relevance measures for question answering, the lia at qa@clef2006
TRANSCRIPT

Relevance Measures for Question Answering,The LIA at QA@CLEF-2006
Laurent Gillard, Laurianne Sitbon, Eric Blaudez,Patrice Bellot, and Marc El-Beze
LIA, Avignon University Science Laboratory,339 ch. des Meinajaries, BP 1228, F-84911 Avignon Cedex 9, France
{laurent.gillard,laurianne.sitbon,eric.blaudez,patrice.bellot,marc.elbeze}@univ-avignon.fr
http://www.lia.univ-avignon.fr
Abstract. This article presents the first participation of the AvignonUniversity Science Laboratory (LIA) to the Cross Language EvaluationForum (CLEF). LIA participated to the monolingual Question Answer-ing (QA) track dedicated to the French language, and to the cross-lingualEnglish to French QA track. After a description of the strategies usedby our system to answer questions, an analysis of the results obtained isdone in order to discuss and outline possible improvements. Two strate-gies were used: for factoid questions, answer candidates are identified asNamed Entities and selected by using key terms density measures (“com-pactness”); on the other hand, for definition questions, our approach isbased on detection of frequent appositive informational nuggets appear-ing near the focus.
Keywords: Question answering, Questions beyond factoids, Definitionquestions, Key Terms density metrics, Compactness, Multilingual ques-tion answering.
1 Introduction
Question Answering (QA) systems aim at retrieving precise answers to questionsexpressed in natural language rather than list of documents that may contain ananswer. They have been particularly studied since 1999 and the first large scaleQA evaluation campaign held as a track of the Text REtrieval Conference [1].The Cross Language Evaluation Forum (CLEF) has been studying multilingualissues of QA and has been providing an evaluation platform for QA dedicatedto many languages since 2003.
It was the first participation of the Avignon University Science Laboratory(LIA) to CLEF (we already participated to monolingual English, TREC-11 [6],and monolingual French, the EQueR Technolangue QA campaign [8]). This year,LIA participation was devoted to two tracks: monolingual French and Englishto French. Both submissions are based on the same system architecture that wasinitially developped for our participation to the EQueR campaign[2]. Moreover,
C. Peters et al. (Eds.): CLEF 2006, LNCS 4730, pp. 440–449, 2007.c© Springer-Verlag Berlin Heidelberg 2007

Relevance Measures for Question Answering, The LIA at QA@CLEF-2006 441
CLEF-2006 allowed us to evaluate some improvements: English question analysismodule, integration of Lucene as a search engine, a module to handle definitionquestions, and another one to experiment a re-ranking mechanism by using re-dundancy for answer candidates. For both tracks, two runs were submitted, thesecond run for each language used a redundancy re-ranking module.
Our QA system (called SQuaLIA) is built according to the typical QA system(QAS) architecture, and involves pipelined main components. A Question Anal-ysis (described in section 2) is first done to extract the semantic type(s) of theexpected answer(s) and key terms but also to decide what strategy must be fol-lowed : factoid or definition one. For factoid questions (section 3), SQuaLIA per-forms consecutive steps: Document Retrieval (section 3.2) to restrict the amountof processed data for next components, Passage Retrieval (section 3.3) to choosethe best answering passages from documents, and lastly, Answer Extraction todetermine the best answer candidate(s) drawn from the previously selected pas-sages. This answer extraction is mainly performed by using a density (section3.4) of the key terms appearing around an answer candidate (bounded as aNamed Entity, NE, section 3.1), but may also involve knowledge bases (section3.4). The definition strategy (section 4) uses frequent appositive nuggets of infor-mation appearing near the focus. We also experimented briefly with redundancyto re-rank answer candidates but this module had some bugs, and did not per-form as expected. In last sections, results of our participation will be presentedand discussed (section 5) with perspectives for future improvements.
2 Question Analysis
Firstly, definition questions are recognized with a simple pattern matchingprocess, which also extracts the focus of the question. All questions which do notfit definition patterns are considered as factual questions, including list questions(and consequently, list questions were wrongly answered as factoid questions withonly one instance instead of a set of instances).
The analysis of factual questions is made of two main independent steps whichare: question classification and key terms extraction. For the questions in English,the key terms extraction step is done after a translation of the question by usingSystran translator1.
