a performance evaluation of the convex spp-1000 scalable shared memory parallel computer
TRANSCRIPT

A Performance Evaluation of the Convex SPP-1000Scalable Shared Memory Parallel Computer
Thomas Sterling �y Daniel Savarese y� Peter MacNeice zKevin Olson x Clark Mobarry { Bruce Fryxell x
Phillip Merkey�Abstract
The Convex SPP-1000 is the first commercial implementation ofa new generation of scalable shared memory parallel computers withfull cache coherence. It employs a hierarchical structure of processingcommunication and memory name-space management resources toprovide a scalable NUMA environment. Ensembles of 8 HP PA-RISC 7100microprocessors employ an internal cross-bar switch and directory basedcache coherence scheme to provide a tightly coupled SMP. Up to 16 pro-cessing ensembles are interconnected by a 4 ring network incorporat-ing a full hardware implementation of the SCI protocol for a full systemconfiguration of 128 processors. This paper presents the findings of aset of empirical studies using both synthetic test codes and full applic-ations for the Earth and space sciences to characterize the perform-ance properties of this new architecture. It is shown that overhead andlatencies of global primitive mechanisms, while low in absolute time,are significantly more costly than similar functions local to an individualprocessor ensemble.
1 Introduction
The Convex SPP-1000 is the first of a new generation of scalable sharedmemory multiprocessors incorporating full cache coherence. After the in-novative but ill-fated KSR-1 [18], parallel computing system vendors brieflypursued more conservative approaches to harnessing the power of state-of-the-art microprocessor technology through parallel system configurations.But issues of ease-of-programming, portability, scalability, and performancehave led to plans by more than one vendor to offer full global name-space�Center of Excellence in Space Data and Information Sciences, NASA Goddard SpaceFlight CenteryDepartment of Computer Science, University of MarylandzHughes STXxInstitute for Computational Science and Informatics, George Mason University{NASA/GSFC Space Data Computing Division, Greenbelt, Maryland1

scalable architectures including the mechanisms for maintaining consistencyacross distributed caches. This paper presents the most in-depth perform-ance study yet published of the Convex SPP-1000.
Extending beyond bus based systems of limited scaling employing snoop-ing protocols such as MESI, this emerging generation of multiprocessors ex-hibits hierarchical structures of processing, memory, and communicationsresources. Correctness of global variable values across the distributed sharedmemories is supported by means of levels of directory based reference treesfor disciplined data migration and copying. When implemented in hardware,such mechanisms greatly reduce the overhead and latencies of global dataaccess. However, in spite of such sophisticated techniques, cache miss pen-alties in this class of parallel architecture can be appreciably greater thanfor their workstation counterparts imposing a NUMA (Non-Uniform MemoryAccess) execution environment. The Convex SPP-1000 provides an op-portunity to better understand the implications of these architectural prop-erties as they relate to performance for real-world applications. This paperpresents findings from studies designed to examine both the temporal costsof this new architecture’s low level mechanisms and its scaling propertiesfor a number of complete scientific parallel programs.
The Convex SPP-1000 architecture reflects three levels of structure tophysically and logically integrate as many as 128 microprocessors into asingle system. At the lowest level, pairs of HP PA-RISC processors are com-bined with up to 32 Mbytes of memory, two communications interfaces, andmemory and cache management logic to form the basic functional units ofthe system. Sets of four of these functional units are combined by a 5 portcross-bar switch into a tightly-coupled cluster, or hypernode. Within a hy-pernode, all memory blocks are equally accessible to all processors and afully hardware supported direct-mapped directory-based protocol providescache coherence. Up to 16 hypernodes are integrated into a single systemby means of four parallel ring interconnects. The SPP-1000 is the first com-mercial system to employ full hardware support for the SCI (Scalable Coher-ence Interface) [17] protocol to manage distributed reference trees for globalcache coherence. Each functional unit of a hypernode connects to one ofthe four global ring interconnects and provides cache copy buffer space inits local memory.
The use of a mix of CMOS and GaAs technology based componentsand strong hardware support for basic mechanisms push the state-of-the-artin what can be achieved with this class of parallel architecture. The stud-ies presented in this paper have yielded detailed measurements exposingthe behavior properties of the underlying system elements and the globalsystem as a whole. Synthetic experiments were performed to reveal thetimes required to perform such critical primitive operations as synchroniz-ation, data access, and message passing. Examples of science problemsfrom the Earth and space science disciplines were used to characterize thescaling properties of the global system. These ranged from problems with2

regular static data structures to applications with irregular dynamic data struc-tures. Both shared memory parallel thread and message passing program-ming/execution styles were examined. The results show a range of behavi-ors that generally favor this class of architecture but which expose problemsdue to its NUMA nature that are not resolved with current techniques.
The next section of this paper provides a more detailed description ofthe Convex SPP-1000 architecture, sufficient for understanding of the ex-perimental results that follow. A brief discussion of the software environ-ment used for programming and resource management is presented in Sec-tion 3. It must be noted that the Convex software environment is in a stateof flux with improvements incorporated on almost a weekly basis. Section 4presents the findings of a suite of experiments performed to expose the char-acteristics of the primitive mechanisms used to conduct and coordinate par-allel processing on the Convex multiprocessor. These findings are followedin Section 5 with the results of scaling studies performed on four Earth andspace science application codes. A detailed discussion of the findings andtheir implications for future architecture development are given in Section 6followed by a summary of conclusions drawn from this evaluation in Sec-tion 7.
2 A Scalable Shared Memory Architecture
The Convex SPP-1000 is a scalable parallel computer employing HP PA-RISC 7100 microprocessors in a hierarchical NUMA structure. The SPP-1000 architecture incorporates full hardware support for global cache co-herence using a multi-level organization that includes the first commercialimplementation of the emerging SCI protocol. The SPP-1000 mixes CMOSand GaAs technologies to provide short critical path times for custom logicand leverage cost effective mass market memory, processor, and interfacecomponents. This section describes the Convex SPP-1000 architecture atsufficient detail to understand the empirical results presented later in the pa-per.
2.1 Organization
The Convex SPP-1000 architecture is a three-level structure of processors,memory, communication interconnects, and control logic as shown in Fig-ure 1. The lowest level is the functional unit comprising two processorswith their caches, main memory, communications interfaces, and logic foraddress translation and cache coherence. The second level combines fourfunctional units in a tightly coupled clustered called a hypernode using afive port cross-bar switch. The fifth path is dedicated to I/O. The third andtop level of the SPP-1000 organization employs four parallel ring networksto integrate up to sixteen hypernodes into a single system. Cache coher-3

