thesis nizar ghoula
TRANSCRIPT

An ontology-based repositoryfor combining heterogeneous
knowledge resources
THESIS
presented to the Faculty of Economics and Managementof the University of Geneva
by
Nizar GhoulaUnder the direction of
Prof. Gilles Falquet
to obtain the title ofDocteur ès économie et managementmention Systèmes d’Information
Jury members:
Dr. Khaled Khelif, Research engineer, Airbus Defence and Space
Prof. Giovanna DI MARZO SERUGENDO, Professor, President of thejury
Dr. Claudine Métral, MER, University of Geneva
Dr. Jacques Guyot, Founder, Olanto Foundation
Thesis n◦2ISBN 978-2-88903-042-2
Geneva, on December 12th 2014


Acknowledgements
I would like to acknowledge my professor Gilles Falquet who helped meduring these years of research and gave me the ability to believe in myselfand in the fact that I can go further at each dead end. I am thankful for hisway of managing my work, his flexibility, advices and openness. Thank youGilles for your support and ideas, I have learned a lot from you and I hopethat the end of this thesis will lead to a beginning of new collaborations.
I want to express my gratitude to professor Giovanna Di Marzo Serugendofor accepting to review my work and being the head of my PhD committee.
I would like to thank especially Dr. Khaled Khelif for accepting to reviewmy work and also for initiating me in the Semantic Web field at the beginningof my research studies.
I am honored to have Dr. Claudine Métral as a reviewer of my humblecontribution and also for being a great and lovely person to work with.
I would like to thank Dr. Jacques Guyot who has been of a great helpby giving critical and inspiring point of views on my work.
I am thankful for the support and help of my friend Hélène de Rib-aupierre. Thank you Hélène for your availability for reading my papers andthesis. I also would like to thank all my colleagues who have been helpful andsupportive and the administrative staff of the CUI for their availability, helpand encouragement, in particular, Marie-France Culebras and Lara Broi.
I would like especially to thank my colleagues Sun Zuchuat-Ji, GloriaLeonie, Nadia Jobin and Anne Dupraz. It was a pleasure working with you.
To my dear friends Mélanie Montagnol, Nathalie Verdon, Yasmina Saïdi,Leif Gröessinger and Jonathan Schad, I am thankful to all the support youhave been offering and the encouragements that helped me through roughmoments. To my friends Fares Mallouli and his wife Imen Khanfir, thankyou for your support and generous attention each time we met. A specialdedication to my first computer science teacher Najoua Ben Romdhane whoencouraged me through all this long path in this field.
For the Fiechter family and especially Robert, Julia, Eva, Diane, Cyriland Max, I am very thankful for having you and very grateful for your helpand amazing support during these past years.


Dedication
To my dear mother who taught me how to read, write and analyze. Thebrilliant woman who, deprived from perusing her studies, has dedicated herlife to educate us and to transmit her thirst for knowledge. To my fatherwho had faith on me, who supported me and taught me the value of timeand work. The man who based his existence for the well being of his family.Words are not enough to say how much I am grateful and proud to have youas parents.
To my dear sisters Kalthoum and Manal, my five brothers, my ninenephews (for the moment), my sisters in law and my whole family whosupported me in my decisions and helped me through this long process.
To my dearest Julia and Robert Fiechter, the kindest and most generousparents, thank you for being there for me. You are and always will be asparents to me. You taught me a lot of things and I have spent the mostamazing times with you.
To Eva, thank you for being there for me...


English abstract
Many tasks related to documents, such as indexing, retrieving, annota-tion, or translation are based on linguistic, terminological and ontologicalknowledge existing in resources of different types such as terminologies, glos-saries, ontologies, multilingual dictionaries or text corpora. These resourcesare represented using various formalisms and languages such as predicatelogic, description logic, semantic networks and conceptual graphs, etc. Aspart of an application that requires the use of external resources, a designer isoften required to perform painstaking research and pre-treatment in order tocollect and build adequate resources to his application needs. This requiresthe representation of heterogeneous knowledge resources using specific for-malisms, extracting the required knowledge and design effective large-scalestorage structures offering operators for resources management. Resourcesrepositories have been created to help in this task by collecting different re-sources in different formalisms. They generally offer a more effective indexingof these resources than general search engines and generate alignments andannotations to ensure interoperability between resources. However, theserepositories treat a single category of resources and do not provide opera-tions for generating new resources.
The aim of this research work is to conceive and design a repository forcombining heterogeneous knowledge resources. Such a repository is a col-lection of heterogeneous resources represented by multiple formalisms andoffers tools and operators to derive new resources by combining the existingones. This derivation may involve operations such as selecting a part of aresource, composing it with another one, translating it to another languageor representing it in a different formalism. To meet these needs in terms ofknowledge engineering and representation, our first contribution is an ontol-ogy for representing heterogeneous resources and knowledge combination op-erators. The representation of these operators supports multiple implemen-tations. Our second contribution is an approach based on the principles ofsemantic web, metadata and ontologies to facilitate the representation, stor-age and alignment of heterogeneous and multilingual resources. Our thirdcontribution is the development of an ontology-based repository for combin-ing alignment resources. This repository is supported by a set of knowledgeengineering operators that composes and aggregate existing alignments gen-erated by different tools. We show in particular that alignment compositioncan effectively improve the results of ontology matchers.


Résumé en Français
L’extraction et la représentation de connaissances sont des problèmeslargement explorés dont une des solutions est basée sur l’utilisation deressources ontologiques, terminologiques et linguistiques. Ces connaissancesexistent actuellement sous forme de ressources de différents types tels queles terminologies, les bases de données terminologiques, les glossaires, les on-tologies (générales ou de domaine), les dictionnaires multilingues ou encoreles corpus de textes. Ces ressources sont représentées à l’aide de divers for-malismes et langages (logique des prédicats, logique de description, réseauxsémantiques, graphes conceptuels, etc.). Dans le cadre d’une application quinécessite l’usage d’un certain nombre de ressources externes, un concepteurest souvent amené à effectuer un travail laborieux de recherche et de pré-traitement afin de rassembler et de fabriquer des ressources adéquates auxbesoins de ses applications.
Le nombre croissant de ce type de ressources a engendré l’apparitiond’entrepôts ou librairies de ressources. Cependant, un nombre limité de cesentrepôts offre une représentation intégrale de plusieurs types de ressourcesà la fois (ressources de type ontologique, linguistique et terminologique).De plus, ils ne fournissent pas un ensemble complet d’opérateurs permet-tant la gestion et le traitement de ces ressources. Ainsi, nous avons iden-tifié deux problématiques: (i) les applications demandent de plus en plusde ressources représentées selon des modèles et formalismes différents; (ii)vu qu’il est indispensable de rechercher et d’adapter des ressources de con-naissances hétérogènes, il faut doter les entrepôts de connaissances avec desoutils génériques pour adapter ces ressources. Un tel entrepôt est donc unecollection de ressources hétérogènes représentées par différents formalismesqui offre des outils pour dériver de nouvelles ressources à partir de la combi-naison des ressources existantes.
Nous proposons une approche pour la modélisation et la constructiond’un entrepôt de ressources. L’objectif principal de cette approche est de con-cevoir un entrepôt de ressources de connaissances pour stocker des ressourceshétérogènes et dériver de nouvelles ressources à partir de la combinaison desressources existantes. Ceci est modélisé et piloté par une ontologie génériquequi formalise les modèles de représentation de ressources et d’opérateurs degestion et de combinaison de ressources de connaissances. Nous prenons enconsidération la possibilité de combiner ces opérateurs afin de modéliser desprocessus complexes tels que l’intégration, l’annotation et l’alignement.


Contents
1 Introduction 11.1 Scientific context and research problem . . . . . . . . . . . . . 11.2 Research areas . . . . . . . . . . . . . . . . . . . . . . . . . . 41.3 Proposed research methodology . . . . . . . . . . . . . . . . . 41.4 Restrictions for the research plan . . . . . . . . . . . . . . . . 51.5 Contributions . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.6 Impacts and applications of the contributions . . . . . . . . . 71.7 Thesis plan . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2 Knowledge representation and repositories for managingknowledge resources 112.1 Knowledge and knowledge representation . . . . . . . . . . . . 11
2.1.1 Knowledge . . . . . . . . . . . . . . . . . . . . . . . . 122.1.2 Knowledge representation . . . . . . . . . . . . . . . . 132.1.3 Knowledge representation formalisms . . . . . . . . . . 15
2.2 knowledge resources repositories . . . . . . . . . . . . . . . . . 162.2.1 Repositories for indexing and retrieving knowledge re-
sources . . . . . . . . . . . . . . . . . . . . . . . . . . . 172.2.2 Repositories for collecting and managing knowledge re-
sources . . . . . . . . . . . . . . . . . . . . . . . . . . . 182.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
I Resources representation and combination approach 23
3 Identification of knowledge resources 253.1 Definitions and typology of knowledge resources . . . . . . . . 26
3.1.1 Knowledge resources . . . . . . . . . . . . . . . . . . . 263.1.2 Resources represented using formal ontology languages 273.1.3 Terminological, Lexical and semantic resources . . . . 303.1.4 Linguistic resources . . . . . . . . . . . . . . . . . . . . 33
3.2 Models and representation approaches for heterogeneousknowledge . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 353.2.1 Metadata representation models . . . . . . . . . . . . 353.2.2 Specific representation models . . . . . . . . . . . . . . 383.2.3 Generic representation models . . . . . . . . . . . . . . 40
3.3 A high level classification of knowledge resources . . . . . . . 413.3.1 Autonomous resources . . . . . . . . . . . . . . . . . . 41

ii Contents
3.3.2 Enrichment resources . . . . . . . . . . . . . . . . . . . 423.3.2.1 Index terms . . . . . . . . . . . . . . . . . . . 423.3.2.2 Annotations . . . . . . . . . . . . . . . . . . 423.3.2.3 Alignments . . . . . . . . . . . . . . . . . . . 43
3.3.3 Combined Resources . . . . . . . . . . . . . . . . . . . 433.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4 TOK: A meta-model for representing heterogeneous knowl-edge resources 454.1 Resources representation aspects for designing the resources
model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.2 Resources representation model: TOK_Onto . . . . . . . . . 48
4.2.1 Metadata representation . . . . . . . . . . . . . . . . . 484.2.2 Resources content representation model . . . . . . . . 50
4.2.2.1 Node Entity . . . . . . . . . . . . . . . . . . 534.2.2.2 Link Entity . . . . . . . . . . . . . . . . . . . 544.2.2.3 Expression Entity . . . . . . . . . . . . . . . 544.2.2.4 Describing content representation models . . 55
4.2.3 The modeling approach of TOK_Onto . . . . . . . . . 564.2.4 Example of using the model to represent WordNet . . 59
4.3 Representing resources management . . . . . . . . . . . . . . 604.3.1 Resources engineering operators representation . . . . 614.3.2 Process monitoring representation . . . . . . . . . . . 624.3.3 Resources evolution-tracking . . . . . . . . . . . . . . 63
4.4 Use case scenario . . . . . . . . . . . . . . . . . . . . . . . . . 644.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
5 A Taxonomy of resources combination operators 695.1 Resources management and combination operators . . . . . . 69
5.1.1 Representation operators . . . . . . . . . . . . . . . . 715.1.1.1 Abstraction . . . . . . . . . . . . . . . . . . . 715.1.1.2 Reification . . . . . . . . . . . . . . . . . . . 725.1.1.3 Resources translation (from a model to an-
other) . . . . . . . . . . . . . . . . . . . . . . 735.1.2 Enrichment operators . . . . . . . . . . . . . . . . . . 75
5.1.2.1 Alignement . . . . . . . . . . . . . . . . . . . 755.1.2.2 Annotation . . . . . . . . . . . . . . . . . . . 76
5.1.3 Derivation and combination operators . . . . . . . . . 775.1.3.1 Selection and derivation . . . . . . . . . . . . 785.1.3.2 Composition . . . . . . . . . . . . . . . . . . 785.1.3.3 Aggregation . . . . . . . . . . . . . . . . . . 79

Contents iii
5.2 Usage of the model and operators to create repository for com-bining terminological resources . . . . . . . . . . . . . . . . . 815.2.1 Storing resources representations . . . . . . . . . . . . 81
5.2.1.1 Generating a lexical ontology from wikipedia 855.2.1.2 Enriching english WordNet with lexical forms
in other languages . . . . . . . . . . . . . . . 875.2.2 Alignment of representation formalisms . . . . . . . . 89
5.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
II Application of the TOK approach on alignment re-sources 95
6 Refining TOK Model with a generic model for representingalignment resources 976.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . 976.2 Definitions and typology of alignments . . . . . . . . . . . . . 98
6.2.1 Definition of alignments . . . . . . . . . . . . . . . . . 986.2.2 Types of alignments . . . . . . . . . . . . . . . . . . . 99
6.3 Formalisms for representing alignments . . . . . . . . . . . . . 1006.4 TOKAlign: a generic model for representing alignments . . . . 1026.5 Importing alignment resources using TOKAlign model . . . . 106
6.5.1 Transforming alignments . . . . . . . . . . . . . . . . . 1066.5.2 Importing and exporting alignments . . . . . . . . . . 108
6.6 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112
7 Operators for combining and aggregating heterogeneousalignment resources 1137.1 Approaches for alignment resources reuse . . . . . . . . . . . 114
7.1.1 Approaches reusing existing alignments . . . . . . . . 1147.1.2 Approaches proposing theories for alignment composi-
tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1167.2 An approach for alignment resources combination . . . . . . . 118
7.2.1 Framework of representing alignment correspondences 1197.2.2 Interpretation of correspondences using fuzzy set theory120
7.2.2.1 Interpretation of alignments as sets of fuzzyrelations . . . . . . . . . . . . . . . . . . . . . 121
7.2.2.2 Interpretation of alignment relations as fuzzysets . . . . . . . . . . . . . . . . . . . . . . . 121
7.2.3 Interpretation for Dempster-Shafer theory . . . . . . . 1237.2.4 Switching from an interpretation to another . . . . . . 124
7.3 Alignment combination operators . . . . . . . . . . . . . . . . 125

iv Contents
7.3.1 Alignment composition . . . . . . . . . . . . . . . . . . 1257.3.1.1 Composing correspondences . . . . . . . . . . 1257.3.1.2 Composing Alignments . . . . . . . . . . . . 128
7.3.2 Alignment aggregation . . . . . . . . . . . . . . . . . . 1297.3.2.1 Aggregating conflicting correspondences us-
ing Dempster-Shafer theory of combination . 1297.3.2.2 Aggregating conflicting correspondences us-
ing fuzzy sets theory . . . . . . . . . . . . . . 1317.3.2.3 Reducing correspondences that contain mul-
tiple relations . . . . . . . . . . . . . . . . . . 1327.3.3 Alignment union . . . . . . . . . . . . . . . . . . . . . 1337.3.4 Alignment intersection . . . . . . . . . . . . . . . . . . 1337.3.5 Alignment difference . . . . . . . . . . . . . . . . . . . 134
7.4 Implementing alignment combination and management oper-ators . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1357.4.1 Implementing fuzzy aggregators . . . . . . . . . . . . . 1367.4.2 Executing combination operators . . . . . . . . . . . . 1377.4.3 Alignments overview, update and edition . . . . . . . . 1407.4.4 Discussion about the aggregation metrics . . . . . . . 142
7.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142
8 Evaluation of alignment resources combination operators 1458.1 Evaluation methodology . . . . . . . . . . . . . . . . . . . . . 146
8.1.1 Building a test corpus . . . . . . . . . . . . . . . . . . 1468.1.2 Computing precision and recall measures . . . . . . . . 1478.1.3 Evaluation of combination and aggregation operators . 148
8.2 Experimentation and results . . . . . . . . . . . . . . . . . . . 1498.2.1 Alignment union evaluation results . . . . . . . . . . . 1518.2.2 Alignment intersection evaluation results . . . . . . . . 1538.2.3 Alignment composition evaluation results . . . . . . . 155
8.2.3.1 Composition of validated alignments . . . . . 1558.2.3.2 Composition of alignments from the same tool 157
8.3 Usage of alignment composition to enrich existing alignments 1598.4 An approach for enhancing composition using the content of
the resources . . . . . . . . . . . . . . . . . . . . . . . . . . . 1608.4.1 Extending composition path finding using the content
of a common resource . . . . . . . . . . . . . . . . . . 1628.4.2 Composition path finding using an alignment exten-
sion operator . . . . . . . . . . . . . . . . . . . . . . . 1648.5 Conclusion and discussion . . . . . . . . . . . . . . . . . . . . 166

Contents v
9 Conclusion and future work 1679.1 Advantages of the TOK approach . . . . . . . . . . . . . . . 1679.2 Limitations and future work with regards to the contributions 1709.3 Use of the methodology for research and industry . . . . . . . 171
A About some uses cases of the repository 173A.1 Enriching an ontology with a bilingual glossary . . . . . . . . 173A.2 Importing the resources . . . . . . . . . . . . . . . . . . . . . 174
B The TOK ontology 179B.1 Potential usage of the TOK ontology . . . . . . . . . . . . . . 179B.2 Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181B.3 Object properties . . . . . . . . . . . . . . . . . . . . . . . . . 195B.4 Data properties . . . . . . . . . . . . . . . . . . . . . . . . . . 197
Bibliography 199


List of Figures
1.1 A repository of heterogeneous knowledge resources. . . . . . . 31.2 Methodology for creating a model for representing and a
repository for managing knowledge resources. . . . . . . . . . 51.3 Application and impacts of the proposed methodology. . . . . 8
2.1 Data-Information-Knowledge model according to[Fahey & Prusak 1998] . . . . . . . . . . . . . . . . . . . . . . 12
2.2 The semiotic triangle of [Ogden & Richards 1927] . . . . . . . 132.3 An overview of semantic web languages according to
[Stephan et al. 2007] . . . . . . . . . . . . . . . . . . . . . . . 152.4 Architecture of Watson (“a gateway for the Semantic Web”)
as described in [d’Aquin et al. 2011] . . . . . . . . . . . . . . 172.5 State of the LOD cloud on “2014-08-30” . . . . . . . . . . . . 21
3.1 Steps for designing a meta-model for representing knowledgeresources . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.2 Types of ontological resources according to[Giunchiglia & Zaihrayeu 2009] adopted from[Uschold & Gruninger 2004] . . . . . . . . . . . . . . . . . . . 27
3.3 Semantic Web languages stack . . . . . . . . . . . . . . . . . . 303.4 OMV: ontology metadata vocabulary [Raúl et al. 2006] . . . . 363.5 NoRMV: Non ontological resources’ metadata vocabulary
[Villazón-Terrazas et al. 2010a] . . . . . . . . . . . . . . . . . 373.6 Ontopath, a model for representing ontologies
[Jiménez-Ruiz et al. 2007] . . . . . . . . . . . . . . . . . . . . 383.7 Terminological entities meta-model from
[Vandenbussche & Charlet 2009] . . . . . . . . . . . . . . . . 393.8 PROTON ontology model for OWLIM [Kiryakov et al. 2005] 393.9 The semiotic triangle in LMM from [Picca et al. 2008] . . . . 403.10 Keys for knowledge resources categorisation . . . . . . . . . . 41
4.1 Lifecycle of a TOK resources within the repository . . . . . . 464.2 Resources representation aspects and interactions . . . . . . . 474.3 From a formalism to its representation language and syntax . 494.4 Excerpt of the metadata representation model of knowledge
resources (TOKMeta) . . . . . . . . . . . . . . . . . . . . . . . 514.5 Excerpt of the content representation model of knowledge re-
sources (TOKCont) . . . . . . . . . . . . . . . . . . . . . . . . 52

viii List of Figures
4.6 Representation of a resource with its metadata and differentrepresentations of its content . . . . . . . . . . . . . . . . . . 55
4.7 Description of a representation model . . . . . . . . . . . . . . 564.8 Representation approach for knowledge resources using mul-
tiple models . . . . . . . . . . . . . . . . . . . . . . . . . . . . 574.9 MOF as an approach for resources representation . . . . . . . 584.10 Semantic Markup for Web Services ontology modules
[Burstein et al. 2004] . . . . . . . . . . . . . . . . . . . . . . . 604.11 OWLS profiles representation [Burstein et al. 2004] . . . . . . 624.12 Usage of the repository and the ontology Tok_Onto . . . . . 654.13 Illustration of the Concept_Hierarchy model from Tok_Onto 66
5.1 Interactions model between the resources and the operatorswithin the repository . . . . . . . . . . . . . . . . . . . . . . . 70
5.2 Resources representation and derivation operators . . . . . . . 715.3 Classes of resources translation operators . . . . . . . . . . . . 745.4 An approach for reusing “Non-Ontological” resources
[Villazón-Terrazas et al. 2010a] . . . . . . . . . . . . . . . . . 755.5 Default representation model for annotation resources . . . . 775.6 Aggregating (Aggr) two views of resources represented with
the same model; this operation gives as a result a new resourcerepresented in the same model and two sets of alignments (A31
and A32) with the original resources . . . . . . . . . . . . . . 805.7 Representation of the WordNet-Like model . . . . . . . . . . 845.8 The list of resources within the repository based on their rep-
resentation model . . . . . . . . . . . . . . . . . . . . . . . . . 855.9 Excerpt of the modelWP_Like representing Wikipedia articles 865.10 Browsing the concepts and terms extracted from Wikipedia . 875.11 Operators involved in the WordNet enrichment process . . . . 885.12 Alignment detection by similarity . . . . . . . . . . . . . . . . 885.13 Representation and alignments of entities within the
lightweight repository . . . . . . . . . . . . . . . . . . . . . . 895.14 Representation and alignments of entities within the
lightweight repository . . . . . . . . . . . . . . . . . . . . . . 895.15 Using TOK model to combine and represent annotated corpora 905.16 Alignment of annotation models . . . . . . . . . . . . . . . . . 91
6.1 Formalisms for representing alignment resources . . . . . . . . 1006.2 Generic model for a representing alignments . . . . . . . . . . 1056.3 Architecture of the resources’ import component . . . . . . . 1096.4 Excerpt of mappings between alignment formalisms and the
generic alignment model . . . . . . . . . . . . . . . . . . . . . 109

List of Figures ix
6.5 AllegroGraph’s Architecture . . . . . . . . . . . . . . . . . . . 1106.6 Importing an alignment between two biomedical ontologies . . 111
7.1 Illustrating alignment relations as fuzzy relations . . . . . . . 1217.2 Illustrating alignment relations as fuzzy sets . . . . . . . . . . 1227.3 Composition of two alignments . . . . . . . . . . . . . . . . . 1277.4 Multiple paths for alignment composition . . . . . . . . . . . 1277.5 Architecture of the alignment repository . . . . . . . . . . . . 1367.6 Operations by alignments interface . . . . . . . . . . . . . . . 1387.7 Operations by resources interface . . . . . . . . . . . . . . . . 139
8.1 Importing alignments for testing . . . . . . . . . . . . . . . . 1508.2 Classic precision and recall measures of the alignment result-
ing from the Union aggregator Using FS and D-S theories . . 1518.3 Advanced precision and recall measures of disjunctive fuzzy
aggregations and Dempster-Shafer aggregation . . . . . . . . 1538.4 Classic precision and recall measures of conjunctive fuzzy ag-
gregations and Dempster-Shafer aggregation . . . . . . . . . . 1548.5 Advanced precision and recall measures of conjunctive fuzzy
aggregations and Dempster-Shafer aggregation . . . . . . . . 1558.6 Classic precision and recall measures for composition followed
by fuzzy aggregations or Dempster-Shafer aggregation . . . . 1568.7 Advanced precision and recall measures for composition fol-
lowed by disjunctive fuzzy aggregations or Dempster-Shaferaggregator . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
8.8 Advanced precision and recall of the composition of align-ments from the same tool using Dempster-Shafer and Fuzzyset aggregators . . . . . . . . . . . . . . . . . . . . . . . . . . 158
8.9 Enriching direct alignments using composed alignments of in-termediary resources . . . . . . . . . . . . . . . . . . . . . . . 160
8.10 Composition path finding using the content of resources . . . 161
B.1 Resources generation using the proposed approach. . . . . . . 179


List of Tables
3.1 Classification of “non-ontological” resources in the literature . 31
4.1 Examples of resource content representation models and theirprincipal components . . . . . . . . . . . . . . . . . . . . . . . 56
7.1 Composition table for logical relations as defined by[Euzenat 2008] . . . . . . . . . . . . . . . . . . . . . . . . . . 126


Chapter 1
Introduction
Contents1.1 Scientific context and research problem . . . . . . . . 11.2 Research areas . . . . . . . . . . . . . . . . . . . . . . . 41.3 Proposed research methodology . . . . . . . . . . . . . 41.4 Restrictions for the research plan . . . . . . . . . . . . 51.5 Contributions . . . . . . . . . . . . . . . . . . . . . . . . 61.6 Impacts and applications of the contributions . . . . 71.7 Thesis plan . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.1 Scientific context and research problem
In the knowledge engineering field, scientists try to solve problems basedon reusing existing knowledge resources [Hendler & Golbeck 2008] to adaptthem for advanced tasks such as information retrieval, conceptual indexing,knowledge extraction from text, service discovery and matching, semanticsearch, as well as advanced annotation or translation. Two questions areimportant to answer in order to define an approach of reusing knowledgeresources:
• Where can we find knowledge resources?
Repositories and libraries have been created to help collecting mul-tiple linguistic, terminological and ontological resources representedwithin different formalisms. For instance, for ontological resources,advanced repositories offer the possibility to generate alignments andannotations to ensure interoperability between them. For example,Swoogle1 indexes approximately 10,000 ontologies; DAML repository2
provides search based on ontology components (classes, properties,. . . ) or metadata (URI, funding source, . . . ); BioPortal3 has similar
1http://swoogle.umbc.edu2http://www.daml.org/ontologies3http://bioportal.bioontology.org

2 Chapter 1. Introduction
searching and browsing features [Noy et al. 2008] and offers the possi-bility to annotate and align different ontologies. Many other portalssuch as Watson [Sabou et al. 2007b] or repositories such as OWLIM[Kiryakov et al. 2005] offer access to index, store and manage ontolog-ical resources.
• How to combine knowledge resources?
To reuse a resource for a specific task, it needs to be adapted. Itsadaptation requires operations such as selecting a part of it, composingit with another one, translating it to another language or representing itin a different formalism. For this purpose, it is necessary to have accessto a set of resources management operators that can be composedto generate adapted (or personalized) knowledge resources (the basicbricks for specifying the production of new knowledge resources).
These resources libraries are each restricted to collecting a specific cate-gory of resources (only ontologies, terminologies or linguistic resources (ACL4
or META-NET5)). The frontiers between knowledge resources are not clearenough in terms of applications [Garshol 2004] even though many researchstudies have proposed formal definitions to categorize and identify types ofknowledge resources [Guarino 1997, Gilchrist 2003]. Consequently, a reposi-tory that can cope with heterogeneous types of knowledge resources can beuseful along with the existing repositories. Hence, models for representingthese resources are required for using them together. In general, there isa need for more than one resource to perform knowledge engineering tasks,then it’s important to have repositories offering access to a more rich set ofknowledge resources represented within multiple formalisms (see figure B.1).
A required feature for resources repositories (or libraries) is the supportof heterogeneous representations of knowledge and the diversity of knowledgeresources. What we propose as a solution is a knowledge engineering sys-tem that is able to represent, and store heterogeneous knowledge resources,align them and offer operators for combining their content. This requiresconsidering knowledge resources regarding different aspects:
• Resources representation aspect: Knowledge resources exist under dif-ferent formats and languages (predicate logic, description logic, seman-tic networks, conceptual graphs, natural language, etc.). This diversityin knowledge representation and the semantics supporting each repre-sentation approach makes it difficult to define or use a unique approachto represent and store these resources.
4http://www.aclweb.org5http://www.meta-net.eu

1.1. Scientific context and research problem 3
• Resources retrieval aspect: Finding linguistic, terminological and onto-logical knowledge resources is not a simple task, it is generally difficultto find the required resources for a specific process. Some knowledge re-sources repositories have been created to offer a more effective indexingfor these resources than common search engines. The representationof the resources metadata and collecting information about the usageof these resources is a key to a better indexing and retrieval of them.
• Resources management aspect: Multiple tools and methodologies forcollecting, combining and reusing knowledge are proposed and manysurveys collected descriptions and specifications of different knowl-edge engineering approaches [Mårtensson 2000, Shvaiko et al. 2006,Scharl et al. 2012, Liao 2003]. However, few models for representingthese tools and classifying them have been proposed [Schreiber 2000,Wielinga et al. 1992] which makes it difficult to represent and shareinformation about knowledge resources engineering.
Resources Repository
User Need Opera'ons
Representa'on
Figure 1.1: A repository of heterogeneous knowledge resources.
The aim of this research project is to build a repository ofknowledge resources. This repository is a collection of hetero-geneous resources represented by multiple formalisms or modelsand allows a user to generate new resources by means of simple orcomplex operators.

4 Chapter 1. Introduction
1.2 Research areas
The quality of a solution to the heterogeneity problem within knowledgerepositories requires to (1) represent heterogeneous resources and organizetheir content using a common vocabulary and representation approach (2)define a set of generic operators for the management and the combinationof these resources. To build a resources repository that satisfies the require-ments, we identify two main problems to solve:
1. Is there a model that can unify heterogeneous models ofknowledge resources?
Since there exist many different (and incompatible) ways to expressknowledge in resources, it is hard to devise a single representationmodel for their content. Moreover, the same resource may be involvedin processes that support a specific model. For instance, an existingontology alignment service may only support as input OWL ontologies,while another service might require terminologies represented with theSKOS formalism. The same is true for other processes like automatedtext annotation, multilingual text alignment, word sense disambigua-tion, etc.
2. What operators can we use for combining resources?
Knowledge management tasks are defined by means of a sequence of ab-stract operators, for example to build a search application the first stepis creating indexes of knowledge resources which is itself a process re-alized over different steps such as tagging, named entity identification,etc. Therefore, there is a need to propose a model for representingknowledge engineering tasks and develop a set of subsequent opera-tors. The definition of these operators depends on the treatment ofthe knowledge within resources. Each operator can be implemented inseveral ways depending on the types of its parameters.
1.3 Proposed research methodology
Since there are two sides of the problem, related to resources representationsand knowledge engineering operators, we have identified the following stepsfor our research:
1. Study the diversity of approaches for representing knowledge resourcesand identify the types of knowledge resources that will be considered.Define a model for creating a common representation of these resources.The representation approach should lead to building a storage facility

1.4. Restrictions for the research plan 5
that collects knowledge from heterogeneous resources. The represen-tation model is intended to be generic in order to allow representingalignments or matchings between entities of heterogeneous knowledgeresources.
2. Define an approach to represent and integrate different implementa-tions of knowledge engineering operators that are intended to manageand combine all kinds of knowledge resources that are stored and rep-resented within the repository.
3. Implement some instances of the defined operators in order to managea specific kind of resources. For instance alignment resources are con-sidered our use case since they are heterogeneous and are representedin different formalisms. These resources are of a great importance todemonstrate the usage of our methodology.
1. Formal representation: building a model
for knowledge resources representation
and management
2. Importing and storing knowledge
resources and define operators for
managing and combining knowledge
from heterogeneous resources
3. Implementing Knowledge engineering operators and
create a repository for managing and combining
heterogeneous alignment resources as an application
Models
Knowledge Base
Corpora of knowledge
resources
Knowledge
resources study
Figure 1.2: Methodology for creating a model for representing and a reposi-tory for managing knowledge resources.
1.4 Restrictions for the research plan
The notion of knowledge resources is quite ambiguous, this is why we con-sider as knowledge resource every resource that represents some general (highlevel) knowledge about a specific domain, as opposed to data and facts usu-ally represented in databases, spreadsheets, etc., (databases may be used to

6 Chapter 1. Introduction
store general knowledge (e.g., Wikipedia or patent datasets) but it is nottheir primary objective). The hypotheses of our research are the following:
1. Types of resources: the resources that we represent, manage and com-bine are supposed to be of a certain level of expressivity and containingknowledge that is linked using relations.
2. Resources transformation and import: functions for transforming re-sources from their original formalism to another formalism or to thecommon representation model are not intended to be neither genericnor exhaustive and are not a requirement for the achievement of theresearch goals. Some of these tools will be implemented depending onthe needs for the experimentations.
1.5 Contributions
Knowledge representation, engineering and management is a wide researchfield with an ascending number of innovative approaches. Working on theidentified research problems led to two categories of contributions, havingeach multiple specific contributions:
C0 A methodology for representing heterogeneous knowledge resources,knowledge engineering abstracts and designing a repository for com-bining heterogeneous knowledge resources:
C01 we defined a categorization of knowledge resources based on thegeneric aspects such as autonomy, type of content, schemas, etc.[Ghoula et al. 2010c];
C02 we proposed a methodology for resources representation and cre-ated an upper level model to represent the common and formalaspects of knowledge resources. The representation approach con-sists on considering three dimensions of knowledge representa-tion (conceptual knowledge, terminological knowledge and lexicalknowledge) and different levels of expressivity (meta-level, schemalevel, resources level) [Ghoula et al. 2010b];
C03 we created common models for representing generic entities andrelations for some categories of the identified resources. Thesemodels were integrated within the proposed resources model (The-sauri entities, ontology entities, etc.); We implemented someknowledge engineering operators within a use case of merging mul-tiple ontological and terminological resources in order to create anenriched version of WordNet [Ghoula et al. 2010a, Ghoula 2012].

1.6. Impacts and applications of the contributions 7
C04 we proposed an approach to represent knowledge engineer-ing operators and proposed a taxonomy of resources manage-ment and combination operators. We created different cate-gories of knowledge engineering operators and we defined newoperators. We also created a library of knowledge engineeringoperators based on the existing operators from the literature[Ghoula et al. 2011, Ajmi et al. 2012, Ghoula & Falquet 2012].
C1 An approach for designing concrete operators for managing and combin-ing heterogeneous alignment resources:
C11 we categorized alignment resources and designed a generic modelfor representing and storing alignments [Ghoula et al. 2013];
C12 we defined an operator for composing alignment resources usinguncertainty theories [Ghoula et al. 2013, Ghoula et al. 2014];
C13 we defined an operator for aggregating alignment resources gen-erated by different matchers using a fuzzy theory and an evidencecombination theory [Ghoula et al. 2014];
C14 we created a repository for alignment resources based on thealignment model and implemented the proposed operators withinan API. The description of these operators was supported by theoperators model [Ghoula et al. 2014];
C15 we applied the proposed operators in the case of ontology match-ing and proposed an evaluation methodology for testing their im-plementation [Ghoula et al. 2014];
C16 we proposed extra tools for enhancing the alignment compositionin order to enrich existing alignments.
The innovation of our methodology is the possibility to build a concreteoriginal repository that allows users to manage and combine their resourcesor resources within the repository using their operators or operators fromthe library of the repository.
1.6 Impacts and applications of the contributions
The current state of the art about knowledge resources combination andengineering lacks organization and formalization. Tools are being built andused without being described and shared efficiently. For adapting knowledgeresources, users need a system that plays the role of a framework that importstheir resources and combine them using multiple built-in or external tools.

8 Chapter 1. Introduction
The contributions of this work are of a great use for research and industry;it proposes the basic elements that support a library of tools for knowledgeengineering. The proposed ontology offers the possibility to integrate knowl-edge resources representation. This insures different levels of interoperabilityand a dynamic representation of knowledge resources. The representation ofknowledge resources operators is a support for building algebra for combiningand composing these operators. Some research issues have been addressedand solved in terms of resources representation and combination. In termsof usage for research, our contributions offer the ground for a potential openrepository where researchers can share their experiences (tools and processes)and their resources (derived, adapted and validated).
TOK LAB Resources Library
OperatorsLibrary
ResourcesOperators
Figure 1.3: Application and impacts of the proposed methodology.
The proposed approach is a candidate for an industrial application. Asystem can be proposed as a laboratory of knowledge resources combina-tion based on commercial or open-source tools that derive knowledge fromexisting public or private resources.
1.7 Thesis plan
The thesis proceeds as follows:
• Chapter 2 describes the background knowledge about knowledge rep-resentation and resources repositories;
• Chapter 3 provides definitions for the knowledge resources that areconsidered in this research and describes the aspects of resources repre-sentations (contribution C0: C01) while presenting our categorizationof knowledge resources and discussing the state of the art of resourcesrepresentation models.

1.7. Thesis plan 9
• Chapter 4 presents our approach of resources representation by de-scribing an upper level model for representing heterogeneous knowledgeresources (contributions C0: C02).
• Chapter 5 proposes a taxonomy of knowledge resources combinationand management operators and describes some examples of concreteapplications of our approach for representing and combining heteroge-neous knowledge resources (contributions C0: C03-C04).
• Chapter 6 presents the first part of an application of our approachby defining a generic model for representing alignment resources asan extension of the proposed model. In this chapter we describe thetransformation of existing alignment representations (based on differ-ent formalisms) into our generic alignment model (contributions C1:C11-C14).
• Chapter 7 details the second part of the application of our methodol-ogy by defining and implementing a framework of interpretation andcombination of heterogeneous alignment resources (contributions C1:C12-C13).
• Chapter 8 is dedicated to the evaluation of the application of ourmethodology by testing the usefulness our alignment combination op-erators. In this chapter we describe a proposal to enhance the compo-sition operator by exploiting the content of resources and discusses thepossibility of enriching existing alignments using the composition andaggregation (contributions C1: C14-C15-C16).
• Chapter 9 provides a discussion about the contributions and a descrip-tion of some future work.


Chapter 2
Knowledge representation andrepositories for managing
knowledge resources
Contents2.1 Knowledge and knowledge representation . . . . . . . 11
2.1.1 Knowledge . . . . . . . . . . . . . . . . . . . . . . . . 12
2.1.2 Knowledge representation . . . . . . . . . . . . . . . . 13
2.1.3 Knowledge representation formalisms . . . . . . . . . . 15
2.2 knowledge resources repositories . . . . . . . . . . . . 16
2.2.1 Repositories for indexing and retrieving knowledge re-sources . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.2 Repositories for collecting and managing knowledge re-sources . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.3 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 19
In this chapter we present an overview of the notions related to the prob-lem of representing and managing heterogeneous knowledge resources. Westart by describing the notion of knowledge and discuss some consensus aboutknowledge representation. Then, in the context of knowledge engineeringwe explore particularly knowledge repositories and knowledge artifacts (re-sources) that can be represented and managed within repositories.
2.1 Knowledge and knowledge representation
Without launching a debate about the definition of “Knowledge”, which is asubject supporting multiple visions and philosophical theories [Moser 1998],we intend to define the characteristics of this notion that are related toknowledge organization and representation [Hjerland 2003].

12Chapter 2. Knowledge representation and repositories for
managing knowledge resources
2.1.1 Knowledge
From an information technology (IT) perspective, the definition of knowl-edge relies on the distinction between data (referred to as syntactic entities),information (defined as interpreted data) and knowledge (defined as learnedinformation) [Aamodt & Nygård 1995]. There are different visions about therelationships between data, information and knowledge, the most commonone is that knowledge is created based on information that are extractedfrom data (the model: data to information to knowledge) [Ackoff 2010].
In a review about knowledge management, [Alavi & Leidner 2001] dis-cussed this vision of knowledge management in IT and relied on the argu-ments of [Tuomi 1999] to stipulate that the data to information to knowledgemodel should be interpreted as knowledge to information to data. The ex-planation of this vision is that “knowledge must exist before informationcan be formulated and before data can be measured from information”.[Fahey & Prusak 1998] proposes a model where knowledge is used to elabo-rate information, interpret data and learn new knowledge (see figure 2.1).
Figure 2.1: Data-Information-Knowledge model according to[Fahey & Prusak 1998]
According to empirical studies [De Jong & Ferguson-Hessler 1996]knowledge can be divided into multiple types: situational, conceptual (propo-sitional/declarative), procedural and strategic. The majority of studiesabout knowledge representation focus on two types, which are declarativeknowledge (“know what”) and procedural knowledge (“know how”).
In the context of our research, our concern is about conceptual (or declar-ative) knowledge which is defined by [De Jong & Ferguson-Hessler 1996] as“static knowledge about facts, concepts and principles that apply within

2.1. Knowledge and knowledge representation 13
a certain domain”. This definition of declarative knowledge does not in-volve the representation aspect, which is important for its usage. Declar-ative knowledge is the kind of knowledge that is related to the descriptionof “Things” using a mental representation of its characteristics, associatedbelief, status and related knowledge.
2.1.2 Knowledge representation
Knowledge representation allows to express, represent, store, reason aboutand exchange knowledge. In the context of declarative knowledge, knowl-edge representation relies on a symbolic unit which is the concept. Multipleinterpretations from different perspectives can be attributed to the concept[Margolis & Laurence 2014].
The concepts can be seen as (1) mental representations (entities to repre-sent internal propositional attitudes in the mind), (2) as abilities (“abilitiesthat are peculiar to cognitive agents” [Margolis & Laurence 2014]), or (3)as abstract objects (which play the role of “constituents of propositions”[Margolis & Laurence 2014] that “mediate between thought and language,on the one hand, and referents, on the other” [Margolis & Laurence 2014]).To represent knowledge, we adopt the third interpretation (abstract objects)which is also the vision of Gottlob Frege1 as detailed in [Zalta 2014].
Figure 2.2: The semiotic triangle of [Ogden & Richards 1927]
We consider a concept as a key element for the declarative knowledgerepresentation. A concept is as an abstract object that brings sense to thenatural language representation and refers to a referent (this is also describedin [Ogden & Richards 1927] see figure 2.2).
1http://fr.wikipedia.org/wiki/Gottlob_Frege

14Chapter 2. Knowledge representation and repositories for
managing knowledge resources
Thus, the concept becomes an entity of knowledge representation de-scribed (or expressed) generally using terms (as labels). For instance, therepresentation of such an entity within ontologies can be primitive (simpleconcepts) or using a composition of primitive concepts to represent a definedconcept. This composition depends on the expressivity of the representationformalism.
Each concept within a knowledge representation formalism has a definednumber of attributes and is connected to other concepts throughRelationsare used to represent links such as subsumption (the kind of relations betweenconcepts is defined by the knowledge representation formalism).
According to [Stephan et al. 2007], knowledge representation “studies theformalization of knowledge and its processing within machines”. From aperspective of Artificial Intelligence, a knowledge representation approachdefines a machine-readable and machine-interpretable representation of adomain of interest. For instance, an ontology is a knowledge representa-tion artifact that defines a vocabulary of domain terms and constraintstheir meaning by indicating how concepts denoted by these terms are inter-related within a specific domain structure.
To clarify the differences in the definition and usage of ontologies in com-puter science and information systems, [Hepp 2008] identified three points ofdisagreement about the definition of this knowledge representation artifactand its fundamental properties:
• “Truth vs consensus”: this point reveals the disagreement between aview of ontologies as models of “true” reality that are independentfrom context and a view of ontologies as a representation of consensualshared human judgment;
• “Formal logic vs. other modalities”: this point reveals the disagreementabout the knowledge representation formalisms that are considered asa fundamental to qualify a resource as an ontology. [Hepp 2008] arguedabout the importance of formal logic as a modality for ontologies;
• “Specification vs. conceptual system”: this point discusses the dis-agreement about whether an ontology is considered as the conceptualsystem (by being an abstraction of a domain’s conceptual elements andtheir relations) or a specification of a conceptual system (by being theexplicit specification of this abstraction using a representation formal-ism). [Hepp 2008] pointed out that it is more popular to consider anontology as a specification of the conceptual system and represent itas a machine-readable artifact.
[Hepp 2008] stated that the nature of these disagreements are not of aterminological aspect (which term to use to qualify the concept of ontologies)

2.1. Knowledge and knowledge representation 15
but the disagreement is originated from different visions. For instance, Incomputer science, the vision is that conceptual entities within ontologies aremainly defined by formal means. In information systems, the concern is moreabout understanding the conceptual elements and their relationships thanthe means of specifications. This statement will be used in the identificationof knowledge resources types (discussed in the section 3.1 of the followingchapter).
2.1.3 Knowledge representation formalisms
Knowledge representation formalisms are the mean for creating machine-readable artifacts representing knowledge of a specific domain. The concreterepresentation of these formalisms is ensured using representation languages.Thus, the syntax of representation languages is defined by a formal grammar(e.g., XML, RDF, OWL). In general, the syntax of knowledge representationlanguages is close to the entity-relation model which can be easily representedas a graph. 3 Knowledge Representation and Ontologies 65
classical semantics
RDF(S)
OWL-Lite
OWL-DL
OWL-Full
DLP
First-OrderPredicate Logic
WSML-DL
WSML-Core
WSML-Flight
F-Logic (LP)
WSML-Rule
Datalog
SWRL
LP semantics
� decidable� undecidable
WSML-Full
mor
e ex
pres
sive
less
exp
ress
ive
DL-SafeRules
semantically embeddedapproximately sem. emb.syntactically embedded
Fig. 3.4. An overview of Semantic Web languages
former can also be expressed in the latter by means of a direct mapping of languages con-structs. A dashed arrow denotes a weaker form of embedding, where not all the features ofthe less expressive language do completely fit the more expressive target language, mean-ing that the former is in principle (approximately) covered by the latter apart from moderatedeficiencies in some language constructs and their semantic interpretation. A dash-dottedarrow denotes a syntactic embedding such that the language constructs of the (syntacti-cally) less expressive language can be directly used in the more expressive one, althoughthey may semantically be interpreted in a different way.
An early initiative to standardise a language for semantic annotation of web resourcesby the World Wide Web consortium (W3C) resulted in RDF and RDFS, which form nowa well established and widely accepted standard for encoding meta data. The RDF(S)language is described in more detail in Section 3.4.2. It can be used to express class-membership of resources and subsumption between classes but its peculiar semantics doesneither fit the classical nor the LP-style. If semantically restricted to a first-order setting,RDF(S) can be mapped to a formalism named description logic programs (DLP) [18], thatis sometimes used to interoperate between DL and LP by reducing expressiveness to theirintersection.
On top of RDF(S), W3C standardisation efforts have produced theOWL family of lan-guages for describing ontologies in the SemanticWeb, which comes in several flavours withincreasing expressiveness. Only the most expressive language variant, namely OWL-Full,
Figure 2.3: An overview of semantic web languages according to[Stephan et al. 2007]
As we described in the previous section, we use the notion of concept as aconstituent of expressions to represent declarative knowledge. The meaning(sense) of an expression is subjective and can be ambiguous if the sense ofthe symbols used to represent it is ambiguous. Thus the sense of symbolsand their combination must be defined using a formal language. This is whya formal semantics is required to explicit the meaning of symbols and theirsemantic relations (subsumption, deductions, etc.). The semantics of repre-

16Chapter 2. Knowledge representation and repositories for
managing knowledge resources
sentation formalisms is expressed using a declarative mathematical languagesuch as predicate logic or description logic.
[Stephan et al. 2007] proposed a categorized description and a surveyabout logic-based knowledge representation formalisms and languages (seefigure 2.3). These types of formalisms reproduce parts of the human reason-ing process based on the notion of logical consequence. [Shadbolt et al. 2006]argue that the success of the Semantic Web is based on the success of cre-ating standards for expressing shared meaning. Thus, knowledge represen-tation is a requirement for knowledge sharing and engineering. KnowledgeEngineering is a field of Artificial Intelligence focused on modeling, extract-ing, representing, storing and reusing knowledge. Knowledge acquisition andreuse is based on reasoning about existing knowledge.
2.2 knowledge resources repositories
One characteristic that represents at the same time a strength and a weaknessof the Semantic Web is the heterogeneity. The diversity of knowledge repre-sentation formalisms and the diversity of knowledge models enrich knowledgeengineering by reflecting a side of the real world (different domains, diversepoint of views, different cognitive models, etc.). This is counted as a positiveaspect when knowledge engineers can define and create their own models forknowledge representations and design applications to extract and generateknowledge according to specific models.
However, when it comes to the principle of knowledge sharing and com-munication between software agents, specific conditions require to be fulfilled.Communication and sharing knowledge between agents requires two levelsof interoperability:
• structural and syntactic interoperability: knowledge within the seman-tic web and knowledge engineering contexts is machine-readable andmodels are provided to exchange structured data;
• semantic interoperability: the semantic aspect of shared knowledgerequires adjustment, so that agents can reason about a shared knowl-edge without being confronted to inconsistency and ambiguity. Thesemantic interoperability requires a common reference model and awell-defined semantics.
Formalisms and standards for representing and sharing knowledge al-low representing and storing knowledge, within resources, having differenttypes (ontologies, dictionaries, thesaurus, etc.). Consequently, reasoningwith shared knowledge requires systems to organize and index these knowl-

2.2. knowledge resources repositories 17
edge resources for easier access. Thus multiple systems for indexing andstoring knowledge resources have been created.
2.2.1 Repositories for indexing and retrieving knowledge re-sources
The increasing number of ontological resources on the web became problem-atic. On one hand, resources representing the same concepts are createdindependently, which leads often to resources that are too customized to bereused and generally application dependent. On the other hand, search en-gines and information retrieval models needed to be adapted to this kind ofresources on the Web (see figure 2.4).
Figure 2.4: Architecture of Watson (“a gateway for the Semantic Web”) asdescribed in [d’Aquin et al. 2011]
Consequently, new search applications that automatically discover andindex Semantic Web documents and answer queries about this kind of re-sources have been developed in the past decade. Swoogle [Finin et al. 2005],Watson [d’Aquin et al. 2011], and OntoSelect [Buitelaar et al. 2004] aresome of the most popular Semantic Web resources repositories of this kind.These repositories are designed based on the following features:
• Categorizing the semantic richness of semantic data to use it for rankingpurposes;
• Representing relations between resources such as “import” or referencesto provide semantic clustering and navigation of resources;
• Providing access mechanisms and interfaces for software agents andhuman users;

18Chapter 2. Knowledge representation and repositories for
managing knowledge resources
These repositories solve one side of the problem, which is the aware-ness, and sharing of Semantic Web documents and ontological resources.Thus, the models for resources representation do not consider the contentof resources and do not solve semantic heterogeneity issues. Consequently,another type of repositories such as ontology libraries have been created tooffer a centralized hosted approach for collecting knowledge resources.
2.2.2 Repositories for collecting and managing knowledge re-sources
The second type of resources repositories includes the systems that donot discover automatically ontological or knowledge resources on the web.These systems rely on registered users that upload and maintain theirresources. This allows collecting and storing resources from differentsources and offer services of exploring and sharing knowledge. In the cat-egory of ontology repositories of this kind (ontology libraries) multiple sys-tems were developed such as BioPortal [Noy et al. 2008], DAML Ontol-ogy Library2, TONES Ontology Repository3, Semantic Web infrastructure[Baclawski & Schneider 2009]. Other types of repositories offer access to lan-guage resources such as TerminoTrad4, etc.
[d’Aquin & Noy 2012] provided a survey of ontology libraries. The au-thors defined a set of features to evaluate their usefulness by reviewing elevenontology libraries. The criteria that were identified in this survey are:
• Purpose and coverage: each ontology library serves a set of purposesthat are related to ontology development and sharing. Some ontologylibraries index and collect ontologies from a specific domain;
• Library content: This feature involves the criteria of the type of proce-dure for collecting ontologies (manual, hybrid or automatic), the typeof gatekeeping which is related to the validation of the submitted re-sources (manual or automatic), the metadata of ontologies and otherkey elements about the characteristics and types of content (mappingsand relations between ontologies);
• Main functions for users: Ontology libraries are evaluated accordingto the main services they offer to the user. The basic functions thatontology libraries provide include search, browsing, selecting and evalu-ating ontologies. Some systems offer programmatic access to ontologiesthrough web services and APIs.
2http://www.daml.org/ontologies/3http://rpc295.cs.man.ac.uk:8080/repository/4http://terminotrad.com

2.3. Discussion 19
• Other features: this category represent all the extra features that arenot considered as basic features for ontology libraries.
This survey represents a first study of a set of ontology libraries. Themain contribution is the categories of features that are defined to evaluateand compare these libraries. This kind of repositories is evolving and becom-ing more and more accurate for an effective sharing and reuse of ontologicalresources.
Another survey tackles the concept of ontology repositories from anotherperspective. [Heymans et al. 2008] study a set of ontology repositories thatstore ontological resources based on their storage schemes. There are two cat-egories of ontology repositories which are native and database-based stores.Native stores use the file system as storage mechanisms. This method hasthe advantage of supporting a large quantity of data. This type of storage ismore popular thanks to its effectiveness in terms of loading and to its open-ness to possibilities of optimization. Allegrograph5, Jena TDB6, sesame7 andOWLIM [Kiryakov et al. 2005] are ones of the most popular native stores.
Database-based stores use database management systems such asMySQL, PostgreSQL or Oracle. This model is less performant than thenative storage for load and update actions but offers more advantages:
• benefit from the use of database systems such as query optimizationmechanisms, transactions, persistence, access control, etc.;
• access knowledge within ontologies and other datasets within differentdatabases. RDF queries can be translated into SQL queries which canbe integrated within other SQL queries that retrieve data from othersources.
Multiple benchmarks are proposed in order to evaluate RDF triple storetechnologies8. Some ontology repositories are considered more relevant thanothers depending on their capabilities of performing reasoning and inference.Evaluating RDF stores is somehow controversial since their performance de-pends on multiple parameters such as the hardware, the cache mechanisms,order of triples within queries, etc.
2.3 Discussion
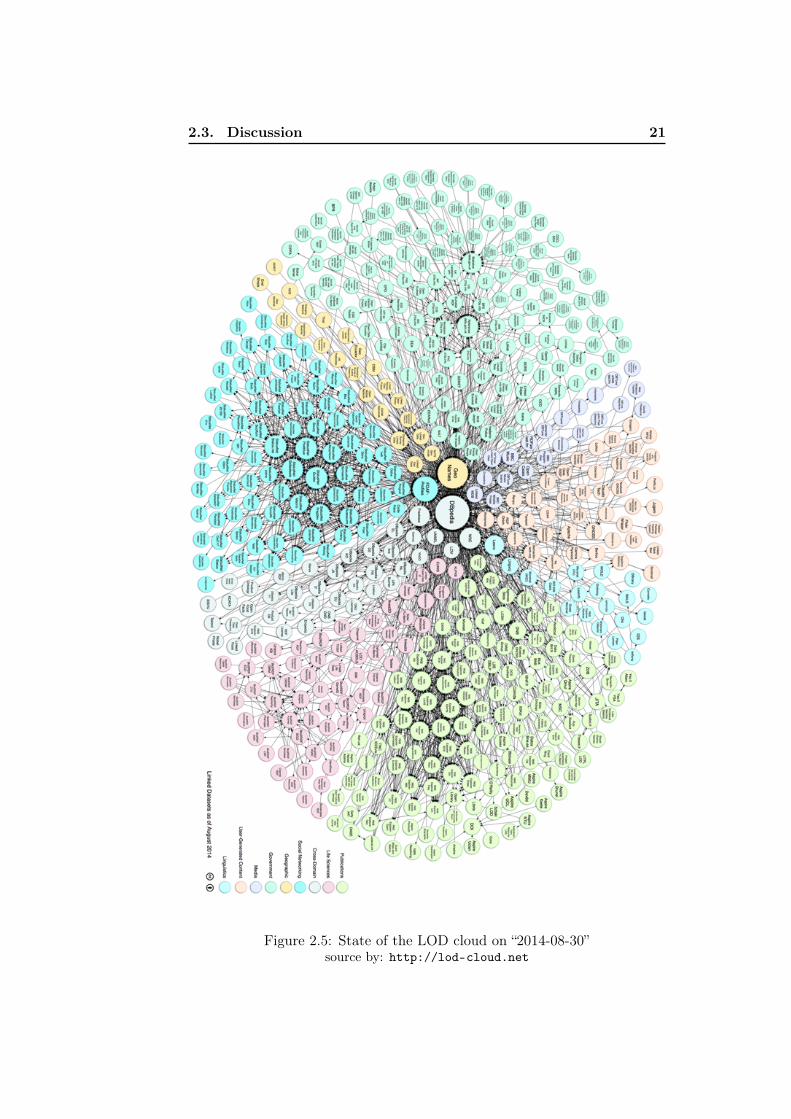
Since the semantic Web is qualified as the Web of data, the paradigm ofLinking Open Data (LOD) [Bizer et al. 2009] was proposed as a solution for
5http://franz.com/agraph/allegrograph/6http://jena.apache.org/documentation/tdb/7http://www.openrdf.org8http://www.w3.org/wiki/RdfStoreBenchmarking

20Chapter 2. Knowledge representation and repositories for
managing knowledge resources
large scale integration of data on the Web (see figure 2.5). This is a morepractical solution than Semantic Web resources indexing and crawling. Thisapproach is a solution for sharing and exchanging instances of knowledgefrom of different origins. For instance, DBPedia [Auer et al. 2007] is anexample of a large linked dataset that represents, publishes and links toother resources the content of Wikipedia.
The scope of our research is not about developing another ontology repos-itory similar to what currently exists in the state of the art. Our main ob-jective is to go beyond collecting ontological resources to considering theircontent and to offering extra services than managing ontologies. The scopeof our research is between knowledge resources libraries and linked data. Weintend to represent knowledge within heterogeneous resources (not only on-tologies) and access the content of these resources to offer operators thatgenerate new elements of knowledge by reusing this content.
There are multiple propositions of technologies for storage mechanismsthat can be used to store knowledge resources. Our intention is not topropose a new design or model to create a native or database-based store.We assume that the existing solutions are useful to effectively store knowledgeand that the performances of triple stores or ontology repositories are alreadygood enough to be used as a support for the resources repository that weintend to design.
A repository containing heterogeneous types of knowledge resources isneeded. Hence, multiple models and formalisms for representing these re-sources are required. For this purpose, it is necessary to develop a set ofknowledge resources operators that can import, export and process these re-sources while keeping a trace of their origin (the provenance of the resources,for example externally imported or generated from the combination of otherresources).
In the next chapter, we focus on defining the kinds of knowledge resourcesthat we will consider. We also investigate the state of the art about theexisting models for representing heterogeneous knowledge and we discussthe aspects that we consider for representing and combining heterogeneousknowledge resources.
2.3. Discussion 21
Figure 2.5: State of the LOD cloud on “2014-08-30”source by: http://lod-cloud.net


Part I
Resources representation andcombination approach


Chapter 3
Identification of knowledgeresources
Contents3.1 Definitions and typology of knowledge resources . . . 26
3.1.1 Knowledge resources . . . . . . . . . . . . . . . . . . . 26
3.1.2 Resources represented using formal ontology languages 27
3.1.3 Terminological, Lexical and semantic resources . . . . 30
3.1.4 Linguistic resources . . . . . . . . . . . . . . . . . . . 33
3.2 Models and representation approaches for hetero-geneous knowledge . . . . . . . . . . . . . . . . . . . . . 35
3.2.1 Metadata representation models . . . . . . . . . . . . 35
3.2.2 Specific representation models . . . . . . . . . . . . . . 38
3.2.3 Generic representation models . . . . . . . . . . . . . 40
3.3 A high level classification of knowledge resources . . 41
3.3.1 Autonomous resources . . . . . . . . . . . . . . . . . . 41
3.3.2 Enrichment resources . . . . . . . . . . . . . . . . . . 42
3.3.3 Combined Resources . . . . . . . . . . . . . . . . . . . 43
3.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 43
In this chapter we state the hypotheses about the kind of knowledge weconsider and about the content we aim to represent within resources. We alsorepresent a state of the art about resources classification and generic modelsfor representing heterogeneous knowledge. The resources that we considerare represented in different formalisms and represent declarative knowledgeusing formal or semi-formal representations. These types of resources repre-sent the domains of human activity and describe them using different sortsof entities that might be related to each other. This criterion makes themcandidates for matching, integration and further knowledge management op-erations. In order to design a generic model to represent heterogeneous re-sources we defined the following steps as key elements for the model’s design(see figure 3.1).

