resisting skew accumulation
TRANSCRIPT

1
Resisting Skew-Accumulationfor Time-Stepped Applications in the Cloud via Exploiting Parallelism
PRESENTED BY MD. HASIBUR RASHID

2AbstractTime-stepped applications are pervasive in scientific computing domain but perform poorly in the cloud because these applications execute in discrete time-step or tick and use logical synchronization barriers at tick boundaries to ensure correctness. As a result the accumulated computational skew and communication skew that were unsolved in each tick can slow down time-stepped applications significantly.
However, the existing solutions have focused only on the skew in each tick and thus cannot resist the accumulation of skew. To fill in this gap, an efficient approach to resisting the accumulation of skew is proposed in this paper via fully exploiting parallelism among ticks.
This new approach allows the user to decompose much computational part (also called asynchronous part) of the processing for an object, into several asynchronous sub-processes which are dependent on one data object.
A data-centric programming model and also a runtime system, namely AsyTick, coupled with an adhoc scheduler are developed. Experimental results show that the proposed approach can improve the performance of time-stepped applications over a state-of-the-art computational skew-resistant approach up to 2:53 times.

3What are Time Stepped Applications?
A time-stepped application is a parallel scientific application organized into logical ticks. Processes in these applications proceed completely in parallel within a tick and exchange messages only at tick boundaries.
The bulk synchronous model allowed scientists easily design and execute in private clusters and HPC environment.
But, when they are executed in cloud, because of studied network latency and hardware virtualization latencies at cloud the logical tick might be pushed in further and creates overall poor performance in public cloud compare to private clusters.

4Different skew
Data skew is caused by an uneven distribution of data because of the wrong selection of distribution columns. It is present at the table level, can be easily identified and avoided by selecting optimal distribution columns.
Computational Skew refers to jobs where the per-value processing costs exhibit heavy variance. to evenly spread these large tasks across machines. . . execution, where additional ``backup'' copies of slow tasks are launched. Computational skew occurs for operations on columns that have low cardinality and a non-uniform distribution.
Communication skew happens in flight when a query is executing and is not as easy to detect. It can happen for various operations like join, sort, aggregation, and various OLAP operations.

