what is being masked in object substitution masking?
TRANSCRIPT

What Is Being Masked in Object Substitution Masking?
Angus Gellatly and Michael PillingThe Open University
Geoff ColeUniversity of Durham
Paul SkarrattUniversity of Hull
Object substitution masking (OSM) is said to occur when a perceptual object is hypothesized that ismismatched by subsequent sensory evidence, leading to a new hypothesized object being substituted forthe first. For example, when a brief target is accompanied by a longer lasting display of nonoverlappingmask elements, reporting of target features may be impaired. J. T. Enns and V. Di Lollo (2000)considered it an outstanding question whether OSM masks some or all aspects of a target. The authorsreport three experiments demonstrating that OSM can selectively affect target features. Participants maybe able to detect a target while being unable to report other aspects of it or to report the color but not theorientation of a target (or vice versa). We discuss these findings in relation to two other visualphenomena.
Keywords: object substitution masking, visual attention
Visual masking is said to occur when two stimulus displays arepresented in close spatial and temporal contiguity and the visibilityof one of them (the target) is reduced by the presence of the other(the mask). The target is flashed only briefly, but the mask displaymay be presented for a shorter or longer period depending on therequirements of the particular study. Over the years, several sup-posedly distinct forms of masking have been proposed. In a recentinfluential article, Enns and Di Lollo (1997) reported what theyclaimed to be a new form of visual masking, which they termedobject substitution masking (OSM). They (Di Lollo, Enns, &Rensink, 2000; Enns, 2004) have contrasted OSM, supposedlyinvolving substitution of one perceptual object by another, withwhat Enns (2004) has called object formation masking (OFM). Thelatter refers to masking that supposedly results from interferencewith the perceptual formation process involved in segmenting thetarget from the camouflage of background and other nearby ob-jects. The term OFM subsumes much of what has previously beenreferred to as integration, interruption, or metacontrast masking,although Di Lollo et al. (2000) and Enns (2004) suggested thatdemonstrations of these purported categories of masking mayoften have included components of both OFM and OSM. It is not
our intention in this article to review the huge literature on visualmasking or to debate fine details of taxonomy and nomenclature inrelation to it. We adopt the terminological dichotomy of OFM andOSM on pragmatic grounds because it serves our present purpose.In recent articles dealing with OSM (e.g., Di Lollo et al., 2000;Enns, 2004; Enns & Di Lollo, 1997; Kahan and Mathis, 2002) ausage has developed in which new labels are sometimes used inplace of terms with a longer history in the literature on masking.Again, we do not wish to argue the superiority of one nomencla-ture over the other. We aim to use both sets of terms interchange-ably and in such a manner as to be understood equally by thoseaccustomed to the more traditional terminology and those familiarwith usage in recent articles dealing with OSM.
According to Di Lollo et al. (2000), OFM is sensitive to factorssuch as contour abutment and overlap and relative luminances oftarget and mask displays. It also depends critically on the exacttiming of target and mask onsets. When studied as integration ormetacontrast masking, OFM typically peaks at a target–maskstimulus onset asynchrony (SOA) of 50 ms or less and is largelyabsent at SOAs of 100 ms or more (see Enns, 2004). OFM is alsolittle affected by manipulations of spatial attention toward or awayfrom the target.
OSM, by contrast, is highly sensitive to attentional manipula-tions but not to the local spatiotemporal contour interactionsthought to give rise to OFM. A standard demonstration of OSMuses what Kahan and Mathis (2002) have called the briefly maskedcontrol method, comparing two conditions in which target andmask onset simultaneously (common onset). In the briefly maskedcontrol (or “no masking” control) condition, they also offset si-multaneously. In the mask condition, the (temporally trailing)mask remains present after target offset. In the earlier literature,these were frequently referred to as simultaneous-offset anddelayed-offset conditions. Reporting of some target feature ismarkedly reduced in the second condition relative to the first.
Angus Gellatly and Michael Pilling, Department of Psychology, TheOpen University, Milton Keynes, United Kingdom; Geoff Cole, Depart-ment of Psychology, University of Durham, Durham, United Kingdom;Paul Skarratt, Department of Psychology, University of Hull, Hull, UnitedKingdom.
Michael Pilling is now at the MRC Institute for Hearing Research,University of Nottingham, Nottingham, United Kingdom.
This research was supported by Economic and Social Research CouncilGrant R000223824.
Correspondence concerning this article should be addressed to AngusGellatly, Department of Psychology, The Open University, Walton Hall,Milton Keynes MK7 6AA, United Kingdom. E-mail: [email protected]
Journal of Experimental Psychology: Copyright 2006 by the American Psychological AssociationHuman Perception and Performance2006, Vol. 32, No. 6, 1422–1435
0096-1523/06/$12.00 DOI: 10.1037/0096-1523.32.6.1422
1422

Because spatial and temporal contour relationships at onset areidentical, the degree of OFM is usually thought to be equal in bothconditions, and the reduction in target visibility is, therefore, takenas a measure of OSM. (An alternative interpretation would be thatthe greater time-integrated energy of the trailing mask simplyproduces a greater degree of OFM than does the simultaneous-offset mask. In our introduction and discussion of Experiment 2,we present evidence and arguments against this interpretation.)
The theory of OSM (Di Lollo et al., 2000) assumes that per-ception arises from continuous and recurrent communication be-tween neurons at lower and higher levels within the visual system.Newly appearing objects stimulate lower level cells with spatiallylocal receptive fields and geometrically simple stimulus require-ments. In a feed-forward sweep, output from these cells activateshigher level neurons, which have larger receptive fields and aretuned to more complex stimulus properties. Competing patternhypotheses are generated at this higher level. Resolution of com-petition between these hypotheses, as well as binding of patterns toprecise spatial locations, is thought to require feedback sweeps.Activations at higher and lower levels are compared for consis-tency, and there may be some number of iterations of forward andbackward sweeps before a stable percept emerges. If the visualscene remains constant over the iterations required to achievedynamic stability, the new object will be consciously perceived.However, if a mismatch is detected between activation at thedifferent levels, the iterative process will begin again only on thebasis of current sensory input. OSM is said to occur as a result ofsuch a mismatch. Onset of target and mask sets up lower levelactivation leading to the hypothesis of target plus mask. If bothoffset simultaneously before the arrival of the feedback sweep, thishypothesis can still be matched to persisting but fading activity atthe lower level. However, if the mask display continues after offsetof the target, the hypothesis will mismatch strong sensory evidencethat there is now only a mask present. Further iterations result inonly the mask being consciously perceived. Perception of thetarget plus mask will have been substituted by perception of themask alone. Spatial attention is thought to modulate the maskingeffect because if attention is already focused at the appropriatelocation, conscious perception of the target will be achieved withfewer iterations than if it is focused elsewhere or is diffuse. In thesame vein, studies by Neill, Hutchinson, and Graves (2002) andTata and Giaschi (2004) have shown that the extent of OSM ismodulated by the power of the mask to capture attention awayfrom the target.
Supposedly, OSM takes place after object formation, at the levelof object representation (Enns, 2004; Lleras & Moore, 2003;Moore & Lleras, 2005). But what does this mean? In one exampleof OSM, a diamond target missing either a left or right corner isbriefly presented (usually 33 ms or less), and the observer has toreport the side of the missing corner. Under a variety of conditions,accuracy of report can be reduced by a mask of just four dotssurrounding but not abutting the target. For example, in Experi-ment 1 reported by Enns and Di Lollo (1997), there were threehorizontally aligned locations at which the briefly presented targetmight appear. After a variable SOA, a four-dot mask appeared for30 ms at the same location as the target or at a different location.Accuracy of reporting the missing corner of the target was greatlyreduced in the former condition relative to the latter. The sameoutcome was obtained by Kahan and Mathis (2002, Experiment 1),
when the target diamond appeared unpredictably in one of fourquadrant positions and a simultaneous-onset four-dot mask withdelayed-offset appeared in the same or in a different quadrant.Similarly, in their Experiment 3, Enns and Di Lollo found thataccuracy of report was reduced for displays containing two dis-tractor diamonds in addition to the masked target as compared withdisplays containing only a masked target.
