multistage indexing algorithms for speeding prolog execution
TRANSCRIPT

SOFTWARE-PRACTICE AND EXPERIENCE, VOL. 24(12). 1097-1 119 (DECEMBER 1994)
Multistage Indexing Algorithms for Speeding Prolog Execution*
TA CHEN AND I. V. RAMAKRISHNAN Department of Computer Science, SUNY at Stony Brook, Stony Brook, NY 11794, U.S.A.
(email: {tchen, ram) @sbcs.sunysb.edu)
R. RAMESH Department of Computer Science, University of Texas at Dallas, Richardson, 7X 7.5083, U.S.A.
(email: ramesh@utdallas. edu)
SUMMARY
In a previous article we proposed a new and efficient indexing technique that utilizes all the functors in the clause-heads and the goal. The salient feature of this technique is that the selected clause-head unifies (modulo nonlinearity) with the goal. As a consequence, our technique results in sharper discrimination, fewer choice points and reduced backtracking.
A naive and direct implementation of our indexing algorithms considerably slowed down the execution speeds of a wide range of programs typically seen in practice. This is because it handled deep and shallow terms, terms with few indexable arguments, small and large procedures un$ormly. To beneficially extend the applicability of our algorithms we need mechanisms that are ‘sensitive’ to term structures and size and complexity of procedures. We accomplish this in the PALS compiler by carefully decomposing our indexing process into multiple stages. The operations performed by these stages increase in complexity ranging from first argument indexing to unification (modulo nonlinearity). Further the indexing process can be terminated at any stage if it is not beneficial to continue further.
We have now completed the design and implementation of PALS. Using it we have enhanced the performance of a broad range of programs typically encountered in practice. Our experience strongly suggests that indexing based on unification (modulo nonlinearity) is a viable idea in practice and that a broad spectrum of useful programs can realize all of its benefits.
KEY WORDS Indexing Logic programming Code optimization Pattern matching and unification
INTRODUCTION
In Reference 1 we proposed a new and efficient indexing technique for quickly filtering clause-heads in a Prolog program into a smaller set of clause-heads that are more likely to unify with the goal. The salient feature of this technique is that the selected clause- head unifies modulo nonlinearity with the goal, i.e. it unifies with the goal after uniquely renaming multiple occurrences of variables in both the clause-head and the goal. Therefore, a clause-head selected by such an indexing algorithm may fail to unify with the goal iff there are multiple instances of a variable either in the clause-head or in the goal. * A preliminary version of this paper appears in the proceedings of JICSLP‘92.
CCC 0038-0644/94/121097-23 01994 by John Wiley 8c Sons, Ltd.
Received 22 December 1992 Revised 22 July 1994

1098 TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
Indexing based on unification modulo nonlinearity (henceforth unification modulo non- linearity is referred to simply as unification whereas complete un$cation will be used to denote unification of nonlinear terms) has the following three main advantages over meth- ods used in existing Prolog compilers (such as Quintus, ALS and Stony Brook Prolog) that index on the first (or some other prespecified) argument.
1. It is more effective. The filtered set produced by indexing based on unification will in general have considerably fewer clause-heads than that produced by indexing based on the first argument alone. This is because the former method examines many more symbols (and so discriminates more sharply) than the latter method. This results in fewer choice points and less backtracking.
2. It is transparent to the programmer. When using indexing based on unification, pro- grams need no longer be organized for effectively exploiting the indexing method. In contrast, programs indexed on the first argument are typically written in such a way so as to exploit it.
3. Indexing alone sometimes suffices to compute the unifiers. When doing unification, if every variable gets at most one substitution, then these substitutions alone are the unifiers. The complete-unification step that typically follows every indexing step can now be skipped.
Note that the fast complete-unification algorithms of Paterson and Wegman’ and Martelli and Montanari3 can be used to perform unification. The main problem in doing so is that, when there are several clause-heads to be selected, the symbols in the goal may need to be reinspected several times. This is quite wasteful and not appropriate for fast indexing.
In our approach, each clause-head is transformed into a set of strings by doing a left-to- right preorder traversal and removing the variables. Thus f(a, g ( X , b ) ) is transformed into f a g and b. Observe that the clause-head strings so obtained contain all the nonvariable symbols in the head. These clause-head strings are then compiled into a string-matching automaton. At run time the goal is scanned and the state transitions made by the automaton are recorded. The information embodied in these states is now used to avoid reinspection of symbols in the goal and thereby improve the running time of the technique. Specifically, our running time is proportional to the number of variables in the clause-head and the goal as opposed to sum of their sizes. In addition to this algorithm, which we will refer to as indexing based on string-matching, we also outlined in Reference 1 another indexing method suitable for small procedures. This method uses a bit-vector model; sets of clause-heads are represented by bit vectors and intersection and union operations on them are assumed to require constant time. So this method, which we will refer to as indexing bused on bit vectors, is suited for Prolog programs in which the number of clause-heads with the same predicate name does not exceed the wordsize.
Our algorithms were not incorporated into any compiler and so their practical utility had not been established. We therefore began a project in June 1991 in collaboration with Applied Logic Systems (in Syracuse, New York) to incorporate our indexing algorithms seamlessly into their portable ALS compiler.
A preliminary implementation based on a nahe and direct transformation of our algo- rithms into code showed that its usefulness was very limited. Only large and complex pro- cedures (not often encountered in practice) seemed to benefit from them. However, typical Prolog programs have small procedures with shallow terms and few indexable arguments. Such programs did not benefit at all from the naive implementation. Even worse it slowed down their execution speeds considerably.

MULTISTAGE INDEXING ALGORITHMS 1099
The main problem with our preliminary implementation was that deep and shallow terms, terms with very few indexable arguments, small and large procedures were all being handled uniformly. A serious drawback with such a uniform use of our algorithms is that indexing small procedures with shallow clause-heads and few indexable arguments is expensive as it results in poor discrimination despite seeing many symbols. For such procedures it is advantageous to use the simple method of first-argument indexing. Although the latter indexing method can result in a lot of backtracking the deterioration in overall execution speed is quite small when compared with use of the former method. The problem now was how to realize the full benefits of our indexing technique (such as transparency, effectiveness and reduced backtracking) over a broad spectrum of Prolog programs ranging from small procedures with a few shallow rules to complex procedures with deep structures, without unduly compromising the performance of any program in the spectrum.
Based on these observations it was evident that our implementation required mechan- isms ‘sensitive’ to term structures and sizes of procedures in order to beneficially extend its practical applicability. One approach to build into such mechanisms is to do indexing in multiple stages; each stage further shrinks the size of the filtered set produced by the preceding stage using operations relatively more complex than the one used in earlier stages. The indexing process can be terminated at any stage whenever it is not beneficial to continue further. So small procedures with simple terms can be indexed quickly using the first few stages whereas all the stages are used for large and complex procedures.
Our indexing method lends itself quite nicely to decomposition into multiple stages. The operations performed by these stages can gradually increase in complexity ranging from as simple an operation as first-argument indexing done in the first stage to the complex oper- ation of unification performed in the last stage. To handle large and small procedures we carefully interleave our string-matching-based algorithm (beneficial for large procedures) with the bit-vector-based algorithm (useful for small procedures) during the indexing pro- cess.
We have now completed the design and implementation of the PALS compiler that incorporates our indexing algorithms based on the ideas described earlier. Using it we have improved the performance of a broad range of programs. Through a careful decomposition of our apparently complex indexing process into multiple stages and interleaving algorithms appropriate for large and small procedures we have been able to extend the range of its practical utility considerably. We have now demonstrated that indexing based on unification is a viable idea in practice and that even small and simple Prolog programs can realize all of its benefits. We remark that, contrary to current practice, programmers can now write programs with complex heads. Such programs can be efficiently indexed by our algorithms resulting in fewer choice points and reduced backtracking.
In this paper we describe the design and implementation of PALS. We also discuss the impact on the run-time performance of Prolog programs compiled using this compiler.
OVERVIEW OF PALS In the current implementation of PALS, we have decomposed our indexing method into three stages. The first stage discriminates among the clause-heads based on the first argu- ment. This is essentially the same as WAM indexing. The clause-heads selected by the first stage are further filtered in the intermediate stage using ‘appropriate’ symbols that follow the first argument in preorder. In essence the operation done by this stage can be viewed as a ‘generalization’ of first-argument indexing. The third and final stage completes uni-

