estadistica aplicada teoria
TRANSCRIPT

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 1/35
PRUEBA DE HIPOTESIS.
Muchos problemas de ingeniería, ciencia, y administración, requieren que se tomeuna decisión entre aceptar o rechazar una proposición sobre algún parámetro.Esta proposición recibe el nombre de hipótesis. Este es uno de los aspectos másútiles de la inferencia estadística, puesto que muchos tipos de problemas de tomade decisiones, pruebas o experimentos en el mundo de la ingeniería, puedenformularse como problemas de prueba de hipótesis.
Una hipótesis estadística es una proposición o supuesto sobre los parámetros deuna o más poblaciones.
Suponga que se tiene interés en la rapidez de combustión de un agente propulsorsólido utilizado en los sistemas de salida de emergencia para la tripulación deaeronaves. El interés se centra sobre la rapidez de combustión promedio. Demanera específica, el interés recae en decir si la rapidez de combustión promedioes o no 50 cm/s. Esto puede expresarse de manera formal como
Înter%Ho; = 50 cm/s
Înter%H1; 50 cm/s
La proposición Ho; = 50 cm/s, se conoce como hipótesis nula, mientras que laproposición H1; 50 cm/s, recibe el nombre de hipótesis alternativa. Puesto que lahipótesis alternativa especifica valores de que pueden ser mayores o menores que50 cm/s, también se conoce como hipótesis alternativa bilateral. En algunassituaciones, lo que se desea es formular una hipótesis alternativa unilateral, comoen
Înter%Ho; = 50 cm/s Ho; = 50 cm/s
Înter%ó
Înter%H1; < 50 cm/s H1; > 50 cm/s.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 2/35
Es importante recordar que las hipótesis siempre son proposiciones sobre lapoblación o distribución bajo estudio, no proposiciones sobre la muestra. Por logeneral, el valor del parámetro de la población especificado en la hipótesis nula sedetermina en una de tres maneras diferentes:
1. Puede ser resultado de la experiencia pasada o del conocimiento del proceso,entonces el objetivo de la prueba de hipótesis usualmente es determinar si hacambiado el valor del parámetro.
2. Puede obtenerse a partir de alguna teoría o modelo que se relaciona con elproceso bajo estudio. En este caso, el objetivo de la prueba de hipótesis esverificar la teoría o modelo.
3. Cuando el valor del parámetro proviene de consideraciones externas, talescomo las especificaciones de diseño o ingeniería, o de obligaciones contractuales.En esta situación, el objetivo usual de la prueba de hipótesis es probar elcumplimiento de las especificaciones.
Un procedimiento que conduce a una decisión sobre una hipótesis en particularrecibe el nombre de prueba de hipótesis. Los procedimientos de prueba dehipótesis dependen del empleo de la información contenida en la muestra aleatoriade la población de interés. Si esta información es consistente con la hipótesis, se
concluye que ésta es verdadera; sin embargo si esta información es inconsistentecon la hipótesis, se concluye que esta es falsa. Debe hacerse hincapié en que laverdad o falsedad de una hipótesis en particular nunca puede conocerse concertidumbre, a menos que pueda examinarse a toda la población. Usualmenteesto es imposible en muchas situaciones prácticas. Por tanto, es necesariodesarrollar un procedimiento de prueba de hipótesis teniendo en cuenta laprobabilidad de llegar a una conclusión equivocada.
La hipótesis nula, representada por Ho, es la afirmación sobre una o más
características de poblaciones que al inicio se supone cierta (es decir, la “creenciaa priori”).
La hipótesis alternativa, representada por H1, es la afirmación contradictoria a Ho,y ésta es la hipótesis del investigador.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 3/35
La hipótesis nula se rechaza en favor de la hipótesis alternativa, sólo si laevidencia muestral sugiere que Ho es falsa. Si la muestra no contradicedecididamente a Ho, se continúa creyendo en la validez de la hipótesis nula.Entonces, las dos conclusiones posibles de un análisis por prueba de hipótesisson rechazar Ho o no rechazar Ho.
DISCREPANCIA.
Cuando dos mediciones de la misma cantidad se hallan en desacuerdo, decimosque existe una discrepancia . Numéricamente, definimos la discrepancia entre dosmediciones como su diferencia:
Discrepancia = diferencia entre dos valores medidos de la misma cantidad
Más específicamente, cada una de las dos mediciones consiste de un valor quees nuestra mejor estimación del verdadero valor, y una incerteza. Cada una deestas mediciones puede ser el resultado de largas series de medidas, las cualesfueron procesadas en la forma vista en la sección anterior. O pueden ser elresultado de dos mediciones individuales, con la incerteza calculada mediante lassimples reglas de propagación del error vistas anteriormente. En cualquier caso,definimos la discrepancia como la diferencia entre las dos mejores estimaciones.Por ejemplo, si dos estudiantes miden la misma resistencia y obtienen lossiguientes valores
Estudiante A: 15 ± 1 ohms; Estudiante B: 25 ± 2 ohms, su discrepancia esdiscrepancia = 25 – 15 = 10 ohms.
Note que una discrepancia puede o no ser significativa. Entre las dos medicionesque acabamos de comentar existe una discrepancia significativa, puesto que noencontramos ningún valor posible de resistencia que sea compatible con ambasmediciones. Obviamente, al menos una de las mediciones es incorrecta, y senecesita en este caso buscar cuidadosamente qué es lo que ha fallado.
Suponga ahora que otros dos estudiantes has reportado los siguientes resultados:
Estudiante C: 16 ± 8 ohms;
Estudiante D: 26 ± 9 ohms.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 4/35
Aquí, nuevamente, la discrepancia es de 10 ohms. Sin embargo, la discrepanciaaquí no es significativa, dado que los márgenes de error de ambos estudiantes sesolapan confortablemente y ambas mediciones podrían ser igualmente correctas.La discrepancia entre dos mediciones de la misma cantidad debe ser evaluada
entonces no por su tamaño, sino por cuán grande es comparada con lasincertezas en las mediciones.
ERRORES DE TIPO I Y DE TIPO II.
En un estudio de investigación, el error de tipo I también denominado error de tipo
alfa (α)1 o falso positivo, es el error que se comete cuando el investigador no
acepta la hipótesis nula (H o ) siendo ésta verdadera en la población. Es equivalente
a encontrar un resultado falso positivo, porque el investigador llega a la conclusión
de que existe una diferencia entre las hipótesis cuando en realidad no existe. Serelaciona con el nivel de significancia estadística.
Representación de los valores posibles de la probabilidad de un error tipo II (rojo)en el ejemplo de un test de significancia estadística para el parámetro μ. El error
tipo II depende del parámetro μ . Mientras más cerca se encuentre este del valor
supuesto bajo la hipótesis nula, mayor es la probabilidad de ocurrencia del errortipo II. Debido a que el verdadero valor de μ es desconocido al hacer la presunción
de la hipótesis alternativa, la probabilidad del error tipo II, en contraste con el errortipo I (azul), no se puede calcular.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 5/35
La hipótesis de la que se parte H 0 aquí es el supuesto de que la situación
experimental presentaría un «estado normal». Si no se advierte este «estado
normal», aunque en realidad existe, se trata de un error estadístico tipo I. Algunos
ejemplos para el error tipo I serían:
Se considera que el paciente está enfermo, a pesar de que en realidad está
sano ; hipótesis nula: El paciente está sano .
Se declara culpable al acusado, a pesar de que en realidad es inocente ;
hipótesis nula: El acusado es inocente .
No se permite el ingreso de una persona, a pesar de que tiene derecho a
ingresar ; hipótesis nula: La persona tiene derecho a ingresar .
En un estudio de investigación, el error de tipo II, también llamado error de tipo
beta (β) (β es la probabilidad de que exista éste error) o falso negativo, se comete
cuando el investigador no rechaza la hipótesis nula siendo ésta falsa en
la población. Es equivalente a la probabilidad de un resultado falso negativo, ya
que el investigador llega a la conclusión de que ha sido incapaz de encontrar una
diferencia que existe en la realidad.
Se acepta en un estudio que el valor del error beta esté entre el 5 y el 20%.
Contrariamente al error tipo I, en la mayoría de los casos no es posible calcular la
probabilidad del error tipo II. La razón de esto se encuentra en la manera en quese formulan las hipótesis en una prueba estadística. Mientras que la hipótesis nula
representa siempre una afirmación enérgica (como por ejemplo H 0: «Promedio μ =
0 ») la hipótesis alternativa, debido a que engloba todas las otras posibilidades, es
generalmente de naturaleza global (por ejemplo H 1: «Promedio μ ≠ 0 » ). El gráfico
de la derecha ilustra la probabilidad del error tipo II (rojo) en dependencia del
promedio μ desconocido.
El poder o potencia del estudio representa la probabilidad de observar en
la muestra una determinada diferencia o efecto, si existe en la población. Es elcomplementario del error de tipo II (1-β).

