regresyon analizi
TRANSCRIPT

Regresyon analiziBağımlı ve bağımsız değişken ve değişkenler arası ilişkileri araştıran bir testtir. Regresyon analizi iki değişken arasında sebep – sonuç ilişkisini ararken, sebep – sonuç ilişkisini ortaya çıkarmaz. Sadece iki değişken arasında bir birlikteliğin olduğunu gösterir. Mesela, pazarlamada personel sayısı ile satışlar arasında bir sebep – sonuç ilişkisi arayabiliriz. Bu ilişkinin varlığı ispatlanırsa, personel sayısı arttıkça, satışlarında artacağı anlamına gelmez. Bu durum sadece iki değişken arasında bir birlikteliğin olduğunu gösterir.

Regresyon analizi şu sorulara cevap arar
• Bağımlı ve bağımsız değişken arasında bir ilişki var mı?
• Söz konusu bu ilişkinin matematiksel olarak yapısı ve formu nasıldır? Doğrusal mı, eğrisel mi?
• Bağımlı değişkenin tahmini değerleri nelerdir?
• Bağımsız değişkene gözlem dışı bir değer verildiğinde, bağımlı değişkenin değeri ne olur?
• Belli bir değişken ya da değişkenler setinin katkılarını değerlendirirken, diğer bağımsız değişkenler kontrol edilebilir mi?

Basit Doğrusal Regresyon Analizi
• Regresyon analizi iki değişken arasındaki nedensellik ilişkisinin var olup olmadığını değil, iki değişken arasındaki birlikteliğin var olup olmadığını verir.
• Regresyon analizi iki değişken arasında fonksiyonel bir ilişkiyi açıklar. Böyle bir ilişkide bağımsız değişken X ile bağımlı değişken Y ile ifade edilirse, iki değişken arasındaki fonksiyonel ilişki;
• Y = f (X) şeklinde yazılabilir.

Basit Doğrusal Regresyon Analizinin Aşamaları
Serpilme diyagramının çizilmesiModelin kurulmasıParametrelerin tahminiStandard regresyon katsayılarının tahmini
Anlamlılık testi Birliktelik anlamlılığının belirlenmesiTahminin doğruluğunun test edilmesiTüm olarak modelin testiModelin yorumlanması

• X’e verilen Xi gibi bir değer yerine konulursa Y tahmin edilebilir. Bunu doğrusal bir fonksiyon olarak görmek istersek,
• f(X) = β0+ β1Xi
• Bu denklemde f(X) = Y olduğuna göre β0 bir sabit olup, X = 0 iken regresyon doğrusunun Y ekseni üzerindeki başlangıç noktasıdır.
• β1 değeri ise Y’nin eğimini gösterir.
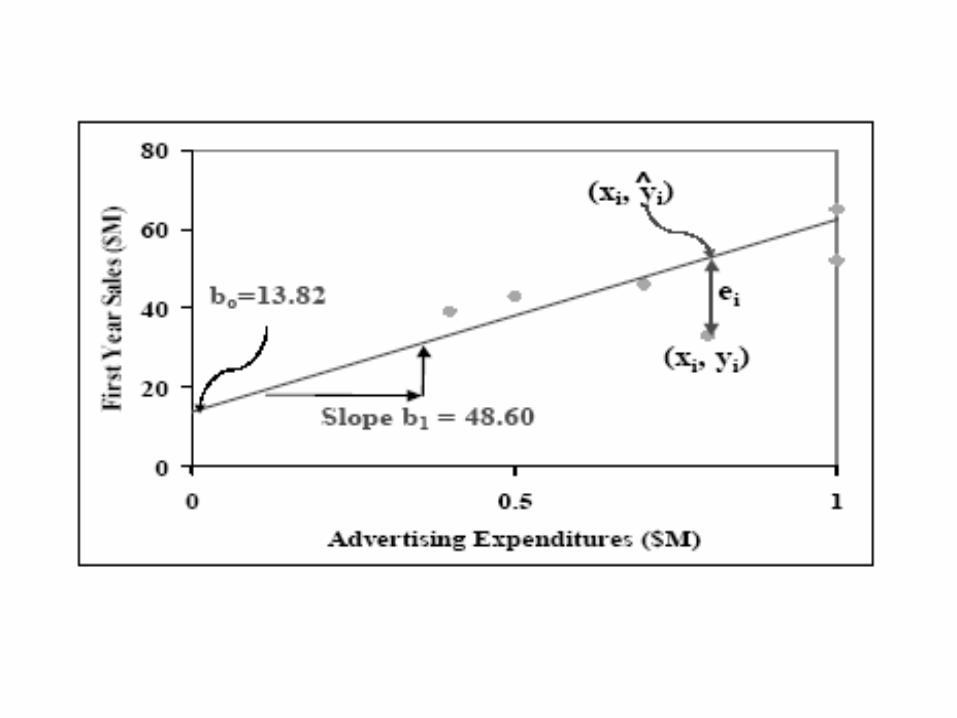

• Regresyon doğrusu tahmini bir doğru olup, gerçek gözlemler bu doğrunun tam üstüne, yukarısına ya da altına düşebilir. Gözlemler, doğrunun tam üstüne düşmesi halinde mutlak doğru tahmini söz konusu olabilir.
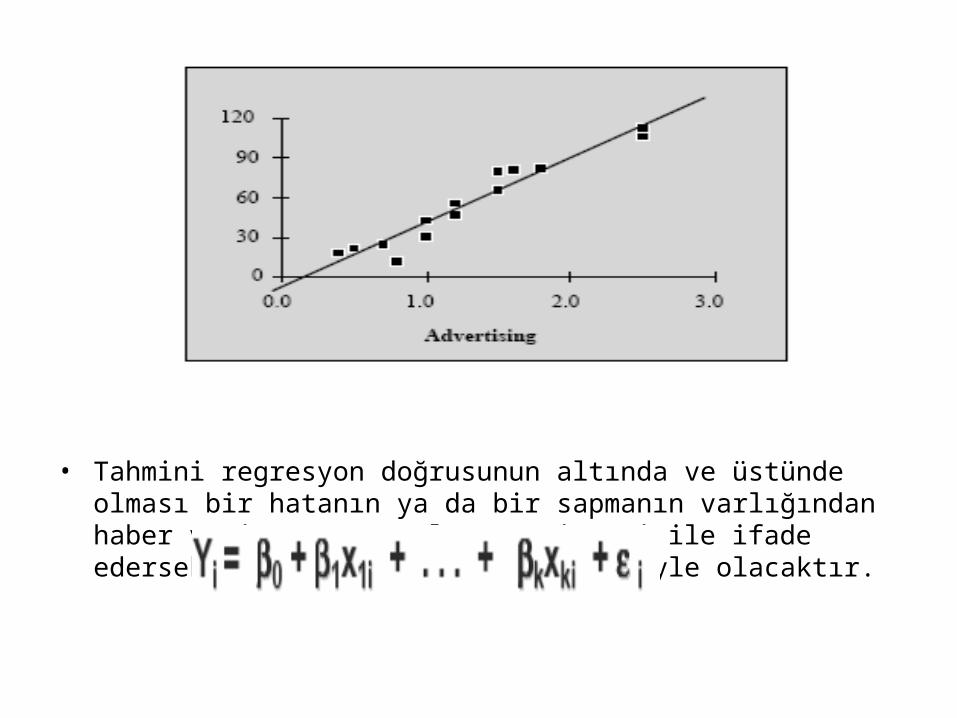
• Tahmini regresyon doğrusunun altında ve üstünde olması bir hatanın ya da bir sapmanın varlığından haber verir. Bu sapmaları Є simgesi ile ifade edersek, regresyon fonksiyonumuz şöyle olacaktır.
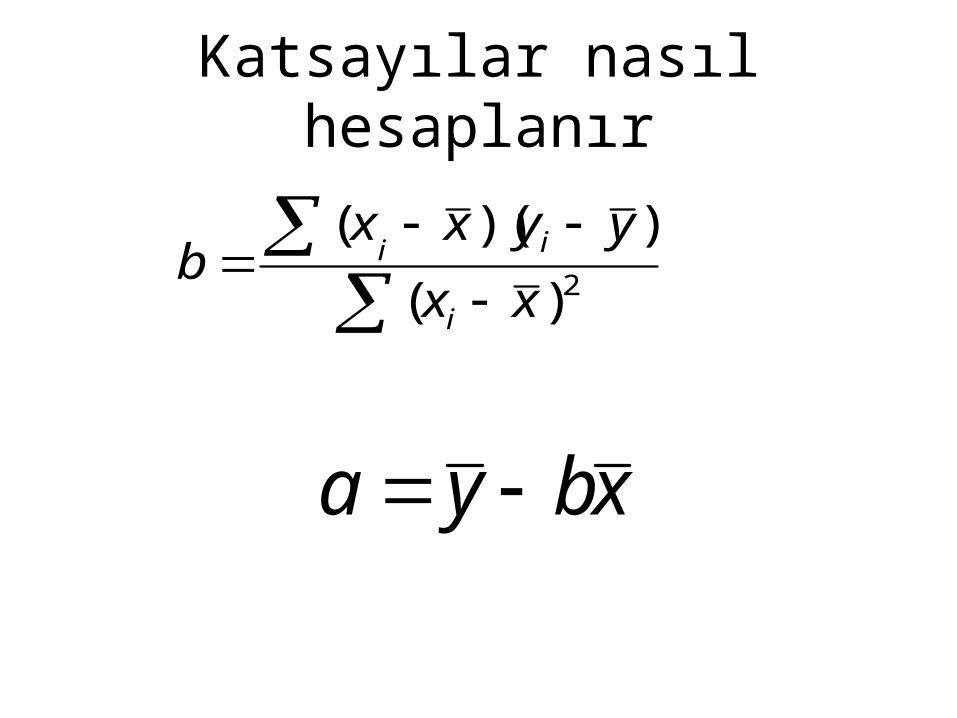
Katsayılar nasıl hesaplanır
2)(
))((xx
yyxxb
i
ii
xbya