Figure 1: Convex SPP-1000 System Organization
ence is implemented within each hypernode and across hypernodes. Withina hypernode, a direct mapped directory based scheme is used. Between hy-pernodes, a distributed linked list directory based scheme based on the SCI(Scalable Coherent Interface) protocol is fully implemented in high speedhardware logic.
2.2 HP Processor
The SPP-1000 system architecture derives its compute capability from HP PA-RISC 7100 [15] microprocessors. The processor architecture is a RISC baseddesign emphasizing simple fixed sized instructions for effective pipelining ofexecution. This 100 MHz clocked chip includes 32 general purpose registersof 32 bit length and 32 floating point registers which may be used singly in32 bit format of in pairs for 64 bit precision; both IEEE floating-point format. Anumber of additional register for control and interrupt handling are included.The HP 7100 supports virtual memory with on-chip translation provided bya Translation Lookaside Buffer. Caches are external with separate 1 Mbytedata and instruction caches and a cache line size of 32 Bytes.
2.3 Functional Unit
The Functional Unit of the SPP-1000 integrates all the basic elements re-quired to perform computation and from which scalable systems can be as-sembled. Each functional unit includes two HP PA-RISC processors withtheir respective instruction and data caches, Two physical memory blocks,each up to 16 Mbytes is located on every functional unit. This provides local,hypernode, and global storage as well as global cache buffer space. TheCCMC element of the functional unit provides all hardware logic requiredto support the multilevel cache consistency protocols at the hypernode andglobal levels. An additional agent element of the functional unit manages4

the communications and address translation, again through hardware logic.The functional unit interfaces to the crossbar switch within its host hyper-node and to one of four ring networks connecting it to all other hypernodeswithin the system.
2.4 Hypernode
Local parallelism is achieved through hypernodes of four functional units.They are tightly coupled by means of a full 5 port crossbar switch. Four ofthe ports are connected, each to a single interface of one of the functionalunits. The fifth port is used to interface to I/O channels external to the sys-tem. Access to any of the memory banks within a hypernode by any of thefunctional units of the hypernode take approximately the same time. Thehypernode supports its own cache coherence mechanism. It is a directorybased scheme using direct mapped tags similar to the experimental DASHsystem [19]. Each cache line is 32 bytes in length and has sufficient tag bitsto indicate the local processors that maintain active copies in their dedicatedcaches. The tags also indicate which other hypernodes in the system sharecopies of the cache line as well. Access to global resources from the hyper-node are through the second communications interface on each functionalunit as described in the next subsection.
2.5 SCI Global Structure
The principal architecture feature providing scalability is the global intercon-nect and cache coherency mechanisms. Four ring networks are used toconnect all (up to 16) hypernodes. Each hypernode is connected to all fourring networks. Within a hypernode, one ring network is interfaced to one ofthe four functional units by that unit’s second high speed interface logic. Thatring network connects one quarter of the system’s total memory together asthe aggregate of the memory on the functional units it joins in the different hy-pernodes. A cache buffer is partitioned out of the functional unit memory tosupport cache line copies from the other hypernode memories on the sameglobal ring. Thus an access to remote memory from a processor first goesthrough the hypernode crossbar switch to the functional unit within that hy-pernode associated with the ring on which the requested cache line resideson the external hypernode. Then the request proceeds from that functionalunit out onto the ring interconnect and into the remote hypernode and func-tional unit holding the sought after data. Cache coherency is provided bya distributed reference tree. Each remote cache line that is shared by an-other hypernode processor(s) is copied to the cache buffer in the local hy-pernode and the functional unit associated with the appropriate ring inter-connect. Thus, future accesses to that cache line from within the hypernodeneed only go to the correct part of the global cache buffer. Writes result in5

the propagation of a cache line invalidation to remote hypernodes where ne-cessary. All management of the globally distributed cache is conducted ac-cording to practice established by the SCI protocol.
2.6 Memory Organization
System memory is organized to provide ease-of-use and adequate controlfor optimization. The physical memory can be configured to provide severallevels of latency that may map to the application programs’ memory accessrequest profile. Where possible, local memory with low latency and no shar-ing management overhead can provide fastest response time on a cachemiss. Memory partitioned to serve processors anywhere in a given hyper-node but precluding access from external hypernodes gives fast responsethrough the cross-bar switch and can be shared among all processors withinthe hypernode. Finally, memory partitioned such that it can be shared byall hypernodes may be organized in two ways. Either the memory may bedefined in blocks which are hosted by a single hypernode or the memoryis uniformly distributed across the collection of hypernodes. In the formercase, the memory block is interleaved across the functional units in the hosthypernode. In the latter case, the memory is interleaved across hypernodesas well as functional units within each participating hypernode. Cache through-put permits on average one data access and one instruction fetch per cycle(10 nsec). A cache miss that can be serviced by memory local to the re-questing functional unit, by memory shared among processors within a givenhypernode, or by global cache buffer within the hypernode all exhibit laten-cies of approximately 50 to 60 cycles depending on cross-bar switch andmemory bank conflicts. The Convex SPP-1000 provides full translation fromvirtual to physical memory addresses.
3 System Software and Programming Model
The underlying system software support and programming interface is a de-termining factor in the efficient use of any architecture. If a system is difficultto use, its potential performance gains become outweighed by the increaseddevelopment time required to exploit the system. The Convex SPP-1000takes a novel approach towards its user interface. Unlike the Cray T3D [11],there is no host system between the user and the machine. Users havedirect access to the system, which appears as a single entity running oneoperating system. In actuality, each hypernode runs its own operating sys-tem kernel that manages interactions with other hypernodes, such as jobscheduling and semaphore accesses. The operating system handles bothprocess and thread resource management. System utilities allow users tooverriding operating system defaults that control where processes will ex-ecute and the type and maximum number of threads to use in parallel pro-6

