3d face recognition using distinctiveness enhanced facial representations and local feature hybrid...
TRANSCRIPT

3D Face Recognition using Distinctiveness Enhanced Facial Representations and Local Feature Hybrid Matching
Di Huang, Guangpeng Zhang, Mohsen Ardabilian, Yunhong Wang, Member, IEEE and Liming Chen, Member, IEEE
Abstract—This paper presents a simple yet effective approach for 3D face recognition. A novel 3D facial surface representation, namely Multi-Scale Local Binary Pattern (MS-LBP) Depth Map, is proposed, which is used along with the Shape Index (SI) Map to increase the distinctiveness of smooth range faces. Scale In-variant Feature Transform (SIFT) is introduced to extract local features to enhance the robustness to pose variations. Moreover, a hybrid matching is designed for a further improved accuracy. The matching scheme combines local and holistic analysis. The former is achieved by comparing the SIFT-based features ex-tracted from both 3D facial surface representations; while the latter performs a global constraint using facial component and configuration. Compared with the state-of-the-art, the proposed method does not require time-consuming accurate registration or any additional data in a bootstrap for training special thre-sholds. The rank-one recognition rate achieved on the complete FRGC v2.0 database is 96.1%. As a result of using local facial features, the approach proves to be competent for dealing with partially occluded face probes as highlighted by supplementary experiments using face masks.
I. INTRODUCTION
The face is potentially one of the best biometrics for people identification-related applications, since it is non-instructive, contactless and socially well accepted. Unfortunately, human faces are similar in their configurations and hence offer low distinctiveness, unlike the other biometrics, i.e., iris and fin-gerprint [1]. Furthermore, intra-class variations, due to factors as diverse as pose, facial expression etc. are often greater than inter-class ones. The past several decades have witnessed the tremendous efforts firstly focused on 2D face images [2] and more recently on 3D face scans [3]. Despite the great progress achieved so far in the field [2], 2D images are still not reliable enough [4], especially in the presence of pose and illumina-tion changes [5]. Along with the development in 3D imaging systems, 2.5D or 3D scans have emerged as a major solution to deal with unsolved issues in 2D face recognition, such as variations of illumination and pose [3][6]. Meanwhile, though 3D face scans capture the facial surface structure, and they are therefore theoretically reputed to be robust to lighting varia-tions, they are likely to be more sensitive to facial expression changes. In addition, they always require an accurate regis-tration step before shape-based 3D matching.
Zhao et al. [2] categorized 2D image-based face recogni-
tion techniques into three main approaches: the holistic ones such as PCA [7] and LDA [8]; the feature-based ones such as Elastic Bunch Graph Matching (EBGM) [9]; the hybrid ones such as Component Eigenfaces [10]. This taxonomy can also be extended to 3D model-based face recognition techniques. For instance, the holistic class includes ICP (Iterative Closest Point) based matching [11], annotated deformable model [12], isometry-invariant description [13] etc. The matching scheme based on holistic facial features generally requires an accurate normalization step with respect to pose and scale, and it has proved sensitive to expression changes and partial occlusions. On the other hand, feature-based matching compares the local descriptive points or regions of 3D face scans and has been explored in several tasks in the literature, containing the point signature approach [14] and more recently, multi-modal local feature-based matching [15]. Feature-based matching has the potential advantages of being robust to facial expression, pose lighting changes and even to partial occlusions. The downside of this scheme is the difficulty extracting sufficient repeatable informative feature points from similar or smooth facial sur-faces. There also exist some papers in the literature presenting hybrid matching schemes which combine global features with local ones: Region-ICP [16], multiple region-based matching [17] and the component and morphable model-based method [18]. The hybrid matching scheme is theoretically the most powerful [2]. However, it also risks inheriting both types of shortcomings: sensitivity to pose variations, difficulty gene-rating enough stable descriptive feature points, etc.
This work was partially carried out within the French FAR3D project supported by ANR under the grant ANR-07-SESU-004 FAR3D.
Di Huang, Mohsen Ardabilian and Liming Chen are with MI Department, LIRIS Laboratory, CNRS 5205, Ecole Centrale Lyon, 69134, Lyon, France (e-mail: [email protected]).
Guangpeng Zhang and Yunhong Wang are with the School of Computer Science and Engineering, Beihang University, 100091, Beijing, China.
In this study, we propose a simple yet effective approach for robust 3D face recognition. Its major contributions can be summarized as:
(1) Since faces are similar and 3D facial surfaces are very smooth, a novel 3D facial representation, namely Multi-Scale Local Binary Pattern (MS-LBP) Depth Map, is proposed and used along with the Shape Index Map to efficiently highlight the distinctiveness of range data.
(2) Most of the existing works in the literature depend on online ICP-based accurate registration which computes ite-ratively and expensively. In contrast to them, an off-the-shelf operator, SIFT, is investigated for 3D face recognition. Due to its insensitiveness to pose variations, the proposed method does not require the time-consuming registration step when dealing with nearly frontal face data, such as the FRGC v2.0 database [20].
