slide 1 istore: introspective storage for data-intensive network services aaron brown, david...
Post on 21-Dec-2015
213 views
TRANSCRIPT

Slide 1
ISTORE: Introspective Storage for Data-Intensive
Network Services
Aaron Brown, David Oppenheimer, Kimberly Keeton,
Randi Thomas, John Kubiatowicz, and David Patterson
Computer Science DivisionUniversity of California, Berkeley
http://iram.cs.berkeley.edu/istore/
CS444I Guest Presentation, 4/29/99

Slide 2
ISTORE Philosophy
• Traditional systems research has focused on peak performance and cost
Traditional Research Priorities
1) Performance1’) Cost 3) Scalability4) Availability5) Maintainability

Slide 3
ISTORE Philosophy
• In reality, maintainability, availability, and scalability are more important– performance & cost mean little if the system isn’t
working
Traditional Research Priorities
1) Performance1’) Cost 3) Scalability4) Availability5) Maintainability
ISTORE Priorities
1) Maintainability2) Availability 3) Scalability4) Performance4’) Cost

Slide 4
ISTORE Philosophy: Introspection
• ISTORE’s solution is introspective systems– systems that monitor themselves and automatically
adapt to changes in their environment and workload– introspection enables automatic self-maintenance and
self-tuning
• ISTORE vision: a framework that makes it easy to build introspective systems
• ISTORE target: high-end servers for data-intensive infrastructure services– single-purpose systems managing large amounts of
data for large numbers of active network users

Slide 5
Outline• Motivation for Introspective Systems• ISTORE Research Agenda and
Architecture– Hardware – Software
• Policy-driven Introspection Example• Research Issues, Status, and Discussion

Slide 6
Motivation: Service Demands• Emergence of a true information
infrastructure– today: e-commerce, online database services,
online backup, search engines, and web servers– tomorrow: more of above (with ever-growing
datasets), plus thin-client/PDA infrastructure support
• Infrastructure users expect “always-on”service and constant quality of service– infrastructure must provide fault-tolerance
and performance-tolerance– failures and slowdowns have major business impact
» e.g., recent E*Trade, Schwab outages

Slide 7
Motivation: Service Demands (2)
• Delivering 24x7 fault- and performance-tolerance requires:– fast adaptation to failures, load spikes, changing
access patterns– easy incremental scalability when existing
resources stop providing desired QoS – self-maintenance: the system handles problems as
they arise, automatically» can't rely on human intervention to fix problems or
to tune performance» humans are too expensive, too slow, prone to
mistakes
• Introspective systems can deliver self-maintenance

Slide 8
Motivation: System Scaling • Infrastructure services are growing rapidly
– more users, more online data, higher access rates, more historical data
– bigger and bigger backend systems are needed» O(300)-node clusters deployed now; thousands of
nodes not far off
– techniques for maintenance and administration must scale with the system to 1000s of nodes
• Today’s administrative approaches don’t scale– systems will be too big to reason about, monitor, or fix– failures and load variance will be too frequent for static
solutions to work
• Introspective, reactive techniques are required

Slide 9
ISTORE Research Agenda• ISTORE goal = create a
hardware/software framework for building introspective servers
– Hardware: plug-and-play intelligent devices with integrated self-monitoring and diagnostics
» intelligence used to collect and filter monitoring data» networked to create a scalable shared-nothing cluster
– Software: toolkit that allows programmers to easily define the system’s adaptive behavior
» provides abstractions for manipulating and reacting to monitoring data

Slide 10
Hardware Support for Introspective Servers
• Introspective, self-maintaining servers need hardware support– tightly-integrated monitoring on all components
» device “health,” performance data, access patterns, environmental info, ...
– shared-nothing architecture for scalability, heterogeneity, availability
– redundancy at all levels– idiot-proof packaging that’s compact, easily
scaled, easily maintained
• ISTORE uses clusters of intelligent device bricks to provide this support

