understanding real world indoor scenes: geometry and
TRANSCRIPT

Understanding Real World Indoor Scenes:Geometry and Semantics
Ankur Handa
University of Cambridge and Imperial College London
October 16, 2016
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Outline
BackgroundSceneNet: Repository of Labelled Synthetic Indoor ScenesResults on Semantic Segmentation on Real World Datagvnn: Neural Network Library for Geometric VisionFuture Ideas
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Outline
BackgroundSceneNet: Repository of Labelled Synthetic Indoor ScenesResults on Semantic Segmentation on Real World Datagvnn: Neural Network Library for Geometric VisionFuture Ideas
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Real-time tracking
Real-time trackingHigh frame-rate seems better but.. today most advancedreal-time tracking is at 10–60Hz.Why? Should we increase the frame-rate in real, modernadvanced tracking problems?
OutlineWe are going to experimentally investigate this usingphoto-realistic synthetic videos.We are going to consider a particular problem of cameratracking against a known 3D rigid model.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Tracking
Isard and Blake, IJCV 1998 Davison, ICCV 2003
What is tracking?Visual tracking means estimating model parameterssequentially from video.Tracking is different from “detection” independently appliedto each frame since we can benefit from prediction — whichgets better as frame-rate increases.With prediction the search for correspondence can be local orguided — prediction from the previous frame can reduce thesearch for correspondences in the next frame.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

3D tracking by whole image alignment
DTAM, 2011 KinectFusion, 2011 Audras et al., 2011
Dense TrackingWe focus on camera tracking in mostly rigid scenes.Dense alignment has active search embedded in it — thebasin of convergence is directly related to the baseline joiningthe images. As the baseline decreases convergence is quicker.Previous frame estimates for initialising the optimisation incurrent frame. The higher the frame-rate, better theinitialisation.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
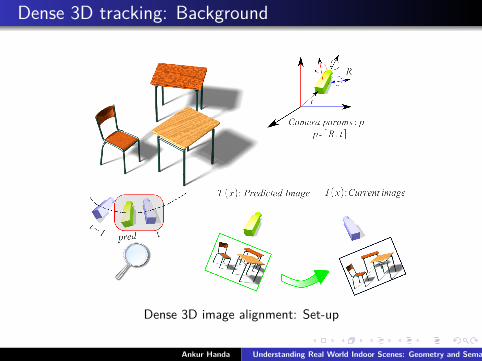
Dense 3D tracking: Background
Dense 3D image alignment: Set-up
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
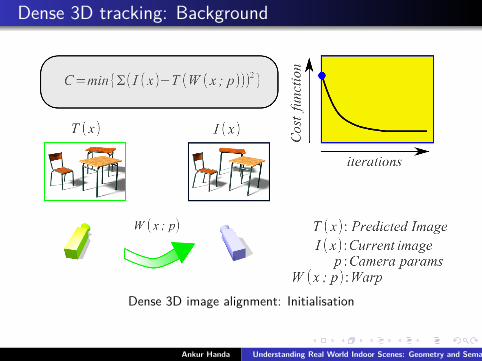
Dense 3D tracking: Background
Dense 3D image alignment: Initialisation
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
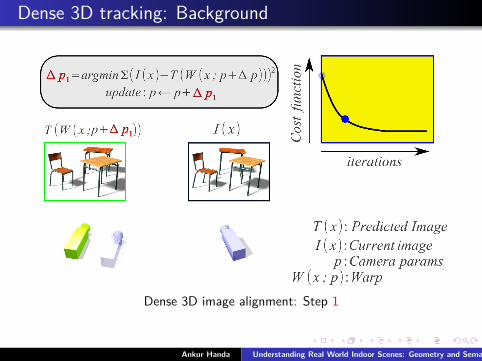
Dense 3D tracking: Background
Dense 3D image alignment: Step 1
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
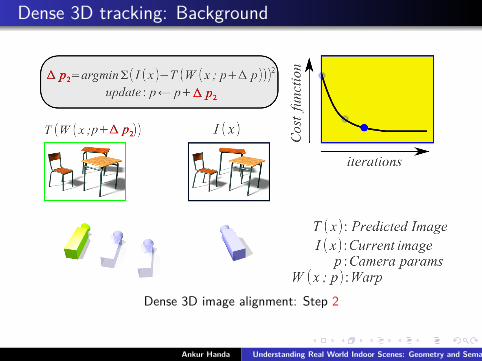
Dense 3D tracking: Background
Dense 3D image alignment: Step 2
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
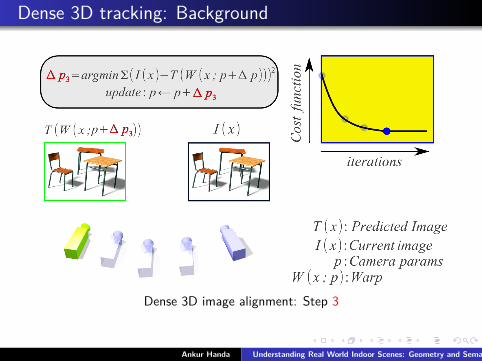
Dense 3D tracking: Background
Dense 3D image alignment: Step 3