Expected Answer Types Classification: The answer expected for a factoidquestion is considered to be a Named Entity (NE) based upon Sekine’s hierarchy[3]. Thus, questions are classified according to this hierarchy. This determinationis done with patterns and rules for questions in French; and, complemented, butonly for English questions, with semantic decision trees (a machine learningapproach introduced by [4] and [5]).
Semantic decision trees are adapted as described in [6] to automatically ex-tract generic patterns from questions in a learning corpus. The corpus CLEFmultinine composed of 900 questions was used for learning. Since all questions1 By means of Google Translator: http://www.google.fr/language tools

442 L. Gillard et al.
Table 1. Evaluation of the categorization process on CLEF-2006 questions
Language Correct Wrong UnknownFrench 86% 2% 12%English 78% 13% 5%
are available in both English and French languages, French questions were au-tomatically tagged according to the French rules based module, then, checkedand paired manually with their English version to be used as a learning corpus.The learning features are words, part-of-speech tags2, lemmas, and length of thequestion (stop words are taken into account).
Table 1 shows the results of a manual post-evaluation of the categorizationof CLEF-2006 questions (first and second columns), but also the percentage ofquestions tagged as Unknown by categorizer (third column). Wrong or Unknowntags prevent the downstream components from extracting answers. In French,only 8 of the 19 Unknown tagged questions were classifiable manually (as beingPerson name or Company name, others are difficult to map to Sekine’s hierar-chy). Due to its “strict” pipelined architecture, the percentage of Correct tagsfixed the maximum score our QAS can achieve. Moreover, some of the correctclassification in English are actually more generic than they could be, for exam-ple President is tagged as Person.
After assigning questions to classes from the hierarchy, a mapping betweenthese classes and available Named Entities (NE) is done. However, the questionhierarchy is much more exhaustive than the named entities that our NE systemis able to recognize.
Key Terms Extraction: Key Terms are importants objects like words, namedentities, or noun phrases extracted from questions. These key terms are expectedto appear near the answer. Actually, our CLEF 2006 experiments used onlylemmatized forms of nouns, adjectives and verbs as key terms. But, noun phrasesmay also help in the ranking of passages. For example, in question Q0178, “worldchampion” is more significant than “world” and “champion” taken separately.Such noun phrases are extracted in French with the help of SxPipe deep parserdescribed in [9], Named Entities are extracted as described in section 3.1. ForEnglish questions, these extractions are done on their French equivalent obtainedafter initial translation.
3 Answering Factoid Questions
Answering factoid questions was done by using the strategy we used for our par-ticipation to EQueR. It mainly relies on density measures to select answers whichare sought as Named Entities (NE) paired with expected answer types (EAT).Two new modules were developed for this CLEF-QA’s participation: Lucene2 Part-of-speech tags and lemmas are obtained with the help of TreeTagger [7].

Relevance Measures for Question Answering, The LIA at QA@CLEF-2006 443
was integrated as the Document Retrieval (DR) search engine (for EQueR as forTREC, Topdoc lists were available, and so, this DR step was facultative) andwe also experimented with redundancy to re-rank candidate answers.
3.1 Named Entity Recognition
Named Entities detection is one of the key elements as each answer that will beprovided must first be located (and bounded) as a semantic information nuggetin the form of a Named Entity. Our named entities hierarchy was created fromand is a subset of the Sekine’s taxonomy [3]. NE detections are done by usingautomata: most of them are implemented by using GATE platform, but also bydirect mapping of many gazetteers gathered from the Web.
3.2 Document Retrieval
The Document Retrieval (DR) step aims at identifying documents that are likelyto contain an answer to the question posed and, thus, restrict search space fornext steps. Indexation and retrieval were done by using Lucene search enginewith its default similarity scoring3. For each document of the collection, onlylemmas are indexed after a stop-listing based upon their TreeTagger’s part-of-speech. Disjunctive queries are formulated from the lemmas of the question keyterms. At retrieval time, only the first 30 documents (at most) returned byLucene were considered and passed to the Passage Retrieval component.
3.3 Passage Retrieval
Our CLEF passage retrieval component considers a question as a set of severalkinds of items: lemmas, Named Entity tags, and expected answer types.
First, a density score s is computed for each occurrence ow of each item w ina given document d. This score measures how far are the items of the questionfrom the other items of the document. This process focuses on areas where theitems of the question are most frequent. It takes into account the number ofdifferent items |w| in the question, the number of question items |w, d| occurringin the document d and a distance μ(ow) that represents the average number ofitems from ow to the other items in d (in case of multiple occurrences of an item,only the nearest occurrence to ow is considered).
