a solution with reconfigurable...
TRANSCRIPT

XD1 massively parallel machine
A Solution with Reconfigurable Computing
Presented by:
Abedellatif Hussein
Yamin Al-Mousa
EECC-756
Multiple Processors Systems
Instructor: Dr Shaaban

Outlines• Introduction.• XD1 Architecture.
– AMD Opetron (the computing heart).– System interconnect:
• communication processors • switching fabric
– Application Accelerator.– Active management Subsystems.
• XD1 Performance.• XD1 Applications.• Summary.• Conclusion• References.

Introduction• History: Designed by OctigaBay Systems Corp.,
Vancouver, Canada……then acquired by Cray in Feb 2004.
• Announced in October 2004. affordable price $ 100k to 2M.
• Targeted for HPC: High Performance Computing• Utilizing reconfigurable H.W. to boost the performance. • Linux, 32 & 64-bit x-86 compatible• High reliability, monitors and maintains system health.• Scalable to hundreds of nodes, high BW with low latency• Programming model : message passing.

XD1 Architecture• Chassis is the basic building block to
scale up in racks• 6 blades in each chassis• Each blade carries two way AMD
Opetron SMP( Dual core supported)• 6 FPGAs as application accelerator
(each blade)• Embedded interconnect switch fabric• Customized communication
processors as communication assists.• Dedicated processor for monitoring &
managements purposes.• Up to 4 PCI-X slots• Associated power supplies and fans• Up to 6 serial ATA (SATA) hard drives
(for each blade)• 8 memory DIMM sockets up to 16 GB
( 8 GB each)
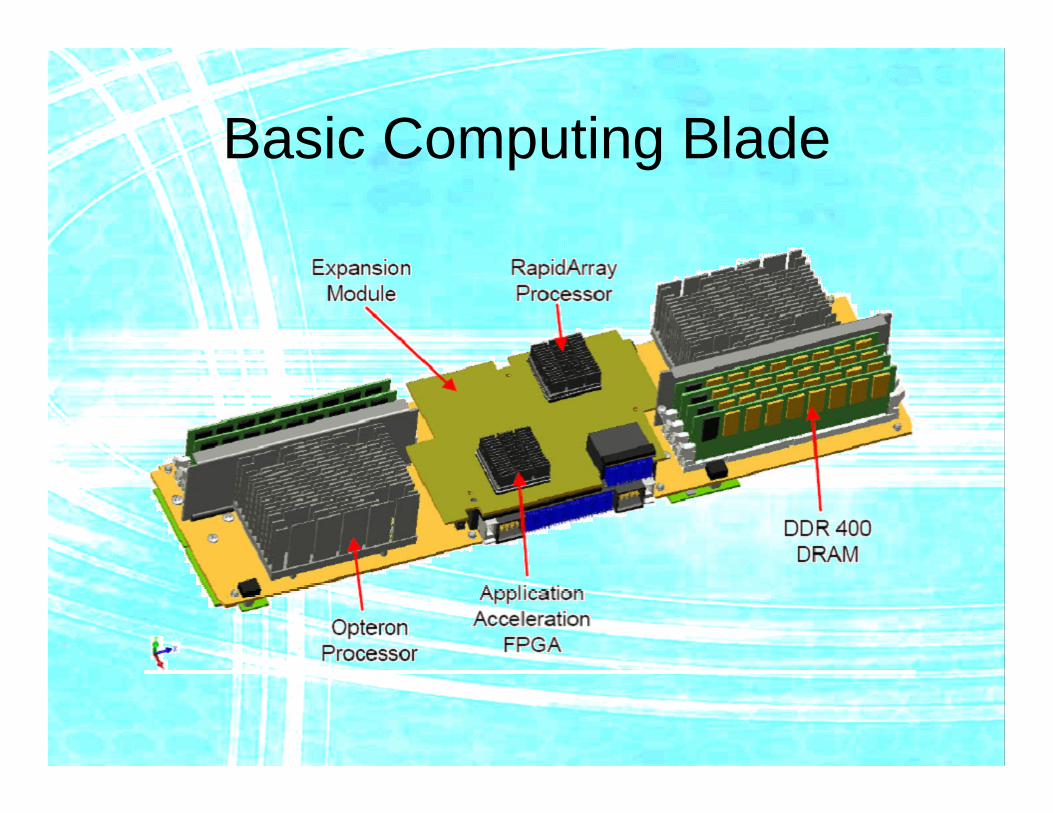
Basic Computing Blade

