programação distribuída e paralela: introdução à...
TRANSCRIPT

1
Programação Distribuída e Paralela:Introdução à computação paralela
Jorge Barbosa

2
Abordagem Clássica
Problema
Observação
TeoriaExperimentaçãoFísica

3
Método cientifico moderno
Problema
Observação
TeoriaExperimentaçãoFísica
SimulaçãoNumérica

4
Supercomputação
• Supercomputação High Performance Computing• HPC permite estudar, por simulação, sistemas
complexos sem recorrer à experiência real.Exemplo: ensaios nucleares.
• Baseado em modelos matemáticos e físicos dos sistemas podemos:– Simular o comportamento do sistema para diferentes
parâmetros do modelo.– Prever o Output do sistema para diferentes inputs.

5
Simulação
• Recorre-se à simulação quando o problema é:– Demasiado complexo– Dispendioso– Perigoso
Ex: aerodinâmica de nave espacial
Ex: http://www.eurekalert.org/features/This Audi A8 car-crash model contains numerous materialsand structural components modeled by 290,000 finiteelements (shown here as squares on a grid). The modelpredicts the extent of deformation in the car after a crash.

6
Simulação
• Principais aplicações de simulação– Aerodinâmica (aeronáutica, automóvel, etc)– Choque automóvel– Simulação de trânsito– Análise de dinâmica de fluidos (Ind. Química)– Análise estrutural (comportamento de materiais)– Desenvolvimento de Medicamentos
• Benefícios– Reduz o tempo de desenvolvimento do produto– Aumento da qualidade do produto– Reduz a necessidade de construir protótipo de teste

7
Computação Paralela
• Porquê usar Computação Paralela
– Possibilidade de resolver problemas maiores e mais realistas (maior detalhe/precisão).
– Desenvolvimento mais económico.
– Maior liberdade de “experimentar”.

8
Supercomputador
Principais características:• Computador de uso geral• Resolve problemas individuais com elevada
capacidade de processamento• Custo tipicamente acima dos 10M€• Utilizados principalmente por laboratórios de
investigação governamentais (EUA, Japão, UE, etc)

9
Supercomputador
A nível comercial:• Inicialmente utilizado por:
– Indústria petrolífera– Indústria automóvel
• Mais recentemente:– Indústria farmacêutica– Telecomunicações– Semicondutores– Etc.

10
Supercomputador
Principais problemas:• Supercomputador ≠ Σ CPUs
– Capacidade de processamento ≠ “throughput”– Sistemas de I/O limitados
• Software– Sistemas operativos proprietários e inadequados– Ambientes de programação inadequados
• Custos elevados de aquisição e manutenção. Custo por processador elevado.
=> Procura de alternativas => Beowulf / Cluster

11
Beowulf
• Processadores de uso geral• Rede de comunicação de uso geral• Linux como Sistema Operativo• Message Passing Interface (MPI)• Em algumas aplicações obtém-se elevado índice
performance/€

12
Formas de obter paralelismo na resolução dos problemas
• Paralelismo Funcional• Paralelismo de Dados• Pipelining

13
Grafo de dependência de Dados
Leitura dos dados imagem
Análise de histograma
Filtro de detecção de arestas X
Filtro de detecção de arestas Y
Módulo
Threshold
• Grafo directo acíclico• Arestas: dependências
funcionais• Vértices: tarefas

14
Paralelismo funcional
• Tarefas independentes efectuam operações diferentes sobre diferentes dados
Exemplo: 1. a = 22. b = 33. m = (a + b) / 24. s = (a2 + b2) / 25. v = s - m2
• Instruções 1 e 2 são independentes• Instruções 3 e 4 dependem de 1 e 2 mas são
independentes entre si.