5Data-centric programming
Data-centric programming language defines a category of programming languages where the primary function is the management and manipulation of data. A data-centric programming language includes built-in processing primitives for accessing data stored in sets, tables, lists, and other data structures and databases, and for specific manipulation and transformation of data required by a programming application.
The SQL relational database language is an example of a declarative, data-centric language. Declarative, data-centric programming languages are ideal for data-intensive computing applications
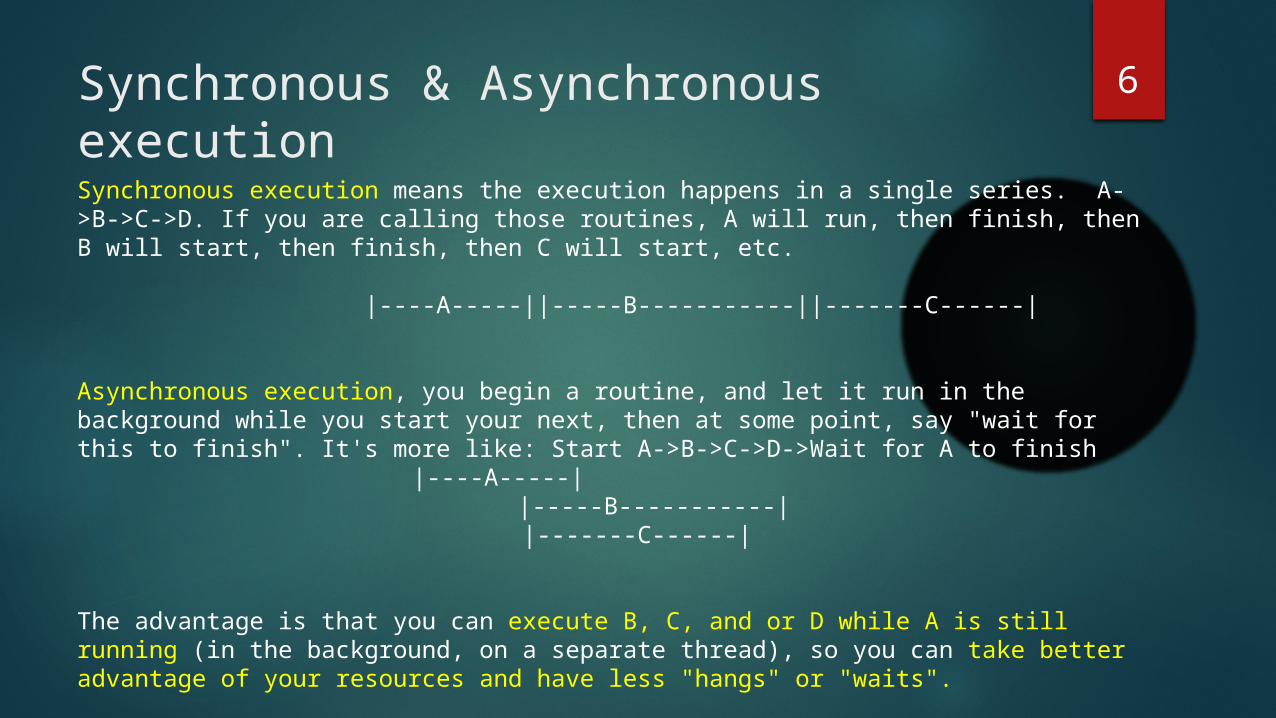
6Synchronous & Asynchronous execution
Synchronous execution means the execution happens in a single series. A->B->C->D. If you are calling those routines, A will run, then finish, then B will start, then finish, then C will start, etc.
|----A-----||-----B-----------||-------C------|
Asynchronous execution, you begin a routine, and let it run in the background while you start your next, then at some point, say "wait for this to finish". It's more like: Start A->B->C->D->Wait for A to finish
|----A-----| |-----B-----------| |-------C------|
The advantage is that you can execute B, C, and or D while A is still running (in the background, on a separate thread), so you can take better advantage of your resources and have less "hangs" or "waits".

7Main Idea of the paper
This paper addresses about the issues in executing scientific applications on cloud environment with resisting the accumulation of skew is proposed in this paper via fully exploiting parallelism among ticks.
The scientific applications here are considered as bulk synchronous, data centric programing model and time stepped modeling category applications.

8Existing solutions?
However, the existing solutions have focused only on the skew in each tick and thus cannot resist the accumulation of skew.
There are few existing solutions provided by HPC community in optimizing time stepped applications.
However, those techniques are developed using model of fixed, unavoidable latency for sending messages across dedicated network. Hence those solutions impairs the productivity of scientists who want to develop new applications without regard for which optimizations to use for communication

9Why cloud environment for scientific parallel data applications?
Cloud offers instant availability of large computational power at affordable price, which avoids job queuing for long time at local cluster and it’s a common practice to commodity interconnect shared resources in current days.

10Proposed Solution
• A general parallel programming model for time-stepped applications that can abstract the jitter and latencies in cloud environment.
• The abstraction and intuitive data driven programming model helps programmers/scientists to completely focus on computational logic without worrying about network jitters.
• Representation of application states as relational tables, change in the states with queries and data decencies as function of queries as pure logical abstraction is intuitive to understand.
• A generic programming model to support any emerging programming language.

11Proposed Solution
• Simple data dependency modeling with set of functions Rd, Rx, Wd,Wx as read dependencies, read exclusiveness and write dependencies and exclusiveness respectively.
• Dependency Scheduling and Computational Replication are two attractive ideas to address the jitter in network; first one performs part of future computation without neighbor messages and updates the results once they arrived. Computation replication performs emulation of dependency message receive by local computation and discarding later received message.
• Computation replication results are preserved to use in further dependencies.
• Run time optimization in the framework.