(3) A new matching step is designed to measure similarities between gallery and probe face samples. It works in a hybrid way by performing local feature-based matching based on the SIFT features and holistic matching using the facial compo-
978-1-4244-7580-3/10/$26.00 ©2010 IEEE

nent and configuration constraint. Tested on the complete FRGC v2.0 database, the proposed
method displays a rank-one face recognition rate up to 96.1%, which is comparable to the best accuracy so far known in the state-of-the-art [12]. Meanwhile, the proposed approach also proves effective to deal with expression variations and partial occlusions without the need for any prior threshold by using additional data in an offline bootstrap as [12] and [21] did.
The remainder of this paper is organized as follows. The framework of the proposed approach is described in section II. Both distinctiveness enhanced facial surface representations, the MS-LBP Depth and SI Map, are introduced in section III, and section IV presents the SIFT-based local feature extrac-tion. The hybrid matching process is illustrated in section V. Experimental results of face recognition are shown and ana-lyzed in section VI. Section VII concludes the paper.
Fig. 1. The framework of the proposed method.
II. THE PROPOSED APPROACH OVERVIEW
Figure 1 illustrates the framework of the proposed method. In both gallery and probe set, only range face images are used. We calculate two distinctiveness enhanced 3D facial surface representations: the MS-LBP Depth Map and the Shape Index (SI) Map, for SIFT-based local feature extraction instead of original range images which capture smooth facial surfaces and similar facial configurations. The SI and MS-LBP Depth Map describe two different aspects of local shape of surfaces: the former shows the geometric character, i.e., spherical cup, spherical cup, saddle etc.; while the latter shows the bending direction and is achieved by introducing LBP operators using neighborhoods with different radius values to range images. Thus, combining both 3D facial representations, local shape of 3D facial surfaces can be described more comprehensively. We hence proceed to extract the SIFT-based local repeatable
features. The hybrid matching process then carries out local feature-based matching based on the SIFT features as well as holistic matching using the facial component and configura-tion constraint. The similarity scores of the MS-LBP and SI Map are further fused for the final decision.
III. DISTINCTIVENESS ENHANCED FACIAL REPRESENTATION
As all the range images capture smooth facial surfaces and are similar in appearance, we propose to apply two interme-diate 3D facial surface representations, the Multi-Scale LBP (MS-LBP) Depth and Shape Index (SI) Map, to highlight the distinctiveness of face data.
A. Multi-Scale LBP Depth Map Local Binary Patterns (LBP), a non-parametric algorithm,
was originally proposed to describe local texture attributes of 2D images [22]. The most important properties of LBP are its tolerance to monotonic illumination variations and computa-tional simplicity. Hence, it has been extensively adopted for 2D face recognition during the last several years [23].
Specifically, the original LBP operator labels each pixel of a given image by thresholding in a 3 3 neighborhood. If the values of the neighboring pixels are not lower than that of the central pixel, their corresponding binary bits are assigned to 1; or they are assigned to 0. A binary number is thus formed by concatenating all the eight binary bits, and the resulting de-cimal value is utilized for labeling. Figure 2 gives a process example.
Fig. 2. An example of the original LBP operator.
Formally, given a pixel at (xc, yc), the derived LBP decimal value is:
8
0
1( , ) ( )2 ; ( )
0 0n
c c n cn
if xLBP x y s i i s x
if x0 (1)
where n covers the eight neighbors of the central pixel, ic and in are gray level values of the central pixel and its surrounding pixels respectively.
According to (1), LBP is invariant to monotonic gray-scale transformations preserving pixel order in local neighborhoods; therefore, it has been considered one of the most effective and popular 2D texture descriptors. Based on the definition of the original LBP operator, when it works on the depth informa-tion of range images, the generated local binary patterns can also describe local geometry structures.
The original LBP operator was extended later with various local neighborhood sizes to handle different scales. The local neighborhood of LBP is defined as a set of sampling points evenly spaced on a circle centered at the pixel to be labelled. The sampling points that do not fall exactly on the pixels are expressed using bilinear interpolation, and thus allowing any value of radius and any number of points in the neighborhood.

Figure 3 shows different LBP neighborhoods. The notation (P,R) denotes the neighborhood of P sampling points on a circle of radius R.
Fig. 3. Operator examples: circular (8, 1), (16, 2), and (8, 2).
LBP facial representation can be achieved in two ways: one is LBP histogram, the other is LBP face. The general idea of the former is that a face can be seen as a composition of mi-cro-patterns described by LBP. The images are divided into a certain number of local regions, from which LBP histograms are extracted. The LBP histograms are concatenated and thus contain both local and global information about the faces. The latter approach regards the corresponding decimal number of the LBP binary code as the intensity value of each pixel, and generates the LBP face.
