wassa-2017 shared task on emotion intensityfbravoma/publications/wassa2017.pdf · the machine...
TRANSCRIPT

WASSA-2017 Shared Task on Emotion Intensity
Saif M. MohammadInformation and Communications Technologies
National Research Council CanadaOttawa, Canada
Felipe Bravo-MarquezDepartment of Computer Science
The University of WaikatoHamilton, New Zealand
Abstract
We present the first shared task on de-tecting the intensity of emotion felt bythe speaker of a tweet. We createthe first datasets of tweets annotated foranger, fear, joy, and sadness intensitiesusing a technique called best–worst scal-ing (BWS). We show that the annota-tions lead to reliable fine-grained intensityscores (rankings of tweets by intensity).The data was partitioned into training, de-velopment, and test sets for the compe-tition. Twenty-two teams participated inthe shared task, with the best system ob-taining a Pearson correlation of 0.747 withthe gold intensity scores. We summarizethe machine learning setups, resources,and tools used by the participating teams,with a focus on the techniques and re-sources that are particularly useful for thetask. The emotion intensity dataset and theshared task are helping improve our under-standing of how we convey more or lessintense emotions through language.
1 Introduction
We use language to communicate not only theemotion we are feeling but also the intensity ofthe emotion. For example, our utterances can con-vey that we are very angry, slightly sad, absolutelyelated, etc. Here, intensity refers to the degree oramount of an emotion such as anger or sadness.1
Automatically determining the intensity of emo-tion felt by the speaker has applications in com-merce, public health, intelligence gathering, andsocial welfare.
1Intensity should not be confused with arousal, whichrefers to activation–deactivation dimension—the extent towhich an emotion is calming or exciting.
Twitter has a large and diverse user basewhich entails rich textual content, including non-standard language such as emoticons, emojis, cre-atively spelled words (happee), and hashtaggedwords (#luvumom). Tweets are often used to con-vey one’s emotion, opinion, and stance (Moham-mad et al., 2017). Thus, automatically detectingemotion intensities in tweets is especially bene-ficial in applications such as tracking brand andproduct perception, tracking support for issues andpolicies, tracking public health and well-being,and disaster/crisis management. Here, for the firsttime, we present a shared task on automaticallydetecting intensity of emotion felt by the speakerof a tweet: WASSA-2017 Shared Task on EmotionIntensity.2
Specifically, given a tweet and an emotion X,the goal is to determine the intensity or degree ofemotion X felt by the speaker—a real-valued scorebetween 0 and 1.3 A score of 1 means that thespeaker feels the highest amount of emotion X. Ascore of 0 means that the speaker feels the low-est amount of emotion X. We first ask human an-notators to infer this intensity of emotion from atweet. Later, automatic algorithms are tested todetermine the extent to which they can replicatehuman annotations. Note that often a tweet doesnot explicitly state that the speaker is experienc-ing a particular emotion, but the intensity of emo-tion felt by the speaker can be inferred nonethe-less. Sometimes a tweet is sarcastic or it conveysthe emotions of a different entity, yet the annota-tors (and automatic algorithms) are to infer, basedon the tweet, the extent to which the speaker islikely feeling a particular emotion.
2http://saifmohammad.com/WebPages/EmotionIntensity-SharedTask.html
3Identifying intensity of emotion evoked in the reader, orintensity of emotion felt by an entity mentioned in the tweet,are also useful tasks, and left for future work.

In order to provide labeled training, develop-ment, and test sets for this shared task, we neededto annotate instances for degree of affect. This isa substantially more difficult undertaking than an-notating only for the broad affect class: respon-dents are presented with greater cognitive loadand it is particularly hard to ensure consistency(both across responses by different annotators andwithin the responses produced by an individual an-notator). Thus, we used a technique called Best–Worst Scaling (BWS), also sometimes referred toas Maximum Difference Scaling (MaxDiff). It isan annotation scheme that addresses the limita-tions of traditional rating scales (Louviere, 1991;Louviere et al., 2015; Kiritchenko and Moham-mad, 2016, 2017). We used BWS to create theTweet Emotion Intensity Dataset, which currentlyincludes four sets of tweets annotated for inten-sity of anger, fear, joy, and sadness, respectively(Mohammad and Bravo-Marquez, 2017). Theseare the first datasets of their kind.
The competition is organized on a CodaLabwebsite, where participants can upload their sub-missions, and the leaderboard reports the results.4
Twenty-two teams participated in the 2017 it-eration of the competition. The best perform-ing system, Prayas, obtained a Pearson correla-tion of 0.747 with the gold annotations. Seventeams obtained scores higher than the score ob-tained by a competitive SVM-based benchmarksystem (0.66), which we had released at the startof the competition.5 Low-dimensional (dense)distributed representations of words (word em-beddings) and sentences (sentence vectors), alongwith presence of affect–associated words (derivedfrom affect lexicons) were the most commonlyused features. Neural network were the most com-monly used machine learning architecture. Theywere used for learning tweet representations aswell as for fitting regression functions. Supportvector machines (SVMs) were the second mostpopular regression algorithm. Keras and Tensor-Flow were some of the most widely used libraries.
The top performing systems used ensembles ofmodels trained on dense distributed representa-tions of the tweets as well as features drawn fromaffect lexicons. They also made use of a substan-tially larger number of affect lexicons than sys-tems that did not perform as well.
4https://competitions.codalab.org/competitions/163805https://github.com/felipebravom/AffectiveTweets
The emotion intensity dataset and the corre-sponding shared task are helping improve our un-derstanding of how we convey more or less in-tense emotions through language. The task alsoadds a dimensional nature to model of basic emo-tions, which has traditionally been viewed as cat-egorical (joy or no joy, fear or no fear, etc.). Ongoing work with annotations on the same datafor valence , arousal, and dominance aims to bet-ter understand the relationships between the cir-cumplex model of emotions (Russell, 2003) andthe categorical model of emotions (Ekman, 1992;Plutchik, 1980). Even though the 2017 WASSAshared task has concluded, the CodaLab competi-tion website is kept open. Thus new and improvedsystems can continually be tested. The best resultsobtained by any system on the 2017 test set can befound on the CodaLab leaderboard.
The rest of the paper is organized as follows.We begin with related work and a brief back-ground on best–worst scaling (Section 2). In Sec-tion 3, we describe how we collected and anno-tated the tweets for emotion intensity. We alsopresent experiments to determine the quality ofthe annotations. Section 4 presents details of theshared task setup. In Section 5, we present a com-petitive SVM-based baseline that uses a number ofcommon text classification features. We describeablation experiments to determine the impact ofdifferent feature types on regression performance.In Section 6, we present the results obtained bythe participating systems and summarize their ma-chine learning setups. Finally, we present conclu-sions and future directions. All of the data, annota-tion questionnaires, evaluation scripts, regressioncode, and interactive visualizations of the data aremade freely available on the shared task website.2
2 Related Work
2.1 Emotion Annotation
Psychologists have argued that some emotions aremore basic than others (Ekman, 1992; Plutchik,1980; Parrot, 2001; Frijda, 1988). However, theydisagree on which emotions (and how many)should be classified as basic emotions—some pro-pose 6, some 8, some 20, and so on. Thus, most ef-forts in automatic emotion detection have focusedon a handful of emotions, especially since manu-ally annotating text for a large number of emotionsis arduous. Apart from these categorical models ofemotions, certain dimensional models of emotion

have also been proposed. The most popular amongthem, Russell’s circumplex model, asserts that allemotions are made up of two core dimensions:valence and arousal (Russell, 2003). We createddatasets for four emotions that are the most com-mon amongst the many proposals for basic emo-tions: anger, fear, joy, and sadness. However, wehave also begun work on other affect categories,as well as on valence and arousal.
The vast majority of emotion annotation workprovides discrete binary labels to the text instances(joy–nojoy, fear–nofear, and so on) (Alm et al.,2005; Aman and Szpakowicz, 2007; Brooks et al.,2013; Neviarouskaya et al., 2009; Bollen et al.,2009). The only annotation effort that providedscores for degree of emotion is by Strapparava andMihalcea (2007) as part of one of the SemEval-2007 shared task. Annotators were given newspa-per headlines and asked to provide scores between0 and 100 via slide bars in a web interface. It is dif-ficult for humans to provide direct scores at suchfine granularity. A common problem is inconsis-tency in annotations. One annotator might assign ascore of 79 to a piece of text, whereas another an-notator may assign a score of 62 to the same text.It is also common that the same annotator assignsdifferent scores to the same text instance at differ-ent points in time. Further, annotators often havea bias towards different parts of the scale, knownas scale region bias.
