afp - an adaptive fragmentation protocol supporting large datagram transmissions
TRANSCRIPT

AFP – an Adaptive Fragmentation ProtocolSupporting Large Datagram Transmissions
Michael Schulze, Philipp Werner, Georg Lukas, Jorg KaiserDepartment of Distributed SystemsUniversity of Magdeburg Germany
Email: [email protected], [email protected], {glukas, kaiser}@ivs.cs.ovgu.de
Abstract—Transferring datagrams is essential for a lotof tasks. If the data does not fit into one network packet,fragmentation is needed. We propose a fragmentation pro-tocol that adapts to different MTUs and to the datagramsize, ensuring efficient bandwidth utilization. The protocolis extensible to allow tailoring to network and applicationdemands. Thus, it is suitable for deploying it in variousscenarios and under different conditions, whereas otherprotocols do not scale well. We demonstrate the applicabilityon low-end embedded devices and in a tele-operated robotscenario. Additionally, we analyze the scalability of ourprotocol, evaluate the induced overhead for different MTUsand datagram sizes, and compare it to other fragmentationprotocols.
I. INTRODUCTION
Transferring amounts of data in a reliable way isessential for a lot of tasks like up or downloading files.However, the exchanged datagrams are almost alwaysbigger than a single maximum transmission unit (MTU)of the network. For example, the MTU on wired Ethernet(IEEE 802.3) is fixed at 1500 Bytes. With the adventof the internet, protocols have been developed for frag-menting datagrams into smaller chunks and reassemblingthem [1].
In industrial or automotive environments, transferringdatagrams that are larger than one MTU is also needed.For example, this is necessary for uploading configu-rations to devices, flashing new software on devices,or communicating complex data between devices. Avery popular automotive field-bus is the Controller AreaNetwork (CAN [2]), which provides an MTU of eightbytes only. Depending on the used higher-level CANprotocol, different solutions for fragmented data exchangelike ISO 15765-2 [3] or SAE J1939 [4] exist. The aimof all existing solutions is saving resources, especiallybandwidth and the number of needed messages. Howeverin general, their scalability is limited, as we discuss inSection II.
For the emerging technology of sensor networks, largedata transmissions have to be supported as well, enablinge. g. software upload in the field or bulk data transfers.However, due to energy saving reasons, efficient transferswith a minimum number of messages are crucial becauseevery additional bit sent or received shortens the life timeof a sensor node.
Manuscript received February 10, 2011; accepted March 23, 2011.
Besides minimizing the number of messages in gen-eral, and being as resource efficient as possible, otherrequirements have to be tackled to deliver large datagramsend-to-end. These requirements can either result from theapplication or be caused by network characteristics. Chal-lenges a transfer protocol has to cope with depend on thenetwork type, but three things that happen with packetsin general are: Duplication, Reordering and Packet loss.These problems have to be appropriately treated withmechanisms like sequence numbers, tackling the reorder-ing and the duplicate problem, or forward error correction,enabling data recovery without retransmissions. However,not all network types are faced with all problems equally.For instance, the CAN-Bus, which is designed for reliablecommunication in cars, has many fault handling proper-ties implemented in the hardware. Thus, problems happenonly under very specific circumstances [5]. Hence, to copewith different network properties, specific fragmentationprotocols have been developed.
When providing applications with a unique communi-cation interface [6], [7] that a) hides the characteristicsof different networks and b) allows for large datagrams,fragmentation needs to be taken care of for each supportednetwork. Instead of using different approaches, a gen-eral adaptable solution reduces development efforts andoverhead significantly. Moreover, such a solution wouldextend to network protocols which do not already providemeans of fragmentation.
Summarizing the requirements, the aim is a config-urable, resource-optimal fragmentation protocol that isdeployable even in resource constrained environmentslike on 8-bit micro-controllers. The main contribution ofour paper is an Adaptive Fragmentation Protocol (AFP),which adapts mainly in two directions. Firstly, it takes thedifferent MTUs of underlying networks into account, andsecondly, it tailors its protocol overhead to be efficient,avoiding bandwidth wasting. Furthermore, it provides anextension mechanism that allows the addition and encap-sulation of further protocols like forward error correction.
The rest of the paper is structured as follows. Westart with a related work discussion. Subsequently weintroduce AFP conceptually, and explain how we realisedit to enable its flexibility and adaptability. Afterwards,we evaluate it and discuss the question of scalability,efficiency, and protocol overhead. In a case study inSection V we show the practical relevance of our protocol.
240 JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011
© 2011 ACADEMY PUBLISHERdoi:10.4304/jcm.6.3.240-248

A summary concludes the paper and gives an outlook onfurther research.
II. RELATED WORK
Fragmentation protocols exist for a long time already.The Internet Protocol (IP) is one of the most wide-spread examples available. Its successor, IPv6, clonesthe approach but introduces some more overhead. In theembedded world, fragmentation protocols are deployedas well. Exemplary we discuss the solutions developedfor CAN networks, having an MTU of just 8 Bytes.This section describes the functionality of fragmentationapproaches and discusses their scalability.
A. Internet Protocol Fragmentation
The Internet Protocol [8] has been designed to connectnetworks with different MTUs with each-other, providingtransparent end-to-end routing. Fragmentation has beenintroduced as a core feature to allow gateways to forwarddata traffic to networks with a smaller MTU, even incases where the packets had been already fragmented. Thereassembly of fragmented packets should be performed atthe destination.