15
Paralelismo de dados
• Tarefas independentes aplicam a mesma operação sobre diferentes dados.
Exemplo:
Os elementos dos vectores podem ser somados de forma independente entre si. A operação soma pode ser aplicada simultaneamente sobre diferentes elementos dos vectores b e c.
For (i = 0; i< 99; i++) a[i] = b[i] + c[i]

16
Pipelining• Estratégia:
– Dividir o processo em etapas – Produzir vários items em simultâneo, igual ao número
de etapas.
Exemplo: linha de montagem automóvelT1
T2
T3
T4

17
Programação de Computadores Paralelos
• Extensão dos compiladores: conversão automática de programas sequencias em paralelos.
• Extensão das linguagens de programação: adicionar operadores paralelos.
• Criar novas linguagens e compiladores de programação paralela

18
Extensão dos compiladores
• Compilador paralelo– Detecta paralelismo em código sequencial– Produz código para ser executado em paralelo
As principais iniciativas tem sido na obtenção de compiladores que convertam programas em Fortan
Vantagens:– Aproveitamento dos milhões de linhas de código já desenvolvido– Simplifica o desenvolvimento de soluções paralelas– Não são necessários novas metodologias de programação– Mais fácil desenvolver código sequencial do que paralelo

19
Extensão dos compiladores
Desvantagens:
– O código sequencial pode estar escrito de tal forma que impeça uma paralelização eficiente.
– Os ganhos obtidos com estes compiladores são ainda pouco satisfatórios.

20
Extensão das linguagens de programação: adicionar operadores paralelos
• Adição de funções a uma linguagem sequencial– Criação e terminação de processos– Sincronização de processos– Comunicação entre processos
Vantagens:– Mais fácil, mais rápido e mais barato– Permite a utilização da tecnologia de compiladores já existente
Desvantagens:– Os compiladores tratam o programa como um conjunto de
subprogramas individuais, não efectuando detecção de erros sobre o que pode ocorrer quando considerado como um todo.
– Programas fáceis de escrever mas difíceis de efectuar Debug.

21
Criar novas linguagens e compiladores de programação paralela
• Desenvolvimento de linguagens paralelas de raiz– Por exemplo: OCCAM
• Adicionar construções paralelas a uma linguagem já existente– Fortran 90
– High Performance Fortran
– C*

22
Criar novas linguagens e compiladores de programação paralela
• Vantagens– Permite que os programadores “comuniquem” o
paralelismo ao compilador– Maior possibilidade de obter elevados desempenhos
• Desvantagens– Desenvolvimento de novos compiladores– Novas linguagens podem não se tornar standard– Resistência por parte dos programadores

23
Programação de Computadores Paralelos:Estado Actual
• A solução de nível mais baixo é a mais frequente:– Acrescentar às linguagens existentes construções
paralelas– Exemplos são MPI e OpenMP
Vantagens:– Eficiência– Portabilidade
Desvantagem:– Maior dificuldade na programação e debuging

24
Principais temas na Computação Paralela
• Paralelismo e Lei de Amdahl• Granularidade• “Data Locality”• Escalonamento e Balanceamento de carga
computacional• Coordenação e sincronização• Modelação de desempenho

25
Paralelismo automático nos processadores modernos
• Paralelismo em operações aritméticas– Operações em vírgula-flutuante
• Paralelismo ao nível da instrução– Mais do que uma instrução por ciclo de instrução
(Intel hyperthreading no novo P IV)
• Paralelismo no acesso à memória– Sobreposição de operações de memória com processamento
• Paralelismo ao nível do SO– Vários processos paralelos em máquinas SMP

26
Paralelismo e Lei de Amdahl
• Numa aplicação existe sempre uma parte que não pode ser paralelizada.
• Lei de Amdahl– Se s for a parte de trabalho sequencial (1-s) será a parte
susceptível de ser paralelizada– P - número de processadores
• Mesmo que a parte paralela seja perfeitamente escalável, o desempenho (Speedup) está limitado pela parte sequencial

