evaluating case-base maintenance algorithms
TRANSCRIPT

Knowledge-Based Systems xxx (2014) xxx–xxx
Contents lists available at ScienceDirect
Knowledge-Based Systems
journal homepage: www.elsevier .com/ locate /knosys
Evaluating Case-Base Maintenance algorithms
http://dx.doi.org/10.1016/j.knosys.2014.05.0140950-7051/� 2014 Elsevier B.V. All rights reserved.
⇑ Corresponding author. Tel.: +34 868887345.E-mail addresses: [email protected] (E. Lupiani), [email protected] (J.M. Juarez),
[email protected] (J. Palma).
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Maintenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/1j.knosys.2014.05.014
Eduardo Lupiani ⇑, Jose M. Juarez, Jose PalmaDepartment of Information and Communications Engineering, Artificial Intelligence and Knowledge Engineering Research Group, University of Murcia, Spain
a r t i c l e i n f o
Article history:Received 24 July 2013Received in revised form 28 April 2014Accepted 10 May 2014Available online xxxx
Keywords:Case-Based ReasoningCase-Base MaintenanceCase-Base ReductionCase SelectionEvaluation
a b s t r a c t
The success of a Case-Based Reasoning (CBR) system closely depends on its knowledge-base, named thecase-base. The life cycle of CBR systems usually implies updating the case-base with new cases. However,it also implies removing useless cases for reasons of efficiency. This process is known as Case-BaseMaintenance (CBM) and, in recent decades, great efforts have been made to automatise this process usingdifferent kind of algorithms (deterministic and non-deterministic). Indeed, CBR system designers find itdifficult to choose from the wealth of algorithms available to maintain the case-base. Despite the impor-tance of such a key decision, little attention has been paid to evaluating these algorithms. Although clas-sical validation methods have been used, such as Cross-Validation and Hold-Out, they are not alwaysvalid for non-deterministic algorithms. In this work, we analyse this problem from a methodologicalpoint of view, providing an exhaustive review of these evaluation methods supported by experimenta-tion. We also propose a specific methodology for evaluating Case-Base Maintenance algorithms (the abevaluation). Experiment results show that this method is the most suitable for evaluating most of thealgorithms and datasets studied.
� 2014 Elsevier B.V. All rights reserved.
1. Introduction
Case-Based Reasoning (CBR) is based on experience-solving oldproblems to find a solution to new problems [1]. In this way, giventhat a problem and its solution conform a case, when newproblems are solved then new cases are created and stored in acase-base. Although the learning ability of CBR is an importantadvantage, this characteristic is not free of drawbacks. For exam-ple, the addition of new cases to the case-base could degrade asystem’s performance [21,38,51] because case-bases with manycases need a long time to retrieve cases similar to an input query.Some reasons for increase in retrieval time are the scalability of thedata structures that represent the case-base, and the case descrip-tions for both problem and solution. Consequently, calculation ofthe similarity function between cases is complex too.
Instead of incrementing hardware power, the alternative way totackle performance problems is to use Case-Base Maintenance(CBM), whose main purpose is to update the existing case-basein order to maintain problem-solving competence [42], definedas the ability to solve new problems within an acceptable intervalof time.
Two different strategies can be considered in CBM. The firststrategy focuses on optimisation of the software that implementsthe case-base, such as tuning the parameters of the retrieval step[11] or changing the data structure used to model the case-base.The second strategy is aimed at removing cases from the case-baseaccording to a given deletion policy [30], deleting redundant ornoisy cases. In other words, the goal is to obtain smaller case-baseswith the same problem-solving competence. The resultingcase-base may not only replace the original case-base, but it mayalso be used as an index to enhance the retrieval of similar cases[27,49].
Algorithms that delete cases have been widely studied in theMachine Learning field [2,6,19,29,47], as well as in the CBR com-munity [12,13,25,31,42,43,51]. All these works show that reducingthe number of cases through a CBM process is an effectiveapproach to decreasing the retrieval time.
When using CBM algorithms, the question that remains iswhether the maintained case-base is better, equivalent to or worstthan the original one. The straightforward approach to answeringthis question is to use classical Machine Learning evaluation meth-ods, such as Hold-Out and Cross-Validation, to analyse and com-pare the outcomes of the same CBR system obtained with thesetwo case-bases. These methods divide the case-base into a numberof training and test sets, and while the training set plays the role ofthe case-base, the test set contains descriptions of all the inputproblems to be solved. In such a way, every problem in the test
0.1016/

2 E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx
set is solved using the cases within the training set, which enablesthe accuracy, sensitivity and specificity to be calculated. WhereasHold-Out uses one training set and one test set, the Cross-Validation usually involves up to five or ten training and test setsin order to finally average the results and obtain more reliableresults. Thus, once the CBM has built the maintained case-basefrom the original, the evaluation method uses both the originaland the maintained case-bases and builds the training and testsets. However, CBM algorithms may drastically reduce the size ofthe original case-base, and there will not be enough cases in themaintained case-base to resolve all the problem from the domain;that is, the competence of the CBR system is reduced.
To avoid this inconvenience, the evaluations for the CBR sys-tems are performed in a different way. This approach consists ofusing the CBM algorithm on the training set created, instead ofthe CBM algorithm on the complete case-base. This strategy canbe used both in Hold-Out evaluation [4,12,27,32,37,42] and inCross-Validation [15,36].
However, this evaluation strategy has its own drawbacks. Non-deterministic CBM approaches, such as those described in[4,22,27,33], return different maintained case-base outputs whenmultiple executions are carried out using the same original case-base, and it is necessary to execute the CBM algorithm severaltimes taking the training set as input in order to obtain an averageand achieve more reliable evaluation results.
In this work, we propose a novel evaluation method designed todeal with deterministic and non-deterministic CBM algorithms. Inorder to demonstrate the suitability of our approach, we recountthe exhaustive experimentation made to compare the results givenby our method and by other known evaluation methods.
Although different evaluation strategies are used in many pub-lications, providing correct results, these results are difficult tocompare precisely because they are obtained by different evalua-tion methods: for instance, building a test set with 40% or 30% ofthe cases, or repeating the Cross-Validation up to 10 times or exe-cuting it only once. The present paper is intended to clarify the dif-ferences between the best known evaluation methods to revealtheir advantages and disadvantages. Furthermore, a new evalua-tion method is presented to solve those disadvantages that arisewhen working with non-deterministic algorithms.
Finally, a Java library implementing the best known CBM algo-rithm and the introduced evaluation method is published for freeaccess.
The remainder of this work is structured as follows: the nextsection revises the related work. Section 3 introduces our a–b eval-uation proposal for evaluating of CBM algorithms. Section 4describes CELSEA, a Java library to perform CBM. Section 5 showsthe experimentation results after performing a set of CBM algo-rithms with a set of experimental case-bases from the UCI reposi-tory [16]. Section 6 is a discussion of the results from Section 5.Finally, in Section 7, we give our conclusions.
2. Related work
2.1. Case-Based Reasoning
Case-Based Reasoning (CBR) is a methodology that makes use ofpast experiences to solve new problems. In a CBR system theatomic unit of knowledge is the case, the knowledge of previouslyexperienced, specific problem situations [1]. The representation ofa case is basically a tuple composed of two descriptions that char-acterise a problem and its solution. When multiple cases are cre-ated to solve problems in a given domain, they conform theknowledge base from which the CBR system can perform its
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
problem-solving process [1]. Within the CBR community, theknowledge base is known as the case-base.
Despite the fact that multiple alternatives may represent a case,the simplest case representation is based on a vector of attributes,which describes the problem, and an attribute describing the solu-tion. Other complex representations are possible, such as work-flows [18], signals [39,41], time sequences [24] or graphs [7]among others.
The most commonly used implementation of a CBR system wasproposed in [1]. Basically, it consists of a four-step process: (1)Retrieve: the system searches for those cases that have a problemdescription with high similarity to the input problem description,for instance using a k-nearest neighbour algorithm [10]; (2) Reuse:using the cases retrieved, the system builds a solution to solve theinput problem; (3) Revise: the system checks whether the solutionproposed in the previous step is correct and, finally, and (4) Retain:a new case is created with the description of the input problem andthe output solution, and this is stored in the case-base.
One of the most important characteristic of this CBR model isthat its learning process is incremental and continuous, sincenew solved cases are added (retained) in the case-base, thus thelearning step is integrated in the problem solving process itself.
2.2. Case-Base Maintenance
Case-Base Maintenance implements policies for revising theorganization or contents (e.g. representations, domain content oraccounting information) of the case-base in order to simplify thefuture problem-solving process subjected to a particular set of per-formance objectives [30]. In particular, according to [53], CBM aimsto reduce the case-base size or to improve the quality of thesolutions provided by the CBR system [42].
The CBM has been studied in depth in Machine Learning disci-plines such as Instance-based Learning, Exemplar-based Learning,as well as in CBR. There are a wealth of approaches to performCBM, such as those published in [6,17,36,42,47,52,53]. Using thek-nearest neighbour algorithm [10] to find the similar cases(neighbours) to a given case, these algorithms usually try to clas-sify the cases within the case-base as redundant or noisy, anddelete them according to a specific deletion policy. The task ofidentifying a redundant case is easier than determining whethera case is noisy. Whereas a case could be considered as redundantwhen most of its neighbours have the same solution, a noisy casehas a solution different to its neighbour’s solutions [35]. Further-more, a case surrounded by cases with a different solution couldbe due to an error in the description, or it could simply be anexception [43]. For instance, in a case-base that contains casesdescribing birds, we can describe a swan as a bird with whitefeathers, although there are infrequent black swans as well. In thisway, it is incorrect to delete those cases that describe a swan like abird with black feathers.
Some authors have proposed different taxonomies of CBM algo-rithms in an attempt to enhance our understanding of them. Forexample, [42] classify the different CBM algorithms according tothe following features: (i) Case Search Direction: to build a main-tained case-base, a CBM algorithm starts with an empty case-baseand continues adding cases to it from the original case-base until atermination condition is reached. This is known as IncrementalCBM; otherwise, the CBM algorithm is known as Decremental.(ii) Order sensitive: when the case-base is sorted in some way andthis order determines the sequence in which cases are pro-cessed,then the CBM is Order Sensitive; otherwise the CBM algo-rithm is known as Order Insensitive. (iii) Selection Criteria: whenthe decision to include or not a case in the case-base relies onlyon the local case parameters. For example, considering the solutiongiven to its neighbours, then the criteria is local, however when all
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx 3
the cases are involved then is global. [53] propose an additionalfeature: (iv) Type of cases to retain: here, there are two approaches:retain those cases that have at least one case within their nearestneighbourhood with different solution (border cases), or retaincases that have all their nearest neighbours with the same solutionas themselves (central cases). In the first scenario, the maintainedcase-base has smooth borders between clusters of cases, while inthe second, the CBM algorithm is aimed at deleting the redundantcases.
