visual computing - csis.pace.educsis.pace.edu/~marchese/cs397z/l8/l8_text_b.pdf · visual computing...
TRANSCRIPT

Visual Computing
Text Visualization
Based on slides by Chris North, Virginia Tech
Jeffrey Heer, Stanford University

Text & Document Visualization • Text not pre-attentive• Text = Abstract Concepts = Very High Dimensionality
– Multiple & ambiguous meanings– Combinations of abstract concepts more difficult to visualize– Different combinations imply different meanings– Language only hints at meaning
based on common understanding “How much is that doggy in the window?”
• Facilitate Information Retrieval– Collection Overview– Visualize which parts of query satisfied by document / collection– Understand why documents retrieved
• Cluster Documents Based on Words in Common– Finds overall similarities among groups of documents– Picks out some themes, ignores others
• Map Clusters onto 2D or 3D Representation– Minimize time/effort to decide which documents to examine

What is text data? Documents• Articles, books and novels• Computer programs• E-mails, web pages, blogs• Tags, comments
Collection of documents• Messages (e-mail, blogs, tags, comments)• Social networks (personal profiles)• Academic collaborations (publications)

Text as Data
Words are (not) nominal?• High dimensional (10,000+) More than
equality tests• Words have meanings and relations
– Correlations: Hong Kong, San Francisco, Bay Area– Order: April, February, January, June, March, May– Membership: Tennis, Running, Swimming, Hiking, Piano– Hierarchy, antonyms & synonyms, entities, …

Text Processing Pipeline
• Tokenization: segment text into terms– Special cases? e.g., “San Francisco”, “L’ensemble”, “U.S.A.”– Remove stop words? e.g., “a”, “an”, “the”, “to”, “be”?
• Stemming: one means of normalizing terms– Reduce terms to their “root”; Porter’s algorithm for English– e.g., automate(s), automatic, automation all map to automat– For visualization, want to reverse stemming for labels– Simple solution: map from stem to the most frequent word
• Result: ordered stream of terms

The Bag of Words Model
• Ignore ordering relationships within the text
• A document ≈ vector of term weights– Each dimension corresponds to a term (10,000+)– Each value represents the relevance– For example, simple term counts
• Aggregate into a document x term matrix– Document vector space model

Document x Term matrix • Each document is a vector of term weights• Simplest weighting is to just count occurrences
Antony and Cleopatra
Julius Caesar
The Tempest
Hamlet Othello Macbeth
Antony 157 73 0 0 0 0
Brutus 4 157 0 1 0 0
Caesar 232 227 0 2 1 1
Calpurnia 0 10 0 0 0 0
Cleopatra 57 0 0 0 0 0
mercy 2 0 3 5 5 1
worser 2 0 1 1 1 0

WordCount (Harris 2004)
http://wordcount.org
WordCount™ is an interactive presentation of the 86,800 most frequently used English words.

Term Vector Theory for Information Retrieval (IR)Vector Space ModelIR systems assign weights to terms by considering
1. local information from individual documents 2. global information from collection of documents
Systems that assign weights to links use Web graph information to properly account for the degree of connectivity between documents.
In IR studies, the classic weighting scheme is the Salton Vector Space Model, commonly known as the "term vector model".
This weighting scheme is given by Term Weight =
where tfi = term frequency (term counts) or number of times a term i occurs in
a document. dfi = document frequency or number of documents containing term i D = number of documents in the database.
Many models that extract term vectors from documents and queries are derived this equation.