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 6/35
Errores en el contraste
Artículo principal: Contraste de hipótesis
Una vez realizado el contraste de hipótesis, se habrá optado por una de las dos
hipótesis, la hipótesis nula o base o la hipótesis alternativa , y la decisiónescogida coincidirá o no con la que en realidad es cierta. Se pueden dar los cuatro
casos que se exponen en el siguiente cuadro:
es cierta es cierta
Seescogió
No hay error (verdaderopositivo)
Error de tipo II (β o falsonegativo)
Se escogióError de tipo I (α o falsopositivo)
No hay error (verdaderonegativo)
Si la probabilidad de cometer un error de tipo I está unívocamente determinada, su
valor se suele denotar por la letra griega α, y en las mismas condiciones, se
denota por β la probabilidad de cometer el error de tipo II, esto es:
En este caso, se denomina Potencia del contraste al valor 1-β, esto es, a la
probabilidad de escoger cuando esta es cierta
.Cuando es necesario diseñar un contraste de hipótesis, sería deseable hacerlo de
tal manera que las probabilidades de ambos tipos de error fueran tan pequeñas
como fuera posible. Sin embargo, con una muestra de tamaño prefijado, disminuir
la probabilidad del error de tipo I, α, conduce a incrementar la probabilidad del
error de tipo II, β.
Usualmente, se diseñan los contrastes de tal manera que la probabilidad α sea el
5% (0,05), aunque a veces se usan el 10% (0,1) o 1% (0,01) para adoptar
condiciones más relajadas o más estrictas. El recurso para aumentar la potenciadel contraste, esto es, disminuir β, probabilidad de error de tipo II, es aumentar
el tamaño muestral, lo que en la práctica conlleva un incremento de los costes del
estudio que se quiere realizar.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 7/35
Contraste de hipótesis.
Dentro de la inferencia estadística, un contraste de hipótesis (tambiéndenominado test de hipótesis o prueba de significación) es un procedimiento para
juzgar si una propiedad que se supone cumple unapoblación estadística es
compatible con lo observado en una muestra de dicha población. Fue iniciada
por Ronald Fisher y fundamentada posteriormente porJerzy Neyman y Karl
Pearson.
Mediante esta teoría, se aborda el problema estadístico considerando una
hipótesis determinada y una hipótesis alternativa , y se intenta dirimir cuál
de las dos es la hipótesis verdadera, tras aplicar el problema estadístico a un
cierto número de experimentos.
Está fuertemente asociada a los considerados errores de tipo I y II en estadística,
que definen respectivamente, la posibilidad de tomar un suceso verdadero como
falso, o uno falso como verdadero.
Existen diversos métodos para desarrollar dicho test, minimizando los errores de
tipo I y II, y hallando por tanto con una determinada potencia, la hipótesis con
mayor probabilidad de ser correcta. Los tipos más importantes son los test
centrados, de hipótesis y alternativa simple, aleatorizados, etc. Dentro de los testsno paramétricos, el más extendido es probablemente el test de la U de Mann-
Whitney.
Introducción.
Si sospechamos que una moneda ha sido trucada para que se produzcan más
caras que cruces al lanzarla al aire, podríamos realizar 30 lanzamientos, tomando
nota del número de caras obtenidas. Si obtenemos un valor demasiado alto, por
ejemplo 25 o más, consideraríamos que el resultado es poco compatible con la
hipótesis de que la moneda no está trucada, y concluiríamos que lasobservaciones contradicen dicha hipótesis.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 8/35
La aplicación de cálculos probabilísticos permite determinar a partir de qué valor
debemos rechazar la hipótesis garantizando que la probabilidad de cometer un
error es un valor conocido a priori . Las hipótesis pueden clasificarse en dos
grupos, según:
1. Especifiquen un valor concreto o un intervalo para los parámetros
del modelo.
2. Determinen el tipo de distribución de probabilidad que ha generado
los datos.
Un ejemplo del primer grupo es la hipótesis de que la media de una variable es 10,
y del segundo que la distribución de probabilidad es la distribución normal.
Aunque la metodología para realizar el contraste de hipótesis es análoga enambos casos, distinguir ambos tipos de hipótesis es importante puesto que
muchos problemas de contraste de hipótesis respecto a un parámetro son, en
realidad, problemas de estimación, que tienen una respuesta complementaria
dando un intervalo de confianza (o conjunto de intervalos de confianza) para dicho
parámetro. Sin embargo, las hipótesis respecto a la forma de la distribución se
suelen utilizar para validar un modelo estadístico para un fenómeno aleatorio que
se está estudiando.
Planteamiento clásico del contraste de hipótesis.
Se denomina hipótesis nula a la hipótesis que se desea contrastar. El nombre
de "nula" significa “sin valor, efecto o consecuencia”, lo cual sugiere que debe
identificarse con la hipótesis de no cambio (a partir de la opinión actual); no
diferencia, no mejora, etc. representa la hipótesis que mantendremos a no ser
que los datos indiquen su falsedad, y puede entenderse, por tanto, en el sentido
de “neutra”. La hipótesis nunca se considera probada, aunque puede serrechazada por los datos. Por ejemplo, la hipótesis de que dos poblaciones tienen
la misma media puede ser rechazada fácilmente cuando ambas difieren mucho,
analizando muestras suficientemente grandes de ambas poblaciones, pero no
puede ser "demostrada" mediante muestreo, puesto que siempre cabe la

