image color content description utilizing perceptual color correlogram
TRANSCRIPT
Seediscussions,stats,andauthorprofilesforthispublicationat:https://www.researchgate.net/publication/4351569
ImagecolorcontentdescriptionutilizingperceptualColorCorrelogram
CONFERENCEPAPER·JULY2008
DOI:10.1109/CBMI.2008.4564947·Source:IEEEXplore
CITATION
1
READS
36
3AUTHORS:
MuratBirinci
TampereUniversityofTechnology
10PUBLICATIONS24CITATIONS
SEEPROFILE
SerkanKiranyaz
QatarUniversity
122PUBLICATIONS823CITATIONS
SEEPROFILE
MoncefGabbouj
TampereUniversityofTechnology
569PUBLICATIONS4,967CITATIONS
SEEPROFILE
Availablefrom:SerkanKiranyaz
Retrievedon:04February2016

1This work was supported by the Academy of Finland, project No. 213462 (Finnish Centre of Excellence Program (2006 - 2011) The research leading to this work was partially supported by the COST 292 Action on Semantic Multimodal Analysis of Digital Media
IMAGE COLOR CONTENT DESCRIPTION UTILIZING PERCEPTUAL COLOR CORRELOGRAM
Murat Birinci, Serkan Kiranyaz and Moncef Gabbouj1 Tampere University of Technology, Tampere, Finland
{murat.birinci, serkan.kiranyaz, moncef.gabbouj }@tut.fi
ABSTRACT
Most of the content-based image retrieval (CBIR) systems frequently utilize color as a discriminative feature among images, due to its robustness to noise, image degradations, and changes in resolution and orientation. While there are vast amount of color descriptors for describing global properties of colors such as “what” and “how much” color present in an image, less research has succeeded in describing the spatial properties among colors such as “where” and “how”. Color Correlogram is one of the most promising spatial color descriptors at the current state of art. However, it has several limitations, which make it infeasible even for ordinary image databases. In this paper we present a perceptual approach that eliminates such restrictions from Correlogram and further increases its discrimination power. Experimental results demonstrate Correlogram’s handicaps and the success of the proposed approach in terms of retrieval accuracy and feasibility.
1. INTRODUCTION
Content-based image retrieval (CBIR) is an ongoing research field yielding several systems such as MUVIS [12], QBIC [6], PicHunter [4], Photobook [14], VisualSEEk [16], Virage [19], VideoQ [3], etc. In such frameworks, database primitives are mapped into some high dimensional feature domain, which may consist of several types of descriptors. Among them careful selection of some sets to be used for a particular application may capture the semantics of the database items in a content-based multimedia retrieval (CBMR) system. In this paper we shall restrict the focus on CBIR domain, which employ only the color descriptor for image retrieval. It is a fact that color alone does not provide complete information for CBIR over general and broad-context image databases; still a proper characterization of color content of visual scenery can be a powerful tool for content-based image retrieval when it is extracted in a perceptual and semantic way. The traditional approach in CBIR is the color histogram [18], which utilizes a static color space quantization where the color palette boundaries are determined empirically or via some heuristics –yet nothing based on human color perception rules. No matter how the quantization levels (number of bins) are set, pixels with similar colors but either side of the
quantization boundary separating two consecutive bins will be clustered into different bins and this is an inevitable source of error in all histogram-based methods. The color quadratic distance [6] proposed in the context of QBIC system provides a solution to this problem by fusing the color bin distances into the total similarity metric. This formulation allows the comparison of different histogram bins with some inter-similarity between them; however it underestimates distances because it tends to accentuate the color similarity [17]. Furthermore, Po and Wong in a recent study [15] show that it does not match the human color perception well enough and may result incorrect ranks between regions with similar salient color distributions. Hence it gives even worse results than the naïve Lp metrics on some particular cases. Moreover, static color space quantization creates a large amount of redundant bins, which are not covered by the colors present in the image or holds insignificant amount of pixels of them. Including such outliers into image similarity computations will not only significantly bias the results, but also consume valuable memory and computational time. Therefore, the resulting descriptor will be noisy, insufficient in terms of discrimination power and unreliable. Another way for color discretization is using a dynamic quantization method, i.e. an image dependent clustering. In other words, instead of quantizing the whole color space, only the existing colors in the image are quantized. Recent studies in human color perception, such