spark by adform research, paulius
TRANSCRIPT
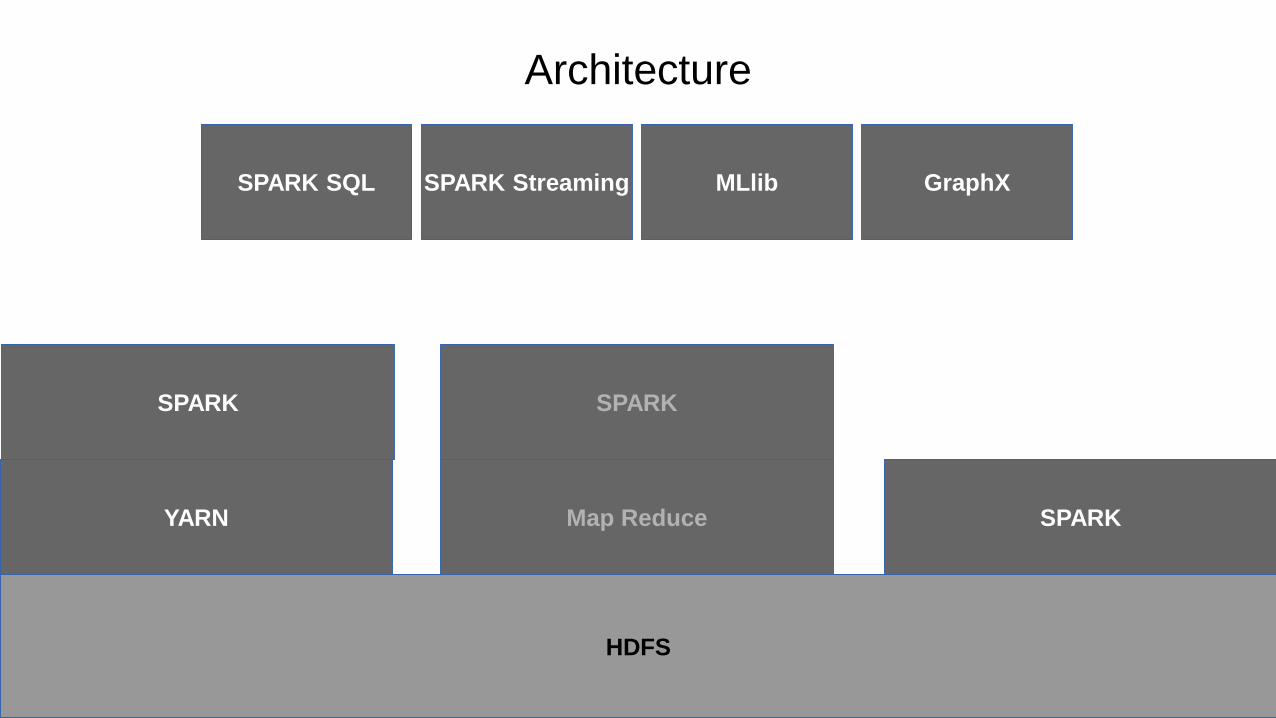
HDFS
YARN Map Reduce SPARK
SPARK SPARK
SPARK Streaming MLlib GraphXSPARK SQL
Architecture

Standalone apps
lScala
lJava
lPython
Deployment
Spark-submit
* .jar (for Java/Scala) or a set of .py or .zip files (for Python),
Development
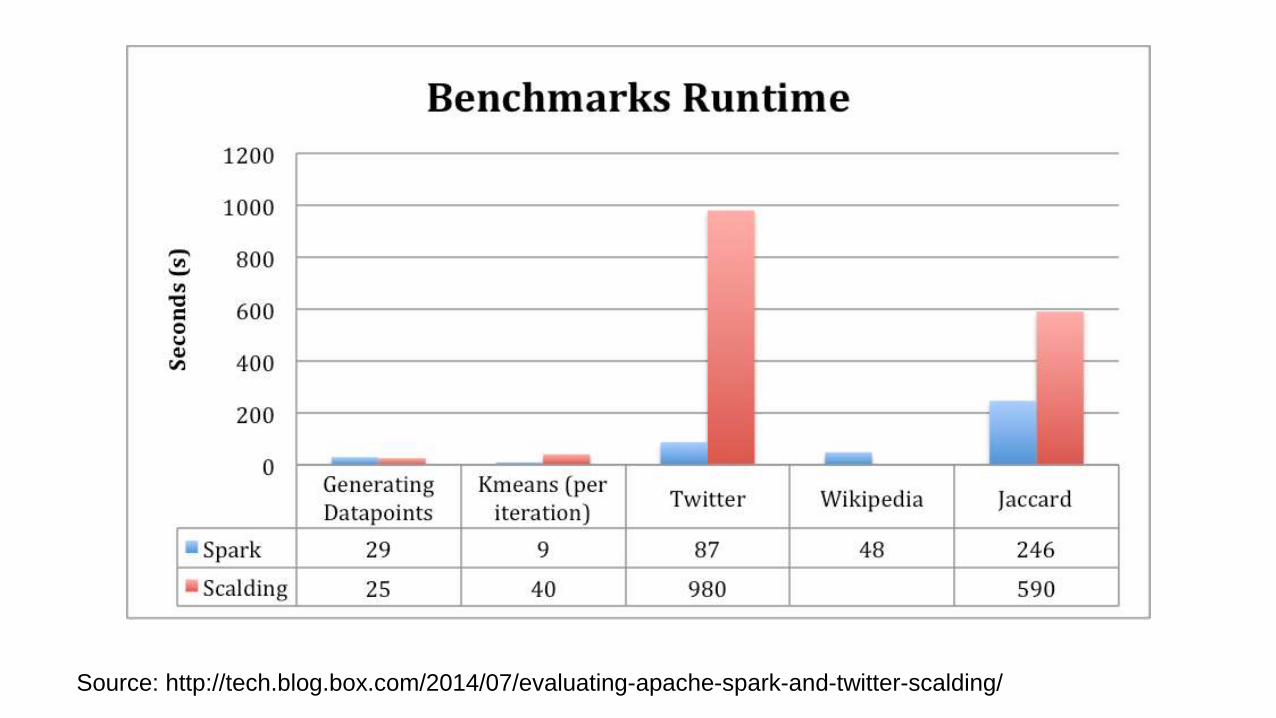
Source: http://tech.blog.box.com/2014/07/evaluating-apache-spark-and-twitter-scalding/
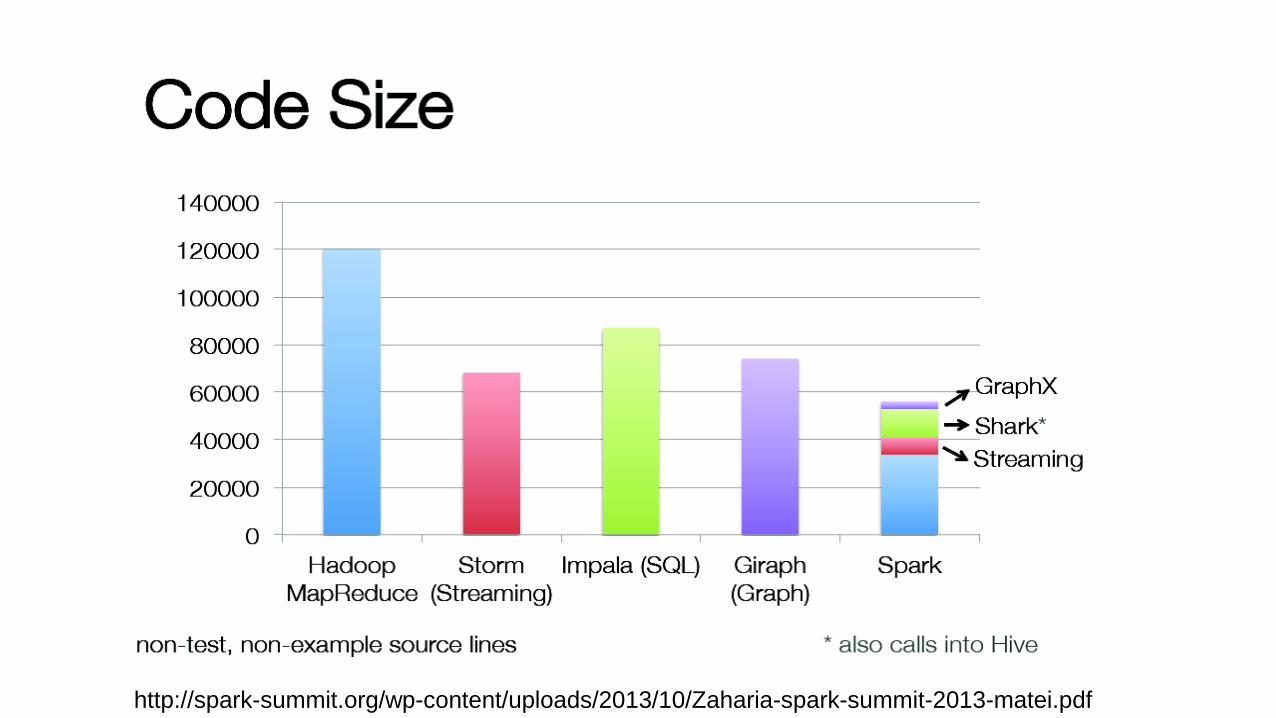
http://spark-summit.org/wp-content/uploads/2013/10/Zaharia-spark-summit-2013-matei.pdf

Wordcount in Spark#Python
file = spark.textFile("hdfs://...")
counts = file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://...")
#Scala
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")

Interactive Live Demo I on Spark REPL