2.2 Best–Worst Scaling
Best–Worst Scaling (BWS) was developed by Lou-viere (1991), building on some ground-breakingresearch in the 1960s in mathematical psychologyand psychophysics by Anthony A. J. Marley andDuncan Luce. Annotators are given n items (an n-tuple, where n > 1 and commonly n = 4). Theyare asked which item is the best (highest in termsof the property of interest) and which is the worst(lowest in terms of the property of interest). Whenworking on 4-tuples, best–worst annotations areparticularly efficient because each best and worstannotation will reveal the order of five of the sixitem pairs. For example, for a 4-tuple with itemsA, B, C, and D, if A is the best, and D is the worst,then A > B, A > C, A > D, B > D, and C > D.
BWS annotations for a set of 4-tuples can beeasily converted into real-valued scores of associ-ation between the items and the property of inter-est (Orme, 2009; Flynn and Marley, 2014). It has
Emotion Thes. Category Head Wordanger 900 resentmentfear 860 fearjoy 836 cheerfulnesssadness 837 dejection
Table 1: Categories from the Roget’s Thesauruswhose words were taken to be the query terms.
been empirically shown that annotations for 2N4-tuples is sufficient for obtaining reliable scores(where N is the number of items) (Louviere, 1991;Kiritchenko and Mohammad, 2016).6
Kiritchenko and Mohammad (2017) showthrough empirical experiments that BWS producesmore reliable fine-grained scores than scores ob-tained using rating scales. Within the NLP com-munity, Best–Worst Scaling (BWS) has thus farbeen used only to annotate words: for exam-ple, for creating datasets for relational similar-ity (Jurgens et al., 2012), word-sense disambigua-tion (Jurgens, 2013), word–sentiment intensity(Kiritchenko et al., 2014), and phrase sentimentcomposition (Kiritchenko and Mohammad, 2016).However, we use BWS to annotate whole tweetsfor intensity of emotion.
3 Data
Mohammad and Bravo-Marquez (2017) describehow the Tweet Emotion Intensity Dataset was cre-ated. We summarize below the approach usedand the key properties of the dataset. Not in-cluded in this summary are: (a) experiments show-ing marked similarities between emotion pairs interms of how they manifest in language, (b) howtraining data for one emotion can be used to im-prove prediction performance for a different emo-tion, and (c) an analysis of the impact of hashtagwords on emotion intensities.
For each emotion X, we select 50 to 100 termsthat are associated with that emotion at differ-ent intensity levels. For example, for the angerdataset, we use the terms: angry, mad, frustrated,annoyed, peeved, irritated, miffed, fury, antago-nism, and so on. For the sadness dataset, we usethe terms: sad, devastated, sullen, down, crying,dejected, heartbroken, grief, weeping, and so on.We will refer to these terms as the query terms.
We identified the query words for an emotion
6At its limit, when n = 2, BWS becomes a paired com-parison (Thurstone, 1927; David, 1963), but then a muchlarger set of tuples need to be annotated (closer to N2).

by first searching the Roget’s Thesaurus to findcategories that had the focus emotion word (or aclose synonym) as the head word.7 The categorieschosen for each head word are shown in Table1. We chose all single-word entries listed withinthese categories to be the query terms for the cor-responding focus emotion.8 Starting November22, 2016, and continuing for three weeks, wepolled the Twitter API for tweets that included thequery terms. We discarded retweets (tweets thatstart with RT) and tweets with urls. We created asubset of the remaining tweets by:
• selecting at most 50 tweets per query term.
• selecting at most 1 tweet for every tweeter–query term combination.
Thus, the master set of tweets is not heavilyskewed towards some tweeters or query terms.
To study the impact of emotion word hashtagson the intensity of the whole tweet, we identifiedtweets that had a query term in hashtag formtowards the end of the tweet—specifically, withinthe trailing portion of the tweet made up solelyof hashtagged words. We created copies of thesetweets and then removed the hashtag query termsfrom the copies. The updated tweets were thenadded to the master set. Finally, our master set of7,097 tweets includes:
1. Hashtag Query Term Tweets (HQT Tweets):1030 tweets with a query term in the formof a hashtag (#<query term>) in the trailingportion of the tweet;
2. No Query Term Tweets (NQT Tweets):1030 tweets that are copies of ‘1’, but with thehashtagged query term removed;
3. Query Term Tweets (QT Tweets):5037 tweets that include:a. tweets that contain a query term in the formof a word (no #<query term>)b. tweets with a query term in hashtag formfollowed by at least one non-hashtag word.
The master set of tweets was then manually an-notated for intensity of emotion. Table 3 shows abreakdown by emotion.
7The Roget’s Thesaurus groups words into about 1000categories, each containing on average about 100 closely re-lated words. The head word is the word that best representsthe meaning of the words within that category.
8The full list of query terms is available on request.
3.1 Annotating with Best–Worst Scaling
We followed the procedure described in Kir-itchenko and Mohammad (2016) to obtain BWSannotations. For each emotion, the annotatorswere presented with four tweets at a time (4-tuples) and asked to select the speakers of thetweets with the highest and lowest emotion inten-sity. 2 × N (where N is the number of tweetsin the emotion set) distinct 4-tuples were ran-domly generated in such a manner that each itemis seen in eight different 4-tuples, and no pair ofitems occurs in more than one 4-tuple. We re-fer to this as random maximum-diversity selection(RMDS). RMDS maximizes the number of uniqueitems that each item co-occurs with in the 4-tuples.After BWS annotations, this in turn leads to di-rect comparative ranking information for the max-imum number of pairs of items.9
It is desirable for an item to occur in sets of 4-tuples such that the the maximum intensities inthose 4-tuples are spread across the range fromlow intensity to high intensity, as then the propor-tion of times an item is chosen as the best is indica-tive of its intensity score. Similarly, it is desirablefor an item to occur in sets of 4-tuples such that theminimum intensities are spread from low to highintensity. However, since the intensities of itemsare not known before the annotations, RMDS isused.
Every 4-tuple was annotated by three indepen-dent annotators.10 The questionnaires used weredeveloped through internal discussions and pilotannotations. (See the Appendix (8.1) for a samplequestionnaire. All questionnaires are also avail-able on the task website.)
The 4-tuples of tweets were uploaded on thecrowdsourcing platform, CrowdFlower. About5% of the data was annotated internally before-hand (by the authors). These questions are referredto as gold questions. The gold questions are inter-spersed with other questions. If one gets a gold
9In combinatorial mathematics, balanced incompleteblock design refers to creating blocks (or tuples) of a handfulitems from a set of N items such that each item occurs in thesame number of blocks (say x) and each pair of distinct itemsoccurs in the same number of blocks (say y), where x and yare integers ge 1 (Yates, 1936). The set of tuples we createhave similar properties, except that since we create only 2Ntuples, pairs of distinct items either never occur together in a4-tuple or they occur in exactly one 4-tuple.
10Kiritchenko and Mohammad (2016) showed that usingjust three annotations per 4-tuple produces highly reliable re-sults. Note that since each tweet is seen in eight different4-tuples, we obtain 8× 3 = 24 judgments over each tweet.

question wrong, they are immediately notified ofit. If one’s accuracy on the gold questions falls be-low 70%, they are refused further annotation, andall of their annotations are discarded. This servesas a mechanism to avoid malicious annotations.11
The BWS responses were translated into scoresby a simple calculation (Orme, 2009; Flynn andMarley, 2014): For each item t, the score is thepercentage of times the t was chosen as having themost intensity minus the percentage of times t waschosen as having the least intensity.12
intensity(t) = %most(t)−%least(t) (1)
Since intensity of emotion is a unipolar scale, welinearly transformed the the −100 to 100 scores toscores in the range 0 to 1.
3.2 Reliability of Annotations
A useful measure of quality is reproducibility ofthe end result—if repeated independent manualannotations from multiple respondents result insimilar intensity rankings (and scores), then onecan be confident that the scores capture the trueemotion intensities. To assess this reproducibility,we calculate average split-half reliability (SHR),a commonly used approach to determine consis-tency (Kuder and Richardson, 1937; Cronbach,1946). The intuition behind SHR is as follows.All annotations for an item (in our case, tuples)are randomly split into two halves. Two sets ofscores are produced independently from the twohalves. Then the correlation between the two setsof scores is calculated. If the annotations are ofgood quality, then the correlation between the twohalves will be high.
Since each tuple in this dataset was annotated bythree annotators (odd number), we calculate SHRby randomly placing one or two annotations pertuple in one bin and the remaining (two or one)annotations for the tuple in another bin. Then twosets of intensity scores (and rankings) are calcu-lated from the annotations in each of the two bins.
11In case more than one item can be reasonably chosen asthe best (or worst) item, then more than one acceptable goldanswers are provided. The goal with the gold annotationsis to identify clearly poor or malicious annotators. In casewhere two items are close in intensity, we want the crowdof annotators to indicate, through their BWS annotations, therelative ranking of the items.