Katsayıların Yorumlanması
• Eğer hiçbir iş yapmazsak yani x=0 olduğu durumda y = a olacaktır ki bu bizim serpme diyagramımızın y eksenini kestiği noktadır.
• b parametresinin katsayısı eğimi gösterir, b deki bir birimlik artışın y de kaç birimlik bir değişime yol açabileceği bilgisini verir.
• b katsayısının işareti bağımlı ve bağımsız değişken arasındaki ilişkinin yönü hakkında bilgi verir.
• Gözlemler arasında bulunmayan bir x değeri denklemde yerine konularak y’yi tahmin edebiliriz.
bxay

• Regresyon doğrusu tahmini bir doğru olduğu için, doğru üzerindeki sapmalarda birer tahmin olup, bu noktaların hatasını göstermektedir. Her nokta için ayrı ayrı “ê” değeri hesaplanabilir. Bütün gözlemler için hesaplandığında, hatâ kareler toplamı (SSR) elde edilir.

Hata kareler toplamı (SSR)
• Her bir nokta için hesaplama yapmak için: y1 – a – bx1= ê1 formülü kullanılacaktır.
• Hata kareler toplamı hesaplanmak istendiğinde ise;

• Doğrusal regresyon denkleminin katsayılarını da aşağıdaki formüllerle hesaplamak mümkündür.
• b = (x∑ i – x) / (x∑ i – x)2
• a = - bx• Bu matematiksel fonksiyonlar sonucunda elde edilen bulguların yorumlanması ise şu şekilde olacaktır.

• Hata terimi “e” her gözlem için ayrı ayrı hesaplanmalıdır. Bunun içinde
• ei = formülünden yararlanılacaktır.
• Bu maksatla ilk başta hesaplamamız gereken ŷ’leri yani her bir bağımsız gözlem için tahmini bağımlı değişkenin alabileceği değerler hesaplanır. Sonra da hatayı (e) leri ve hatanın kareleri toplamını hesaplamak mümkün olacaktır.
• Hata ile ilgili varsayımlar ise; y∑ i = ∑ŷ sağlanmalıdır. Bu eşitlik sağlandığı taktirde ikinci varsayım olan e∑ i=(yi - ŷ) = 0 eşitliği de sağlanmış olacaktır. Ayrıca her bir gözlem için hesaplanan (e) değeri tahmini regresyon doğrusuna ne kadar yaklaşılıp uzaklaşıldığını da bize gösterecektir.

• Bir istatistiksel işlem hata içeriyorsa orada standart sapma ve varyans da var demektir. Regresyon analizinde iki tür varyans vardır. İlki modelin toplam varyansı, ikincisi de parametrelerin varyansıdır. Kuşkusuz bu varyanslar da tahmini olup örnek gözlemlerden hesaplanırlar.
• = 1/ (n-m)

• a =( /n) x∑ i2/ (x∑ i-x)2
• b = / (x∑ i-x)2
• Formülde yer alan (n) gözlem sayısını (m) ise değişken sayısını göstermektedir.

Determinasyon katsayısı• Regresyon doğrusunun gözlemlere ne denli uyduğunu ortaya koyan göstergelerden biri determinasyon (belirlilik) katsayısıdır. Bu katsayı aynı zamanda, bağımlı değişkendeki değişmelerin yüzde kaçının bağımlı değişken ya da değişkenler tarafından açıklandığını gösterir. Determinasyon katsayısı 0 ile 1 arasında pozitif bir değer olup, korelasyonun karesidir. Determinasyon katsayısından hareketle regresyon modelinin bir bütün olarak geçerliliğini de test etmek mümkündür.

• Gözlenen yi değerlerinin ortalama y değerinden farklarının kareleri toplamına “kareler toplamı” denir ve şu şekilde hesaplanır.
• SST(y,y)= ∑(yi – y)2
• Regresyon doğrusunun gözlemlere uygunluğu yükseldikçe hata kareler toplamı küçülür. Bütün gözlenen değerler tahmini regresyon doğrusu üzerinde olsaydı hata kareler toplamı 0 olurdu.
• Bir regresyon denkleminin başarısı açıklana bilen bağımlı değişkenin büyüklüğüne diğer bir ifadeyle determinasyon katsayısının büyüklüğü ile yakından ilgilidir.

Determinasyon katsayısının hesaplanması
• R2= ∑(ŷi – y)2/ [∑(ŷi – y)2 +∑(yi – ŷi)2]• R2= 1- [∑(yi – ŷi)2 / [∑(ŷi – y)2 +∑(yi – ŷi)2]• R2= 1- [∑(yi – ŷi)2 / ∑(ŷi – y)2]• Bütün gözlemler regresyon doğrusu üzerinde olursa R2 = 1 olur. Regresyon doğrusu, gözlemleri temsil etmekten uzaklaştıkça R2 de küçülür.
• R2 değeri bağımlı değişkenin ne kadarının bağımsız değişkenler tarafından açıklandığını gösterirken 1- R2 değeri ise modelde yer almayan diğer bağımsız değişkenlerce açıklanan kısmı vermektedir.

• Önemli olan R2 değeridir. Bazı istatistikçiler determinasyon katsayısını daha da güvenilir hale getirmek için düzeltilmiş şeklini kullanmaktadırlar.
• R2= 1- [∑(yi – ŷi)2 /(n – m)] / [∑(ŷi – y)2 +∑(yi – ŷi)2/ (n – m)]

• Regresyon denkleminde açıklayıcı (bağımsız) değişken sayısı arttıkça determinasyon katsayısı sürekli artış gösterir. Bu da yanıltıcı olabilir. Bu yüzden düzeltilmiş regresyon katsayısına başvurmak gerekir. Çünkü, düzeltilmiş determinasyon katsayısında bağımsız değişkenler arttıkça düşüş gösterebilir.