The IP header contains three fields meant for frag-mentation and reassembly: An identification field is a16-bit number unique for every fragmented packet. It isused to identify fragments belonging together. A fragmentoffset is a 13-bit address, giving the position of thecurrent fragment in the packet with an 8-Byte granularity,allowing a maximum packet size of 64 KBytes. Finally,a more fragments bit shows if the current fragment isthe last one in a packet. Together with two reserved bits,the fragmentation header makes up for 32 bits. For IPv6,these fields have been relocated into their own, optional,header of 64 bits. In addition, fragmentation is prohibitedon gateway nodes, instead the sender is notified of theMTU limitation via a control message (ICMP). However,the principal functionality and the 64 KByte limit havebeen preserved.
The IP scheme has several design drawbacks [9].Firstly, it does not allow to determine the datagram’s sizefrom its first fragment. This means, the required storagefor reassembly can not be reserved in advance. Secondly,IP does not provide an acknowledgment mechanism, incase of a fragment loss the incomplete datagram remainsin memory for a certain reassembly timeout and is thendropped. A retransmission of single fragments is notpossible and the whole datagram has to be re-sent ifrequired. Finally, IP does not provide any means forupper-layer protocols to determine the optimal payloadsize to avoid or at least to minimize the fragmentationoverhead.
Regarding scalability, IP fragmentation can not be usedon links with an MTU lower than 28 Bytes. This is dueto the fact that IP fragments have to begin at an 8-Byteboundary and the IP header (20 Bytes at least) has to beprepended to each fragment. The upper limit to the packetsize is 65,535 Bytes, including at least 20 Bytes for the
IP header. Due to these limitations, IP fragmentation cannot be used as a general solution.
B. Fragmentation approaches for CAN
CAN [2] is meant to connect embedded controllerswithout using a host computer. It is a specification forthe physical and data link layers to be used, allowingthe transmission of packets with a maximum payloadof 8 Bytes. Because it does not provide support forfragmentation, different solutions exist at higher levels.
One such protocol is the ISO Transport Protocol (ISO-TP [3]). It requires handshaking between sender andreceiver to coordinate the size of the receive buffer (BlockSize) and the time to wait between single fragments.Depending on configuration, one payload byte may beused for Extended Addressing. One byte is reserved forthe Protocol Control Information, which distinguishes iffragmentation is used. The maximum payload for frag-mented datagrams is defined to be 4095 Bytes. Datagramswith up to 7 Bytes (6 when Extended Addressing is used)are not fragmented. Whenever Block Size bytes have beentransmitted, the receiver has to send an acknowledgementmessage.
Another transport protocol is defined by SAE J1939 [4].Its Connection Mode Data Transfer (CMDT) uses the firstpayload byte as the fragment number, allowing for up to255 fragments with 7 Bytes each (1785 Bytes maximumpayload size).
DeviceNet [10] is a communication protocol on topof CAN used for data exchange. It provides two differenttypes of communication, Explicit and I/O messages. Bothallow the transmission of fragmented datagrams withoutan upper payload size limit. The first payload byte con-tains a two-bit message type, indicating the beginning,middle and ending frames as well as acknowledgementframes. The other six bits are used for a sequence number.With Explicit message fragmenting, every fragment hasto be acknowledged, leading to a very high overhead. I/Omessages have no acknowledgement at all on the otherhand.
CAN Application Layer (CAL) [11] is an application-level protocol allowing device discovery and identifierassignment based on objects and services. It is usuallycombined with CANopen [12], a CAN-based automationprotocol defining the binary representation for data typesand device profiles for all communication components.CAL specifies a client-server protocol to transfer objectsof unlimited length (Service Data Objects, SDO), whichis used by CANopen as well. The transfers are alwaysclient-triggered and use 7 Bytes of the CAN payload forthe actual data.
It can be seen that most fragmentation protocols onCAN are specifically tailored to the small MTU. Theyreserve one byte for the fragmentation header, eitherlimiting the overall payload size (J1939), or requiring acertain number of acknowledgement messages to copewith potential fragment loss. Whereas CANopen/CALand DeviceNet require two messages for every fragment,
JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011 241
© 2011 ACADEMY PUBLISHER

effectively doubling the total overhead, ISO-TP allows totransfer a whole block at once, which is then acknowl-edged by the receiver.
III. ADAPTIVE FRAGMENTATION PROTOCOL
During the development of FAMOUSO [7], [13], ourevent-based communication middleware, there was anincreasing demand for supporting large datagram trans-missions over different networks. Therefore, we devel-oped AFP, the Adaptive Fragmentation Protocol, becausenone of the existing solutions was generic enough andfulfilled the scalability requirements. To be precise, AFPis not intended to replace other fragmentation protocolswithin their respective stacks, because it is a higher layerprotocol. For example, if the path MTU in an IP networkis known and AFP is used on top of IP with this MTU,the IP fragmentation will not be used but instead AFPwill be responsible for the fragmentation and reassembly.
AFP defines a header format optimized for size whileoffering full scalability and extensibility. The fragmenta-tion adapts to the network’s MTU and also to the sizeof every datagram to minimize protocol overhead. Thismeans that 1) any datagram size can be sent regardlessof network-specific restrictions, and 2) this is possible forany underlying network with an MTU of at least 2 Bytes.Because different requirements may arise from networktype and application, we split the header in two parts: anessential basic header and optional extension headers thatmay encapsulate further user-defined protocol headers.
A. Concept
In the following, we describe the format of the variable-length encoding, which is employed in interest of scala-bility and low overhead. Subsequently, we introduce theformat of AFP’s basic and extension header.