A few LBP histogram-based tasks changed the neighbor-hood of the LBP operator to improve performance. By vary-ing the value of radius R, LBP of different resolutions is thus obtained, namely Multi-Scale LBP (MS-LBP). It was firstly applied to texture classification [22], and this technique was also introduced to 2D face recognition [24] [25]. In [26], Shan and Gritti investigated MS-LBP for facial expression recog-nition by first using MS-LBP to extract LBP histogram fea-tures, and then applying AdaBoost to learn the most discri-minative bins. The boosted classifier of MS-LBP is observed to consistently outperform that of the single-scale LBP, and the selected LBP bins distribute at all scales. Hence, MS-LBP can be considered as an efficient method for facial represen-tation.
In 3D domain, LBP histogram based approaches have been used for face recognition [19] [34]. However, LBP histogram loses 2D spatial information for representing 3D surfaces. In this study, the LBP image is investigated for 3D facial surface description. We propose to extract LBP images from original range data using the same multi-scale definition of LBP his-togram. These LBP images, named MS-LBP Depth Maps, are finally utilized to represent 3D facial surfaces, which is quite a different and novel use of LBP. The local binary patterns at different radii capture local shape variations. As a result, the associated LBP Depth Maps emphasize local shape variations and thus highlight details, compared with the range face im-ages. They are, therefore, more suitable for the extraction of local prominent features, such as SIFT-based features.
Fig. 4. LBP Depth Maps of a range image with different radii, the upper from 1 to 4, the lower from 5 to 8 (from left to right).
MS-LBP Depth Maps of range face image can be achieved by varying the neighborhood size of LBP operator, or by first down-sampling the range image and then adopting the LBP operator with a fixed radius. The samples are shown in Fig.4. The number of sampling points is 8, and the value of radius varies from 1 to 8. As we can see, the original range image is very smooth, while the resulting MS-LBP Depth Map con-tains many more local shape details, thus enhancing the dis-tinctiveness of 3D face models.
B. Shape Index Map The Shape Index (SI) was firstly proposed by Koenderink
and Doorn [27] to describe surface attributes of shapes. The Shape Index value at point p is defined as:
1 2
1 2
( ) ( )1 1( ) arctan2 ( )
k p k pS pk p k p( )
where k1 and k2 represent maximum and minimum principal curvatures respectively. As principal curvature is invariant to variations of pose, so is the Shape Index. The value of the Shape Index lies in the scale of [0, 1]. The local shape at point p is a spherical cup when S(p) = 0, and a spherical cap when S(p) = 1. When the value of the Shape Index varies from 0 to 1, the local shape changes from spherical cup to spherical cap. Figure 5 (c) shows an example of the SI Map, in which dark pixels represent lower values; bright pixels represent higher values. As seen in Fig.5, local shape variations are also hig-hlighted in such a 3D facial representation. More details are provided by [11] for calculating the Shape Index.
(2)
IV. LOCAL FEATURE EXTRACTION
The use of local feature to describe facial appearance pro-vides the robustness to pose changes, facial expression vari-ations and even to partial occlusions. Currently local feature extraction, i.e., anthropometric landmarks, is mostly operated on 2D or 3D smooth face images directly, leading to few local features with low distinctiveness. In this study, we propose to apply the widely-used SIFT (Scale Invariant Feature Trans-form) [28] features extracted from both the previous distinc-tiveness enhanced 3D facial surface representations: SI Map and MS-LBP Depth Map. Alternatively, other local feature descriptors can also be explored.
SIFT makes use of the scale-space Difference-of-Gaussian (DOG) to detect keypoints in images. The original image is repeatedly convolved with Gaussians of different scales se-parated by a constant factor k to produce an octave in scale space. As for an input image, I(x, y), the scale space is defined as a function, L(x, y, ), produced from the convolution of a variable scale Gaussian G(x, y, ) with the input image I, and the DOG function D(x, y, ) can be computed from the dif-ference of two nearby scales:
( , , ) ( ( , , ) ( , , )) * ( , )( , , ) ( , , )
D x y G x y k G x y I x yL x y k L x y
Then extrema of D(x, y, ) are detected by comparing each pixel with its 26 neighbors in 3 3 regions at the current and adjacent scales (8 at the current scale and 9 at both adjacent scales, thus 26 in total). At each scale, the gradient magnitude,
(3)

m(x, y), and orientation, (x, y), is computed using pixel dif-ferences in (4) and (5).
2
2
( , ) ( ( 1, ) ( 1, ))( ( , 1) ( , 1))
m x y L x y L x yL x y L x y
2
(4)
1 ( , 1) ( , 1)( , ) tan( 1, ) ( 1, )
L x y L x yx yL x y L x y
For each detected keypoint, a feature vector is extracted as a descriptor from the gradients of sampling points within its neighborhood. To achieve orientation invariance, coordinates and gradient orientations of sampling points in neighborhood are rotated relative to the keypoint orientation. Then a Gaus-sian function is used to assign a weight to the gradient mag-nitude of each point. Points close to the keypoint are given more emphasis than those far from it (see [28] for parameters of SIFT). The orientation histograms of 4 4 sample regions are calculated, each with eight orientation bins. Thus a feature vector with a dimension of 128 (4 4 8) is produced.
