi-neering, and medicine. He has a BS incomputer engineering from North CarolinaState University, and an MS and a PhD incomputer science and engineering from theUniversity of Michigan, Ann Arbor. He is amember of the IEEE, the ACM, and theAmerican Association for the Advancementof Science (AAAS).
Direct questions and comments aboutthis article to Allen C. Cheng, Dept. ofElectrical and Computer Engineering, Uni-versity of Pittsburgh, 3700 O’Hara Street,Pittsburgh, PA 15261; [email protected].
For more information on this or any
other computing topic, please visit our
Digital Library at http://computer.org/
csdl.
........................................................................
JULY–AUGUST 2008 91