• Determinasyon katsayısından hareketle bir bütün olarak regresyon denkleminin geçerliğini test etmemiz mümkündür. Bunun içinde F testi uygulanır.
• F testinin hesaplanmasında • F = R2 (n – 2) / 1 – R2 şeklinde hesaplanır.
SPSS UYGULAMASI
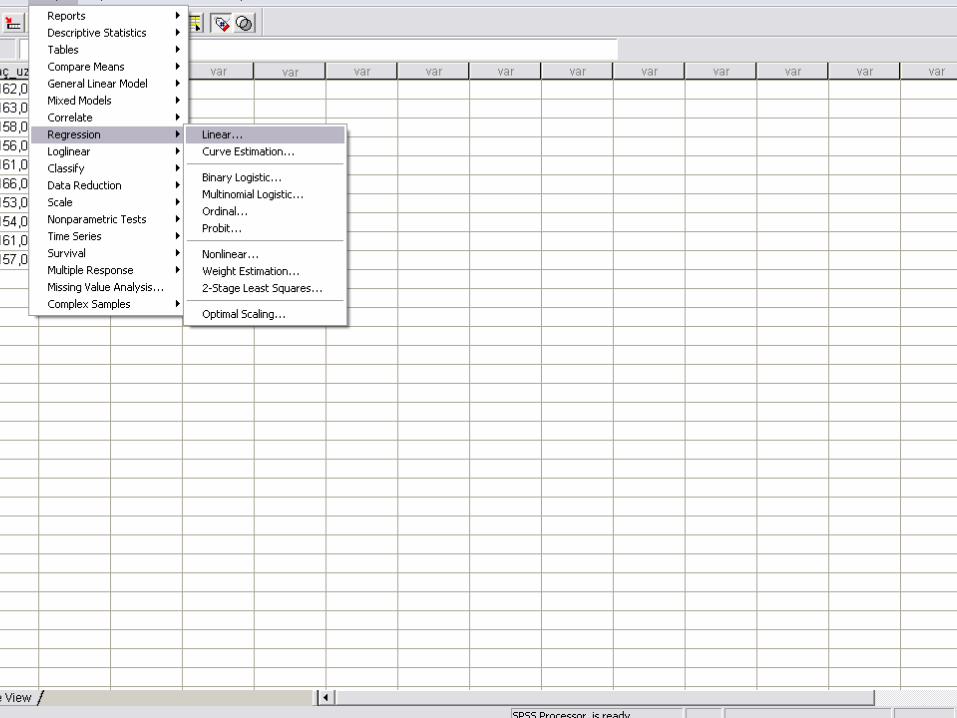
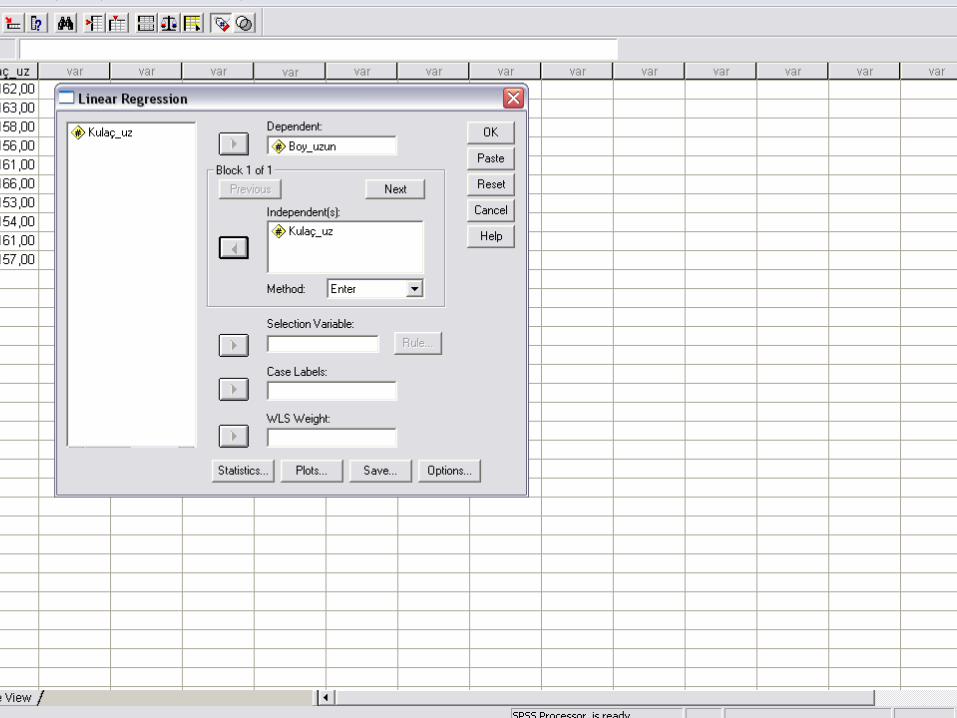
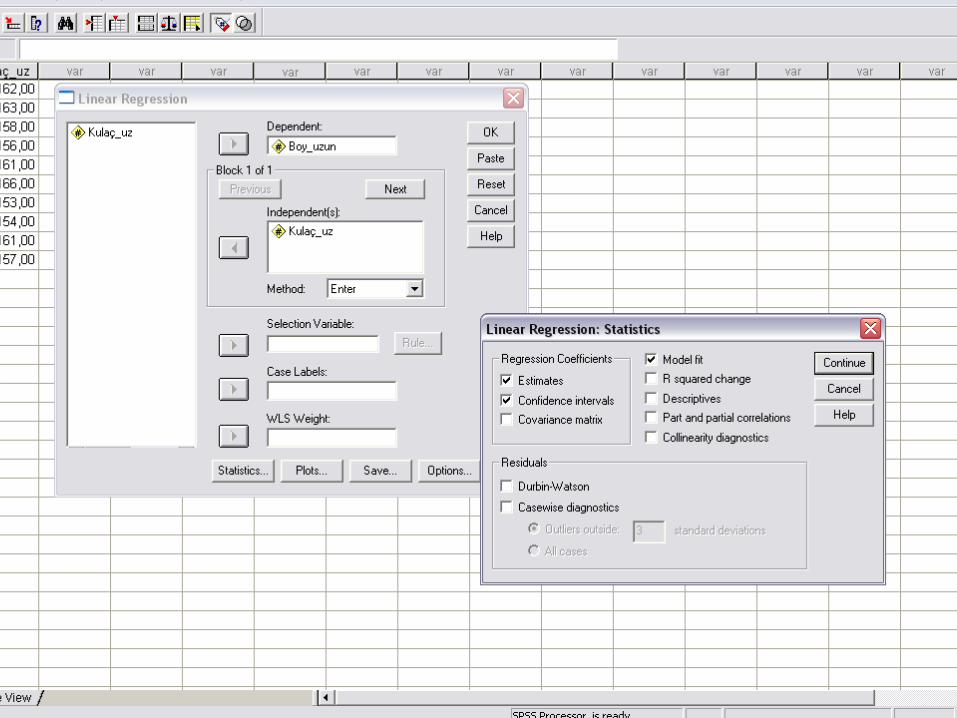
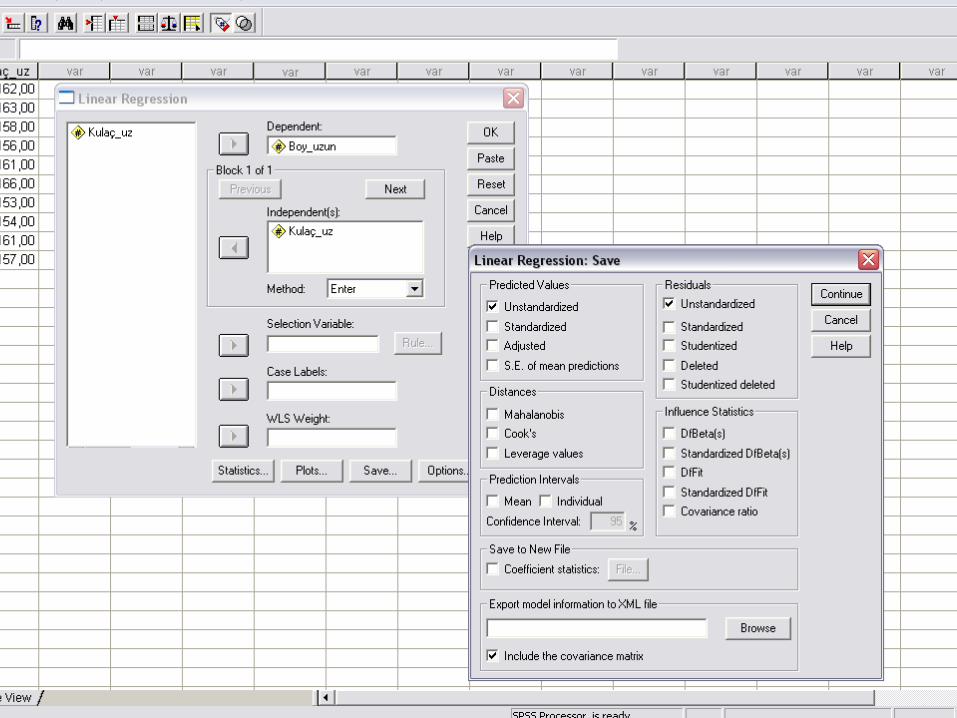
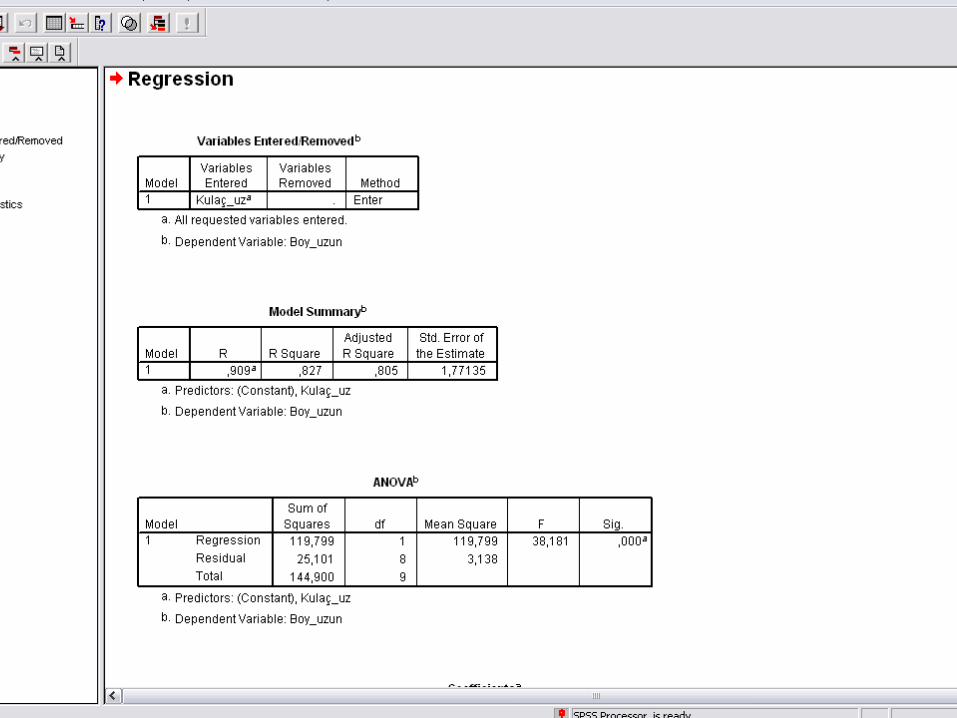
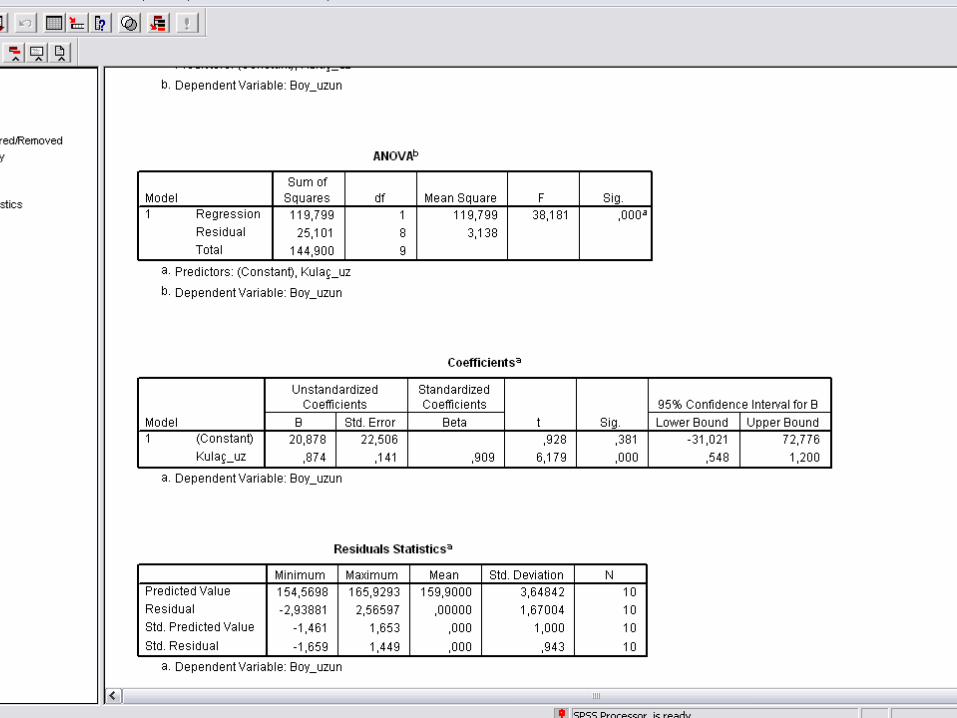
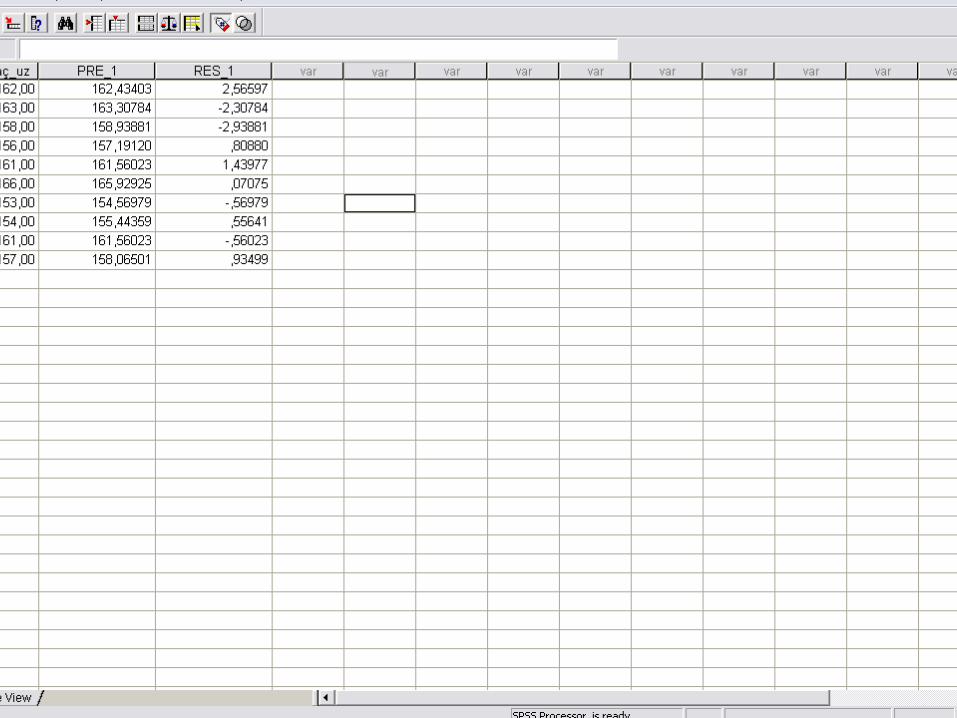