We are interested in the following question: When, in studiessuch as those just cited, observers are unable to report the side ofthe missing corner of the diamond, what is it that is being masked?For example, are observers unaware that a target was presented?Given that detection performance is generally a more sensitivemeasure than discrimination performance, it seems unlikely thatthis need be the case. However, the proposal that OSM occurs atthe level of object tokens has about it the suggestion that allrepresentation of the target object is erased from perception. Al-though we are unaware of published data that address the issue,statements by several authors come very close to such a claim. Forexample, in relation to four-dot masking of a diamond, Kahan andMathis (2002) stated that “the phenomenological experience ofthis effect is that a mask surface replaces the target” (p. 1249).Neill et al. (2002) reported for four-dot masking of a letter that“not only does the space inside the dots appear blank, but there isa strong subjective impression of the contours of a square con-necting the �masking� dots” (p. 683). For masking of variouslyoriented C shapes, Di Lollo et al. (2000) stated,
Although the four-dot mask was insufficient as a source of contourinterference, it was entirely adequate for defining a trailing configu-ration (a square surface) that replaced the target as an object ofperception . . . .At longer durations of the trailing mask . . . the fourdots appeared to be clearly visible, but the target location appearedempty. (p. 492)
While for similar displays, Tata (2002) reported that by contrastwith previous metacontrast masking effects in which “visibility ofthe target is reduced, but its presence is nevertheless detected,” inhis studies masking “was phenomenologically complete . . . theobservers reported seeing a blank space among the distractorswhere the target should have been” (p. 1036). Clearly, Di Lollo etal. and Tata were open to the possibility that OSM may eliminateall trace of the target representation. In contrast to these strong ifintrospectively based claims, Enns and Di Lollo (2000, p. 351)took a more cautious position and considered it an outstandingquestion whether OSM (which in the context they termedcommon-onset masking) interferes with the perception of some orall aspects of a target. They wrote,
For example, many iterative cycles might be required to perceivespecific attributes of the target such as its detailed shape or colour.Simpler attributes such as mere presence or absence might requirefewer cycles, in which case masking for these attributes would bereduced or eliminated. (p. 351)
The first aim of the present article is to provide data to address thisoutstanding question identified by Enns and Di Lollo.
Before we proceed further, it is important to emphasize the logicof inquiry in relation to this matter. Suppose the phenomenologicalclaims reported above were supported by behavioral evidence thatobservers could not discriminate between presence and absence ofthe target. What would this demonstrate? Consider that Di Lollo et
1423OBJECT SUBSTITUTION MASKING

al. (2000) used displays with up to 15 distractors and thus had 16potential targets and target locations. It is possible that in condi-tions of such high perceptual load, target detection might indeed beat the level of chance. This would not prove that OSM necessarilyinvolves elimination of all trace of the target. It would simply showthat there happen to be conditions in which detection performanceis reduced to chance and that also produce OSM. However, prov-ing the obverse case, that OSM for some feature of a target canoccur without all trace of the target having been erased fromconscious perception, requires only a single counterdemonstration.If a substantial degree of OSM can be obtained for a particulartarget feature in conditions that produce a much smaller decrementin detection performance and if the level of detection is higher thanthe level of discrimination, then there must be some trials on whichthe target is detectable while the feature is not discriminable. InExperiment 1 we had the aim of investigating this issue.
Our results may be summarized as the following: Experiment 1showed that strong four-dot masking can occur for a discrimina-tion task under conditions in which reporting of presence orabsence is much less affected. This raised the further question ofwhether, in OSM, properties such as color and orientation can beindependently masked. The results of Experiment 2 indicate thatmasking of different properties is at least partially independent,and those of Experiment 3 reveal that it can be fully independent.Theoretical implications of this independent processing arediscussed.
Experiment 1: Detection and Discrimination Under OSM
This study was closely modeled on Enns and Di Lollo’s (1997)Experiment 3. Participants reported either which corner of amasked diamond was missing (discrimination) or whether a targethad been present or absent at the masked location (detection).
Method
Participants. Ten postgraduate students and employees at the OpenUniversity served as paid participants. All had normal or corrected-to-normal vision.
Materials and procedure. Stimuli were presented on a PC monitor.Following a warning tone, a trial began with presentation of two blue bars,2° above and below the center of the screen, between which participantswere instructed to fixate throughout the trial. After 400 ms, three diamondswere presented for 17 or 33 ms, each with either the left or right cornerdeleted at random. One diamond, the target, was surrounded by foursimultaneously appearing dots (except on half of the detection trials, onwhich the two distractor diamonds appeared with the dots surrounding anempty location). Mask dots either offset simultaneously with target anddistractors (unmasked or simultaneous-offset condition) or remained for500 ms (trailing mask or delayed-offset condition). For discrimination, the
missing corner of the target was to be indicated with the left or right slashkey. For detection, the same keys were used to report target presence orabsence, with this response mapping and the order of the two taskscounterbalanced across participants. Target and mask (or mask alone)appeared randomly and equally often in each of the three locations. Eachtask comprised demonstration trials (with extended frame durations), fol-lowed by 32 practice trials and four blocks of 48 experimental trials. Thewhole session lasted approximately 40 min.
Stimuli were presented on a PC controlled by custom software and wereviewed from 70 cms. Target and distractors were white diamonds (allmonitor color guns at 63) on black (all monitor color guns at 0); they were0.9° on a side with a corner missing (triangular section 0.25°on its equalsides). Masking dots were squares 0.4° on a side, forming a virtual squareof 2°. Target and distractors appeared at the center and 3° to left and rightof center.
Results
Accuracy for both tasks is shown in Table 1. False positiveerrors occurred on less than 1% of target-absent detection trials.An initial analysis of variance (ANOVA) on the accuracy datashowed target duration did not produce a significant main effect orinteractions with other factors (F � 1.5 in all cases), therefore thedata were subsequently collapsed across durations. A two-wayrepeated-measures ANOVA showed significant main effects oftask, F(1, 9) � 63.3, p � .001, and masking, F(1, 9) � 23.5, p �.001, and a significant interaction between these two factors, F(1,9) � 14.5, p � .005, reflecting the larger effect of masking ondiscrimination performance than on detection performance. Posthoc one-tailed tests showed, however, that masking had a signif-icant effect on both discrimination, t(9) � 5.04, p � .005, anddetection, t(9) � 2.12, p � .05.
Discussion
Targets that masking has reduced in visibility or even renderedphenomenally absent may serve as effectively as unmasked targetsto elicit implicit measures of detection such as response time todisplay onset (Fehrer & Biederman, 1962; Fehrer & Raab, 1962)or two-alternative forced choice discrimination (Schiller & Smith,1966). Present or absent responses are thought to more closelyreflect phenomenal experience, although see Jacoby (1998) for adiscussion of the relative contributions of conscious and uncon-scious processes to performance on explicit performance tests.Nevertheless, the present results indicate that four-dot masking canreduce explicit detection performance even for fairly low-loadvisual displays. The effect is quite small in the present experiment,but it is significant. On this basis, it is possible that in differentcircumstances, especially with higher load displays such as thoseused by Di Lollo et al. (2000), the effect might be much larger,
Table 1Percentage Mean Correct Responses and Standard Deviations on Present/Absent Detection Taskand Left/Right Discrimination Task in Experiment 1
Unmasked Masked Masking effect
% Correct SD % Correct SD % Correct SD
Present–absent detection 93.8 2.3 89.8 6.8 4.0 5.9Left–right discrimination 81.2 7.2 65.1 12.0 16.1 10.1
1424 GELLATLY, PILLING, COLE, AND SKARRATT

with detection performance possibly even down at chance level (asimplied in the quotations cited earlier). Be that as it may, however,in Experiment 1 OSM had a much greater effect on discriminationthan on detection, indicating that on some proportion of trials thetarget must have been detectable while the missing corner was notdiscriminable.
The answer to the question posed by Enns and Di Lollo (2000)is that OSM can interfere to a greater extent with one aspect of atarget than with another. Contrary to one reading of the introspec-tive reports cited earlier, OSM need not be an all-or-none affair; itdoes not have to entail complete substitution of the consciousrepresentation of the target (Di Lollo et al., 2000). So exactly whataspects of the target do get masked in OSM? A striking feature ofOSM is that aspects of a target can be obscured by maskingelements or even a single element (Lleras & Moore, 2003) verydifferent from it in shape and location. Typically, however, OSMexperiments use target and mask stimuli that differ in variousuncontrolled ways and are poorly matched psychophysically. Thediamond targets and masking dots used in Experiment 1 and inseveral previous studies of OSM (e.g., Enns & Di Lollo, 1997;Kahan & Mathis, 2002) were characteristic in this respect. Thedots were actually small squares; target and mask objects differedgreatly in size and by 45° in their major orientation (although thetruncated diamonds contain a vertical edge also). That such dif-ferently shaped and spatially distant mask elements could impairperception of the target was, of course, precisely what made theOSM demonstration so impressive. At the same time, however, itleft open the question of whether the intensity of OSM may bedetermined by the extent of the physical differences between targetand mask objects. Although there have been careful parametricstudies in relation to OSM of target–mask SOA, target–maskseparation, and number of distractors (e.g., Di Lollo et al., 2000;Enns, 2004), we are unaware of any studies of OSM that havesystematically varied feature differences between target and maskelements (though see Moore & Lleras, 2005). In our next twoexperiments we used target and mask stimuli that differed in acontrolled manner on two physical dimensions. As in Experiment1, a target item was surrounded by four masking items, but allthese were identically shaped rectangles. Target and mask barscould differ in color, orientation, both, or neither.
In Experiments 2 and 3, we addressed the question of whetherdiscrimination of target color and target orientation can be inde-pendently subject to OSM. One way of putting this is to askwhether what gets substituted is the representation of an integratedobject or of a bundle of stimulus features that remain somewhatunbound and independent (Wolfe & Cave, 1999). If OSM occursat the level of object representations, it might be expected thatfeatures would already be bound together and so not subject toindependent OSM. We defer full consideration of such theoreticalissues until the data have been reported.
