regularization, ridge regression - university of...
TRANSCRIPT

1
©2005-2013 Carlos Guestrin 1
Regularization, Ridge Regression
Machine Learning – CSEP546 Carlos Guestrin University of Washington
January 13, 2014
2
The regression problem n Instances: <xj, tj> n Learn: Mapping from x to t(x) n Hypothesis space:
¨ Given, basis functions ¨ Find coeffs w={w1,…,wk}
¨ Why is this called linear regression??? n model is linear in the parameters
n Precisely, minimize the residual squared error:
©2005-2014 Carlos Guestrin
2
3
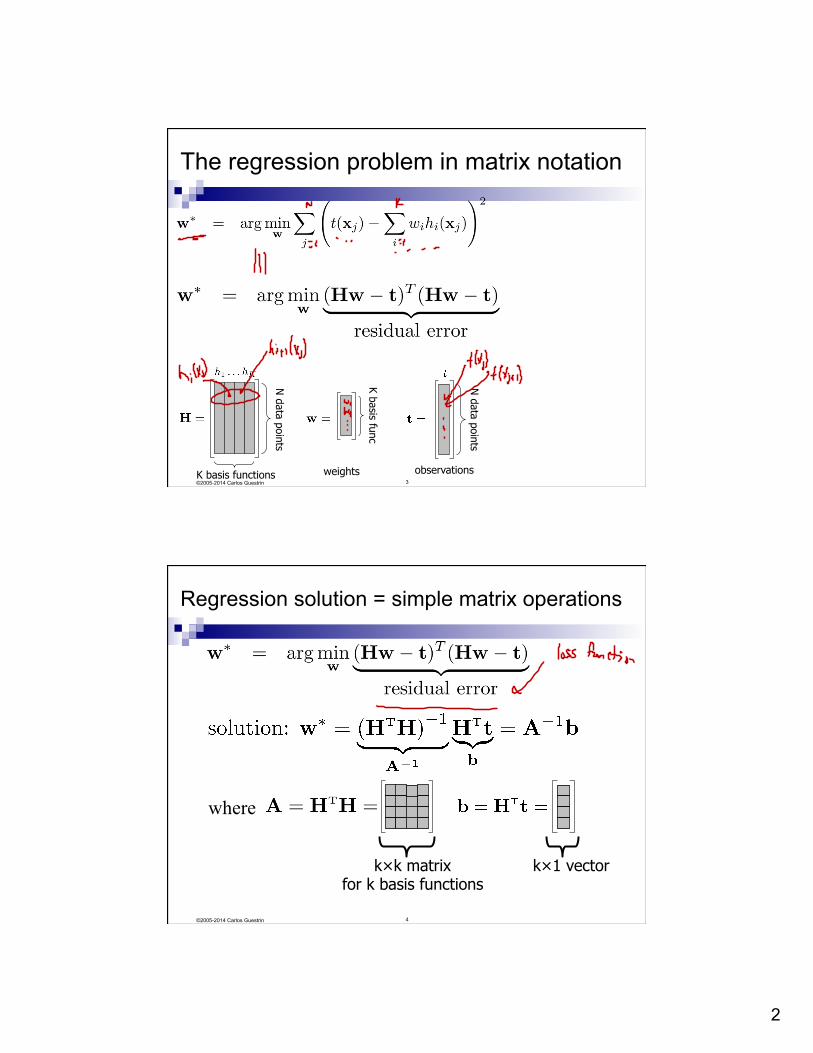