cd /home/grf/Downloads/spark-1.0.2-bin-hadoop1/bin
./spark-shell
val f = sc.textFile("README.md")
val wc = f.flatMap(l => l.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
wc.saveAsTextFile("wc_result.txt")
wc.toDebugString

Interactive Live Demo II on Spark REPL
cd /home/grf/Downloads/spark-1.0.2-bin-hadoop1/bin
./spark-shell
val rm = sc.textFile("README.md")
val rm_wc = rm.flatMap(l => l.split(" ")).filter(_ == "Spark").map(workd => (word, 1)).reduceByKey(_ + _)
rm_wc.collect()
val cl = sc.textFile("CHANGES.txt")
val cl_wc = cl.flatMap(l => l.split(" ")).filter(_ == "Spark").map(word => (word, 1)).reduceByKey(_ + _)
cl_wc.collect()
rm_wc.join(cl_wc).collect()

Running on EMR
#Starting the cluster/opt/elastic-mapreduce-cli/elastic-mapreduce --create --alive --name "Paul's Spark/Shark Cluster" --bootstrap-action s3://elasticmapreduce/samples/spark/0.8.1/install-spark-shark.sh --bootstrap-name "Install Spark/Shark" --instance-type m1.xlarge --instance-count 10
Spark 1.0.0 is available on YARN and on SPARK platforms (haven't properly tested yet).
ssh hadoop@<FQDN> -i /opt/rnd_eu.pem
cd /home/hadoop/spark
./bin/spark-shell
./bin/spark-submit
./bin/pyspark
Monitoring:<FQDN>:8080

alter table rtb_transactions add if not exists partition (dt='${DATE}');
INSERT OVERWRITE TABLE
rtb_transactions_export PARTITION (dt ='${DATE}', cd)
SELECT
ChannelId,
RequestId,
Time,
CookieId,
<...>
FROM
rtb_transactions t
JOIN
placements p ON (t.PlacementId = p.PlacementId)
WHERE
dt = '${DATE}'
and (p.AgencyId=107
or p.AgencyId=136
or p.AgencyId=590);
35 lines
val tr = sc.textFile("path_to_rtb_transactions").