Experiment 2: OSM for Reporting Color or Orientation ofTarget
The task for Experiments 2 and 3 is illustrated in Figure 1.Participants fixated between two blue bars presented for 500 msand reported either the color or orientation (Experiment 2), or both(Experiment 3), of a target bar. Target and distractors occurredcentrally and to the left and right. The 17-ms target display
contained either the target and two distractor bars or just twodistractors. Target location was identified by four horizontal mask-ing bars surrounding one of the three potential targets’ locations.There were three masking conditions. The mask display couldonset and offset simultaneously with the target, the simultaneous-offset, or (briefly masked) control condition. Or the mask displaycould onset simultaneously with the target but remain present for500 ms, the delayed-offset, or trailing mask condition. Or, finally,the mask could onset at a 100 ms SOA following target onset andremain present for 500 ms, the delayed-onset condition. Partici-pants pressed the left slash key (for Orange or Horizontal or theright slash key (for Red or Vertical) to indicate either the color orthe orientation of the target, or the space bar if they either did notknow the color or orientation of the target or thought that no targethad been presented. They were instructed not to guess the color ororientation of the target if they were uncertain but to press thespace bar in such cases. Responses of this kind are referred to asomission responses as opposed to correct responses (reporting thecorrect color or orientation) and error responses (reporting theincorrect color or orientation).
The wording of these instructions and the inclusion of target-absent trials require explanation. Two-alternative forced choicedecisions are commonly used in psychophysical work becausethey have the advantage that, in principle, data interpretation neednot take response bias into account. The use of target-absent trials,as well as the instruction to report color or orientation only whenfairly confident of them, potentially introduces issues of responsebias to the interpretation of our data. However, we deliberatelychose this method rather than a two-alternative forced choicedecision precisely to avoid the danger of a particular response bias.Our participants were required to report either the color or theorientation of a target bar fleetingly presented at the center of fourclearly visible horizontal bars that themselves had one of the two
500 ms
17 ms
500 ms
Till Response(s)
17 ms
Till Response(s)
Simultaneousoffset
Delayedoffset
500 ms
Figure 1. Presentation sequence for the control mask (simultaneous off-set) and trailing mask (delayed offset) conditions of Experiments 2 and 3.
1425OBJECT SUBSTITUTION MASKING

values of color and orientation that the target could take. During arun of repetitive experimental trials, participants reporting near-threshold experiences might sometimes unconsciously respondwith the color (orientation) of the mask bars rather than with whatthey thought might be the color (orientation) of the target. Alter-natively, participants might very consciously adopt a strategy ofresponding with the color (orientation) of the mask when theywere uncertain about the color (orientation) of the target preciselybecause they hypothesized that target color (orientation) was morediscernible when different from that of the mask. In other words,a possible strategy would be, “when you don’t see the color(orientation) of the target, respond with the value of the mask.”Inclusion of target-absent trials and instructions not to guess whenuncertain was intended to discourage use of this strategy.1 Thisseems to have worked, so much so that there were even signs of anopposite strategy having been adopted by some participants inExperiment 3. It also allowed us to assess whether participantsdistinguished between absence and presence of a masked target, asthey had in Experiment 1. If the false positive rate was low, thentarget-absent trials were not being mistaken for target-presenttrials. Note, though, that because of the nature of our instructions,false negative responses—omission responses on target presenttrials—could not be interpreted as failures to detect the target. Theparticipant may have detected that “something was there” but notknown its color or orientation. Indeed, the results of Experiment 1and the very low false positive rates we report for Experiments 2and 3 strongly suggest that this was usually the case when anomission response was made, suggesting that in these experimentsOSM occurred at the feature level. Moreover, we believe that therobust pattern of data across Experiments 2 and 3 justifies ourdecision on this matter of method.
Mask objects in Experiments 2 and 3 were narrowly separatedfrom the target, and some target contour was paralleled by maskcontour. In order to draw any conclusions about OSM, one mustdemonstrate that the results obtained do not simply reflect OFM.One way to do this is to use the briefly masked control methodused in Experiment 1, which involves comparing a simultaneous-offset mask with a delayed-offset (trailing) mask. Because bothconditions involve simultaneous onset of target and mask theextent of OFM is usually thought to be equal in both cases, so—asdescribed earlier—any difference in performance on the two con-ditions is then attributed to OSM alone. Alternatively, OSM issometimes thought to be demonstrated by comparing asimultaneous-onset and delayed-offset (trailing) mask with thesame duration mask presented at an SOA of (in our case) 100 ms,a delayed-onset mask. As just described, the former condition isthought potentially to give rise to both OFM, because of simulta-neous onset of mask and target, and OSM, because of the delayedoffset of the mask elements (though see also below). In thedelayed-onset condition, by contrast, this interpretation predictsthat there should be little if any OFM because with a 100 ms SOAbetween target onset and mask onset, OFM will be greatly atten-uated if not absent (Spencer & Shuntich, 1970), leaving only OSMcaused by the trailing mask elements.
In Experiment 2 we used both control methods to ensure that theeffects we reported were indeed examples of OSM, not OFM. Notethat we did not attempt to establish whether OFM actually oc-curred in any of the conditions of Experiment 2. One way to havedone this would have been to vary the separation between target
and mask elements. If separation had no effect on the extent ofmasking, it could have been concluded that only OSM and notOFM was affecting performance (Enns & Di Lollo, 1997, Exper-iment 2). However, a problem arises with this method of distin-guishing between OSM and OFM if target–mask separation doesprove to have an effect on performance because there is no meansof measuring the relative contribution of each type of masking.Accordingly, instead of adopting this procedure, we followed thelogic of common-onset masking (Di Lollo et al., 2000; Enns & DiLollo, 2000). As just described, the usual argument here is that ifOFM has occurred, its strength should be equal for simultaneous-offset and delayed-offset masks because both involve an identicalsimultaneous onset. As noted earlier, however, it could be arguedthat the greater time-integrated energy of the trailing mask simplycauses more OFM than does the simultaneous-offset mask. Ouruse of a delayed-onset mask with the same energy as the trailingmask should allow us to distinguish between these competinginterpretations. Because OFM is known to decrease with target–mask SOA and to be almost absent at SOAs at or beyond 100 ms(Spencer & Shuntich, 1970), then on either account the delayed-onset mask should cause less OFM than the simultaneous-onsettrailing mask. If the two types of mask cause similar degrees ofmasking, this indicates that both are causing OSM rather thanOFM.
To summarize, the logic of the experiments was as follows.Target and mask could have the same orientation and color, coulddiffer on color or orientation, or could differ on both features. IfOSM occurs after object features have been bound into an inte-grated representation, then the extent of masking in any conditionshould be equal for reporting of either feature. This follows be-cause if the representation of the target (plus mask) has beensubstituted by a representation of the mask alone, then access to arecord of either target feature should be equally impossible. Bycontrast, if OSM occurs prior to the binding of features into anintegrated representation, then it presumably occurs at the level ofindividual features. Therefore, when target and mask differ on asingle feature, reporting of that feature should evidence less mask-ing than reporting of the feature that is the same for target andmask elements. This is because the signal-to-noise ratio is greaterfor the former than for the latter. By the same reasoning, becausereporting of a feature should reflect only the signal-to-noise ratiofor that feature, accuracy of reporting should be unaffected by
1 One method of avoiding the problem might have been to borrowtechniques used by Mounts and Melara (1999) and to use two pairs ofsimilar colors such as red or orange and green or blue. A red or orangetarget, for example, could have been surrounded by either red and orangemask elements (similar condition) or by green and blue mask elements(dissimilar condition). In this case, participants would not have been ableto utilize a strategy of simply responding with either the mask color or itsopposite. However, pilot testing and the results of Experiments 2 and 3show how difficult it is to hold performance on the present task belowceiling even when the color difference between target and mask elementsin the dissimilar color condition is very small (i.e., red vs. orange). Thisrules out use of the method just described. Following the same logic,Mounts and Melara also used pairs of orientations that were close tovertical or close to horizontal. But this technique was also inapplicable tothe present studies because of ceiling and floor effects and the impossibilityof matching for contour proximity across similar and dissimilar conditions.
1426 GELLATLY, PILLING, COLE, AND SKARRATT

whether there is a match or mismatch between target and mask onthe other feature. The extent of masking should vary across con-ditions. Reporting of color should be affected only by match ormismatch on color, and reporting of orientation should be affectedonly by match or mismatch on orientation.
Method
Participants. Twenty University of Keele undergraduates with normalor corrected-to-normal vision served as participants in the experiment inpartial fulfillment of a course requirement, half reporting target color andhalf target orientation.
Equipment and stimuli. Stimuli were presented as for Experiment 1and viewed from 70 cm. Following a warning tone, two horizontal bluefixation lines appeared. After 500 ms they were joined by the targetdisplay, containing two or three bars at the three potential target locations,at the center of the screen and 3° to left and right. Target, distractor, andmask bars were 1° � 0.2° and colored red (45, 0, 0) or orange (45, 28, 0).They were photometrically matched for on-screen luminance. Simulta-neously with target onset (control and trailing mask conditions) or 100 mslater (delayed mask condition), one location was surrounded by four red ororange horizontal masking bars, centered 0.5° above or below and 0.8° leftor right of the location center. After 17 ms, the target (if any) and distractorbars offset. The mask bars offset either simultaneously (control) or afterbeing present for 500 ms (trailing mask and delayed mask). The targetlocation contained a target bar on two thirds of trials. Unmasked locationsalways contained horizontal distractors the same color as the mask bars.When a target was present at the masked location, it was equally often thesame color and orientation as the mask (SC–SO), different color and sameorientation (DC–SO), same color and different orientation (SC–DO), ordifferent on both features (DC–DO).