(5)
Fig. 5. SIFT-based Keypoints of (a) range image; (b) LBP Depth Map, and (c) Shape Index Map.
The SIFT operator works on each LBP Depth Map and SI Map separately. As a consequence of the LBP Depth Map and SI Map which highlight the local shape characteristics of the range images, many more SIFT-based keypoints are detected for the following matching process in both 3D facial surface representations than those in the original range image. Some statistical work was done along with the experiments on the FRGC v2.0 dataset. The average number of descriptors ex-tracted from each LBP Depth Map is 687 and 862 from the SI Map, while that of each range image is limited to 41. Figure 5 shows the SIFT-based keypoints extracted from an original range face image, one of its associated LBP Depth Maps, and its corresponding SI Map, respectively.
V. THE HYBRID MATCHING PROCESS
After local facial features are extracted from the MS-LBP Depth Map and SI Map, a hybrid matching process is carried out, combining a local matching step based on SIFT features with a global one under the facial component and configura-tion constraint.
A. Local Feature-Based Matching Given the local features extracted from the MS-LBP and SI
based 3D facial surface representation respectively, the two facial keypoint sets of the gallery and probe face scan can be matched. Matching one keypoint to another is accepted only if the matching distance is less than a predefined threshold ttimes the distance to the second closest match. In this research, t is empirically set at 0.6 as in [28].
For one probe face, the number of matched keypoint pairs can be achieved by calculating and comparing the distances
with the local features of all the gallery faces. Here, NLi and NSI denote the number of matched keypoints in, respectively, the ith LBP Depth Map pair, generated by the LBP operator from the range image with a parameter setting of Li, and the SI Map pair.
B. Holistic Facial Matching Unlike samples utilized in object detection, all human faces
possess the same physical components and share the similar global configuration. Holistic matching is hence carried out to constrain the matched local features with respect to the facial components and configuration.
1) Facial Component Constraint: We propose to divide the entire range face image into some sub-regions, each of which describes roughly a component of the nearly frontal faces, to restrict the matched keypoints of gallery and probe face scans only to those with similar physical meaning. That means the matched keypoints from the same facial component should be more important. Instead of the costly clustering process car-ried out in [29] to automatically construct sub-regions based on the keypoint locations from training samples, we simply make use of our common sense of facial component position, and divide the entire face region into 3 3 rectangle blocks of the same size. The similarity measure of the facial component constraint is defined from this facial composition scheme. A range face image I is represented as (m1, m2,..., mk); k is 9 in our case and mi is the number of detected SIFT keypoints fall within the ith component. The local SIFT-based descriptors in all the k components can be denoted by:
1 21 1 11 1 2 2( , ..., , , ..., , ..., , ..., )kmm m
k kI f f f f f f where fi
j means the jth descriptor in the ith facial component. Then the similarity between a gallery face Ig and a probe face Ip is computed by:
(6)
1
,1( , ) (max( ))i i
i i
x ykp g
p g x yi p g
f fC I I
k f f (7)
where x [1, ..., mpi]; y [1, ..., mgi]. < > denotes the inner product of two vectors, and denotes the norm of one vector. The bigger C indicates the more similar attribute of the two faces represented by the LBP Depth Map or SI Map. We obtain the similarity values, CLi for each LBP Depth Map and CSI for the SI Map.
2) Facial Configuration Constraint: The former paragraph on facial component constraint emphasizes the importance of matching between the local facial features of the same com-ponent-based face region in the gallery and probe set, and we further improve the holistic constraint by facial configuration.
All the range face images are normalized to a certain size to build a public coordinate system. For each 3D face model, the LBP Depth Maps and SI Map are extracted from the range image, and there is a pixel-to-pixel correspondence between these images. Therefore, all the keypoints of two facial sur-face representations share the same XY-plane with the range face image, and the pixel values of the corresponding range image can be regarded as the Z-axis values of these keypoints. Thus every keypoint has its position in 3D space. After local

feature-based matching, a 3D graph is formed for each LBP Depth Map or the SI Map of one probe Fp, by simply linking every two of its keypoints which have a matching relationship with the corresponding keypoints on a gallery face image Fg.The matched keypoints of Fg also construct a corresponding graph of Fp. Intuitively, if faces Fg and Fp are from the same subject, the corresponding graphs should have similar shapes and locations in 3D space.
One similarity measure between the two graphs is
1
1 e
i
n
e pie
d dn igd
(8)
where dpi and dgi are the lengths of corresponding edges in the probe and gallery graphs respectively. The value ne is the total number of edges. If the number of matched keypoints is nn, newill be nn*(nn -1)/2. Equation 8 is an efficient way to measure the spatial error between the matched keypoint pairs of probe and gallery features.
Another similarity between two graphs is calculated as the mean Euclidean distance dn between corresponding nodes:
1
1 n
i
n
n pin
d nn ign
n
)
(9)
where npi and ngi are the coordinates of corresponding key-points in a gallery and its probe graph respectively. nn is the number of matched keypoints.
