bÁo cÁo project 1-trung
TRANSCRIPT

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 1/35
TRƢƠNG ĐẠI HỌC BÁCH KHOA HÀ NỘI
VIỆN ĐIỆN TỬ - VIỄN THÔNG
------o0o------
Project 1
Đề bài: Thu Thập Dữ Liệu Web Vớ i Phần Mềm
WEBDOCUMENTGETTER
Họ Tên Sinh Viên : Nguyễn Toàn Trung
MSSV:20082794 - ĐT3 - K53
Giảng viên hƣớ ng dẫn :Th.s Nguyễn Quang Minh.
Hà Nội,12/2011

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 2/35
2
LỜI CẢM ƠN
Sau khoảng thờ i gian nghiên cứu project I, dƣớ i sự chỉ bảo tận tình của thầy
Th.s Nguyễn Quang Minh.Em không chỉ hoàn thành projet I mà còn học hỏi đƣợ crất nhiều kiến thức mớ i.
Để đƣợc nhƣ vậy Em vô cùng biết ơn thầy đã tận tình giảng dạy, hƣớ ng dẫn,truyền đạt những kiến thức, kinh nghiệm quý báu cho Em trong khoảng thờ i gianqua.Vớ i lòng biết ơn chân thành,em xin gửi lờ i chúc sức khoẻ và những gì tốt đẹpnhất đến các thầy cô trong khoa, trong nhà trƣờng và đặc biệt là thầy Th.s NguyễnQuang Minh.
Sinh Viên Thực Hiện
Trung
Nguyễn Toàn Trung

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 3/35
3
NHẬN XÉT CỦA GIÁO VIÊN
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………….
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………………
………………………………………………………………………………………………………………………………………………………………….
Chữ Ký Của Giáo Viên

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 4/35
4
TÓM TẮT ĐỀ TÀI PROJECT 1
Ngày nay vớ i sự phát triển mạnh mẽ nhƣ vũ bão của Internet, cuộc sống của
con ngƣời đã càng ngày càng trở nên phong phú và đa dạng hơn.Internet đã làmthay đổi đáng kể nhiều lĩnh vực, từ học tập, nghiên cứu cho đến kinh doanh vàthƣơng mại. Tuy nhiên con ngƣời vẫn không dừng lại, họ luôn có những khát khaotìm tòi, phát triển và khai thác các tiềm năng của máy tính và Internet.Những côngnghệ và thiết bị tiên tiến này con ngƣời vẫn luôn tìm cách làm cho có thể hỗ trợ đƣợc cho con ngƣời nhiều hơn nữa, thậm chí là làm thay cho con ngƣời.
Cùng vớ i sự phát triển mạnh mẽ của Internet thì lƣợng thông tin trên Internetcàng ngày càng khổng lồ,điều này khiến cho việc sử dụng các công cụ hiện có đểkhai thác các thông tin hữu ích trên world wide web (www), phục vụ cho các mụcđích con ngƣời luôn có những khó khăn cần khắc phục.Một vấn đề đặt ra hiện naylà thu thập các thông tin chuyên biệt với khối lƣợng lớn trên web, chẳng hạn mộtcông ty quảng cáo muốn thu thập thật nhiều thông tin liên lạc của các doanhnghiệp trong nhiều lĩnh vực để gửi thƣ quảng cáo. Những công việc nhƣ thế nàynếu đƣợc thực hiện thủ công bằng sức ngƣời thì sẽ mất rất nhiều thời gian, côngsức, và chúng cũng khá tẻ nhạt do tính chất phải lặp đi lặp một vài thao tác củaviệc thu thập dữ liệu.
Đề tài project này em quyết định xây dựng một trình thu thậpWEBDOCUMENTGETTER có khả năng giúp con ngƣời trong những bài toán thuthập dữ liệu, một cách tự động.Trình thu thập sẽ cố gắng làm thay cho con ngƣời ở một số công đoạn, giúp giảm thời gian và sức lực của con ngƣời trong việc thuthập dữ liệu từ các website.
Đƣợ c thầy Th.s Nguyễn Quang Minh tận tình giúp đỡ cùng sự cố gắng củabản thân, project này đã hoàn thành đúng kế hoạch.Do thờ i gian ,tài liệu và năng
lực bản thân còn hạn chế nên project này không thể tránh khỏi những sai sót.Vậykính mong thầy và các bạn đóng góp thêm ý kiến để chúng tôi tiếp tục hoàn thiệnproject này trong thờ i gian tớ i.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 5/35
5
MỤC LỤC
LỜI CẢM ƠN ............................................................................................................ 2
NHẬN XÉT CỦA GIÁO VIÊN ................................................................................ 3 TÓM TẮT ĐỀ TÀI PROJECT 1 ............................................................................... 4
Chƣơng 1 : Đặt Vấn Đề ............................................................................................. 6
Chƣơng 2 : Chƣơng Trình WEBDOCUMENTGETTER .......................................... 8
1.Giớ i Thiệu Về WEBDOCUMENTGETTER. ..................................................... 8
2.Tính Năng Chính Của WEBDOCUMENTGETTER. ......................................... 9
3.Giải Thích Về Mã Nguồn Chƣơng Trình. .........................................................10
Chƣơng 3.Các Kết Quả Đạt Đƣợ c. ..........................................................................23
KẾT LUẬN ..............................................................................................................31
HƢỚNG PHÁT TRIỂN TƢƠNG LAI....................................................................32
PHỤ LỤC .................................................................................................................33
TÀI LIỆU THAM KHẢO .......................................................................................35