Procedure and design. We explained the task by using demonstrationtrials with prolonged frame durations. Participants were informed thatresponse speed was unimportant and that their sole aim was to be accuratein color or orientation decisions and response key selection. They were alsotold (a) that they should not be reluctant to press the space bar to indicateeither “target absent” or that they were uncertain as to the color ororientation of the target, and (b) that on one third of trials no target wouldbe presented. Central fixation throughout a trial was emphasized. Partici-pants completed a practice block of 40 trials making color or orientationjudgments followed by 18 experimental blocks of 60 randomly orderedtrials of the same judgment. There were 60 target-present and 30 target-absent trials per combination of target type (SC/SO, DC/SO, SC/DO,DC/DO) and mask condition (control/trailing/delayed).
Results
The false positive rate was very low, with participants correctlypressing the space bar on 99% of target-absent trials. Responses ontarget-present trials were either correct, omissions, or errors. Er-rors—giving the wrong color or orientation of a presented target—occurred on only 1.1% of target-present trials, indicating thatparticipants were able to follow the instruction not to guess whenuncertain as to target color or orientation. A 2 � 3 � 4 ANOVAon the error data with factors of reported dimension (color/orien-tation), mask condition (control/trailing/delayed-onset) and targettype (SC/SO, DC/SO, SC/DO, DC/DO) gave no significant effects(F � 2, p � .15 in all cases). Because error rates did not differacross condition, guessing corrections were not applied, and wereported the percentage of correct responses (out of 60) for eachcondition. The low error rate also means that the vast majority ofnoncorrect responses were, therefore, omissions (“no target” or
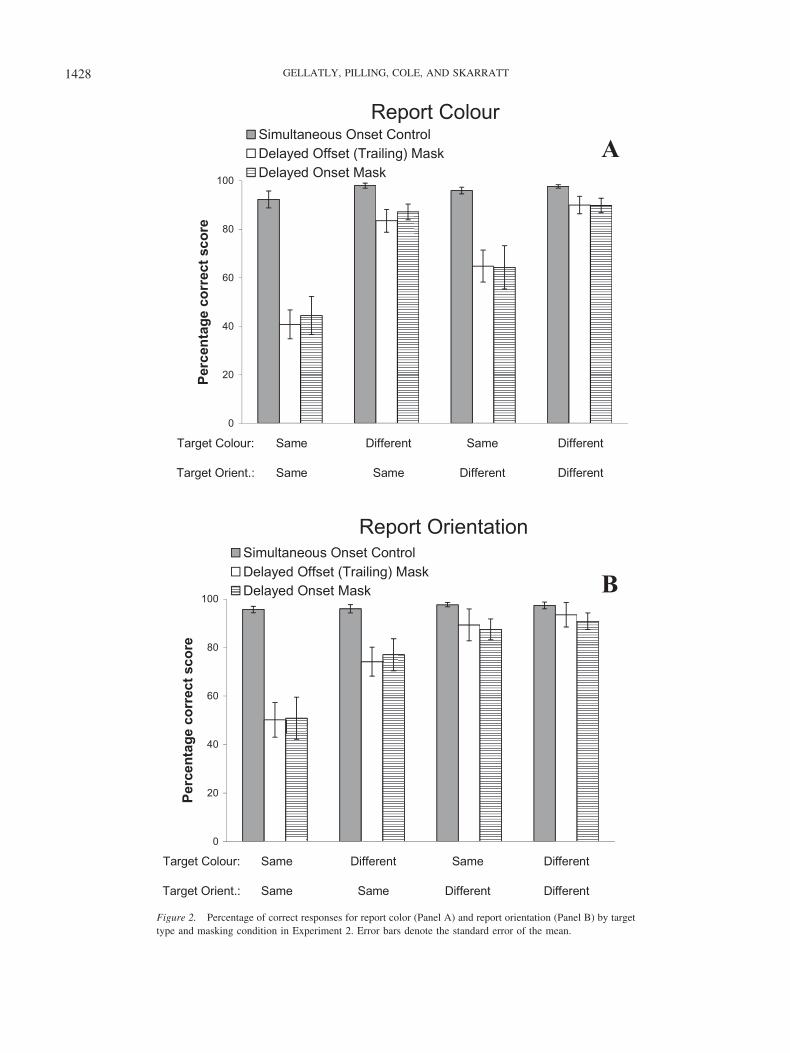
“don’t know”) and that the percentage of omissions was effec-tively the inverse of the percentage of correct responses. The latterfigures are shown in Panel A of Figure 2 for reporting color andPanel B for reporting orientation. For the simultaneous-offsetcontrol condition, reporting of both dimensions was highly accu-rate for all target types. For the delayed-offset (trailing) mask anddelayed-onset mask conditions, data patterns and absolute accu-racy levels were highly similar. In both, reporting of target colorwas greatly improved by a target–mask difference in color and toa lesser extent by a difference in orientation. Similarly, for bothconditions, reporting of target orientation was greatly improved bya target–mask difference in orientation and to some extent by adifference in color.
To compare the delayed-offset (trailing) mask and delayed-onset mask conditions, we conducted a 2 � 2 � 4 mixed ANOVAwith related variables of mask type (delayed-offset/delayed-onset)and target type (SC/SO, DC/SO, SC/DO, DC/DO) and an unre-lated variable of reported dimension (color/orientation). Mask typehad a nonsignificant effect and did not enter into any significantinteractions, F � 1 in all cases. We do not comment on otheraspects of this analysis because they recurred in the analyses thatfollow and are considered in the next paragraph. Also, becausethese two sets of data were indistinguishable, only one of them wasused in further analysis.
We calculated masking scores by subtracting for each partici-pant his or her scores in the delayed-offset (trailing) mask condi-tion from the corresponding score in the simultaneous-offset con-trol condition. These data were entered into separate 2 � 2within-participant ANOVAs for the report color and report orien-tation groups, with factors of target color (same/different) andorientation (same/different). For the report color group, there weresignificant main effects of target color, F(1, 9) � 36.72, p � .001,and orientation, F(1, 9) � 23.67, p � .001. Target color had aslightly larger effect when target and mask orientation were thesame rather than different, but this interaction effect was nonsig-nificant, F(1, 9) � 3.36, p � .1. For reporting orientation, therewere main effects of target color, F(1, 9) � 26.81, p � .001, andorientation, F(1, 9) � 23.09, p � .001, and a significant interac-tion, F(1, 9) � 10.44, p � .01, because target orientation had alarger effect when target and mask color were the same rather thandifferent.
Discussion
Experiment 2 was designed to provide two checks on whetherthe pattern of data obtained with the delayed-offset (trailing) maskreflected OSM, OFM, or a combination of the two. The firstinvolved comparing the simultaneous-offset and delayed-offsetconditions. Figure 2 shows that these produced very differentpatterns of data, suggesting that the pattern for the delayed-offsetcondition was due to OSM rather than to OFM. However, thestrength of this conclusion could be open to question. There is apotential problem because performance with the simultaneous-offset mask was at or close to ceiling for all conditions. It ispossible that if performance with this control mask had beensufficiently below ceiling, then the same pattern of results mighthave been obtained as with the delayed-offset (trailing) mask,which would have suggested that in both cases OFM was at work.This would be consistent with the interpretation that says that the
1427OBJECT SUBSTITUTION MASKING
A
B
Report Colour
Report Orientation
0
20
40
60
80
100
Per
cen
tag
e co
rrec
tsc
ore
Simultaneous Onset ControlDelayed Offset (Trailing) MaskDelayed Onset Mask
Target Colour:
Target Orient.:
Same
Same
Different
Same
Same
Different
Different
Different
0
20
40
60
80
100
Per
cen
tag
e c
orr
ect
sco
re
Simultaneous Onset ControlDelayed Offset (Trailing) MaskDelayed Onset Mask
Target Colour:
Target Orient.:
Same
Same
Different
Same
Same
Different
Different
Different
Figure 2. Percentage of correct responses for report color (Panel A) and report orientation (Panel B) by targettype and masking condition in Experiment 2. Error bars denote the standard error of the mean.
1428 GELLATLY, PILLING, COLE, AND SKARRATT

more intense masking with the trailing mask was due to its greaterenergy causing a higher degree of OFM. However, evidenceagainst this comes from the second check built into the experiment.Results for the delayed-offset (trailing) mask and the delayed-onset (also trailing) mask are indistinguishable. If the former hadits effect largely by means of OFM, then much smaller maskingeffects should have been caused by the latter. That this was not thecase indicates that the identical effects seen in both these condi-tions were the result of OSM, not OFM.