Örnek I• Bir işletmeye ait 6 yıllık satışları ile tutundurma harcamaları ile ilgili verilere sahibiz. Bu işletmenin satışları ve tutundurma harcamaları arasında anlamlı bir ilişki var mıdır?
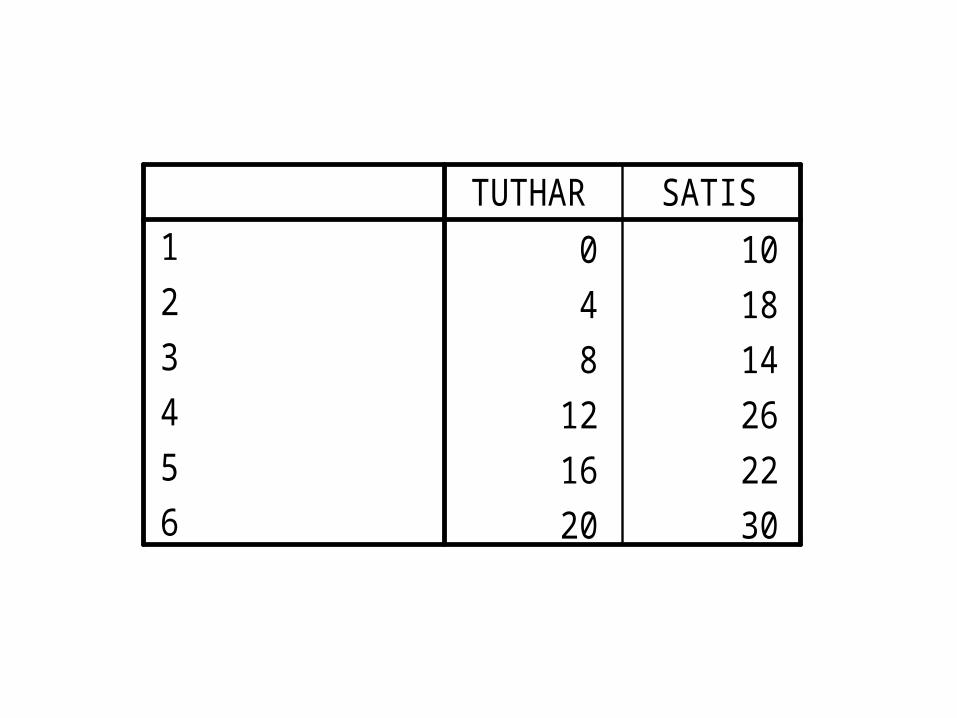
0 104 188 14
12 2616 2220 30
123456
TUTHAR SATIS
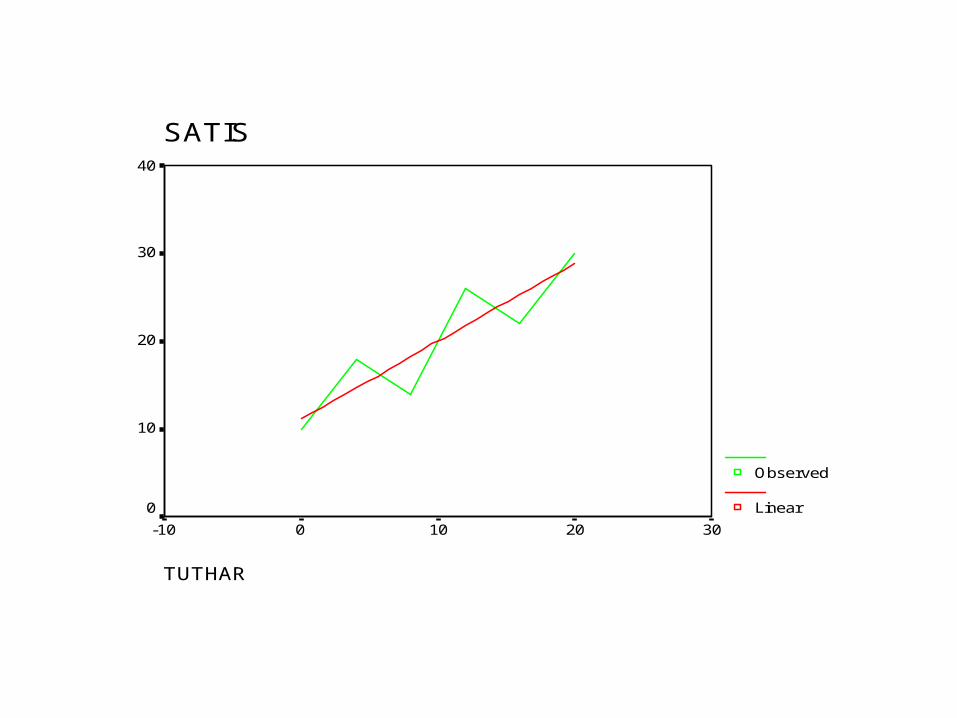
SATIS
TUTHAR
3020100-10
40
30
20
10
0
Observed
Linear
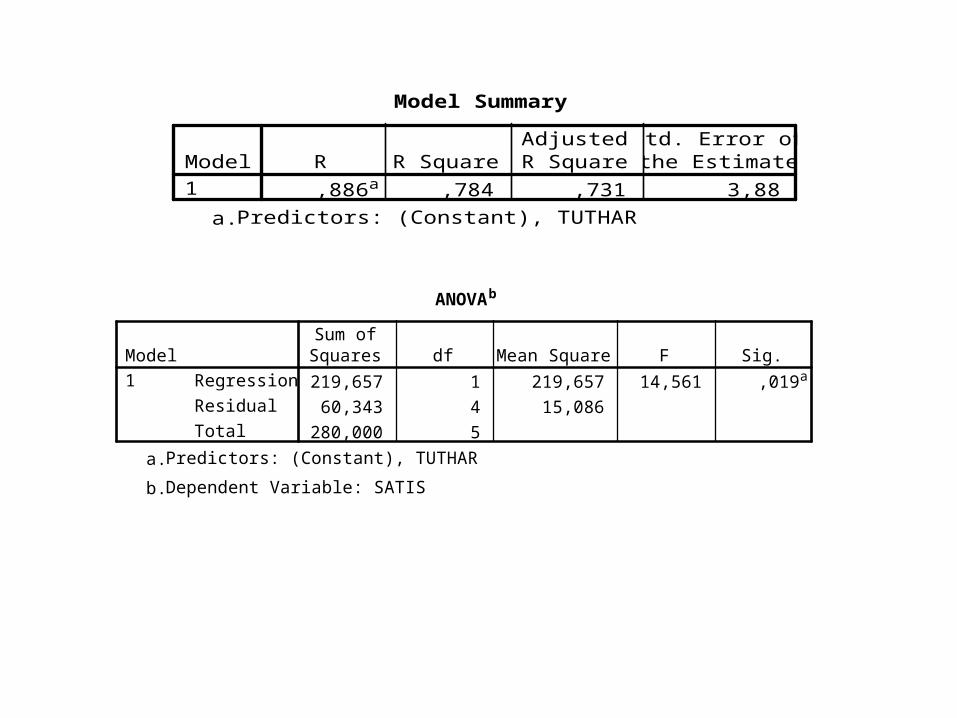
Model Summary
,886a ,784 ,731 3,88Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), TUTHARa.
ANOVAb
219,657 1 219,657 14,561 ,019a60,343 4 15,086
280,000 5
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), TUTHARa. Dependent Variable: SATISb.
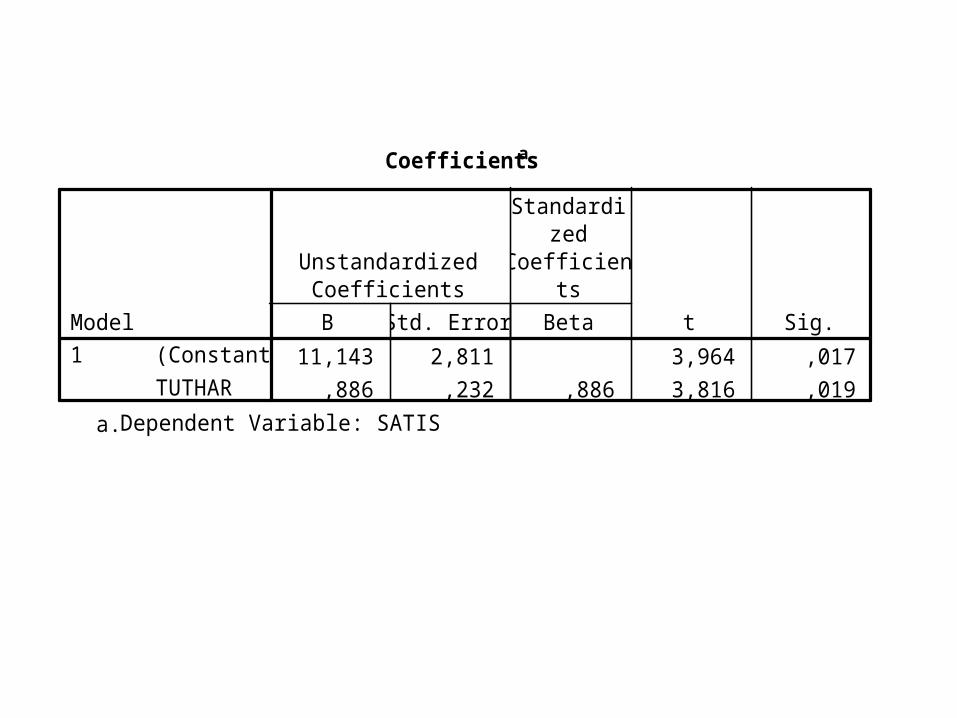
Coefficientsa
11,143 2,811 3,964 ,017,886 ,232 ,886 3,816 ,019
(Constant)TUTHAR
Model1
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: SATISa.