Other classifications can be made according to whether a CBMalgorithm is deterministic or non-deterministic. Whereas a deter-ministic CBM generates the same maintained case-base from agiven case-base, a non-deterministic CBM builds different main-tained case-bases each time that the algorithm is executed. Mostof the CBM algorithms in the literature are deterministic becausetheir deletion policy is fixed and constrained by the order of casesin the original case-base, and because they always apply the sameaction (removal) when they classify a case as noisy or redundant.
The retrieval time is usually proportional to the case-base sizeamong other factors, such as the number of features (attributes)and the representation complexity of each attribute. Therefore, toachieve good performance the number of learned cases in a CBRsystem must be kept to a minimum. However, the exact numberof cases is difficult to estimate [31].
2.3. CBM algorithms
The simplest CBM algorithm consists of a random deletion ofcases until the case-base reaches a certain number of cases [34].However, CBM algorithms generally try to select cases in such away that the CBR system using the maintained case-base has bet-ter or equal problem-solving capabilities than when the originalcase-base is used. To summarize the CBM algorithms proposed inthe literature, we propose a classification based on four families:Nearest Neighbour algorithms (NN), Instance-Based algorithms,DROP family, Competence and Complexity models.
Some algorithms are actually composite methods, whereby themaintenance task is divided into two steps. The first step is usuallyaimed at reducing the amount of noisy cases, and the second stepis the maintenance process itself.
Algorithms from NN family select cases according to a nearestneighbour policy. One of the first attempts to reduce case-base sizewas the Condensed Nearest Neighbour (CNN) [19]. Starting with arandom case of each existing solution as initial case-base, the algo-rithm uses the rest of them as test sets and classifies them usingthe selected cases with a k nearest neighbours classifier (K-NN).If a case is misclassified then it is added to the final case-base.The process stops when all the original cases are correctly classi-fied. Although size reduction is possible, this algorithm does notcheck for noisy cases, due to which, the Reduced Nearest Neigh-bour Rule (RNN)[17] was introduced as an extension of CNN toremove noisy instances from the resulting case-base after the useof CNN. Each case of the final case-base is removed, and if no casefrom the original case-base is misclassified then the candidate isfinally removed, otherwise the case is added again. The EditedNearest Neighbour (ENN) removes misclassified cases accordingto the solutions of their three nearest neighbours [52]. WhenENN is executed multiple times, taking each output as input ofthe next execution, then the method is called Repeated ENN(RENN). All-kNN consists of executing k times ENN, where eachexecution uses from 1 to k neighbours respectively to flag a casefor no selection [50]. Some authors claim ENN and its variationsare actually noise removal techniques [53].
The Instance-based Family consists of algorithms that representcases as instances (a data structure with a vector of features and anattribute class), and could be understood as a simplified
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
representation of a case. IB2 and IB3 algorithms modify the IB1 clas-sifier to perform CBM [3,2]. In the IB2 algorithm, if a case is misclas-sified by its nearest neighbours then this case is added to the finalcase-base. The IB3 algorithm includes a more restrictive conditionto keep a selected case inside the final case-base by reducing noise.Shrink algorithm executes CNN and, finally, it removes from theresulting case-base those cases misclassified by their nearestneighbours [26].
The CBM algorithms DROP1, DROP2 and DROP3 belong to theDROP family [53]. All these methods introduce the concept of asso-ciate case, which is a case within the set of nearest neighbour caseswith the same solution. In DROP1, a case is removed if most of itsassociates already in the maintained case-base are solved correctlyby the CBR system with the case-base without it. In DROP2, a caseis removed if most of its associates in the original case-base aresolved correctly without it. DROP3 uses ENN to remove the noisycases before executing DROP1.
The algorithms from the Competence Model and the Complex-ity Profiling Family are distinguished from the aforementionedfamilies because they explode the implicit information of thecase-base to build a maintenance model. The CompetenceModel[47,46] defines concepts as Coverage, Reachability and Rela-tive Coverage [48]. For each concept, a new CBM algorithm is pro-posed. COV and RFD use Coverage Set and Reachability cardinalityto sort the case-base, respectively, and RC uses the Relative Cover-age model. Finally, the sorted case-base is the input to CNN, whichperforms the maintenance. Complexity Profiling estimates the pro-portion of redundant and noisy cases, as well as the existing errorrate in the case-base [35,36]. The basis of this approach is a localcomplexity measure that provides the probability of findinganother case in the nearest neighbourhood of a case with the samesolution. Although the local complexity measure is useful for casediscovery [35], it does not provide enough information to evaluatethe case-base competence. Lastly, Weighting, Clustering, Outliersand Internal cases Detection based on DBscan and Gaussian Means(WCOID-DG) [45], use the competence concepts to reduce boththe storage requirements and search time and to focus on balanc-ing case retrieval efficiency and competence for a case-base.WCOID-GM is mainly based on the idea that a large case-base withweighted features is transformed to a small case-base withimproving its quality.
2.4. Evolutionary approach to perform CBM
The main objective of the CBM algorithms is to find the smallestsubset of cases that provides the CBR system with a good problem-solving capabilities, usually through the removal of irrelevant orredundant cases. This problem can be modelled as a multi-objective optimization problem: minimising the number of caseswithin the case-base and maximising the CBR system accuracy.In this sense, Evolutionary Algorithms (EA) have been recognisedas appropriate techniques for multi-objective optimisation becausethey perform a search for multiple solutions in parallel [8]. Currentevolutionary approaches for multi-objective optimisation includemulti-objective EAs based on the Pareto optimality notion, inwhich all objectives are optimised simultaneously to find multiplenon-dominated solutions in a single run of the EA. For example,some examples of the application of Evolutionary Algorithms inCBM can be found in [4,22,27,33]. Such evolutionary approachesare non-deterministic CBM algorithms, because each executiongenerates a different maintained case-base from the originalcase-base. Nonetheless, the algorithm outputs converge to a setof cases with similar sizes and accuracy. Therefore, whereas thereare different cases distribution among the set of different main-tained cases-bases, these case-bases are able to solve similarlythe given problem domain.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

4 E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx
2.5. Measures for evaluating a CBR system
The accuracy of a given CBR system can be understood as theability to solve the input problem with the right solution. A com-mon wide practice to analyse a CBR system is the use of a testset, which is a set of cases from the original case-base, and to builda confusion matrix. Table 1 shows an example of a confusionmatrix for a CBR system with fs1; s2; . . . ; sng possible solutionsand N test cases.
Once all the cases in the test set are solved, then it is possible tocalculate statistical measures such as accuracy, recall (sensitivity)and specificity (true negative rate) of one particular solution, andglobal recall and global specificity, among others [40]. The formaldefinitions of these measures are given in the expressions(1)–(5), respectively.
accuracy ¼Xn
i¼1
pi;i
,N ð1Þ
recallðsiÞ ¼ pi;i
Xn
j¼1
pj;i
,ð2Þ
specificityðsiÞ ¼X
j2½1;n�j–i
pj;j
!, Xj;l2½1;n�j;l–i
pj;l
0@
1A ð3Þ
globalrecall ¼Xn
i¼1
recallðsiÞ,
n ð4Þ
globalspecificity ¼Xn
i¼1
specificityðsiÞ,
n: ð5Þ
Other relevant measures are the achieved reduction rate by themethod, and the difference between the retrieval time before andafter the appliance of the CBM algorithm [44]. Given the originalcase-base M and the maintained case-base Mr obtained using theCBM algorithm r, the reduction rate is defined as:
Reduction rate ¼ j Mr j
j M j ð6Þ
2.6. Evaluation of CBM
Once a CBM finishes its execution, the next step is to figure outwhether the resulting maintained case-base is better, worse orequivalent to the original one. Generally, this is done through acomparison of evaluation results or statistical measures, forinstance accuracy, false positive and the kappa index, which aregiven by the CBR system using the original and maintained case-bases.
Two of the most common evaluation methods are Cross-Validation and Hold-Out, which provide a good estimations of sta-tistical measures, e.g. accuracy [20]. The basis of both evaluations issimilar since they divide the case-base into subsets of cases, whereat least one of them is the test set and the remaining became part ofthe training set. Usually, the training set conforms the case-base of
Table 1Confusion matrix for a multi-solution classification.
Actual solution
s1 s
Output solution s1 p1;1 p
s2 p2;1 p
. . . . . . .
sn pn;1 p
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
the CBR system, whereas the test set are the input problems tosolve. Whereas the Hold-Out divides the case-base just into twoto create the test set and training set, usually using 30% of the casesto create the test set, Cross-Validation divides the case-base into nsubsets, known as folds. The number of folds decides the number ofevaluations, thus 10 Cross-Validation folds make up 10 training setsand test sets. Generally, five or ten folds are suitable to perform anevaluation [5,28].
Working with one particular evaluation method rather than theother depends on the type of case-base in question. Hold-out issuitable when the training and test sets are large enough for themto be representative of the original case-base and the problemdomain. However, in situations where this is not possible, perhapsbecause the case-base is quite small, Cross-Validation is the moreappropriate evaluation approach.
The question remains as to how these evaluation methodswould be applied. The first idea is to apply the CBM algorithm tothe original case-base, and then to evaluate the maintained case-base with either Hold-Out or Cross-Validation. However, thisapproach has an important drawback: the resulting maintainedcase-base would probably be smaller than the original case-basedue to the removal of redundant and noisy cases; consequently,the test and training sets generated are not equivalent to the origi-nal case-base. In this case, statistical measures are not reliablebecause they are not representative of reality.
For this reason, both Cross-Validation and Hold-Out have beenwidely used in the CBR literature with some modifications. Insteadof first applying the CBM algorithm, the evaluation method is usedon the original case-base to generate the training and test sets.Then, the CBM is applied to the training sets, which are equivalentto the original case-base. Below, we shall comment on the mostcommon evaluation method on the CBR field.