map(_.split("\t")).
map(r => (r(11), r))
val pl = sc.textFile("path_to_placements").
map(_.split("\t")).
filter(c => Set(107, 136,590).contains(c(9).trim.toInt)).
map(r => (r(0), r))
pl.join(tr).map(tuple => "%s".format(tuple._2._2.mkString("\t"))).
coalesce(1).
saveAsTextFile("path_to_rtb_transactions_sampled")
12 lines
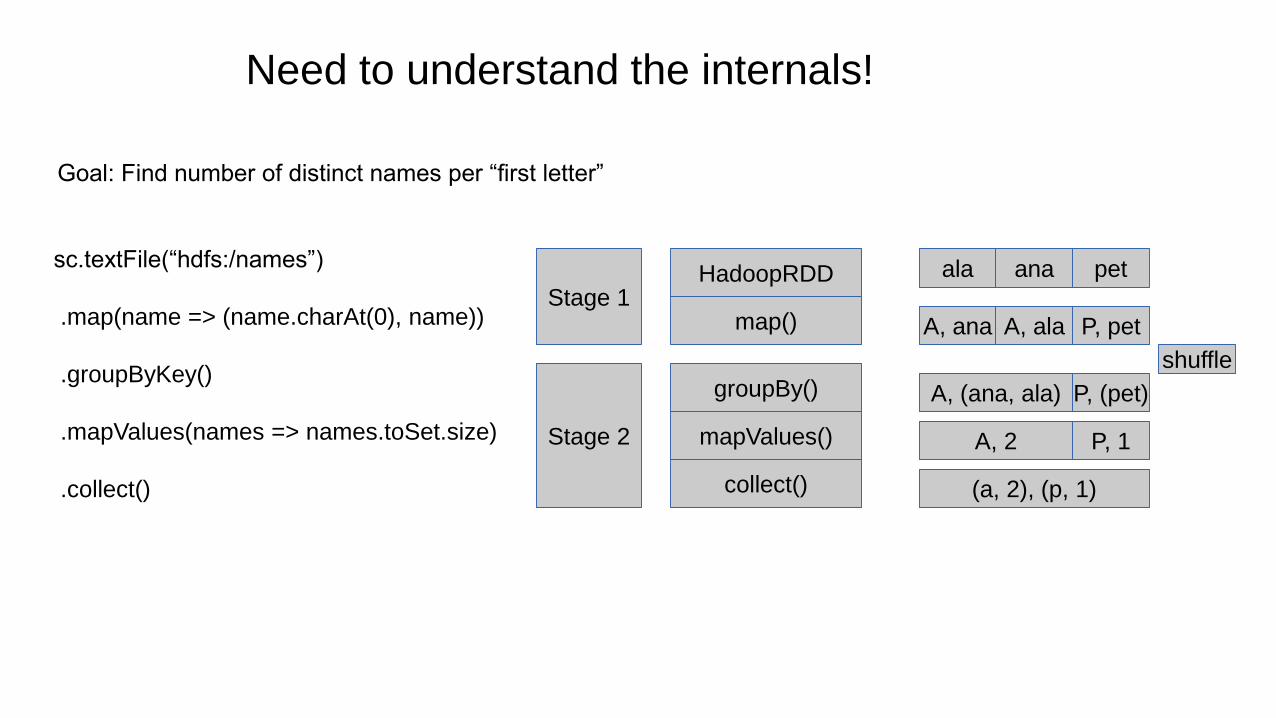
Need to understand the internals!