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 9/35
posibilidad de que las medias difieran en una cantidad δ lo suficientemente
pequeña para que no pueda ser detectada, aunque la muestra sea muy grande.
A partir de una muestra de la población en estudio, se extrae un estadístico (esto
es, una valor que es función de la muestra) cuya distribución de probabilidad estérelacionada con la hipótesis en estudio y sea conocida. Se toma entonces
el conjunto de valores que es más improbable bajo la hipótesis como región de
rechazo, esto es, el conjunto de valores para el que consideraremos que, si el
valor del estadístico obtenido entra dentro de él, rechazaremos la hipótesis.
La probabilidad de que se obtenga un valor del estadístico que entre en la región
de rechazo aún siendo cierta la hipótesis puede calcularse. De esta manera, se
puede escoger dicha región de tal forma que la probabilidad de cometer este error
sea suficientemente pequeña.
Siguiendo con el anterior ejemplo de la moneda trucada, la muestra de la
población es el conjunto de los treinta lanzamientos a realizar, el estadístico
escogido es el número total de caras obtenidas, y la región de rechazo está
constituida por los números totales de caras iguales o superiores a 25. La
probabilidad de cometer el error de admitir que la moneda está trucada a pesar de
que no lo está es igual a la probabilidad binomial de tener 25 "éxitos" o más en
una serie de 30 ensayos de Bernoulli con probabilidad de "éxito" 0,5 en cada uno,
entonces: 0,0002, pues existe la posibilidad, aunque poco probable, que lamuestra nos dé más de 25 caras sin haber sido la moneda trucada.
Procedimientos de prueba.
Un procedimiento de prueba es una regla con base en datos muestrales, para
determinar si se rechaza .
Ejemplo:
Una prueba de : p = .10 contra : p < .10, podría estar basada en el examen
de una muestra aleatoria de n = 200 objetos. Representamos con X el numero deobjetos defectuosos de la muestra, una variable aleatoria binomial; x representa el
valor observado de X. si es verdadera, E(X) = np = 200(.10) = 20, mientras,
podemos esperar menos de 20 objetos defectuosos si es verdadera. Un valor
de x ligeramente debajo de 20 no contradice de manera contundente a asi que
es razonable rechazar solo si x es considerablemente menor que 20. Un

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 10/35
procedimiento de prueba es rechazar si x≤15 y no rechazar de otra forma.
En este caso, la región de rechazo esta formada por x = 0, 1, 2, , y 15. no sera
rechazada si x= 16, 17,…, 199 o 200.
Un procedimiento de prueba se especifica por lo siguiente:
1. Un estadístico de prueba: una función de los datos muestrales en los
cuales se basa la decisión de rechazar o no rechazar .
2. Una región de rechazo, el conjunto de todos los valores del
estadístico de prueba para los cuales será rechazada.
Entonces, la hipótesis nula será rechazada si y solo si el valor observado o
calculado del estadístico de prueba se ubica en la región de rechazo
En el mejor de los casos podrían desarrollarse procedimientos de prueba para loscuales ningún tipo de error es posible. Pero esto puede alcanzarse solo si una
decisión se basa en un examen de toda la población, lo que casi nunca es
práctico. La dificultad al usar un procedimiento basado en datos muestrales es que
debido a la variabilidad en el muestreo puede resultar una muestra no
representativa.
Un buen procedimiento es aquel para el cual la probabilidad de cometer cualquier
tipo de error es pequeña. La elección de un valor particular de corte de la región
de rechazo fija las probabilidades de errores tipo I y II. Estas probabilidades deerror son representadas por α y β, respectivamente.
Enfoque actual de los contrastes de hipótesis.
El enfoque actual considera siempre una hipótesis alternativa a la hipótesis nula.
De manera explícita o implícita, la hipótesis nula, a la que se denota habitualmente
por , se enfrenta a otra hipótesis que denominaremos hipótesis alternativa y
que se denota . En los casos en los que no se especifica de manera
explícita, podemos considerar que ha quedado definida implícitamente como “
es falsa”.
Si por ejemplo deseamos comprobar la hipótesis de que dos distribuciones tienen
la misma media, estamos implícitamente considerando como hipótesis alternativa

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 11/35
“ambas poblaciones tienen distinta media”. Podemos, sin embargo considerar
casos en los que no es la simple negación de . Supongamos por ejemplo
que sospechamos que en un juego de azar con un dado, este está trucado para
obtener 6. Nuestra hipótesis nula podría ser “el dado no está trucado” queintentaremos contrastar, a partir de una muestra de lanzamientos realizados,
contra la hipótesis alternativa “el dado ha sido trucado a favor del 6”. Cabría
realizar otras hipótesis, pero, a los efectos del estudio que se pretende realizar, no
se consideran relevantes.
Un test de hipótesis se entiende, en el enfoque moderno, como una función de la
muestra, corrientemente basada en un estadístico. Supongamos que se tiene una
muestra de una población en estudio y que se han
formulado hipótesis sobre un parámetro θ relacionado con la distribuciónestadística de la población. Supongamos que se dispone de un
estadístico T (X ) cuya distribución con respecto a θ, se conoce.
Supongamos, también, que las hipótesis nula y alternativa tienen la siguiente
formulación:
Un contraste, prueba o test para dichas hipótesis sería una función de la muestra
de la siguiente forma:
Donde significa que debemos rechazar la hipótesis nula, (aceptar
) y , que debemos aceptar (o que no hay evidencia estadística
contra ). A Ω se la denomina región de rechazo. En esencia, para construir el
test deseado, basta con escoger el estadístico del contraste T (X ) y la región de
rechazo Ω.
Se escoge Ω de tal manera que la probabilidad de que T(X) caiga en su interior
sea baja cuando se da .
Errores en el contraste.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 12/35
Artículo principal: Errores de tipo I y de tipo II
Una vez realizado el contraste de hipótesis, se habrá optado por una de las dos
hipótesis, o , y la decisión escogida coincidirá o no con la que en realidades cierta. Se pueden dar los cuatro casos que se exponen en el siguiente cuadro:
es cierta es cierta
Se escogió No hay error Error de tipo II
Se escogió Error de tipo I No hay error
Si la probabilidad de cometer un error de tipo I está unívocamente determinada, su
valor se suele denotar por la letra griega α, y en las mismas condiciones, se
denota por β la probabilidad de cometer el error de tipo II, esto es:
En este caso, se denomina Potencia del contraste al valor 1-β, esto es, a la
probabilidad de escoger cuando ésta es cierta
.
Cuando es necesario diseñar un contraste de hipótesis, sería deseable hacerlo de
tal manera que las probabilidades de ambos tipos de error fueran tan pequeñascomo fuera posible. Sin embargo, con una muestra de tamaño prefijado, disminuir
la probabilidad del error de tipo I, α, conduce a incrementar la probabilidad del
error de tipo II, β.
Usualmente, se diseñan los contrastes de tal manera que la probabilidad α sea el
5% (0,05), aunque a veces se usan el 10% (0,1) o 1% (0,01) para adoptar
condiciones más relajadas o más estrictas. El recurso para aumentar la potencia
del contraste, esto es, disminuir β, probabilidad de error de tipo II, es aumentar
el tamaño muestral, lo que en la práctica conlleva un incremento de los costes delestudio que se quiere realizar.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 13/35
Contraste más potente.
El concepto de potencia nos permite valorar cual entre dos contrastes con la
misma probabilidad de error de tipo I, α, es preferible. Si se trata de contrastar dos
hipótesis sencillas sobre un parámetro desconocido, θ, del tipo:
Se trata de escoger entre todos los contrastes posibles con α prefijado aquel que
tiene mayor potencia, esto es, menor probabilidad β de incurrir en el error de tipo
II.
En este caso el Lema de Neyman-Pearson garantiza la existencia de un contrastede máxima potencia y determina cómo construirlo.
Contraste uniformemente más potente.
En el caso de que las hipótesis sean compuestas, esto es, que no se limiten a
especificar un único posible valor del parámetro, sino que sean del tipo:
donde y son conjuntos de varios posibles valores, las probabilidades α y β
ya no están unívocamente determinadas, sino que tomarán diferentes valores
según los distintos valores posibles de θ. En este caso se dice que un
contraste tiene tamaño α si
esto es, si la máxima probabilidad de cometer un error de tipo I cuando la hipótesis
nula es cierta es α. En estas circunstancias, se puede considerar β como una
función de θ, puesto que para cada posible valor de θ en la hipótesis alternativa se
tendría una probabilidad distinta de cometer un error de tipo II. Se define entonces
y, la función de potencia del contraste es entonces