The regression problem in matrix notation
N data points
K basis functions
N data points
observations weights
K basis func
©2005-2014 Carlos Guestrin
4
Regression solution = simple matrix operations
where
k×k matrix for k basis functions
k×1 vector
©2005-2014 Carlos Guestrin
3
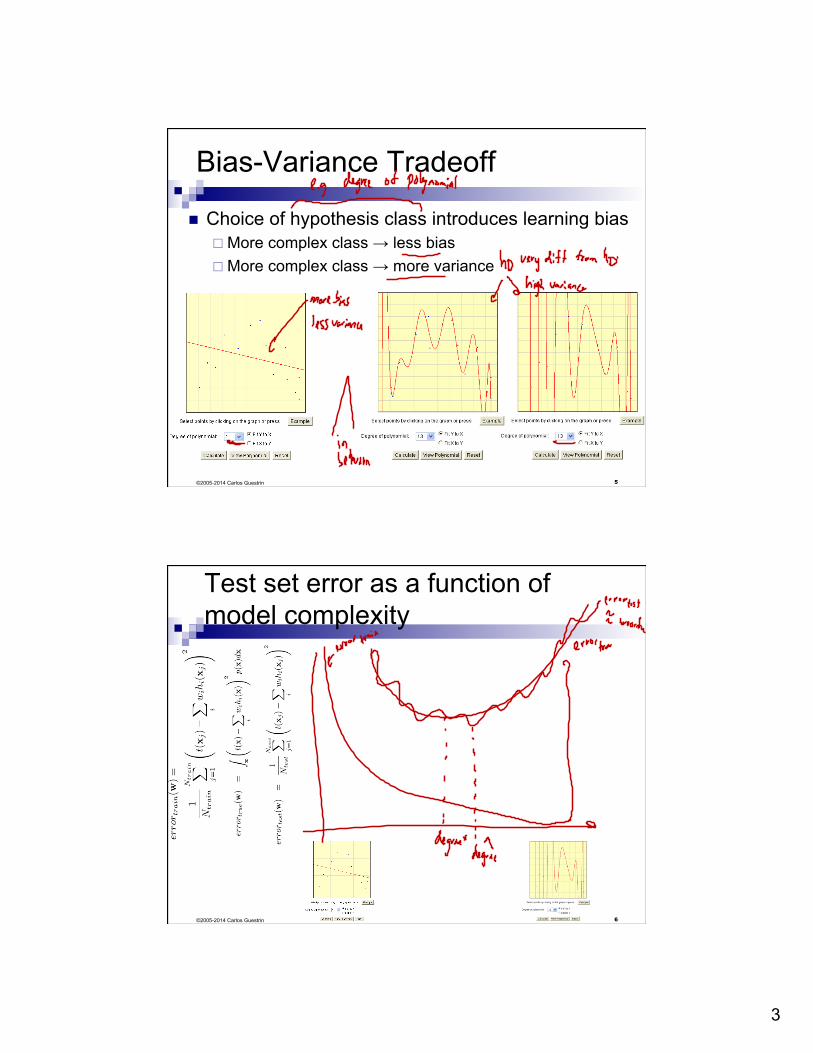
Bias-Variance Tradeoff
n Choice of hypothesis class introduces learning bias ¨ More complex class → less bias ¨ More complex class → more variance
©2005-2014 Carlos Guestrin 5
Test set error as a function of model complexity
©2005-2014 Carlos Guestrin 6