Örnek II• 20 orta kademe yöneticisine daha verimli çalışma yapabilmeleri için bir “etkili yönetim semineri” verilmiştir. Seminerden 24 ve 48 gün sonra söz konusu bu yöneticilere, sorumlu olduğu personeli en uygun ve verimli çalıştırma, zamanında ve doğru karar verme, vb. konularda puanlar verilmiştir. 24 günlük puanları ile 48 günlük puanları arasında anlamlı bir ilişki var mıdır?
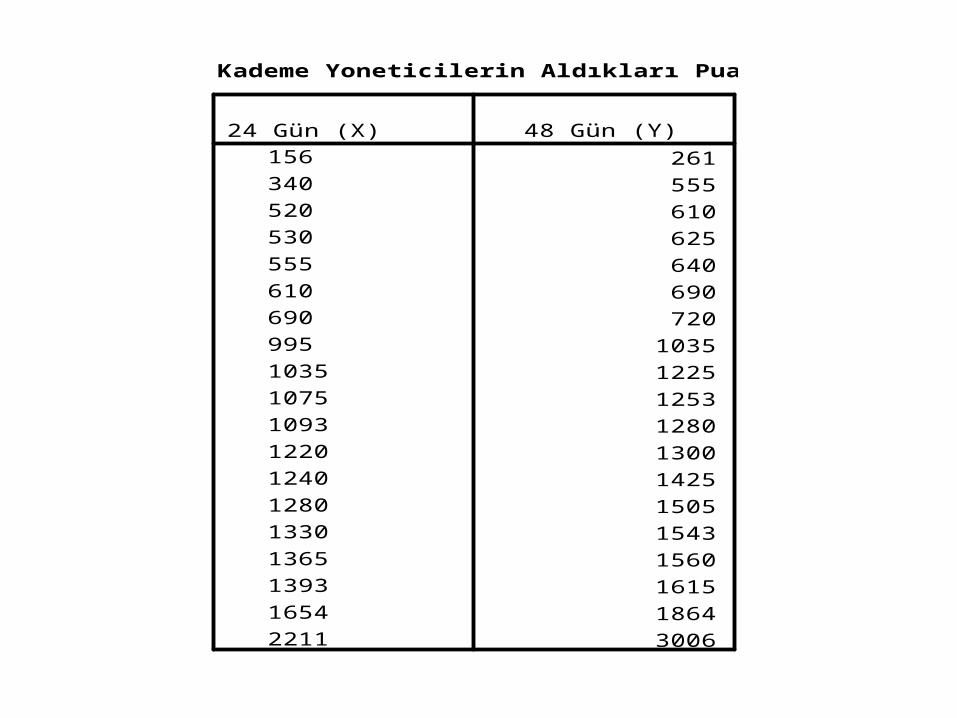
Orta Kademe Yoneticilerin Aldıkları Puanlar
261555610625640690720
103512251253128013001425150515431560161518643006
24 Gün (X)15634052053055561069099510351075109312201240128013301365139316542211
48 Gün (Y)