26 Chapter 3. Identification of knowledge resources
Identifying knowledge resources. (Section 3.1)
Classify the selected resources. (Section 3.2)
Explore existing resources models. (Section 3.3)
Usage of the proposed model. (chapter 5)
Propose a common resources model. (Chapter 4)
Figure 3.1: Steps for designing a meta-model for representing knowledgeresources
3.1 Definitions and typology of knowledge re-sources
Some research works explore the organizational aspect of knowledge resources[Holsapple & Joshi 2001], other works define procedures for reusing knowl-edge resources [Markus 2001] and many other research methodologies defineknowledge resources based on specific use cases or for representing proceduralknowledge about applications.
3.1.1 Knowledge resources
For our research methodology, we consider resources that represent somegeneral (high level) knowledge about a domain, as opposed to specific facts.Formal representation is always interconnected with lexical representations;for instance, formal ontologies use vocabularies for identifying concepts, re-lations, individuals, or other entities.
In fact, using natural language is one way to connect a formal represen-tation to the reality it represents. In less formal resources such as glossariesand encyclopedias, natural language is the only way to describe concepts andother entities. Even in formalized resources, natural language appears in thedescription of logical formulae, classes, relations, etc.
Definition 1 (Knowledge Resource) We define a knowledge resource asa named resource representing some knowledge of a domain and having acreation origin, content and a usage purpose. The content is representedusing a knowledge representation formalism that has a specific semantics.
Many research studies have pointed out the importance of knowledge re-sources and defined their properties. The main characteristics of a knowledge

3.1. Definitions and typology of knowledge resources 27
resource are: (1) the intention of its usage (domain, application, etc.), (2) thesize (or volume), (3) the linguistic expressivity (linguistic model and lexicalrelations around terms), (4) the model and standards used for its represen-tation and (5) the expressivity level of it representation formalism and se-mantics. These resources are represented using formal languages and explicitsemantics (e.g. ontologies) or represented using less formal languages. Someresearch studies consider structured resources as ontological resources andclassify them using the representation formalism [Uschold & Gruninger 2004](see figure 3.2).
Figure 3.2: Types of ontological resources according to[Giunchiglia & Zaihrayeu 2009] adopted from [Uschold & Gruninger 2004]
[Villazón-Terrazas et al. 2010b] classifies knowledge resources into onto-logical and non-ontological resources based on the fact that the semantics ofthe latter resources is not formalized and defined explicitly using ontologicalrepresentation. In this section, we identify and describe different kinds ofresources and explore their entities and representations.
3.1.2 Resources represented using formal ontology languages
An ontology is used to represent a specification of a conceptualization ofa domain [Gruber 1995]. It consists on defining domain concepts and re-lations between them. Ontologies are expressed using formalisms offeringconstructors for the definition of its entities [Wang et al. 2007].
A formal ontology is a knowledge resource that is explicitly representedusing an ontology representation formalism. The representation formalismexpresses meaningful statements of a specific context or domain using theresource’s entities. Formal constraints are applied for an ontology repre-

28 Chapter 3. Identification of knowledge resources
sentation formalism,which defines its semantic (Definition of a statement ora fact, type of entities involved in an assertion, etc.). Ontologies can beexpressed using high-level languages in order to be understood by human(e.g., natural language, UML, conceptual graphs [Chein & Mugnier 1992]and semantic networks [Sowa 2006] representations). These formalisms arenot machine-readable unless they have a concrete syntax that is processedby computers. Thus, multiple formalisms have been defined for representingformal ontologies (see surveys [Nguyen 2011] [Stephan et al. 2007]). Theseformalisms have different levels of expressiveness. For instance, represen-tation formalisms based on first-order logics are more expressive than for-malisms based on description logics [Baader et al. 2005]. The higher thelevel of expressivity the more complete the knowledge representation be-comes. Consequently, reasoning on knowledge becomes more efficient andrepresentative. The high level of expressivity requires better performancesin terms of reasoning, more expertise in understanding logic and more spec-ification for representing knowledge. [Nguyen 2011] proposes the followingclassification of ontology representation formalisms:
1. Traditional Ontology Languages: Ontologies are represented usingframe-based languages, which are based on frames and slots. A framerepresents a concept and the frame’s slots represent its associated at-tributes:
• Frame Logic (F-Logic) [Kifer & Lausen 1989] is a declarativeknowledge representation formalism that combines frame basedlanguages with concept modeling. Frame languages give this for-malism a compact syntax. Its semantic is defined based on logicsand a closed world assumption1;
• Knowledge Interchange Format (KIF) [Genesereth et al. 1992] isa declarative frame-based language dedicated to interchangingknowledge between systems that supports non-monotonic reason-ing2. KIF is a formal language that describes facts as objects,functions, relations and rules in first order logic;
• CycL: a declarative formal ontology representation languagebased on first-order logic and modal operators. This languagewas developed to represent the Cyc Knowledge Base [Lenat 1995]using constants, functions, rules and generalization/specializationrelations;
1A true statement is also known to be true and what is not currently known to be true,is false
2A consequence relation is not monotonic: adding a formula to a theory might reduceits set of consequences (revision of knowledge)

3.1. Definitions and typology of knowledge resources 29
• Other formalisms such as LOOM [MacGregor & Bates 1987],which is a frame-based formalism where declarative knowl-edge is represented using definitions, rules, facts, and defaultrules, or OCML (Operational Conceptual Modelling Language)[Motta 1998], which “allows the specification and operationaliza-tion of functions, relations, classes, instances and rules.”3.
2. Web Ontology Languages: they are based on XML [Bray et al. 1998]and RDF [Klyne & Carroll 2006] and are intended to be used for theinteroperability of resources on the web. These languages are widelydescribed and multiple surveys are available for a detailed descriptionof each of them:
• Ontology Inference Layer (OIL) [Corcho et al. 2004] is an ontol-ogy representation formalism that is based on description logicsand exchange standards such as RDF and RDFS. DAML+OIL[Fensel et al. 2003] is a combination between DAML (DARPAAgent Markup Language)4 and OIL, which is more expressivethan OIL and less based on frames representations;
• Other formalisms such as XML-based Ontology Exchange Lan-guage (XOL) [Karp et al. 1999] and Simple HTML Ontology Ex-tension (SHOE) [Heflin & Hendler 2000] are formalisms for ex-changing knowledge representation on the Web within HTMLpages;
• Web Ontology Language (OWL) [McGuinness et al. 2004] is aformalism and a standard for representing ontological resourceswithin the context of the Semantic Web. This formalism is basedon DAML+OIL and therefore close to description logics, frame-based representation and RDF. Three main languages are pro-posed for this formalism: (1) OWL-Lite is the least expressivelanguage for OWL, which is adapted for hierarchical representa-tions and classification; (2) OWL-DL has a decidable inferenceprocedure. This language is close to the description logics and (3)OWL-Full is the most expressive one and its semantics is close tofirst-order logic. The differences between the three languages forOWL are mainly due to the difference of definitions of owl:classand owl:ObjectPropertyType.
3source: http://projects.kmi.open.ac.uk/ibrow/toolset.htm4http://www.daml.org

30 Chapter 3. Identification of knowledge resources
Figure 3.3: Semantic Web languages stacksource by: http:
//bnode.org/blog/2009/07/08/the-semantic-web-not-a-piece-of-cake
Choosing a formalism for ontology representation depends on its appli-cation: knowledge exchange, referencing, automatic reasoning (logical in-ference) or knowledge structuring [Wache et al. 2001]. For instance if theontology is supposed to be generic and its goals are not precise then theframe-based representation languages are more adequate for its representa-tion.
3.1.3 Terminological, Lexical and semantic resources
Researchers use different names refer to these resources; they qualify themas ontologies or light weighed ontologies. Their entities are generallyinterpreted differently than ontological entities. Some researchers qual-ify hese resources as termino-ontological resources[Reymonet et al. 2007,Aussenac-Gilles et al. 2006, Badra et al. 2011], others use the term lexi-cal ontologies [Hirst 2009, McCrae et al. 2011, Nédellec et al. 2010] or “non-ontological” resources [García-Silva et al. 2008, Gangemi & Presutti 2009,Matusov et al. 2013]. In table 3.1 below we present an excerpt of some re-search works that have considered and categorized these types of resources.These classifications are not standard and each of them depends on the scope

3.1. Definitions and typology of knowledge resources 31
of the research survey and some criteria that may be relevant for one studyand non relevant for another. Besides relevance, the categorization criteria,models representing elements of this category were not taken into consider-ation.
Authors Classification
[Gangemi et al. 1998]• Catalogue of normalized terms• Glossed Catalogue• Taxonomy
[Maedche & Staab 2001]• Text• Dictionary• Knowledge base• Relational schemata
[Sabou et al. 2007a]• Unstructured• Semi-structured• Structured
[García-Silva et al. 2008]• Glossaries• Lexicons• Classification schemes• Thesauri• Folksonomies
Table 3.1: Classification of “non-ontological” resources in the literature
These classifications are based on the structure of the re-sources [Sabou et al. 2007a] or the entities within these resources[Gangemi et al. 1998]. [García-Silva et al. 2008] defined an approachfor categorizing “non-ontological” resources. His methodology is based onthree different features: (1) the type of a “non-ontological” resource, whichrefers to the type of knowledge encoded by the resource; (2) the data modelused to represent this knowledge; and (3) the resource’s implementation.The methodology of [Villazón-Terrazas et al. 2010b] aimed to build guide-lines and patterns to transform “non-ontological” resources into ontologicalresources. The model for representing these resources according to theauthors will be described in the section 3.2.
[Hodge 2000] defines a methodology for classifying Knowledge resourcesthat are not clearly defined as ontologies based on criteria such as structureand complexity. Thus, he classifies “non-ontological” resources under threecategories. We describe each item of this classification in order to identify

32 Chapter 3. Identification of knowledge resources
their entities and the difference between them:
• Term Lists: resources that contain terminological entities linked toeach other using terminological relations.– Terminologies: resources that represent concepts of a par-
ticular domain and associates them to terms and label[Wright & Budin 1997, Tudhope et al. 2006]. Each domain, sub-domain or specialty has a specific terminology to identify theterms to use;
– Gazetteers: or geographical dictionaries, are resources represent-ing information about a specific type of entities (places or loca-tions) [Toral & Munoz 2006, Souza et al. 2005];
– Glossaries: (referred to as a vocabulary) is a resource that rep-resents a list of terms that describe a domain’s concepts by asso-ciating definitions to them [Kohavi & Provost 1998]. The entitiesof a glossary are concepts (labeled by terms), definitions and theassociations between them within a monolingual or multilingualcontext;
• Classifications and categories: resources that contain conceptual enti-ties linked to each other using hierarchical relations.– Categorization schemes: these resources describe the representa-
tion of objects in a detailed manner in order to define principlesfor identifying and understanding the link between an object anda category (or a class) [Rosch 1999];
– Subject headings: (index terms, subject terms, or descriptor) areresources representing a set of terms associated to concepts thatrepresent another resource’s content. For instance, the usage ofthese resources enhances information retrieval. Two typical ex-amples of these resources are MeSH (Medical Subject Headings)[Lowe & Barnett 1994] and LCSH (Library of Congress SubjectHeadings) [Chan 1995];
– Classification schemes: these resources represent a hierarchicalstructure of kinds of things (or classes) associated to some descrip-tions. Objects having common characteristics are often groupedunder a specific class and individuals having different criteria aredivided into different groups [Hafellner 1988].
– Taxonomies: are resource that represents a hierarchical classifica-tion of a domain’s concepts (labelled by terms). The hierarchicalrelation between entries of a taxonomy are multiple such as whole-part, genus-species and type-instance, etc.;

3.1. Definitions and typology of knowledge resources 33
– Folksonomies: [Peters & Stock 2007] these resource are collec-tions of tags used to organize and categorize content. These tagsare proposed by multiple users as a result of a collaborative task[Lambiotte & Ausloos 2005] (social tagging).
• Relationship lists
– Semantic networks: are resources that represent knowledge as agraph of concepts linked by semantic relations. These resourcesare used to support reasoning about knowledge [Sowa 2006];
– Thesauri : terminological resources in, which terms are organizedaccording to a limited number of semantic relationships (hierar-chical, equivalence and associative) [Foskett 1980];
To this list we add documents, which are a valuable support of informa-tion. This type of resources is a particle popular subject for several studiesand is an essential artifact of knowledge engineering. Documents can betranslated or associated to specific domains and annotated or indexed usingthesauri or ontologies;
Some research works consider all these structured resources as ontologiesand others classify them differently. In this contribution, our concern is notabout representing these heterogeneous resources under one unique formalrepresentation, we intend to keep the aspects of their entities.
3.1.4 Linguistic resources
For developing tools of Natural Language Processing (NLP) and ontologyengineering, (which is a field of research, for studying human-computer in-teraction through natural language, that finds its origin in the early worksof Alan Turing on intelligence [Turing 1950]), designers from research andindustry need to collect large amounts of encoded natural language repre-sentations in order to base their design on real cases of language usage. Thiskind of resource is generally called “linguistic resources”.
A linguistic resource is an artifact that collects machine-readable infor-mation of written or spoken language productions. These resources can beof different types:
• Written corpora: written texts and transcriptions of spoken languageproductions that are encoded using a specific standard for text repre-sentation in digital form such as the Text Encoding Initiative (TEI)5.This type of linguistic resources is divided into raw corpora (only rawdigital resources), annotated corpora (data is annotated using specific
5http://www.tei-c.org/index.xml

34 Chapter 3. Identification of knowledge resources
indications related to the structure of the text semantic or morphosyn-tactic) and aligned corpora (textual content translated into multiplelanguages);
• Spoken corpora: audio content that is related to conversations, dis-course, radio or TV broadcasts, text reading, and other of oral formsof language productions. These corpora can be enriched by differenttypes of information such as information about the meaning (sense),the soundscape, speakers, or contexts and other kinds of enrichmentdata.
• Lexicon: is a representation of a natural language’s words and gram-mar. These resources can be represented as sets of lexemes. A lexemeis an entity that represents a word and associates if to descriptionsabout all its usage forms [Laskowski 1987];
• Dictionaries: (referred to as a lexicon in some cases) are set of wordsthat are similar to lexicons. A dictionary entity is similar to a lex-eme but it is associated to additional information such as definitions,pronunciation, translation and other types of information.
• Other types such as lexical databases, which are resources that repre-sent a linguistic-aware approach for knowledge representation. Word-Net [Fellbaum 1998] is a typical example of a manually constructed lex-ical ontology (which is in the category of linguistic resources). Lexicalobjects are represented by synsets. Synsets are organized semanticallywith a distinction of their part of speech (nouns, verbs, adverbs andadjectives) in a hierarchy by hypernymy-hyponymy relationships.
These resources are heterogeneous in terms of the linguistic informationthey represent, scope, content granularity, format of data, granularity ofrepresentations, type of knowledge (declarative or procedural), etc.
The main purpose of linguistic resources is to serve as a refer-ence to Natural Language Processing approaches for machine translation[Koehn 2005], ontology engineering [Pazienza & Stellato 2006] or content ex-traction [Strassel et al. 2008]. For instance, the usage of linguistic resourcesto support building ontologies is motivated by the need to ensure that theconceptual knowledge representation is associated to all of its available ex-pressions (language expressions that design a concept). As a counterexample,the YAGO6 ontology [Suchanek et al. 2007] is founded on english Wikipedia,which limits its ability of representing conceptual elements. In this ontology
6https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/yago-naga/yago/

3.2. Models and representation approaches for heterogeneousknowledge 35
a concept is not considered as such if there is no entry of any label repre-senting it in “english”. This is understandable since the approach of buildingthe YAGO ontology is based on Wikipedia and WordNet [Fellbaum 1998](the common language for both resources is English). As a concrete illus-tration of this issue, the article “http://fr.Wikipedia.org/wiki/Vésenaz”that exists only in French Wikipedia represents an entry for a fact that thevillage “Vésenaz” has as “Canton” the city of “Genève”. Thus, linguistic re-sources are very useful to achieve a high level of expressivity by enrichingthe semantic representation using lexical expressions in natural language.
These resources are widely used as support for building tools[Dipper et al. 2006] for:
• training systems: train some algorithms and tools based on machine-learning such as search engines, classifiers, statistical translation, re-sources generators, etc.;
• evaluating approaches: large corpora of linguistic resources are of-ten used to evaluate tools for information retrieval, classification,filtering, or other kinds of applications that are related to doc-uments and language. Multiple evaluations campaigns are basedon corpora of linguistic resources such as TREC7(Text REtrieval,Conference), which is an evaluation corpora for text retrieval tools[Collins-Thompson et al. 2014].
Building linguistic resources relies on collecting generic or domain specificoriginal digital or digitalized data. In general, these data are then processedfor a better usability (structural, morphosyntactic and semantic annotation).
3.2 Models and representation approaches for het-erogeneous knowledge
There are many models and languages for knowledge representation, gener-ally each model represents a certain aspect of the resources without coveringall their types: ontological, terminological, lexical, textual, documentary,etc. It is more difficult to find models representing a variety of knowledgeresources of different kinds.
3.2.1 Metadata representation models
Many representation models were built for representing knowledge resources’metadata. OMV [Raúl et al. 2006] is an exhaustive model and standard for
7http://trec.nist.gov

36 Chapter 3. Identification of knowledge resources
representing ontological resources’ metadata. This vocabulary (figure 3.4)has been proposed to solve the problem that surrounded ontology engineeringin terms of management and reuse of ontologies within research or industrialprojects. For instance, OMV metadata elements that can be used to managedifferent versions of a specific ontology or represent the different locationswhere the ontology is deployed with regard to its application.
0:n imports
0:1 priorVersion
0:n incompatibleWith
0:n backwardCompatible
OntologyBase
• baseName
• baseAcronym
• baseDescription
• baseDocumentation
• baseKeyword
• baseSubject
OntologyDocument
• docName
• docAcronym
• docDescription
• docDocumentation
• docKeyword
• docSubject
• status
• creationDate
• modifiedDate
• language
• numClasses
• numProperties
• numIndividuals
• numAxioms
0:1 realizes
Party
• partyAcronym
• homepage
• address
Organisation
• organisationName
• organisationAcronym
• location
Person
• firstName• lastName• eMail• phoneNumber• faxNumber
subclass-of subclass-of
1:n baseCreator0:n baseContributor0:n baseReviewer1:
n docCreator
0:n docContributor
0:n docReviewer
0:n appliedBy
OntologyEngineering-Tool
• toolName
• toolAcronym
• toolDescription
• toolDocumentation
0:n usedTool
0:n affiliated
0:n employs0:n contactPerson
LicenseModel
• licenseName
• licenseAcronym
• licenseDescription
• licenseDocumenation
0:n toolDeveloperClass Name
DatatypeProperty
ObjectProperty
Range
Domain
MIN:MAX Cardinality
0:1 docLicense
1:1 docType
OntologyLanguage• languageName
• languageAcronym
• languageDescription
• languageDoc
OntologySyntax• syntaxName
• syntaxAcronym
• syntaxDescription
• syntaxDoc
1:1 ontologyLanguage
1:1 ontologySyntax
KM-Method
• methodName
• methodAcronym
• licenseDescription
• licenseDocumenation
0:1 usedMethod
0:n [...]DevelopedBy
0:1 baseLicense
OntologyType
• typeName
• typeAcronym
• typeDescription
• typeDocumenation
Fig. 2. General OMV overviewFigure 3.4: OMV: ontology metadata vocabulary [Raúl et al. 2006]
This vocabulary is provided in a core version and multiple extensions.The extensions are modules that are able to represent ontology changes,mappings and ontology engineering workflows. The extensions of this vo-

3.2. Models and representation approaches for heterogeneousknowledge 37
cabulary are separated from the core version.In order to generalize OMV and represent metadata of other resources
than ontologies, [Villazón-Terrazas et al. 2010a] proposed NoRMV as a“metadata vocabulary for describing non-ontological resources”. NoRMV ex-tends OMV and provides a specific classification for non-ontological resources(figure 3.5). This model is intended to represent and create metadata ele-ments that are useful for reusing non-ontological resources.
CHAPTER 5. REUSING NON-ONTOLOGICAL RESOURCES
Resource Metadata Vocabulary (NoRMV). This vocabulary allows (1) describingthe non-ontological resources available, and (2) including in the ontology gener-ated the provenance information by extending the Ontology Metadata Vocabulary(OMV) [HPS05].
5.2.1 NoRMV Core Metadata Entities
The main classes and properties of the NoRMV are illustrated in Figure 5.325
omv:Ontology
URLnameacronymdescriptioncreationDateversion
normv:NOR
normv:Domain
normv:Implementation
hasDomain
builtByReusing
normv:ClassificationScheme normv:Thesaurus normv:Lexicon
hasImplementation
normv:Party
firstNamelastNameemail
normv:Personnameacronym
normv:Organisation
hasCreator
normv:PathEnumeration normv:AdjacencyList
normv:Snowflakenormv:Flattened
normv:RecordBased normv:RelationBased
hasDatamodel
hasDatamodel
hasDatamodelhasDatamodel hasDatamodel
hasDatamodelhasDatamodel
normv:XML
normv:Spreadsheet
normv:Database
normv:FlatFile
Figure 5.3: NoRMV: A metadata vocabulary for non-ontological resources
Besides the main NOR class, the metadata model contains elements describ-ing various aspects related to the creation, management and usage of a NOR. Webriefly discuss these in the following section. The NOR class includes as datatypeproperties, the URL, name, acronym, description, creation date and version of thenon-ontological resource. As already described in section 5.1, we classify NOR intoClassification Scheme, Thesaurus, and Lexicon, among others. Re-garding the datamodel, a ClassificationScheme may have a Flattened,a PathEnumeration, an AdjacencyList, or a Snowflake data model. Onthe other hand, a Thesaurus may have RecordBased or RelationBaseddata model. And the same occurs to a Lexicon, that is, it may have Record-Based or RelationBased data model. Regarding the Implementation,it may be classified into XML, Spreadsheet, Database, and FlatFile. Inaddition, a NOR has a Domain, and a creator, Person(s) or Organization(s).
25Please note that not all classes and properties are included. The ontology is available for down-loading at http://mccarthy.dia.fi.upm.es/normv
76
Figure 3.5: NoRMV: Non ontological resources’ metadata vocabulary[Villazón-Terrazas et al. 2010a]
This kind of models are only useful for organizing knowledge about theapplication and multiple usages of knowledge resources and their interac-tion with other resources but they do not describe their content. Otherapproaches focus on representing the knowledge within resources by specify-ing a model for each type of resources and other approaches propose more

38 Chapter 3. Identification of knowledge resources
generic models.
3.2.2 Specific representation models
[Jiménez-Ruiz et al. 2007] proposed a model that represents ontologies andtheir entities independently from a specific formalism. It uses types of ontol-ogy entities from different ontological models (figure 3.6). This model definesabstract relations between abstract ontology elements (properties, classes, in-dividuals, etc.). A query language called OntoPath is based on this modelin order to extract ontology modules with the possibility to specify the levelof details in the concept hierarchy.
Figure 3.6: Ontopath, a model for representing ontologies[Jiménez-Ruiz et al. 2007]
The extracted ontology fragments are stored as graphs. The usage of thismodel for representing ontological entities generates a usage of new types ofexplicit relations from ontology axioms. This model is only useful to solveheterogeneity issues between ontology formalisms cannot directly representterminological or linguistic resources.
For the integration of heterogeneous knowledge organization resources,[Vandenbussche & Charlet 2009] have proposed a generic model for repre-senting terminological and ontological resources that is used within the ITMtool [Delaporte & Amardeilh 2004]. The model represented in figure 3.7 pro-vides a general formalism that provides new constructors for ensuring moreexpressivity within terminologies. Despite its wide coverage, this model isnot generic enough to represent other resources such as alignments or on-tologies.
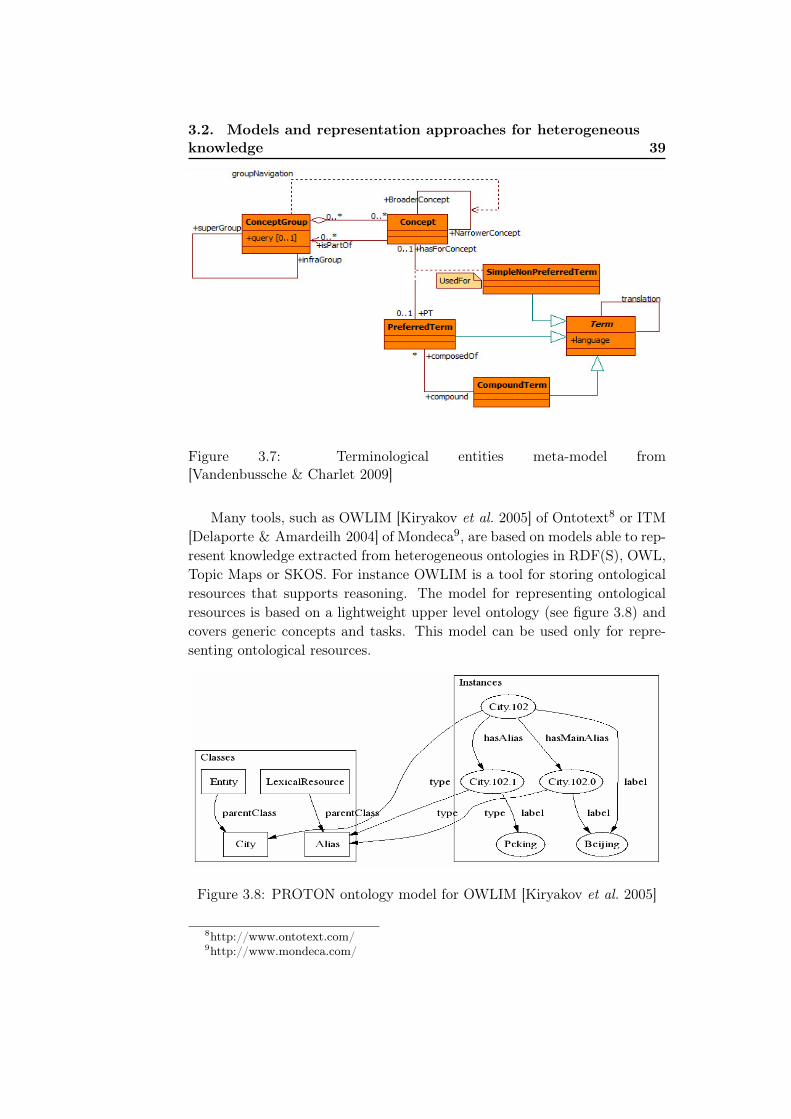
3.2. Models and representation approaches for heterogeneousknowledge 39
Méta-modèle général de RTOs
FIGURE 3 – Présentation UML simplifiée d’une partie de notre méta-modèle concernant la lin-guistique et les groupements de concepts. Cette figure montre l’utilisation de sous-classes de Termpour capturer les notions de termes préférés et non préférés reliées à un concept. La notion deConceptGroup faisant référence à un ensemble de concepts définis en intension ou en extension,peut être organisée hiérarchiquement.
correspondant à une utilisation ou à une vue sur la ressource, aurait la possibilité d’être réuti-lisé ou partagé (pour cela, notre groupement doit avoir un identifiant unique). Nous distinguonsdeux définitions des concepts dans un Concept Group. Premièrement, nous avons ceux définis parintension : ensemble des concepts vérifiant la requête d’appartenance au groupement. Deuxiè-mement, ceux définis par extension : ensemble des concepts pointant sur le groupement. LesConcept Groups sont également hiérarchisés par une relation.
Ce travail que nous sommes en train de mettre en œuvre a été soumis au groupe de recherchepour l’élaboration de la nouvelle norme ISO 25964. Ils ont ajouté cette primitive mais sans ladéfinition d’appartenance par intension. La définition de la primitive Concept Group dans notreméta-modèle répond à la problématique d’utilisation d’un sous-ensemble d’une RTO. Nous avonsainsi introduit par cet élément, de nouveaux points d’entrée dans la RTO : à la recherche arbores-cente vient s’ajouter une recherche orthogonale par groupement.
6 Discussions et conclusionsL’opérationnalisation de ressources terminologiques et ontologiques gérées de façon cohérente
est un enjeu majeur dans l’ingénierie de la connaissance. Les apports d’un méta-modèle généralpermettent de faciliter l’interopérabilité au sein d’une même application ou entre plusieurs sys-tèmes d’information et d’améliorer l’utilisation de ces ressources. Sur ce dernier point, le choixdes primitives définies dans le méta-modèle va déterminer l’exploitation directe des ressourcesqu’il sera possible de faire. Que ce soit en linguistique ou pour les groupements de concepts,il est possible grâce à l’expressivité d’un méta-modèle, d’améliorer l’utilisation, le partage et lacollaboration autour de ces ressources.
Les apports théoriques présentés dans cet article ont déjà été la source d’enrichissements denormes (cf. 5.3). Leurs mises en œuvre au sein de notre outil ITM nous donne l’assurance desrésultats d’une telle approche. La description de notre méta-modèle avec une logique mathéma-tique enrichira les traitements automatiques faits par des ordinateurs. Notre modèle ne couvre
Figure 3.7: Terminological entities meta-model from[Vandenbussche & Charlet 2009]
Many tools, such as OWLIM [Kiryakov et al. 2005] of Ontotext8 or ITM[Delaporte & Amardeilh 2004] of Mondeca9, are based on models able to rep-resent knowledge extracted from heterogeneous ontologies in RDF(S), OWL,Topic Maps or SKOS. For instance OWLIM is a tool for storing ontologicalresources that supports reasoning. The model for representing ontologicalresources is based on a lightweight upper level ontology (see figure 3.8) andcovers generic concepts and tasks. This model can be used only for repre-senting ontological resources.
The %total materialization/ strategy has its obvious drawbacks, as discussed in [1] (section 6). For specific ontologies and KBs, the count of the implicit statements can appear to grow rapidly3. What is even more important, the delete operation is really slow, which means that OWLIM is not suitable for applications where removal of data is a typical transaction.
The most obvious disadvantage of the in-memory reasoning is that the size of the KB, which can be handled, is limited by the size of the available RAM. Considering the currently available commodity hardware, OWLIM can handle millions of state-ments on desktop machines and above ten millions on an almost-entry-level server.
3 Ontology and Dataset
We took the PROTON light-weight upper-level ontology as a basis for our experi-ment. It contains about 300 classes and 100 properties, providing coverage of the general concepts necessary for a wide range of tasks, with special focus on named entities and concrete domains (i.e. people, organizations, locations, numbers, dates, addresses). The ontology is encoded in a fragment of OWL DLP. It is split into four modules: System, Top, Upper, and KM. The PROTON ontology itself and related documents can be found at http://proton.semanticweb.org.
Fig. 1. Sample Representation of an Entity Description
PROTON is also heavily used within the KIM platform. As a start, part of KIM is the so-called World Knowledge Base (WKB), which consist of thousands of entity (instance) descriptions. Each entity is described by its most specific type, aliases, attributes (e.g. the latitude of a Location), and relations (e.g. subRegionOf of another Location). A simplified schema of the entity representation is demon-strated in Fig. 1. WKB is populated with entities of general importance, which serve as a seed for KIM to perform automatic semantic annotation of text and ontology
3 Still, for many real-live scenarios the amount of implicit statements is comparable to this of
the explicit ones [ for instance KIM and the examples available in section 6 of [1].
Figure 3.8: PROTON ontology model for OWLIM [Kiryakov et al. 2005]
8http://www.ontotext.com/9http://www.mondeca.com/

40 Chapter 3. Identification of knowledge resources
3.2.3 Generic representation models
A model of the multilingual aspect in ontology has been proposed by[Montiel-Ponsoda et al. 2008], its application is an association between ameta-model of ontologies and a linguistic model. This model is based onOMV [Hartmann et al. 2005] and provides a generic modeling of lexical re-sources. An other model to unify the management of linguistic resources inmultilingual environments has been developed to centralize the representa-tion of linguistic resources within a platform called Intuition [Cailliau 2006].This model is characterized by its exploration of the structure of linguisticforms. The application of this model allows representing ontological enti-ties and identifying lexical units by taking into account the syntactic andsemantic multilingual relations.
[Picca et al. 2008] proposed a Linguistic Meta-Model (LMM) (see figure3.9) allowing a semiotic-cognitive representation of knowledge and linguisticresources using OWL−DL. It represents individuals and facts in an open do-main perspective. This model describes resources in the context of a semiotictriangle [Peirce 1974] and is composed by three classes Reference, Meaning
and Expression. This model is intended to represent lexical knowledge fromdictionary-like or encyclopedia-like resources. For representing ontologicalresources the model needs to be adapted to cover other aspects such as ax-ioms and rules. The authors provided alignments between their model andother models such as WordNet [Fellbaum 1998], SKOS [Miles et al. 2005].
Figure 3.9: The semiotic triangle in LMM from [Picca et al. 2008]
A more generic and simple model have been designed by[Suchanek et al. 2007]. The authors used this model to define an ap-proach for representing and defining the Y AGO ontology. This ontology isbased on using three types of elements representing facts. Elements that arenot denoting facts or relations are represented by a set of common entitiesC. Facts are represented using a set of identifiers I and relations betweenentities are represented using a set of relations names R. This model isvery generic since it represents an extension of RDFSit allows representing

3.3. A high level classification of knowledge resources 41
relations between facts and between relations too. The authors designedand built this model to combine different resources. This model is quiterestrictive in case of needing to represent expressions.
3.3 A high level classification of knowledge re-sources
The resources that we consider contain terminological, conceptual and lexi-cal entities. For building a repository of these resources there is no need toa precise classification of these resources. The diversity of knowledge repre-sentation within resources is correlated with the requirements of their usageand applications. When knowledge is extracted from resources, knowledgeengineering approaches are based on linguistics and natural language pro-cessing in order to extract and express the content using terminological orconceptual elements.
Conceptual Level
Sense
Terminological LevelLexical Level
LabelMeaning
Form
Figure 3.10: Keys for knowledge resources categorisation
The resources that we consider are based on the three aspects that areillustrated by the figure 3.10. The conceptual level is used to represent thesense for the terminological level that offers the meaning to the lexical level[Jackendoff 1989]. A concept is recognized and defined by a list of label orterminological items. We classify the resources that we represent into threecategories: autonomous, enrichment and combined resources.
3.3.1 Autonomous resources
We consider autonomous resources, the knowledge resources that can be usedwithout reference to other resources such as thesauri, terminologies, docu-ments, corpora or ontologies. However, these resources can be interdependent(importing a part or a whole of another resource) without questioning theirautonomy. The representation and categorization of these resources is a dif-ficult task since they may have informal or formal representations, complexor simple structures and obey or not to some usage constraints. Ontologiesrepresent a subclass of autonomous resources altogether with any type of theresources described in the first section.

42 Chapter 3. Identification of knowledge resources
3.3.2 Enrichment resources
We define enrichment resources as knowledge resources that interconnect el-ements from one or multiple autonomous resources. Enrichment resourcesare the result of applying an automated or manual process involving a setof elements that can be entities or resources. These resources are generallyconfused with the original resources. Our aim is to treat these resources asindependent elements of knowledge representation. Even if their interpreta-tion and semantics is dependent of the semantics of the resources they areenriching, their representation formalism can be independent.
3.3.2.1 Index terms
Indexing is the action of arranging data, information or knowledge basedin the form of specific entries attached to a detailed content, which is aclassical problem in research and industry [Stevens 1970, Korfhage 2008].Many techniques for indexing resources have been proposed during the pastdecades [Pooch & Nieder 1973, Doermann 1998]. There is no clear definitionof an index since it depends on the type of the indexed resources. Informationretrieval methodologies and tools are based on this kind of resources. Inour context we consider indexes as enrichment resources, which cannot beautonomous due to the fact that their usage depends on the resources theyare indexing.
To be able to represent these resources or define their structure and con-tent, we need to categorize the existing index models [Fuhr 2001] that areused for information retrieval. In general, an index is a set of non duplicatedentries (which can be concepts, terms, tokens or expressions) attached eachto a list of document identifiers: idxentry = (doc1, ....., dock). For instance,if we want to represent the index structure for the category of vector spacemodels [Salton et al. 1975], each item in the document list would be rep-resented as an object dock = (docid, weightk). Otherwise in case of usinginformation retrieval models requiring term-interdependency and in particu-lar belief based theories [Ribeiro & Muntz 1996], then the index model willbe a directed acyclic graph model.
3.3.2.2 Annotations
An annotation is the result of associating a content from a resource A toa node or a graph that uses elements from a (or a set of) structured re-source(s) B. These resources are generally intended to enrich an initialresource by associating to its content some conceptual elements from anontological resource. Elements of an annotated resource are easier to beaccessed and interpreted by other applications. In particular, a semantic

3.4. Discussion 43
annotation is a formalization of the interpretation of the text as a meta-data[Kiryakov et al. 2004]. The annotation is often used to convert individualtacit knowledge into explicit knowledge [Uren et al. 2006].
Multiple annotation models are possible and each application can cre-ate and use its own model. In 2012, a new working group from the W3C10
community-called Open Annotation Community Group11- published “TheOpen Annotation Extension Specification”, which is a working draft to es-tablish an “Open Annotation data model”.
3.3.2.3 Alignments
They are mappings between two resources of the same type[Euzenat & Shvaiko 2007a]. The alignment process is based on findingsimilar entities in different resources while preserving their independenceand integrity. Typical examples are parallel texts (texts in differentlanguages with aligned sentences), translation memories (text segmentstogether with theirs translation), or aligned ontologies. This type ofresources is studied in the chapter 6 with an exhaustive review of alignmentmodels and formalisms and a proposition or an alignment meta-model.
3.3.3 Combined Resources
These resources combine a set of autonomous resources with some enrich-ment resources into standalone resources. For example, a parallel corporaor a comparable corpora is a resource of this kind since it contains doc-uments (autonomous) and alignments between their content (enrichment)[Wallis & Nelson 2001]. Semantic hypertexts are also combined resourcescombining linguistic resources indexed by terms or concepts from termino-logical or ontological resources (e.g., Wikipedia). Large biomedical ontolo-gies may result from merging different vocabularies or terminologies usingalignments between them.
3.4 Discussion
In the second chapter of the book “In Search of an Integrative Vision for Tech-nology” [Strijbos & Basden 2006], Andrew Basden discussed the facilitatesto consider for easily representing knowledge. He defined some characteris-tics of knowledge representation aspects such as irreducibility (aspects areequally important), dependency (aspects are dependent from each other butnot reducible) and non-absoluteness (aspects are not absolute individually in
10http://www.w3.org11http://www.w3.org/community/openannotation

44 Chapter 3. Identification of knowledge resources
terms of foundation of meaning and all aspects taken together are not abso-lute in general). The author states that aspects of knowledge may be derivedfrom Herman Dooyeweerd’s ontology of modal aspects [Basden 2002]:
• items: the analytical aspect of representing knowledge (concepts);
• relationships: the structural aspect that defines relationships betweenthe items;
• values: the quantitative aspect of knowledge;
• spatial: the spatial aspect that defines the extension of knowledge;
• text: the lingual aspect that defines signification of knowledge;
The interesting fact about Basden’s discussion is the claim that “Modalaspects are irreductibe spheres of meaning that are more than categories;they enable being, doing, relating, properties, norms, and each of these in-dicate a difference portion of KRF.” [Strijbos & Basden 2006, p. 37]. Theconclusion of the author is that a proper knowledge representation approachshould create a knowledge representation formalism for each aspect and thenintegrate them together.
In this chapter we defined a categorization of knowledge resources basedon the generic aspects such as autonomy, type of content, schemas, etc[Ghoula et al. 2010c]. We also presented some knowledge resources repre-sentation models that are close in terms of representation to the model thatwe intend to build. None of the proposed models can be adopted as suchfor resources representation since each of these models lacks a required com-ponent for representing all the kinds of knowledge that we consider (formal,conceptual, terminological and lexical all combined).
We will use this claim as a principle for the knowledge representationmodel that we will propose for representing heterogeneous knowledge re-sources [Ghoula 2012]. Consequently and based on a restriction of the re-sources representation aspects we intend to focus on representing conceptual,terminological, and lexical knowledge. Then the aspects that we are consid-ering for building a model for representing knowledge resources are:
• type of entities to represent (concepts, terms, lexical forms, etc.);
• types of relationships between items (structure of the resources);
• types of knowledge resources: the ability to represent knowledge basedon different formalisms;

Chapter 4
TOK: A meta-model forrepresenting heterogeneous
knowledge resources
Contents4.1 Resources representation aspects for designing the
resources model . . . . . . . . . . . . . . . . . . . . . . 46
4.2 Resources representation model: TOK_Onto . . . . 48
4.2.1 Metadata representation . . . . . . . . . . . . . . . . . 48
4.2.2 Resources content representation model . . . . . . . . 50
4.2.3 The modeling approach of TOK_Onto . . . . . . . . . 56
4.2.4 Example of using the model to represent WordNet . . 59
4.3 Representing resources management . . . . . . . . . . 60
4.3.1 Resources engineering operators representation . . . . 61
4.3.2 Process monitoring representation . . . . . . . . . . . 62
4.3.3 Resources evolution-tracking . . . . . . . . . . . . . . 63
4.4 Use case scenario . . . . . . . . . . . . . . . . . . . . . . 64
4.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 66
In this chapter we describe our approach of representing different typesof terminological, ontological, and linguistic knowledge resources. This ap-proach leads to a common representation formalism that serves as a modelof a centralized knowledge repository. We first introduce our meta-model forrepresenting the content of heterogeneous resources. Finally we show somescenarios for using the representation approach that we propose. We de-scribe TOK, a meta-model for representing knowledge resources of differenttypes. We choose this name as a reference to Terminological and OntologicalKnowledge resources.

46Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
4.1 Resources representation aspects for designingthe resources model
In order to design our model, we first identified and categorized the resourcesthat we represent. Then, for each type of these resources we investigatedtheir structure, entities and semantics. For defining and validating TOK,we followed an iterative process by trying different abstract models, testingthem on resources from each category and then refining them or modifyingthem depending on their capacity of representing all the types of resources.
To properly describe and use these heterogeneous resources we need todefine their lifecycle within the repository (see figure 4.1). A resource isimported using a specific operator that represents its content using our modeland stores it into the repository. Any resource can be involved in differentknowledge engineering operations that generate new knowledge resources.
Resource
import
Resource Representa-on operations Resource
Representation
Derived Resource
Resources Meta-‐model
export
instance of
Figure 4.1: Lifecycle of a TOK resources within the repository
Resources representation within a knowledge repository does not onlyinvolve metadata and content but also other aspects such as resources’ evo-lution and involvement in different knowledge engineering tasks. After mul-tiple versions and conducting several changes, we identified the structure ofthe resources representation model (figure 4.2). This model is an aggregationof five components:
1. Resources Metadata and Content: Representing resources withinthe same repository requires to design a model that is able to describethe metadata and content of these resources in a generic way witha decidable consistency (described in section 4.2).
2. Knowledge Operators Representation: Knowledge engineeringoperators within the repository are represented using a dedicated modeland may have multiple implementations and different kinds of inputand output (described in section 4.3).

4.1. Resources representation aspects for designing the resourcesmodel 47
3. Evolution Representation: Knowledge resources within a reposi-tory are subject to change and evolution, which might be problematicif not monitored within the repository. This is why we created a modelto represent the types of changes that may occur during each resource’slifecycle (described in section 4.3).
4. Process Execution Monitoring: This aspect uses the resources andthe operators’ representations to store each execution of any kind ofoperation that involves specific resources within the repository. This isuseful to re-execute a process each time a change occurs in an operatoror a resource that have been involved in it (described in section 4.3).
5. Change Execution Monitoring: The second component uses theevolution model and the operators model to monitor the changes oneach resource during its lifecycle (described in section 4.3).
Model of TOK resources
Evolution Representation
Knowledge Operators Representation
Processes Execution Monitoring
Resources Representation
Change Execution Monitoring
UsesUses
triggers
UsesUses
Figure 4.2: Resources representation aspects and interactions
The representation of common metadata elements in resources and thedefinition of axioms on these elements is a key for their interoperability. Ourapproach defines a representation model that is able to:
• represent existing knowledge representation formalisms and integratedifferent models;
• represent resources metadata and content;
• create new knowledge representation models that are convenient forspecific tasks, e.g. Concept hierarchy, or WordNet-like;

48Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
• define import/export and model mapping (transformation) operations;
• represent operations, knowledge engineering processes, etc.
4.2 Resources representation model: TOK_Onto
This model allows to describe the metadata of any kind of knowledge re-source and then describes its content in many languages (formalisms), whichare by themselves represented in the repository by means of a common ter-minology (namespace of the repository).
Since there exist many different (and incompatible) ways to expressknowledge in resources (from formal first order or description logic to semi-formal models and natural languages), it is difficult to create a single expres-sive, decidable and consistent universal representation model for the contentof resources. Different aspects represented by different formalisms, cannotbe reduced to a single one (see [Kutz et al. 2010]). Moreover, a resourcemight be involved in processes that can handle only one kind of knowledgerepresentation formalism.
Consequently, after trying different design alternatives and applying sev-eral improvements and more expressiveness in the meta-model, we proposeto create a generic model that supports multiple representations for the con-tent of a resource [Ghoula et al. 2010a]. The challenge is to create a modelrepresenting heterogeneous resources (multiple representation models) andto perform operations that involve several resources (single representationmodel).
The implementation of this model includes an ontology, calledTOK_Onto1 2 3 [Ghoula et al. 2010b] that imports the OMV ontology.TOK_Onto is expressed in OWL-DL (ALCHIQD) containing 297 classes,196 object properties, 63 data properties and 1456 axioms.
4.2.1 Metadata representation
Metadata elements are used to describe the resources and to index themwithin the repository. We identified (see figure 4.4) a set of key elements fordescribing knowledge resources and imported all the possible useful metadatarepresentations from OMV and NoRMV (see section 3.2.1). Multiple ontol-ogy repositories use OMV to represent meta-data elements of ontologies. Weconsider also NoRMV in order to include extra meta-data elements.
1Ontology file: http://cui.unige.ch/isi/onto/tok/TOK.owl2Ontology documentation in HTML: http://cui.unige.ch/isi/onto/tok/OWL_Doc/3Ontology imports: http://cui.unige.ch/isi/onto/tok/

4.2. Resources representation model: TOK_Onto 49
The properties that are used to describe a resource’s metadata are mainlybased on the following aspects:
• Domain: allows to classify the resources by their coverage. A resourcecan cover from one to multiple domains (e.g., Wikipedia). The in-stances of domains (or the hierarchy of domains and subdomains) canbe imported from a specific ontology;
• Formalism: this metadata element describes the original representa-tion mechanism of a resource. A resource can be associated to mul-tiple representations in different formalisms (SKOS, OWL, DL, etc.).Representation formalisms were divided into logical approaches (suchas description logics, predicate logic or first order logic) and non logicalapproaches (such as conceptual graphs and semantic networks);
Formalism Representation Language Resource Syntax
Description Logic OWL-DL RDF/XML
Figure 4.3: From a formalism to its representation language and syntax
• Representation Language: is a reference to the representation languagethat supports the resource’s formalism (cf. figure 4.3);
• Resource Syntax : is a reference to the syntax of the representationlanguage of the resource (cf. figure 4.3);
• Resource Type: defines the type of the resource according to the classifi-cation descried in the section 3.1. A resource’s type can be ontological,terminological, or linguistic, etc. This metadata criterion is importantfor classifying the resources and defining default rules for managingthem;
• Language: is a metadata element allowing to attach a resource to oneor more natural languages. For multilingual resources this metadataelement can be defined as a list of values;
• Usage: this criteria stores the concrete usages of a specific resource inorder to enhance its indexing and attach it automatically to knowledgeengineering tasks that are compatible with its usage. For example acorpora can be used for a purpose of automatic learning, an ontology(representing a detailed set and hierarchy of named entities) can be

50Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
mainly used for semantic annotation and information retrieval, a vali-dated ontology alignment can be used as a reference for query rewriting;
• Version: this criteria stores the evolution of the resource and allowsto store versioning information within the repository. This metadataelement is crucial for a better usage of a resource and for managingcompatibility and ensuring knowledge consistency. For example, sometools can be compatible and coherent with one version of a resource andnot any newer or older versions of it. The versioning criteria is enrichedby other metadata elements from OMV such as backward compatibility,prior version, etc.;
• Provenance: the origin of a resource is very important for a betteridentification of the resource and its usage or original purpose;
• Evolution and processes: these aspects ares required to monitor theresource’s evolution and keeps track of all the operations where it hasbeen used.
• Links to other resources: the link to other resources such as import,annotation, association, belonging, ext. are required to supervise theevolution of resources within their environment.
4.2.2 Resources content representation model
We are aiming to build an exhaustive resource model for heterogeneous re-sources represented in different languages and having different categories(terminological, ontological, linguistic, etc.). We intend to preserve the orig-inality of all resources and their representation language to have less informa-tion loss (to keep the resources independent while begin aligned or to deriveeasily new representations or views from the original formalism).
In order to handle multiple content representations, the ontology containsupper level classes that can be refined using classes from specific represen-tation models. A resource is described using the class Knowledge_Resourceand its metadata are represented using the model in figure 4.4.
A first version of our model represented the entity types of differentresources as subclasses of Resource_Entity but we realized that an entitymight belong (or be imported) to another resource and its aspect and contextchanges. Consequently, we separated the representation of the entity itselffrom its context of belonging. Thus we defined another class that representssome contexts or aspects that a resource’s entity might have.
The content of a resource is represented using the class Resource_Entity,which is an upper level descriptor of the generic aspects of a resource’s item.