In [4,27] the accuracy of the maintained CBR system is studiedusing Hold-Out, and a k-nearest neighbour (K-NN) is used as a clas-sifier. Following the same evaluation method, in [32] compare theretrieval time and the size reduction rate.
Another evaluation that uses Hold-Out and a K-NN classifier ispresented in [37,12]. In [37] each case-base is divided randomlyinto two partitions: an 80% training set and a 20% test set. In[12] the evaluation divides the case-base at random into threesplits: 60% for the training set, 20% for the test set and the remain-ing is ignored. In both papers, CBM algorithm is applied to eachtraining set in order to reduce their size. Later, the maintainedtraining sets are validated with the test set to obtain the accuracy.The process is repeated from 10 to 30 times. At the end, the authorsaverage the accuracies to obtain the final accuracy estimationbefore comparing it with the accuracy given by the original case-base.
In [13] is proposed a more complex variation of Cross-Validation.The authors suggest splitting the case-base into three: 60% for thetraining set, 20% for the test set and 20% for cross-validation. Thesesets are used in a two-step evaluation process. Given a set of CBMalgorithms to evaluate, in the first step all the CBM algorithms areapplied to the training set and the resulting case-bases are validated
2 . . . sn Total
1;2 . . . p1;nPn
i¼1p1;i
2;2 . . . p2;nPn
i¼1p2;i
. . . . . . . .
n;2 . . . pn;nPn
i¼1pn;i
Total N
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx 5
using the cross-validation set. In the second step, the case-base withbest results is chosen and the test set is used to obtain the final eval-uation results. The observed measures are the percentage of casesdeleted and the accuracy given using a K-NN classifier.
In [36], a 10-fold Cross-Validation is used. The CBM algorithmsare applied to each training set and the resulting maintained case-base size is recorded. Test set accuracy is measured for the originalcase-base and for each of the maintained case-bases created by theCBM algorithms. The evaluation is performed up to 10 times, andfinally, the accuracy results are averaged and compared with theaccuracy average given by the original case-base.
Some authors propose new measures such as Competence toevaluate a case-base [42]. This measure highlights the proportionalimprovement in terms of accuracy of the maintained case-baseagainst the original. The authors use Hold-Out as evaluationmethod, using 30% of the cases as test set and the remaining astraining set. The CBM algorithm is applied to the training set andvalidated on the test set. The observed measures are the reductionsize ratio and their proposed Competence measure. The process isrepeated up to 20 times, and the results are averaged to comparethem with the original measures. The classifier 1-NN is chosen toretrieve the most similar cases to an input problem.
3. ab Evaluation
In this work, we propose the ab evaluation method. Whereasclassical methods are aimed to evaluate the results of a CBR sys-tem, such as Cross-Validation and Hold-Out, the aim of ab is toevaluate the CBM algorithm and its effects on the CBR system afterthe maintenance is finished. The main differences with classicalmethods are the use of the CBM algorithm on the training setinstead of applying it on the original case-base, and the introduc-tion of two new parameters: a and b. The a parameter is aimedat enhancing the reliability of the results by repeating the CBMalgorithm under observation is non-deterministic, while the bparameter is intended to repeat the entire Cross-Validation processb times. Furthermore, ab evaluation performs a pre-processing ofthe original case-base to decrease the time needed to run theevaluation.
The ab evaluation produces two sets of decision scores for agiven CBR system using a particular case-base. The first set is com-posed of the Performance Decision Scores, while the second set iscomposed of the Quality Decision Scores. Whereas the PerformanceDecision Scores comprise measures to quantify the reduction ofthe case-base and the CBM execution runtime, the Quality DecisionScores conform basic statistical measures that helps to determinethe suitability of the CBR system to solve the problem domain fromthe given case-base. For instance, some of these statistical mea-sures are accuracy, recall and specificity, whose definitions aregiven by the expressions (1), (4) and (5).
In order to compute the decision scores, the evaluation beginswith a case-base pre-process. First, the most relevant attributesof the problem description are selected. The purpose of this attri-bute selection is to decrease the number of problem features of acase in order to reduce the similarity complexity between casesand to speed up the evaluation process. Attribute selection is madewith a genetic algorithm, whereby each individual is a binarystring with element values in the domain ftrue; falseg. Each indi-vidual represents features selected from the problem description.If the i-th position is set to true then the i-th feature is selected.That is, an individual with n positions represents a case-base thathas n features to describe a problem, and the positions with thevalue set to true are the selected features of the problem. The
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
population size and the number of generations are set to 100.The one point cross-over probability is 0.9 and the mutation is0.033. The fitness value of each individual is the accuracy givenby a 10-fold Cross-Validation using the equivalent case-base tothe individual. Once feature selection is completed, duplicate casesare deleted and where missing values are present, they arereplaced with the mean value of the corresponding feature. Finally,all the case features are normalized in the interval ½0;1�.
3.1. ab Evaluation process
Once the data pre-processing finishes, the evaluation processstarts. Algorithm 1 depicts in detail the steps needed to performthe ab evaluation:
Initialization of performance and quality decision scores: The firststep is to initialise the Performance and Quality Decision Scores.Since quality decision scores rely on statistical measures, confu-sion matrices are used to compute the scores. For each givenCBM algorithm, the decision scores are initialised (Algorithm1 in lines 1–4). Then, confusion matrices are created, whichhave as many dimensions as the number of different solutionsthat exist in the case-base (Algorithm 1 from line 6 to 8). CMr
refers to the confusion matrix of the r algorithm, and CM½x; y�denotes the number of times that the actual solution of thequery case is x and the solution provided by the CBR systemis y, while both x and y might be the same solution or not. Eachgiven CBM algorithm r has its own quality and performancedecision score, represented as /r and qr, respectively.b loop: In each iteration a new training set and test set aregenerated. This process is repeated b times (Algorithm 1, lines9–26).
ten
Training and test sets creation: The original case-base M isdivided into 10 sub-case-bases with a similar number ofcases. These sub-case-bases are denoted by Mi. Stratificationis used to improve the representativeness of each solution tobuild the sub-case-bases. Furthermore, every case in M ispresent in at least one of the sub-case-bases Mi. The trainingsets, denoted by Mi, comprise those cases in M that are not inMi. The function complementary create the training sets(Algorithm 1, lines 10 to 12).Training and test sets iteration: Since CBM algorithms are exe-cuted on each Mi, and the resulting case-base is evaluatedusing the case-bases in Mi as queries (Algorithm 1). The loopin line 11 iterates over each i-th element of both sets.a loop: Because CBM algorithms may generate differentmaintained case-bases with the same input case-base, theloop generates a set of maintained case-bases for each algo-rithm r in order to generate a high number of results, and,consequently, to better estimate the real values associatedwith the quality decision scores (Algorithm 1, lines 13–24).CBM execution and confusion matrix updating: all the CBMalgorithms, R, are performed on each Mi to generate a newmaintained case-base Mr
i . For each case in Mi with solutionx, the CBR system using the Mr
i returns a solution y. Withboth solution x and y, the confusion matrix CMr is updated(see Algorithm 1, lines 14–23).
Calculation of decision scores: As each CBM algorithm r is exe-cuted 10ab times, the performance decision score qr containsthe average execution time and the reduction rate. The qualitydecision scores /r are calculated from the confusion matrixCMr (see Algorithm 1, lines 27–30).
ance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

1 CELSEA project http://perseo.inf.um.es/�aike/celsea.
6 E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx
Algorithm 1. ab Evaluation
Require A CBR system with a case-base M, and aset R of CBM algorithms.
Ensure A set of decision scores for each CBM algorithm.1: for all r 2 R do
2: /r /accuracyr ;/specificity
r ; . . .� �
/⁄ quality decision scores,
initialised to 0 ⁄/3: qr qtime
r ;qreductionr
� �/⁄ performance decision scores,
initialised to 0 ⁄/4: end for5: S number of different solutions in M6: for all r 2 R do
7: CMr 01;1 � � � 01;S
..
. . .. ..
.
0S;1 � � � 0S;S
264
375 /⁄ Confusion matrix
of S� S dimensions ⁄/.8: end for9: for 1 to b do10: test Mi : Mi � M ^Mi is stratifiedfj i 2 ½1;10� ^ 8c 2 M; 9c 2 Mig.
11: for all Mi 2 test do12: Mi complementaryðMiÞ13: for 1 to a do14: for all r 2 R do15: t current time16: Mr
i rðMiÞ /⁄ Perform the CBM algorithm r ⁄/17: qr qtime
r þ ðt � current timeÞ;qreductionr þ jMj
ri
jMj
� �18: for all p 2 Mi do/ ⁄ loop over the cases
in the test set⁄/19: x solutionðpÞ /⁄ Get the real solution ⁄/
20: y CBR Mri ; p
� �/⁄ Get the solution given
by the CBR system ⁄/21: CMr½x; y� CMr½x; y� þ 1 /⁄ Update the
confusion matrix ⁄/22: end for23: end for24: end for25: end for26: end for27: for all r 2 R do
28: qr qtime
ra�b�10 ;
qreductionr
a�b�10
� �29: /r statistical measuresðCMrÞ /⁄ Calculate measures
such as accuracy, specificity, . . . ⁄/30: end for31: return /; q
3.2. Values of a and b
Setting the b parameter will configure the evaluation process torepeat the Cross-Validation evaluation b times. With b ¼ 1 anda ¼ 1, this evaluation is a Cross-Validation, whereby the CBM algo-rithms are applied to each training set. With higher values of b theCross-Validation is repeated. This is the case of the evaluationmethods adopted in [15,36], which repeat Cross-Validation 10and 20 times, respectively.
On the other hand, changing the a parameter will lead to eachCBM algorithm being repeated up to a times with the same train-ing set. This parameter is useful when the CBM algorithm is non-deterministic. That is, multiple executions of a CBM with the sametraining set and order of cases return different case-base outputs.
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
4. A library for Case-Base Maintenance: CELSEA
In this work, we present CELSEA1 (CasE Library SElection Api), aframework for experimenting and evaluating case selection meth-ods. This framework has a triple objective. First, CELSEA provides asimple infrastructure for developing CBM algorithms. Second, CEL-SEA includes a catalogue of implemented methods to experimentwith case-bases and databases. Finally, CELSEA implements the abevaluation proposed in Section 3 (see Fig. 1).