The final similarity measure value of the facial configura-tion constraint is:
where we and wn are the corresponding weights of de and dn,designed according to the scheme adopted in similarity fusion, and the smaller D indicates the more similar attribute of two range faces represented by the LBP Depth Map or SI Map. As in the facial component constraint, DLi denotes the similarity of each LBP Depth Map and DSI denotes that of the SI Map.
* *e e nD w d w d (10)
C. Similarity Fusion: In summary, the matching step of gallery and probe range
face images contains three types of similarities: the number of matched keypoint pairs N, similarity C of the facial compo-nent constraint as well as similarity D of the facial configu-ration constraint. Except for D, all the other similarity meas-ures are with a positive polarity (a bigger value means a better matching relationship). A face of probe set is matched with every face in the gallery, resulting in three vectors SN, SC and SD. The nth element of each score vector corresponds to the similarity measure between the probe and the nth gallery face. Each vector is normalized to the interval of [0, 1] using the min-max rule. Elements of SD are subtracted from 1 in order to reverse its polarity. The final similarity of the probe face with the faces in the gallery set is then calculated using a basic weighted sum rule:
* * * (1N N C C D DS w S w S w S The corresponding weights: wN, wC, and wD are calculated
dynamically during the online step using the scheme in [15]:
(11)
1
2
( ) min ( )( ) min ( )i
i iS
i
mean S Swmean S S
where i corresponds to the three similarities: N, C, and D, and operators min1(Si) and min2(Si) produce the first and second minimum value of the vector Si. The gallery face image which has the maximum value in vector S is declared as the identity of the probe face image when the decision is to be made on each LBP Depth Map or the SI Map independently. Matching scores are also normalized and fused according to the same weighted sum rule to combine the scores of the LBP Depth Maps with different scales to generate the MS-LBP score, and so is the final score produced by using a fusion of the result of the MS-LBP Depth Map and the SI Map. Figure 6 shows an example of matching results using the original range image, the LBP Depth Map as well as the SI Map.
Fig. 6. An matching example: the upper shows matching between the same subject; the lower shows matching between different subjects.
VI. EXPERIMENTAL RESULTS
The experiments were carried out on the FRGC v2.0 [20], one of the most comprehensive and popular databases, con-taining 4007 3D face models of 466 subjects. One range face image is extracted from 3D each face model. A preprocessing step was applied to remove spikes with the median filter and fill holes using cubic interpolation. As a result of using local features, we did not perform any registration on these 3D face scans, in contrast to the work done in [12] and [30]. The range images were cropped using a basic bounding box based on the mask provided by a 3D scanner indicating if the point is valid or not. Cropped images have pose, expression variations, and partial occlusions caused by hair. All the faces are normalized to 100 100 pixels for computation simplicity.
Fig. 7. Probes with eight types of missing quadrant.
The proposed method was tested by face recognition tasks. One 3D face scan with a neutral expression was selected from each subject to make a gallery of 466. The remaining 3D face scans (4007-466=3541) were treated as probes. The probe set was then divided into two subsets according to their expres-sion labels to evaluate its insensitiveness to facial expression variations. The first subset contains face scans with the neu-tral expression; while the other one with face scans possess-ing non-neutral expressions. Besides the experiment of Neu-tral vs. All, two additional experiments of Neutral vs. Neutral and Neutral vs. Non-Neutral were also carried out. In Neutral vs. Neutral and Neutral vs. Non-Neutral, only the neutral and non-neutral probe subsets were used, respectively. In addition, we also analyze the proposed method with partially occluded probes, using eight types of face models with up to 50% of the quadrants missing (see Fig.7).