Computing WeightsTerm Frequencyt = term were are searching fortftd = count(t) in ddft = # docs containing tN = # of docs
TF.IDF: Term Freq by Inverse Document Freqtf.idftd = tftd × log(N/dft)
• This is the relative importance in the document• Word is more important in the fewer document it appears.
— We are more interested in a words that appear often in a single document not in the collection as a whole

Term vectors for Group of Docs with tf-idf weights

Visualizing Document Content

Tag Cloud: Word Counts
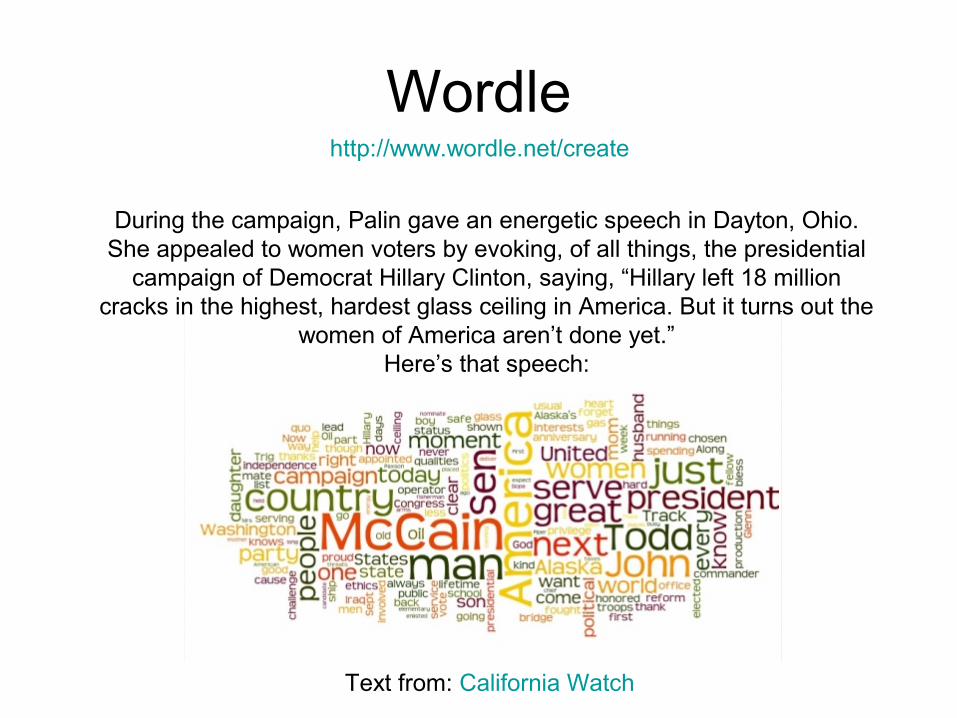
Wordle
During the campaign, Palin gave an energetic speech in Dayton, Ohio. She appealed to women voters by evoking, of all things, the presidential
campaign of Democrat Hillary Clinton, saying, “Hillary left 18 million cracks in the highest, hardest glass ceiling in America. But it turns out the
women of America aren’t done yet.”Here’s that speech:
Text from: California Watch
http://www.wordle.net/create

Weaknesses of Tag Clouds
• Sub-optimal visual encoding (size vs. position) • Inaccurate size encoding (long words are bigger) • May not facilitate comparison (unstable layout) • Term frequency may not be meaningful• Does not show the structure of the text

Word Tree: Word Sequences


Arc Diagrams – M. Wattenberg
Les Misérables character interaction. Each character is represented by a circle and the connecting arc represents co-occurrence in a chapter. The character's size indicates the number of appearances they have over the entire work.

Literature Fingerprinting
Problem: Authorship Attribution• Determine, if a text was written by an
author or not.• A common problem in literary analysis.• What features are useful for
discrimination?• Case study on some books by Jack
London and Mark Twain.

Variables for Literary Analysis
• Statistical measures– Syllables per word– Sentence length– Proportions of parts of speech– ...
• Vocabulary measures– Frequencies of specific words– Type-token ratio– Simpson’s index– Hapax (dis)legomena– ...
• Syntax measures

Average Sentence Length

Structured Document Collections
• Multi-dimensional:• author, title, date, journal, …
• Trees:• Dewey decimal system
• Graphs:• web, citations