In the two trailing mask conditions (delayed-offset and delayed-onset), a target or mask difference on either color or orientationreduced masking more for that feature than for the other feature.This indicates a degree of dimensional independence in OSM,which in turn implies that what was being masked was not anintegrated representation of the target object, an object token.Conversely, the fact that for reporting of both color and orienta-tion, masking was also significantly reduced by a target or maskdifference on the other dimension suggests that independence ofdimensional processing may have been less than complete. Thedata from Experiment 2 are, then, somewhat ambiguous withrespect to the predictions outlined earlier. Once again, however,account has to be taken of the possible role of ceiling effects.Performance in reporting of either dimension was close to ceilingfor all target types in the simultaneous-offset control condition(and for some target types—particularly DC–DO—in the delayed-offset and delayed-onset conditions). By obscuring possible dif-ferences between target–mask conditions, these high levels ofperformance may have distorted the calculated masking scores.Our main aim in Experiment 3 was to test the same predictions asdescribed for Experiment 2 under conditions in which ceiling levelperformance could be avoided.
Experiment 3: OSM for Reporting Color and Orientationof Target
To this end, we made target signals for color and orientationsmaller in Experiment 3 by reducing the size of the stimuluselements. Also, because the delayed-offset mask and the delayed-onset mask had produced indistinguishable results in Experiment2, only the former condition was included in Experiment 3. Fi-nally, instead of reporting either color or orientation of the target,participants in Experiment 3 were required to report both featureswith equal priority. We made this change because the ambiguousevidence of dimensional selectivity of OSM observed in Experi-ment 2 might have resulted from participants selectively attendingto their to-be-reported dimension. Such a top-down attentional setmight have biased participants against forming an integrated rep-resentation of the target object, resulting in data that reflected onlya contingent and partial dimensional independence of masking.Requiring participants to report both dimensions was intended toensure that they attended equally to both features and that, to theextent this might be subject to top-down control, they were biasedto form an integrated representation of the target from which bothfeatures could be read off.
Method
Participants. There were 10 new participants from the Open Univer-sity, as described for Experiment 1.
Equipment and stimuli. Equipment and stimuli were as in Experiment2, except the bar stimuli were one third of their previous length anddistances between locations were halved.
Procedure and design. The procedure and design were as in Experi-ment 2, except for the changes already indicated, and there were 48 ratherthan 60 target-present trials per condition. As previously, one third of trialscontained no target. Half of participants reported color before orientation,half the reverse.
Results
The false positive rate was again very low, with participantscorrectly pressing the space bar on 98.5% of target-absent trials.For target-present trials, responses were either correct, omissions,or errors. As in Experiment 2, the large majority of noncorrectresponses were omissions. However, errors (reporting the wrongcolor or orientation of a presented target) averaged 3% for thesimultaneous-offset control mask and 10% for the delayed-offset(trailing) mask, being higher for color reports of same-color targetsthan of different-color targets and higher for orientation reports ofsame-orientation targets than of different-orientation targets. Be-cause errors clearly were not evenly distributed across conditions,guessing corrections were applied to individual participant data foreach combination of mask type and target type. For reportingcolor, errors on SC/SO were subtracted from number correct onDC/SO and vice versa, and similarly for SC/DO and DC/DO. Forreporting orientation, errors on SC/SO were subtracted from num-ber correct on SC/DO and vice versa, and similarly for DC/SO andDC/DO. The guessing-corrected scores are shown in Figure 3. Thecorrection procedure reduced effect sizes but did not alter the datapattern. Accuracy for reporting color in the simultaneous-offsetcontrol condition remained close to ceiling for all target types,even with smaller stimuli and a requirement to report both targetdimensions. However, accuracy for reporting orientation in thecontrol condition was lower in all conditions. Data of the controlconditions were entered into a two-way related ANOVA withfactors of reported dimension (color/orientation) and target type(SC–SO, DC–SO, SC–DO, DC–DO). There was a main effect ofreported dimension, F(1, 9) � 15.58, p � .01, and also of targettype, F(3, 27) � 5.34, p � .01 but, it is important to note, nointeraction, F(3, 27) � 1.80.
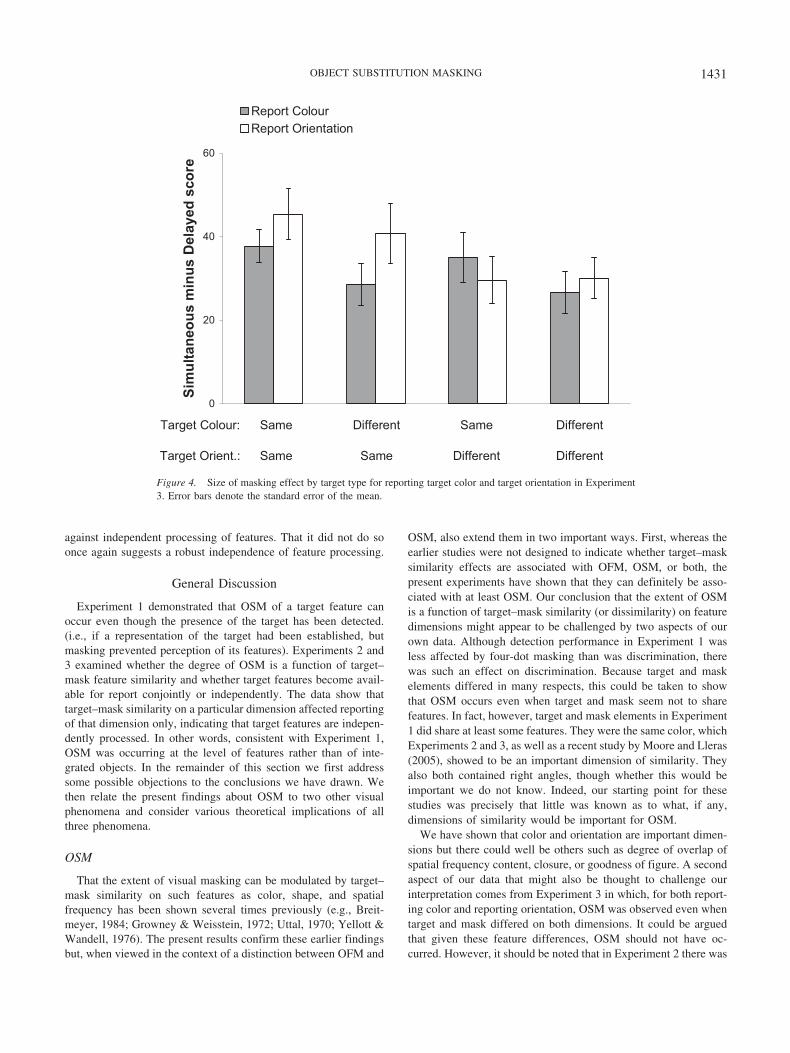
For the delayed-offset (trailing) mask condition, performancefor reporting both features was well below ceiling and, as can beseen from Figure 3, target type appeared to have differential effectson reporting of color and orientation. Masking scores were calcu-lated as in Experiment 2, by subtracting guessing-correcteddelayed-offset scores from guessing-corrected simultaneous-offsetscores (See Figure 4). For reporting of each feature, a two-wayANOVA was computed with factors of target color (same/differ-ent) and target orientation (same/different). For reporting color,there was a main effect of target color, F(1, 9) � 6.13, p � .05, butno effect of target orientation and no interaction, F � 1 in bothcases. For reporting orientation, there was a main effect of targetorientation, F(1, 9) � 14.13, p � .005, but no effect of target colorand no interaction (F � 1.3 in both cases).
Discussion
Comparing Figures 2 and 3 demonstrates that there are clearsimilarities in the pattern of results obtained in Experiments 2 and
1429OBJECT SUBSTITUTION MASKING
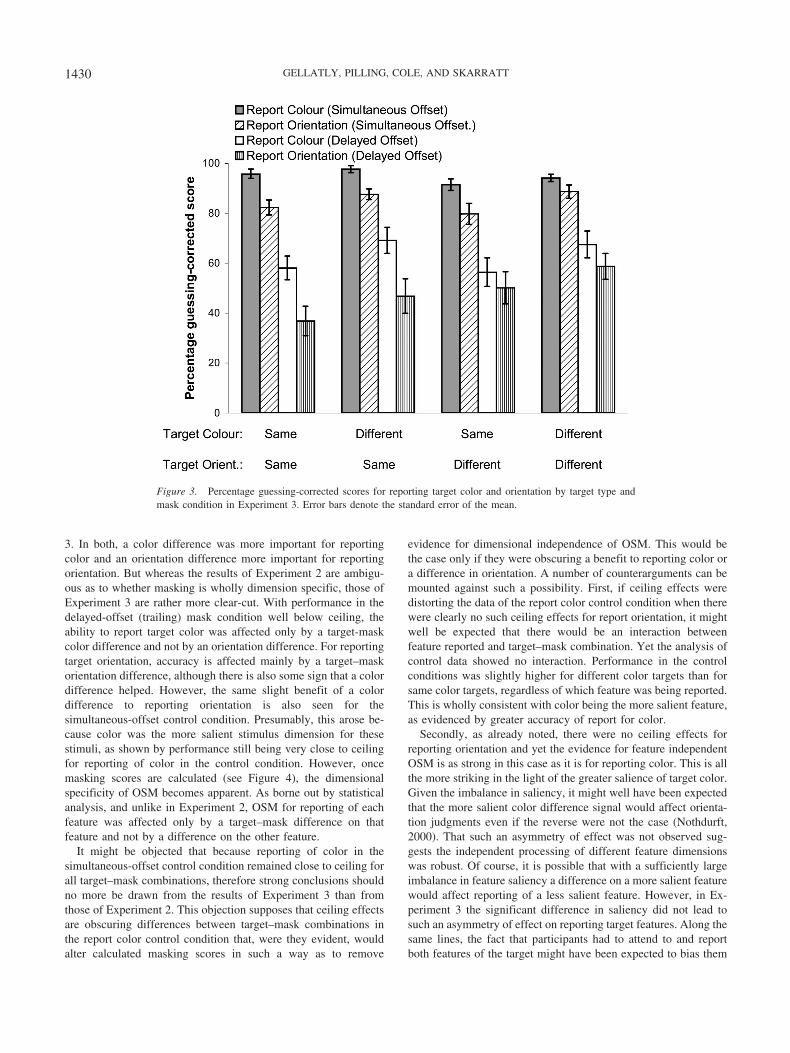
3. In both, a color difference was more important for reportingcolor and an orientation difference more important for reportingorientation. But whereas the results of Experiment 2 are ambigu-ous as to whether masking is wholly dimension specific, those ofExperiment 3 are rather more clear-cut. With performance in thedelayed-offset (trailing) mask condition well below ceiling, theability to report target color was affected only by a target-maskcolor difference and not by an orientation difference. For reportingtarget orientation, accuracy is affected mainly by a target–maskorientation difference, although there is also some sign that a colordifference helped. However, the same slight benefit of a colordifference to reporting orientation is also seen for thesimultaneous-offset control condition. Presumably, this arose be-cause color was the more salient stimulus dimension for thesestimuli, as shown by performance still being very close to ceilingfor reporting of color in the control condition. However, oncemasking scores are calculated (see Figure 4), the dimensionalspecificity of OSM becomes apparent. As borne out by statisticalanalysis, and unlike in Experiment 2, OSM for reporting of eachfeature was affected only by a target–mask difference on thatfeature and not by a difference on the other feature.