as [1], [9], [11] claim that human eye can not perceive large number of colors present in an image at the same time. Moreover, our eyes can not distinguish between similar colors. In other words, even if we have, say a 24-bit image (16 777 216 colors), what a human eye perceives is just a few prominent colors, i.e. the so called Dominant Colors (DCs). Thus, dynamic quantization clusters the existing colors into few DCs and keeps the color content perceptually the same while providing a drastic decrease in the number of colors. Accordingly, in [10] it has been shown that the two color patterns that have similar DCs are perceived as similar and two multicolored patterns are perceived as similar if they possess the same (dominant) color distributions regardless of their content, directionality, placement or repetitions of a structural element. Leading up from these facts various DC descriptors are developed, such as [1], [5], [9] and
978-1-4244-2044-5/08/$25.00 c©2008 IEEE. 200 CBMI 2008

[11], that utilize dynamic quantization and extract few prominent colors based on the image content. Furthermore, human color perception is strongly dependent on the variations in their adjacency, thus the spatial distribution of the prominent colors should also be inspected in a similar manner. The color Correlogram [7], is one of the most promising approaches in the current state of art, which is a table where the kth entry for the color histogram bin pair (i, j) specifies the probability of finding a pixel of color-bin j at a distance k within a maximum range d, from a pixel of color-bin i in an image I with dimensions W x H quantized with m colors. Accordingly, Ma and Zhang [8], conducted a comprehensive performance evaluation among several global/spatial color descriptors for CBIR and reported that Correlogram achieves the best retrieval performance among many others, such as color histograms, Color Coherence Vector (CCV) [13], color moments, etc. However, it comes along with many infeasibility problems such as its massive memory requirement and computational complexity. Since the size of Color-Correlogram table is O(m2.d), it requires a substantial amount of memory for a reasonable range and color quantization (i.e. number of bins used in RGB histogram). For instance, a choice of (say 8x8x8 bins) 512 colors for representing the RGB color space and a range of 100 pixels, which is still fairly small to be called a spatial descriptor considering today’s megapixel image dimensions, the memory required for a single image exceeds 200 Mbytes. Thus, a simplified version, the so-called Auto-Correlogram, which only captures the spatial correlation between the same colors and thus reduces the feature vector size to O(m.d) bytes, has been proposed in [7]. Still, considering today’s database and image sizes, it is obvious that the memory restriction of the Color-Correlogram is and will be significantly restraining even with the Auto-Correlogram.
Figure 1: First 6 ranks of Correlogram retrieval (via QBE)
in a 10K database. Top-left is the query image Another restrictive factor in the feasibility of the Correlogram is its extreme computational complexity. The naïve algorithm takes O(W.H.d2), which is a massive computation. The fast algorithm introduced in [7] reduces
this to O(W.H.d) however requiring O(W.H.d.m) memory space. For the aforementioned Correlogram settings (m=512, d=100) and a 1 Mpel image Correlogram requires ~820 Gbyte memory space for the fast computation, which is obviously infeasible. Apart from the aforementioned feasibility problems, using the probability alone makes the descriptor insensitive to the dominance of a color or its area (weight) in the image. This might be a desirable property in finding the similar images simply “zoomed” as in [7], and hence the color areas significantly vary but the distance probabilities do not; however it also causes severe mismatches especially in large databases, as one typical example is shown in Figure 1. In this paper, stemming from the earlier discussions, a perceptual approach is proposed in order to overcome the shortcomings of the Correlogram, namely its lack of perceptuality and infeasible system requirements. We present a color descriptor that utilizes a dynamic color clustering and extracts the DCs present in an image in order to bring in the nonexistent perceptuality to the Correlogram. Global color properties are thus obtained from these clusters. DCs are than back-projected onto the image to capture the spatial color distribution (SCD) via DC-based Correlogram. Finally, a penalty-trio model combines both global properties extracted from the DCs and their spatial similarities obtained through Correlogram, forming a perceptual distance metric. The rest of the paper is organized as follows. The formation of the descriptor and penalty trio model is given in Section 2. Section 3 demonstrates the transcendence of the descriptor experimentally and Section 4 concludes the paper.