1100 TA CHEN, I . V. RAMAKRISHNAN AND R. RAMESH
fication of the clause-heads with the goal. Herein we use both the string-matching-based and bit-vector-based algorithms. Specifically, if the number of clause-heads selected by the intermediate stage is less than the wordsize of the computer we then only use the bit-vector- based algorithm. Otherwise we deploy the string-matching-based algorithm to reduce the size of the filtered set and finally finish off the process using the bit-vector-based algorithm.
We mention that in the entire indexing process no symbol is ever examined more than once and hence no stage ever repeats the work done by any other stage. Furthermore symbols in the goal subterms that occur within variable substitutions of every clause-head are never examined.
Finally we remark that it is possible to introduce additional stages in between the in- termediate and final stage. For example, one such stage can be designed to do the same operation as that of the intermediate stage but using the last argument instead. Our main objective in this first prototype of PALS was to validate the practical applicability of our indexing method. For ease and simplicity of implementation we chose to design only one intermediate stage.
Using PALS we have compiled and run several Prolog programs. We summarize below the impact on the execution speed of a representative sample of Prolog programs compiled using PALS.
Impact on Prolog execution speed In our experiments we compiled programs using the ALS and PALS compiler. We then
ran them on a Sun-3/160 and measured the total time of execution. These programs (see Figures 8, 9, 10, and 11) include the dutch nationalJag problem given in Reference 4, the border predicate in the CHAT-80 system,’ the replace program and the 8-queens problem, both of which are ALS benchmarks, and programs to parse strings using LL(k) grammars. The speedup of a program in our performance figures refers to the ratio of execution speed of the program compiled using PALS to that of the same program compiled using ALS. Based on our experiments we can reach the following conclusions on the impact of PALS on execution speeds of Prolog programs.
1 . Prolog programmers typically tend to write programs in which all the input arguments precede the outputs. We can improve the speed of such programs especially if some of the input arguments are nonvariables. An example is the dutch nationalfig problem where we obtain speedups ranging from 28 to 36 per cent on our test queries. These increases can be larger or smaller but are never lower than ALS.
2. We can quickly select facts; the lower the priority* of the selected fact the faster is the selection. An example is the border program where we show improvements of 97 per cent when searching through a very small database of eight facts. Each fact is a flat structure with only two arguments.
3. We can reduce nondeterminism in Prolog programs that have a lot of nonvariable symbols in clause-heads; the larger the number of such symbols the faster the execution is. For example, by putting the lookahead symbols in the clause-head we can parse LL( k) grammars deterministically, i.e. our indexing method always chooses only one clause-head. We obtain improvements of 11, 23, and 31 per cent for parsing LL(l) , LL(2) and LL(3) programs respectively. Note that the nonvariable symbols in clause- heads keep increasing for larger k and hence our speedups also rise accordingly.
* We say that clause p has higher priority over clause q if p appears before q in the program text.

1101 MULTISTAGE INDEXING ALGORITHMS
clause-head strings: f y n n h , An - golo lint
(a) goal (1)) c~liLllsr-llmfl (1:) automaton
Figure 1. goal, clause-head and the automaton for clause-head strings and their suf ies
4. Finally, we do not degrade the performance of programs that do not benefit from our indexing algorithms. An example of this is 8-queens. Our running times are almost identical to those obtained using ALS.
REVIEW OF INDEXING ALGORITHMS
To make the paper self-contained, we briefly review the main conceptual ideas underlying string-matching-based and bit-vector-based algorithms. The details can be found in Refer- ence 1.
String-matching-based algorithm Conceptually, our indexing method selects a clause-head whenever the constant parts
of the goal and the clause-head match. A match between the two terms (the goal and the clause-head) is computed as follows. For every variable occurring in one term we delete the subterm occurring at the corresponding position in the other term. If the resulting structures are identical then the two terms match. In this process if we delete a subterm t on behalf of the variable X then t is referred to as a substitution for X. We can verify whether the goal and clause-head match quite easily by traversing them in preorder and comparing the labels of node-pairs one at a time. Obviously this is quite slow and not appropriate for fast indexing.
The key idea in our approach is not to examine the node-pairs one at a time. Instead a sequence of node-pairs with nodes having successive preorder numbers is compared in one operation. This is done by transforming the sequence of node-pair comparisons into a string- matching problem. For example, during the selection of the clause-head in Figure 1, we compare three node-pair sequences: ((1,9), (2, lo), (3, ll)), ((5,13)) and ((7,15), (8,16)). These comparisons will be transformed into three string-matching problems verifying: (i) the occurrence of fga in the preorder of the goal; (ii) the occurrence of h in the preorder of the clause-head; and (iii) the occurrence of ha in the preorder of the goal. We refer to the strings obtained by breaking the preorder traversal of a clause-head (goal) at the variables as the clause-head (goal) strings. In the previous example, fgaah and ha are clause-head strings whereas fga and haha are goal strings.

1102
Clause-head states All I A12 1 A13 AM Ais '? AI I A2 - Info (compiled) preorder f g a a h y h a
Goal preorder f g a X h a h a Information states Ail I A12 I A13 '? AI ? AI I A2
TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
.
(b) Data obtained by compiling and scanning
Figure 2. Fail tree and scannedcompiled data used in string-matching steps
Given a goal, we perform a series of complex string-matching steps using clause-head strings and goal strings. The outcomes of these steps are then correlated to obtain the filtered set. We have shown in Reference 1 that all the string-matching questions that can possibly arise in the selection are special cases of the generic question: 'Does the prefix of length I (not necessarily a proper prefix) of a clause-head (or goal) string occur at the ith position in a goal (respectively, clause-head) string?'.
To answer these questions we preprocess the clause-heads at compile time and build an automaton to recognize instances of clause-head strings and their suffixes (see Figure l(c) for an illustration). The automaton is built using the algorithm in Reference 6. It has two types of links: goto and failure. By deleting all (and only) the the goto links (respectively, failure links) we obtain what is known as the fail tree (goto tree) of the automaton. The fail tree for the automaton in Figure l(c) is given in Figure 2(a). We say that the state A in the automaton represents string a if the (unique) path in the goto tree between the root (i.e. start state) and A spells a. For example, state A9 in the automaton represents gaa. The following properties of the automaton (see Reference 1 for details) are essential for answering our generic string matching questions.
1. Each prefix of a clause-head string is represented by a unique state in the automaton. 2. Every prefix of a goal string occurring in a clause-head string is also represented by
a unique state in the automaton. 3. While scanning the text ula2. . . , a, if the automaton reaches state A (representing a)
on reading uj then a is the longest suffix of ala2 . . . aj among the strings represented by the automaton.
4. If a and /3 are the strings represented by states A and B respectively then a is a suffix of /3 iff A is an ancestor of B in the fail tree.
The selection begins by scanning the goal and recording with each symbol the states reached upon reading it. Subsequently, the states thus recorded are used to answer any string- matching question that arises in selection as follows. To verify the occurrence of a prefix of a clause-head string Q in goal string /? at i , we (i) obtain the state, say A, representing a (see Property (1)); (ii) obtain the state stored at the (i + Icy1 - 1)th position in /3 (see Property (3)); and (iii) verify whether A is an ancestor of B in the fail tree (see Property (4)). On the other hand to check whether a prefix of the goal string y occurs in the clause-head