1) Variable-Length Header Data Coding: To get max-imum scalability, we need to be able to store large num-bers. We deploy variable-length coding, whose storagespace scales with the number’s size. Using a fixed lengthcoding would lower the scalability by limiting the rangeof representable numbers.
There are already some approaches that encodenumbers in variable-length, like variable-length quan-tity (VLQ). VLQ is utilized in the standard MIDI fileformat [14] and it uses an arbitrarily long sequence ofbytes, each with the same structure. The most significantbit, the chaining bit, is reserved to indicate whetheranother byte follows the current one. The remaining 7 bitscontain a part of the number in binary encoding. Becauseeach byte only contains 7 bits of the number, a lot ofbit operations are needed for encoding and decoding.However, shifts over byte boundaries are expensive onembedded platforms only having 8-bit registers and canbe avoided by using another coding.
In UTF-8 [15], which maps Unicode characters tovariable-length byte sequences, the length is unary codedin the most significant bits of a sequence’s first byte.This is advantageous for processing on low-end embedded
10
1 0h-1
exth
fsth+1
fseqh+2 8h-1
h bits→ basic headerlength: h Bytes
7h− 2 bits
Figure 1. AFP basic header binary format
systems. But UTF-8 spends further bits to other featureswe do not need, like distinction of starting and followingbytes and ASCII compatibility.
To address the above mentioned shortcomings, wepropose an encoding scheme based on UTF-8 (see Fig. 1).The idea is to use only unary encoding and omit the rest.Thus, the first part of our encoding defines the length h,which is not less than one, in unary coding. Therefore,the first h− 1 bits are set to one, delimited by a zero bit.These are followed by 7h data bits. Both fields togetherare h Bytes in length. So, having n bits of data, we needdn7 e = h Bytes to add length information and achievebyte alignment.
As we use the coding, fseq contains an unsigned integerin binary representation without the leading zero bits. Allnumbers are encoded in network byte order (big endian)and aligned to the right.
2) Basic Header Format: AFP fragments start witha basic header, which contains essential information forcorrect defragmentation independent of application ornetwork requirements. A basic header starts always withits length unarily encoded as shown in Figure 1, and therest of the header contains the following elements:
ext: If the extension bit is set, there is an extensionheader behind the basic header. The fragment’spayload data is stored behind the last header.
fst: The first bit is set to one if the current fragmentis the first of a series of fragments belongingtogether. In this case, the fseq field defines thecount of fragments the datagram was split into.
fseq: Stored using variable-length encoding; the frag-ment sequence number, specifies how many datafragments follow after the current fragment.Thus, fragmenting a datagram into c pieces, thesequence number is counting down from c − 1to 0. In this way the first fragment containsinformation about the total number of fragmentsthe datagram consists of. The sequence numberis also useful for ordering of fragments, packetloss detection, and packet duplicate detection ifit is necessary.
The header length h not only adapts to each datagram,but may also vary between fragments of one datagram.Because the fragment sequence number fseq is countingdown, the header length hi decreases for every fragmentsequence number value i representable in a header oflength hi − 1. This happens for each i with:
i = 27n−2 − 1, n ∈ N1. (1)
242 JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011
© 2011 ACADEMY PUBLISHER

Require: p ≥ 1 ∧m ≥ 2prem ← p {remaining payload to be fragmented}c← 0 {total fragment count}h← 1 {current header length}ch ← 32 {max. frag. count with header length = h}cmax ← 32 {max. frag. count with header length≤ h}
{need bigger headers to fit remaining payload?}while prem > ch(m− h) do{subtract payload size fitting with current headerlength}prem ← prem − ch(m− h)c← c+ ch
h← h+ 1{check that header is still smaller than MTU}if h ≥ m then
return error: p too largeend ifch ← 127cmax
cmax ← 128cmax
end whilec← c+d prem
m− he {add count of remaining fragments}
hc−1 ← hreturn (c, hc−1)
Figure 2. Algorithm calculating fragment count c and first fragment’sbasic header length hc−1 for MTU m and datagram size p.
Because the full MTU m can be used, the variablefragment payload length is m − hi for each fragment,except for the last one. The last fragment may be smallerif the datagram size p does not exactly match the sum ofall fragment’s payloads.
Since the first fragment’s sequence number is c − 1,we have to calculate the fragment count c in advance.The algorithm presented in Figure 2 solves this task.It also returns the first fragment’s header length hc−1.The algorithm starts considering the lowest header length,which will be used for the last fragments. If the payloaddoes not fit into the fragments with such a header,additional fragments with longer headers are needed. Theheader length and the total fragment count are increasediteratively until the remaining payload fits into fragmentswith the current header length. The algorithm runs witha complexity of O(log p) for payload size p.
An overview on the fragmentation is given in Figure 3.To fragment a p Byte datagram, first the fragment count cand the first fragment’s header length hc−1 must becalculated from p and the MTU m using the describedalgorithm. Then the first fragment can be constructed fromthe AFP basic header (containing the fragment sequencenumber i = c− 1) and the first m − hc−1 Bytes of thedatagram. The next fragment consists of an AFP basicheader of length hc−2 (with the sequence number i =c− 2) and the next m− hc−2 Bytes of the datagram. Asalready described, the sequence number i is decremented
fragment by fragment until it reaches zero for the lastfragment, which contains the remaining data that may beless than m − h0 = m − 1 Bytes. The header length hi
is the minimal sufficient encoding for the number i. Theheader length is equal for wide ranges of i, but reduced byone byte for values of i given in Formula 1, like 4095 and31. This is especially important for the protocol efficiencyon small-MTU networks.