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
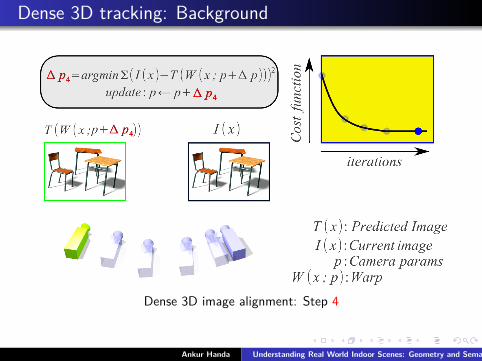
Dense 3D tracking: Background
Dense 3D image alignment: Step 4
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
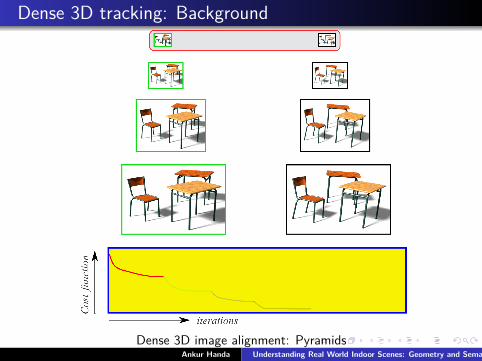
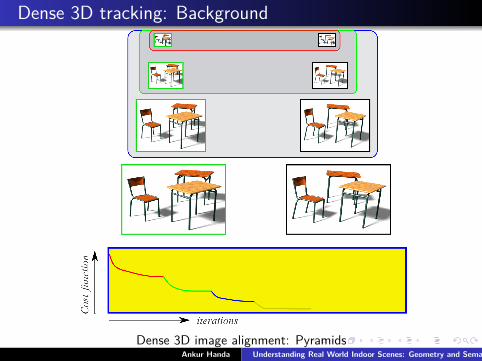
Dense 3D tracking: Background
Dense 3D image alignment: PyramidsAnkur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
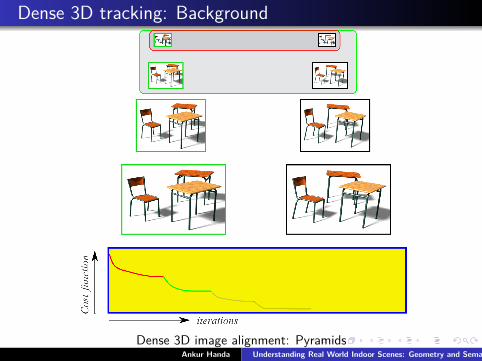
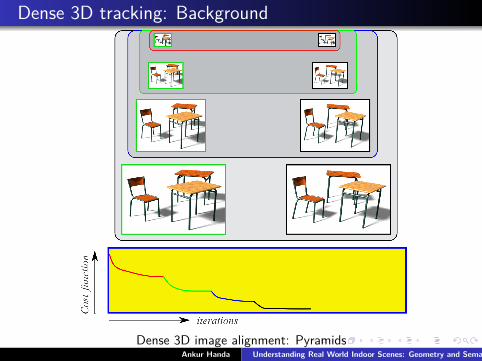
Dense 3D tracking: Background
Dense 3D image alignment: PyramidsAnkur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
Dense 3D tracking: Background
Dense 3D image alignment: PyramidsAnkur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
Dense 3D tracking: Background
Dense 3D image alignment: PyramidsAnkur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Synthetic Scenes with POVRay
Why synthetic data?We needed repeatable trajectories at different frame-rates.We wanted fixed light settings to carry out the experiments.Synthetic data allowed us to exercise full control on allparameters.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Experiments
InterpretationsWe ran our dense tracker on trajectories taken at differentframe-rates.Error is mean absolute distance between predicted and groundtruth pose.We will get Pareto Fronts showing the optima choice offrame-rate as a function of compute power.Verified with real world experiments, PhD Thesis, 2013.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
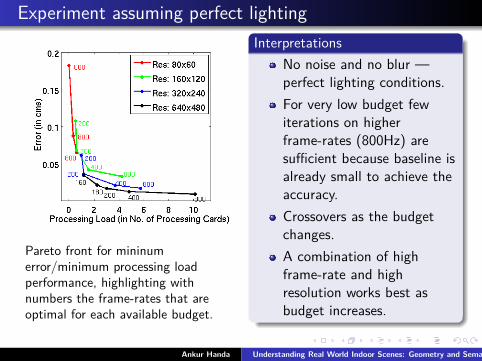
Experiment assuming perfect lighting
Pareto front for mininumerror/minimum processing loadperformance, highlighting withnumbers the frame-rates that areoptimal for each available budget.
InterpretationsNo noise and no blur —perfect lighting conditions.For very low budget fewiterations on higherframe-rates (800Hz) aresufficient because baseline isalready small to achieve theaccuracy.Crossovers as the budgetchanges.A combination of highframe-rate and highresolution works best asbudget increases.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Realistic lighting conditions
CharacterisationsReal lighting conditions mean there is noise and blur inimages.The degree of noise depends on the shutter-time as well asstrength of scene lighting.The strength of scene lighting is quantified by a parameterα ∈ {1, 10, 40}.Motion blur is generated by averaging the irradiance and notimage brightness — Debevec et al., SIGGRAPH 1997.Matching of blurry image is against a blurry predicted imageobtained from the model.Our tracking results will be again represented in the form of aPareto-Front.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
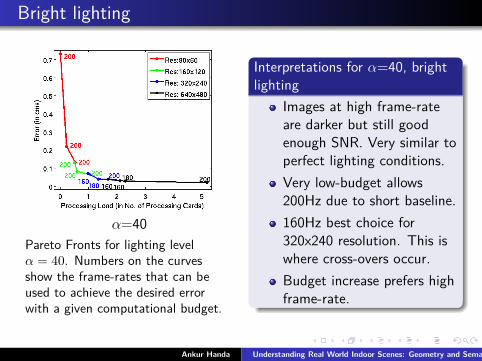
Bright lighting
α=40Pareto Fronts for lighting levelα = 40. Numbers on the curvesshow the frame-rates that can beused to achieve the desired errorwith a given computational budget.