MULTISTAGE INDEXING ALGORITHMS 1103
string 6 at i, we (i) obtain the state A stored at the last position in y; (ii) check whether A represents y, i.e. check whether the depth of A in the goto tree equals Iyl (see Properties 3 and 2); (iii) obtain the state B representing the prefix of length (i + Iyl - 1) in 6; and (iv) check whether A is an ancestor of B in the fail tree.
We illustrate this method using Figure 2(b). The first string-matching step verifies if prefix fga of the first clause-head string occurs starting from the first position in the goal. This is done by checking whether state A13-representing the prefix fga-is an ancestor of the state A13 stored with the third symbol in the goal. This string-matching step succeeds as A13 is trivially its ancestor. Next we make a substitution for goal variable X and proceed to the second string-matching step. In this step we check whether the second goal-string prefix h occurs at the fifth position in the first clause-head string. Clearly, A1 represents the goal prefix h (see Figure l(c)). Furthermore, the state representing the first clause-head string, namely A ~ s , is a descendant of A1 in the fail tree. Hence the second string-matching step also succeeds. After this we compute a substitution for the variable Y . In the next string-matching step, we look for the occurrence of the second clause-head string starting at the third position in the second goal string. Again we note that the state stored with the last goal symbol is the same as that representing the second clause-head string. Therefore this string-matching step also succeeds and the clause-head is selected to be included in the filtered set.
Note that both the goto tree and fail tree are constructed at compile time. Therefore we can compute the depth of each state in the goto tree at compile time. Similarly, we can also compute, for each state X , its preorder number p n ( X ) and the number of its descendants n d ( X ) using the fail tree. Since X is an ancestor of Y iff p n ( X ) 5 pn(Y) 5 p n ( X ) + n d ( X ) , we conclude that each string-matching step takes only O( 1) time after scanning the goal. Suppose G is the portion of the goal scanned and wi is the number of substitutions computed in the selection of the ith clause-head. Then this method requires O( IGl + CiEy vi) time to index n clause-heads.
Bit-vector-based algorithm
We use the notion of a position to refer to nodes as well as subterms rooted at these nodes in a term as follows. A position is either the empty string A that reaches the root or p.i (where p is a position and i is an integer) which reaches the ith argument of the subterm reached by p . We denote the position of a node 2) (and the subterm rooted at v) by pos(v). We assume that the edges are labeled in a term tree. Specifically, the edge between node w and its ith child (in left-to-right order) is assumed to be labeled by the integer i. Given a node v, the pathstring up to v in a term t is the alternating sequence of node and edge labels on the path from root of t to v. If v is labeled by a variable then its label is not included in the pathstring up to w. For example, the pathstring up to node v4 in Figure 3(e) is f l f2a whereas the pathstring up to node v3 is f l f l . Let v be a node in t. The prefix tree of t up to w, denoted by pre(t ,v), is obtained as follows. First we mark children of v and those of v’s ancestor that appear after v in preorder. Next we replace subtrees rooted at marked nodes by a single node labeled by a new variable. The resulting tree is pre( t , v), Given pre(t , v) we obtain pre(t, v) by replacing the subterm in pre( t , v) at pos(v) by that in t. For the term t in Figure 3(b), pre( t , v) and pre(t, v) are shown in Figures 3(c) and 3(d) respectively.

1104 TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
Figure 3. Data structures used in trie-based method
Our trie-based method begins with a bit-vector representing the set of all clause-heads. The selection is performed by incrementally updating this set by visiting the goal nodes that appear successively in preorder. Specifically, upon visiting goal node w, the set is updated so that every clause-head in it unifies with the goal's prefix tree up to v. Upon visiting the last node in the preorder of the goal we obtain the filtered set.
We use a trie for updating this clause-head set at each step. This trie is built from the set of all root-to-leaf pathstrings in the clause-heads. The construction of the trie is quite straightforward (see Reference 1 for details). The trie constructed for clause-heads r1 = f ( X , g ( a ) ) and 7-2 = f(f(a, Y), 2) is shown in Figure 3(a). With each node 21 of the trie T , we associate two sets of clause-heads S, and M,. S, contains clause-head T if the sequence of edges in the path from root of T to w is a proper prefix of a root-to-leaf pathstring in r. Similarly, M, contains r if this sequence of edges is identical to a root-to- leaf pathstring in r. For the trie in Figure 3(a), M3 is 0 whereas S3 is ( ~ 2 ) . This is because the sequence f l f of edge labels in the path from root of T to node 3 is not identical to any root-to-leaf pathstring in the clause-heads r1 and 7-2. Instead, it is only a proper prefix of the root-to-leaf pathstrings f l f l a and f l f 2 in 7-2.
The operations performed at each node of the goal g in conjunction with trie T are outlined in Figure 4. TrieSeZ begins selection at the root of the goal with root of 9, root of T , and set of all clause-heads as the three parameters. It scans the goal one symbol at a time and updates the clause-head set using the sets S,s and Mvs associated with the trie nodes. For exposition assume that the goal has been traversed in preorder up to u'. Let u be the preorder successor of u'. Further let S be the set of all clause-heads that unify with pre(g, u'). Now, TrieSeZ(u, v, S) is invoked to update S so that it contains only those clause-heads that unify with pre(g, u). Suppose u is labeled by a variable then pre(g, u') = pre(g, u). Therefore TrieSeZ returns S without any modification (see line 1). On the other hand suppose u is labeled with a function symbol, say f . Then a clause-head in S will unify with pre(g, u) iff it has a node at pos(u) that is either labeled by a variable or by the symbol f . Observe, by the construction of T, Mu contains all clause-heads that have variable nodes at pos(u). This means every clause-head in M I = S n M, will unify

MULTISTAGE INDEXING ALGORITHMS 1105
function TrieSel(u, v, S) {u, goal node; v, trie node; S, set of selected clause-heads} 1 .
3.
5 . 6. 7. 8. end 9. return(S1 U MI) 10.
if u is labeled by a variable return(S)
if there is an edge e in T leaving v towards w labeled by u then begin 2. M ~ = S ~ M , ,
4. S1 =Sn(S ,UM,) for each edge e, leaving w towards a nonleaf node w, do
let ui be the ith child of u Sl = SI n TrieSel(ui, w,, Sl)
end else return(M1 U (S n z))
Figure 4. Clause-head selection with trie T
with pre(g, u). In addition, some clause-heads in S - M I may also unify with pre(g, u). Now observe that if there is a clause-head that has a node at pos(u) labeled by f then there must be an edge in T from v to w labeled by f . Suppose there is no such edge in T then clearly every clause-head in SnS, has a node at pos(u) labeled by a symbol different from f . These clause-heads are deleted from S by returning M I U (S f l z) (see line 10). On the other hand, suppose there is an edge from v to w labeled by the symbol f. Then, Sw U M, contains all clause-heads that have a node labeled f at pos(u). Among these clause-heads only those in S1 = S n (Sw U M,) will unify with pre(g, u). Furthermore only a subset of these clause-heads may unify with pre(g,u). In order to compute this subset TrieSeZ makes a number of recursive calls that inspect nodes below u in the goal (see line 7). Suppose u1, u2, . . . , uk are the children of u then the ith call shrinks S1 to contain only those clause-heads that unify with pre(g, ui). When the last recursive call returns, S1 U M1 contains all clause-heads in S that unify with pre(g,u). TrieSeZ returns this set as the output in this case (see line 9). After this the selection is carried out by the invocations of TrieSeZ made at the ancestors of u. The selection is complete when the first call made at the root of the goal returns with the filtered set. From this discussion it is easy to see that this set contains all the clause-heads that unify with the goal. By maintaining S,, M,, and S as bit strings in a word it is possible to update S in 0(1) time using bitwise and, or and not operations. Hence if G is the portion of the goal scanned then this method takes O( IGl) time.
We now illustrate the trie-based selection with the goal g and trie T in Figure 3. Let S = { T I , 7-2) be the set of clause-heads with which T is built. The selection starts with the call TrieSeZ(vl,O, S ) . Node v1 of the goal is labeled with f which matches the edge between 0 and 1 in 7’. Therefore two recursive calls are made at line 5 of TrieSeZ to explore nodes below v1 and to select based on their labels. In the first recursive call TrieSeZ(v2,2, Sn(SlU M I ) = S) , we again find that the label of node q matches that of the edge between 2 and 3 in T. Hence another recursive call TrieSeZ(vs,4, (7-2)) is made to check whether r2 unifies with pre(g,v3). Since node 213 is labeled with the variable X , 7-2 unifies with pre(g,v3) and hence this recursive call returns { Q } unmodified. As M2 = {q}, TrieSeZ(v2,2, S ) returns with { T I , 7-2). At this point the recursive call TrieSeZ(v4,7, S ) is made. The goal node in this case is labeled with b which does not match the edge between 7 and 8 in T.