Citation NetworksANNOTATIONS TYPESCRIPT select source | ?b 434 | <16 lines of accounting information removed> search on author | ?s au=card sk | search S1 had 7 results | S1 7 AU=CARD SK type S1 format 3 result 1 | ?t 1/3/1 | | 1/3/1 | DIALOG(R)File 434:Scisearch(R) | (C) 1994 Inst For Sci Info. All Rts. Reserv. | | 12204937 Genuine Article#: KU797 No. Reference... | Title: INFORMATION VISUALIZATION USING 3D INTERAC... first author | Author(S): ROBERTSON GG; CARD SK; MACKINLAY JD | Corporate Source: XEROX CORP,PALO ALTO RES CTR,33... | ALTO//CA/94304 year, vol, page | Journal: COMMUNICATIONS OF THE ACM, 1993, V36, N4... | ISSN: 0001-0782 | Language: ENGLISH Document Type: ARTICLE search for citers | ?s cr=robertson gg, 1993, v36, p56, ? | search S2 had 1 result | S2 1 CR=ROBERTSON GG, 1993, V36, P56, ?
This annotated typescript from a DIALOG session shows a search of the Science Citation Database for articles that include S. K. Card as an author. Typescripts like this do not particularly show the structure of a search.

Butterfly Browser - Mackinlay et al (PARC)Based on four key ideas: • Visualizations Of References And Citers
– Visualize scholarly articles as user interface objects with two wings, one wing for listing an article's references and the other wing for listing the article's citers.
• Link-Generating Queries– Automatically create link-generating queries that link an article's
record to the corresponding records for the article's references and citers
• Asynchronous Query Processes– Uses asynchronous processing for information access so the
user does not have to wait for queries to complete • Embedded Process Control
– User can explicitly create and terminate query processes

Butterfly Browser
Butterfly:Left = refsRight = citersYellow = #citersBlue = visited
3d plot:date, Name,# citers


Unstructured Document Collections
• Focus on Full Text• Examples:
• digital libraries, news archives, web pages• email archives, image galery
• Tasks:• Search • Browse• Classification, structurization• Statistics, keyword usage, languages• Subjects, themes, coverage

Visualization Strategies
• Cluster Maps• Keyword Query results
• Relationships• Reduced representation• User controlled layout

Cluster Map
• Create a “map” of the document collection• Similar documents near each other• Dissimilar documents far apart
• “Library” or “Grocery store” concept

Document VectorsDoc1 Doc2 Doc3 …
• “aardvark” 1 2 0• “banana” 2 1 0• “chris” 0 0 3• …
• Now it’s a Multi-D visualization problem?• Dimensionality reduction:
• Projection: e.g. Principal Components Analysis (PCA)• Similarity-based methods:
1. Compute “Similarity” between pair of docs2. Layout documents in 1/2/3-D map by similarity

Similarity MatrixDoc1 Doc2 Doc3 …
• “aardvark” 1 2 0• “banana” 2 1 0• “chris” 0 0 3• …
• Similarity metrics?• dot product•
Doc1 Doc2 Doc3 …Doc1 1 0.66 0Doc2 0.66 1 0Doc3 0 0 1…

Layout Mapping
• Spring model of graph layout• Multi-Dimensional Scaling (MDS)• Self-organizing Map (kohonen map)• Clustering: Partition, hierarchical
• How to label a group?
• …

Cluster Algorithms• Partition clustering:
Partition into k subsets• Pick k seeds• Iteratively attract nearest neighbor
• Hierarchical clustering: Dendrogram
• Group nearest-neighbor pair• Iterate
Top down
Bottom up

Landscapes• Wise et al, “Visualizing the non-visual”• ThemeScapes, Cartia, IN-SPIRE (PNNL)• Mountain = topical theme• Mountain height = number of relevant documents

LandScapes• Abstract, 3D landscapes of information• Convey relevant information about topic or
themes without the cognitive load• Spatial relationships reveal the intricate
interconnection of thems• Dominant themes are shown in a relief map of
natural terrain. • Themes are represented by peaks and their
height indicates relative strength within the document set.

Advantages
• Displays much of the complex content of the document database
• Utilizes innate human abilities for pattern recognition and spatial reasoning
• Communicative invariance across levels of textual scale
• Promotes analysis

ThemeRiver - PNNL• Displays changes to themes over time• Helps users identify time-related patterns, trends, and
relationships across a large collection of documents. • Themes in the collection are represented by a "river" that
flows left to right through time. • The river widens or narrows to depict changes in the
collective strength of selected themes in the underlying documents.
• Individual themes are represented as colored "currents" flowing within the river. The theme currents narrow or widen to indicate changes in individual theme strength at any point in time.