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 6/35
6
Chƣơng 1 : Đặt Vấn Đề
Với sự phát triển mạnh mẽ của Internet trong những năm gần đây, đặc biệt là
sự bùng nổ của World Wide Web, con ngƣời càng ngày càng phát sinh những nhucầu về tìm kiếm và sử dụng thông tin. Những ngƣời dùng bình thƣờng có thể tìmkiếm thông tin trên web một cách dễ dàng nhờ vào các máy tìm kiếm (searchengine), họ có thể đánh dấu (bookmark) các trang kết quả hoặc sao chép nội dunghọ muốn vào một nguồn nào đó để tham khảo về sau. Tuy nhiên nếu lƣợng thôngtin mà họ cần tổng hợp lại quá nhiều thì quá trình duyệt web, trích xuất và lƣu trữtheo cách thủ công lại trở thành một công việc đầy khó khăn và hao tốn nhiều sứclực, thời gian của con ngƣời. Một số ví dụ có thể kể ra nhƣ: nhu cầu trích xuất
thông tin về tất cả các mặt hàng thuộc một chuyên mục của một website bán hàngnào đó nhằm phục vụ mục đích khảo sát thị trƣờng, nhu cầu tổng hợp tin tức từ cácwebsite tin tức để xây dựng các trang web thông tin tổng hợp, nhu cầu thu thậpthông tin về các doanh nghiệp thuộc một ngành nào đó trên website danh bạ doanh nghiệp để gửi email quảng cáo, tiếp thị, v.v… Chính những ví dụ thực tế nhƣ trênđã nảy sinh ra nhu cầu: cần phải có một phƣơng thức hoặc công cụ nào đó có khảnăng tìm kiếm, trích xuất thông tin trên web và lƣu trữ lại thông tin đó theo ý muốncủa con ngƣời, một cách tự động và hiệu quả, và đó cũng chính là mục tiêu của đề
tài project này.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 7/35
7
Hƣớng giải quyết
- Tìm hiểu về các kỹ thuật thu thập dữ liệu tự động từ các website.
- Hiện thực một kỹ thuật để thu thập dữ liệu trên một website cụ thể.
- Bài Tập làm trong 13 tuần .
- Kết thúc project có báo cáo và sản phẩm là một trình thu thập làm trên nền java thỏa mãn yêu cầu của project là thu thập dữ liệu trên web.Trình này thu thậpdữ liệu tự động từ các website.Bƣớc đầu thu thập dữ liệu thô trên web về máy tính.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 8/35
8
Chƣơng 2 : Chƣơng Trình WEBDOCUMENTGETTER
1.Giới Thiệu Về WEBDOCUMENTGETTER.
Chƣơng trình đƣợ c phát triển từ mã nguồn JOBO.WEBDOCUMENTGETTER đƣợc tham khảo từ website :
http://www.matuschek.net/jobo/
Sau quá trình tìm hiểu nguồn code từ website chúng em đã nghiên cứu và cóđƣợc phần theo nhƣ yêu cầu của đề tài project 1.
Vậy nên chúng em xin chân thành cãm ơn nhóm jobo đã cung cấp nguồn codemẫu để chúng em tham khảo.
WEBDOCUMENTGETTER là một chƣơng trình đơn giản để tải các trangweb về máy ngƣờ i dùng. Bên trong nó có các tính năng cơ bản của một webspider.Trình thu thập có lợ i thế so vớ i các công cụ download khác là có thể tự động điền vào các hình thức hoạt động (ví dụ nhƣ đăng nhập tự động) và cũng cóthể sử dụng cookie để xử lý session.Giao diện rất đơn giản, nhƣng đầy đủ các tínhnăng về thu thập dữ liệu! Bạn có biết bất kỳ công cụ tải về mà cho phép nóđể đăng nhập vào một máy chủ web và tải về nội dung nếu máy chủ có sử dụngmột hình thức web để đăng nhập và cookie để xử lý phiên? Nó cũng có tínhnăng quy định rất linh hoạt để hạn chế tải theo URL. kích cỡ ,hoặc kiểu MIME.Hơnnữa nó cung cấp cho lập trình viên một đặc tính mô hình đối tƣợ ng rất linh hoạtvà dễ dàng mở rộng - phát triển module mới trong tƣơng lai! Nó đƣợ c thựchiện trong Java và mã nguồn có sẵn. Nếu bạn muốn thực hiện web spider củariêng bạn, lớ p WebRobot là một điểm khởi đầu tốt.Thậm chí nếu bạn khôngmuốn sử dụng nó nhƣ một công cụ download thì cũng có thể dùng nó cho việc lậpchỉ mục để kiểm tra liên kết, hoặc bất cứ thứ gì bạn muốn.
WEBDOCUMENTGETTER là trình thu thập tốt.Quá trình lấy tài liệu và xử cáctài liệu là hoàn toàn tách biệt - do đó bạn có thể kết nối trong Module riêng của bạnmột cách dễ dàng.
Đây là giao diệ n chính củ a WEBDOCUMENTGETTER:

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 9/35
9
2.Tính Năng Chính Của WEBDOCUMENTGETTER.
Hai phiên bản: phiên bản Command line (dòng lệnh) và phiên bản đồ họa . Tìm kiếm đệ quy tất cả các tài liệu bắt đầu từ một địa chỉ nhất định. Hỗ trợ các thẻ <a> <AREA> <IMG> thẻ <frame> . Ngƣờ i sử dụng có thể kiểm soát độ sâu tìm kiếm tối đa. Tên ngƣời dùng đại lý có thể đƣợ c định nghĩa. Hỗ trợ giớ i thiệu các tiêu đề. Hỗ trợ xử lý hình thức tự động có thể điền vào các domain vớ i các giá trị xác
định . Hỗ trợ Cookie . Cấu hình XML. Băng thông sử dụng có thể đƣợ c giớ i hạn. Cho phép hoặc từ chối tải kích thƣớ c tài liệu . Cho phép hoặc từ chối download các biểu thức thông thƣờ ng (ví dụ nhƣkhông tải về / cgi-bin). Tải về các tập tin mớ i sau những khoảng thờ i gian nhất định(do ngƣờ i
dùng quy định) Có thể tạm dừng và sau đó tiếp tục công việc.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 10/35
10
3.Giải Thích Về Mã Nguồn Chƣơng Trình.
Gói MainCrawler :
1. Lớp AllowedListFrame.Lớp này tác dụng chính để :
- Quản lý các danh mục URL hợp lệ. - Khởi tạo form làm việc cho phần mềm. - Tạo các nút thiết lập cho phần mềm ( mục chạy , thiết lập….)- Tạo list các URL sau đó cho phép ngƣời dùng thêm hoặc xóa các URL.
+Lớp AllowedListFrame :public class AllowedListFrame extends JHideFrame
+Tóm Tắt Hàm Tạo :
public AllowedListFrame(Vector<String> urls)
+ Tóm Tắt Phƣơng Thức :
protected void addURL()
protected void deleteURL()
+Hàm tạo Chi Tiết :
AllowedListFramepublic AllowedListFrame(Vector<String> urls)
+ Phƣơng Thức Chi Tiết :
addURL
protected void addURL()
deleteURLprotected void deleteURL()
2. Lớp Crawler.Lớp này tác dụng chính để :
- Tạo các form mới cho phần mềm.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 11/35
11
- Gán nhãn cho các nút.- Kiểm tra xem phần mềm có dang chạy không. - Sau đó xóa cokies lần chạy cuối. - Tạo hộp thoại thiết lập cho các robot.
Thiết lập loại URL Thiết lập bộ lọc tài liệu cần tìm. - Cập nhật các thiết lập ngƣời dùng vừa cài đặt. - Gọi lại giao diện cho http tool
Kích thƣớc tài liệu. Tỷ lệ …..
- Cập nhập trạng thái cho các thành phần động.
+ Gói Crawler
public class Crawler extends JFrame implementsHttpToolCallback,WebRobotCallback(Code)+ Field Summaryfinal static StringVERSION
+ Tóm Tắt Hàm Tạo: public Crawler ()
+ Tóm Tắt Phƣơng Thức : public static void main(String[] args)public void setHttpToolDocCurrentSize(int size)public void setHttpToolDocSize(int size)public void setHttpToolDocUrl(String url)public void setHttpToolStatus(int status)protected void updateControls()protected StringurlToString(URL u)public void webRobotDone()
public void webRobotRetrievedDoc(String url, int size)public void webRobotSleeping(boolean sleeping)public void webRobotUpdateQueueStatus(int length)
+ Chi Tiết Hàm Tạo : Crawler
public Crawler ()

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 12/35
12
+ Chi Tiết Phƣơng Thức : main
public static void main(String[] args)
setHttpToolDocCurrentSizepublic void setHttpToolDocCurrentSize(int size) setHttpToolDocSize
public void setHttpToolDocSize(int size) setHttpToolDocUrl
public void setHttpToolDocUrl(String url) setHttpToolStatus
public void setHttpToolStatus(int status) updateControls
protected void updateControls() urlToString
protected String urlToString(URL u) webRobotDone
public void webRobotDone() webRobotRetrievedDoc
public void webRobotRetrievedDoc(String url, int size) webRobotSleeping
public void webRobotSleeping(boolean sleeping) webRobotUpdateQueueStatus
public void webRobotUpdateQueueStatus(int length)
+ Ngoài ra còn có các hàm kế thừa từ : javax.swing.Jframe. javax.swing.Jframe. java.awt.Frame. java.awt.Frame. java.awt.Window. java.awt.Container.
java.awt.Component.
3. Lớp Crawlerbase.Lớp này tác dụng chính để :
- Khởi tạo giao diện comand line cho phần mềm. - Khởi tạo hệ thống đăng nhập phụ log4j. - Tạo các thiết lập cho robot nhƣ:

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 13/35
13
Đọc các thuộc tính từ tập tin cấu hình đăng nhập. Lấy tùy chọn dòng lệnh. Chiều sâu tối đa. Cách thức truy cập vào các hosts.
Thƣ mục lƣu trữ các tập tin đã đƣợc thu thập. Kích thƣớc tối thiểu của tập tin mà phần mềm sẽ thu thập. Bỏ qua robots.txt Thời gian chờ ...
+ Crawler cơ bản :
public class Crawlerbase+ Tóm Tắt Field :
protected static Category log+ Tóm Tắt Phƣơng Thức : public static void initializeLogging()public static void main(String[] argv)public static void printUsage()
+ Chi Tiết Field : log
protected static Category log
+ Chi Tiết Phƣơng Thức : initializeLogging
public static void initializeLogging() main
public static void main(String[] argv) throws Exception printUsage
public static void printUsage()
4. Lớp CrawlerData.
Lớp này tác dụng chính để : - Đây là một lớp đơn giản có chứa tất cả các tính năng cần thiết đó cho phần
mềm (tải về các quy tắc, RegExpUrlCheck ...)
+Dữ Liệu Crawler :public class CrawlerData

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 14/35
14
+ Tóm Tắt HÀm Tạo : public CrawlerData()
+ Tóm Tắt Phƣơng Thức :
public void configureRobot()public static CrawlerDatacreateFromXML()public static CrawlerDatacreateFromXML(String configDirectory)public DownloadRuleSetgetDownloadRuleSet()public boolean getLocalizeLinks()public WebRobotgetRobot()
public StringgetStorageDirectory()public boolean getStoreCGI()public RegExpURLCheckgetURLCheck()public void initializeFilters()public void registerHttpToolCallback(HttpToolCallback cb)public void registerWebRobotCallback(WebRobotCallback cb)public void saveConfig(String filename)
public void setDownloadRuleSet(DownloadRuleSet downloadRuleSet)public void setLocalizeLinks(boolean localize)public void setRobot(WebRobot robot)public void setStorageDirectory(String storageDirectory)public void setStoreCGI(boolean storeCGI)public void setURLCheck(RegExpURLCheck urlcheck)
+ Chi Tiết Hàm Tạo : CrawlerData
public CrawlerData() throws ClassNotFoundException
+ Chi Tiết Phƣơng Thức : configureRobot
public void configureRobot() createFromXML
public static CrawlerData createFromXML() throws ClassNotFoundException createFromXML

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 15/35
15
public static CrawlerData createFromXML(String configDirectory) throwsClassNotFoundException
getDownloadRuleSetpublic DownloadRuleSet getDownloadRuleSet()
getLocalizeLinkspublic boolean getLocalizeLinks()
getRobotpublic WebRobot getRobot()
getStorageDirectorypublic String getStorageDirectory()
getStoreCGIpublic boolean getStoreCGI()
getURLCheckpublic RegExpURLCheck getURLCheck()
initializeFilterspublic void initializeFilters()
registerHttpToolCallbackpublic void registerHttpToolCallback(HttpToolCallback cb)
registerWebRobotCallbackpublic void registerWebRobotCallback(WebRobotCallback cb)
saveConfigpublic void saveConfig(String filename)
setDownloadRuleSetpublic void setDownloadRuleSet(DownloadRuleSet downloadRuleSet)
setLocalizeLinkspublic void setLocalizeLinks(boolean localize)
setRobotpublic void setRobot(WebRobot robot)
setStorageDirectorypublic void setStorageDirectory(String storageDirectory)
setStoreCGIpublic void setStoreCGI(boolean storeCGI)
setURLCheckpublic void setURLCheck(RegExpURLCheck urlcheck)
5. Lớp FilterConfigFrame.Lớp này tác dụng chính để :
- Tạo hộp thoại thiết lập cho các bộ lọc. - Cập nhật các thiết lập của phần mềm.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 16/35
16
+ FilterConfigFramepublic class FilterConfigFrame kế thừa JHideFrame
+ Tóm Tắt Hàm Tạo : public FilterConfigFrame()
+ Tóm Tắt Phƣơng Thức : protected void initComponents()protected void updateAndHide()
+ Chi Tiết Hàm Tạo : FilterConfigFrame
public FilterConfigFrame()
+ Chi Tiết Phƣơng Thức : initComponents
protected void initComponents()
updateAndHideprotected void updateAndHide()
+ Phƣơng pháp kế thừa từ net.swing.JHideFrame
protected void exitForm()protected void installCloseHandler()
6. Lớp LogFrame.Lớp này tác dụng chính để :
- Tạo một JFRAME đơn giản để đăng nhập log4j - Tạo khung logic mới
+ Khung đăng nhập : public class LogFrame kế thừa JHideFrame
+ Tóm Tắt Hàm Tạo : public LogFrame()
+ Tóm Tắt Phƣơng Thức : public void addMsg(String msg)public void clearLog()