Slide 11
ISTORE-1 Hardware Prototype• Based on intelligent disk bricks (64 nodes)
– fast embedded CPU performs local monitoring tasks, runs parallel application code
– diagnostic hardware provides fail-fast behavior, self-testing, additional monitoring
IntelligentChassis:scalable
redundantswitching,
power,env’t monitoring
IntelligentDisk “Brick”
Disk
CPU, memory,redundant NICs

Slide 12
ISTORE-1 Hardware Design• Brick
– processor board» mobile Pentium-II, 366 MHz, 128MB SODRAM» PCI and ISA busses/controllers, SuperIO (serial
ports)» Flash BIOS» 4x100Mb Ethernet interfaces» Adaptec Ultra2-LVD SCSI interface
– disk: one 18.2GB 10,000 RPM low-profile SCSI disk
– diagnostic processor

Slide 13
ISTORE-1 Hardware Design (2)• Network
– primary data network» hierarchical, highly-redundant switched Ethernet» uses 16 20-port 100Mb switches at the leaves
•each brick connects to 4 independent switches» root switching fabric is two ganged 25-port Gigabit
switches (PacketEngines PowerRails)
– diagnostic network

Slide 14
Diagnostic Support• Each brick has a diagnostic processor
– Goal: small, independent, trusted piece of hardware running hand-verifiable monitoring/control software
» monitoring: CPU watchdog, environmental conditions» control
•reboot/power-cycle main CPU•inject simulated faults: power, bus transients, memory errors, network interface failure, ...
• Separate “diagnostic network” connects the diagnostic processors of each brick– provides independent network path to diagnostic
CPU» works when brick CPU is powered off or has failed» separate failure modes from Ethernet interfaces

Slide 15
Diagnostic Support Implementation
• Not-so-small embedded Motorola 68k processor– provides the flexibility needed for research
prototype» can communicate with CPU via serial port, if desired
– still can run just a small, simple monitoring and control program if desired (no OS, networking, etc.)
• CAN (Controller Area Network) diagnostic interconnect– one brick per “shelf” of 8 acts as gateway from
CAN to redundant switched Ethernet fabric– CAN connects directly to automotive environmental
monitoring sensors (temperature, fan RPM, ...)

Slide 16
ISTORE Research Agenda• ISTORE goal = create a
hardware/software framework for building introspective servers
– Hardware
– Software: toolkit that allows programmers to easily define the system’s adaptive behavior
» provides abstractions for manipulating and reacting to monitoring data

Slide 17
A Software Framework for Introspection
• ISTORE hardware provides device monitoring– applications could write ad-hoc code to collect, process,
and react to monitoring data
• ISTORE software framework should simplify writing introspective applications– rule-based adaptation engine encapsulates the
mechanisms of collecting, processing monitoring data– policy compiler and mechanism libraries help turn
application adaptation goals into rules & reaction code– these provide a high-level, abstract interface to the
system’s monitoring and adaptation mechanisms

Slide 18
Rule-based Adaptation• ISTORE’s adaptation framework built on
model of active database– “database” includes:
» hardware monitoring data: device status, access patterns, performance stats
» software monitoring data: app-specific quality-of-service metrics, high-level workload patterns, ...
– applications define views and triggers over the DB» views select and aggregate data of interest to app.» triggers are rules that invoke application-specific
reaction code when their predicates are satisfied
– SQL-like declarative language used to specify views and trigger rules

Slide 19
Benefits of Views and Triggers• Allow applications to focus on adaptation,
not monitoring– hide the mechanics of gathering and processing
monitoring data– can be dynamically redefined without altering
adaptation code as situation changes
• Can be implemented without a real database– views and triggers implemented as device-local and
distributed filters and reaction rules– defined views and triggers control frequency,
granularity, types of data gathered by HW monitoring– no materialized database necessary

Slide 20
Raising the Level of Abstraction:
Policy Compiler and Mechanism Libs• Rule-based adaptation doesn’t go far
enough– application designer must still write views, triggers,
and adaptation code by hand» but designer thinks in terms of system policies
• Solution: designer specifies policies to system; system implements them– policy compiler automatically generates views,
triggers, adaptation code– uses preexisting mechanism libraries to implement
adaptation algorithms– claim: feasible for common adaptation mechanisms
needed by data-intensive network service apps.