1106 TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
(a) Sample Program
p: switch-on-term con, f a i l , f a i l , C1
con: switch-on-const {‘a’:Ll, ‘b’:R3}
L1: t r y R1 r e t r y 82 t r u s t R4
<code f o r f i r s t fac t>
C2: retry-me C3 R2 : . . .
<code f o r second f a c e . . .
C3: retry-me C4 R3 : . . .
<code f o r t h i r d fact> . . .
C4 : t r u s t m e R4 : . . .
<code f o r fou r th fact>
(c) WAM code for Indexing (b) Unindexed WAM Code for p
Figure 5. WAM code for first-argument indexing
Hence this call returns with (7-2) = (Sfl M7) U ( S f l s ) as the output. Since MO = 8, (r2) is returned as the filtered set by the first TrieSeZ call invoked at the root of the goal.
DESIGN AND IMPLEMENTATION OF PALS Recall that our indexing method is decomposed into three stages. We now describe their design and methods for efficiently implementing them. We also describe the interfaces (or hooks) between the stages and the criteria used for continuing the indexing process beyond a particular stage. Since we will be compiling indexing code for WAM we first review how first-argument indexing is done in WAM-based Prolog compilers.
Review of WAM indexing
The Warren abstract machine, or WAM; is an abstract model for compiling Prolog programs. Typically, Prolog programs are compiled into a set of WAM instructions and the resulting code is executed by a WAM emulator running on a host computer. An excellent exposition of WAM and its internal organization can be found in Reference 8. Here we outline the key steps in WAM indexing.
In the absence of any indexing, WAM code sequentially tries all clauses of a given procedure. The code skeleton for a sample procedure p that implements this sequential execution is given in Figure 5(b). Observe that the code for individual clauses are ‘chained’

MULTISTAGE INDEXING ALGORITHMS 1107
together using the try-me/retry-me/trust-me sequence of instructions. The execution of p starts at the beginning of this default chain with the try-me C2 instruction. This creates a choicepoint saving the current state of WAM as well as the next choice C2. After this, the code for the first program clause for p that follows the try-me C2 instruction is executed. If this execution fails then the state of WAM is restored using the choicepoint and the next choice stored at C2 is tried. The retry-me C3 instruction at C2 updates the current choicepoint record to contain C3 as the next choice. After this the second program clause is executed. This process is repeated until either the execution succeeds or the last choice is tried. Note that execution of the last choice begins with the trust-me instruction which removes the choicepoint created by the try-me instruction. Consequently, failure of the fourth clause will result in failure of the goal that invoked p.
Indexing in WAM is achieved by building several chains in addition to the default one and threading the control through the appropriate chain. In WAM terminology each such chain is referred to as the try-me-retry-me-trust-me chain. For first-argument indexing four (not necessarily disjoint) chains are constructed. These chains are identified by the type of first goal argument, namely variable, constant, fist or structure. The variable chain merely links all clauses together and, therefore, it is the default chain. The other three chains contain clauses appropriate to that chain. Specifically, the list chain links all clauses in which the head contains a list as its first argument. However, unlike variable and list chains, the constant and structure chains are further divided into subchains, one for each constant (or structure symbol) that appears in the program. For example, the constant chain for p has two subchains: one for constant a containing clauses 1, 3 and 4; and the other for b containing only clause 2. To perform indexing based on first argument, additional WAM code is added to each procedure that selects the appropriate chain based on the goal’s first argument.
The code added to implement indexing for p is given in Figure 5(c). Execution of p begins with a switch-on-term instruction that has the four chains as arguments. Note that for p the chains for structure and list are empty. Consequently, the keyword ‘fail’ appears corresponding to these chains. Based on the type of goal’s first argument WAM branches to the instruction pointed by one of the arguments in the switch-on-term instruction. For example, if the goal is p(a ,? ,?) then WAM branches to the switch-on-const in- struction. The argument to this instruction is a table of pointers that points to WAM code implementing the subchains for each constant. The switch-on-const instruction uses the first argument of the goal to index into this table. A successful lookup results in branching to a WAM instruction with an address stored in the table. On the other hand a failure marks the end of execution for p. For the goal p ( a , ? , ? ) lookup retrieves a pointer to instruction labeled L1. The WAM code at L 1 implements the subchain for a using the try/retry/trust instruction sequence. This instruction sequence specifies a subsequence of the default chain that needs to be executed to accomplish indexing. In particular, the arguments of try/retry/trust sequence following the label L l specify that code belong- ing to clauses 1 , 3, and 4 are to be executed. The execution of a try/retry/trust is similar to that of the try-me/retry-me/trust-me sequence except for the semantics of the argument. Specifically, try lays a choice point, retry updates and trust deletes the choice point.
First stage
The design of the first stage in our method is relatively straightforward. In this stage, selection is done by examining the first-argument symbol only. This is exactly the operation

1108 TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
done by WAM indexing which is also the indexing method adopted in the ALS compiler. We therefore chose to retain WAM indexing to do selection in the first stage of PALS also.
Second stage
Recall that this stage is a generalization of first-argument indexing. Specifically, this stage will select a set of clause-heads such that the first string of every clause-head in the set is either a prefix of the goal’s first string or vice versa. Let 91 be the goal’s first string. Let S1 be the set of all those clause-heads in which first strings are prefixes of 91. Let S2 be the set of clause-heads such that g1 is a prefix of their first strings. The objective of stage 2 is to compute S1 U S 2 .
Suppose the first string p of a clause-head T matches a prefix Q of 91. By Property 1 (see page 1102) of the automaton, Q can be entirely scanned without making any failure transitions. Based on this observation S , can be constructed as follows. The automaton scans the symbols in g1 as long as it makes only goto transitions. During such a scan if the automaton enters an accepting state for p then T is included in Sl. Construction of S1 is complete either when we reach a state from which no further goto transitions are possible or when scanning of g1 is complete. Next we describe how to compute S 2 . Suppose g1 is a prefix of p. Clearly in this case the automaton can scan 91 entirely without making any failure transitions at all. Let A denote the state reached on completely scanning 91. If g1 is a prefix of p then the accepting state of p must be a descendant of A in the goto tree. Therefore S 2 will consist of only those clause-heads such that the accepting states of their first strings are descendants of A in the goto tree.
During compilation with each state A, we keep a set CA of all those clause-heads for which A is an accepting state for their first strings. Similarly, we also maintain another set DA of clause-heads such that the accepting states of their first strings are descendants of A in the goto tree. During the scan of g1 if the automaton enters an accepting state A then the clause-heads in CA are added to 5’1. If g1 can be completely scanned and this scan takes the automaton to state B then S2 is Dg. Otherwise S2 is 8.
A preliminary implementation of the second stage based on the ideas just described resulted in poor performance. In what follows we discuss the methods used to speed it up.
There were two sources for improving the efficiency of the implementation. First Sf U S2 was being computed at run time by doing several unions of CAS. Second the automaton was being used interpretively. Consequently, to make any transition from one state to another required one memory reference to fetch the symbol based on which the transition is made. Moreover, a test for empty transition (i.e. no goto transition) is also made at every state. (Note a state with empty transition denotes a final state.)
Optimization 1.
The first optimization was to precompute S1 US2 at compile time. With every state A we keep a set C i where C i = UvB CB such that B is an ancestor of A in the goto tree. It can be shown that the (worst-case) blow-up in space now is at most quadratic in the sum of sizes of the clause-heads.
In addition we also have DA as before. On scanning g1 at run time suppose the first state at which a failure occurs is y. Then S1 = C; and S 2 = 8. If we are able to scan