4.2. Resources representation model: TOK_Onto 51
omv:acronymomv:nameomv:descriptiontok:creation_dateomv:versionomv: hasPriorVersionomg:IsBackwardCompatibleWithtok:location_fileomv:URIomg:useImportsetc.
Knowledge_Resource
∃aligned_to∀composedBy / belongsTo∃annotates / annotatedBy∀etc.
∀omv:isOfType
Resource_Type
Autonomous_Resource
Enrichment_Resource
Combined_Resource
Resources_Management_Operator
∃provenance
Knowledge_Engineering_Tool∃treatedBy
Knowledge_Engineering_Task
Process_Monitoring_Element
∀used_for_task
∀used_in_process
Resource_Evolution_Execution
∀involved_in_evolution_action
Figure 4.4: Excerpt of the metadata representation model of knowledge re-sources (TOKMeta)
The meta-model for representing a resource’s content unfolds it under acommon semantics (see figure 4.5). We classify entities of any resource intothree categories:
Node entities: represents the set of atomic entities that can be representedin knowledge resources. These entities have a certain type (term, con-cept, sentence, label, lexical form, etc.) and are used to define ordescribe other entities;
Link entities: represents the set of relations and roles that can be repre-sented in knowledge resources. These links have a certain domain andrange, which can be a resource or a resource entity;
Expression entities: represents the set of complex entities within knowledgeresources. Their definition relies on describing facts between resourceentities using link entities or as sets of restrictions and expressionson resources entities using link entities (example: triples, restrictions,logical expressions, etc.).
Specific relations between resources entities are represented in this model.
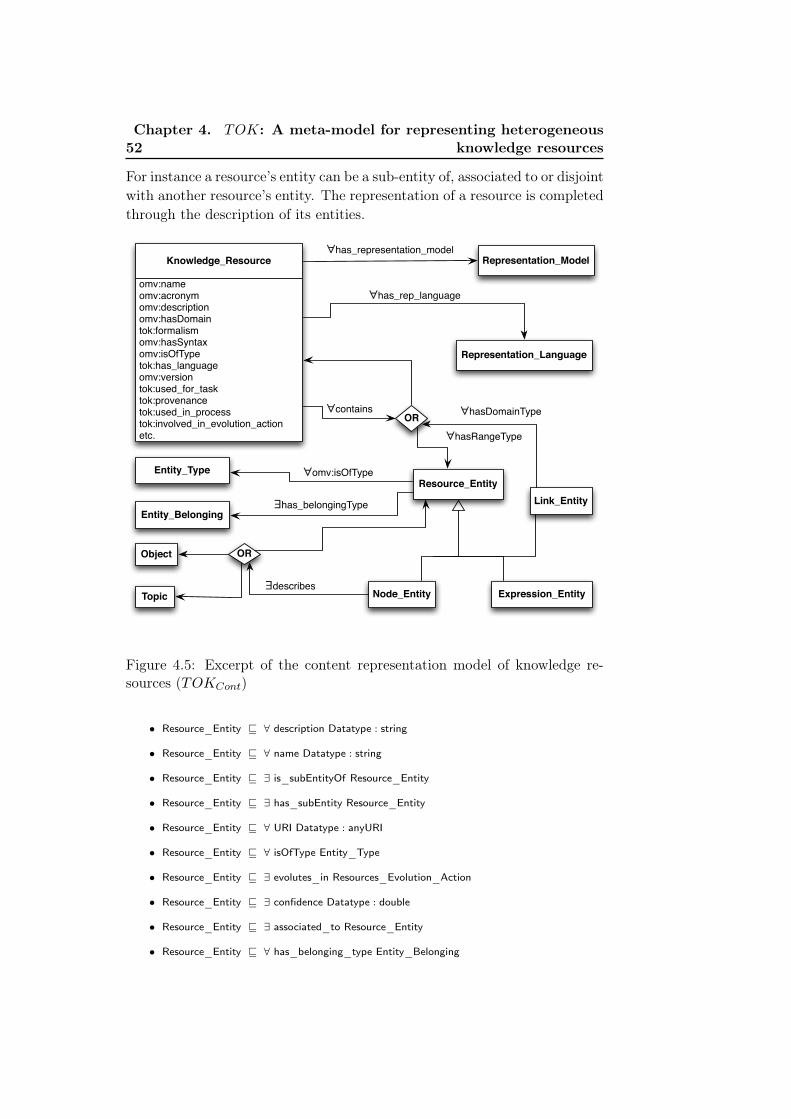
52Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
For instance a resource’s entity can be a sub-entity of, associated to or disjointwith another resource’s entity. The representation of a resource is completedthrough the description of its entities.
omv:nameomv:acronymomv:descriptionomv:hasDomaintok:formalismomv:hasSyntaxomv:isOfTypetok:has_languageomv:versiontok:used_for_tasktok:provenancetok:used_in_processtok:involved_in_evolution_actionetc.
Knowledge_Resource
∃has_belongingType
∀omv:isOfType
Representation_Model∀has_representation_model
Representation_Language
∀has_rep_language
OR
Resource_EntityEntity_Type
Entity_Belonging
Node_Entity
Link_Entity
Expression_Entity
∀hasDomainType
∃describes
OR
Topic
Object
∀contains
∀hasRangeType
Figure 4.5: Excerpt of the content representation model of knowledge re-sources (TOKCont)
• Resource_Entity v ∀ description Datatype : string
• Resource_Entity v ∀ name Datatype : string
• Resource_Entity v ∃ is_subEntityOf Resource_Entity
• Resource_Entity v ∃ has_subEntity Resource_Entity
• Resource_Entity v ∀ URI Datatype : anyURI
• Resource_Entity v ∀ isOfType Entity_Type
• Resource_Entity v ∃ evolutes_in Resources_Evolution_Action
• Resource_Entity v ∃ confidence Datatype : double
• Resource_Entity v ∃ associated_to Resource_Entity
• Resource_Entity v ∀ has_belonging_type Entity_Belonging

4.2. Resources representation model: TOK_Onto 53
• Resource_Entity v ∃ is_definedBy Resource_Entity
• Resource_Entity v ∃ involved_in_expression Expression_Entity
An entity is represented in the repository as it is described in the originalresource. To define the type of the entity we associated it with the righttype of belonging. The types of belonging are described under the classEntity_Belonging and using the property has_belonging_type (e.g., Ontol-ogy_Entity, Glossary_Entity, Alignment_Entity, etc.). When the same en-tity is referenced by another type of resource, then a new belonging propertyis attached to it.
4.2.2.1 Node Entity
A Node_Entity represents the elementary basic bricks of knowledge withina resource. These entities are named and have a unique URI. A node entitywithin any resource is every entity that is not a role, property or relationand that does not require an expression to represent it (only facts).
The types of node entities are described as a subclass of Entity_Typeunder Node_Type (e.g., Conceptual_Entity, Terminological_Entity, Individ-ual_Entity, Text_Fragment, etc.).
If a resource is a graph of linked knowledge, this graph is representedusing nodes and edges. Node entities are the elements that can be directlyidentified and extracted. The expressions that define node entities are inde-pendent entities that are not generally named and that we do not consideras node entities (cf. section 4.2.2.3).
• Node_Entity v ∀ isOfType Node_Type
• Node_Entity v = has_definition (Node_Entity u ∀ isOfType Definition_Entity)
• Node_Entity v = has_natural_language Natural_Language
• Node_Entity v ∀ descibes (Object t Resource_Domain t Resource_Entity t Topic)
• Node_Entity v Resource_Entity
• Node_Entity v ∀ provenance (Knowledge_Engineering_Task t Party)
• Node_Entity v ∃ has_label (Node_Entity u ∀ isOfType (Lexical_Form t Term_Entity))
• Node_Entity v ∀ has_context Context
The type and definition of a node entity is different from one resource toanother (it can be defined as a concept in one resource or as a term or an in-dividual in another resource). An abstraction of this element requires takinginto consideration all kinds of relations to other entities that can be specificproperties under some formalisms, which lead to the class Link_Entity.

54Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
4.2.2.2 Link Entity
A Link_Entity is the key element of content description, it allows expressingrelationships between a resource’s entities or with other entities. A linkentity can be a property, a predefined relation within a specific namespaceor any kind of other relation. It links together different elements, which canbe resources or entities.
The types of link entities are described as a subclass of Entity_Typeunder Link_Type (e.g., Concept_To_Concept, Concept_To_Term,Term_To_Concept, Concept_To_Resource, etc.). Specific link entitiessuch as semantic relations and logical relations are described as subclassesof Link_Entity.
• Link_Entity v ∃ has_symbol Symbol_Indicator
• Link_Entity v ∃ isOfType Link_Type
• Link_Entity v ∀ hasDomainType (Knowledge_Resource t Resource_Entity)
• Link_Entity v ∃ isInverseOf Link_Entity
• Link_Entity v ∀ hasRangeType (Knowledge_Resource t Resource_Entity)
• Link_Entity v ∃ has_subRelation Link_Entity
• Link_Entity v Resource_Entity
• Link_Entity v ∃ is_subRelationOf Link_Entity
4.2.2.3 Expression Entity
An Expression_Entity is the element used to express restrictions, rules andconstraints defining the content of a resource. It uses references to nodeentities and link entities to elaborate the content’s representation by meansof expressions. The basic simple expression entity is the Factual_Expression(such as triples), which use two node entities or link entities and describea relationship between them via a link entity. An expression entity canbe a complex logical expression, axiom restrictions on some type of linkentities, or any other kind of expression that involves node entities and linkentities. The different kinds of expression entities are described as a subclassof Expression_Entity.
The node-link modeling approach is generic enough to represent differentkinds of expressions. For example a simple DL restriction is represented asa class axiom that applies a rule over an entity using a link entity and somelogical quantifier (existential or universal).
• Simple_Restriction_Expression v = onRelation Link_Entity
• Simple_Restriction_Expression v = on_Entity (Axiom_Restriction t Logical_Expressiont Node_Entity)

4.2. Resources representation model: TOK_Onto 55
• Simple_Restriction_Expression v ∃ uses_quantifier Quantifier
• Simple_Restriction_Expression v Axiom_Restriction
4.2.2.4 Describing content representation models
Each resource can be represented according to one or more content repre-sentation models (see figure 4.6). The Representation_Model class is theabstract superclass of all content representation models. Each representa-tion model uses a set of vocabulary for representing resources entities (term,concept, class, sentence, glossary entity, property, role, relation).
Resource
Metadata ContentContent
Representation Entity
M2M1
r
Resource e.x. Fichier OWL, corpus, ...
Abstraction
c1
c2
contains useslanguage“OWL”
creation2010-03
uses
TOK_Ontoclasses
contains
Figure 4.6: Representation of a resource with its metadata and differentrepresentations of its content
Each model representing a kind of knowledge resources (ontology, the-saurus, taxonomy, etc.) is formally defined by a set of ontological axiomsthat indicate the type of entities that belong to it and the way they areinterconnected (see figure 4.7).
Entities used in a model’s definition are subclasses of the Resource_Entityclass. The actual representation of a resource’s content according to a rep-resentation model is thus represented as specifications (subClassOf ) of themodel’s classes. Each element (concept, property, axiom, individual, term,etc.) is treated as a subclass of either Node_Entity, Link_Entity or Expres-sion_Entity, and linked to a representation model.

56Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
Representation_Model OR
Node_Entity
Link_Entity
∃has_representation_generator
∀uses
Resources_Management_Operator Representation_Operator
Figure 4.7: Description of a representation model
Typical content representation models are: concept hierarchies (a modelfor simple concept taxonomies); lexical ontologies such as WordNet; descrip-tion logic ontologies; BiText or TMX (corpus of parallel or comparable text)[Somers 2003]; translation memory (text aligned with other text in otherlanguages), etc.
Table 4.2.2.4 shows some examples of models that have been implementedin the current version of TOK_Onto.
Model ComponentsConcept hierarchy Concept, ISA_Relation, . . .WordNet Like Concept, Term, Lexical_Form,
Hypernym_Relation, Meronym_Relation,Term_Form_Relation,Term_Meaning_Relation, . . .
Description Logics Class, Property, Property_Restriction, Union,. . . , Axiom, SubClass_Relation, Equiva-lency_Relation, etc.
Class Diagram Class, Association, . . .
Table 4.1: Examples of resource content representation models and theirprincipal components
4.2.3 The modeling approach of TOK_Onto
The approach of representing knowledge resources that we propose dividesresources representation into four main levels. The upper level representsthe meta-meta-elements by defining abstract classes that describe entitiesof knowledge resources in a generic manner. The second level refines thefirst one using specific representation models that describe entities in a moredetailed and contextualized manner based on the formalisms of knowledge
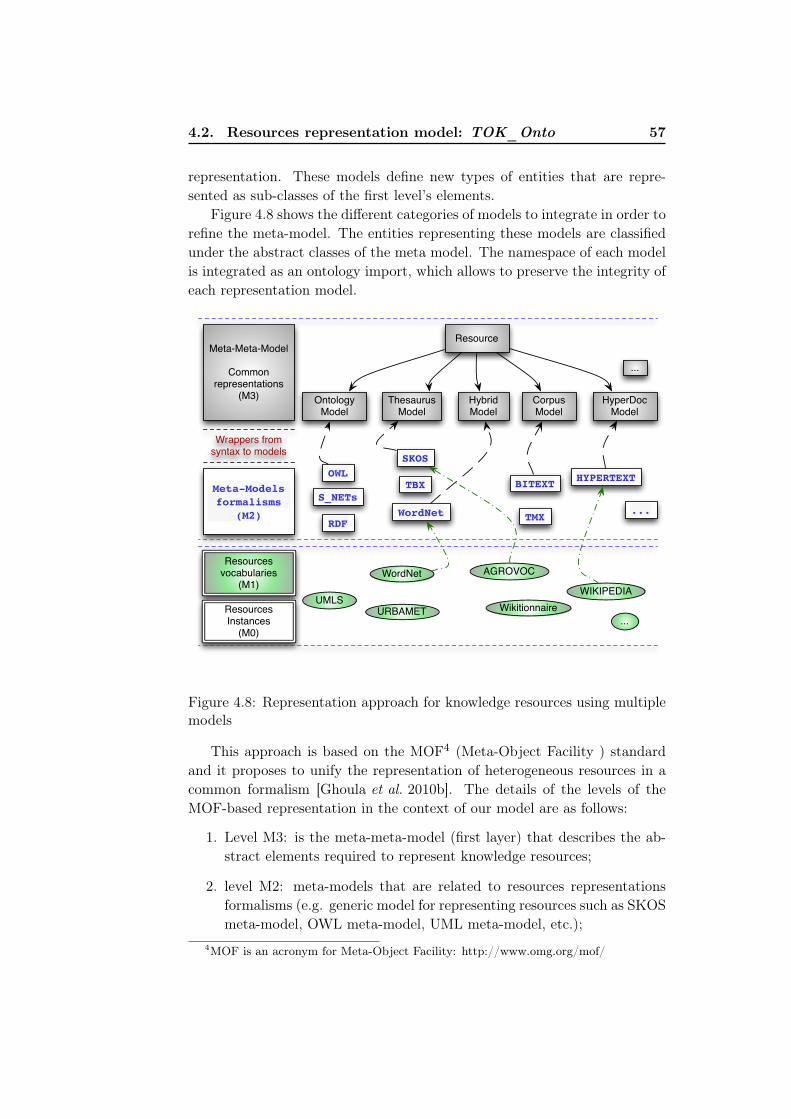
4.2. Resources representation model: TOK_Onto 57
representation. These models define new types of entities that are repre-sented as sub-classes of the first level’s elements.
Figure 4.8 shows the different categories of models to integrate in order torefine the meta-model. The entities representing these models are classifiedunder the abstract classes of the meta model. The namespace of each modelis integrated as an ontology import, which allows to preserve the integrity ofeach representation model.
ResourceMeta-Meta-Model
Common representations
(M3)
Resourcesvocabularies
(M1)UMLS
URBAMET
AGROVOC
WIKIPEDIA
Ontology Model
Thesaurus Model
Corpus Model
HyperDoc Model
OWLSKOS
BITEXTTBX
RDF TMX
HYPERTEXT
S_NETs
WordNet
WikitionnaireResources Instances
(M0)
WordNet
Hybrid Model
...
...
...
Meta-Models formalisms
(M2)
Wrappers from syntax to models
Figure 4.8: Representation approach for knowledge resources using multiplemodels
This approach is based on the MOF4 (Meta-Object Facility ) standardand it proposes to unify the representation of heterogeneous resources in acommon formalism [Ghoula et al. 2010b]. The details of the levels of theMOF-based representation in the context of our model are as follows:
1. Level M3: is the meta-meta-model (first layer) that describes the ab-stract elements required to represent knowledge resources;
2. level M2: meta-models that are related to resources representationsformalisms (e.g. generic model for representing resources such as SKOSmeta-model, OWL meta-model, UML meta-model, etc.);
4MOF is an acronym for Meta-Object Facility: http://www.omg.org/mof/

58Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
3. level M1: the resources models using knowledge representation for-malisms of each knowledge resource. These models are representedthrough entities (nodes, links and expressions) that are extractedbased on their description within the resources (type skos:concept, typeskos:prefLabel, owl:Class, owl:equivalentClass, etc.);
4. level M0: the individual entities within the resources if any.
The resources schemas or models represent the type of elements that areused to express the vocabulary of a resource or its terminological box (cf.figure 4.9)). This was detailed in the section 4.2.2. At each one of thesetwo levels resources and entities are represented by instances of a globalrepresentation model. The way of representing the content of a resourcedepends on each model. Resources representation models share the use ofthe resource’s entities and define the content of the resource’s representation.
< rdfs:subClassOf >
EntityResource
Meta-Meta-Model(M3)
ResourcesRepresentation
Meta-ModelSchema
Definitions (M2)
owl:Ontologyowl:ObjectProperty
Resources vocabulary (entities)
(M1)+
Instances(M0)
owl:Class
Homer "Witches Abroad"
contains
PersonBIB
BIB:Book
BIB:reads
Node Entity
Link Entity
is_a
is_a
rdfs:domainrdfs:range
rdfs:range
rdfs:domain
rdf:typerdf:type
< rdf:type >
Figure 4.9: MOF as an approach for resources representation
A typical example that illustrates the need for these multiple representa-tions is the task of ontology alignment. Some ontology alignment algorithmsalign OWL ontologies while focusing only on the hierarchy of the ontologyand its labels. This kind of usage does not require such a level of expressivity(OWL-DL). The structure of hierarchy of the ontology is generally used asa graph (e.g., if there is a link labelled P between the classes C1 and C2,

4.2. Resources representation model: TOK_Onto 59
this means that there exists an axiom C1 v P only/some C2). In this caseit is more appropriate to represent the OWL ontologies as a labelled graphinstead of importing all OWL meta-model and semantics. Thus alignmentalgorithms will be compatible with multiple ontology formalisms providedthat these formalisms are transformed into a labelled graph representation.
4.2.4 Example of using the model to represent WordNet
As an example of representing a resource in a specific model, WordNet[Fellbaum 1998] is a set of lexical forms linked between each other using se-mantic relations. This representation of the content is specific to a model thatwe adapted from WordNet and called WordNet_Like. This model uses nodeentities such as Concept, Term, LexicalForm, Sentence, Part_Of_Speech andassociative relations as link entities represented by the class WordNetRelation.
Here are some axioms representing WordNet_Like:
• WordNet_Like v uses only (Concept or Term or LexicalForm or
Sentence or Par_Of_Speech or WordNetRelation)
• Concept v Node_Entity
• Term v Node_Entity
• LexcalForm v Node_Entity
• Sentence v Node_Entity
• Par_Of_Speech v Node_Entity
• Sem_Relation vWordNetRelation
• Sem_Relation v tok : hasDomainTypeonlyConcept
• Sem_Relation v tok : hasRangeTypeonlyConcept
• Term_Relation vWordNetRelation
• Term_Relation v tok : hasDomainTypeonlyTerm
• Term_Relation v tok : hasRangeTypeonlyTerm
• Form_Relation vWordNetRelation
• Form_Relation v tok : hasDomainTypeonly LexicalForm
• Form_Relation v tok : hasRangeTypeonly LexicalForm
• hypernym v Sem_Relation

60Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
• hyponym v Sem_Relation
• hyponym v tok : isInverseOf only hypernym
• meroynm v Sem_Relation
• holonym v Sem_Relation
• meroynm v tok : isInverseOf only holonym
• . . .
The aim of a resources repository is not only to collect heteroge-nous knowledge resources but especially to offer instruments for reusingthem. In order to formalize the definition of processes over these resources,we have defined a set of generic primitive operations [Grau et al. 2008,Falquet et al. 2008]. We represent them using an abstract class within theTOK_Onto. Each operator can support multiple implementations depend-ing on the resources that are used as input. These operators are applied inorder to generate new resources, which leads to the evolution of resources.
4.3 Representing resources management
For defining the ontology modules that are used for representing resourcesmanagement operators and resources evolution, we will use elements of anexisting ontology called OWL-S [Burstein et al. 2004]. The semantic markupfor web services is an ontology that models services in a declarative way inorder to build a standard vocabulary for service descriptions. This ontologycontains three modules for representing profiles, services and groundings (seefigure 4.10). We imported the profiles module into our ontology.
Figure 4.10: Semantic Markup for Web Services ontology modules[Burstein et al. 2004]

4.3. Representing resources management 61
4.3.1 Resources engineering operators representation
The definition of resources management operators depends on the usage ofthe resources within the context of knowledge management and reuse. Manycontributions in the literature propose tools and models for reusing and shar-ing knowledge. We define a resources management operator as an entity thatuses one or multiple knowledge resources and provokes changes on entitiesof theses resources to generate modified new resource.
In the OWL-S ontologies, services are represented using a profile defini-tion. Within the specifications document, a service profile is referred to as:“An OWL-S Profile describes a service as a function of three basic types of in-formation: what organization provides the service, what function the servicecomputes, and a host of features that specify characteristics of the service.”5.We made the choice of using of the OWL-S ontology to describe resourcesmanagement and combination operators within the repository because thisontology represents the standard vocabulary for service representation.
In the process of defining and representing knowledge resources manage-ment and combination (i.e. engineering) operators (alignment, integration,annotations, composition, etc.) we realized that they can be modeled asservices profiles. The model of resources operators is intended to define theirsignatures and types. Each profile is then instantiated by a specific im-plementation. For example, an ontology matching operator can be definedas a matching operator that has as category “Ontology Matcher’ ’, as inputat least two resources of type “Ontology” and as result a resource of type“Ontology alignment”, etc.
The profile representation in OWL-S (see figure 4.11) is used as a providerof the model that represents knowledge resources engineering operators butthe actual representation of these operators in the TOK_Onto is defined bythe class Resources_Management_Operator, which is a subclass of Profile.The following restrictions are applied in order to give a specific representationof these operators in the context of the our research area (Heterogeneousknowledge resources combination and management).
• Resources_Management_Operator v Profile
• Resources_Management_Operator v ∃ input Knowledge_Resource
• Resources_Management_Operator v ∀ keywords Datatype : string
• Resources_Management_Operator v ∃ output Knowledge_Resource
• Resources_Management_Operator v ∀ name Datatype : string
• Resources_Management_Operator v ∀ uses_method Knowledge_Processing_Method
5Source http://www.w3.org/Submission/OWL-S/

62Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
• Resources_Management_Operator v ∀ description Datatype : string
• Resources_Management_Operator v ∃ argument Object
• Resources_Management_Operator v ∀ uses_implementation Implementation_Source
• Resources_Management_Operator v ∀ uses_methodologyKnowledge_Engineering_Methodology
Figure 4.11: OWLS profiles representation [Burstein et al. 2004]
4.3.2 Process monitoring representation
The application of operators for managing and combining knowledge re-sources generates new knowledge resources and can also change the contentor the representation of a specific resource. Since the provenance of eachresource is a required element for their presentation, the application of anoperator or a sequence of operators on a set of knowledge resources have tobe represented and stored as a provenance element.
Besides the application of operators, transforming or combining knowl-edge from different resources requires the application of a sequence ora set of operators, which leads us to a need for representing not onlyknowledge engineering processes but also knowledge engineering operations.We define a process as a sequence of operators applied on the resourcesand their content. The process is represented using the class Knowl-edge_Engineering_Task. and an element of a process is represented by theProcess_Monitoring_Element class:

4.3. Representing resources management 63
• Knowledge_Engineering_Task v ∀ acronym Datatype : string
• Knowledge_Engineering_Task v ≤ 1 description
• Knowledge_Engineering_Task v ∀ name Datatype : string
• Knowledge_Engineering_Task v ∀ description Datatype : string
• Knowledge_Engineering_Task v ≤ 1 documentation
• Knowledge_Engineering_Task v ≤ 1 acronym
• Knowledge_Engineering_Task v ∀ documentation Datatype : string
• Knowledge_Engineering_Task v ≥ 1 composedOf Process_Monitoring_Element
• Process_Monitoring_Element v ∃ reference Datatype : anyURI
• Process_Monitoring_Element v ∃ description Datatype : string
• Process_Monitoring_Element v ∃ uses_algorithm Algorithm
• Process_Monitoring_Element v ∀ uses_operator Resources_Management_Operator
• Process_Monitoring_Element v ∀ uses_method Knowledge_Processing_Method
• Process_Monitoring_Element v ∀ output Knowledge_Resource
• Process_Monitoring_Element v ∀ has_run_date Datatype : dateTime
• Process_Monitoring_Element v ∀ argument Datatype : anyURI
• Process_Monitoring_Element v ∀ input Knowledge_Resource
• Process_Monitoring_Element v ∀ executedBy Party
• Process_Monitoring_Element v ∃ status Datatype : string
• Process_Monitoring_Element v ∃ acronym Datatype : string
By means of processes descriptions we aim to construct a process dictio-nary that stores each instance of a process and apply it each time there isan evolution of the involved resources. To describe these processes we usedthe OWL-S derive module, which is able to represent services of a certainprofile or a composition of services of different profiles. The execution of atask that changes a resource creates an evolution-tracking element.
4.3.3 Resources evolution-tracking
Knowledge resources engineering within a repository requires tracking all theevents that initiate a change of a resource. There are multiple approachesthat have been proposed for modelling evolution and changes within re-sources [Berkes 2009, Stojanovic 2004]. We define an evolution as a changewithin an entity or a version of a resource within the repository. A change

64Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
action is represented as a modification that has as range either a resource asa whole or an entity of a resource.
Since we are managing knowledge resources and the processes that weare monitoring are applied on resources, then a change is always brought tothe scale of the resource and an evolution is then represented as follows:
• Resource_Evolution_Execution v ∃ executedBy Party
• Resource_Evolution_Execution v ∀ has_run_date Datatype : dateTime
• Resource_Evolution_Execution v ∀ documentation Datatype : anyURI
• Resource_Evolution_Execution v ∀ acronym Datatype : anyURI
• Resource_Evolution_Execution v ∀ endorsedBy Party
• Resource_Evolution_Execution v ∀ uses_operator Resources_Management_Operator
• Resource_Evolution_Execution v ∀ description Datatype : string
• Resource_Evolution_Execution v ∀ evolution_action Resources_Evolution_Action
• Resource_Evolution_Execution v ∀ status Datatype : string
• Resource_Evolution_Execution v ∃ involves (Knowledge_Resource t Resource_Entity)
• Resource_Evolution_Execution v ∀ reference Datatype : anyURI
• Resource_Evolution_Execution v ∀ applied_to Knowledge_Resource
When a resource is modified (partially or wholly) as a result to an ap-plication of a process then all the processes executions that use this sameresource are triggered to be re-executed to generate in their turn new ver-sions of the existing output. Many techniques can be used to manage theprocess execution and resource evolution within the repository. We preparedthe models and structures to represent these events but we will not focus ondefining an approach for resources evolution management.
4.4 Use case scenario
As a practical scenario for using the repository, let’s consider that an ontol-ogy designer wants to enrich an ontology in the field of “aeronautics”. Thisontology is in the form of a concept hierarchy. She/he wants to add defini-tions in two languages (English and French) to the named concepts of thisontology. She/he wants also to refine the classification by adding new classesand missing term descriptors.
For this task there is a need for external resources such as glossaries,terminologies or bilingual dictionaries. To have access to relevant resourcesthe designer can query the repository for all the resources describing the fieldof “aeronautics”, having as languages French and/or English. She/he may

4.4. Use case scenario 65
specify other criteria according to the requirements to fulfill. As a result therepository returns a number of resources, for example, an aligned corpus inEnglish and French of materials on “aeronautics”, Wikipedia articles in thissame domain classified by category and an English thesaurus of aeronauticsand Space terminology.
To generate an enriched ontology (concept labels in two languages anddefinitions) and supposing that the repository is fully implemented based onthe ontology that we described in the previous sections, these are the stepsto follow for fulfilling this task:
1. find relevant resources of the same domain or allow the user to importthem into the reository;
2. extract knowledge from these resources and generate an ontology usingthe Concept_Hierarchy model (see figure 4.13) where every concept isassociated to term descriptor in both languages and described by a textfragment as a definition;
3. import the ontology to enrich and run an ontology matcher to alignthe concepts of this ontology with those of the generated ontology fromthe step 2;
4. finally merge the aligned ontologies to produce a new extended ontol-ogy.
Figure 4.12 shows how the different levels of the model are involved inresources processing such as importing an ontology, retrieving some comple-mentary resources and generating new resources.
Query
Modified Ontology
Retrieval
Instancesofresourcesand
en22es
Importing
LanguageType
Domain
Model
SizeTok_Onto
Warehouse(resources)
Instances(resourcesanden22es)
Processing
Original Ontology
Figure 4.12: Usage of the repository and the ontology Tok_Onto

66Chapter 4. TOK: A meta-model for representing heterogeneous
knowledge resources
Within this example we involved four modules of the resources ontologyTok_Onto: (1) The resources metadata representation model for retrievingthe resources from the repository; (2) The resources content representationmodel for extracting entities and generating new derivations in an othercontent representation model (Concept_Hierarchy); (3) the operators repre-sentation model to trigger the ontology matching operator (or service); and(4) the process monitoring module to create an instance of the knowledgeengineering task that has been performed. For a detailed description aboutthe operators and the pattens involved in this use case please refer to sectionA.1 appendix A.
C_H
uses
tok:hasLabel tok:hasDefinition
C
D T
C C
. . .
. . .
tok:hasSubEntity
tok:isSubEntityOf
Figure 4.13: Illustration of the Concept_Hierarchy model from Tok_Onto
In the next chapter we will create a taxonomy of resources managementand combination abstract operators by defining some of their characteristicsand criteria and give some examples from the literature.
4.5 Discussion
We described our model for representing knowledge resources. We classifyknowledge into three categories: (1) Conceptual knowledge represented us-ing conceptual entities, this kind of knowledge offers the sense to the (2)Terminological knowledge represented using terminological entities that playthe role of labels the conceptual entities and as a meaning to the (3) Lexicalknowledge. The representation approach consists on considering three levelsof knowledge representation (conceptual knowledge, terminological knowl-edge and lexical knowledge) and different levels of expressivity (meta-level,

4.5. Discussion 67
schema level, resources level) [Ghoula et al. 2010b].The proposed representation approaches belong to two categories:
generic representation models and resources representation models[Ghoula et al. 2010c]. The vocabulary of the generic models is not adaptedto represent all kinds of resources or to manage a knowledge repository. Thevocabulary of specific representation models does not cover all the aspects ofknowledge resources as we defined them in the previous chapter. Since it hasbeen proven that representation languages or formalisms cannot be reducedto a single one, our approach relies on the definition of a meta-model thatrepresents the generic aspects of knowledge resources and a set of differentmodels that represent each specific aspects of a category or type of resources(formal, ontological, conceptual, terminological, lexical, etc.).
This model is used as a pivot language for providing a syntactic andsemantic interoperability between heterogeneous knowledge resources. Ourapproach requires transforming knowledge representation from a specific lan-guage to another that is coherent with the proposed model.
We have shown that using the model we are able to represent specific orgeneric knowledge using different levels of expressivity. The main principleof the approach is the ability to extend the model by adding subsequentspecific resources representation models. This requirement is satisfied sincethe proposed model is implemented using an ontology, which led to the usageof “SubClassOf” property to describe new models using the vocabulary of theproposed ontology.
The resources representation approach covers the treatment of abroad spectrum of resources represented in different formalisms. Thismodel is useful to ensure resources interoperability in its three levels[Ouksel & Sheth 1999]: (i) syntactic level [Jovellanos 2003], also calledsyntactic integration, which defines a common format of knowledge rep-resentation in, which resources are represented; (ii) structural level[Ouksel & Sheth 1999], which represents the elements of the resource ac-cording to a definite structure controlled by a model; (iii) semantic level[Heiler 1995], which provides the consistent understanding of the sense ofelements within different resources.


Chapter 5
A Taxonomy of resourcescombination operators
Contents5.1 Resources management and combination operators . 69
5.1.1 Representation operators . . . . . . . . . . . . . . . . 71
5.1.2 Enrichment operators . . . . . . . . . . . . . . . . . . 75
5.1.3 Derivation and combination operators . . . . . . . . . 77
5.2 Usage of the model and operators to create reposi-tory for combining terminological resources . . . . . 81
5.2.1 Storing resources representations . . . . . . . . . . . . 81
5.2.2 Alignment of representation formalisms . . . . . . . . 89
5.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . 92
In this chapter we propose a taxonomy of knowledge resources combina-tion and combination operators. We focus on defining the generic aspectsof these operators without considering a specific type of resources. Some ofthese operators have been described in the literature and multiple method-ologies propose different implementations. Since we are using the OWL-Smodel for describing these operators, our intention of reusing existing oper-ators is fulfilled. For testing the approach we proposed and implemented aset of resources combination and combination operators that are detailed inthe next chapters. Some example of use cases is given to show the usage ofthe proposed taxonomy of resources engineering operators.
5.1 Resources management and combination oper-ators
A key element to knowledge engineering is the possibility to design,implement and execute processes over resources that represent differentkinds of knowledge. Many systems and algorithms have been proposedin the literature (see surveys [Liao 2003, Studer et al. 1999]). Moreover,

70 Chapter 5. A Taxonomy of resources combination operators
tools have been created to manage knowledge extracted from different re-sources [Doerr & Fundulaki 1998, Haase et al. 2004, Pottebaum et al. 2007,Wright & Budin 1997, Hepp 2008]. Each type of operation on knowledgeresources became a discipline (e.g. ontology matching or schema matching[Shvaiko & Euzenat 2005, Euzenat & Shvaiko 2007a, Tzitzikas et al. 2007]).
A repository that represents knowledge extracted from heterogeneous re-sources is a system that requires a set of tools for combining these resources.Keeping openness to multiple models of knowledge representations is thebasic principle of our methodology. Consequently, there is no unique possi-ble way to combine the resources represented in the repository. Thus, thisrequires representing and applying multiple knowledge engineering method-ologies adapted each to the type of the knowledge representation model thatis used (see figure 5.1).
M1 M2
R1
R2
Rx
Derive, Align, Select, . . .
r1
r2
r3 r4
µ(M1,M2)
i
ie
repr_of
repr_of
repr_of repr_of
trans(r3, µ(M1,M2))◦
We assume that M1 and M2 are content representa-tion models of the resources (r1, r2, r3, r4).i : abstraction, e : reificatione ◦ i = id, i ◦ e 6= id.
Figure 5.1: Interactions model between the resources and the operatorswithin the repository
As we explained in the section 4.3 of chapter 4, the model that we adoptedfrom the OWL-S and adapted to the repository allows to define different pro-files of knowledge resources combination and combination operators. Eachprofile of an operator depends on the type of the input resources, the typeof the representation model that is used and the number and types of therequired parameters. Based on multiple surveys and studies of resourcescombination disciplines in our research area and in the area of knowledge

5.1. Resources management and combination operators 71
engineering, we define a taxonomy of operators that represents three cate-gories:
• Representation operators;
• Derivation and combination operators;
• Enrichment operators;
Other operations such as the edition, updates and versioning are sup-posed to be built-in components within the repository and do not requiremultiple implementations. These operators are also part of knowledge re-sources combination operators but they are not represented as a category inour taxonomy [Ghoula & Falquet 2012].
5.1.1 Representation operators
These are the basic construction operators for representations. The abstrac-tion and reification operations map physical resources to their representationin the repository and produce new resources from derivation (see figure 5.2).Model mapping operations create new representations in other models. Thiscategory of operators is represented in the repository with basic implemen-tations. We did not implement all the possible representation operators thatare required to import, export and transform all types of knowledge resourceswithin the repository.
Resource (language) Resource (model)
i : abstraction
e : reification
σ : derivation
Figure 5.2: Resources representation and derivation operators
5.1.1.1 Abstraction
Also called import, this operator is the constructor for representations ofknowledge resources within the repository. It takes as input a resource,expressed in given language or format and generates a representation of itscontent according to a given representation model.
It is not always necessary to preserve the entire content of a resourcewhen imported [Seidenberg & Rector 2006]. In particular, if the representa-tion model is less expressive than the original resource model, it is obvious

72 Chapter 5. A Taxonomy of resources combination operators
that some knowledge will be lost in the transformation process. For in-stance, importing an OWL ontology into the WordNet-like model (describedin section 4.2.4) will result in the loss of the semantics expressed in complexaxioms. However, the aim of the repository is not to faithfully representresources, it is to create versions or views (derivations) of these resourceswithin different models in order to optimize their usage for knowledge en-gineering tasks. Thus, the content representation model must be chosenaccording to the operations to perform and the functions to fulfill by theresulting resource.
We denote by iR,M the import operation that produces an instance of aresource R in the resources repository and by creating the content of theresource represented according to a content representation model M . Thisoperation can be followed by an other operation that produces a derivationof the resource in a different content representation model. For examplean ontology can be imported in the OWL or DL representation model andthen another ontology represented in the Concept_Hierarchy model can bederived from it.
Let M the set of content representation models available in the reposi-tory.
The signature of the abstraction operator is of the form:
iR,M : Resource→M ∈M
R→ rM
Where rM is the instance of the resource R in the repository representedusing the content representation model M .
5.1.1.2 Reification
We denote by eR,M,S the export operation that transforms a derivation of aresource represented in the repository by an instance r expressed in a modelM into a physical resource in an external file of a specific syntax S. Reifi-cation is generally used at the end of a process (sequence of operations) toproduce a new resource. It may also be used within a process that requiresthe application of some external operators. In this case resources represen-tations must be reified, exported, processed and re-imported.
This operator can have as much implementations as the possible combina-tions from the representation languages in the repository (for example OWL,UML, DL, Graphs, etc.) to the possible required formats (txt, xml, rdf, ttl,n3, etc.). Since abstraction may not preserve the content of a resource, thecomposition eR,M,S(iR,M (R1)) does not necessarily yield the initial resourceR1. However, it is possible, and desirable, that iR,M (eR,M,S(r2)) = r2 holds

5.1. Resources management and combination operators 73
(r2 is the representation of a resource R2 using a content representationmodel M).
Let R be the set of resources already imported in the repository,M theset of content representation models available in the repository and S theset of syntax languages that are supported by the exporting operators.
The signature of the reification operator is of the form:
er,M,S : r ∈ R,M ∈M→ R : Resource, S ∈ S
(r,M)→ RM,S
Where RM,S is a physical resource R exported from the repository and rep-resented using the content representation model M and one of its associatedsyntax representations S.
5.1.1.3 Resources translation (from a model to another)
This abstract operator is used to create new representations (views) of aresource using a content representation model (the resource is already rep-resented in the repository). For instance, a resource imported from UMLclass diagram could be represented in the repository using the content rep-resentation model Class_Association, then a derivation of this resource canbe represented in the Concept_Hierarchy content representation model (bydropping all the associations except part-of and subClassOf ).
A translation creates a new instance of a resource, which is required to beassociated to the original instance. This operator requires a usage of a modelmapping as a parameter to perform the transformation of the resource. Amodel mapping µM1,M2 is a set of correspondences between the elements of acontent representation model M1 and another content representation modelM2. The mapping µM2,M1 is not required to be the inverse of µM1,M2 .
Many tools and approaches propose converters between content rep-resentation models. For instance, from SKOS to OWL or OWLto SKOS many tools12 and mappings are available [Jupp et al. 2008,Van Assem et al. 2006]. In this research work, we created some convert-ers for the specific use cases that we implemented (explained in the followingsections and chapters) but we assume that enough tools for converting con-tent representation models are available. The important fact is to be able tointegrate and represent them in the repository, which is the case. Otherwise,if we create a new content representation model it should have at least oneimplementation of the abstraction operator and one implementation of thereification operator.
1http://www.heppnetz.de/projects/skos2owl/2http://mowl-power.cs.man.ac.uk:8080/owl2skos/

74 Chapter 5. A Taxonomy of resources combination operators
Let R be the set of resources already imported in the repository,M theset of content representation models available in the repository and µ the setof mappings between these models represented in the repository.
The signature of the translation operator is of the form:
dR,M1,M2 : r1 ∈ R,M1 ∈M, µM1,M2 ∈ µ→ r2 ∈ R,M2 ∈M
(r1,M1)→ (r2,M2)
It is not always necessary to preserve the entire content of a resource whenderiving a new representation of it (this can be compared to generating aview in the relational approach). In particular, if the second representationmodel is less expressive than the original representation model, it is obviousthat some knowledge will be lost.
Inner SET mapping Inter SET mapping
Representation Models SETi Representation Models
SETj
Figure 5.3: Classes of resources translation operators
Knowledge representations formalisms have different levels of expressiv-ity. We define two classes of translation operators (see figure 5.3). The classof inner set mappings, which are translations within the same level of ex-pressivity (We can also qualify this as a translation from one vocabulary ornamespace to another without loosing in terms of expressivity). The secondclass of translation operators transform the resource within a new represen-tation model that has a different level of expressivity than the first model,which leads to transforming the descriptions of the resource’s content.
An example of approaches for extracting and transform-ing knowledge from multiple resources is the methodology of[Villazón-Terrazas et al. 2010a]. The author proposed a pattern basedapproach for re-engineering non-ontological resources into ontologies (seefigure 5.4).
The API and guidelines of transforming “Non-Ontological resources”into ontologies are directly relevant to be considered and integrated to

5.1. Resources management and combination operators 75
create a set of standard operators for importing resources such as the-saurus, classification schemes, lexicons and other resources as defined in[Villazón-Terrazas et al. 2010b].
Resource 2 Resource 1
Folksonomy
Lexicon Glossary
Database
Type of non ontological resource
Implementation
XML File
Flat File
Adjacency List
Data model
Classification Scheme
Classification scheme modelled using a Path Enumeration model and stored in a database.
….
Path Enumeration
Flattened
Spreadsheet
Classification scheme modelled using a Path Enumeration model and stored in an XML file.
Snowflake
Thesauri
Figure 5.4: An approach for reusing “Non-Ontological” resources[Villazón-Terrazas et al. 2010a]
5.1.2 Enrichment operators
The enrichment operations generate enrichment resources such as alignment,annotation and indexing resources from resources representations that arestored in the repository. These operators are generally based on sophisticatedalgorithms (more precisely heuristics) and use auxiliary resources like lexicalontologies.
5.1.2.1 Alignement
Alignment is an operator that generates a resource containing facts thatexpress explicitly the relationship between elements from different resources[Kalfoglou & Schorlemmer 2003]. An alignment method consists of defining

76 Chapter 5. A Taxonomy of resources combination operators
a function that calculates a distance between entities of different resource andthen generating the best match between them [Euzenat & Shvaiko 2007b].
An alignment operator takes as input:
• A set of knowledge resources (at least two) represented in one or mul-tiple content representation models;
• A set of auxiliary resources such as lexical ontologies, glossaries ordictionaries to help disambiguate and fetch alignments;
• A set of other parameters such as methods for calculating distancebetween lexical entities (formulas, etc.);
• The content representation model to be used for the output.
Many approaches and tools are proposed in the literature and canbe used to implement different instances of this operator (see surveys[Shvaiko & Euzenat 2005, Euzenat & Shvaiko 2007a, Tzitzikas et al. 2007,Choi et al. 2006]).
A typical example of the need for the translation operator is that someimplementations of the alignment operator require specific content repre-sentation formalisms and if a resources is not originally represented in therequired formalism, the translation operator can be applied to generate aversion of this resource that is compatible with the alignment operator’s in-put. In some cases, when there is a need to align only named entities andconcepts based on the hierarchy of the ontology, it is much more appropri-ate to represent an OWL ontology by its structure graph instead of the fulldescription logic model. Alignment algorithms will be much easier to writeand they will be able to align any type of ontology that can be expressed asa labelled graph.
5.1.2.2 Annotation
The annotation operator is used to describe elements of a resource R interms of one or multiple other structured resources. The result of this op-eration is an annotation resource that contains elements representing enti-ties from the annotated resource associated to entities or expressions fromthe annotating resources according an annotation model. Multiple researchstudies defined tools and approaches for generating annotations (see surveys[Uren et al. 2006, Kiryakov et al. 2004]).
To represent annotation resources we use as default content representa-tion model the “Open Annotation Data Model”3 developed by the “OpenAnnotation Community Group”. This model (see figure 5.5)represents an
3URL: http://www.openannotation.org/spec/core/core.html

5.1. Resources management and combination operators 77
annotation as an element that has a body and a target, which are related toeach other.
An annotation operator takes as input:
• A knowledge resources represented in a content representation modelsas the mains resource with the content to annotate;
• A set of other resources such as ontologies or a structured resourcesfrom a specific domain;
• A set of other parameters such as methods for natural language pro-cessing for extracting terms and identifying expressions and namedentities;
• The content representation model to be used for the output.
Figure 5.5: Default representation model for annotation resourcessource by:
http://www.openannotation.org/spec/core/core.html#BodyTarget
For example, word sense disambiguation is a kind of annotation operator.Starting from a natural language text and a reference lexical ontology (andpossibly other resources), it produces a set of correspondences between thetext words and their meanings (the concepts of an ontology).
5.1.3 Derivation and combination operators
These operations are intended to generate new resources either from theselection of a part of an existing resource or from the aggregation or thecomposition of multiple resources. Many tools and approaches have been

78 Chapter 5. A Taxonomy of resources combination operators
proposed this kind of knowledge engineering (see surveys [Sattler et al. 2009,Vaníček et al. 2009]).
5.1.3.1 Selection and derivation
This type of operation selects entities from a resource R to generate a newresource represented in the same content model having as content a subset ofentities from R. The selection operator applies filters on the entities of theoriginal resource in order to extract only part of this resource. The filteringoptions may involve restrictions based on the resource’s entities and/or otherentities associated to them by means of annotations or alignments.
For instance, in a description logic ontology, this operator can selectindividuals in the ABox (Assertional Box), leaving the TBox (TerminologicalBox) untouched (as in a database selection) or it can select a subset of theTBox, and hence drop the ABox entities that depend on unselected TBoxentities or roles (as in a database projection).
Let R be the set of resources already imported in the repository,M theset of content representation models available in the repository and z theset of filters to be applied on a resources for extracting parts of their content.
The signature of the derivation operator is of the form:
DR,M,z : r1 ∈ R,M ∈M, f ∈ z→ r2 ∈ R,M ∈M
(r1,M1, f)→ (r2,M2); r2 v r1.
Applications in the literature propose different implementations of theselection operator qualified by different names such as module extraction forontological resources [Doran et al. 2007, d’Aquin et al. 2006] or knowledgeextraction for other types of resources [Wimalasuriya & Dou 2010].
5.1.3.2 Composition
Composition operators are applicable only on different resources repre-senting common entities linked to each other using transitive links. Thisoperator may be applied on ontologies, dictionaries, terminologies, paral-lel corpora, comparable corpora, alignments or annotations. This oper-ator is applied on resources represented by the same content representa-tion model. It generates a new resource represented in the same model asthe composed resources. Multiple approaches proposed tools and method-ologies for building knowledge resources by combining or composing enti-ties from other resources. We assume that these tools can be adaptedto the context of a knowledge resources repository and used as composi-tion operators. For instance, [Mangeot et al. 2010, Otero & Campos 2010,

5.1. Resources management and combination operators 79
Nerima & Wehrli 2008, Klavans & Tzoukermann 1995] propose tools forbuilding multilingual lexical resources using transitivity (composition opera-tor for terminological resources) and [Mitra & Wiederhold 2004, Klein 2001,Jannink et al. 1998] propose methodologies for composing ontologies (com-position operator for ontological resources).
The composition of two alignment resources from R1 to R2 and from (R2
to R3 results in a new alignment resource from R1 to R3. The semantics(relation type) of the resulting alignment depends on the relation types ofthe representation model of the input resources. We define and propose inchapter 7 some operators for composing alignment resources.
We assume that the facts of resources to be composed are representedas triples where two entities (node, link or expression entities) ex and eyare associated to each other using a role or relation li (the semantics of therelation is defined in the content representation model) 〈ex, li, ey〉.
Let R be the set of resources already imported in the repository, Mthe set of content representation models available in the repository and tworesources R1 ∈ R and R2 ∈ R. Let f1 and f2 be two facts where f1 =
〈ex, li, ey〉 ∈ R1 and f2 = 〈ey, lj , ez〉 ∈ R2.If li is a transitive relation or the composition of two instances of link
entities li and lj is supported by the content representation model M ∈ M,then the facts f1, f2 are compose able and their composition is a new factf1◦2 where:
f1◦2 = 〈ex, li ◦ lj , ez〉 ∈ R3.
where R3 is a new resource represented in the model M .
5.1.3.3 Aggregation
The aggregation of knowledge resources is an operator that combines mul-tiple resources and generates an aggregated resource (see figure 5.6). Thecombination of theses resources can be seen as a union followed by an op-erator that solves conflicts and inconsistencies. The idea of the aggregationis to safely combine all the entities and facts imported from a set of re-sources [Porello & Endriss 2011, Noy & Musen 2003, Pinto & Martins 2001,de Bruijn et al. 2004, Predoiu et al. 2005]. Depending on the representationlanguage, the operation can take different forms.
For example, using the aggregation operator on two ontologies in thelanguage DL (description logic) is reduced to perform the union operationof their vocabularies and axioms:
• (merge) disjoint union of the vocabularies and axioms plus equivalenceand subsumption axioms from both ontologies;

80 Chapter 5. A Taxonomy of resources combination operators
• (replace) if a named concept C of the ontology O1 is aligned (equiv-alence) to a named concept D of the ontology O2 then the operatorskeeps every axiom that defines C (C ≡ . . . and C v . . .), keeps theaxioms that define D and adds the axiom C ≡ D. This is a way toreplace the definitions given in O1 by those in O2 (used, for instance,when O2 is considered as more reliable than O1);
• (check consistency) apply a reasoning process over the generated ontol-ogy and extract all the facts and axioms that generate inconsistencies;
• (solve inconsistency) use an operator that solves the consistency prob-lems, otherwise annotate inconsistent facts and add explanation;
M1 M2 M3
r1 r′1 r′2 r2
r3
Aggr
R1 R2R3
i i
trans trans
in in
outA31 A32
e
Figure 5.6: Aggregating (Aggr) two views of resources represented with thesame model; this operation gives as a result a new resource represented inthe same model and two sets of alignments (A31 and A32) with the originalresources
This operator takes as parameters a list of resources represented usingthe same content representation model and uses auxiliary resources such asalignments between them (see figure 5.6). Aggregating multiple alignmentresources requires that they have the same source and target resources. Ag-gregating multiple annotation resources requires that they annotate the sameresource. We define and propose in chapter 7 some operators for aggregatingalignment resources.
The previous description of operators provides a general framework forrepresenting knowledge engineering tasks applied to the resources that arerepresented in the repository. The full description of an operator is repre-sented using the model of resources combination and combination operators(previous chapter). For each class of operators described in this taxonomywe define the type of input, output and the set of parameters.

5.2. Usage of the model and operators to create repository forcombining terminological resources 81
5.2 Usage of the model and operators to cre-ate repository for combining terminological re-sources
In this section, we present two examples of scenarios reflecting the usage ofthe model proposed in the previous chapter and the operators described inthe previous section. The first scenario have been fully implemented andtested. The second scenario is proposed only to illustrate another type ofuse case and no experimentation have been conducted.
5.2.1 Storing resources representations
We have built a prototype of a lightweight repository [Ghoula et al. 2010a]using the meta-model that we described in the previous chapter. We imple-mented the model as a relational database because the aim of this applicationwas to build a terminological knowledge base containing multiple terminolog-ical resources that is stored in a database. The usage of a DBMS is justifiedby its performance and scalability in the case of importing and combiningvoluminous resources. The generic node-link model of resources as describedin the previous chapter was simplified in order to reduce the number of factsto store in the repository4.
The node link model is represented using the following classes:
1. Resources (a.k.a. tok:Knowledge_Resource): indicating the prove-nance of entities (Wordnet, Wikipedia, etc.);
2. Languages: representing the main language of an entity;
3. Kinds: representing the types of the elements within the repository.For example nodes types contain:
• C: Concept;
• F: Lexical Form;
• GLE: GLossary entity;
• S: Sentence;
• P: Part of Speech;
• T: Term (Word in WordNet);
• . . .4This was done for a first experiment, in the current version of the prototype we use
an RDF triple store based on our ontology

82 Chapter 5. A Taxonomy of resources combination operators
4. Relations (a.k.a. tok:Link_Entity): indicating the type of relationsbetween the nodes (eventually the inverse relation) and the type ofnodes on, which each relation is applicable. For example relations aredescribed as follows:
• label: hypon,source: WN16,inverse: hyper,usage: FROM is an Hyponym of TO;
• label: hyper,source: WN16,inverse: hypon,usage: FROM is an Hypernym of TO;
• label: defof,source: WN16,inverse: defby,usage: FROM is defined by TO;
• label: defby,source: WN16,inverse: defby,usage: FROM is a definition of TO;
• . . .
5. Nodes (a.k.a. tok:Node_Entity): indicating the entities of resources.Each node has:
• a type;
• a language;
• a provenance;
• . . .
6. Links (a.k.a. tok:Expression_Entity): indicating the links betweenthe entities from the resources within the repository. Each link has:
• a relation (reference to a relation and consequently its inverse);
• a node source (domain);
• a node target (range);
• a resource;
• a confidence measure ∈ [0, 1];
• a sequence number for its order;

5.2. Usage of the model and operators to create repository forcombining terminological resources 83
• . . .
7. Properties: for storing metadata elements about nodes and resources;
8. Models (a.k.a Representation_Model): for storing the list of mod-els represented in the repository. A model is a set of nodes havingeach a specific type and some defined links between these nodes. Weimplemented the following models:
• WordNet-synset
• WordNet-synset + synonym (thesaurus)
• Glossary
• Translation list
• Document
• Sentence
• Word
• Concept alignment
Our methodology is based on importing resources into a structured stor-age repository, which allows to combine them easily. The importation processuses three modules.
• An entity extraction module that identifies and extract entities fromthe imported resource;
• A relation extraction module that allows to identify relations betweenthe extracted entities;
• A module for storing and indexing the extracted entities. This moduleallows to manage URIs and IDs in order to add new records in thedatabase for node entities.
• A module for representing relations, ensuring the representation andstorage of relations between the node entities. These relations aregenerally subsumptions, hierarchical relationships (simple or complex)between concepts and properties or relations that are extracted fromthe resources.
We stored these resources by generating a set of conceptual and termino-logical entities. These entities were associated to each other using link enti-ties, which are of the type Term_To_Concept and Term_To_Term. Theselinks were established using the relation extractor module. The detection ofrelation is based on the structure of the imported resources and the explicit

84 Chapter 5. A Taxonomy of resources combination operators
relations that these resources declare between entities. We developed a set ofSQL scripts to import the resources that were stored and represented withinother databases (e.g. WordNet). We imported and transformed the contentof these resources from multiple heterogeneous schemas to a common modelcalled WordNet − Like represented using the node-link model (see figure5.7). We also developed an importer for the resources that were representedin OWL/XML and HTML (Wikipedia).
sense/form
T
C
. . .
T T
Synset
. . .
P
ispos/mopos
dscby/dscof
F F F
C/C
TS
T/T
S
defof/defby
Synonym
Figure 5.7: Representation of the WordNet-Like model
We imported AGROVOC [Caracciolo et al. 2013] in 17 languages, Word-Net in English, German, Catalan, Spanish [Bond & KYONGHEE 2012],UNL in French, Arabic, Japanese [Uchida & Zhu 2001], CityGML[Kolbe et al. 2009] and URBAMET [Guyot et al. 2010]:
• AGROVOC is a multilingual structured controlled vocabulary devel-oped by the FAO terminology covering all domains related to agri-culture, fisheries, food and related fields. There are multiple ways toaccess this resource since it is represented using SKOS formalisms andpublished in different syntaxes such as XML, RDF. There is also a rep-resentation of this resources using OWL. For this experiment, we usedthe MYSQL version of this resource;
• UNL (Universal Networking Language) is an artificial language thatcan be used as a pivot language for translation systems or as a languageof knowledge representation.
• CityGML is a model for representing 3D objects in urban environments.

5.2. Usage of the model and operators to create repository forcombining terminological resources 85
• URBAMET is bibliographic database on French urban planning, landuse, cities, housing and accommodation, architecture, utilities, trans-port, local government, etc.
The result of the importation created a repository that contains approx-imately 950 000 different lexical forms in 24 languages, 173 000 concepts ofontologies and 335 000 sentences from 13 different resources.
Figure 5.8 shows an excerpt of the resources imported within the repos-itory. The left column represents the list of representation models that areused to represent the resources. The right column shows the list of theresources that are represented within the selected model, which is Word-Net_Like.
Figure 5.8: The list of resources within the repository based on their repre-sentation model
5.2.1.1 Generating a lexical ontology from wikipedia
Wikipedia is a combined resource, which has a category hierarchy that canbe considered as an ontology and a collection of articles in the form of hyper-text documents containing different sections that can represent definitionsand descriptions of concepts. Some sections are used for term or conceptdisambiguation. Links to the same articles in other languages can representlabels of the concept in different languages. We created a model to representthis resources (described in figure 5.9).