4
Overfitting
n Overfitting: a learning algorithm overfits the training data if it outputs a solution w when there exists another solution w’ such that:
©2005-2014 Carlos Guestrin 7
Regularization in Linear Regression
n Overfitting usually leads to very large parameter choices, e.g.:
n Regularized or penalized regression aims to impose a “complexity” penalty by penalizing large weights ¨ “Shrinkage” method
-2.2 + 3.1 X – 0.30 X2 -1.1 + 4,700,910.7 X – 8,585,638.4 X2 + …
8 ©2005-2013 Carlos Guestrin

5
Quadratic Penalty (regularization)
n What we thought we wanted to minimize:
n But weights got too big, penalize large weights:
9 ©2005-2013 Carlos Guestrin
Ridge Regression
10
n Ameliorating issues with overfitting:
n New objective:
©2005-2013 Carlos Guestrin

6
11
Ridge Regression in Matrix Notation
N data points
K+1 basis functions
N data points
observations weights
K+1 basis func
©2005-2013 Carlos Guestrin
h0 . . . hk
+ � wT I0+kw
wridge = argminw
NX
j=1
t(xj)� (w0 +
kX
i=1
wihi(xj))
!2
+ �
kX
i=1
w
2i
Minimizing the Ridge Regression Objective
12
wridge = argminw
NX
j=1
t(xj)� (w0 +
kX
i=1
wihi(xj))
!2
+ �
kX
i=1
w2i
= (Hw � t)T (Hw � t) + � wT I0+kw
©2005-2013 Carlos Guestrin
MLE

7
Shrinkage Properties
13
n If orthonormal features/basis:
wridge = (HTH + � I0+k)�1HT t
HTH = I
©2005-2013 Carlos Guestrin
Ridge Regression: Effect of Regularization
14
n Solution is indexed by the regularization parameter λ n Larger λ
n Smaller λ
n As λ à 0
n As λ à∞
wridge = argminw
NX
j=1
t(xj)� (w0 +
kX
i=1
wihi(xj))
!2
+ �
kX
i=1
w
2i
©2005-2013 Carlos Guestrin
8
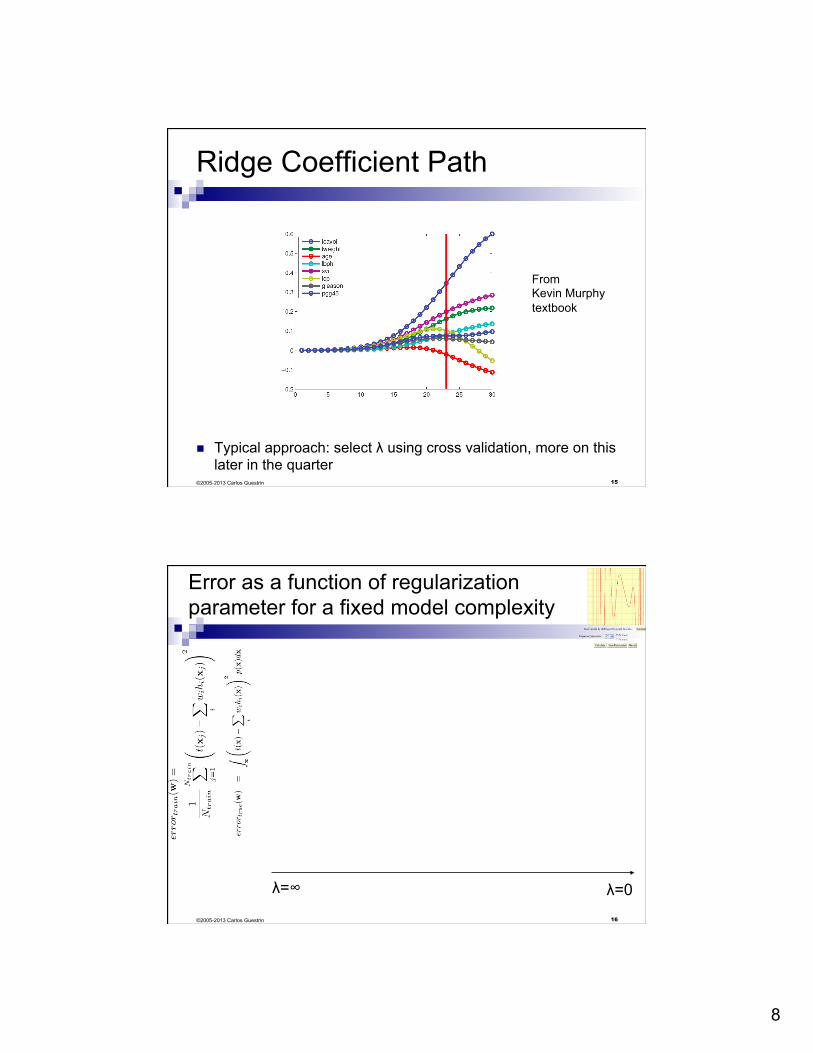
Ridge Coefficient Path
n Typical approach: select λ using cross validation, more on this later in the quarter
15
From Kevin Murphy textbook
©2005-2013 Carlos Guestrin
Error as a function of regularization parameter for a fixed model complexity
λ=∞ λ=0
©2005-2013 Carlos Guestrin 16