Architecture: AMD Opetron• Commodity of the shelf. Affordable
price.• 32/64-bit floating point performance.• Integrated memory controller with
high BW and low latency.• Deliver 53 GFLOPS (12
processors).• HyperTransport links 19.2 GB/s for
I/O data transfer. (three links).• DCP: directly connecting
processors in the blade to overcome the PCI and shared memory bottlenecks.
• Outstanding MPI transfer performance. HyperTransport

System interconnect: communication processors
• 6 or 12 custom communication processors (CA) per chassis.
• Link the blades to the switching fabric.
• Reliable message Routing between processors.
• Handles message transactions to Allows overlapping between communication and computations.
• Supported libraries include MPI, OpenMP and GA with special optimizations to meet the architecture design.
• Deliver 4 GB/s (or 8 GB/s) BW, and 1.7 Us latency

System interconnect: switching fabric
• 48 GB/s (96 GB/s optional) non-blocking crossbar switching fabric 24 ports.
• Divided into 24 links of 2 GB/s
• Each communication processor handles two links.
• 12 (24) ports for blade interconnection, 12 (24) ports for inter chassis connections.
• No need for extra switches between chassis and up to certain limit.

System interconnect: switching fabric
• Directly connected
• Up to 13 chassis• No need for extra
switches• All hops in Rapid
Array links
• Fat tree• Supports up to 24
chassis• Suggested for large
systems or expected to be
• External Rapid Array switches are needed
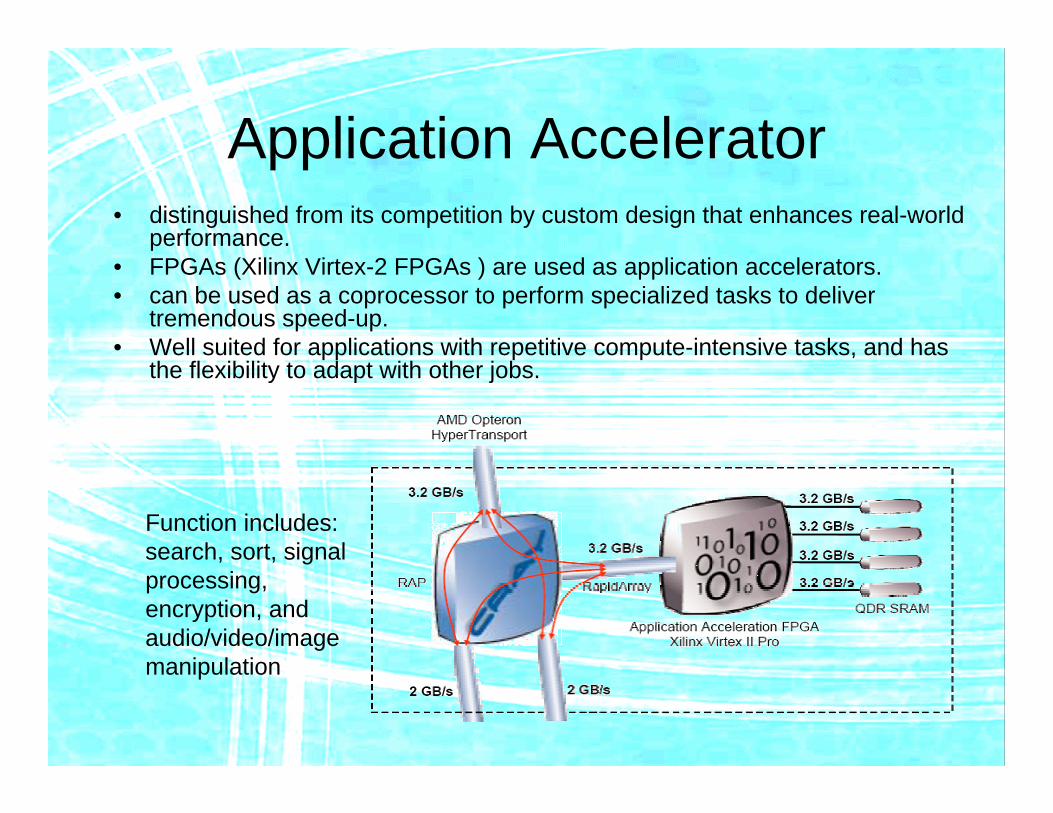
Application Accelerator• distinguished from its competition by custom design that enhances real-world
performance.• FPGAs (Xilinx Virtex-2 FPGAs ) are used as application accelerators.• can be used as a coprocessor to perform specialized tasks to deliver
tremendous speed-up.• Well suited for applications with repetitive compute-intensive tasks, and has
the flexibility to adapt with other jobs.
Function includes: search, sort, signal processing, encryption, and audio/video/image manipulation