12Kiritchenko and Mohammad (2016) provide codefor generating tuples from items using RMDS, as wellas code for generating scores from BWS annotations:http://saifmohammad.com/WebPages/BestWorst.html
Emotion Spearman Pearsonanger 0.779 0.797fear 0.845 0.850joy 0.881 0.882sadness 0.847 0.847
Table 2: Split-half reliabilities (as measured byPearson correlation and Spearman rank correla-tion) for the anger, fear, joy, and sadness tweetsin the Tweet Emotion Intensity Dataset.
The process is repeated 100 times and the correla-tions across the two sets of rankings and intensityscores are averaged. Table 2 shows the split-halfreliabilities for the anger, fear, joy, and sadnesstweets in the Tweet Emotion Intensity Dataset.13
Observe that for fear, joy, and sadness datasets,both the Pearson correlations and the Spearmanrank correlations lie between 0.84 and 0.88, indi-cating a high degree of reproducibility. However,the correlations are slightly lower for anger indi-cating that it is relative more difficult to ascertainthe degrees of anger of speakers from their tweets.Note that SHR indicates the quality of annotationsobtained when using only half the number of an-notations. The correlations obtained when repeat-ing the experiment with three annotations for each4-tuple is expected to be even higher. Thus thenumbers shown in Table 2 are a lower bound onthe quality of annotations obtained with three an-notations per 4-tuple.
4 Task Setup
4.1 The Task
Given a tweet and an emotion X, automatic sys-tems have to determine the intensity or degree ofemotion X felt by the speaker—a real-valued scorebetween 0 and 1. A score of 1 means that thespeaker feels the highest amount of emotion X. Ascore of 0 means that the speaker feels the low-est amount of emotion X. The competition is or-ganized on a CodaLab website, where participantscan upload their submissions, and the leaderboardreports the results.14
13Past work has found the SHR for sentiment intensity an-notations for words, with 8 annotations per tuple, to be 0.98(Kiritchenko et al., 2014). In contrast, here SHR is calculatedfrom 3 annotations, for emotions, and from whole sentences.SHR determined from a smaller number of annotations andon more complex annotation tasks are expected to be lower.
14https://competitions.codalab.org/competitions/16380

Emotion Train Dev. Test Allanger 857 84 760 1701fear 1147 110 995 2252joy 823 74 714 1611sadness 786 74 673 1533All 3613 342 3142 7097
Table 3: The number of instances in the TweetEmotion Intensity dataset.
4.2 Training, development, and test sets
The Tweet Emotion Intensity Dataset is partitionedinto training, development, and test sets for ma-chine learning experiments (see Table 3). For eachemotion, we chose to include about 50% of thetweets in the training set, about 5% in the develop-ment set, and about 45% in the test set. Further, weensured that an No-Query-Term (NQT) tweet isin the same partition as the Hashtag-Query-Term(HQT) tweet it was created from.
The training and development sets were madeavailable more than two months before the two-week official evaluation period. Participants weretold that the development set could be used to tuneones system and also to test making a submissionon CodaLab. Gold intensity scores for the devel-opment set were released two weeks before theevaluation period, and participants were free totrain their systems on the combined training anddevelopment sets, and apply this model to the testset. The test set was released at the start of theevaluation period.
4.3 Resources
Participants were free to use lists of manu-ally created and/or automatically generated word–emotion and word–sentiment association lexi-cons.15 Participants were free to build a systemfrom scratch or use any available software pack-ages and resources, as long as they are not againstthe spirit of fair competition. In order to assisttesting of ideas, we also provided a baseline Wekasystem for determining emotion intensity, that par-ticipants can build on directly or use to determinethe usefulness of different features.16 We describethe baseline system in the next section.
15A large number of sentiment and emo-tion lexicons created at NRC are available here:http://saifmohammad.com/WebPages/lexicons.html
16https://github.com/felipebravom/AffectiveTweets
4.4 Official Submission to the Shared Task
System submissions were required to have thesame format as used in the training and test sets.Each line in the file should include:id[tab]tweet[tab]emotion[tab]score
Each team was allowed to make as many as tensubmissions during the evaluation period. How-ever, they were told in advance that only the fi-nal submission would be considered as the officialsubmission to the competition.
Once the evaluation period concluded, we re-leased the gold labels and participants were able todetermine results on various system variants thatthey may have developed. We encouraged par-ticipants to report results on all of their systems(or system variants) in the system-description pa-per that they write. However, they were asked toclearly indicate the result of their official submis-sion.
During the evaluation period, the CodaLableaderboard was hidden from participants—sothey were unable see the results of their submis-sions on the test set until the leaderboard was sub-sequently made public. Participants were, how-ever, able to immediately see any warnings or er-rors that their submission may have triggered.
4.5 Evaluation
For each emotion, systems were evaluated by cal-culating the Pearson Correlation Coefficient of thesystem predictions with the gold ratings. Pearsoncoefficient, which measures linear correlations be-tween two variables, produces scores from -1 (per-fectly inversely correlated) to 1 (perfectly corre-lated). A score of 0 indicates no correlation. Thecorrelation scores across all four emotions was av-eraged to determine the bottom-line competitionmetric by which the submissions were ranked.
In addition to the bottom-line competition met-ric described above, the following additional met-rics were also provided:
• Spearman Rank Coefficient of the submissionwith the gold scores of the test data.Motivation: Spearman Rank Coefficient consid-ers only how similar the two sets of rankingare. The differences in scores between adja-cently ranked instance pairs is ignored. On theone hand this has been argued to alleviate somebiases in Pearson, but on the other hand it canignore relevant information.

• Correlation scores (Pearson and Spearman) overa subset of the testset formed by taking in-stances with gold intensity scores ≥ 0.5.Motivation: In some applications, only thoseinstances that are moderately or strongly emo-tional are relevant. Here it may be much moreimportant for a system to correctly determineemotion intensities of instances in the higherrange of the scale as compared to correctly de-termine emotion intensities in the lower rangeof the scale.
Results with Spearman rank coefficient werelargely inline with those obtained using Pearsoncoefficient, and so in the rest of the paper we reportonly the latter. However, the CodaLab leaderboardand the official results posted on the task websiteshow both metrics. The official evaluation script(which calculates correlations using both metricsand also acts as a format checker) was made avail-able along with the training and development datawell in advance. Participants were able to useit to monitor progress of their system by cross-validation on the training set or testing on the de-velopment set. The script was also uploaded onthe CodaLab competition website so that the sys-tem evaluates submissions automatically and up-dates the leaderboard.
5 Baseline System for AutomaticallyDetermining Tweet Emotion Intensity
5.1 System
We implemented a package called Affec-tiveTweets (Mohammad and Bravo-Marquez,2017) for the Weka machine learning workbench(Hall et al., 2009). It provides a collection offilters for extracting features from tweets forsentiment classification and other related tasks.These include features used in Kiritchenko et al.(2014) and Mohammad et al. (2017).17 We usethe AffectiveTweets package for calculating fea-ture vectors from our emotion-intensity-labeledtweets and train Weka regression models on thistransformed data. The regression model used isan L2-regularized L2-loss SVM regression modelwith the regularization parameter C set to 1,
17Kiritchenko et al. (2014) describes the NRC-Canadasystem which ranked first in three sentiment shared tasks:SemEval-2013 Task 2, SemEval-2014 Task 9, and SemEval-2014 Task 4. Mohammad et al. (2017) describes a stance-detection system that outperformed submissions from all 19teams that participated in SemEval-2016 Task 6.
implemented in LIBLINEAR18. The system usesthe following features:19
a. Word N-grams (WN): presence or absence ofword n-grams from n = 1 to n = 4.b. Character N-grams (CN): presence or absenceof character n-grams from n = 3 to n = 5.c. Word Embeddings (WE): an average of theword embeddings of all the words in a tweet. Wecalculate individual word embeddings using thenegative sampling skip-gram model implementedin Word2Vec (Mikolov et al., 2013). Word vectorsare trained from ten million English tweets takenfrom the Edinburgh Twitter Corpus (Petrovicet al., 2010). We set Word2Vec parameters:window size: 5; number of dimensions: 400.20
d. Affect Lexicons (L): we use the lexicons shownin Table 4 by aggregating the information for allthe words in a tweet. If the lexicon provides nom-inal association labels (e.g, positive, anger, etc.),then the number of words in the tweet matchingeach class are counted. If the lexicon provides nu-merical scores, the individual scores for each classare summed. and whether the affective associa-tions provided are nominal or numeric.