4.1. Main modules
CELSEA is a Java library composed of five main modules (seeFig. 2): distance-classifier, cbr, case selection, evaluation and test.The distance-classifier module implements a K-NN classifier andits catalogue of distance functions. The CBR module includes thecase structure, the case-base and its efficient memory representa-tion (light memory). This module also includes a functionality forexperiment reporting in spreadsheet format (report). The caseselection module is a catalogue of the following well known CBMalgorithms: CNN, RNN, ENN, RENN, All-KNN, Shrink, IB2, IB3, ICF,DROP1, DROP2, DROP3,COV_RNN, RFC_CNN, RC_CNN, COV_CG,RFC_CG and RC_CG (see Section 2). The evaluation module imple-ments the Cross-Validation engine, a and b loops, etc. Finally, thetest module includes different evaluation implementations, suchas the evaluation ab.
4.2. Usage
CELSEA can be used for development and experimental purposes.Experiments using CELSEA can be made using command lines pro-viding the case-base file (in CSV format), a CBM file (in XML format)and the configuration of their parameters (in XML format). The CBMfile consists of a list of the CBM algorithms to be analysed and theirparameters configuration. Finally, the configuration file includes theimplementation path to the CBM (r), the database meta-informa-tion, and the values of the parameters described in the evaluationmethodology proposed, that is: a, b, the number of partitions (orfolders), and the classifier configuration.
5. Experimentation
The following experiments were aimed at deepening our under-standing of the ab evaluation, and, at showing how both a and bparameters can affect the decision score results. In particularexperiments were made using deterministic and non-deterministicCBM algorithms with different values for both parameters. Wehave chosen CNN as the deterministic CBM algorithm since it isone of the simplest and most widely used CBM algorithms, whilethe NSGA-II was chosen as the non-deterministic algorithm [14],which uses the fitness function proposed in [33], in order to per-form CBM. Such fitness function has three objectives aimed to beminimised: (1) the number of redundant cases, (2) an estimationof the error, and (3) the difference between the current numberof cases in the solution and the estimated number of non-redun-dant cases, which is computed at the beginning of the maintenancealgorithm. When NSGA-II algorithm finishes, it obtains a set ofpotential solutions that represent different maintained case-bases.So as to choose the output of the algorithm, the solution represent-ing the case-base with highest accuracy is returned, where thisaccuracy is given by the evaluation process, not by the fitnessfunction.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

Fig. 1. Data flow for the ab evaluation. The original case-base M is partitioned into10 Mi (test sets) and Mi (training sets). Later, the CBM method r is used on thetraining sets to create a maintained case-bases Mr
i , which are used to compute theQuality and Performance Decision Scores qr and /r . The process is repeated up to btimes, and finally, the average is done to calculate the Decision Scores.
Fig. 2. CELSEA framework: main package structure.
E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx 7
The organization of the experimental section to obtain the qual-ity decision scores is as follows: first, we study different configura-tions of a and b separately. Secondly, we compare the best resultsof ab with the accuracy results given by other evaluation method-ologies, such as Cross-Validation, Hold-Out, and Pan’s proposal(Pan) [42]. This evaluation basically consists of repeating 20 timesthe Hold-Out evaluation. On the other hand, the performance deci-sion score that we evaluate is the reduction rate of the CBM algo-rithm. Finally, we study the complexity and runtime of eachevaluation method since this will help decide which evaluationmethod is the best.
5.1. Experimental setup
All the experiments share the same CBR system configuration,that is, only the case-base is different for each experiment. TheCBR system retrieves the most similar cases using a K-NN approachwith k ¼ 3. Owing to the fact that multiple solutions can beretrieved, a majority voting system is used. That is, CBR system out-put is the most common solution among the retrieved solution. Incase all the solutions are different, the solution with the lowestdistance to the input problem is chosen.
First, a case-base pre-processing is performed to decrease thetime needed to run each experimentation. This pre-processincludes selection of the most relevant attributes, deletion of dupli-cate cases and replacement of missing values with the mean of theattribute values. Finally, all the features values in each case-baseare normalised in the interval ½0;1�. Attribute selection is madewith a genetic algorithm, where each individual is a binary string
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
with element values in the domain ftrue; falseg. Each individualrepresents the features which are selected from the problemdescription. If the element is true then the feature is selected. Thatis, an individual with n elements represents a case-base with n fea-tures describing a problem, and the elements with the value set totrue are the selected features of the problem. The population sizeand the number of generation are set to 100. The one pointcross-over probability is 0.9 and the mutation is 0.033. The fitnessvalue of each individual is the accuracy given by a 10-fold Cross-Validation using the equivalent case-base to the individual.
The experiments are made with the following public datasets:iris, liver-bupa, bridges-version1 and zoo from UCI repository [16].To build the case-base, each instance in a dataset is transformedinto a case, where the problem description takes all the instanceattributes except for the class, which is the solution description.All the experiments are performed 10 times in order to provideenough experimental results. Finally, the results are averaged toobserve the differences between all the evaluation results.
5.2. Adjusting a and b parameters
In this section, the a and b influence on the evaluation resultsare analysed. Second, a comparative of ab against other evaluationmethods will be carried out.
In order to analyse how different values of a and b influencesthe evaluation results, the values of a and b under considerationare a ¼ f1;3;5;7g, and b ¼ f1;5;10;15g. These values are selectedin order to analyse how incremental changes on a and b valuesaffect the results of the evaluation.
5.2.1. Values of a for deterministic and non-deterministic CBMFig. 3 depicts the accuracy results of the CNN algorithm with the
four different case-bases. In this experiments the b is constant(b ¼ 1) and a varies its value (a ¼ f1;3;5;7g).
Fig. 4 shows the accuracy results for NSGA-II in each case-base.The results obtained with a ¼ 1 show a larger variation, whilea P 3 provides more regular results.
5.2.2. b values for deterministic and non-deterministic CBM algorithmsFig. 5 depicts the results of the recorded accuracies for each
case-base with the CNN algorithm. The value of a is equal to 1,and only b varies its value (b ¼ f1;5;10;15g).
Fig. 6 depicts the accuracy results for each case-base usingNSGA-II as the applied CBM algorithm. The value of a is 1.
5.2.3. Comparing a and b parameters for non-deterministic CBMThe question that remains is whether a and b can be used
simultaneously to enhance the reliability of the evaluation results.The following experiment is performed using the ab evaluationwith the values a ¼ 3 and b ¼ 5, and NSGA-II as the CBM algorithmunder observation, using the fitness function given in [33]. Theresults are compared with the accuracy averages given by theexperiments made with a ¼ 1; b ¼ 5 and a ¼ 3; b ¼ 1.
Fig. 7 depicts the accuracy results for the case-bases iris, liver-bupa, bridges-version1 and zoo.
5.3. Comparing ab with other evaluation methods
To analyse whether ab evaluation is more suitable than otherevaluation methods, we compare the ab evaluation results withthose provided by Cross-Validation, Hold-Out and Pan [42]. Notethat both Cross-Validation and Hold-Out take as input the main-tained case-base returned by the CBM algorithm under study,whereas, both ab and Pan evaluations execute the CBM algorithmon each training set.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

●
●
●●
1 3 5 7
0.90
0.92
0.94
0.96
Accuracy results of CNN in iris
Accu
racy
α
●
1 3 5 7
0.560.580.600.620.64
Accuracy results of CNN in liver−bupa
Accu
racy
α
1 3 5 7
0.50
0.55
0.60
Accuracy results of CNN in bridges−version1
Accu
racy
α
●
●
●
1 3 5 70.88
0.90
0.92
0.94
Accuracy results of CNN in zoo
Accu
racy
α
Fig. 3. Experiments varying the a parameter for CNN (a ¼ f1;3;5;7g, and b ¼ 1).
●
●
●
1 3 5 7
0.94
0.95
0.96
0.97Accuracy results of NSGA−II in iris
Accu
racy
α1 3 5 7
0.540.560.580.600.62
Accuracy results of NSGA−II in liver−bupaAc
cura
cy
α
●
●
●●
1 3 5 7
0.54
0.56
0.58
Accuracy results of NSGA−II in bridges−version1
Accu
racy
α
●
●
1 3 5 7
0.870.880.890.900.910.92
Accuracy results of NSGA−II in zoo
Accu
racy
α
Fig. 4. Experiments varying the a parameter for NSGA-II (a ¼ f1;3;5;7g, and b ¼ 1).
●
●
1 5 10 15
0.910.920.930.940.95
Accuracy results of CNN in iris
Accu
racy
β
●
●●
1 5 10 15
0.570.580.590.600.610.62
Accuracy results of CNN in liver−bupa
Accu
racy
β
1 5 10 15
0.520.540.560.580.60
Accuracy results of CNN in bridges−version1
Accu
racy
β
●
●
1 5 10 15
0.900.910.920.930.94
Accuracy results of CNN in zoo
Accu
racy
β
Fig. 5. Experiments varying the b parameter for CNN ða ¼ 1;b ¼ f1;5;10;15gÞ.
8 E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx
First, the experiments will focus on how the evaluation affectsthe results provided by CNN, a deterministic CBM algorithm. Thevalues for a and b in this experiments are set to 1 and 10, respec-
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
tively. Values chosen because a is only useful with non-determin-istic CBM algorithms, and the experiments made in subSection 5.2show that the most suitable value for b is 10 or more.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

1 5 10 15
0.9450.9500.9550.9600.9650.970
Accuracy results of NSGA−II in iris
Accu
racy
β
●
1 5 10 15
0.560.570.580.590.600.61
Accuracy results of NSGA−II in liver−bupa
Accu
racy
β
●
●
●
1 5 10 15
0.520.530.540.550.560.57
Accuracy results of NSGA−II in bridges−version1
Accu
racy
β1 5 10 15
0.87
0.88
0.89
0.90
Accuracy results of NSGA−II in zoo
Accu
racy
β
Fig. 6. Experiments varying the b parameter for NSGA-II ða ¼ 1;b ¼ f1;5;10;15gÞ.
(3, 5) (1, 5) (3, 1)
0.9550.9600.9650.970
Accuracy of NSGA−II in iris
Accu
racy
αβ(3, 5) (1, 5) (3, 1)
0.550.560.570.580.590.60
Accuracy of NSGA−II in liver−bupaAc
cura
cy
αβ
(3, 5) (1, 5) (3, 1)
0.50
0.55
0.60Accuracy of NSGA−II in bridges−version1
Accu
racy
αβ(3, 5) (1, 5) (3, 1)
0.88
0.89
0.90
0.91Accuracy of NSGA−II in zoo
Accu
racy
αβ
Fig. 7. Results of NSGA-II for three different configurations of ab evaluation: ða ¼ 3; b ¼ 5Þ; ða ¼ 1;b ¼ 5Þ; ða ¼ 3;b ¼ 1Þ.