Interpretations for α=40, brightlighting
Images at high frame-rateare darker but still goodenough SNR. Very similar toperfect lighting conditions.Very low-budget allows200Hz due to short baseline.160Hz best choice for320x240 resolution. This iswhere cross-overs occur.Budget increase prefers highframe-rate.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
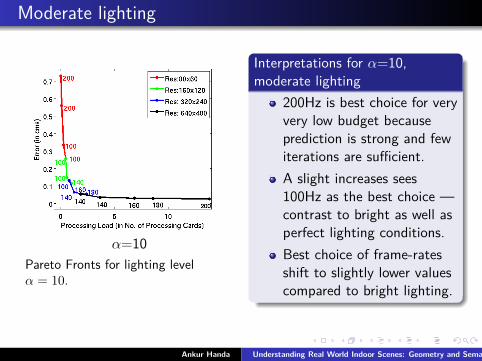
Moderate lighting
α=10Pareto Fronts for lighting levelα = 10.
Interpretations for α=10,moderate lighting
200Hz is best choice for veryvery low budget becauseprediction is strong and fewiterations are sufficient.A slight increases sees100Hz as the best choice —contrast to bright as well asperfect lighting conditions.Best choice of frame-ratesshift to slightly lower valuescompared to bright lighting.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
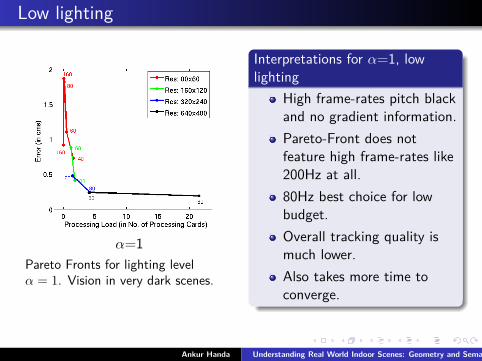
Low lighting
α=1Pareto Fronts for lighting levelα = 1. Vision in very dark scenes.
Interpretations for α=1, lowlighting
High frame-rates pitch blackand no gradient information.Pareto-Front does notfeature high frame-rates like200Hz at all.80Hz best choice for lowbudget.Overall tracking quality ismuch lower.Also takes more time toconverge.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Discussion
DiscussionGiven perfect lighting condition and therefore a highsignal-to-noise ratio (SNR), the highest accuracy is achievedusing a combination of high frame-rate and high resolution.Using a realistic camera model, there is an optimal frame-ratefor given lighting conditions due to trade-off between SNRand motion blur.Realistic conditions mean that there is a combination ofoptimal frame-rate and high resolution for accuracy.We cannot separate resolution from frame-rate given thenature of camera tracking algorithm.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

More synthetic scenes with POVRay
Where can large scale synthetic dataset be useful?Perfect instance segmentation and semantic segmentationground truth.Getting perfect ground truth poses, and depth and 3D.Ground truth for transparent objects and surfaces.Physics?
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
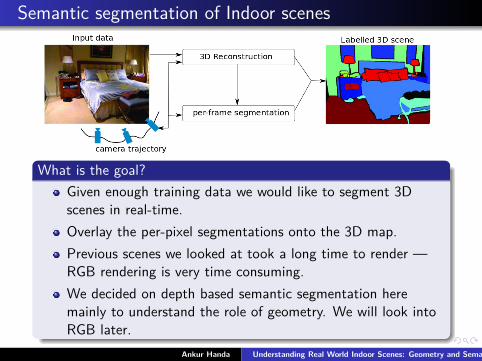
Semantic segmentation of Indoor scenes
What is the goal?Given enough training data we would like to segment 3Dscenes in real-time.Overlay the per-pixel segmentations onto the 3D map.Previous scenes we looked at took a long time to render —RGB rendering is very time consuming.We decided on depth based semantic segmentation heremainly to understand the role of geometry. We will look intoRGB later.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
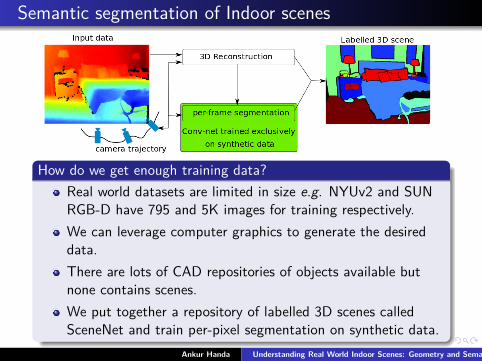
Semantic segmentation of Indoor scenes
How do we get enough training data?Real world datasets are limited in size e.g. NYUv2 and SUNRGB-D have 795 and 5K images for training respectively.We can leverage computer graphics to generate the desireddata.There are lots of CAD repositories of objects available butnone contains scenes.We put together a repository of labelled 3D scenes calledSceneNet and train per-pixel segmentation on synthetic data.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Outline
BackgroundSceneNet: Repository of Labelled Synthetic Indoor ScenesResults on Semantic Segmentation on Real World Datagvnn: Neural Network Library for Geometric VisionFuture Ideas
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet
Repository of labelled 3D synthetic scenes.