5.2 Experiments
We developed the baseline system by learningmodels from each of the Tweet Emotion IntensityDataset training sets and applying them to the cor-responding development sets. Once the systemparameters were frozen, the system learned newmodels from the combined training and develop-ment corpora. This model was applied to the testsets. Table 5 shows the results obtained on thetest sets using various features, individually andin combination. The last column ‘avg.’ showsthe macro-average of the correlations for all of theemotions.
Using just character or just word n-grams leadsto results around 0.48, suggesting that they are rea-sonably good indicators of emotion intensity bythemselves. (Guessing the intensity scores at ran-dom between 0 and 1 is expected to get correla-tions close to 0.) Word embeddings produces sta-tistically significant improvement over the ngrams(avg. r = 0.55).21 Using features drawn from af-
18http://www.csie.ntu.edu.tw/∼cjlin/liblinear/19See Appendix (A.3) for further implementation details.20Optimized for the task of word–emotion classification on
an independent dataset (Bravo-Marquez et al., 2016).21We used the Wilcoxon signed-rank test at 0.05 signifi-
cance level calculated from ten random partitions of the data,for all the significance tests reported in this paper.

Twitter Annotation Scope LabelAFINN (Nielsen, 2011) Yes Manual Sentiment NumericBingLiu (Hu and Liu, 2004) No Manual Sentiment NominalMPQA (Wilson et al., 2005) No Manual Sentiment NominalNRC Affect Intensity Lexicon (NRC-Aff-Int) (Mohammad, 2017) Yes Manual Emotions NumericNRC Word-Emotion Assn. Lexicon (NRC-EmoLex) (Mohammad and Turney, 2013) No Manual Emotions NominalNRC10 Expanded (NRC10E) (Bravo-Marquez et al., 2016) Yes Automatic Emotions NumericNRC Hashtag Emotion Association Lexicon (NRC-Hash-Emo) Yes Automatic Emotions Numeric
(Mohammad, 2012a; Mohammad and Kiritchenko, 2015)NRC Hashtag Sentiment Lexicon (NRC-Hash-Sent) (Mohammad et al., 2013) Yes Automatic Sentiment NumericSentiment140 (Mohammad et al., 2013) Yes Automatic Sentiment NumericSentiWordNet (Esuli and Sebastiani, 2006) No Automatic Sentiment NumericSentiStrength (Thelwall et al., 2012) Yes Manual Sentiment Numeric
Table 4: Affect lexicons used in our experiments.
fect lexicons produces results ranging from avg.r = 0.19 with SentiWordNet to avg. r = 0.53with NRC-Hash-Emo. Combining all the lexiconsleads to statistically significant improvement overindividual lexicons (avg. r = 0.63). Combiningthe different kinds of features leads to even higherscores, with the best overall result obtained us-ing word embedding and lexicon features (avg. r= 0.66).22 The feature space formed by all thelexicons together is the strongest single featurecategory. The results also show that some fea-tures such as character ngrams are redundant inthe presence of certain other features.
Among the lexicons, NRC-Hash-Emo is themost predictive single lexicon. Lexicons that in-clude Twitter-specific entries, lexicons that in-clude intensity scores, and lexicons that labelemotions and not just sentiment, tend to bemore predictive on this task–dataset combination.NRC-Aff-Int has real-valued fine-grained word–emotion association scores for all the words inNRC-EmoLex that were marked as being associ-ated with anger, fear, joy, and sadness.23 Improve-ment in scores obtained using NRC-Aff-Int overthe scores obtained using NRC-EmoLex also showthat using fine intensity scores of word-emotionassociation are beneficial for tweet-level emotionintensity detection. The correlations for anger,fear, and joy are similar (around 0.65), but the cor-relation for sadness is markedly higher (0.71). Wecan observe from Table 5 that this boost in perfor-mance for sadness is to some extent due to wordembeddings, but is more so due to lexicon fea-tures, especially those from SentiStrength. Sen-tiStrength focuses solely on positive and negativeclasses, but provides numeric scores for each.
To assess performance in the moderate-to-highrange of the intensity scale, we calculated correla-
22The increase from 0.63 to 0.66 is statistically significant.23http://saifmohammad.com/WebPages/AffectIntensity.htm
Pearson correlation ranger fear joy sad. avg.
Individual feature setsword ngrams (WN) 0.42 0.49 0.52 0.49 0.48char. ngrams (CN) 0.50 0.48 0.45 0.49 0.48word embeds. (WE) 0.48 0.54 0.57 0.60 0.55all lexicons (L) 0.62 0.60 0.60 0.68 0.63Individual Lexicons
AFINN 0.48 0.27 0.40 0.28 0.36BingLiu 0.33 0.31 0.37 0.23 0.31MPQA 0.18 0.20 0.28 0.12 0.20NRC-Aff-Int 0.24 0.28 0.37 0.32 0.30NRC-EmoLex 0.18 0.26 0.36 0.23 0.26NRC10E 0.35 0.34 0.43 0.37 0.37NRC-Hash-Emo 0.55 0.55 0.46 0.54 0.53NRC-Hash-Sent 0.33 0.24 0.41 0.39 0.34Sentiment140 0.33 0.41 0.40 0.48 0.41SentiWordNet 0.14 0.19 0.26 0.16 0.19SentiStrength 0.43 0.34 0.46 0.61 0.46
CombinationsWN + CN + WE 0.50 0.48 0.45 0.49 0.48WN + CN + L 0.61 0.61 0.61 0.63 0.61WE + L 0.64 0.63 0.65 0.71 0.66WN + WE + L 0.63 0.65 0.65 0.65 0.65CN + WE + L 0.61 0.61 0.62 0.63 0.62WN + CN + WE + L 0.61 0.61 0.61 0.63 0.62
Over the subset of test set where intensity ≥ 0.5WN + WE + L 0.51 0.51 0.40 0.49 0.47
Table 5: Pearson correlations (r) of emotion inten-sity predictions with gold scores. Best results foreach column are shown in bold: highest score bya feature set, highest score using a single lexicon,and highest score using feature set combinations.
tion scores over a subset of the test data formed bytaking only those instances with gold emotion in-tensity scores ≥ 0.5. The last row in Table 5 showsthe results. We observe that the correlation scoresare in general lower here in the 0.5 to 1 range ofintensity scores than in the experiments over thefull intensity range. This is simply because this isa harder task as now the systems do not benefit bymaking coarse distinctions over whether a tweet isin the lower range or in the higher range.

6 Official System Submissions to theShared Task
Twenty-two teams made submissions to the sharedtask. In the subsections below we present the re-sults and summarize the approaches and resourcesused by the participating systems.
6.1 Results
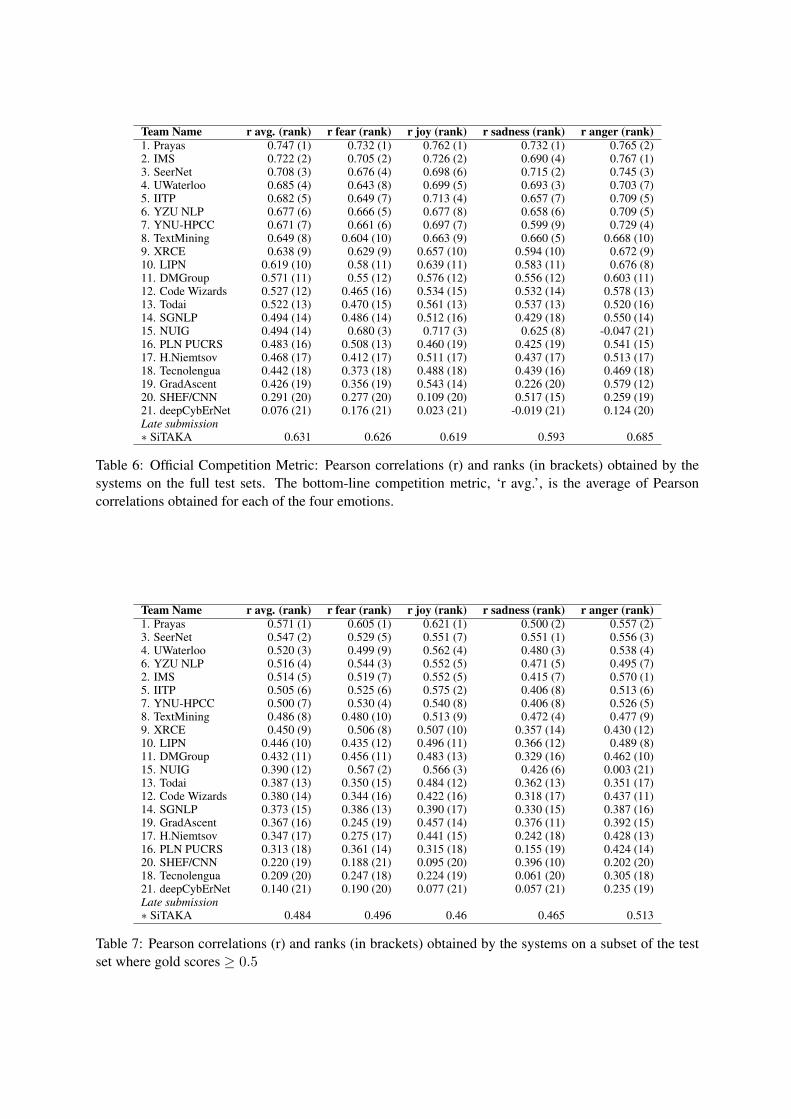
Table 6 shows the Pearson correlations (r) andranks (in brackets) obtained by the systems on thefull test sets. The bottom-line competition met-ric, ‘r avg.’, is the average of Pearson correlationsobtained for each of the four emotions. (The taskwebsite shows Spearman rank coefficient as well.Those scores are close in value to the Pearson cor-relations, and most teams rank the same by eithermetric.) The top ranking system, Prayas, obtainedan r avg. of 0.747. It obtains slightly better cor-relations for joy and anger (around 0.76) than forfear and sadness (around 0.73). IMS, which rankedsecond overall, obtained slightly higher correla-tion on anger, but lower scores than Prayas on theother emotions. The top 12 teams all obtain theirbest correlation on anger as opposed to any of theother three emotions. They obtain lowest correla-tions on fear and sadness. Seven teams obtainedscores higher than that obtained by the publiclyavailable benchmark system (r avg. = 0.66).