It might be objected that because reporting of color in thesimultaneous-offset control condition remained close to ceiling forall target–mask combinations, therefore strong conclusions shouldno more be drawn from the results of Experiment 3 than fromthose of Experiment 2. This objection supposes that ceiling effectsare obscuring differences between target–mask combinations inthe report color control condition that, were they evident, wouldalter calculated masking scores in such a way as to remove
evidence for dimensional independence of OSM. This would bethe case only if they were obscuring a benefit to reporting color ora difference in orientation. A number of counterarguments can bemounted against such a possibility. First, if ceiling effects weredistorting the data of the report color control condition when therewere clearly no such ceiling effects for report orientation, it mightwell be expected that there would be an interaction betweenfeature reported and target–mask combination. Yet the analysis ofcontrol data showed no interaction. Performance in the controlconditions was slightly higher for different color targets than forsame color targets, regardless of which feature was being reported.This is wholly consistent with color being the more salient feature,as evidenced by greater accuracy of report for color.
Secondly, as already noted, there were no ceiling effects forreporting orientation and yet the evidence for feature independentOSM is as strong in this case as it is for reporting color. This is allthe more striking in the light of the greater salience of target color.Given the imbalance in saliency, it might well have been expectedthat the more salient color difference signal would affect orienta-tion judgments even if the reverse were not the case (Nothdurft,2000). That such an asymmetry of effect was not observed sug-gests the independent processing of different feature dimensionswas robust. Of course, it is possible that with a sufficiently largeimbalance in feature saliency a difference on a more salient featurewould affect reporting of a less salient feature. However, in Ex-periment 3 the significant difference in saliency did not lead tosuch an asymmetry of effect on reporting target features. Along thesame lines, the fact that participants had to attend to and reportboth features of the target might have been expected to bias them
Figure 3. Percentage guessing-corrected scores for reporting target color and orientation by target type andmask condition in Experiment 3. Error bars denote the standard error of the mean.
1430 GELLATLY, PILLING, COLE, AND SKARRATT
against independent processing of features. That it did not do soonce again suggests a robust independence of feature processing.
General Discussion
Experiment 1 demonstrated that OSM of a target feature canoccur even though the presence of the target has been detected.(i.e., if a representation of the target had been established, butmasking prevented perception of its features). Experiments 2 and3 examined whether the degree of OSM is a function of target–mask feature similarity and whether target features become avail-able for report conjointly or independently. The data show thattarget–mask similarity on a particular dimension affected reportingof that dimension only, indicating that target features are indepen-dently processed. In other words, consistent with Experiment 1,OSM was occurring at the level of features rather than of inte-grated objects. In the remainder of this section we first addresssome possible objections to the conclusions we have drawn. Wethen relate the present findings about OSM to two other visualphenomena and consider various theoretical implications of allthree phenomena.
OSM
That the extent of visual masking can be modulated by target–mask similarity on such features as color, shape, and spatialfrequency has been shown several times previously (e.g., Breit-meyer, 1984; Growney & Weisstein, 1972; Uttal, 1970; Yellott &Wandell, 1976). The present results confirm these earlier findingsbut, when viewed in the context of a distinction between OFM and
OSM, also extend them in two important ways. First, whereas theearlier studies were not designed to indicate whether target–masksimilarity effects are associated with OFM, OSM, or both, thepresent experiments have shown that they can definitely be asso-ciated with at least OSM. Our conclusion that the extent of OSMis a function of target–mask similarity (or dissimilarity) on featuredimensions might appear to be challenged by two aspects of ourown data. Although detection performance in Experiment 1 wasless affected by four-dot masking than was discrimination, therewas such an effect on discrimination. Because target and maskelements differed in many respects, this could be taken to showthat OSM occurs even when target and mask seem not to sharefeatures. In fact, however, target and mask elements in Experiment1 did share at least some features. They were the same color, whichExperiments 2 and 3, as well as a recent study by Moore and Lleras(2005), showed to be an important dimension of similarity. Theyalso both contained right angles, though whether this would beimportant we do not know. Indeed, our starting point for thesestudies was precisely that little was known as to what, if any,dimensions of similarity would be important for OSM.
We have shown that color and orientation are important dimen-sions but there could well be others such as degree of overlap ofspatial frequency content, closure, or goodness of figure. A secondaspect of our data that might also be thought to challenge ourinterpretation comes from Experiment 3 in which, for both report-ing color and reporting orientation, OSM was observed even whentarget and mask differed on both dimensions. It could be arguedthat given these feature differences, OSM should not have oc-curred. However, it should be noted that in Experiment 2 there was
0
20
40
60
Sim
ult
aneo
us
min
us
Del
ayed
sco
re
Report ColourReport Orientation
Target Colour:
Target Orient.:
Same
Same
Different
Same
Same
Different
Different
Different
Figure 4. Size of masking effect by target type for reporting target color and target orientation in Experiment3. Error bars denote the standard error of the mean.
1431OBJECT SUBSTITUTION MASKING

no masking of targets that differed on both dimensions. Indeed, itwas in order to avoid such ceiling effects that the color andorientation feature differences in Experiment 3 were deliberatelyreduced in comparison with those of Experiment 2. Our overallresults indicate that the extent of OSM is a function of the degreeof target–mask similarity along various feature dimensions, ofwhich color and orientation are two. Varying target–mask separa-tion (or overlap, or signal-to-noise ratio) on one of these featuredimensions affects reporting of that dimension only and not re-porting of the other. But for the stimuli of Experiment 3, thefeature values deliberately varied by such small amounts that eventargets differing on both dimensions were subject to some degreeof OSM. That feature-specific OSM has been demonstrated withthe present displays does not preclude the possibility that, withattention spread across larger and busier displays including moreeccentric targets, OSM may be obtainable with target–mask com-binations differing as much as possible on as many features aspossible. In addition to feature-level OSM, there may also beobject-level OSM (Lleras & Moore, 2003; Moore & Lleras, 2005;Treisman & Kanwisher, 1998), a topic to which we return later inthis article.
The second way in which our results go beyond previous studiesof target–mask similarity is in demonstrating that under conditionsof OSM, the effect of similarity is a function of what target featureis to be reported. That is, target–mask similarity cannot be speci-fied simply in terms of the physical features of the stimulusconfiguration but must also be defined with respect to what theobserver is reporting.2 We go on now to consider two other visualphenomena that have been shown to exhibit this kind of task-specific tuning.
Feature Specificity of Pop-Out and Sparse Representation
Mounts and Melara (1999) asked participants to report the coloror orientation of a target that preattentively popped out of a48-item array from which it differed in either color or orientation.All items in the array were subject to interruption masking. Par-ticipants were better able to report the color than the orientation ofa color pop-out target and better able to report the orientation thanthe color of an orientation pop-out target. Furthermore, and con-sistent with the results of Experiment 3, this was the case evenwhen both features had to be reported on every trial. Mounts andMelara attributed the effect to the fact that in their experiments thetarget was more discriminable from distractors on the pop-outdimension than on the non-pop-out dimension. Unlike in thepresent study, the design of Mounts and Melara’s experiments didnot distinguish between OFM and OSM nor allow an evaluation ofwhether featural processing was wholly or only partially indepen-dent. Mounts and Melara interpreted their findings as evidenceagainst object-based theories of attention (e.g., Driver & Baylis,1989; Duncan, 1984; Duncan & Humphreys, 1992; Egly, Driver,& Rafal, 1994), according to which objects are selected in anall-or-none fashion, so knowing an object’s color should entailknowing equally its orientation and vice versa. Mounts and Melara(1999) concluded that, whether linkages among features are set upin terms of a common spatial location or of a common objecttoken, attentional selection is coordinated at the level of features.They saw their results as consistent with more recent object-basedmodels of attention that allow for partially independent processing
of object features (Duncan, 1996; Logan, 1996, 2004). The presentdata, especially from Experiment 3, push this line of reasoning stillfurther by evidencing wholly independent processing of differentfeatures of the same object. But if object features are processedcompletely independently, then in what sense can selection inthese conditions be said to be object based?