9
What you need to know…
n Regularization ¨ Penalizes for complex models
n Ridge regression ¨ L2 penalized least-squares regression ¨ Regularization parameter trades off model complexity
with training error
17 ©2005-2013 Carlos Guestrin
©2005-2013 Carlos Guestrin 18
Cross-Validation
Machine Learning – CSEP546 Carlos Guestrin University of Washington
January 13, 2014

10
Test set error as a function of model complexity
©2005-2013 Carlos Guestrin 19
How… How… How???????
n How do we pick the regularization constant λ… ¨ And all other constants in ML, ‘cause one thing ML
doesn’t lack is constants to tune… L
n We could use the test data, but…
20 ©2005-2013 Carlos Guestrin

11
(LOO) Leave-one-out cross validation
n Consider a validation set with 1 example: ¨ D – training data ¨ D\j – training data with j th data point moved to validation set
n Learn classifier hD\j with D\j dataset n Estimate true error as squared error on predicting t(xj):
¨ Unbiased estimate of errortrue(hD\j)!
¨ Seems really bad estimator, but wait!
n LOO cross validation: Average over all data points j: ¨ For each data point you leave out, learn a new classifier hD\j ¨ Estimate error as:
21
errorLOO =1
N
NX
j=1
�t(xj)� hD\j(xj)
�2
©2005-2013 Carlos Guestrin
LOO cross validation is (almost) unbiased estimate of true error of hD!
n When computing LOOCV error, we only use N-1 data points ¨ So it’s not estimate of true error of learning with N data points! ¨ Usually pessimistic, though – learning with less data typically gives worse answer
n LOO is almost unbiased!
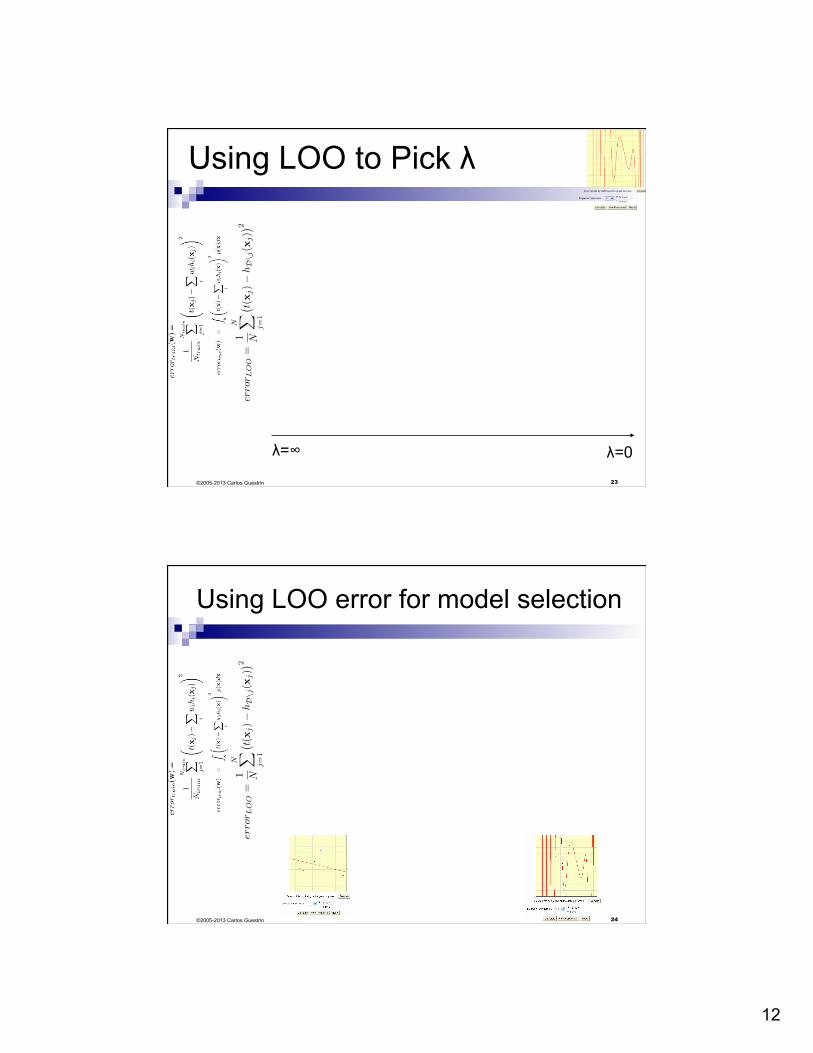
n Great news! ¨ Use LOO error for model selection!!! ¨ E.g., picking λ
22 ©2005-2013 Carlos Guestrin
12
Using LOO to Pick λ
λ=∞ λ=0
©2005-2013 Carlos Guestrin 23
error
LOO=
1
N
N X j=1
� t(x
j)�
h
D\j(x
j)� 2
Using LOO error for model selection
24
error
LOO=
1
N
N X j=1
� t(x
j)�
h
D\j(x
j)� 2
©2005-2013 Carlos Guestrin