MULTISTAGE INDEXING ALGORITHMS 1109
automaton-@() { L1: if (ISVAR(firstarg)) { return({ I , 2,3,4}); }
if (ISSYM(first-arg)) { if (SYMBOL(first-arg) == 'a') goto L2; if (SYMBOL(first-arg) == 'b') return((3)); }
L2: if (ISVAR(second-arg)) { return({ 1,2,4}); } if (ISSTRUCT(second-arg)) {
return((4)); L3: return({ 1,4});
if (FUNCTOR(second-arg) == 'g') goto L4; if (FUNCTOR(second-arg) == 'f) goto L3; }
L4: retum({2,4}); 1
(b)
Figure 6. Automaton and its translated C code
g1 completely without making failure transitions and the state reached upon scanning is p then S1 = Ch and S2 = Dp. Thus the try-me/retry-me/trust-me chain is computed at compile time for every state.
We illustrate the idea using the example in Figure 5(a). The first strings for the above facts are paJ pug, pb and p , respectively. Figure 6(a) shows the part of the automaton relevant for the second stage. In this figure, the set above a state, say u, is CL and the one below is CL UD,. Given a goal, e.g. p(a, g(A, B) , el, the transitions for its first string pug end at state 5 after scanning it completely. Therefore Ci U D 4 , which contains facts 2 and 4, is returned. If the goal is p (a, h( 1 , 2 , 3) , c ) , scanning its first string pah123c fails at state 2 on symbol h. So C;, which includes fact 4 only, is returned.
Optimization 2.
Our second optimization step was not to use the automaton interpretively. Instead we compile the automaton into case statements .* In our current version we translate it into case expressions in C. Consequently, the symbols on which transitions are made now become C constants, thereby saving a memory reference for each symbol comparison. Furthermore, at the final states where no transition is possible, the translated code simply returns without checking whether the goto transition list is empty. Each Prolog procedure's corresponding automaton is translated into a C procedure, which is called when necessary to perform the intermediate-stage indexing. To illustrate the idea, consider the same program as before. The translated C procedure corresponding to the automaton in Figure 6(a) is shown in Figure 6(b). Although our current implementation translates the automaton into C, it can also be directly translated into assembly instructions or even machine instructions, which will make it even more efficient.
When the branching factor from a state is quite smdl as in Figure 6(b) we compile it into if instead of case statements in C.

1110 TA CHEN, 1. V. RAMAKRISHNAN AND R. RAMESH
Third stage Recall that in this stage we do unification completely. Our strategy here is to use either the
bit-vector algorithm or a combination of string-matching and bit-vector algorithms. We use the former when the number of clause-heads remaining after selection by the previous stages does not exceed the wordsize. Otherwise we employ the latter strategy. Implementation of both the string-matching and bit-vector-based algorithms is routine. For efficiency we again compile the trie used in the bit-vector-based algorithm into case expressions in C. The interesting part is the design of the combination. Note that we are able to compute the try-me/retry-me/trust-me chains at compile time for both the first and second stages. One such precomputed chain will serve as the input to the third stage. So at compile time we examine all such chains. Suppose the number of clauses in one such chain is more than the wordsize. Specifically, suppose the wordsize is say 32 bits and the number of clauses in the chain is n and n > 32. We then construct a trie for the last 32 clause-heads in the chain. At run time if this chain is selected as the input to stage 3 then we initiate our string-matching-based algorithm on the first n - 32 clauses and then finish off the selection process on the last 32 clauses using the bit-vector-based algorithm. Note that it is possible for a clause-head to appear in more than one chain and hence may appear in more than one trie. But we can again show that the (worst-case) blow-up in space is at most quadratic in the sum of sizes of all the clause-heads.
Criterion for continuation beyond a stage Note that it should be possible to stop the indexing process at any stage whenever it
is not beneficial to continue any further. We have a simple criterion for doing so in our current version. We stop the indexing process whenever the number of clause-heads selected is 1 . From both the first and second stages we move on to the next stage whenever the try-me/retry-me/trust-me chain selected has more than one clause. It is possible to develop a more sophisticated criterion by doing program analysis. For instance we can analyse the clause-heads to identify nonvariable positions in them. We can continue indexing if among the clause-heads in the selected chain there are nonvariables symbols that have not been examined. Note that for any clause-head in a selected try-me/retry-me/trust-me chain we can identify at compile time exactly all of its symbols that would have been seen so far. Another possibility is to do mode analysis. If the remaining unscanned arguments of the goal are all outputs, then obviously there is no point in continuing the indexing process any further.
Interstage interface We now describe how the stages are hooked together. For this purpose we create the
following three new WAM instructions: switch-on-automata, switch-on-string and switch-on-trie. The switch-on-automata instruction requires one argument and is used to begin the selection process of the second stage. The argument specifies the state of the automaton from which further scanning is to be continued. Using this argument we avoid reinspecting any symbol seen by the first stage. The switch-on-string and swit ch-on-trie instructions require one and two arguments respectively. These instruc- tions are used for starting the third stage. The switch-on-string instruction starts off our string-matching-based algorithm whereas the switch-on-trie instruction initiates the

MULTISTAGE INDEXING ALGORITHMS 1111
p: switch-on-term con, f a i l , f a i l , var
con : s w i t ch-on-const { ‘a’ :Ll , ‘b’:R3}
var: switch-on-trie node-5, OxF L1: switch-on-automata state-2
varl: t r y R1 retry R3 trust R4
var2: try R2 retry R3 trust R4
var3: try R3 retry R4
C1: tryme C2 ... <code same as that in Figure 5(b)>
Figure 7. Three-stage indexing code for p in Figure S(a)
bit-vector based algorithm. The arguments for switch-on-trie instruction are the node of the trie from which further scanning is to be performed and the bit vector representing the set of currently selected clause-heads. The argument of swit ch-on-strings instruction points to the list of currently selected clauses. Using these instructions we interface the second and third stage with WAM indexing. In the following we present the details of this interface and illustrate key steps with the example program in Figure 5.
Recall that in WAM, indexing begins with the instruction switch-on-term followed by four pointers, each one pointing to one of the four chains. We modify each pointer to hook the stage appropriate to that chain. We begin with the variable chain that is used whenever the first argument of the goal is a variable. The first string of the goal in this case is empty. We therefore regard it as being vacuously scanned and bypass the second stage altogether. To do this we replace the variable chain pointer by another one that points to either switch-on-string or switch-on-trie instruction. Execution of this instruction will initiate our third stage. At the end of this stage a block containing try/retry/trust will be identified and executed. For illustration the WAM code for p incorporating our three-stage indexing method is given in Figure 7. Observe that the variable chain in this example points to a switch-on-trie instruction that will start at node-5 of the trie with the initial set containing all four clause-heads. The execution of C code for this instruction will result in selection of one of the try/retry/trust blocks at varl, var2 or var3. For example with the goal p ( X , f ( a ) , 2) the third stage will jump to varl whereas for the goal p ( X , g(a, Z), Y ) it will jump to var2. Similarly the third stage can also reach either var3 or the default chain at C1.
For the ‘list’ chain we initiate the second (or third) stage only when there is more than one clause-head for which the first argument is a list. In such a case if the list begins with a nonvariable symbol then we start the second stage; otherwise the first string has only one