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 14/35
esto es, la probabilidad de discriminar que la hipótesis alternativa es cierta para
cada valor posible de θ dentro de los valores posibles de esta misma hipótesis.
Se dice que un contraste es uniformemente más potente de tamaño α cuando,
para todo valor es mayor o igual que el de cualquier otrocontraste del mismo tamaño. En resumen, se trata de un contraste que garantiza
la máxima potencia para todos los valores de θ en la hipótesis alternativa.
Es claro que el caso del contraste uniformemente más potente para hipótesis
compuestas exige el cumplimiento de condiciones más exigentes que en el caso
del contraste más potente para hipótesis simples. Por ello, no existe un
equivalente al Lema de Neyman-Pearson para el caso general.
Sin embargo, sí existen muchas condiciones en las que, cumpliéndose
determinadas propiedades de las distribuciones de probabilidad implicada y para
ciertos tipos de hipótesis, se puede extender el Lema para obtener el contraste
uniformemente más potente del tamaño que se desee.
Aplicaciones de los contrastes de hipótesis.
Los contrastes de hipótesis, como la inferencia estadística en general,
son herramientas de amplio uso en la ciencia en general. En particular, lamoderna Filosofía de la cienciadesarrolla el concepto de falsabilidad de
las teorías científicas basándose en los conceptos de la inferencia
estadística en general y de los contrastes de hipótesis. En este contexto,
cuando se desea optar entre dos posibles teorías científicas para un
mismo fenómeno (dos hipótesis) se debe realizar un contraste estadístico
a partir de los datos disponibles sobre el fenómeno que permitan optar
por una u otra.
Las técnicas de contraste de hipótesis son también de amplia aplicaciónen muchos otros casos, como ensayos clínicos de nuevos
medicamentos, control de calidad, encuestas, etcétera .

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 15/35
FUNDAMENTO BÁSICOS DEL SPSS.
SPSS es un programa de estadísticas popular usado en una variedad dedisciplinas científicas. Se compone de dos facetas, el paquete estadístico propio y
el lenguaje de SPSS, un sistema de sintaxis que se utiliza para ejecutar comandosy procedimientos. Del mismo modo, existen dos enfoques para la utilización deSPSS: (a) a través del sistema de menús y de apuntar y hacer clic aproximación y(b) a través del uso de la sintaxis de programación de SPSS. La mayoría de losusuarios encontrarán una combinación de estos enfoques más efectivos parallevar a cabo sus análisis de datos. En la Universidad del Norte de Texas, se hanobtenido las licencias del software para Windows y Mac OSX. En esta serie, quese centrará en el programa SPSS para Windows, que es un programa de análisisde datos completa con muchas capacidades y aplicaciones. Los requisitos paraPC y Mac son los siguientes.
De SPSS 16.0 para Windows.
Sistema Operativoo Microsoft Windows XP (versiones de 32 bits) o Windows Vista
(32-bit o 64-bit)
Hardwareo Intel ® o AMD x86 procesador a 1 GHz o superioro RAM: 512 MB de RAM, se recomienda 1 GBo 450 MB de espacio disponible en el disco duroo CD-ROMo Super VGA (800x600) o un monitor de alta resolucióno Para conectar con un servidor SPSS, un adaptador de
red que ejecute el protocolo de red TCP / IP
Softwareo Internet Explorer 6 o superior
Si bien estos requisitos son para la versión 16 de los laboratorios en elcampus no cuentan aún con 16 (y desde nuestro punto de vista en el RSSque están en mejor situación como tal).
----Las variables en SPSS cuentan con una serie de propiedades que deben ser
definidas por el investigador o usuario antes de realizar cualquier tipo de análisis con
ella. De la correcta

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 16/35
II. ¿Quién puede utilizar SPSS?
SPSS software se distribuye a través de licencia de sitio de launiversidad. UNT tiene una licencia de sitio que permite a los estudiantes autilizar el software en cualquier laboratorio de acceso general en elcampus. Para los estudiantes que deseen instalar el software en sus propiasmáquinas, las versiones del software están disponibles para la venta en la librería de UNT en los precios con descuento académico.
Para los precios actuales en la mayoría de los estudiantes UNT libreríausted puede comunicarse con ellos al 940-565-2592, sin embargo el precioes de $ 200 para el 'Grad Pack' y $ 100 por una versión para estudiantes
lisiados que vence cada año. La única razón para comprarlo es para usoprivado, es otra forma ubicua en el campus.
SÓLO profesores a tiempo completo y el personal puede solicitar lainstalación de SPSS en sus máquinas en la escuela o en casa. ¿Está ustedde la facultad? ¿Es usted alguien que pone en 40 horas a la semana en elcampus de una capacidad completamente no-alumno? Si su respuesta esno tanto a continuación, usted no califica de ninguna manera, forma o formade una copia personal de nosotros en RSS. No hay ninguna ambigüedad enel uso de la palabra "sólo" aquí, a pesar de lo que es mejor amigo de tuprimo que es un estudiante en un departamento al otro lado del campus le
haya dicho. Y no, no vamos a creer por un segundo que su profesorprincipal se envía a través de su copia.
III. ¿Cómo SPSS trabajo?
SPSS tiene tres archivos básicos, a saber. los datos, la sintaxis y el archivode salida.
SPSS Data
La ventana de datos contiene los archivos del sistema SPSS y muestra los
datos en formato de hoja de cálculo. Con la versión 14, usted ahora puedetener varios archivos de datos abiertos. Con 16 SPSS también está basadoen Java, lo que parece haber dado lugar a SPSS perder parte de su"facilidad de uso" la ventaja que tenía en relación con otros algunospaquetes otra estadística, ya que incluso el uso ocasional puede revelaralgunas peculiaridades. Para entrada de datos simple que funciona muy

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 17/35
bien, pero si usted ya está familiarizado con Excel que no necesariamentese encuentra mucha ventaja.
Aquí es donde entrará directamente los datos en SPSS. Las filas songeneralmente considerados como unidades de observación (por ejemplo,los sujetos en estudio), y las columnas se consideran las variables de lasunidades de observación. Usted puede cortar, pegar y borrar registros(unidades de observación) y columnas (variables) como se desee desdeesta ventana, así como los casos y las variables se mueven haciendo clic yarrastrando. SPSS archivos del sistema se almacena de formapredeterminada con la extensión *. sav, pero se pueden guardar comomuchos otros tipos de archivos. En particular, se recomienda guardar unconjunto de datos completa como un archivo *. Por (portátil) al menos una
vez para salvar a posibles problemas de compatibilidad. La ventana dedatos tiene dos puntos de vista, la vista de datos reales por encima y elpunto de vista variable, se ve aquí.
Es con el punto de vista variable que se le pueda asignar el tipo de variable,varían los anchos de columna, crear etiquetas de las variables, asignarvalores que faltan, etc Le sugerimos que haga todo lo que no es realmenteun nombre, por ejemplo, país o nombre de la persona, como numéricos conetiquetas en su lugar, a menos que seas del tipo sádico entonces adelante yañadir lo que probablemente será un par de horas de trabajo mástarde. Como nota final, dejar los datos solo. Usuarios de Excel, en particular,vienen al análisis de datos con los malos hábitos como colorear las células y
jugar con los tamaños de fuente, etc. Si desea hacer lo mismo con laproducción, tienen en él, pero deja el archivo de datos en sí, como lo es amenos que desee un dolor de cabeza más adelante.
Sintaxis SPSS
SPSS es un poco raro para mí. A la gente le gusta por sus menús, pero losmenús son tan limitantes que inevitablemente se tiene que ir a la sintaxispara realizar un análisis que vale la pena (o, más probablemente, a otropaquete de estadísticas). Sin embargo, si usted va a utilizar la sintaxis,