27
Lei de Amdahl
A lei de Amdahl impõe um limite no Speedup que pode ser obtido com P processadores.
PTTSpeedup 1=
sP
sTP +−
=)1(
sP
sSpeedup+
−= 1
1
O ganho obtido com a utilização de paralelismo é designado por Speedup :
Exemplo: se o tempo total de execução de um algoritmo for 93s e o tempo sequencial mas susceptível de ser paralelizado for 90s, então:(1-s) = 90/93=0.968 96.8% do código é paralelizávels = 1-0.968 = 0.032 3.2% é inerentemente sequencial

28
Lei de AmdahlCódigo susceptível de ser paralelizado:
Parte do código que executa com Speedup=P se for executado utilizando P processadores.
Código inerentemente sequencial:Parte do código não paralelizável, como entrada e saída de dados, inicialização de variáveis, etc.
Se P ∞ o Speedup=1/s.
Para o exemplo anterior o Speedup máximo será: SpeedupMáximo = 1/0.032 = 31.25
Em conclusão: por mais máquinas que se usasse o speedup não ultrapassaria 31.25.

29
Lei de Amdahl
Speedup teórico segundo Amdahl
Duas considerações importantes são tiradas da lei de Amdahl:
1. Permite ter uma visão realista, perante um algoritmo, sobre o que se pode esperar do paralelismo.
2. Mostra que para obter ganhos elevados é necessário reduzir ou eliminar os blocos sequenciais do algoritmo.

30
Lei de AmdahlSpeedup ObservadoNa realidade o Speedup observado quando se aumenta P é exemplificado na figura ao lado. A diferença surge devido ao factor inerentemente sequencial s não ser constante quando P aumenta.
O aumento do número de processadores leva a um aumento dos tempos de comunicação, conflitos no acesso a recursos (memória, rede), ciclos de CPU dispendidos na organização do paralelismo e sincronização de processos.
A função Speedup apresenta uma forma crescente até um determinado valor de P,a partir do qual decresce. O número ideal de processadores a usar será inferior ao obtido pela lei de Amdahl.

31
Formas de Paralelismo • HPC- high performance computing:
– Sistema único com muitos processadores, com rede dedicada, a trabalharem em conjunto no mesmo problema.
• Redes de computadores pessoais:– Vários sistemas sem rede dedicada (“loosely coupled”)
a trabalhar no mesmo problema.
• Grid Computing– Sistemas geograficamente distribuídos, de elevado
desempenho, que colaboram de forma dedicada na solução de um problema complexo.

32
www.top500.org 11/2003
64000073049984
ResearchIBM SPSP Power3 375 MHz high node
SeaborgSP Power3 375 MHz 16 way / 6656IBM
NERSC/LBNLUnited States/2002
9
640000730412288
ResearchIBM SPSP Power3 375 MHz high node
ASCI White, SP Power3 375 MHz / 8192IBM
Lawrence Livermore National LaboratoryUnited States/2000
8
35000075000
763411060
ResearchNOW - Intel PentiumNOW Cluster - Intel Pentium - Quadrics
MCR Linux Cluster Xeon 2.4 GHz - Quadrics / 2304Linux Networx/Quadrics
Lawrence Livermore National LaboratoryUnited States/2002
7
761160109208
805111264
ResearchNOW - AMDNOW Cluster - AMD - Myrinet
LightningOpteron 2 GHz, Myrinet / 2816Linux Networx
Los Alamos National LaboratoryUnited States/2003
6
835000140000
863311616
ResearchHP ClusterIntegrity rx2600 Itanium2 Cluster
Mpp2Integrity rx2600 Itanium2 1.5 GHz, Quadrics / 1936HP
Pacific Northwest National LaboratoryUnited States/2003
5
630000981915300
AcademicDell ClusterPowerEdge 1750, Myrinet
TungstenPowerEdge 1750, P4 Xeon 3.06 GHz, Myrinet / 2500Dell
NCSAUnited States/2003
4
520000152000
1028017600
AcademicNOW - PowerPCG5 Cluster
X1100 Dual 2.0 GHz Apple G5/Mellanox Infiniband4X/Cisco GigE / 2200Self-made
Virginia TechUnited States/2003
3
633000225000
1388020480
ResearchHP AlphaServerAlpha-Server-Cluster
ASCI Q - AlphaServer SC45, 1.25 GHz / 8192HP
Los Alamos National LaboratoryUnited States/2002
2
1.0752e+06266240
3586040960
ResearchNEC VectorSX6
Earth-Simulator / 5120NEC
Earth Simulator CenterJapan/2002
1
Nmaxnhalf
RmaxRpeak
Inst. typeInstallation Area
Computer FamilyModel
Computer / ProcessorsManufacturer
SiteCountry/Year
Rank