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 17/35
17
+Chi Tiết Hàm Tạo : LogFrame
public LogFrame()
+ Chi Tiết Phƣơng Thức : addMsg
public void addMsg(String msg) clearLog
public void clearLog()
+Phƣơng pháp kế thừa từ net.swing.JHideFrame protected void exitForm()protected void installCloseHandler()
7. Lớp LogFrameAppender.Lớp này tác dụng chính để :
- Đối tƣợng đơn giản để kết nối với các khung logic WEBDOCUMENTGETTER * Log4J.
+ LogFrameAppenderpublic class LogFrameAppender extends AppenderSkeleton
+ Tóm Tắt Hàm Tạo : public LogFrameAppender(LogFrame log)
+ Tóm Tắt Phƣơng Thức : public void append(LoggingEvent e)public void close()public boolean requiresLayout()
+ Chi Tiết Hàm Tạo : LogFrameAppender
public LogFrameAppender(LogFrame log)
+ Chi Tiết Phƣơng Thức : append
public void append(LoggingEvent e)

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 18/35
18
closepublic void close()
requiresLayoutpublic boolean requiresLayout()
8. Lớp RegExpRuleTableModel.Lớp này tác dụng chính để :
+ RegExpRuleTableModel
public class RegExpRuleTableModel extends AbstractTableModel
+ Tóm Tắt Field :
final static String[] columnsVector rules
+ Tóm Tắt Hàm Tạo :
public RegExpRuleTableModel(Vector rules)
+ Tóm Tắt Phƣơng Thức :
public ClassgetColumnClass(int col)public int getColumnCount()public StringgetColumnName(int col)public int getRowCount()public ObjectgetValueAt(int row, int col)public boolean isCellEditable(int row, int column)
public void setValueAt(Object value, int row, int col)
+ Chi Tiết Field : columns
final static String[] columns+ Chi Tiết Hàm Tạo :
RegExpRuleTableModel

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 19/35
19
public RegExpRuleTableModel(Vector rules)
+ Chi Tiết Phƣơng Thức : getColumnClass
public Class getColumnClass(int col) getColumnCountpublic int getColumnCount()
getColumnNamepublic String getColumnName(int col)
getRowCountpublic int getRowCount()
getValueAtpublic Object getValueAt(int row, int col)
isCellEditablepublic boolean isCellEditable(int row, int column)(Code)
setValueAtpublic void setValueAt(Object value, int row, int col)
+ Những lĩnh vực thừa hƣởng từ : javax.swing.table.AbstractTableModel javax.swing.table.AbstractTableModel
9. Lớp RobotConfigFrame.
Lớp này tác dụng chính để : - Thiết lập các chức năng chính cho phần mềm. - Cập nhật các thiết lập của ngƣời dùng cho phần mềm.
+ Khung Cấu Hình Cho Robot: public class RobotConfigFrame extends JHideFrame
+ Tóm Tắt Field :JtextField agentNameField
JcheckBox allowCachingJcheckBox allowWholeDomainJcheckBox allowWholeHostJtextField bandwidthFieldJcheckBox cookiesEnabledJcheckBox flexibleHostCheckJcheckBox ignoreRobotsTxt

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 20/35
20
CrawlerData CrawlerDataJcheckBox localizeLinksJtextField maxAgeFieldJtextField maxDepthField
JtextField proxyFieldWebRobot robotJtextField sleepFieldJtextField startRefererFieldJcheckBox storeCGI
+ Tóm Tắt Hàm Tạo : public RobotConfigFrame( CrawlerData CrawlerData )
+ Tóm Tắt Phƣơng Thức :
protected void initComponents()protected void updateAndHide()protected void updateFormFromRobot()protected boolean updateRobotFromForm()
+ Chi Tiết Field : agentNameField
JTextField agentNameField allowCaching
JCheckBox allowCaching allowWholeDomain
JCheckBox allowWholeDomain allowWholeHost
JCheckBox allowWholeHost bandwidthField
JTextField bandwidthField cookiesEnabled
JCheckBox cookiesEnabled
flexibleHostCheckJCheckBox flexibleHostCheck ignoreRobotsTxt
JCheckBox ignoreRobotsTxt CrawlerData
CrawlerData CrawlerData localizeLinks