Hosted at http://robotvault.bitbucket.org
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet
SceneNet Basis ScenesRoom Type Number of ScenesLiving Room 10
Bedroom 11Office 15
Kitchens 11Bathrooms 10
In total we have 57 very detailed scenes with about 3700 objects.We build upon these scenes to create unlimited number of sceneslater for large scale training data.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
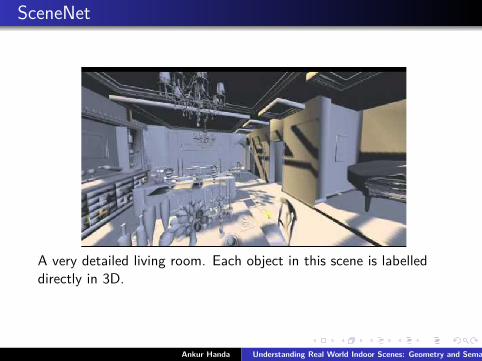
SceneNet
A very detailed living room. Each object in this scene is labelleddirectly in 3D.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
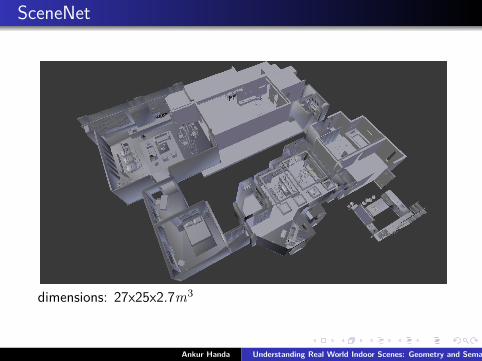
SceneNet
dimensions: 27x25x2.7m3
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Generating indoor scenes as energy minimisation problemSceneNet is still very limited sized dataset with 57 scenes.We would like to have potentially unlimited scenes with lots ofvariety and shapes.However.... we could use layouts of SceneNet and the objectco-occurrence statistics, i.e. which objects likely co-occurtogether.We can then sample objects from object repositories likeModelNet and arrange them according to theseco-occurrence statistics to create more scenes.We empirically scale the ModelNet CAD models to metricspace i.e. chairs should be ∼ 0.8-1m in height.Placing objects in the scene could be turned into an energyminimisation problem.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Generating indoor scenes as energy minimisation problemBounding box constraint.
Each object must maintain a safe distance from the other.Pairwise Constraint.
Objects that co-occur should not be more than a fixeddistance from each other, e.g. beds and nightstands
Visibility Constraint.Objects with visibility constraint must not have anythingjoining their line of sight joining their centers, e.g. sofa,tableand TV must not having anything in between them.
Distance to Wall Constraint.Some objects are more likely to occur next to walls e.g.cupboards, sofa etc.
Use simulated annealing to solve this energy minimisationproblem.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
wall
othe
rpro
pflo
orbe
d
pictur
e
pillo
w
othe
rfurn
iturelam
p
nigh
t sta
nd
blinds
chairbo
x
book
s
clot
hes
dres
serdo
or
pape
r
windo
w
curta
inde
skba
g
ceilin
g
book
shelf
cabine
t
table
shelve
s
othe
rstru
ctur
e
television
sofa
floor
mat
mirr
or
towel
pers
on
coun
ter
refri
dger
ator
show
er cur
tain
white
boar
dto
iletsink
bath
tub
wall
otherprop
floor
bed
picture
pillow
otherfurniture
lamp
night stand
blinds
chair
box
books
clothes
dresser
door
paper
window
curtain
desk
bag
ceiling
bookshelf
cabinet
table
shelves
otherstructure
television
sofa
floor mat
mirror
towel
person
counter
refridgerator
shower curtain
whiteboard
toilet
sink
bathtub
Co-occurrence statistics of objectsfrom NYUv2 bedrooms.