33
www.top500.org 11/2004
981915300
TungstenPowerEdge 1750, P4 Xeon 3.06 GHz, Myrinet / 2500Dell
NCSAUnited States/2003
10
1031020019.2
eServer pSeries 655 (1.7 GHz Power4+) / 2944IBM
Naval Oceanographic Office (NAVOCEANO)United States/2004
9
1168016384
BlueGene/L DD1 Prototype (0.5GHz PowerPC 440 w/Custom) / 8192IBM/ LLNL
IBM - RochesterUnited States/2004
8
1225020240
System X1100 Dual 2.3 GHz Apple XServe/Mellanox Infiniband 4X/Cisco GigE / 2200Self-made
Virginia TechUnited States/2004
7
1388020480
ASCI QASCI Q - AlphaServer SC45, 1.25 GHz / 8192HP
Los Alamos National LaboratoryUnited States/2002
6
1994022938
ThunderIntel Itanium2 Tiger4 1.4GHz - Quadrics / 4096California Digital Corporation
Lawrence Livermore National LaboratoryUnited States/2004
5
2053031363
MareNostrumeServer BladeCenter JS20 (PowerPC970 2.2 GHz), Myrinet / 3564IBM
Barcelona Supercomputer CenterSpain/2004
4
3586040960
Earth-Simulator / 5120NEC
The Earth Simulator CenterJapan/2002
3
5187060960
ColumbiaSGI Altix 1.5 GHz, Voltaire Infiniband / 10160SGI
NASA/Ames Research Center/NASUnited States/2004
2
7072091750
BlueGene/L beta-SystemBlueGene/L DD2 beta-System (0.7 GHz PowerPC 440) / 32768IBM
IBM/DOEUnited States/2004
1
RmaxRpeak
Computer / ProcessorsManufacturer
SiteCountry/Year
Rank

34
Legenda• Rank: Position within the TOP500 ranking • Manufacturer: Manufacturer or vendor• Computer: Type indicated by manufacturer or vendor• Installation: Site Customer• Location: Location and country• Year: Year of installation/last major update• Installation Area: Field of Application• Processors: Number of processors• Rmax : Maximal LINPACK performance achieved• Rpeak : Theoretical peak performance• Nmax : Problem size for achieving Rmax
• N1/2 : Problem size for achieving half of Rmax
The benchmark used in the LINPACK Benchmark is to solve a densesystem of linear equations.

35
Programação Paralela
Modelo Tarefa/Canal de comunicação Abstracção apropriada para desenvolver programas paralelos.
Tarefacanal

36
Programação Paralela
Computação Paralela = conjunto de tarefas, executadas de forma concorrente.
• Tarefa – Programa sequencial (modelo de von Neumann)– Memória local– Conjunto de portas de I/O
• As tarefas interagem enviando mensagens pelos canais de comunicação

37
Programação Paralela
Metodologia de desenvolvimento de programas paralelos:
• Divisão do Problema
• Padrões de Comunicação
• Granularidade da paralelização
• Escalonamento
Abordagem que considera primeiro as características do problema, como a dependência de dados, e deixa para mais tarde os aspectos que dependem da máquina paralela.

38
Programação Paralela
ProblemaPartição
Comunicação
GranularidadeEscalonamento

39
Partição
• Consiste na divisão da computação em tarefas e dos dados em blocos mais pequenos.
• Decomposição do domínio– Divisão dos dados em blocos
– Determinar como processar os dados
• Decomposição Funcional– Divisão do processamento
– Determinar como associar o processamento aos dados do problema
Nesta fase ignora-se as questões práticas, como por exemplo, o número de processadores a utilizar. A atenção deve ser colocada em identificar no problema oportunidades de execução paralela.