The described variable-length header format offershigher scalability and protocol efficiency compared tofixed-length encodings. The protocol adapts to all MTUsof at least 2 Bytes. The maximum count of fragments perdatagram is only limited by the MTU m. The variable-length header may encode up to 27(m−1)−2 differentfragment numbers, because the header length is limited tom−1 Bytes and two bits of the header are reserved next tothe fragment sequence number. Like the maximum frag-ment count, the maximum fragmentable payload pmax
grows exponentially with the MTU as well.
pmax =
m−1∑h=1
ch · (m− h)
= 1281272
7m−9 − 32127
Of course, for tiny MTUs the maximum payload issmall and the overhead is large. However, our protocolalready works very well for quite small MTUs, like8 Bytes on the widely used CAN field-bus. Here ithas a theoretical limit of about 129 TBytes payload per
p Bytes
datagram
hc−1 Bytes
c-1 data 0
c-2 data 1
...h32 = 2 Bytes
32 data c-33
31 data c-32
h31 = 1 Byte ...
1 data c-2
0 data c-1
m Bytes
cfr
agm
ents
Figure 3. Fragmentation of a p-Bytes datagram into c fragments
JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011 243
© 2011 ACADEMY PUBLISHER

datagram. In addition, our protocol can be stacked as oftenas desired by using fragments produced by one AFP layeras datagrams for the lower AFP layer. Hence, it is evenpossible to support arbitrarily large datagrams on top ofa network with a 2 Bytes MTU.
One key feature of AFP is that the number of data-gram fragments is given in the first fragment, thus therequired storage for reassembly is allocatable in advance.Consequently, if a large datagram does not fit into thesystem’s memory, all fragments of such a datagramwill be dropped, avoiding memory cluttering. Only ifpacket reordering delays the first fragment’s arrival, somefragments must be buffered before the decision aboutdecoding or dropping is taken.
AFP was designed to work on top of any network type,including unidirectional channels. That is why there isno built-in acknowledge or retransmission mechanism. Ifthe communication reliability does not meet the require-ments, it is possible to integrate further protocols thatmay be encapsulated using the extension header format.For example that might be forward error correction oran acknowledge-or-retransmit mechanism if bidirectionalcommunication is possible.
3) Extension Header Format: To keep our protocolflexible to many possible requirements, we provide ageneric extension header format. Extension headers areoptional and may vary between datagrams. They allowspecifying information to be sent with each fragment ofa datagram, providing additional functionality. Datagramidentification and forward error correction are typical usecases, and further extension header types can be definedeasily. However, the calculation of the payload size andfragment count has to consider the deployed extensionheaders.
AFP neither limits the number of possible types northe length of the extension headers by using the variable-length header data encoding. It supports two categoriesof extension headers: One which encodes the header datalength explicitly and another with length depending onthe extension type.
Explicit length encoding is more generic. Headers ofthe same type may differ in length. Additionally, it ispossible to make the implementation ignore unknownheaders by skipping the given number of header bytes.
In contrast, using implicit length encoding, the headerlength is defined by the header type, and thus, it isconstant for such types. All communicating nodes mustbe in agreement about the unique type-to-length mapping.The benefit of the known header length is a reducedprotocol overhead.
Our binary encoding supports both header styles (seeFig. 4). It consists of the following elements:
ext: It has the same meaning as in the basic header.esb: The explicit size bit is set if the header data
length is given explicitly. Otherwise it is implicitthrough the unique type-to-length mapping.
type: This field is used to distinguish different exten-sion header types. As for the fragment sequence
number in the basic header, the type identifierlength is given in unary coding in front of the extbit. Type identifiers may be encoded arbitrarily,e. g. as a binary number or a character string.
size: As usual, the header data length is kept here invariable-length unsigned integer unary encoding(network byte order) cutting off leading zerobits. This field only occurs if esb is set.
data: The header data contain the protocol informationof the extension. The field’s length is giveneither implicit or explicit in dependence of theesb.
As shown, our protocol provides a scalable extensionmechanism limiting neither the number of possible exten-sions, nor the length of an extension. Hence, applicationor network related requirements can be handled in anextension for the adaptive fragmentation protocol. Fur-thermore, extensions create no protocol overhead (excepta chaining bit) if they are not needed, because they arejust omitted in this case.
B. Implementation
AFP, which is part of the FAMOUSO middleware [7],[13], was implemented with template metaprogrammingtechniques in C++, leading to a highly configurable soft-ware. Thus, it is possible to combine several configurationoptions at compile time to get an optimized AFP version,fitting exactly to the application requirements. Configura-tion options include whether to use the extension headerswe defined:
• Datagram identification: If multiple datagrams getfragmented concurrently, it may result in interleavedtransmission of fragments belonging to differentdatagrams. In this case a receiver has to be able to as-sign each fragment to the datagram it is a part of. Wesolve this issue by adding a datagram identificationnumber to each fragment via an extension header.All packets a datagram gets fragmented to have toshare the same datagram identification. It has todiffer from all identifications of other datagrams thatreach the receiver before reassembly is completed.Datagram identification is also needed, if packet lossor reordering influences the sequence of receivedfragments while datagrams are sent at a high rate.Our implementation offers various policy classes toconfigure whether to add datagram identification,to support concurrent reassembly of multiple data-grams, whether to check for duplicates or whetherAFP needs to be able to handle reordering.