Let s(ow, d) be the density score of ow in document d:
s(ow, d) =log [μ(ow) + (|w| − |w, d|) .p]
|w| (1)
where p is an empirically fixed penalty. The score of each sentence S is themaximum density score of the question items it contains:
s(S, d) = maxow∈S
s(ow, d) (2)
3 Lucene version 1.4.3, using TermVector and similarity: http://lucene.apache.org/java/docs/api/org/apache/lucene/search/Similarity.html

444 L. Gillard et al.
Passages are composed of a maximum of three sentences: the sentence S itself,the previous and following sentences (if they exit). The first (and at most) 1000best passages are then considered by the Answer Extraction component.
3.4 Answer Extraction
Answer extraction by using a density metric. To choose the best answerto provide to a question, another density score is calculated inside the previouslyselected passages for each answer candidate (a Named Entity) adequately pairedwith an expected answer type for current question. This density score (calledcompactness) is centered on each candidate and involves extracted key terms(let QSet be this set) from the question during the question analysis step.
The assumption behind our compactness score is that the best candidate an-swer is closely surrounded by the important words (actually extracted key terms)of the question. Every word not appearing in the question can disturb the rela-tion between a candidate answer and its responsiveness to a question. Moreover,in QA, term frequencies are not as useful as for Document Retrieval: an answerword can appear only once, and it is not guaranteed that words of the questionwill be repeated in the passage, particularly in the sentence containing the an-swer. A score improvement can come from incorporating an inverse documentfrequency or linguistic features for non QSet encountered words to further takeinto account any variation of closeness.
For each answer candidate ACi, compactness score is computed as follow:
compactness(ACi) =
∑
y∈QSet
pyn,ACi
|QSet| (3)
with yn the nearest occurrence key term y from ACi and:
pyn,ACi =|W |
2R + 1(4)
R = distance(yn, ACi) (5)W = {z|z ∈ QSet,distance (z, ACi) ≤ R} (6)
For both runs submitted, only unigrams were considered for inclusion in QSet.All answers candidates are then ranked by their score, best scoring answer isprovided as final answer.
Answer extraction by using knowledge databases. For some questions,answers are quite invariable over time like, for example, questions asking aboutthe capital of a country, the authors of book, etc.
To answer these questions one may use (static) knowledge databases (KDB).We had built such KDB for our participation to TREC-11 [6], and translatedthem to a French equivalent for our participation to EQueR (they were par-ticularly tuned on CLEF-2004 questions). For CLEF-2006, we used the sameunchanged KDB module. It provided answer patterns, which were used to mined

Relevance Measures for Question Answering, The LIA at QA@CLEF-2006 445
Table 2. Knowledge databases coverage for CLEF 2004-06
runs 2004 2005 2006 FR-FRQ covered (/200) 51 26 24 (10)
Passages matching pattern 48 ne 11Correct answers (C) 38-40 ne 11
passages from Passage Retrieval step. Table 2 shows the coverage of these databasesfor CLEF from 2004 to 2006 (ne stands for “not evaluated”), the number of pas-sages coming from PR matching a KDB pattern, and number of right supportedanswers. Also, for CLEF 2006 experiments, 10 questions covered by this modulewere finally handled directly by the new definition module). EN-FR results werelower due to translation errors (9C or 7C).
4 Answering Definition Questions
For our participation to EQueR [2], most of the definition questions were unan-swered by the strategy described in the previous section. Indeed, it mainly relieson the detection of an entity paired with a question type, but, for definitionquestions, such pairing to an entity is far more difficult: the expected answercan be anything qualifying the object to define (even if, when asking about aperson definition, the answer sought is often its main occupation - which mayconstitute a common Named Entity - it can still be tricky to recognize all possi-ble occupations or reasons why someone maybe “famous”). Also, one can noticethat while for TREC-QA campaign all vital nuggets should be retrieved, for theEQueR and CLEF exercises, retrieving only - one - vital was sufficient.
So, the problem we wanted to address was to find one of the best definitionsavailable inside the corpora. Therefore, we developed a simple approach basedon appositive and redundancy to deal with these questions:
– the focus to define is extracted from the question and is used to filter andkeep all sentences of the corpora containing it.
– then, appositives nuggets such as < focus , (comma) nugget , (comma) >, < nugget , (comma) focus , (comma) > , or < definite article (“le” or“la”) nugget focus > are sought.