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 21/35
21
JCheckBox localizeLinks maxAgeField
JTextField maxAgeField maxDepthField
JTextField maxDepthField proxyField
JTextField proxyField robot
WebRobot robot sleepField
JTextField sleepField startRefererField
JTextField startRefererField storeCGI
JCheckBox storeCGI
+Chi Tiết Hàm Tạo :
Khung Cấu Hình Cho Robot : public RobotConfigFrame( CrawlerData CrawlerData )
+Chi Tiết Phƣơng Thức :
initComponentsprotected void initComponents()
updateAndHideprotected void updateAndHide()(Code)
updateFormFromRobotprotected void updateFormFromRobot()
updateRobotFromFormprotected boolean updateRobotFromForm()
+ Phƣơng pháp kế thừa từ net.swing.JhideFrame.protected void exitForm()protected void installCloseHandler()
10. Lớp URLCheckConfigFrame.Lớp này tác dụng chính để :
- Check lại các thiết lập của phần mềm.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 22/35
22
- Update các thông tin mới cho phần mềm.
+Khung Cấu Hình Cho URLpublic class URLCheckConfigFrame extends JHideFrame
+ Tóm Tắt Field :RegExpURLCheck check
+ Tóm Tắt Hàm Tạo : public URLCheckConfigFrame(RegExpURLCheck check)
+ Tóm Tắt Phƣơng Thức :
protected void initComponents()protected void updateAndHide()protected void updateFormFromURLCheck()protected boolean updateURLCheckFromForm()+Chi Tiết Field
checkRegExpURLCheck check
+Chi Tiết Hàm Tạo : URLCheckConfigFramepublic URLCheckConfigFrame(RegExpURLCheck check)
+ Method Detail initComponents
protected void initComponents() updateAndHide
protected void updateAndHide() updateFormFromURLCheck
protected void updateFormFromURLCheck() updateURLCheckFromForm
protected boolean updateURLCheckFromForm()+ Phƣơng pháp kế thừa từ net.swing.JHideFrame protected void exitForm()protected void installCloseHandler()

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 23/35
23
Chƣơng 3.Các Kết Quả Đạt Đƣợc.
- Phần mềm bƣớc đầu đã thu thập đƣợ c dữ liệu thô trên các trang web.
Giao diện phần mềm :
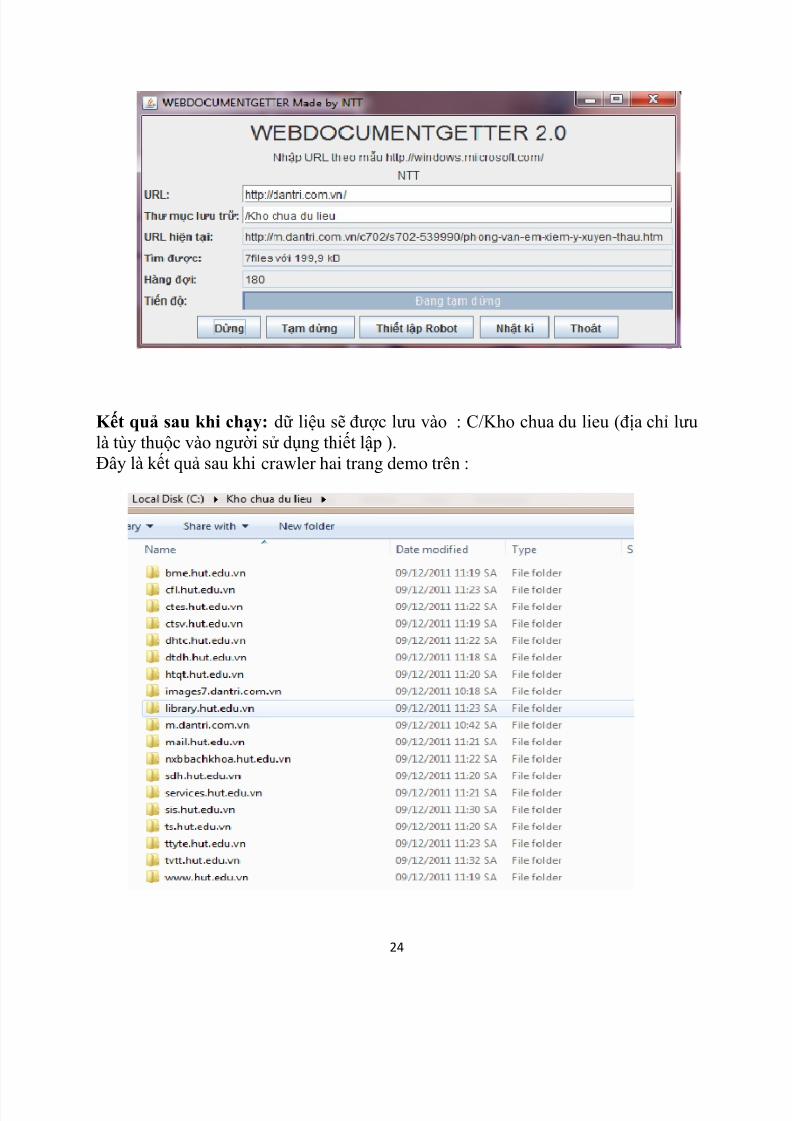
Giao diện khi crawler http://dantri.com.vn/ :+ Đầu tiên ta nhập địa chỉ website cần crawler ( ở đây mình demo trang
http://dantri.com.vn/ và http://sis.hut.edu.vn/ ).+ Sau đó chọn tên thƣ mục lƣu trữ. Ở đây mình lƣu vào ổ C/Kho chua du lieu. + Khi chạy : phần mềm sẽ thông báo địa chỉ trang hiện tại ( trong mục URL
hiện tại ).Đồng thời báo số file và tổng kích thƣớc của chúng ( trong mục Tìmđƣợc ). Ngoài ra có mục hàng đợi và mục tiến độ báo kết quả crawler.
5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 24/35
24
Kết quả sau khi chạy: dữ liệu sẽ đƣợc lƣu vào : C/Kho chua du lieu (địa chỉ lƣulà tùy thuộc vào ngƣời sử dụng thiết lập ). Đây là kết quả sau khi crawler hai trang demo trên :