Table 7 shows the Pearson correlations (r) andranks (in brackets) obtained by the systems onthose instances in the test set with intensity scores≥ 0.5. Prayas obtains the best results here toowith r avg. = 0.571. SeerNet, which ranked thirdon the full test set, ranks second on this subset. Asfound in the baseline results, system results on thissubset overall are lower than than on the full testset. Most systems perform best on the joy data andworst on the sadness data.
6.2 Machine Learning Setups
Systems followed a supervised learning approachin which tweets were mapped into feature vectorsthat were then used for training regression models.
Features were drawn both from the trainingdata as well as from external resources such aslarge tweet corpora and affect lexicons. Table8 lists the feature types (resources) used by theteams. (To save space, team names are abbre-viated to just their rank on the full test set (asshown in Table 6).) Commonly used featuresincluded word embeddings and sentence repre-
sentations learned using neural networks (sen-tence embeddings). Some of the word embed-dings models used were Glove (SeerNet, UWa-terloo, YZU NLP), Word2Vec (SeerNet), andWord Vector Emoji Vectors (SeerNet). The mod-els used for learning sentence embeddings in-cluded LSTM (Prayas, IITP), CNN (SGNLP),LSTM–CNN combinations (IMS, YMU-HPCC),bi-directional versions (YZU NLP), and aug-mented LSTMs models with attention layers (To-dai). High-dimensional sparse representationssuch as word n-grams or character n-grams wererarely used. Affect lexicons were also widelyused, especially by the top eight teams. Someteams built their own affect lexicons from addi-tional data (IMS, XRCE).
The regression algorithms applied to the fea-ture vectors included SVM regression or SVR(IITP, Code Wizards, NUIG, H.Niemstov), NeuralNetworks (Todai, YZU NLP, SGNLP), RandomForest (IMS, SeerNet, XRCE), Gradient Boosting(UWaterLoo, PLN PUCRS), AdaBoost (SeerNet),and Least Square Regression (UWaterloo). Ta-ble 9 provides the full list.
Some teams followed a popular deep learn-ing trend wherein the feature representation andthe prediction model are trained in conjunction.In those systems, the regression algorithm corre-sponds to the output layer of the neural network(YZU NLP, SGNLP, Todai).
Many libraries and tools were used for imple-menting the systems. The high-level neural net-works API library Keras was the most widely usedoff-the-shelf package. It is written in Python andruns on top of either TensorFlow or Theano. Ten-sorFlow and Sci-kit learn were also popular (alsoPython libraries).24 Our AffectiveTweets Wekabaseline package was used by five participatingteams, including the teams that ranked first, sec-ond, and third. The full list of tools and librariesused by the teams is shown in Table 10.
In the subsections below, we briefly summa-rize the three top-ranking systems. The Ap-pendix (8.3) provides participant-provided sum-maries about each system. See system descriptionpapers for detailed descriptions.
24TensorFlow provides implementations of a number ofmachine learning algorithms, including deep learning onessuch as CNNs and LSTMs.
Team Name r avg. (rank) r fear (rank) r joy (rank) r sadness (rank) r anger (rank)1. Prayas 0.747 (1) 0.732 (1) 0.762 (1) 0.732 (1) 0.765 (2)2. IMS 0.722 (2) 0.705 (2) 0.726 (2) 0.690 (4) 0.767 (1)3. SeerNet 0.708 (3) 0.676 (4) 0.698 (6) 0.715 (2) 0.745 (3)4. UWaterloo 0.685 (4) 0.643 (8) 0.699 (5) 0.693 (3) 0.703 (7)5. IITP 0.682 (5) 0.649 (7) 0.713 (4) 0.657 (7) 0.709 (5)6. YZU NLP 0.677 (6) 0.666 (5) 0.677 (8) 0.658 (6) 0.709 (5)7. YNU-HPCC 0.671 (7) 0.661 (6) 0.697 (7) 0.599 (9) 0.729 (4)8. TextMining 0.649 (8) 0.604 (10) 0.663 (9) 0.660 (5) 0.668 (10)9. XRCE 0.638 (9) 0.629 (9) 0.657 (10) 0.594 (10) 0.672 (9)10. LIPN 0.619 (10) 0.58 (11) 0.639 (11) 0.583 (11) 0.676 (8)11. DMGroup 0.571 (11) 0.55 (12) 0.576 (12) 0.556 (12) 0.603 (11)12. Code Wizards 0.527 (12) 0.465 (16) 0.534 (15) 0.532 (14) 0.578 (13)13. Todai 0.522 (13) 0.470 (15) 0.561 (13) 0.537 (13) 0.520 (16)14. SGNLP 0.494 (14) 0.486 (14) 0.512 (16) 0.429 (18) 0.550 (14)15. NUIG 0.494 (14) 0.680 (3) 0.717 (3) 0.625 (8) -0.047 (21)16. PLN PUCRS 0.483 (16) 0.508 (13) 0.460 (19) 0.425 (19) 0.541 (15)17. H.Niemtsov 0.468 (17) 0.412 (17) 0.511 (17) 0.437 (17) 0.513 (17)18. Tecnolengua 0.442 (18) 0.373 (18) 0.488 (18) 0.439 (16) 0.469 (18)19. GradAscent 0.426 (19) 0.356 (19) 0.543 (14) 0.226 (20) 0.579 (12)20. SHEF/CNN 0.291 (20) 0.277 (20) 0.109 (20) 0.517 (15) 0.259 (19)21. deepCybErNet 0.076 (21) 0.176 (21) 0.023 (21) -0.019 (21) 0.124 (20)Late submission∗ SiTAKA 0.631 0.626 0.619 0.593 0.685
Table 6: Official Competition Metric: Pearson correlations (r) and ranks (in brackets) obtained by thesystems on the full test sets. The bottom-line competition metric, ‘r avg.’, is the average of Pearsoncorrelations obtained for each of the four emotions.
