on query execution over encrypted data
TRANSCRIPT

SECURITY AND COMMUNICATION NETWORKSSecurity Comm. Networks (2014)
Published online in Wiley Online Library (wileyonlinelibrary.com). DOI: 10.1002/sec.982
RESEARCH ARTICLE
On query execution over encrypted dataTinu Baby and Aswani Kumar Cherukuri*
School of Information Technology and Engineering, VIT University, Vellore, 632014, India
ABSTRACT
To ensure the confidentiality of the encrypted data in a database-as-a-service model, the sensitive data need to be encrypted.When this encrypted data are queried, complete record has to be decrypted to fetch the actual results. This paper is concentratingon improving the performance of different query operations, that is, non-aggregate, aggregate, and user-defined queryoperations on encrypted data. The performance of these query operations over the encrypted data is compared with that ofthe available methods in terms of the execution time, and it is found that the efficiency of the proposed approach is better thanthat of the traditional approach. Effectiveness of different types of non-aggregate query operations is identified in terms of filterratio and false ratio. The analysis has shown that the filter ratio increases and the false ratio decreases with increase in size ofsensitive string and the reachability matrix generated for non-aggregate attribute. Copyright © 2014 John Wiley & Sons, Ltd.
KEYWORDS
cloud computing; encryption; query translation; reachability matrix
*Correspondence
Aswani Kumar Cherukuri, School of Information Technology and Engineering, VIT University, Vellore 632014, India.E-mail: [email protected]
1. INTRODUCTION
Data in the enterprise keep increasing day by day, and hence,an efficient data management system is also becoming a ma-jor requirement. Installing the database management systemin each and every computer increases the storage andmaintenance cost. Hence, the data are being stored, accessed,andmaintained at the server’s database [1], instead of doing itin each and every client’s databases. This makes it possiblefor the client to store, retrieve, and modify data stored at theserver through the Internet and thereby reducing the overallcost at the client’s side. This scenario can be applied in acloud as database-as-a-service model [2]. But maintainingthe sensitivity of such data is a critical issue. Hence, the datashould be stored in encrypted format at a non-trusted server inthe service provider’s site to ensure privacy. In this scenario,if the client queries over the encrypted data, the followingthree steps may be performed: (i) transfer the encrypted datato the client; (ii) decrypt the entire database; and (iii) performthe query operation. But this may reduce the performance ofthe system, with an increase in the communication cost aswell as computational cost required for the transfer anddecryption of the entire database. Hence, balancing thesecurity and performance of any system is a major challenge.This paper aims to improve the performance of differenttypes of query operations over encrypted data. The rest of
Copyright © 2014 John Wiley & Sons, Ltd.
the paper is organized as follows. Section 2 presents theliterature survey. Proposed framework is discussed inSection 3. Section 4 explains different query operations oversensitive encrypted data. Experimental analysis is presentedin Section 5. Section 6 presents the conclusion.
2. LITERATURE ANALYSIS
Search over encrypted data is performed in three scenarios,that is, in host-based system, in client–server model, and ina cloud environment. In a host-based system, the dataencrypted within the system can be searched by decryptingall the data using a symmetric key or password [3], whichis used to encrypt the whole data. In a client–server model,when a query is sent from client to server, the serverdecrypts the entire data and applies the query over thedatabase. The results of the query can again be encryptedusing the public key for transferring securely to the client.At the client, the query results can be decrypted using theprivate key of the client. Park [4] has proposed an efficientmethod for hidden vector encryption where the data storedat the server in encrypted form can be searched by theclient without having any other information about theencrypted data. Song et al. [5] have investigated ondifferent schemes for searching over encrypted data. In this

Query execution over encrypted data T. Baby and A. K. Cherukuri
approach, when the client wants to retrieve the encrypteddocuments with any particular keyword, the server willreturn the results with query isolation, that is, the querywould not reveal anything to the untrusted server includingthe word for which the search is performed. Bevensee [6]has investigated on Feigenbaum algorithm based onrenormalization group theory and described the encryptionsecurity involved. Hakan et al. [1] have brought out theconcept of third party service provider, which can store,modify, and retrieve data from the host site through theinternet, and have also investigated on the challenges in thedatabase-as-a-service model, including the issues of dataaccess from a third party service provider and its security.