i (12)
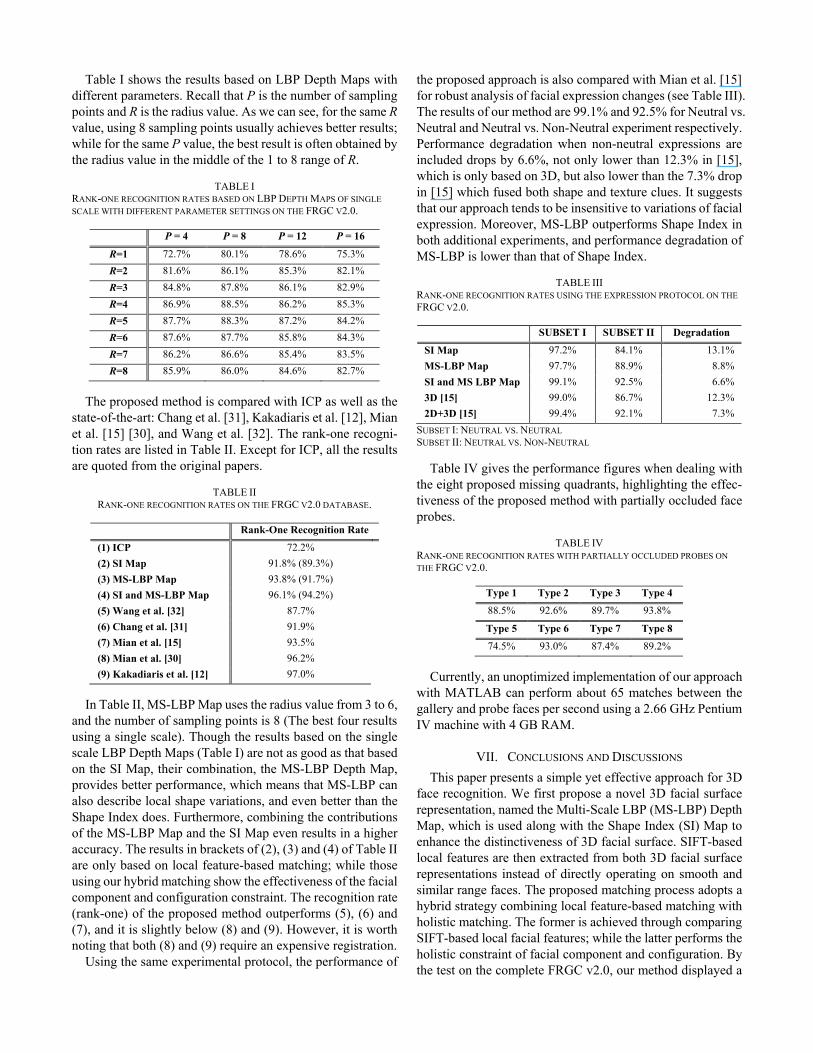
Table I shows the results based on LBP Depth Maps with different parameters. Recall that P is the number of sampling points and R is the radius value. As we can see, for the same Rvalue, using 8 sampling points usually achieves better results; while for the same P value, the best result is often obtained by the radius value in the middle of the 1 to 8 range of R.
TABLE IRANK-ONE RECOGNITION RATES BASED ON LBP DEPTH MAPS OF SINGLE SCALE WITH DIFFERENT PARAMETER SETTINGS ON THE FRGC V2.0.
P = 4 P = 8 P = 12 P = 16
R=1 72.7% 80.1% 78.6% 75.3%R=2 81.6% 86.1% 85.3% 82.1%R=3 84.8% 87.8% 86.1% 82.9%R=4 86.9% 88.5% 86.2% 85.3%R=5 87.7% 88.3% 87.2% 84.2%R=6 87.6% 87.7% 85.8% 84.3%R=7 86.2% 86.6% 85.4% 83.5%R=8 85.9% 86.0% 84.6% 82.7%
The proposed method is compared with ICP as well as the state-of-the-art: Chang et al. [31], Kakadiaris et al. [12], Mian et al. [15] [30], and Wang et al. [32]. The rank-one recogni-tion rates are listed in Table II. Except for ICP, all the results are quoted from the original papers.
TABLE II RANK-ONE RECOGNITION RATES ON THE FRGC V2.0 DATABASE.
Rank-One Recognition Rate
(1) ICP 72.2% (2) SI Map 91.8% (89.3%) (3) MS-LBP Map 93.8% (91.7%) (4) SI and MS-LBP Map 96.1% (94.2%) (5) Wang et al. [32] 87.7% (6) Chang et al. [31] 91.9% (7) Mian et al. [15] 93.5% (8) Mian et al. [30] 96.2% (9) Kakadiaris et al. [12] 97.0%
In Table II, MS-LBP Map uses the radius value from 3 to 6, and the number of sampling points is 8 (The best four results using a single scale). Though the results based on the single scale LBP Depth Maps (Table I) are not as good as that based on the SI Map, their combination, the MS-LBP Depth Map, provides better performance, which means that MS-LBP can also describe local shape variations, and even better than the Shape Index does. Furthermore, combining the contributions of the MS-LBP Map and the SI Map even results in a higher accuracy. The results in brackets of (2), (3) and (4) of Table II are only based on local feature-based matching; while those using our hybrid matching show the effectiveness of the facial component and configuration constraint. The recognition rate (rank-one) of the proposed method outperforms (5), (6) and (7), and it is slightly below (8) and (9). However, it is worth noting that both (8) and (9) require an expensive registration.
Using the same experimental protocol, the performance of
the proposed approach is also compared with Mian et al. [15] for robust analysis of facial expression changes (see Table III). The results of our method are 99.1% and 92.5% for Neutral vs. Neutral and Neutral vs. Non-Neutral experiment respectively. Performance degradation when non-neutral expressions are included drops by 6.6%, not only lower than 12.3% in [15], which is only based on 3D, but also lower than the 7.3% drop in [15] which fused both shape and texture clues. It suggests that our approach tends to be insensitive to variations of facial expression. Moreover, MS-LBP outperforms Shape Index in both additional experiments, and performance degradation of MS-LBP is lower than that of Shape Index.
TABLE III RANK-ONE RECOGNITION RATES USING THE EXPRESSION PROTOCOL ON THE FRGC V2.0.