86 Chapter 5. A Taxonomy of resources combination operators
Hypertext_Doc Hypertext_Link
Doc_Part Translation_Link
X
Y
hasDomainType
hasRangeTypecontains
name
role
subClassOf
Figure 5.9: Excerpt of the model WP_Like representing Wikipedia articles
In order to import elements from Wikipedia, we created a simplifiedmodel of this resource. Then, we instantiated its elements, using a termextractor and links extractor to identify the relation between concepts.
1. The import of a set of elements from wikipedia is performed by theidentification of articles, their type and their metadata to represent itin the model WP_Like:Wiki page —> Hypertext_Doc (rdf:type Knowledge_Resource);URL suffix —> name (a property: the name of the article)Links to pages in other languages —> Translation_Link;HTML section—> Doc_Part(rdf:type Node_Entity);
2. The identification of annotation and translation elements is performedusing a procedure that attributes the role ‘Definition’ to the part of thedocument that describes the concept that is represented by the article.This procedure parses all the linked articles in the languages section inorder to extract lexical forms in other languages and attach them to theconcept as labels using an intermediary entity, which is the Term. Aconcept is labelled by a term that is represented by a lexical form in aspecific language. The extracted labels in different languages representthe terms attached to the original concept and can be considered as atranslation record. The figure 5.10 represents an interface allowing tonavigate the entities imported from wikipedia into the repository.
3. The change in a model is done by transforming the representation of aresource using mappings between WP_Like to the model WordNet_Like
model. The mapping between both models is done using the followingcorrespondences:

5.2. Usage of the model and operators to create repository forcombining terminological resources 87
Hypertext_Doc → Concept The URL of the documentbecomes a concept
value of name → LexicalForm within a specific language
Translation_Link → Form_Relation with the construction of a Termin case of need to link aconcept and a lexical form
. . . . . . . . . . . .
Figure 5.10: Browsing the concepts and terms extracted from Wikipedia
5.2.1.2 Enriching english WordNet with lexical forms in otherlanguages
This example shows the usage of our approach of representing knowledgeresources using a common model. The enrichment of WordNet is generatedautomatically using an operator that detects similar concepts from differ-ent terminological and linguistic resources. We used an english version ofWordNet, AGROVOC, URBAMET and UNL within the repository. Theseresources contain multiple concepts and lexical forms in different languagesrepresented by the representation model WordNet_Like.
Using an operator that we called ALG − ISI1, we created a collectionof alignment records called AL_HS containing a set of concepts of typeUC (Common concept). This operator collects evident mappings between

88 Chapter 5. A Taxonomy of resources combination operators
node entities that represent the same concepts and creates alignment entities(correspondences). The figure 5.11 defines the process that have been createdto implement this use case (first, import the resources, then align them andfinally merge the results and generate an aggregated resource).
UNL5
Import (WN)
UNL5 (WN)
AGROVOC Import (WN) AGROVOC (WN)
A1 Align
WordNet Import (WN) WordNet (WN)
Align A2
Join
Join
Union
WordNet+U
WordNet+A
WordNet+UA
Figure 5.11: Operators involved in the WordNet enrichment process
For a detailed description about the operators and the pattens involvedin this use case please refer to a similar example in the section A.1 appendixA.
In order to have a compact representation, the alignments are representedas a set of equivalent concepts from multiple resources that we named UAR(see figure 5.12). The alignments within the repository are extracted bycomparing the lexical forms attached to the concepts (in different languages).If the similarity is higher than a specific threshold then a new correspondenceis added to the alignment. These correspondences (819 alignments for thefour resources) are used to disambiguate concepts.
C
F
C
T
F
T
parent
table
furniture
Source X
C
F
C
T
F
T
parent
table
furniture
Source Y UC = =
UC
UAR
co/ie
Seq
UC UC
C C C
Figure 5.12: Alignment detection by similarity

5.2. Usage of the model and operators to create repository forcombining terminological resources 89
In the following example, the concept number “161185” is described bythe lexical form “table” in english, which is ambiguous and represents a termthat is used as a label for different concepts.
Figure 5.13: Representation and alignments of entities within the lightweightrepository
The alignment of this concept to other concepts from the different aggre-gated resources associates other lexical forms in other languages to it. Forinstance, (see figure 5.13) the alignment provides a new association betweenthe lexical form “mesa” in Spanish to the concept “161185” solves the am-biguity and classes this concept under the category “furniture ” (see figure5.14).
Figure 5.14: Representation and alignments of entities within the lightweightrepository
5.2.2 Alignment of representation formalisms
In many cases, such as information retrieval and classification, we need anannotated corpus, to perform tests, to build a classifier or create knowledge
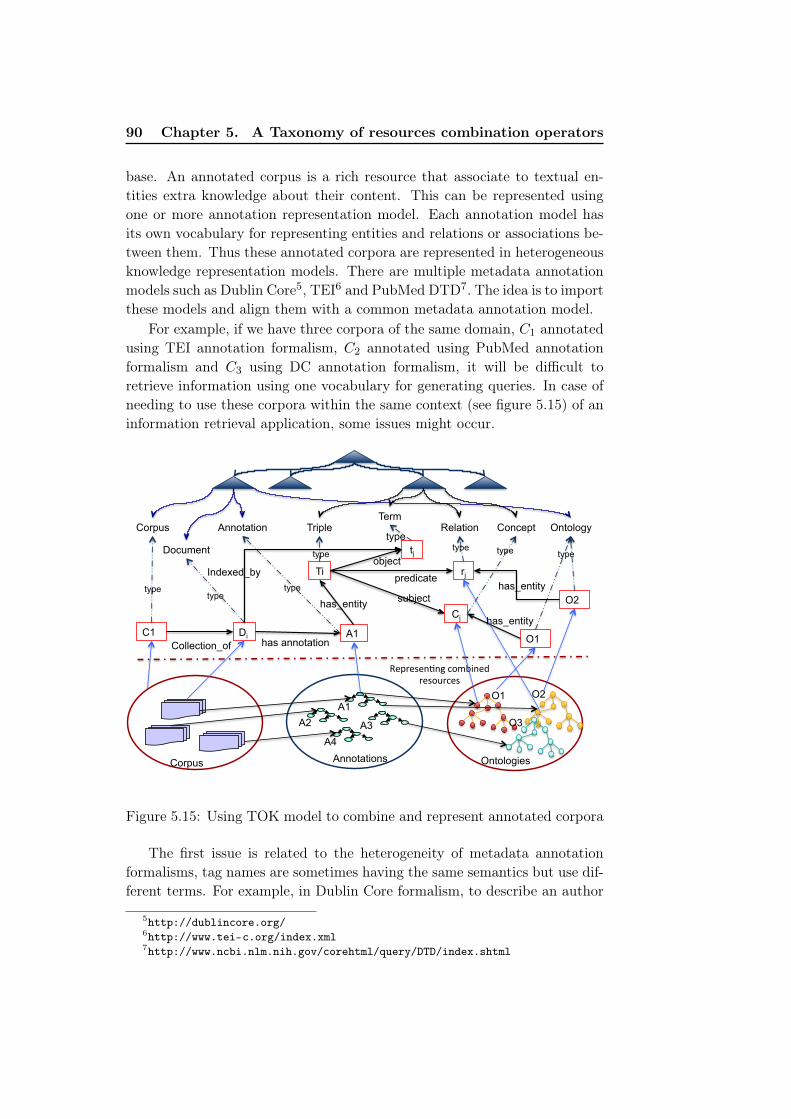
90 Chapter 5. A Taxonomy of resources combination operators
base. An annotated corpus is a rich resource that associate to textual en-tities extra knowledge about their content. This can be represented usingone or more annotation representation model. Each annotation model hasits own vocabulary for representing entities and relations or associations be-tween them. Thus these annotated corpora are represented in heterogeneousknowledge representation models. There are multiple metadata annotationmodels such as Dublin Core5, TEI6 and PubMed DTD7. The idea is to importthese models and align them with a common metadata annotation model.
For example, if we have three corpora of the same domain, C1 annotatedusing TEI annotation formalism, C2 annotated using PubMed annotationformalism and C3 using DC annotation formalism, it will be difficult toretrieve information using one vocabulary for generating queries. In case ofneeding to use these corpora within the same context (see figure 5.15) of aninformation retrieval application, some issues might occur.
O1 O2
O3
Ontologies
A1 A2
A4 A3
Annotations
subject
Corpus
has_entity
has annotation
predicate object
Collection_of
type
Corpus
Ti
Represen'ng combined resources
C1 Di
Document
type
A1
Annotation
type
Triple type
Cj
rj
tj
Term
Indexed_by
Relation
type
Concept
type
O1
O2
Ontology
type type
has_entity
has_entity
Figure 5.15: Using TOK model to combine and represent annotated corpora
The first issue is related to the heterogeneity of metadata annotationformalisms, tag names are sometimes having the same semantics but use dif-ferent terms. For example, in Dublin Core formalism, to describe an author
5http://dublincore.org/6http://www.tei-c.org/index.xml7http://www.ncbi.nlm.nih.gov/corehtml/query/DTD/index.shtml

5.2. Usage of the model and operators to create repository forcombining terminological resources 91
W3C recommend the use of DC.creator, but in TEI, the tag <author> isused. The second issue is the ambiguity of certain annotation models. Thesemantics of some tags can be very close, even similar to other tags in thesame formalism. For instance, it’s the case in Dublin Core, DC.Creatorrefers to the author, but also DC.Contributor means more or less the samething.
To solve this issue we can perform an alignment operation on these for-malisms represented by an annotation model [Ghoula et al. 2011]. At first,these formalisms are imported into the repository. Then, we align betweeneach of them with the common metadata annotation model (Mann). Finally,the annotated corpora are imported and their annotations are representedusing the original formalisms. Through the global model and its alignmentwith the other models we can examine the corpus with a single query.
Assuming that we have the required implementations of the import andalignment operators, it seems more convenient to import each corpora andrepresent its annotations using is original annotation model. This preservesthe originality of the corpora, which might be used within other applicationsbased on some specific annotation models.
TEI
DC
PubMed
Mann
TEIMann
DCMann
PMMann
Mann
c1
c2
c3
dm
dn
do
import annot contains
Figure 5.16: Alignment of annotation models
Let Mann be the common metadata annotation model representing enti-ties types and relations for annotation, and Mal, an alignment model repre-senting equivalency and subsumption relationships between concepts. Thesteps of building the unified corpora for the information retrieval applicationare the following:
1. import TEI, DC, PubMed and the Mann annotation models:
TEI = iXML(TEI.xml)
DC = iRDF (DC.rdf)
PM = iXML(PubMed.xml)
Mann: Mann = iOWL(Mann.owl)
2. align TE, DC and PM to Mann:

92 Chapter 5. A Taxonomy of resources combination operators
(TEI −Mann)Mal= AlignMal
(TEI,Mann)
(DC −Mann)Mal= AlignMal
(DC,Mann)
(PM −Mann)Mal= AlignMal
(PM,Mann)
3. import C1 using the TEI annotation model, C2 using DC and C3
using PM :
C1TEI = iXML,TEI(C1)
C2DC = iXML,DC(C2)
C3PM = iXML,PM (C3)
4. select the entities of C1 where the tags are aligned with Mann:C1Mann
= selectrel_type(Mann, (TEI −Mann)Mal)(C1TEI )
5.3 Conclusion
In this chapter we described some knowledge engineering operators within ause case of merging multiple ontological and terminological resources in orderto create an enriched version of WordNet [Ghoula et al. 2010a, Ghoula 2012].We proposed an approach to represent knowledge engineering operators andproposed a taxonomy of resources combination and combination operators[Ghoula et al. 2011, Ajmi et al. 2012, Ghoula & Falquet 2012].
These operators have different signatures and can be represented usingthe operator’s model. The proposed operators support multiple implemen-tations within the repository based on the type of the resources that areinvolved or the type of the tasks to perform. Implementations can be rep-resented as instances of the operators within the repository and can be trig-gered using web services invocations. This requires creating a set of webservices that implement each operator. In the second part of this chapter,we explained the usage of these operators and the repository via two scenar-ios. We explored the first scenario and described an implementation of themodel and some resources combination operators to show the usefulness ofsuch a repository.
The next chapter describes the first step of a full application of our re-search methodology. We choose to work on alignment resources because theyare valuable resources, which are useful for knowledge integration. These re-sources are also heterogeneous and are represented in different formalisms(ontological, terminological and linguistic). To be able to experiment thepotential of our approach we narrowed our case study to terminological andontological alignment resources. Language resources are also covered by this

5.3. Conclusion 93
methodology and we are conducting a separate experiment for combiningthem, which is not described in this manuscript.


Part II
Application of the TOK
approach on alignmentresources


Chapter 6
Refining TOK Model with ageneric model for representing
alignment resources
Contents6.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . 97
6.2 Definitions and typology of alignments . . . . . . . . 98
6.2.1 Definition of alignments . . . . . . . . . . . . . . . . . 98
6.2.2 Types of alignments . . . . . . . . . . . . . . . . . . . 99
6.3 Formalisms for representing alignments . . . . . . . . 100
6.4 TOKAlign: a generic model for representing alignments102
6.5 Importing alignment resources using TOKAlign model 106
6.5.1 Transforming alignments . . . . . . . . . . . . . . . . . 106
6.5.2 Importing and exporting alignments . . . . . . . . . . 108
6.6 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 112
In this chapter we describe the steps of defining a model for representingalignment resources and the details of implementation for importing het-erogeneous alignments using this model. For the sake of simplicity we usethe term alignment to designate an alignment resource. This model is arefinement of the upper-level model that we described in the chapter 4.
6.1 Introduction
The entity-matching problem consists of establishing relations between en-tities that belong to different knowledge resources (terminologies, ontolo-gies, encyclopedias, text corpora, etc.). This problem is known under dif-ferent names, depending on the resources to be matched: ontology align-ment, schema matching/integration, (multilingual) sentence or word leveltext alignment, etc. The meta-model that we presented in the previouschapter allows already to represent alignments but in order to consider a

98Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
specific semantics we intend to create a model that refines our meta-modeland describes these resources more precisely. In order to build a genericformalism or model for representing alignment resources, we have identifiedthese steps to follow:
1. Identify alignment resources types;
2. Study alignment representation approaches;
3. Organize and manage to find a common representation in order tosupport the majority of existing formalisms;
6.2 Definitions and typology of alignments
From a practical point of view, entity matching has become crucial for manydomains. For instance, within the context of the Semantic Web, knowledge-based applications and services generally use several knowledge resourcesto carry out their task. Therefore, resources representing the same domainand containing similar entities should be matched together. Many alignmentmethods have been proposed and evaluated in order to automatize the pro-cess of creating bridges between knowledge resources [Aguirre et al. 2012].
6.2.1 Definition of alignments
Alignments are used to explicitly express relationships between resources andtheir usefulness is supported by research studies [Euzenat & Shvaiko 2007b].An alignment method consists of identifying and representing some relationsbetween entities belonging to different resources and calculating the bestmatch between them [Shvaiko & Euzenat 2013]. An alignment resource isthe result of applying a matching tool on two or more different knowledgeresources (generally ontologies).
Definition 2 (Alignment [Euzenat 2008]) An Alignment A between twoOntologies Os and Ot is:
• a set of correspondences between Os and Ot;
• described by a set of additional metadata (a method, tool, date, prop-erties, etc.).
This definition can be generalized to any kind of resources notonly ontologies. Every tool or method for creating alignments be-tween different resources represents the result in a specific formalism[Euzenat & Valtchev 2003, David et al. 2011]. Some methods use the same

6.2. Definitions and typology of alignments 99
formalism and others propose their own [Shvaiko & Euzenat 2013]. Each ofthese alignment formalisms represents alignment records or alignment enti-ties as correspondences.
Definition 3 (Correspondence [Shvaiko & Euzenat 2013]) Havingtwo ontologies O and O′, a correspondence between O and O′ is a quadruple:
〈id, e1, e2, r〉
where:
• id is a unique identifier to the correspondence;
• e1 and e2 are respectively entities from O and O′ (concepts, roles, etc.);
• r is an alignment relation than has an attributed weight or a confidencemeasure.
For the sake of simplicity, we will omit the representation of the id in theexamples but it remains part of the correspondence’s attributes.
6.2.2 Types of alignments
The types of alignments are related to the types of resources to be aligned andalso to the specifications of the matching tool. We identified three categoriesof alignment resources:
Formal alignments : matching resources represented in a logical for-malism and using logical relations to express correspondences be-tween their entities. These entities can be simple (node entities)or complex represented as logical expressions using specific construc-tors (i.e. Description logics constructors, first order logic expres-sions etc.) [Euzenat & Valtchev 2003, Kalfoglou & Schorlemmer 2003,Suchanek et al. 2007].
Terminological alignments : bridging between resources representedin a semantic formalism and using terminological relations(Broader_Term, BroadMatch, Translation, ExactMatch, etc.) toexpress semantic correspondences between entities (Generally Ter-minological or conceptual entities) [Isaac et al. 2009, Kefi et al. 2006,Noy & Musen 2001].
Linguistic alignments : expressing correspondences between two syntac-tic structures generally for multilingual resources. It is generally ex-pressing equivalency between two parse trees in order to match different

100Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
n-grams in two sentences [Buschmeier et al. 2010, Pang et al. 2003] orsimply maps of translation links between pairs of linguistic entities.
Many types of formalisms represent these kinds of alignment resources.Each type of alignments has its own semantics and uses specific relations tolink between resources’ entities. The matched entities are specifically of acertain type, for instance, a terminological alignment uses only terminolog-ical relations to bridge between terminological entities. In the next sectionwe discuss some of the most used alignment formalisms that represent align-ments in the context of matching ontological, terminological and linguisticresources.
6.3 Formalisms for representing alignments
Alignment formalisms were defined based on the need for representing andusing alignments within applications (some of these formalisms are describedin figure 6.2). For instance, [Euzenat 2004] defined a formalism that is mainlyused by the majority of ontology matching tools. This formalism expressescorrespondences between entities using logical relations (equivalence (≡);generalization (A); specification (@); overlap (G) and disjunction (⊥)).
[0, 1]
RDF/XML
-
BITEXT
*..*
*..*OWL
�
1..1
[0, 1]
*..*
SWRL
[0, 1]
�, �, �, �,
sameAs, closeMatch, exactMatch, broadMatch,
narrowMatch, relatedMatch
Langage
1..1
SEKT-ML
Multiplicity
1..1
-
LOOM
RULEML Restrictions and variables
EDOAL
1..1
-
mappingRelation, closeMatch, exactMatch, broadMatch,
narrowMatch, relatedMatch
�, �, �, �,
-
�, �, �, �,
C-OWL
*..*
RDF/XML
Formalisme
SEKT-ML �, �, �, �,
-
Relations
OLA
Confidence
SKOS
subClassOf, equivalentClass, sameAs, disjoint,
differentFrom, disjointWith, ComplementOf
OWL
-
RDF/XML
SKOS
1..1
TMX
RDF/XML
Figure 6.1: Formalisms for representing alignment resources
Regarding the number of alignment tools and the different types of re-sources, the number of alignment formalisms is increasing. For instance, for

6.3. Formalisms for representing alignments 101
ontology alignments almost each matching tool has an alignment represen-tation formalism/language [Aguirre et al. 2012].
• C-OWL: Conceptualized OWL [Stuckenschmidt et al. 2004,Bouquet et al. 2003] is an extension of OWL used to representmatching records between entities of two ontologies. It matches onlysimple or atomic entities defined by their URI. These correspon-dences, called bridging rules, representing matchings between classes,properties and individuals.
• SWRL: Semantic Web Rule Language is a rule-based language forknowledge representation within the semantic web. This language isused to express complex alignments thanks to its ability to representexpressions [Horrocks et al. 2004]. SWRL is a combination of OWLand RuleML and expresses rules on ontological entities. These rulesare considered as correspondences if the used entities are belonging todifferent ontologies (resource source and resource target). The struc-ture of SWRL formalism and the description of its important tags usesthe following namespace:
ruleml:imp is a tag used to describe correspondences (rules) betweentwo expressions involving entities from a source and a target on-tologies;
ruleml:_body is a tag used to describe the source expres-sion, which is a set of constructors (Atom) involvingentities from the source ontology. These constructorscan be classAtom [C(x)], individualPropertyAtom ordataRangePropertyAtom [P(x,y)], sameIndividualAtom
[sameAs(x,y)], differentIndividualsAtom [differentFrom(x,y)],or builtinAtom [builtIn(r,x,...)], where C is an OWL entity(generally a Class), P is an OWL property, r is a built-inrelation, x and y can be variables, OWL individuals or OWLdata values;
ruleml:_head is the target expression using the same constructorsad the ruleml : _body tag.
• OLA: OWL Lite Alignment is a formalism originally designed torepresent ontology alignments produced by the “Alignment API ”[Euzenat et al. 2004] and used as an export formalism for many on-tology matching tools. This formalism defines correspondences usinglogical relations between atomic entities. It allows also to representsome metadata about the alignment such as its cardinality and level

102Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
of expressivity, etc. Expressive and Declarative Ontology AlignmentLanguage [David et al. 2011] is an extension of this formalism allowingto represent complex correspondences and precisely describe relationsbetween all types of ontological entities.
• Parallel text alignments: BiText and TMX (Translation MemoryeXchange) are formalisms representing documents containing text unitswhere each unit in a source language is attached to another unit ina target language [Martínez et al. 1998]. A BiText can be seen as amerged document from two other documents in two different languagesand is designed for human use while programs use TMX. The usageof both formalisms is recommended generally when there is a need topreserve the context of the sentences and their order within the orig-inal documents. This formalism is mostly used to represent sentencealignment in parallel corpora.
• LOOM1: is a formalism designed to represent ontology alignments gen-erated by the NCBO2 matching tool. This tools uses semantic relations(SKOS) to deduce correspondences between synonym entities (skos :
closeMatch) or entities having identical URIs (skos : exactMatch).
Alignment formalisms share mainly the same structure. In the next sec-tion we will introduce a proposition of a generic alignment model that refinesthe meta-model (Chapter 2) and represents in a more detailed manner align-ment resources. This model is a direct application of the representationapproach described in the figure 4.8 of the chapter 4. OLA and EDOALformalisms may be used as main formalisms for representing heterogeneousalignments but they have a restricted set of alignment relations, which doesnot serve our approach and their semantics will be restrictive for our ap-proach of integrating heterogeneous resources.
6.4 TOKAlign: a generic model for representingalignments
We use the definitions from the ontology matching theory[Marshall et al. 2006]. In our case, we extend the usage of the basicdefinition of a correspondence [Shvaiko & Euzenat 2013] by opening theset of alignment relations to any kind of relation and by considering thepossibility of having a conjunction of multiple sets of disjunctive relationshaving each a certain weight or confidence. This choice of extension is
1http://www.bioontology.org/wiki/index.php/BioPortal_Mappings2http://www.bioontology.org

6.4. TOKAlign: a generic model for representing alignments 103
justified by the need to aggregate and compose multiple alignment resourcesfrom different tools, which leads to a wide range of possibilities for specificparticular cases, which needs to be represented in order to be treated[Ghoula et al. 2013].
Definition 4 (Extended alignment correspondence) An alignmentrecord between two knowledge resources Rs et Rt is a quadruple,
〈id, e1, e2, R〉
where:
• id is a unique identifier of the correspondence (we will not representthis element in the examples);
• e1 et e2 are entities belonging to Rs and Rt respectively;
• R is a set of pairs {(r1, w1), . . . , (rn, wn)} where ri is a relation thatbelongs to a relation algebra A and wi is a confidence level
A correspondence 〈e1, e2, {(r1, w1), . . . , (rn, wn)}〉 represents the fact that(e1 r1 e2) holds with confidence w1 and . . . and e1 rn e2 holds with confidencewn.
Based on the studied alignment formalisms, entities can be used as theyare defined in the semantics of the resource (named concepts, classes, prop-erties, individuals, terms, sentences, labels, etc.) or within expressions thatinvolve logical constructors (axioms, property restrictions, DL expressions,etc.). These entities were represented and described in the section 4.2.2.The complex entities can be expressed in the vocabulary and semantics ofthe originating resources or using constructors proper to an alignment for-malism [David et al. 2011].
Alignment resources are instances of the “Alignment” (see figure 6.2)class and are represented as sets of elements represented each as an in-stance of the “Correspondence” class. A correspondence is an element thathas some metadata information and links between a source and a targetentity (instances of the “Resource_Entity” class) using an alignment re-lation. An alignment relation is represented by an instance of the classMeta_Alignment_Relation, which is a set of pairs (Alignment_Relation,confidence measure).
• Alignment v ∀ has_align_target Knowledge_Resource
• Alignment v Enrichment_Resource
• Alignment v ∀ hasType Datatype : string

104Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
• Alignment v ∀ has_align_source Knowledge_Resource
• Alignment v ∀ contains Correspondence
• Alignment v ∀ alignsBetween Knowledge_Resource
• Alignment v ∀ has_Method Datatype : string
• Correspondence v ∀ source_entity Resource_Entity
• Correspondence v = alignsBetween Resource_Entity
• Correspondence v ∀ confidence_measure Datatype : float
• Correspondence v Expression_Entity
• Correspondence v = alignRelation Meta_Alignment_Relation
• Correspondence v ∀ target_entity Resource_Entity
• Meta_Alignment_Relation v Alignment_links
• Alignment_links v Link_Entity
• Meta_Alignment_Relation v ≥ 2 conjunction_of Correspondence_Alignment_Relation
Each alignment relation (class: Alignment_Relation) is represented byan identifier and a list of symbols (e.g. : “equal”, “exactMacth” or “=” aresymbols for the equivalency relation). For representing logical and semanticalignment relations we have identified nine types of relations used by differentformalisms to express correspondences between entities. These relations area classification of logical relation3 and terminological or semantic relations4.
• Alignment_Relation v Alignment_links
• Alignment_Relation v ∀ has_symbol Align_Relation_Symbol
• Correspondence_Alignment_Relation v ∀ confidence_measure Datatype : float
• Correspondence_Alignment_Relation v ∃ has_symbol Align_Relation_Symbol
• Correspondence_Alignment_Relation v Alignment_links
• Correspondence_Alignment_Relation v ∃ disjunction_of Alignment_Relation
Relations between entities are defined by the alignment formalism andnot by the original resources. Generally, the semantics and representationof these relations is at the same level of expressivity as the formalism repre-senting the aligned resources. However, there is no restriction or constraintson using any type of alignment relation on any type of entity. The modelis open to any kind of alignment relation as long as it is represented as asubclass of Alignment_Relation.
3Mapping in OWL, http://www.w3.org/TR/2004/REC-owl-guide-20040210/#OntologyMapping
4See relations section of the SKOS namespace, http://www.w3.org/TR/skos-reference/#mapping

6.4. TOKAlign: a generic model for representing alignments 105
Knowledge_Resource
Alignement
Resource_EntityidCorrespondence
Alignment_Relation
Expression_Entity
Constructor
C_Alignment_Relation
1..*
Variable
1..*
1..*
1..*
1..*
Complex_Correspondence
Simple_Correspondence
ComplexAlignement
SimpleAlignement
∀has_align_source
float [0..1]
Resources_Management_Operator
1..*
1..*
∀provenance
∀target_entity
∀contains∀contains
1..*
∃contains∀disjunction_of
∀align_relation
∀confidence
∀argument
∀argument
∀argument ∀argument
Meta_Alignment_Relation
∀conjunction_of
∀has_align_target
∀target_entity
∀source_entity
OR
∀source_entity
Figure 6.2: Generic model for a representing alignments
This model (see figure 6.2) is represented by a combination of a newvocabulary representing specific entities of this kind of resources and thevocabulary of the meta-model from the ontology TOK_Onto. This is an ap-plication of the representation approach that we described in the first part ofthis thesis. As a reminder, the principle of representing knowledge resourcesis to use the meta-model’s classes as top level representations and refine themwith specific classes that represent models of specific resources. The meta-model on its own can be used to represent these resources, but we use thismodel in order to represent detailed aspects of alignment resources and espe-cially use a common definition and representation of correspondences that isrequired to define generic operators for managing and combining alignmentresources.

106Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
6.5 Importing alignment resources using TOKAlign
model
The import is a process using specific correspondences between the local for-malisms and the global model. As we stated earlier, we consider terminolog-ical and ontological alignment resources as an use case of our methodology,many methods and tools have been proposed and evaluated but it is stilldifficult to find a proper repository for collecting and combining ontologyalignments.
6.5.1 Transforming alignments
We have created an importing tool based on wrappers that match the names-pace of existing alignment formalisms with the namespace of the alignmentmodel. Some element of the generic model does not have corresponding el-ements in the specific formalisms such as the alignment relations (in TMXor SWRL) and the confidence measure. Default values will be assigned inthese cases:
• if the relation is not explicitly stated then the equivalence is used asan alignment relation;
• if the confidence measure is not indicated in the original correspondencethen it will be considered as a full confidence “1”.
From OLA to the generic alignment model
Each namespace element of the OLA formalism is matched to a namespaceelement of the generic model as follows:
• The resources [source and target] are represented by the elements<ola:onto1> and <ola:onto2>;
• The correspondences are represented by the element <ola:Cell>;
• The entities [source and target] are represented by the elements<ola:entity1> and <ola:entity2>;
• The alignment relations are represented by the element <ola:relation>;
• The confidence measure is represented by the element <ola:measure>

6.5. Importing alignment resources using TOKAlign model 107
From C-OWL to the generic alignment model
Each namespace element of the C-OWL formalism is matched to a namespaceelement of the generic model as follows:
• The resources [source and target] are represented by the elements<cowl:sourceOntology> and <cowl:targetOntology>;
• The correspondences are represented by the element<cowl:bridgeRule>;
• The entities [source and target] are represented by the elements<cowl:source> and <cowl:target>;
• The alignment relations are extracted from the attributes of the ele-ment (<cowl:bridgeRule>)
• Confidence measures are assigned a default value “1”.
From LOOM to the generic alignment model
The LOOM formalism represents some differences from the generic alignmentmodel:
• The resources [source and target] are represented by the entities’ URIswithin correspondences;
• The correspondences are represented by the element <map-pings:One_To_One_Mapping>;
• The entities [source and target] are represented by the elements <map-pings:source> and <mappings:target>;
• The alignments relations are represented by the tag <map-pings:relation>;
• Confidence measures are assigned a default value “1”.
From SWRL to the generic alignment model
The SWRL formalism is very similar to our model except the lack of explicitlydefining the source and target resources, which can be retrieved from theentities’ URIs.
• The resources [source and target] are retrieved from the URIs of sourceand target entities within the correspondences;
• Correspondences are represented with the element<ruleml:imp>;

108Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
• [source and target] entities (Expression) are represented by the tags<ruleml:_body> and <ruleml:_head>;
• The arguments of [source and target] entities or (Constructor) arerepresented by the element <ruleml:_Atom>;
• The alignment relations are explicitly represented as “equivalent”;
• Confidence measures are assigned a default value “1”.
From TMX to the global alignment model
The TMX formalism is the only formalism among the studied ones that re-quires further treatment for importing. Only the correspondences are clearlyidentified (<tu>). In order to identify other components we created a properimporter for this formalism:
• The resources [source and target] are identified by the attributes in ofthe tag <tuv>;
• The correspondences are identified by the tag <tu>;
• The [source and target] entities are represented by the tag <seg>;
• The alignment relations are explicitly represented as “equivalent”;
• Confidence measures are assigned a default value “1”.
6.5.2 Importing and exporting alignments
This operator extracts alignment entities represented in different alignmentformalisms and creates representations of the imported alignments within therepository using the global alignment model that we defined in the previoussection.
Instead of creating a parser for each alignment formalism, we collectmapping between these formalisms and the global alignment model and useit for extracting alignments from the input files and then we create instancesof these resources and their content within the repository. The mapping fileguides the parser and enables the program to identify alignment entities andtransform them into instances within the repository.
The transformation and import (see figure 6.3) of an alignment repre-sented using one of the previously described alignment formalisms followsthese steps:
1. Parse the configuration file and get the tags of the required elementsbased on the alignment file’s format.

6.5. Importing alignment resources using TOKAlign model 109
2. Analyse the content of the alignment’s file, or URL, using an XMLparser based on the STAX5 API and create an instance of the align-ment resource as an “Alignment” and instances of its content as cor-respondences, entities, and relations;
3. Store the “Alignment” in the repository.
Parser
Alignement TripleStoreAllegrograph
input
[Mapping - Formats]
[Mapping - Relations]
[Alignment files]
output
[RDF Triples][Generic representation]
Figure 6.3: Architecture of the resources’ import component
The figure 6.4 represents an excerpt of the XML mapping file that is usedas input for the abstraction operator (or import).
Figure 6.4: Excerpt of mappings between alignment formalisms and thegeneric alignment model
Since we are using ontologies as a means of knowledge representation andRDF as a formalism for storing instances of the ontology TOK_Onto, wechoose to implement the repository as a Triplestore. When the alignment isrepresented using the global model, we use Jena6 API in order to store it
5http://docs.oracle.com/javase/tutorial/jaxp/stax/api.html6http://jena.apache.org/
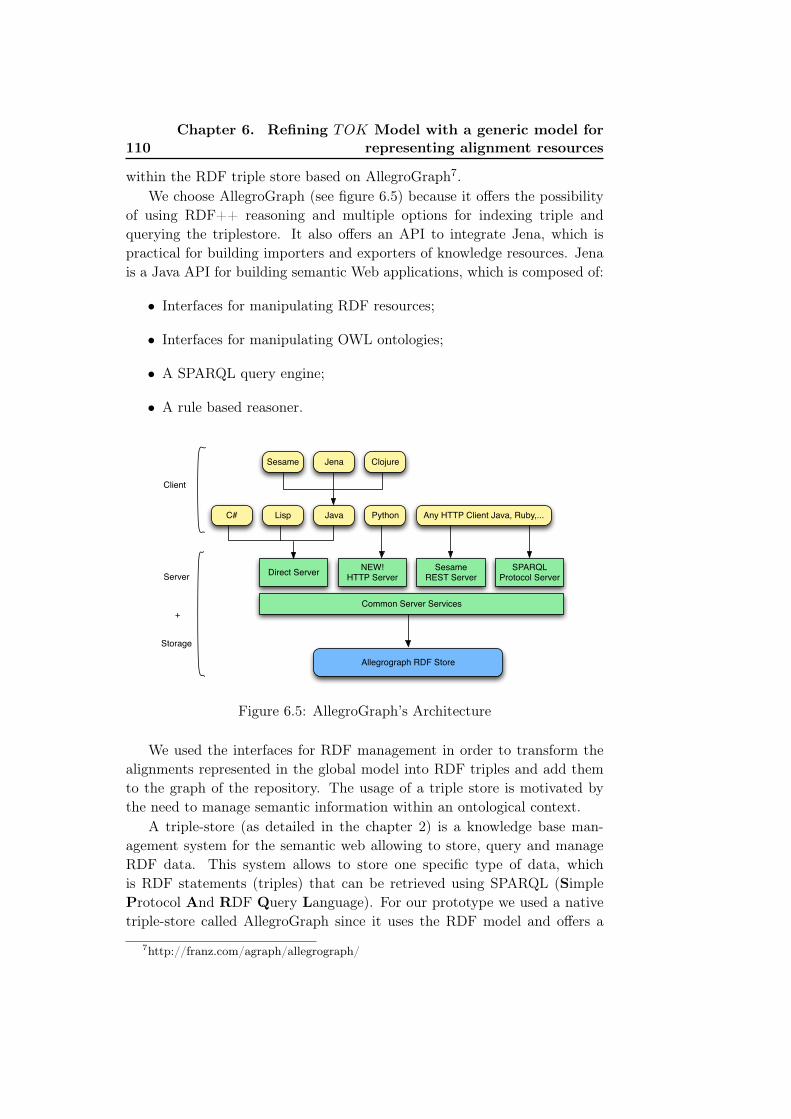
110Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
within the RDF triple store based on AllegroGraph7.We choose AllegroGraph (see figure 6.5) because it offers the possibility
of using RDF++ reasoning and multiple options for indexing triple andquerying the triplestore. It also offers an API to integrate Jena, which ispractical for building importers and exporters of knowledge resources. Jenais a Java API for building semantic Web applications, which is composed of:
• Interfaces for manipulating RDF resources;
• Interfaces for manipulating OWL ontologies;
• A SPARQL query engine;
• A rule based reasoner.
C#
JenaSesame
Lisp PythonJava
Clojure
Any HTTP Client Java, Ruby,...
Direct Server NEW!HTTP Server
SesameREST Server
SPARQLProtocol Server
Common Server Services
Allegrograph RDF Store
Client
Server
Storage
+
Figure 6.5: AllegroGraph’s Architecture
We used the interfaces for RDF management in order to transform thealignments represented in the global model into RDF triples and add themto the graph of the repository. The usage of a triple store is motivated bythe need to manage semantic information within an ontological context.
A triple-store (as detailed in the chapter 2) is a knowledge base man-agement system for the semantic web allowing to store, query and manageRDF data. This system allows to store one specific type of data, whichis RDF statements (triples) that can be retrieved using SPARQL (SimpleProtocol And RDF Query Language). For our prototype we used a nativetriple-store called AllegroGraph since it uses the RDF model and offers a
7http://franz.com/agraph/allegrograph/

6.5. Importing alignment resources using TOKAlign model 111
Java client that integrates Jena API. Each imported alignment can be ex-ported using the generic alignment namespace. The export algorithm usesthe resource’s graph represented within the repository and generates an RDFfile.
Once alignment resources have been imported and stored in the reposi-tory, operations such as Merge, Intersection or Composition are possibleto be executed and can generate new alignments that will be added to therepository. Each alignment is stored and associated to some metadata ele-ments describing its provenance (generating tool, institution, author, source,target, etc.). Entities used in the alignments are unique and used by makingreference to their URIs (no risk of duplication or redundancy). Figure 6.6represents the interface of the repository of alignment resources that is builtusing the ontology TOK_Onto and the generic alignment model. This in-terface represents the form for uploading alignment files represented in oneof the previously described formalisms. When the alignment is uploaded andimported successfully an excerpt of its metadata is displayed.
Figure 6.6: Importing an alignment between two biomedical ontologies

112Chapter 6. Refining TOK Model with a generic model for
representing alignment resources
6.6 Discussion
In this chapter we categorized alignment resources and designed a genericmodel for representing and storing alignments [Ghoula et al. 2013].
The alignment representation model is one of the proposed refinementsto the resources representation model that applies our approach of resourcesrepresentations. The approach states that resources are described in generalusing the meta-model and their content is described as subclasses of themeta-model (Node_Entity, Link_Entity and Expression_Entity). Theproposed model in this chapter defines a generic representation of all theresources of the type “Alignment”.
The vocabulary of this model is integrated in the resources model(TOK) using class subsumption axioms (e.g. Correspondence v Expres-sion_Entity v Resource_Entity ). This shows the flexibility of the repre-sentation approach and the ability to represent resources using specific orgeneric vocabularies.
In the next chapter we will use this model as a basic framework to defineoperators for managing and combining alignment resources. This is a directapplication of the proposed methodology for combining knowledge resources.

Chapter 7
Operators for combining andaggregating heterogeneous
alignment resources
Contents7.1 Approaches for alignment resources reuse . . . . . . . 114
7.1.1 Approaches reusing existing alignments . . . . . . . . 1147.1.2 Approaches proposing theories for alignment composi-
tion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1167.2 An approach for alignment resources combination . . 118
7.2.1 Framework of representing alignment correspondences 1197.2.2 Interpretation of correspondences using fuzzy set theory1207.2.3 Interpretation for Dempster-Shafer theory . . . . . . . 1237.2.4 Switching from an interpretation to another . . . . . . 124
7.3 Alignment combination operators . . . . . . . . . . . . 1257.3.1 Alignment composition . . . . . . . . . . . . . . . . . 1257.3.2 Alignment aggregation . . . . . . . . . . . . . . . . . . 1297.3.3 Alignment union . . . . . . . . . . . . . . . . . . . . . 1337.3.4 Alignment intersection . . . . . . . . . . . . . . . . . . 1337.3.5 Alignment difference . . . . . . . . . . . . . . . . . . . 134
7.4 Implementing alignment combination and manage-ment operators . . . . . . . . . . . . . . . . . . . . . . . 135
7.4.1 Implementing fuzzy aggregators . . . . . . . . . . . . . 1367.4.2 Executing combination operators . . . . . . . . . . . . 1377.4.3 Alignments overview, update and edition . . . . . . . 1407.4.4 Discussion about the aggregation metrics . . . . . . . 142
7.5 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . 142
In this chapter we propose a methodology for combining alignment re-sources. The approach defines a set of knowledge engineering operators thatare used to derive new alignments from existing ones generated by different

114Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
tools. For instance we propose a composition operator that generates a setof correspondences between entities from two knowledge resources based onthe alignments between them. We describe two types of interpretations foralignments. Both interpretations are based on two different uncertainty the-ories (fuzzy set theory and Dempster-Shafer theory). The comparison of theresults of both theories is detailed in the following chapter.
Alignments are the output of a matching process that generates corre-spondences between entities of heterogeneous knowledge resources. A largenumber of alignment methods have been proposed to contribute to automa-tizing and creating bridges between different kinds of resources (ontologies,terminologies, corpora, etc.). A considerable amount of alignments is beingcreated either by human experts or using automatic matching tools. Thus,collecting and managing the constructed alignments is useful in order tocompare them or combine them to enhance their quality.
7.1 Approaches for alignment resources reuse
Alignments of a good quality between complex knowledge resources are costlyto create, mostly because they are validated or built by a human expert.The result of a matching process of this kind is a valuable resource thatmust be stored, shared and reused. In particular, the idea of generatingnew alignments by composing already existing ones is appealing. Indeedseveral studies stated the importance and usefulness of composing alignmentsand multiple systems and tools have been proposed to combine alignmentmethods [Euzenat 2004, Parida et al. 1998].
Nevertheless, only few concrete tools such as the alignment server[David et al. 2011] have been created to manage alignment resources. A no-table exception can be found in the natural language processing area whereit is a common practice to build bilingual lexicons or aligned sentences bytransitivity. We classified theses methods into two categories:
1. to show the utility of reusing alignment resources we describe someapproaches that use existing alignments to generate new ones;
2. to show the current state of the art about alignment combination wedescribe some approaches that propose algebra for alignment relationsand theoretical backgrounds for defining alignment composition.
7.1.1 Approaches reusing existing alignments
In the case of ontology alignment, the majority of alignment tools use thesame strategy of combining different alignment methods (structural, lexi-

7.1. Approaches for alignment resources reuse 115
cal similarity, terminological, etc.), as described in [Euzenat 2007], in or-der to aggregate confidence measures calculated using different methods.For other types of alignments many approaches combine metrics in orderto define associations between resources entities (e.g., machine translation)[Lin & Hovy 2003].
• In the context of detecting transitivity in lexicons, [Wehrli et al. 2009]propose the MulTra system aiming to develop a grammar-based trans-lation model able of handling a large number of languages in order toprepare the required data and tools for achieving that goal. The au-thors proposed a formalism for expressing the structural diversity ofdifferent languages and to capture the “generalizations hidden behindobvious surface diversity”. The interesting part related to our approachis the fact that the authors proposed a method for automatically de-riving bilingual lexicons by transitivity, using two existing ones. Forinstance, having correspondences for language pair l1 → l2 and anotherlanguage pair l2 → l3 the system can build a dictionary for l1 → l3.
• Alignment resources are not only about ontologies and their relationsare not only logical. There are many tools for generating alignmentsbetween lexical, linguistic and terminological resources and having aspecific semantics of alignment relations each. Few approaches havebeen proposed for offering tools in order to combine linguistic or ter-minological alignment resources. For instance [Macken et al. 2008] de-fined and applied operations such as intersection and union in orderto combine linguistic alignments in both directions. The authors haveused the results of these heuristics in order to create a good quality setof data to compare it with the results of their approach, which createsa sub-sentential alignment system that linguistically aligns sentences inparallel texts based on lexical correspondences and syntactic similarity.
• [Hecht et al. 2014] proposed a methodology for ontology alignmentbased on exploiting existing alignments by combining their outcomeand detecting new correspondences. The authors claim that their ap-proach enhances ontology matching and give comparable yet sometimesbetter results than other alignment tools. This methodology detectsambiguous correspondences and categorizes them in order to removeinconsistent ones. Two methods are used for categorizing correspon-dences: (1) redundancy in the correspondences is used as a supportfor correctness; and (2) correspondences between an entity and morethan one other entity should be supported by a relation between thecorresponding entities on the web.

116Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
• [Gal et al. 2005] defined a framework for modeling semantic reconcilia-tion (relations between entities are not taken into consideration). Theauthors identify the impact factors on the effectiveness of matchingtools. Based on the study of the identified factors the authors proposeguidelines for designing better matching algorithms. This approachproposes a framework based on a fuzzy model for computing confi-dence measures between domain concepts based on aggregating differ-ent measures provided by different algorithms. This research work aimsto identify the features of a reliable automatic matching and representthe uncertainty in matching process outcome. If a matching satisfies aspecific feature, then a high confidence measure can be interpreted as agood semantic mapping. This framework is useful as a background foraggregating matchers and demonstrates the importance of aggregatingconfidence measures based on a theory and an experiment.
7.1.2 Approaches proposing theories for alignment composi-tion
Multiple systems for knowledge engineering used operations on lexi-cal, linguistic, terminological or ontological alignment resources. Someof these approaches combine ontological and terminological align-ments [Roche et al. 2009]. Other tools such as the Alignment Server[David et al. 2011] manage only ontology alignments:
• [Zimmermann et al. 2006] proposes a theoretical background to buildthe semantics of a composition operator for ontology alignments overa network of ontologies. The authors note the difference of the rep-resentation context between the local theory for representing entitieswithin ontologies and the local theory for representing correspondencesbetween entities within alignments. This difference can be the originof inconsistency when ontologies and alignments are combined. Tocope with this difference of interpretation the authors propose a for-mal theory of ontology alignment based on the category theory whereontologies are used as objects.
The authors define the notion of V-alignments and prepare the groundsfor an algebra for ontology merging, alignment composition, union andintersection. The proposed theory does not support the aggregationof confidence measures. This theory is useful to define these operatorsand some of their properties but its major contribution is a distributedrepresentation of ontology alignments.
• [Chowdhury & Dou 2011] proposed a methodology for improving theaccuracy of ontology alignments through Ensemble Fuzzy Clustering.

7.1. Approaches for alignment resources reuse 117
The authors note that similarity measures are not always helpful orreliable for indicating the quality of a semantic matching. Some toolsmay associate medium or even low confidence measures to quality cor-respondences. The authors address also the problem of ambiguity incorrespondences by considering the gap between confidence measuresgiven to the same correspondence by different tools. The approach isinteresting for creating clusters of alignments but does not cover allthe types of alignments (the alignments without confidence measuresand the alignments supporting relations other than the equivalence areexcluded).
• In the case of formal alignments, the relations used for expressing cor-respondences of entities from the matched resources are equivalencyor subsumption. For advanced tools that require more sophisticatedrepresentations there is a need for alignment relations and also an al-gebra of these relations. [Euzenat 2008] addresses this problem fromthe ontological point of view to focus on the outcomes of (1) expressingdisjunctive relations for ontology alignment, (2) merging alignments indifferent ways, (3) enriching alignments with relations of different levelof expressivity and (4) composing alignments. This approach proposesa full algebra for defining semantics for new relations resulting from ap-plying the union, intersection and the composition of alignments. TheA5 algebra is based on a set of logical relations, which is {equivalence(≡); generalization (w); specification (v); overlap (G) and disjunction(⊥))}. With the proposed algebra the author has also defined metricsand properties to aggregate confidence measures while combining orcomposing alignments. This research is completely theoretical withoutan experimental background to compare it with some few existing ap-proaches. However the author claims that, “the algebra of relations isa well-studied domain and it can be applied straight away to ontologyalignment”.
Considering the A5 algebra proposed by [Euzenat 2008], we assume thatthe theoretical aspects of alignment aggregation and composition are well es-tablished. This is useful to our approach since it has defined all the propertiesand requirements to build operators for composing, merging and aggregatingformal alignments. To consider multiple relations between the same entitiesor combining confidence measures while composing or aggregating alignmentrelations, to our knowledge, no approaches have been proposed.
Since we are seeking for generality and for treating all kinds of alignmentresources, we consider different types of relations and not only relations thatare proposed by the A5 Algebra. To design operators for managing align-

118Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
ments on heterogeneous resources we should take into consideration the di-versity of alignment formalisms, the semantics of alignment relations, andthe possible methods for treating uncertainty within correspondences.
Definition 5 (Reminder: Alignment correspondence) A correspon-dence between two entities from two knowledge resources Rs et Rt is atriple,
〈e1, e2, R〉
where:
• e1 et e2 are entities belonging to Rs and Rt respectively;
• R is a set of pairs {(r1, w1), . . . , (rn, wn)} where ri is a relation thatbelongs to a relation algebra A and wi is a confidence level
7.2 An approach for alignment resources combina-tion
According to our model for representing alignments, a correspondence〈e1, e2, {(r1, w1), . . . , (rn, wn)}〉 represents the fact that e1 r1 e2 holds withconfidence w1 and . . . and e1 rn e2 holds with confidence wn.
[Euzenat 2008] proposes to define the set of alignment relations to beconsidered Θ as the power set of a set Γ of basic mutually exclusive re-lations. The idea is that a subset {s1, . . . , sk} represents the disjunctions1 ∨ · · · ∨ sk (e.g. subClassOf or disjoint). With this approach it becomesstraightforward to define an algebra over Θ by using the usual set operationstogether with a composition operation. This algebra can then be used todefine operations such as union, intersection, or composition of alignments.
Collecting alignments from different origins in order to compose and ag-gregate them makes it difficult to use the current definition of an alignmentcorrespondence [Ghoula et al. 2014]. We consider multiple alignment rela-tions between two entities, which is represented as a conjunction of disjunc-tive relations having each a confidence measure (see definition in section6.4).
We note that this definition does not forbid “competing” correspondences(when two correspondences have the same source and target entities). Wemay have, for instance,
〈City,Town, {({=}, 0.2), ({A}, 0.6)}〉
and〈City,Town, {({=}, 0.4), ({G}, 0.4)}〉

7.2. An approach for alignment resources combination 119
in the same alignment (taking relations in the A5 relation algebra). Wedescribe a method and define an operator to aggregate this type of corre-spondences (see section 7.3.2).
Definition 6 (Conflicting correspondences) Having two correspon-dences c1 = 〈e1, e2, R1〉 and c2 = 〈e3, e4, R2〉, then c1 and c2, are conflictingif ((e1 = e3) ∧ (e2 = e4)).
We will see in the following sections that (1) detecting these correspon-dences is necessary to define an associative alignment composition operationand (2) there are normalization/aggregation operators to resolve these am-biguities. With our definition of correspondence it is possible to representalignments with conflicting correspondences
7.2.1 Framework of representing alignment correspondences
This methodology relies on the algebraic approach of [Euzenat 2008] andproposes to operationalize it, i.e., to define operations that can be readilyimplemented in alignment management tools and that take into account theconfidence measures attributed to relations.
If we consider two knowledge resources (A and B), several matching toolscan be applied and each on of them generates an alignment between A andB. In the following section, we will introduce some operators to aggregatethese alignments in order to generate a unique alignment between A and B.The definition of these operators implies a definition of a clear semantics forinterpreting alignments.
Relations between alignments can be of any kind and any type. In orderto combine or aggregate these relations we classify them by category (logicalrelation such as the relations defined by A5, semantic relations used to repre-sent associations between terminological entities such as the relations definedwithin the SKOS formalism or other types of relations such as translationlinks and other associations).
The semantics of these relations is different, which makes it rather impos-sible to combine them or to use them within the same level of expressivity.The approach that we will define in the following sections is applicable foreach category of alignment relations taken individually but not for the wholemixed set of alignment relations. In order to consider and combine heteroge-neous alignments we transform (translate) the alignment relations from oneformalism to another and apply the approach on a coherent formalism (forexample skos : exactMatch can be transformed to =).
Since the majority of alignment tools assign a confidence measure toeach alignment correspondence (for an alignment relation), the interpreta-

120Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
tion of this measure leads to the notion of uncertainty. Probability, possi-bility and fuzzy based approaches define different theories for representingand interpreting uncertainty. Many research studies compared the groundsof these theories and tried to represent their common criteria [Gaines 1978]in order to establish a proper comparison between fuzzy and probabilistictheories. [Gal et al. 2005] states that a probabilistic approach encodes in-complete knowledge as “probabilities about events” where fuzzy approaches“model the intrinsic imprecision of features”.
Some other studies compared the expressivity of these theories and theircomputational efficiency. [Drakopoulos 1995] demonstrated that probabilis-tic models are more expressive than fuzzy sets but less efficient since theycarry too much information, which makes it very difficult to process cor-related events. For these reasons we will base our choice of interpretingconfidence measures within correspondences as fuzzy measures (fuzzy settheory) or belief (Dempster-Shafer theory).
7.2.2 Interpretation of correspondences using fuzzy set the-ory
Fuzzy set theory (we use also FS as short form of this expression) was definedby [Zadeh 1965] as an approach for representing the belonging of an elementto a set from a fuzzy angle by assigning to each element a membershipdegree. This theory represents the same operators as classical set theory,which satisfy the same properties as classical set operators. We define twodimensions of possible interpretations of alignments using this theory (viewthe alignment from two different point of views):
1. from the first point of view, an alignment is described as a collectionof fuzzy relations between two sets of entities where the membershipfunction associates values to a couple of elements from both sets (binaryfunction). This interpretation of an alignment makes it possible to usethe default fuzzy composition operator to compose alignments (seefigure 7.1);
2. from a specific point of view on a couple of entities from differentresources, the alignment relation between these entities is defined asthe reference context, which makes it interpreted as a fuzzy set by itself.Each alignment correspondence between the same couple of entities isrepresented as an element of this fuzzy set having a membership degree(unary function). The interpretation of an alignment on this dimensionis used for defining aggregation operators of alignments (see figure 7.2).

7.2. An approach for alignment resources combination 121
7.2.2.1 Interpretation of alignments as sets of fuzzy relations
Let Γ be the set of individual alignment relations of a certain category (log-ical, semantic or other). Let Θ be the power set of Γ.
An alignment A is a set of fuzzy relations defined over pairs of entitiesfrom R1 × R2. For each pair of entities e1 ∈ R1, e2 ∈ R2 and for eachrelation ri ∈ Θ the alignment A provides a membership function for thecorrespondence: ⟨
e1, e2, {(ri, µriA(e1, e2))}⟩
where:µriA ∈ [0, 1], ri ∈ Θ
(rm ,μAr (e1, e2))
(rs ,μAr (e1, e2))
(rj ,μAr (e1, e2))
Resource 1
Resource 2
Alignment A
(ri , μAri ((x1, y1))
Θ=2Γ
xn
x1
y1 yn
(ri , μAri ((xk, y1))
(ri , μAri ((xn, y1))
Figure 7.1: Illustrating alignment relations as fuzzy relations
Since multiple relations can be represented within a correspondence of analignment, then each relation between both entities is interpreted as a fuzzyrelation.
7.2.2.2 Interpretation of alignment relations as fuzzy sets
As represented in the figure 7.2 a correspondence between two entities (es, et)of different resources (R1, R2) can be interpreted as a fuzzy membershipfunction that assigns a membership value to each relation between bothentities that belongs to the set of relations that are true between es and et.
Let Γ be the set of individual alignment relations of a certain category(logical, semantic or other). Let Θ be the power set of Γ. Let X be the set

122Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
of relations that are true between es and et.An alignment A between R1 and R2 contains an element C = 〈es, et, R〉
where R ⊂ X is the set of relations between es and et as couples (relation,membership):
R = {(r, µA(r))}
where:µA ∈ [0, 1], r ∈ Θ
es et
es -- R(true) -- et
Resource 1 Resource 2
Alignments: 1 - 2
AB
C
(ri , μAes-et(ri))
(ri , μBes-et(rj))
(rk , μCes-et(rk))
Figure 7.2: Illustrating alignment relations as fuzzy sets
The above-defined fuzzy set interpretation imposes the following condi-tion on the weights associated to the relations of a correspondence within analignment A:
Condition 1 If ri ⇒ rj then in any correspondence〈es, et, [(r1, µA(r1)), . . .]〉, we must have µA(ri) ≤ µA(rj).
In order to respect this condition we apply the following normalizationthat filters the correspondences that are in conflict with the condition 1.
Normalizing confidence measures
If we have two alignment relations within a correspondence〈es, et, [(r1, µA(r1)), (r2, µA(r2))]〉 where r1 ⊆ r2 and µA(r1) ≥ µA(r2),then r2 is removed from the list of relations since the first one entails it.