Hakan et al. [7] have addressed the scenario in whichthe client does not trust the service provider. In theirproposal, the data are stored in the encrypted format atthe service provider’s site. However, the data may includeboth sensitive and nonsensitive data. Hence, the computa-tional cost of decrypting even the nonsensitive attributesis an issue. Wang et al. [8] have proposed a method thatstores a characteristic index value corresponding to thesensitive character string with respect to a characteristicfunction. By doing so, many of the tuples will be filteredout at the server side itself just by referring the characteris-tic index value of its sensitive attributes. The remainingtuples are sent back to the client for the decryption of theremaining tuples, over which the actual query will beapplied. This can reduce the computational cost requiredfor the decryption at the client side. For numerical data, aB+ tree index was created before encryption in order tomaintain the ordering of each index in the record. Forfurther improving the efficiency while querying theencrypted character strings, Shi et al. [9] have designed amulti-dimensional range query over encrypted data. Liet al. [10] have shown the need for search capability onsensitive data while reducing the privacy exposure. Toachieve it they have proposed a scalable authorizationframework. Wu et al. [2] have used an n-phase reachabilitymatrix for the generation of the characteristic index valuefor the sensitive character strings. Hakan et al. [11] haveinvestigated on aggregation query over encrypted data ina cloud. Cormode et al. [12] have introduced a Linear Inte-ger Constraint Model to answer the conjunctive and aggre-gate queries over data. Optimizing the computation ofrange aggregate queries and aggregate continuous queriesis discussed in [13] and [14], respectively. Boneh andSahai [15] have introduced private linear broadcast encryp-tion and have built a fully collusion resistant traitor tracingwith short cipher texts and private keys. Curtmola et al.[16] provided the improved definitions for searchable sym-metric encryption where each party store the data in an-other party in a private manner and selectively searchesthe data. Boneh et al. [17] have used a gateway to searcha keyword from a large data encrypted using public key en-cryption method without the need to decrypt rest of themessage. Private searching over streaming data and itspractical applications are investigated in [18] and [19].Various other techniques for search over encrypted data
in a cloud have been discussed in [20] and [21]. In this sec-tion, different methods for searching the encrypted data ina host-based system, client–server model, and the cloudenvironment are studied. But every method has consideredonly a single type of query operation, that is, either aggre-gate query operation or non-aggregate query operation,over the encrypted data.
3. PROPOSED FRAMEWORK
Motivated by the analysis in [2], this paper aims to im-prove the performance of executing queries over encrypteddata. The existing methods for search over encrypted datahave considered only any one particular query operation[2], [11]. This paper is mainly concentrating on improvingthe performance of mainly three types of query operations,that is, non-aggregate, aggregate, and user-defined queryoperations over the encrypted data stored at the server.Non-aggregate query operations consist of similarityqueries and range queries. This type of query operationgenerates a characteristic index value, which is stored asa separate attribute along with the encrypted characterstring. When the user applies any similarity or range queryover the encrypted attribute, characteristic index value willbe referred instead of the sensitive encrypted characterstrings. For aggregate query operation such as COUNT,AVERAGE, SUM…, and so on over encrypted characterstrings, the aggregation result is obtained directly fromthe encrypted attribute. This eliminates the need of decryp-tion for finding the aggregate and then storing the queriedaggregation result at the user’s system, thereby reducingthe computational cost and communicational cost. Foruser-defined query operation, an attribute is added in therecord that indicates how frequently the tuple is being que-ried with the same operands. Frequently queried encryptedtuples are sent back to the client where their result of theuser-defined function (UDF) is stored along with theencrypted value. Hence, for the same query at a later pointof time, the result would be fetched directly from this table.
Figure 1 shows the proposed system architecture of exe-cuting query operations over encrypted data. When the userwants to store the sensitive data, they are first identified asthe data over aggregate column, non-aggregate column, andUDF column. For non-aggregate column, an index is gener-ated for each of the sensitive attribute value in the index gen-erator using themeta-data before encrypting it. Aggregate andUDF columns are directly given for the encryption process.When the user query over this encrypted data, the query oper-ations are classified as non-aggregation operation, aggrega-tion operation, and UDF operation. For non-aggregationquery and UDF query, the query undergoes query translationto form server side query.