Application Accelerator• Can be accessed from the processor through the reads and writes (HT)• The processor can transfer the data in and out the FPGA by using the
simple DMA engine in the rapid array transport core.• The FPGA can access the processor’s memory with read and write
requests. Can access also the rapid array interconnect.• Accessing the memory does not result in interrupt for the processor• Memory coherency is
maintained by the processor
16 MB

Application AcceleratorFPGA Linux API
Admininstration Commandsfpga_open/close – allocate or deallocate the fpgafpga_load/unload – program or clear the fpga
Operation Commandsfpga_start/reset – release the user logic from or place it into reset
Communication Commandsfpga_register/dreg_ftrmem – map application memory to allow access by fpgafpga_memmap – map fpga ram into application virtual spacefpga_rd/wrt_appif_val – read/write data from/to the FPGAfpga_intwait – blocks process waits for fpga interrupt
Status Commandsfpga_is_loaded – check if the fpga has been programmedfpga_status – get status of fpga

Active management Subsystems• Maintained by a dedicated processor to
offload the main processor, the same case for the RAP.
• Manage partitioning the system into number of logical subsystems.
• Enable the administrator to operate the partitions rather than the individual AMD processors.
• Management functions include: resources, storage, queuing, security and networking
• Self healing: extensive fault detection, isolation and prediction capabilities.
• Fault detection: done by a dedicated processor per shelf. (voltage, temperature, parity errors and component diagnostics.
• Proactive management: for a wide range of operating parameters to keep the system at its maximum performance.
• Recovery from hardware failures does not require system shutdown because of available redundancy. (N + 1)