InterpretationsHeat-map of objectco-occurrence.Training sets in NYUv2 andSceneNet basis scenes areused to obtain thesestatistics.Shows that bed, picture,pillow and nightstandco-occur together.We sample objects fromModelNet and arrangethem using these objectco-occurrence statistics.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Random placement With Pairwise only All constraints
ConstraintsObjects that co-occur in real world should be placed together,e.g. beds and nightstands.Visibility constraint - nothing in the line of sight betweensofa-table and TV.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Very simple scenes with curtains.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Common room obtained from hierarchically optimising chairs andtable combination.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Living Room. Note that the inset objects are from Stanford Scenesand have been grouped together already.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
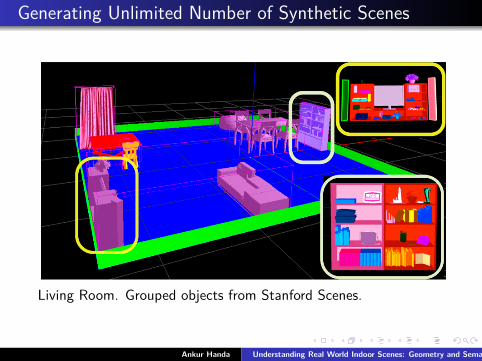
Generating Unlimited Number of Synthetic Scenes
Living Room. Grouped objects from Stanford Scenes.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Data CollectionCollecting trajectories with joy-stick (though we haverandomised them now).Using OpenGL glReadPixels to obtain the depth as well asground truth labels.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Generating Unlimited Number of Synthetic Scenes
Depth Height Angle with gravity
AssumptionsHere we only study the segmentation from just depth-data inthe form of DHA images i.e. depth, height from ground planeand angle with gravity vector.Allows us to study the effects of geometry in isolation.Texturing takes time and needs careful photo-realisticsynthesis. But we have added a custom raytracer to studyRGB-D based segmentation now.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
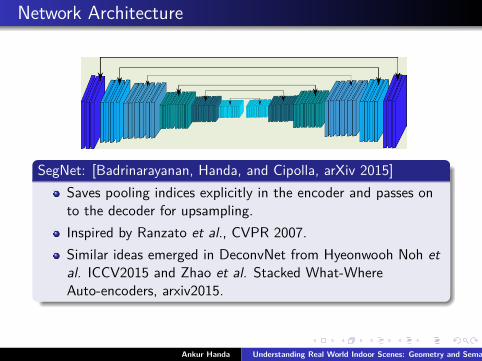
Network Architecture
SegNet: [Badrinarayanan, Handa, and Cipolla, arXiv 2015]Saves pooling indices explicitly in the encoder and passes onto the decoder for upsampling.Inspired by Ranzato et al., CVPR 2007.Similar ideas emerged in DeconvNet from Hyeonwooh Noh etal. ICCV2015 and Zhao et al. Stacked What-WhereAuto-encoders, arxiv2015.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Carefully synthesising realistic depth-maps
Adding noise to depth-map Denoising depth-map Angle with gravity maps
Adapting synthetic data to match real world dataSynthetic depth-maps are injected with appropriate noisemodels.We then denoise these depth-maps to ensure that inputimages look similar to the NYUv2 dataset.Side by side comparison of synthetic bedroom with one of theNYUv2 bedrooms.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Outline
BackgroundSceneNet: Repository of Labelled Synthetic Indoor ScenesResults on Semantic Segmentation on Real World Datagvnn: Neural Network Library for Geometric VisionFuture Ideas
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Results on Semantic Segmentation on Real World Data
NYUv2 test images
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Results on Semantic Segmentation on Real World Data
Ground truth segmentation
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Results on Semantic Segmentation on Real World Data
Training on NYUv2 training set only
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Results on Semantic Segmentation on Real World Data
Training on SceneNet and fine-tuning on NYUv2
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
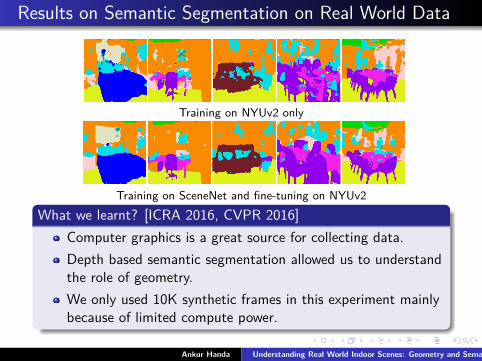
Results on Semantic Segmentation on Real World Data
Training on NYUv2 only
Training on SceneNet and fine-tuning on NYUv2What we learnt? [ICRA 2016, CVPR 2016]
Computer graphics is a great source for collecting data.Depth based semantic segmentation allowed us to understandthe role of geometry.We only used 10K synthetic frames in this experiment mainlybecause of limited compute power.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
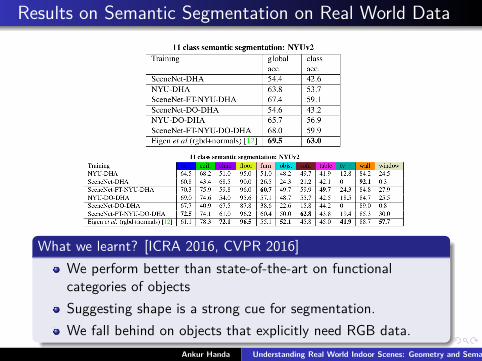
Results on Semantic Segmentation on Real World Data
What we learnt? [ICRA 2016, CVPR 2016]We perform better than state-of-the-art on functionalcategories of objectsSuggesting shape is a strong cue for segmentation.We fall behind on objects that explicitly need RGB data.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Results on Semantic Segmentation on Real World Data
What we learnt? [ICRA 2016, CVPR 2016]We perform better than state-of-the-art on functionalcategories of objectsSuggesting shape is a strong cue for segmentation.We fall behind on objects that explicitly need RGB data.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Results on Semantic Segmentation on Real World Data
What we learnt? [ICRA 2016, CVPR 2016]We perform better than state-of-the-art on functionalcategories of objectsSuggesting shape is a strong cue for segmentation.We fall behind on objects that explicitly need RGB data.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SemanticFusion Mccormac et al. 2016
NotesSemantic mapping at the level of objectsCombines real-time 3D mapping system with a per-frameCNN semantic predictions in a recursive bayesian loop.Able to map large scale areas.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Limitations
What we learnt? [ICRA 2016, CVPR 2016]The cost functions are still primitive - per-pixel discrepancysummed up assumes that pixels are independent. Maybebetter cost functions that take global context into account aladiscriminator in GANs can help.Actually, we don’t need to segment the whole image at once -attention can help?Still hard to get sharp boundaries with segmentationalgorithms today.Extracting thin structures is still very hard.Benchmarking could be misleading...