Slide 21
Adaptation Policies• Policies specify system states and how
to react to them– high-level specification: independent of “schema”
of system, object/node identity» that knowledge is encapsulated in policy compiler
• Examples– self-maintenance and availability
» if overall free disk space is below 10%, compress all but one replica/version of least-frequently-accessed data
» if any disk reports more than 5 errors per hour, migrate all data off that disk and shut it down
» invoke load-balancer when new disk is added to system– performance tuning
» place large, sequentially-accessed objects on outer tracks of fast disks as space becomes available
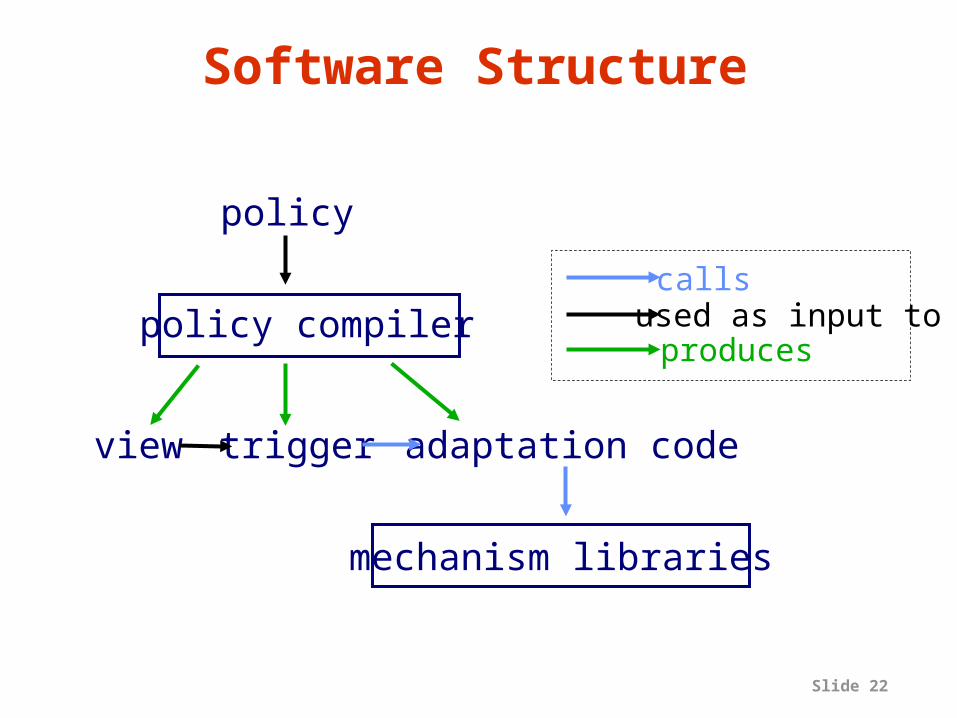
Slide 22
Software Structure
policy
view trigger adaptation code
mechanism libraries
policy compilercallsused as input toproduces

Slide 23
Detailed Adaptation Example• Policy: quench hot spots by migrating
objects
policy
view trigger adaptation code
mechanism libraries
policy compilercallsused as input toproduces
while ((average queue length for any disk D) > (120% of average for whole system)) migrate hottest object on D to disk with shortest average queue length

Slide 24
policy
view trigger adaptation code
policy compiler
Example: View Definitionwhile ((average queue length for any disk D) > (120% of average for whole system)) migrate hottest object on D to disk with shortest average queue length
DEFINE VIEW (average_queue_length= SELECT AVG(queue_length) FROM disk_stats,queue_length[]= SELECT queue_length FROM disk_stats,disk_id[]= SELECT disk_id FROM disk_stats,
short_disk= SELECT disk_id FROM disk_stats WHERE queue_length = MIN(SELECT queue_length FROM disk_stats))
mechanism libraries

Slide 25
DEFINE VIEW (average_queue_length=...,queue_length[]=...,disk_id[]=...,short_disk=...)
policy
view trigger adaptation code
policy compiler
Example: Triggerwhile ((average queue length for any disk D) > (120% of average for whole system)) migrate hottest object on D to disk with shortest average queue length
foreach disk_id from_disk { if (queue_length[from_disk] > 1.2*average_queue_length) user_migrate(from_disk,short_disk)}
mechanism libraries