●
αβ Pan CV HO
0.920.940.960.981.00
Accuracy with iris and no CBM
Accu
racy
Evaluation methodαβ Pan CV HO
0.560.580.600.620.640.66
Accuracy with liver−bupa and no CBM
Accu
racy
Evaluation method
αβ Pan CV HO0.400.450.500.550.600.65
Accuracy in bridges−version1 and no CBM
Accu
racy
Evaluation method
●
● ●
αβ Pan CV HO
0.85
0.90
Accuracy with zoo and no CBM
Accu
racy
Evaluation method
Fig. 8. Comparative study of the evaluation methods ab, Pan, Cross-Validation (CV) and Hold-Out (HO), when None CBM algorithm is executed.
E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx 9
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Maintenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/j.knosys.2014.05.014

●
αβ Pan CV HO
0.20.40.60.8
Accuracy of CNN in iris
Accu
racy
Evaluation method
●
αβ Pan CV HO
0.3
0.4
0.5
0.6Accuracy of CNN in liver−bupa
Accu
racy
Evaluation method
αβ Pan CV HO
0.20.30.40.5
Accuracy of CNN in bridges−version1
Accu
racy
Evaluation method
●●
αβ Pan CV HO
0.4
0.6
0.8
Accuracy of CNN in zoo
Accu
racy
Evaluation method
Fig. 9. Comparative study of the evaluation methods: ab, Pan, Cross-Validation (CV) and Hold-Out (HO) evaluations, when CNN algorithm is executed.
●●
αβ Pan CV HO
0.94
0.96
0.98
1.00Accuracy of NSGAII in iris
Accu
racy
Evaluation method
●
αβ Pan CV HO
0.5
0.6
0.7
0.8Accuracy of NSGAII in liver−bupa
Accu
racy
Evaluation method
●●●
●
●
●
●
αβ Pan CV HO
0.4
0.6
0.8
Accuracy of NSGAII in bridges−version1
Accu
racy
Evaluation method
●
●
αβ Pan CV HO
0.7
0.8
0.9
1.0Accuracy of NSGAII in zoo
Accu
racy
Evaluation method
Fig. 10. Comparative study of the evaluation methods: ab, Pan, Cross-Validation (CV) and Hold-Out (HO), when NSGA-II algorithm is executed.
10 E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx
Secondly, the experiments will deal with a non-deterministicalgorithm (NSGA-II) using the fitness function to perform CBM pro-posed in [33]. In this occasion, the parameters values of a and b areset to 3 and 5, respectively, values that have shown good results, asFig. 7 depicts.
Additionally, each case-base is first evaluated without any caseselection. For the sake of clarity, we call None the CBM algorithmthat does not perform any case selection.
Fig. 8 portrays the accuracy results for each evaluation methodand with the None algorithm, and Fig. 9 depicts the results of theCNN algorithm. Finally, Fig. 10 shows the results with thealgorithm NSGA-II. In order to identify differences between theevaluation methods, the Analysis of Variance (ANOVA) is carriedout. Tables 3, 5 and 7 show the ANOVA results for the accuracyresults given by each evaluation with None, CNN and NSGA-II,respectively. With this test, the hypothesis is that the accuracyaverages are equal between the results given by each evaluationmethod. We pay special attention to the F value and p-value, wherethe F value is the difference between the accuracy results of eachevaluation method, and p-value is the probability for the accuracyaverages to be the same. In other words, lower the p-value, higherthe evidence that the accuracy averages are different. Table 2depicts the codes used by the ANOVA tables.
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
We also focus on the comparison between every pair of evalu-ation method by carrying out the Tukey Honest Significant Differ-ences test (Tukey HSD) [54]. Tables 4, 6 and 8 show the p-value forall the studied case-bases, from the results of two evaluation meth-ods with Tukey HSD. Within those tables, low values of p-valuemean low probability that the two evaluation methods have thesame results variance.
Lastly, other important issue is the difference between the accu-racy results given by the different evaluation processes wheneither they do not use a CBM algorithm or some deterministic/non-deterministic CBM algorithm. In order to study these differ-ences, an ANOVA analysis is performed between the accuracyresults given with no CBM, CNN and NSGA-II, respectively, for eachevaluation process. Therefore, Table 9 shows the ANOVA resultsafter comparing the accuracy variances given by the ab, Pan, CVand HO evaluations results.
5.4. Experiments of performance decision scores
Despite the importance of accuracy, the improvement achievedby a CBM algorithm in terms of performance is also fundamental.In this subsection we focus on the reduction rates and the execu-tion time of each CBM algorithm.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/
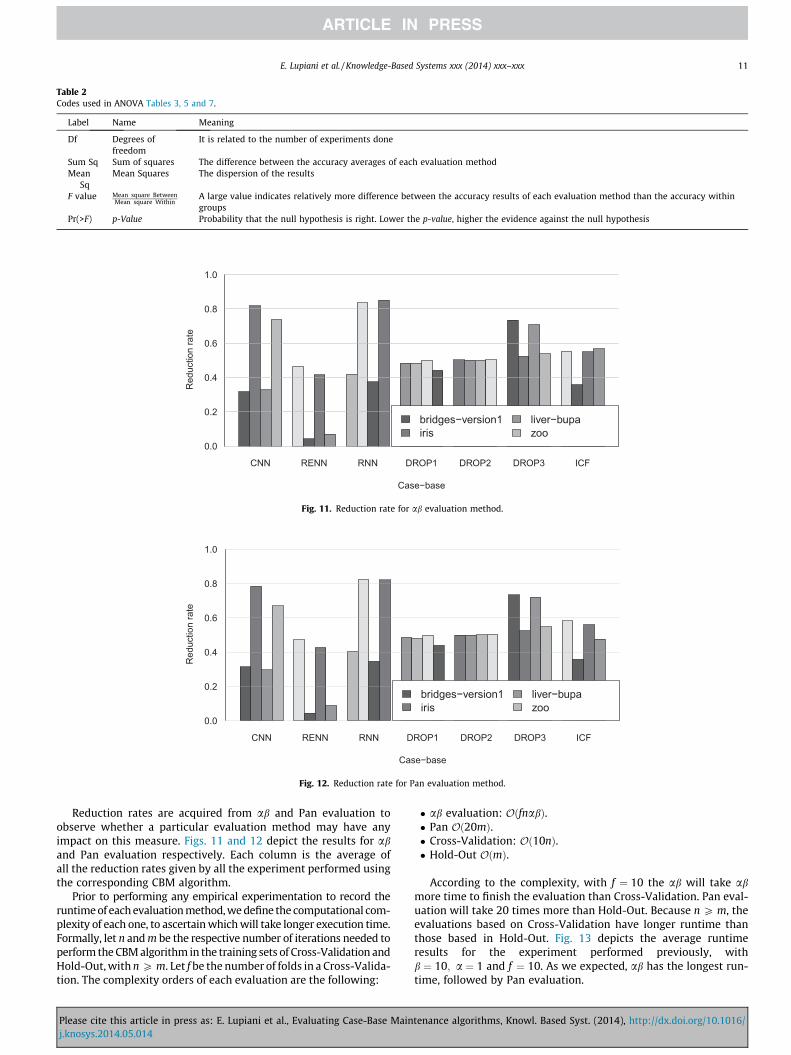
Table 2Codes used in ANOVA Tables 3, 5 and 7.
Label Name Meaning
Df Degrees offreedom
It is related to the number of experiments done
Sum Sq Sum of squares The difference between the accuracy averages of each evaluation methodMean
SqMean Squares The dispersion of the results
F value Mean square BetweenMean square Within
A large value indicates relatively more difference between the accuracy results of each evaluation method than the accuracy withingroups
Pr(>F) p-Value Probability that the null hypothesis is right. Lower the p-value, higher the evidence against the null hypothesis
CNN RENN RNN DROP1 DROP2 DROP3 ICF
Case−base
Red
uctio
n ra
te
0.0
0.2
0.4
0.6
0.8
1.0
bridges−version1iris
liver−bupazoo
Fig. 11. Reduction rate for ab evaluation method.
CNN RENN RNN DROP1 DROP2 DROP3 ICF
Case−base
Red
uctio
n ra
te
0.0
0.2
0.4
0.6
0.8
1.0
bridges−version1iris
liver−bupazoo
Fig. 12. Reduction rate for Pan evaluation method.
E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx 11
Reduction rates are acquired from ab and Pan evaluation toobserve whether a particular evaluation method may have anyimpact on this measure. Figs. 11 and 12 depict the results for aband Pan evaluation respectively. Each column is the average ofall the reduction rates given by all the experiment performed usingthe corresponding CBM algorithm.
Prior to performing any empirical experimentation to record theruntime of each evaluation method, we define the computational com-plexity of each one, to ascertain which will take longer execution time.Formally, let n and m be the respective number of iterations needed toperform the CBM algorithm in the training sets of Cross-Validation andHold-Out, with n P m. Let f be the number of folds in a Cross-Valida-tion. The complexity orders of each evaluation are the following:
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
� ab evaluation: O fnabð Þ.� Pan O 20mð Þ.� Cross-Validation: O 10nð Þ.� Hold-Out O mð Þ.