– the nuggets are divided in two sets: the first, and preferred one, containsnuggets that can be mapped, by using their TreeTagger part-of-speech tags,on a minimal noun phrase structure while the second set contains all others(it can be seen as a kind of “last chance” definition set).
– both sets are ordered by their nuggets frequency in the corpora. But the“noun phrase set” is also ordered by taking into account its head nounfrequency, the overlapping count of nouns inside it among the most frequentnouns appearing inside all the nuggets retrieved and its length. All thesefrequency measures are aimed to choose what is expected to be “the mostcommon informative definition”.

446 L. Gillard et al.
– best nugget of the first set or of the second, if first is empty, or by defaultNIL, is provided as final answer.
This strategy was also used to answer to the acronyms/expanded acronymsdefinitions, as the same syntactic punctuation clues can be used for these ques-tions such as the frequent < acronym ( (opening parenthesis) expanded acronym) (closing parenthesis) > or < expanded acronym ( (opening parenthesis)acronym ) (closing parenthesis) > - and it performed very well as all answersof this year set were retrieved (even if, due to a bug in the matching processbetween answer and justification, the “TDRS”/Q0145 wasn’t finally answered,while the correct answer was found).
5 Results and Analysis
On the 200 test questions, and for our best run (FR-FR1), 93 right answers (89+ 4 lists) were correct. Table 3 presents the breakdown according to Factual,Definition and Temporally restricted questions of our two basic runs (i.e. withoutre-ranking, our second runs, which contained errors).
Table 3. CLEF-QA 2006 breakdown for our basic FR-FR and EN-FR runs, derivedfrom official evaluation
Correct Answers NIL Answers othersruns Fact. Def. Temp. Total Correct answered ineXact Unsupp.
FR-FR1 44 33 12 89 2 33 7 2EN-FR1 31 28 8 67 5 35 7 2
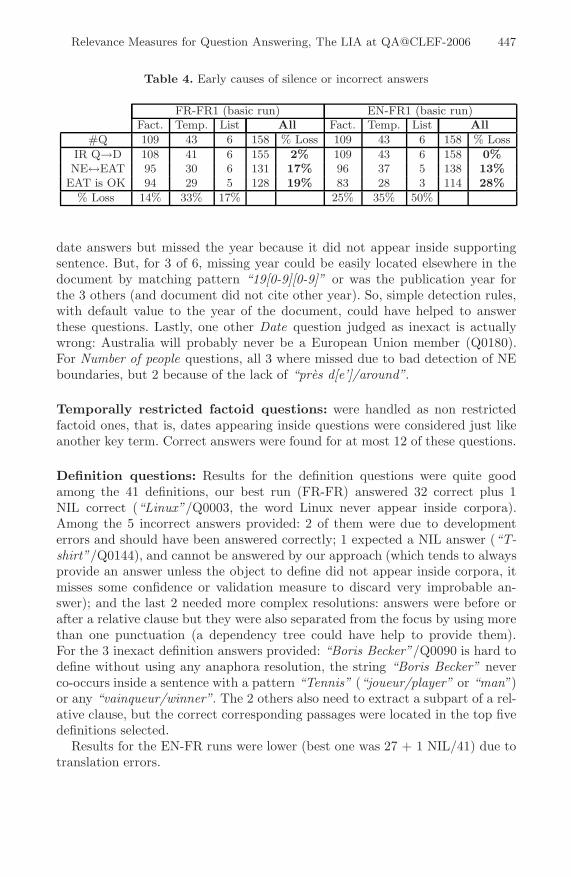
Results analysis: because our QAS is composed of pipelined components, earlysilences or errors in the chain lead to incorrect or no final answers. As shownin Table 4, and without verifying whether a correct answer is present in thedocuments, early silences coming from Information Retrieval (IR) step (firstrow), missing or wrong pairing between Expected Answer Types (EAT) andNamed Entities (NE) (second row), or the fact that EAT is wrongly assigned(third row) may all cause a final error. Thus for FR-FR run, our IR step preventsfrom finding any correct answer for 2% of questions, errors between NE andEAT is up 17%, and not searching for correct EAT raises this percent to 19%.Similarly, For EN-FR, and due to these earliest errors, no correct answer mightbe mined for 28% of questions.