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 18/35
SPSS no es flexible ni eficaz en comparación con otros paquetes. Sulenguaje se desarrolló cuando la gente sólo este tipo de cosas en losordenadores centrales y que nunca cambia, a pesar de que la computaciónen continua evolución. Para compensar esto, SPSS cuenta con add-ons que
permiten utilizar lenguajes de programación como Python verdad y R. Perosi puedes usar los como un investigador académico aplicado, no habríaninguna razón para estar con el programa SPSS en el primer lugar . Encualquier caso, si prefieren SPSS la mejor manera de utilizarlo es con lasintaxis o muy complementados con ella, la ventana de la que se muestra acontinuación.
Como veremos en el próximo curso, sin duda hace que SPSS para elanálisis de datos mucho más eficiente con la sintaxis en lugar de utilizar losmenús, y hay trucos que uno puede hacer hay que no están disponibles enlos menús (por ejemplo, los poderosos procedimiento MANOVA). Sinembargo, tenga en cuenta que los menús están todavía disponibles en laventana de sintaxis, así que usted puede utilizar si es necesario. Archivosde sintaxis SPSS *. sps. Además, con la versión 17.0 del editor de sintaxisha cambiado un poco, sobre todo para mejor. Sin embargo, existen posiblesproblemas de compatibilidad correr la sintaxis de 17 en las versionesanteriores.
SPSS salida
El tercer tipo de archivo común de SPSS es el archivo de salida (con 16creo que debe llamar a un visor de archivos).

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 19/35
Data_view

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 20/35
En cierto modo, SPSS tiene una ventaja sobre otros paquetes porque lascosas salen un poco más fácil en los ojos con la información de texto, y losestudiantes que he tenido parece que se enamoran de texto en las redes,por alguna razón. Además, es muy fácil de exportar a HTML o Powerpoint
para su presentación. Desafortunadamente, esto tiene un precio, es decir,que no se puede hacer nada con los resultados en la salida, por ejemplo, losutilizan como insumo en un nuevo análisis (al menos no sin una ciertafinagaling sintáctica notable). Los usuarios del principiante no creo que esoes una gran cosa. Investigadores más experimentados saben mejor. Dijoque con la versión 16 de salida es ahora muy lenta para llegar, y los gráficosde SPSS han quedado muy por detrás de la mayoría de los paquetesestadísticos importantes para un rato ahora. En resumen, el texto bastanteno es una razón para utilizar un paquete, y mientras que usted puedeexportar los gráficos, esto ya no es una ventaja que tiene sobre otrospaquetes. Una nota final: los usuarios de 16 años no puede ver el antiguo
archivos *. spo sin necesidad de instalar el visor de herencia, que no seinstala por defecto, pero está disponible para cualquier usuario de SPSS. Laextensión del archivo es ahora *. SPV.
IV. Obtención de datos en SPSS.
Hay tres maneras principales de obtener los datos en SPSS: (a) crear unnuevo archivo de datos SPSS, (b) la apertura de los archivos existentes dedatos de SPSS, y (c) la importación de datos de otra fuente, como unarchivo ASCII, una hoja de cálculo Excel, etc .
1. La creación de nuevos archivos de datos SPSS.Los datos se pueden introducir directamente en similar a una hoja de cálculoExcel SPSS. Sin embargo, si se van a introducir los datos directamente,tendrá que nombrar y definir las variables.
2. La apertura de los archivos existentes del sistema SPSS.
La apertura de los archivos existentes de SPSS es un procedimientobastante sencillo, similar a la apertura de otros archivos deWindows. Seleccione "Abrir" en el menú Archivo, y se encuentra un cuadro
de diálogo que se parece a la figura de abajo. También se puede ver que sepuede abrir cualquier tipo de archivo SPSS, no sólo archivos de datos, asícomo llamar fácilmente de los archivos que ha utilizado recientemente (elnúmero de archivos recientes se pueden ajustar en Editar / Opciones).

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 21/35
Como se mencionó anteriormente, los archivos de SPSS del sistema sealmacenan con la extensión *. sav. Por defecto, SPSS se supone que deseaentrar en un archivo del sistema SPSS, aunque hay muchos tipos dearchivos que pueden acceder a la importación directa, y esto siempre va aconseguir a alguien que en lugar de estar buscando un archivo de Excel("Te juro que lo puso en el escritorio !!"). A continuación, puede ir aldirectorio donde se almacena el archivo de datos que desea abrir y abrir el
archivo.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 22/35
3. Importar datos desde un archivo ASCII.
Por varias razones, los datos son a menudo en formato ASCII o texto, lamás grande es que cualquier programa pueda leer. Con el fin de utilizar los
datos en SPSS, los datos deben ser convertidos a un formato de archivoque SPSS puede reconocer, es decir, algo en formato *. sav. SPSS puedeleer los datos ASCII, que luego se pueden guardar en formato *. sav. Elenfoque básico a través de los menús A continuación se muestra, sinembargo, si usted está tirando de los archivos de datos de gran tamaño dela web, por ejemplo, a través de ICPSR, que va a utilizar la sintaxis que seproporciona normalmente.
4. Importar datos desde otros formatos de archivo
SPSS permite al usuario para que abra directamente los datos en SPSS a
partir de diferentes formatos de archivo. Por ejemplo, SPSS directamente seabrirá Excel, SAS, Stata y los archivos *. dbf (database). El usuario sólotiene que hacer es ir al menú Archivo, seleccione "Abrir", seleccione el tipode archivo correcto en el "Tipo de archivo" del menú desplegable ydesplácese hasta el archivo que desea abrir.
V. Opciones de menú
Como se puede ver arriba , hay varios menús disponibles y necesarios en eltranscurso del análisis. Para empezar, se sugiere que pasar algún tiempo lapersonalización de la salida de SPSS y las opiniones a su gusto con Editar /
Opciones. El menú Archivo es similar a otros (Windows), como es el meuEditar, y el más utilizado para el investigador aplicado será el de datos,transformación, y Analizar los menús. Tenga en cuenta que muchos de losanálisis vienen con opciones de trazado específico para ellos y que no estándisponibles en el menú de gráficos, pero como se mencionó anteriormente,SPSS cuenta con capacidades gráficas muy pobres en general.
Una palabra de advertencia acerca de los menús. Sólo porque usted puedehacer clic fácilmente su camino a través de un análisis, no quiere decir,a. Usted ha hecho nada de forma apropiada b. Su análisis es más valor queel papel que podría imprimir en. Los menús se pueden hacer más fácil para
obtener resultados, pero eso no significa que sea útil. En resumen laproducción no analyis igual . En RSS hemos conseguido muchos clientesque vienen en el que han hecho clic en su camino a través de los terriblesresultados, que eran pobres, ya que fue directamente al análisis. Que porsupuesto se debe evitar.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 23/35
VI. Ventajas y Disadvanatges
Ventajas: SPSS ofrece una facilidad de uso que la mayoría de los paquetesson sólo ahora ponerse al día. Es popular, y sin embargo, que no es
ciertamente una razón para elegir un paquete estadístico, muchos conjuntosde datos son fáciles de cargar en él y otros programas pueden importararchivos de SPSS. A partir de la versión 16 y 17, ahora es compatible con Ry Python (suponiendo que se instalan en la máquina), que puede darle lafuncionalidad que de otra manera carece o sería demasiado torpe en supropia sintaxis.
Desventajas: Sólo para uso académico de SPSS se queda sobre tododetrás de SAS, R, e incluso tal vez otros que están en la más matemática envez de lado los datos estadísticos para el análisis moderno (por ejemplo, losenfoques robustos y de fácil acceso bootstrapping a cabo en otros lugares
no existen o son muy difíciles de hacer, las pruebas básicas de supuestosanalíticos menudo no están disponibles). Su oferta de menús suelen ser losmás básicos de un análisis y, a veces carecen incluso entonces, y lo hacehaciendo un análisis inadecuado muy fácil. Los gráficos por defecto sonpobres y no son fácilmente adaptables para hacerlas mejores. Es caro, aveces ridículamente así (por ejemplo, muchos de sus complementos songratis en otro lado o una parte de la base de instalación de otros paquetes),y aún cuando usted compra usted es realmente sólo leasing, y su licenciadefinitivamente no es fácil de usar . A menudo hay problemas decompatibilidad con versiones anteriores.
VII. ResumenSPSS ofrece un poco como un programa general de estadísticas, y es librey ampliamente disponible para todos en el campus a través de loslaboratorios, y, si profesores calificados, o el personal para su usopersonal. Hay tres archivos básicos para trabajar con (aunque otros estándisponibles), y SPSS ha hecho mucho para desarrollar una interfaz gráficade usuario. Si usted es parcial a los enfoques GUI SPSS es, sin duda pordelante de algunos, pero no todos, los demás en ese departamento, peroeso es lo único que cuenta con más de otros que probablemente unllamamiento a la investigadora académica aplicada. Si usted está buscando
para obtener ayuda e información sobre SPSS, hay una gran cantidad deella en la web debido a su popularidad, así que siéntete libre para hacer labúsqueda por su cuenta. Usted encontrará que la mayoría de los librossobre el uso de SPSS ofrecen mucho menos de lo que es de libre y fácil deobtener en la web.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 24/35