2. THE PERCEPTUAL CORRELOGRAM
In order to obtain the global color properties, DCs are extracted in a way human visual system perceives them, and then back-projected onto the image so as to extract their spatial relations via DC-based Correlogram. The overview of the feature extraction (indexing) process is illustrated in Figure 2. In the retrieval phase, a penalty-trio model is utilized that penalizes both global and spatial dis-similarities in a joint scheme. 2.1. Formation of the Color Descriptor
The adopted DC extraction algorithm is similar to one in [5] where the method is entirely designed with respect to human color perceptual rules and configurable with few thresholds:
• ST (color similarity)
• AT (minimum area)
• Dε (minimum distortion)
• maxDCN (maximum number of DCs)
201

As the first step, the true number of DCs present in the image (i.e. max1 DCDC NN ≤≤ ) are extracted in CIE-Luv
color domain. Let iC represents the ith DC class (cluster) with the following members: ci the color value (centroid), wi the weight (unit normalized area). Due to the DC thresholds set beforehand, SjiAi TccTw >−> , for
DCNji ≤≤ ,1 . The extracted DCs are then back-projected to the image for further analysis, namely extraction of the SCD.
Spatial distribution of the extracted DCs is represented as a Correlogram table as described in [7], except the fact that the colors utilized are the ones coming from the DC extraction; hence, DCNm = . Thus, for every DC pair on the back-projected image, the probability of finding a pixel of DC ci from a pixel of DC cj at distance of k pixels is calculated. The extracted Correlogram table and the global features ( ii wc , ) are stored in the database’s feature vector.
Figure 2: Overview of the proposed approach
2.2. Retrieval via Penalty-trio Model
In the retrieval phase, whilst judging the similarity of two image’s global and spatial color properties, two DC lists together with their Correlogram tables are to be compared. The more dissimilar colors are present, the larger their (dis-)similarity distance should be. In order to do so, DCs in both images are subjected to a one-to-one matching. The proposed model penalizes for the mismatching colors together with the global and spatial dis-similarities between the matching through the following properties:
• φP : The amount of different (mismatching) DCs • The differences of the matching DCs in:
o GP : Global differences o CorrP : Correlogram differences
So the overall penalty (color dis-similarity) between query image Q and a database image I over all color properties can be expressed as:
)),()1(),((),(),( IQPIQPIQPIQP CorrG ααφ −++=Σ (1)
where 1≤ΣP is the (unit) normalized total penalty, which corresponds to (total) color similarity distance and
10 << α is the weighting factor between global and
spatial color properties of the matching DCs. Therefore, the model computes a complete distance measure from all color properties. In order to get a better understanding of the penalty terms, consider two sets of matching ( MS ) and mismatching ( φS ) colors selected among the colors of a database I ( IC ) and query Q ( QC ) images, thus
QIM CCSS +=+ φ . Here φS consists of the colors
that holds φSccTcc jiSji ∈∀>− , and the sub-
set MS holds the rest of the (matching) colors. Accordingly φP can be defined directly as:
12
)|(),( ≤
∈= ∑
φ
φScw
IQP ii (2)
Consider the case where { }φ=MS , which means there are no matching colors between images Q and I. Thus 1==∑ φPP , which makes sense since color-wise there is nothing similar between two images. Conversely, if { } 0=⇒= φ
φ φ PS , the dis-similarity will only emerge from the global and spatial distribution of colors, i.e. GP and CorrP which are expressed as follows:
202

where )(,
kcc ji
γ is the probability of finding DC ci at a
distance k from DC cj and 10 << β in GP provides the adjustment between color area (weight) difference (i.e. 1st term) and DC (centroid) difference of the matching colors (i.e. 2nd term). Note that the distance function used for comparing two Correlogram tables ( CorrP ) is not the one proposed in [7], which avoids division-by-zero case via adding a ‘+1’ term to the denominator. However, values in Correlogram are the probabilities that hold 10 )(
, << kcc ji
γ , thus such an
addition becomes relatively significant and introduces a bias to distances; hence strictly avoided in our distance calculations. As a result, the weighted combination of GP and
CorrP represent the amount of dis-similarity that occur in the color properties and the unit normalization allows the combination in a configurable way with weight α, which can favor one color property to another. With the combination of φP , the penalty trio models a complete similarity distance metric between two color compositions.