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
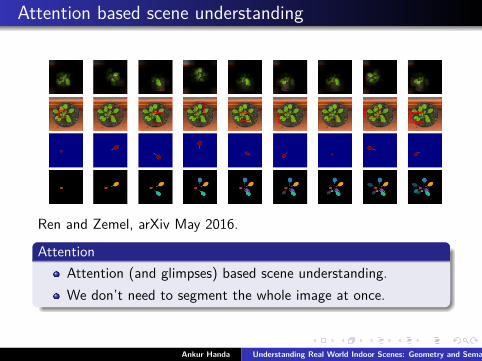
Attention based scene understanding
Ren and Zemel, arXiv May 2016.
AttentionAttention (and glimpses) based scene understanding.We don’t need to segment the whole image at once.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Physics
Adding PhysicsSince then we have extended SceneNet quite a lot.Adding physics allows us to create scenes with arbitraryclutter.Placing pens and other small objects on tables is relativelyeasy with physics.We don’t want chairs always in upright positions. Physicsallows us to explore the space of poses of objects relativelyeasy.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Raytracing
Adding RaytracingModelNet used in our previous experiment was not a bigrepository.Now, we use a much bigger repository, ShapeNets, to sampleobjects.Most CAD repositories do not have models in metric scales.Use 3D bounding boxes in SUN RGB-D to get the metricscales of objects.Use physics to add clutter in the scenes.Render RGB using a customised raytracer on GPU.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
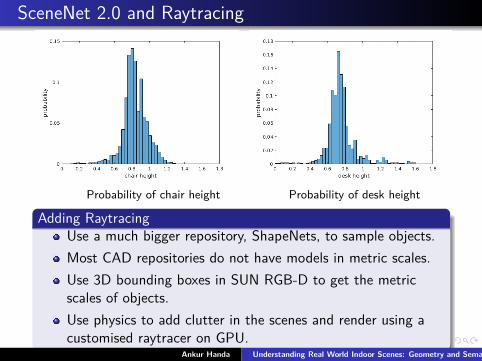
SceneNet 2.0 and Raytracing
Probability of chair height Probability of desk height
Adding RaytracingUse a much bigger repository, ShapeNets, to sample objects.Most CAD repositories do not have models in metric scales.Use 3D bounding boxes in SUN RGB-D to get the metricscales of objects.Use physics to add clutter in the scenes and render using acustomised raytracer on GPU.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
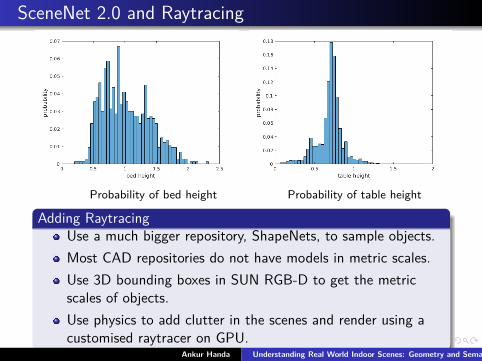
SceneNet 2.0 and Raytracing
Probability of bed height Probability of table height
Adding RaytracingUse a much bigger repository, ShapeNets, to sample objects.Most CAD repositories do not have models in metric scales.Use 3D bounding boxes in SUN RGB-D to get the metricscales of objects.Use physics to add clutter in the scenes and render using acustomised raytracer on GPU.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
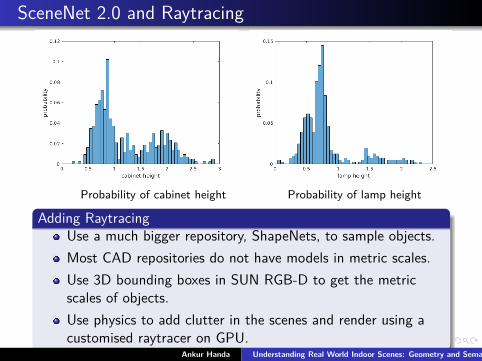
SceneNet 2.0 and Raytracing
Probability of cabinet height Probability of lamp height
Adding RaytracingUse a much bigger repository, ShapeNets, to sample objects.Most CAD repositories do not have models in metric scales.Use 3D bounding boxes in SUN RGB-D to get the metricscales of objects.Use physics to add clutter in the scenes and render using acustomised raytracer on GPU.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Raytracing
Low-res on laptop High quality
Adding RaytracingSufficient Photorealism is desirable.Depth sensors have limited range.RGB is universal and allows us to model various differentcameras.Need good approximation of shadows, lighting, and variousother global lighting artefacts.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Raytracing
RandomnessTextures on the layouts are randomised.Object textures are from ShapeNets.Random lighting.Random positions of objects and random camera trajectories.We have 2.5 million rendered images now and rendering.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Raytracing
RandomnessTextures on the layouts are randomised.Object textures are from ShapeNets.Random lighting.Random positions of objects and random camera trajectories.We have 2.5 million rendered images now and rendering.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Raytracing
RandomnessTextures on the layouts are randomised.Object textures are from ShapeNets.Random lighting.Random positions of objects and random camera trajectories.We have 2.5 million rendered images now and rendering.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Raytracing: High quality renders
RandomnessTextures on the layouts are randomised.Object textures are from ShapeNets.Random lighting.Random positions of objects and random camera trajectories.We have 2.5 million rendered images now and rendering.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

SceneNet 2.0 and Raytracing: High quality renders
Where can large scale synthetic dataset be useful?Getting perfect ground truth poses, and depth and 3D andphysics?Instance and semantic segmentation ground truth.Optical flow ground truth for non-rigid scene understanding.Ground truth for transparent objects and surfaces.We are working on these problems now.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Outline
BackgroundSceneNet: Repository of Labelled Synthetic Indoor ScenesResults on Semantic Segmentation on Real World Datagvnn: Neural Network Library for Geometric VisionFuture Ideas
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