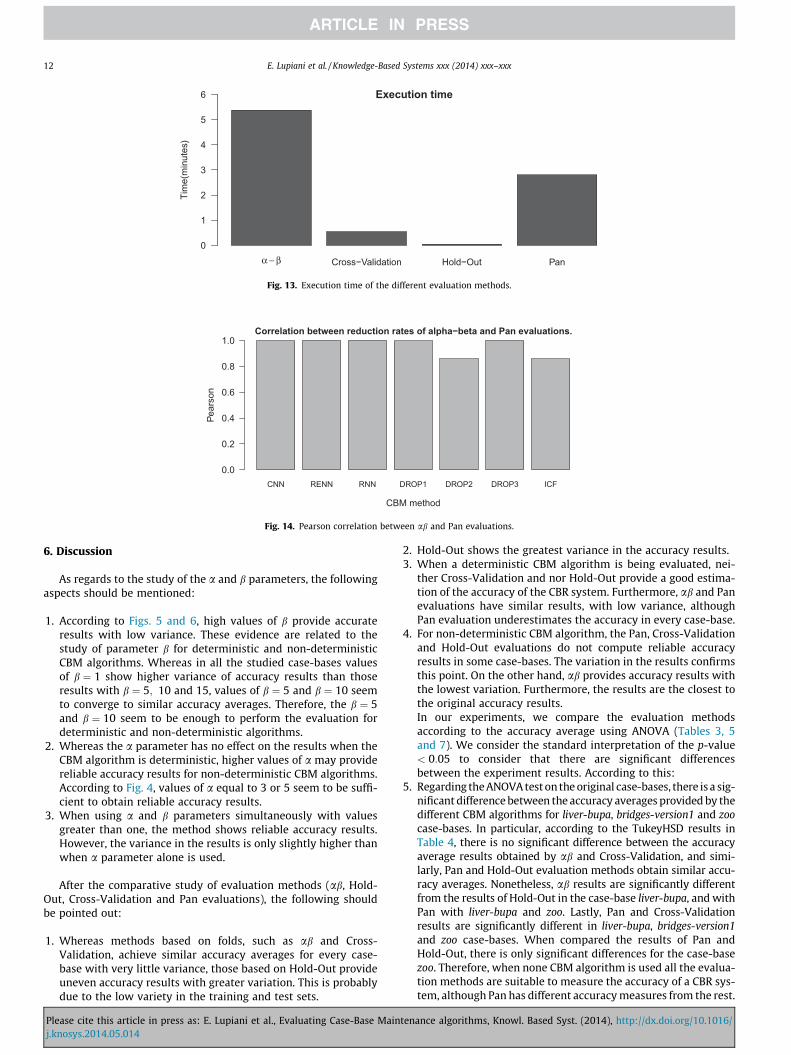
According to the complexity, with f ¼ 10 the ab will take abmore time to finish the evaluation than Cross-Validation. Pan eval-uation will take 20 times more than Hold-Out. Because n P m, theevaluations based on Cross-Validation have longer runtime thanthose based in Hold-Out. Fig. 13 depicts the average runtimeresults for the experiment performed previously, withb ¼ 10; a ¼ 1 and f ¼ 10. As we expected, ab has the longest run-time, followed by Pan evaluation.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/
α − β Cross−Validation Hold−Out Pan
Execution time
Tim
e(m
inut
es)
0
1
2
3
4
5
6
Fig. 13. Execution time of the different evaluation methods.
CNN RENN RNN DROP1 DROP2 DROP3 ICF
Correlation between reduction rates of alpha−beta and Pan evaluations.
CBM method
Pear
son
0.0
0.2
0.4
0.6
0.8
1.0
Fig. 14. Pearson correlation between ab and Pan evaluations.
12 E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx
6. Discussion
As regards to the study of the a and b parameters, the followingaspects should be mentioned:
1. According to Figs. 5 and 6, high values of b provide accurateresults with low variance. These evidence are related to thestudy of parameter b for deterministic and non-deterministicCBM algorithms. Whereas in all the studied case-bases valuesof b ¼ 1 show higher variance of accuracy results than thoseresults with b ¼ 5; 10 and 15, values of b ¼ 5 and b ¼ 10 seemto converge to similar accuracy averages. Therefore, the b ¼ 5and b ¼ 10 seem to be enough to perform the evaluation fordeterministic and non-deterministic algorithms.
2. Whereas the a parameter has no effect on the results when theCBM algorithm is deterministic, higher values of a may providereliable accuracy results for non-deterministic CBM algorithms.According to Fig. 4, values of a equal to 3 or 5 seem to be suffi-cient to obtain reliable accuracy results.
3. When using a and b parameters simultaneously with valuesgreater than one, the method shows reliable accuracy results.However, the variance in the results is only slightly higher thanwhen a parameter alone is used.
After the comparative study of evaluation methods (ab, Hold-Out, Cross-Validation and Pan evaluations), the following shouldbe pointed out:
1. Whereas methods based on folds, such as ab and Cross-Validation, achieve similar accuracy averages for every case-base with very little variance, those based on Hold-Out provideuneven accuracy results with greater variation. This is probablydue to the low variety in the training and test sets.
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
2. Hold-Out shows the greatest variance in the accuracy results.3. When a deterministic CBM algorithm is being evaluated, nei-
ther Cross-Validation and nor Hold-Out provide a good estima-tion of the accuracy of the CBR system. Furthermore, ab and Panevaluations have similar results, with low variance, althoughPan evaluation underestimates the accuracy in every case-base.
4. For non-deterministic CBM algorithm, the Pan, Cross-Validationand Hold-Out evaluations do not compute reliable accuracyresults in some case-bases. The variation in the results confirmsthis point. On the other hand, ab provides accuracy results withthe lowest variation. Furthermore, the results are the closest tothe original accuracy results.In our experiments, we compare the evaluation methodsaccording to the accuracy average using ANOVA (Tables 3, 5and 7). We consider the standard interpretation of the p-value< 0:05 to consider that there are significant differencesbetween the experiment results. According to this:
5. Regarding the ANOVA test on the original case-bases, there is a sig-nificant difference between the accuracy averages provided by thedifferent CBM algorithms for liver-bupa, bridges-version1 and zoocase-bases. In particular, according to the TukeyHSD results inTable 4, there is no significant difference between the accuracyaverage results obtained by ab and Cross-Validation, and simi-larly, Pan and Hold-Out evaluation methods obtain similar accu-racy averages. Nonetheless, ab results are significantly differentfrom the results of Hold-Out in the case-base liver-bupa, and withPan with liver-bupa and zoo. Lastly, Pan and Cross-Validationresults are significantly different in liver-bupa, bridges-version1and zoo case-bases. When compared the results of Pan andHold-Out, there is only significant differences for the case-basezoo. Therefore, when none CBM algorithm is used all the evalua-tion methods are suitable to measure the accuracy of a CBR sys-tem, although Pan has different accuracy measures from the rest.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/
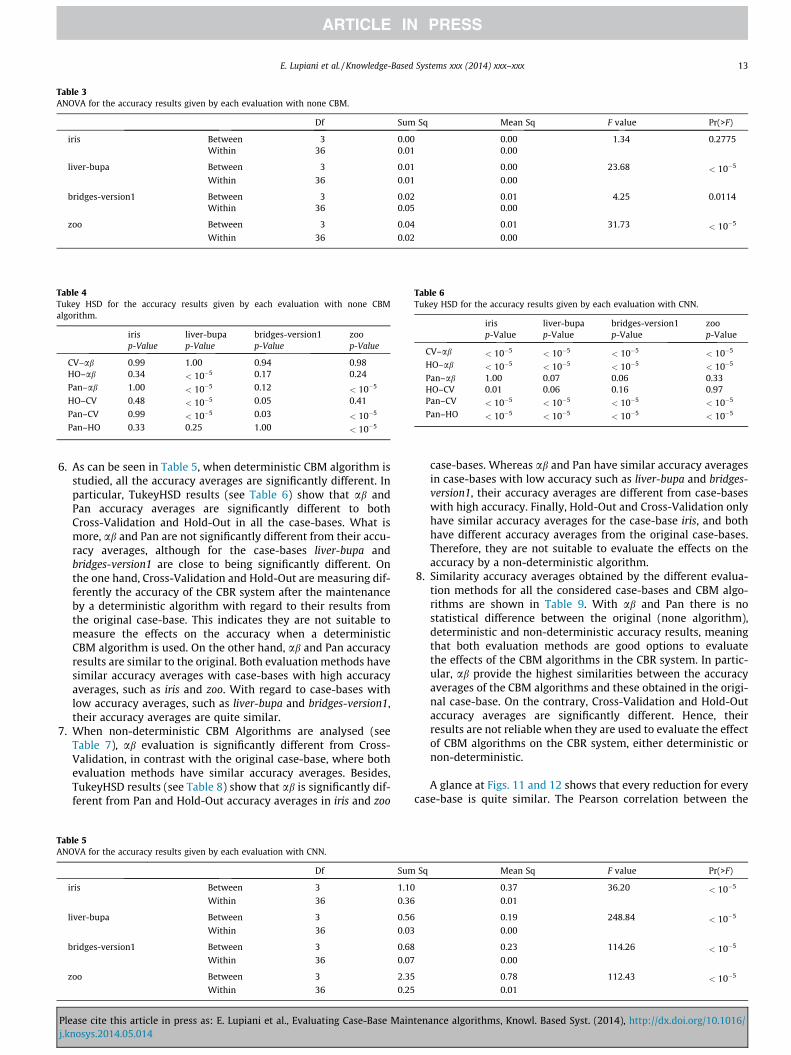
Table 3ANOVA for the accuracy results given by each evaluation with none CBM.
Df Sum Sq Mean Sq F value Pr(>F)
iris Between 3 0.00 0.00 1.34 0.2775Within 36 0.01 0.00
liver-bupa Between 3 0.01 0.00 23.68 < 10�5
Within 36 0.01 0.00
bridges-version1 Between 3 0.02 0.01 4.25 0.0114Within 36 0.05 0.00
zoo Between 3 0.04 0.01 31.73 < 10�5
Within 36 0.02 0.00
Table 4Tukey HSD for the accuracy results given by each evaluation with none CBMalgorithm.
iris liver-bupa bridges-version1 zoop-Value p-Value p-Value p-Value
CV–ab 0.99 1.00 0.94 0.98HO–ab 0.34 < 10�5 0.17 0.24
Pan–ab 1.00 < 10�5 0.12 < 10�5
HO–CV 0.48 < 10�5 0.05 0.41
Pan–CV 0.99 < 10�5 0.03 < 10�5
Pan–HO 0.33 0.25 1.00 < 10�5
Table 6Tukey HSD for the accuracy results given by each evaluation with CNN.
iris liver-bupa bridges-version1 zoop-Value p-Value p-Value p-Value
CV–ab < 10�5 < 10�5 < 10�5 < 10�5
HO–ab < 10�5 < 10�5 < 10�5 < 10�5
Pan–ab 1.00 0.07 0.06 0.33HO–CV 0.01 0.06 0.16 0.97Pan–CV < 10�5 < 10�5 < 10�5 < 10�5
Pan–HO < 10�5 < 10�5 < 10�5 < 10�5
E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx 13
6. As can be seen in Table 5, when deterministic CBM algorithm isstudied, all the accuracy averages are significantly different. Inparticular, TukeyHSD results (see Table 6) show that ab andPan accuracy averages are significantly different to bothCross-Validation and Hold-Out in all the case-bases. What ismore, ab and Pan are not significantly different from their accu-racy averages, although for the case-bases liver-bupa andbridges-version1 are close to being significantly different. Onthe one hand, Cross-Validation and Hold-Out are measuring dif-ferently the accuracy of the CBR system after the maintenanceby a deterministic algorithm with regard to their results fromthe original case-base. This indicates they are not suitable tomeasure the effects on the accuracy when a deterministicCBM algorithm is used. On the other hand, ab and Pan accuracyresults are similar to the original. Both evaluation methods havesimilar accuracy averages with case-bases with high accuracyaverages, such as iris and zoo. With regard to case-bases withlow accuracy averages, such as liver-bupa and bridges-version1,their accuracy averages are quite similar.