SUBSET I SUBSET II Degradation
SI Map 97.2% 84.1% 13.1%MS-LBP Map 97.7% 88.9% 8.8%SI and MS LBP Map 99.1% 92.5% 6.6%3D [15] 99.0% 86.7% 12.3%2D+3D [15] 99.4% 92.1% 7.3%
SUBSET I: NEUTRAL VS. NEUTRALSUBSET II: NEUTRAL VS. NON-NEUTRAL
Table IV gives the performance figures when dealing with the eight proposed missing quadrants, highlighting the effec-tiveness of the proposed method with partially occluded face probes.
TABLE IV RANK-ONE RECOGNITION RATES WITH PARTIALLY OCCLUDED PROBES ON THE FRGC V2.0.
Type 1 Type 2 Type 3 Type 4
88.5% 92.6% 89.7% 93.8%
Type 5 Type 6 Type 7 Type 8
74.5% 93.0% 87.4% 89.2%
Currently, an unoptimized implementation of our approach with MATLAB can perform about 65 matches between the gallery and probe faces per second using a 2.66 GHz Pentium IV machine with 4 GB RAM.
VII. CONCLUSIONS AND DISCUSSIONS
This paper presents a simple yet effective approach for 3D face recognition. We first propose a novel 3D facial surface representation, named the Multi-Scale LBP (MS-LBP) Depth Map, which is used along with the Shape Index (SI) Map to enhance the distinctiveness of 3D facial surface. SIFT-based local features are then extracted from both 3D facial surface representations instead of directly operating on smooth and similar range faces. The proposed matching process adopts a hybrid strategy combining local feature-based matching with holistic matching. The former is achieved through comparing SIFT-based local facial features; while the latter performs the holistic constraint of facial component and configuration. By the test on the complete FRGC v2.0, our method displayed a

rank-one recognition rate up to 96.1% which is comparable to the best performance on the same dataset so far known in the literature. Meanwhile, thanks to the utilization of local facial features extracted from the 3D facial surface representations, the proposed approach does not require the time-consuming ICP-based registration step or any additional data in a boot-strap to train special thresholds. Moreover, it proves effective to deal with partial face occlusions.
The range images of 3D faces are generally pose-sensitive, though the extraction and matching step of local features like those, e.g. by SIFT, softens such sensitiveness, making our method registration-free only for nearly frontal 3D face scans. To deal with faces with severe pose variations, only a coarse pose correction based on a few automatic landmarking points, i.e. nose tip and the two inner corners of the eyes, is sufficient to adjust them to nearly frontal status as [33] did.
REFERENCES
[1] A. K. Jain, A. Ross, and S. Prabhakar. “An introduction to biometric recognition,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 14, no. 1, pp. 4–20, 2004.
[2] W. Zhao, R. Chellappa, P. J. Phillips, and A. Rosenfeld, “Face recog-nition: a literature survey,” ACM Computing Survey, vol. 35, no. 4, pp. 399–458, 2003.
[3] K. W. Bowyer, K. Chang, and P. J. Flynn, “A survey of approaches and challenges in 3D and multi-modal 3D+2D face recognition,” Computer Vision and Image Understanding, vol. 101, no. 1, pp. 1-15, 2006.
[4] A. F. Abate, M. Nappi, D. Riccio, and G. Sabatino, “2D and 3D face recognition: a survey,” Pattern Recognition Letters, vol. 28, no. 14, pp. 1885-1906, 2007.
[5] P. J. Phillips, H. Moon, P. J. Rauss, and S. Rizvi, “The FERET evalu-ation methodology for face recognition algorithms,” IEEE Transac-tions on Pattern Analysis and Machine Intelligence, vol. 22, no. 10, pp. 1090-1104, 2000.
[6] A. Scheenstra, A. Ruifrok, and R. C. Veltkamp, “A survey of 3D face recognition methods,” International Conference on Audio and Video based Biometric Person Authentication, 2005.
[7] M. Turk and A. Pentland, “Eigenfaces for recognition,” Journal of Cognitive Neuro-Science, vol. 3, no. 1, pp. 71-86, 1991.
[8] P. Belhumeur, J. Hespanha, and D. Kriegman, “Eigenfaces vs. fisher-faces: recognition using class specific linear projection,” IEEE Trans-actions on Pattern Analysis and Machine Intelligence, vol. 19, no. 7, pp. 711-720, 1997.
[9] L. Wiskott, J. M. Fellous, N. Kruger, and C. v. d. Malsburg, “Face recognition by elastic bunch graph matching,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 19, no. 7, pp. 775–779, 1997.
[10] A. Pentland, B. Moghaddam, and T. Starner, “View-based and modular eigenspaces for face recognition,” IEEE International Conference on Computer Vision and Pattern Recognition, pp. 84-91, 1994.
[11] X. Lu, A. K. Jain, and D. Colbry, “Matching 2.5D face scans to 3D models,” IEEE Transactions on Pattern Analysis and Machine Intel-ligence, vol. 28, no. 1, pp. 31-43, 2006.