gvnn: Geometric Vision with Neural Networks
What is gvnn?A new library inspired by Spatial Transformer Networks(STN).Implemented in torch.Includes various different transformations often used ingeometric computer vision.These transformations are implemented as new layers thatallow backpropagation as in STN.Brings together the domain knowledge in geometry within theneural network.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Different new layers in gvnn
What is gvnn?Original Spatial Transformer (NIPS 2015) had 2Dtransformations mainly.Added SO3, SE3 and Sim3 layers for global transformation onthe image.Optical flow, over-parameterised Optical flow, Slanted planedisparity.Pin-Hole Camera Projection layer.Per-pixel SO3, SE3 and Sim3 for non-rigid registration.Different robust M-estimators.Very useful for 3D alignment, unsupervised warping with opticflow or disparity and geometric invariance for placerecognition.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
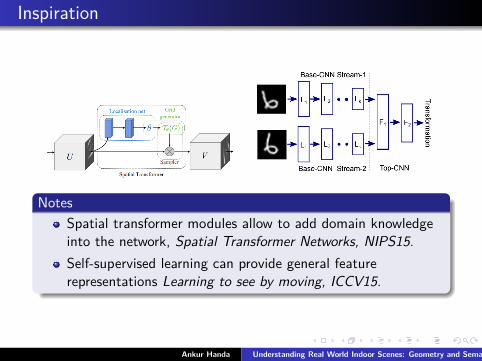
Inspiration
NotesSpatial transformer modules allow to add domain knowledgeinto the network, Spatial Transformer Networks, NIPS15.Self-supervised learning can provide general featurerepresentations Learning to see by moving, ICCV15.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Global Transformations in gvnn
SO3 Layer (SE3 and Sim3 follow easily from here) for 3D Rotations
∂C∂v = ∂C
∂R(v) ·∂R(v)∂v (1)
∂R(v)∂vi
= vi [v]× + [v× (I− R)ei ]×||v||2 R (2)
NotesC is the cost function being minimised.v = (v1, v2, v3) is the SO3 vector. Note the derivative is notat vi ≈ 0 and ei is the i th column of the Identity matrix.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Global Transformations in gvnn
NotesC is the cost function being minimised.v = (v1, v2, v3) is the SO3 vector. Note the derivative is notat vi ≈ 0 and ei is the i th column of the Identity matrix.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Global Transformations in gvnn
NotesC is the cost function being minimised.v = (v1, v2, v3) is the SO3 vector. Note the derivative is notat vi ≈ 0 and ei is the i th column of the Identity matrix.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Global Transformations in gvnn
(a) v = (0.2, 0.0, 0.0) (b) v = (0.0, 0.3, 0.0) (c) v = (0.0, 0.0, 0.4)
NotesC is the cost function being minimised.v = (v1, v2, v3) is the SO3 vector. Note the derivative is notat vi ≈ 0 and ei is the i th column of the Identity matrix.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Per-pixel 2D Transformations in gvnn
Optical flow and Over-parameterised Optical Flow
(x ′y′
)=
(x + txy + ty
)(3)
(x ′y′
)=
a0 a1 a2
a3 a4 a5
x
y1
(4)
NotesOver-parameterised optical flow also needs extraregularisation.2D and 6D transformations per-pixel. Useful for warpingimages (and unsupervised learning), Patraucean, et al.ICLRW2016.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Per-pixel 2D Transformations in gvnn
Optical flow warping with gvnn
(x ′y′
)=
(x + txy + ty
)(5)
Useful for warping one image on top of other - learning opticalflow with a CNN.Self-supervised learning, Patraucean, et al. ICLRW2016.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Per-pixel 2D Transformations in gvnn
Optical flow warping with gvnn
(x ′y′
)=
(x + txy + ty
)(6)
Useful for warping one image on top of other - learning opticalflow with a CNN.Self-supervised learning, Patraucean, et al. ICLRW2016.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Per-pixel 2D Transformations in gvnn
Disparity and Slated Plane disparity
(x ′y′
)=
(x + d
y
)(7)
d = ax + by + c (8)
NotesFitting slanted planes at each pixel.Again, very useful for warping images (and unsupervisedlearning), Garg et al. ECCV2016.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Per-pixel 2D Transformations in gvnn
NotesFitting slanted planes at each pixel.Again, very useful for warping images (and unsupervisedlearning), Garg et al. ECCV2016.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Camera Projection Layer in gvnn
Pin Hole Camera Projection Layer
π
uvw
=
fx uw + px
fy vw + py
(9)
∂C∂p = ∂C
∂π(p) ·∂π(p)∂p (10)
∂π
uvw
∂
uvw
=
fx 1w 0 −fx u
w2
0 fy 1w −fy v
w2
(11)
Useful in differentiable renderer ala OpenDR.Reasoning from 3D to 2D.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Camera Projection Layer in gvnn
Rezende et al., arXiv 2016
NotesUseful in differentiable renderer ala OpenDR.Reasoning from 3D to 2D.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Non-rigid per-pixel transformation
Non-rigid registration for point clouds: 6DoF and 10DoFPer-pixel 6DoF and 10DoF transformations.