One approach to the issue is that of sparse representation, a viewadvocated by various authors over the years (e.g., Hochberg, 1984;MacKay, 1973; O’Regan, 1992; Rensink, 2000). According to thisview, there is no rich and detailed internal representation of thevisual world. Representation of a particular object or area will beonly as detailed as it need be for the task at hand. We initiallyposed the question “Is what gets substituted in OSM the represen-tation of an integrated object or of a bundle of stimulus featuresthat remain somewhat unbound and independent?” On the sparserepresentation view, the question itself is faulty because it takes forgranted that, given adequate presentation conditions, visual repre-sentations inevitably get rich and detailed independently of thetask at hand.3 The alternative is that we never see whole objectsbut only those aspects of an object relevant to what we need to do.A frequently cited analogy is with the perception of an object heldin the hand (MacKay, 1973; O’Regan, 1992). The experience is ofa complete object although it is one based on a fragmentaryrepresentation, with sensory input restricted to just those objectparts actually in contact with the skin (plus haptic information).The experience of visual scenes and complete visual objects issimilarly derived from partial input and representation. Accordingto Rensink (2000) and others, a seen object seems to appear beforeus as real and fully complete only because any particular propertycan be made explicit as required simply by interrogating theexternal world. In Rensink’s coherence theory (CT), preattentionyields proto-objects, which can be surprisingly detailed—for in-stance, including three-dimensional organization—but are coher-ent only over small spatial and temporal extents, having constantlyto be regenerated. Focused attention is a process by which one (ora few) of these proto-objects acquires a high degree of coherencesuch that it can retain its identity across brief interruptions, and itsvarious features and their interrelationships can be experienced asrequired.
CT has much in common with Treisman’s (1988) feature inte-gration theory (FIT). For example, in CT attention selects a proto-object, which is transformed into a coherence field, or visual object(Rensink, 2000). In FIT, attention selects “loosely organized fea-ture bundles (Wolfe & Cave, 1999, p. 17) the features of which arethen glued together to make an integrated visual object. So far, sosimilar. How the two approaches seem to differ is that in CT thefeatures of the attended object are represented only as required,whereas in FIT all the features of the attended object are automat-ically represented, by which it is meant that they are boundtogether. How many objects may be so richly represented at onetime depends in FIT on the overall perceptual and cognitive load(Lavie, 2005; Treisman, 1995). Rensink (2000) was somewhatambivalent as to whether there is rich representation of an attendedobject, first saying we may “instead of simultaneously representing
2 We thank Jim Enns for pointing out this way of thinking about ourresults.
3 We thank Jim Enns for pointing this out to us.
1432 GELLATLY, PILLING, COLE, AND SKARRATT

in detail all of the objects in our surroundings, represent only thoseobjects – and only those particular properties of those objects –needed for the task at hand” (p. 1475, italics added) but then lateron more ambiguously suggesting, “An interesting possibility inthis regard is the binding problem may be illusory – it may be thatthe properties of only one object at a time are ever bound together”(p. 1484). A very strong version of the sparse representation viewhas been defended by Enns and Austen (2003, in press), who haveargued that not all features of even a single attended object arenecessarily represented perceptually. Consistent with this view,Droll, Hayhoe, Triesch, and Sullivan (2005) reported evidence thatobject features may be represented only while they remain relevantto action selection, and Rafal, Danziger, Giordano, Machado, &Ward (2005) argued that explicit object representation is at thelevel needed to select task relevant actions. Our results for Exper-iment 3, in which both features had to be reported, together withthose of Mounts and Melara (1999), show that representation oftask-relevant features is constrained independently by the qualityof the data (signal:noise ratio) on each feature.
Nevertheless, however sparsely or not features may be repre-sented, they require to be linked to an object representation ofsome kind. We turn now to consideration of token and typerepresentations and their possible involvement in OSM.
Repetition Blindness and Type–Token binding
Another visual phenomenon shown to exhibit task-specific tun-ing is repetition blindness (RB). Kanwisher, Driver, and Machado(1995) found that spatial RB is modulated by selective attention tostimulus dimensions. Their participants were briefly presentedwith two simultaneous characters (C1 and C2), each followed byan interruption mask; each character could be one of three lettersand one of three colors. Participants reported the identity or colorof first the left (C1) then the right (C2) character, responding “nocharacter” when they thought a location had been empty. Report-ing of the relevant feature (identity or color) was markedly lessaccurate when its value was repeated across C1 and C2 than whenit was not repeated but was unaffected by repetition of the non-relevant feature. For example, if both characters were red, report-ing of their colors was less accurate than if they were differentcolors, regardless of the identities of the two letters, whereas ifboth letters were Es, reporting of their identities was less accuratethan if they were different, regardless of the colors of the twoletters. For reporting either feature there was RB for the relevantbut not for the irrelevant stimulus dimension, and this was shownto be unrelated to unwillingness to repeat a response. As with thepresent results, variation on an irrelevant dimension did not affectaccuracy of reporting the relevant dimension.
Kanwisher (1987; Kanwisher et al., 1995) has argued that RBarises because although repeated characters (or colors) are usuallyappropriately recognized (matched to stored types), they are lesslikely than unrepeated characters to be individuated as distinctperceptual tokens. This failure of type–token binding supposedlyapplies equally to temporal or spatial repetition of items. Consid-eration of the type–token distinction raises the question of how itmay apply to the phenomenon of OSM. The present maskingdisplays were similar in many ways to the displays used byKanwisher et al. (1995) to demonstrate spatial RB. Consider thoseconditions in which target and mask elements onset simulta-
neously (i.e., all conditions of all three experiments other than thedelayed mask condition of Experiment 2). The location of themask indicated which of the three potential targets had to bereported on, so it was necessary to attend first to the mask elementsand then to the target itself, which was similar to Kanwisher’sparticipants having to attend first to C1 then to C2. Just as C2might repeat one, both, or neither of the features of C1, so targetsin our Experiments 2 and 3 repeated one, both, or neither of thefeatures of the mask. And in both cases, repetition on a dimensionreduced accuracy of report for that dimension—more RB in theKanwisher et al. study, more OSM in our experiments—whereasrepetition on the other dimension had no effect. Perhaps the twoperformance deficits reflect a common processing failure. In theRB literature, in which there has been an emphasis on similaritybetween C1 and C2, this has been taken to be a failure to individ-uate separate occurrences of a type. In the OSM literature, inwhich—especially in relation to four-dot masking—the emphasishas been on dissimilarity between mask elements and the target,the failure has been taken to be in maintaining a representation (ofsome sort) of the target.
In OSM terminology, cells early in the system initially code forfeatures, with cells later in the system synthesizing candidateobject descriptions. However, drawing parallels between OSM andRB reminds us that there is a distinction between type and tokenrepresentations (see also Lleras & Moore, 2003; Moore & Lleras,2005). Just as the present experiments included no-target trials, theexperiments of Kanwisher et al. (1995) included trials in whicheither C1 or C2 was omitted. As in our experiments, participantswere well able to distinguish target absence from a target glimpsedindistinctly. Kanwisher et al. stressed that their results “reflect afailure in binding the appropriate identity (type) to distinct objectrepresentations (tokens) when a type is repeated, rather than acomplete failure to set up distinct tokens” (pp. 329–330). In theterms of OSM theory, it may be that early visual cells not onlyprocess an object’s features but also cause an object token repre-sentation to be set up on the master map of locations (Treisman,1988). Later cells would then synthesize a candidate type repre-sentation, which reentrant processing would link (or not) to theappropriate object token on the master map. Our findings withreporting of both features, along with those of Mounts and Melara(1999), imply that under impoverished conditions different fea-tures need not be equally well bound into the type representationnor, consequently, into the token representation. (Indeed, for visualobjects as structurally and semantically pared down as brief col-ored bars, perhaps the type representation is no more than a looseconjunction of more or less well-represented features.)