Hipotezlerin Belirlenmesi
• H0: Orta kademe yöneticilerin 24 gün sonunda aldıkları puanlarla 48 gün sonra aldıkları puanlar arasında anlamlı bir ilişki yoktur.
• H1: Orta kademe yöneticilerin 24 gün sonunda aldıkları puanlarla 48 gün sonra aldıkları puanlar arasında anlamlı bir ilişki vardır.
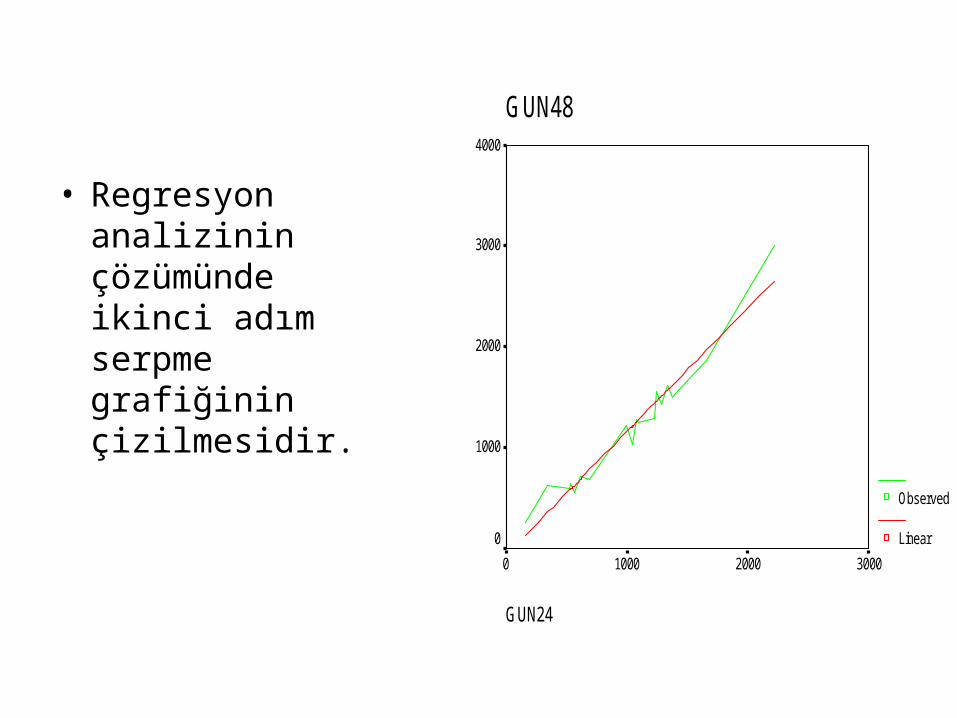
• Regresyon analizinin çözümünde ikinci adım serpme grafiğinin çizilmesidir.
G UN48
G UN24
3000200010000
4000
3000
2000
1000
0
Observed
Linear

• Serpme grafiği bize hem doğrusal bir ilişkinin olup olmadığını hem de mutlak doğru tahminin yapılıp yapılmadığını göstermektedir.
Variables Entered/Removedb
GUN24 a , EnterModel1
VariablesEntered
VariablesRemoved Method
All requested variables entered.a. Dependent Variable: GUN48b.

R regresyon değerini vermektedir. Değer 1 çok yakın olduğu için ilişkinin güçlü olduğu yani, 48 günlük başarı puanları ile 24 günlük başarı puanları arasında bir illiyet ilişkisinin varlığından bahsedilebilir. Yukarıdaki tablo bunun yanı sıra, R Suquare başlığı altında determinasyon katsayısını vermiştir. Bu sonuç bağımlı değişkenimizi elimizdeki bağımlı değişkenin açıklama gücü hakkında bilgi vermektedir. Çoklu regresyonda daha çok işimize yaramasına rağmen burada da düzeltilmiş determinasyon katsayısına bakmakta fayda vardır. Bu katsayı bağımsız değişken sayısından çok fazla etkilenmemektedir.
Model Summary
,974a ,948 ,945 143,34Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), GUN24a.

• Model Summary tablosundaki son sütunda yer alan tahmin edilen standart hata bize modelin toplam standart sapmasını vermektedir. ANOVAb
6747484 1 6747483,602 328,410 ,000a369826,9 18 20545,9427117311 19
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), GUN24a. Dependent Variable: GUN48b.

• ANOVA tablosu bize determinasyon katsayısına bağlı olarak regresyon denkleminin geçerliliği ile ilgili bilgi vermektedir. Bunun içinde F testi sonucuna bakmak gerekir. F testi sonucuna göre H1 hipotezimizin kabul edilmesi gerektiği değişkenlerimiz arasında bir ilişkinin var olduğu söylenebilir.
• Bu ilişkide ki hata kareler toplamını ise Residual satırındaki kareler toplamı sütunu vermektedir.

• y = f (x) fonksiyonunda hareketle oluşturulacak matematiksel regresyon denklemimizi oluşturduğumuzda ise,
• y = a + bx denklemini oluşturan parametrelerimizin belirlenmesinde Coefficient tablosundan faydalanmamız gerekmektedir. Coefficientsa
-52,776 75,566 -,698 ,4941,220 ,067 ,974 18,122 ,000
(Constant)GUN24
Model1
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: GUN48a.

• Tabloda yer alan constant a sabit parametremizin değerini verirken, gün 24 satırında yer alan B sütunundaki değer ise bize denklemin eğimini vermektedir. Her iki parametrenin birlikte anlamlı çıkması arzu edilen bir durumdur. Ancak, sonuç her zaman böyle çıkmayabilir. F testi anlamlı çıktığında genelde b katsayısının da anlamlı çıkması beklenir. b katsayısı anlamlı ise direkt olarak F testinin anlamlılık durumuna bakılır. Şayet o da anlamlı ise, bu takdirde modelin anlamlı olduğu kabul edilir. Anlamsız ise model ret edilir.
• Buna bağlı olarak da bağımsız değişkenin, bağımlı değişkendeki değişmeleri açıklamadığı kabul edilir.
• Buradan hareketle de b katsayısının geçerliliğinin a katsayısının geçerliliğinden daha önemli olduğu söylenebilir.