x ′iy′iz ′i
= Ti
xiyizi1
(12)
x′i = si(Ri(xi − pi) + pi) + ti (13)
Also useful for volumetric spatial transformers when using voxelgrid representation.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Non-rigid per-pixel transformation
SE3-Nets Byravan and Fox, arXiv 2016
Non-rigid predictionUseful for predicting the dynamics of the objects.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
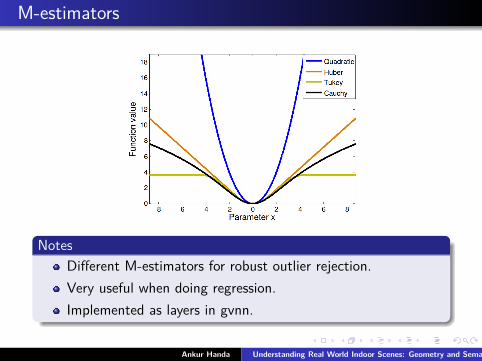
M-estimators
NotesDifferent M-estimators for robust outlier rejection.Very useful when doing regression.Implemented as layers in gvnn.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SO3)
NotesGeneral dense image registration with global transformation.Can use optical flow/disparity for dense per-pixel imageregistration either with a CNN or RNN.Initial experiments with supervised learning.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SO3)
NotesGeneral dense image registration with global transformation.Can use optical flow/disparity for dense per-pixel imageregistration either with a CNN or RNN.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SO3)
NotesGeneral dense image registration with global transformation.Can use optical flow/disparity for dense per-pixel imageregistration either with a CNN or RNN.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SO3)
NotesGeneral dense image registration with global transformation.Can use optical flow/disparity for dense per-pixel imageregistration either with a CNN or RNN.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SO3)
NotesGeneral dense image registration with global transformation.Can use optical flow/disparity for dense per-pixel imageregistration either with a CNN or RNN.Aim to train on large scale data from SceneNet and RGBvideos for unsupervised learning.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SO3)
δupdate = fsiamese(Ikt , It+1) (14)
δk = δk−1 + δupdate (15)Ik
t = fwarping(It , δk) (16)I0
t = It (17)δ0 = 0 (18)
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SE3)
NotesNeeds explicitly the depth to do warping.This can either come from a sensor or an extra CNN/RNNmodule that learns depth.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Sanity Checks on End-to-End Image Registration (SE3)
(a) Prediction (b) Ground Truth (c) Residual (difference)
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Aligning images taken at different times of the day
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

New libraries: gvrnn
Maggiori et al., arXiv 2016gvrnn
CNNs are good at localisation but not good with accuracy.Implements various PDE solvers as layers in torch.Primal-dual optimisations (Pock et al. 2011).Iterative image alignment.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Outline
BackgroundSceneNet: Repository of Labelled Synthetic Indoor ScenesResults on Semantic Segmentation on Real World Datagvnn: Neural Network Library for Geometric VisionFuture Ideas
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Future Ideas
PhysNet, Lerer et al. ICML 2016 SceneNet2.0
Physical scene understanding with SceneNet to reason abouthow the dynamics of the scene is going to evolve over time.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Future Ideas
Deep learning with geometry: ExampleUnderstanding dynamic scenes.CNNs provide relatively stable features for images of samescene taken across different lighting conditions.These images cannot be aligned with geometry basedper-pixel dense image alignment methods.We can put this together with change detection segmentationto also reason about dynamic scenes.Easy to collect data with SceneNet.
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics
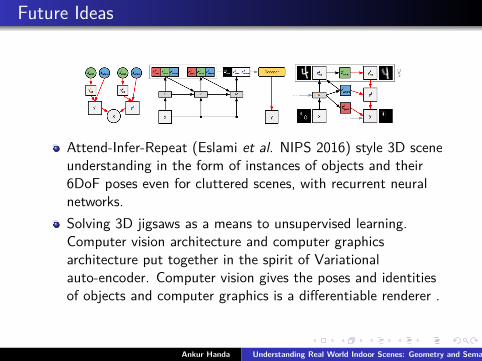
Future Ideas
Attend-Infer-Repeat (Eslami et al. NIPS 2016) style 3D sceneunderstanding in the form of instances of objects and their6DoF poses even for cluttered scenes, with recurrent neuralnetworks.Solving 3D jigsaws as a means to unsupervised learning.Computer vision architecture and computer graphicsarchitecture put together in the spirit of Variationalauto-encoder. Computer vision gives the poses and identitiesof objects and computer graphics is a differentiable renderer .
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics

Acknowledgements
Thank youVijay Badrinarayanan, Viorica Patraucean, Simon Stent, andRoberto Cipolla, University of CambridgeZoubin Ghahramani, University of CambridgeJohn McCormac and Andrew Davison, Imperial CollegeLondonDaniel Cremers, TUM Munich
Ankur Handa Understanding Real World Indoor Scenes: Geometry and Semantics