40
Exemplo de Decomposição de Domínio
3 tarefas
3x3 tarefas
3x3x6 tarefas

41
Exemplo de Decomposição Funcional
Aquisição de Imagem
Aquisição de Imagem
DeterminaçãoContorno
Calculo de Vectores Próprios
Matching
DeterminaçãoContorno
Calculo de Vectores Próprios

42
Checklist da fase de partiçãoAs perguntas seguintes devem ter resposta positiva:• A partição gerou um número significativo de tarefas em comparação com os
processadores disponíveis (10x)?
– Se não, teremos pouca flexibilidade nos passos seguintes do desenvolvimento.
• A partição minimiza computação redundante e armazenamento redundante de dados?
– Se não, o algoritmo poderá não ser escalável.
• As tarefas geradas têm dimensão equivalente?
– Se não, podemos ter dificuldade na divisão equilibrada do trabalho pelos processadores.
• O número de tarefas aumenta com a dimensão do problema?
– Idealmente o número de tarefas deve crescer com o problema, em vez do tamanho individual das tarefas. Caso contrário o programa paralelo poderá não beneficiar de ter mais processadores disponíveis.

43
Padrões de Comunicação
As tarefas geradas pela partição deverão executar de forma concorrente mas, em geral, não são independentes. É necessário determinar as comunicações para coordenar a execução das tarefas, as estruturas e algoritmos de comunicação.
• Determinação dos valores a comunicar entre tarefas
• Comunicação Local– Cada tarefa precisa de dados de um conjunto pequeno de outras tarefas
para completar o seu trabalho.
• Comunicação Global– Os dados de uma tarefa são necessários a muitas outras, efectuando por
isso uma comunicação global.

44
Padrões de Comunicação
Na comunicação em anel a mensagem não será a mesma do principio ao fim.
Notar que o padrão de comunicação ideal para a partição efectuada poderá não ser realizável na máquina alvo. Exemplo: a árvore binária numa rede tipo barramento teria de ser convertida num pipe uma vez que não é possível efectuar comunicações em paralelo.
Comunicação 1:m com complexidade Log2P
Complexidade P para os outros casos

45
Checklist da fase de Comunicação
• As tarefas efectuam um número equivalente de comunicações?– Se não, podemos ter alguma estrutura concentrada numa tarefa que dificultará o
escalamento do sistema. Por exemplo, podemos distribuir essa estrutura ou replicá-la pelas tarefas.
• As tarefas comunicam com um número limitado de tarefas?
• As comunicações podem ser efectuadas de forma concorrente?– Tentar obter padrões de comunicação que possibilitem a concorrência de
comunicações, independentemente do computador alvo o permitir.
• As tarefas podem executar de forma concorrente?
– Ou estão sequencializadas pelo padrão de comunicação?

46
Granularidade da paralelização: aglomeração de tarefas
Granularidade: quantidade de computação entre cada comunicação de dadosObjectivos:• Melhorar o desempenho na máquina alvo• Manter o programa escalável• Simplificar a programação
As tarefas e as estruturas de comunicação desenvolvidas nas 2 fases anteriores são avaliadas em relação à performance esperada. Atendendo às características da máquina alvo podemos ter de reduzir o número de tarefas, juntando tarefas pequenas para formar tarefas maiores.
Na programação por Passagem de Mensagens (PVM,MPI) é frequentar tentar obter apenas uma tarefa por processador

47
Granularidade da paralelização: aglomeração de tarefas
A divisão dos dados tem impacto na quantidade de dados trocada durante o processamento e do número de mensagens.
O número de mensagens poderá ter maior impacto numa arquitectura tipo cluster.