• Forward error correction: In the presence of packetloss it might be useful to decrease the probability oflosing a whole datagram at the expense of transmit-ting redundant information, especially if there is nofeedback channel to trigger a retransmission. For thispurpose we provide forward error correction policyclasses that generate an extension header and a user-defined number r of redundant fragments. Then the
244 JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011
© 2011 ACADEMY PUBLISHER

10
1 0a-1
exta
1a+1
typea+2 8a-1
defines lengthof type field
selects module forheader decoding
10
1 0b-1
sizeb 8b-1
data0 8s-1
defines lengthof size field
defines headerdata length s
s Bytes header data
explicit size bit
10
1 0a-1
exta
0a+1
typea+2 8a-1
data0 8s-1
defines lengthof type field
selects module for headerdecoding; implicitlydefines data length s
s Bytes header data
Figure 4. AFP extension header binary format with and without explicit header size
datagram can be reconstructed if not more than rfragments are lost.
Our Datagram identification and Forward error correc-tion extension headers use the implicit size format thatdefines the header data length by the header type. Doingso saves the overhead of encoding the header length.
If received fragments contain an extension header notsupported by the used configuration, the datagram isdropped, because a correct reassembly is impossible.
AFP is entirely written in standard-compliant C++. Ithas been successfully deployed on Linux, Windows andon 8-bit Atmel AVR micro-controllers. Running AFP onanother platform usually requires only a configuration andcompilation for that platform.
To tackle the resource constraint problems on embed-ded platforms, we offer configuration options to adjust thetrade-off between resource consumption and applicationrequirements. For example, if a platform has no supportfor heap memory allocation, a static buffer will be usedfor defragmentation. A precondition is to know the sizeand number of concurrently expected datagrams. How-ever, with this knowledge, AFP automatically chooses thesmallest fitting data type to represent datagram sizes inthe code. If it is smaller than 256 Bytes, this saves RAMand instructions on 8-bit micro-controllers.
IV. EVALUATION
AFP is intended to be a scalable and extensible frag-mentation protocol with low overhead suitable for differ-ent network types and applications. In the following, wediscuss the theoretical scalability limits of AFP, considerits protocol overhead comparing it to other fragmentationsolutions, and discuss the resource requirements of theAFP implementation.
A. Scalability
As already discussed in Section III, AFP is scalablein terms of the supported MTUs and the maximumdatagram size that can be fragmented. It can be used withvery small MTUs, starting from 2 Bytes. The maximumdatagram size grows exponentially with rising MTU,
already reaching 129 TBytes for CAN with a low MTUof 8 Bytes. If AFP is applied multiple times recursively,the maximum datagram size can be increased further. Inthis way, arbitrarily large datagrams can be fragmentedwith any MTU above 1 Byte.
B. Protocol overhead
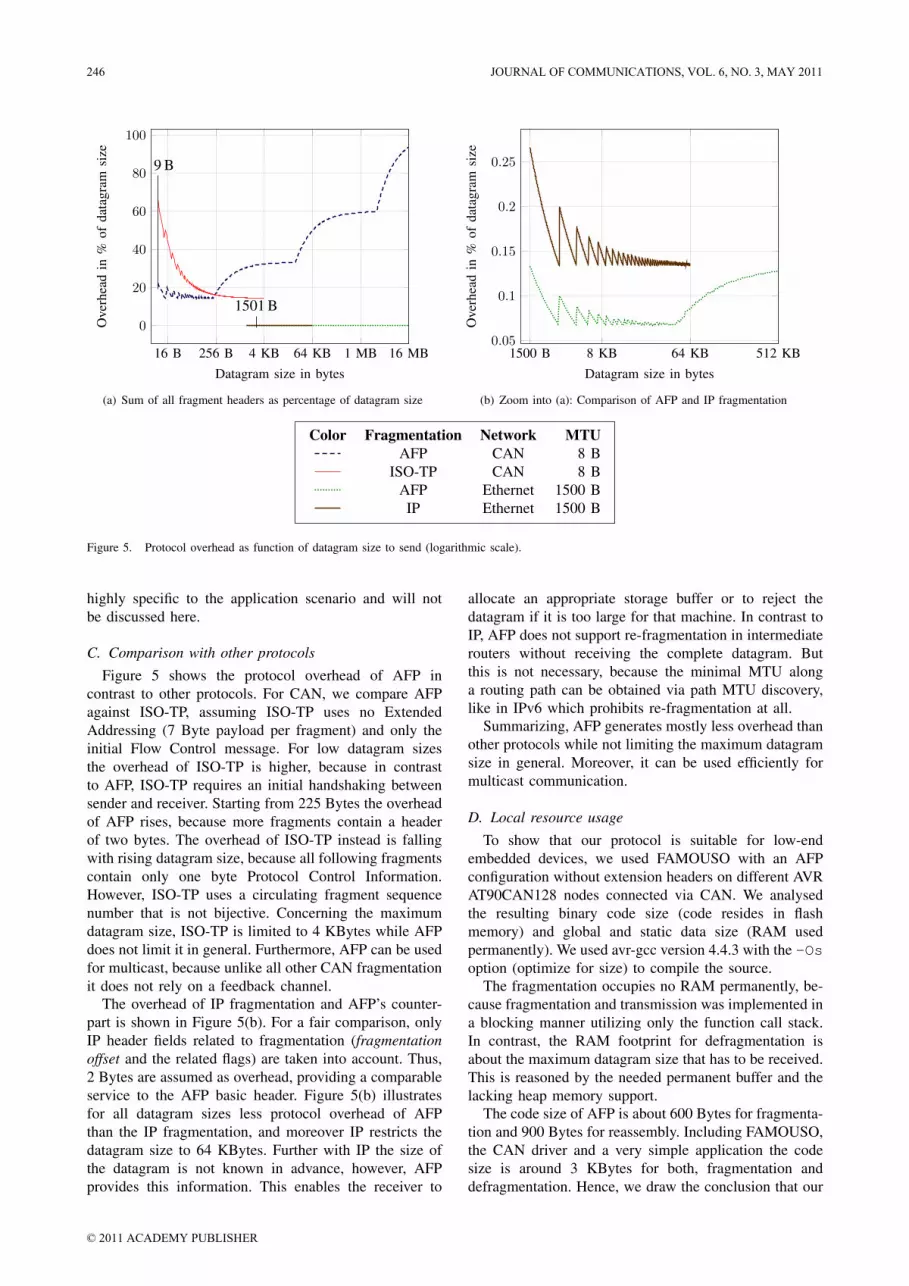
Figure 5 gives an overview about the protocol overheadof AFP and compares it to other protocols. Section IV-Cgives attention to the comparison.