Team Name r avg. (rank) r fear (rank) r joy (rank) r sadness (rank) r anger (rank)1. Prayas 0.571 (1) 0.605 (1) 0.621 (1) 0.500 (2) 0.557 (2)3. SeerNet 0.547 (2) 0.529 (5) 0.551 (7) 0.551 (1) 0.556 (3)4. UWaterloo 0.520 (3) 0.499 (9) 0.562 (4) 0.480 (3) 0.538 (4)6. YZU NLP 0.516 (4) 0.544 (3) 0.552 (5) 0.471 (5) 0.495 (7)2. IMS 0.514 (5) 0.519 (7) 0.552 (5) 0.415 (7) 0.570 (1)5. IITP 0.505 (6) 0.525 (6) 0.575 (2) 0.406 (8) 0.513 (6)7. YNU-HPCC 0.500 (7) 0.530 (4) 0.540 (8) 0.406 (8) 0.526 (5)8. TextMining 0.486 (8) 0.480 (10) 0.513 (9) 0.472 (4) 0.477 (9)9. XRCE 0.450 (9) 0.506 (8) 0.507 (10) 0.357 (14) 0.430 (12)10. LIPN 0.446 (10) 0.435 (12) 0.496 (11) 0.366 (12) 0.489 (8)11. DMGroup 0.432 (11) 0.456 (11) 0.483 (13) 0.329 (16) 0.462 (10)15. NUIG 0.390 (12) 0.567 (2) 0.566 (3) 0.426 (6) 0.003 (21)13. Todai 0.387 (13) 0.350 (15) 0.484 (12) 0.362 (13) 0.351 (17)12. Code Wizards 0.380 (14) 0.344 (16) 0.422 (16) 0.318 (17) 0.437 (11)14. SGNLP 0.373 (15) 0.386 (13) 0.390 (17) 0.330 (15) 0.387 (16)19. GradAscent 0.367 (16) 0.245 (19) 0.457 (14) 0.376 (11) 0.392 (15)17. H.Niemtsov 0.347 (17) 0.275 (17) 0.441 (15) 0.242 (18) 0.428 (13)16. PLN PUCRS 0.313 (18) 0.361 (14) 0.315 (18) 0.155 (19) 0.424 (14)20. SHEF/CNN 0.220 (19) 0.188 (21) 0.095 (20) 0.396 (10) 0.202 (20)18. Tecnolengua 0.209 (20) 0.247 (18) 0.224 (19) 0.061 (20) 0.305 (18)21. deepCybErNet 0.140 (21) 0.190 (20) 0.077 (21) 0.057 (21) 0.235 (19)Late submission∗ SiTAKA 0.484 0.496 0.46 0.465 0.513
Table 7: Pearson correlations (r) and ranks (in brackets) obtained by the systems on a subset of the testset where gold scores ≥ 0.5

TeamFeatures 1 2 3 4 5 6 7 8 9 ∗ 10 11 12 13 14 15 16 17 18 19 20 21N-grams X X
CN XWN X X X
Word Embeddings X X X X X X X X X X X X X XGlove X X X X X X X X X XEmoji Vectors X XWord2Vec X X X XOther X X X
Sentence EmbeddingsCNN X X X X X X X X XLSTM X X X X X X X X XOther X X X X
Affective Lexicons X X X X X X X X X X X XAFINN X X X X XANEW XBingLiu X X X X X XHappy Ratings XLingmotif XLIWC XMPQA X X X X XNRC-Aff-Int X X X XNRC-EmoLex X X X X X X XNRC-Emoticon-Lex X X X X XNRC-Hash-Emo X X X X X X XNRC-Hash-Sent X X X X XNRC-Hashtag-Sent. X X XNRC10E X X X XSentiment140 X X X X XSentiStrength X X XSentiWordNet X X X X X XVader XWord.Affect XIn-house lexicon X X X
Linguistic Features XDependency Parser X
Table 8: Feature types (resources) used by the participating systems. Teams are indicated by their rank.
TeamRegression 1 2 3 4 5 6 7 8 9 ∗ 10 11 12 13 14 15 16 17 18 19 20 21AdaBoost XGradient Boosting X X XLinear Regression XLogistic Regression X XNeural Network X X X X X X X X X X XRandom Forest X X XSVM or SVR X X X X X X X XEnsemble X X X X X
Table 9: Regression methods used by the participating systems. Teams are indicated by their rank.
TeamTools 1 2 3 4 5 6 7 8 9 ∗ 10 11 12 13 14 15 16 17 18 19 20 21AffectiveTweets-Weka X X X X XGensim X XGlove X X X X XKeras X X X X X X X X X X XLIBSVM XNLTK X XPandas X X XPyTorch XSci-kit learn X X X X X X XTensorFlow X X X X X XTheano X X XTweetNLP XTweeboParser XTweetokenize XWord2Vec X X X XXGBoost X X
Table 10: Tools and libraries used by the participating systems. Teams are indicated by their rank.

6.3 Prayas: Rank 1
The best performing system, Prayas, used an en-semble of three different models: The first is afeed-forward neural network whose input vector isformed by concatenating the average word embed-ding vector with the lexicon features vector pro-vided by the AffectiveTweets package (Moham-mad and Bravo-Marquez, 2017). These embed-dings were trained on a collection of 400 milliontweets (Godin et al., 2015). The network has fourhidden layers and uses rectified linear units as ac-tivation functions. Dropout is used a regulariza-tion mechanisms and the output layer consists ofa sigmoid neuron. The second model treats theproblem as a multi-task learning problem with thelabeling of the four emotion intensities as the foursub-tasks. Authors use the same neural networkarchitecture as in the first model, but the weightsof the first two network layers are shared acrossthe four subtasks. The weights of the last two lay-ers are independently optimized for each subtask.In the third model, the word embeddings of thewords in a tweet are concatenated and fed intoa deep learning architecture formed by LSTM,CNN, max pooling, fully connected layers. Sev-eral architectures based on these layers are ex-plored. The final predictions are made by com-bining the first two models with three variationsof the third model into an ensemble. A weightedaverage of the individual predictions is calculatedusing cross-validated performances as the relativeweights. Experimental results show that the en-semble improves the performance of each individ-ual model by at least two percentage points.
6.4 IMS: Rank 2
IMS applies a random forest regression model to arepresentation formed by concatenating three vec-tors: 1. a feature vector drawn from existing af-fect lexicons, 2. a feature vector drawn from ex-panded affect lexicons, and 3. the output of aneural network. The first vector is obtained usingthe lexicons implemented in the AffectiveTweetspackage. The second is based on an extendedlexicons built from feed-forward neural networkstrained on word embeddings. The gold trainingwords are taken from existing affective norms andemotion lexicons: NRC Hashtag Emotion Lex-icon (Mohammad, 2012b; Mohammad and Kir-itchenko, 2015), affective norms from Warrineret al. (2013), Brysbaert et al. (2014), and ratings
for happiness from Dodds et al. (2011). The thirdvector is taken from the output of neural networkthat combines CNN and LSTM layers.
6.5 SeerNet: Rank 3
SeerNet creates an ensemble of various regres-sion algorithms (e.g, SVR, AdaBoost, random for-est, gradient boosting). Each regression modelis trained on a representation formed by the af-fect lexicon features (including those provided byAffectiveTweets) and word embeddings. Authorsalso experiment with different word embeddingsmodels: Glove, Word2Vec, and Emoji embed-dings (Eisner et al., 2016).
7 Conclusions
We conducted the first shared task on detectingthe intensity of emotion felt by the speaker of atweet. We created the emotion intensity datasetusing best–worst scaling and crowdsourcing. Wecreated a benchmark regression system and con-ducted experiments to show that affect lexicons,especially those with fine word–emotion associa-tion scores, are useful in determining emotion in-tensity.
Twenty-two teams participated in the sharedtask, with the best system obtaining a Pearson cor-relation of 0.747 with the gold annotations on thetest set. As in many other machine learning com-petitions, the top ranking systems used ensem-bles of multiple models (Prayas-rank1, SeerNet-rank3). IMS, which ranked second, used randomforests, which are ensembles of multiple decisiontrees. The top eight systems also made use of asubstantially larger number of affect lexicons togenerate features than systems that did not per-form as well. It is interesting to note that despiteusing deep learning techniques, training data, andlarge amounts of unlabeled data, the best systemsare finding it beneficial to include features drawnfrom affect lexicons.
We have begun work on creating emotion inten-sity datasets for other emotion categories beyondanger, fear, sadness, and joy. We are also creatinga dataset annotated for valence, arousal, and domi-nance. These annotations will be done for English,Spanish, and Arabic tweets. The datasets will beused in the upcoming SemEval-2018 Task #1: Af-fect in Tweets (Mohammad et al., 2018).25
25http://alt.qcri.org/semeval2018/

Acknowledgment
We thank Svetlana Kiritchenko and Tara Small forhelpful discussions. We thank Samuel Larkin forhelp on collecting tweets.
ReferencesCecilia Ovesdotter Alm, Dan Roth, and Richard
Sproat. 2005. Emotions from text: Machine learn-ing for text-based emotion prediction. In Proceed-ings of the Joint Conference on HLT–EMNLP. Van-couver, Canada.
Saima Aman and Stan Szpakowicz. 2007. Identifyingexpressions of emotion in text. In Text, Speech andDialogue, volume 4629 of Lecture Notes in Com-puter Science, pages 196–205.
Johan Bollen, Huina Mao, and Alberto Pepe. 2009.Modeling public mood and emotion: Twitter senti-ment and socio-economic phenomena. In Proceed-ings of the Fifth International Conference on We-blogs and Social Media. pages 450–453.
Felipe Bravo-Marquez, Eibe Frank, Saif M. Moham-mad, and Bernhard Pfahringer. 2016. Determiningword–emotion associations from tweets by multi-label classification. In Proceedings of the 2016IEEE/WIC/ACM International Conference on WebIntelligence. Omaha, NE, USA, pages 536–539.