Goal: Find number of distinct names per “first letter”
sc.textFile(“hdfs:/names”)
.map(name => (name.charAt(0), name))
.groupByKey()
.mapValues(names => names.toSet.size)
.collect()
HadoopRDD
map()
groupBy()
mapValues()
collect()
Stage 1
Stage 2
ala ana pet
A, ana A, ala P, pet
P, (pet)A, (ana, ala)
A, 2 P, 1
(a, 2), (p, 1)
shuffle
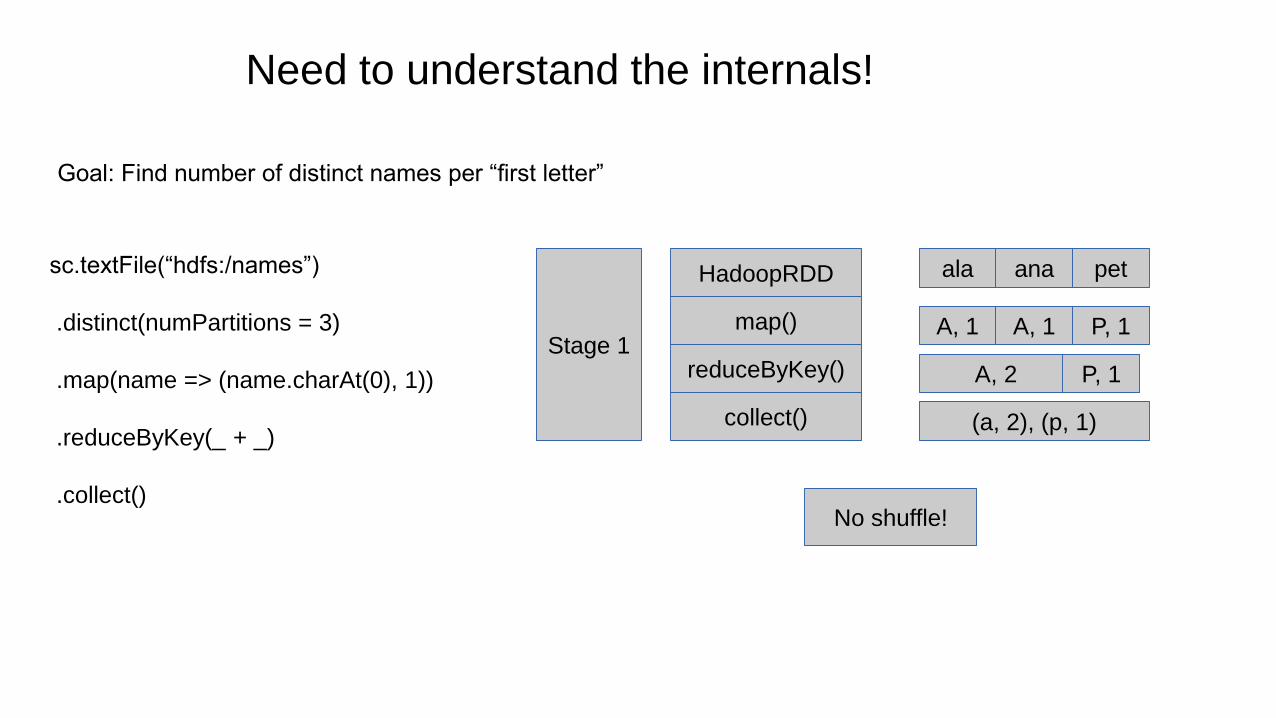
Need to understand the internals!
Goal: Find number of distinct names per “first letter”
HadoopRDD
map()
reduceByKey()
collect()
Stage 1
ala ana pet
A, 1 A, 1 P, 1
A, 2 P, 1
(a, 2), (p, 1)
sc.textFile(“hdfs:/names”)
.distinct(numPartitions = 3)
.map(name => (name.charAt(0), 1))
.reduceByKey(_ + _)
.collect()No shuffle!

Key points:
Handles batch, interactive and real-time processing within a single framework
Native integration with Python, Scala and Java
Programming at a higher level of abstraction
More general: MR is just one set of supported constructs (??)