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 25/35
PRUEBAS DE SIGNOS.
La mayor parte de las técnicas estudiadas hacen suposiciones sobre lacomposición de los datos de la población. Las suposiciones comunes son que lapoblación sigue una distribución normal, que varias poblaciones tienen varianzasiguales y que los datos se miden en una escala de intervalos o en una escala derazón. Este tema presentará un grupo de técnicas llamadas no páramétricas queson útiles cuando estas suposiciones no se cumplen.
¿Porqué los administradores deben tener conocimientos sobre estadística noparamétrica?
La respuesta a esta pregunta es muy sencilla; las pruebas de ji cuadrada sonpruebas no paramétricas. Tanto la prueba de la tabla de contingencia como la debondad de ajuste analizan datos nominales u ordinales. Estas pruebas, se usanampliamente en las aplicaciones de negocios, lo que demuestra la importancia dela habilidad para manejar datos categóricos o jerarquizados además de loscuantitativos.
Existen otras muchas pruebas estadísticas diseñadas para situaciones en las queno se cumplen las suposiciones críticas o que involucran datos cuantitativos ocategóricos. Los analistas que manejan estos datos deben familiarizarse con librosque abordan tales pruebas, conocidas comúnmente como pruebas estadísticas noparamétricas. Se presentarán aquí unas cuantas de las pruebas no paramétricasque mas se usan.
¿Qué ocurre con las pruebas no paramétricas frente a las que si lo son?
Las pruebas no paramétricas nonecesitan suposiciones respecto a la composiciónde los datos poblacionales. Las pruebas no paramétricas son de uso común:
1.- Cuando no se cumplen las suposiciones requeridas por otras técnicas usadas,por lo general llamadas pruebas paramétricas.
2.- Cuando es necesario usar un tamaño de muestra pequeño y no es posibleverificar que se cumplan ciertas suposiciones clave.
3.- Cuando se necesita convertir datos cualitativos a información útil para la tomade decisiones.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 26/35
Existen muchos casos en los que se recogen datos medidos en una escalanominal u ordinal. Muchas aplicaciones de negocios involucran opiniones osentimientos y esos datos se usan de manera cualitativa.
Las pruebas no paramétricas tienen varias ventajas sobre las pruebasparamétricas:
1.- Por lo general, son fáciles de usar y entender.
2.- Eliminan la necesidad de suposiciones restrictivas de las pruebasparamétricas.
3.- Se pueden usar con muestras pequeñas.
4.- Se pueden usar con datos cualitativos.
También las pruebas no paramétricas tienen desventajas:
1.- A veces, ignoran, desperdician o pierden información.
2.- No son tan eficientes como las paramétricas.
3.- Llevan a una mayor probabilidad de no rechazar una hipótesis nula falsa(incurriendo en un error de tipo II).
Las pruebas no paramétricas son pruebas estadísticas que no hacen suposiciones
sobre la constitución de los datos de la población.Por lo general, las pruebas paramétricas son mas poderosas que las pruebas noparamétricas y deben usarse siempre que sea posible. Es importante observar,que aunque las pruebas no paramétricas no hacen suposiciones sobre ladistribución de la población que se muestrea, muchas veces se apoyan endistribuciones muestrales como la normal o la ji cuadrada.
EL CONTRASTE DE SIGNOS.
La prueba de los signos es quizá la prueba no paramétrica mas antigua. En ella
está, basadas muchas otras. Se utiliza para contrastar hipótesis sobre elparámetro de centralización y es usado fundamentalmente en el análisis decomparación de datos pareados. Consideremos una muestra aleatoria de tamañon tal que sus observaciones estén o puedan estar clasificadas en dos categorías:0 y 1, + y -, . etc.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 27/35
Podemos establecer hipótesis acerca de la mediana, los centiles, cuartiles, etc.Sabemos que la mediana deja por encima de sí tantos valores como por debajo;Considerando que Xi - Mdn > 0 , darán signos positivos (+) y Xi - Mdn < 0 signosnegativos (-) , en la población original tendremos tantos (+) como (-). Se tratara de
ver hasta que punto el numero de signos (+) esta dentro de lo que cabe esperarque ocurra por azar si el valor propuesto como mediana es verdadero. Lo mismose puede decir respecto a los cuartiles, centiles, o deciles.
Teniendo en cuenta que se trabaja con dos clases de valores, los que están porencima y los que están por debajo, es decir, los (+) y los (-) , los estadísticos decontraste seguirán la distribución binomial, si se supone independencia yconstancia de probabilidad en el muestreo.
La mejor forma de entender este apartado es mediante un ejemplo practico; Demodo que en la tabla que pondremos a continuación se pueden ver los resultados
de un experimento sobre comparación de sabores. Un fabricante de alubias estaconsiderando una nueva receta para la salsa utilizada en su producto. Eligio unamuestra aleatoria de ocho individuos y a cada uno de ellos le pedio que valoraraen una escala de 1 a 10 el sabor del producto original y el nuevo producto. Losresultados se muestran en la tabla, donde también aparecen las diferencias en lasvaloraciones para cada sabor y los signos de estas diferencias. Es decir,tendremos un signo + cuando el producto preferido sea el original, un signo -cuando el preferido sea el nuevo producto y un 0 si los dos productos sonvalorados por igual. En particular en este experimento, dos individuos hanpreferido el producto original y cinco el nuevo; Uno los valoro con la mismapuntuación.
La hipótesis nula es que ninguno de los dos productos es preferido sobre el otro.Comparamos las valoraciones que indican la preferencia por cada producto,descartando aquellos casos en los que los dos productos fueron valorados con lamisma puntuación. Así el tamaño muestral efectivo se reduce a siete, y la únicainformación muestral en que se basara nuestro contraste será la de los dosindividuos de los siete que prefirieron el producto original.
La hipótesis nula puede ser vista como aquella en la que la media poblacional delas diferencias sea 0. Si esta hipótesis fuese cierta, nuestra sucesión dediferencias + y - podría ser considerada como una muestra aleatoria de una
población en la que las probabilidades de + y - fueran cada una 0,5. En este caso,las observaciones constituirían una muestra aleatoria de una población con unadistribución binomial, con probabilidad de + 0,5. Es decir, si p representa laverdadera proporción en la población de +,la hipótesis nula será:
H0: p = 0,5
5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 28/35
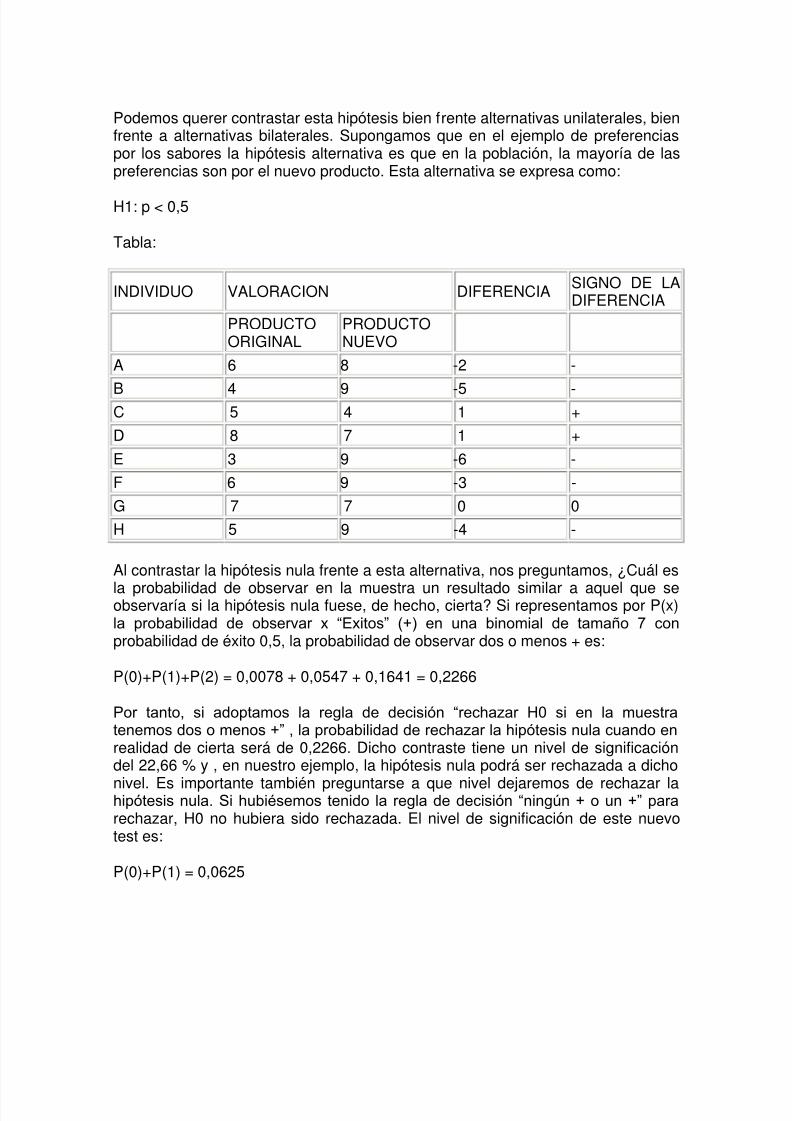
Podemos querer contrastar esta hipótesis bien frente alternativas unilaterales, bienfrente a alternativas bilaterales. Supongamos que en el ejemplo de preferenciaspor los sabores la hipótesis alternativa es que en la población, la mayoría de laspreferencias son por el nuevo producto. Esta alternativa se expresa como:
H1: p < 0,5
Tabla:
INDIVIDUO VALORACION DIFERENCIA SIGNO DE LADIFERENCIA
PRODUCTOORIGINAL
PRODUCTONUEVO
A 6 8 -2 -
B 4 9 -5 -C 5 4 1 +
D 8 7 1 +
E 3 9 -6 -
F 6 9 -3 -
G 7 7 0 0
H 5 9 -4 -
Al contrastar la hipótesis nula frente a esta alternativa, nos preguntamos, ¿Cuál es
la probabilidad de observar en la muestra un resultado similar a aquel que seobservaría si la hipótesis nula fuese, de hecho, cierta? Si representamos por P(x)la probabilidad de observar x “Exitos” (+) en una binomial de tamaño 7 conprobabilidad de éxito 0,5, la probabilidad de observar dos o menos + es:
P(0)+P(1)+P(2) = 0,0078 + 0,0547 + 0,1641 = 0,2266
Por tanto, si adoptamos la regla de decisión “rechazar H0 si en la muestratenemos dos o menos +” , la probabilidad de rechazar la hipótesis nula cuando enrealidad de cierta será de 0,2266. Dicho contraste tiene un nivel de significacióndel 22,66 % y , en nuestro ejemplo, la hipótesis nula podrá ser rechazada a dicho
nivel. Es importante también preguntarse a que nivel dejaremos de rechazar lahipótesis nula. Si hubiésemos tenido la regla de decisión “ningún + o un +” pararechazar, H0 no hubiera sido rechazada. El nivel de significación de este nuevotest es:
P(0)+P(1) = 0,0625