Michael Brooks, Katie Kuksenok, Megan K Torkild-son, Daniel Perry, John J Robinson, Taylor J Scott,Ona Anicello, Ariana Zukowski, and Harris. 2013.Statistical affect detection in collaborative chat. InProceedings of the 2013 conference on Computersupported cooperative work. San Antonio, Texas,USA, pages 317–328.
Marc Brysbaert, Amy Beth Warriner, and Victor Ku-perman. 2014. Concreteness ratings for 40 thousandgenerally known english word lemmas. Behaviorresearch methods 46(3):904–911.
LJ Cronbach. 1946. A case study of the splithalf relia-bility coefficient. Journal of educational psychology37(8):473.
Herbert Aron David. 1963. The method of paired com-parisons. Hafner Publishing Company, New York.
Peter Sheridan Dodds, Kameron Decker Harris, Is-abel M. Kloumann, Catherine A. Bliss, and Christo-pher M. Danforth. 2011. Temporal patterns ofhappiness and information in a global social net-work: Hedonometrics and Twitter. PloS One6(12):e26752.
Ben Eisner, Tim Rocktaschel, Isabelle Augenstein,Matko Bosnjak, and Sebastian Riedel. 2016.emoji2vec: Learning emoji representations fromtheir description. In Proceedings of The Fourth
International Workshop on Natural Language Pro-cessing for Social Media. Association for Computa-tional Linguistics, Austin, TX, USA, pages 48–54.http://aclweb.org/anthology/W16-6208.
Paul Ekman. 1992. An argument for basic emotions.Cognition and Emotion 6(3):169–200.
Andrea Esuli and Fabrizio Sebastiani. 2006. SENTI-WORDNET: A publicly available lexical resourcefor opinion mining. In Proceedings of the 5thConference on Language Resources and Evaluation(LREC). Genoa, Italy, pages 417–422.
T. N. Flynn and A. A. J. Marley. 2014. Best-worst scal-ing: theory and methods. In Stephane Hess and An-drew Daly, editors, Handbook of Choice Modelling,Edward Elgar Publishing, pages 178–201.
Nico H Frijda. 1988. The laws of emotion. Americanpsychologist 43(5):349.
Kevin Gimpel, Nathan Schneider, et al. 2011. Part-of-speech tagging for Twitter: Annotation, features,and experiments. In Proceedings of the AnnualMeeting of the Association for Computational Lin-guistics (ACL). Portland, OR, USA.
Frederic Godin, Baptist Vandersmissen, WesleyDe Neve, and Rik Van de Walle. 2015. Named entityrecognition for twitter microposts using distributedword representations. ACL-IJCNLP 2015:146–153.
Mark Hall, Eibe Frank, Geoffrey Holmes, BernhardPfahringer, Peter Reutemann, and Ian H. Witten.2009. The WEKA data mining software: Anupdate. SIGKDD Explor. Newsl. 11(1):10–18.https://doi.org/10.1145/1656274.1656278.
Minqing Hu and Bing Liu. 2004. Mining and summa-rizing customer reviews. In Proceedings of the tenthACM SIGKDD international conference on Knowl-edge discovery and data mining. ACM, New York,NY, USA, pages 168–177.
David Jurgens. 2013. Embracing ambiguity: A com-parison of annotation methodologies for crowd-sourcing word sense labels. In Proceedings of theAnnual Conference of the North American Chap-ter of the Association for Computational Linguistics.Atlanta, GA, USA.
David Jurgens, Saif M. Mohammad, Peter Turney, andKeith Holyoak. 2012. Semeval-2012 task 2: Mea-suring degrees of relational similarity. In Proceed-ings of the 6th International Workshop on SemanticEvaluation. Montreal, Canada, pages 356–364.
Svetlana Kiritchenko and Saif M. Mohammad. 2016.Capturing reliable fine-grained sentiment associa-tions by crowdsourcing and best–worst scaling. InProceedings of The 15th Annual Conference of theNorth American Chapter of the Association forComputational Linguistics: Human Language Tech-nologies (NAACL). San Diego, California.

Svetlana Kiritchenko and Saif M. Mohammad. 2017.Best-worst scaling more reliable than rating scales:A case study on sentiment intensity annotation. InProceedings of The Annual Meeting of the Associa-tion for Computational Linguistics (ACL). Vancou-ver, Canada.
Svetlana Kiritchenko, Xiaodan Zhu, and Saif M. Mo-hammad. 2014. Sentiment analysis of short infor-mal texts. Journal of Artificial Intelligence Research(JAIR) 50:723–762.
G Frederic Kuder and Marion W Richardson. 1937.The theory of the estimation of test reliability. Psy-chometrika 2(3):151–160.
Jordan J. Louviere. 1991. Best-worst scaling: A modelfor the largest difference judgments. Working Paper.
Jordan J. Louviere, Terry N. Flynn, and A. A. J. Mar-ley. 2015. Best-Worst Scaling: Theory, Methods andApplications. Cambridge University Press.
Tomas Mikolov, Kai Chen, Greg Corrado, and JeffreyDean. 2013. Efficient estimation of word represen-tations in vector space. In Proceedings of Workshopat ICLR.
Saif Mohammad. 2012a. #Emotional tweets. In TheFirst Joint Conference on Lexical and Computa-tional Semantics (*SEM 2012). Montreal, Canada.
Saif M. Mohammad. 2012b. From once upon a timeto happily ever after: Tracking emotions in mail andbooks. Decision Support Systems 53(4):730–741.
Saif M. Mohammad. 2017. Word affect intensities.arXiv preprint arXiv:1704.08798 .
Saif M. Mohammad and Felipe Bravo-Marquez. 2017.Emotion intensities in tweets. In Proceedings of thesixth joint conference on lexical and computationalsemantics (*Sem). Vancouver, Canada.
Saif M. Mohammad, Felipe Bravo-Marquez, Svet-lana Kiritchenko, and Mohammad Salameh. 2018.Semeval-2018 Task 1: Affect in tweets. In Proceed-ings of International Workshop on Semantic Evalu-ation (SemEval-2018).
Saif M. Mohammad and Svetlana Kiritchenko. 2015.Using hashtags to capture fine emotion cate-gories from tweets. Computational Intelligence31(2):301–326. https://doi.org/10.1111/coin.12024.
Saif M. Mohammad, Svetlana Kiritchenko, and Xiao-dan Zhu. 2013. NRC-Canada: Building the state-of-the-art in sentiment analysis of tweets. In Pro-ceedings of the International Workshop on SemanticEvaluation. Atlanta, GA, USA.
Saif M. Mohammad, Parinaz Sobhani, and SvetlanaKiritchenko. 2017. Stance and sentiment in tweets.Special Section of the ACM Transactions on Inter-net Technology on Argumentation in Social Media17(3).
Saif M. Mohammad and Peter D. Turney. 2013.Crowdsourcing a word–emotion association lexicon.Computational Intelligence 29(3):436–465.
Alena Neviarouskaya, Helmut Prendinger, and Mit-suru Ishizuka. 2009. Compositionality principle inrecognition of fine-grained emotions from text. InProceedings of the Proceedings of the Third Inter-national Conference on Weblogs and Social Media(ICWSM-09). San Jose, California, pages 278–281.
Finn Arup Nielsen. 2011. A new ANEW: Evaluationof a word list for sentiment analysis in microblogs.In Proceedings of the ESWC Workshop on ’Mak-ing Sense of Microposts’: Big things come in smallpackages. Heraklion, Crete, pages 93–98.
Bryan Orme. 2009. Maxdiff analysis: Simple count-ing, individual-level logit, and HB. Sawtooth Soft-ware, Inc.
W Parrot. 2001. Emotions in Social Psychology. Psy-chology Press.
Sasa Petrovic, Miles Osborne, and Victor Lavrenko.2010. The Edinburgh Twitter corpus. In Proceed-ings of the NAACL HLT 2010 Workshop on Com-putational Linguistics in a World of Social Media.Association for Computational Linguistics, Strouds-burg, PA, USA, pages 25–26.
Robert Plutchik. 1980. A general psychoevolutionarytheory of emotion. Emotion: Theory, research, andexperience 1(3):3–33.
James A Russell. 2003. Core affect and the psycholog-ical construction of emotion. Psychological review110(1):145.
Carlo Strapparava and Rada Mihalcea. 2007. Semeval-2007 task 14: Affective text. In Proceedings ofSemEval-2007. Prague, Czech Republic, pages 70–74.
Mike Thelwall, Kevan Buckley, and Georgios Pal-toglou. 2012. Sentiment strength detection for thesocial web. Journal of the American Society for In-formation Science and Technology 63(1):163–173.
Louis L. Thurstone. 1927. A law of comparative judg-ment. Psychological review 34(4):273.