3. EXPERIMENTAL RESULTS
The proposed color descriptor Perceptual Correlogram and the two traditional descriptors, Correlogram and MPEG-7 Dominant Color Descriptor (DCD), are implemented as a Feature eXtraction (FeX) module within MUVIS framework [12], in order to test and compare the
performances in the context of CBIR. All descriptors are tested over two separate databases using a PC with P4 3.2Ghz CPU and 2Gb of RAM. First database has 1088 synthetic images that are formed of arbitrary shaped and colored regions. In this way, the color matching accuracy can visually be tested and the penalty terms, i.e. φP , GP and CorrP , can individually be analyzed via changing the shape and/or size of any color regions. Furthermore, the robustness against resolution, translation and rotation changes can be compared against the traditional Correlogram. First 12 retrievals of two queries from synthetic database are shown in Figure 3. In Q1, Correlogram’s area insensitivity, due to its probabilistic nature, can clearly be observed. It can retrieve the first relevant image only at the 8th rank whilst the proposed Perceptual Correlogram retrieved 7 similar color compositions on the first page using d=10, it still fails to bring them to higher ranks due to the limited range value (d=10). When d is set as 40, all relevant images sharing with similar color compositions can be retrieved in the highest ranks. Q2 in Figure 3 demonstrates the resolution dependency of the Correlogram, where it fails to retrieve the image with identical color structure but different resolution in the first page. Even though the penalty trio model aids to overcome resolution dependence problem, note that the proposed descriptor still utilizes Correlogram as the spatial descriptor and hence the proposed Perceptual Correlogram manages to retrieve it only at the 3rd rank and despite severe resolution differences, it can further retrieve most of the relevant images on the first page.
∑ ∑
∑∑
∈ =
=
=
+
−
==
=
≤−
−+−=
M
jiji
jiji
jiji
M
M
Sji
d
k kcc
kcc
kcc
kcc
kcc
kcc
Corr
MS
N
i
Ii
QiN
i
Ii
QiG
elseIQ
IQ
IQif
IQP
NT
ccwwIQP
, 1 )(,
)(,
)(,
)(,
)(,
)(,
1
2
1
)()(
)()(
0)()(0
),(
1)(
)1(),(
γγ
γγγγ
ββ
(3)
203
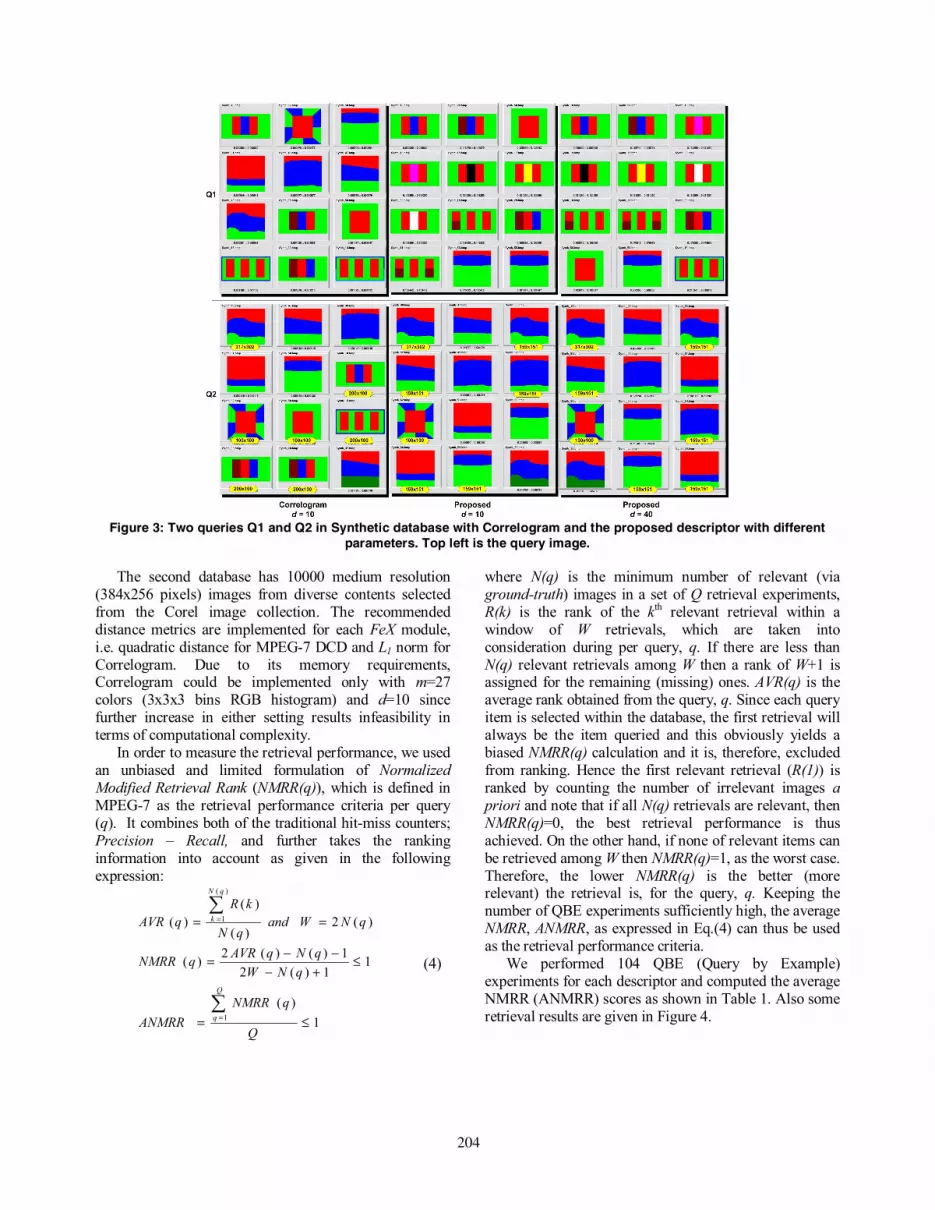
Figure 3: Two queries Q1 and Q2 in Synthetic database with Correlogram and the proposed descriptor with different