13
Computational cost of LOO
n Suppose you have 100,000 data points n You implemented a great version of your learning
algorithm ¨ Learns in only 1 second
n Computing LOO will take about 1 day!!! ¨ If you have to do for each choice of basis functions, it will
take fooooooreeeve’!!! n Solution 1: Preferred, but not usually possible
¨ Find a cool trick to compute LOO (e.g., see homework)
25 ©2005-2013 Carlos Guestrin
Solution 2 to complexity of computing LOO: (More typical) Use k-fold cross validation
n Randomly divide training data into k equal parts ¨ D1,…,Dk
n For each i ¨ Learn classifier hD\Di using data point not in Di ¨ Estimate error of hD\Di on validation set Di:
n k-fold cross validation error is average over data splits:
n k-fold cross validation properties: ¨ Much faster to compute than LOO ¨ More (pessimistically) biased – using much less data, only m(k-1)/k ¨ Usually, k = 10 J
26
errorDi =k
N
X
xj2Di
�t(xj)� hD\Di
(xj)�2
©2005-2013 Carlos Guestrin

14
ML Pipeline
27 ©2005-2013 Carlos Guestrin
data
What you need to know…
n Never ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever ever train on the test data
n Use cross-validation to choose magic parameters such as λ
n Leave-one-out is the best you can do, but sometimes too slow ¨ In that case, use k-fold cross-validation
28 ©2005-2013 Carlos Guestrin

15
©2005-2013 Carlos Guestrin 29
Variable Selection LASSO: Sparse Regression Machine Learning – CSEP546 Carlos Guestrin University of Washington
January 13, 2014
Sparsity n Vector w is sparse, if many entries are zero:
n Very useful for many tasks, e.g., ¨ Efficiency: If size(w) = 100B, each prediction is expensive:
n If part of an online system, too slow n If w is sparse, prediction computation only depends on number of non-zeros
¨ Interpretability: What are the relevant dimension to make a prediction?
n E.g., what are the parts of the brain associated with particular words?
n But computationally intractable to perform “all subsets” regression
30
Eat Push Run
Mean of
independently
learned signatures
over all nine
participants
Participant
P1
Pars opercularis
(z=24mm)
Postcentral gyrus
(z=30mm)
Superior temporal
sulcus (posterior)
(z=12mm)
Figure from Tom
Mitchell
©2005-2013 Carlos Guestrin