7. When non-deterministic CBM Algorithms are analysed (seeTable 7), ab evaluation is significantly different from Cross-Validation, in contrast with the original case-base, where bothevaluation methods have similar accuracy averages. Besides,TukeyHSD results (see Table 8) show that ab is significantly dif-ferent from Pan and Hold-Out accuracy averages in iris and zoo
Table 5ANOVA for the accuracy results given by each evaluation with CNN.
Df Sum
iris Between 3 1.10
Within 36 0.36
liver-bupa Between 3 0.56
Within 36 0.03
bridges-version1 Between 3 0.68
Within 36 0.07
zoo Between 3 2.35
Within 36 0.25
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
case-bases. Whereas ab and Pan have similar accuracy averagesin case-bases with low accuracy such as liver-bupa and bridges-version1, their accuracy averages are different from case-baseswith high accuracy. Finally, Hold-Out and Cross-Validation onlyhave similar accuracy averages for the case-base iris, and bothhave different accuracy averages from the original case-bases.Therefore, they are not suitable to evaluate the effects on theaccuracy by a non-deterministic algorithm.
8. Similarity accuracy averages obtained by the different evalua-tion methods for all the considered case-bases and CBM algo-rithms are shown in Table 9. With ab and Pan there is nostatistical difference between the original (none algorithm),deterministic and non-deterministic accuracy results, meaningthat both evaluation methods are good options to evaluatethe effects of the CBM algorithms in the CBR system. In partic-ular, ab provide the highest similarities between the accuracyaverages of the CBM algorithms and these obtained in the origi-nal case-base. On the contrary, Cross-Validation and Hold-Outaccuracy averages are significantly different. Hence, theirresults are not reliable when they are used to evaluate the effectof CBM algorithms on the CBR system, either deterministic ornon-deterministic.
A glance at Figs. 11 and 12 shows that every reduction for everycase-base is quite similar. The Pearson correlation between the
Sq Mean Sq F value Pr(>F)
0.37 36.20 < 10�5
0.01
0.19 248.84 < 10�5
0.00
0.23 114.26 < 10�5
0.00
0.78 112.43 < 10�5
0.01
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/
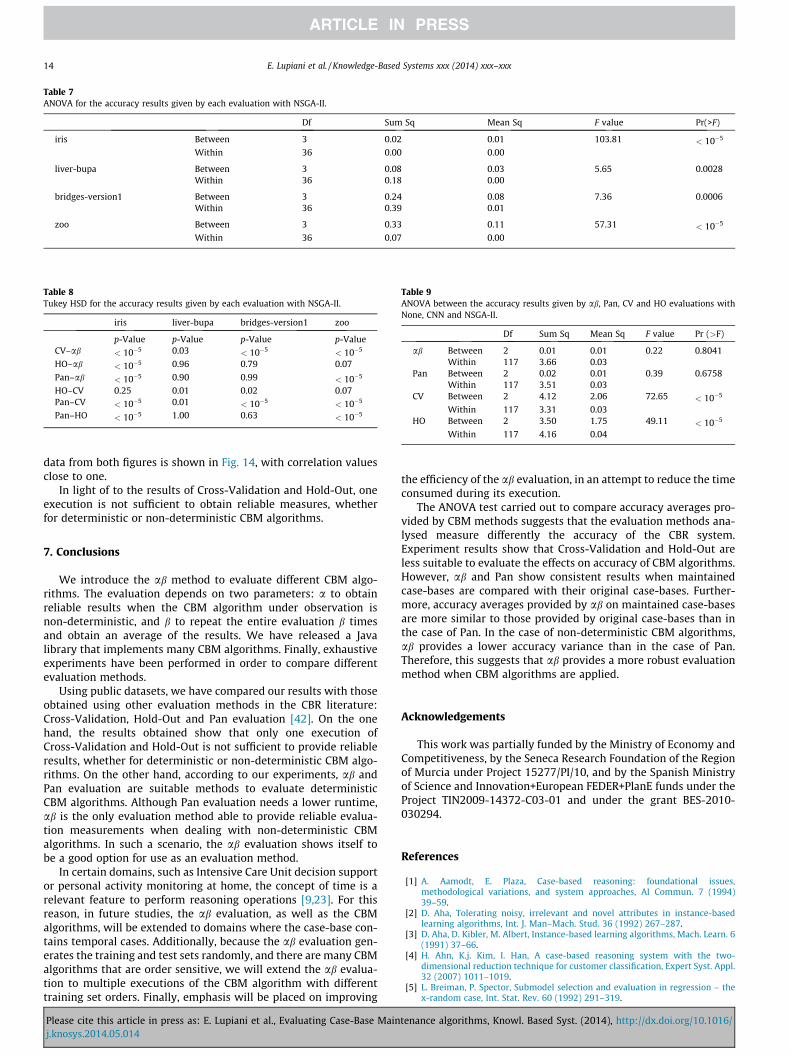
Table 7ANOVA for the accuracy results given by each evaluation with NSGA-II.
Df Sum Sq Mean Sq F value Pr(>F)
iris Between 3 0.02 0.01 103.81 < 10�5
Within 36 0.00 0.00
liver-bupa Between 3 0.08 0.03 5.65 0.0028Within 36 0.18 0.00
bridges-version1 Between 3 0.24 0.08 7.36 0.0006Within 36 0.39 0.01
zoo Between 3 0.33 0.11 57.31 < 10�5
Within 36 0.07 0.00
Table 8Tukey HSD for the accuracy results given by each evaluation with NSGA-II.
iris liver-bupa bridges-version1 zoo
p-Value p-Value p-Value p-ValueCV–ab < 10�5 0.03 < 10�5 < 10�5
HO–ab < 10�5 0.96 0.79 0.07
Pan–ab < 10�5 0.90 0.99 < 10�5
HO–CV 0.25 0.01 0.02 0.07Pan–CV < 10�5 0.01 < 10�5 < 10�5
Pan–HO < 10�5 1.00 0.63 < 10�5
Table 9ANOVA between the accuracy results given by ab, Pan, CV and HO evaluations withNone, CNN and NSGA-II.
Df Sum Sq Mean Sq F value Pr (>F)
ab Between 2 0.01 0.01 0.22 0.8041Within 117 3.66 0.03
Pan Between 2 0.02 0.01 0.39 0.6758Within 117 3.51 0.03
CV Between 2 4.12 2.06 72.65 < 10�5
Within 117 3.31 0.03HO Between 2 3.50 1.75 49.11 < 10�5
Within 117 4.16 0.04
14 E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx
data from both figures is shown in Fig. 14, with correlation valuesclose to one.
In light of to the results of Cross-Validation and Hold-Out, oneexecution is not sufficient to obtain reliable measures, whetherfor deterministic or non-deterministic CBM algorithms.
7. Conclusions
We introduce the ab method to evaluate different CBM algo-rithms. The evaluation depends on two parameters: a to obtainreliable results when the CBM algorithm under observation isnon-deterministic, and b to repeat the entire evaluation b timesand obtain an average of the results. We have released a Javalibrary that implements many CBM algorithms. Finally, exhaustiveexperiments have been performed in order to compare differentevaluation methods.
Using public datasets, we have compared our results with thoseobtained using other evaluation methods in the CBR literature:Cross-Validation, Hold-Out and Pan evaluation [42]. On the onehand, the results obtained show that only one execution ofCross-Validation and Hold-Out is not sufficient to provide reliableresults, whether for deterministic or non-deterministic CBM algo-rithms. On the other hand, according to our experiments, ab andPan evaluation are suitable methods to evaluate deterministicCBM algorithms. Although Pan evaluation needs a lower runtime,ab is the only evaluation method able to provide reliable evalua-tion measurements when dealing with non-deterministic CBMalgorithms. In such a scenario, the ab evaluation shows itself tobe a good option for use as an evaluation method.
In certain domains, such as Intensive Care Unit decision supportor personal activity monitoring at home, the concept of time is arelevant feature to perform reasoning operations [9,23]. For thisreason, in future studies, the ab evaluation, as well as the CBMalgorithms, will be extended to domains where the case-base con-tains temporal cases. Additionally, because the ab evaluation gen-erates the training and test sets randomly, and there are many CBMalgorithms that are order sensitive, we will extend the ab evalua-tion to multiple executions of the CBM algorithm with differenttraining set orders. Finally, emphasis will be placed on improving
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
the efficiency of the ab evaluation, in an attempt to reduce the timeconsumed during its execution.
The ANOVA test carried out to compare accuracy averages pro-vided by CBM methods suggests that the evaluation methods ana-lysed measure differently the accuracy of the CBR system.Experiment results show that Cross-Validation and Hold-Out areless suitable to evaluate the effects on accuracy of CBM algorithms.However, ab and Pan show consistent results when maintainedcase-bases are compared with their original case-bases. Further-more, accuracy averages provided by ab on maintained case-basesare more similar to those provided by original case-bases than inthe case of Pan. In the case of non-deterministic CBM algorithms,ab provides a lower accuracy variance than in the case of Pan.Therefore, this suggests that ab provides a more robust evaluationmethod when CBM algorithms are applied.
Acknowledgements
This work was partially funded by the Ministry of Economy andCompetitiveness, by the Seneca Research Foundation of the Regionof Murcia under Project 15277/PI/10, and by the Spanish Ministryof Science and Innovation+European FEDER+PlanE funds under theProject TIN2009-14372-C03-01 and under the grant BES-2010-030294.
References
[1] A. Aamodt, E. Plaza, Case-based reasoning: foundational issues,methodological variations, and system approaches, AI Commun. 7 (1994)39–59.