7.2. An approach for alignment resources combination 123
7.2.3 Interpretation for Dempster-Shafer theory
This theory (we use alsoD-S as short form of this expression) was introducedby Dempster in 1967 [Dempster 1967] and then extended by Shafer in 1976[Shafer 1976]. It allows to model hypotheses with accumulation of evidence.The Dempster-Shafer theory uses a belief function that assigns a number inthe range [0, 1] to support the hypothesis using an evidence. The evidenceagainst an hypothesis is considered as an evidence for the negation of thehypothesis from a set of possibilities (Γ). 2Γ, is the domain of all subsetsof Γ, which contains all the possible combinations of hypotheses. The basicprobability assignment (bpa) function (m) assigns a number in [0, 1] to everyelement in 2Γ (0 for the empty set ∅) in a way the sum of all the bpa is 1.
Let Θ be the power set of Γ. The Dempster-Shafer-oriented interpretationof a correspondence c from an alignment A between R1 and R2 is as follows:
c = 〈e1, e2, [(r1,mA(r1)), . . . , (rn,mA(rn))]〉 ,mA ∈ [0, 1], ri ∈ Θ, i = 1,−n
Where the mA(ri)s are the masses associated to the relations r1, ..., rn ofΘ, as opposed to a fuzzy-set interpretation. In our case, since the importedvalues of relations within correspondences are associated to belief, the massvalues are calculated using this formula:
mA(r) =∑s|s⊆r
(−1)|r−s|BelA(s);
|r− s| is the cardinality of the set difference between r and s, where s isan element in the set r.
In this interpretation, each mA(ri) is considered as the amount of evi-dence in favor of ri, excluding the evidence in favor of any “smaller” relationsrj such that rj ⊆ ri (or rj ⇒ ri). Consequently a normalization of masses isnecessary to follow the condition:
∑i=1,nmA(ri) = 1.
BelA(r) =∑s|s⊆r
mA(s);
Normalizing confidence measures
Using the definition 5, when the confidence measures of each alignment re-lation within the correspondence does not sum to 1 (
∑i≤nmi 6= 1) we apply
the following procedure:
• if∑
i≤nmi ≥ 1, then divide each assigned mass mi by the sum;
• else if∑
i≤nmi ≤ 1 then:

124Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
– if > /∈ R then add > to R and assign to it the mass: m =
1−∑
i≤nmi;
– else divide each assigned mass mi by the sum;
7.2.4 Switching from an interpretation to another
If we compute the beliefs of the ris (belA(ri) =∑
rj⊆ri mA(rj)), we obtaina measure that can be interpreted as the degree to, which ri actually holdsbetween e1 and e2. In other words, this measure can be interpreted as thedegree to, which ri belongs to the set of relations that are true between e1
and e2.
The obtained fuzzy set is consistent with the inclusion between relations(condition 1). If ri ⊆ rj , then Bel(ri) ≤ Bel(rj), i.e., when ri ⇒ rj the fuzzymembership of rj is greater than the fuzzy membership of ri.
For example, if c = 〈e1, e2, {[({=}, 0.3), ({@}, 0.5)], (>, 0.2)}〉, its FStranslation is:
c =
⟨e1, e2, {
[({=}, 0.3), ({@}, 0.5)],
({A}, 0), ({@=}, 0.8), ({@ ⊥}, 0.5),
({@AG}, 0.5), . . . , (>, 1)
}
⟩
If we use a correspondence that is represented in the FS interpretationwe can switch back to the D-S representation using the mass calculationfunction:
mA(r) =∑s|s⊆r
(−1)|r−s|BelA(s);
With this simple conversion we can transform the interpretation of analignment from D-S to FS interpretation and back. For instance we canconvert two correspondences to their FS values (beliefs), then compute thefuzzy union or intersection of them, and then reconvert the obtained be-lief values to masses. This provides one more way to aggregate conflictingcorrespondences.
For a practical purpose, within each correspondence we calculate eachof these values (mass, belief or fuzzy membership and plausibility) and weassociate them to the relation in order to easily use these aspects withoutrecalculating it each time when needed.

7.3. Alignment combination operators 125
7.3 Alignment combination operators
These operators represent instances of the subclasses of the combina-tion operators that are described in the taxonomy of operators (fromchapter 5). The input and output of these operators are alignment re-sources and they use aggregation methods that are instances of the classKnowledge_Processing_Method (e.g., Fuzzy set aggregators or Dempster-Shafer aggregators). In this section, we define operators for alignment com-position, alignment aggregation, union and intersection.
In the following sections and for the sake of simplicity wi is the repre-sentation of the membership value or mass for an alignment A. This is usedto represent generic aspects of operators that do not depend from the usedtheory for interpreting alignments. When needed we use the right represen-tation for the confidence within the alignment relations (i.e., mA(ri), µA(ri)
or µriA(e1, e2))).
7.3.1 Alignment composition
For running some alignment methods or processes on heterogeneous re-sources, there is sometimes a need for a starting set of correspondences as aparameter to build more sophisticated alignments [Shvaiko & Euzenat 2013].The starting set of correspondences is whether created manually or built bycomposing other alignments. The composition of alignment resources is anoperator that creates a new alignment from two existing alignments sharinga common resource. In order to define an operator for composing alignmentresources, at first, we need to define the composition at the correspondencelevel and, then, at the alignment level.
7.3.1.1 Composing correspondences
Given two correspondences c1 = 〈ex, ey, R1〉 and c2 = 〈et, ez, R2〉 where,R1 = {(r1, w1), . . . , (rn, wn)} and R2 = {(s1, b1), . . . , (sm, bm)} and ey = et,the composition of c1 and c2 is a correspondence:
ccomp = Compζ(c1, c2) = 〈ex, ez, Rcomp〉
whereRcomp = {(ri ∗ sj , wiζwj)|i = 1,−n; j = 1,−m}
∗ is the composition operator for the considered relation algebra (e.g. Table7.1), and ζ is an associative operator for combining the confidence levels (inour case max−min).
Other than the alignment relations defined by the A5 algebra, our ap-proach considers semantic relations used in a large alignment repositories

126Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
(such as Bioportal [Noy et al. 2008]). Thus, we created a similar table forcomposing semantic relations (such as “exactMatch”, “narrowMatch”, etc.).We used the SKOS entailment rules for defining this table. In the caseof composing heterogeneous alignment relations (logical with semantic), wecreated transformation tables from one type of relations to the other.
◦ @ A ≡ ⊥ G@ @ > @ ⊥ @,⊥,GA @,A,≡,G A A A,⊥,G A,G≡ @ A ≡ ⊥ G⊥ @,⊥,G ⊥ ⊥ > @,⊥,GG @,G A,⊥,G G A,⊥,G >
Table 7.1: Composition table for logical relations as defined by[Euzenat 2008]
Condition 2 Let Γ be the set of individual alignment relations of a certaincategory (logical, semantic or other). Let Θ be the power set of Γ (Θ = 2Γ).
The set of alignment relations Θ should have closure under the composi-tion operator (∗): ∗ : Θ×Θ→ Θ
There are many fuzzy composition operators defined in the litera-ture [Portilla et al. 2000]. We define a composition operator that usesthe fuzzy relation composition and implements different methods for com-bining confidence measure such as the max−min and max−product[Loetamonphong & Fang 2001] compositions.
In order to calculate the new confidence that is attributed to each com-posed alignment relation, we use the fuzzy relation interpretation (see sec-tion 7.2.2.1) and the “max−min” composition of fuzzy sets [Zadeh 1971,Abbasbandy et al. 2006]. By definition this composition is associative, con-sequently the alignment composition is associative.
The confidence measure attributed to the relation ri ∗sj that we denotedas wiζwj is calculated as follows:
wiζwj = µri∗sjA1◦A2
(ex, ez) = maxey
(min(µriA1(ex, ey), µ
sjA2
(ey, ez)))
where µriA1(ex, ey) is the membership function of the fuzzy relation be-
tween ex and ey for the specific alignment relation ri and µRA1◦A2is the
membership function that calculates the confidence measure of the resultingfuzzy relation R.
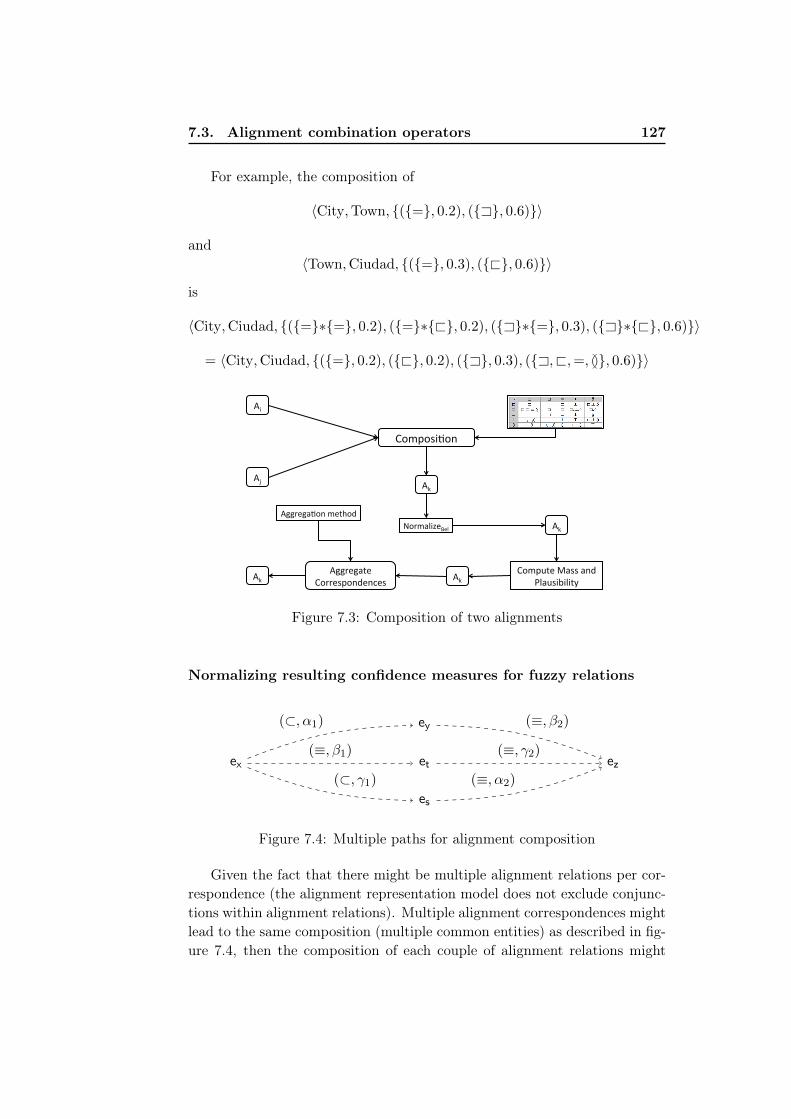
7.3. Alignment combination operators 127
For example, the composition of
〈City,Town, {({=}, 0.2), ({A}, 0.6)}〉
and〈Town,Ciudad, {({=}, 0.3), ({@}, 0.6)}〉
is
〈City,Ciudad, {({=}∗{=}, 0.2), ({=}∗{@}, 0.2), ({A}∗{=}, 0.3), ({A}∗{@}, 0.6)}〉
= 〈City,Ciudad, {({=}, 0.2), ({@}, 0.2), ({A}, 0.3), ({A,@,=, G}, 0.6)}〉
Ai
Composi)on
NormalizeBel
Aj Ak
Ak
Compute Mass and Plausibility
Aggregate Correspondences Ak Ak
Aggrega)on method
Figure 7.3: Composition of two alignments
Normalizing resulting confidence measures for fuzzy relations
ex
ey
et
es
ez
(⊂, α1) (≡, β2)
(≡, β1) (≡, γ2)
(⊂, γ1) (≡, α2)
Figure 7.4: Multiple paths for alignment composition
Given the fact that there might be multiple alignment relations per cor-respondence (the alignment representation model does not exclude conjunc-tions within alignment relations). Multiple alignment correspondences mightlead to the same composition (multiple common entities) as described in fig-ure 7.4, then the composition of each couple of alignment relations might

128Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
give as a result the same relation (cf. composition table). For instance, thecompositions ⊂ ∗ ≡, ⊂ ∗ ⊂ and ≡ ∗ ⊂ give the same composed relations,which is ⊂. This leads to calculating alignment confidences for each relation.
In this case we apply a simple aggregation to group all the results ofcalculating the confidence measures using the fuzzy “max” aggregator. Thus,if multiple paths of composition or multiple relations composition have ledto the same composed relation r ∈ Θ, then we group the results by r and weaggregate the membership functions using the “max” aggregator.
In order to aggregate the membership functions that have been computedfor each relation between the two entities ei and ej , we use the fuzzy setinterpretation (see section 7.2.2.2). This means that each relation rk of Rcompthat denotes the set of true relations between both entities has a membershipfunction µAcomp(rk)
Let c1 = 〈ex, ey, R1〉 and c2 = 〈ey, ez, R2〉 be two alignment corre-spondences, the composition of c1 and c2 is a correspondence ccomp =
〈ex, ez, Rcomp〉 where Rcomp{(rk, µAcomp(rk)), rk = (ri ∗ sj)|ri ∈ R1, sj ∈R2, i = 1,−n, j = 1,−m}.
Two normalizations are applied:
1. if Rcomp contains couples of fuzzy relations (rk, µAcomp(rk)),(rs, µAcomp(rs)) where rk = rs = r, then we group these relations ina subset R and we apply a max triangular co-norm to aggregate theirmembership value and remove all duplicates in Rcomp.
Normmax(Rcomp) = {(r,maxri∈R
(µAcomp(ri))}
2. if Rcomp contains couples of fuzzy relations (rk, µAcomp(rk)),(rs, µAcomp(rs)) where rk ⊆ rs and µAcomp(rk) ≥ µAcomp(rs), then rsis removed from the list of relations since the first one entails it.
7.3.1.2 Composing Alignments
Let A1 and A2 be two alignments, we define:
• Paths(ex, ez, A1, A2) = {(c1, c2)|∃ey ∃R ∃S : c1 = 〈ex, R, ey〉 ∈ A1 andc2 = 〈ey, S, ez〉 ∈ A2} as the set of correspondences associating e1 toe3;
• Corrζ(ex, ez) = {Compζ(ci, cj)|(ci, cj) ∈ Path(ex, ez)} as the set ofconflicting correspondences resulting from composing each pair of cor-respondences from Path(ex, ez). ζ is the confidence combination func-tion (max−min).

7.3. Alignment combination operators 129
• If Path(ex, ez) is empty then Corr(ex, ez) = ∅
Finally we define the composition of two alignments A1 and A2 aligningrespectively R1 to R2, R2 to R3 as:
Compφζ(A1, A2) = Aggrφ({Corrζ(ex, ez)|ex ∈ R1, ez ∈ R3})
Where Aggrφ is an operator that normalizes conflicting correspondencesas defined in the following section.
Alignment composition is a complex operation especially for ontologi-cal resources with regard to consistency issues. At the current level of ourresearch we define a composition operator and then we apply an aggrega-tion function to avoid inconsistency (only for treating conflictual correspon-dences). For further consistency checking, we assume that an external toolcan be used.
7.3.2 Alignment aggregation
The alignment composition may generate different correspondences havingthe same source and target entities. These correspondences are called con-flicting (see definition 6) since they may introduce incoherency within thealignment. The conflict can be solved using the combination of the alignmentrelations of both correspondences using an aggregation function.
e1
ex
ey
e3A1−>2 A2−>3
c1,2 c2,3
c′1,2 c′2,3
The aggregation of conflicting correspondences is the fact of merging bothcorrespondences into one correspondence with an aggregated set of weightedalignment relations.
In case of detecting conflicting correspondences within the generatedalignment, we define an aggregation function that aggregates the differentalignment relations within one set of relations for each correspondence. Inthis contribution, we propose two methods for defining an aggregation opera-tor, (1) an aggregation based on the Dempster-Shafer theory of combinationand (2) an aggregation based on the fuzzy sets theory. Our model for repre-senting correspondences is necessary to apply Dempster-Shafer theory.
7.3.2.1 Aggregating conflicting correspondences using Dempster-Shafer theory of combination
The application of this theory on normalizing alignments containing con-flicting correspondences is possible. Let X be the set of alignment relations

130Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
r1, . . . , rk within a correspondence. We suppose that these relations are ex-clusive and having respectively confidence measures proposed by differentalignments. The mass attributed to an alignment relation r ∈ 2Γ expressesthe proportion of all proofs available supporting r, and not any other relationof 2Γ or sub-relation of r.
Let c1 = 〈e1, e2, R〉 and c2 = 〈e1, e2, S〉 be two alignment correspondencesand two alignments A1 and A2 where c1 ∈ A1 and c2 ∈ A2 providing twosets of relations R and S between the same pair of entities. Let mA1 andmA2 be the functions assigning the masses for each element in the each setof relation where: ∑
ri∈RmA1(ri) = 1 and
∑sj∈S
mA2(sj) = 1
The application of Dempster-Shafer theory of combination on both corre-spondences generates a combined correspondence c3 = AggrD−S(c1, c2) =
〈e1, e2, Ragg〉 where:mA1,A2(∅)=0
for each relation ragg ∈ Ragg, s ∈ S and r ∈ R
mA1,A2(ragg) =1
1−K∑
r∩s=ragg 6=∅
mA1(r)mA2(s)
The coefficientK represents the conflict between both correspondences. Thiscoefficient is the sum of the product between the masses of different relationsets.
K =∑r∩s=∅
mA1(r)mA2(s)
Example 1 Let A be an alignment containing two conflict-ing correspondences 〈es, et, [({≡}, 0.7), ({@}, 0.2), ({A}, 0.1)]〉 and〈es, et, [({≡}, 0.6), ({@}, 0.3), ({A}, 0.1)]〉.
c1c2{≡}0.7 {@}0.2 {A}0.1
{≡}0.6
{@}0.3
{A}0.1
{≡}0.42 {∅}0.12 {∅}0.06
{∅}0.21 {@}0.06 {∅}0.03
{∅}0.07 {∅}0.02 {A}0.01
By applying the Dempster-Shafer theory to combine both correspondenceswe find the values:
K = 0.7× 0.3 + 0.7× 0.1 + 0.2× 0.6 + 0.2× 0.1 + 0.1× 0.6 + 0.1× 0.2 = 0.51

7.3. Alignment combination operators 131
Andm1,2(≡) = 0.7× 0.6/0.49;
m1,2(@) = 0.2× 0.3/0.49;
m1,2(A) = 0.1× 0.1/0.49.
The resulting correspondence is:
〈es, et, [({≡}, 0.857), ({@}, 0.122), ({A}, 0.020)]〉
In some cases the combination of both correspondences can be impossible,in case of a strong divergence between the alignment relations. for exampleif R1 = {({≡}, 0.5), ({@}, 0), ({A}, 0.5)} and R2 = {({≡}, 0), ({@}, 1), ({A}, 0)}, then K = 1, which leads to suppressing both correspondences fromthe resulting alignment.
7.3.2.2 Aggregating conflicting correspondences using fuzzy setstheory
Using fuzzy sets theory we assume that each relation within an alignmentcorrespondence is an element of a fuzzy set. For this operator, we use thesecond interpretation (see section 7.2.2.2).The confidence measure associatedto the relation is a degree of membership to the fuzzy set representing thealignment relation. The usage of fuzzy sets theory supports the associativityproperties of the composition operator. In this case the sum of all confidencemeasures is not necessarily 1.
Let c1 = 〈e1, e2, R〉, c2 = 〈e1, e2, S〉 be two conflicting correspondences,and R, S be two sets of weighted alignment relations.
if R = {(r1, α1), ..., (rn, αn)} and S = {((s1, β1), ..., (sm, βm))} then:
AggrZadeh(c1, c2) = c3 = 〈e1, e2, Rθ〉
where:Rθ = {(rk, θ(αi, βj))|(rk, αi) ∈ R, (rk, βj) ∈ S}
and θ is a fuzzy function of type t-norm or t-conorm.If the function θ is a triangular norm (t − norm), then Aθ is a fuzzy
intersection of R and S; Otherwise if θ is a triangle conorm (t − conorm),then Aθ is a fuzzy union of R and S.
The t-norm functions are used to assign a membership degree lower orequal to the minimum of the combined degrees (t−norm(α, β) 6 min(α, β)).
The t-conorm functions are used to assign a membership degree higheror equal to the maximum of the combined membership degrees (t −conorm(α, β) > max(α, β)). The max operator is one of the most used

132Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
triangular co-norms and is commonly applied as a representative of fuzzydisjunctions (used for the aggregation by union Aggr∨).
With min and max obviously preserve the condition 1: if c =
〈e1, e2, [(r1, wi), . . .]〉 and d = 〈e1, e2, [(r1, y1), . . .]〉 and ri ⇒ rj , then wi ≤ wjand yi ≤ yj , and, therefore min(wi, yi) ≤ min(wj , yj).
The same is true for max and ×. In fact it is it true for any t − normand t− conorm because they are monotonic by definition.
Thus the aggregation of alignments with a t− norm or t− conorm pre-serves the condition. The aggregation with D-S also maintains this propertybecause the D-S rule works on the masses, which are then transformed tobeliefs and the transformation satisfies the condition, as noted above (seesection 7.2.2.2).
When multiple alignment resources are generated using different match-ing tools. There is a need to aggregate these alignments in order to createa unified alignment between two resources. Two methods of aggregation areapplicable in this case the union and the intersection.
7.3.2.3 Reducing correspondences that contain multiple relations
In order to export an alignment that does not contain multiple relations (canbe confusing for an automatic usage), we apply an operator that selects oneon the relations based on calculating its plausibility (or “upper probabilityfunction”). The calculation of the plausibility is based on the masses thatare attributed to each relation r in the relations set of a correspondence.
Let ck = 〈ex, ey, Rk[. . . , (ri,mA(ri), . . .]〉 be a correspondence in an ag-gregated alignment A.
pl(ri) = 1−∑
ri∩rj=∅
mA(rj); for each rj ∈ Rk
For example if we have the correspondence c as:
〈e1, e3, R = {({=}, 0.45), ({@}, 0.45), ({@, G}, 0.1)}〉
the plausibility of each relation in the set R is:
Pl({=}) = 1− 0.45− 0.1 = 0.45,
P l({@}) = 1− 0.45 = 0.55,
P l({G}) = 1− 0.45− 0.45 = 0.1,
P l({⊥}) = 1− 0.45− 0.45− 0.1 = 0 = Pl({A})

7.3. Alignment combination operators 133
As a result the reduced correspondence is then represented as follows:
〈e1, e3, (@, 0.55)〉
7.3.3 Alignment union
Considering a given alignment A, if another alignment B “agrees” about acorrespondence with A, then it is considered that the alignment A brings anextra proof that the alignment relation holds between two entities. Conse-quently, an aggregation in favour of maximising the confidence measure ofthe correspondences is applied.
Let A be a set of alignments Ai of a size n matching the same resourcesRsource and Rtarget,the union of the alignments Ai is an alignment Aaggrmatching between the same resources Rsource and Rtarget and constructed asfollows:
1. Create a new empty alignment A⋃ and generate its metadata;
2. For each alignment Ai get its correspondences and add them to thealignment A⋃;
3. Divide the resulting correspondences set into subsets of conflicting cor-respondences Cconf . (Reminder: conflicting correspondences are cor-respondences having the same source and target entities).
4. Aggregate each set of conflicting correspondences using the max aggre-gator Aggr∨
A⋃ =m−1⋃k=0
{Aggr∨({Cconf})}
where m is the size of the list of sets of conflicting correspondences.The importance of this operation is to enrich alignments between re-
sources by adding new correspondences to them, which can be resumed to aUnion operation.
7.3.4 Alignment intersection
In the case of having multiple alignment resources matching the same tworesources, some applications may require more precision in the alignments.To be sure about a correspondence and its correctness or usefulness, thesimilarity measure is not the only indicator, the correspondence must beproposed by different alignment tools. Considering a given alignment A, ifanother alignment B “does not agree” with A about a correspondence, then

134Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
it is considered that the alignment A brings more an extra proof against thealignment relation that might hold between two entities. Consequently, anaggregation in favour of minimizing the confidence measure of the correspon-dences is applied.
LetA be a set of alignments Ai of a size nmatching the same resources Rsand Rt, the intersection of the alignments Ai is an alignment Aaggr matchingbetween the same resources Rs and Rt and constructed as follows:
1. Create a new empty alignment A⋂ and generate its metadata;
2. For each alignment Ai get its correspondences and add them to thealignment A⋂.
3. Divide the resulting correspondences set into subsets of conflicting cor-respondences Cconf . If the size of each set is lower than the size of thelist A then drop all the correspondences of this set from the alignment.
4. For the rest of the sets, aggregate the correspondences of each, usingthe min aggregator Aggr∧
A⋂ =m−1⋃k=0
{Aggr∧({Cconf})}
where m is the size of the list of sets of conflicting correspondences.The importance of this operation is to enhance the quality of alignments
between resources by keeping only the correspondences that provided andagreed on by all the aggregated alignments.
7.3.5 Alignment difference
In order to analyze alignment quality and compare alignments between tworesources R1 and R2, an operator for extracting the difference between align-ments is needed. This operator calculates and extracts the difference betweenan alignment Ai and an alignment Aj .
A = Ai \Aj = {(ck)ck ∈Ai ∧ (ck /∈ Aj)} = Ai ∩ ¬Aj
For the correspondences that are found in both align-ments we introduce the difference between correspondences.Let cl =
⟨ex, ey, [(r1, µAj (r1)), . . . , (rn, µAj (rn))]
⟩and ck =
〈ex, ey, [(r1, µAi(r1)), . . . , (rn, µAi(rn))]〉 where ri ∈ Θ, then for each pair ofconflicting correspondences we define a difference between correspondencesas:

7.4. Implementing alignment combination and managementoperators 135
ck \ cl = Aggr∧(ck,¬cl)
where:
¬cl =⟨ex, ey, [(> \ r1, (1− µAj (r1))), . . . , (> \ rn, (1− µAj (rn)))]
⟩7.4 Implementing alignment combination and man-
agement operators
In order to manage alignment resources within the repository and based onthe alignment model that we described in the chapter 6. We implemented thecombination operators and a set of other operators for managing alignmentresources (The repository can be accessed online1). This repository is a directapplication of our approach for representing and managing heterogeneousknowledge resources. We show that the proposed methodology is applicableon alignment resources and the abstract operators for resources combinationand management are useful to generate new resources from existing ones.
As explained in chapter 6, the repository is implemented using a triplestore technology (Allegrograph) and is based on the TOK_Onto describedin the chapter 4. We described the ability of the alignment model to supportalignment resources represented in different formalisms. Figure 7.5 representsthe architecture of the repository. In this section, we focus on describing theimplementation of alignment management operators.
The implemented repository offers the following functionalities:
1. Managing alignment resources using operations such as: importing,updating, editing and exporting alignment resources;
2. Combining alignment resources by implementing the operators de-scribed above in the section 7.2: Composition, Aggregation, Union,Intersection, Difference.
3. Exploring entities within the repository:
(a) Search for resources;
(b) Search for composition paths between two resources based on theiralignments;
(c) Executing SPARQL queries.
1To access the repository please follow this URL:http://129.194.69.195/tokonto/index.php, the content is subject to change since weare driving multiple tests

136Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
Triplestore (AllegroGraph)
Alignment Resources
Import
Ressources Selector
Operation(Composition, ...)
GeneratedAlignement
Queries(SPARQL)Resultts
interactive Interface
ScriptInterface
OR
Global Alignment Model
Figure 7.5: Architecture of the alignment repository
7.4.1 Implementing fuzzy aggregators
The fuzzy aggregation operators (fuzzy conjunction and fuzzy disjunction)are well defines in literature and their properties have been established[Gupta & Qi 1991]. For instance, the min operator is one of the most usedtriangular norms and is commonly applied as a fuzzy conjunction (appliedfor the aggregation by intersection Aggr∧).
In the literature [Gupta & Qi 1991], a triangular norm is defined as afunction t defined as follows:
t : [0, 1]× [0, 1]→ [0, 1]
(x, y) 7→ a

7.4. Implementing alignment combination and managementoperators 137
The t − norm operator satisfies the following axioms for each x, y, z ∈[0, 1]:
• monotonicity: x ≤ y =⇒ t(x, z) ≤ t(y, z)
• boundary condition: t(x, 1) = x
• associativity: t(x, t(y, z)) = t(t(x, y), z)
• commutativity: t(x, y) = t(y, x)
In our case of study we implemented three aggregation operators thatinterpret fuzzy conjunction using each a different t − norm from the threetypical following operators:
• minimum t− norm: tm(x, y) = min(x, y)
• product t− norm: tp(x, y) = x.y
• Lukasiewicz t− norm [Łukasiewicz 1968]: tl(x, y) = max(x+ y − 1, 0)
For the fuzzy disjunction operators we implemented three aggregationoperators that use each a different t−conorm from the three typical followingoperators:
• maximum t− conorm: tcm(x, y) = max(x, y)
• product t− conorm: tcp(x, y) = x+ y − x.y
• Lukasiewicz t− conorm [Łukasiewicz 1968]: tcl (x, y) = min(x+ y, 1)
All the properties of these operators are defined in the literature[Gupta & Qi 1991] and many of their aspects explored especially the relation∀x, y ∈ [0, 1], tl(x, y) ≤ tp(x, y) ≤ tm(x, y).
7.4.2 Executing combination operators
A corpora of heterogeneous alignment resources represented in various for-malisms and generated by different tools are available within the repository.In order to execute the combination operators described above we createdtwo types of interfaces for applying them:
1. Operations by alignment: the entry point for executing alignment com-bination operators is the alignment itself;
2. Operations by resources: the entry point for executing alignment com-bination operators are the resources [source and target].

138Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
In order to execute a specific operation (composition, intersection, union,etc.) other parameters need to be specified:
1. choose the operation to perform;
2. the list of alignment resources to be involved in the operation (thealignments must have the same source and target resources);
3. the aggregation method to be applied (t − norm and t − conorm ag-gregators);Home Alignment Operation Search SPARQL
TOKOnto
Operation by Alignment
Select operation Intersection
Alignment URI * http://cui.unige.ch/isi/onto/tok/ola1.rdf
Alignment URI * http://cui.unige.ch/isi/onto/tok/cowl1.rdf +
Method * min(x,y)
submit reset
Alignment :
URI - null
Type - simple
Created from - intersection
Alignments used :
http://cui.unige.ch/isi/onto/tok/ola1.rdf
http://cui.unige.ch/isi/onto/tok/cowl1.rdf
Comment :
Source - http://book.ontologymatching.org/example/culture-shop.owl
Target - http://book.ontologymatching.org/example/library.owl
Number of correspondences : 1
Correspondence :
Entity Source = http://book.ontologymatching.org/example/culture-shop.owl#Book
Entity Target = http://book.ontologymatching.org/example/library.owl#Volume
Relations :
Relation = moreSpecific, Similarity = 0.6363
Alignment URI [Result] *
Comments
Save Alignment Cancel
Copyright © 2013 ICLE GroupUniversity of GenevaFigure 7.6: Operations by alignments interface
When the parameters are set (see figure 7.6), a command is generatedto execute the process and a new instance of the process is created in the

7.4. Implementing alignment combination and managementoperators 139
repository. The URI of the process execution instance is defined as theprovenance of the generated alignment.
Execute : java -jar tokonto.jar [operation] [uris] [method] printOnce the operation is executed the result is recovered and displayed.
Metadata information such as the name of the generated alignment andits description are required to save the alignment and associate it to itsprovenance process.
Save : java -jar tokonto.jar [operation] [uris] [method] printIn order to apply operations on alignments using the second entry point,
which is the resources (see figure 7.7) there is a possibility to select tworesources from the repository. Once these resources identified then a pathfinding operation is applicable in order to selects all the alignments in therepository matching both resources (either direct alignments or path align-ments). Once the alignments are found, then there is a possibility to triggeroperations on these alignments.
Figure 7.7: Operations by resources interface
The commands that are executed for each option are:
• To retrieve direct alignments: java -jar tokonto.jar getAlignsByResuri1 uri2

140Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
• To retrieve composition paths: java -jar tokonto.jar find uri1 uri2In order to find all composition paths between two resources A and B
within the repository we implement an in-depth graph parser.
Algorithm 1 : Alignment path Finding algorithm (between two resources)Data uris : Uri of the source resource
urit : Uri of the target resourceResult Paths : list of paths (path is a list of Alignment Uris)Variables visited : list of Alignments visited during the path searching
Aligns = model.listResources(TOKJena.has_align_source, uris);foreach Aligni ∈ Aligns do
visited.add(Aligni);findPath(Aligni, urit, visited, Paths);
end foreachreturn Paths;
Algorithm 2 : Alignment path finding (based on an alignment)Data Align: alignment
urit : URI of the target resourcevisited : List of visited Alignments (URI)Paths : List of paths
tUri = Align.getTargetResource();if tUri.equals(urit) thenPaths.add(visited);
elseAligns = model.listResources(TOKJena.has_align_source, tUri);foreach Aligni ∈Aligns do
if visited.contains(Aligni.getURI())then
continue;elsetemp = new List(visited);temp.add(Aligni);findPath(Aligni, uriT , temp, Paths);
end ifend foreach
end if
7.4.3 Alignments overview, update and edition
We created interfaces for viewing, editing and updating alignment resources.The edit and update operators are monitored within the repository and their

7.4. Implementing alignment combination and managementoperators 141
execution generates a change event that creates a new version of the align-ment resource and triggers the execution of all the processes where the cur-rent alignment has been used.
Algorithm 3 : Update AlgorithmData Align: new alignment
uri : URI of the alignment to update
model = maker.openGraph(uri);model .removeAll();import(Align);updateAssociated(Align);
Algorithm 4 : Re-generation of derived alignmentsData Align: new alignmenturi = Align.getURI();
// Getting alignments associated with Alignuri_aligns=model.listResourcesWithProperty(TOKJena.Collection_of,
tUri);foreach uriAi ∈uri_aligns do
// Getting alignments used to create uriAi
uri_used = model.listObjectOfProperty(model.getResource(uriAi),TOKJena.Collection_of );
foreach uri_uj ∈uri_used doAligns.add(export(uri_uj));
end foreach// Getting the operation used to create uriAi
operation = uri_uj.getProprety(TOKJena.Created_from);newAlign = operation(Aligns);
// Updating the alignment uri_ujmod = maker.openGraph(uri_uj);mod .removeAll();import(newAlign);updateAssociated(newAlign);
end foreach
We retrieve all the alignments having as provenance a process that usesoperations involving the current modified alignment. For each alignment inthe list we re-execute the generation process (which triggers again an updateevent).

142Chapter 7. Operators for combining and aggregating
heterogeneous alignment resources
7.4.4 Discussion about the aggregation metrics
Our approach for combining alignment resources is based on a mathematicalbackground and does not arbitrarily combine or optimize some parametersto enhance the results. The interpretation of the alignments as sets of fuzzyrelations or using the Dempster-Shafer theory were explained and detailedin section 7.2.2 and section 7.2.3. Operators for respecting the coherence ofthe properties and aspects of each interpretation were proposed and imple-mented. Our framework for alignment combination is an original combina-tion between the algebra of alignment relations [Euzenat 2008] as a theoryfor combining alignment relations and robust belief combination theories.
For combining confidence measures there is a need to apply functionsand metrics to calculate the resulting belief or mass associated to an align-ment relation within a correspondence. The metrics that we described insection 7.4.1 are proposed in the literature and have the required propertiesto respect the mathematical grounding of our combination operators. Thesemetrics are also used for the composition and their usage preserves the as-sociativity of the proposed alignment combination operators (composition,aggregation, intersection, etc.).
Associativity is a very important aspect in our context of applicationsince it can be used in the context of combining multiple alignments. If thecomposition operator were not associative, then for each of its applications,especially to compose a path of alignments between two resources, multiplecombinations would be possible (which is not desired in this context).
7.5 Discussion
In this chapter, we defined a set of combination and management operatorsdesigned for alignment resources. We proposed an operator for composingalignment resources using uncertainty theories and an operator for aggregat-ing alignment resources generated by different matchers using a fuzzy theoryand an evidence combination theory. We also created a repository for align-ment resources based on the alignment model and implemented the proposedoperators within an API. The description of these operators was supportedby the operators model [Ghoula et al. 2014];
These operators are instances of the abstract operators that we describedin chapter 5. We implemented these operator on top of a triple store based onthe alignment representation model that we introduced in chapter 6. We de-fined a theoretical background for interpreting alignments using uncertainty-based theories. These interpretations allowed us to define composition andaggregation operators and to create a framework for managing and combin-ing alignment resources.

7.5. Discussion 143
We did not focus on the semantic aspects in this contribution, we as-sume that the alignment consistency checking can be implemented usingcurrent guidelines [Beisswanger & Hahn 2012] or components integrated inalignment tools [Zimmermann & Jérôme 2006, Jiménez-Ruiz & Grau 2011].The next chapter is dedicated to define en evaluation methodology for theimplemented alignment repository and describe experimental results of ap-plying the combination operators.


Chapter 8
Evaluation of alignmentresources combination
operators
Contents8.1 Evaluation methodology . . . . . . . . . . . . . . . . . 146
8.1.1 Building a test corpus . . . . . . . . . . . . . . . . . . 146
8.1.2 Computing precision and recall measures . . . . . . . 147
8.1.3 Evaluation of combination and aggregation operators . 148
8.2 Experimentation and results . . . . . . . . . . . . . . . 149
8.2.1 Alignment union evaluation results . . . . . . . . . . . 151
8.2.2 Alignment intersection evaluation results . . . . . . . 153
8.2.3 Alignment composition evaluation results . . . . . . . 155
8.3 Usage of alignment composition to enrich existingalignments . . . . . . . . . . . . . . . . . . . . . . . . . . 159
8.4 An approach for enhancing composition using thecontent of the resources . . . . . . . . . . . . . . . . . 160
8.4.1 Extending composition path finding using the contentof a common resource . . . . . . . . . . . . . . . . . . 162
8.4.2 Composition path finding using an alignment exten-sion operator . . . . . . . . . . . . . . . . . . . . . . . 164
8.5 Conclusion and discussion . . . . . . . . . . . . . . . . 166
In this chapter, we propose a methodology for evaluating the align-ment combination operators that we described, defined and implementedin the previous chapter. We used the resources representation model andthe generic model for representing alignment resources to build a repositoryof alignment resources. We choose to evaluate the approach using ontologyalignment resources and we apply the operators of aggregation and composi-tion to see if they can effectively improve the quality of ontology alignments.The usage of ontology alignments as an evaluation case is motivated by the

146Chapter 8. Evaluation of alignment resources combination
operators
availability of these resources and by the nature of challenges in this re-search field. We can also apply these operators as they were implementedon terminological or linguistic alignments.
8.1 Evaluation methodology
In order to evaluate the proposed combination and consequently the aggre-gation functions we used the metrics of precision and recall to compare thegenerated alignments with reference alignments. The evaluation methodol-ogy is based on the following steps:
1. building a test corpora containing:
• knowledge resources from different domains;
• reference alignments between these resources;
• a set of alignment tools to create multiple alignments between theresources.
2. compare the resulting alignments from the application of the combina-tion operators with the reference alignments and then the best align-ment tools.
8.1.1 Building a test corpus
For the evaluation of alignment composition and aggregation, we need tobuild a corpus of heterogeneous alignment resources. Alignments must berepresented in different formalisms and between two resources we need tocollect more than one alignment to have the right ingredients for aggregatingand composing alignments and to create at each case a reference alignmentto compare results with. Thus, the requirements for building this kind ofcorpus are:
• the matching process between resources from the same domain shouldgenerate a non empty set of alignments;
• for each resource there exists at least another resource in the corporawhere the alignment between them is not empty;
• the corpora must contain ontologies represented in different levels ofexpressivity (to consider a wider evaluation, resources in this cor-pora must be of different kinds: ontological, terminological, termino-ontological or lexical);

8.1. Evaluation methodology 147
• for each pair of aligned resources, there must be a possibility to easilyreuse or build a reference alignment.
In order to control the quality of combined alignments, there is a need forreference alignments between the resources of the corpora. For example, forthe set of resources: {Rx, Ry, Rz, Ru} from the same domain, the referencealignments that must be found or built are between the couples of resources:(Rx, Ry); (Rx, Rz); (Rx, Ru); (Ry, Rz); (Ry, Ru) and (Rz, Ru).
Multiple matching tools and services generate alignments between re-sources. Using the resources’ corpus and a set of matchers (ontology match-ers, terminology matchers, linguistic matchers, etc.), a corpus of alignmentresources can be generated.
8.1.2 Computing precision and recall measures
The usage of precision and recall calculation in most alignments evaluationcampaigns are based only on the existence or not of the required relationwithin the resulting alignment compared to a reference alignment. The con-fidence measure is not taken into consideration although it is an importantfeature within matching tools.
For instance, if an alignment tool detects a correspondence c =
〈ex, ey, {≡}0.5〉, and the reference alignment contains cref = 〈ex, ey, {≡}〉,the correspondence is computed as a relevant answer (which is not reallyfully relevant). [Euzenat 2007] proposed new metrics about semantic preci-sion and recall calculation for evaluating ontology alignments but they alsodo not consider the confidence measures.
Precision ={OriginalCorrespondances} u {RetrievedCorrespondances}
{RetrievedCorrespondances}
Recall ={OriginalCorrespondances} u {RetrievedCorrespondances}
{OriginalCorrespondances}
Since confidence measures combination is an important feature in ourapproach, we propose to consider the margin value between the confidencemeasure of the reference correspondences and the generated (aggregated)correspondences. Let cref and ccomp be two correspondences respectivelymembers of a reference alignment and a generated alignment. The compari-son of both correspondences is done as follows:
1. Feature 1: If the evaluation method is based on the basic defi-nition of precision and recall measurements, then these metrics are

148Chapter 8. Evaluation of alignment resources combination
operators
applied and if both correspondences are equal then count it as arelevant one. For example, if an alignment tool detects a corre-spondence c = 〈ex, ey, {≡}0.2〉, and the reference alignment containscref = 〈ex, ey, {≡}〉, then we increment the number of relevant corre-spondences within the resulting alignment by “1”.
2. Feature 2: If we consider the value of the confidence measure withinthe alignment, then the number of correct correspondences is increasedby the margin value between the confidence measure of the referencecorrespondence and the confidence measure of the generated corre-spondence. Thus, instead of incrementing the number of relevant cor-respondences by “1”, it is incremented by (1 − (ABS(cref .degree −ccomp.degree))). For instance, if an alignment tool detects a corre-spondence c = 〈ex, ey, {≡}0.2〉, and the reference alignment containscref = 〈ex, ey, {≡}〉, then we increment the number of relevant corre-spondences within the resulting alignment by “0.2”.
We refer to these two types of calculation of the precision and recallvalues in the following section as “both features”.
8.1.3 Evaluation of combination and aggregation operators
The quality of an alignment composition result depends on the completenessand the quality of used alignments between the designated resources. Let Rx,Ry and Rz be three different resources involved in the evaluation procedure.We propose an evaluation method that assesses the quality of generatedalignments within different scenarios:
• Aggregation using union: This scenario is based on the usage of avalidated reference alignment and the multiple alignments generatedusing different tools between the resources Rx and Ry. All alignmentsbetween (Rx, Ry) except the reference alignment are aggregated andthen compared to the reference alignment. Both features of the preci-sion and recall measures of the aggregated alignment are compared tothe precision and recall of the best alignment between Rx and Ry.
• Aggregation using intersection: This scenario is based on the usage ofa validated reference alignment and the multiple alignments generatedusing different tools between the resources Rx and Ry. All alignmentsbetween (Rx, Ry) except the reference alignment are aggregated andthen compared to the reference alignment. Both features of the preci-sion and recall measures of the aggregated alignment are compared tothe precision and recall of the best alignment between Rx and Ry.

8.2. Experimentation and results 149
• Composition
1. Reference Evaluation: This scenario is based on the usage of val-idated reference alignments. Both reference alignments between(Rx, Ry) and (Ry, Rz) are composed. The resulting alignment,from composition, between (Rx, Rz) is compared to the referencealignment. A measure of precision and recall is calculated accord-ing to both features and the results are compared to the precisionand recall measure of the best tool that generates automaticallyan alignment between Rx and Rz.
2. Inner tool evaluation: The first step of this scenario is collectingalignments between (Rx, Ry), (Ry, Rz) and (Rx, Rz) using analignment tool. Then, the alignments between (Rx, Ry) and (Ry,Rz) are composed. The resulting alignment, from composition,between (Rx, Rz) is compared to the reference alignment between(Rx, Rz). A measure of precision and recall is calculated accordingto both features and the results are compared to the precision andrecall measures of the best tool that generated automatically analignment between Rx and Rz.
3. Cross tool evaluation: The first step of this evaluation procedureis getting alignments between (Rx, Ry) using one alignment tool,and between (Ry, Rz) using a second alignment tool and (Rx, Rz)using both alignment tools. Then, the alignments between (Rx,Ry) and (Ry, Rz) are composed. The resulting alignment, fromcomposition, between (Rx, Rz) is compared to the three align-ments (Rx, Rz). A measure of precision and recall is calculatedaccording to both features and the results are compared to theprecession and recall measures of the alignment between Rx andRz generated by the first tool and alignment between Rx and Rzgenerated by the second tool.
8.2 Experimentation and results
Alignment resources have been imported and stored in the repository (seefigure 8.1), each alignment is stored and described by multiple metadata de-scribing its provenance (generating tool, institution, author, source, target,etc.). We used the alignment tool LogMap [Jiménez-Ruiz & Grau 2011] andthe (OAEI) [Grau et al. 2013] Ontology Alignment Evaluation Initiative’scorpora of anatomy alignments and UMLS repaired reference alignmentsprovided by [Bodenreider 2004, Jiménez-Ruiz et al. 2011, Meilicke 2011,

150Chapter 8. Evaluation of alignment resources combination
operators
Pesquita et al. 2013]1.
Resources
Alignment services
Alignment resources
Import
Resources Repository Triple Store
N * K * (N-1)
N
K
A 1,3
A 1,2
• Intersection • Union • Composition
LogMap + OAEI results
Figure 8.1: Importing alignments for testing
In order to thoroughly compare alignments we calculate precision on re-call based on the two methods described at the section 8.1. Computing theprecision and recall measures of an alignment is processed by a compari-son operator that we created for the purpose, this operator implement bothcomparison methods (the classic method and the new method that takes intoconsideration the confidence measures)2.
For the application of the union, intersection and composition there is aneed to functions that aggregate the alignments used in these operators, wehave implemented two classes of aggregators (see section 7.3.2 of the previouschapter):
1. An aggregator based on the Dempster-Shafer theory implemented asthe description in the section 7.3.2.1;
2. An aggregator based on the fuzzy set theory implemented as the de-scription in the section 7.3.2.2, there are two subclasses of this aggre-gator:
• The fuzzy conjunction operators (t− norm) using three differentmethods (min, product and Lukasiewicz see: section 7.4.1);
1We acknowledge the OAEI for publishing and sharing their results and corpora. Weused the repaired UMLS mappings as reference mappings for testing the resulting align-ments generated by the composition
2The implementation of the evaluation metrics is available on this link:http://129.194.69.195/tokonto/stats.php
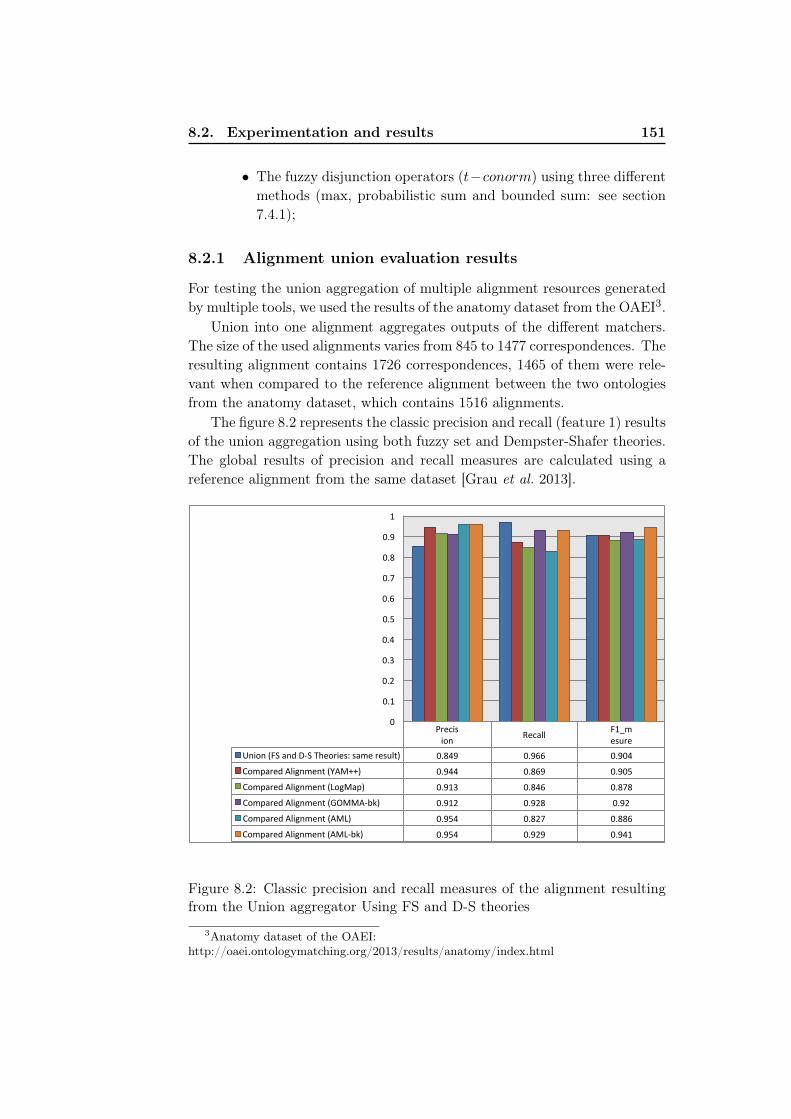
8.2. Experimentation and results 151
• The fuzzy disjunction operators (t−conorm) using three differentmethods (max, probabilistic sum and bounded sum: see section7.4.1);
8.2.1 Alignment union evaluation results
For testing the union aggregation of multiple alignment resources generatedby multiple tools, we used the results of the anatomy dataset from the OAEI3.
Union into one alignment aggregates outputs of the different matchers.The size of the used alignments varies from 845 to 1477 correspondences. Theresulting alignment contains 1726 correspondences, 1465 of them were rele-vant when compared to the reference alignment between the two ontologiesfrom the anatomy dataset, which contains 1516 alignments.
The figure 8.2 represents the classic precision and recall (feature 1) resultsof the union aggregation using both fuzzy set and Dempster-Shafer theories.The global results of precision and recall measures are calculated using areference alignment from the same dataset [Grau et al. 2013].
Precision Recall F1_m
esure Union (FS and D-‐S Theories: same result) 0.849 0.966 0.904
Compared Alignment (YAM++) 0.944 0.869 0.905
Compared Alignment (LogMap) 0.913 0.846 0.878
Compared Alignment (GOMMA-‐bk) 0.912 0.928 0.92
Compared Alignment (AML) 0.954 0.827 0.886
Compared Alignment (AML-‐bk) 0.954 0.929 0.941
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Figure 8.2: Classic precision and recall measures of the alignment resultingfrom the Union aggregator Using FS and D-S theories
3Anatomy dataset of the OAEI:http://oaei.ontologymatching.org/2013/results/anatomy/index.html