16
Simple greedy model selection algorithm
n Pick a dictionary of features ¨ e.g., polynomials for linear regression
n Greedy heuristic: ¨ Start from empty (or simple) set of
features F0 = ∅ ¨ Run learning algorithm for current set
of features Ft n Obtain ht
¨ Select next best feature Xi*
n e.g., Xj that results in lowest training error learner when learning with Ft + {Xj}
¨ Ft+1 ç Ft + {Xi*}
¨ Recurse 31 ©2005-2013 Carlos Guestrin
Greedy model selection
n Applicable in many settings: ¨ Linear regression: Selecting basis functions ¨ Naïve Bayes: Selecting (independent) features P(Xi|Y) ¨ Logistic regression: Selecting features (basis functions) ¨ Decision trees: Selecting leaves to expand
n Only a heuristic! ¨ But, sometimes you can prove something cool about it
n e.g., [Krause & Guestrin ’05]: Near-optimal in some settings that include Naïve Bayes
n There are many more elaborate methods out there
32 ©2005-2013 Carlos Guestrin

17
When do we stop???
n Greedy heuristic: ¨ … ¨ Select next best feature Xi
* n e.g., Xj that results in lowest training error
learner when learning with Ft + {Xj} ¨ Ft+1 ç Ft + {Xi
*} ¨ Recurse
When do you stop??? n When training error is low enough? n When test set error is low enough? n
33 ©2005-2013 Carlos Guestrin
Regularization in Linear Regression
n Overfitting usually leads to very large parameter choices, e.g.:
n Regularized or penalized regression aims to impose a “complexity” penalty by penalizing large weights ¨ “Shrinkage” method
-2.2 + 3.1 X – 0.30 X2 -1.1 + 4,700,910.7 X – 8,585,638.4 X2 + …
34 ©2005-2013 Carlos Guestrin

18
Variable Selection by Regularization
35
n Ridge regression: Penalizes large weights
n What if we want to perform “feature selection”? ¨ E.g., Which regions of the brain are important for word prediction? ¨ Can’t simply choose features with largest coefficients in ridge solution
n Try new penalty: Penalize non-zero weights ¨ Regularization penalty:
¨ Leads to sparse solutions ¨ Just like ridge regression, solution is indexed by a continuous param λ ¨ This simple approach has changed statistics, machine learning &
electrical engineering
©2005-2013 Carlos Guestrin
LASSO Regression
36
n LASSO: least absolute shrinkage and selection operator
n New objective:
©2005-2013 Carlos Guestrin
19
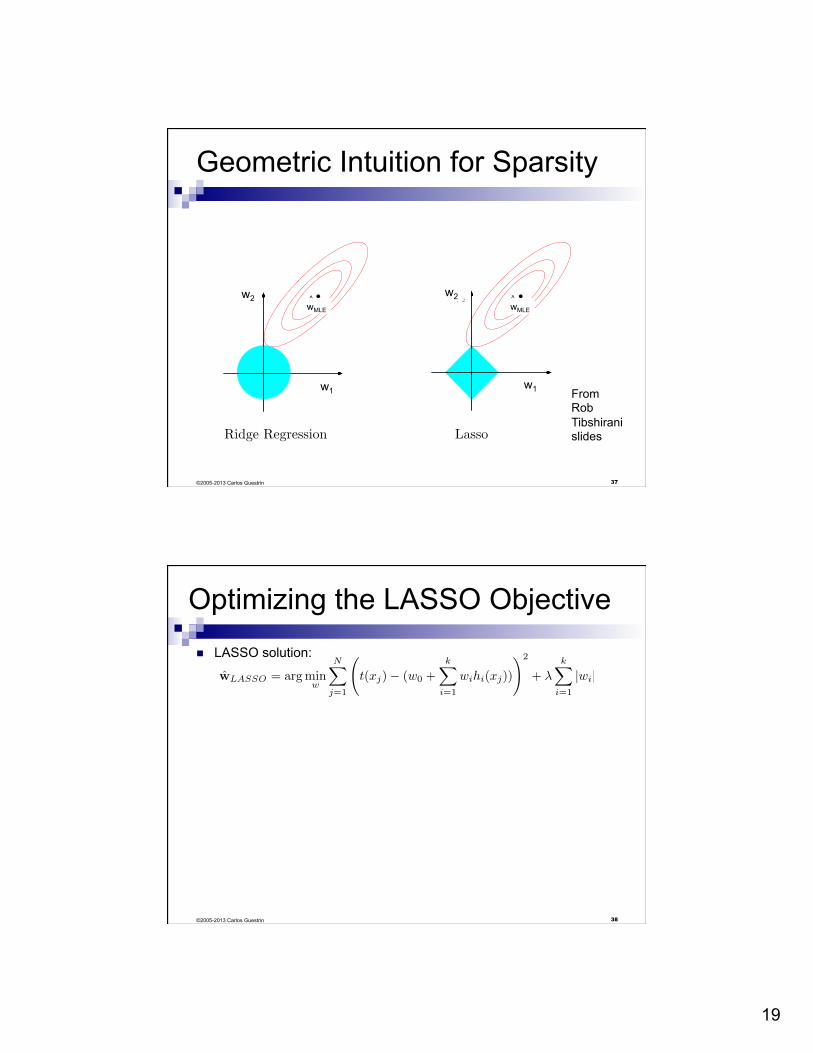
Geometric Intuition for Sparsity
37
4
Picture of Lasso and Ridge regression
β β2. .β
1
β 2
β1
β
Lasso Ridge Regression
From Rob Tibshirani slides
4
Picture of Lasso and Ridge regression
β β2. .β
1
β 2
β1
β
Lasso Ridge Regression
w1
w2 wMLE
w1
w2 wMLE
©2005-2013 Carlos Guestrin
Optimizing the LASSO Objective n LASSO solution:
38 ©2005-2013 Carlos Guestrin
wLASSO = argminw
NX
j=1
t(xj)� (w0 +
kX
i=1
wihi(xj))
!2
+ �
kX
i=1
|wi|