Knowledge Databases: The knowledge databases best contribution added 11correct answers. However, without using KDB, 5 of these would have been alsofound. Final best KBD contribution added 6 correct answers.
IneXact answers: If we examine all the inexact answers from all our 4 runs, 8of 20 where Date and 3 of 20 were Number of people. For Date, 6 of 8 were correct
Relevance Measures for Question Answering, The LIA at QA@CLEF-2006 447
Table 4. Early causes of silence or incorrect answers
FR-FR1 (basic run) EN-FR1 (basic run)Fact. Temp. List All Fact. Temp. List All
#Q 109 43 6 158 % Loss 109 43 6 158 % LossIR Q→D 108 41 6 155 2% 109 43 6 158 0%NE↔EAT 95 30 6 131 17% 96 37 5 138 13%
EAT is OK 94 29 5 128 19% 83 28 3 114 28%% Loss 14% 33% 17% 25% 35% 50%
date answers but missed the year because it did not appear inside supportingsentence. But, for 3 of 6, missing year could be easily located elsewhere in thedocument by matching pattern “19[0-9][0-9]” or was the publication year forthe 3 others (and document did not cite other year). So, simple detection rules,with default value to the year of the document, could have helped to answerthese questions. Lastly, one other Date question judged as inexact is actuallywrong: Australia will probably never be a European Union member (Q0180).For Number of people questions, all 3 where missed due to bad detection of NEboundaries, but 2 because of the lack of “pres d[e’]/around”.
Temporally restricted factoid questions: were handled as non restrictedfactoid ones, that is, dates appearing inside questions were considered just likeanother key term. Correct answers were found for at most 12 of these questions.
Definition questions: Results for the definition questions were quite goodamong the 41 definitions, our best run (FR-FR) answered 32 correct plus 1NIL correct (“Linux”/Q0003, the word Linux never appear inside corpora).Among the 5 incorrect answers provided: 2 of them were due to developmenterrors and should have been answered correctly; 1 expected a NIL answer (“T-shirt”/Q0144), and cannot be answered by our approach (which tends to alwaysprovide an answer unless the object to define did not appear inside corpora, itmisses some confidence or validation measure to discard very improbable an-swer); and the last 2 needed more complex resolutions: answers were before orafter a relative clause but they were also separated from the focus by using morethan one punctuation (a dependency tree could have help to provide them).For the 3 inexact definition answers provided: “Boris Becker”/Q0090 is hard todefine without using any anaphora resolution, the string “Boris Becker” neverco-occurs inside a sentence with a pattern “Tennis” (“joueur/player” or “man”)or any “vainqueur/winner”. The 2 others also need to extract a subpart of a rel-ative clause, but the correct corresponding passages were located in the top fivedefinitions selected.
Results for the EN-FR runs were lower (best one was 27 + 1 NIL/41) due totranslation errors.

448 L. Gillard et al.
List questions: Our QAS wrongly classified the 6 list questions4 as factoidquestions and answered with only one answer by question. For our basic FR-FR run, we provided correct answers for 4 questions, and for 3 of these, thejustification contained all other needed correct answers. For our basic EN-FRrun, only 1 correct answer was provided but the justification contained all theother correct instances, the second run found 2 correct answers but justificationsdid not contain other needed instances.
6 Conclusion and Future Works
We have presented the Question Answering system used for our first participa-tion to the QA@CLEF-2006 Evaluation. We participated in monolingual French(FR-FR), and cross-lingual English to French (EN-FR) tracks. Results obtainedwere acceptable with an accuracy of 46% for FR-FR, and 35% for EN-FR.
However, performance can also easily be improved at every step as shownin the detailed analysis of our results. For example, our broken redundancycriterion, by changing order among the top five answers, allowed us to answersome questions that were previously wrongly answered.
Inadequate Named Entities (NE) were also a bottleneck in the processingchain, and many of them should still be added (or improved). To compensatethis known weakness, we tried to include in our system a simple reformulationmodule, notably for the “What/Which (something)” questions. It would havebeen in charge of verifying answers already extracted by the factoid extractionstrategy and, particularly, of completing it when NE was unknown. But our pre-liminary experiments showed us that such question rewriting was tricky. To ouropinion, questions were (intentionally or not) formulated such that it is difficultby changing words order to match an answering sentence (synonyms might helphere). Another problem is, when using the Web to match such reformulation,results obtained are noisy: we experiment it for presidents or events (OlympicGames) but CLEF corpora deals with years 1994 and 1995 whereas Web em-phasizes on recent era.