48
Granularidade da paralelização: aglomeração de tarefas
A aglomeração pode melhorar o desempenho:• Elimina as comunicações entre as tarefas que foram aglomeradas (a)• Redução do número de comunicações (b)

49
Checklist da fase de definição de granularidade
• A aglomeração de tarefas reduziu os custos de comunicação?
• Se resultou replicação de computação, o seu custo não excede a redução na comunicação?
• Se resultou replicação de dados, o problema continua a ser escalável? I.e., mantém o mesmo desempenho para problemas maiores, com mais processadores?
• Resultaram tarefas com idênticos custos de computação e comunicação?
• O número de tarefas cresce com a dimensão do problema?– Se não, o programa não é escalável. Não será adequado para resolver problemas
maiores em computadores maiores.
• Pode o número de tarefas ser ainda mais reduzido, sem prejudicar o balanceamento de carga ou a escalabilidade do programa?
• Se estamos a paralelizar uma aplicação sequencial já existente, a aglomeração obtida permite a utilização desse código sequencial, reduzindo assim os custos de desenvolvimento?

50
EscalonamentoObjectivo: Atribuir as tarefas aos processadores minimizando o tempo de
processamento.
Para atingir o mínimo tempo de processamento é necessário:• Atribuir a mesma quantidade de trabalho aos processadores (load balancing)• Maximizar a utilização dos processadores, reduzindo os pontos de
sincronismo/comunicação• Minimizar as comunicações
Dois tipos de abordagem:1. Escalonamento Estático
• Menor número de tarefas e de maior duração temporal2. Escalonamento Dinâmico
• Muitas tarefas de pequena duração
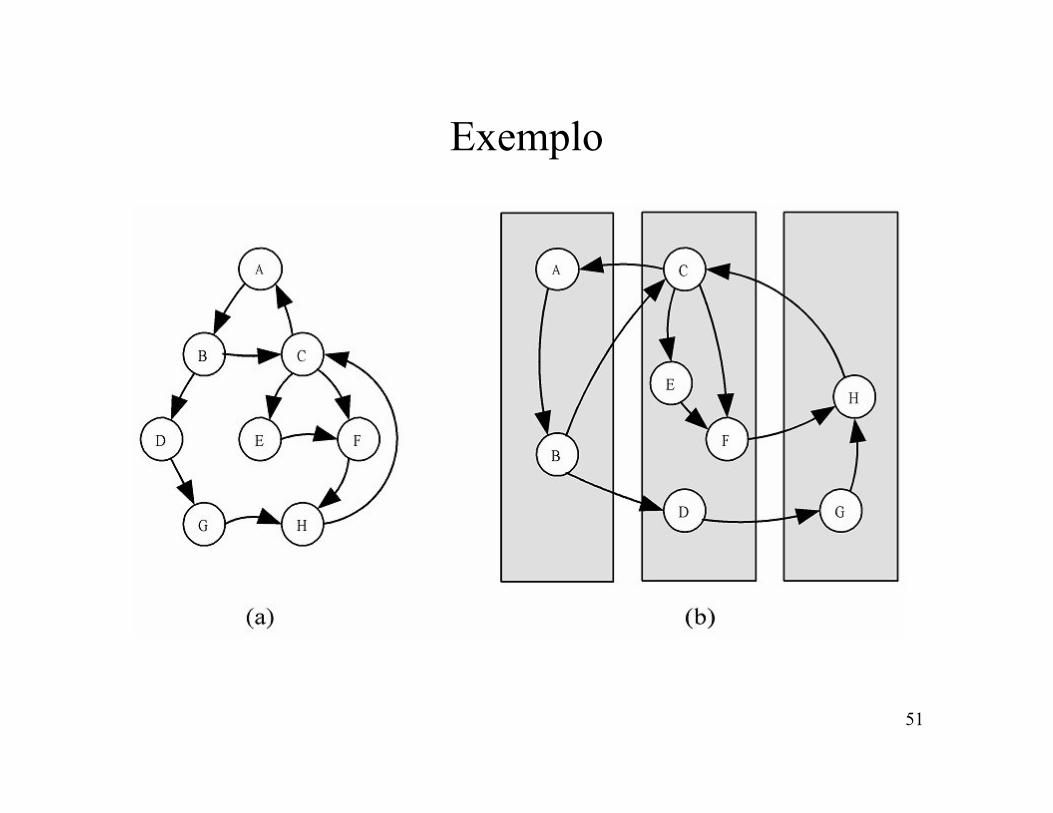
51
Exemplo