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 25/35
25
Kết quả crawler về sẽ đƣợ c WEBDOCUMENTGETTER ra thành các folder.Mỗi folder là một mục lƣu các file tƣơng ứng mà WEBDOCUMENTGETTER vừadown về.
Folder chứ a ảnh :

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 26/35
26
Folder chứ a các banner và logo của trang web vừ a crawler .
Nhấp chuột vào mục logo sẽ hiện lên các logo của trang vừ a crawler :
5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 27/35
27
Các banner :
Folder chứ a các index của web :
5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 28/35
28
Nhấp vào một chỉ số bất kỳ trong folder .Trang web mặc định của ta sẽ dẫn tớiđịa chỉ web đã đƣợc đánh dấu ở trên .
Ví dụ nhấn vào LopHuy20083 : google chrome của tôi đã dẫn tới địa chỉ sau:
Folder chứa các file nhƣ pdf và file word:
Nhấn vào folder từ 2008 tới 2011 ở trên ta sẽ thấy có folder thông báo

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 29/35
29
Ví dụ năm 2010 :
Bên trong folder thông báo là các file chỉ số ngoài ra còn có các file của excel.Đây là file thông báo của trƣờn đâị học Bách Khoa Hà Nội cho sinh viên các nămtƣơng ứng ở đây là năm 2010.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 30/35
30
Phần thiết lập cho phần mềm :

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 31/35
31
KẾT LUẬN
Vớ i những nỗ lực trong thờ i gian qua và sự hƣớ ng dẫn tận tình của Thầy Th.SNguyễn Quang Minh , đề tài project 1 của tôi cũng đã đạt đƣợ c một số kết quả nhất
định.Điều này đƣợ c thẻ hiện ở WEBDOCUMENTGETTER là trình thu thập màthời gian qua tôi đã tìm hiểu và tham khảo để hoàn thiện nhằm đáp ứng yêu cầucủa project.Công cụ thu thập đƣợc dữ liệu phần thô trên web nhƣ các file
pdf,doc,xsl, các file ảnh …Nhƣng không tránh khỏi một vài hạn chế do điều kiệnthờ i gian không cho phép. Vì vậy trong thờ i gian tớ i tôi sẽ cố gắng để hoàn thiệnnó.Không chỉ để hoàn thành bài tập project mà để có thể ứng dụng nó vào thực tế.
Trong quá trình tìm hiểu project 1 tôi cũng đã tìm hiểu đƣợ c một lƣợ ng kiếnthức lớ n về World Wide Web, các kỹ thuật sử dụng của các web crawler và web
scraper….Nhƣng do trình độ còn hạn chế nên khả năng am hiểu về các vấn đề làchƣa sâu .Vậy mong thầy và các bạn đóng góp thêm ý kiến giúp tôi hoàn thành cả về lý thuyết và bài tập lần này một cách tốt nhất.
Tôi xin chân thành cám ơn sự giúp đỡ của Th.s Nguyễn Quang Minh,các bạnsinh viên lớp ĐT3-K53 trong nhóm đã giúp tôi hoàn thành project này.

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 32/35
32
HƢỚNG PHÁT TRIỂN TƢƠNG LAI
- WEBDOCUMENTGETTER : bƣớc đầu đã thu đƣợc dữ liệu thô nên trongtƣơng lai tới em sẽ cố gắng hoàn thiện nó thành một công cụ tốt hơn cả vềgiao diện và tính năng. + Cố gắng tạo thêm cho công cụ một tính năng mới nhƣ tìm kiếm theo từkhóa ( nhập vào một từ crawler thì nó sẽ tìm các trang các văn bản iên quantới từ khó đó…) + Công cụ sẽ đi sau vào thu thập một lĩnh vực nào đó nhƣimage,video,text… + Các thu mục lƣu trữ sẽ phân biệt rõ ràng giữa mục lƣu ảnh , mục lƣu text
- Đặc biệt trong tƣơng lai em sẽ cố gắng tìm hiểu nhu cầu của ngƣời dùng đểđƣa ra các tính năng mới phù hợp với yêu cầu mới.
- Tuy nhiên với sự bùng nổ của internet thì khó khăn đặt ra để hoàn thiệnđƣợc một phần mềm là rất khó .Nhƣng chúng em sẽ cố gắng tìm hiểu đểkhắc phục .