parameters. Top left is the query image. The second database has 10000 medium resolution (384x256 pixels) images from diverse contents selected from the Corel image collection. The recommended distance metrics are implemented for each FeX module, i.e. quadratic distance for MPEG-7 DCD and L1 norm for Correlogram. Due to its memory requirements, Correlogram could be implemented only with m=27 colors (3x3x3 bins RGB histogram) and d=10 since further increase in either setting results infeasibility in terms of computational complexity. In order to measure the retrieval performance, we used an unbiased and limited formulation of Normalized Modified Retrieval Rank (NMRR(q)), which is defined in MPEG-7 as the retrieval performance criteria per query (q). It combines both of the traditional hit-miss counters; Precision – Recall, and further takes the ranking information into account as given in the following expression:
1)(
11)(2
1)()(2)(
)(2)(
)()(
1
)(
1
≤=
≤+−
−−=
==
∑
∑
=
=
Q
qNMRRANMRR
qNWqNqAVRqNMRR
qNWandqN
kRqAVR
Q
q
qN
k
(4)
where N(q) is the minimum number of relevant (via ground-truth) images in a set of Q retrieval experiments, R(k) is the rank of the kth relevant retrieval within a window of W retrievals, which are taken into consideration during per query, q. If there are less than N(q) relevant retrievals among W then a rank of W+1 is assigned for the remaining (missing) ones. AVR(q) is the average rank obtained from the query, q. Since each query item is selected within the database, the first retrieval will always be the item queried and this obviously yields a biased NMRR(q) calculation and it is, therefore, excluded from ranking. Hence the first relevant retrieval (R(1)) is ranked by counting the number of irrelevant images a priori and note that if all N(q) retrievals are relevant, then NMRR(q)=0, the best retrieval performance is thus achieved. On the other hand, if none of relevant items can be retrieved among W then NMRR(q)=1, as the worst case. Therefore, the lower NMRR(q) is the better (more relevant) the retrieval is, for the query, q. Keeping the number of QBE experiments sufficiently high, the average NMRR, ANMRR, as expressed in Eq.(4) can thus be used as the retrieval performance criteria. We performed 104 QBE (Query by Example) experiments for each descriptor and computed the average NMRR (ANMRR) scores as shown in Table 1. Also some retrieval results are given in Figure 4.