[12] I. A. Kakadiaris, G. Passalis, G. Toderici, M. N. Murtuza, Y. Lu, N. Karampatziakis, and T. Theoharis, “Three-dimensional face recogni-tion in the presence of facial expressions: an annotated deformable model approach,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 4, pp. 640-649, 2007.
[13] A. M. Bronstein, M. M. Bronstein, and R. Kimmel, “Three dimensional face recognition,” International Journal of Computer Vision, vol. 64, no. 1, pp. 5-30, 2005.
[14] C. Chua, F. Han, and Y. K. Ho, “3D human face recognition using point signature,” IEEE International Conference on Automatic Face and Gesture Recognition, pp. 233-238, 2000.
[15] A. S. Mian, M. Bennamoun, and R. Owens, “Keypoint detection and local feature matching for textured 3D face recognition,” International Journal of Computer Vision, vol. 79, no. 1, pp. 1-12, 2008.
[16] K. Ouji, B. B. Amor, M. Ardabilian, L. Chen, and F. Ghorbel, “3D face recognition using R-ICP and geodesic coupled approach,” Interna-tional Multimedia Modeling Conference, 2009.
[17] A. S. Mian, M. Bennamoun, and R. Owens, “Region-based matching for robust 3D face recognition,” British Machine Vision Conference,2005.
[18] J. Huang, B. Heisele, and V. Blanz, “Component-based face recogni-tion with 3D morphable models,” International Conference on Audio and Video Based Biometric Person Authentication, pp. 27-34, 2003.
[19] S. Z. Li, C. Zhao, M. Ao, and Z. Lei, “Learning to fuse 3D+2D based face recognition at both feature and decision levels,” 2nd International Workshop on Analysis and Modeling of Faces and Gesture, pp. 44-54, 2005.
[20] P. J. Phillips, P. J. Flynn, T. Scruggs, K. W. Bowyer, K. I. Chang, K. Hoffman, J. Marques, J. Min, W. Worek, “Overview of the face rec-ognition grand challenge. IEEE International Conference on Computer Vision and Pattern Recognition, vol. I, pp. 947-954, 2005.
[21] Y. Wang, X. Tang, J. Liu, G. Pan, and R. Xiao, “3D face recognition by local shape difference boosting,” European Conference on Computer Vision, pp. 603-616, 2008.
[22] T. Ojala, M. Pietikäinen, and T. Maenpaa, “Multiresolution gray-scale and rotation invariant texture classification with local binary patterns,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 7, pp. 971–987, 2002.
[23] T. Ahonen, A. Hadid, and M. Pietikäinen, “Face recognition with local binary patterns,” European Conference on Computer Vision, 2004.
[24] S. Yan, H. Wang, X. Tang, and T. S. Huang, “Exploring feature de-scriptors for face recognition,” International Conference on Acoustics, Speech, and Signal Processing, vol. I, pp. 629-632, 2007.
[25] C. Chan, J. Kittler, and K. Messer, “Multi-scale local binary pattern histograms for face recognition,” International Conference on Biome-trics, pp. 809-818, 2007.
[26] C. Shan and T. Gritti, “Learning discriminative LBP-histogram bins for facial expression recognition,” British Machine Vision Conference,2008.
[27] J. J. Koenderink and A. J. Doorn, “Surface shape and curvature scales,” Image and Vision Computing, vol. 10, no. 8, pp. 557-565, 1992.
[28] D.G. Lowe, “Distinctive image features from scale-invariant key-points,” International Journal of Computer Vision, vol. 60, no. 4, pp. 91-110, 2004.
[29] J. Luo, Y. Ma, E. Takikawa, S. Lao, M. Kawade, and B. Lu, “Per-son-specific SIFT features for face recognition,” IEEE International Conference on Acoustics, Speech and Signal Processing, 2007.
[30] A. S. Mian, M. Bennamoun, and R. Owens, “An efficient multimodal 2D-3D hybrid approach to automatic face recognition,” IEEE Trans-actions on Pattern Analysis and Machine Intelligence, vol. 29, no. 11, pp. 1927-1943, 2007.
[31] K. I. Chang, K. W. Bowyer, P. J. Flynn, “Adaptive rigid multi-region selection for handling expression variation in 3D face recognition,” IEEE Workshop on Face Recognition Grand Challenge, 2005.
[32] Y. Wang, G. Pan, and Z. Wu, “3D face recognition in the presence of expression: guidance-based constraint deformation approach,” IEEE Conference on Computer Vision and Pattern Recognition, 2007.
[33] P. Szeptycki, M. Ardabilian, L. Chen, “A coarse-to-fine curvature analysis-based rotation invariant 3D face landmarking,” International Conference on Biometrics: Theory, Applications and Systems, 2009.
[34] Y. Huang, Y. Wang, T. Tan, “Combining statistics of geometrical and correlative features for 3D face recognition,” British Machine Vision Conference, 2006.