152Chapter 8. Evaluation of alignment resources combination
operators
The results show that the recall becomes closer to 1, which is by hy-pothesis the expected behavior of this operator. What is interesting is thatoverall quality of the resulting alignment is higher than “0.9”. The quality ofthe result of aggregation by union depends on the quality of the alignmentsinvolved as input for this operation. Therefore, the quality of the aggrega-tion depends on the relevance of the matching tool to the type of resourcesto align (some ontology matchers are more efficient for a specific type of on-tology, see [Grau et al. 2013]). There is a possible approach to enhance thequality of the aggregation operator by considering extra parameters aboutthe alignment tool and using reasoning.
Since both theories have given the same results we used the secondmethod for calculating the precision and recall (feature 2) to investigatefurther and see the differences within the confidence measures that arecalculated differently. We compare the three fuzzy disjunction operators(t − conorm). We identify, which theory attributes belief to the correspon-dences the closest to the reference alignment. We also recalculated the ad-vanced precision and recall using our metric (feature 2) over the alignmentgenerated by the best tool for this category to make a comparison betweenthe result of these different aggregation methods and the alignment toolswith regards to the confidence measures.
The figure 8.3 shows the results of the advanced precision and recall met-ric over the alignment generated using the union aggregation based on boththeories. We found out that the Dempster-Shafer aggregator for union resultsare the same using both metrics, which means that this operator for beliefcombination works better on attributing evidence to the combined beliefsthan the fuzzy set theory. Another observation that confirms the boundedsum t−conorm gives results that are closer to the reference confidences whenit comes to combining membership values using fuzzy set theory.
The results show that the confidence measures that are attributed to thecorrespondences are closer to the reference alignment’s values than the bestalignment tool. This is useful to rate these approaches for combining oraggregating confidence measures.
The majority of matching tools define a threshold to select the mostrelevant correspondences and attribute the maximum value of confidence (1)to them. In our case, we are studying the details of belief combination withincorrespondences. Thus, we assume that the closer the confidence measuresare to the reference measure, the easier it becomes to define an optimalthreshold.
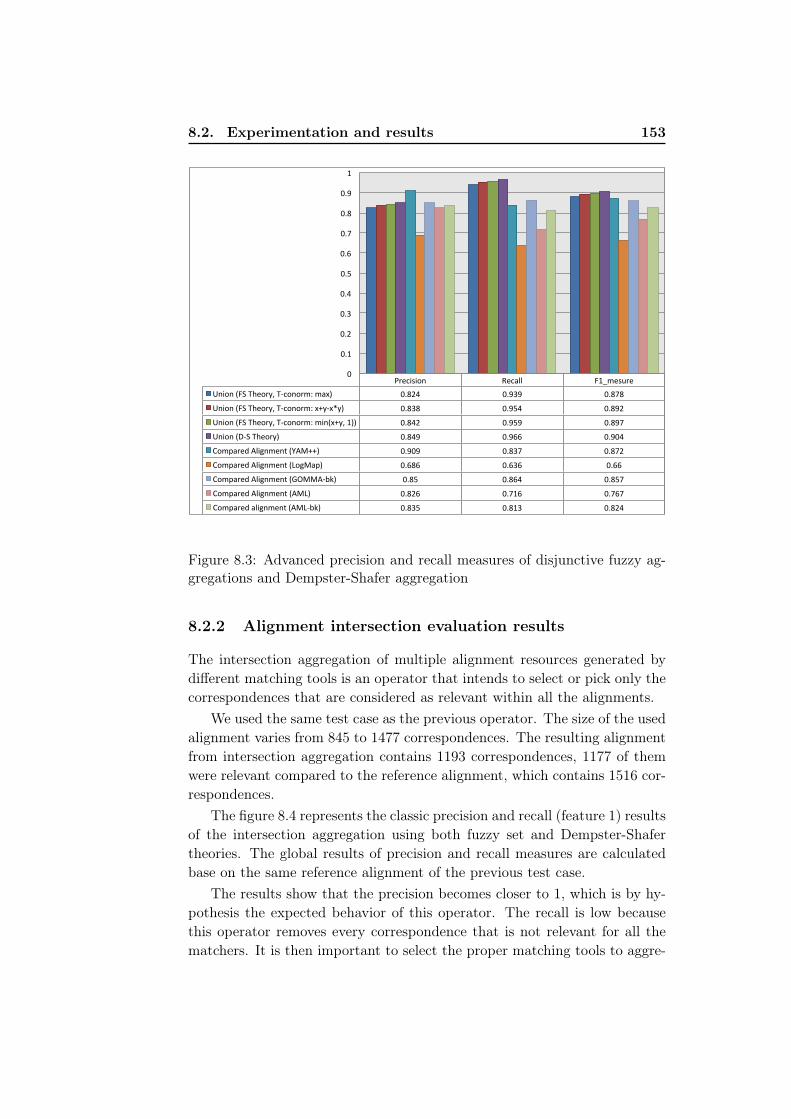
8.2. Experimentation and results 153
Precision Recall F1_mesure Union (FS Theory, T-‐conorm: max) 0.824 0.939 0.878
Union (FS Theory, T-‐conorm: x+y-‐x*y) 0.838 0.954 0.892
Union (FS Theory, T-‐conorm: min(x+y, 1)) 0.842 0.959 0.897
Union (D-‐S Theory) 0.849 0.966 0.904
Compared Alignment (YAM++) 0.909 0.837 0.872
Compared Alignment (LogMap) 0.686 0.636 0.66
Compared Alignment (GOMMA-‐bk) 0.85 0.864 0.857
Compared Alignment (AML) 0.826 0.716 0.767
Compared alignment (AML-‐bk) 0.835 0.813 0.824
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Figure 8.3: Advanced precision and recall measures of disjunctive fuzzy ag-gregations and Dempster-Shafer aggregation
8.2.2 Alignment intersection evaluation results
The intersection aggregation of multiple alignment resources generated bydifferent matching tools is an operator that intends to select or pick only thecorrespondences that are considered as relevant within all the alignments.
We used the same test case as the previous operator. The size of the usedalignment varies from 845 to 1477 correspondences. The resulting alignmentfrom intersection aggregation contains 1193 correspondences, 1177 of themwere relevant compared to the reference alignment, which contains 1516 cor-respondences.
The figure 8.4 represents the classic precision and recall (feature 1) resultsof the intersection aggregation using both fuzzy set and Dempster-Shafertheories. The global results of precision and recall measures are calculatedbase on the same reference alignment of the previous test case.
The results show that the precision becomes closer to 1, which is by hy-pothesis the expected behavior of this operator. The recall is low becausethis operator removes every correspondence that is not relevant for all thematchers. It is then important to select the proper matching tools to aggre-
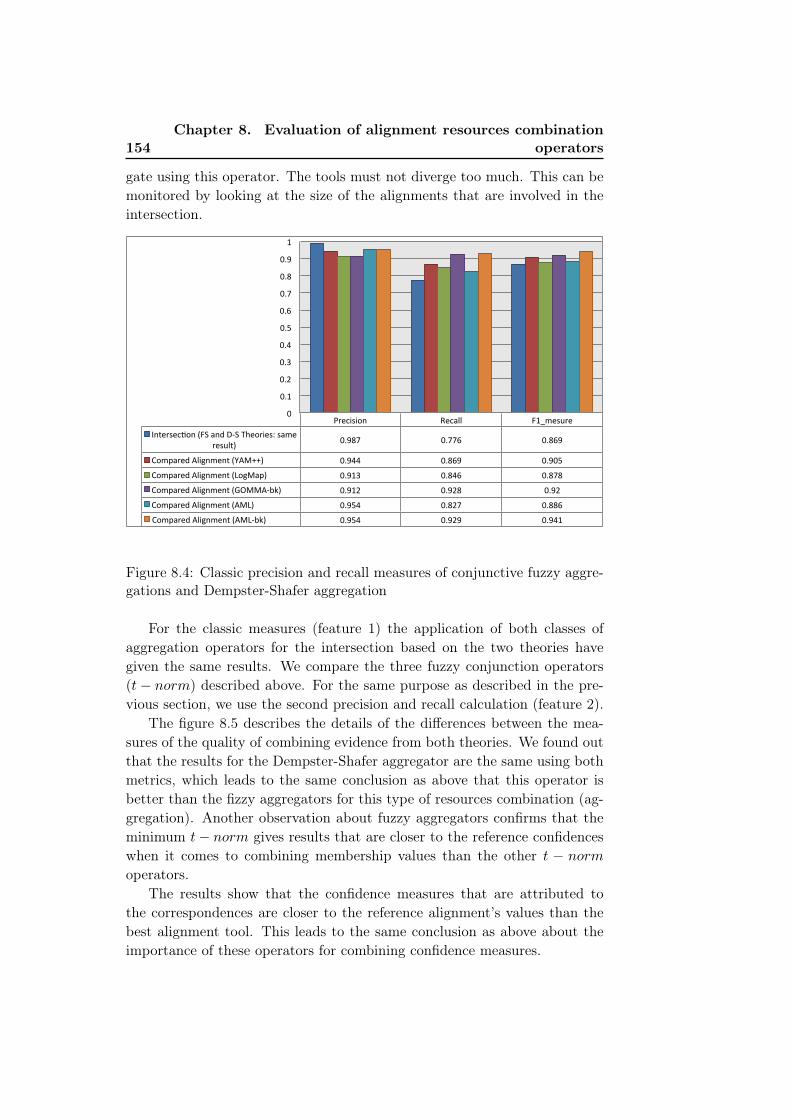
154Chapter 8. Evaluation of alignment resources combination
operators
gate using this operator. The tools must not diverge too much. This can bemonitored by looking at the size of the alignments that are involved in theintersection.
Precision Recall F1_mesure Intersec4on (FS and D-‐S Theories: same
result) 0.987 0.776 0.869
Compared Alignment (YAM++) 0.944 0.869 0.905
Compared Alignment (LogMap) 0.913 0.846 0.878
Compared Alignment (GOMMA-‐bk) 0.912 0.928 0.92
Compared Alignment (AML) 0.954 0.827 0.886
Compared Alignment (AML-‐bk) 0.954 0.929 0.941
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Figure 8.4: Classic precision and recall measures of conjunctive fuzzy aggre-gations and Dempster-Shafer aggregation
For the classic measures (feature 1) the application of both classes ofaggregation operators for the intersection based on the two theories havegiven the same results. We compare the three fuzzy conjunction operators(t − norm) described above. For the same purpose as described in the pre-vious section, we use the second precision and recall calculation (feature 2).
The figure 8.5 describes the details of the differences between the mea-sures of the quality of combining evidence from both theories. We found outthat the results for the Dempster-Shafer aggregator are the same using bothmetrics, which leads to the same conclusion as above that this operator isbetter than the fizzy aggregators for this type of resources combination (ag-gregation). Another observation about fuzzy aggregators confirms that theminimum t− norm gives results that are closer to the reference confidenceswhen it comes to combining membership values than the other t − norm
operators.The results show that the confidence measures that are attributed to
the correspondences are closer to the reference alignment’s values than thebest alignment tool. This leads to the same conclusion as above about theimportance of these operators for combining confidence measures.
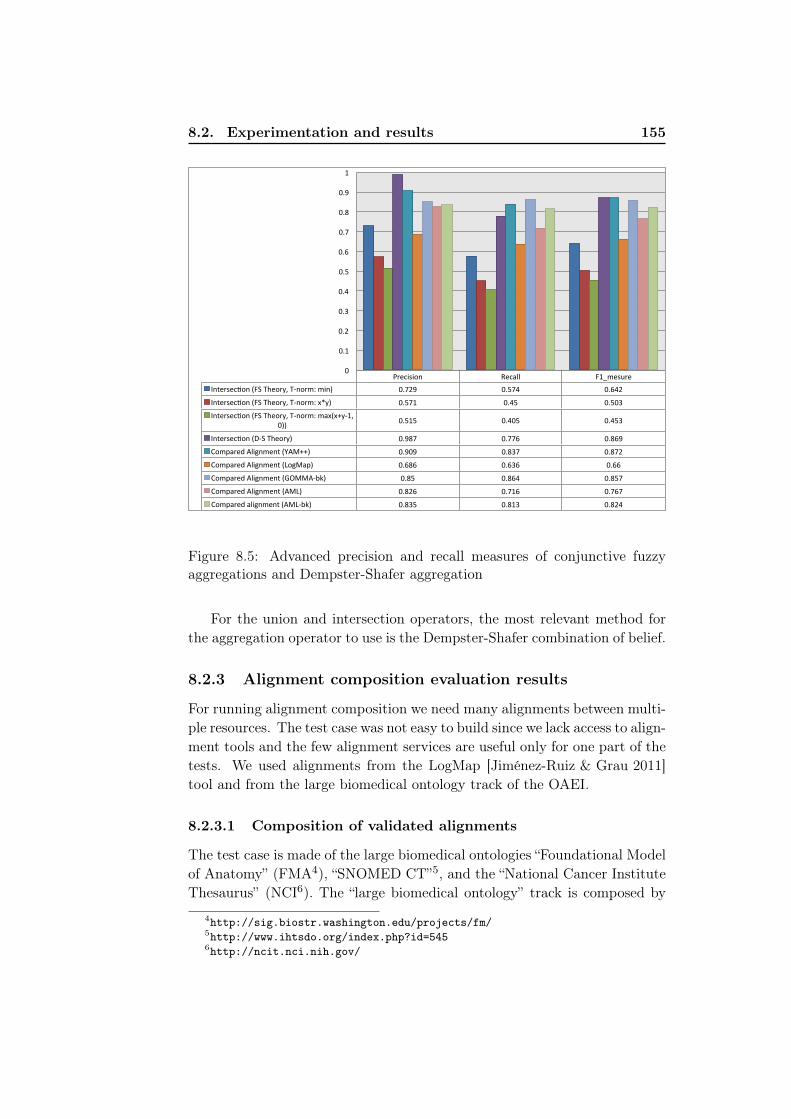
8.2. Experimentation and results 155
Precision Recall F1_mesure Intersec4on (FS Theory, T-‐norm: min) 0.729 0.574 0.642
Intersec4on (FS Theory, T-‐norm: x*y) 0.571 0.45 0.503
Intersec4on (FS Theory, T-‐norm: max(x+y-‐1, 0)) 0.515 0.405 0.453
Intersec4on (D-‐S Theory) 0.987 0.776 0.869
Compared Alignment (YAM++) 0.909 0.837 0.872
Compared Alignment (LogMap) 0.686 0.636 0.66
Compared Alignment (GOMMA-‐bk) 0.85 0.864 0.857
Compared Alignment (AML) 0.826 0.716 0.767
Compared alignment (AML-‐bk) 0.835 0.813 0.824
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Figure 8.5: Advanced precision and recall measures of conjunctive fuzzyaggregations and Dempster-Shafer aggregation
For the union and intersection operators, the most relevant method forthe aggregation operator to use is the Dempster-Shafer combination of belief.
8.2.3 Alignment composition evaluation results
For running alignment composition we need many alignments between multi-ple resources. The test case was not easy to build since we lack access to align-ment tools and the few alignment services are useful only for one part of thetests. We used alignments from the LogMap [Jiménez-Ruiz & Grau 2011]tool and from the large biomedical ontology track of the OAEI.
8.2.3.1 Composition of validated alignments
The test case is made of the large biomedical ontologies “Foundational Modelof Anatomy” (FMA4), “SNOMED CT”5, and the “National Cancer InstituteThesaurus” (NCI6). The “large biomedical ontology” track is composed by
4http://sig.biostr.washington.edu/projects/fm/5http://www.ihtsdo.org/index.php?id=5456http://ncit.nci.nih.gov/
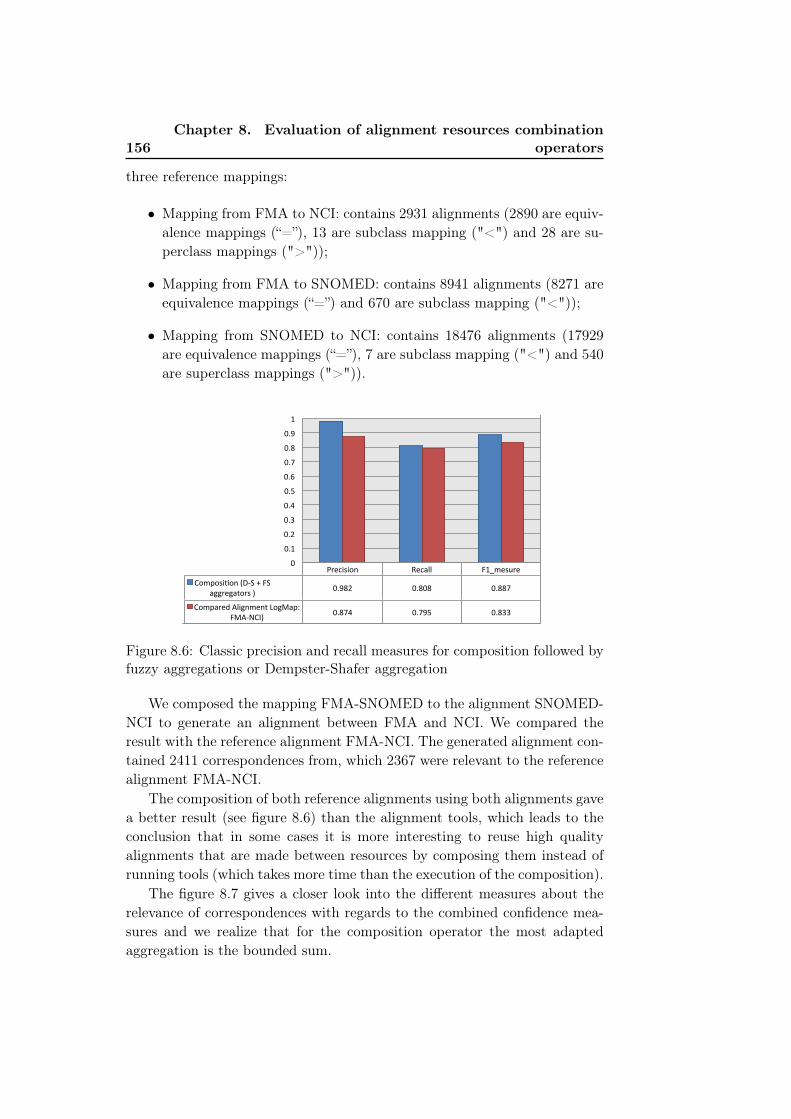
156Chapter 8. Evaluation of alignment resources combination
operators
three reference mappings:
• Mapping from FMA to NCI: contains 2931 alignments (2890 are equiv-alence mappings (“=”), 13 are subclass mapping ("<") and 28 are su-perclass mappings (">"));
• Mapping from FMA to SNOMED: contains 8941 alignments (8271 areequivalence mappings (“=”) and 670 are subclass mapping ("<"));
• Mapping from SNOMED to NCI: contains 18476 alignments (17929are equivalence mappings (“=”), 7 are subclass mapping ("<") and 540are superclass mappings (">")).
Precision) Recall) F1_mesure)Composi4on)(D7S)+)FS)
aggregators))) 0.982) 0.808) 0.887)
Compared)Alignment)LogMap:)FMA7NCI)) 0.874) 0.795) 0.833)
0)
0.1)
0.2)
0.3)
0.4)
0.5)
0.6)
0.7)
0.8)
0.9)
1)
Figure 8.6: Classic precision and recall measures for composition followed byfuzzy aggregations or Dempster-Shafer aggregation
We composed the mapping FMA-SNOMED to the alignment SNOMED-NCI to generate an alignment between FMA and NCI. We compared theresult with the reference alignment FMA-NCI. The generated alignment con-tained 2411 correspondences from, which 2367 were relevant to the referencealignment FMA-NCI.
The composition of both reference alignments using both alignments gavea better result (see figure 8.6) than the alignment tools, which leads to theconclusion that in some cases it is more interesting to reuse high qualityalignments that are made between resources by composing them instead ofrunning tools (which takes more time than the execution of the composition).
The figure 8.7 gives a closer look into the different measures about therelevance of correspondences with regards to the combined confidence mea-sures and we realize that for the composition operator the most adaptedaggregation is the bounded sum.
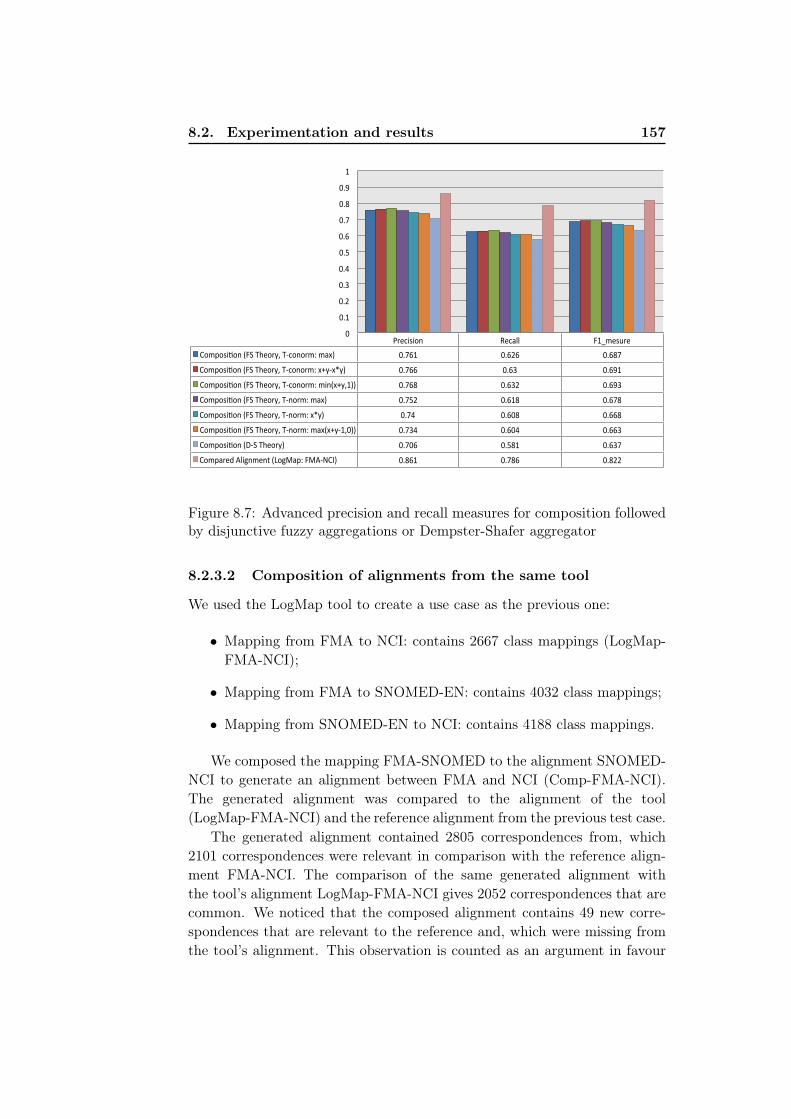
8.2. Experimentation and results 157
Precision) Recall) F1_mesure)Composi4on)(FS)Theory,)T;conorm:)max)) 0.761) 0.626) 0.687)
Composi4on)(FS)Theory,)T;conorm:)x+y;x*y)) 0.766) 0.63) 0.691)
Composi4on)(FS)Theory,)T;conorm:)min(x+y,1))) 0.768) 0.632) 0.693)
Composi4on)(FS)Theory,)T;norm:)max)) 0.752) 0.618) 0.678)
Composi4on)(FS)Theory,)T;norm:)x*y)) 0.74) 0.608) 0.668)
Composi4on)(FS)Theory,)T;norm:)max(x+y;1,0))) 0.734) 0.604) 0.663)
Composi4on)(D;S)Theory)) 0.706) 0.581) 0.637)
Compared)Alignment)(LogMap:)FMA;NCI)) 0.861) 0.786) 0.822)
0)
0.1)
0.2)
0.3)
0.4)
0.5)
0.6)
0.7)
0.8)
0.9)
1)
Figure 8.7: Advanced precision and recall measures for composition followedby disjunctive fuzzy aggregations or Dempster-Shafer aggregator
8.2.3.2 Composition of alignments from the same tool
We used the LogMap tool to create a use case as the previous one:
• Mapping from FMA to NCI: contains 2667 class mappings (LogMap-FMA-NCI);
• Mapping from FMA to SNOMED-EN: contains 4032 class mappings;
• Mapping from SNOMED-EN to NCI: contains 4188 class mappings.
We composed the mapping FMA-SNOMED to the alignment SNOMED-NCI to generate an alignment between FMA and NCI (Comp-FMA-NCI).The generated alignment was compared to the alignment of the tool(LogMap-FMA-NCI) and the reference alignment from the previous test case.
The generated alignment contained 2805 correspondences from, which2101 correspondences were relevant in comparison with the reference align-ment FMA-NCI. The comparison of the same generated alignment withthe tool’s alignment LogMap-FMA-NCI gives 2052 correspondences that arecommon. We noticed that the composed alignment contains 49 new corre-spondences that are relevant to the reference and, which were missing fromthe tool’s alignment. This observation is counted as an argument in favour
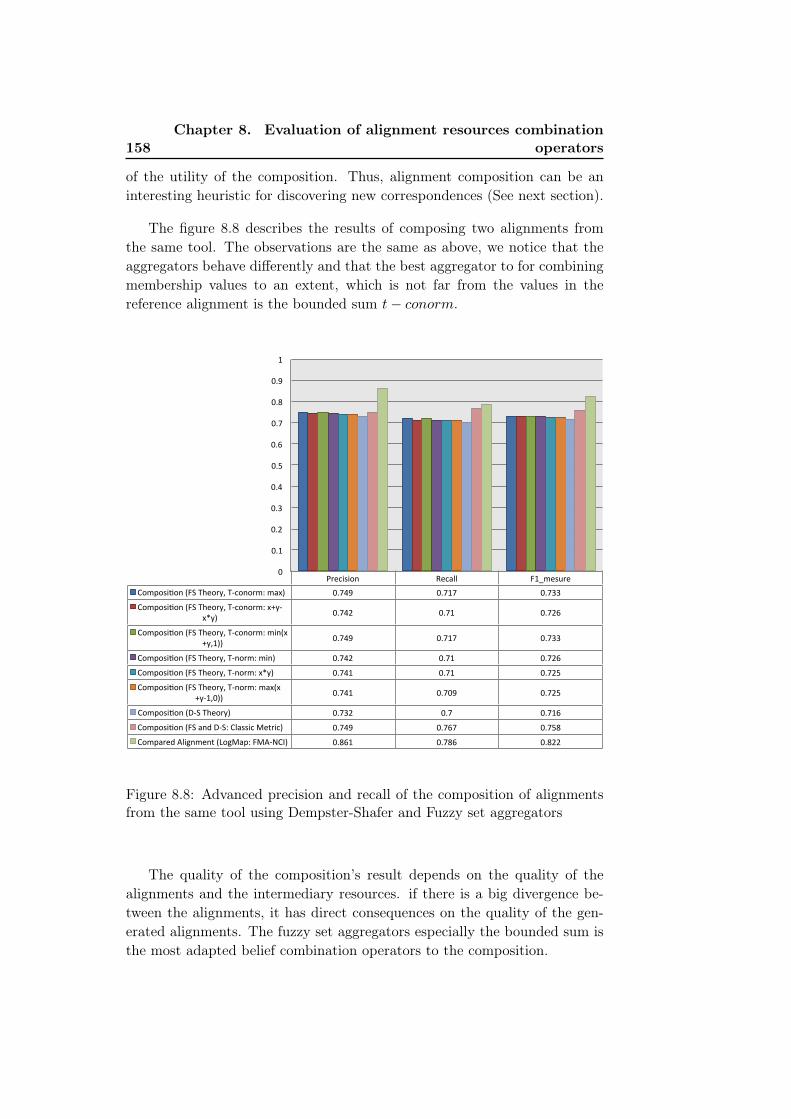
158Chapter 8. Evaluation of alignment resources combination
operators
of the utility of the composition. Thus, alignment composition can be aninteresting heuristic for discovering new correspondences (See next section).
The figure 8.8 describes the results of composing two alignments fromthe same tool. The observations are the same as above, we notice that theaggregators behave differently and that the best aggregator to for combiningmembership values to an extent, which is not far from the values in thereference alignment is the bounded sum t− conorm.
Precision) Recall) F1_mesure)Composi4on)(FS)Theory,)T;conorm:)max)) 0.749) 0.717) 0.733)
Composi4on)(FS)Theory,)T;conorm:)x+y;x*y)) 0.742) 0.71) 0.726)
Composi4on)(FS)Theory,)T;conorm:)min(x+y,1))) 0.749) 0.717) 0.733)
Composi4on)(FS)Theory,)T;norm:)min)) 0.742) 0.71) 0.726)
Composi4on)(FS)Theory,)T;norm:)x*y)) 0.741) 0.71) 0.725)
Composi4on)(FS)Theory,)T;norm:)max(x+y;1,0))) 0.741) 0.709) 0.725)
Composi4on)(D;S)Theory)) 0.732) 0.7) 0.716)
Composi4on)(FS)and)D;S:)Classic)Metric)) 0.749) 0.767) 0.758)
Compared)Alignment)(LogMap:)FMA;NCI)) 0.861) 0.786) 0.822)
0)
0.1)
0.2)
0.3)
0.4)
0.5)
0.6)
0.7)
0.8)
0.9)
1)
Figure 8.8: Advanced precision and recall of the composition of alignmentsfrom the same tool using Dempster-Shafer and Fuzzy set aggregators
The quality of the composition’s result depends on the quality of thealignments and the intermediary resources. if there is a big divergence be-tween the alignments, it has direct consequences on the quality of the gen-erated alignments. The fuzzy set aggregators especially the bounded sum isthe most adapted belief combination operators to the composition.

8.3. Usage of alignment composition to enrich existingalignments 159
8.3 Usage of alignment composition to enrich ex-isting alignments
While analyzing the results of the “Inner tool evaluation” (section 8.1), wenoticed that there are some relevant and relevant correspondences within thecomposed alignments that are not in the tool’s alignment. Consequently, wepropose a use case that shows the advantage of alignment composition andits utility for enriching existing alignments.
Let the resources resource R1, R2, Ra, Rb and Rc and A1,2 an alignmentbetween the couple of resources (R1, R2).
Let A1,x = {A1,a, A1,b, A1,c} be the set of alignment resultingfrom the application of a matching tool on the couples of resources(R1, Ra); (R1, Rb); (R1, Rc).
Let Ax,2 = {Aa,2, Ab,2, Ac,2} be the set of alignment resultingfrom the application of a matching tool on the couples of resources(Ra, R2); (Rb, R2); (Rc, R2).
For instance, the application of the compositions (A1,a◦Aa,2), (A1,b◦Ab,2)
and (A1,a ◦Aa,2) to enrich A1,2 depends on the following cases:
1. the alignment A1,2 covers all the possible matchings between both re-sources (perfect precision and recall: in the case of manual alignments).In this case the composition is of no usage;
2. the alignment A1,2 does not cover all the possible matchings. In thiscase the composition might be of a usage and can detect new matchingsbetween both resources’ entities. We can state the hypothesis that themore intermediary resources to involve, the more possible correspon-dences to discover.
Composing alignments between resources depends highly on the commonresource that is used. The quality and coverage of the resulting alignment isproportional to the size of the intermediary resource. For instance, havinga resource R1 containing n entities, a resource R2 containing m, entitiesand a resource Ra containing k entities. If we consider the three resultingalignments A1,a, Aa,2 and A1,2 from the application of a matching tool, thenthe quality of the composition A1,a ◦Aa,2 depends on the following cases:
• if m ≥ n and m ≥ k, there is a possibility that the composition A1,a ◦Aa,2 covers the majority of entities from the resources R1 and R2 butthis is not conclusive;
• if m ≤ n and m ≤ k, then the composition A1,a ◦Aa,2 is likely to be ofa less quality than a direct alignment, but it can be useful to discovernew correspondences between entities.

160Chapter 8. Evaluation of alignment resources combination
operators
R1R2
Ra
Rb
A1,2
Rc
A1,a Aa,2
A1,b Ab,2
A1,c
Ac,2
Figure 8.9: Enriching direct alignments using composed alignments of inter-mediary resources
The composition is not a substitute for matching tools but it can be usedas a complementary module to enrich existing alignments or to enhancethe performances of alignment tools. The figure 8.9 illustrates this case byshowing that the usage of multiple resources as intermediary elements forentity matching can enhance the coverage of alignments since it can discovera mapping path between entities using the extra correspondences betweenthem and also the content of these resources. The approach that we proposeis to calculate all the possible composition and aggregate them with thedirect alignment using the max aggregator.
8.4 An approach for enhancing composition usingthe content of the resources
During the experimentation, we realized that the content of resources werenot exploited during the composition process. We used only the content ofalignments between both resources. What we propose in this extension doesnot affect at any level the definition or the implementation of the compositionoperator since the composition paths between entities are given based on thecontent of alignments.

8.4. An approach for enhancing composition using the content ofthe resources 161
In the section 7.3.1.2, we introduced the path finding function as follows:
Paths(ex, ez, A1, A2) = {(c1, c2)|∃ey ∃R ∃S : c1 = 〈ex, R, ey〉 ∈ A1
and c2 = 〈ey, S, ez〉 ∈ A2}
as the set of correspondences associating ex to ez from both alignments A1
and A2;
Rx Ry
Rz
A1,2 A2,3
A1,3?
Figure 8.10: Composition path finding using the content of resources
As illustrated in the figure 8.10, sometimes the “Paths” function does notreturn any possible composition path to generate a correspondence between asource entity from Rx and a target entity from Rz. We propose two methodsfor coping with this case. The first method extends the path finding toconsider only content of the intermediary resource for a richer compositionpath within the composed alignments. The second method applies a heavierprocedure by involving the content of the three resources and by extendingthe alignments before composing them. In the current state we choose toapply the first method but we intend in a further work to compare bothprocedures in terms of quality of the generated alignment:
1. A method that extends the Paths function and returns an extendedcomposition path between a source entity from Rx and a target entityfrom Rz. This method has as additional parameter the intermediaryresource Ry;
2. An operator that extends alignments between two resources. This op-erator saturates the alignments by adding all the possible omitted cor-respondences between entities by involving both an alignment and bothresources (source and target).

162Chapter 8. Evaluation of alignment resources combination
operators
8.4.1 Extending composition path finding using the contentof a common resource
In order to extend the result of the Paths function to find a richer compositionpath we need to extract omitted correspondences between different entitiesfrom the common resource of the composed alignments.
As an example let’s consider a case of ontology alignment. For instance,if we have three ontologies O1, O2 and O3 where:
1. entities within the second ontology are defined as the facts:
• f1 = 〈O2 : ea L :@ O2 : eb〉
• f2 = 〈O2 : ea L :≡ O2 : ec〉 . . .
where L is the language used for representing the content of ontologies(e.g.: L:@ is a representation of owl:SubClassOf).
2. an alignment A1,2 represents a set of correspondences between bothontologies O1 and O2:
c1,2 = 〈es, Rx, ea〉
where Rx = {({≡}, 0.7)}.
3. an alignment A2,3 represents a set of correspondences between bothontologies O2 and O3:
c12,3 = 〈eb, s1, et〉
where s1 = {({A}, 0.9)}. and
c22,3 = 〈ed, s2, et〉
where s2 = {({≡}, 0.8)}.
Using the original path finding function as defined in the previous chap-ter, the resulting composition path between es from O1 and et from O3 is:
Paths(es, et,A1,2,A2,3) = ∅
Using the content of the ontology O2 we find that the target entity in thealignment A1,2, ea, is in fact linked to two entities eb and ec that have each adirect correspondence with et, then the resulting composition path betweenes from O1 and et from O3 is:
Pathsext(cs, ct,A1,2,A2,3,O2) = {(c′1,2, c12,3), (c′′1,2, c
22,3)}

8.4. An approach for enhancing composition using the content ofthe resources 163
wherec′1,2 = c1,2 ◦ f1 =
⟨es, r
′1, eb
⟩; r′1 = {({@}, 0.7)}
andc′′1,2 = c1,2 ◦ f2 =
⟨es, r
′′1 , ec
⟩; r′′1 = {({≡}, 0.7)}.
knowing that (≡ ◦ @ = @) and (≡ ◦ ≡ = ≡).In order to implement this method, we need to define at first the seman-
tics of relations between entities that are considered in the composition pathfinding. The composition of relations from an alignment formalism and re-lation from a resource representation formalism is possible only if they havethe same semantics.
The composition of a correspondence and a fact is supposed to generatea correspondence this is why we need to define a transformation functionthat turns facts into correspondences. Then we apply the correspondencecomposition operator that we defined in the section 7.3.1.1
Let L be the set of resources representation formalisms within the reposi-tory, we define QL as the set of relations between types of entities representedby L (e.g.: owl : SubclassOf ∈ QL, skos : narrower ∈ QL).
Definition 7 (Entity relation transformation) We define a transfor-mation σ of a relation in QL to a relation within an alignment formalism asfollows:
σ : QL → Θ× [0, 1]
r 7→ (s, 1)
The next step then is to define an operator that transforms relationalfacts that are retrieved from a resource into a correspondence as representedin the definition 4 in the section 6.4.
Definition 8 (Facts to correspondences transformation) We define atransformation Λ of a fact in a resource R to a correspondence in an align-ment L as follows:
Λ : L→ A
〈es, r, et〉 7→ 〈es, σ(r), et〉
To find the proper fact to extract from a resource we created a functionthat has as input two entities ex and ey from a given resource and as outputthe fact that connects both entities. For the sake of simplicity, this functionbrowses the structure of the resource as a graph of transitive relations be-tween entities (For a complex approach we can consider composing relationswithin multiple facts). For example let’s consider that we are looking for afact between ex and ey in O2 and having:

164Chapter 8. Evaluation of alignment resources combination
operators
• f1 = 〈O2 : ex L :≡ O2 : ea〉
• f2 = 〈O2 : ea L :@ O2 : eb〉
• f3 = 〈O2 : eb L :≡ O2 : ec〉
• f4 = 〈O2 : ec L :≡ O2 : ey〉
Finally using the content of a resource Ry, which is common between twoalignment A1,2 and A1,3, we define the Pathsext function as follows:
Pathsext(ex, ez,A1,2,A2,3,Ry) = {(comp(c1,Λ(fi)), c2)|∃ey ∃es ∃R ∃S, ∃t ∈ QL
wherec1 = 〈ex, R, ey〉 ∈ A1,2
and fi = 〈ey, t, es〉 ∈ Ry
and c2 = 〈et, S, ez〉 ∈ A2,3}
8.4.2 Composition path finding using an alignment extensionoperator
To consider a composition of alignments that takes into consideration allthe possible composition paths between the correspondences, we propose amethod for creating saturated alignments. This means that, based on anexisting alignment between two resources, this operators uses the content ofboth resources (source and target) in order to generate all possible corre-spondences between entities from the aligned resources. For instance let’sconsider an alignment A1,2 between two ontologies O1 and O2 where:
1. entities within both ontologies defined as:
• O1 : eb @ O1 : ea . . .
• O2 : e′d A O2 : e′c . . .
2. alignment A1,2 represents a set of correspondences between both on-tologies:
c1 =⟨ea, Rx, e
′c
⟩∈ A1,2 . . .
where Rx = {({≡}), 0.9}.
The saturation operator applies an internal composition of alignmentrelations and adds two correspondences to the A1,2 alignment. This generatesan extended or “Saturated” alignment between both ontologies that containsthe following correspondences:

8.4. An approach for enhancing composition using the content ofthe resources 165
1. c1 = 〈ea, Rx, e′c〉 where Rx = {({≡}), 0.9};
2. c2 = 〈ea, Ry, e′d〉 where Ry = {({@}), 0.9};
3. c3 = 〈eb, Rz, e′c〉 where Rz = {({@}), 0.9};
4. c4 = 〈eb, Ru, e′d〉 where Ru = {({@}), 0.9}.
Extending correspondences
Let Rx and Ry be two resources within the repository andlet A1,2 an alignment between Rx and Ry and cx,y =
〈ex, ey, Rx,y = {(rx, w1), . . . , (rn, wn)}〉 ∈ A1,2, we define:
• LeftExt(ex ∈ Rx, cx,y ∈ A1,2, Rx) = {ci = Λ(fi)|∃ei ∈ Rx ∃rk ∈QL and fi = 〈ei, rk, ex〉 ∈ Rx} as the set of correspondences repre-senting all the related entities ek to ex within the resource Rx;
• RightExt(ey ∈ Ry, cx,y ∈ A1,2, Ry) = {cj = Λ(fj |∃ej ∈ Ry ∃st ∈QLand fj = 〈ey, st, ej〉 ∈ Ry} as the set of correspondences represent-ing all the related entities ej to ey within the resource Ry;
Finally we define the extension of a correspondence in A1,2 as the set:
Extζ(cx,y ∈ A1,2, Rx, Ry) = {
{Compζ(ci, cx,y)|ci ∈ LeftExt(ex, cx,y, Rx)}⋃{Compζ(cx,y, cj)|cj ∈ RightExt(ey, cx,y, Ry)}
}
where ζ is the confidence combination function (max−min).
Extending alignments
Let Rx and Ry be two resources within the repository and let A1,2 an align-ment between Rx and Ry. For each cx,y = 〈ex, ey, Rx,y}〉 ∈ A1,2, we definethe extension of A1,2 as an alignment AExt1,2 :
AExt1,2 = Aggrφ({Extζ(cx,y)|cx,y ∈ A1,2})
Where Aggrφ is a the aggregation operator that combines conflicting corre-spondences within an alignment.
For composing two alignments A1,2 and A2,3 is an alignment:

166Chapter 8. Evaluation of alignment resources combination
operators
A1,3 = Compφ(AExt1,2 , AExt2,3 ).
8.5 Conclusion and discussion
Our approach of alignment combination and management is a contributionto initiate a discussion around the usefulness and applications of alignmentcomposition. The results are conclusive enough to consider the importanceand the potential of composition. We experimented the operators that wedefined for aggregating and composing alignments. The results showed thepotential of these operators to enhance the quality of alignments or find newcorrespondences by composing existing ones. The usefulness of alignmentaggregation and composition has been investigated within the test cases.
The usage of matching tools is quite complex; it is rare to find an in-dependent service or online tool for matching knowledge resources. In or-der to be uses, the majority of tools need to be adapted, implemented orinstalled. Ideally, it could be easier if each alignment tool were designedto be used as a web service or using a web interface such as LogMap[Jiménez-Ruiz & Grau 2011]. This could help end users to upload theirresources, adjust certain parameters and launch a process and at the enddownload the resulting alignment. Using this kind of architectures couldenhance resources sharing and reuse; if an alignment between two resourceshas been created and validated, it is very useful to publish and share it tosave time for other knowledge resources users.
Using our operator the composed alignment was generated in 5 seconds(8GB memory and dual core processor), while the used tool, which is aperformant one took 45 minutes to provide the alignment. Choosing thecommon resource between the resources to align is very important and has abig impact on the composed alignment (see section 8.3). As for the previoustest cases we intend to select the proper aggregation method able to give theclosest results to the reference in terms of confidence measures.
As shown in the section 8.3, we can find usage scenarios that support theutility of alignment composition, the composition might even be requiredin the case of incompatible resources. For instance, if two resources fromthe same type are aligned using an automatic matching tool and one ofthese resources is manually bridged to a third resources of a different typewhere a matching devise cannot be applied then the composition operatorcan generate alignment to match different kinds of resources. The applicationof this operator takes less time than matching tools but this operator cannotbe useful on its own for all cases.

Chapter 9
Conclusion and future work
The increasing number of ontological resources on the web became problem-atic. On one hand, knowledge resources exist under different formats andlanguages (predicate logic, description logic, semantic networks, conceptualgraphs, text, etc.). This diversity in knowledge representation and the se-mantics behind each representation approach makes it difficult to define oruse a unique approach to manage these resources and derive them. On theother hand, tools for collecting, combining and reusing knowledge to pro-duce new resources are lacking organization. For this purpose, we proposedan approach for storing and combining knowledge resources by (i) defininga model for representing heterogeneous knowledge resource and (ii) by de-signing a model for representing operators that compose knowledge fromheterogeneous resources to produce new knowledge resources.
9.1 Advantages of the TOK approach
In this thesis we described our contributions related to the subject of com-bining knowledge from heterogeneous resources. We narrowed the scopeof the managed knowledge to the declarative type and we used the notionof concept as a key element for the declarative knowledge representation.We consider a concept as an abstract object that brings sense to the nat-ural language representation and refers to a referent. We focused then onrepresenting conceptual, terminological, and lexical knowledge based on thefollowing aspects:
• type of entities to represent (concepts, terms, lexical forms, etc.);
• types of relationships between items (structure of the resources);
• types of knowledge resources: the ability to represent knowledge basedon different formalisms;
In order to ensure a rich but formal representation of knowledge resources,we proposed an MOF-based representation approach that defines on a meta-model for representing the generic aspects of resources and their entities.We refined the meta-model by defining specific models and vocabularies to

168 Chapter 9. Conclusion and future work
represent different aspects of knowledge resources. To enable the integra-tion and exchange of our approach within and across the Semantic Web, weexpressed our representation using an ontology. Since it has been proventhat representation languages or formalisms cannot be reduced to a singleone, our approach relies on the definition of a model that is defined in twolayers. The first layer is a meta-model that represents the generic aspectsof knowledge resources. The second layer is a set of different model thatrepresent specific aspects of a specific category or type of resources (formal,ontological, conceptual, terminological, lexical, etc.).
The solution that we proposed is based on a centralized representationand storage of knowledge resources within a knowledge repository. We de-fined the TOK model and represented it using an ontology TOK_Onto. Thismodel is used as a pivot language for providing a syntactic and semantic in-teroperability between heterogeneous knowledge resources. Our approachrequires transforming knowledge representation from a specific language toa representation that is coherent with the proposed model. The content ofthe represented knowledge resources is represented at the instance level ofthe proposed model. Instances of the knowledge resources are not consid-ered within the meta-model since we represent the conceptual aspects butin practice these entities can be represented using this model as instances ofthe type “Individual entities”.
We have shown that the model allows representing specific or genericknowledge using different levels of expressivity. The main principle of theapproach is the ability to extend the model by adding subsequent specificresources representation models. This requirement is satisfied since the pro-posed model is implemented using an ontology, which led to the usage of“SubClassOf” property to describe new models using the vocabulary of theproposed ontology. We use the OWL DL as a formal language to representour model and describe its semantics.
The representation approach that we are using respects the provenance ofknowledge and the independence of knowledge resources. Each resource canbe derived to another resource if we need to change the level of expressivity orthe representation model. Since we use the URI as identifiers for knowledgeresources entities, then duplication of knowledge is not possible unless there isan explicit need to change the representation of entities. The considerationof alignment resources as independent knowledge representation artifacts,allows to express similarity between entities and explicit their relations.
The representation model by itself was was not the solution for combiningknowledge within knowledge resources. The second ingredient was the defini-tion of a taxonomy of knowledge engineering operators that are the requiredbricks to define complex processes for creating new knowledge resources. We

9.1. Advantages of the TOK approach 169
developed some instances of these operators and applied them on a type ofknowledge resources that are heterogeneous even if they represent similar as-pects of knowledge. We implemented use cases for testing our approach, thefirst use case was built using a simplified version of the meta-model that wasrepresented using a database schema and the set of knowledge combinationoperators were developed to generate a terminological knowledge base that isuseful for translation. The second use case was built using the full ontologyof the proposed model and an RDF triple store. We created SPARQL andjava based operators to extract and transform knowledge within the resultingrepository.
In terms of methodological contributions, we propose an original man-ner for representing knowledge resources based on knowledge engineering,semantics and meta-modeling. This approach intends to generalize the re-sources representation by supporting multiple formalisms and different levelsof expressivity under the pivot model. We also proposed models for integrat-ing and representing knowledge engineering processes by reusing and exist-ing ontology and refining its representation by adding certain constraints tocontextualize these resources combination and management operators. Foran application we designed and proposed an approach for aggregating andcomposing alignment resources, which represents few concrete methodologiesthat addresses this issue.
In terms of practical contributions, we implemented an API and a repos-itory for managing alignment resources and developed an operator for im-porting this type of resources from six different formalisms. In order to rep-resent and combine confidence measures within alignment correspondences,we applied multiple uncertainty combination methods from two differenttheories (Fuzzy set and Dempster-Shafer theories). We experimented theoperators that we defined for aggregating and composing alignments. Theresults showed the potential of these operators to enhance the quality ofalignments or find new correspondences by composing existing ones. Theusefulness of alignment aggregation and composition has been investigatedwithin the test cases. The composition operator is an operator that is ableto discover new mappings between entities of aligned resources.
Our approach for combining alignment resources is based on a mathe-matical background and does not arbitrarily combine or optimize some pa-rameters to enhance the results. Operators for respecting the coherence ofthe properties and aspects of interpreting confidence measures were imple-mented. Our framework for alignment combination is an original combina-tion between the algebra of alignment relations [Euzenat 2008] as a theoryfor combining alignment relations and robust belief combination theories.

170 Chapter 9. Conclusion and future work
9.2 Limitations and future work with regards to thecontributions
The proposed approach is a first step towards a concrete new concept ofknowledge resources repository. The proposed repository is only a proof ofconcept since it is not scalable for large resources and it does not implementall the aspects that are required for its management (users management,versioning, implement services, implement sophisticated search interfaces,etc.). We did not work on this because it was not included in the researchproblems and multiple solutions and propositions are available in the stateof the art.
For the scalability issue, we assume that there are enough solutions tobuild this repository based on the proposed model on top of a performantRDF triple store. For the versioning and process execution issues, the modelprovides all the required elements that make implementing versioning andprocess monitoring algorithms an engineering matter. Users managementand resources sharing issues can be solved by representing users and theirresources from a social network perspective, which allows to a user to managehis own resources and share them and edit their visibility and status (thisis also an engineering matter and does not require further studies except ofusing the right model). Other features such as domain management can beimplemented easily, since the representation model covers it.
Besides implementations of missing components there are further researchproblems and research areas to explore. For instance, we used a SemanticWeb-based approach in order to be able to apply reasoning over knowledgeresources in order to discover mappings between ontological entities. An-other interesting aspect to consider is the possibility to use abduction as areasoning mechanism for discovering missing facts that prevent the execu-tion of a specific process: What are the missing operators or elements in apossible chain for generating a resource based on existing ones? It meansfor realizing a process, we should find out automatically what is required tomake it possible (e.g. align a SKOS vocabulary with an OWL ontology, itshould know that depending on the alignment operator, we need to trans-form the vocabulary into OWL to make the alignment possible). Anotherperspective is to help a user pick the most relevant knowledge engineeringoperator for his resources. For example, in case of having multiple matchingservices that are available (implemented or imported) within the repository,we will be able to automatically pick the right matching tool for a specificresource based on the tool’s and the resource’s criteria [Ajmi et al. 2012].

9.3. Use of the methodology for research and industry 171
9.3 Use of the methodology for research and indus-try
The amount of approaches and tools for linked data and semantic web tech-nologies (such as alignment, indexing, cleaning, combining and transformingknowledge resources) is becoming more and more considerable. Organizingall this knowledge about the field of semantic web and knowledge manage-ment will make it easier for scientists from this field to disseminate for theirmethodologies, share them and compare them with other methodologies ortools in order better reuse or compose them. The number of approaches forthese operations evolved during the last decades. Researchers from differ-ent backgrounds design tools before the birth of the Semantic Web concept.Problems such as web services representation and compositions are alreadyexplored and multiple solutions are available. This offers a solid technicalbackground to build such a system. Regarding the number of available tools,a designer of a knowledge management approach considers existing method-ologies for a purpose of reusing them to reduce design and development costsand enhance the quality of his/her solution.
In order to collect the necessary knowledge about available knowledgeengineering resources and methodology, a designer is obliged to go througha large amount of scientific papers or industrial documentation. This docu-mentation can have different types going from detailed specifications to onlygeneral information. This variety in the description cannot fulfill the infor-mation need of a knowledge engineer. This domain is quite rich and large,so it is time consuming to be aware of all the novelties that may be useful ina particular case to manage an amount of heterogeneous information (datasets) that have to be combined and reused.
This is why we propose to use our approach to build an ontology drivenlarge knowledge repository that allows a knowledge engineer to share and getall the information he needs about the knowledge resources and operatorsthat are relevant for his/her context. Building this ontology of knowledgeresources and processes relies on defining their formal representation andclassify them based on their evaluation and usage, which is already fulfilledby the current model.
The contributions of this work are of a great use for research and in-dustry; It proposes the basic elements that support a library of tools forknowledge engineering. The proposed ontology offers the possibility to in-tegrate knowledge resources representation. This insures different levels ofinteroperability and a dynamic representation of knowledge resources. Therepresentation of knowledge resources operators is a support for building analgebra for combining and composing these operators. Some research issues

172 Chapter 9. Conclusion and future work
have been addressed and solved in terms of resources representation and com-bination. In terms of usage for research, our contributions offer the groundfor a potential open repository where researchers can share their experiences(tools and processes) and their resources (derived, adapted and validated).
The proposed approach is a candidate for an industrial application. Asystem can be proposed as a laboratory of knowledge resources combina-tion based on commercial or open-source tools that derive knowledge fromexisting public or private resources.

Appendix A
About some uses cases of therepository
ContentsA.1 Enriching an ontology with a bilingual glossary . . . 173A.2 Importing the resources . . . . . . . . . . . . . . . . . 174
This appendix is about showing some details about the use cases de-scribed in the previous chapters. The first use case is was presented in thesection 4.4 about the need of an ontology designer to enrich an ontology inthe field of ‘Aeronautics’. She/he wants to add definitions in two languages(English and French) to the named concepts of this ontology.
A.1 Enriching an ontology with a bilingual glossary
The task of enriching a domain ontology there requires external resourcesthat can be found either within the repository or provided by the user (ownedresources or extracted from other repositories). For this particular use case,let us consider that the designer has these resources:
• the input ontology (aero.owl) in OWL about ‘Aeronautics and air-crafts’;
• an English glossary (aeroglo_en.rdf) represented in SKOS about thesame domain;
• a French glossary (aeroglo_fr.rdfs) represented in RDFS about thesame domain;
• a bilingual dictionary (aerodict_en_fr.tbx) represented in TBX aboutthe same domain;
To generate an enriched ontology (concept having labels in two languagesand associated to definitions in both languages) these are the steps to followfor fulfilling this task:

174 Appendix A. About some uses cases of the repository
prefix tok: <http://cui.unige.ch/isi/onto/tok.owl#>
IMPORT:aeroOnto_CH = tok:import_CH (aero.owl, ‘OWL’)aeroGlo_en_CH = tok:import_CH (aeroglo_en.rdf, ‘SKOS’)aeroGlo_fr_CH = tok:import_CH (aeroglo_fr.rdfs, ‘RDFS’)aeroDict_en_fr_CH = tok:import_CH (aerodict_en_fr.tbx, ‘TBX’)
ConceptH:A_en.en_Aero_CH = tok:ConceptH_CH (aeroOnto_CH , aeroGlo_en_CH)A_en.fr_Aero_CH = tok:ConceptH_CH (aeroOnto_CH , aeroGlo_fr_CH, aeroDict_en_fr_CH)
MERGE:aeroOnto_ext_CH = tok:merge_CH(aeroOnto_CH, aeroGlo_en_CH, A_en.en_Aero_CH )aeroOnto_ext_CH = tok:merge_CH(aeroOnto_CH, aeroGlo_fr_CH, A_en.fr_Aero_CH )
EXPORT:aeroext.owl = tok:export_CH(aeroOnto_ext_CH, ‘OWL’)
In the following sections we detail each part of this process and we giveexcerpts of the algorithms used for the implementation of the used operators.
A.2 Importing the resources
For this use case we use the concept hierarchy model which is described asfollows:
• Concept_Hierarchy_Model v Representation_Model
• Concept_Hierarchy_Model v ∀ uses (Knowledge_Resource t(Node_Entity u ∀ isOfType Conceptual_Entity) t(Node_Entity u ∀ isOfType Definition_Entity) t(Node_Entity u ∀ isOfType (Lexical_Form t Term_Entity)) t(Link_Entity u ∀ isOfType Concept_To_Concept ) t(Link_Entity u ∀ isOfType Concept_To_Term ) t(Link_Entity u ∀ isOfType Concept_To_LexicalForm ))
Using OWL manchester format, some excerpts of the instances of theresources, operators and the process are described as follows:
prefix tok: <http://cui.unige.ch/isi/onto/tok.owl#>prefix omv: <http://omv.ontoware.org/2005/05/ontology#>prefix owls: <http://www.daml.org/services/owl-s/1.2/Profile.owl#Profile>prefix process:<http://www.daml.org/services/owl-s/1.2/Process.owl#>
Individual: aeroOnto_CHTypes: omv:OntologyFacts:

A.2. Importing the resources 175
omv:KnownUsage "Terminology of aircraft concepts",tok:has_language tok:EN,omv:hasDomain tok:Aeronautics,omv:modificationDate "2014-08-25T22:30:00-05:00"^^xsd:dateTime,omv:creationDate "2014-08-25T23:30:00-05:00"^^xsd:dateTime,tok:has_original_file <http://cui.unige.ch/isi/usecase/aero.owl>,tok:has_representation_model tok:Concept_Hierarchy,tok:provenance tok:importOWL_CH,tok:created_from "Import from OWL to the Concept Hierarchy model"^^xsd:string,tok:has_syntax tok:RDF_XML,tok:used_in_process tok:AeroEnrich001...
Individual: import_aero_OWL_CHTypes: tok:Resource_ImportFacts:tok:uses_implementation tok:importService_9,tok:input <http://cui.unige.ch/isi/onto/usecase/aero.owl>,tok:output tok:aeroOnto_CH,tok:argument "OWL"^^xsd:string,tok:executedBy tok:nizar,tok:has_run_date "2014-08-25T23:30:00-05:00"^^xsd:dateTime,omv:description "import from OWL to Concept Hierarchy"^^xsd:string,omv:name "OWL2CH",omv:keywords "OWL, CH, Concept, Hierarchy, import, service"^^xsd:string,tok:has_execution_priority ‘1’^^xsd:Integer...
Individual: import_aero_SKOS_CHTypes: tok:Resource_ImportFacts:tok:uses_implementation tok:importService_9,tok:input <http://cui.unige.ch/isi/onto/usecase/aeroglo_en.rdf>,tok:output tok:aeroGlossary_EN_CH,tok:argument "SKOS"^^xsd:string,tok:executedBy tok:nizar,tok:has_run_date "2014-08-25T00:00:00-05:00"^^xsd:dateTime,omv:description "import from SKOS to Concept Hierarchy"^^xsd:string,omv:name "SKOS2CH"^^xsd:string,omv:keywords "SKOS, CH, Concept, Hierarchy, import, service"^^xsd:string,tok:has_execution_priority ‘2’^^xsd:Integer...
Individual: import_aero_RDFS_CHTypes: tok:Resource_ImportFacts:tok:uses_implementation tok:importService_9,tok:input <http://cui.unige.ch/isi/onto/usecase/aeroglo_fr.rdfs>,tok:output tok:aeroGlossary_FR_CH,tok:argument "RDFS"^^xsd:string,tok:executedBy tok:nizar,

176 Appendix A. About some uses cases of the repository
tok:has_run_date "2014-08-25T23:00:00-05:00"^^xsd:dateTime,omv:description "import from RDFS to Concept Hierarchy"^^xsd:string,omv:name "RDFS2CH"^^xsd:string,omv:keywords "RDFS, CH, Concept, Hierarchy, import, service"^^xsd:string,tok:has_execution_priority ‘3’^^xsd:Integer...
Individual: import_aero_TBX_CHTypes: tok:Resource_ImportFacts:tok:uses_implementation tok:importService_9,tok:input <http://cui.unige.ch/isi/onto/usecase/aerodict_en_fr.tbx>,tok:output tok:aeroDictionary_EN_FR_CH,tok:argument "TBX"^^xsd:string,tok:executedBy tok:nizar,tok:has_run_date "2014-08-25T01:00:00-05:00"^^xsd:dateTime,omv:description "import from TBX terminology to Concept Hierarchy"^^xsd:string,omv:name "TBX2CH"^^xsd:string,omv:keywords "TBX, CH, Concept, Hierarchy, import, service"^^xsd:string,tok:has_execution_priority ‘4’^^xsd:Integer...
Individual: importService_9Types: tok:Implementation_SourceFacts:omv:description: "Importer from OWL, RDF, RDFS, XML, SKOS, and ttl",tok:has_original_file <http://cui.unige.ch/isi/onto/usecase/aero.owl>...
Individual: enrichProcessAeroTypes: tok:Resources_Management_TaskFacts:process:composedOf tok:import_aero_OWL_CH,process:composedOf tok:import_aero_SKOS_CH,process:composedOf tok:import_aero_RDFS_CH,process:composedOf tok:import_aero_TBX_CH,process:composedOf tok:ConceptH_en.en_Aero_CH,process:composedOf tok:ConceptH_en.fr_Aero_CH,process:composedOf tok:merge_en.en_Aero_CH,process:composedOf tok:merge_en.en_Aero_CH,process:composedOf tok:exportAero_CH_OWL,omv:acronym ‘E_AERO_Onto’^^xsd:string,omv:description ‘import then enrich the aero.owl ontology’^^xsd:string,omv:documentation <http://cui.unige.ch/isi/onto/usecase/aeroProcess.pdf>,omv:name ‘Aero Ontology Process’^^xsd:string,process:computedOutput tok:aeroOnto_ext_CH,process:computedInput <http://cui.unige.ch/isi/usecase/aero.owl>,process:invocable ‘true’^^xsd:string,process:name tok:enrichProcessAero...
For example a resource importer within a model can be written as follows:

A.2. Importing the resources 177
public void import_CH(Ontology onto, AGGraphMaker maker) {try {
AGModel model = new AGModel(maker.createGraph(onto.getUri()));
// Comment - URIResource ConceptH = model.createResource(onto.getUri(),
TOKJena.Complex_Comment);
ConceptH.addProperty(TOKJena.hasURI, onto.getUri());
// Nameonto.setName(getNameConceptH(onto.getUri()));
ConceptH.addProperty(TOKJena.has_Name, onto.getName());
// TypeConceptH.addProperty(TOKJena.hasType, onto.getType());
// DomainConceptH.addProperty(OmvJena.hasDomain,onto.getCreation_Method());
// Operator ImportConceptH.addProperty(TOKJena.provenance, onto.getOrigin());
// Dateonto.setDateCreation(FunctionsJena.dateJena());
Literal datetime = model.createTypedLiteral(onto.getDateCreation(),XSDDatatype.XSDdateTime);ConceptH.addProperty(TOKJena.has_creation_date, datetime);
// Created FromConceptH.addProperty(TOKJena.created_from,onto.getCreated_from());
// Concepts usedfor (int i = 0; i < onto.getConcepts.size(); i++) {
ConceptH.addProperty(TOKJena.collection_of,onto.getConcepts().get(i));
}
// Links usedfor (int i = 0; i < onto.getConcepts.size(); i++) {
ConceptH.addProperty(TOKJena.contains,onto.getLinksForConcept(onto.getConcepts.get(i)));
}
model.setNsPrefix("TOK", uri + "#");

178 Appendix A. About some uses cases of the repository
...
...
...
} catch (Exception e) {System.out.println("Error\n (Cplx Import) : " + e.getMessage());System.exit(0);
}}

Appendix B
The TOK ontology
ContentsB.1 Potential usage of the TOK ontology . . . . . . . . . 179B.2 Classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181B.3 Object properties . . . . . . . . . . . . . . . . . . . . . 195B.4 Data properties . . . . . . . . . . . . . . . . . . . . . . 197
B.1 Potential usage of the TOK ontology
The main objective of our approach is to derive new resources from the com-bination of existing ones in the repository. These resources are instantiatedwithin the repository’s ontology (TOK_Onto). Based on the developed stor-age repository, we are able to generate, integrate, and reuse knowledge toproduce new resources in various formalisms.
Process
R
Resulting resource
Input
Output
Operator
Original ResourceRepository
Figure B.1: Resources generation using the proposed approach.
These practices help to create rules about associations between knowledgeengineering tasks and types of knowledge resources. As described in the

180 Appendix B. The TOK ontology
ontology, tasks are defined as sequences of combination operators. Theseoperators allow the user to simply generate the knowledge resources thatmeets his needs. The definition of the profile of these operators depends onthe treatment of the resources in the input. Multiple potential usages arepossible for the proposed ontology:
• TOK_Onto can be proposed as a recommendation or a standard forrepresenting heterogeneous knowledge resources;
• The ontology offers also the grounding for representing an storingknowledge engineering tools as processes or operators;
• The ontology is modular and each of its components is open for exten-sions;
• The ontology can also readapted and used for managing a social net-work about knowledge engineering methodologies. Organizing all thisknowledge about the field of semantic web and knowledge manage-ment will make it easier for scientists from this field to disseminate fortheir tools and approaches, share them and compare them with othermethodologies in order better reuse or compose them.
Each operator can be implemented in several ways depending on the na-ture of the involved resources and other parameters. These implementationsare used to build a framework that the user can browse to select operatorsor processes that satisfy the needs of specific knowledge engineering applica-tions.
The ontology can be extended by defining rules and axioms that canmodel each knowledge engineering task by specifying the corresponding rep-resentation or combination operators to involved in it. The steps of imple-menting these rules within the ontology are:
1. define a profile for each task using the operators model based on OWL-S;
2. examine the needs and define rules for linking to each task all thecandidate resources that can be used as input;
3. define an algebra or a language for composing the resources manage-ment and combination operators to construct a knowledge engineeringtask.