The overhead of AFP depends primarily on the usedMTU and secondarily on the size of the datagram tosend. The plots show the protocol overhead for two typicalMTUs (CAN and Ethernet) above a logarithmic scale ofthe datagram size. The overhead on CAN is much higherthan on Ethernet in general and it increases faster. Thatis the price to pay for transmitting masses of data via asmall MTU network. The overhead and its growth shrinksignificantly with rising MTU, because one fragment canhold more data. So we need less fragments resulting in alower ratio of header data.
The shapes of the AFP overhead functions are similar,but they are stretched in the amplitude and differ intheir origins. Looking at the CAN graph, the overheadpaces up and down below the 224 Bytes datagram size.It rises every time a new fragment is needed, becausethe additional header byte increases the header rationoticeably for small datagram sizes. The amplitude of thisoscillation falls with increasing datagram size. Startingfrom 225 Bytes, we see rounded steps caused by thevariable header length. With the beginning of each stepthe header size increases by one. The overhead heightenswith the datagram size, because more fragments containan enlarged header.
All plots start with datagram sizes greater than theMTU, assuming that fragmentation is omitted for data-grams that fit into one packet. The illustrated protocoloverhead does not include any extension headers. Addingextension headers will increase the overhead dependingon the size of the specific extension header. This is
JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011 245
© 2011 ACADEMY PUBLISHER
16 B 256 B 4 KB 64 KB 1 MB 16 MB
0
20
40
60
80
100
Datagram size in bytes
Ove
rhea
din
%of
data
gram
size
9 B
1501 B
(a) Sum of all fragment headers as percentage of datagram size
1500 B 8 KB 64 KB 512 KB0.05
0.1
0.15
0.2
0.25
Datagram size in bytes
Ove
rhea
din
%of
data
gram
size
(b) Zoom into (a): Comparison of AFP and IP fragmentation
Color Fragmentation Network MTUAFP CAN 8 B
ISO-TP CAN 8 BAFP Ethernet 1500 BIP Ethernet 1500 B
Figure 5. Protocol overhead as function of datagram size to send (logarithmic scale).
highly specific to the application scenario and will notbe discussed here.
C. Comparison with other protocolsFigure 5 shows the protocol overhead of AFP in
contrast to other protocols. For CAN, we compare AFPagainst ISO-TP, assuming ISO-TP uses no ExtendedAddressing (7 Byte payload per fragment) and only theinitial Flow Control message. For low datagram sizesthe overhead of ISO-TP is higher, because in contrastto AFP, ISO-TP requires an initial handshaking betweensender and receiver. Starting from 225 Bytes the overheadof AFP rises, because more fragments contain a headerof two bytes. The overhead of ISO-TP instead is fallingwith rising datagram size, because all following fragmentscontain only one byte Protocol Control Information.However, ISO-TP uses a circulating fragment sequencenumber that is not bijective. Concerning the maximumdatagram size, ISO-TP is limited to 4 KBytes while AFPdoes not limit it in general. Furthermore, AFP can be usedfor multicast, because unlike all other CAN fragmentationit does not rely on a feedback channel.
The overhead of IP fragmentation and AFP’s counter-part is shown in Figure 5(b). For a fair comparison, onlyIP header fields related to fragmentation (fragmentationoffset and the related flags) are taken into account. Thus,2 Bytes are assumed as overhead, providing a comparableservice to the AFP basic header. Figure 5(b) illustratesfor all datagram sizes less protocol overhead of AFPthan the IP fragmentation, and moreover IP restricts thedatagram size to 64 KBytes. Further with IP the size ofthe datagram is not known in advance, however, AFPprovides this information. This enables the receiver to
allocate an appropriate storage buffer or to reject thedatagram if it is too large for that machine. In contrast toIP, AFP does not support re-fragmentation in intermediaterouters without receiving the complete datagram. Butthis is not necessary, because the minimal MTU alonga routing path can be obtained via path MTU discovery,like in IPv6 which prohibits re-fragmentation at all.
Summarizing, AFP generates mostly less overhead thanother protocols while not limiting the maximum datagramsize in general. Moreover, it can be used efficiently formulticast communication.