1112 TA CHEN, I. V. RAMAKRISHNAN A N D R. RAMESH
symbol which has already been inspected in the first stage. Therefore we skip the second stage and proceed to the third stage directly. In the former case, the second stage is hooked to the first stage by replacing the pointer to the list chain in switch-on-term instruction by a pointer to a switch-on-automata instruction. Similarly, if we only need to start the third stage then we replace the list-chain pointer by a pointer to either switch-on-string or switch-on-trie instruction.
Recall that indexing for constant and structure symbols is done by transferring con- trol from the switch-on-term instruction to either the switch-on-constant or the swit ch-on-structure instructions. For these cases, we hook our second (or third) stage through switch-on-constant and switch-on-structure instructions instead of the swit ch-on-term instruction.
Specifically, we change the pointers stored in the index table (given as the argument to these instructions) so they point to appropriate swit ch-on-automat a instructions. Again we introduce the second (or third) stage only when there is more than one clause in a chain. For p, this has the effect of replacing the try/retry/trust sequence at L1 (see Figure 5(c)) by a switch-on-automata instruction. As the table for constant b has only one clause in the chain, the corresponding pointer is not changed. These modifications appear in Figure 7. Observe from Figure 6 that the argument to the switch-on-automata instruction in this case is state 2. Note that we skip the second stage whenever there are no uninspected symbols in the clause-heads belonging to a chain. Specifically, for those chains that only contain clause-heads in which the first strings are one symbol long the second stage will be skipped. Instead, for these chains we will initiate the third stage by branching to a third stage instruction.
We now describe the interface between the second and third stages. Recall that in our method the second stage is implemented by compiled C code that scans the goal. To make a transition from the second to the third stage we maintain a pointer final with each automaton state. This pointer points to the next WAM instruction to be executed. If the number of clauses at the end of the second stage is more than one then the final pointer points to a switch-on-string or switch-on-trie instruction. Otherwise it directly points to the WAM code of the selected clause. For example, in Figure 6, the lines labeled L3 and L4 will contain a switch-on-trie instruction whereas the statement return((3)) will be replaced by a jump R3 instruction where R3 is the label of the block of WAM instructions for the third fact for p.
Finally, we outline briefly how symbols seen in previous stages are not re-examined in the third stage. In the string-matching-based algorithm the problem is nonexistent since the same data structure (i.e. the Aho-Corasick automaton) is used uniformly in all the stages. The difficulty arises when combining the Aho-Corasick automaton with the trie used in the bit- vector-based algorithm. However, observe that each state in the Aho-Corasick automaton corresponds to a position reached in the trie. So we maintain a pointer pos(s) in every state s to its corresponding position in the trie. Whenever the bit-vector-based algorithm is initiated from a state, say A at run time, then we traverse the trie from pos(A) onwards thereby avoiding re-examination of symbols seen prior to reaching pos( A ) .
DISCUSSION OF BENCHMARKS
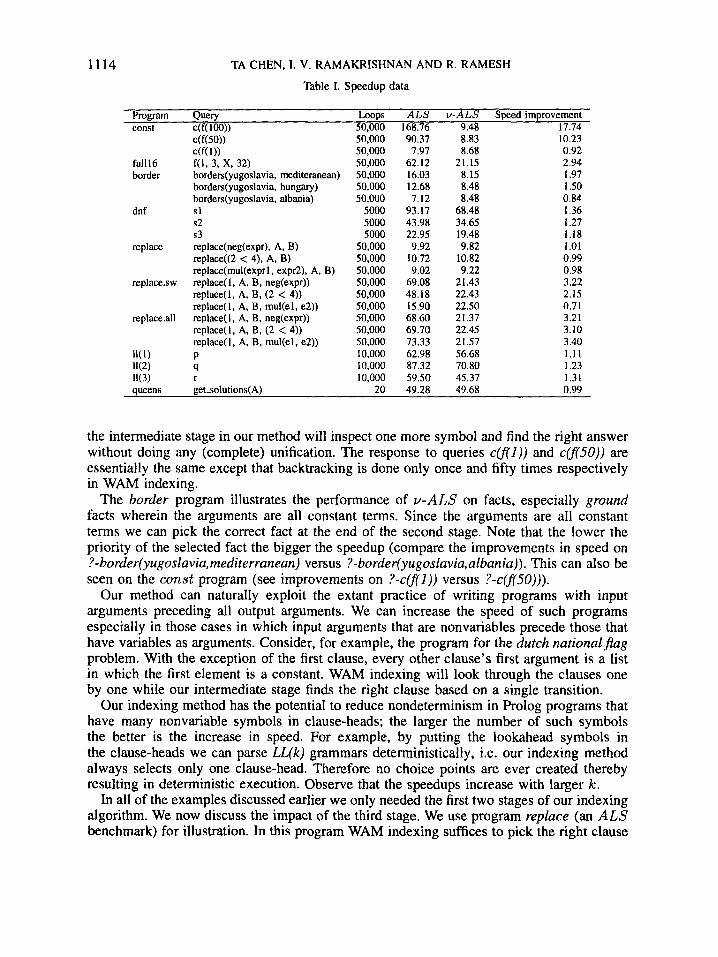
Tables I and I1 summarize the results obtained in our experiments. In Table I we give a performance comparison of ALS and V-ALS compilers whereas in Table I1 we outline the effect of each stage on the performance of PALS. We first discuss the results in Table I.