The essential idea behind the concept of OSM is that it is a formof masking that takes place at the level of object representation (DiLollo et al., 2000; Enns, 2004; Enns & Di Lollo, 1997). Thepresent demonstration of feature-specific OSM indicates that whatis masked need not be an integrated object representation, but wehave already conjectured that, dependent on experimental condi-tions, there could be different forms of OSM involving eitherfeature-specific or object-level representations. Lleras and Moore(2003; Moore & Lleras, 2005) have presented evidence for OSMinvolving object-level representations, favoring the term objecttoken in their first study and object file in the second. Moore andLleras showed that OSM was reduced when mask and target weredifferent colors and when, through the use of apparent motion, the
1433OBJECT SUBSTITUTION MASKING

mask appeared to slide across the target, so only incidentallysurrounding it briefly. Their interpretation was that “susceptibilityto OSM is determined by the extent to which separate objectrepresentations can be established for the target and mask prior tomask offset; when separate object representations can be estab-lished, target information associated with that representation canbe protected from OSM” (p. 1178). Although this is certainly aninteresting argument, we note that the reductions in OSM couldalso be due to target and mask having differed on the features ofcolor and motion or stationarity, respectively. Although the idea ofseparate object-level and feature-level OSM effects is an intriguingpossibility, empirically distinguishing between levels is likely topose considerable challenges (Scholl, 2001).
Although it is important to try to theoretically relate differentvisual phenomena to each other, it would be unwise at this stage toforce the comparison between OSM and RB too far. It may be thatthey are similar yet distinct phenomena. Only empirical investiga-tion will reveal whether, for example, one can be obtained underconditions in which the other cannot or whether it may be possibleto obtain additive effects of the two. These are issues we arecurrently pursuing.
Summary
The present findings suggest that the theory of OSM needs to beexpanded to take account of the distinction between type and tokenrepresentations. OSM can occur independently for separate targetfeatures (Experiments 2 & 3) and has similarities to RB in thatboth phenomena can be thought of as failures of type–tokenbinding. However, there may be examples of OSM involvingmasking of object tokens or object files, as well as examplesinvolving failure to bind feature and/or type representations ap-propriately to a token representation. Possibly, the answer to ouroriginal questions may be that OSM can operate at more than onelevel. Certainly, it can operate at the level of independent features.
References
Breitmeyer, B. G. (1984). Visual masking: An integrative approach. NewYork: Oxford University Press.
Di Lollo, V., Enns, J. T., & Rensink, R. A. (2000). Competition forconsciousness among visual events: The psychophysics of reentrantvisual processes. Journal of Experimental Psychology: General, 129,481–507.
Driver, J., & Baylis, G. C. (1989). Movement and visual attention: Thespotlight metaphor breaks down. Journal of Experimental Psychology:Human Perception and Performance, 15, 448–456.
Droll, J. A., Hayhoe, M. M., Triesch, J., & Sullivan, B. T. (2005). Taskdemands control acquisition and storage of visual information. Journalof Experimental Psychology: Human Perception and Performance, 31,1416–1438.
Duncan, J. (1984). Selective attention and organization of visual informa-tion. Journal of Experimental Psychology: General, 113, 501–517.
Duncan, J. (1996). Cooperating brain systems in selective perception andaction. In T. Inui & J. L. McClelland (Eds.), Attention and performanceXVI: Information integration in perception and communication (pp.549–578). Cambridge, MA: MIT Press.
Duncan, J., & Humphreys, G. W. (1992). Beyond the search surface:Visual search and attentional engagement. Journal of ExperimentalPsychology: Human Perception and Performance, 18, 578–588.
Egly, R., Driver, J., & Rafal, R. D. (1994). Shifting visual attention
between objects and locations: Evidence from normal and parietal lesionsubjects. Journal of Experimental Psychology: General, 123, 161–177.
Enns, J. T. (2004). Object substitution and its relation to other forms ofvisual masking. Vision Research, 44, 1321–1331.
Enns, J. T., & Austen, E. (2003). Change detection in an attended facedepends on the expectations of the observer. Journal of Vision, 3, 64–74.
Enns, J. T., & Austen, E. (in press) Mental schemata and the limits ofperception. In Peterson, M. A., Gillam, B., & Sedgwick, H. A. (Eds.), Inthe mind’s eye: Julian Hochberg on the perception of pictures, film, andthe world. New York: Oxford University Press.
Enns, J. T., & Di Lollo, V. (1997). Object substitution: A new form ofmasking in unattended visual locations. Psychological Science, 8, 135–139.
Enns, J. T., & Di Lollo, V. (2000). What’s new in visual masking? Trendsin Cognitive Science, 4, 345–352.
Fehrer, E., & Biederman, I. (1962). A comparison of reaction time andverbal report in the detection of masked stimuli. Journal of ExperimentalPsychology, 64, 126–130.
Fehrer, E., & Raab, D. (1962). Reaction time to stimuli masked bymetacontrast. Journal of Experimental Psychology, 63, 143–147.
Growney, R., & Weisstein, N. (1972). Spatial characteristic of metacon-trast. Journal of the Optical Society of America, 62, 690–696.
Hochberg, J. (1984). Form perception: Experience and explanations. InP. C. Dodwell & T. Caelli (Eds.) Figural synthesis (pp. 1–30). Hillsdale,N. J.: Erlbaum.
Jacoby, L. L. (1998). Invariance in automatic influences on memory:Toward a user’s guide for the process dissociation procedure. Journal ofExperimental Psychology: Learning, Memory, and Cognition, 24, 3–26.
Kahan, T. A., & Mathis, K. M. (2002). Gestalt grouping and common onsetmasking. Perception & Psychophysics, 64, 1248–1259.
Kanwisher, N. (1987). Repetition blindness: Type recognition withouttoken individuation. Cognition, 27, 117–143.
Kanwisher, N., Driver, J., & Machado, L. (1995). Spatial repetition blind-ness is modulated by selective attention to colour or shape. CognitivePsychology, 29, 303–337.
Lavie, N. (2005). Distracted and confused?: Selective attention under load.Trends in Cognitive Science, 9, 75–82.
Lleras, A., & Moore, C. M. (2003). When the target becomes a mask:Using apparent motion to isolate the object component of object-substitution masking. Journal of Experimental Psychology: Human Per-ception and Performance, 29, 106–120.
Logan, G. D. (1996). The CODE theory of visual attention: An integrationof space- based and object-based attention. Psychological Review, 103,603–649.
Logan, G. D. (2004). Cumulative progress in formal theories of attention.Annual Review of Psychology, 55, 207–234.
MacKay, D. M. (1973). Visual stability and voluntary eye movements. InR. Jung (Ed.), Handbook of sensory physiology (Vol. VII/3A, pp. 307–331). Berlin: Springer.
Moore, C. M., & Lleras, A. (2005). On the role of object representations inobject substitution masking. Journal of Experimental Psychology: Hu-man Perception and Performance, 31, 1171–1180.
Mounts, J. R. W., & Melara, R. D. (1999). Attentional selection of objectsor features: Evidence from a modified search task. Perception & Psy-chophysics, 61, 322–341.
Neill, W. T., Hutchinson, K. A., & Graves, D. F. (2002). Masking by objectsubstitution: Dissociation of masking and cuing effects. Journal ofExperimental Psychology: Human Perception and Performance, 28,682–694.
Nothdurft, H.-C. (2000). Salience from feature contrast: Additivity acrossdimensions. Vision Research, 40, 1183–1202.
O’Regan, J. K. (1992). Solving the “real” mysteries of visual perception:The world as an outside memory. Canadian Journal of Psychology, 46,461–488.
1434 GELLATLY, PILLING, COLE, AND SKARRATT

Rafal, R., Danziger, S., Giordano, G. Machado, L., & Ward, R. (2002).Visual detection is gated by attending for action: Evidence from hemis-patial neglect. Proceedings of the National Academy of Sciences, 99,16371–16375.
Rensink, R. A. (2000). Seeing, sensing and scrutinizing. Vision Research,40, 1469–1487.
Schiller, P. H., & Smith, M. C. (1966). Detection in metacontrast. Journalof Experimental Psychology, 71, 32–39.
Scholl, B. J. (2001). Objects and attention: The state of the art. Cognition,80, 1–46.
Spencer, T. J., & Shuntich, R. (1970). Evidence for an interruption theoryof backward masking. Journal of Experimental Psychology, 85, 198–203.
Tata, M. S. (2002). Attend to it now or lose it forever: Selective attention,metacontrast masking and object substitution. Perception & Psycho-physics, 64, 1028–1038.
Tata, M. S., & Giaschi, D. E. (2004). Warning: Attending to a mask maybe hazardous to your perception. Psychonomic Bulletin & Review, 11,262–268.
Treisman, A. M. (1988). Features and objects: The fourteenth BartlettMemorial lecture. Quarterly Journal of Experimental Psychology: Hu-man Experimental Psychology, 40(A), 201–237.
Treisman, A. M. (1995). Modularity and attention: Is the binding problemreal? Visual Cognition, 2, 303–311.
Treisman, A. M., & Kanwisher, N. G. (1998). Perceiving visually pre-sented objects: Recognition, awareness, and modularity. Current Opin-ion in Neurobiology, 8, 218–226.
Uttal, W. R. (1970). On the physiological basis of masking with dottednoise. Perception & Psychophysics, 7, 321–327.
Wolfe, J. M., & Cave, K. R. (1999). The psychophysical evidence for abinding problem in human vision. Neuron, 24, 11–17.
Yellott, J. L., & Wandell, B. A. (1976). Colour properties of the contrastflash effect: Monoptic vs dichoptic comparisons. Vision Research, 16,1275–1280.
Received August 17, 2005Revision received April 19, 2006
Accepted April 19, 2006 �
1435OBJECT SUBSTITUTION MASKING