204

Figure 4: 4 queries in Corel 10K database. In each query top-left is the query image.
205

Table 1: ANMRR results for 10K database
MPEG7 DCD
Corr. d=10
Proposed d=10
Proposed d=40
ANMRR 0,495 0,422 0,391 0,401 The proposed Perceptual Correlogram extracts both global and spatial color properties throughout the whole image, thus erroneous queries such as in Figure 1 can be avoided where global color properties vary significantly (e.g. see Fig. 5).
Figure 5: Retrieval performances the proposed approach
for the query in Figure 1 As discussed earlier, in some particular cases, traditional Correlogram may yield a better retrieval performance than the proposed descriptor. Figure 6 shows a typical example where the retrieved images by Correlogram are the zoomed versions of the query image or they are all taken from different viewpoints. Apart from such special query examples, the proposed descriptor achieved better retrieval performance on the majority of the queries performed. Yet the most important point is the feasibility issue of both descriptors. Note that the utilization of the traditional Correlogram is only possible because image resolution is fairly low (384x256 pixels), database contains only 10000 images and the range value (d) is quite limited, i.e. d=10. Even with such settings, the Correlogram required 556Mb disc space and 850Mb memory (fast algorithm) during the feature extraction phase, where the proposed method takes 53Mb disk space and 250Mb memory for max
DCN =8 and d=10 achieving a ~%90 reduction in storage space and ~%70 in computational memory requirement (fast algorithm). Henceforth, only the proposed descriptor can be used if a further increase occurs in any of the settings.
Figure 6: A special case where Correlogram works better
than the proposed descriptor
4. CONCLUSIONS
In this paper we proposed a perceptual color descriptor, which is primarily designed to overcome the drawbacks of Color-Correlogram and brings a solution to its infeasibility problems. Utilization of dynamic color quantization instead of a static color space quantization, not only achieves a more perceptual description of the color content, but also significantly decreases the number of colors. By doing so, the size of the Correlogram table is reduced to feasible limits and since the memory limitations are also suppressed, implementation with higher range values (d) has become possible. But still, it should be noted that such pixel based proximity measure is highly resolution dependent and if large image resolutions are considered, increasing the d value would become a restrictive factor in terms of memory and speed. Since a dynamic color quantization is applied, the obtained DCs do not have fixed centroids as in static quantization. Therefore, during the retrieval phase comparison of such colors were taken care of a one-to-one color matching scheme, which is preferred due to its accurate and fast computation. Yet much complex color matching methods are also possible, such as one to many matching, that involves comparison and/or combination of many global and spatial features. Apart from efficient and perceptual description of the color content, as discussed earlier use of spatial differences only, particularly in terms of probabilities, leaves a color descriptor incomplete. Retrievals on the synthetic databases also demonstrate that global properties are indispensable in judging the color content similarity. They further show that the proposed penalty trio model effectively combines spatial and global features into a similarity distance metric. Although the main aim of the proposed descriptor was to solve the infeasibility problems of the traditional Correlogram, the induced perceptuality and addition of global properties further increased the discrimination power. Experimental results and the ANMRR scores also demonstrate such superiority. However, it should be noted
206

that color alone does not fully describe the entire image content and it can be associated with it only in a certain extend.