grams. The Convex SPP-1000 supports both the message passing and sharedmemory programming models to achieve parallelism in programs.
3.1 Message Passing
Message passing on the SPP-1000 is performed using the Convex imple-mentation of Parallel Virtual Machine (PVM) [26, 9], which is perhaps themost widely used message passing library in use today. Distributed sys-tems running PVM, such as a cluster of workstations, run one PVM daemonon each node (workstation or processor) to coordinate message buffer man-agement, task synchronization, and the sending/receiving of messages. Be-cause the SPP-1000 is a shared memory system, ConvexPVM does not al-locate one daemon per processor. Instead one PVM daemon runs on theentire machine, coordinating intrahypernode and interhypernode commu-nication. This model minimizes the interference present in purely distributedsystems caused by daemon processes running on the same processors asPVM tasks.
To reduce the cost of message passing, ConvexPVM allows tasks to usea shared message buffer space, instead of forcing each task to allocate buf-fers in private memory. A sending process packs data into a shared memorybuffer that the receiving process accesses after the send is complete. Thisprocess does not require any interaction with the PVM daemon [9] and re-duces the number of copies necessary to transfer data.
Because the cost of passing messages with PVM on the SPP-1000 issignificantly less than that of transmitting them across a local area network(see figure 4), PVM tasks function much like coarse-grained threads. In fact,as will be seen in section 5, a PVM implementation of an application canachieve almost one half the performance of a shared memory implementa-tion.
3.2 Shared Memory
Although the SPP-1000 provides relatively efficient message passing sup-port, adopting a shared memory programming style more efficiently exploitsthe system’s parallelism. Convex currently provides an ANSI compliant Ccompiler with parallel extensions and a Fortran compiler supporting Fortran77, as well as a subset of Fortran 90, with future plans to support C++.
Programs can run in parallel on the SPP-1000 by spawning executionthreads managed by the operating system and sharing the same virtual memoryspace. Threads can be created either by using the vendor’s low level Com-piler Parallel Support Library (CPSlib), which provides primitives for threadcreation and synchronization, or a high level parallel directive interface usedby the compilers to generate parallel code. The compilers can automaticallyparallelize code they determine can run in parallel, but we have found that7

they do not do a good job of weighing the overheads of parallelism in makingtheir decisions.
It is unreasonable to expect a compiler to make perfect decisions in choos-ing what code to parallelize, which is why it is important for there to be ex-tensive support for user specification of parallelism. The vendor providedcompilers support an extensive range of parallel directives that allow themto efficiently parallelize code. They also allow some flexibility in the alloc-ation of memory and placement of data structures in the memory space ofexecuting threads. Five classes of virtual memory are available to programs:
Thread Private - Data structures in memory of this type are private to eachthread of a processes. Each thread possesses its own copy of the datastructure that maps to a unique physical address. Threads cannot ac-cesses other threads’ thread private data.
Node Private - Data structures in memory of this type are private to all thethreads running on a given hypernode. Each hypernode posses itsown copy of the data structure which is shared by all the threads run-ning on it.
Near Shared - Data structures in memory of this type are assigned one vir-tual address mapping to a unique physical address located on the phys-ical of a single hypernode. All threads can access the same uniquecopy of the data structure.
Far Shared - Data structures in memory of this type are assigned one vir-tual address. However, the memory pages of the data are distributedround robin across the physical memories of all the hypernodes.
Block Shared - This is identical to Far Shared memory except that the pro-grammer can specify a block size that is used as the unit for distributingdata instead of the page size.
Classes of parallelism supported include both synchronous and asyn-chronous threads. Synchronous threads are spawned together and join in abarrier when they finish; the parent thread cannot continue execution until allchildren have terminated. Asynchronous threads continue execution inde-pendent of one another; the parent thread continues to execute without wait-ing for its children to terminate. Ordering of events and mutual exclusion canbe managed with high level compiler directives called critical sections, gates,and barriers which allow the compiler to generate appropriate object codethat allocates and properly coordinates the use of semaphores. Althoughthe abstraction of low level parallel mechanisms through the use of compilerdirectives facilitates the programming process, the programmer still has tohave a more than cursory understanding of the memory hierarchy to writeefficient programs. Parallel loops can achive marked performance gains justby making scalar variables thread private to eliminate cache thrashing.8

Figure 2: Cost of Fork-Join
4 Global Control Mechanisms
A set of synthetic codes were written to measure the temporal cost of specificparallel control constructs. These measurements were conducted acrossboth hypernodes, first scaling with high locality (first 8 threads are on onehypernode) and next with uniform distribution (each hypernode has an equalnumber of threads running on it). The accuracy of the measurements werelimited by the resolution of the timing mechanisms available and the intru-sion resulting from their use. The multitasking nature of resource schedulingalso proved to be a source of error, prompting the execution of many exper-imental runs to expose the true system behavior. Depending on the meas-urement of interest, either averages of the combined measurements or theminimum values observed were used.
4.1 Fork-Join Mechanism
Figure 2 shows the fork-join time in microseconds as a function of the num-ber of threads spawned. The graph shows two plots that highlight the in-creased cost of a fork-join across two hypernodes. The high locality plotdemonstrates the cost of the fork-join where the first 8 threads are spawnedon the same hypernode and subsequent threads are spawned on the re-maining hypernode. The uniform distribution plot shows the cost of the fork-join where an equal number of threads are spawned on each hypernode (ex-cept in the 1 thread case).
The principal observations to be garnered from Figure 2 are:� The fork-join time is proportional to the number of threads spawnedwith high locality across a single hypernode. Moving from 2 to 8 pro-9

Figure 3: Cost of Barrier Synchronization
cessors each additional pair of threads costs approximately 10 micro-seconds.� The fork-join time is roughly proportional to the number of threads spawnedwith uniform distribution between hypernodes. Moving from 2 to 16processors each additional pair of threads costs approximately 20 mi-croseconds.� A significant overhead, on the order of 50 microseconds, is incurredonce threads start to be spawned on two hypernodes.
4.2 Barrier Synchronization
Figure 3 reports two metrics for both the high locality and uniform distributioncases:
Last In - First Out: the minimum time measured from when the last threadenters the barrier to when the first thread afterward continues.
Last In - Last Out: the minimum time measured from when the last threadenters the barrier to when the last thread continues.
The results from our earlier study of only one hypernode of the SPP-1000[24] are also shown. Both the previous and current study used the sameexperimental method. A time-stamp was taken before each thread enteredthe barrier and after each thread exited the barrier. From this data an ap-proximation of the barrier costs could be derived. All timing data have beencorrected for the overhead involved in performing the measurements.
Figure 3 shows that the minimum time for a barrier (last in - first out) in-volving more than one thread is approximately 3.5 microseconds on a single10