B.2. Classes 181
prefix tok:=http://cui.unige.ch/isi/onto/tok/TOK.owl#prefix xsd:=http://www.w3.org/2001/XMLSchema#
B.2 Classes
APIAPI v Implementation_Source
Abstract_ElementsAbstract_Elements v ∀ descrip-tion Datatype xsd:string
AlgorithmAlgorithm v Knowl-edge_Processing_Method
Align_ModelAlign_Model v Non_Logical_Approach
Align_Relation_SymbolAlign_Relation_Symbol v Sym-bol_Indicator
AlignmentAlignment v ∃ has_align_target Knowl-edge_ResourceAlignment v Enrichment_ResourceAlignmentv ∃ hasType Datatype xsd:stringAlignment v ∃ has_align_source Knowl-edge_ResourceAlignment v ∃ contains CorrespondenceAlignment v ∃ alignsBetween Knowl-edge_ResourceAlignment v ∃ has_Method Datatypexsd:string
AlignmentReferenceAlignmentReference v Con-cept_To_Concept
Alignment_EntityAlignment_Entity v Entity_Belonging
Alignment_RelationAlignment_Relation v Alignment_linksAlignment_Relation v ∃ has_symbolAlign_Relation_Symbol
Alignment_linksAlignment_links v Link_Entity
AnnotationAnnotation v Enrichment_Resource
Annotation v = annotates Knowl-edge_ResourceAnnotation v ≥ 1 anno-tates_using Knowledge_Resource
Annotation_ElementAnnotation_Element v Expres-sion_Entity
Annotation_EntityAnnotation_Entity v Entity_Belonging
ApplicationApplication v Knowl-edge_Engineering_Tool
ArgumentArgument v Argument_Elements
Argument_Elements
Associative_RelAssociative_Rel v Semantic_Relation
Autonomous_ResourceAutonomous_Resource v Knowl-edge_Resource
Axiom_RestrictionAxiom_Restriction v Expression_Entity
Bitext_ModelBitext_Model v Non_Logical_Approach
Classic_LogicClassic_Logic v Logical_Approach
Close_RelClose_Rel v Semantic_Relation
Combination_OperatorCombination_Operator v Re-sources_Management_Operator
Combination_TheoryCombination_Theory v Knowl-edge_Processing_Method
Combined_ResourceCombined_Resource v Knowl-edge_ResourceCombined_Resource v ≥ 1 contains En-richment_Resource u ≥ 1 contains Knowl-edge_Resource
Comparable_CorpusComparable_Corpus v Multilin-gual_Corpus

182 Appendix B. The TOK ontology
Complex_AlignmentComplex_Alignment v ∀ contains (Com-plex_Correspondence t Correspondence)Complex_Alignment v Alignment
Complex_CorrespondenceComplex_Correspondence v Correspon-denceComplex_Correspondence v ∃ tar-get_entity Expression_EntityComplex_Correspondence v∃ source_entity Expression_Entity
ComponentComponent v Knowl-edge_Engineering_Tool
Concept_Hierarchy_ModelConcept_Hierarchy_Model vNon_Logical_Approach
Concept_To_ConceptConcept_To_Concept v Link_Type
Concept_To_LexicalFormConcept_To_LexicalForm v Link_Type
Concept_To_ResourceConcept_To_Resource v Link_Type
Concept_To_TermConcept_To_Term v Link_Type
Conceptual_EntityConceptual_Entity v Node_Type
Conceptual_Graph_ModelConceptual_Graph_Model vNon_Logical_Approach
Connexional_ContextConnexional_Context v Context
ConstructorConstructor v ∃ argument Expres-sion_EntityConstructor v ∃ argument Re-source_EntityConstructor v ∃ argument VariableConstructor v Axiom_Restriction
ContextContext v Abstract_Elements
Controlled_IndexingControlled_Indexing v Index-ing_Operator
Corpora_EntityCorpora_Entity v Entity_Belonging
CorpusCorpus v ∀ has_size Datatype xsd:intCorpus v ∀ collection_of Knowl-edge_ResourceCorpus v ∀ has_timeCover Time_CoverCorpus v Autonomous_ResourceCorpus v ∃ has_register Lan-guage_Register
CorrespondenceCorrespondence v ∀ source_entity Re-source_EntityCorrespondence v = alignsBetween Re-source_EntityCorrespondence v ∀ confi-dence_measure Datatype xsd:floatCorrespondence v Expression_EntityCorrespondence v = alignRela-tion Meta_Alignment_RelationCorrespondence v ∀ target_entity Re-source_Entity
Correspondence_Alignment_RelationCorrespondence_Alignment_Relationv ∃ dis-junction_of Alignment_RelationCorrespondence_Alignment_Relation v∀ confidence_measure Datatype xsd:floatCorrespondence_Alignment_Relation v∃ has_symbol Align_Relation_SymbolCorrespondence_Alignment_Relation vAlignment_links
CrossReferenceCrossReference v Concept_To_Concept
DataType_PropertyDataType_Property v Re-source_Property
Database_Scheme_ModelDatabase_Scheme_Model vNon_Logical_Approach
Defined_ConceptDefined_Concept v Conceptual_EntityDefined_Concept v ¬ Primitif_Concept
Definition_EntityDefinition_Entity v Node_Type
Dempster_Shafer_TheoryDempster_Shafer_Theory v Combina-tion_Theory

B.2. Classes 183
Description_LogicDescription_Logic v Logical_Approach
DictionaryDictionary v Autonomous_Resource
Dictionnary_EntityDictionnary_Entity v Entity_Belonging
Disjoint_RelDisjoint_Rel v Logical_Relation
Doc_ModelDoc_Model v Non_Logical_Approach
DocumentDocument v ∀ has_index Term_EntityDocument v ∀ has_topic (Re-source_Domain t Topic)Document v Autonomous_Resource
Document_AbstractDocument_Abstract v Entity_Belonging
Document_EntityDocument_Entity v Entity_Belonging
Document_ModelDocument_Model v ≥ 1 indexes Knowl-edge_ResourceDocument_Model v Enrich-ment_Resource
Electronic_DocElectronic_Doc v Autonomous_Resource
Enrichment_OperatorEnrichment_Operator v Re-sources_Management_Operator
Enrichment_ResourceEnrichment_Resource v Knowl-edge_ResourceEnrichment_Resource v ∃ en-riches Knowledge_ResourceEnrichment_Resource v ∃ gener-ated_from Re-sources_Management_Operator
Entity_Belonging
Entity_ExtractionEntity_Extraction v Extrac-tion_Operator
Entity_Type
Equivalent_RelEquivalent_Rel v Logical_Relation
Equivalent_TermEquivalent_Term v Term_StatusEquivalent_Term v ¬ Generic_TermEquivalent_Termv ¬Non_Preferred_TermEquivalent_Term v ¬ Preferred_TermEquivalent_Term v ¬ Related_TermEquivalent_Term v ¬ Scope_NoteEquivalent_Term v ¬ Specific_TermEquivalent_Term v ¬ Generic_TermNon_Preferred_Term v ¬ Generic_TermPreferred_Term v ¬ Generic_TermRelated_Term v ¬ Generic_TermScope_Note v ¬ Generic_TermSpecific_Term v ¬ Generic_TermEquivalent_Termv ¬Non_Preferred_TermGeneric_Term v ¬ Non_Preferred_TermPreferred_Termv ¬Non_Preferred_TermRelated_Term v ¬ Non_Preferred_TermScope_Note v ¬ Non_Preferred_TermSpecific_Term v ¬ Non_Preferred_TermEquivalent_Term v ¬ Preferred_TermGeneric_Term v ¬ Preferred_TermNon_Preferred_Term v ¬ Pre-ferred_TermRelated_Term v ¬ Preferred_TermScope_Note v ¬ Preferred_TermSpecific_Term v ¬ Preferred_TermEquivalent_Term v ¬ Related_TermGeneric_Term v ¬ Related_TermNon_Preferred_Term v ¬ Related_TermPreferred_Term v ¬ Related_TermScope_Note v ¬ Related_TermSpecific_Term v ¬ Related_TermEquivalent_Term v ¬ Scope_NoteGeneric_Term v ¬ Scope_NoteNon_Preferred_Term v ¬ Scope_NotePreferred_Term v ¬ Scope_NoteRelated_Term v ¬ Scope_NoteSpecific_Term v ¬ Scope_NoteEquivalent_Term v ¬ Specific_TermGeneric_Term v ¬ Specific_TermNon_Preferred_Term v ¬ Specific_TermPreferred_Term v ¬ Specific_TermRelated_Term v ¬ Specific_TermScope_Note v ¬ Specific_Term
Existancial_QuantifierExistancial_Quantifier v Quantifier
Expression_EntityExpression_Entity v Resource_Entity
Extraction_Indexing

184 Appendix B. The TOK ontology
Extraction_Indexing v Index-ing_Operator
Extraction_OperatorExtraction_Operator v Re-sources_Management_Operator
Factual_ExpressionFactual_Expression v ∃ predi-cate Link_EntityFactual_Expression v ∃ object Re-source_EntityFactual_Expression v Expression_EntityFactual_Expression v ∃ subject Re-source_Entity
First_Order_LogicFirst_Order_Logic v Classic_Logic
Form_AlignForm_Align v Non_Logical_Approach
FormalityLevel
Frame_ModelFrame_Model v Non_Logical_Approach
Fuzzy_CompositionFuzzy_Composition v Fuzzy_Theory
Fuzzy_IntersectionFuzzy_Intersection v Fuzzy_Theory
Fuzzy_TheoryFuzzy_Theory v Knowl-edge_Processing_Method
Fuzzy_UnionFuzzy_Union v Fuzzy_Theory
Generic_TermGeneric_Term v Term_StatusGeneric_Term v ¬ Equivalent_TermNon_Preferred_Term v ¬ Equiva-lent_TermPreferred_Term v ¬ Equivalent_TermRelated_Term v ¬ Equivalent_TermScope_Note v ¬ Equivalent_TermSpecific_Term v ¬ Equivalent_TermGeneric_Term v ¬ Equivalent_TermGeneric_Term v ¬ Non_Preferred_TermGeneric_Term v ¬ Preferred_TermGeneric_Term v ¬ Related_TermGeneric_Term v ¬ Scope_NoteGeneric_Term v ¬ Specific_TermEquivalent_Termv ¬Non_Preferred_TermGeneric_Term v ¬ Non_Preferred_Term
Preferred_Termv ¬Non_Preferred_TermRelated_Term v ¬ Non_Preferred_TermScope_Note v ¬ Non_Preferred_TermSpecific_Term v ¬ Non_Preferred_TermEquivalent_Term v ¬ Preferred_TermGeneric_Term v ¬ Preferred_TermNon_Preferred_Term v ¬ Pre-ferred_TermRelated_Term v ¬ Preferred_TermScope_Note v ¬ Preferred_TermSpecific_Term v ¬ Preferred_TermEquivalent_Term v ¬ Related_TermGeneric_Term v ¬ Related_TermNon_Preferred_Term v ¬ Related_TermPreferred_Term v ¬ Related_TermScope_Note v ¬ Related_TermSpecific_Term v ¬ Related_TermEquivalent_Term v ¬ Scope_NoteGeneric_Term v ¬ Scope_NoteNon_Preferred_Term v ¬ Scope_NotePreferred_Term v ¬ Scope_NoteRelated_Term v ¬ Scope_NoteSpecific_Term v ¬ Scope_NoteEquivalent_Term v ¬ Specific_TermGeneric_Term v ¬ Specific_TermNon_Preferred_Term v ¬ Specific_TermPreferred_Term v ¬ Specific_TermRelated_Term v ¬ Specific_TermScope_Note v ¬ Specific_Term
GlossaryGlossary v Autonomous_ResourceGlossary v = restriction_of LexiconGlossary v ∀ collection_of Defini-tion_EntityGlossaryv ∀ has_size Datatype xsd:integerGlossary v ∀ has_title Datatype xsd:stringGlossary v = has_context Context
Glossary_EntityGlossary_Entity v Entity_Belonging
Hierarchical_RelHierarchical_Rel v Semantic_Relation
HierarchyHierarchy v Autonomous_ResourceHierarchy v ∃ hierarchyOf Term_Entity
HypertextHypertext v Autonomous_Resource
Hypertext_DocHypertext_Doc v Autonomous_Resource

B.2. Classes 185
Implementation_SourceImplementation_Source v Ab-stract_Elements
Index_EntityIndex_Entity v Entity_Belonging
Indexing_OperatorIndexing_Operator v Re-sources_Management_Operator
IndicatorIndicator v Symbol_Indicator
KnowledgeRepresentationParadigmKnowledgeRepresentationParadigm vNon_Logical_Approach
Knowledge_Engineering_MethodologyKnowledge_Engineering_Methodology v≤ 1 documentationKnowledge_Engineering_Methodology v∀ name Datatype xsd:stringKnowledge_Engineering_Methodology v∀ documentation Datatype xsd:stringKnowledge_Engineering_Methodology v≤ 1 descriptionKnowledge_Engineering_Methodology v≤ 1 acronymKnowledge_Engineering_Methodology v= nameKnowledge_Engineering_Methodology v∀ acronym Datatype xsd:stringKnowledge_Engineering_Methodology v∀ description Datatype xsd:stringKnowledge_Engineering_Methodology v∀ developedBy Party
Knowledge_Engineering_TaskKnowledge_Engineering_Task v∀ acronym Datatype xsd:stringKnowledge_Engineering_Task v≤ 1 descriptionKnowledge_Engineering_Task v∀ name Datatype xsd:stringKnowledge_Engineering_Task v∀ description Datatype xsd:stringKnowledge_Engineering_Task v= nameKnowledge_Engineering_Task v ≤ 1 doc-umentationKnowledge_Engineering_Task v≤ 1 acronym
Knowledge_Engineering_Task v ∀ docu-mentation Datatype xsd:stringKnowledge_Engineering_Task v ≥ 1 com-posedOf Process_Monitoring_Element
Knowledge_Engineering_ToolKnowledge_Engineering_Tool v ≤ 1 de-scriptionKnowledge_Engineering_Tool v ∀ de-scription Datatype xsd:stringKnowledge_Engineering_Tool v ∀ devel-opedBy PartyKnowledge_Engineering_Tool v = nameKnowledge_Engineering_Tool v ≤ 1 doc-umentationKnowledge_Engineering_Toolv ∀ acronymDatatype xsd:stringKnowledge_Engineering_Toolv≤ 1 acronymKnowledge_Engineering_Tool v ∀ nameDatatype xsd:stringKnowledge_Engineering_Tool v ∀ docu-mentation Datatype xsd:string
Knowledge_Processing_MethodKnowledge_Processing_Method v ∀ de-velopedBy PartyKnowledge_Processing_Method v ∀ refer-ence Datatype xsd:anyURIKnowledge_Processing_Method v ∃ argu-ment ThingKnowledge_Processing_Method v ∀ doc-umentation Datatype xsd:anyURIKnowledge_Processing_Method v∃ has_Method Datatype xsd:stringKnowledge_Processing_Method v ∃ de-scription Datatype xsd:stringKnowledge_Processing_Method v ∃ nameDatatype xsd:string
Knowledge_ResourceKnowledge_Resourcev ∀ has_language Nat-ural_LanguageKnowledge_Resource v ∀ knownUsageDatatype xsd:stringKnowledge_Resource v ≤ 1 modification-DateKnowledge_Resourcev ∃ has_original_fileDatatype xsd:anyURIKnowledge_Resource v ∃ annotat-edBy Knowledge_ResourceKnowledge_Resource v ≤ 1 status

186 Appendix B. The TOK ontology
Knowledge_Resource v ∃ in-volved_in_evolution_action Re-source_Evolution_ExecutionKnowledge_Resourcev ∃ used_in_processProcess_Monitoring_ElementKnowledge_Resource v ≤ 1 isOfT-ype ThingKnowledge_Resource v ≤ 1 hasFormal-ityLevel ThingKnowledge_Resource v ∀ notes Datatypexsd:stringKnowledge_Resource v ≤ 1 notesKnowledge_Resource v ∃ treat-edBy Knowledge_Engineering_ToolKnowledge_Resource v ∀ URI Datatypexsd:stringKnowledge_Resource v ∃ used_for_taskKnowledge_Engineering_TaskKnowledge_Resource v ∀ name Datatypexsd:stringKnowledge_Resourcev ∃ aligned_to Knowl-edge_ResourceKnowledge_Resourcev ∀ has_entitynumberDatatype xsd:integerKnowledge_Resource v ∀ hasDomain Re-source_DomainKnowledge_Resource v = URIKnowledge_Resource v = descriptionKnowledge_Resource v ∃ enriches Knowl-edge_ResourceKnowledge_Resource v ∀ key-Classes Datatype xsd:stringKnowledge_Resource v ∀ hasCre-ator PartyKnowledge_Resource v ∀ isOfType Re-sources_TypesKnowledge_Resource v ∀ resourceLoca-tor Datatype xsd:stringKnowledge_Resource v = acronymKnowledge_Resource v ∃ provenance Re-sources_Management_OperatorKnowledge_Resource v ∀ has_entity(Knowledge_Resource t Re-source_Entity)Knowledge_Resource v ∃ cre-ated_from Datatype xsd:stringKnowledge_Resource v ∀ sta-tus Datatype xsd:stringKnowledge_Resource v ∀ hasSyntax Re-source_Syntax
Knowledge_Resource v ∀ hasFormal-ityLevel FormalityLevelKnowledge_Resource v = versionKnowledge_Resource v ∀ hasContribu-tor PartyKnowledge_Resource v ∀ creation-Date Datatype xsd:stringKnowledge_Resourcev ∀ has_rep_languageRepresentation_LanguageKnowledge_Resource v ≤ 1 hasPriorVer-sion ThingKnowledge_Resource v ∀ key-words Datatype xsd:stringKnowledge_Resource v ∃ isBackward-CompatibleWith Knowledge_ResourceKnowledge_Resource v ≤ 1 hasLi-cense ThingKnowledge_Resource v ≥ 1 hasCre-ator ThingKnowledge_Resource v = resourceLocatorKnowledge_Resource v ∃ com-posedBy Knowledge_ResourceKnowledge_Resource v ∀ descrip-tion Datatype xsd:stringKnowledge_Resourcev ∀ acronym Datatypexsd:stringKnowledge_Resource v ∃ isIncompatible-With Knowledge_ResourceKnowledge_Resource v ∀ naturalLan-guage Datatype xsd:stringKnowledge_Resource v = creationDateKnowledge_Resource v ∀ useIm-ports Knowledge_ResourceKnowledge_Resource v ∀ hasPriorVer-sion Knowledge_ResourceKnowledge_Resource v ∀ hasLicense Li-censeModelKnowledge_Resource v ∀ ver-sion Datatype xsd:stringKnowledge_Resource v ≥ 1 nameKnowledge_Resource v ∀ documenta-tion Datatype xsd:stringKnowledge_Resource v ≤ 1 hasSyn-tax Resource_SyntaxKnowledge_Resource v ∀ en-dorsedBy PartyKnowledge_Resource v∃ has_representation_modelRepresentation_ModelKnowledge_Resource v ≤ 1 documenta-tion

B.2. Classes 187
Knowledge_Resource v ∀ modification-Date Datatype xsd:stringKnowledge_Resourcev ∀ linked_to Knowl-edge_Resource
Language_RegisterLanguage_Register v Abstract_ElementsLanguage_Register v ∀ related_to (Docu-ment t Topic)
LexicalForm_To_ConceptLexicalForm_To_Concept v Link_Type
LexicalForm_To_LexicalFormLexicalForm_To_LexicalFormv Link_Type
LexicalForm_To_ResourceLexicalForm_To_Resource v Link_Type
LexicalForm_To_termLexicalForm_To_term v Link_Type
Lexical_CategoryLexical_Category v Word_Class
Lexical_FormLexical_Form v Node_TypeLexical_Form v ∃ has_language Natu-ral_Language
LexiconLexicon v = has_language Natu-ral_LanguageLexicon v Autonomous_ResourceLexicon v ∀ has_size Datatype xsd:integerLexicon v ∀ related_to Terminology
LicenseModel
LinguisticLinguistic v Resources_Types
Linguistic_ContextLinguistic_Context v Context
Link_EntityLink_Entity v ∃ has_symbol Sym-bol_IndicatorLink_Entity v ∃ isOfType Link_TypeLink_Entity v ∀ hasDomainType (Knowl-edge_Resource t Resource_Entity)Link_Entity v ∃ isInverseOf Link_EntityLink_Entity v ∀ hasRangeType (Knowl-edge_Resource t Resource_Entity)Link_Entity v ∃ has_subRelationLink_Entity
Link_Entity v Resource_EntityLink_Entity v ∃ is_subRelationOfLink_Entity
Link_TypeLink_Type v Entity_Type
Logical_ApproachLogical_Approach v Representa-tion_ModelLogical_Approachv ¬Non_Logical_Approach
Logical_ExpressionLogical_Expression v = argument (Ax-iom_Restriction t Logi-cal_Expression t Node_Entity)Logical_Expressionv= uses_logical_operatorLogical_OperatorLogical_Expression v Expression_Entity
Logical_OperatorLogical_Operator v Abstract_Elements
Logical_RelationLogical_Relation v Link_Entity
Meta_Alignment_RelationMeta_Alignment_Relation v Align-ment_linksMeta_Alignment_Relation v ≥ 2 con-junction_of Correspon-dence_Alignment_Relation
Module_ExtractionModule_Extraction v Extrac-tion_Operator
Monolingual_CorpusMonolingual_Corpus v CorpusMonolingual_Corpusv= has_language Nat-ural_Language
More_General_RelMore_General_Rel v Logical_Relation
More_Specific_RelMore_Specific_Rel v Logical_Relation
Multilingual_CorpusMultilingual_Corpus v ∀ source_languageNatural_LanguageMultilingual_Corpus v ∀ tar-get_language Natural_LanguageMultilingual_Corpus v Corpus
Multiple_FormalismsMultiple_Formalisms v Resources_Types

188 Appendix B. The TOK ontology
Multiple_Restriction_ExpressionMultiple_Restriction_Expression v= uses_logical_operator Logi-cal_OperatorMultiple_Restriction_Expression v Ax-iom_RestrictionMultiple_Restriction_Expression v= argument (Multi-ple_Restriction_Expression t Sim-ple_Restriction_Expression)
Named_ConceptNamed_Concept v Defined_ConceptNamed_Concept v ¬ UnNamed_Concept
Natural_LanguageNatural_Language v Natural_Language
Natural_Language_ModelNatural_Language_Model vNon_Logical_Approach
Node_EntityNode_Entity v ∀ isOfType Node_TypeNode_Entity v = has_definition(Node_Entity u ∀ isOfType Defini-tion_Entity)Node_Entity v = has_natural_languageNatural_LanguageNode_Entity v ∀ descibes (Object t Re-source_Domain t Re-source_Entity t Topic)Node_Entity v Resource_EntityNode_Entity v ∀ provenance (Knowl-edge_Engineering_Task t Party)Node_Entityv ∃ has_label (Node_Entity u∀ isOfType (Lexi-cal_Form t Term_Entity))Node_Entity v ∀ has_context Context
Node_LinkNode_Link v Logical_Approach
Node_TypeNode_Type v Entity_Type
Non_Logical_ApproachNon_Logical_Approach v Representa-tion_ModelNon_Logical_Approach v ¬ Logi-cal_Approach
Non_Preferred_TermNon_Preferred_Term v Term_StatusGeneric_Term v ¬ Equivalent_Term
Non_Preferred_Term v ¬ Equiva-lent_TermPreferred_Term v ¬ Equivalent_TermRelated_Term v ¬ Equivalent_TermScope_Note v ¬ Equivalent_TermSpecific_Term v ¬ Equivalent_TermEquivalent_Term v ¬ Generic_TermNon_Preferred_Term v ¬ Generic_TermPreferred_Term v ¬ Generic_TermRelated_Term v ¬ Generic_TermScope_Note v ¬ Generic_TermSpecific_Term v ¬ Generic_TermNon_Preferred_Term v ¬ Equiva-lent_TermNon_Preferred_Term v ¬ Generic_TermNon_Preferred_Term v ¬ Pre-ferred_TermNon_Preferred_Term v ¬ Related_TermNon_Preferred_Term v ¬ Scope_NoteNon_Preferred_Term v ¬ Specific_TermEquivalent_Term v ¬ Preferred_TermGeneric_Term v ¬ Preferred_TermNon_Preferred_Term v ¬ Pre-ferred_TermRelated_Term v ¬ Preferred_TermScope_Note v ¬ Preferred_TermSpecific_Term v ¬ Preferred_TermEquivalent_Term v ¬ Related_TermGeneric_Term v ¬ Related_TermNon_Preferred_Term v ¬ Related_TermPreferred_Term v ¬ Related_TermScope_Note v ¬ Related_TermSpecific_Term v ¬ Related_TermEquivalent_Term v ¬ Scope_NoteGeneric_Term v ¬ Scope_NoteNon_Preferred_Term v ¬ Scope_NotePreferred_Term v ¬ Scope_NoteRelated_Term v ¬ Scope_NoteSpecific_Term v ¬ Scope_NoteEquivalent_Term v ¬ Specific_TermGeneric_Term v ¬ Specific_TermNon_Preferred_Term v ¬ Specific_TermPreferred_Term v ¬ Specific_TermRelated_Term v ¬ Specific_TermScope_Note v ¬ Specific_TermNon_Preferred_Term v ¬ Pre-ferred_Term
ObjectObject v Abstract_Elements
Object_Property

B.2. Classes 189
Object_Property v Resource_Property
OntologyOntology v Autonomous_Resource
OntologyDomainOntologyDomain v Resource_Domain
OntologyEngineeringMethodologyOntologyEngineeringMethodologyvKnowl-edge_Engineering_Methodology
OntologyEngineeringToolOntologyEngineeringTool v Knowl-edge_Engineering_Tool
OntologyLanguageOntologyLanguage v Representa-tion_Language
OntologySyntaxOntologySyntax v Resource_Syntax
OntologyTaskOntologyTask v Knowl-edge_Engineering_Task
OntologyTypeOntologyType v Resources_Types
Ontology_EntityOntology_Entity v Entity_Belonging
Overlap_RelOverlap_Rel v Logical_Relation
ParagraphParagraph v Text_Fragment
Parallel_CorpusParallel_Corpus v Multilingual_Corpus
Parameter_ElementParameter_Element v Argu-ment_Elements
PartOfSpeechPartOfSpeech v Word_Class
Party
Point_Of_ViewPoint_Of_View v ∀ acronymDatatype xsd:stringPoint_Of_View v ∀ key-words Datatype xsd:stringPoint_Of_View v Abstract_Elements
Preferred_Term
Preferred_Term v ∀ descibes Concep-tual_EntityPreferred_Term v Term_StatusGeneric_Term v ¬ Equivalent_TermNon_Preferred_Term v ¬ Equiva-lent_TermPreferred_Term v ¬ Equivalent_TermRelated_Term v ¬ Equivalent_TermScope_Note v ¬ Equivalent_TermSpecific_Term v ¬ Equivalent_TermEquivalent_Term v ¬ Generic_TermNon_Preferred_Term v ¬ Generic_TermPreferred_Term v ¬ Generic_TermRelated_Term v ¬ Generic_TermScope_Note v ¬ Generic_TermSpecific_Term v ¬ Generic_TermEquivalent_Termv ¬Non_Preferred_TermGeneric_Term v ¬ Non_Preferred_TermPreferred_Termv ¬Non_Preferred_TermRelated_Term v ¬ Non_Preferred_TermScope_Note v ¬ Non_Preferred_TermSpecific_Term v ¬ Non_Preferred_TermPreferred_Term v ¬ Equivalent_TermPreferred_Term v ¬ Generic_TermPreferred_Termv ¬Non_Preferred_TermPreferred_Term v ¬ Related_TermPreferred_Term v ¬ Scope_NotePreferred_Term v ¬ Specific_TermEquivalent_Term v ¬ Related_TermGeneric_Term v ¬ Related_TermNon_Preferred_Term v ¬ Related_TermPreferred_Term v ¬ Related_TermScope_Note v ¬ Related_TermSpecific_Term v ¬ Related_TermEquivalent_Term v ¬ Scope_NoteGeneric_Term v ¬ Scope_NoteNon_Preferred_Term v ¬ Scope_NotePreferred_Term v ¬ Scope_NoteRelated_Term v ¬ Scope_NoteSpecific_Term v ¬ Scope_NoteEquivalent_Term v ¬ Specific_TermGeneric_Term v ¬ Specific_TermNon_Preferred_Term v ¬ Specific_TermPreferred_Term v ¬ Specific_TermRelated_Term v ¬ Specific_TermScope_Note v ¬ Specific_TermPreferred_Termv ¬Non_Preferred_Term
Primitif_ConceptPrimitif_Concept v Conceptual_EntityPrimitif_Concept v ¬ Defined_Concept

190 Appendix B. The TOK ontology
Process_Monitoring_ElementProcess_Monitoring_Element v ∀ out-put Knowledge_ResourceProcess_Monitoring_Element v ∃ refer-ence Datatype xsd:anyURIProcess_Monitoring_Element v∃ uses_algorithm AlgorithmProcess_Monitoring_Element v ∃ de-scription Datatype xsd:stringProcess_Monitoring_Element v∀ has_run_date Datatype xsd:dateTimeProcess_Monitoring_Element v∀ uses_operator Re-sources_Management_OperatorProcess_Monitoring_Element v∀ uses_method Knowl-edge_Processing_MethodProcess_Monitoring_Element v ∀ argu-ment Datatype xsd:anyURIProcess_Monitoring_Element v ∀ in-put Knowledge_ResourceProcess_Monitoring_Element v∃ acronym Datatype xsd:stringProcess_Monitoring_Element v ∃ sta-tus Datatype xsd:stringProcess_Monitoring_Element v ∀ execut-edBy Party
Profile
Program_FileProgram_File v Implementation_Source
Proposition_LogicProposition_Logic v Classic_Logic
QuantifierQuantifier v Abstract_Elements
Reference_RelationReference_Relation v ∀ referred_to Hy-pertext_DocReference_Relation v Link_Entity
Related_TermRelated_Term v Term_StatusGeneric_Term v ¬ Equivalent_TermNon_Preferred_Term v ¬ Equiva-lent_TermPreferred_Term v ¬ Equivalent_TermRelated_Term v ¬ Equivalent_TermScope_Note v ¬ Equivalent_TermSpecific_Term v ¬ Equivalent_TermEquivalent_Term v ¬ Generic_Term
Non_Preferred_Term v ¬ Generic_TermPreferred_Term v ¬ Generic_TermRelated_Term v ¬ Generic_TermScope_Note v ¬ Generic_TermSpecific_Term v ¬ Generic_TermEquivalent_Termv ¬Non_Preferred_TermGeneric_Term v ¬ Non_Preferred_TermPreferred_Termv ¬Non_Preferred_TermRelated_Term v ¬ Non_Preferred_TermScope_Note v ¬ Non_Preferred_TermSpecific_Term v ¬ Non_Preferred_TermEquivalent_Term v ¬ Preferred_TermGeneric_Term v ¬ Preferred_TermNon_Preferred_Term v ¬ Pre-ferred_TermRelated_Term v ¬ Preferred_TermScope_Note v ¬ Preferred_TermSpecific_Term v ¬ Preferred_TermRelated_Term v ¬ Equivalent_TermRelated_Term v ¬ Generic_TermRelated_Term v ¬ Non_Preferred_TermRelated_Term v ¬ Preferred_TermRelated_Term v ¬ Scope_NoteRelated_Term v ¬ Specific_TermEquivalent_Term v ¬ Scope_NoteGeneric_Term v ¬ Scope_NoteNon_Preferred_Term v ¬ Scope_NotePreferred_Term v ¬ Scope_NoteRelated_Term v ¬ Scope_NoteSpecific_Term v ¬ Scope_NoteEquivalent_Term v ¬ Specific_TermGeneric_Term v ¬ Specific_TermNon_Preferred_Term v ¬ Specific_TermPreferred_Term v ¬ Specific_TermRelated_Term v ¬ Specific_TermScope_Note v ¬ Specific_Term
RepositoryRepository v Autonomous_Resource
Representation_LanguageRepresentation_Language v ThingRepresentation_Language v∀ has_documentation DocumentRepresentation_Language v ∀ descrip-tion Datatype xsd:stringRepresentation_Language v∀ name Datatype xsd:stringRepresentation_Language v ∀ develope-dBy PartyRepresentation_Language v∀ acronym Datatype xsd:string

B.2. Classes 191
Representation_Language v ∀ conform-sToKnowledgeRepresentation-Paradigm Representation_ModelRepresentation_Language v ∀ hasSyn-tax Resource_Syntax
Representation_ModelRepresentation_Model v∃ has_representation_generator Represen-tation_Operator
Representation_OperatorRepresentation_Operator v Re-sources_Management_Operator
Resource_ConstantResource_Constant v Node_Type
Resource_DomainResource_Domain v ∀ URI Datatypexsd:anyURIResource_Domain v Abstract_ElementsResource_Domain v ∀ isSubDo-mainOf Resource_DomainResource_Domain v ∀ name Datatypexsd:stringResource_Domain v ∀ dev-ided_to Point_Of_View
Resource_EntityResource_Entity v ∀ has_belonging_typeEntity_BelongingResource_Entity v ∀ description Datatypexsd:stringResource_Entity v ∀ name Datatypexsd:stringResource_Entity v ∃ is_subEntityOf Re-source_EntityResource_Entity v ∃ in-volved_in_expression Expression_EntityResource_Entity v ∀ URI Datatypexsd:stringResource_Entity v ∃ definedBy Re-source_EntityResource_Entity v ∃ has_subEntity Re-source_EntityResource_Entity v ∃ evolutes_in Re-sources_Evolution_ActionResource_Entity v ∀ isOfType En-tity_TypeResource_Entity v ∃ confi-dence Datatype xsd:doubleResource_Entity v ∃ associated_to Re-source_Entity
Resource_Evolution_ExecutionResource_Evolution_Execution v ∃ exe-cutedBy PartyResource_Evolution_Execution v ∀ evolu-tion_action Resources_Evolution_ActionResource_Evolution_Execution v∀ has_run_date Datatype xsd:dateTimeResource_Evolution_Execution v ∀ sta-tus Datatype xsd:stringResource_Evolution_Execution v ∀ docu-mentation Datatype xsd:anyURIResource_Evolution_Executionv ∀ acronymDatatype xsd:anyURIResource_Evolution_Execution v ∃ in-volves (Knowledge_Resource t Re-source_Entity)Resource_Evolution_Execution v ∀ en-dorsedBy PartyResource_Evolution_Execution v ∀ refer-ence Datatype xsd:anyURIResource_Evolution_Execution v∀ uses_operator Re-sources_Management_OperatorResource_Evolution_Execution v ∀ ap-plied_to Knowledge_ResourceResource_Evolution_Execution v ∀ de-scription Datatype xsd:string
Resource_ExportResource_Export v Representa-tion_Operator
Resource_ImportResource_Import v Representa-tion_Operator
Resource_IndividualResource_Individual v Node_Type
Resource_ItemResource_Item v Entity_Belonging
Resource_PropertyResource_Property v Link_Entity
Resource_SyntaxResource_Syntax v ∀ name Datatypexsd:stringResource_Syntax v ∀ acronym Datatypexsd:stringResource_Syntax v ThingResource_Syntax v ∀ descrip-tion Datatype xsd:stringResource_Syntax v ∀ developedBy Party

192 Appendix B. The TOK ontology
Resource_Syntax v ∀ has_documentationDocument
Resource_To_ConceptResource_To_Concept v Link_Type
Resource_To_LexicalFormResource_To_LexicalForm v Link_Type
Resource_To_ResourceResource_To_Resource v Link_Type
Resource_To_TermResource_To_Term v Link_Type
Resources_AggregationResources_Aggregation v Combina-tion_Operator
Resources_AlignmentResources_Alignment v Enrich-ment_Operator
Resources_AnnotationResources_Annotation v Enrich-ment_Operator u Indexing_Operator
Resources_CompositionResources_Composition v Combina-tion_Operator
Resources_DerivationResources_Derivation v Representa-tion_Operator
Resources_Evolution_ActionResources_Evolution_Action v ∃ nameDatatype xsd:stringResources_Evolution_Action v ∀ docu-mentation Datatype xsd:anyURIResources_Evolution_Action v ∀ refer-ence Datatype xsd:anyURIResources_Evolution_Action v ∀ acronymDatatype xsd:anyURIResources_Evolution_Action v ∃ descrip-tion Datatype xsd:stringResources_Evolution_Action v ∃ in-volves (Knowledge_Resource t Re-source_Entity)
Resources_IntersectionResources_Intersection v Combina-tion_Operator
Resources_Management_OperatorResources_Management_Operator v ∃ in-put Knowledge_Resource
Resources_Management_Operatorv ∀ key-words Datatype xsd:stringResources_Management_Operatorv ∃ out-put Knowledge_ResourceResources_Management_Operatorv ∀ nameDatatype xsd:stringResources_Management_Operator v∀ uses_method Knowl-edge_Processing_MethodResources_Management_Operator v Pro-fileResources_Management_Operator v ∀ de-scription Datatype xsd:stringResources_Management_Operator v ∃ ar-gument ObjectResources_Management_Operator v∀ uses_implementation Implementa-tion_SourceResources_Management_Operator v∀ uses_methodology Knowl-edge_Engineering_Methodology
Resources_MergeResources_Merge v Combina-tion_Operator
Resources_TranslationResources_Translation v Enrich-ment_Operator
Resources_Types
Resources_UnionResources_Union v Combina-tion_Operator
Role_To_RoleRole_To_Role v Link_Type
SKOS_ModelSKOS_Model v Non_Logical_Approach
Scenario_ModelScenario_ModelvNon_Logical_Approach
Scope_NoteScope_Note v Term_StatusGeneric_Term v ¬ Equivalent_TermNon_Preferred_Term v ¬ Equiva-lent_TermPreferred_Term v ¬ Equivalent_TermRelated_Term v ¬ Equivalent_TermScope_Note v ¬ Equivalent_TermSpecific_Term v ¬ Equivalent_TermEquivalent_Term v ¬ Generic_Term

B.2. Classes 193
Non_Preferred_Term v ¬ Generic_TermPreferred_Term v ¬ Generic_TermRelated_Term v ¬ Generic_TermScope_Note v ¬ Generic_TermSpecific_Term v ¬ Generic_TermEquivalent_Termv ¬Non_Preferred_TermGeneric_Term v ¬ Non_Preferred_TermPreferred_Termv ¬Non_Preferred_TermRelated_Term v ¬ Non_Preferred_TermScope_Note v ¬ Non_Preferred_TermSpecific_Term v ¬ Non_Preferred_TermEquivalent_Term v ¬ Preferred_TermGeneric_Term v ¬ Preferred_TermNon_Preferred_Term v ¬ Pre-ferred_TermRelated_Term v ¬ Preferred_TermScope_Note v ¬ Preferred_TermSpecific_Term v ¬ Preferred_TermEquivalent_Term v ¬ Related_TermGeneric_Term v ¬ Related_TermNon_Preferred_Term v ¬ Related_TermPreferred_Term v ¬ Related_TermScope_Note v ¬ Related_TermSpecific_Term v ¬ Related_TermScope_Note v ¬ Equivalent_TermScope_Note v ¬ Generic_TermScope_Note v ¬ Non_Preferred_TermScope_Note v ¬ Preferred_TermScope_Note v ¬ Related_TermScope_Note v ¬ Specific_TermEquivalent_Term v ¬ Specific_TermGeneric_Term v ¬ Specific_TermNon_Preferred_Term v ¬ Specific_TermPreferred_Term v ¬ Specific_TermRelated_Term v ¬ Specific_TermScope_Note v ¬ Specific_Term
Script_FileScript_File v Implementation_Source
SemanticSemantic v Resources_Types
Semantic_Network_ModelSemantic_Network_Model vNon_Logical_Approach
Semantic_RelationSemantic_Relation v Link_EntitySemantic_Relation v Semantic_Relation
SentenceSentence v Text_Fragment
Sentence_AlignSentence_AlignvNon_Logical_Approach
Sequence_EntitySequence_Entity v Node_Type
ServiceService v Knowledge_Engineering_Tool
Simple_AlignmentSimple_Alignment v AlignmentSimple_Alignment v ∀ contains Sim-ple_Correspondence
Simple_CorrespondenceSimple_Correspondence v Correspon-dence
Simple_Restriction_ExpressionSimple_Restriction_Expression v = on-Relation Link_EntitySimple_Restriction_Expressionv= on_Entity(Axiom_Restriction t Logi-cal_Expression t Node_Entity)Simple_Restriction_Expression v∃ uses_quantifier QuantifierSimple_Restriction_Expression v Ax-iom_Restriction
Situational_ContextSituational_Context v Context
Specific_Language_DomainSpecific_Language_Domain v Ab-stract_Elements
Specific_TermSpecific_Term v Term_StatusGeneric_Term v ¬ Equivalent_TermNon_Preferred_Term v ¬ Equiva-lent_TermPreferred_Term v ¬ Equivalent_TermRelated_Term v ¬ Equivalent_TermScope_Note v ¬ Equivalent_TermSpecific_Term v ¬ Equivalent_TermEquivalent_Term v ¬ Generic_TermNon_Preferred_Term v ¬ Generic_TermPreferred_Term v ¬ Generic_TermRelated_Term v ¬ Generic_TermScope_Note v ¬ Generic_TermSpecific_Term v ¬ Generic_TermEquivalent_Termv ¬Non_Preferred_TermGeneric_Term v ¬ Non_Preferred_TermPreferred_Termv ¬Non_Preferred_TermRelated_Term v ¬ Non_Preferred_Term

194 Appendix B. The TOK ontology
Scope_Note v ¬ Non_Preferred_TermSpecific_Term v ¬ Non_Preferred_TermEquivalent_Term v ¬ Preferred_TermGeneric_Term v ¬ Preferred_TermNon_Preferred_Term v ¬ Pre-ferred_TermRelated_Term v ¬ Preferred_TermScope_Note v ¬ Preferred_TermSpecific_Term v ¬ Preferred_TermEquivalent_Term v ¬ Related_TermGeneric_Term v ¬ Related_TermNon_Preferred_Term v ¬ Related_TermPreferred_Term v ¬ Related_TermScope_Note v ¬ Related_TermSpecific_Term v ¬ Related_TermEquivalent_Term v ¬ Scope_NoteGeneric_Term v ¬ Scope_NoteNon_Preferred_Term v ¬ Scope_NotePreferred_Term v ¬ Scope_NoteRelated_Term v ¬ Scope_NoteSpecific_Term v ¬ Scope_NoteSpecific_Term v ¬ Equivalent_TermSpecific_Term v ¬ Generic_TermSpecific_Term v ¬ Non_Preferred_TermSpecific_Term v ¬ Preferred_TermSpecific_Term v ¬ Related_TermSpecific_Term v ¬ Scope_Note
Symbol_Indicator
Syntactic_CategorySyntactic_Category v Word_Class
Term_EntityTerm_Entity v ∀ has_scope Scope_NoteTerm_Entity v Node_TypeTerm_Entity v ∃ has_part_of_speechWord_ClassTerm_Entityv ∃ has_status Term_StatusTerm_Entity v ∀ evolutes_in Re-source_DomainTerm_Entity v ≥ 1 has_lexicalForm Lex-ical_Form
Term_Status
Term_To_ConceptTerm_To_Concept v Link_Type
Term_To_LexicalFormTerm_To_LexicalForm v Link_Type
Term_To_ResourceTerm_To_Resource v Link_Type
Term_To_TermTerm_To_Term v Link_Type
TerminologicalTerminological v Resources_Types
TerminologyTerminology v ∀ collec-tion_of Term_EntityTerminology v ∀ applied_to Spe-cific_Language_DomainTerminology v Autonomous_Resource
Terminology_EntityTerminology_Entity v Entity_Belonging
Text_FragmentText_Fragment v Node_Type
ThesauriThesauri v ∀ structured_by SKOS_ModelThesauri v ∀ hierarchyOf (Concep-tual_Entity t Term_Entity)Thesauri v Autonomous_ResourceThesauri v ∀ has_definition Seman-tic_RelationThesauri v ∃ Document_Model Knowl-edge_ResourceThesauri v ∃ constants Resource_Entity
Thesaurus_EntityThesaurus_Entity v Entity_Belonging
Thing
Time_CoverTime_Cover v Abstract_Elements
TopicTopic v Abstract_Elements
UML_Diagram_ModelUML_Diagram_Model vNon_Logical_Approach
UnNamed_ConceptUnNamed_Concept v Defined_ConceptUnNamed_Concept v ¬ Named_Concept
Universal_QuantifierUniversal_Quantifier v Quantifier
VariableVariable v Argument_Elements
WN_LikeModelWN_LikeModelvNon_Logical_Approach
Web_Service

B.3. Object properties 195
Web_Service v Implementation_Source
WellFormed_CorpusWellFormed_Corpus v = has_timeCoverTime_CoverWellFormed_Corpusv= has_register Lan-guage_RegisterWellFormed_Corpus v CorpusWellFormed_Corpusv= has_language Nat-ural_LanguageWellFormed_Corpus v ≥ 1000 has_size
Word_Class
B.3 Object properties
Document_Model
alignRelation
aligned_to
alignsBetween
annotatedBytok:annotates ≡ tok:annotatedBy−
annotatestok:annotates ≡ tok:annotatedBy−
annotates_using
applied_to
argument
associated_to
belongsTotok:composedBy ≡ tok:belongsTo−
collection_of
composedBytok:composedBy ≡ tok:belongsTo−
composedOf
conformsToKnowledgeRepresentation-
Paradigmv has_representation_model
conjunction_of
constants
contains
definedBy
v topObjectProperty
definesv topObjectProperty
descibes
developedByv topObjectProperty
developsv topObjectProperty
devided_to
disjunction_ofv topObjectProperty
endorsedByv topObjectProperty
endorsesv topObjectProperty
enriches
evolutes_in
evolution_action
executedBy
generalization_ofv associated_to
generated_from
hasAffiliatedParty
hasContributor
hasCreator
hasDomainv topObjectProperty
hasDomainType
hasFormalityLevelv topObjectProperty
hasLicensev topObjectProperty
hasPriorVersionv topObjectProperty
hasRangeType
hasSyntax
hasValue
has_Indicator

196 Appendix B. The TOK ontology
tok:indicates ≡ tok:has_Indicator−
has_align_sourcetok:involved_in_alignment ≡tok:has_align_source−
has_align_targettok:involved_in_alignment ≡tok:has_align_target−
has_belonging_type
has_content
has_context
has_definition
has_documentation
has_entity
has_equivalent_lang
has_formalism
has_index
has_label
has_language
has_lexicalForm
has_natural_language
has_part_of_speech
has_point_of_view
has_register
has_rep_language
has_representation
has_representation_generator
has_representation_model
has_scope
has_status
has_subEntitytok:is_subEntityOf ≡tok:has_subEntity−
has_subRelationtok:is_subRelationOf ≡tok:has_subRelation−
has_symbol
has_timeCover
has_topic
hierarchyOf
indexes
indicatestok:indicates ≡ tok:has_Indicator−
input
involved_in_alignmenttok:involved_in_alignment ≡tok:has_align_target−
tok:involved_in_alignment ≡tok:has_align_source−
involved_in_evolution_action
involved_in_expression
involved_in_operation
involves
isBackwardCompatibleWith
isIncompatibleWith
isInverseOftok:isInverseOf ≡ tok:isInverseOf−
isLocatedAtv topObjectProperty
isOfType
isSubDomainOfv topObjectProperty
is_disjointWith
is_subEntityOftok:is_subEntityOf ≡ tok:has_subEntity−
is_subRelationOftok:is_subRelationOf≡ tok:has_subRelation−
linked_to
object
onRelation
on_Entity
output
predicate
provenance
referred_to
related_to

B.4. Data properties 197
restriction_of
source_entity
source_language
specification_ofv associated_to
structured_by
subject
target_entity
target_language
topObjectProperty
translation_ofv associated_to
treatedBy
useImportsv topObjectProperty
used_for_task
used_in_process
uses_algorithm
uses_implementation
uses_logical_operator
uses_method
uses_methodology
uses_operator
uses_quantifier
B.4 Data properties
URI
acronym
argument
confidence
confidence_measure
created_from
creationDate
description
documentation
hasType
has_Method
has_axiomnumberv has_entitynumber
has_conceptnumberv has_entitynumber
has_correspondancesnumberv has_entitynumber
has_entitynumberv topDataProperty
has_original_file
has_propertynumberv has_entitynumber
has_run_date
has_sentencenumberv has_entitynumber
has_size
has_termnumberv has_entitynumber
has_title
keyClasses
keywords
knownUsage
modificationDate
name
naturalLanguage
notes
reference
resourceLocator
status
topDataProperty
version


Bibliography
[Aamodt & Nygård 1995] Agnar Aamodt and Mads Nygård. Different rolesand mutual dependencies of data, information, and knowledge?an AIperspective on their integration. Data & Knowledge Engineering,vol. 16, no. 3, pages 191–222, 1995. (Cited on page 12.)
[Abbasbandy et al. 2006] S Abbasbandy, E Babolian and M Allame. Nu-merical solution of fuzzy max–min systems. Applied mathematicsand computation, vol. 174, no. 2, pages 1321–1328, 2006. (Cited onpage 126.)
[Ackoff 2010] Russell L Ackoff. From data to wisdom. Journal of appliedsystems analysis, vol. 16, pages 3–9, 2010. (Cited on page 12.)
[Aguirre et al. 2012] José Luis Aguirre, Bernardo Cuenca Grau, Kai Eck-ert, Jérôme Euzenat, Alfio Ferrara, Robert Willem van Hague, LauraHollink, Ernesto Jimenez-Ruiz, Christian Meilicke, Andriy Nikolov,Dominique Ritze, François Scharffe, Pavel Shvaiko, Ondrej Sváb-Zamazal, Cássia Trojahn and Benjamin Zapilko. Results of the Ontol-ogy Alignment Evaluation Initiative 2012. In Proc. 7th ISWC work-shop on ontology matching (OM), pages 73–115, Boston, États-Unis,2012. No commercial editor. aguirre2012a Infra-Seals. (Cited onpages 98 and 101.)
[Ajmi et al. 2012] Oumaima Ajmi, Nizar Ghoula and Gilles Falquet.Méthodologie de construction d’outil d’aide à la décision pour le choixde techniques d’alignement à travers les évaluations. 2012. (Cited onpages 7, 92 and 170.)
[Alavi & Leidner 2001] Maryam Alavi and Dorothy E Leidner. Review:Knowledge management and knowledge management systems: Con-ceptual foundations and research issues. MIS quarterly, pages 107–136, 2001. (Cited on page 12.)
[Auer et al. 2007] Sören Auer, Christian Bizer, Georgi Kobilarov, JensLehmann, Richard Cyganiak and Zachary Ives. Dbpedia: A nucleusfor a web of open data. Springer, 2007. (Cited on page 20.)
[Aussenac-Gilles et al. 2006] Nathalie Aussenac-Gilles, Anne Condaminesand Florence Sèdes. Evolution et maintenance des ressources termino-ontologique: une question à approfondir. Cépaduès, 2006. (Cited onpage 30.)