For aggregation operation, the query first checks aggregatedatabase, that is, its local cache, whether the result is storedalready. If the data are present, query can directly fetch theaggregate from it. Otherwise, query has to undergo querytranslation to generate server side query. The translated query
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec

Figure 1. Architecture of executing query operations over encrypted data in a database-as-a-service model.
Figure 2. Flow chart for storing the sensitive and nonsensitive data.
Query execution over encrypted dataT. Baby and A. K. Cherukuri
is executed over the encrypted database at the server. For non-aggregation query operation, the filtered results are sent to thetemporary database. For UDF operation, frequency of the que-ried tuple is checked. Frequency above a threshold indicatesthat the decrypted results are present in database at client. Iffrequency is less than the threshold, the encrypted data are sentto the temporary database fromwhere the decrypted results arestored at the new table database. For the aggregation query atthe server, the results are sent to the aggregate database at theclient side. Finally, the query executor executes the actualclient side query over the data from the temporary database,the aggregate database, and the new table database over thenon-aggregate column, aggregate column, and user-definedcolumn, respectively. Architecture proposed by Wu et al.[2] shows only the query operation over non-aggregate data,whereas the proposed architecture is applicable for the dataover non-aggregate, aggregate, and UDF column.
Figure 2 describes the flow chart to store the sensitiveand nonsensitive data in the database. While thenonsensitive data are stored without any changes, sensitivedata are stored only after encryption. A characteristic indexvalue is stored along with each of the encrypted non-aggregate value. Figure 3 shows the flow chart forperforming the non-aggregate query operation. For non-aggregate query operation, the client side query is processedusing query translator. Resulting server side query is appliedover encrypted database, which filters out some of thenontargeted tuples. Rest of the tuples are sent to the temporarydatabase at client for decryption. Now, the client side query isagain applied on these tuples to obtain the actual query result.
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec
Figure 4 shows the flow chart for performing the aggre-gate query operation. After translation, the query checkswhether the aggregate result is actually present in the

Figure 3. Flow chart for performing non-aggregate queryoperation.
Figure 4. Flow chart for performing aggregate query operation.
Query execution over encrypted data T. Baby and A. K. Cherukuri
aggregate database. If yes, return the result directly to theuser. Otherwise, it will check the encrypted database atthe server and return the result to the aggregate databaseand user.
Flow chart for user-defined query operation is shownin Figure 5. This operation has an additional attributecount in the server’s database to find the frequency ofaccessing the tuple. First, the counts for all tuples areinitialised to 0. Each time when the tuple is accessed,the count will be incremented. If count is greater thanthreshold, fetch the decrypted result directly from theUDF table and perform the UDF. If the count is equalto threshold, decrypt the tuple, store it in UDF table, andthen perform UDF. If the count is less than threshold,decrypt the tuple, store it in temporary table, and thenperform UDF.
4. QUERY OPERATIONS OVERSENSITIVE DATA
Sensitive attributes are encrypted by any of the traditionaldata encryption techniques such as Advanced Encryption
Standard (AES), RSA, Blowfish, or DES [24]. However,in our implementation, we have used AES encryptionalgorithm for encrypting the sensitive data as shown inFigure 6. Let R be a relation consisting of all the sensitiveand nonsensitive attributes (A1,A2….At….An). The sensi-tive attribute At, is stored as Ate, that is, the encrypted formof At, and in case of non-aggregate column, the character-istic index value Aind, generated for that sensitive value isalso stored. Hence, the relation will be stored as Rd
(A1,A2….Ate….An….Aind). The tuple ti at the databaseservice provider will be stored as follows:
tenc ¼ a1; a2; encrypt a3ð Þ…encrypt atð Þ…:an;index atð Þ� �(1)
tenc is the tuple stored at the server where encrypt functionis applied over all the sensitive data and index value isfound for non-aggregate column n is the number ofattributes in a relation.
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec

Figure 5. Flow chart for performing user-defined query operation.
Figure 6. Database with encrypted sensitive data and non-encrypted nonsensitive data.