hypernode, incurring an additional cost of 1 microsecond once threads on asecond hypernode become involved. The release time of the barrier, thetotal time to continue all suspended threads, possesses a more complexbehavior. In the high locality case on just one hypernode, the barrier ap-pears to cost roughly 2 microseconds per thread beyond the second threadinvolved. Once threads on a second hypernode become involved, there isan additional penalty, as evidenced by both the high locality and uniform dis-tribution cases.
This behavior may be caused by the implementation of the barrier prim-itive, which has each thread decrement an uncached counting semaphore[4] and then enter a while loop, waiting for a shared variable to be set to aparticular value. The last thread to enter the barrier sets the shared variableto the expected value, thus releasing the other threads from their spin wait-ing. Because this shared variable is cached by all of the threads, coherencymechanims are invoked when the final thread alters its value. This incursa variable temporal cost depending on the status of the system referencetree. Figure 3 would seem to reflect the increased cost of maintaining co-herency and updating the reference tree as a greater number of processorsbecome involved. The behavior of the uniformly distributed case is accoun-ted for by the parallel updates of internal system data structures of the twohypernodes.
4.3 Message Passing
The impact of the global interconnect is examined from the point of view ofmessage passing. For reasons of measurement accuracy, the experimentsperformed measure the time it takes to send a message out to a receivingprocessor and to get the message back. The time measured does not in-clude the cost of buidling the message in the first place. The round trip timeswere measured between a pair of processors on a single hypernode andthen again on a pair of processors on separate hypernodes. The experi-mental results of measurements taken for different message size are shownin Figure 4.
For messages under 8K bytes in size, the round trip message passingtime is approximately constant for both local and global messages. Localmessages take about 30 microseconds round trip while messages betweenhypernodes over the SCI interconnect require approximately 70 microsecondsfor a ratio of 2.3 between global and local message passing. This is an ex-cellent behavior on the part of the global mechanisms. From the standpointof message passing, the SPP-1000 can be considered as truly scalable.This of course does not include possible compounding factors as conten-tion which would result in a more heavily burdened system. However, earlierexperiments on a single hypernode showed little degradation as messagetraffic was increased appreciably [24].
Degradation is observed as the message size exceeds 8K byte size. As11

Figure 4: Cost of Round Trip Message Passing
the message size, measured in pages, doubles we find a substantial increasein message transfer times for both the local and global cases. Some com-plex behaviors are seen and an exact explanation for the rate on transfertime is not immediately clear.
5 Applications
In this section we investigate the performance of the SPP1000 on four dif-ferent applications.
5.1 PIC Introduction
Particle in cell(PIC) codes are extensively used in numerical modelling ofplasmas. Their strength is studying kinetic behaviour of collisionless plas-mas with spatial dimensions in the range from tens to thousands of debyelengths. They have also on occassion been used in N-body astrophysicalsimulations and are very closely related to vortex methods used in CFD.
PIC codes attempt to mimic the kinetic behaviour of the charged particleswhich constitute the plasma. They do this by tracking the motion of a largenumber of representative particles as they move under the influence of thelocal electromagnetic field, while consistently updating the field to take ac-count of the motion of the charges. Also known as particle-mesh(PM) codes,they have an hybrid eulerian/lagrangian character. The particle data is dis-tributed in proportion to the mass density and in that sense the codes are lag-rangian. However, for efficiency reasons the forces acting on the particlesare calculated by solving field equations using finite difference approxima-tions on a fixed mesh which adds an eulerian character. For statistical ac-12

curacy reasons we would like to use as many particles as possible. Ma-chine limitations have dictated particle numbers in the range of 105 – 107.The particles are finite sized charge clouds, not point particles. The use ofpoint particles would introduce too much short wavelength noise in the elec-tric field. These charge clouds are comparable in size to a single cell of themesh used to solve the field equations.
In this paper we report on a 3D electrostatic PIC code running on theConvex SPP1000 at Goddard Space Flight Center, using both shared memoryand message passing programming styles, and for reference purposes quotethe performance of the same application on one processor of a Cray YMP-C90.
5.1.1 Plasma PIC Code Definition
For each of the N particles in the model we must solve the equations of mo-tion, ddtxi = vi (1)and ddt(v)i = 1miF (xi) (2)where subscript i denotes the ith particle, and x, v, F and m are position,velocity, force and mass respectively.
In an electrostatic code the force on particle i isF i = qiE(xi) (3)where qi is the particles charge and E the electric field. The electric fieldE,is obtained by solving Poisson’s equation,r2� = ��(x) (4)for the electric potential, where � is the charge density and then evaluatingits gradient, E(x) = �r�: (5)
At each timestep the code has to perform the following basic steps:
1. Compute the charge density. This is a scatter with add. The modelparticles are small but finite sized charge clouds which contribute tothe charge density of any grid cells with which they overlap.
2. Solve for � and then E at the grid points.
3. InterpolateE to the particle locations in order to estimate the force act-ing on each particle. This is a gather step.
4. Push the particles, ie. integrate equations (1) and (2) over �t for eachparticle. 13