200 Bibliography
[Baader et al. 2005] Franz Baader, Ian Horrocks and Ulrike Sattler. Descrip-tion logics as ontology languages for the semantic web. In MechanizingMathematical Reasoning, pages 228–248. Springer, 2005. (Cited onpage 28.)
[Baclawski & Schneider 2009] Kenneth Baclawski and Todd Schneider. Theopen ontology repository initiative: Requirements and research chal-lenges. In Proceedings of Workshop on Collaborative Construction,Management and Linking of Structured Knowledge at the ISWC,2009. (Cited on page 18.)
[Badra et al. 2011] Fadi Badra, Sylvie Despres and Rim Djedidi. Ontologyand lexicon: the missing link. In Workshop Proceedings of the 9thInternational Conference on Terminology and Artificial Intelligence,pages 16–18, 2011. (Cited on page 30.)
[Basden 2002] Andrew Basden. The critical theory of Herman Dooyeweerd?Journal of Information Technology, vol. 17, no. 4, pages 257–269,2002. (Cited on page 44.)
[Beisswanger & Hahn 2012] Elena Beisswanger and Udo Hahn. Towardsvalid and reusable reference alignments: ten basic quality checks forontology alignments and their application to three different referencedata sets. Journal of Biomedical Semantics, vol. 3, no. 1, 2012. (Citedon page 143.)
[Berkes 2009] Fikret Berkes. Evolution of co-management: Role of knowl-edge generation, bridging organizations and social learning. Journalof environmental management, vol. 90, no. 5, pages 1692–1702, 2009.(Cited on page 63.)
[Bizer et al. 2009] Christian Bizer, Tom Heath and Tim Berners-Lee. Linkeddata-the story so far. International journal on semantic web and in-formation systems, vol. 5, no. 3, pages 1–22, 2009. (Cited on page 19.)
[Bodenreider 2004] Olivier Bodenreider. The unified medical language sys-tem (UMLS): integrating biomedical terminology. Nucleic acids re-search, vol. 32, no. suppl 1, pages D267–D270, 2004. (Cited onpage 150.)
[Bond & KYONGHEE 2012] Francis Bond and P KYONGHEE. A Surveyof WordNets and their Licenses. In Proceedings of the 6th Interna-tional Global WordNet Conference, pages 64–71, 2012. (Cited onpage 84.)

Bibliography 201
[Bouquet et al. 2003] Paolo Bouquet, Fausto Giunchiglia, Frank Van Harme-len, Luciano Serafini and Heiner Stuckenschmidt. C-OWL : Contex-tualizing ontologies. In Journal Of Web Semantics, pages 164–179.Springer Verlag, 2003. (Cited on page 101.)
[Bray et al. 1998] Tim Bray, Jean Paoli, C Michael Sperberg-McQueen, EveMaler and François Yergeau. Extensible markup language (XML).World Wide Web Consortium Recommendation REC-xml-19980210.http://www. w3. org/TR/1998/REC-xml-19980210, 1998. (Cited onpage 29.)
[Buitelaar et al. 2004] Paul Buitelaar, Thomas Eigner and Thierry Declerck.OntoSelect: A dynamic ontology library with support for ontology se-lection. In In Proceedings of the Demo Session at the InternationalSemantic Web Conference. Citeseer, 2004. (Cited on page 17.)
[Burstein et al. 2004] Mark Burstein, Jerry Hobbs, Ora Lassila, Drew Mc-dermott, Sheila Mcilraith, Srini Narayanan, Massimo Paolucci, BijanParsia, Terry Payne, Evren Sirinet al. OWL-S: Semantic markup forweb services. W3C Member Submission, 2004. (Cited on pages viii,60 and 62.)
[Buschmeier et al. 2010] Hendrik Buschmeier, Kirsten Bergmann and StefanKopp. Empirical methods in natural language generation. chapitreModelling and evaluation of lexical and syntactic alignment with apriming-based microplanner, pages 85–104. Springer-Verlag, Berlin,Heidelberg, 2010. (Cited on page 100.)
[Cailliau 2006] Frederik Cailliau. Un modèle pour unifier la gestion deressources linguistiques en contexte multilingue. In Piet Mertens, edi-teur, Verbum ex machina: actes de la 13e Conférence sur le Traite-ment Automatique des Langues Naturelles (TALN 2006) : Leuven.,pages 454–461. Presses univ. de Louvain, 2006, 2006. (Cited onpage 40.)
[Caracciolo et al. 2013] Caterina Caracciolo, Armando Stellato, Ahsan Mor-shed, Gudrun Johannsen, Sachit Rajbhandari, Yves Jaques and Jo-hannes Keizer. The agrovoc linked dataset. Semantic Web, vol. 4,no. 3, pages 341–348, 2013. (Cited on page 84.)
[Chan 1995] Lois Mai Chan. Library of congress subject headings: principlesand application. ERIC, 1995. (Cited on page 32.)

202 Bibliography
[Chein & Mugnier 1992] Michel Chein and Marie-Laure Mugnier. Concep-tual graphs: Fundamental notions. In Revue d’intelligence artificielle.Citeseer, 1992. (Cited on page 28.)
[Choi et al. 2006] Namyoun Choi, Il-Yeol Song and Hyoil Han. A survey onontology mapping. ACM Sigmod Record, vol. 35, no. 3, pages 34–41,2006. (Cited on page 76.)
[Chowdhury & Dou 2011] Nafisa Afrin Chowdhury and Dejing Dou. Im-proving the accuracy of ontology alignment through ensemble fuzzyclustering. In On the Move to Meaningful Internet Systems: OTM2011, pages 826–833. Springer, 2011. (Cited on page 116.)
[Collins-Thompson et al. 2014] Kevyn Collins-Thompson, Paul Bennett,Fernando Diaz, Charles L Clarke and Ellen M Voorhees. TREC 2013Web Track Overview. Rapport technique, DTIC Document, 2014.(Cited on page 35.)
[Corcho et al. 2004] Óscar Corcho, Asunción Gómez-Pérez, RafaelGonzález-Cabero and M Carmen Suárez-Figueroa. ODEval: atool for evaluating RDF (S), DAML+ OIL, and OWL concepttaxonomies. In Artificial Intelligence Applications and Innovations,pages 369–382. Springer, 2004. (Cited on page 29.)
[d’Aquin & Noy 2012] Mathieu d’Aquin and Natalya F Noy. Where to pub-lish and find ontologies? A survey of ontology libraries. Web Seman-tics: Science, Services and Agents on the World Wide Web, vol. 11,pages 96–111, 2012. (Cited on page 18.)
[d’Aquin et al. 2006] Mathieu d’Aquin, Marta Sabou and Enrico Motta.Modularization: a key for the dynamic selection of relevant knowl-edge components. 2006. (Cited on page 78.)
[d’Aquin et al. 2011] Mathieu d’Aquin, Li Ding and Enrico Motta. Semanticweb search engines. In Handbook of Semantic Web Technologies,pages 659–700. Springer, 2011. (Cited on pages vii and 17.)
[David et al. 2011] Jérôme David, Jérôme Euzenat, François Scharffe andCássia Trojahn dos Santos. The Alignment API 4.0. Semantic Web,vol. 2, no. 1, pages 3–10, 2011. (Cited on pages 98, 102, 103, 114and 116.)
[de Bruijn et al. 2004] Jos de Bruijn, F Martin-Recuerda, Dimitar Manovand Marc Ehrig. D4. 2.1 state-of-the-art-survey on ontology mergingand aligning v1. SEKT Project deliverable D, vol. 4, pages 2–1, 2004.(Cited on page 79.)

Bibliography 203
[De Jong & Ferguson-Hessler 1996] Ton De Jong and Monica GM Ferguson-Hessler. Types and qualities of knowledge. Educational psychologist,vol. 31, no. 2, pages 105–113, 1996. (Cited on page 12.)
[Delaporte & Amardeilh 2004] Gilles Delaporte and Florence Amardeilh.ITM et intelligence économique: MONDECA = ITM software andcompetitive intelligence:MONDECA. Veille stratégique scientifiqueet technologique, vol. 2, pages 365–366, 2004. (Cited on pages 38and 39.)
[Dempster 1967] A. P. Dempster. Upper and Lower Probabilities Inducedby a Multivalued Mapping. The Annals of Mathematical Statistics,vol. 38, no. 2, pages pp. 325–339, 1967. (Cited on page 123.)
[Dipper et al. 2006] Stefanie Dipper, Erhard Hinrichs, Thomas Schmidt, An-dreas Wagner and Andreas Witt. Sustainability of linguistic resources.In Proc. of the LREC 2006 Satellite Workshop Merging and LayeringLinguistic Information, pages 48–54, 2006. (Cited on page 35.)
[Doermann 1998] David Doermann. The indexing and retrieval of docu-ment images: A survey. Computer Vision and Image Understanding,vol. 70, no. 3, pages 287–298, 1998. (Cited on page 42.)
[Doerr & Fundulaki 1998] Martin Doerr and Irini Fundulaki. SIS-TMS: Athesaurus management system for distributed digital collections. InResearch and Advanced Technology for Digital Libraries, pages 215–234. Springer, 1998. (Cited on page 70.)
[Doran et al. 2007] Paul Doran, Valentina Tamma and Luigi Iannone. On-tology module extraction for ontology reuse: an ontology engineeringperspective. In CIKM ’07: Proceedings of the sixteenth ACM con-ference on Conference on information and knowledge management,pages 61–70, New York, NY, USA, 2007. ACM. (Cited on page 78.)
[Drakopoulos 1995] John A Drakopoulos. Probabilities, possibilities, andfuzzy sets. Fuzzy Sets and Systems, vol. 75, no. 1, pages 1–15, 1995.(Cited on page 120.)
[Euzenat & Shvaiko 2007a] Jérôme Euzenat and Pavel Shvaiko. Ontol-ogy matching. Springer-Verlag, Heidelberg (DE), 2007. (Cited onpages 43, 70 and 76.)
[Euzenat & Shvaiko 2007b] Jérôme Euzenat and Pavel Shvaiko. Ontologymatching. Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2007.(Cited on pages 76 and 98.)

204 Bibliography
[Euzenat & Valtchev 2003] Jérôme Euzenat and Petko Valtchev. An integra-tive proximity measure for ontology alignment. In Proc. ISWC-2003workshop on semantic information integration, Sanibel Island (FLUS), pages 33–38, 2003. (Cited on pages 98 and 99.)
[Euzenat et al. 2004] Jérôme Euzenat, David Loup, Mohamed Touzani andPetko Valtchev. Ontology Alignment with OLA. In In Proceedings ofthe 3rd EON Workshop, 3rd International Semantic Web Conference,pages 59–68. CEUR-WS, 2004. (Cited on page 101.)
[Euzenat 2004] Jérôme Euzenat. An API for Ontology Alignment. InSheilaA. McIlraith, Dimitris Plexousakis and Frank van Harmelen,editeurs, The Semantic Web Conference SWC 2004, volume 3298 ofLecture Notes in Computer Science, pages 698–712. Springer BerlinHeidelberg, 2004. (Cited on pages 100 and 114.)
[Euzenat 2007] Jérôme Euzenat. Semantic Precision and Recall for OntologyAlignment Evaluation. In Proceedings of the 20th International JointConference on Artifical Intelligence, IJCAI’07, pages 348–353, SanFrancisco, CA, USA, 2007. Morgan Kaufmann Publishers Inc. (Citedon pages 115 and 147.)
[Euzenat 2008] Jérôme Euzenat. Algebras of Ontology Alignment Relations.In Proceedings of the 7th International Conference on The SemanticWeb, ISWC ’08, pages 387–402, Berlin, Heidelberg, 2008. Springer-Verlag. (Cited on pages xi, 98, 117, 118, 119, 126, 142 and 169.)
[Fahey & Prusak 1998] Liam Fahey and Laurence Prusak. The eleven dead-liest sins of knowledge management. California management review,vol. 40, no. 3, page 265, 1998. (Cited on pages vii and 12.)
[Falquet et al. 2008] Gilles Falquet, Claire-Lise Mottaz Jiang and JacquesGuyot. Un modèle et une algèbre pour les systèmes de gestiond’ontologies. In EGC, pages 697–702, 2008. (Cited on page 60.)
[Fellbaum 1998] Christiane Fellbaum, editeur. Wordnet: An electronic lex-ical database. Language, Speech, and Communication. MIT Press,Cambridge, Mass., 1998. (Cited on pages 34, 35, 40 and 59.)
[Fensel et al. 2003] Dieter Fensel, Frank Van Harmelen and Ian Horrocks.OIL and DAML+ OIL: Ontology languages for the semantic web.Towards the Semantic Web: ontology-driven knowledge management,pages 11–31, 2003. (Cited on page 29.)

Bibliography 205
[Finin et al. 2005] Tim Finin, Li Ding, Rong Pan, Anupam Joshi, PranamKolari, Akshay Java and Yun Peng. Swoogle: Searching for knowledgeon the Semantic Web. In PROCEEDINGS OF THE NATIONALCONFERENCE ON ARTIFICIAL INTELLIGENCE, volume 20,page 1682. Menlo Park, CA; Cambridge, MA; London; AAAI Press;MIT Press; 1999, 2005. (Cited on page 17.)
[Foskett 1980] D. J. Foskett. Thesaurus. In A. Kent, H. Lancour and J. E.Daily, editeurs, Encyclopedia of Library and Information Science -Volume 30, pages 416–462. Marcel Dekker, New York, 1980. (Citedon page 33.)
[Fuhr 2001] Norbert Fuhr. Models in information retrieval. In Lectures oninformation retrieval, pages 21–50. Springer, 2001. (Cited on page 42.)
[Gaines 1978] Brian R. Gaines. Fuzzy and probability uncertainty logics. In-formation and Control, vol. 38, no. 2, pages 154 – 169, 1978. (Citedon page 120.)
[Gal et al. 2005] Avigdor Gal, Ateret Anaby-Tavor, Alberto Trombetta andDanilo Montesi. A framework for modeling and evaluating automaticsemantic reconciliation. The VLDB Journal?The International Jour-nal on Very Large Data Bases, vol. 14, no. 1, pages 50–67, 2005.(Cited on pages 116 and 120.)
[Gangemi & Presutti 2009] Aldo Gangemi and Valentina Presutti. Ontologydesign patterns. In Handbook on Ontologies, pages 221–243. Springer,2009. (Cited on page 30.)
[Gangemi et al. 1998] Aldo Gangemi, Domenico Pisanelli and Geri Steve.Ontology Integration: Experiences with Medical Terminologies. In. InNicola Guarino, editeur, Formal Ontology in Information Systems,pages 46–98. Ios Press, 1998. (Cited on page 31.)
[García-Silva et al. 2008] Andrés García-Silva, Asunción Gómez-Pérez,Mari Carmen Suárez-Figueroa and Boris Villazón-Terrazas. A Pat-tern Based Approach for Re-engineering Non-Ontological Resourcesinto Ontologies. In Proceedings of the 3rd Asian Semantic Web Con-ference on The Semantic Web, ASWC ’08, pages 167–181, Berlin,Heidelberg, 2008. Springer-Verlag. (Cited on pages 30 and 31.)
[Garshol 2004] Lars Marius Garshol. Metadata? Thesauri? Taxonomies?Topic maps! Making sense of it all. Journal of information science,vol. 30, no. 4, pages 378–391, 2004. (Cited on page 2.)

206 Bibliography
[Genesereth et al. 1992] Michael R Genesereth, Richard E Fikeset al. Knowl-edge interchange format-version 3.0: Reference manual. 1992. (Citedon page 28.)
[Ghoula & Falquet 2012] Nizar Ghoula and Gilles Falquet. Towards anontology based large repository for managing heterogeneous knowl-edge resources. In Ernesto Jiménez-Ruiz, Horacio Saggion, MaríaJosé Aramburu Cabo, Roxana Dánger, Antonio Jimeno-Yepes, ElenaLloret and Manuel Palomar, editeurs, Proceedings of the 2nd In-ternational Workshop on Exploiting Large Knowledge Repositories,Castellón de la Plana, Spain, September 7, 2012, volume 882 of CEURWorkshop Proceedings. CEUR-WS.org, 2012. (Cited on pages 7, 71and 92.)
[Ghoula et al. 2010a] Nizar Ghoula, Gilles Falquet and Jacques Guyot. Mod-èle d’entrepôt de ressources hétérogènes pour le traitement sémantiquedes documents. Revue Document Numérique, vol. 13, pages 97–124,September 2010. (Cited on pages 6, 48, 81 and 92.)
[Ghoula et al. 2010b] Nizar Ghoula, Gilles Falquet and Jacques Guyot. Tok:A meta-model and ontology for heterogeneous terminological, linguis-tic and ontological knowledge resources. In Web Intelligence and In-telligent Agent Technology (WI-IAT), 2010 IEEE/WIC/ACM Inter-national Conference on, volume 1, pages 297–301. IEEE, 2010. (Citedon pages 6, 48, 57 and 67.)
[Ghoula et al. 2010c] Nizar Ghoula, Gilles Falquet and Jacques Guyot.TOK: Une ontologie de ressources linguistiques, terminologiques etontologiques. In Michel Crampes, editeur, Actes des 21es JournéesFrancophones d’Ingénierie des Connaissances, Nimes, France, Juin8-11, 2010. (Cited on pages 6, 44 and 67.)
[Ghoula et al. 2011] Nizar Ghoula, Hélène de Ribaupierre, Camille Tardyand Gilles Falquet. Opérations sur des ressources hétérogènes dans unentrepôt de données à base d’ontologie. In Actes de la 4ème édition desJournées Francophones sur les Ontologies (JFO), Juin 22-23, pages203–216, Montréal, Canada, 2011. (Cited on pages 7, 91 and 92.)
[Ghoula et al. 2013] Nizar Ghoula, Herve Nindanga and Gilles Falquet. Ameta-model and ontology for managing heterogenous alignment re-sources. In IEEE/WIC/ACM International Joint Conferences on WebIntelligence (WI) and Intelligent Agent Technologies (IAT), 2013, vol-ume 3, pages 167–170. IEEE, 2013. (Cited on pages 7, 103 and 112.)

Bibliography 207
[Ghoula et al. 2014] Nizar Ghoula, Herve Nindanga and Gilles Falquet.Opérateurs de gestion des alignements de ressources de connaissanceshétérogènes. In Workshop SoWeDo’2014, IC’2014, At Clermont-Ferrand (France), 2014. (Cited on pages 7, 118 and 142.)
[Ghoula 2012] Nizar Ghoula. An ontology based repository for managingheterogeneous Knowledge resources. In Nathalie Aussenac-Gilles andNathalie Hernandez, editeurs, Proceedings of the EKAW 2012 PhDSymposium, (EKAW’12), 2012. (Cited on pages 6, 44 and 92.)
[Gilchrist 2003] Alan Gilchrist. Thesauri, taxonomies and ontologies–an et-ymological note. Journal of documentation, vol. 59, no. 1, pages 7–18,2003. (Cited on page 2.)
[Giunchiglia & Zaihrayeu 2009] Fausto Giunchiglia and Ilya Zaihrayeu.Lightweight ontologies. In Encyclopedia of Database Systems, pages1613–1619. Springer, 2009. (Cited on pages vii and 27.)
[Grau et al. 2008] Bernardo Cuenca Grau, Ian Horrocks, Yevgeny Kazakovand Ulrike Sattler. Modular reuse of ontologies: theory and practice.J. Artif. Int. Res., vol. 31, no. 1, pages 273–318, 2008. (Cited onpage 60.)
[Grau et al. 2013] Bernardo Cuenca Grau, Zlatan Dragisic, Kai Eckert,Jérôme Euzenat, Alfio Ferrara, Roger Granada, Valentina Ivanova,Ernesto Jiménez-Ruiz, Andreas Oskar Kempf, Patrick Lambrixet al.Results of the ontology alignment evaluation initiative 2013. In Proc.8th ISWC workshop on ontology matching (OM), pages 61–100, 2013.(Cited on pages 149, 151 and 152.)
[Gruber 1995] Thomas R. Gruber. Toward principles for the design of on-tologies used for knowledge sharing? Int. J. Hum.-Comput. Stud.,vol. 43, no. 5-6, pages 907–928, 1995. (Cited on page 27.)
[Guarino 1997] Nicola Guarino. Semantic matching: Formal ontological dis-tinctions for information organization, extraction, and integration. InInformation Extraction A Multidisciplinary Approach to an Emerg-ing Information Technology, pages 139–170. Springer, 1997. (Citedon page 2.)
[Gupta & Qi 1991] MM Gupta and J Qi. Theory of T-norms and fuzzy infer-ence methods. Fuzzy sets and systems, vol. 40, no. 3, pages 431–450,1991. (Cited on pages 136 and 137.)

208 Bibliography
[Guyot et al. 2010] Jacques Guyot, Gilles Falquet and Jacques Teller. Incre-mental development of a shared urban ontology: the Urbamet experi-ence. Formamente, 2010. (Cited on page 84.)
[Haase et al. 2004] Peter Haase, York Sure and Denny Vrandecic. OntologyManagement and Evolution–Survey, Methods and Prototype. 2004.(Cited on page 70.)
[Hafellner 1988] J Hafellner. Principles of classification and main taxonomicgroups. CRC handbook of lichenology, vol. 3, pages 41–52, 1988.(Cited on page 32.)
[Hartmann et al. 2005] Jens Hartmann, Y Sure, P Haase, R Palma andM del C Suárez-Figueroa. OMV–ontology metadata vocabulary. InISWC 2005 Workshop on Ontology Patterns for the Semantic Web.Citeseer, 2005. (Cited on page 40.)
[Hecht et al. 2014] Thomas Hecht, Patrice Buche, Juliette Dibie-Barthélemy, Liliana Ibanescu and Cássia Trojahn dos Santos.Alignement d’ontologies : exploitation des ontologies liées sur le webde données. In EGC’14, pages 23–34, 2014. (Cited on page 115.)
[Heflin & Hendler 2000] Jeff Heflin and James Hendler. Searching the webwith shoe. Defense Technical Information Center, 2000. (Cited onpage 29.)
[Heiler 1995] Sandra Heiler. Semantic interoperability. ACM Comput. Surv.,vol. 27, no. 2, pages 271–273, 1995. (Cited on page 67.)
[Hendler & Golbeck 2008] James Hendler and Jennifer Golbeck. Metcalfe’slaw, Web 2.0, and the Semantic Web. Web Semant., vol. 6, pages14–20, February 2008. (Cited on page 1.)
[Hepp 2008] Martin Hepp. Ontologies: State of the Art, Business Potential,and Grand Challenges. In Martin Hepp, Pieter De Leenheer, AldoDe Moor and York Sure, editeurs, Ontology Management, volume 7of Computing for Human Experience, pages 3–22. Springer US, 2008.(Cited on pages 14 and 70.)
[Heymans et al. 2008] Stijn Heymans, Li Ma, Darko Anicic, Zhilei Ma,Nathalie Steinmetz, Yue Pan, Jing Mei, Achille Fokoue, AdityaKalyanpur, Aaron Kershenbaumet al. Ontology reasoning with largedata repositories. In Ontology Management, pages 89–128. Springer,2008. (Cited on page 19.)

Bibliography 209
[Hirst 2009] Graeme Hirst. Ontology and the lexicon. In Handbook on on-tologies, pages 269–292. Springer, 2009. (Cited on page 30.)
[Hjerland 2003] Birger Hjerland. Fundamentals of knowledge organization.Knowledge organization, vol. 30, no. 2, pages 87–111, 2003. (Citedon page 11.)
[Hodge 2000] Gail Hodge. Systems of knowledge organization for digitallibraries: Beyond traditional authority files. ERIC, 2000. (Cited onpage 31.)
[Holsapple & Joshi 2001] Clyde W Holsapple and Kshiti D Joshi. Organiza-tional knowledge resources. Decision support systems, vol. 31, no. 1,pages 39–54, 2001. (Cited on page 26.)
[Horrocks et al. 2004] Ian Horrocks, Peter F Patel-Schneider, Harold Boley,Said Tabet, Benjamin Grosof and Mike Dean. SWRL: A SemanticWeb Rule Language Combining OWL and RuleML. 2004. (Cited onpage 101.)
[Isaac et al. 2009] Antoine Isaac, Shenghui Wang, Claus Zinn, HenkMatthezing, Lourens van der Meij and Stefan Schlobach. EvaluatingThesaurus Alignments for Semantic Interoperability in the LibraryDomain. IEEE Intelligent Systems, vol. 24, no. 2, pages 76–86, 2009.(Cited on page 99.)
[Jackendoff 1989] Ray Jackendoff. What is a Concept, that a Person MayGrasp It? 1. Mind & language, vol. 4, no. 1-2, pages 68–102, 1989.(Cited on page 41.)
[Jannink et al. 1998] Jan Jannink, Srinivasan Pichai, Danladi Verheijen andGio Wiederhold. Encapsulation and composition of ontologies. InProceedings of AAAI Workshop on AI & Information Integration,volume 1998, 1998. (Cited on page 79.)
[Jiménez-Ruiz & Grau 2011] Ernesto Jiménez-Ruiz and Bernardo CuencaGrau. LogMap: Logic-based and Scalable Ontology Matching. In Pro-ceedings of the 10th International Conference on The Semantic Web- Volume Part I, ISWC’11, pages 273–288, Berlin, Heidelberg, 2011.Springer-Verlag. (Cited on pages 143, 149, 155 and 166.)
[Jiménez-Ruiz et al. 2007] E. Jiménez-Ruiz, R. Berlanga, V. Nebot andI. Sanz. OntoPath: a language for retrieving ontology fragments.In Proceedings of the 2007 OTM Confederated international confer-ence on On the move to meaningful internet systems: CoopIS, DOA,

210 Bibliography
ODBASE, GADA, and IS - Volume Part I, OTM’07, pages 897–914,Berlin, Heidelberg, 2007. Springer-Verlag. (Cited on pages vii and 38.)
[Jiménez-Ruiz et al. 2011] Ernesto Jiménez-Ruiz, Bernardo Cuenca Grau,Ian Horrocks and Rafael Berlanga. Logic-based assessment of thecompatibility of UMLS ontology sources. Journal of biomedical se-mantics, vol. 2, no. 1, pages 1–16, 2011. (Cited on page 150.)
[Jovellanos 2003] Chito Jovellanos. Semantic and syntactic interoperability:in transactional systems. In EC ’03: Proceedings of the 4th ACMconference on Electronic commerce, pages 266–267, New York, NY,USA, 2003. ACM. (Cited on page 67.)
[Jupp et al. 2008] Simon Jupp, Sean Bechhofer and Robert Stevens. SKOSwith OWL: Don’t be Full-ish! In OWLED, volume 432, pages 2009–2,2008. (Cited on page 73.)
[Kalfoglou & Schorlemmer 2003] Yannis Kalfoglou and Marco Schorlemmer.Ontology mapping: the state of the art. Knowl. Eng. Rev., vol. 18,no. 1, pages 1–31, 2003. (Cited on pages 75 and 99.)
[Karp et al. 1999] Peter D Karp, Vinay K Chaudhri and Jerome Thomere.XOL: An XML-based ontology exchange language, 1999. (Cited onpage 29.)
[Kefi et al. 2006] Hassen Kefi, Brigitte Safar and Chantal Reynaud. Aligne-ment de taxonomies pour l’interrogation de sources d’informationhétérogènes. In Presses Universitaires François Rabelais, editeur,Quinzième congrès francophone Reconnaissance des Formes et In-telligence Artificielle (RFIA 2006), volume 2 of Sciences, Tech-nologie Informatique, page 126, Tours France, 2006. Laboratoired’Informatique de l’Université françois-Rabelais de Tours. (Cited onpage 99.)
[Kifer & Lausen 1989] Michael Kifer and Georg Lausen. F-logic: a higher-order language for reasoning about objects, inheritance, and scheme.In ACM SIGMOD Record, volume 18, pages 134–146. ACM, 1989.(Cited on page 28.)
[Kiryakov et al. 2004] Atanas Kiryakov, Borislav Popov, DamyanOgnyanoff, Dimitar Manov and Kirilov Miroslav Goranov. Se-mantic annotation, indexing, and retrieval. Journal of WebSemantics, vol. 2, pages 49–79, 2004. (Cited on pages 43 and 76.)

Bibliography 211
[Kiryakov et al. 2005] Atanas Kiryakov, Damyan Ognyanov and DimitarManov. OWLIM - A Pragmatic Semantic Repository for OWL. InWISE Workshops, pages 182–192, 2005. (Cited on pages vii, 2, 19and 39.)
[Klavans & Tzoukermann 1995] Judith Klavans and Evelyne Tzoukermann.Combining corpus and machine-readable dictionary data for buildingbilingual lexicons. Machine Translation, vol. 10, no. 3, pages 185–218,1995. (Cited on page 79.)
[Klein 2001] Michel Klein. Combining and relating ontologies: an analysis ofproblems and solutions. In IJCAI-2001 Workshop on ontologies andinformation sharing, pages 53–62, 2001. (Cited on page 79.)
[Klyne & Carroll 2006] Graham Klyne and Jeremy J Carroll. Resource de-scription framework (RDF): Concepts and abstract syntax. 2006.(Cited on page 29.)
[Koehn 2005] Philipp Koehn. Europarl: A parallel corpus for statistical ma-chine translation. In MT summit, volume 5, pages 79–86, 2005. (Citedon page 34.)
[Kohavi & Provost 1998] Ron Kohavi and Foster Provost. Glossary of terms.Machine Learning, vol. 30, no. 2-3, pages 271–274, 1998. (Cited onpage 32.)
[Kolbe et al. 2009] Thomas H Kolbe, Gerhard König, Claus Nagel andAlexandra Stadler. 3D-Geo-Database for CityGML, 2009. (Citedon page 84.)
[Korfhage 2008] Robert R Korfhage. Information storage and retrieval. 2008.(Cited on page 42.)
[Kutz et al. 2010] Oliver Kutz, Till Mossakowski and Dominik Lücke. Car-nap, Goguen, and the Hyperontologies: Logical Pluralism and Hetero-geneous Structuring in Ontology Design. Logica Universalis, vol. 4,no. 2, pages 255–333, 2010. (Cited on page 48.)
[Lambiotte & Ausloos 2005] Renaud Lambiotte and Marcel Ausloos. Collab-orative tagging as a tripartite network. CoRR, vol. abs/cs/0512090,2005. (Cited on page 33.)
[Laskowski 1987] Roman Laskowski. On the concept of the lexeme. Scando-Slavica, vol. 33, no. 1, pages 169–178, 1987. (Cited on page 34.)

212 Bibliography
[Lenat 1995] Douglas B Lenat. CYC: A large-scale investment in knowledgeinfrastructure. Communications of the ACM, vol. 38, no. 11, pages33–38, 1995. (Cited on page 28.)
[Liao 2003] Shu-hsien Liao. Knowledge management technologies and ap-plications?literature review from 1995 to 2002. Expert systems withapplications, vol. 25, no. 2, pages 155–164, 2003. (Cited on pages 3and 69.)
[Lin & Hovy 2003] Chin-Yew Lin and Eduard Hovy. Automatic evaluationof summaries using n-gram co-occurrence statistics. In Proceedings ofthe 2003 Conference of the North American Chapter of the Associa-tion for Computational Linguistics on Human Language Technology-Volume 1, pages 71–78. Association for Computational Linguistics,2003. (Cited on page 115.)
[Loetamonphong & Fang 2001] Jiranut Loetamonphong and Shu-CherngFang. Optimization of fuzzy relation equations with max-product com-position. Fuzzy Sets and Systems, vol. 118, no. 3, pages 509–517, 2001.(Cited on page 126.)
[Lowe & Barnett 1994] Henry J Lowe and G Octo Barnett. Understandingand using the medical subject headings (MeSH) vocabulary to performliterature searches. Jama, vol. 271, no. 14, pages 1103–1108, 1994.(Cited on page 32.)
[Łukasiewicz 1968] Jan Łukasiewicz. On three-valued logic. The Polish Re-view, pages 43–44, 1968. (Cited on page 137.)
[MacGregor & Bates 1987] Robert MacGregor and Raymond Bates. TheLoom Knowledge Representation Language. Rapport technique,DTIC Document, 1987. (Cited on page 29.)
[Macken et al. 2008] Lieve Macken, Els Lefever and Veronique Hoste.Linguistically-based sub-sentential alignment for terminology extrac-tion from a bilingual automotive corpus. In Proceedings of the 22ndInternational Conference on Computational Linguistics - Volume 1,COLING ’08, pages 529–536, Stroudsburg, PA, USA, 2008. Associa-tion for Computational Linguistics. (Cited on page 115.)
[Maedche & Staab 2001] Alexander Maedche and Steffen Staab. OntologyLearning for the Semantic Web. IEEE Intelligent Systems, vol. 16,no. 2, pages 72–79, March 2001. (Cited on page 31.)

Bibliography 213
[Mangeot et al. 2010] Mathieu Mangeot, Sereysethy Touchet al. MotÀMotproject: building a multilingual lexical system via bilingual dictionar-ies. SLTURL, 2010. (Cited on page 79.)
[Margolis & Laurence 2014] Eric Margolis and Stephen Laurence. Concepts.In Edward N. Zalta, editeur, The Stanford Encyclopedia of Philoso-phy. Spring 2014 édition, 2014. (Cited on page 13.)
[Markus 2001] M Lynne Markus. Toward a theory of knowledge reuse: Typesof knowledge reuse situations and factors in reuse success. Journal ofmanagement information systems, vol. 18, no. 1, pages 57–94, 2001.(Cited on page 26.)
[Marshall et al. 2006] Byron Marshall, Hsinchun Chen and Therani Mad-husudan. Matching knowledge elements in concept maps using a sim-ilarity flooding algorithm. Decision Support Systems, vol. 42, no. 3,pages 1290 – 1306, 2006. (Cited on page 102.)
[Mårtensson 2000] Maria Mårtensson. A critical review of knowledge man-agement as a management tool. Journal of knowledge management,vol. 4, no. 3, pages 204–216, 2000. (Cited on page 3.)
[Martínez et al. 1998] Raquel Martínez, Joseba Abaitua and Arantza Casil-las. Bitext correspondences through rich mark-up. In Proceedings ofthe 17th international conference on Computational linguistics - Vol-ume 2, COLING ’98, pages 812–818, Stroudsburg, PA, USA, 1998.Association for Computational Linguistics. (Cited on page 102.)
[Matusov et al. 2013] Eugene Matusov, Katherine von Dyuke and SohyunHan. Community of Learners: Ontological and non-ontologicalprojects. Outlines. Critical Practice Studies, vol. 14, no. 1, pages41–72, 2013. (Cited on page 30.)
[McCrae et al. 2011] John McCrae, Dennis Spohr and Philipp Cimiano.Linking lexical resources and ontologies on the semantic web withlemon. In The Semantic Web: Research and Applications, pages245–259. Springer, 2011. (Cited on page 30.)
[McGuinness et al. 2004] Deborah L McGuinness, Frank Van Harmelenet al.OWL web ontology language overview. W3C recommendation, vol. 10,no. 10, page 2004, 2004. (Cited on page 29.)
[Meilicke 2011] Christian Meilicke. Alignment incoherence in ontologymatching. PhD thesis, Universitätsbibliothek Mannheim, 2011.(Cited on page 150.)

214 Bibliography
[Miles et al. 2005] Alistair Miles, Brian Matthews, Michael Wilson and DanBrickley. SKOS core: simple knowledge organisation for the web. InInternational Conference on Dublin Core and Metadata Applications,pages pp–3, 2005. (Cited on page 40.)
[Mitra & Wiederhold 2004] Prasenjit Mitra and Gio Wiederhold. Anontology-composition algebra. In Handbook on ontologies, pages 93–113. Springer, 2004. (Cited on page 79.)
[Montiel-Ponsoda et al. 2008] Elena Montiel-Ponsoda, GuadalupeAguado de Cea, Asunción Gómez-Pérez and Wim Peters. ModellingMultilinguality in Ontologies. In Coling 2008: Companion volume:Posters, pages 67–70, Manchester, UK, August 2008. Coling 2008Organizing Committee. (Cited on page 40.)
[Moser 1998] Paul K. Moser. The theory of knowledge: A thematic intro-duction. Oxford University Press, 1998. (Cited on page 11.)
[Motta 1998] Enrico Motta. An overview of the OCML modelling language.In the 8th Workshop on Methods and Languages. Citeseer, 1998.(Cited on page 29.)
[Nédellec et al. 2010] Claire Nédellec, Wiktoria Golik, Sophie Aubin andRobert Bossy. Building large lexicalized ontologies from text: a usecase in automatic indexing of biotechnology patents. In Knowledge En-gineering and Management by the Masses, pages 514–523. Springer,2010. (Cited on page 30.)
[Nerima & Wehrli 2008] Luka Nerima and Eric Wehrli. Generating BilingualDictionaries by Transitivity. In LREC, 2008. (Cited on page 79.)
[Nguyen 2011] Van Nguyen. Ontologies and information systems: a litera-ture survey. 2011. (Cited on page 28.)
[Noy & Musen 2001] Natalya F. Noy and Mark A. Musen. Anchor-PROMPT: Using Non-Local Context for Semantic Matching. InWorkshop on Ontologies and Information Sharing at the SeventeenthInternational Joint Conference on Artificial Intelligence (IJCAI-2001), Seattle, WA, 2001. (Cited on page 99.)
[Noy & Musen 2003] Natalya F Noy and Mark A Musen. The PROMPTsuite: interactive tools for ontology merging and mapping. Interna-tional Journal of Human-Computer Studies, vol. 59, no. 6, pages 983–1024, 2003. (Cited on page 79.)

Bibliography 215
[Noy et al. 2008] Natalya Fridman Noy, Nigam Shah, Benjamin Dai,Michael Dorf, Nicholas Griffith, Clement Jonquet, Michael Montegut,Daniel L. Rubin, Cherie Youn and Mark A. Musen. BioPortal: A WebRepository for Biomedical Ontologies and Data Resources. In Inter-national Semantic Web Conference (Posters & Demos), 2008. (Citedon pages 2, 18 and 126.)
[Ogden & Richards 1927] CK Ogden and IA Richards. The Meaning ofMeaning (London, 1927), 1927. (Cited on pages vii and 13.)
[Otero & Campos 2010] Pablo Gamallo Otero and José Ramom Pichel Cam-pos. Automatic generation of bilingual dictionaries using intermedi-ary languages and comparable corpora. In Computational Linguis-tics and Intelligent Text Processing, pages 473–483. Springer, 2010.(Cited on page 79.)
[Ouksel & Sheth 1999] A. M. Ouksel and A. Sheth. Semantic interoperabilityin global information systems. SIGMOD Rec., vol. 28, no. 1, pages5–12, 1999. (Cited on page 67.)
[Pang et al. 2003] Bo Pang, Kevin Knight and Daniel Marcu. Syntax-basedalignment of multiple translations: extracting paraphrases and gener-ating new sentences. In Proceedings of the 2003 Conference of theNorth American Chapter of the Association for Computational Lin-guistics on Human Language Technology - Volume 1, NAACL ’03,pages 102–109, Stroudsburg, PA, USA, 2003. Association for Com-putational Linguistics. (Cited on page 100.)
[Parida et al. 1998] Laxmi Parida, Aris Floratos and Isidore Rigoutsos.MUSCA: an algorithm for constrained alignment of multiple data se-quences. GENOME INFORMATICS SERIES, pages 112–119, 1998.(Cited on page 114.)
[Pazienza & Stellato 2006] Maria Teresa Pazienza and Armando Stellato.Exploiting Linguistic Resources for building linguistically motivatedontologies in the Semantic Web. In Proceedings of OntoLex Work-shop, 2006. (Cited on page 34.)
[Peirce 1974] Charles Sanders Peirce. Collected papers of charles sanderspeirce, volume 5. Harvard University Press, 1974. (Cited on page 40.)
[Pesquita et al. 2013] Catia Pesquita, Daniel Faria, Emanuel Santos andFrancisco M Couto. To repair or not to repair: reconciling correctnessand coherence in ontology reference alignments. In OM, pages 13–24,2013. (Cited on page 150.)

216 Bibliography
[Peters & Stock 2007] Isabella Peters and Wolfgang G Stock. Folksonomyand information retrieval. Proceedings of the American Society forInformation Science and Technology, vol. 44, no. 1, pages 1–28, 2007.(Cited on page 33.)
[Picca et al. 2008] Davide Picca, Alfio Massimiliano Gliozzo and AldoGangemi. LMM: an OWL-DL MetaModel to Represent Heteroge-neous Lexical Knowledge. In LREC. European Language ResourcesAssociation, 2008. (Cited on pages vii and 40.)
[Pinto & Martins 2001] Helena Sofia Pinto and Joâo P. Martins. A method-ology for ontology integration. In K-CAP’01:Proceedings of the 1stinternational conference on Knowledge capture, pages 131–138, NewYork, NY, USA, 2001. ACM. (Cited on page 79.)
[Pooch & Nieder 1973] Udo W Pooch and Al Nieder. A survey of indexingtechniques for sparse matrices. ACM Computing Surveys (CSUR),vol. 5, no. 2, pages 109–133, 1973. (Cited on page 42.)
[Porello & Endriss 2011] Daniele Porello and Ulle Endriss. Ontology mergingas social choice. In Computational Logic in Multi-Agent Systems,pages 157–170. Springer, 2011. (Cited on page 79.)
[Portilla et al. 2000] MI Portilla, P Burillo and ML Eraso. Properties ofthe fuzzy composition based on aggregation operators. Fuzzy sets andsystems, vol. 110, no. 2, pages 217–226, 2000. (Cited on page 126.)
[Pottebaum et al. 2007] Jens Pottebaum, Stasinos Konstantopoulos, RainerKoch and Georgios Paliouras. SaR resource management based on de-scription logics. In MobileResponse’07: Proceedings of the 1st inter-national conference on Mobile information technology for emergencyresponse, pages 61–70, Berlin, Heidelberg, 2007. Springer-Verlag.(Cited on page 70.)
[Predoiu et al. 2005] Livia Predoiu, Cristina Feier, Francois Scharffe, Josde Bruijn, F Martin-Recuerda, Dimitar Manov and Marc Ehrig. D4.2.2 State-of-the-art survey on Ontology Merging and Aligning V2.EU-IST Integrated Project IST-2003-506826 SEKT, 2005. (Cited onpage 79.)
[Raúl et al. 2006] Palma Raúl, Hartmann Jens, Gómez-Pérez Asunción,Sure York, Haase Peter, Suárez-Figueroa Mari del Carmen and StuderRudi. Towards an Ontology Metadata Standard. In Poster at 3rdEuropean Semantic Web Conference, ESWC 2006, 2006. (Cited onpages vii, 35 and 36.)

Bibliography 217
[Reymonet et al. 2007] Axel Reymonet, Jérôme Thomas, NathalieAussenac-Gilleset al. Modélisation de ressources termino-ontologiquesen owl. Actes des Journées Francophones d’Ingénierie des Connais-sances (IC 2007), pages 169–180, 2007. (Cited on page 30.)
[Ribeiro & Muntz 1996] Berthier AN Ribeiro and Richard Muntz. A beliefnetwork model for IR. In Proceedings of the 19th annual internationalACM SIGIR conference on Research and development in informationretrieval, pages 253–260. ACM, 1996. (Cited on page 42.)
[Roche et al. 2009] Christophe Roche, Marie Calberg-Challot, Luc Damasand Philippe Rouard. Ontoterminology - A New Paradigm for Termi-nology. In Jan L. G. Dietz, editeur, KEOD, pages 321–326. INSTICCPress, 2009. (Cited on page 116.)
[Rosch 1999] Eleanor Rosch. Principles of categorization. Concepts: corereadings, pages 189–206, 1999. (Cited on page 32.)
[Sabou et al. 2007a] Marta Sabou, Sofia Angeletou, Mathieu d?Aquin, Je-sus Barrasa, Klaas Dellschaft, Aldo Gangemi, Jos Lehmann, HolgerLewen, Diana Maynard, Dunja Mladenicet al. D2. 2.1 methods forselection and integration of reusable components from formal or in-formal user specifications. NeOn Project Deliverable D, vol. 2, 2007.(Cited on page 31.)
[Sabou et al. 2007b] Marta Sabou, Martin Dzbor, Claudio Baldassarre, SofiaAngeletou and Enrico Motta. WATSON: A Gateway for the SemanticWeb. In Poster session of the European Semantic Web Conference,ESWC, 2007. (Cited on page 2.)
[Salton et al. 1975] Gerard Salton, Anita Wong and Chung-Shu Yang. Avector space model for automatic indexing. Communications of theACM, vol. 18, no. 11, pages 613–620, 1975. (Cited on page 42.)
[Sattler et al. 2009] Ulrike Sattler, Thomas Schneider and Michael Za-kharyaschev. Which kind of module should I extract? DescriptionLogics, vol. 477, 2009. (Cited on page 78.)
[Scharl et al. 2012] Arno Scharl, Marta Sabou and Michael Föls. Climatequiz: a web application for eliciting and validating knowledge fromsocial networks. In Proceedings of the 18th Brazilian symposiumon Multimedia and the web, pages 189–192. ACM, 2012. (Cited onpage 3.)
[Schreiber 2000] Guus Schreiber. Knowledge engineering and management:the commonkads methodology. MIT press, 2000. (Cited on page 3.)

218 Bibliography
[Seidenberg & Rector 2006] Julian Seidenberg and Alan Rector. In WWW’06: Proceedings of the 15th international conference on World WideWeb, pages 13–22, New York, NY, USA, 2006. ACM. (Cited onpage 71.)
[Shadbolt et al. 2006] Nigel Shadbolt, Tim Berners-Lee and Wendy Hall.The Semantic Web Revisited. IEEE Intelligent Systems, vol. 21, no. 3,pages 96–101, July 2006. (Cited on page 16.)
[Shafer 1976] G. Shafer. A mathematical theory of evidence. PrincetonUniversity Press, 1976. (Cited on page 123.)
[Shvaiko & Euzenat 2005] Pavel Shvaiko and Jérôme Euzenat. A survey ofschema-based matching approaches. In Journal on Data SemanticsIV, pages 146–171. Springer, 2005. (Cited on pages 70 and 76.)
[Shvaiko & Euzenat 2013] Pavel Shvaiko and Jérôme Euzenat. OntologyMatching: State of the Art and Future Challenges. IEEE Trans.Knowl. Data Eng., vol. 25, no. 1, pages 158–176, 2013. (Cited onpages 98, 99, 102 and 125.)
[Shvaiko et al. 2006] Pavel Shvaiko, Fausto Giunchiglia, Marco Schorlem-mer, Fiona McNeill, Alan Bundy, Maurizio Marchese, Mikalai Yatske-vich, Ilya Zaihrayeu, Bo Ho, Vanessa Lopezet al. OpenKnowledgeDeliverable 3.1.: Dynamic ontology matching: a survey. 2006. (Citedon page 3.)
[Somers 2003] Harold Somers. Translation memory systems. BenjaminsTranslation Library, vol. 35, pages 31–48, 2003. (Cited on page 56.)
[Souza et al. 2005] Ligiane A Souza, Clodoveu A Davis, Karla AV Borges,Tiago M Delboni and Alberto HF Laender. The role of gazetteersin geographic knowledge discovery on the web. In Web Congress,2005. LA-WEB 2005. Third Latin American, pages 9–pp. IEEE, 2005.(Cited on page 32.)
[Sowa 2006] John F Sowa. Semantic networks. Encyclopedia of CognitiveScience, 2006. (Cited on pages 28 and 33.)
[Stephan et al. 2007] Grimm Stephan, Hitzler Pascal and Abecker Andreas.Knowledge Representation and Ontologies. In Rudi Studer, StephanGrimm and Andreas Abecker, editeurs, Semantic Web Services, pages51–105. Springer Berlin Heidelberg, 2007. (Cited on pages vii, 14, 15,16 and 28.)

Bibliography 219
[Stevens 1970] Mary Elizabeth Stevens. Automatic Indexing: A State-of-the-Art Report. 1970. (Cited on page 42.)
[Stojanovic 2004] Ljiljana Stojanovic. Methods and tools for ontology evolu-tion. 2004. (Cited on page 63.)
[Strassel et al. 2008] Stephanie Strassel, Mark A Przybocki, Kay Peterson,Zhiyi Song and Kazuaki Maeda. Linguistic Resources and EvaluationTechniques for Evaluation of Cross-Document Automatic Content Ex-traction. In LREC, 2008. (Cited on page 34.)
[Strijbos & Basden 2006] Sytse Strijbos and Andrew Basden. In search ofan integrative vision for technology: interdisciplinary studies in in-formation systems. Springer, 2006. (Cited on pages 43 and 44.)
[Stuckenschmidt et al. 2004] H. Stuckenschmidt, F. van Harmelen L. Ser-afini, Heiner Stuckenschmidt, F. Giunchiglia, Frank Van Harmelen,P. Bouquet, Fausto Giunchiglia and Luciano Serafini. Using C-OWLfor the Alignment and Merging of Medical Ontologies. In In FirstInternational Workshop on formal Biomedical Knowledge Represen-tation. Collocated with KR 2004, 2004. (Cited on page 101.)
[Studer et al. 1999] Rudi Studer, Dieter Fensel, Stefan Decker andV Richard Benjamins. Knowledge engineering: survey and futuredirections. Springer, 1999. (Cited on page 69.)
[Suchanek et al. 2007] Fabian Suchanek, Gjergji Kasneci and GerhardWeikum. YAGO: A Core of Semantic Knowledge - Unifying Word-Net and Wikipedia. In Carey L. Williamson, Mary Ellen Zurko andPrashant J. Patel-Schneider Peter F. Shenoy, editeurs, 16th Interna-tional World Wide Web Conference (WWW 2007), pages 697–706,Banff, Canada, 2007. ACM. (Cited on pages 34, 40 and 99.)
[Toral & Munoz 2006] Antonio Toral and Rafael Munoz. A proposal to auto-matically build and maintain gazetteers for Named Entity Recognitionby using Wikipedia. NEW TEXT Wikis and blogs and other dynamictext sources, vol. 56, 2006. (Cited on page 32.)
[Tudhope et al. 2006] Douglas Tudhope, Traugott Koch and Rachel Heery.Terminology services and technology: JISC state of the art review.2006. (Cited on page 32.)
[Tuomi 1999] Ilkka Tuomi. Data is more than knowledge: Implications of thereversed knowledge hierarchy for knowledge management and organi-zational memory. In Systems Sciences, 1999. HICSS-32. Proceedings

220 Bibliography
of the 32nd Annual Hawaii International Conference on, pages 12–pp.IEEE, 1999. (Cited on page 12.)
[Turing 1950] Alan M Turing. Computing machinery and intelligence. Mind,pages 433–460, 1950. (Cited on page 33.)
[Tzitzikas et al. 2007] Yannis Tzitzikas, Anastasia Analyti, Nicolas Spyratosand Panos Constantopoulos. An algebra for specifying valid compoundterms in faceted taxonomies. Data Knowl. Eng., vol. 62, no. 1, pages1–40, 2007. (Cited on pages 70 and 76.)
[Uchida & Zhu 2001] Hiroshi Uchida and Meiying Zhu. The universal net-working language beyond machine translation. In International Sym-posium on Language in Cyberspace, Seoul, pages 26–27, 2001. (Citedon page 84.)
[Uren et al. 2006] Victoria Uren, Philipp Cimiano, José Iria, Siegfried Hand-schuh, Maria Vargas-Vera, Enrico Motta and Fabio Ciravegna. Se-mantic Annotation for Knowledge Management: Requirements and aSurvey of the State of the Art. Web Semant., vol. 4, no. 1, pages14–28, January 2006. (Cited on pages 43 and 76.)
[Uschold & Gruninger 2004] Michael Uschold and Michael Gruninger. On-tologies and Semantics for Seamless Connectivity. SIGMOD Rec.,vol. 33, no. 4, pages 58–64, December 2004. (Cited on pages viiand 27.)
[Van Assem et al. 2006] Mark Van Assem, Véronique Malaisé, Alistair Milesand Guus Schreiber. A method to convert thesauri to skos. Springer,2006. (Cited on page 73.)
[Vandenbussche & Charlet 2009] Pierre-Yves Vandenbussche and JeanCharlet. Méta-modèle général de description de ressources termi-nologiques et ontologiques. In Fabien L. Gandon, editeur, Actes d’IC,pages 193–204. PUG, 2009. (Cited on pages vii, 38 and 39.)
[Vaníček et al. 2009] J Vaníček, I Vrana and S Aly. Fuzzy aggregation andaveraging for group decision making: A generalization and survey.Knowledge-Based Systems, vol. 22, no. 1, pages 79–84, 2009. (Citedon page 78.)
[Villazón-Terrazas et al. 2010a] Boris Villazón-Terrazas, María del CarmenSuárez-Figueroa and Asunción Gómez-Pérez. A Pattern-BasedMethod for Re-Engineering Non-Ontological Resources into Ontolo-gies. Int. J. Semantic Web Inf. Syst., vol. 6, no. 4, pages 27–63, 2010.(Cited on pages vii, viii, 37, 74 and 75.)

Bibliography 221
[Villazón-Terrazas et al. 2010b] Boris Villazón-Terrazas, Mari CarmenSuárez-Figueroa and Asunción Gómez-Pérez. A pattern-based methodfor re-engineering non-ontological resources into ontologies. Interna-tional Jounal on Semantic Web and Information Systems, vol. 6, no. 4,pages 27–63, 2010. (Cited on pages 27, 31 and 75.)
[Wache et al. 2001] Holger Wache, Thomas Voegele, Ubbo Visser, HeinerStuckenschmidt, Gerhard Schuster, Holger Neumann and SebastianHübner. Ontology-based integration of information-a survey of ex-isting approaches. In IJCAI-01 workshop: ontologies and informa-tion sharing, volume 2001, pages 108–117. Citeseer, 2001. (Cited onpage 30.)
[Wallis & Nelson 2001] Sean Wallis and Gerald Nelson. Knowledge Discov-ery in Grammatically Analysed Corpora. Data Mining and KnowledgeDiscovery, vol. 5, no. 4, pages 305–335, 2001. (Cited on page 43.)
[Wang et al. 2007] Yimin Wang, Peter Haase and Jie Bao. A Survey of For-malisms for Modular Ontologies. In International Joint Conferenceon Artificial Intelligence 2007 (IJCAI’07) Workshop SWeCKa, Hy-derabad, India, JAN 2007. (Cited on page 27.)
[Wehrli et al. 2009] Eric Wehrli, Luka Nerima and Yves Scherrer. Deep lin-guistic multilingual translation and bilingual dictionaries. In Pro-ceedings of the Fourth Workshop on Statistical Machine Translation,StatMT ’09, pages 90–94, Stroudsburg, PA, USA, 2009. Associationfor Computational Linguistics. (Cited on page 115.)
[Wielinga et al. 1992] Bob J Wielinga, A Th Schreiber and Jost A Breuker.KADS: A modelling approach to knowledge engineering. Knowledgeacquisition, vol. 4, no. 1, pages 5–53, 1992. (Cited on page 3.)
[Wimalasuriya & Dou 2010] Daya C Wimalasuriya and Dejing Dou.Ontology-based information extraction: An introduction and a surveyof current approaches. Journal of Information Science, 2010. (Citedon page 78.)
[Wright & Budin 1997] Sue Ellen Wright and Gerhard Budin, editeurs.Handbook of terminology management, volume 1 — Basic Aspectsof Terminology Management. John Benjamins, Amsterdam, 1997.(Cited on pages 32 and 70.)
[Zadeh 1965] L.A. Zadeh. Fuzzy sets. Information and Control, vol. 8, no. 3,pages 338 – 353, 1965. (Cited on page 120.)

222 Bibliography
[Zadeh 1971] Lotfi Asker Zadeh. Similarity relations and fuzzy orderings.Information sciences, vol. 3, no. 2, pages 177–200, 1971. (Cited onpage 126.)
[Zalta 2014] Edward N. Zalta. Gottlob Frege. In Edward N. Zalta, editeur,The Stanford Encyclopedia of Philosophy. Fall 2014 édition, 2014.(Cited on page 13.)
[Zimmermann & Jérôme 2006] Antoine Zimmermann and Jérôme. Three Se-mantics for Distributed Systems and Their Relations with AlignmentComposition. In Isabel Cruz, Stefan Decker, Dean Allemang, ChrisPreist, Daniel Schwabe, Peter Mika, Mike Uschold and LoraM. Aroyo,editeurs, The Semantic Web - ISWC 2006, volume 4273 of LectureNotes in Computer Science, pages 16–29. Springer Berlin Heidelberg,2006. (Cited on page 143.)
[Zimmermann et al. 2006] Antoine Zimmermann, Markus Krötzsch, JérômeEuzenat and Pascal Hitzler. Formalizing Ontology Alignment andits Operations with Category Theory. In Proceedings of the 2006conference on Formal Ontology in Information Systems: Proceedingsof the Fourth International Conference (FOIS 2006), pages 277–288,Amsterdam, The Netherlands, The Netherlands, 2006. IOS Press.(Cited on page 116.)