Örnek III• 12 satış bölgesi olan bir ilaç firmasının bölgeler itibariyle satışları ve her bölgede çalışan eleman sayısı ile o bölgede kullanılan araba sayıları aşağıda verilmiştir. Bu bölgeler itibariyle satışlar ile eleman sayısı ve elemanların kullandığı satış arabası sayısı arasında anlamlı bir ilişki var mıdır?
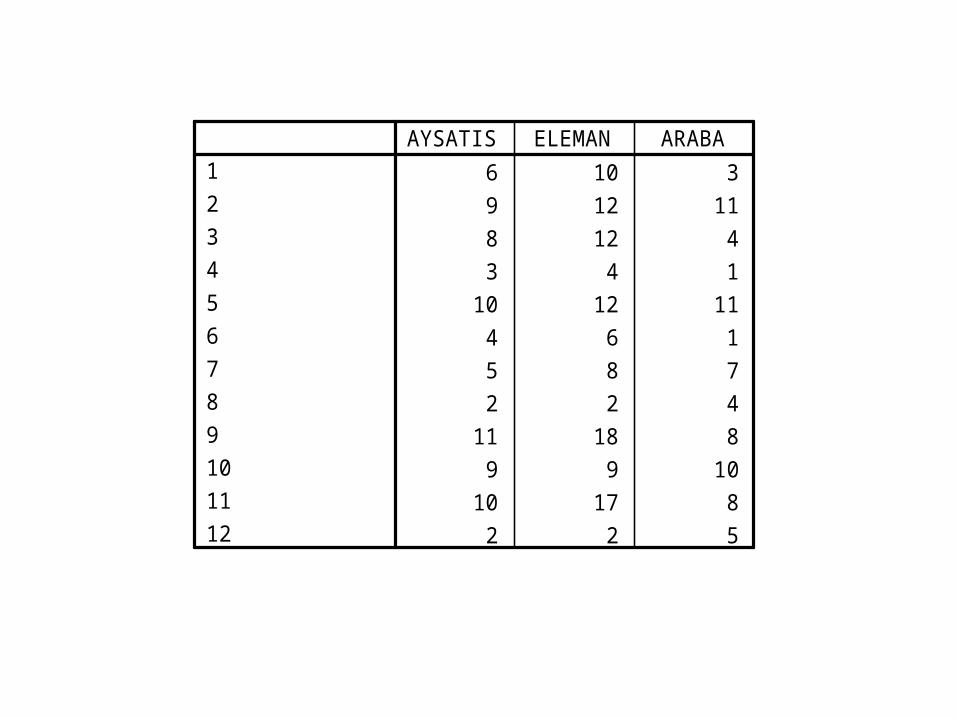
6 10 39 12 118 12 43 4 1
10 12 114 6 15 8 72 2 4
11 18 89 9 10
10 17 82 2 5
123456789101112
AYSATIS ELEMAN ARABA
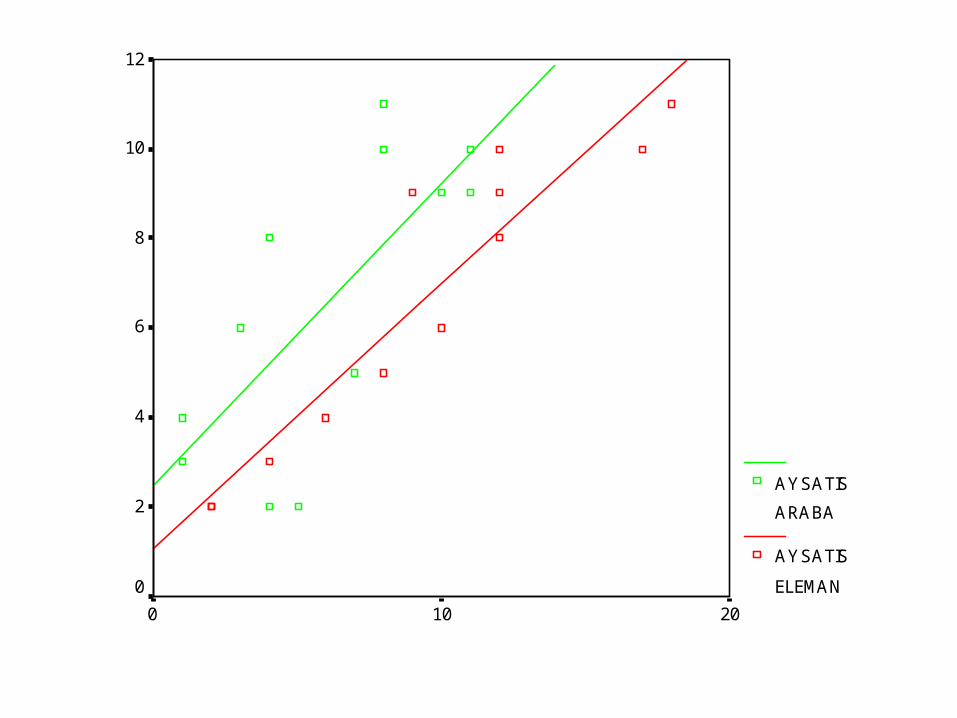
20100
12
10
8
6
4
2
0
AYSATISARABA
AYSATISELEMAN
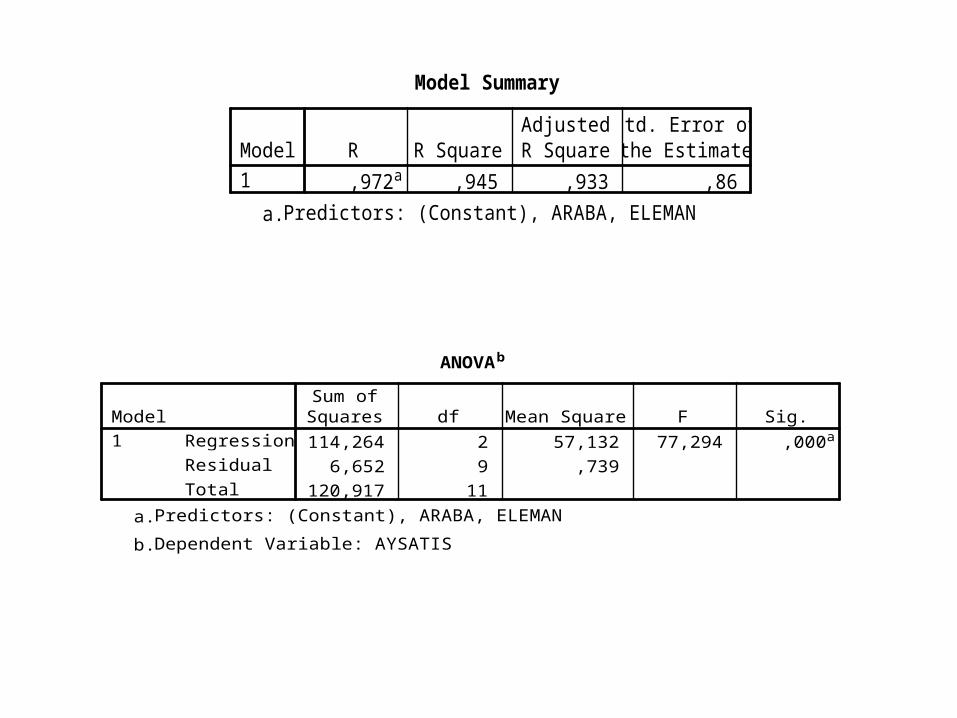
Model Summary
,972a ,945 ,933 ,86Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), ARABA, ELEMANa.
ANOVAb
114,264 2 57,132 77,294 ,000a6,652 9 ,739
120,917 11
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), ARABA, ELEMANa. Dependent Variable: AYSATISb.
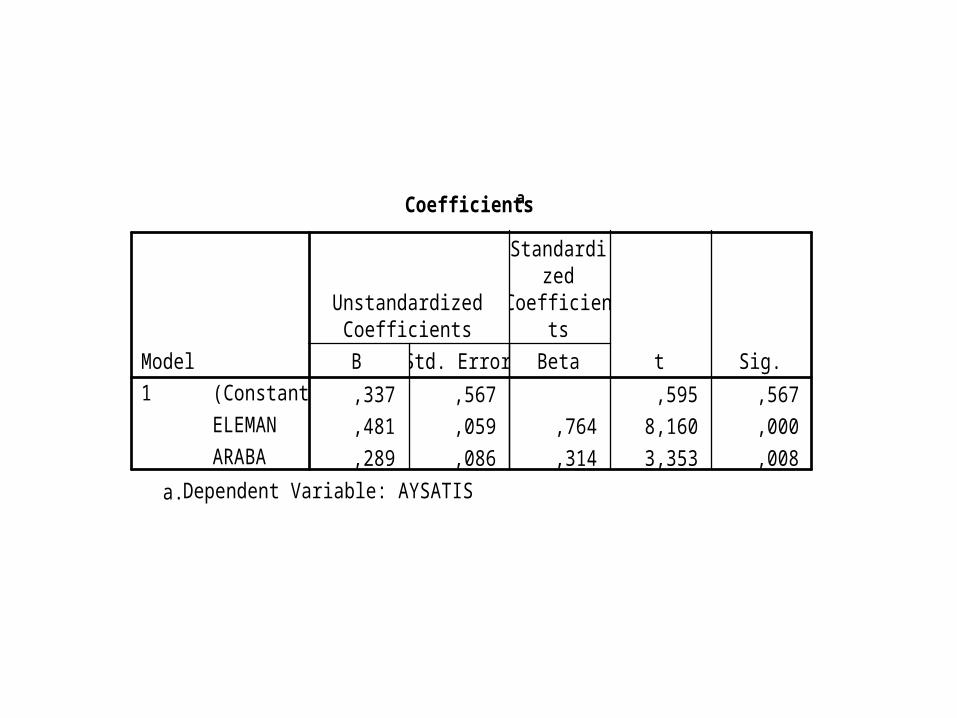
Coefficientsa
,337 ,567 ,595 ,567,481 ,059 ,764 8,160 ,000,289 ,086 ,314 3,353 ,008
(Constant)ELEMANARABA
Model1
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: AYSATISa.

Soru • Yukarıda verilen regresyon çıktılarından ve örnekten hareketle matematiksel regresyon fonksiyonunu yazarak, 20 eleman ve 12 satış arabasıyla ulaşılabilecek aylık satış miktarını hesaplayınız.