Load initial particlepositions and velocities
Deposit particle chargeon mesh − a scatter operation
Solve for Eon the mesh
Interpolate E to particlepositions and compute F− a gather operation
Solve particleequations of motion ∆t
Figure 5: Flowchart for a Particle-Mesh code.
The flow chart for this scheme is shown in figure 5.In combination these four steps of the PIC algorithm involve computation
and communication between two different data structures. The field datahas the qualities of an ordered array in the sense that each element hasspecific neighbors. The particle data has the qualities of a randomly orderedvector, in which element i refers to particle i, and no element has any specialrelationship to its neighbors in the vector.
Steps 2 and 4 are parallelizable in rather obvious ways, since they in-volve only simple and completely predictable data dependencies, and donot couple the two data structures. Steps 1 and 3 however do couple thetwo data structures, with complicated and unpredictable data dependencieswhich evolve during the simulation. It is these steps which invariably dom-inate the execution times of parallel PIC codes.
The particle equations of motion are advanced in time using an efficientsecond order accurate leap frog integration scheme.
Periodic boundary conditions were assumed in all 3 directions. To ob-tain field solutions, equation (4) was solved by transforming it into fourierwavenumber space using fft routines called from the system VECLIB, solv-ing the resulting algebraic equation in wavenumber space, and then revers-ing the transforms.
The test problem run was of a monoenergetic electron beam propagatingthrough a population of plasma electrons with maxwellian velocity distribu-tion. The beam was distributed throughout the physical domain and had a14
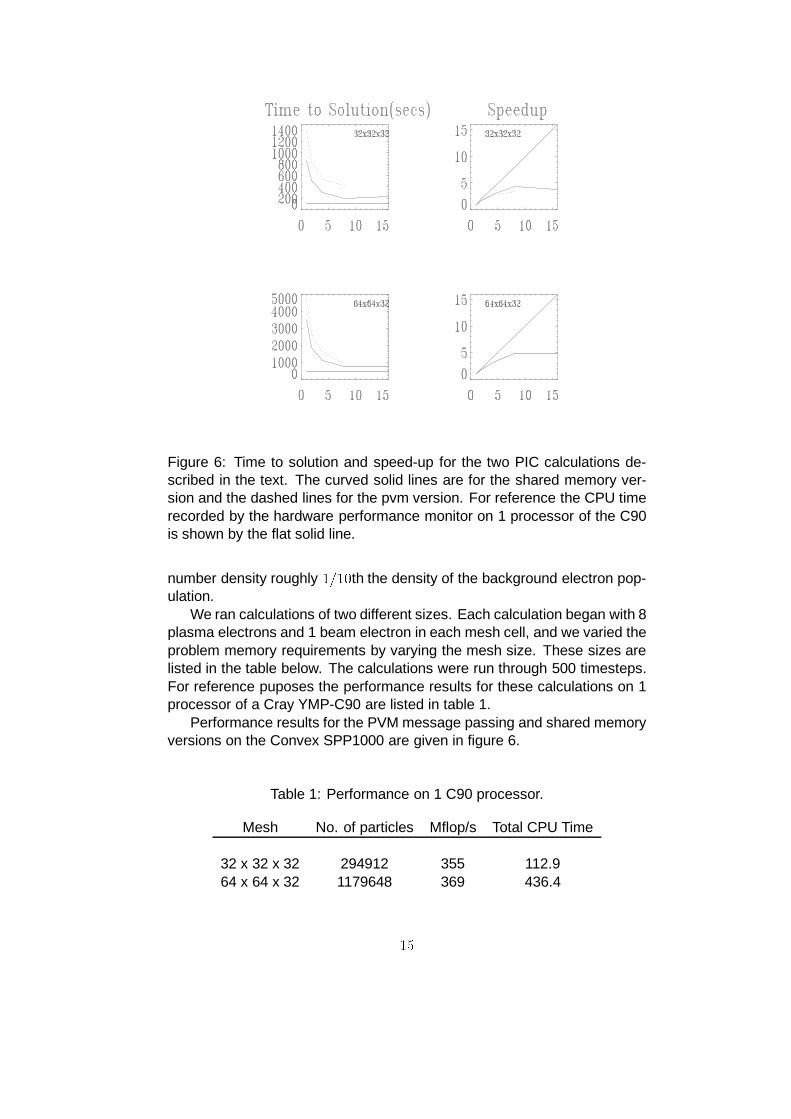
Figure 6: Time to solution and speed-up for the two PIC calculations de-scribed in the text. The curved solid lines are for the shared memory ver-sion and the dashed lines for the pvm version. For reference the CPU timerecorded by the hardware performance monitor on 1 processor of the C90is shown by the flat solid line.
number density roughly 1=10th the density of the background electron pop-ulation.
We ran calculations of two different sizes. Each calculation began with 8plasma electrons and 1 beam electron in each mesh cell, and we varied theproblem memory requirements by varying the mesh size. These sizes arelisted in the table below. The calculations were run through 500 timesteps.For reference puposes the performance results for these calculations on 1processor of a Cray YMP-C90 are listed in table 1.
Performance results for the PVM message passing and shared memoryversions on the Convex SPP1000 are given in figure 6.
Table 1: Performance on 1 C90 processor.
Mesh No. of particles Mflop/s Total CPU Time
32 x 32 x 32 294912 355 112.964 x 64 x 32 1179648 369 436.415

Each particle requires 11 data words to specify its properties. This ac-counts for most of the memory required by the shared memory model. Thesize of the smallest problem was chosen so that it would barely fill the cacheon the 16 processor machine.
The shared memory version consistently outperforms the pvm version,as we would expect.
5.2 Finite Element Simulations of Fluids
The Finite Element Method (FEM) has been extensively used to model solidmaterials and fluid flow. The FEM simulates a physical system by partition-ing the physical world into a collection of finite elements (triangles or tetra-hedra). Because of its versatility, it is lately gaining popularity in the Earthand space science community. Some examples of its applications are nu-merical weather prediction, the simulation of solar wind interaction with plan-etary atmospheres, and the modeling of magnetohydrodynamic turbulence.
Several features make the FEM attractive. Its unstructured nature allowsthe modeling of relatively intricate geometries. The simulation of realisticboundary conditions is also possible and relatively simple. In addition, theFEM is naturally suited for adaptive mesh refinement, a technique by whichhigh spatial resolution is dynamically applied only in the regions where it isdetermined to be necessary, thereby enabling the efficient use of availableresources.
5.2.1 FEM Algorithm Description
To many people to the distinguishing characteristic of the FEM is the fairlyarbitrary and adaptable spatial meshes that it allows. The FEM partitionsspace into small non-overlapping regions called elements. An element istypically a triangle in 2D or a tetrahedron in 3D. The vertices of the elementsare co-located with the points in space where the prognostic quantities arestored. The meshes of elements and points can be quite arbitrary in prin-ciple. However, meshes with elements with fairly uniform size and compactshape produce the best numerical results.
The computational phases are divided into computation on elements andcomputation on points with communication phases separating them. Thecomputation on elements involves the evaluation of spatial derivatives. Thecomputation on points involves the aggregation of vertex contributions andthe evaluation of transport fluxes for the prognostic quantities.
A FEM application needs to address issues of irregular global commu-nications among processors. There are three classes of global communic-ations used in the discrete evolution equations. First, there are global max-ima (minima) found to find quantities such as the largest permissible timestep. Second, the are global gathering of data from points of the mesh tothe vertices of the elements. Third, there are global aggregations of data16

(add, maximum, or minimum) from vertices of the elements to the points ofthe mesh. The second and third classes of global communication are crit-ical to the performance of any parallel implementation, in particular the thirdclass is called the “scatter-add” problem.
The prototype FEM application currently solves two-dimensional gas dy-namics problems with general boundary conditions. A simple first-order inspace (lumped mass matrix) and time, unstructured, 2D, FEM, gas dynam-ics code written in Fortran-77 with compiler directives was chosen as the testapplications to allow quick turn around time in source text modifications.
Morton ordering[27] was performed on the points and elements to en-hance cache locality for the gathers and scatters.
5.2.2 FEM Application Performance
The prototype FEM application was run on the Exemplar for two differentdata set sizes and two different codings of the same algorithm. The smalldata set was chosen to be about the size of the aggregate cache size of theExamplar with 16 processors.
The small data set has a mesh with 46545 points and 92160 elements;and the large data set has a mesh with 263169 points and 524288 elements.Note that there is about two elements to every point on the mesh; and an av-erage (maximum) of 6 (7) elements communicating with every point of the2D meshes. Depending on how a mesh is generated, these critical para-meters will vary and so will FEM code performance.
The tightest serial coding of the prototype FEM algorithm is used to com-pute useful Mflop/s. The minimal number of Cray Research Incorporated(CRI) “hpm” floating point operations per point update measured as on thesmall size data set is 437 floating point operations/point update (220 floatingpoint operations/element update). These numbers will be used as a con-version factor to useful Mflop/s for our data sets. The algorithm optimizedfor the CRI C90 runs at 0.57 point updates/microsecond (1.14 element up-dates/microsecond) on a single head of a C90. Thus we claim 250 Mflop/sversus the 293 Mflop/s measured by “hpm” for the C90 optimized code, be-cause we made it run with a smaller wall clock time by introducing redundanttransport flux calculations at the vertices.
The algorithm with vector style coding compiled with the serial compiler (-O2) ran at 0.072 point updates/microsecond (0.14 element updates/microsecond)on the Morton ordered data sets (31 Mflop/s). However the same code com-piled with the current (April 1995) parallelizing compiler (-O3) ran at 0.042point updates/microsecond (0.083 element updates/microsecond).
A graph of the scaling of the performance for the two problem sizes isgiven in Figure 7. The non-monotonic scaling between 8 and 9 processorsis being investigated. 17