Query execution over encrypted dataT. Baby and A. K. Cherukuri
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec

Query execution over encrypted data T. Baby and A. K. Cherukuri
4.1. Non-aggregate query operation
Non-aggregate query operations are performed over thesensitive attributes by using the characteristic index value.Let S= {s1,s2…….st} be the sensitive string over whichnon-aggregation query operation has to be performed, t isthe number of characters in a string (t≥ 1). P= (p1,p2….
pm) be the already defined subset of sequence over whichthe sensitive characters are defined where m indicates thenumber of partitions over complete character set (m≥ 1).For finding the n-phase reachability matrix, connected pairelements CPn at each phase are found as shown in thesucceeding text:
If t≤n+1,CPn= (si,sn+ i)where (1≤ i≤ t-n), otherwiseΦ.
Then, we define three bijective functions g1, g2, and g3,each having m elements.
g1�> 1; 2 :::::mf gg2�> 1; 2 :::::mf g
g3�> 1; 2 :::::mf g
Now, the n-phase reachability matrix can be obtained asfollows:
Mn ¼ rij mþ1ð Þ�m (2)
When i≥ 1, j≤m,
rij ¼1; if g1�1 ið Þ; g2�1 jð Þ� �
∈ CP1 ∪ CP2 ∪…CPnð Þ0; otherwise: g
(
Figure 7. Characteristic index value for sensitive non-ag
And for the last row, that is, when i= (1 +m), 1≤ j≤m,
rij ¼1; if g3�1 jð Þ ¼ si or g3�1 jð Þ ¼ st
0; otherwise:
(
The matrix Mn thus formed by the aforementioned con-ditions will be a Boolean matrix. The characteristic indexvalue generated using this matrix is shown in Figure 7.The size of this matrix will be depended on the numberof subsets over which the sensitive character string is de-fined. All the strings defined over the same subsets willhave the same size. The matrix Mn is a row matrix and isdenoted as Rbit (M
n). By using this matrix, the similarityamong the strings and the substring of an encrypted stringcan be found. To find whether a string Sa is present in an-other string Sb, another three matrices have to be generatedfor the string sequence Sa, as follows:
Mnleft ¼ rij mþ1ð Þ�m (3)
Mnright ¼ tij mþ1ð Þ�m (4)
Mnmid ¼ uij mþ1ð Þ�m (5)
When i≥ 1, j≤m,
rij ¼ tij ¼ uij ¼1; if g1�1 ið Þ; g2�1 jð Þ� �
∈ CP1∪CP2 ∪…CPnð Þ0; otherwise:
(
gregate value using a four-phase reachability matrix.
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec

Query execution over encrypted dataT. Baby and A. K. Cherukuri
And for the last row, that is, when i= (1 +m), 1≤ j≤m,
Mn ¼rij ¼ 1; tij ¼ 0; uij ¼ 0 ; if g3�1 jð Þ ¼ si
rij ¼ 0; tij ¼ 1; uij ¼ 0 ; if g3�1 jð Þ ¼ st
rij ¼ 0; tij ¼ 0; uij ¼ 0 ; otherwise
8><>:
From the aforementioned three matrices, Mnleft,M
nright,
and Mnmid, generated for Sa, we can infer whether Sa is a
substring present in the front, tail, or middle of a stringSb. If Sa is present in front of Sb, then,
Rbit Mnleft Sað Þð Þ ¼ Rbit M
nleft Sað Þð Þ ∩ Rbit M
n Sbð Þð Þ (6)
If Sa is a substring at the end of Sb, then,
Rbit Mnright Sað Þ� � ¼ Rbit Mn
right Sað Þ� �∩ Rbit M
n Sbð Þð Þ (7)
And if Sa is a substring that is present at the middle ofSb, then,
Rbit Mnmid Sað Þð Þ ¼ Rbit M
nmid Sað Þð Þ∩ Rbit M
n Sbð Þð Þ (8)
The matricesMnleft, M
nright, M
nmid can be used to filter out
the results at the server, for the queries over the encryptedcharacters given by the user.
Two-phase filtering algorithm [2] is used to filter out thetuples communicated between user and the server. The firstphase consists of two steps: (i) the actual query given by
Figure 8. Filtered tuples for non-aggregate
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec
the user is converted to the server side query based onthe characteristic index value; and (ii) server side query isapplied on the encrypted database at the server, wheremuch of the tuples are filtered out based on Equations (6),(7), and (8). In the second phase, the filtered results fromthe server are stored in the temporary database at the client.Then, the query executor executes the actual query appliedover these filtered tuples after its decipherment. Theresulting tuples after the second phase are returned backto the user as shown in Figure 8.