20
Coordinate Descent n Given a function F
¨ Want to find minimum
n Often, hard to find minimum for all coordinates, but easy for one coordinate n Coordinate descent:
n How do we pick next coordinate?
n Super useful approach for *many* problems ¨ Converges to optimum in some cases, such as LASSO
39 ©2005-2013 Carlos Guestrin
How do we find the minimum over each coordinate?
n Key step in coordinate descent: ¨ Find minimum over each coordinate
n Standard approach:
40 ©2005-2013 Carlos Guestrin
Illustration from Wikipedia

21
Optimizing LASSO Objective One Coordinate at a Time
n Taking the derivative: ¨ Residual sum of squares (RSS):
¨ Penalty term:
41 ©2005-2013 Carlos Guestrin
NX
j=1
t(xj)� (w0 +
kX
i=1
wihi(xj))
!2
+ �
kX
i=1
|wi|
@
@w`RSS(w) = �2
NX
j=1
h`(xj)
t(xj)� (w0 +
kX
i=1
wihi(xj))
!
Coordinate Descent for LASSO (aka Shooting Algorithm)
n Repeat until convergence ¨ Pick a coordinate l at (random or sequentially)
n Set:
n Where:
¨ For convergence rates, see Shalev-Shwartz and Tewari 2009 n Other common technique = LARS
¨ Least angle regression and shrinkage, Efron et al. 2004 42
w` =
8<
:
(c` + �)/a` c` < ��0 c` 2 [��,�]
(c` � �)/a` c` > �
a` = 2NX
j=1
(h`(xj))2
c` = 2NX
j=1
h`(xj)
0
@t(xj)� (w0 +X
i 6=`
wihi(xj))
1
A
©2005-2013 Carlos Guestrin