52
Escalonamento Óptimo
• Os algoritmos são representados por DAGs (direct acyclic graph) onde se evidencia a precedência entre as tarefas.
• Encontrar o escalonamento óptimo é um problema NP-difícil.• Solução: recurso a heurísticas
T1 T2 T3
T7
T4 T5 T6
T8
T1
T2 T3
T7
T4T5
T6
T8T8 T9
T1
T2
T3
T7
T4
T5
T6
Problema NP-difícil: significa que não existe um algoritmo que em tempo polinomial encontre a solução óptima.

53
Escalonamento Estático
A distribuição de carga é efectuada antes de iniciar o processamento do algoritmo. O tempo gasto com o escalonamento é na fase inicial.
Aplica-se para:
• Paralelismo por decomposição de domínio.
• Problemas regulares onde se sabe a priori o número de operações a executar por elemento de dados (domínio regular).
– Exemplo: soma de dois vectores de tamanho n
• Quando as comunicações são estruturadas.
• Quando a máquina tem uma disponibilidade de processamento constante durante o tempo esperado de processamento.

54
Caracterização do Escalonamento Estático
Desvantagens:
• É necessário ter um modelo fiável da máquina paralela para poder estimar o tempo de processamento dos programas submetidos.
• Conhecer a disponibilidade de processamento da máquina na hora de execução.
• Garantir que as condições de processamento e comunicação durante a execução são iguais às consideradas na fase de escalonamento.
• Considerar as dependências funcionais entre tarefas.
Vantagens:
• Não ocupa tempo de processamento durante a execução.
• É sempre estável.

55
Escalonamento Dinâmico
A distribuição de carga é efectuada durante o processamento.
Aplica-se para:
• Paralelismo funcional.
• Paralelismo de dados com domínio irregular.– Exemplo: resolução de um sistema de equações esparso
• Disponibilidade de processamento variável durante o tempo esperado de processamento.
• Muitas tarefas a executar, sem se saber a priori a evolução da carga computacional.
– Exemplo: processos de vários utilizadores.

56
Caracterização do Escalonamento Dinâmico
Desvantagens:
• Ocupa tempo de processamento durante a execução.
• Poderá ser instável nas duas situações opostas do sistema: muito e pouco carregado.
Vantagens:
• Redistribuição da carga computacional durante o processamento.
– Transferência de tarefas de processadores mais carregados para outros mais disponíveis
• Não é necessário conhecer o comportamento do sistema (modelo).
• Não é necessário estimar o tempo de processamento.

57
Escalonamento Dinâmico: componentes
Um algoritmo dinâmico tem os seguintes componentes:
– Controlo e avaliação da carga dos processadores
• Definição de um índice de carga dos processadores
– Início da acção de equilíbrio de carga
• Acção do receptor (passiva), Acção do emissor (activa) e mista
– Definição do trabalho a transferir
• Quantidade de trabalho
– Escolha das tarefas
• Quais as tarefas a transferir.

58
Avaliação dos algoritmos de escalonamento
• Estabilidade
– Um algoritmo é estável se a sua utilização não origina a falha do sistema.
• Efectividade
– Um algoritmo é efectivo se o desempenho do sistema melhorar com a sua utilização.
• Expansibilidade
– Um algoritmo é expansível se mantiver as mesmas características em problemas de maior dimensão em dados e processadores.
• Qualidade de Serviço
– O tempo de espera médio de um processo pelos recursos do sistema atéterminar a sua execução.

59
Estudo de casos
• Detecção de arestas: operador de convolução