4.2. User-defined query operation
For performing user-defined query operation over theencrypted database, the frequency with which the queriedtuple is used are found, which is based on how many timesthe same tuple of the database has been queried before,with the same operand. This value is stored in the separateattribute of the database as a count value. A particularthreshold value is set for this count value, above which,it will be considered as a frequently used tuple. Thisfrequently used encrypted tuples are sent to client forperforming decryption, necessary UDF over the tuples,and the result is stored in client’s database. When thesetuples are queried next time, the result is retrieved directlyfrom the client’s database, instead of decrypting theattributes again and again to perform UDF. Hence, bydoing so, the cost of decrypting the attributes and the
query using characteristic index value.
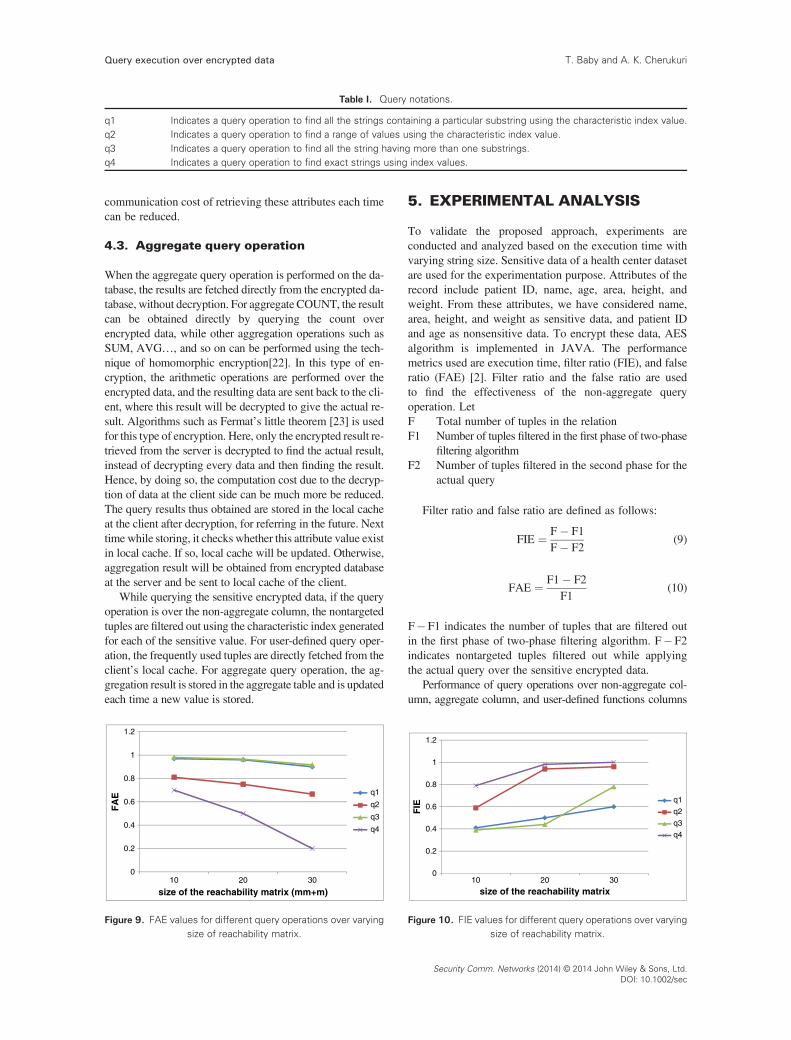
Table I. Query notations.
q1 Indicates a query operation to find all the strings containing a particular substring using the characteristic index value.q2 Indicates a query operation to find a range of values using the characteristic index value.q3 Indicates a query operation to find all the string having more than one substrings.q4 Indicates a query operation to find exact strings using index values.
Query execution over encrypted data T. Baby and A. K. Cherukuri
communication cost of retrieving these attributes each timecan be reduced.