With an accuracy of 76%, performance on definition questions was quite goodeven if it could still benefit from anaphora resolution. Moreover, our methodologyis mostly language independent as it does not involve any language knowledge(other than detecting appositive mark up, a similar approach was used by [10] toanswer Spanish definition questions). We are interested in improving it in manyways: first, to locate more difficult definitions (as the one we missed); but alsoto choose better qualitative definitions (by combining better statistics), and fi-nally to synthesize these qualitative definitions. For example, “Bill Clinton” wasdefined as an “‘American president”, “Democrat president”, “democrat”, “pres-ident”, he can be best defined as an “American democrat president”. “Airbus”was defined as “European consortium”, or “Aeronautic consortium”, so definingit as a “European Aeronautic consortium” could be even better.4 (4 questions were misclassified by the CLEF staff and are not actual list questions:
Q0133, Q0195, Q099, Q0200).

Relevance Measures for Question Answering, The LIA at QA@CLEF-2006 449
Concerning date and temporally restricted questions, we could not achieve thedevelopment of a complete processing chain, so this is a future work (actually,by the time of the CLEF evaluation, we only have built a module to extract timeconstraints from the question). We also need to complete our post-processing toselect or to synthesize complete date (with the difficulties one can expect forrelative dates).
Lastly, our QAS still misses confidence scores after each pipelined componentsto be able to do: some constraint relaxations (for example on key terms), anyloop back or simply to decide when a NIL answer must be provided.
References
1. Voorhees, E.M.: Chapter 10. Question Answering in TREC. In: Voorhees, E.M.,Harman, D. (eds.) TREC Experiment and Evaluation in Information Retrieval,pp. 233–257. MIT Press, Cambridge, Massachusetts (2005)
2. Gillard, L., Bellot, P., El-Beze, M.: Le LIA a EQueR (campagne Technolangue dessystemes Questions-reponses) In: proceedings of TALN-Recital, vol. 2, pp. 81-84.Dourdan, France (2005)
3. Sekine, S., Sudo, K., Nobata, C.: Extended Named Entity Hierarchy. In: proceed-ings of The Third International Conference on Language Resources and Evaluation(LREC 2002), Las Palmas, Canary Islands, pp. 1818–1824 (2002)
4. Kuhn, R., De Mori, R.: The Application of Semantic Classification Trees to NaturalLanguage Understanding. IEEE Transactions on Pattern Analysis and MachineIntelligence 17, 449–460 (1995)
5. Bechet, F., Nasr, A., Genet, F.: Tagging Unknown Proper Names Using DecisionTrees. In: proceedings of the 38th Annual Meeting of the Association for Compu-tational Linguistics, Hong-Kong, China, pp. 77–84 (2000)
6. Bellot, P., Crestan, E., El-Beze, M., Gillard, L., de Loupy, C.: Coupling NamedEntity Recognition, Vector-Space Model and Knowledge Bases for TREC-11Question-Answering Track. In: proceedings of The Eleventh Text REtrieval Con-ference (TREC 2002) NIST Special Publication, pp. 500–251 (2003)
7. Schmid, H.: Probablistic Part-of-Speech Tagging Using Decision Trees. In: proceed-ings of The First International Conference on New Methods in Natural LanguageProcessing (NemLap-94), Manchester, U.K, pp. 44–49 (1994)
8. Ayache, C., Grau, B., Vilnat, A.: EQueR: the French Evaluation Campaign ofQuestions Answering Systems. In: proceedings of The Fifth International Confer-ence on Language Resources and Evaluation (LREC 2006), Genoa, Italy (2006)
9. Sagot, B., Boullier, P.: From Raw Corpus to Word Lattices: Robust Pre-parsingProcessing with SxPipe. Special Issue on Human Language Technologies as a Chal-lenge for Computer Science and Linguistics, Archives of Control Sciences 15, 653–662 (2005)
10. Ferres, D., Kanaan, S., Gonzalez, E., Ageno, A., Rodrıguez, H., Turmo, J.: TheTALP-QA System for Spanish at CLEF-2005. In: Peters, C., Gey, F.C., Gonzalo,J., Muller, H., Jones, G.J.F., Kluck, M., Magnini, B., de Rijke, M., Giampiccolo,D. (eds.) CLEF 2005. LNCS, vol. 4022, Springer, Heidelberg (2006)