ThemeRiver
http://infoviz.pnl.gov/images/ThemeRiver.mov

Galaxies
• Displays cluster and document interrelatedness
• 2D scatterplot of ‘docupoints’• Simple point and click exploration• Sophisticated tools
– Facilitate more in-depth analysis– Ex) temporal slicer

IN-SPIRE™ - PNNL
• The Galaxy visualization uses the metaphor of stars in the night sky where each star represents a document.
• Closely related documents cluster together while unrelated documents are further apart.
• Galaxies help users to understand what is in a document collection and allows them to explore the context of their specific interests.
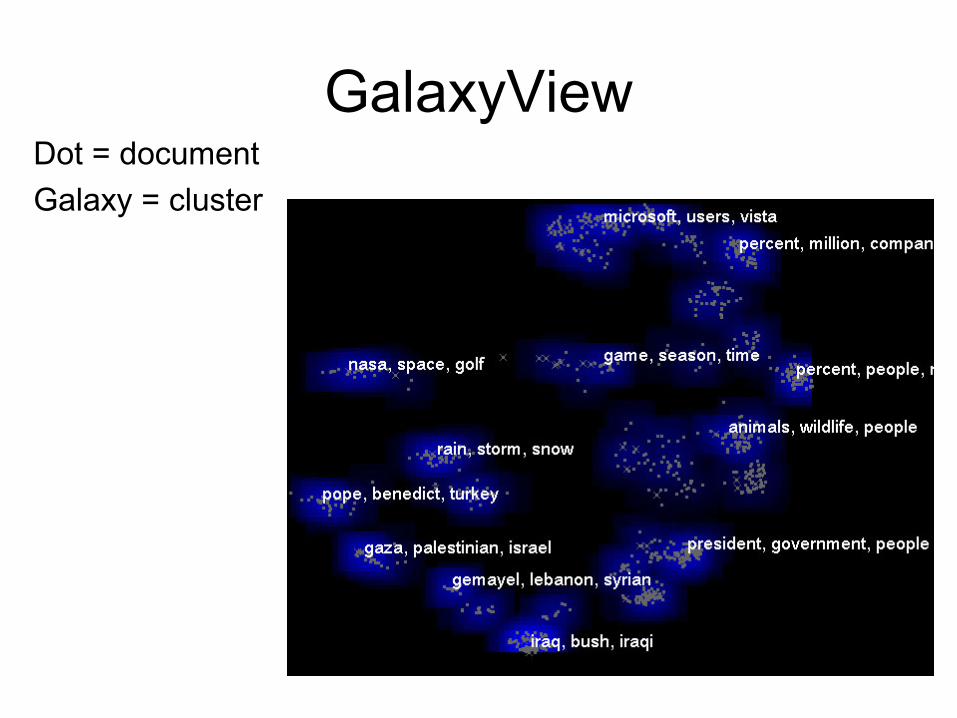
GalaxyViewDot = document Galaxy = cluster

StarLight - PNNL• Relationships to geography, etc.

The Self-Organizing Map (SOM)
• Data visualization technique invented by Teuvo Kohonen which reduces the dimensions of data through the use of self-organizing neural networks.
• SOMs reduce dimensions by producing a map of 1 or 2 dimensions that plots the similarities of the data by grouping similar data items together.

Components of SOM
1. Sample Data– e.g. RGB (3 dimensions)
1. Weight vectors– two components:
• The data itself• The data’s natural location
– e.g. 2D array of weight vectors (say, colors at right)

Components of SOM
• AlgorithmInitialize Map For t from 0 to 1
Randomly select a sampleGet best matching unit Scale neighbors Increase t a small amount
End for

Self-organizing Maps• Xia Lin, “Document Space”• Kohonen map, http://faculty.cis.drexel.edu/sitemap/index.html