Amy Beth Warriner, Victor Kuperman, and Marc Brys-baert. 2013. Norms of valence, arousal, and dom-inance for 13,915 English lemmas. Behavior Re-search Methods 45(4):1191–1207.
Theresa Wilson, Janyce Wiebe, and Paul Hoffmann.2005. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the JointConference on HLT and EMNLP. Stroudsburg, PA,USA, pages 347–354.
Frank Yates. 1936. Incomplete randomized blocks.Annals of Human Genetics 7(2):121–140.

8 Appendix
8.1 Best–Worst Scaling Questionnaire usedto Obtain Emotion Intensity Scores
The BWS questionnaire used for obtaining fearannotations is shown below.
Degree Of Fear In English Language TweetsThe scale of fear can range from not fearful at all(zero amount of fear) to extremely fearful. Onecan often infer the degree of fear felt or expressedby a person from what they say. The goal of thistask is to determine this degree of fear. Since it ishard to give a numerical score indicating the de-gree of fear, we will give you four different tweetsand ask you to indicate to us:
• Which of the four speakers is likely to be theMOST fearful, and
• Which of the four speakers is likely to be theLEAST fearful.
Important Notes
• This task is about fear levels of the speaker (andnot about the fear of someone else mentionedor spoken to).
• If the answer could be either one of two ormore speakers (i.e., they are likely to be equallyfearful), then select any one of them as theanswer.
• Most importantly, try not to over-think theanswer. Let your instinct guide you.
EXAMPLE
Speaker 1: Don’t post my picture on FB #grrrSpeaker 2: If the teachers are this incompetent, Iam afraid what the results will be.Speaker 3: Results of medical test today #terrifiedSpeaker 4: Having to speak in front of so manypeople is making me nervous.
Q1. Which of the four speakers is likely to be theMOST fearful?– Multiple choice options: Speaker 1, 2, 3, 4 –Ans: Speaker 3
Q2. Which of the four speakers is likely to be theLEAST fearful?– Multiple choice options: Speaker 1, 2, 3, 4 –Ans: Speaker 1
The questionnaires for other emotions are similarin structure. In a post-annotation survey, the re-spondents gave the task high scores for clarity ofinstruction (4.2/5) despite noting that the task it-self requires some non-trivial amount of thought(3.5 out of 5 on ease of task).
8.2 An Interactive Visualization to Explorethe Tweet Emotion Intensity Dataset
We created an interactive visualization to allowease of exploration of the Tweet Emotion IntensityDataset. This visualization was made public afterthe the official evaluation period had concluded –so participants in the shared task did not have ac-cess to it when building their system. It is worthnoting that if one intends to evaluate their emotionintensity detection system on the Tweet EmotionIntensity Dataset, then as a matter of commonly-followed best practices, they should not use the vi-sualization to explore the test data in the systemdevelopment phase (until all the system parame-ters are frozen).
The visualization has three main components:
1. Tables showing the percentage of instances ineach of the emotion partitions (train, dev, test).Hovering over a row shows the correspondingnumber of instances. Clicking on an emotionfilters out data from all other emotions, in allvisualization components. Similarly, one canclick on just the train, dev, or test partitions toview information just for that data. Clickingagain deselects the item.
2. A histogram of emotion intensity scores. Aslider that one can use to view only thosetweets within a certain score range.
3. The list of tweets, emotion label, and emotionintensity scores.
Notably, the three components are interconnected,such that clicking on an item in one componentwill filter information in all other components toshow only the relevant details. For example, click-ing on ‘joy’ in ‘a’ will cause ‘b’ to show the his-togram for only the joy tweets, and ‘c’ to showonly the ‘joy’ tweets. Similarly one can click onthe test/dev/train set, a particular band of emotionintensity scores, or a particular tweet. Clickingagain deselects the item. One can use filters incombination. For e.g., clicking on fear, test data,and setting the slider for the 0.5 to 1 range, showsinformation for only those fear–testdata instanceswith scores ≥ 0.5.
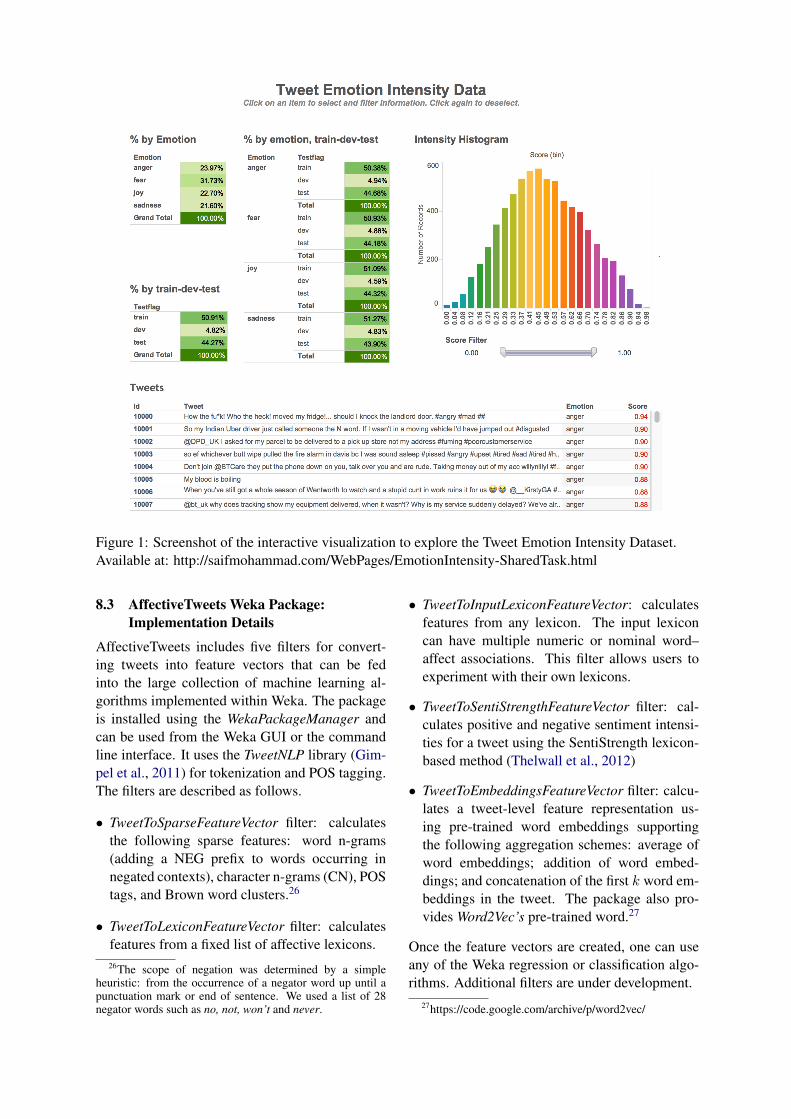
Figure 1: Screenshot of the interactive visualization to explore the Tweet Emotion Intensity Dataset.Available at: http://saifmohammad.com/WebPages/EmotionIntensity-SharedTask.html
8.3 AffectiveTweets Weka Package:Implementation Details
AffectiveTweets includes five filters for convert-ing tweets into feature vectors that can be fedinto the large collection of machine learning al-gorithms implemented within Weka. The packageis installed using the WekaPackageManager andcan be used from the Weka GUI or the commandline interface. It uses the TweetNLP library (Gim-pel et al., 2011) for tokenization and POS tagging.The filters are described as follows.
• TweetToSparseFeatureVector filter: calculatesthe following sparse features: word n-grams(adding a NEG prefix to words occurring innegated contexts), character n-grams (CN), POStags, and Brown word clusters.26
• TweetToLexiconFeatureVector filter: calculatesfeatures from a fixed list of affective lexicons.26The scope of negation was determined by a simple
heuristic: from the occurrence of a negator word up until apunctuation mark or end of sentence. We used a list of 28negator words such as no, not, won’t and never.
• TweetToInputLexiconFeatureVector: calculatesfeatures from any lexicon. The input lexiconcan have multiple numeric or nominal word–affect associations. This filter allows users toexperiment with their own lexicons.
• TweetToSentiStrengthFeatureVector filter: cal-culates positive and negative sentiment intensi-ties for a tweet using the SentiStrength lexicon-based method (Thelwall et al., 2012)
• TweetToEmbeddingsFeatureVector filter: calcu-lates a tweet-level feature representation us-ing pre-trained word embeddings supportingthe following aggregation schemes: average ofword embeddings; addition of word embed-dings; and concatenation of the first k word em-beddings in the tweet. The package also pro-vides Word2Vec’s pre-trained word.27
Once the feature vectors are created, one can useany of the Weka regression or classification algo-rithms. Additional filters are under development.
27https://code.google.com/archive/p/word2vec/