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 33/35
33
PHỤ LỤC
Các thách thức cho công cụ tìm kiếm trong tƣơng lai cần tìm hiểu :
+ Thách thức thứ nhất: Dữ liệu Web 2.0:
Không cần phải đề cập nhiều, sự bùng nổ của Web 2.0 kéo theo trào lƣungƣời dùng tham gia tạo nội dung trên Internet.Dữ liệu gia tăng đột biến vềlƣợng. Lƣợng dữ liệu này tồn tại trên các diễn đàn, blog, wiki, socialnetwork, multimedia service,... dữ liệu cá nhân đƣợc sinh ra và tồn tại trênInternet ngày càng nhiều. Chúng có thể đƣợc bảo vệ bởi sự riêng tƣ hoặc rấtkhó truy vấn theo phƣơng pháp lần liên kết (link) thông thƣờng. Hơn nữa,nhiều Web 2.0 sử dụng script để sinh URL hoặc chọn phƣơng thức Post
(HTTP Post) khi truy vấn dữ liệu. Vậy làm sao để máy tìm kiếm có thể quéthết dữ liệu trên Internet? Đây là một thách thức khó khăn đặt ra cho Crawler của các Search Engine. Dĩ nhiên, không phải đến thời 2.0, Search Enginemới phải đối mặt với Invisible Web (Web ẩn) nhƣng khi mạng dịch vụ dữliệu bùng nổ, Invisible web trở nên phức tạp và và rắc rối hơn nhiều.
+ Thách thức thứ hai: Lọc bỏ dữ liệu rác và trùng lặp:
Nhƣ đã đề cập ở phần trên, chi phí về mặt lƣu trữ phải đƣợc tính toán sao
cho rẻ nhất. Do đó, càng ít dữ liệu nháp, ít dữ liệu trùng lặp càng tốt. Nhữngdữ liệu kiểu này còn ảnh hƣởng đến tốc độ tiếp cận và chất lƣợng kết quảsearch trả về cho ngƣời dùng. Trong khi vấn nạn thƣ rác đang hoành hoànhthì vấn nạn dữ liệu rác cũng làm đau đầu các công cụ tìm kiếm.
Do đó, Search Engine phải biết khoanh vùng dữ liệu. Cụ thể hơn là chianhỏ vùng dữ liệu để giới hạn phạm vi truy vấn giúp ngƣời dùng tiếp cậnnhanh và chính xác hơn. Thêm nữa, do đặc thù dữ liệu, tin tức, giá cả hànghóa, chứng khoán, kiếm việc,... cần cập nhật thƣờng xuyên với tốc độ nhanhhơn các thảo luận trên diễn đàn hoặc blog. Chia nhỏ vùng dữ liệu nằm cả ở khía cạnh quét, lƣu trữ và tìm kiếm dữ liệu.
+ Thách thức thứ ba: Vertical Search và các hình thái truy vấn dữ liệu.
Với một từ khóa, ta có thể nhận lại hàng trăm triệu trang Web chứa nó từSearch Engine. Nhƣng thực sự, chúng ta không cần nhiều đến thế. Chẳnghạn khi tìm chữ Nokia, tôi muốn nhận lại các kết quả từ các trang rao bánđiện thoại Nokia cũ. Làm ơn đừng trả lại tin tức hay địa chỉ cửa hàng bán

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 34/35
34
điện thoại Nokia mới. "Kỹ năng" tìm kiếm đƣợc sử dụng để thêm lần nữangƣời dùng tự sàng lọc kết quả trả về. Nhƣng tƣơng lai sẽ không dễ dàngnhƣ thế.Hàng tỉ, hàng tỉ trang web có thể đƣợc trả đến bạn. Mọi kỹ năng trở nên vô tác dụng với lƣợng dữ liệu quá lớn.
+ Thách thức thứ 4: Tăng cường ngữ nghĩa.
Bổ sung nội dung liên quan trong kết quả tìm kiếm.Rút trích ý hoặc tómtắt nội dung giúp ngƣời dùng tiếp cận hoặc rà soát nhanh hơn.Internet giốngnhƣ mạng nhện cả ở khía cạnh vật lý lẫn những trang web tồn tại trên nó.Các liên kết ràng buộc, đan xem, chỉ trỏ tới nhau tạo thành một mạng lƣới.
+ Thách thức thứ 5: Máy tìm kiếm không chỉ đánh chỉ mục web.
Ngƣời dùng đang quen dần với việc nhờ vả mọi thứ vào các máy tìm
kiếm. Ví dụ: tôi muốn nó giải hộ một phƣơng trình bậc 3 có vẽ đồ thị....

5/12/2018 BÁO CÁO PROJECT 1-trung - slidepdf.com
http://slidepdf.com/reader/full/bao-cao-project-1-trung 35/35
35
TÀI LIỆU THAM KHẢO
Website :
1.http://www.java2s.com 2. http://www.matuschek.net/jobo/
Luận án Tiến sĩ Khoa học Máy tính của trƣờng Đại học của Chile :
“ EffectiveWeb Crawling by Carlos Castillo”