D. Local resource usageTo show that our protocol is suitable for low-end
embedded devices, we used FAMOUSO with an AFPconfiguration without extension headers on different AVRAT90CAN128 nodes connected via CAN. We analysedthe resulting binary code size (code resides in flashmemory) and global and static data size (RAM usedpermanently). We used avr-gcc version 4.4.3 with the -Osoption (optimize for size) to compile the source.
The fragmentation occupies no RAM permanently, be-cause fragmentation and transmission was implemented ina blocking manner utilizing only the function call stack.In contrast, the RAM footprint for defragmentation isabout the maximum datagram size that has to be received.This is reasoned by the needed permanent buffer and thelacking heap memory support.
The code size of AFP is about 600 Bytes for fragmenta-tion and 900 Bytes for reassembly. Including FAMOUSO,the CAN driver and a very simple application the codesize is around 3 KBytes for both, fragmentation anddefragmentation. Hence, we draw the conclusion that our
246 JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011
© 2011 ACADEMY PUBLISHER

Figure 6. Operator View
protocol creates only little overhead concerning code sizeand permanent RAM consumption. Thus, it is suitable forembedded systems with very strict resource constraints.
V. CASE STUDY: TELEOPERATED ROBOT
To demonstrate the scalability of our approach, weenhance the evaluation with a real-world case study. Amobile robot is controlled by an operator, where controlcommands and sensors values are sent over a WirelessMesh Network (WMN [16]). In addition, a live videois transmitted from the robot to the operator. To allowthe integration of the robot’s CAN-based sensors andactuators into the WMN, we deploy the FAMOUSOmiddleware [17] for all communication.
The video frames from the robot’s two cameras (Fig-ure 6) are generated with 10 frames per second at 640x480pixels each. We are compressing them using the wavelet-based Progressive Graphics Format (PGF [18]), whichdoes not consider inter-frame dependencies. PGF encodeseach frame into four layers with increasing resolution. Thetypical layer size is between 5 KBytes and 10 KBytes,depending on image content. To reconstruct the image upto a certain layer, all previous layers have to be present.
The video frame layers exceed the Wireless LAN MTUand thus need to be fragmented for transmission. Sincethe WMN is faced with possible packet loss, additionalmeans are required to provide at least a minimal qualityview to the operator. To achieve this, at least layer 0(lowest resolution) needs to be delivered. To compensatefor lost layer 0 packets, we add additional forward errorcorrection packets (see Figure 7). This ensures that at leasta low-quality image can be displayed without increasingthe network overhead too much. If the successive layerfragments are transmitted successfully, the image qualitycan be increased, allowing for fine-grained robot opera-tion.
In this scenario, the complexity of fragmenting thelayers of a video frame and the addition of partial forwarderror correction is transparently handled by AFP, allowing
L0
PGF data fragments FEC redundancy
L1L2L3
Figure 7. Fragmentation of video frame layers with forward errorcorrection on layer 0
the application to concentrate efforts on the capturing anddisplay of the video. The flexible interface provided byAFP has shown its practical usability. In addition, it iseasily possible to adapt to other networks, e.g. by addingmore FEC packets where higher bandwidth is availablebut packets might be lost, or by completely removing theFEC when no packet loss can occur. These changes can beperformed by reconfiguring AFP alone, without changingthe application.
VI. CONCLUSION
In this paper we present AFP, a fragmentation protocolthat adapts to different network MTUs as well as todifferent datagram sizes, while using the system resourcesefficiently. The protocol can be tailored to the needs ofapplications, allowing to deploy it in a lot of differentscenarios ranging from low-scale embedded devices upto higher end systems.
Due to its adaptive nature, AFP is very reusable andcan reduce development efforts significantly. Especially,it is well suited as a general fragmentation solution forsoftware that provides a communication interface whichhides different networks’ characteristics like FAMOUSOdoes. Thus, by utilizing AFP, a middleware can offer equalservice on top of various networks, independently of thenetworks’ fragmentation support and maximum datagramsize.
We describe AFP’s basic concepts that employ variable-length encoding to enable maximum scalability whileguaranteeing low protocol overhead. Following the idea ofminimising protocol overhead, we split the AFP protocolinformation into an essential basic header and optionalextension headers. The basic header is used for thegeneral fragmentation task, and the extensions allow forsupporting different application demands, like forwarderror correction mechanisms in case of a transmissionover an unreliable network.
To evaluate AFP, we analyze the protocol overhead ofthe basic header for different MTUs and datagram sizes,showing the scalability and its usability in case of tinyMTUs. By applying the protocol recursively, it is possibleto send arbitrarily-large datagrams over any network withan MTU of at least 2 Bytes. We also compare AFPto other widely used fragmentation protocols and showAFP’s properties in terms of scalability and adaptability.Furthermore, we measure the resource consumption ona typical 8-bit micro-controller, where AFP has a verylow footprint. As a practical use case, we deploy AFP
JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011 247
© 2011 ACADEMY PUBLISHER

in a tele-operating robot scenario. Here datagrams aretransferred through a WMN in a high rate. We employAFP’s extensions for datagram identification and forwarderror correction to enable a reliable video stream, allowingthe correct steering of the robot.
Future work will cover the specification of typical ex-tension header types. We will consider extension headersfor example to allow retransmissions of lost fragmentsand to handle security issues. Next, we will evaluate theoverhead of the extensions in terms of used bandwidthand needed RAM/ROM.
Our implementation of AFP, which is part of theFAMOUSO middleware, is Open Source and can bedownloaded and used without a charge [7].