Örnek IV• İşletme II sınıf öğrencilerin istatistik dersi başarı durumları 20 puan üzerinden değerlendirilmiştir. Bu değerleme yapılırken öğrencilerin motivasyon durumları ve heyecanları da ölçülmüştür. Öğrencilerin başarıları ile motivasyon ve heyecan durumları arasında anlamlı bir ilişki var mıdır?
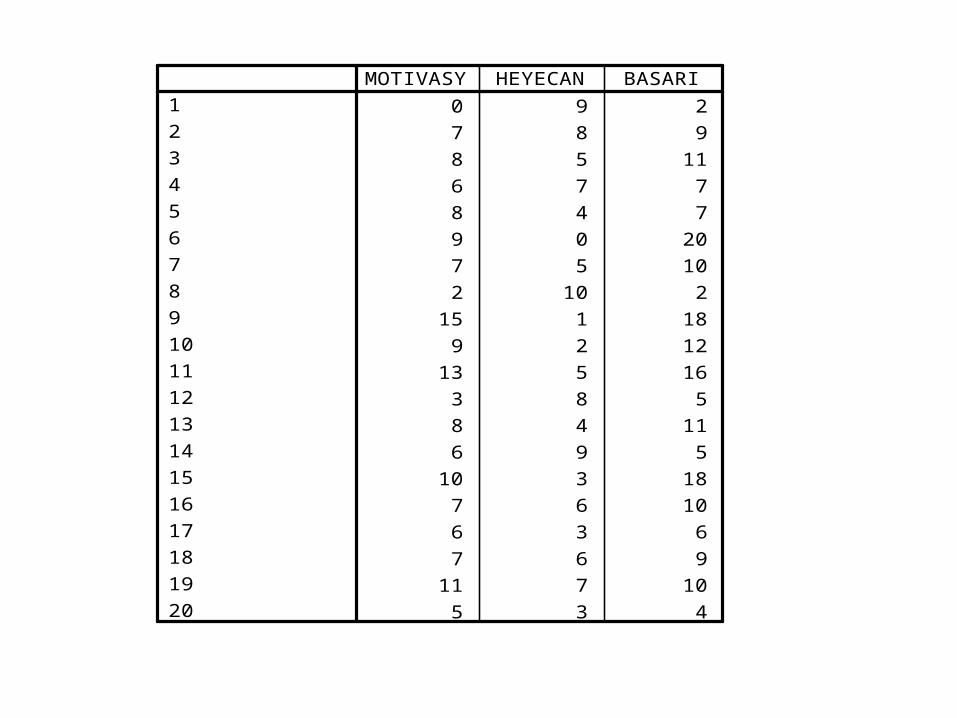
0 9 27 8 98 5 116 7 78 4 79 0 207 5 102 10 2
15 1 189 2 12
13 5 163 8 58 4 116 9 5
10 3 187 6 106 3 67 6 9
11 7 105 3 4
1234567891011121314151617181920
MOTIVASY HEYECAN BASARI
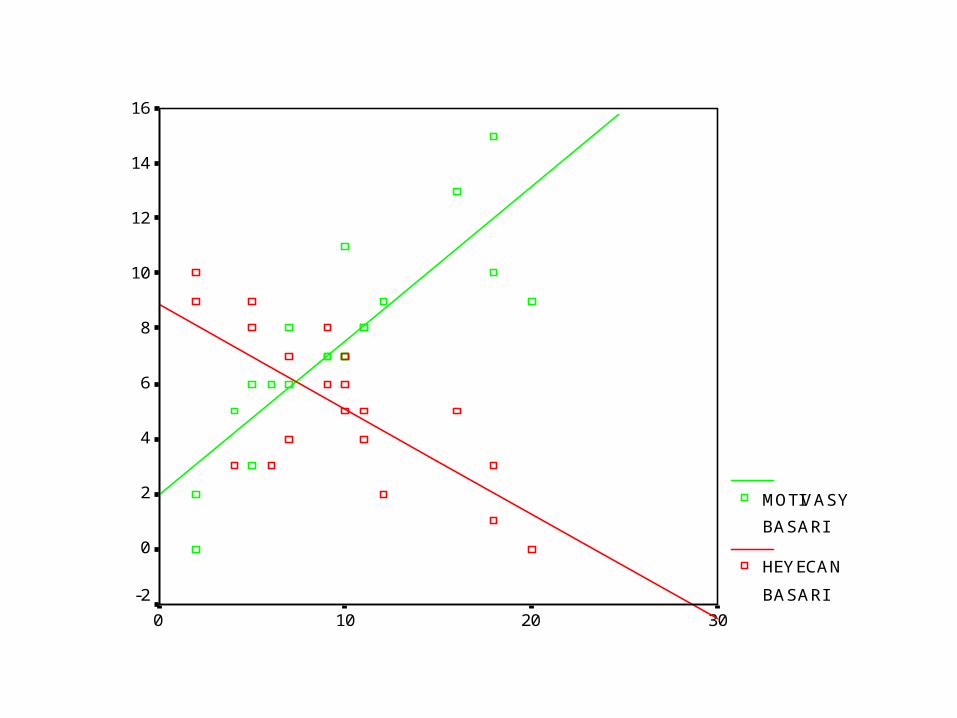
3020100
16
14
12
10
8
6
4
2
0
-2
MOTIVASYBASARI
HEYECANBASARI
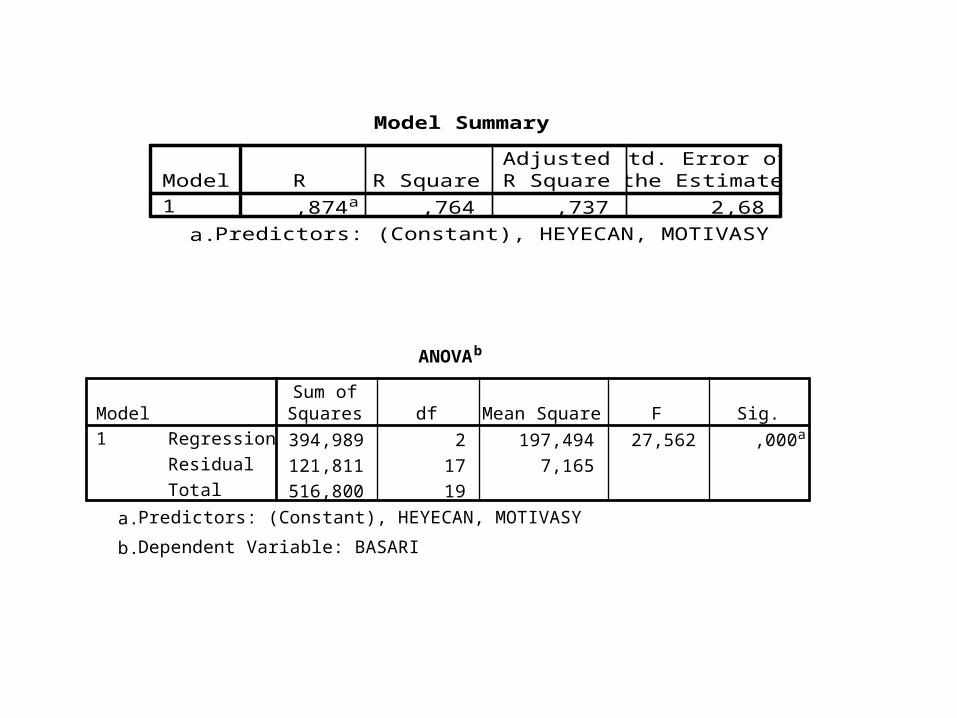
Model Summary
,874a ,764 ,737 2,68Model1
R R SquareAdjustedR Square
Std. Error ofthe Estimate
Predictors: (Constant), HEYECAN, MOTIVASYa.
ANOVAb
394,989 2 197,494 27,562 ,000a121,811 17 7,165516,800 19
RegressionResidualTotal
Model1
Sum ofSquares df Mean Square F Sig.
Predictors: (Constant), HEYECAN, MOTIVASYa. Dependent Variable: BASARIb.
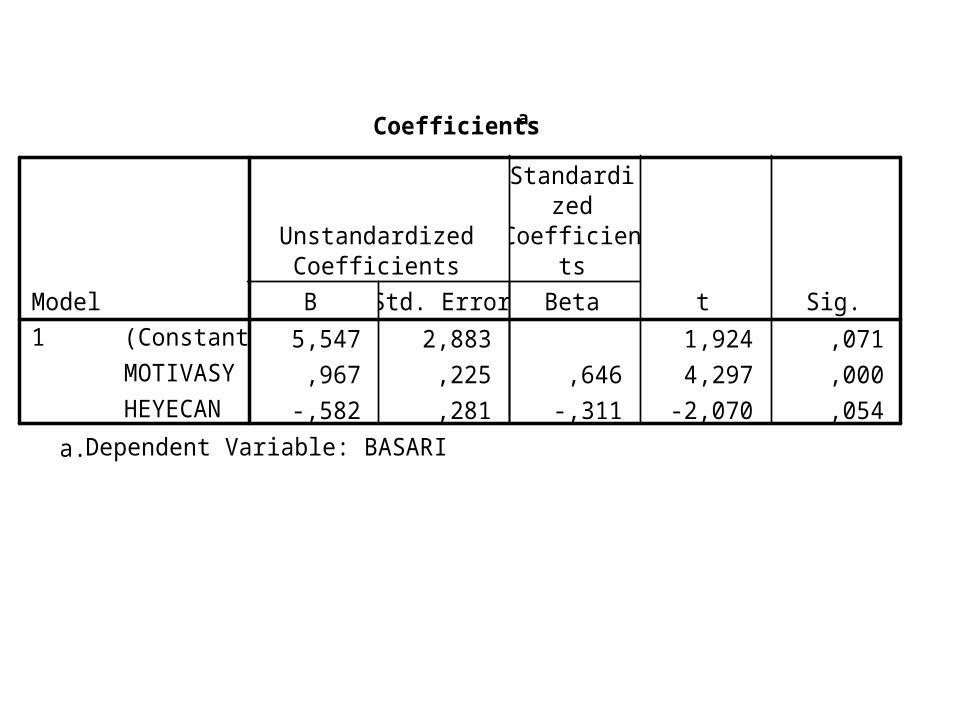
Coefficientsa
5,547 2,883 1,924 ,071,967 ,225 ,646 4,297 ,000
-,582 ,281 -,311 -2,070 ,054
(Constant)MOTIVASYHEYECAN
Model1
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: BASARIa.