4.3. Aggregate query operation
When the aggregate query operation is performed on the da-tabase, the results are fetched directly from the encrypted da-tabase, without decryption. For aggregate COUNT, the resultcan be obtained directly by querying the count overencrypted data, while other aggregation operations such asSUM, AVG…, and so on can be performed using the tech-nique of homomorphic encryption[22]. In this type of en-cryption, the arithmetic operations are performed over theencrypted data, and the resulting data are sent back to the cli-ent, where this result will be decrypted to give the actual re-sult. Algorithms such as Fermat’s little theorem [23] is usedfor this type of encryption. Here, only the encrypted result re-trieved from the server is decrypted to find the actual result,instead of decrypting every data and then finding the result.Hence, by doing so, the computation cost due to the decryp-tion of data at the client side can be much more be reduced.The query results thus obtained are stored in the local cacheat the client after decryption, for referring in the future. Nexttime while storing, it checks whether this attribute value existin local cache. If so, local cache will be updated. Otherwise,aggregation result will be obtained from encrypted databaseat the server and be sent to local cache of the client.
While querying the sensitive encrypted data, if the queryoperation is over the non-aggregate column, the nontargetedtuples are filtered out using the characteristic index generatedfor each of the sensitive value. For user-defined query oper-ation, the frequently used tuples are directly fetched from theclient’s local cache. For aggregate query operation, the ag-gregation result is stored in the aggregate table and is updatedeach time a new value is stored.
0
0.2
0.4
0.6
0.8
1
1.2
10 20 30
FA
E
size of the reachability matrix (mm+m)
q1
q2
q3
q4
Figure 9. FAE values for different query operations over varyingsize of reachability matrix.
5. EXPERIMENTAL ANALYSIS
To validate the proposed approach, experiments areconducted and analyzed based on the execution time withvarying string size. Sensitive data of a health center datasetare used for the experimentation purpose. Attributes of therecord include patient ID, name, age, area, height, andweight. From these attributes, we have considered name,area, height, and weight as sensitive data, and patient IDand age as nonsensitive data. To encrypt these data, AESalgorithm is implemented in JAVA. The performancemetrics used are execution time, filter ratio (FIE), and falseratio (FAE) [2]. Filter ratio and the false ratio are usedto find the effectiveness of the non-aggregate queryoperation. Let
F0
0.2
0.4
0.6
0.8
1
1.2
FIE
Figure
Total number of tuples in the relation
F1 Number of tuples filtered in the first phase of two-phasefiltering algorithm
F2 Number of tuples filtered in the second phase for theactual query
Filter ratio and false ratio are defined as follows:
FIE ¼ F� F1F� F2
(9)
FAE ¼ F1� F2F1
(10)
F�F1 indicates the number of tuples that are filtered outin the first phase of two-phase filtering algorithm. F� F2indicates nontargeted tuples filtered out while applyingthe actual query over the sensitive encrypted data.
Performance of query operations over non-aggregate col-umn, aggregate column, and user-defined functions columns
size of the reachability matrix
q1
q2
q3
q4
10 20 30
10. FIE values for different query operations over varyingsize of reachability matrix.
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec

Query execution over encrypted dataT. Baby and A. K. Cherukuri
are compared with the traditional system with respect to theirexecution time. In traditional model, querying any data at theservice provider’s site transmits the entire encrypted database
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
4 6 8 10 12
FIE
Size of the sensitive string
q4
q3
q2
q1
Figure 11. FIE values for different query operations over varyingsize of sensitive string.
0
0.5
1
1.5
2
2.5
3
3.5
4
4 6 8 10 12
FA
E
Size of the sensitive string
q4
q3
q2
q1
Figure 12. FAE values for different query operations over vary-ing size of sensitive string.
Figure 13. Execution time for performing non-aggre
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec
back to the client, and then performs the decryption of thewhole database to apply the actual query. The execution timeincludes the time required for query processing, encryptionprocess, and decryption process. Table I shows different queryconditions q1, q2, q3, and q4, which are applied overencrypted data.
Size of the reachability matrix is proportional to thenumber of partitions made for the sequence defined overa sensitive character string. For n-phase reachability matrixn+ 1 partitions are defined. Suppose m= n+ 1, then, thesize of the reachability matrix =m *m +m. For example,in four-phase reachability matrix, there will be five parti-tions, and hence, the size of reachability matrix is 30 bits(5 * 5 + 5). For three-phase and two-phase, the size ofreachability matrix is 20 and 12, respectively.