5. REFERENCES
[1] G. P. Babu, B. M. Mehtre, and M. S. Kankanhalli, “Color Indexing for Efficient Image Retrieval”, Multimedia Tools and Applications, vol. 1, pp. 327-348, Nov. 1995.
[2] E. L. van den Broek, P. M. F. Kisters, and L. G. Vuurpijl, ”The utilization of human color categorization for content-based image retrieval”, in Proc. of Human Vision and Electronic Imaging IX, pp. 351-362, San José, CA (SPIE, 5292), 2004.
[3] S.F. Chang, W. Chen, J. Meng, H. Sundaram and D. Zhong, “VideoQ: An Automated Content Based Video Search System Using Visual Cues”, In Proc. of ACM Multimedia, Seattle, 1997.
[4] I. J. Cox, M. L. Miller, S. O. Omohundro, O. N. Yianilos, ”PicHunter: Bayesian Relevance Feedback for Image Retrieval”, In Proc. of ICPR’96, pp. 361-369, 1996.
[5] Y. Deng, C. Kenney, M. S. Moore, and B. S. Manjunath, “Peer Group Filtering and Perceptual Color Image Quantization”, in Proc. of IEEE Int. Symposium on Circuits and Systems, ISCAS, vol. 4, pp. 21-24, 1999.
[6] J. Hafner, H. S. Sawhney, W. Esquitz, M. Flickner, W. Niblack, “Efficient Color Histogram Indexing for Quadratic Form Distance Functions”, IEEE Trans. Pattern Analysis and Machine Int., vol. 17, pp. 729-736, 1995.
[7] J. Huang; S.R. Kumar, M. Mitra, W.-J. Zhu, R. Zabih, “Image indexing using color correlograms”, in Proc. of Computer Vision and Pattern Recognition, pp.762-768, 17-19 Jun. 1997
[8] W. Y. Ma and H. J. Zhang, ”Benchmarking of Image Features for Content-based Retrieval”, in Proc. Conf. Signals, Systems and Computers, pp. 253-257, 1998.
[9] B. S. Manjunath, J.-R. Ohm, V. V. Vasudevan, and A. Yamada, “Color and Texture Descriptors”, IEEE Trans. On Circuits and Systems for Video Technology, vol. 11, pp. 703-715, Jun. 2001.
[10] A. Mojsilovic, J. Kovacevic, J. Hu, R. J. Safranek, K. Ganapathy, “Matching and Retrieval based on the Vocabulary and Grammar of Color Patterns”, in IEEE Trans. on Image Processing, vol. 9, no. 1, pp. 38-54, Jan. 2000.
[11] A. Mojsilovic, J. Hu and E. Soljanin, “Extraction of Perceptually Important Colors and Similarity Measurement for Image Matching, Retrieval and Analysis”, IEEE Trans. On Image Proc., vol. 11, pp. 1238-1248, Nov. 2002.
[12] MUVIS. [Online] http://muvis.cs.tut.fi/
[13] G. Pass, R. Zabih, and J. Miler, “Comparing Images Using Color Coherence Vectors”, in Proc. of the ACM Multimedia’96, pp. 65-72, Boston, Nov. 1996.
[14] A. Pentland, R.W. Picard, S. Sclaroff, “Photobook: Tools for Content Based Manipulation of Image Databases”, In Proc. of SPIE (Storage and Retrieval for Image and Video Databases II), 2185, pp. 34-37, 1994.
[15] L.-M. Po and K.-M. Wong, “A New Palette Histogram Similarity Measure for MPEG-7 Dominant Color Descriptor”, In Proc. Int. Conf. on Image Proc., ICIP 2004, pp. 1533-1536, 2004.
[16] J.R. Smith and S. F. Chang, “VisualSEEk: a fully automated content-based image query system”, In Proc. of ACM Multimedia, Boston, November 1996.
[17] M. Stricker and M. Orengo, “Similarity of Color Images”, in Proc. SPIE, pp. 381-392, 1995.
[18] M. J. Swain, D. H. Ballard, “Color indexing”, International Journal of Computer Vision, vol. 7(1), pp. 11–32, 1991.
[19] Virage. [Online] www.virage.com
207