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 29/35
La hipótesis nula no será rechazada a un nivel de significación del contraste del6,25 %. La hipótesis nula de que en la población las preferencias por un productou otro son iguales es rechazada contra la hipótesis alternativa de que la mayoríade la población prefiere el nuevo producto utilizando un test con nivel de
significación del 22,66% . Si embargo la hipótesis nula no puede ser rechazadautilizando el test con nivel de significación del 6,25%.
Por tanto, estos datos muestran una modesta evidencia contra la hipótesis nula deque la población tenga preferencias iguales por un producto u otro, aunque dichaevidencia no es muy grande. En nuestro caso, esto puede ser una consecuenciadel pequeño tamaño muestral. Tenemos que considerar el caso en el que lahipótesis alternativa sea bilateral, es decir:
H1: p " 0,5
En nuestro ejemplo, esta hipótesis significa que la población puede preferir uno uotro producto. Si las alternativas a cada valor postulado por la hipótesis nula sontratados de forma simétrica, una regla de decisión que nos conduciría a rechazarla hipótesis nula para estos datos seria “rechazas Ho si la muestra contiene dos omenos, o cinco o mas +”. El nivel de significación para este contraste es:
P(0) + P(1) + P(2) + P(5) + P(6) + P(7) = 2 [P(0) + P(1) + P(2)] = 0.4532
Ya que la función de probabilidad de la distribución binomial es simétrica para p =0,5. La hipótesis nula no será rechazada si no tomamos como regla de decisión“rechazar H0 si la muestra contiene dos o menos o seis o mas +s”.Este contraste
tiene nivel de significación:P(0) + P(1) + P(6) + P(7) = 2 [ P(0) + P(1)] = 0,1250
Por tanto, a un nivel de significación del contraste del 12,5 %, la hipótesis nula deque la mitad de los miembros de la población con alguna preferencia prefieren elnuevo producto no será rechazado frente a la hipótesis alternativa bilateral.
El contraste de signos puede ser utilizado para contrastarla hipótesis nula de quela mediana de una población es 0. Supongamos que tomamos una muestraaleatoria de una población y eliminamos aquellas observaciones iguales a 0,
quedando en total n observaciones. La hipótesis nula a contrastar será que laproporción p de observaciones positivas en la población es 0,5 es decir:
H0 : p = 0,5