12
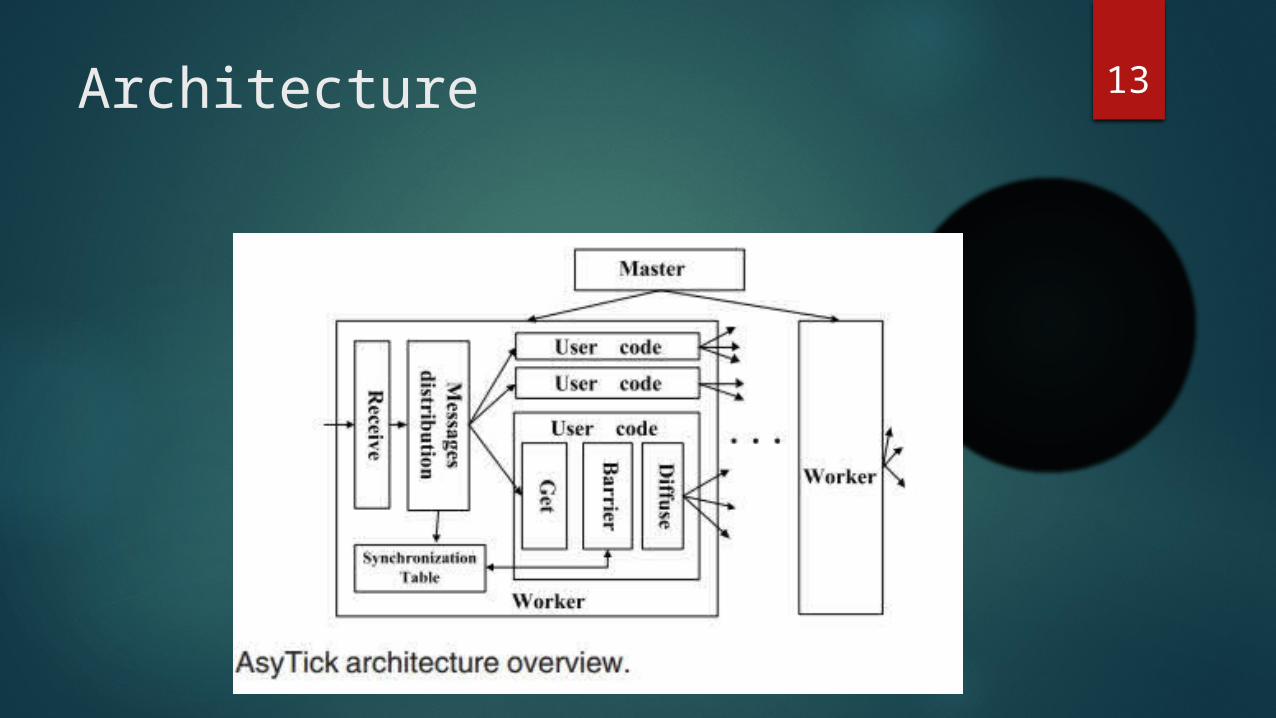
13Architecture

14Programing Model

15Experimental Results And EvaluationUnsolved computational skew and communication skew still exist in time-stepped applications subject to the current solutions, and then show how much such unsolved skew can be eliminated by the proposed AsyTick.
The hardware platform used in our experiments is a Cluster with 256 cores residing on 16 nodes, while the network interconnection is a 2 Gigabit Ethernet. Each node is a two-way octuple-core with Intel Xeon(R) CPU E5-2670 at 2:60 GHz CPUs and 64 GB memory. Each node has 16 cores and thus a maximum of 16 workers are spawned for each node to run applications.
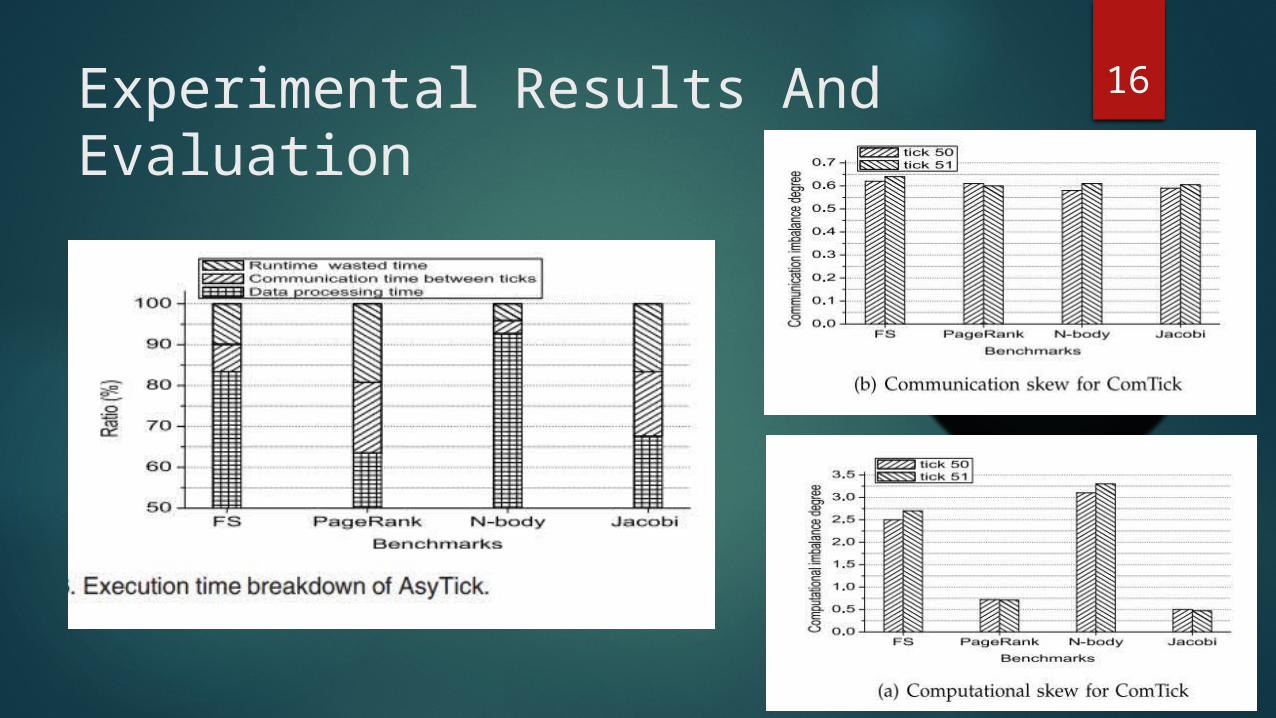
16Experimental Results And Evaluation

17Concepts I felt like glassed over are• Paper does not talk about overhead of performing Computation replication and
correctness of computation replication results compared to actual messages/results sent by neighbor processes.
• Generic equation or method to calculate optimal depth value or how to calculate depth value in case of dependency scheduling and computational replication without performing set of simulations, based on application workload characteristics and user provided jitter factor.
• Cost associated to updating values/results with later received messages in dependency scheduling.
• Majorly addressed network-jitters and not many details related to load imbalance or other latencies.
• Active storage is major assumption and jobs are compute bound, paper does not talk about applicability of proposed programming model if the environment is not active storage and jobs are less compute bound

18Conclusion
We have developed an approach to efficiently supporting the execution of time-stepped applications which can be decomposed, we will investigate which time stepped applications can be decomposed and how to correctly decompose these applications in our future work.
Furthermore, we will incorporate our approach into other skew-resistant approaches and analyses their performance together to show its efficiency, and also employ it to more time-stepped applications in order to demonstrate its feasibility.

19
Thank YouMD. Hasibur Rashid // MSc. in CSE, KUET, Bangladesh