Figure 7: The performance of the FEM codes on the small and large datasets. The horizontal line is the performance of a single head of a C90.Curves small1 and large were computed using the same code. Curve small2was computed using a second coding of the same numerics.
5.3 The Gravitational N-body Problem
The solution of the gravitational N-body problem in Astrophysics is of gen-eral interest for a large number of problems ranging from the breakup ofcomet Shoemaker/Levy 9 to galaxy dynamics to the large scale structureof the universe. This problem is defined by the following relation where thegravitational force on particle i in a system of N gravitationally interactingparticles is given by, ~Fi = NXj=1 Gmimj ~rij(r2ij + �2)3=2 (6)where G is the universal gravitational constant, mi and mj are the massesthe particles i and j, ~rij is the vector separating them, and � is a smoothinglength which can be nonzero and serves to eliminate diverging values in ~Fiwhen ~rij is small. This parameter also serves to define a resolution limitto the problem. This equation also shows that the problem scales as N2and modeling systems with particle numbers larger than several thousandis infeasible. 18

5.3.1 Tree Code Definition
Tree codes are a collection of algorithms which approximate the solution toequation 6 [2, 14, 21]. In these algorithms the particles are sorted into aspatial hierarchy which forms a tree data structure. Each node in the treethen represents a grouping of particles and data which represents averagequantities of these particles (e.g. total mass, center of mass, and high ordermoments of the mass distribution) are computed and stored at the nodes ofthe tree. The forces are then computed by having each particle search thetree and pruning subtrees from the search when the average data stored atthat node can be used to compute a force on the searching particle belowa user supplied accuracy limit. For a fixed level of accuracy this algorithmscales as N log(N) although O(N) algorithms are also possible. Since thetree search for any one particle is not known a priori and the tree is unstruc-tured, frequent use is made of indirect addressing. Further, the tree data isupdated during a simulation as the particles move through space. There-fore, this algorithm is not only of interest for its scientific application, but isalso of computational interest due to its unstructured and dynamic nature.
5.3.2 Performance Results for Tree Code
We have ported a FORTRAN 90 version of a tree code to the Convex SPPwhich was initially developed for the Maspar MP-2 and implemented usingthe algorithm described in Olson and Dorband [21]. The changes to the ori-ginal code were straightforward and the compiler directives and the sharedmemory programming model facilitated a very simple minded approach tobe taken. The main alterations to the MasPar code were to distribute all theparticle calculations evenly among the processors and make all intermedi-ate variables in the force calculation thread-private. Each processor thencalculates the forces of its subset of particles in a serial manner. All indirectaccesses are made by each thread of execution into the tree data stored inglobal shared memory. Further, these indirect addresses are made in theinnermost loop of the tree search algorithm, thus relying on the ability to util-ize rapid, fine grained memory accesses allowed by the shared memory pro-gramming model. This scheme also allows for more efficient use of the datacache on subsequent floating point operations.
The program was run on three problem sizes (32K, 256K and 2M particles),applying from 1 to 16 processors in two configurations of the processors.The first configuration ran 1,2,4 and 8 processors on a single hypernode andthe second ran 2,4,8 and 16 processors across two hypernodes. Figure 8shows the parallel speedup for each of the cases measured relative to thesingle processor rate of 27.5 Mflop/s. We see that the performance degrad-ation incurred across multiple hypernodes is small; it is between 2 and 7 per-cent. It is also clear that the performance at 16 processors is affected by theproblem size. The task granularity changes linearly with the problem size as19

Figure 8: N-Body Performance Scaling
do the overall memory requirements. However, the balance between localand global memory accesses varies non-linearly; it is determined by the pro-portion of information at each level of the tree and by the proportion of thedepths searched by the algorithm. To determine the effect of multiple hyper-nodes on the scaling of this application, tests should be run on a system withmore than two hypernodes. From this initial data it is not possible to predicthow speedup will change as additional hypernodes are added. Finally, the16 processor 384 Mflop/s result compares favorably to a highly vectorized,public domain tree code [14] which achieves 120 Mflop/s on one head of aC90.
A message passing version of this code has also been developed usingthe PVM library (Olson and Packer 1995). This code has been ported tovasious architectures such as a network of distributed workstations, the IntelParagon, the Cray T3D, and the Beowulf clustered workstation [23]. Sincethe Convex SPP also supports the PVM libaries, the code was easily portedto this architecture. The single processor performance of the code was quitegood in this case and is somwhat faster than that quoted above for the codewritten using the shared memory programming model and is also faster thanfor any of the archtitectures mentioned above. The overheads of packing20

and sending messages, however, are prohibitive and overall performance isdegraded relative to the shared memory version of the code. Optimizationsof this code continue.
5.4 Piece-wise Parabolic Method
The first code to be discussed solves Euler’s equations for compressiblegas dynamics on a structured, logically rectangular grid. The code, namedPROMETHEUS [13], has been used primarily for computational astrophys-ics simulations, such as supernova explosions [3, 20], non-spherical accre-tion flows [12], and nova outbursts [25]. The equations are solved in theform @�@t +r � �~v = 0 (7)@�~v@t +r � �~v~v +rP = �~g (8)@�E@t +r � (�E + P )~v = �~v � ~g (9)where � is the gas density, ~v is a vector specifying the gas velocity, P is thegas pressure, E is the internal plus kinetic energy per unit mass, ~g is theacceleration due to gravity, and t is the time coordinate. In order to com-plete the equations, one must also include an equation of state for comput-ing the pressure from the energy and density. These equations are solvedusing the Piecewise-Parabolic Method (PPM) for hydrodynamics [6]. Thisis a very high-resolution finite volume technique, which is particularly well-suited to calculation of flows which contain discontinuities such as shockfronts and material interfaces. This is especially important for astrophys-ics calculations, where hypersonic flows are frequently encountered and vis-cosities tend to be extremely small. The original formulation of the algorithmhas been extended to allow the use of a general equation of state [7]. In ad-dition, the capability of following an arbitrary number of different fluids hasbeen incorporated. Systems can be studied in either one, two, or three spa-tial dimensions using rectangular, cylindrical, or spherical coordinates. Theresults discussed below are for calculations performed on a two-dimensionalrectangular grid.
This code was parallelized using a domain decomposition technique, inwhich the grid was divided into a number of rectangular tiles. This approachhas been used successfully on a large number of parallel computers, in-cluding the Cray C-90, MasPar MP-1 and MP-2, IBM SP-1 and SP-2, CrayT3D, and Intel Paragon. For the case of the SPP1000, each processor isassigned one or more tiles to calculate. Each tile is surrounded by a frameof “ghost” points which are used for specifying boundary conditions. Sincethe formulation of the PPM algorithm used in PROMETHEUS is a nine-pointscheme, the “ghost” points need to be updated only once per time step if21