XD1 performanceMessage latency of
about 1.7 Us
Maintaining acceptable BW with scalability
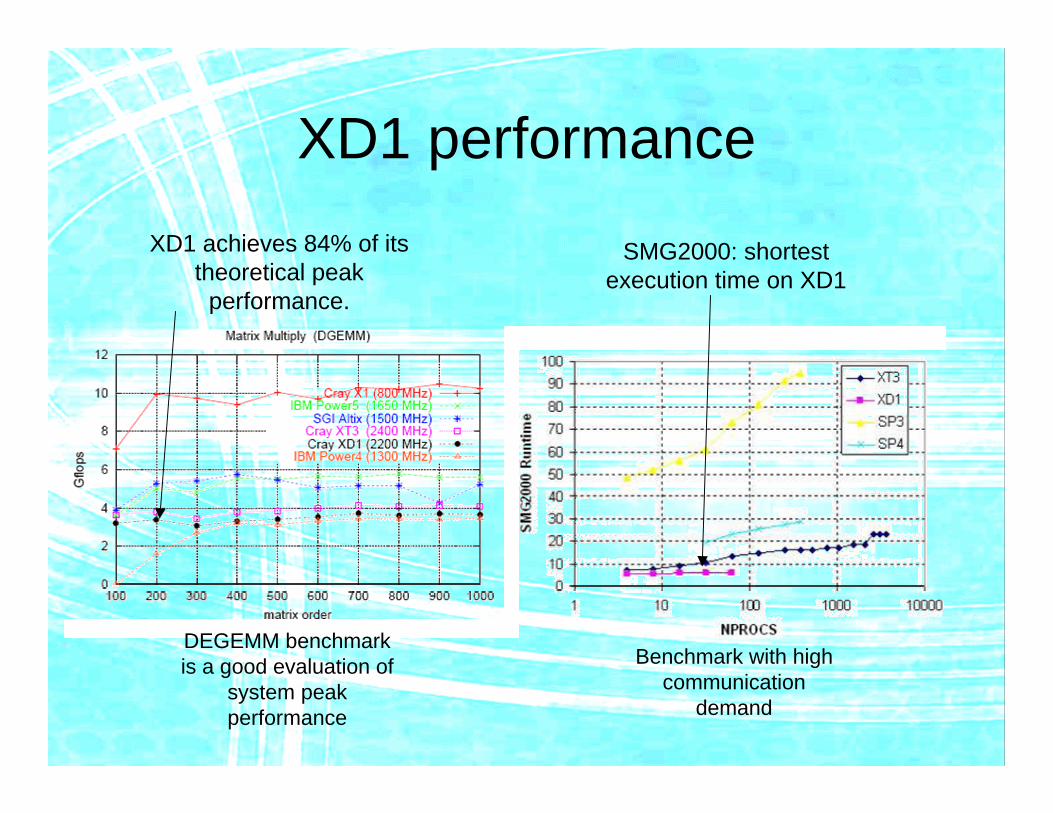
XD1 performanceXD1 achieves 84% of its
theoretical peak performance.
DEGEMM benchmark is a good evaluation of
system peak performance
SMG2000: shortest execution time on XD1
Benchmark with high communication
demand

XD1 performance
• Implementing “Mersenne Twister” algorithm for Monte Carlo analysis which generates uniformly distributed random integers.
• The generated numbers are transferred directly to the processor memory.• Using FPGAs results in a speed up of 3X.

XD1 Applications
• Scientific research.• Weather• Chemistry• computer-aided engineering (CAE)• markets• particularly automotive• Aerospace• shipbuilding

Conclusions• XD1 is a new solution for affordable Massively Parallel
Machines…compared to others!!• The XD1 is truly a purpose-built system, distinguished from its competition
by custom design that enhances real-world performance using FPGA.• FPGA is inherent in the design and built up with it. (not like other solutions
using PCI-X bus).• The application accelerators can be in some cases the cause of
tremendous enhancement in performance.• The RAP is there to allow the overlapping between the communication and
computation.• Various topologies are supported without extra H.W.( hypercube & toroid ).• A dedicated management processor to achieve the maximum performance
for the system.• The RAP and the management processor are offloading the AMD processor
for other usefull computations tasks.

Summery
721894.51.5Internal Disk Storage (TB)
4,8001,15257628896Max. Main Memory (GB)
3,68692246123077Aggregate MemoryBandwidth (GB/s)
2.32.32.02.01.7Interprocessor latency(Microseconds)
64 - 128 Tb/s**9 - 18 Tb/s**864**
288**
48/96**
Aggregate Switching Capacity (GB/s)
2,99574937218662Performance (GFLOPS)
--------- Fully Interconnected Mesh --------------- Fat Tree ^---
---
Interconnect Topology 57614472 3612Compute Processors 4812631Chassis

References• http://www.cray.com/products/xd1/index.html• http://www.csm.ornl.gov/evaluation/docs/2005/Fahey_paper.pdf• http://www.ksc.re.kr/sc2004/papers/october6/(WW4-2).pdf• http://www.cray.com/downloads/dhbrown_crayxd1_oct2004.pdf• http://klabs.org/mapld04/presentations/session_f/cray_f.pdf• http://www.csm.ornl.gov/evaluation/docs/2005/Fahey_slides.pdf• http://www.cse.clrc.ac.uk/disco/mew15-cd/Talks/Shan_Cray.pdf• http://www.arsc.edu/news/archive/fpga/Tue-1130-Woods.pdf• http://web.ccr.jussieu.fr/ccr/Documentation/Calcul/XD1/documents/S-2453-
121_CrayXD1ReleaseDescription.pdf