22
Soft Thresholding
43
From Kevin Murphy textbook
w` =
8<
:
(c` + �)/a` c` < ��0 c` 2 [��,�]
(c` � �)/a` c` > �
c`
©2005-2013 Carlos Guestrin
Recall: Ridge Coefficient Path
n Typical approach: select λ using cross validation
44
From Kevin Murphy textbook
©2005-2013 Carlos Guestrin
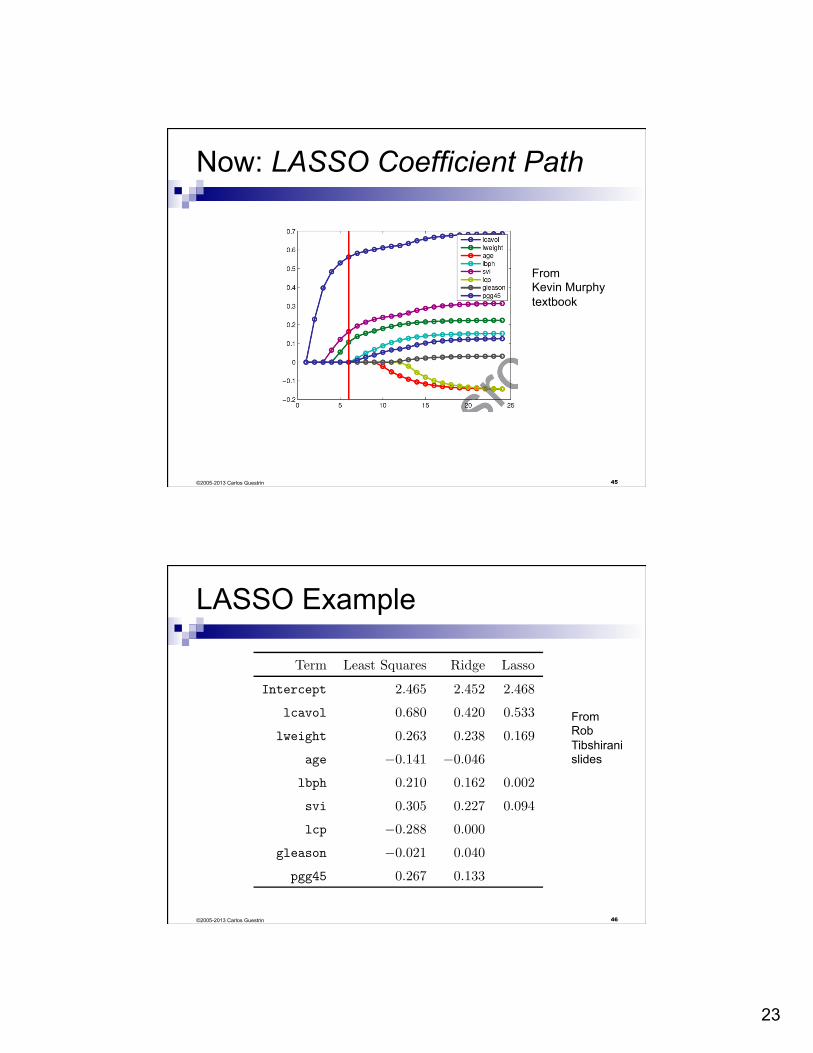
23
Now: LASSO Coefficient Path
45
From Kevin Murphy textbook
©2005-2013 Carlos Guestrin
LASSO Example
46
6
Estimated coe!cients
Term Least Squares Ridge Lasso
Intercept 2.465 2.452 2.468
lcavol 0.680 0.420 0.533
lweight 0.263 0.238 0.169
age !0.141 !0.046
lbph 0.210 0.162 0.002
svi 0.305 0.227 0.094
lcp !0.288 0.000
gleason !0.021 0.040
pgg45 0.267 0.133
From Rob Tibshirani slides
©2005-2013 Carlos Guestrin

24
Debiasing
47
From Kevin Murphy textbook
©2005-2013 Carlos Guestrin
What you need to know
n Variable Selection: find a sparse solution to learning problem
n L1 regularization is one way to do variable selection ¨ Applies beyond regressions ¨ Hundreds of other approaches out there
n LASSO objective non-differentiable, but convex è Use subgradient
n No closed-form solution for minimization è Use coordinate descent
n Shooting algorithm is very simple approach for solving LASSO
48 ©2005-2013 Carlos Guestrin