Table 2: PMM Performance
Grid Size No. of Tiles No. of Procs Mflop/s120� 480 4� 16 1 29.9120� 480 4� 16 2 58.2120� 480 4� 16 4 118.8120� 480 4� 16 8 228.5120� 480 12� 48 1 23.8120� 480 12� 48 2 47.8120� 480 12� 48 4 95.9120� 480 12� 48 8 186.2120� 480 4� 16 1 29.9240� 960 4� 16 4 118.5
frame is four grid points wide. The only communication required using thisapproach is that four rows of values must be exchanged between adjacenttiles once per time step. Since a few thousand floating point operations areneeded to update each zone for a single time step, the ratio between com-munication costs and computational costs is quite low. The results of theseruns is given in table 2.
6 Discussion
The studies described in this paper have been a rich source of experience inthe use of the SPP-1000. Those experiences have ranged from frustration todelight. Elation over successes have been tempered by difficulties in achiev-ing them. Frustration with system flaws has been mitigated by unpleasantexperiences with a number of competing machines. Under favorable condi-tions, it has been observed that the HP PA-RISC processor has proven tobe an effective, often superior computing element than those used on othermultiprocessors in terms of sustained performance on real problems. As anexample, efficient implementation of floating point divide provided signific-antly improved performance over other processors for at least one of ourproblems. Programming a single hypernode proved remarkably easy andreturned excellent scaling across eight processors in all cases. When start-ing with a good sequential code, parallelizing was often easy for a singlehypernode. Under favorable but achievable circumstances, a single hyper-node sustained performance approached that of a single head of a CRI C-90. 22

The primitive mechanisms provided by hardware support yielded verygood performance compared to what would be expected by software sup-port. But global operation of these mechanisms incurred measureable cost.In some cases, this was in the range of a factor of 2 which is entirely accept-able. In other cases, the difference in intra-hypernode versus inter-hypernodebehavior could be between a factor of 4 and 10. Under such circumstances,domain decomposition and problem partitioning became crucial to minimizeperformance degradation. Scaling of full applications ranged widely from ex-cellent (better than 80%) efficiency to poor where performance was seen todegrade between 8 and 16 processors.
In spite of the original intent of cache based systems, this class of memoryhierarchy is not transparent to the computational scientist and is a signific-ant factor in optimizing the parallel code. It was observed that problemsthat largely resided in cache versus those that were big enough to consumelarge portions of main memory code easily show performance difference ofa factor of three for the same application and this just on a single hyper-node. Cache miss penalties to global data versus hypernode local data weremeasured at about a factor of eight on average. While this is excellent com-pared to software message passing methods, that difference still could pro-duce serious degradation for the naive programmer.
A valued aid in achieving such optimized codes was the availability ofhardware supported instrumentation including counters for cache miss enu-meration and timing. Also, an excellent tool, CXpa provided good averagebehavior profiling that exposes at least coarse grained imbalances in exe-cution across the parallel resources. With these means of observing sys-tem behaviour, code modifications were made rapidly and to good effect.If vendors are going to insist on gambling system performance on latencyavoidance through caches, then they should make available the means toobserve the consequences of cache operation.
An unanticipated problem results from the general nature of the com-puter operating system. It can run on various numbers of processors and isfully multitasking. The problem is that most scientific applications are writ-ten with data structures and control processes based on powers of 2. Mostof the test codes required 16 processors and could not easily be recast torun on 15 processors. As a result, operating system functions shared ex-ecution resources with the applications. Because these applications main-tained their heritage of beinging statically allocated to processors, there wasno way to dynamically schedule threads and adaptively respond to variousprocessor workloads. Thus critical path length depended on exigencies ofoperating system demands as well as those of the applications of interest.
Finally, the Convex SPP-1000 system, particularly the system supportsoftware, is still in a state of maturing. This restricted access to some of theoptimizations that will shortly be available. It is anticipated that performancewill continue to improve in the near future as improvements migrate into userenvironments. One of these involved means of memory partitioning. Neither23

node-private nor block-shared modes were operational, limiting control ofmemory locality. Another involved the parallelizing compiler that did not yetincorporate all of the optimizations found in the serial processor compiler. Alast requirement yet to be fully satisfied is the need for fine-tuned libraries forcertain critical subroutines such as parallel FFT, sorting, and scatter-add.
7 Conclusion
The Convex SPP-1000 shared memory multiprocessor is a new scalableparallel architecture with unique architectural attributes. Its hierarchical struc-ture combined with multilevel cache coherence mechanisms makes it oneof the most interesting parallel architectures commercially available today.This paper has reported the findings of a set of studies conducted to evalu-ate the performance characteristics of this architecture. The system beha-vior has been examined from the perspectives of fine grain mechanisms andapplication level scalability. Synthetic test programs were developed to ex-ercise basic mechanisms for synchronization, scheduling, and communica-tions. Full application codes were drawn for the Earth and space sciencescommunity and selected to invoke varying degrees of global system inter-action.
It was determined that hardware support for critical mechanisms yieldedexcellent operation compared to software alternatives, but that the costs ofglobal interactions greatly exceeded equivalent operation at the local level.Scaling was impacted by the additional costs of global communication andaddress space sharing. While some applications showed good, if somewhatdepressed, scaling globally, other demonstrated poor or even negative scal-ing for the high end of system configurations tested. Of course, this wasinfluenced by programming style and mapping and alternative implementa-tions of the same applications might yield improved behavior.
As part of the overall experience, it was found that programming withinthe shared memory environment was easier than the distributed memorycontexts of some other machines and that availability of performance instru-mentation and visualization tools greatly assisted in optimizing applicationperformance. Many of the experiments performed exhibited sensitivity tocache behavior and it was concluded that even in this globally cache coher-ent system, the cache structure was too restrictive to permit a generalizedprogramming methodology with acceptable level of effort approaching thatof vector based hardware systems.
In spite of the set of tests conducted and reported here, significant workhas yet to be done before the performance behavior is fully understood andcan be predicted. Among the near term activities to be undertaken is runningon larger configuration platforms. Also, more detailed characteristics of therange of cache behaviors need to be revealed. Finally, more dynamic loadbalancing and lightweight threads needs to be developed and implemented24