[2] D. Aha, Tolerating noisy, irrelevant and novel attributes in instance-basedlearning algorithms, Int. J. Man–Mach. Stud. 36 (1992) 267–287.
[3] D. Aha, D. Kibler, M. Albert, Instance-based learning algorithms, Mach. Learn. 6(1991) 37–66.
[4] H. Ahn, K.j. Kim, I. Han, A case-based reasoning system with the two-dimensional reduction technique for customer classification, Expert Syst. Appl.32 (2007) 1011–1019.
[5] L. Breiman, P. Spector, Submodel selection and evaluation in regression – thex-random case, Int. Stat. Rev. 60 (1992) 291–319.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/

E. Lupiani et al. / Knowledge-Based Systems xxx (2014) xxx–xxx 15
[6] H. Brighton, C. Mellish, On the consistency of information filters for lazylearning algorithms, in: Principles of Data Mining and Knowledge Discovery,1999, pp. 283–288.
[7] H. Bunke, C. Irniger, M. Neuhaus, Graph matching – challenges and potentialsolutions, in: Proceedings of the 13th international conference on ImageAnalysis and Processing, 2005, pp. 1–10.
[8] C.C. Coello, G. Lamont, D. van Veldhuizen, Evolutionary Algorithms for SolvingMulti-Objective Problems, Genetic and Evolutionary Computation, Springer,2007.
[9] C. Combi, M. Gozzi, B. Oliboni, J.M. Juarez, R. Marin, Temporal similaritymeasures for querying clinical workflows, Artif. Intell. Med. 46 (2009) 37–54.
[10] T. Cover, P. Hart, Nearest neighbor pattern classification, IEEE Trans. Inform.Theory 13 (1967) 21–27.
[11] S. Craw, J. Jarmulak, R. Rowe, Maintaining retrieval knowledge in a case-basedreasoning system, Comput. Intell. 17 (2001) 346–363.
[12] L. Cummins, D. Bridge, Maintenance by a committee of experts: the MACEapproach to case-base maintenance, in: Case-Based Reasoning Research andDevelopment, Proceedings, 2009, pp. 120–134.
[13] L. Cummins, D.G. Bridge, Choosing a case base maintenance algorithm using ameta-case base, in: SGAI Conf., 2011, pp. 167–180.
[14] K. Deb, A. Pratap, S. Agarwal, T. Meyarivan, A fast and elitist multiobjectivegenetic algorithm: NSGA-II, IEEE Trans. Evol. Comput. 6 (2002) 182–197.
[15] S. Delany, P. Cunningham, An analysis of case-base editing in a spam filteringsystem, in: Proceedings, Advances in Case-Based Reasoning, 2004, pp. 128–141.
[16] A. Frank, A. Asuncion, UCI Machine Learning Repository, 2010. <http://archive.ics.uci.edu/ml>.
[17] G. Gates, Reduced nearest neighbor rule, IEEE Trans. Inform. Theory 18 (1972)431+.
[18] Y. Gil, Reproducibility and efficiency of scientific data analysis: scientificworkflows and case-based reasoning, in: Case-Based Reasoning Research andDevelopment, LNCS, vol. 7466, 2012, pp. 2–2.
[19] P. Hart, Condensed nearest neighbor rule, IEEE Trans. Inform. Theory 14 (1968)515+.
[20] T. Hastie, R. Tibshirani, J. Friedman, The Elements of Statistical Learning,Springer Series in Statistics, Springer Inc., New York, 2001.
[21] T.G. Houeland, A. Aamodt, The utility problem for lazy learners – towards anon-eager approach, in: I. Bichindaritz, S. Montani (Ed.), 18th InternationalConference on Case-Based Reasoning, Case-Based Reasoning Research andDevelopment, ICCBR, 2010, pp. 141–155.
[22] H. Ishibuchi, T. Nakashima, M. Nii, Genetic-algorithm-based instance andfeature selection, in: H. Liu, H. Motoda (Eds.), Instance Selection andConstruction for Data Mining. Springer US, The Springer International Seriesin Engineering and Computer Science, vol. 608, 2001, pp. 95–112. http://dx.doi.org/10.1007/978-1-4757-3359-4_6.
[23] J.M. Juárez, M. Campos, J.T. Palma, R. Mar2́, T-CARE: temporal case retrievalsystem, Expert Syst. 28 (2011) 324–338.
[24] J.M. Juarez, F. Guil, J. Palma, R. Marin, Temporal similarity by measuringpossibilistic uncertainty in CBR, Fuzzy Sets Syst. 160 (2009) 214–230.
[25] J.M. Juárez, E. Lupiani, J. Palma, Case selection evaluation methodology, in:Industrial Conference on Data Mining – Workshops, 2011b, pp. 17–29.
[26] D. Kibler, D. Aha, Learning representative exemplars of concepts: an initialcase study, in: Proceedings of the Fourth International Workshop on MachineLearning, 1987, pp. 24–30.
[27] K. Kim, I. Han, Maintaining case-based reasoning systems using a geneticalgorithms approach, Expert Syst. Appl. 21 (2001) 139–145.
[28] R. Kohavi, A study of cross-validation and bootstrap for accuracy estimationand model selection, in: IJCAI’95, 1995, pp. 1137–1145.
[29] L. Kuncheva, L. Jain, Nearest neighbor classifier: simultaneous editing andfeature selection, Pattern Recogn. Lett. 20 (1999) 1149–1156.
[30] D. Leake, D. Wilson, Categorizing case-base maintenance: dimensions anddirections, in: Advances in Case-Based Reasoning, 1998, pp. 196–207.
Please cite this article in press as: E. Lupiani et al., Evaluating Case-Base Mainj.knosys.2014.05.014
[31] D. Leake, M. Wilson, How many cases do you need? assessing and predictingcase-base coverage, in: Proceedings of the 19th International Conference onCase-Based Reasoning Research and Development, 2011, pp. 92–106.
[32] Y. Li, S. Shiu, S. Pal, Combining feature reduction and case selection in buildingCBR classifiers, IEEE Trans. Knowl. Data Eng. 18 (2006) 415–429.
[33] E. Lupiani, S. Craw, S. Massie, J.M. Juárez, J.T. Palma, A multi-objectiveevolutionary algorithm fitness function for case-base maintenance, in: ICCBR,2013, pp. 218–232.
[34] S. Markovitch, P. Scott, The role of forgetting in learning, in: Proceedings of theFifth International Conference on Machine Learning, 1988, pp. 459–465.<http://www.cs.technion.ac.il/�shaulm/papers/pdf/Markovitch-Scott-icml1988.pdf>.
[35] S. Massie, S. Craw, N. Wiratunga, Complexity-guided case discovery for casebased reasoning, in: Proceedings of the 20th national conference on ArtificialIntelligence, vol. 1, 2005, pp. 216–221.
[36] S. Massie, S. Craw, N. Wiratunga, Complexity profiling for informed case-baseediting, in: Proceedings, Advances in Case-Based Reasoning, 2006, pp. 325–339.
[37] E. McKenna, B. Smyth, Competence-guided case-base editing techniques, in:Proceedings, Advances in Case-Based Reasoning, 2001, pp. 186–197.
[38] S. Minton, Quantitative results concerning the utility of explanation-basedlearning, Artif. Intell. 42 (1990) 363–391.
[39] S. Montani, L. Portinale, G. Leonardi, R. Bellazzi, R. Bellazzi, Case-basedretrieval to support the treatment of end stage renal failure patients, Artif.Intell. Med. 37 (1) (2006) 31–42.
[40] E. Mosqueira-Rey, V. Moret-Bonillo, Validation of intelligent systems: a criticalstudy and a tool, Expert Syst. Appl. 18 (2000) 1–16. doi:10.1016/S0957-4174(99)00045-7.
[41] E. Olsson, P. Funk, N. Xiong, Fault diagnosis in industry using sensor readingsand case-based reasoning, J. Intell. Fuzzy Syst. 15 (1) (2004) 41–46.
[42] R. Pan, Q. Yang, S.J. Pan, Mining competent case bases for case-basedreasoning, Artif. Intell. 171 (2007) 1039–1068.
[43] E.L. Rissland, Black swans, gray cygnets and other rare birds, in: Proceedings ofthe 8th International Conference on Case-Based Reasoning: Case-BasedReasoning Research and Development, 2009, pp. 6–13.
[44] A. Smiti, Z. Elouedi, Article: overview of maintenance for case based reasoningsystems, Int. J. Comput. Appl. 32 (2011) 49–56.
[45] A. Smiti, Z. Elouedi, WCOID-DG: an approach for case base maintenance basedon weighting, clustering, outliers, internal detection and Dbsan-Gmeans, J.Comput. Syst. Sci. 80 (2014) 27–38. http://dx.doi.org/10.1016/j.jcss.2013.03.006.
[46] B. Smyth, Case-base maintenance, in: IEA/AIE, vol. 2, 1998, pp. 507–516.[47] B. Smyth, M. Keane, Remembering to forget – a competence-preserving case
deletion policy for case-based reasoning systems, in: IJCAI-95 – Proceedings ofthe Fourteenth International Joint Conference on Artificial Intelligence, vols. 1and 2, 1995, pp. 377–382.
[48] B. Smyth, E. Mckenna, Building compact competent case-bases, in: Case-BasedReasoning Research and Development, 1999, pp. 329–342.
[49] B. Smyth, E. McKenna, Competence guided incremental footprint-basedretrieval, Knowl.-Based Syst. 14 (2001) 155–161.
[50] I. Tomek, Experiment with edited nearest-neighbor rule, IEEE Trans. Syst. ManCybernet. 6 (1976) 448–452.
[51] E. Tsang, X. Wang, An approach to case-based maintenance: selectingrepresentative cases, Int. J. Pattern Recogn. Artif. Intell. 19 (2005) 79–89.
[52] D. Wilson, Asymptotic properties of nearest neighbor rules using edited data,IEEE Trans. Syst. Man Cybernet. SMC2 (1972) 408–&.
[53] D. Wilson, T. Martinez, Reduction techniques for instance-based learningalgorithms, Mach. Learn. 38 (2000) 257–286.
[54] B. Yandell, Practical Data Analysis for Designed Experiments, Chapman & Hall/CRC Texts in Statistical Science, Taylor & Francis, 1997.
tenance algorithms, Knowl. Based Syst. (2014), http://dx.doi.org/10.1016/