MULTISTAGE INDEXING ALGORITHMS 1113
const full16 border borders(yugoslavia.albania). borders(yugoslavia,austria). borders( yugoslavia,bulgaria).
f(1, 2, x, 1). f(l, 2, x, 2).
C(f(1)).
c(f(2)). f(1, 2, X, 16). f(1, 3, X, 17). f(l. 3. X, 18). c(f( 100)).
?- c(f(1)). ?- c(f(50)). ?- c(f(100)).
f(1, 3, X, 32).
?- f(1, 3, X, 32).
borders(yugoslavia,greece). borders(yugoslavia,hungary). borders(yugoslavia,italy). borders( yugoslavia~omania). borders(yugos1avia.mediteranean).
?- borders(yugos1avia. mediteranean) ?- borders(yugoslavia, hungary) ?- borders(yugoslavia, albania)
dnf top(In, Out) :- dnf( In, Out, Outl, Outl, Out2, Out2, [I). dnf([l, R, R, W, W, B, B). dnf([r 1 Item], [r I Rl] , R, WO, W, BO, B) :- dnf(Item, R1, R, WO, W, BO, B). dnf([w I Item], RO, R, [w I Wl]. W, BO, B) :- dnf(Item, RO, R, W1, W, BO, B). dnf([b 1 Item], RO, R, WO. W, [b 1 BI], B) :- dnf(Item, RO, R, WO, W, B1, B). s 1 1- top([b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,
b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,r,r.r,r,rl, A). s2 :- top([b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,b,r,r,r,r,r], A). s3 :- top([b,b,b,b,b,b,w,w,w,w,w,w,r,r,r,r,r,r], A).
?- sl . ?- s2. ?- s2.
Figure 8. Benchmark programs const, fu1116, border and dnf
Following that we evaluate the effect of each stage on the performance of PALS. The data in the tables were obtained by running a set of benchmark programs on one
or more queries. The figures under Loops indicate the number of times the corresponding query is run. Times are measured in seconds and speedups are computed as the ratio of the running time of programs compiled using ALS over that using PALS. All programs are run on a Sun-3/160. The programs include the dutch national&g (Figure 8) problem given in Reference 4, the border (Figure 8) predicate in the CHAT-80 system5, the replace (Figure 10) program and the 8-queens (Figure 9) problem, both of which are ALS bench- marks, and programs to parse LL(lc) (Figure 11) grammars. The first two programs const and full16 (both in Figure 8) are atypical programs contrived to highlight key aspects of our indexing algorithm.
The const program illustrates the advantage of PALS whenever it is beneficial to look beyond the first argument. On the query cdf(lOO)), WAM indexing stops after inspecting the principal functorf of the first argument. However, nothing is achieved at all since all the one hundred clauses have the same symbol there. Therefore, it has to resort to unification and backtracking through ninety-nine clauses before the right one is finally found whereas
1114 TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
Table I. Speedup data
Program Query Loops ALS V-ALS Speed improvement const c(f( 100)) 50,000 168.76 9.48 17.74
full 16 border
dnf
replace
replace.sw
replace.al1
1 N I ) W2) 1K3) aueens
c(f(50)) C(f(1)) f(1, 3, X, 32) borders(yugoslavia, mediteranean) borders(yugos1avia. hungary) borders(yugoslavia, albania) s l s2 s3 replace(neg(expr), A, B) replace((2 < 4), A. B) replace(mul(expr1, expr2), A, B) replace( 1, A, B, neg(expr)) replace(1, A, B, (2 < 4)) replace(1, A, B, rnul(el, e2)) replace(1, A, B, neg(expr)) replace(1, A, B. (2 < 4)) replace(1, A, B, rnul(e1, e2)) P 9 r eet-solutions( A)
50,000 50,000 50,000 50,000 50,000 50,000
5000 5000 5000
50,000 50,000 50,000 50,000 50,000 50,000 50,000 50,000 50,000 10,000 10,000 10,000
20
90.37 7.97
62.12 16.03 12.68 7.12
93.17 43.98 22.95 9.92
10.72 9.02
69.08 48.18 15.90 68.60 69.70 73.33 62.98 87.32 59.50 49.28
8.83 8.68
21.15 8.15 8.48 8.48
68.48 34.65 19.48 9.82
10.82 9.22
2 1.43 22.43 22.50 21.37 22.45 21.57 56.68 70.80 45.37 49.68
10.23 0.92 2.94 1.97 1 S O 0.84 1.36 1.27 1.18 1.01 0.99 0.98 3.22 2.15 0.71 3.21 3.10 3.40 1.11 1.23 1.31 0.99
the intermediate stage in our method will inspect one more symbol and find the right answer without doing any (complete) unification. The response to queries ~(’1)) and c(f(50)) are essentially the same except that backtracking is done only once and fifty times respectively in WAM indexing.
The border program illustrates the performance of PALS on facts, especially ground facts wherein the arguments are all constant terms. Since the arguments are all constant terms we can pick the correct fact at the end of the second stage. Note that the lower the priority of the selected fact the bigger the speedup (compare the improvements in speed on ?-border(yugoslavia,mediterranean) versus ?-border(yugoslavia,albania)). This can also be seen on the const program (see improvements on ?-ccf(l)) versus ?-c(f(50))).
Our method can naturally exploit the extant practice of writing programs with input arguments preceding all output arguments. We can increase the speed of such programs especially in those cases in which input arguments that are nonvariables precede those that have variables as arguments. Consider, for example, the program for the dutch national j a g problem. With the exception of the first clause, every other clause’s first argument is a list in which the first element is a constant. WAM indexing will look through the clauses one by one while our intermediate stage finds the right clause based on a single transition.
Our indexing method has the potential to reduce nondeterminism in Prolog programs that have many nonvariable symbols in clause-heads; the larger the number of such symbols the better is the increase in speed. For example, by putting the lookahead symbols in the clause-heads we can parse LL(k) grammars deterministically, i.e. our indexing method always selects only one clause-head. Therefore no choice points are ever created thereby resulting in deterministic execution. Observe that the speedups increase with larger k.
In all of the examples discussed earlier we only needed the first two stages of our indexing algorithm. We now discuss the impact of the third stage. We use program replace (an ALS benchmark) for illustration. In this program WAM indexing suffices to pick the right clause
MULTISTAGE INDEXING ALGORITHMS 1115 Table 11. Effect of each stage on the performance gain
Program Query Loops Stages Used 1 only 1 and 3 1 and 2 all
( A W (PALS) const C(f(lc@)) 50,000 168.76 29.52 - 9.48
full 16 border
dnf
replace
replacesw
replace.ai1
1 ) W2) N3) Queens
90.37 7.97
62.12 16.03 12.68 7.12
93.17 43.98 22.95 9.92
10.72 9.02
69.08 48.18 15.90 68.60 69.70 73.33 62.98 87.32 59.50 49.28
27.55 26.02 21.00 12.85 11.39 9.89
95.68 46.28 26.24 - - -
21.39 22.74 21.05 - - -
73.06 85.41 54.69 -
- 8.83 - 8.68
22.94 21 .I5 - 8.15 - 8.48 - 8.48 - 68.48 - 34.65 - 19.48 - 9.82 - 10.82 - 9.22
61.31 21.43 43.29 22.43 16.17 22.50 - 21.37 - 22.45 - 21.57 - 56.68 - 70.80 - 45.37 - 49.68
c(f(50)) c(f( 1 )) f(1, 3, X, 32) borders(yugos1avia. mediteranean) borders(yugos1avia. hungary) borders(yugos1avia. albania) sl s2 s3 replace(neg(expr), A, B) replace((2 < 4). A, B) replace(mul(expr1, expr2), A, B) replace(1, A, B, neg(expr)) replace(], A, B, (2 < 4)) replace(], A, 9, mul(e1, e2)) replace(1, A, B, neg(expr)) replace(1, A, B, (2 < 4)) replace(1, A, B, muI(e1, e2)) P 9 r
50,000 50,000 50,000 50,000 50,000 50,000
5000 5000 5000
50,000 50,000 50,000 50,000 50,000 50,000 50,000 50,000 50,000 10,000 10,000 10,000
getsolutions(A) 20 .~
in all the queries shown in the table. Hence our speeds are comparable with that of ALS. So in repluce.sw we switch the first argument of every clause in replace to the last and put a constant 1 at its original position in order to nullify the effect of the first two stages. Therefore all the twelve clauses appear as input to the final stage. The queries that look for the last and fourth clause in the program obtain improvements of 3.22 and 2.15 respectively. There is a slowdown when selecting the first clause. This is because the overhead in our final stage becomes a dominant factor when selecting very high priority clauses. (See the discussion on improving such cases in Section 6.) In our current implementation we have observed that we start gaining whenever we have to select clauses with priority greater than three. Program full26 is another example that uses all the three stages.
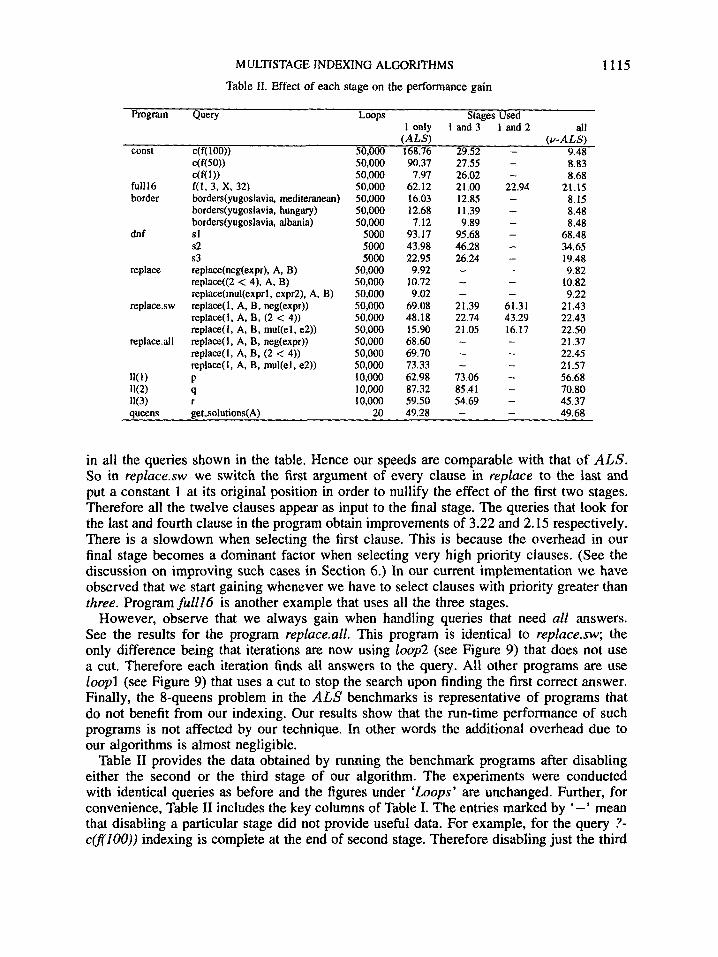
However, observe that we always gain when handling queries that need all answers. See the results for the program repluce.al1. This program is identical to replace.sw; the only difference being that iterations are now using loop2 (see Figure 9) that does not use a cut. Therefore each iteration finds all answers to the query. All other programs are use loop1 (see Figure 9) that uses a cut to stop the search upon finding the first correct answer. Finally, the 8-queens problem in the ALS benchmarks is representative of programs that do not benefit from our indexing. Our results show that the run-time performance of such programs is not affected by our technique. In other words the additional overhead due to our algorithms is almost negligible.
Table I1 provides the data obtained by running the benchmark programs after disabling either the second or the third stage of our algorithm. The experiments were conducted with identical queries as before and the figures under ‘Loops’ are unchanged. Further, for convenience, Table I1 includes the key columns of Table 1. The entries marked by ‘-’ mean that disabling a particular stage did not provide useful data. For example, for the query ?- c(’Z00)) indexing is complete at the end of second stage. Therefore disabling just the third