on this system to ease the programming burden. But as it is, this systemstands as among the most advanced currently available.
8 Acknowledgments
This research has been supported by the NASA High Performance Comput-ing and Communication Initiative.
References
[1] A. Agarwal, D. Chaiken, K. Johnson, et al. “The MIT Alewife Machine: ALarge-Scale Distributed-Memory Multiprocessor,” M. Dubois and S.S.Thakkar, editors, Scalable Shared Memory Multiprocessors, KluwerAcademic Publishers, 1992, pp. 239-261.
[2] J.E. Barnes and P. Hut, “A Hierarchical O(n log n) Force Calculation Al-gorithm,” Nature, vol. 342, 1986.
[3] A. Burrows, and B. Fryxell, Science, 258, 1992, p. 430.
[4] CONVEX Computer Corporation, “Camelot MACH Microkernel Inter-face Specification: Architecture Interface Library,” Richardson, TX, May1993.
[5] D. Chaiken, J. Kubiatowitz, and A. Agarwal, “LimitLESS Directories: AScalable Cache Coherence Scheme,” Proceedings of the Fourth In-ternational Conference on Architectural Support for ProgrammingLanguages and Operating Systems (ASPLOS IV), 1991, pp. 224-234.
[6] P. Colella and P. R. Woodward, “The Piecewise-Parabolic Method for Hy-drodynamics,” Journal of Computational Physics, 54, 1984, p. 174.
[7] P. Colella and H. M. Glaz, J. Comput. Phys, 59, 1985, p. 264.
[8] CONVEX Computer Corporation, “Exemplar Architecture Manual,”Richardson, TX, 1993.
[9] CONVEX Computer Corporation, “ConvexPVM User’s Guide for Exem-plar Systems,” Richardson, TX, 1994.
[10] CONVEX Computer Corporation, “Exemplar Programming Guide,”Richardson, TX, 1993.
[11] Cray Research, Inc., “CRAY T3D System Architecture Overview,”Eagan, Minnesota. 25

[12] B. Fryxell and R.E. Taam, “Numerical Simulations of Non-Axisymmetric Accretion Flow,”Astrophysical Journal, 335, 1988, pp. 862-880.
[13] B. Fryxell, E. Muller, and D. Arnett“Hydrodynamics and Nuclear Burn-ing,” Max-Planck-Institut fur Astrophysik, Preprint 449.
[14] L. Hernquist, “Vectorization of Tree Traversals,” Journal of Computa-tional Physics, vol. 87, 1990.
[15] Hewlett Packard Company, “PA-RISC 1.1 Architecture and InstructionSet Reference Manual,” Hewlett Packard Company, 1992.
[16] Intel Corporation, “Paragon User’s Guide,” Beaverton, Oregon 1993.
[17] IEEE Standard for Scalable Coherent Interface, IEEE, 1993.
[18] Kendall Square Research Corporation, “KSR Technical Summary,”Waltham, MA, 1992.
[19] D. Lenoski, J. Laudon, K. Gharachorloo, A. Gupta, and J. Hennes-sey, “The Directory-Based Cache Coherence Prototocl for the DASHMultiprocessor,” Proceedings of the 17th Annual International Sym-posium on Computer Architecture, pp. 49-58, June 1990.
[20] E. Muller, B. Fryxell, and D. Arnett, Astron. and Astrophys., 251,1991, p. 505.
[21] K. Olson and J. Dorband, “An Implementation of a Tree Code on aSIMD Parallel Computer,” Astrophysical Journal Supplement Series,September 1994.
[22] Thinking Machines Corporation, “Connection Machine CM-5 TechnicalSummary,” Cambridge, MA, 1992.
[23] T. Sterling, D. Becker, D. Savarese, et al., “BEOWULF: A Parallel Work-station for Scientific Computation,” To appear in Proceedings of the In-ternational Conference on Parallel Processing, 1995.
[24] T. Sterling, D. Savarese, P. Merkey, J. Gardner, “An Initial Evaluationof the Convex SPP-1000 for Earth and Space Science Applications,”Proceedings of the First International Symposium on High Perform-ance Computing Architecture, January 1995.
[25] A. Shankar, D. Arnett and B. Fryxell, Ap. J. (Letters), 394, 1992, p.L13.
[26] V. Sunderam, “PVM: A Framework for Parallel Distributed Computing,”Concurrency: Practice and Experience, December 1990, pp. 315-339. 26

[27] M.S. Warren and J.K. Salmon, “A Parallel Hashed Oct-tree N-BodyAlgorithm,” Proceedings of Supercomputing ’93, Washington: IEEEComputer Society Press, 1993.
Authors
Thomas Sterling
Thomas Sterling recevied his Ph.D. in electrical engineering from MIT, sup-ported through a Hertz Fellowship. Today he is Director of the Scalable Sys-tems Technology Branch at the University Space Research Association (USRA)Center of Excellence in Spcae Data and Information Sciences. He is alsocurrently an Associate Adjunct Professor at the University of Maryland De-partment of Computer Science.
Prior to joining CESDIS in 1991, Dr. Sterling was a Research Scient-ist at the IDA SRC investigating multithreading architectures and perform-ance modeling and evaluation. Dr. Sterling is a member of IEEE, ACM, andSigma Xi. His current research includes the development of the ESS ParallelBenchmarks, the design of the Beowulf Parallel Workstation, and participa-tion in the PetaFLOPS computing initiative. He can be contacted via e-mailat [email protected].
Daniel Savarese
Daniel Savarese graduated with a B.S. in astronomy from the University ofMaryland in 1993. He is currently a Ph.D. student in the Department of Com-puter Science at the University of Maryland. His current research involvesthe performance analysis of caches in shared-memory parallel architectures.His research interests include parallel computer systems architecuture, par-allel algorithms, real-time sound and image processing. He can be contac-ted via e-mail at [email protected].
Phillip Merkey
Phillip Merkey obtained his Ph.D. in mathematics from the University of Illinoisin 1986. Dr. Merkey joined the Center of Excellence in Space Data and In-formation Sciences in 1994 after working for the Supercomputing ResearchCenter as Research Staff Member. He is a member of the Scalable SystemsTechnology Branch involved in the development of the ESS Parallel Bench-marks, performance evaluation, modeling and analysis of parallel computers.Other interests include discrete mathematics, information theory, coding the-ory and algorithms. 1He can be contacted via e-mail at [email protected]