Slide 26
policy
view trigger adaptation code
policy compiler
Example: Adaptation Codewhile ((average queue length for any disk D) > (120% of average for whole system)) migrate hottest object on D to disk with shortest average queue length
foreach disk_id from_disk { if (queue_length[from_disk] > 1.2*average_queue_length) user_migrate(from_disk,short_disk)}
DEFINE VIEW (average_queue_length=...,queue_length[]=...,disk_id[]=...,short_disk=...)
user_migrate(from_disk,to_disk) { diskObject x; x = find_hottest_obj(from_disk); migrate(x, to_disk);}
mechanism libraries

Slide 27
policy
view trigger adaptation code
policy compiler
Example: Mechanism Lib. Callswhile ((average queue length for any disk D) > (120% of average for whole system)) migrate hottest object on D to disk with shortest average queue length
foreach disk_id from_disk { if (queue_length[from_disk] > 1.2*average_queue_length) user_migrate(from_disk,short_disk)}
DEFINE VIEW (average_queue_length=...,queue_length[]=...,disk_id[]=...,short_disk=...)
user_migrate(from_disk,to_disk) { diskObject x; x = find_hottest_obj(from_disk); migrate(x, to_disk);}
mechanism libraries

Slide 28
Mechanism Libraries• Unify existing techniques/services found in
single-node OSs, DBMSs, distributed systems– distributed directory services– replication and migration– data layout and placement– distributed transactions– checkpointing– caching– administrative (human UI) tasks
• Provide a place for higher-level monitoring• Simplify creation of adaptation code
– for humans using the rule system directly– for the policy compiler auto-generating code
select key mechanisms fordata-intensive
network services

Slide 29
Open Research Issues• Defining appropriate software abstractions
– how should views and triggers be declared?– what is the system’s “schema”?
» how should heterogeneous hardware be integrated?» can it be extended by the user to include new types
and statistics?
– what should the policy language look like?– what level of policies can be expressed?
» how much of the implementation can the system figure out automatically?
» to what extent can the system reason about policies and their interactions?
– what functions should mechanism libraries provide?

Slide 30
More Open Research Issues• Implementing an introspective system
– what default policies should the system supply?– what are the internal and external interfaces? – debugging
» visualization of states, triggers, ...» simulation/coverage analysis of policies, adaptation code» appropriate administrative interfaces
• Measuring an introspective system– what are the right benchmarks for maintainability,
availability, scalability?
• O(>=1000)-node scalability– how to write applications that scale and run well
despite continual state of partial failure?

Slide 31
Related Work• Hardware:
– CMU and UCSB Active Disks
• Software:– Adaptive databases: MS AutoAdmin, Informix
NoKnobs– Adaptive OSs: MS Millennium, adaptive VINO
– Adaptive storage: HP AutoRAID, attribute-managed storage
– Active databases: UFL Gator, TriggerMan
• ISTORE unifies many of these techniques in a single system

Slide 32
Status and Conclusions• ISTORE’s focus is on introspective systems
– a new perspective on systems research priorities
• Proposed framework for building introspection– intelligent, self-monitoring plug-and-play hardware– software that provides a higher level of abstraction
for the construction of introspective systems» flexible, powerful rule system for monitoring» policy specification automates generation of adaptation
• Status– ISTORE-1 hardware prototype being constructed now– software prototyping just starting

Slide 33
ISTORE: Introspective Storage for Data-Intensive
Network Services
For more information:
http://iram.cs.berkeley.edu/istore/

Slide 34
Backup Slides

Slide 35
ISTORE-1 Hardware Design• Brick
– processor board» mobile Pentium-II, 366 MHz, 128MB SODRAM» PCI and ISA busses/controllers, SuperIO (serial ports)» Flash BIOS» 4x100Mb Ethernet interfaces» Adaptec Ultra2-LVD SCSI interface
– disk: one 18.2GB 10,000 RPM low-profile SCSI disk– diagnostic processor
» Motorola MC68376, 2MB Flash or NVRAM» serial connections to CPU for console and monitoring» controls power to all parts on board» CAN interface