REFERENCES
[1] J. Shoch, “Packet fragmentation in inter-network protocols,”Computer Networks (1976), vol. 3, no. 1, pp. 3–8,1979. [Online]. Available: http://linkinghub.elsevier.com/retrieve/pii/0376507579900497
[2] Robert Bosch GmbH, CAN Specification Version 2.0. RobertBosch GmbH, September 1991.
[3] ISO 15765-2:2004, Road vehicles – Diagnostics on ControllerArea Networks (CAN) – Part 2: Network layer services. ISO,Geneva, Switzerland, 2004.
[4] Truck Bus Control & Com. Network Subcom., RecommendedPractice for a Serial Control and Communications Vehicle Net-work (SAE J1939), 2005th ed. Warrendale Pa.: Society ofAutomotive Engineers, 2005.
[5] J. Kaiser and M. A. Livani, “Achieving Fault-Tolerant orderedbroadcasts in CAN,” in Proceedings of the Third EuropeanDependable Computing Conference on Dependable Computing(EDCC-3). Prague, Czech Republic: Springer-Verlag, September1999, pp. 351–363.
[6] S. Zug, M. Schulze, A. Dietrich, and J. Kaiser, “Programmingabstractions and middleware for building control systems as net-works of smart sensors and actuators,” in Proceedings of EmergingTechnologies in Factory Automation (ETFA ’10), Bilbao, Spain,September 13-16 2010.
[7] M. Schulze, “FAMOUSO project website,” 2008-2011, [(online),as at: 25.02.2010]. [Online]. Available: http://famouso.sourceforge.net
[8] RFC 791 – Internet Protocol Specification, Information SciencesInstitute, University of Southern California, September 1981.[Online]. Available: http://www.ietf.org/rfc/rfc791.txt
[9] C. A. Kent and J. C. Mogul, “Fragmentation considered harmful,”SIGCOMM Comput. Commun. Rev., vol. 25, no. 1, pp. 75–87,1995.
[10] ODVA, DeviceNet Specifications, Release 2.0, vol. I: Communi-cation Model and Protocol, vol. II: Device Profiles and ObjectLibrary. Open DeviceNet Vendor Association Inc., 1998.
[11] CAN in Automation, CiA DS 201-207 V1.1: CANopen ApplicationLayer for Industrial Applications. CiA, CANopen, 1996.
[12] ——, CiA DS 301 V4.02: CANopen Application Layer and Com-munication Profile. CiA, CANopen, 2002.
[13] M. Schulze, “FAMOUSO – Eine adaptierbare Publish/ SubscribeMiddleware fur ressourcenbeschrankte Systeme,” ElectronicCommunications of the EASST (ISSN: 1863-2122), vol. 17,p. 12, 2009, workshops der Wissenschaftlichen KonferenzKommunikation in Verteilten Systemen 2009 (WowKiVS2009). [Online]. Available: http://eceasst.cs.tu-berlin.de/index.php/eceasst/article/view/195/213
[14] Standard MIDI-File Format Spec. 1.1, The International MIDIAssociation.
[15] Unicode Consortium, The Unicode Standard, Version 4.0.Addison-Wesley, 2003, ch. 3.9 and 3.10, p. 77 ff. [Online].Available: http://www.unicode.org/versions/Unicode4.0.0/ch03.pdf
[16] I. Akyildiz, X. Wang, and W. Wang, “Wireless Mesh Networks: asurvey,” Computer Networks, vol. 47, no. 4, pp. 445–487, 2005.
[17] A. Herms, M. Schulze, J. Kaiser, and E. Nett, “ExploitingPublish/Subscribe Communication in Wireless Mesh Networks forIndustrial Scenarios,” in Proceedings of Emerging Technologies inFactory Automation (ETFA ’08), Hamburg, Germany, September15-18 2008, pp. 648–655. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=4638465
[18] C. Stamm, “PGF - A New Progressive File Format for Lossy andLossless Image Compression,” in WSCG, 2002, pp. 421–428.
Michael Schulze received his diploma de-gree in computer science from the Otto-von-Guericke University of Magdeburg in 2002.Since 2005 he has been a member of theEmbedded and Operating Systems (EOS) re-search group in the Department of DistributedSystems supervised by Prof. Jorg Kaiser. HisPhD research focuses on adaptable event-basedmiddleware for resource-constraint embeddedsystems.
Philipp Werner received his diploma de-gree in computer science from the Otto-von-Guericke University of Magdeburg in 2011.Currently he starts his PhD research with focuson medical image processing in the Faculty ofElectrical Engineering and Information Tech-nology.
Georg Lukas received his diploma degree incomputer science from the Otto-von-GuerickeUniversity of Magdeburg in 2005. Since 2006he has been a member of the Realtime Systemsand Communication (EUK) research group inthe Department of Distributed Systems super-vised by Prof. Edgar Nett. His PhD researchfocuses on reliable wireless mesh networks.
Jorg Kaiser is a Full Professor in the Facultyof Computer Science at the Otto-von-GuerickeUniversity of Magdeburg where he leads theDepartment for Embedded Systems and Op-erating Systems (EOS). His research workranges from computer architecture, operatingsystems, distributed systems and middlewarewith emphasis to component-orientation, faulttolerance, and real-time. His research areasnow have a strong emphasis on large-scaledistributed real-time systems supervising and
controlling real-world applications. He recently co-initiated a Compe-tence Centre for Service Robotics together with the Fraunhofer IFF inMagdeburg to foster the exchange between academia and more industry-oriented development.
248 JOURNAL OF COMMUNICATIONS, VOL. 6, NO. 3, MAY 2011
© 2011 ACADEMY PUBLISHER