1116 TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
queens size(8). int( 1). int(2). int(3). int(4). int(5). int(6). int(7). int(8). getsolutions(So1n) :- solve([], Soln). newsq([]. sq(1. X)) :- int(X). newsq([sq(I,J) I Rest], sq(X,Y)) :- X is I + 1, int(Y), no-threat(1. J, X, Y).
safe([], X, Y). safe([sq(I,J) 1 L], X, Y) :- noAreat(1, J, X, Y). safe(L, X, Y). no-threat([, J, X, Y) :- I =\= X. J =\= Y, I-J =\= X-Y, ItJ =\= X+Y. solve([sq(Bs,Y) I L], [sq(Bs,Y) 1 L]) :- size(Bs). solve(Init, Fin) :- newsq(1nit. Next), solve([Next I Init], Fin).
?- getsolutions(A).
safe(Rest, X, Y).
loop1 loop2 repeat(0) :- !. repeat(K) :- cdl(x), Kl is K-1, !,
repeat(0) :- !. repeat(K) :- call(x), fail. repeat(K) :- K1 is K - 1, repeat(K1). repeat( K 1).
Figure 9. Benchmark program queens
stage alone did not change the performance. Observe that for the const program indexing can be completed in the first two stages.
By disabling the second stage we force the algorithm to proceed to the third stage where it performs the selection usually done by the skipped second stage. Further this computation is carried out using the string-matching based method. As the operations performed in this method are more complex than any of the other methods we see a slow down in performance. Based on the data in Table I1 we conclude that the string-matching based selection can be about three times slower than our second stage. However, the running times are still better than that obtained by first argument indexing alone (see column under ALS).
Like the const program, border is also a collection of facts. However, border is smaller and hence we can perform the third stage using the bit-vector method. Although the bit- vector method is not as general as the string-matching method, its run-time overhead is significantly smaller. First, it need not scan the goal prior to selection and second, all rules are processed together as a set. Consequently, the effect of disabling the second stage is less dramatic in this case. In fact we see only a 50 per cent slow down in this case. Again the performance with just the third stage alone is superior to the first-argument indexing of ALS.
Both d n f and ZZ(k) programs are examples where the second stage is critical. Each procedure in these programs is quite small. Therefore backtracking over them is relatively inexpensive. In such programs the effectiveness of the indexing method depends on its speed in addition to its ability to discriminate sharply. Note that in our method the third stage is slower than the second stage. In fact the performance difference between them is sufficiently large so that enabling just the third stage alone is not beneficial. This is because the reduction in running time due to the reduced backtracking (with indexing) is smaller than the running time of our third stage. Consequently the performance in this case is worse even when compared with the first-argument indexing in ALS.
In all of these programs, we compared the effect of the second stage with that of the third stage for programs that can be indexed by either one of the two stages. In the following we discuss programs that need both these stages to complete indexing. fuZZ16 is a program that

MULTISTAGE INDEXING ALGORITHMS 1117
replace replace(mul(A,B), replace(abs(X), replace((A+B), replace((A-B), replace((A*B), replace((A/B), replace((A <B), replace( (A > B), replace((A>=B), replace((A=<B), repIace(eq(A,B). replace(neg(X).
replacesw replace(1, Z, mul(A,B,Z), replace( 1, V, abs(X,V), replace(1, Z. (Z is A+B), replace(1, Z. (Z is A-B), replace(1. Z, (Z is A*B), replace(1, Z, (Z is AIB), replace( 1, Z. It(A,B,Z), replace(1, Z, gt(A,B,Z), replace(1, Z, ge(A,B,Z), replace( 1, Z, le(A,B,Z), replace(1, Z, eq(A,B,Z), replace(1, T. neg(X,T),
?- replace(neg(expr), A, B). ?- replace((2 < 4), A, B). ?- replace(mul(expr1, expr2), A, B).
?- replace(1, A, B, neg(expr)). ?- replace(1, A, B, (2 < 4)). ?- replace(1, A, B, mul(e1, e2)).
Figure 10. Benchmark programs replace and replacesw
has the most crucial indexing symbol as the last argument in the clause-head. Since the first two stages do not inspect this symbol we need the third stage. However, the data in Table I1 indicate that the third stage does not provide a significant speedup compared with the first two stages. We believe that this is again due to relatively little overhead associated with backtracking. (The (complete) unification in this case is very simple.) Observe that with first-argument indexing all 32 clauses need to be tried through backtracking whereas with second stage it is reduced to sixteen. It appears that further reduction at the cost of including the third stage seems to improve the performance only slightly due to the relatively high run-time overhead associated with the third stage.
Unlike fu1116, the repZace.sw program obtains significant improvement from the third stage. Observe from the data for repZace.sw that skipping the third stage produces running times close to those of first-argument indexing. This is because of the following two reasons. First, the second stage does not improve the selection at all as the first strings obtained from the clause-heads in this case are identical. Therefore no filtering is achieved and we are left with all 12 clauses in the third stage. Second, each clause-head is quite complex requiring subterms to be constructed in the heap during (complete) unification. This makes backtracking very costly. So, skipping the third stage (despite its overhead) is detrimental to performance. Actually, in this case the number of clauses indexed in the third stage is smaller than that indexed in thefiZtZ6 program (12 versus 16). Nevertheless the third stage improves performance showing the importance of the third stage especially when clause-heads are complex.
In summary, the data in Table I1 suggest that, in general, it is always beneficial to include the first two stages. The exceptions are either when first-argument indexing is sufficient or the program consists of very small procedures with very simple clause-heads. The third stage becomes significant for programs that cannot be indexed effectively by the first two stages and have complex clause-heads requiring substantial time for the (complete) unification that follows the indexing. This suggests that the three-stage indexing method can be made more effective by a better criterion for invoking the next stage. In particular, the structure of the remaining clause-heads needs to be inspected before invoking the next stage. Note that this analysis can be done at compile time as it only involves inspecting clause-heads.

1118 TA CHEN, I. V. RAMAKRISHNAN AND R. RAMESH
Program e(A, B) :- t(A,C), el(C, B). el([ id I A I, [ id I A 1). el([ + I A I, B) :- t(A, C), el(C, B). tl([l. [I).
f([ id I A I , A). p :- e([id,+,id,+,id,+, id, +, id, +, id, +, id, +, id, *, id, *, id,*, id, *, id, *,
el([l, 11). el([ * I A I. [ * I A I). t(A, B) :- f(A, C), tl(C, B). tl([ id 1 A 1, [ id I A I).
tU[ + I A I. [ + I A I). t1([ * I A 1, B) :- f(A, C), tl(C, B).
id, *, id, *, id], A).
?- p.
W) 1K3) Grammar Grammar S +c I abA A -+b 1 SA’ A’--raa S + c 1 abA A --tab 1 aabAA’ I aA’
Figure 1 I. Benchmark programs for l l (k) grammars
CONCLUSIONS
We have described the design and implementation of the PALS compiler that incorpo- rates an indexing technique based on unification. The technique appeared to be beneficial to atypical Prolog programs (e.g. deep term structures and large number of clauses con- stituting procedures). To extend its applicability to a broad spectrum of Prolog programs we decomposed the technique to do indexing in multiple stages. Each stage further shrinks the size of its input set by employing operations relatively more complex than those used in previous stages. We validated the practical viability of our approach by showing good improvements over a range of Prolog programs typically encountered in practice.
We remark that there is room for further improvement such as optimizing our code based on a more comprehensive compile time analysis. For example, the interstage interface can be improved based on the structure of the clause-heads selected at the end of each stage. Similarly, if during indexing we compute at most one substitution for any variable then the complete-unification step that follows indexing can be skipped. Including these optimizations can further improve the speed of execution.
ACKNOWLEDGEMENTS
We express our sincere thanks to David S. Warren for his stimulating ideas, enthusiasm and constant encouragement that enabled the completion of this project. We also thank Dr R.C. Sekar for valuable discussions that made us focus on tangible implementation goals.

MULUSTAGE INDEXING ALGORITHMS 1119
The first two authors’ research was supported by NY grant RDG-90173 and NSF grant CCR9102159. The third author was supported by the NSF under grant CCR 9110055.
REFERENCES
1 . R. Ramesh, I. V. Ramakrishnan and D. S. Warren, ‘Automata-driven indexing of Prolog clauses’, Seven- teenth Annual ACM Symp. on Principles of Programming Languages, Sun Francisco, 1990, pp. 281-290.
2. M. S. Paterson and M. N. Wegman, ‘Linear unification’, J. Comput. Sys. Sci., 16, 158-167 (1978). 3 . A. Martelli and U. Montanari, ‘An efficient unification algorithm’. Trans. Programming Languages and
Systems, 4(2), 258-282 (1982). 4. R. A. O’Keefe, The Crafr of Prolog, MIT Press, MA, 1990. 5. D. H. D. Warren and F. C. N. Pereira, ‘An efficient easily adaptable system for interpreting natural language
queries’, Amer. J. Comput. Linguistics, S(3-4), 110-122 (1982). 6. A, V. Aho and M. J. Corasick, ‘Efficient string matching: An aid to bibliographic search’, Commun. ACM,
7. D. H. D. Warren, ‘An abstract Prolog instruction set, Technical Note 309, SRI International, 1983. 8. H. Aft-Kaci, ‘The WAM: A (real) tutorial’, Technical Report, Paris Research Laboratory, Digital Equipment
Corporation, January 1990.
18(6), 333-340 (1975).