Figure 9 shows the false ratio for different query condi-tions over varying size of reachability matrix. It is clearfrom the graph that for all the different types of query,the false ratio decreases with increase in the size ofreachability matrix. It is expected that the false ratio willbe zero for very high size of reachability matrix. The queryq4 is found to have the minimum false ratio. Query q1 andq3 are having almost the same false ratio and is highcompared to that of q4 and q2. Figure 10 plots a graph toshow the filter ratio for different query operations overvarying size of reachability matrix. Here, the q4 and q2are showing the maximum filter ratio, and q3 and q1 areshowing comparatively less filter ratio. It is understoodfrom the graph that the filter ratio increases with increasein size of the reachability matrix, that is, number ofnontargeted tuples filtered out at each phase will be morefor a very high-phase reachability matrix.
Figure 11 gives the filter ratio for different queryoperations over varying size of sensitive string. The graph in-dicates that the filter ratio increases with the increase in sizeof sensitive string represented as a characteristic index value.This happens because, as the size of sensitive string
gation query operation with varying string size.

Figure 14. Execution time for performing aggregation query operation with varying string size.
Figure 15. Execution time for performing user-defined query operation with varying string size.
Query execution over encrypted data T. Baby and A. K. Cherukuri
increases, the connecting pairs found in the string becomesmore, and hence, most of the strings are filtered out thestrings without having these many numbers of connectingpairs. Because the number of tuples filtered to the next phasedecrease with the increase in the size of sensitive string, thefalse ratio reduces as the string becomes bigger and biggeras shown in Figure 12. In order to validate the efficiency ofdifferent query operations, graphs are plotted for the execu-tion times of different query operations, over varying sizeof the sensitive string. The execution time of the two-phasealgorithm over a query condition is the sum of the time toexecute coarse query at the database, the time to transmitthe encrypted data from server to client, the time to decryptthe data, and the time to execute original query at the client.
Figures 13, 14, and 15 plot the execution time forperforming non-aggregation query operation, aggregationquery operation, and user-defined query operation over
sensitive strings against increasing string size, respec-tively. Considering the same set of encrypted databasein both traditional and proposed systems, the graphclearly states that the execution time required forquerying the sensitive character strings in the proposedmethod is less compared to that of the traditionalapproach, in all the three query operations.
6. CONCLUSION
This paper aimed at executing different types of query oper-ations over encrypted data in database-as-a-service model.The data are classified under aggregation, non-aggregation,and UDFs. Non-aggregated sensitive data are stored alongwith the index and is queried based on this index. For the dataunder aggregation and UDF’s column, the frequently used
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec

Query execution over encrypted dataT. Baby and A. K. Cherukuri
data are being sent to the local cache of the client for the futurequeries. Efficiency of the approach is found to be better thanthat of traditional method in terms of the execution time. Theeffectiveness of the indexing approach for different types ofnon-aggregate query operations is observed by using filter ra-tio and false ratio against varying size of reachability matricesand varying size of sensitive string. In future, this work can beextended by using homomorphic encryption [20] or hiddenvector encryption [4] for user-defined query operation andaggregate query operation. By using these encryptiontechniques, the mathematical operations can be performedover the encrypted data without even the need of decryptionand storing in the temporary database.
ACKNOWLEDGEMENT
Authors sincerely acknowledge the financial support fromthe National Board of Higher Mathematics, Departmentof Atomic Energy, Government of India under the grantnumber 2/48(11)/2010-R&D II/10806. Also, authors thankthe anonymous reviewers for their useful suggestions.
REFERENCES
1. Hakan H, Bala L, Sharad M. Providing database as ser-vice. In Proceedings of ICDE’02: Sanjose, Canada,2002; pp. 29–38.
2. Wu Z, Xu G, Yu Z, Yi X, Chen E, Zhang Y. Executing sqlqueries over encrypted character strings in a database-as-servicemodel.Knowledge-Based Systems2012;35:765–781.