Slide 36
ISTORE-1 Hardware Design (2)• Network
– primary data network» hierarchical, highly-redundant switched Ethernet» uses 16 20-port 100Mb switches at the leaves
•each brick connects to 4 independent switches» root switching fabric is two ganged 25-port Gigabit
switches (PacketEngines PowerRails)
– diagnostic network» point-to-point CAN network connects bricks in a
shelf» Ethernet fabric described above is used for shelf-to-
shelf communication» console I/O from each brick can be routed through
diagnostic network

Slide 37
Motivation: Technology Trends• Disks, systems, switches are getting smaller
• Convergence on “intelligent” disks (IDISKs)– MicroDrive + system-on-a-chip => tiny IDISK nodes
• Inevitability of enormous-scale systems– by 2006, a O(10,000) IDISK-node cluster with 90TB of
storage could fit in one rack
IBM MicroDrive(340MB, 5MB/s)
World’s Smallest Web Server(486/66, 16MB RAM, 16MB ROM)

Slide 38
Disk Limit• Continued advance in capacity (60%/yr)
and bandwidth (40%/yr)• Slow improvement in seek, rotation (8%/yr)• Time to read whole disk
Year Sequentially Randomly (1 sector/seek)
1990 4 minutes 6 hours2000 12 minutes 1 week(!)
• 3.5” form factor make sense in 5-7 years?

Slide 39
ISTORE-II Hardware Vision• System-on-a-chip enables computer,
memory, redundant network interfaces without significantly increasing size of disk
• Target for + 5-7 years:• 1999 IBM MicroDrive:– 1.7” x 1.4” x 0.2”
(43 mm x 36 mm x 5 mm)– 340 MB, 5400 RPM,
5 MB/s, 15 ms seek
• 2006 MicroDrive?– 9 GB, 50 MB/s
(1.6X/yr capacity, 1.4X/yr BW)

Slide 40
2006 ISTORE• ISTORE node
– Add 20% pad to MicroDrive size for packaging, connectors
– Then double thickness to add IRAM– 2.0” x 1.7” x 0.5” (51 mm x 43 mm x 13 mm)
• Crossbar switches growing by Moore’s Law– 2x/1.5 yrs 4X transistors/3yrs– Crossbars grow by N2 2X switch/3yrs– 16 x 16 in 1999 64 x 64 in 2005
• ISTORE rack (19” x 33” x 84”)(480 mm x 840 mm x 2130
mm) – 1 tray (3” high) 16 x 32 512 ISTORE nodes– 20 trays+switches+UPS 10,240 ISTORE nodes(!)

Slide 41
Benefits of Views and Triggers (2)
• Equally useful for performance and failure management– Performance tuning example: DB index
management» View: access patterns to tables, query predicates used» Trigger: access rate to table above/below average» Adaptation: add/drop indices based on query stream
– Failure management example: impending disk failure
» View: disk error logs, environmental conditions» Trigger: frequency of errors, unsafe environment» Adaptation: redirect requests to other replicas, shut
down disk, generate new replicas, signal operator

Slide 42
More Adaptation Policy Examples
• Self-maintenance and availability– maintain two copies of all dirty data stored only in
volatile memory– if a disk fails, restore original redundancy level for
objects stored on that disk
• Performance tuning– if accesses to a read-mostly object take more than
10ms on average, replicate the object on another disk
• Both (like HP AutoRAID)– if an object is in the top 10% of frequently-accessed
objects, and there is only one copy, create a new replica. if an object is in the bottom 90%, delete all replicas and stripe the object across N disks using RAID-5.

Slide 43
Mechanism Library Benefits• Programmability
– libraries provide high-level abstractions of services– code using the libraries is easier to reason about,
maintain, customize
• Performance– libraries can be highly-optimized– optimization complexity is hidden by abstraction
• Reliability– libraries include code that’s easy to forget or get
wrong» synchronization, communication, memory allocation
– debugging effort can be spent getting libraries right» library users inherit the verification effort