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 30/35
En este caso, el contraste estará basado en el hecho de que el numero deobservaciones positivas en la muestra tiene una distribución binomial ( p = 0,5 bajola hipótesis nula).
Si el tamaño muestral es grande, se podrá utilizar la aproximación de ladistribución binomial a la normal para realizar el contraste de signos. Esta es unaconsecuencia del teorema central del límite.
Si el numero de observaciones no iguales a 0 es grande, el contraste de signosesta basado en la aproximación de la binomial a la normal. El contraste es:
H0 : p = 0,5
EJEMPLO
A una muestra aleatoria de cien niños se les pidió que comparasen dos nuevossabores de helados: vainilla y fresa. 56 de los niños prefirieron el sabor a vainilla,40 prefirieron el sabor a fresa, y a 4 de ellos les daba igual. Se quiere contrastarfrente a una alternativa bilateral la hipótesis nula de que no existe en la poblaciónuna preferencia por un sabor u otro.
Si p es la proporción de niños en la población que prefieren el sabor a vainilla, loque queremos contrastar es H0: p=0,5 frente a H1: p"0,5.
Como cuatro de los niños no han preferido un sabor a otro, tenemos un tamañomuestral de 96 niños. La proporción de niños que han preferido el sabor a vainilla
es:Px = 56 / 96 = 0,583
Para un nivel de significación , la regla de decisión es:
Px - 0,5
Rechazar H0 si -------------------- < -Z /2
"(0,5)(0,5) / n
ó
Px - 0,5
-------------------- > -Z /2

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 31/35
"(0,5)(0,5) / n
En nuestro caso
Px - 0,5 0,583 - 0,5-------------------- = ------------------------ = 1,63
"(0,5)(0,5) / n "(0,5)(0,5) / 96
Vemos, que si Z /2 = 1,63, /2= 0,0516, de manera que = 0,1032. Por tanto, lahipótesis nula podrá ser rechazada para todos los niveles de significaciónsuperiores al 10,32%. Si la hipótesis nula de que el mismo número de niñosprefieren el sabor a vainilla que el sabor a fresa fuese cierta, la probabilidad de
observar unos resultados maestrales tan extremos, o mas extremos que losactualmente obtenidos, será ligeramente superior a uno sobre diez. En nuestrocaso, los datos muestran una modesta evidencia en contra de dicha hipótesis.
La figura muestra las probabilidades de las colas de una distribución normalcorrespondientes al 5,16% inferior y superior del área total bajo la función dedensidad.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 32/35
PRUEBA DE LOS SIGNOS DE WILCOXON.
La prueba de los signos de Wilcoxon es una prueba no paramétrica para comparar
la mediana de dos muestras relacionadas y determinar si existen diferencias entreellas. Se utiliza como alternativa a la prueba t de Student cuando no se puede
suponer la normalidad de dichas muestras. Debe su nombre a Frank Wilcoxon,
que la publicó en 1945.
Se utiliza cuando la variable subyacente es continua pero presupone ningún tipo
de distribución particular.
Planteamiento.
Supóngase que se dispone de n pares de observaciones, denominadas (x i ,y i ). El
objetivo del test es comprobar si puede dictaminarse que los valores x i e y i son o
no iguales.
1. Si z i = y i − x i , entonces los valores z i son independientes.
2. Los valores z i tienen una misma distribución continua y simétrica respecto a
una mediana común θ.
Método.
La hipótesis nula es H 0: θ = 0. Retrotrayendo dicha hipótesis a los
valores x i ,y i originales, ésta vendría a decir que son en cierto sentido del mismo
tamaño.
Para verificar la hipótesis, en primer lugar, se ordenan los valores
absolutos y se les asigna su rango R i . Entonces, el estadístico de laprueba de los signos de Wilcoxon, W + , es

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 33/35
Es decir, la suma de los rangos R i correspondientes a los valores positivos de z i .
La distribución del estadístico W + puede consultarse en tablas para determinar si
se acepta o no la hipótesis nula.
En ocasiones, esta prueba se usa para comparar las diferencias entre dos
muestras de datos tomados antes y después del tratamiento, cuyo valor central se
espera que sea cero. Las diferencias iguales a cero son eliminadas y el valor
absoluto de las desviaciones con respecto al valor central son ordenadas de
menor a mayor. A los datos idénticos se les asigna el lugar medio en la serie. la
suma de los rangos se hace por separado para los signos positivos y los
negativos. S representa la menor de esas dos sumas. Comparamos S con el valor
proporcionado por las tablas estadísticas al efecto para determinar si rechazamos
o no la hipótesis nula, según el nivel de significación elegido.
PRUEBA U DE MANN-WHITNEY.
En estadística la prueba U de Mann-Whitney (también llamada de Mann-Whitney-
Wilcoxon, prueba de suma de rangos Wilcoxon, o prueba de Wilcoxon-Mann-
Whitney) es una prueba no paramétrica aplicada a dos muestras independientes.
Es, de hecho, la versión no paramétrica de la habitual prueba t de Student.
Fue propuesto inicialmente en 1945 por Frank Wilcoxon para muestras de igual
tamaños y extendido a muestras de tamaño arbitrario como en otros sentidos
por Henry B. Mann y D. R. Whitney en 1947.
Planteamiento de la prueba.
La prueba de Mann-Whitney se usa para comprobar la heterogeneidad de dos
muestras ordinales. El planteamiento de partida es:
1. Las observaciones de ambos grupos son independientes
2. Las observaciones son variables ordinales o continuas.
3. Bajo la hipótesis nula, las distribuciones de partida de ambas distribuciones
es la misma

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 34/35
4. Bajo la hipótesis alternativa, los valores de una de las muestras tienden a
exceder a los de la otra: P(X > Y ) + 0.5 P(X = Y ) > 0.5.Cálculo del estadístico
Para calcular el estadístico U se asigna a cada uno de los valores de las dosmuestras su rango para construir
donde n 1 y n 2 son los tamaños respectivos de cada muestra; R 1 y R 2 es la
suma de los rangos de las observaciones de las muestras 1 y 2
respectivamente.El estadístico U se define como el mínimo de U 1 y U 2.
Los cálculos tienen que tener en cuenta la presencia de observaciones
idénticas a la hora de ordenarlas. No obstante, si su número es pequeño, se
puede ignorar esa circunstancia.
Distribución del estadístico.
La prueba calcula el llamado estadístico U , cuya distribución para muestras
con más de 20 observaciones se aproxima bastante bien a la distribución
normal.
La aproximación a la normal, z , cuando tenemos muestras lo suficientemente
grandes viene dada por la expresión:
z = (U − m U ) / σU
Donde mU y σU son la media y la desviación estándar de U si la hipótesis
nula es cierta, y vienen dadas por las siguientes fórmulas:
m U = n 1n 2 / 2.

5/14/2018 estadistica aplicada teoria - slidepdf.com
http://slidepdf.com/reader/full/estadistica-aplicada-teoria 35/35