3. Abadi M, Warinschi B. Password based encryptionanalysed. Automata, Languages and Programming,LNCS 2005; 3580:664–676.
4. Park JH. Hidden vector encryption for conjuctivequeries on encrypted data. IEEE Transaction on Knowl-edge and Data Engineering 2011; 23:1483–1497.
5. Song DX,Wagner D, Perring A. Practical techniques forsearches on encrypted data. In: Proceedings of the IEEESymposium on security and privacy 2000; pp.34.
6. Bevensee RM. Feigenbaum encryption of messages.Potentials IEEE 2001; 20:39–41.
7. Hakan H, Bala L, Chen L. SQL over encrypted data inthe database service provider model. In Proceedings ofSIGMOD’ 02. Madison, ACM Press: New York, 2002;216–227.
8. Wang ZF, Wang W, Shi BL. Storage and query overencrypted character and numerical data in database. In:Proceedings of CIT’ 05, Shanghai, China, 2005; pp. 77–81.
9. Shi E, Bethencourt J, Hubert Chan TH, Song D, PerrigA. Multi-dimensional range query over encrypted data,In: Proceedings of the 2007 IEEE Symposium onSecurity and Privacy 2007; pp. 350–364.
Security Comm. Networks (2014) © 2014 John Wiley & Sons, Ltd.DOI: 10.1002/sec
10. Li M, Yu S, Cao N, Lou W. Authorized private keywordsearch over encrypted data in cloud computing. In:Proceedings of the 31st International Conference onDistributed Computing Systems 2011; pp. 383–392.
11. Hakan H, Bala L, Sharad M. Efficient execution of ag-gregation queries over encrypted relational databases.In: Proceedings of DASFAA’04, South Korea,Springer-Verlag, Berlin, 2004; pp. 125–136.
12. Cormode G, Srivastava D, Shen E, Yu T. Aggregatequery answering on possibilistic data with cardinality con-straints. In: Proceedings of 28th IEEE International Con-ference on Data Engineering (ICDE) 2012; pp.258–269.
13. Zhang Y, Lin X, Tao Y, Zhang W, Wang H. Efficientcomputation of range aggregates against uncertainlocation-based queries. In: IEEE Transactions on Knowl-edge and Data Engineering 2012, 24; 1244–1258.
14. Guirguis S, Sharaf MA, Chrysanthis PK, Labrinidis A.Three-level processing of multiple aggregate continu-ous queries. In: Proceedings of Data Engineering(ICDE) 2012; pp. 929–940.
15. Boneh D, Sahai A, Waters. Fully collusion resistanttraitor tracing with short ciphertexts and private keys.In: EUROCRYPT 2006; LNCS, pp. 573–592.
16. Curtmola R, Garay J, Kamara S, Ostrovsky R. Search-able symmetric encryption: improved definitions andefficient constructions. In: Proceedings of the 13thACM conference on Computer and communicationssecurity, 2006; pp. 79–88.
17. Boneh D, Crescenzo GD, Ostrovsky R, Persiano G.Public key encryption with keyword search. In:Proceedings of EUROCRYPT 2004; pp. 506–522.
18. Bethencourt J, Song D, Waters B. New constructionsand practical applications for private stream searching,In: Proceedings of IEEE Symposium on Security andPrivacy (S&P’06) 2006; pp. 132–139.
19. Ostrovsky R, SkeithWE. Private searching on streamingdata. In: Proceedings of CRYPTO 2005, pp. 223–240.
20. Hakan H, Bala L. Query optimization in encrypted da-tabase systems. In Proceedings of DASFAA’ 05.Beijing, Springer-Verlag: Berlin, 2005; 43–55.
21. Cui BG, Liu DX, Wang T. Practical techniques for fastsearches on encrypted string data in databases. Com-puter Science 2006; 33(6):115–120.
22. Domingo-Ferrer J. Newprivacy homomorphism and appli-cations. Information Processing Letters 1996; 60:277–282.
23. Guangli X, Zhuxiao C. The algebra homomorphic encryp-tion scheme based on fermat’s little theorem. In: Proceed-ings of International Conference on CommunicationSystems and Network Technologies 2012; pp.978–981.
24. Aswani Kumar Ch., Baby T. Implementing query op-erations over encrypted sensitive data. In: Proceedingsof 7th International Multi Conference on InformationProcessing, 2013; pp. 106–113.